Sensitivity Analysis of an OLS Multiple Regression Inference with Respect to Possible Linear Endogeneity in the Explanatory Variables, for Both Modest and for Extremely Large Samples



Abstract
1. Introduction
1.1. Motivation
1.2. Relation to Previous Work on OLS Multiple Regression Estimation/Inference
- Improved Sampling Distribution Derivation, via a Restriction to “Linear Endogeneity”In response to the critique in Kiviet (2016) of the OLS parameter sampling distribution under endogeneity given in Ashley and Parmeter (2015a), we now obtain this asymptotic sampling distribution, in a particularly straightforward fashion, by limiting the universe of possible endogeneity to solely-linear relationships between the explanatory variables and the model error. In Section 2 we show that the OLS parameter sampling distribution does not then depend on the third and fourth moments of the joint distribution of the explanatory variables and the model errors under this linear-endogeneity restriction. This improvement on the Kiviet and Niemczyk (2007, 2012) and Kiviet (2013, 2016) sampling distribution results—which make no such restriction on the form of endogeneity, but do depend on these higher moments—is crucial to an empirically-usable sensitivity analysis: we see no practical value in a sensitivity analysis which quantifies the impact of untestable exogeneity assumptions only under empirically-inaccessible assumptions with regard to these higher moments. On the other hand, while endogeneity that is linear in form is an intuitively understandable notion—and corresponds to the kind of endogeneity that will ordinarily arise from the sources of endogeneity usually invoked in textbook discussions—this restriction to the sensitivity analysis is itself somewhat limiting; this issue is further discussed in Section 2 below.
- Analytic Results for a Non-Trivial Special CaseWe now obtain closed-form results for the minimal degree of explanatory-variable to model-error correlation necessary in order to overturn any particular hypothesis testing result for a single linear restriction, in the special (one-dimensional) case where the exogeneity of a single explanatory variable is under scrutiny.2
- Simulation-Based Check with Regard to Sample-Length AdequacyBecause the asymptotic bias in depends on , the population variance-covariance matrix of the explanatory variables in the regression model, sampling error in —the usual (consistent) estimator of —does affect the asymptotic distribution of when this estimator replaces in our sensitivity analysis, as pointed out in Kiviet (2016). Our algorithm now optionally uses bootstrap simulation to quantify the impact of this replacement on our sensitivity analysis results.We find this impact to be noticeable, but manageable, in our illustrative empirical example, the classic Mankiw, Romer, and Weil (Mankiw et al. 1992) examination of the impact of human capital accumulation (“”), which uses observations. This example does not necessarily imply that this particular sample length is either necessary or sufficient for the application of this sensitivity analysis to other models and data sets; we consequently recommend performing this simulation-based check (on the adequacy of the sample length for this purpose) at the outset of the sensitivity analysis in any particular regression modeling context.3
- Sensitivity Analysis with Respect to Coefficient Size—Especially for Extremely Large SamplesIn some settings—financial and agricultural economics, for example—analysts’ interest centers on the size of a particular model coefficient rather than on the p-value at which some particular null hypothesis with regard to the model coefficients can be rejected. The estimated size of a model coefficient is generally also a better guide to its economic (as opposed to its statistical) significance—as emphasized by McCloskey and Ziliak (1996).Our sensitivity analysis adapts readily in such cases, to instead depict how the estimated confidence interval for a particular coefficient varies with the vector of correlations between the explanatory variables and the model error term; we denote this is as “parameter-value-centric” sensitivity analysis below. For a one-dimensional analysis, where potential endogeneity is contemplated in only a single explanatory variable, the display of such results is easily embodied in a plot of the estimated confidence interval for this specified regression coefficient versus the single endogeneity-correlation in this setting.We supply two such plots, embodying two such one-dimensional “parameter-value-centric” sensitivity analyses, in Section 4 below; these plots display how the estimated confidence interval for the Mankiw, Romer and Weil (MRW) human capital coefficient (on their “” explanatory variable in our illustrative example) separately varies with the posited endogeneity correlation in each of two selected explanatory variables in the model. Our implementing algorithm itself generalizes easily to multi-dimensional sensitivity