We discuss how our results apply to the finite sample theory and to identification robust inference. An application to US treasury yields is given.
4.1. Finite Sample Theory
The finite sample distribution of cointegration rank tests have been studied in various ways. When there are no nuisance parameters, the asymptotic distributions generally give good approximations. An example is the test for a unit root in a first order autoregression, where the finite sample distribution and the asymptotic distribution are nearly indistinguishable for
observations, see
Nielsen (
1997). A Bartlett correction improves the asymptotic distribution further. Once there are nuisance parameters the situation is different. Under the rank hypothesis the asymptotic distribution differs if there are additional unit roots. This arises either with rank deficiency like here where the distributions tend to be shifted to the left and when there are double roots as in I(2) systems where the distributions are shifted to the right.
Nielsen (
2004) analyzed this through simulation and suggested to apply local-to-unity approximation that would average between the different asymptotic distributions. A similar idea was implemented analytically for canonical correlation models in
Nielsen (
1999). In a follow-up paper,
Nielsen (
2001) analyzed the effects of plugging parameter estimates into such corrections.
Johansen (
2002) suggested a Bartlett correction for such models. This works quite well when the nuisance parameters are such that they are far from giving additional unit roots. The issue is that the Bartlett correction asymptotes to infinity when there are additional unit roots. More recently, bootstrap methods have been explored by
Swensen (
2004) and by
Cavaliere et al. (
2012).
Johansen (
2000) derives a Bartlett-type correction for the tests on the cointegrating relations. In Table 2 he considers the finite sample properties of a test comparing the test statistic
with the asymptotic
-approximation. Null rejection frequencies are simulated for dimensions
, a variety of parameter values, and a finite sample size
T. In all the reported simulations the data generating process has rank of unity. The table shows that null rejection frequency can be very much larger for a nominal 5% test when the rank is nearly deficient.
Theorem 2 sheds some light on the behaviour of the test as the rank approaches deficiency. The Theorem shows that the test statistic converges for all deficient ranks.
Table 2 indicates that the distribution shifts to the right in the rank deficient case. Thus, we should expect that null rejection frequency increases as the rank approaches deficiency, but it should be bounded away from unity.
4.2. Identification Robust Inference
Khalaf and Urga (
2014) were concerned with tests on cointegation vectors in situations where the cointegration rank is nearly deficient. Their results can be developed a little further using the present results.
The notation in
Khalaf and Urga (
2014) differs slightly from the present notation. The hypothesis of known cointegration vectors is stated as
for some known
, corresponding to the present hypotheses
and
. The test statistics are
for
. Moreover they consider the hypothesis
, say, of a known impact matrix
of rank
r. This is tested through the statistic
When the rank is not deficient the test statistic
is asymptotically
, see
Johansen (
1995, Section 7). The test statistic
has a Dickey-Fuller type distribution as derived in Theorem 2 for the case without deterministic terms, contradicting the
asymptotics suggested by
Khalaf and Urga (
2014, Section 4).
Table 2 indicates that this distribution is close to, but different from, a
-distribution when
and
. When
and
, the limiting distribution is further from a
-distribution. Likewise, the statistic
converges to a Dickey-Fuller-type distribution. This can be proved through a modification of the proof of Theorem 2.
Khalaf and Urga’s Theorem 1 is concerned with bounding the distribution of the likelihood ratio statistic for the hypothesis , where are known -matrices so that b has rank r, against the alternative where is unrestricted. The idea of their Theorem is to come up with a bound to the critical value when may have deficient rank . Unfortunately, their theorem evolves around the incorrect distribution although unit root testing is implicitly involved. We therefore reformulate the result in terms of the limiting distributions derived herein.
We consider the test statistic
when the rank of
is nearly deficient. Suppose the rank is nearly deficient in the sense that
for some matrix
M along the lines of the theory in
Section 2.6. Then, intuitively, the limiting distribution will be a combination of those arising when the true rank is 0 and when it is 1. The asymptotic theory developed here gives the relevant bounds. In the case of the zero level model the Theorems 1 and 2 imply the following pointwise result.
Theorem 11. Let θ denote the parameters of the model (1). Consider the parameter space where the hypothesis holds. Here are both of dimension . Here α is unknown, while b is known and has full column rank. Suppose the data generating process satisfies the condition with . Let be the asymptotic quantile of when the data generating process satisfies for . Let . Then it holds for all that The simulated values in
Table 2 show that for
then
The interpretation is as follows. Suppose the hypothesis has not been rejected, but it is unclear whether the rank could be nearly deficient. Then the hypothesis of a known is rejected if the statistic is larger than .
The bound for
seems very extreme. Khalaf and Urga therefore suggest to use the alternative statistic
. Theorem 11 could be modified to cover this statistic. The simulations in
Table 3 indicate that we would then use bounds
We can establish a similar result for the constant level model using Theorems 8 and 9. However, it is necessary to exclude the possibility of a linear trends in the rank deficient model as this would give a very complicated result.
