1. Introduction
This paper concerns the estimation and inference on the structural parameters in the linear instrumental variables (IV) model estimated with ridge regression. This estimator differs from previous ridge regression estimators in three important areas. First, the regularization tuning parameter is selected using a randomly selected test sample from the observed data. Second, the empirically selected tuning parameter’s impact on the estimates of the parameters of interest is accounted for by deriving their asymptotic joint distribution, which is a mixture. Third, the traditional Generalized Method of Moments (GMM) framework is used to characterize the asymptotic distribution.
The ridge estimator belongs to a family of estimators which utilize regularization, see (
Bickel et al. 2006) and (
Hastie et al. 2009) for overviews. Regularization requires tuning parameters and procedures to select them can be split into three broad areas. (1) Plugin-type. For a given criteria function, an optimal value is determined in terms of the model’s parameters. These model’s parameters are then estimated with the data set and plugged into the formula. Generalization include adjustments to reduce bias and iterative procedures until a fixed point is achieved. (2) Test sample. The data set is randomly split into a training and a test sample. The tuning parameter and estimates from the training sample are used to evaluate some criteria function on the test sample to determine the optimal tuning parameter and model. Generalizations include k-fold cross-validation and generalized cross-validation. (3) Rate of convergence restriction. The tuning parameter must converge at an appropriate rate to guarantee consistency and a known asymptotic distribution for the estimates of the parameters of interest. A key feature is that the tuning parameter only converges to zero asymptotically and is restricted from zero in finite samples. Previous ridge estimators have relied on plugin-type and rate of convergence restrictions. We study the test sample approach.
This estimator builds on a large literature. The ridge regression estimator was proposed in (
Hoerl and Kennard 1970) to obtain smaller MSE relative to the OLS estimates in the linear model when the covariates are all exogenous but have multicollinearity. It was shown that for fixed tuning parameter,
, the bias and variance of the ridge estimator implied that there exists an
value with lower MSE than for the OLS estimator. Assuming that
is fixed,
Hoerl et al. (
1975) proposed selecting
to minimizing the MSE of the ridge estimator. This resulting formula became a plugin selection for
. Subsequent research has followed the same approach of selecting the tuning parameter to minimize MSE where
is assumed fixed, see (
Dorugade 2014) and the papers cited there. A shortcoming of this plugin-type approach is that the form of the MSE assumes the tuning parameter is fixed, however it is then selected on the observed sample and hence is stochastic, see (
Theobald 1974) and (
Montgomery et al. 2012). Instead of focusing on reducing the MSE, we focus on the large sample properties of the estimates of the parameters of interest. In this literature the work closest to ours is (
Firinguetti and Bobadilla 2011) where the sampling distribution is considered for a ridge estimator. However, this estimator is built on minimizing the MSE where the tuning parameter is assumed fixed, see (
Lawless and Wang 1976). Our ridge estimator is derived knowing that the tuning parameter is stochastic. This leads to the joint asymptotic distribution for the estimates of the parameters of interest and the tuning parameter.
The supervised learning (machine learning) literature focuses on the ability to generalize to new data sets by selecting the tuning parameters to minimize the prediction error for a test (or holdout or validation) sample. Starting with (
Larsen et al. 1996), a test sample is used to select optimal tuning parameters for a neural network model. The problem reduces to finding a local minimum of the criteria function evaluated on the test sample. Extensions of the test sample approach include backward propagation, see (
Bengio 2000;
Habibnia and Maasoumi 2019), but as the number of parameters increases the memory requirements become too large. This has led to the use of stochastic gradient decent, see (
Maclaurin et al. 2015). Much research in this area has focused on effecient ways to optimally select the hyperparameters to minimize prediction errors. We select the tuning parameter to address its impact on the estimates of the model’s coefficients and do not focus on the model’s predictive power.
A number of papers extend the linear IV model with tuning parameters. Structural econometrics (
Carrasco 2012) allows the number of instruments to grow with the sample size and (
Zhu 2018) considers models where the number of covariates and instruments is larger than the sample size. In genetics the linear IV model is widely used to model gene regulatory networks, see (
Chen et al. 2018;
Lin et al. 2015). In this setting the number of covariates and instruments can be larger than the number of observations and the tuning parameter is restricted from being zero in finite samples. In contrast to these models, we fix the number of covariates and instrument to determine the asymptotic distribution and permit the tuning parameter to take the value zero.
Within the structural econometrics literature, ridge type regularization concepts are not new. Notable contributions are (
Carrasco and Tchuente 2016;
Carrasco and Florens 2000;
Carrasco et al. 2007) which allow for a continuum of moment conditions. The authors use ridge regularization to find the inverse of the optimal weighting operator (instead of optimal weighting matrix in traditional GMM). In these papers and in (
Carrasco 2012) the rate of convergence restriction is used to select the tuning parameter.
Several types of identification and asymptotic distributions can occur with linear IV models e.g., strong instruments, nearly-strong instruments, nearly-weak instrument and weak instruments, see (
Antoine and Renault 2009) for a summary. For this taxonomy, this paper and estimator is in the strong instruments setting. The models considered in this paper are closest to the situation considered in (
Sanderson and Windmeijer 2016). However, unlike (
Sanderson and Windmeijer 2016) we provide point estimates instead of testing for weak instruments and restrict attention to fixed parameters that do not drift to zero. The models we study are explicitly strongly identified, however in a finite sample the precision can be low.