analyses—i.e., sensitivity analysis with respect to possible (simultaneous) endogeneity in more than one explanatory variable—and several examples of such two-dimensional sensitivity analysis results, with regard to the robustness/fragility of the rejection p-values for hypothesis tests involving coefficients in the MRW model, are presented in Section 4. We could thus additionally display the results of a two-dimensional “parameter-value-centric” sensitivity analysis for this model coefficient—e.g., plotting how the estimated confidence interval for the MRW human capital coefficient varies with respect to possible simultaneous endogeneity in both of these two MRW explanatory variables—but the display of these confidence interval results would require a three-dimensional plot, which is more troublesome to interpret.4Perhaps the most interesting and important applications of this “parameter-value-centric” sensitivity analysis will arise in the context of models estimated using the extremely large data sets now colloquially referred to as “big data.” In these models, inference in the form of hypothesis test rejection p-values is frequently of limited value, because the large sample sizes in such settings quite often render all such p-values uninformatively small. In contrast, the “parameter-value-centric” version of our endogeneity sensitivity analysis adapts gracefully to such large-sample applications: in these settings each estimated confidence interval will simply shrink to what amounts to a single point, so in such cases the “parameter-value-centric” sensitivity analysis will in essence be simply plotting the asymptotic mean of a key coefficient estimate against posited endogeneity-correlation values. It is, of course, trivial to artificially extend our MRW example to a huge sample and display such a plot for illustrative purposes, and this is done in Section 4 below. But consequential examples of this sort of sensitivity analysis must await the extension of the OLS-inference sensitivity analysis proposed here to the nonlinear estimation procedures typically used in such large-sample empirical work.5
1.3. Preview of the Rest of the Paper
2. Sampling Distribution of the OLS Multiple Regression Parameter Estimator With Linearly-Endogenous Covariates
3. Proposed Sensitivity Analysis Algorithm
3.1. Obtaining Inference Results and the Endogeneity Correlation Vector (), Given the Endogeneity Covariance Vector ()
3.2. Calculation of , the Minimal-Length Endogeneity Correlation Vector Overturning the Hypothesis Test Rejection
3.3. Closed-Form Result for the Minimal-Length Endogeneity Correlation () Overturning the Hypothesis Test Rejection in the One-Dimensional Case
3.4. Simulation-Based Check on Sample-Length Adequacy with Regard to Substituting for
3.5. Preliminary Remarks on the Interpretation of the Length of as Characterizing the Robustness/Fragility of the Inference
3.6. Extension to “Parameter-Value-Centric” Sensitivity Analysis
4. Revised Sensitivity Analysis Results for the Mankiw, Romer, and Weil Study
- First of all, we did not need to make any additional model assumptions beyond those already present in the MRW study. In particular, our sensitivity analysis does not require the specification of any information with regard to the higher moments of any of the random variables—as in Kiviet (2016, 2018)—although it does restrict attention to linear endogeneity and brings in the issue of sampling variation in .
- Second, we were able to examine the robustness/fragility with respect to possible explanatory variable endogeneity for both of the key MRW inferences, one of which was the rejection of a simple zero-restriction and the other of which was the failure to reject a more complicated linear restriction.25
- Third, we found clear evidence of both robustness and fragility in the MRW inferences, depending on the null hypothesis and on the explanatory variables considered.
- Fourth, we did not—in this data set—find that the multi-dimensional sensitivity analyses (with respect to two or three of the explanatory variables at a time) provided any additional insights not already clearly present in the one-dimensional sensitivity analysis results, the latter of which are computationally very inexpensive because they can use our analytic results.
- And fifth, we determined that the bootstrap-simulated standard errors in the values (arising due to sampling variation in the estimated explanatory-variable variances) are already manageable—albeit not negligible—at the MRW sample length, of . Thus, doing the bootstrap simulations is pretty clearly necessary with a sample of this length; but it also sufficient, in that it suffices to show that this sample is sufficiently long as to yield useful sensitivity analysis results.26
- We could just as easily have used 500 or 5000 endogeneity-covariance values: because (in contrast to the computation of ) these calculations do not involve a numerical minimization, the production of these figures requires only a few seconds of computer time regardless.