Theorem 12. Let θ denote the parameters of the model (14). Consider the parameter space where the hypothesis holds. Here are both of dimension , while is a scalar. Further are known and . Suppose the data generating process satisfies the condition with or . Let be the asymptotic quantile of when the data generating process satisfies for . Let . Then it holds for all that The simulated values in
Table 7 show that for
then
If the alternative is taken as
instead of
the bounds are modified as
The bounds (
32), (
33) for the constant level model appear further apart than the corresponding bounds (
29), (
30) for the zero level model. So in the constant level case there is perhaps less reason to use the test against the unrestricted model.
4.3. Empirical Illustration
The identification robust inference can be illustrated using a series of monthly US treasury zero-coupon yields over the period 1987:8 to 2000:12. The data are taken from
Giese (
2008) and runs from the start of Alan Greenspan’s chairmanship of the Fed and finishes before the burst of the dotcom bubble. Giese considers 5 maturities (1, 3, 18, 48, 120 months), but here we only consider 2 maturities (12, 24 months). The empirical analysis uses OxMetrics, see
Doornik and Hendry (
2013).
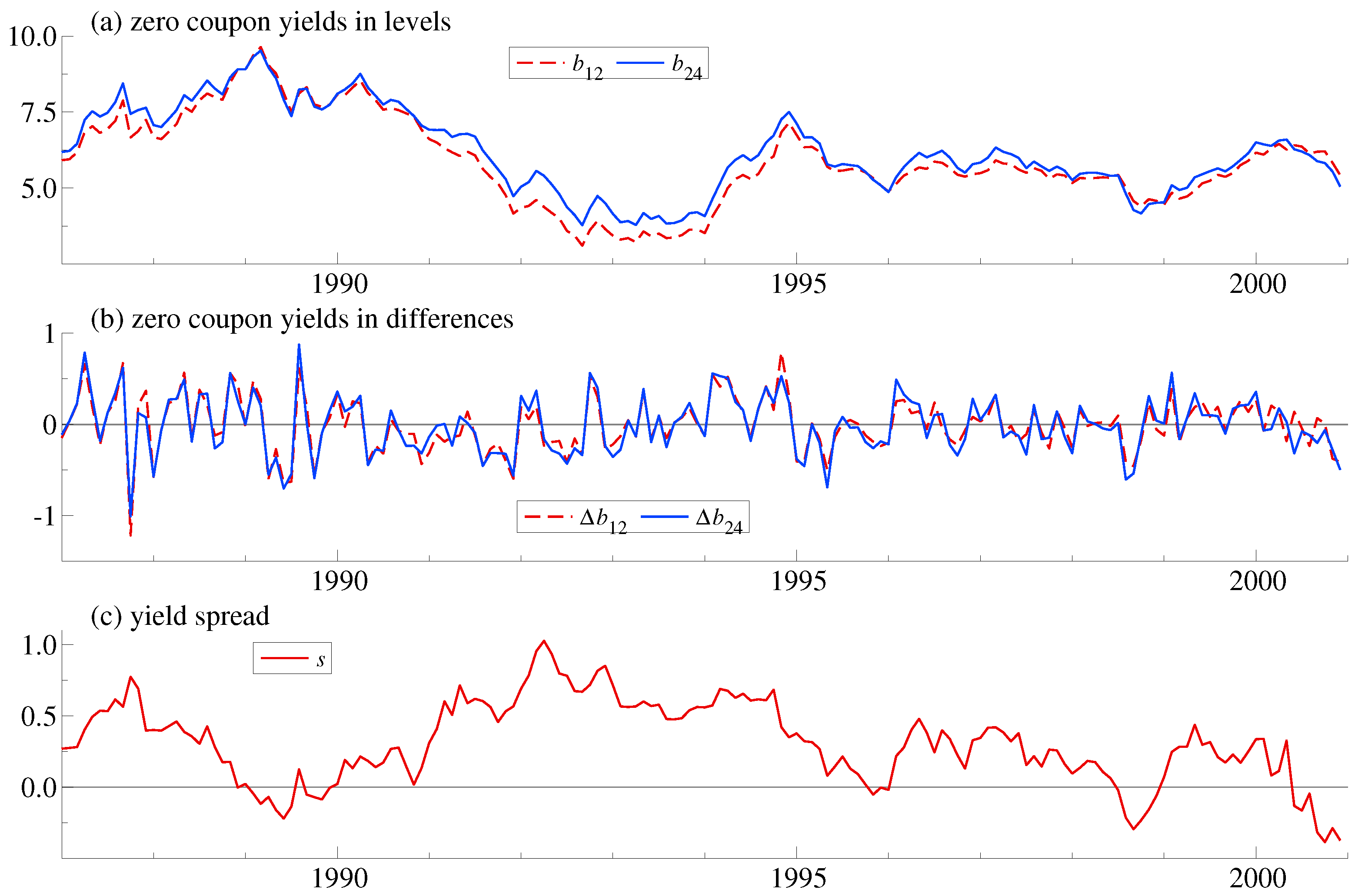
Figure 1 shows the data in levels and differences along with the spread. The spread does not appear to have much of a mean reverting behaviour. It is not crossing the long-run average for periods of up to 4 years. This point towards a random walk behaviour which contradicts the expectations hypothesis in line with Giese’s analysis. She finds two common trends among five maturities. The two common trends can be interpreted as short-run and long-run forces driving the yield curve. The cointegrating relations match an extended expectations hypothesis where spreads are not cointegrated but two spreads cointegrate. This is sometimes called butterfly spreads and gives a more flexible match to the yield curve. This is in line with earlier empirical work.