This ridge estimator extends the literature in five important dimensions. First, this estimator allows a meaningful prior. When the prior is ignored, or equivalently set to zero, the model penalizes variability about the origin. However, in structural economic models a more appropriate penalty will be variability about some economically meaningful prior. Second, the regularization tuning parameter is selected empirically using the observed data. This removes the internally inconsistent argument about the minimum MSE when the tuning parameters is assumed fixed. Third, the tuning parameter is allowed to take the value zero in finite samples. Fourth, empirically selecting the tuning parameter impacts the asymptotic distribution of the parameter estimates. As stressed in (
Leeb and Pötscher 2005), the final asymptotic distribution will depend on empirically selected tuning parameters. We address this directly by characterizing the joint asymptotic distribution that includes both the parameters of interest and the tuning parameter. Fifth, the GMM framework is used to characterize the asymptotic distribution.
1 The GMM framework is used because it is better suited to the social science setting where this estimator will be most useful. Rarely does a social science model imply the actual distribution for an error. Unconditional expectations of zero are more typical in social science theories and are the foundation for the GMM estimator. Adding a regularization penalty term and splitting the observed data into a training and test samples, takes the estimator out of the traditional GMM framework. We present new moment conditions in the traditional GMM framework which include the first order conditions for the ridge estimator.
Section 2 presents the linear IV framework, describes the precision problem and the ridge estimator.
Section 3 characterizes the asymptotic distribution of the ridge estimator in the traditional GMM framework. Small sample properties are analyzed via simulations in
Section 4. The procedure is applied to the returns to education data set from
Angrist and Krueger (
1991) in
Section 5.
Section 6 summarizes the results and presents directions for future research.
2. Ridge Estimator for Linear Instrumental Variables Model
This section presents the ridge regression estimator where regularization tuning parameter is empirically determined by splitting the data into training and test samples. This estimator is then fit into the traditional GMM framework to characterize its asymptotic distribution. Consider the model
where
Y is
,
X is
,
is
,
,
,
full rank, and conditional on
Z,
This model allows for both endogenous
X’s that are correlated with
and exogenous
X’s that are uncorrelated with
. Endogenous regressors imply OLS will be inconsistent. The
Z instruments allow consistent estimates with the IV estimator that minimizes the residual sum of squares projected onto the instruments and has the closed form
where
is the projection matrix for
Z. The well known asymptotic distribution is
and the covariance can be consistently estimated with
where
. Let
.
For a finite sample let
2 have the spectral decomposition
, where
is a positive definite diagonal
matrix, and
C is orthonormal,
. A precision problem occurs when some of the eigenvectors explain
very little variation, as represented by the magnitude of the corresponding eigenvalues. This occurs when the objective function is relatively flat along these dimensions and the resulting covariance estimates are large because as Equation (
4) shows, the variance of
is proportional to
The flat objective function, or equivalently large estimated variances, leads to a relatively large MSE. The ridge estimator addresses this problem by shrinking the estimated parameter toward a prior. The IV estimate still has low bias (it is consistent) and has the asymptotically minimum variance. However, accepting a little higher bias can have a dramatic reduction in the variance and thus provide a point estimate with lower MSE.
The ridge objective function augments the usual IV objective function (
3) with a quadratic penalty centered at a prior value,
, weighted by a regularization tuning parameter
The objective function’s second derivative is The regularization parameter injects stability since has eigenvalues for which are decreasing in . This results in smaller variance but higher bias.
Denote the ridge solution given
as
Equation (6) shows how the tuning parameter, creates a smooth curve in the parameter space between the low bias-high variance IV estimate, , (when ) to the high bias-no variance prior, , (when ).
Different values of
result in different estimated values for
. The optimal value of
is determined empirically by splitting the data into training and test samples. The training sample is a randomly drawn sample of
observations, denoted,
,
, and
, and are used to calculate a path between the IV estimate and the prior as in Equation (
6). The estimate using the training sample, conditional on
is
where
is the projection matrix onto
and
is the greatest integer function. The first order conditions for an internal solution are
or alternatively
The closed form solution is
As
goes from 0 towards infinity, this gives a path from the IV estimator,
(at
), to the prior,
(the limit as
). Following this path, the optimal
is selected to minimize the IV least squares objective function (
3) over the remaining
observations, the test sample, denoted
,
and
. The optimal value for the tuning parameter is defined by
where
where
is the projection matrix onto
or alternatively
The ridge regression estimate
is then characterized by
or alternatively
The first order conditions that characterize the ridge estimator, Equations (
8), (
11), and (
12), are
equations in the
parameters and have the structure of sample averages being set to zero. However, the functions being averaged do not fit into the traditional GMM framework. In Equations (
8), (
11), and (
12) the terms in the curly brackets depend on the entire sample and not just the data for index
i and the parameters. The terms in the curly brackets will converge at
and must be considered jointly with the asymptotic distributions of
.
The asymptotic distribution of the ridge estimator can be determined with the GMM framework using the parameterization
where
stacks the elements from a matrix into a column vector and
stacks the unique elements from a symmetric matrix into a column vector. The population parameter values are
The ridge estimator is part of the parameter estimates defined by the just identified system of equations
where
and the training and test samples are determined with the indicator function
Using the structure of Equation (
13), the system
can be seen as seven sets of equations. The first four sets are each self-contained systems of equal numbers of equations and parameters. The fifth set has
k equations and introduces
k new parameters,
. The six is a single equation with the new parameter
. The seventh set has
k equations and introduces the final
k parameters,
. Identification occurs because the expectation of the gradient is invertible. This is presented in the
Appendix A and
Appendix B.
3. Asymptotic Behavior
Three assumptions are sufficient to obtain asymptotic distribution for the ridge estimator.