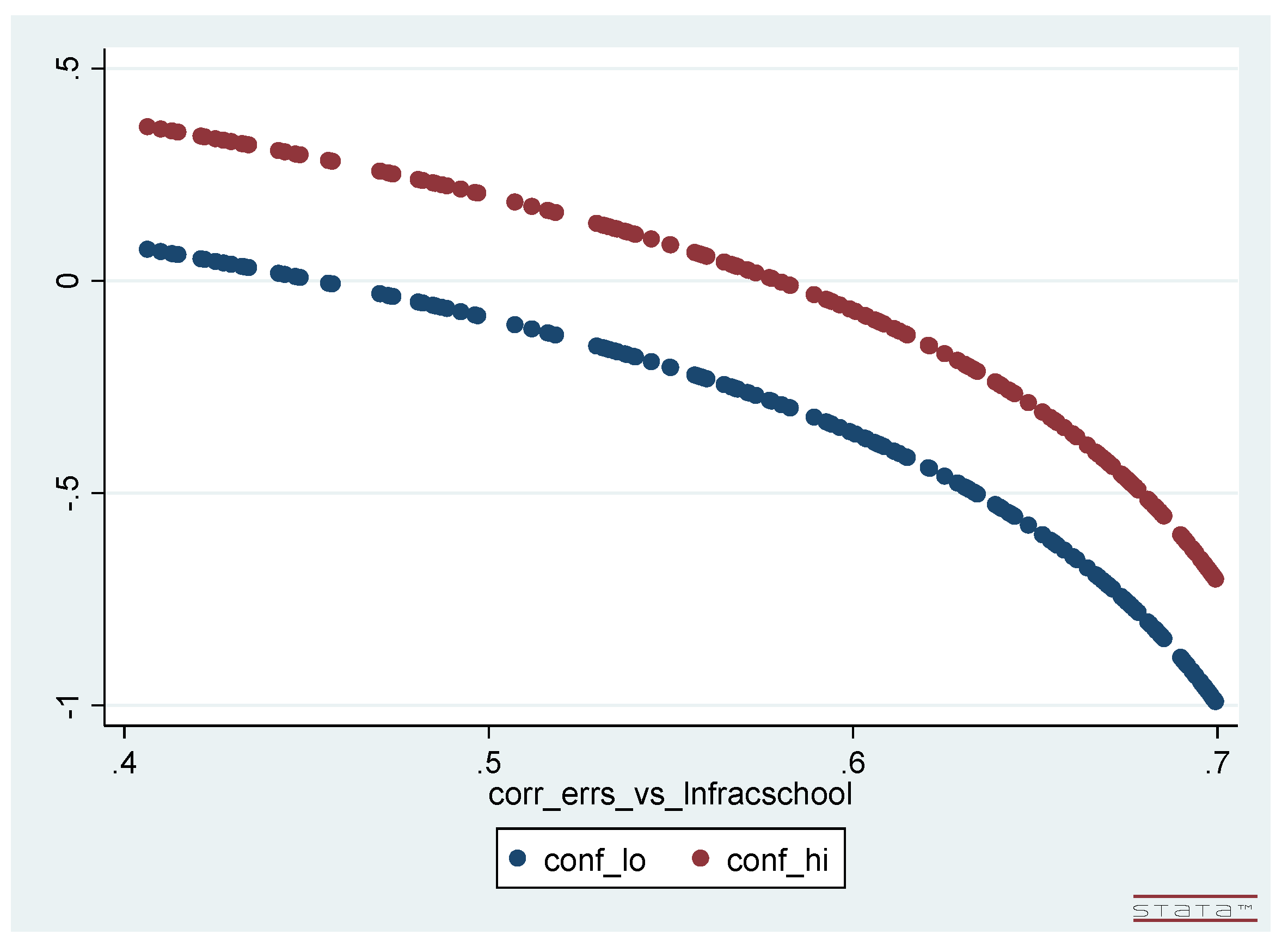
- These plots of the upper and lower limits of the confidence intervals are nonlinear—although not markedly so—and the (vertical) length of each interval does depend (somewhat) on the degree of endogeneity-correlation.
- For a two-dimensional, “parameter-value-centric” sensitivity analysis—analogous to the “ & ” column in Table 1 listing our “hypothesis-testing-centric” sensitivity analysis results—the result would be a single three-dimensional plot, displaying (as its height above the horizontal plane) how the confidence interval for varies with the two components of the endogeneity-correlation vector which are now non-zero. In the present (linear multiple regression model) setting, this three-dimensional plot is graphically and computationally feasible, but not clearly more informative than Figure 1 and Figure 2 from the pair of one-dimensional analyses. And for a three-dimensional “parameter-value-centric” sensitivity analysis—e.g., analogous to the “All Three” column in Table 1—it would still be easily feasible to compute and tabulate how the confidence interval for varies with the three components of the endogeneity-correlation vector which are now non-zero; but the resulting four dimensional plot is neither graphically renderable nor humanly visualizable, and a tabulation of these confidence intervals (while feasible to compute and print out) is not readily interpretable.