Hall et al. (
1992), among others, found only one common trend when looking at short-term maturities, while
Shea (
1992);
Zhang (
1993) and
Carstensen (
2003) found more than one common trend when including longer maturities.
A vector autoregression of the form (
14) with an intercept,
lags as well as a dummy variable for 1987:10 was fitted to the data. This has the form
where
is the bivariate vector of the 12 and 24 month zero-coupon yields and periods
and
correspond to 1987:8 and 2000:12 giving
.
The dummy variable matches the policy intervention after the stock market crash on 19 October 1987. Empirically, the dummy variable can be justified in two ways. First, the plot of yield differences in
Figure 1b indicate a sharp drop in yields at that point. Secondly, the robustified least squares algorithm analyzed in
Johansen and Nielsen (
2016) could be employed for each of the two equations in the model. The algorithm uses a cut-off for outliers in the residuals that is controlled in terms of the gauge, which is the frequency of falsely detected outliers that can be tolerated. The gauge is chosen small in line with recommendations of
Hendry and Doornik (
2014, Section 7.6), see also
Johansen and Nielsen (
2016). Thus, we choose a cut-off of 3.02 corresponding to a gauge of 0.25%. When running the autoregressive distributed lag models without outliers, only 1987:10 has an absolute residual exceeding the cut-off. Next, when re-running the model including a dummy for 1987:10, no further residuals exceed the cut-off. This is a fixed point for the algorithm. The detection of outliers may have some impact on specification tests, estimation, and inference.
Johansen and Nielsen (
2009,
2016) analyze the impact on estimation when the data generating process has no outliers. They find that outlier detection only gives a modest efficiency loss compared to standard least squares when the cut-off is as large as chosen here.
Berenguer-Rico and Nielsen (
2017) find a considerable impact on the normality test employed above. At present, there is no theory for these algorithms for data generating processes with outliers, albeit some results are available for cointegration analysis with known break date, including the broken trend analysis of
Johansen et al. (
2000) and the structural change model of
Hansen (
2003).
Table 10 reports cointegration rank tests. The fifth column shows conventional
p-values based on
Table 4 and
Table 6 for
corresponding to
Johansen (
1995, Tables 15.2, 15.3). The sixth column shows
p-values based on
Table 5 and
Table 6 assuming data have been generating by a model satisfying
. In both cases the
p-values are approximated by fitting a Gamma distribution to the reported mean and variance, see
Nielsen (
1997);
Doornik (
1998) for details. As expected, the latter
p-values tend to be higher than the former. Overall this provide overwhelming evidence in favour of a pure random walk model in line with
Giese (
2008).
If we have a strong belief in the expectation hypothesis we would, perhaps, ignore the rank tests and seek to test the expectations hypothesis directly. If we maintain the model
, we could have to contemplate that the cointegration vectors could be nearly unidentified. A mild form of the expectation hypothesis is that the spread is zero mean stationary. Thus, we test the restriction
. The likelihood ratio statistic is 4.0. Assuming the data generating process satisfies either
or
, but not by
, we can apply the Khalaf-Urga (2014)-type bound test established in Theorem 12. The 95% bound in (
32) is 14.05 so the hypothesis cannot be rejected based on this test. This contrasts with the above rank tests which gave strong evidence against the expectations hypothesis. The results reconcile if the bounds test does not have much power in the weakly identified case. Indeed, this seems to be the case when looking at
Table 3,
-panels in
Khalaf and Urga (
2014), corresponding to near rank deficiency or weak identification. Thus, assuming the rank is one when in fact the data generating process appears to be nearly rank deficient seems to reduce power for tests on the cointegrating vector. That is, when the alleged cointegrating vector is not cointegrating it would be useful to be able to falsify the economic hypothesis. The above mentioned simulations indicate that this is not the case.




{kind=link}