1. Introduction
The coefficient matrix of explanatory variables in multivariate time series models can be rank deficient due to some modelling assumptions, and the parameter constancy of the rank deficient matrix may be questionable. This may happen, for example, in the factor model, which construct very few factors by using a large number of macroeconomic and financial predictors, while the factor loadings are suspect to be time-varying.
Stock and Watson (
2002) state that it is reasonable to suspect temporal instability taking place in factor loadings, and later
Stock and Watson (
2009) and
Breitung and Eickmeier (
2011) find empirical evidence of instability. Another setting where instability may arise is in cointegrating relations (see e.g.,
Bierens and Martins (
2010)), hence in the the reduced rank cointegrating parameter matrix of a vector error-correction model.
There are solutions in the literature to the modelling of the temporal instability of reduced rank parameter matrices. Such parameters are typically regarded as unobserved random components and in most cases are modelled as random walks on a Euclidean space; see, for example,
Del Negro and Otrok (
2008) and
Eickmeier et al. (
2014). In these works, the noise component of the latent processes (factor loading) is assumed to have a diagonal covariance matrix in order to alleviate the computational complexity and make the estimation feasible, especially when the dimension of the system is high. However, the random walk assumption on the Euclidean space cannot guarantee the orthonormality of the factor loading (or cointegration) matrix, while this type of assumption identifies the loading (or cointegration) space. Hence, other identification restrictions on the Euclidean space are needed. Moreover, the diagonality of the error covariance matrix of the latent processes contradicts itself when a permutation of the variables is performed.
In this work, we develop new state-space models on the Stiefel manifold, which do not suffer from the problems on the Euclidean space. It is noteworthy that
Chikuse (
2006) also develops state-space models on the Stiefel manifold. The key difference between
Chikuse (
2006) and our work is that we keep the Euclidean space for the measurement evolution of the observable variables, while
Chikuse (
2006) puts them on the Stiefel manifold, which is not relevant for modelling economic time series. By specifying the time-varying reduced rank parameter matrices on the Stiefel manifold, their orthonormality is obtained by construction, and therefore their identification is guaranteed.
The corresponding recursive nonlinear filtering algorithms are developed to estimate the a posteriori distributions of the latent processes of the reduced rank matrices. By applying the matrix Langevin distribution on the a priori distributions of the latent processes, conjugate a posteriori distributions are achieved, which gives great convenience in the computational implementation of the filtering algorithms. The predictive step of the filtering requires solving an integral on the Stiefel manifold, which does not have a closed form. To compute this integral, we resort to a Laplace method.
The paper is organized as follows.
Section 2 introduces the general framework of the vector models with time-varying reduced rank parameters. Two specific forms of the time-varying reduced rank parameters, which the paper is focused on, are given.
Section 3 discusses some problems in the prevalent literature on modelling the time dependence of the time-varying reduced rank parameters, which underlie our modelling choices. Then, in
Section 4, we present the novel state-space models on the Stiefel manifold.
Section 5 presents the nonlinear filtering algorithms that we develop for the new state-space models.
Section 6 presents several simulation based examples. Finally,
Section 7 concludes and gives possible research extensions.
2. Vector Models with Time-Varying Reduced Rank Parameters
Consider the multivariate time series model with partly time-varying parameters
where
is a (column) vector of dependent variables of dimension
p,
and
are vectors of explanatory variables of dimensions
and
,
and
are
and
matrices of parameters, and
is a vector belonging to a white noise process of dimension
p, with positive-definite covariance matrix
. For quasi-maximum likelihood estimation, we further assume that
.
The distinction between
and
is introduced to separate the explanatory variables between those that have time-varying coefficients (
) from those that have fixed coefficients (
). In the sequel, we always consider that
is not void (i.e.,
). The explanatory variables may contain lags of
, and the remaining stochastic elements (if any) of these vectors are assumed to be weakly exogenous. Equation (
1) provides a general linear framework for modelling time-series observations with time-varying parameters, embedding multivariate regressions and vector autoregressions. For an exposition of the treatment of such a model using the Kalman filter, we refer to Chapter 13 of
Hamilton (
1994).
We assume furthermore that the time-varying parameter matrix
has reduced rank
. This assumption can be formalized by decomposing
as
, where
and
are
and
full rank matrices, respectively. If we allow both
and
to be time-varying, the model is not well focused and hard to explain, and its identification is very difficult. Hence, we focus on the cases where either
or
is time-varying, that is, on the following two cases:
Next, we explain how the two cases give interesting alternatives to modelling different kinds of temporal instability in parameters.
The case 1 model (Equations (
1) and (
2)) ensures that the subspace spanned by
is constant over time. This specification can be viewed as a cointegration model allowing for time-varying short-run adjustment coefficients (the entries of
) but with time-invariant long-run relations (cointegrating subspace). To see this, consider that model (
1) corresponds to a vector error-correction form of a cointegrated vector autoregressive model of order
k with
as the dependent variables, if
,
,
contains
for
, as well as some predetermined variables. There are papers in the literature arguing that the temporal instability of the parameters in both stationary and non-stationary macroeconomic data does exist and cannot be overlooked. For example,
Swanson (
1998) and
Rothman et al. (
2001) give convincing examples in investigating the Granger causal relationship between money and output using a nonlinear vector error-correction model. They model the instability in
by means of regime-switching mechanisms governed by some observable variable. An alternative to that modelling approach is to regard
as a totally latent process.
The case 1 model also includes as a particular case the factor model with time-varying factor loadings. In the factor model context, the factors
are extracted from a number of observable predictors
by using the
r linear combinations
. Note that
is latent since
is unknown. Then, the corresponding factor model (neglecting the
term) takes the form
where
is a matrix of the time-varying factor loadings. The representation is quite flexible in the sense that
can be equal to
and then we reach exactly the same representation as
Stock and Watson (
2002), but we also allow them to be distinct. In
Stock and Watson (
2002), the factor loading matrix
is time-invariant and the identification is obtained by imposing the constraints
and
. Notice that, if
is time-varying but
time-invariant, these constraints cannot be imposed.
The case 2 model (Equations (
1) and (
3)) can be used to account for time-varying long-run relations in cointegrated time series, as
is changing.
Bierens and Martins (
2010) show that this may be the case for the long run purchasing power parity. In the case 2 model, there exist
linearly independent vectors
that span the left null space of
, such that
. Therefore, the case 2 model implies that the time-varying parameter matrix
vanishes in the structural vector model
for any column vector
, where
denotes the space spanned by
, thus implying that the temporal instability can be removed in the above way. Moreover,
does not explain any variation of
.