- One can easily read off from each of these two figures the result of the corresponding one-dimensional, “hypothesis-testing-centric” sensitivity analysis for the null hypothesis —i.e., the value of : One simply observes the magnitude of the endogeneity-correlation value for which the graph of the upper confidence interval limit crosses the horizontal () axis and the magnitude of the endogeneity-correlation value for which the graph of the lower confidence interval limit crosses this axis: is the smaller of these two magnitudes.27
- Finally, if the MRW sample were expanded to be huge—e.g., by repeating the 98 observations on each variable an exceedingly large number times—then the upper and lower limits of the confidence intervals plotted in Figure 1 and Figure 2 would collapse into one another. The plotted confidence intervals in these figures would then essentially become line plots, and each figure would then simply be a plot of the “” component of versus the single non-zero component of the endogeneity correlation vector, .28 Such an expansion is, of course, only notional for an actual data set of modest length, but—in contrast to hypothesis testing in general (and hence to “hypothesis-testing-centric” sensitivity analysis in particular—this feature of the “parameter-value-centric” sensitivity analysis results illustrates how useful this kind of analysis would remain in the context of modeling the huge data sets recently becoming available, where the estimational/inferential distortions arising due to unaddressed endogeneity issues do not diminish as the sample length expands.
5. Implementation Considerations
6. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Arellano, Manuel, Richard Blundell, and Stephane Bonhomme. 2018. Nonlinear Persistence and Partial Insurance: Income and Consumption Dynamics in the PSID. AEA Papers and Proceedings 108: 281–86. [Google Scholar] [CrossRef]
- Ashley, Richard A. 2009. Assessing the Credibility of Instrumental Variables with Imperfect Instruments via Sensitivity Analysis. Journal of Applied Econometrics 24: 325–37. [Google Scholar] [CrossRef]
- Ashley, Richard A., and Christopher F. Parmeter. 2015a. When is it Justifiable to Ignore Explanatory Variable Endogeneity in a Regression Model? Economics Letters 137: 70–74. [Google Scholar] [CrossRef][Green Version]
- Ashley, Richard A., and Christopher F. Parmeter. 2015b. Sensitivity Analysis for Inference in 2SLS Estimation with Possibly-Flawed Instruments. Empirical Economics 49: 1153–71. [Google Scholar] [CrossRef]
- Ashley, Richard A., and Christopher F. Parmeter. 2019. Sensitivity Analysis of OLS Multiple Regression Inference with Respect to Possible Linear Endogeneity in the the Explanatory Variables. Working Paper. Available online: https://vtechworks.lib.vt.edu/handle/10919/91478 (accessed on 6 October 2019).
- Caner, Mehmet, and Melinda Sandler Morrill. 2013. Violation of Exogeneity: A Joint Test of Structural Parameters and Correlation. Available online: https://4935fa4b-a-bf11e6be-s-sites.googlegroups.com/a/ncsu.edu/msmorrill/files/CanerMorrill_NT (accessed on 4 March 2020).