Assumption 1. is iid with finite fourth moments and has full rank.
Assumption 2. Conditional on Z, are iid vectors with zero mean, full rank covariance matrix with possibly nonzero off-diagonal elements.
Assumptions 1 and 2 imply and satisfies the CLT.
Assumption 3. The parameter space Θ is defined by: is restricted to a symmetric positive definite matrix with eigenvalues for , is of full rank with for , and where , , and are positive and finite.
First consider the tuning parameter. Even though it is empirically selected using the training and testing samples, its limiting value and rate of convergence are familiar.
Lemma 1. Assumptions 1, 2 and 3 imply
- (1)
and
- (2)
Lemma 1 implies that the population parameter value for the tuning parameter is zero,
, which is on the boundary of the parameter space. This results in a nonstandard asymptotic distribution which can be characterized by appealing to Theorem 1 in (
Andrews 2002). The approach in (
Andrews 2002) requires the root-
n convergence of the parameters. Lemma 1, traditional TSLS and method of moments establishes this for all the parameters in
. Equation Equation (
13) puts the ridge estimator in the form of the first part of (14) from (
Andrews 2002). Because the system is just identified, the weighting matrix does not affect the estimator and is set to the identity matrix. The scaled GMM objective function can be expanded into a quadratic approximation about the centered and scaled population parameter values
The first term does not depend on
and the last term converges to zero in probability. This suggests that selecting
to minimize
will result in the asymptotic distribution of
being the same as the distribution of
where
takes its minimum, where the random variable is defined as
and
This indeed is the result by Theorem 1 of (
Andrews 2002). The needed assumptions are given in (
Andrews 2002). The estimator is defined as
Theorem 1. Assumptions 1–3 imply the asymptotic distribution of is equivalent to the distribution of The objective function can be minimized at a value of the tuning parameter in or possibly at The asymptotic distribution of the tuning parameter will be composed of two parts, a discrete mass at and a continuous function over . The asymptotic distribution over the other parameters can be thought of as being composed of two parts, the distribution conditional on and the distribution over
In terms of the framework presented in (
Andrews 2002), the random sample is used to create a random variable. This is then projected onto the parameter space, which is a cone. The projection onto the cone results in the discrete mass at
and the continuous mass over
. As noted in (
Andrews 2002), this type of a characterization of the asymptotic distribution can be easily programmed and simulated.
4. Small Sample Properties
To investigate the small sample performance, linear IV models are simulated and estimated using TSLS and the ridge estimator. The model is given in Equations (1) to (4) with
and
. To standardize the model, set
and
= (0, 0)’. Endogeneity is created with
The strength of the instrument signal is controlled by the parameter
3 in
To judge the behavior of the estimator, three different dimensions of the model are adjusted.
- 1.
Sample size. For smaller sample sizes, the ridge estimator should have better properties whereas for larger sample sizes, TSLS should perform better. We consider sample sizes of , 50, 250 and 500.
- 2.
Precision. Signal strength of the instruments is one way to vary precision. The instrument signal strength decreases with the value of above, conditional on holding the other model parameters fixed. For lower precision settings or smaller signal strengths the ridge estimator should perform better. We consider values of , 0.25, 0.5 and 1. Note that while leads to a high precision setting for all sample sizes considered, leads to a low precision setting in smaller samples and a high precision setting in larger samples.
- 3.
Prior value relative to
. For the prior closer to the population parameter values the ridge estimator should perform relatively better. We consider values of
which were (a) one standard deviation
4 from the true value
, (b) two standard deviations from the true value
and (c) three standard deviations from the true value
5.
We simulate a total of 48 model specifications corresponding to 4 sample sizes
n, 4 values of the precision parameter
and 3 values of the prior
. Each specification is simulated 10,000 times and both TSLS and ridge estimator are estimated. We compare estimated
values on bias, variance and MSE. For the ridge estimator we use
to split the sample between training and test samples.
6The regularization parameter
is selected in two steps—first, we search in the log-space going from
to
; second, we perform a grid search
7 in a linear space around the value selected in the first step. A final selected value of
in the second step corresponds to a “no regularization” scenario which implies the ridge estimator ignores the prior in favor of the data and the value
corresponds to an “infinite regularization” scenario which implies the ridge estimator ignores the data in favor of the prior.
Table 1 and
Table 2 compare the performance of the TSLS estimator with the ridge estimator for different precision levels and sample sizes when the prior is fixed at
and
respectively. Recall, our parameter of interest is
. We compare the estimators based on (a) bias, (b) standard deviation of the estimates, (c) MSE values of the estimates and (d) sum of MSE values of
and
. In both tables, the TSLS estimator performs as expected—both bias and standard deviation of estimates fall as sample size increases and as instrument signal strength increases. In smaller samples, the TSLS estimators exhibit some bias, which confirms that TSLSL estimators are consistent but not unbiased.
Table 1 presents a scenario where the prior for the ridge estimator is one standard deviation away from the true parameter estimate. We note that in the low precision setting of
the ridge estimator has lower MSE for all sample sizes considered in the simulations. However as precision improves, we note that for larger sample sizes the TSLS estimator has lower MSE.