Another possible application for the case 2 model is the instability in the factor composition. Considering the factor model , with time-invariant factor loading , the factor composition may be slightly evolving through in .
3. Issues about the Specification of the Time-Varying Reduced Rank Parameter
In the previous section, we have introduced two models with time-varying reduced rank parameters. In this section, in order to motivate our choices presented in
Section 4, we discuss the specification in the literature of the dynamic process governing the evolution of the time-varying parameters.
Since the sequences
or
in the two cases are unobservable in practice, it is quite natural to write the two models into the state-space form with a measurement equation like (
1) for the observable variables and transition equations for
or
. To build the time dependence in the sequences of
or
is of great practical interest as it enables one to use the historical time series data for conditional forecasting, especially by using the prevalent state-space model based approach. How to model the evolution of these time-varying parameters, nevertheless, is an open issue and needs careful investigation. Almost all the works in the literature of time series analysis hitherto only deal with state-space models on the Euclidean space. See, for example, the books by
Hannan (
1970);
Anderson (
1971);
Koopman (
1974);
Durbin and Koopman (
2012); and more recently
Casals et al. (
2016).
Consider, for example, the factor model (
4) with time-varying factor loading
, but notice that the following discussion can be easily adapted to the cointegration model, where only
is time-varying. The traditional state-space framework on the Euclidean space assumes that the elements of the time-varying matrix
evolve like random walks on the Euclidean space, see for example
Del Negro and Otrok (
2008) and
Eickmeier et al. (
2014). That is,
where vec denotes the vectorization operator, and the sequence of
is assumed to be a Gaussian strong white noise process with constant positive definite covariance matrix
. Thus, Labels (
1) and (
6) form a vector state-space model, and the Kalman filter technique can be applied for estimating
.
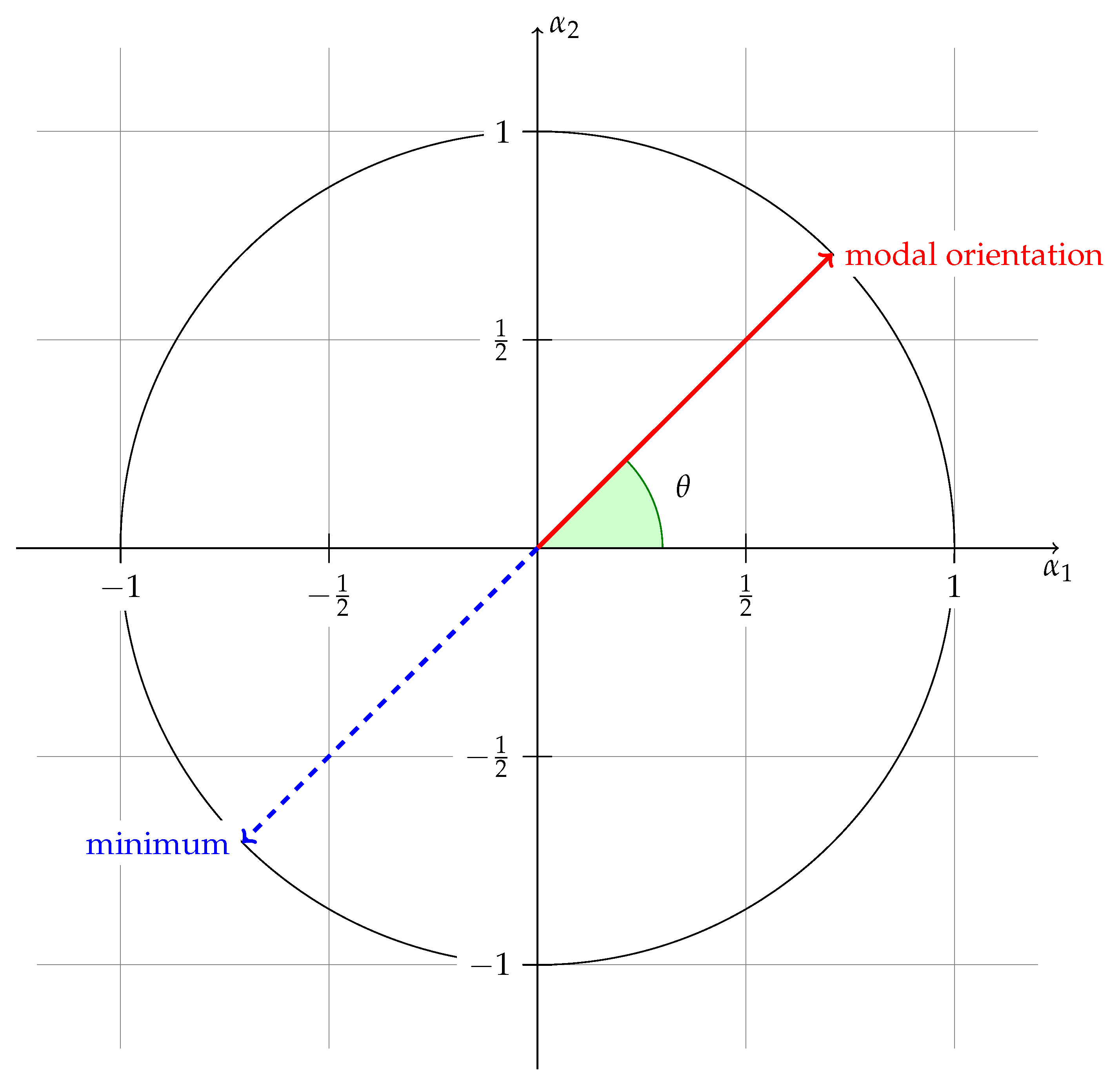
A first problem of the model (
6) is that the latent random walk evolution on the Euclidean space is strange. Consider the special case
and
: in
Figure 1, points 1–3 are possible locations of the latent variable
. Suppose that the next state
evolves as in (
6) with a diagonal covariance matrix
. The circles centered around points 1–3 are contour lines such that, say, almost all the probability mass lies inside the circles. The straight lines OA and OB are tangent lines to circle 1 with A and B the tangent points; the straight lines OC and OD are tangent lines to circle 2; and the straight lines OE and OF are tangent lines to circle 3. The angles between the tangent lines depend on the location of the points 1-2-3: generally, the more distant a point from the origin, the smaller the corresponding angle despite some special ellipses. The plot shows that the distributions of the next subspace based on the current point differ for different subspaces (angles for 3 and 2 smaller than the angle for 1); even for the same subspace (points 2 and 3), the distribution of the subspace is different (angle for 3 smaller than angle for 2).