- Davidson, Russell, and James G. MacKinnon. 1993. Estimation and Inference in Econometrics. New York: Oxford University Press. [Google Scholar]
- Efron, Bradley. 1979. Bootstrapping Methods: Another Look at the Jackknife. Annals of Statistics 7: 1–26. [Google Scholar] [CrossRef]
- Friedman, Milton. 1953. Essays in Positive Economics. Chicago: University of Chicago Press. [Google Scholar]
- Johnston, Jack. 1992. Econometric Methods. New York: McGraw-Hill. [Google Scholar]
- Kiviet, Jan F. 2013. Identification and Inference in a Simultaneous Equation Under Alternative Information Sets and Sampling Schemes. The Econometrics Journal 16: S24–59. [Google Scholar] [CrossRef]
- Kiviet, Jan F. 2016. When is it Really Justifiable to Ignore Explanatory Variable Endogeneity in a Regression Model? Economics Letters 145: 192–95. [Google Scholar] [CrossRef][Green Version]
- Kiviet, Jan F. 2018. Testing the Impossible: Identifying Exclusion Restrictions. Journal of Econometrics. forthcoming. [Google Scholar]
- Kiviet, Jan F., and Jerzy Niemczyk. 2007. The Asymptotic and Finite Sample Distributions of OLS and Simple IV in Simultaneous Equations. Computational Statistics & Data Analysis 51: 3296–318. [Google Scholar]
- Kiviet, Jan F., and Jerzy Niemczyk. 2012. Comparing the Asymptotic and Empirical (Un)conditional Distributions of OLS and IV in a Linear Static Simultaneous Equation. Computational Statistics & Data Analysis 56: 3567–86. [Google Scholar]
- Kraay, Aart. 2012. Instrumental Variables Regression with Uncertain Exclusion Restrictions: A Bayesian Approach. Journal of Applied Econometrics 27: 108–28. [Google Scholar] [CrossRef]
- Leamer, Edward E. 1983. Let’s Take the Con Out of Econometrics. American Economic Reivew 73: 31–43. [Google Scholar]
- Lewbel, Arthur. 2012. Using Heteroscedasticity to Identify and Estimate Mismeasured and Endogenous Regressor Models. Journal of Business and Economic Statistics 30: 67–80. [Google Scholar] [CrossRef]
- Mankiw, N. Gergory, David Romer, and David N. Weil. 1992. A Contribution to the Empirics of Economic Growth. The Quarterly Journal of Economics 107: 407–37. [Google Scholar] [CrossRef]
- McCloskey, Deirdre N., and Stephen T. Ziliak. 1996. The Standard Error of Regressions. Journal of Economic Literature 34: 97–114. [Google Scholar]
- Rasmussen, Lars Hvilsted, Torben Bjerregaard Larsen, Karen Margrete Due, Anne Tønneland, Kim Overvad, and Gergory Y. H. Lip. 2011. Impact of Vascular Disease in Predicting Stroke and Death in Patients with Atrial Fibrillation: The Danish Diet, Cancer and Health Cohort Study. Journal of Thrombosis and Homeostasis 9: 1301–7. [Google Scholar] [CrossRef] [PubMed]
| 1. | |
| 2. | Our results are easily-computable (but not analytic) for the general (multi-dimensional) sensitivity analysis proposed here—where possible (linear) endogeneity in any number of explanatory variables is under consideration, and where what is at issue is either a confidence interval for a single parameter or the null hypothesis rejection p-value for a test of multiple linear (and/or non-linear) restrictions: in that general setting our and implementations then require a bit more in the way of numerical computation. These issues are addressed in Section 3 and Section 5 below. |
| 3. | These simulations do require a non-negligible computational effort, but this calculation needs only to be done once in any particular setting, and is already coded up in the implementation of the algorithm. One might argue that a more wide-ranging initial simulation effort (subsuming this particular calculation) has value in any case, as a check on the degree to which the sample is more broadly sufficiently large for the use of the usual asymptotic inference machinery. |
| 4. | The underlying sensitivity analysis itself extends quite easily to a consideration of more than two possibly-endogeneous explanatory variables; however, the resulting still-higher-dimensional confidence interval plots of this nature would be outright infeasible to visualize. On the other hand, one could in principle resort to tabulating the confidence interval results from such multi-dimensional “parameter-value-centric” sensitivity analyses; Kiviet (2016) has already suggested such a tabulation as a sensitivity analysis display mechanism. |
| 5. | Examples of such work include Rasmussen et al. (2011) on stroke mortality in Danish patients and Arellano et al. (2018) on microeconometric consumption expenditures modeling using the U.S. PSID and the extensive Norwegian population-register administrative data set. |
| 6. | Multiplication of Equation (2) by and taking expectations yields . |
| 7. | E.g., from (Johnston 1992, sct. 9-2), or from many earlier sources. |
| 8. | The asymptotic variance of given by Equation (4) would no longer be valid where var(), but one could in that case use White-Eicker or Newey-West standard error estimates. |
