
Quantile Regression with Generated Regressors


Abstract
1. Introduction
2. Quantile Regression with Generated Regressors
2.1. Model
2.2. Estimation
- Step 1
- Estimate from (3) and compute the fitted values for , and then obtain the generated regressors for .
- Step 2
3. Asymptotic Properties
- (i)
- ,
- (ii)
- ,
- (iii)
- .
- (i)
- , where is Jacobian of ,
- (ii)
- , where .
4. Inference
4.1. Variance-Covaraince Matrix Estimation
4.2. Testing
5. Monte Carlo Simulations
5.1. Monte Carlo Design
5.2. Simulation Results
5.2.1. Location Shift Model
5.2.2. Location-Scale Shift Model
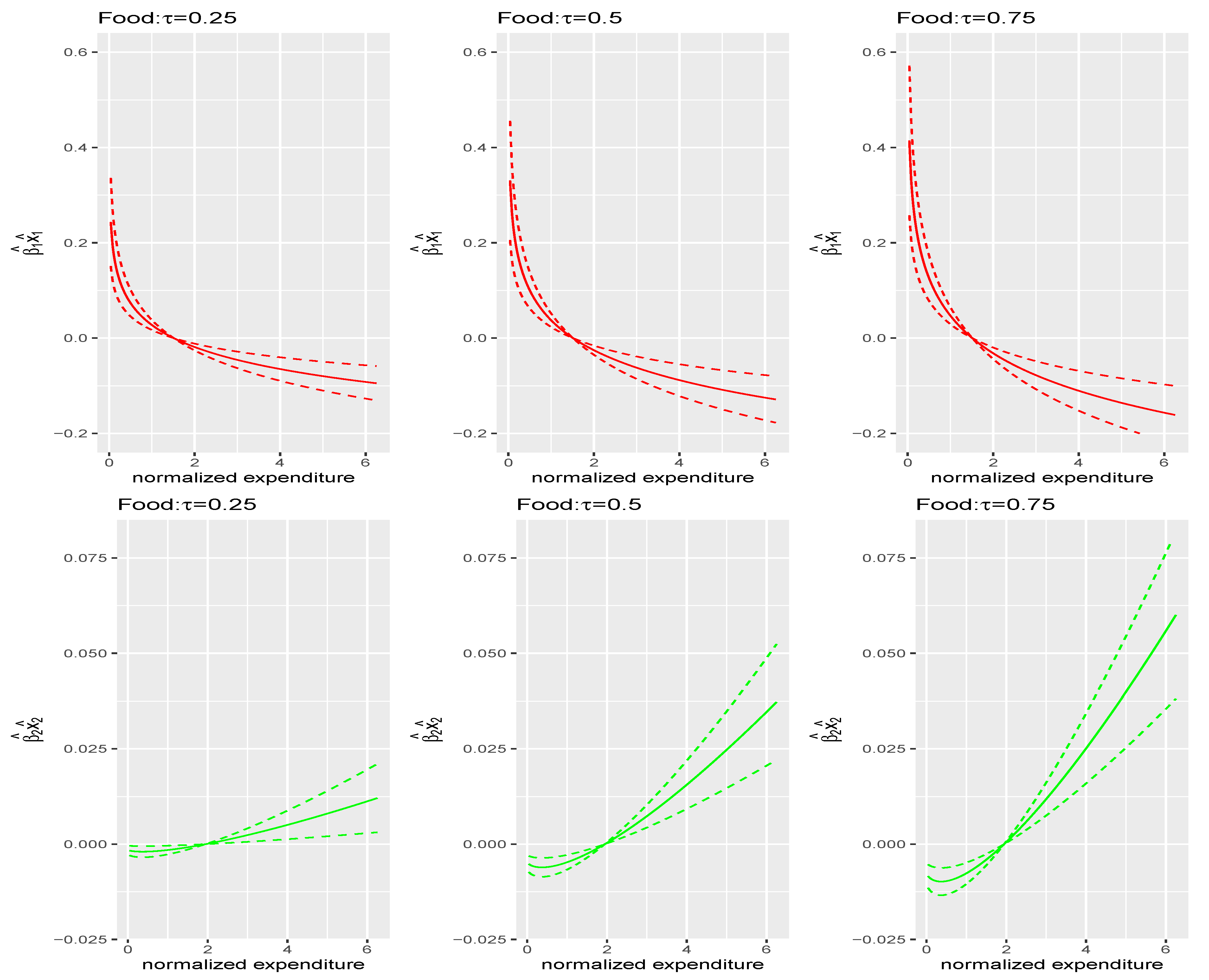
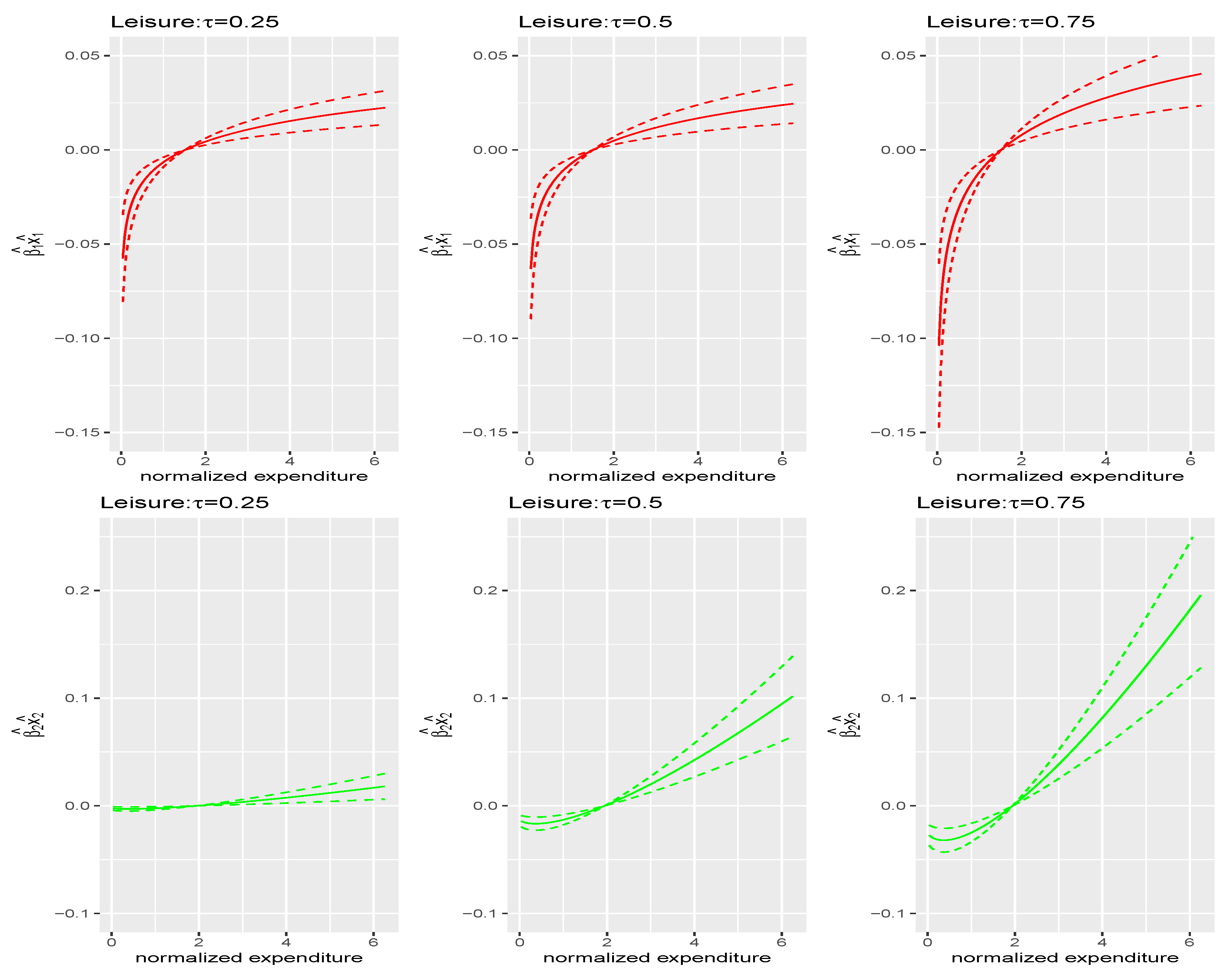
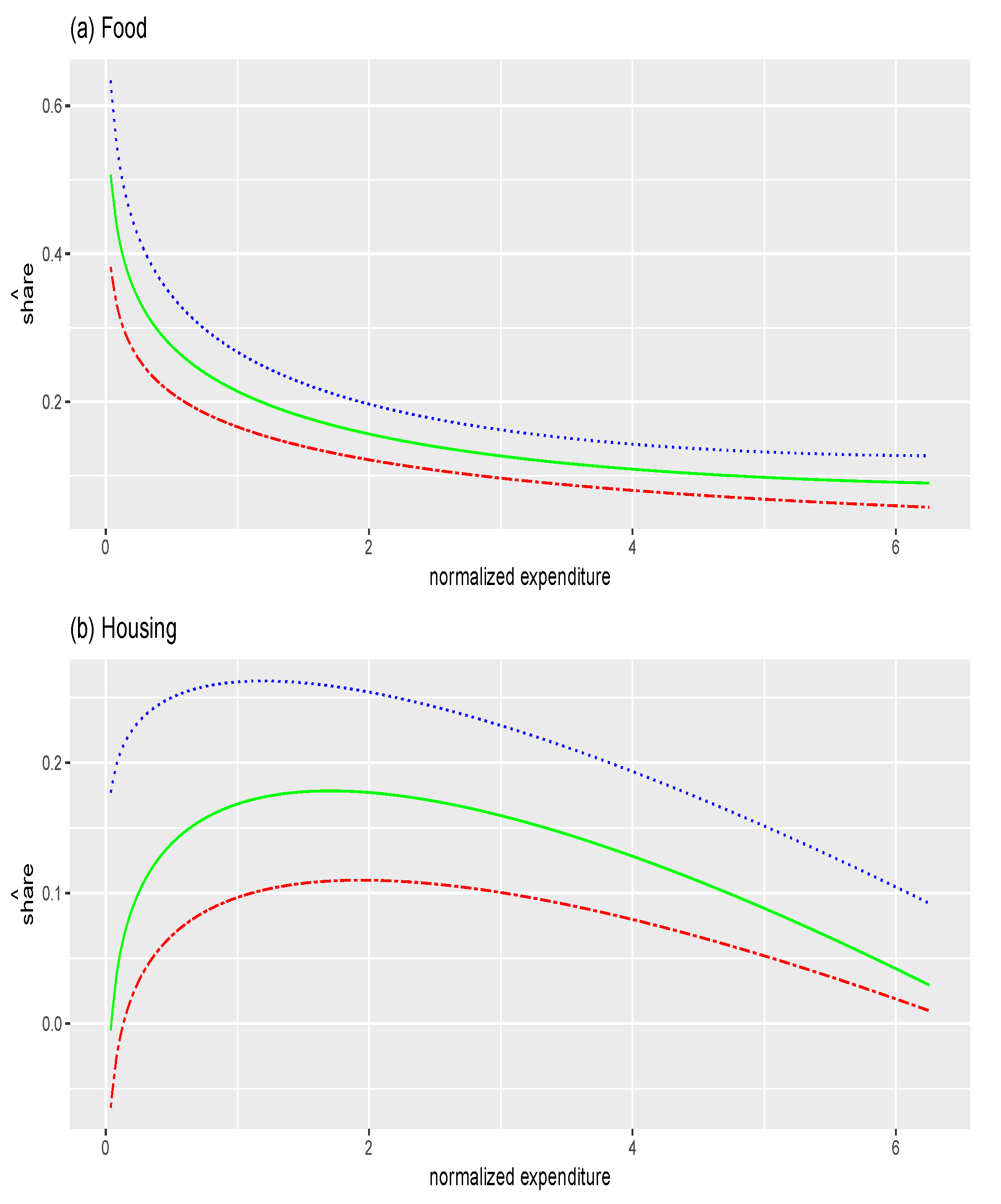
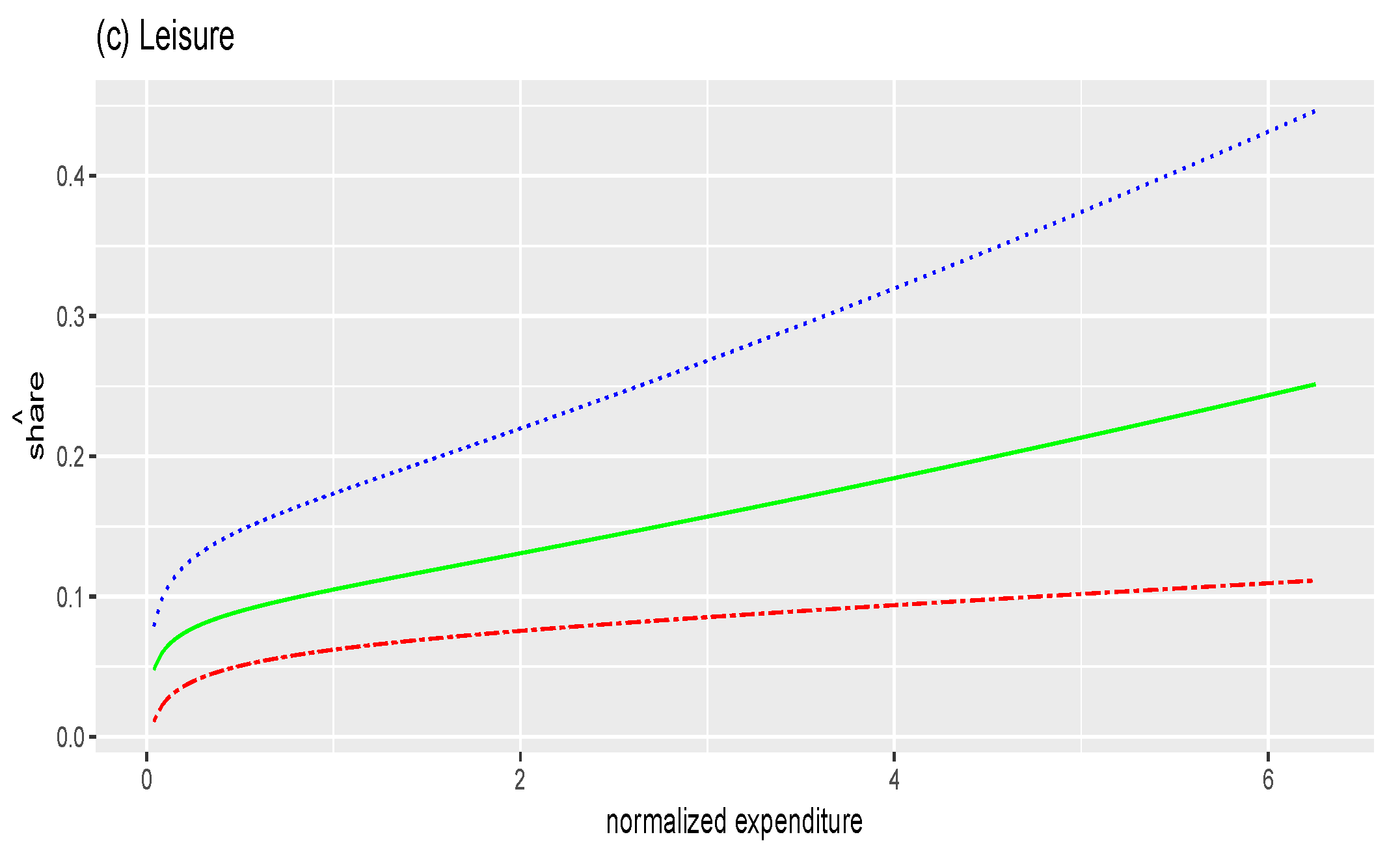
6. Application
6.1. A Brief Literature Review on Engel Curves
6.2. Data Description
6.3. Empirical Analysis
- Step 1
- Obtain the fitted values (generated regressors) of the first two motives by regressing the corresponding factors on functions of the total expenditure as following:
- Step 2
- Run a quantile regression of budget shares y on the three motives where the third motive is associated with a constant:with .