A second problem is the identification issue. The pair of
and
should be identified before we can proceed with the estimation of (
1) and (
6). If both
and
are time-invariant, it is common to assume the orthonormality (or asymptotic orthonormality)
or
to identify the factors and then to estimate them by using the principle components method. However, when
is evolving as (
6), the orthonormality of
can never be guaranteed for all
t on the Euclidean space.
The alternative solution to the identification problem is to normalize the time-invariant part as . The normalization is valid when the upper block of is invertible, but if the upper block of is not invertible, one can always permute the rows of to find an invertible submatrix of order r rows for such a normalization. The permutation can be performed by left-multiplying by a permutation matrix to make its upper block invertible. In practice, it should be noted that the choice of the permutation matrix is usually arbitrary and casual.
Even though the model defined by (
1) and (
6) is identified by some normalized
, if one does not impose any constraint on the elements of the positive definite covariance matrix
, the estimation can be very difficult due to computational complexity. A feasible solution is to assume that
is cross-sectionally uncorrelated. This restriction reduces the number of parameters, alleviates the complexity of the model, and makes the estimation much more efficient, but it may be too strong and imposes a priori information on the data. However, a third problem then arises. In the following two propositions, we show that any design like (
1) and (
6) with the restriction that
is diagonal is casual in the sense that it may lead to contradiction since the normalization of
is arbitrarily chosen.
Proposition 1. Suppose that the reduced rank coefficient matrix in (
1)
with rank r has the decomposition (
2)
. By choosing some permutation matrix (), the time-invariant component β can be linearly normalized if the upper block inis invertible. Then, the corresponding linear normalization isand the time-varying component is re-identified as . Assuming that the time-varying component evolves by following Consider another permutation with the corresponding , , and . The variance–covariance matrices of and are both diagonal if and only if .
Proposition 2. Suppose that the reduced rank coefficient matrix in (
1)
with rank r has the decomposition (
3)
. By choosing some permutation matrix (), the constant component α can be linearly normalized if the upper block inis invertible. The corresponding linear normalization isand the time-varying component is re-identified as . Assuming that the time-varying component evolves by followingConsider another permutation with the corresponding , , and . The variance–covariance matrices of and are both diagonal if and only if . The two corollaries below follow Propositions 1 and 2 immediately, showing that the assumption that the variance–covariance matrix is always diagonal for any linear normalization is inappropriate.
Corollary 1. Given the settings in Propostion 1, the variance–covariance matrices of the error vectors in forms like (
9)
based on different linear normalizations cannot be both diagonal if where and are the upper block square matrices in forms like (
7)
. Corollary 2. Given the settings in Proposition 2, the variance–covariance matrices of the error vectors in forms like (
12)
based on different linear normalizations cannot be both diagonal if where and are the upper block square matrices in forms like (
10)
. One may argue that there is a chance for the two covariance matrices to be both diagonal, i.e., when . It should be noticed that the condition does not imply that . Instead, it implies that the permutation matrices move the same variables to the upper part of with the same order. If this is the case, the two permutation matrices and are distinct but equivalent as the order of the variables in the lower part is trivial for linear normalization.
Since the choice of the permutation and the corresponding linear normalization is arbitrary in practice, which is simply the order of ( for case 2), the models with different are telling different stories about the data. In fact, the model has been over-identified by the assumption that must be diagonal. Consequently, the model becomes -normalization dependent, and the -normalization imposes some additional information on the data. This can be serious when the forecasts from the models with distinct normalizations of give totally different results. A solution to this ”unexpected” problem may be to try all possible normalizations of and do model selection, that is, after estimating every possible model, pick the best model according to an information criterion. However, this solution is not always feasible because the number of possible permutations for , which is equal to , can be huge. When the number of predictors is large, which is common in practice, the estimation of each possible model based on different normalization becomes a very demanding task.
Stock and Watson (
2002) propose the assumption that the cross-sectional dependence between the elements in
is weak and the variances of the elements are shrinking with the increase of the sample size. Then, the aforementioned problem may not be so serious, as, intuitively, different normalizations with diagonal covariance matrix
may produce approximately or asymptotically the same results.
We have shown that the modelling of the time-varying parameter matrix in (
2) as a process like (
6) on the Euclidean space involves some problems. Firstly, the evolution of the subspace spanned by the latent process on the Euclidean space is strange. Secondly, the process does not comply with the orthonormality assumption to identify the pair of
and
. Thus, a linear normalization is employed instead of the orthonormality. Thirdly, the state-space model on the Euclidean space suffers from the curse of dimensionality, and hence the diagonality of the covariance of the errors is often used with the linear normalization in order to alleviate the computational complexity when the dimension is high. This leads to two other problems: firstly, the diagonality assumption is inappropriate in the sense that different linear normalizations may lead to a contradiction; secondly, the model selection can be a tremendous task when there are many predictors.
In the following section, we propose that the time-varying parameter matrices and evolve on the Stiefel manifold, instead of the Euclidean space, and we show that the corresponding state-space models do not suffer from the aforementioned problems.
5. The Filtering Algorithms
In this section, for the models (18) and (19) defined in the previous section, we propose nonlinear filtering algorithms to estimate the a posteriori distributions of the latent processes based on the Gaussian error assumption in the measurement equations.
We start with Model 1 which has time-varying
. The filtering algorithm consists of two steps:
where the symbol
stands for the differential form for a Haar measure on the Stiefel manifold. The predictive density in (26) represents the a priori distribution of the latent variable before observing the information at time
t. The updating density, which is also called the filtering density, represents the a posteriori distribution of the latent variable after observing the information at time
t.
The prediction step is quite tricky in the sense that, even if we can find the joint distribution of and , which is the product , we must integrate out over the Stiefel manifold. The density kernel appearing in the integral in the first line of (27) comes from the previous updating step and is quite straightforward as it is proportional to the product of the density function of and the predicted density of (see the updating step in (27)).