| 9. | Repeatedly simulating data sets on (Y, X, ) in this way would lead to a simulated distribution for (X, ) which could not be jointly Gaussian, and it would lead to a collection of simulated values whose variance would in fact differ as one varied the value of used in the simulation generating mechanism, in the manner predicted by the sampling distribution result given in Kiviet (2016). |
| 10. | Many econometrics programs—e.g., —make it equally easy to calculate analogous rejection p-values for null hypotheses which consist of a specified set of nonlinear restriction on the components of ; so the -based implementation of the sensitivity analysis described here readily extends to tests of nonlinear null hypotheses. |
| 11. | As shown in Section 2, this variance exceeds , the fitting-error variance in the model as actually estimated using OLS, because the inconsistency in the OLS parameter estimate strips out of the estimated model errors the portions of which are—due to the assumed endogeneity—correlated with the columns of X. Note that also follows mathematically from Equation (6), because is positive definite. |
| 12. | The value of M is limited to more like 1000 to 10,000 when (as described in Section 3.4) the entire sensitivity analysis is simulated multiple times so as to quantify the dispersion in generated by the likely sampling errors in . |
| 13. | The resulting value of is itself insensitive to the form of the distribution used to generate the vectors used in such a Monte-Carlo search, so long as this distribution has sufficient dispersion. A multivariate Gaussian distribution was used in Ashley and Parmeter (2015b), but the reader is cautioned that this is a numerical device only: Gaussianity is not being assumed thereby for any random variable in the econometric analysis. |
| 14. | For simplicity of exposition this passage is written for the case where the null hypothesis is rejected in the original OLS model, so that vectors yielding p-values exceeding 0.05 are overturning this observed rejection. Where the original-model inference is instead a failure to reject the null hypothesis, , , and the concomitant rejection p-value are instead written out to the spreadsheet file only when this p-value is less than 0.05. In this case one would instead denote this collection of vectors as the “No Longer Not Rejecting” set; the sensitivity analysis is otherwise the same. |
| 15. | Illumination aside, the substantial computational efficiency improvement afforded by this essentially analytic calculation is quite useful when—in Section 3.4 below—a bootstrap-based simulation is introduced so as to obtain an estimated standard error for , quantifying the dispersion induced in it when one allows for the likely sampling errors in . |
| 16. | |
| 17. | We note that, where n is not adequate to the estimation of in a particular regression setting, then skepticism is also warranted in this setting as to whether the size of n is more broadly inadequate for asymptotic parameter inference work—i.e., estimation of confidence intervals and/or hypothesis test rejection p-values—even aside from concerns with regard to explanatory variable endogeneity. |
| 18. | (Davidson and MacKinnon 1993, pp. 764–65)) provides a brief description of the mechanics of the usual bootstrap and a list of references to this literature, including (of course) Efron (1979). |
| 19. | Perfectly exogenous instruments are generally unavailable also, so it is useful to note again that Ashley and Parmeter (2015b) provides an analogous sensitivity analysis procedure allowing one to quantify the robustness (or fragility) of IV-based inference rejection p-values to likely flaws in the instruments used. |
| 20. | A straightforward rearrangement of Equation (7) yields the confidence interval for the jth component of , where endogeneity is considered possible in the mth explanatory variable and the value of the single non-zero component in the endogeneity covariance vector is . |
| 21. | Such a tabulation was suggested in Kiviet (2016) as a way to display the kind of sensitivity analysis results proposed in Ashley and Parmeter (2015a); his sampling distribution for , as highlighted prior, requires knowledge of the third and fourth moments of the joint distribution of the explanatory variables and the model errors, however. |
| 22. | (Mankiw et al. 1992, p. 421) explicitly indicates that this sum is to equal zero under the null hypothesis: the indication to the contrary in Ashley and Parmeter (2015a) was only a typographical error. |
| 23. | We note that, because of the way his approach frames and tabulates the results, Kiviet’s procedure cannot address scenarios in which either two or more explanatory variables are simultaneously considered to be possibly endogenous. |
| 24. | The full vector is of much greater interest in the analogous sensitivity analysis with respect to the validity of the instruments in IV estimation/inference provided in Ashley and Parmeter (2015b). In that context, the relative fragility of the instruments is very much to the point, as one might well want to drop an instrument which leads to inferential fragility. |