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix A.1. Proof of the Main Results
Appendix A.2. OLS with Generated Regressors
| 1. | Examples of generated regressors include models of interest involving expectations of future variables, such as expected prices or sales or inflation that have been generated as the predictions of some dynamic model (Engle (1982)). “Unanticipated” components of aggregate money growth in macroeconomic models (Barro (1977); Barro (1978)). |
| 2. | In particular, Xiao and Koenker (2009) develop QR with GR in the context of GARCH models. Chen et al. (2015) propose a quantile factor model. Lee (2007) applied a control function approach to generate instruments and resolve the endogeneity, and Ma and Koenker (2006) develop QR for recursive structural equation models. Chernozhukov et al. (2015) suggest QR with censoring and endogeneity. Arellano and Bonhomme (2016) discuss the correction of the QR estimates for nonrandom sample selection. Chernozhukov and Hansen (2005, 2006) develop a model of quantile treatment effects. Ackerberg et al. (2014) suggest two-step GMM where the moment functions can be seen as the score of QR. |
| 3. | R codes are provided for all methods, simulations, and applications. |
| 4. | We note that where for . We also note that for any and for all i, and . Additionally, by applying A2, A4 and A5. |
| 5. | These data have been previously used by Barigozzi and Moneta (2016). |
| 6. | The way to aggregate consumption follows Barigozzi and Moneta (2016). |
| 7. | RPI is obtained from UK Office for National Statistics (http://www.ons.gov.uk/ (accessed on January 2019)). To deflate the data, we divided the nominal total expenditure by the aggregate price index. Additionally, the nominal budget share, as a ratio of nominal level of expenditure over nominal total budget, was multiplied by a ratio of the total price index over a price index for the particular expenditure. |
References
- Ackerberg, Daniel, Xiaohong Chen, Jinyong Hahn, and Zhipeng Liao. 2014. Asymptotic efficiency of semiparametric two-step gmm. Review of Economic Studies 288: 919–43. [Google Scholar] [CrossRef]
- Arellano, Manuel, and Stéphane Bonhomme. 2018. Sample selection in quantile regression: A survey. In Handbook of Quantile Regression. Edited by Koenker Roger, Victor Chernozhukov, Xuming He and Limin Peng. Boca Raton: CRC/Chapman-Hall. [Google Scholar]
- Bai, Jushan, and Serena Ng. 2002. Determining the number of factors in approximate factor models. Econometrica 70: 191–221. [Google Scholar] [CrossRef]
- Barigozzi, Matteo, and Alessio Moneta. 2016. Identifying the independent sources of consumption variation. Journal of Applied Econometrics 31: 420–49. [Google Scholar] [CrossRef]
- Barro, Robert J. 1977. Unanticipated money growth and unemployment in the united states. The American Economic Review 67: 101–15. [Google Scholar]