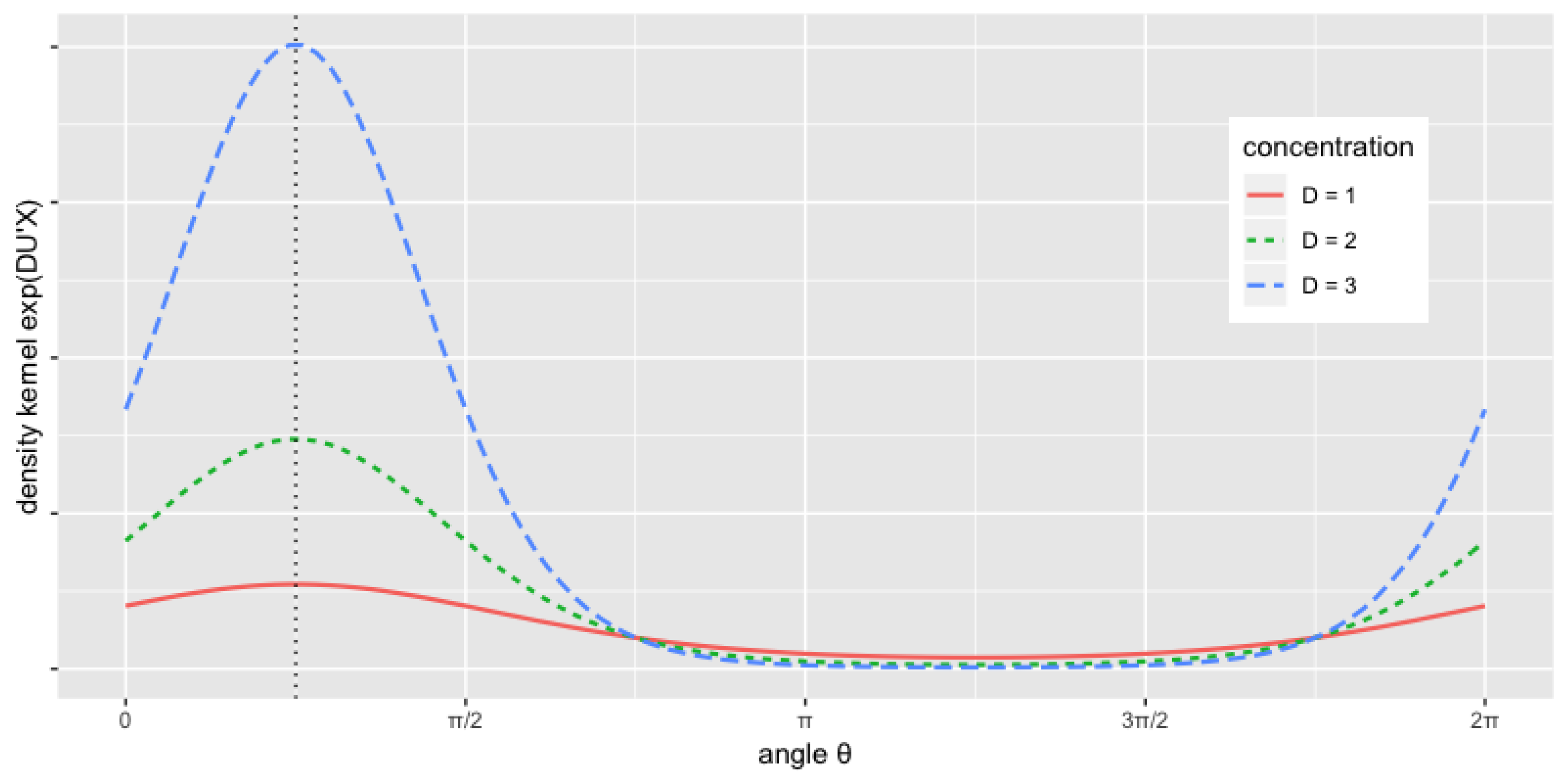
The initial condition for the filtering algorithm can be a Dirac delta function such that when where is the modal orientation and zero otherwise, but the integral is exactly equal to one.
The corresponding nonlinear filtering algorithm is recursive like the Kalman filter in linear dynamic systems. We start the algorithm with
and proceed to the updating step for
as follows:
where
,
,
. Then, we move to the prediction step for
and obtain the integral as follows:
where
due to (
13) and (
15), and
in (29). Hence, we have
where
does not depend on
and
. Unfortunately, there is no closed form solution to the integral (30) in the literature.
Another contribution of this paper is that we propose to approximate this integral by using the Laplace method. (see
Wong (
1989, chps. 2 and 9) for a detailed exposition). Rewrite the integral (30) as
where
p is the dimension of
,
is bounded, and
which is twice differentiable with respect to
and is assumed to be convergent to some nonzero value when
.
Then, the Laplace method can be applied since the Taylor expansion on which it is based is valid in the neighbourhood for any point on the Stiefel manifold. It follows that, with
, the integral (30) can be approximated by
where
Given , then it can be shown that has the same form as (29) with , .
Thus, by induction, we have the following proposition for the recursive filtering algorithm for state-space Model 1.
Proposition 3. Given the state-space Model 1 in (18)
with the quasi-likelihood function (24)
based on Gaussian errors, the Laplace approximation based recursive filtering algorithm for is given bywhere , , , and Likewise, we have the recursive filtering algorithm for the state-space Model 2.
Proposition 4. Given the state-space Model 2 in (19)
with the quasi-likelihood function (25)
based on Gaussian errors, the Laplace approximation based recursive filtering algorithm for is given bywhere , , , and Several remarks related to the propositions follow.
Remark 1. The distributions of predicted and updated and in the recursive filtering algorithms are conjugate.
The predictive distribution and the updating or filtering distribution are both known as the matrix Langevin–Bingham (or matrix Bingham–von Mises–Fisher) distribution; see, for example,
Khatri and Mardia (
1977). This feature is desirable as it gives great convenience in the computational implementation of the filtering algorithms.
Remark 2. When estimating the predicted distribution of and , a numerical optimization for finding is required.
There are several efficient line-search based optimization algorithms available in the literature which can be easily implemented and applied. See
Absil et al. (
2008, chp. 4) for a detailed exposition.
Remark 3. The predictive distributions in (38) and (41) are Laplace type approximations. Therefore, the dimensions of the data in Model 1 and the predictors in Model 2 are expected to be high enough in order to achieve good approximations.
For the high-dimensional factor models that use a large number of predictors, the filtering algorithms are natural choices to model the possible temporal instability, while a small value of the rank r implies the dimension reduction in forecasting. In the next section, our finding from simulation is that, even for small p and , the approximations of the modal orientations can be very good.
Remark 4. The recursive filtering algorithms make it possible to use both maximum likelihood estimation and the Bayesian analysis for the proposed state-space models.