| 25. | The joint null hypothesis that both of these linear restrictions hold could have been examined here also (either using the Monte Carlo algorithm or solving the quadratic polynomial equation which would result from the analog of Equation (7) in that instance), had that been deemed worthwhile in this instance. |
| 26. | These standard error estimates would be smaller—and their estimation less necessary—in substantially larger samples. In substantially smaller samples, however, these bootstrap-simulated standard errors could in principle be so large as to make the sensitivity analysis noticeably less useful; it is consequently valuable that this addendum to the sensitivity analysis allows one to easily check for this. We envision a practitioner routinely obtaining these bootstrap-simulated standard errors for the values. However—because of its computational cost—we see these calculations being done only once or twice: at the outset of the analysis for any particular model and data set, and perhaps again at the very end. |
| 27. | These two crossings correspond to the two solutions for in Equation (8) in Section 3.3. |
| 28. | As derived in Section 3.1 , the consistent estimator of , given the endogeneity covariance vector, . |
| 29. | For completeness, we note that the user also needs to provide a value for M which is sufficiently large that the routine can numerically find the shortest endogeneity-correlation vector reaching the “No Longer Rejecting” set with adequate accuracy and, if needed, the number of bootstrap simulations to be used in estimating standard errors for the estimates. |
| 30. | Three versions of the software are available. One version implements the analytic result derived in Section 3.3 for the value of minimizing the length of ; this version is written for the special case of a null hypothesis which is a single linear restriction and a single possibly-endogenous explanatory variable, but could be fairly easily extended to the testing of more complicated null hypotheses. A second version already allows for the analysis of any kind of null hypothesis—even compound or nonlinear—but still restricts the dimensionality of the sensitivity analysis to possible endogeneity in a single explanatory variable; this script requires a line-search over putative values of —here scalar-valued—but is still very fast. A third version extends the sensitivity analysis to the simultaneous consideration of possible endogoeneity in multiple explanatory variables; this version is a bit more computationally demanding, as it implements either a multi-dimensional grid search or a Monte-Carlo minimization over a range of vectors. |
| 31. | The joint determination of the dependent variable and one or more of the explanatory variables in a set of nonlinear simultaneous equations would yield nonlinear endogeneity, but this is not the kind of simultaneity most usually discussed. |
| 32. | In particular, our procedure readily extends to linear regression models with autocorrelated and/or heteroscedastic errors, and to fixed-effects panel data models. |
| 33. | |
| 34. | We also note that the “parameter-value-centric” sensitivity analysis eliminates the specification (necessary in the “hypothesis-testing-centric” sensitivity analysis) of any particular value for the significance level. |



{kind=link}
{kind=link}
| Variable | & | All Three | |||
|---|---|---|---|---|---|
| 0.94 | 0.57 | 0.45 | 0.38 | 0.65 | |
| [0.03] | [0.09] | [0.08] | [0.06] | [0.11] | |
| 0.11 | 0.22 | 0.72 | 0.28 | 0.59 | |
| [0.04] | [0.11] | [0.19] | [0.11] | [0.07] | |
| 19.4 % | 8.3 % | 2.2% | 2.0% | 0.0% | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
A. Ashley, R.; F. Parmeter, C. Sensitivity Analysis of an OLS Multiple Regression Inference with Respect to Possible Linear Endogeneity in the Explanatory Variables, for Both Modest and for Extremely Large Samples. Econometrics 2020, 8, 11. https://doi.org/10.3390/econometrics8010011
A. Ashley R, F. Parmeter C. Sensitivity Analysis of an OLS Multiple Regression Inference with Respect to Possible Linear Endogeneity in the Explanatory Variables, for Both Modest and for Extremely Large Samples. Econometrics. 2020; 8(1):11. https://doi.org/10.3390/econometrics8010011
Chicago/Turabian StyleA. Ashley, Richard, and Christopher F. Parmeter. 2020. "Sensitivity Analysis of an OLS Multiple Regression Inference with Respect to Possible Linear Endogeneity in the Explanatory Variables, for Both Modest and for Extremely Large Samples" Econometrics 8, no. 1: 11. https://doi.org/10.3390/econometrics8010011
APA StyleA. Ashley, R., & F. Parmeter, C. (2020). Sensitivity Analysis of an OLS Multiple Regression Inference with Respect to Possible Linear Endogeneity in the Explanatory Variables, for Both Modest and for Extremely Large Samples. Econometrics, 8(1), 11. https://doi.org/10.3390/econometrics8010011