- Barro, Robert J. 1978. Unanticipated money, output, and the price level in the united states. Journal of Political Economy 86: 549–80. [Google Scholar] [CrossRef]
- Blundell, Richard, Xiaohong Chen, and Dennis Kristensen. 2007. Semi-nonparametric iv estimation of shape-invariant engel curves. Econometrica 75: 1613–69. [Google Scholar] [CrossRef]
- Buchinsky, Moshe, and Jinyong Hahn. 1998. An alternative estimator for the censored quantile regression model. Econometrica 66: 653–71. [Google Scholar] [CrossRef]
- Chai, Andreas, and Alessio Moneta. 2010. Retrospectives: Engel curves. Journal of Economic Perspectives 24: 225–40. [Google Scholar] [CrossRef]
- Chen, Liang, Juan Jose Dolado, and Jesus Gonzalo. 2015. Quantile factor models. arXiv arXiv:1911.02173. [Google Scholar]
- Chernozhukov, Victor, Ivan Fernandez-Val, and A. E. Kowalski. 2015. Quantile regression with censoring and endogeneity. Journal of Econometrics 186: 201–21. [Google Scholar] [CrossRef]
- Chernozhukov, Victor, and Christian Hansen. 2005. An iv model of quantile treatment effects. Econometrica 73: 245–61. [Google Scholar] [CrossRef]
- Chernozhukov, Victor, and Christian Hansen. 2006. Instrumental quantile regression inference for structural and treatment effects models. Journal of Econometrics 132: 491–525. [Google Scholar] [CrossRef]
- Engel, Ernst. 1857. Die productions-und consumtionsverhältnisse des königreichs sachsen. Zeitschrift des Statistischen Bureaus des Königlich Sächsischen Ministeriums des Innern 8: 1–54. [Google Scholar]
- Engle, Robert F. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica 50: 987–1007. [Google Scholar] [CrossRef]
- Firpo, Sergio, Antonio F. Galvao, and Suyong Song. 2017. Measurement errors in quantile regression models. Journal of Econometrics 198: 146–64. [Google Scholar] [CrossRef]
- Hahn, Jinyong, and Geert Rider. 2013. Asymptotic variance of semiparametric estimators with generated regressors. Econometrica 81: 315–40. [Google Scholar]
- Hendricks, Wallace, and Roger Koenker. 1991. Hierarchical spline models for conditional quantiles and the demand for electricity. Journal of the American Statistical Association 87: 58–68. [Google Scholar] [CrossRef]
- Koenker, Roger, and Gilbert Bassett. 1978. Regression quantiles. Econometrica 46: 33–50. [Google Scholar] [CrossRef]
- Koenker, Roger, and Gilbert Bassett. 1982a. Robust tests for heteroscedasticity based on regression quantiles. Econometrica 50: 43–61. [Google Scholar] [CrossRef]
- Koenker, Roger, and Gilbert Bassett. 1982b. Tests of linear hypotheses and l1 estimation. Econometrica 50: 1577–84. [Google Scholar] [CrossRef]
- Koenker, Roger, and José A. F. Machado. 1999. Goodness of fit and related inference processes for quantile regression. Journal of the American Statistical Association 94: 1296–310. [Google Scholar] [CrossRef]
- Lee, Sokbae. 2007. Endogeneity in quantile regression models: A control function approach. Journal of Econometrics 141: 1131–58. [Google Scholar] [CrossRef]