Next, we consider the models in (20) and (21). The corresponding filtering algorithms are similar to Propositions 3 and 4. The filtering algorithm for Model 1
is given by
where
,
,
. In addition, for Model 2
, we have
where
,
,
. We have the following remarks for both models.
Remark 5. The predictive distributions do not depend on any previous information, which is due to the assumption of sequentially independent latent processes.
Remark 6. The predictive and filtering distributions for Model 1 and Model 2 are not approximations.
We do not need to approximate integral like (30). Since does not depend on in Model 1 and does not depend on in Model 2, and can be directly moved outside the integral.
The smoothing distribution is defined to be the a posteriori distribution of the latent parameters given all the observations. We have the following two propositions for the smoothing distributions of the state-space models.
Proposition 5. The smoothing distribution of Model 1 is given bywhere , , and . Proposition 6. The smoothing distribution of Model 2 is given by, , . There is no closed form for the smoothing distributions as the corresponding normalizing constants are unknown.
Hoff (
2009) develops a Gibbs sampling algorithm that can be used to sample from these smoothing distributions.
6. Evaluation of the Filtering Algorithms by Simulation Experiments
To investigate the performance of the filtering algorithm in Proposition 3, we consider several settings based on data generated from Model 1 in (18) for different values of its parameters.
Recall that at each iteration of the recursive algorithm, the predictive density kernel in (38) is a Laplace type approximation of the true predictive density which takes an integral form as (30), and hence the resulting filtering density is an approximation as well. It is of great interest to check the performance of the approximation under different settings. Since the exact filtering distributions of the latent process are not available, we resort to comparing the true (i.e., generated) value and the filtered modal orientation at time t from the filtering distribution , which is as defined in (40). The modal orientations are expected to be distributed around the true values across time if the algorithm performs well.
Then, a measure of distance between two points in the Stiefel manifold is needed for the comparison. We consider the squared Frobenius norm of the difference between two matrices or column vectors:
If the two matrices or column vectors
X and
Y are points in the Stiefel manifold, then it holds that
, and
takes the minimum 0 when
(closest) and the maximum
when
(furthest). Thus, we employ the normalized distance
which is matrix dimension free.