Table 2 describes a scenario where the ridge estimator does not have any particular advantage since it is biased to a prior which is 3 standard deviations away from the true parameter value. However, even when prior values are far from true parameter values, there are a number of scenarios where the ridge estimator outperforms the TSLS estimator in terms of MSE. In particular, in small samples and low precision settings, the ridge estimator leads to smaller MSE. When
, the ridge estimator leads to lower MSE values for all sample sizes except
. When
and the model has high precision, the ridge estimator has higher MSE than TSLS. Thus as the signal strength improves and low precision issues subside, TSLS dominates. The bias-variance trade-off is at work here. Consider the results corresponding to
and
. The ridge estimator has
higher bias compared to the TSLS estimator for both parameters, however this is compensated by considerably smaller standard deviation values leading to smaller MSE. This table also demonstrates scenarios where for a given
value, as the sample size increases the estimator with lower MSE changes from ridge to TSLS. For
, the ridge estimator performs better for sample sizes
whereas TSLS performs better for
. Similarly, for
, the ridge estimator outperforms TSLS only for the smallest sample size of
.
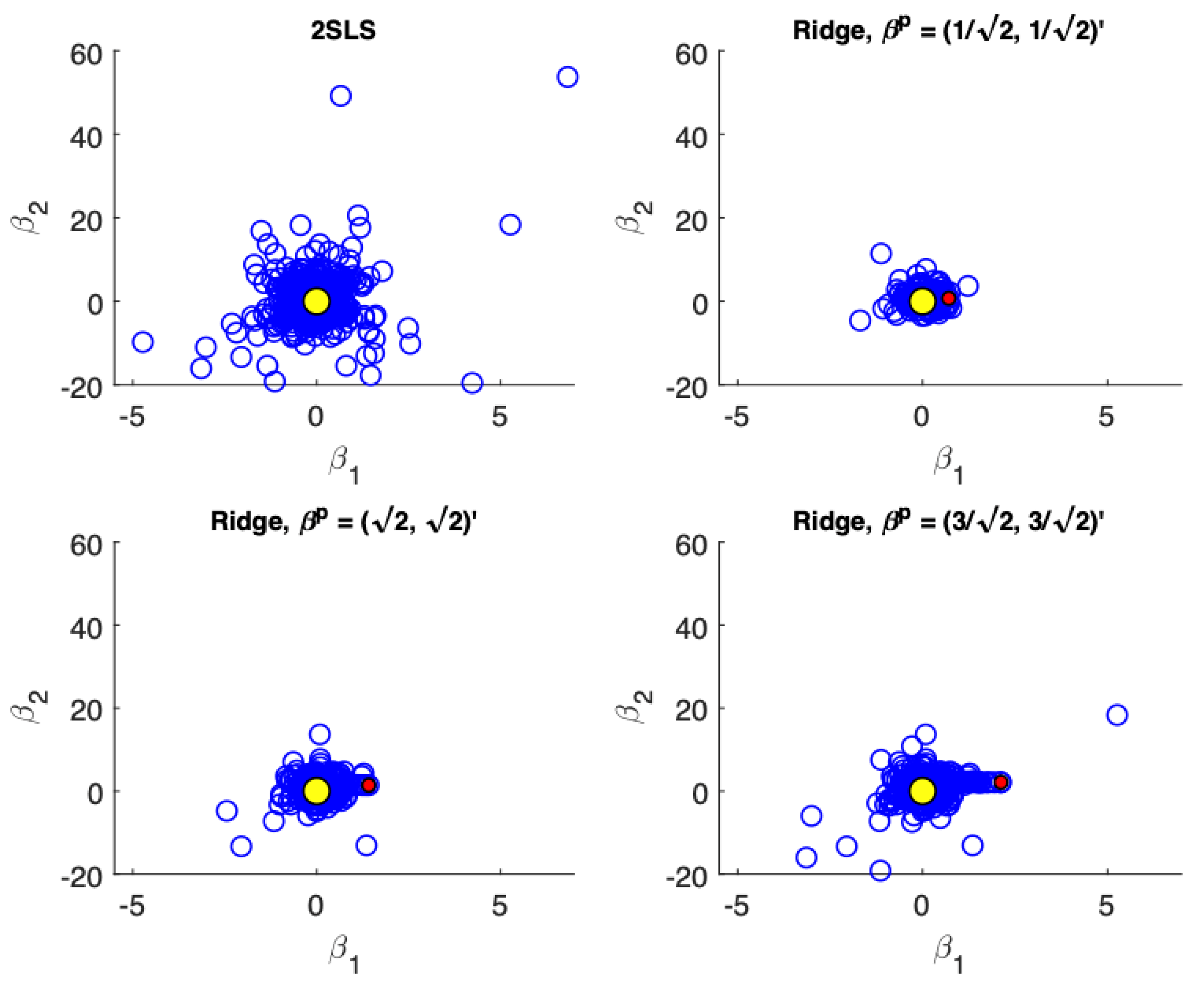
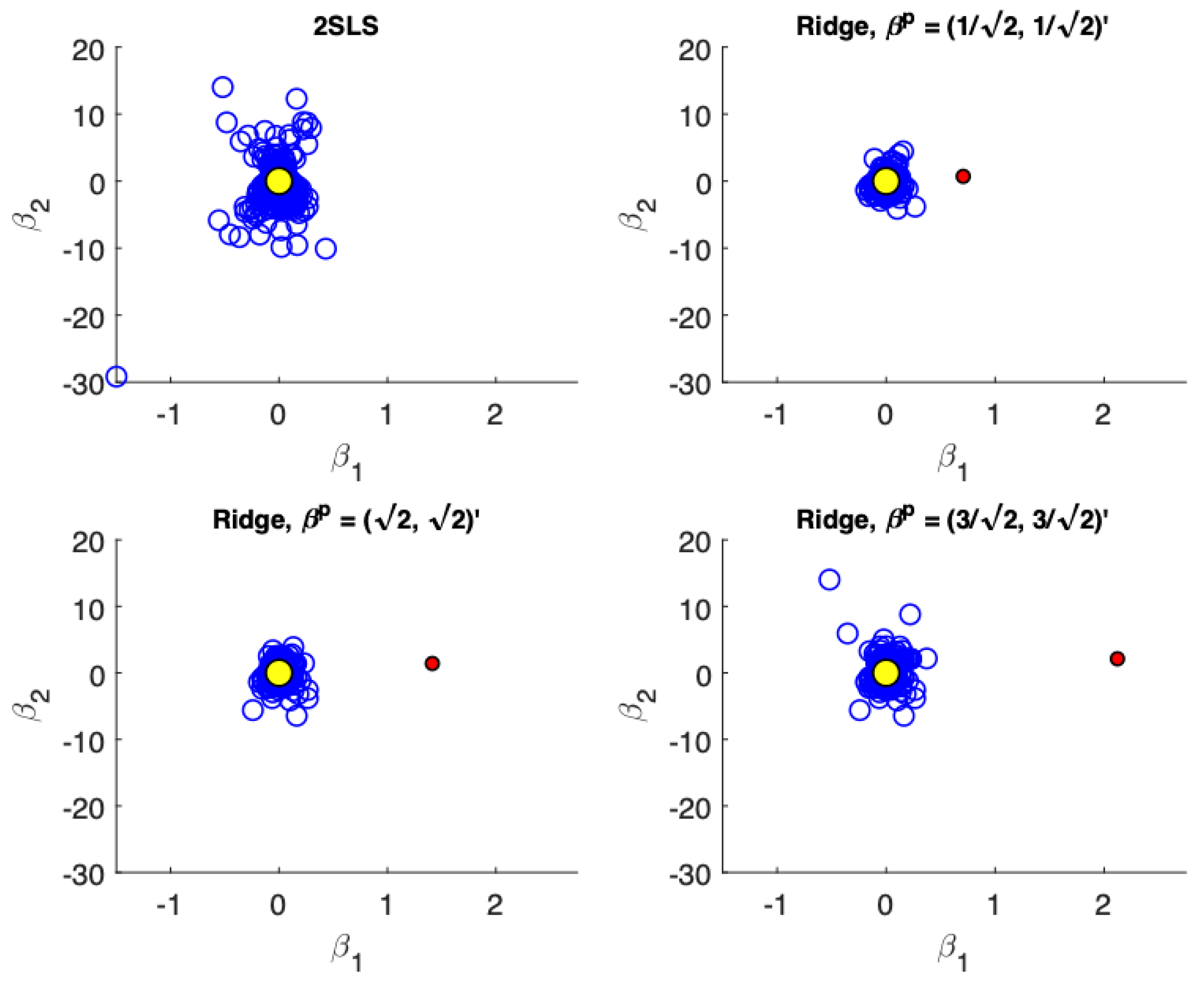
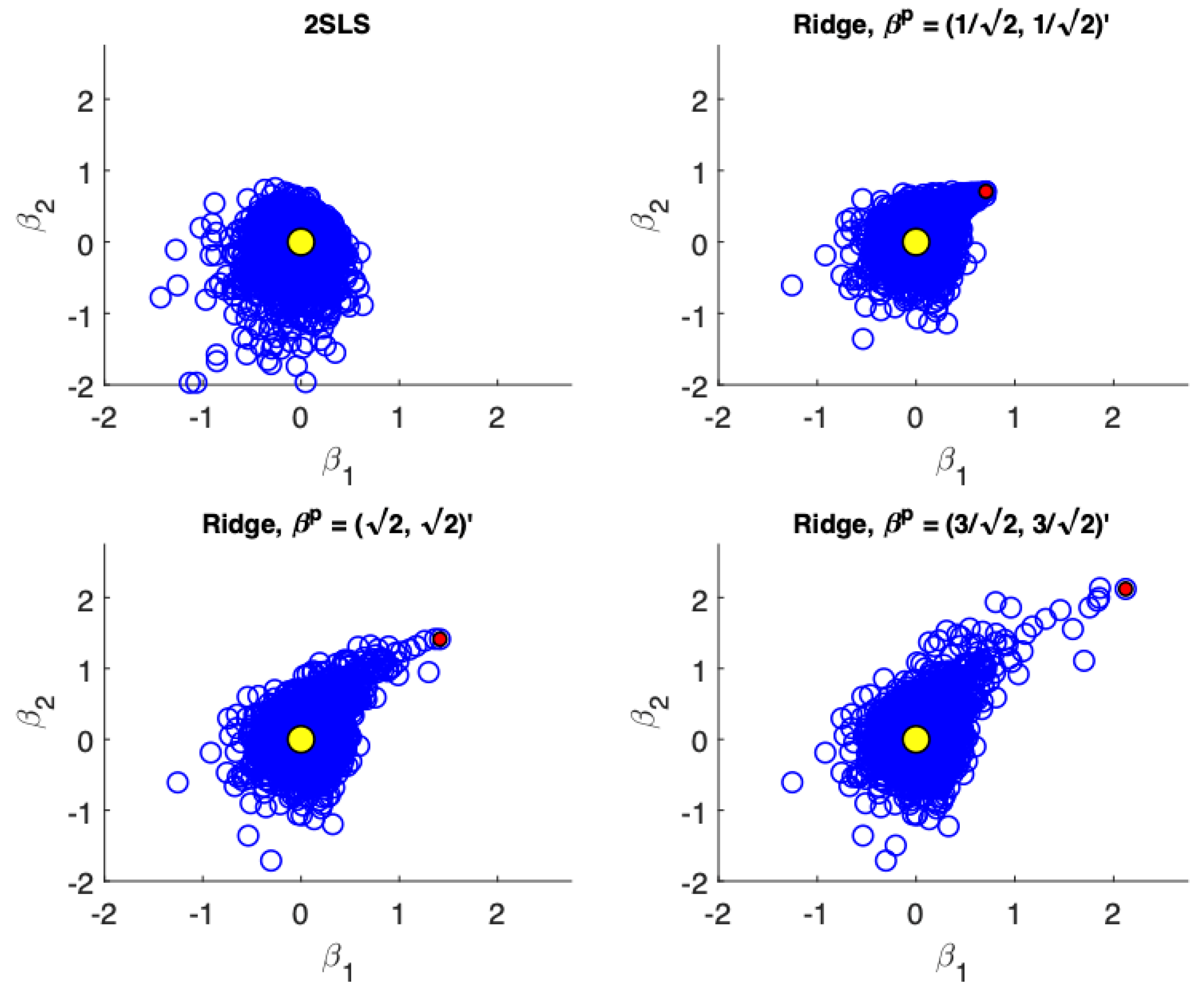
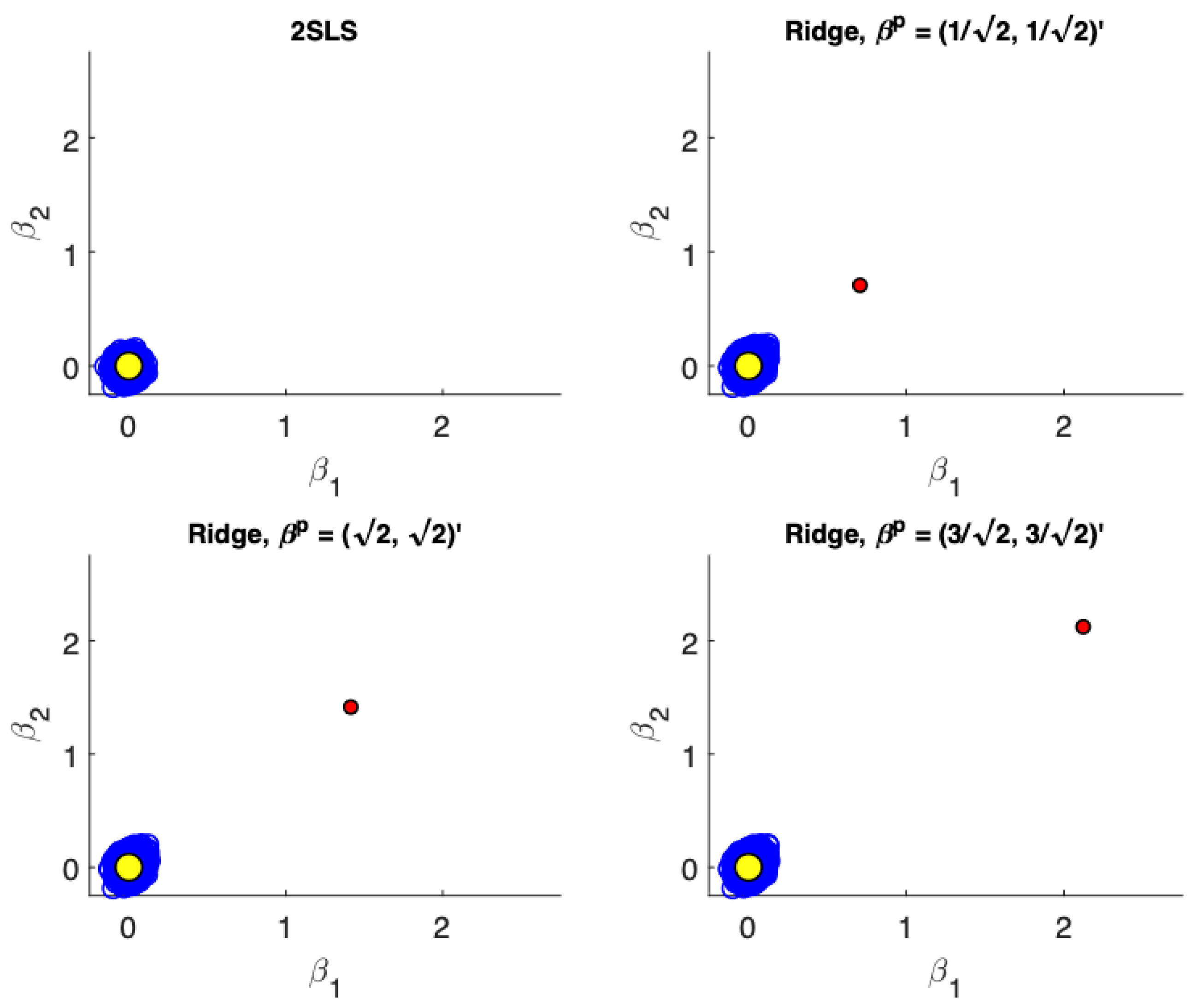
Figure 1,
Figure 2,
Figure 3 and
Figure 4 present scatter plots of the estimates from TSLS and ridge estimator with different priors for the following cases: (a) low precision, small sample size; (b) low precision, large sample size; (c) high precision, small sample size; (d) high precision, large sample size. These figures demonstrate the influence of the priors. The prior pulls the ridge estimates away from the population parameter values. For low precision models (
), the variance associated with TSLS estimates is larger than the ridge estimates, even in larger sample sizes. The ridge estimator is biased towards the prior which is demonstrated by the estimates not being distributed symmetrically around the true value. On the other hand, for high precision models (
) the variance reduction from TSLS for the ridge estimator is not as dramatic. In fact, while the variance reduction appears substantial for the prior value of
, it is unclear at least visually if there is a reduction in variance for a poorly specified prior at
. In larger samples with high precision (
Figure 4) the TSLS estimates outperform the ridge estimators which is demonstrated by larger clouds which are slightly off-center from the true parameter values. However, ridge estimators using different priors are still competitive and don’t lead to a drastically worse performance (as a reference compare the performance of the TSLS estimates to the ridge estimates in
Figure 1).