- Lewbel, Arthur. 1997. Consumer demand systems and household equivalence scales. Handbook of Applied Econometrics 2: 167–201. [Google Scholar]
- Lewbel, Arthur. 2008. Engel curves. The New Palgrave Dictionary of Economics 2: 1–4. [Google Scholar]
- Ma, Lingjie, and Roger Koenker. 2006. Quantile regression methods for recursive structural equation models. Journal of Econometrics 134: 471–506. [Google Scholar] [CrossRef]
- Mammen, Enno, Christoph Rothe, and Melanie Schienle. 2012. Nonparametric regression with nonparametrically generated covariates. Annals of Statistics 40: 1132–70. [Google Scholar] [CrossRef]
- Murphy, Kevin M., and Robert H. Topel. 2002. Estimation and inference in two-step econometric models. Journal of Business & Economic Statistics 20: 88–97. [Google Scholar]
- Pagan, Adrian. 1984. Econometric issues in the analysis of regressions with generated regressors. International Economic Review 25: 221–47. [Google Scholar] [CrossRef]
- Powell, James L. 1991. Estimation of monotonic regression models under quantile regressions. In Nonparametric and Semiparametric Models in Econometrics. Edited by William A. Barnett, James Powell and George E. Tauchen. Cambridge: Cambridge University Press. [Google Scholar]
- Wang, Huixia Judy, Leonard A. Stefanski, and Zhongyi Zhu. 2012. Corrected-loss estimation for quantile regression with covariate measurement errors. Biometrika 99: 405–21. [Google Scholar] [CrossRef]
- Wei, Ying, and Raymond J. Carroll. 2009. Quantile regression with measurement error. Journal of the American Statistical Association 104: 1129–43. [Google Scholar] [CrossRef] [PubMed]
- Working, Holbrook. 1943. Statistical laws of family expenditure. Journal of the American Statistical Association 38: 43–56. [Google Scholar] [CrossRef]
- Xiao, Zhijie, and Roger Koenker. 2009. Conditional quantile estimation for generalized autoregressive conditional heteroscedasticity models. Journal of the American Statistical Association 104: 1696–712. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bias | SE | RMSE | Bias | SE | RMSE | ||
| QR | 0.000 | 0.012 | 0.012 | 0.000 | 0.004 | 0.004 | |
| QR-GR | −0.002 | 0.107 | 0.107 | −0.002 | 0.032 | 0.032 | |
| QR | 0.000 | 0.009 | 0.009 | 0.000 | 0.003 | 0.003 | |
| QR-GR | 0.003 | 0.101 | 0.101 | 0.000 | 0.032 | 0.032 | |
| QR | 0.000 | 0.008 | 0.008 | 0.000 | 0.003 | 0.003 | |
| QR-GR | −0.002 | 0.102 | 0.102 | 0.001 | 0.031 | 0.031 | |
| QR | 0.000 | 0.009 | 0.009 | 0.000 | 0.003 | 0.003 | |
| QR-GR | 0.003 | 0.099 | 0.099 | −0.002 | 0.032 | 0.032 | |
| QR | 0.000 | 0.011 | 0.011 | 0.000 | 0.004 | 0.004 | |
| QR-GR | 0.005 | 0.102 | 0.102 | 0.000 | 0.032 | 0.032 | |
| Empirical SE | Proposed QR-GR SE | Naive QR SE | |
|---|---|---|---|
| 0.032 | 0.032 | 0.004 | |
| 0.032 | 0.032 | 0.003 | |
| 0.031 | 0.032 | 0.003 | |
| 0.032 | 0.032 | 0.003 | |
| 0.032 | 0.032 | 0.004 |
| Bias | SE | RMSE | Bias | SE | RMSE | ||
| QR | 0.053 | 0.286 | 0.291 | 0.138 | 0.092 | 0.166 | |