Note that the modal orientation of the filtering distribution is not supposed to be consistent to the true value of the latent process with the increase of the sample size T. As a matter of fact, the sample size is irrelevant to the consistency which can be seen from the filtering density (39). We should note that the filtering distribution in (39) also has concentration or dispersion which is determined by , (the inverse of ) and (the current information, i.e. , and ), together with the parameters, while the previous information has limited influence only through the orthonormal matrix . Since the concentration of the filtering distribution does not shrink with the increase of the sample size, we use in all the experiments. If the filtering distribution has big concentration, the filtered modal orientations are expected to be close to the true values and hence the normalized distances close to zero and less dispersed.
The data generating process follows Model 1 in (18). Since we input the true parameters in the filtering algorithm, the difference is perfectly known and then there is no need to consider the effect of . Thus, it is natural to exclude from the data generating process.
We consider the settings with different combinations of
, the sample size,
, the dimension of the dependent variable
, the rank of the matrix
, the explanatory variable vector has dimension ensuring that always holds, and each is sampled independently (over time) from a ,
, the initial value of sequence for the data generating process,
, the covariance matrix of the errors is diagonal with
, and .
The simulation based experiment of each setting consists of the following three steps:
We sample from Model 1 by using the identified version in (18). First, simulate given , and then given . We save the sequence of the latent process , .
Then, we apply the filtering algorithm on the sampled data to obtain the filtered modal orientation , .
We compute the normalized distances and report by plotting them against the time t.
We use the same seed, which is one, for the underlying random number generator throughout the experiments so that all the results can be replicated. Sampling values form the matrix Langevin distribution can be done by the rejection method described in Section 2.5.2 of
Chikuse (
2003).
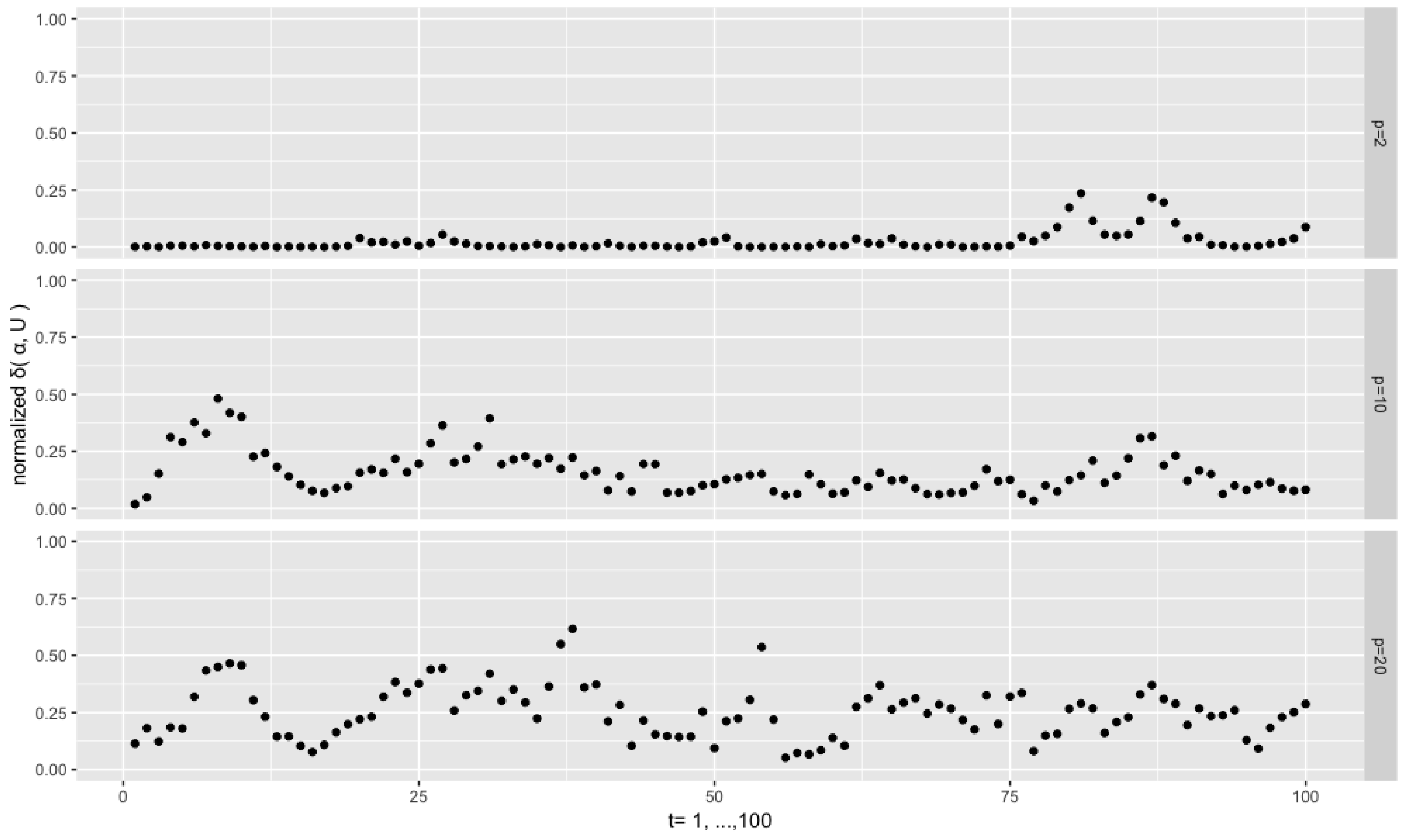
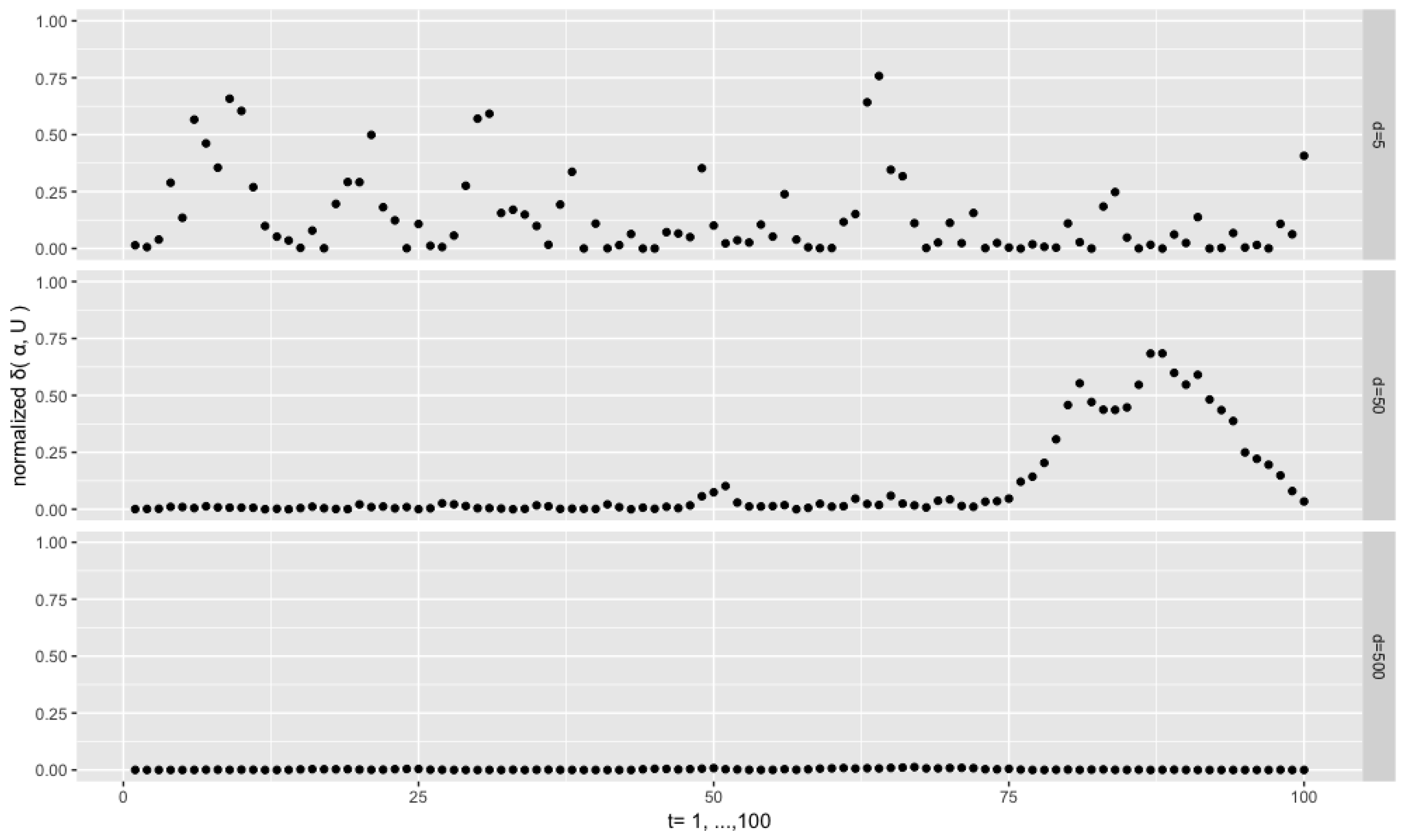
Figure 4 depicts the results from the setting
,
,
and
. We see that the sequences of the normalized distances
are persistent. This is a common phenomenon throughout the experiments, and, intuitively, it can be attributed to the fact that the current
depends on the previous one through the pair of
and
. For the low dimensional case
, almost all the distances are very close to 0, which means that the filtered modal orientations are very close to the true ones, despite few exceptions. However, for the higher dimensional cases
and 20, the distances are at higher levels and are more dispersed. This is consistent with the fact that, given the same concentration
, an increase of the dimension the orthonormal matrix or vector goes along with an increase of the dispersion of the corresponding distributions on the Stiefel manifold, as the volume of the manifold explodes with the increase of the dimensions (both
p and
r).