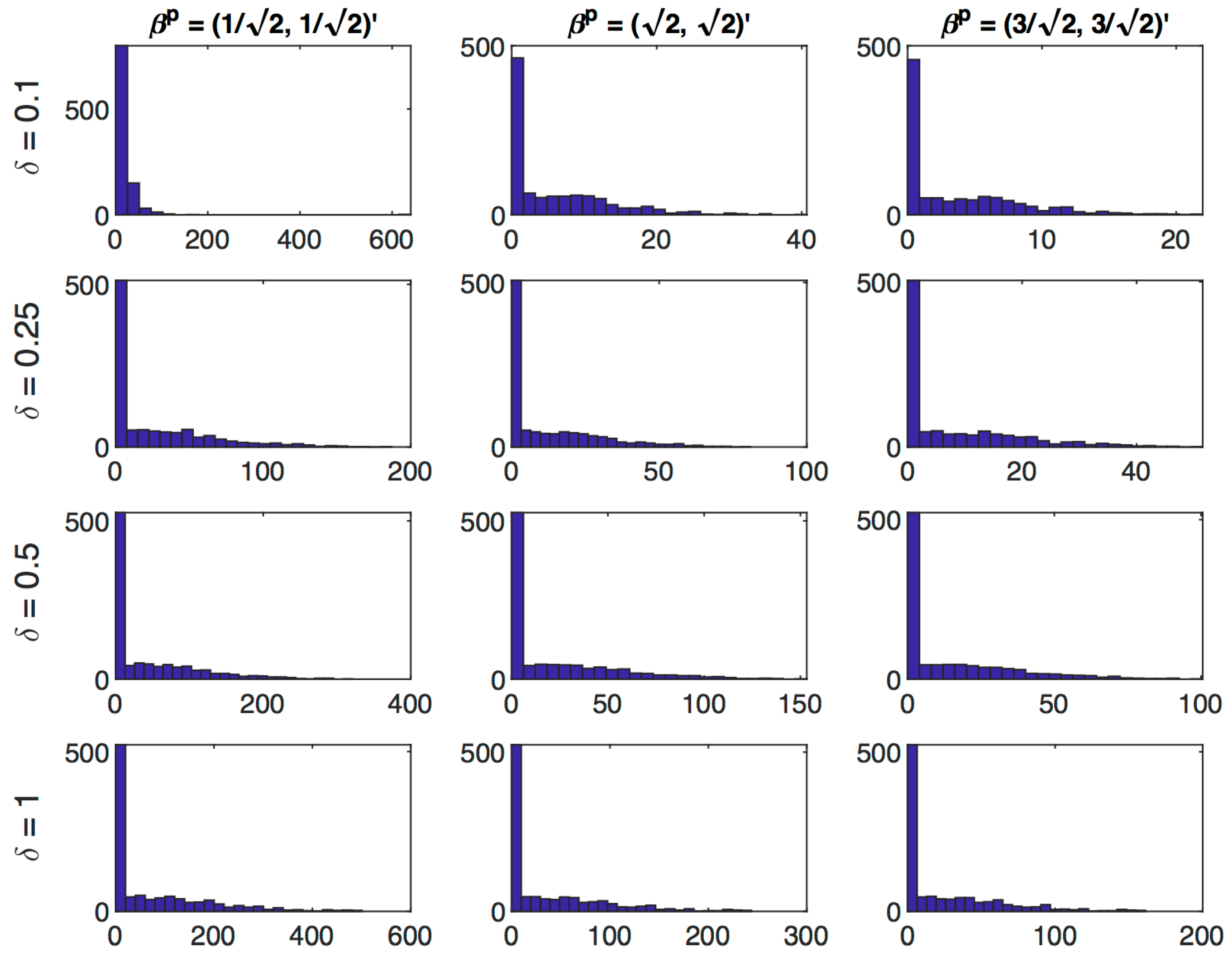
Table 3, summarizes the distribution of the estimated regularization parameter
for different precision levels, sample sizes and prior values. Recall Theorem 1 implies the asymptotic distribution will be a mixed distribution with some discrete mass at
Table 3 reports the proportion of cases which correspond to “no regularization” (
), “infinite regularization” (
) and “some regularization” (
). In all cases, there is a substantial mass of the distribution concentrated at
. On the other hand we note that except in the cases where the prior is located at the true parameter value, there is no mass concentrated at
. We see some interesting variations corresponding to different prior values. In low precision settings (particularly
), keeping sample size fixed, as the prior moves away from the true value, the proportion of cases with “no regularization” increases whereas the proportion of cases with “some regularization” falls. Similarly for high precision settings (particularly
), as the sample size increases, the proportion of cases with “no regularization” increases whereas the proportion of cases with “some regularization” falls. In this table we also present results for large sample sizes of
10,000, which demonstrate that the mass at
approaches
asymptotically, as predicted by Theorem 1. Distributions of
for large sample sizes of
10,000 via histograms are presented in
Figure 5.