| QR-GR | 0.087 | 0.447 | 0.455 | 0.140 | 0.140 | 0.197 | |
| QR | 0.014 | 0.207 | 0.207 | 0.028 | 0.061 | 0.067 | |
| QR-GR | 0.048 | 0.510 | 0.512 | 0.037 | 0.148 | 0.152 | |
| QR | 0.001 | 0.183 | 0.183 | −0.002 | 0.055 | 0.055 | |
| QR-GR | 0.005 | 0.573 | 0.573 | 0.006 | 0.165 | 0.165 | |
| QR | −0.015 | 0.205 | 0.205 | −0.028 | 0.064 | 0.070 | |
| QR-GR | −0.009 | 0.635 | 0.635 | −0.047 | 0.200 | 0.206 | |
| QR | −0.048 | 0.270 | 0.274 | −0.144 | 0.094 | 0.172 | |
| QR-GR | −0.109 | 0.803 | 0.811 | −0.158 | 0.237 | 0.285 | |
| Empirical SE | Proposed QR-GR SE | Naive QR SE | |
|---|---|---|---|
| 0.140 | 0.136 | 0.092 | |
| 0.148 | 0.162 | 0.088 | |
| 0.165 | 0.185 | 0.089 | |
| 0.200 | 0.207 | 0.088 | |
| 0.237 | 0.241 | 0.093 |
| Sample Size | Min | Max | Mean | Std. Dev. |
|---|---|---|---|---|
| Total expenditure | 9.97 | 1587.95 | 442.92 | 253.96 |
| Housing net | −0.18 | 0.97 | 0.18 | 0.12 |
| Fuel light power | −0.15 | 0.79 | 0.04 | 0.04 |
| Food | 0.00 | 0.88 | 0.19 | 0.09 |
| Alcoholic drink | 0.00 | 0.53 | 0.04 | 0.05 |
| Tobacco | 0.00 | 0.81 | 0.02 | 0.05 |
| Clothing and footwear | 0.00 | 0.63 | 0.05 | 0.06 |
| Household goods | 0.00 | 0.84 | 0.07 | 0.08 |
| Household services | 0.00 | 0.89 | 0.06 | 0.05 |
| Personal goods and services | 0.00 | 0.82 | 0.04 | 0.04 |
| Motoring | −1.90 | 0.88 | 0.13 | 0.12 |
| Fares and other travel | 0.00 | 0.76 | 0.02 | 0.05 |
| Leisure goods | 0.00 | 0.85 | 0.04 | 0.05 |
| Leisure services | 0.00 | 1.15 | 0.12 | 0.12 |
| (a) Food | ||||||
| QR-GR SE | QR SE | QR-GR SE | QR SE | |||
| = 0.25 | 0.103 | 0.020 | 0.002 | 0.005 | 0.002 | 0.001 |
| = 0.5 | 0.140 | 0.027 | 0.003 | 0.014 | 0.003 | 0.002 |
| = 0.75 | 0.176 | 0.034 | 0.003 | 0.023 | 0.004 | 0.002 |
| (b) Housing | ||||||
| QR-GR SE | QR SE | QR-GR SE | QR SE | |||
| = 0.25 | −0.078 | 0.015 | 0.002 | −0.060 | 0.010 | 0.002 |
| = 0.5 | −0.084 | 0.017 | 0.003 | −0.079 | 0.013 | 0.002 |
| = 0.75 | −0.042 | 0.010 | 0.006 | −0.073 | 0.013 | 0.004 |
| (c) Leisure | ||||||
| QR-GR SE | QR SE | QR-GR SE | QR SE | |||
| = 0.25 | −0.024 | 0.005 | 0.002 | 0.007 | 0.002 | 0.002 |
| = 0.5 | −0.027 | 0.006 | 0.003 | 0.038 | 0.007 | 0.003 |
| = 0.75 | −0.044 | 0.009 | 0.004 | 0.073 | 0.013 | 0.005 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Galvao, A.F.; Song, S. Quantile Regression with Generated Regressors. Econometrics 2021, 9, 16. https://doi.org/10.3390/econometrics9020016
Chen L, Galvao AF, Song S. Quantile Regression with Generated Regressors. Econometrics. 2021; 9(2):16. https://doi.org/10.3390/econometrics9020016
Chicago/Turabian StyleChen, Liqiong, Antonio F. Galvao, and Suyong Song. 2021. "Quantile Regression with Generated Regressors" Econometrics 9, no. 2: 16. https://doi.org/10.3390/econometrics9020016
APA StyleChen, L., Galvao, A. F., & Song, S. (2021). Quantile Regression with Generated Regressors. Econometrics, 9(2), 16. https://doi.org/10.3390/econometrics9020016