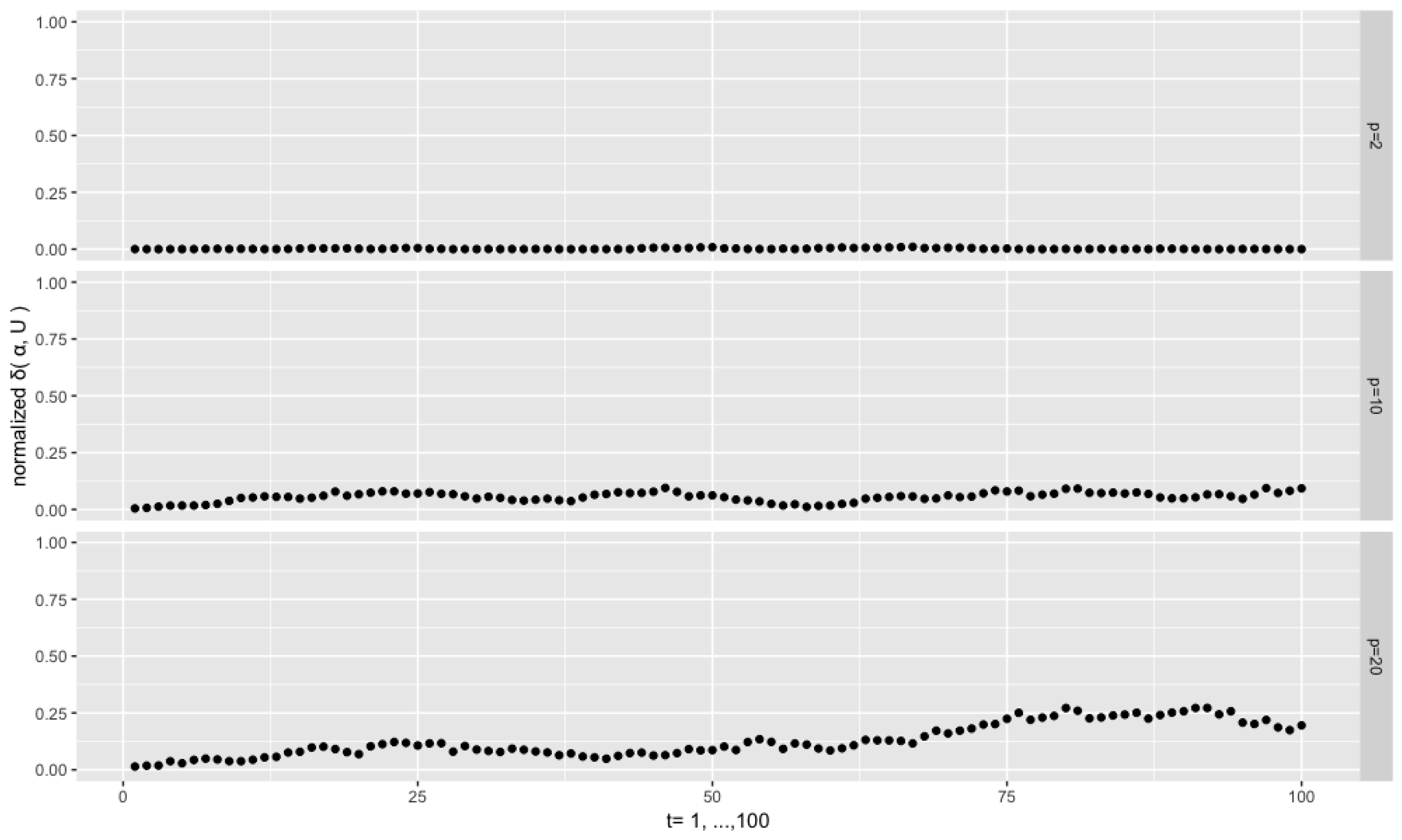
Figure 5 displays the results for the same setting
,
,
but with a much higher concentration
. We see that the curse of dimensionality can be remedied through a higher concentration as the distances for the high dimensional cases are much closer to zero than when
.
The magnitude
of the variance of the errors affects the results of the filtering algorithm as well, as it determines the concentration of the filtering distribution, which can be seen from (39) through
and
(both depend on the inverse of
). The following experiments apply the settings
,
and
showing the impact of different
on the filtering results.
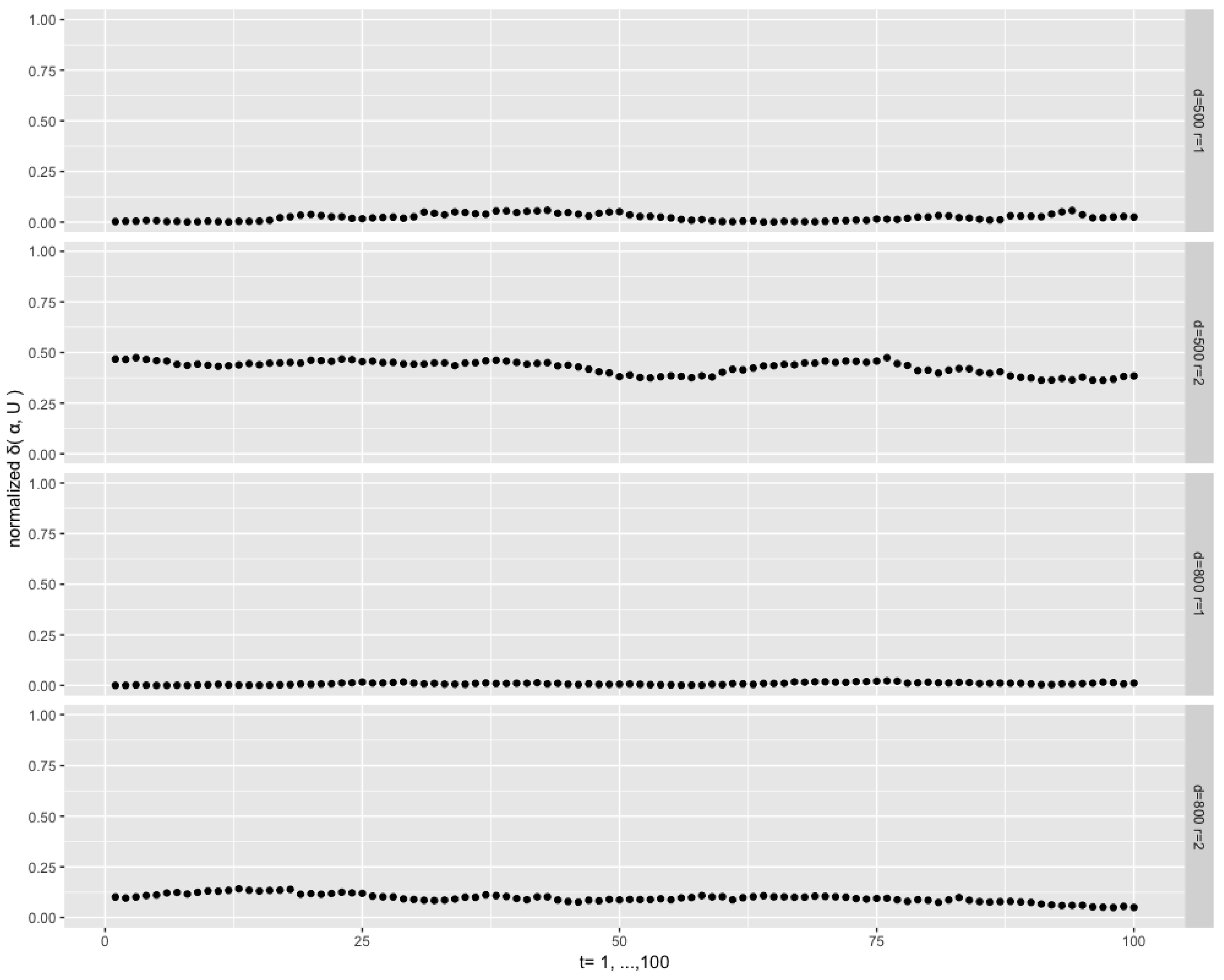
Figure 6 depicts the results with
, and
Figure 7 with
. We see that the normalized distances become closer to zero when a lower
is applied. Their variability also decreases for the lowest value of
and for the intermediate value
. It is worth mentioning that, in the two cases corresponding to the two bottom plots of the figures, the matrix
dominates the density function, which implies that the filtering distribution resembles a highly concentrated matrix Langevin.