Table 4 presents summaries of the smallest singular value of the matrix
8 for different values of
and
n. The estimated asymptotic standard deviation is inversely related to the smallest singular value, or equivalently smaller singular values are associated with flatter objective functions at their minimum values. As the precision parameter increases from
to
, the mean of the smallest singular value increases. As the sample size increases, the variance of the smallest singular values decreases.
5. Returns to Education
This section revisits the question of returns to schooling in
Angrist and Krueger (
1991). The key insight of that paper was the use of quarter of birth indicator variables as instruments to uniquely identify the impact of years of education on wages. The data are Public use Micro Sample of the 1980 U.S. Census and includes men born between 1920 and 1949 with positive earnings in 1979 and no missing observations. The sample is divided into three data sets, one for each decade. The empirical results are summarized in
Table 5.
The specification explains the log of weekly wages with the years of education; with race, standard metropolitan statistical area, marital status, region dummies, and year of birth dummies as controls
9. The same data set was used in (
Staiger and Stock 1997) which focused on weak instruments using the quarter of birth interacted with year of birth to create 30 instruments. To avoid weak instruments, we restrict attention to the quarter of birth dummy variables as instruments. This gives three instruments for years of education. The resulting first stage F-tests give no indication of weak instruments. The appropriateness of the specification is tested with the Basmann test for overidentify restrictions. The specification is not rejected for the 1920s and 1930s. However, the specification is rejected for the 1940s.
Each sample is split into a training sample with
and a testing sample. The empirical results will be sensitive to this randomization. For each decade, the data was read into R from the Stata data set from the Angrist Data Archive at MIT, dplyr was used to filter the data for each decade and the random seed was set in R with “set.seed(12345)”. The samples have hundreds of thousands of observations,
n, with 22 parameters estimated. However, there are precision problems with these estimates. As noted above in
Section 2, the precision can be judged by the magnitude of the smallest eigenvalue of the second derivative of the objective function at the TSLS estimate for the entire sample, these are denoted
. The precision can also be judged with the condition number for the second derivatives which varies between 12 million and 282 million.
The prior for the ridge estimates was set empirically to judge the variability in the parameter estimates in the least informative dimension of the parameter space. The prior was set at four times the eigenvector associated with the smallest eigenvalue of the second derivative of the TSLS objective function for the training sample. This is moving four unit lengths away from the TSLS estimate in the flattest (least informative) direction. The ridge estimator is then defined by the value of that minimizes the TSLS objective function using the test sample.
Even with the large sample sizes, the prior impacts the estimates. For the 1930s and 1940s the ridge estimate is between the OLS and the TSLS estimates. For the 1920s the ridge estimate is below both the TSLS estimate and the OLS estimate.
A final simulation exercise compares TSLS estimates with ridge estimates using the
Angrist and Krueger (
1991) data. As above the specification explains the log of weekly wages with the years of education; with race, standard metropolitan statistical area, marital status, region dummies, and year of birth dummies as controls. The quarter of birth dummies provide three instruments for years of education. Using the parameter estimates obtained by running the TSLS estimation on the entire sample from 1930s we obtain residuals
and
and their estimated covariance matrix. We then draw
10,000 random samples of size
n with replacement for the instruments and control variables and use these along with the full sample parameter estimates and error covariance to obtain simulated values of years of education and log of weekly wages.
TSLS and ridge estimates are obtained for each random sample and compared on the basis of bias, standard deviation and root mean square error (RMSE). For the ridge estimates each sample is split into a training sample with
and a testing sample. Priors for all parameters are set to
i.e., the TSLS parameter estimate using only the training sample, except the parameter corresponding to returns to education. Three priors are considered for the returns to education parameter:
,
and
. Results presented in
Table 6 demonstrate that for the smallest sample size of
n = 1000 ridge estimates corresponding to all three priors produce lower RMSE values for the parameter of interest compared to TSLS. On the other hand for the larger sample size of
100,000 TSLS estimates produce lower RMSE values compared to ridge estimates for all three priors.
6. Conclusions
The asymptotic distribution of the ridge estimator when the tuning parameter is selected with a test sample has been characterized. This estimator incorporates a non-zero prior and allows the non-negative tuning parameter to be zero. The resulting asymptotic distribution is a mixture with discrete mass on zero for the tuning parameter, a novel result, which follows from the true value of the tuning parameter lying on the boundary of the parameter space.
Simulations demonstrate where the ridge estimator produced lower MSE than the TSLS estimator, specifically when model precision is low, particularly in smaller samples and often even in larger samples. Where the TSLS estimator has lower MSE, particularly when precision is high, the ridge estimator remains competitive. As an empirical application, we have applied this procedure to the returns from education dataset used in (
Angrist and Krueger 1991). Importantly, even with over 200,000 observations, the prior still influences the point estimates.
The ridge estimator will be particularly useful in addressing applied empirical questions where TSLS is appropriate but the available data suffers from low precision or where the sample size available is small. The characterization the asymptotic distribution of the ridge estimator also provides a useful framework for other estimators that involve tuning parameters.
Extensions and improvements of the approach are worthwhile to pursue. Different loss functions can be applied to the test sample (e.g., k-fold cross validation), we can allow for multiple tuning parameters, consider models without a closed form solution, allow the number of covariates to grow with the sample size, allow the number of tuning parameters to grow with the sample size, consider situation with weak instruments or nearly weak instruments, allow other penalty terms such as the LASSO or elastic-net.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}