In the following experiments, our focus is on the investigation of the filtering algorithm when
r approaches
p. We consider the setting
with the rank number
, with
and
.
Figure 8 depicts the results. The normalized distances are stable at a low level for the case
with
, but a high level (around 0.5) in the case
with
. A higher concentration (
) reduces the latter level to about 0.12, as can be seen on the lower plot of
Figure 8. We conclude that the approximation of the true filtering distribution tends to fail when the matrix
tends to a square matrix, that is,
, and therefore the filtering algorithms proposed in this paper seems to be appropriate when
p is sufficiently larger than
r.
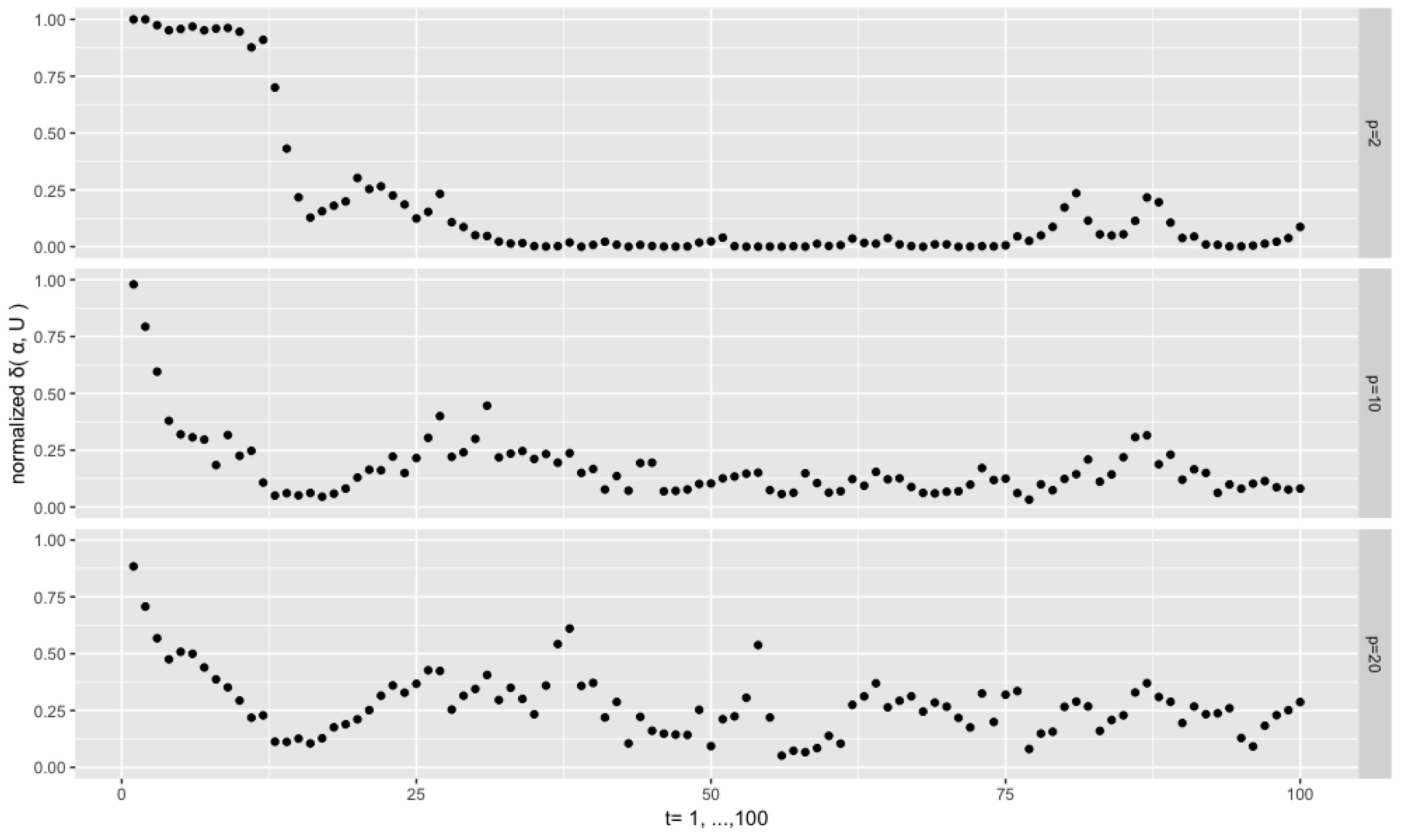
All the previous experiments are based on the true initial value
, but, in practice, this is unknown. The filtering algorithm may be sensitive to the choice of the initial value. In the following experiments, we look into the effect of a wrong initial value. The setting is
,
,
and
, and we use as initial value
, which is the furthest point in the Stiefel manifold away from the true one.
Figure 9 depicts the results. We see that in all the experiments the normalized distances move towards zero, hence the filtered values approach the true values in no more than 20 steps. After that, the level and dispersion of the distance series are similar to what they are in
Figure 4 where the true initial value is used. Thus, we can conclude that the effect of a wrongly chosen initial value is temporary.
We have conducted similar simulation experiments for Model 2 in (19) to investigate the performance of the algorithm proposed in Proposition 4. We find similar results to those for Model 1. All the experiments that we have conducted are replicable using the R code available at
https://github.com/yukai-yang/SMFilter_Experiments, and the corresponding R package SMFilter implementing the filtering algorithms of this paper is available at the Comprehensive R Archive Network (CRAN).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








