Assessing News Contagion in Finance

Abstract
:1. Introduction and Motivation
2. The Model
- : given a topic k, the vector of document counts showing a topic prevalence larger than a specified threshold with regards to country q at time t.
- : given a topic k, the vector of document counts showing a topic prevalence larger than a specified threshold with regards to country p at time t.
3. The Data
- Monthly-based: The time stamp of each news has been grouped on a monthly basis, obtaining 85 months starting with October 2006 (Month 1) and ending with November 2013 (Month 85).
- Weekly-based: The time stamp of each news has been grouped on a weekly basis, obtaining 370 weeks starting with 23rd October 2006 (Week 1) and ending with 19th November 2013 (Week 370).
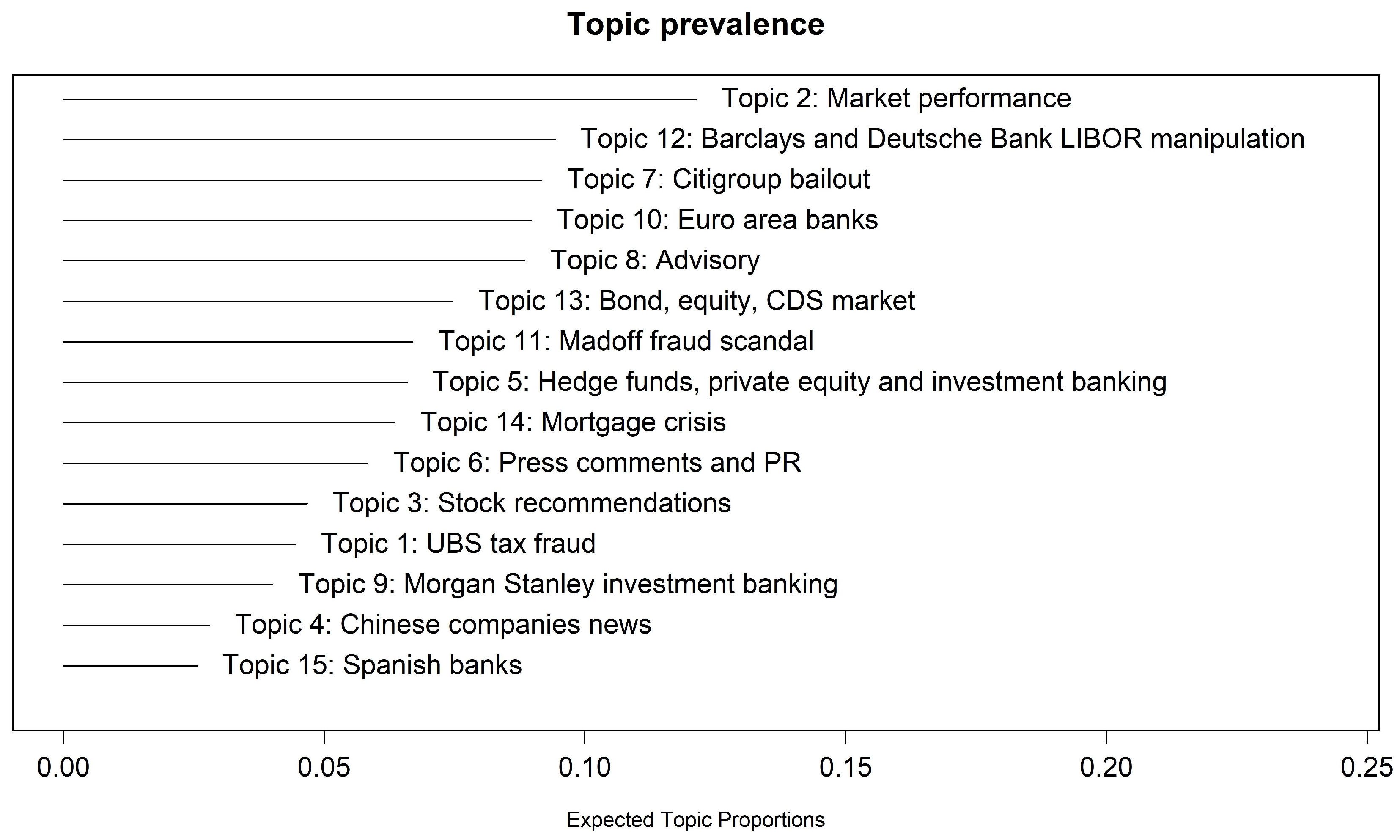
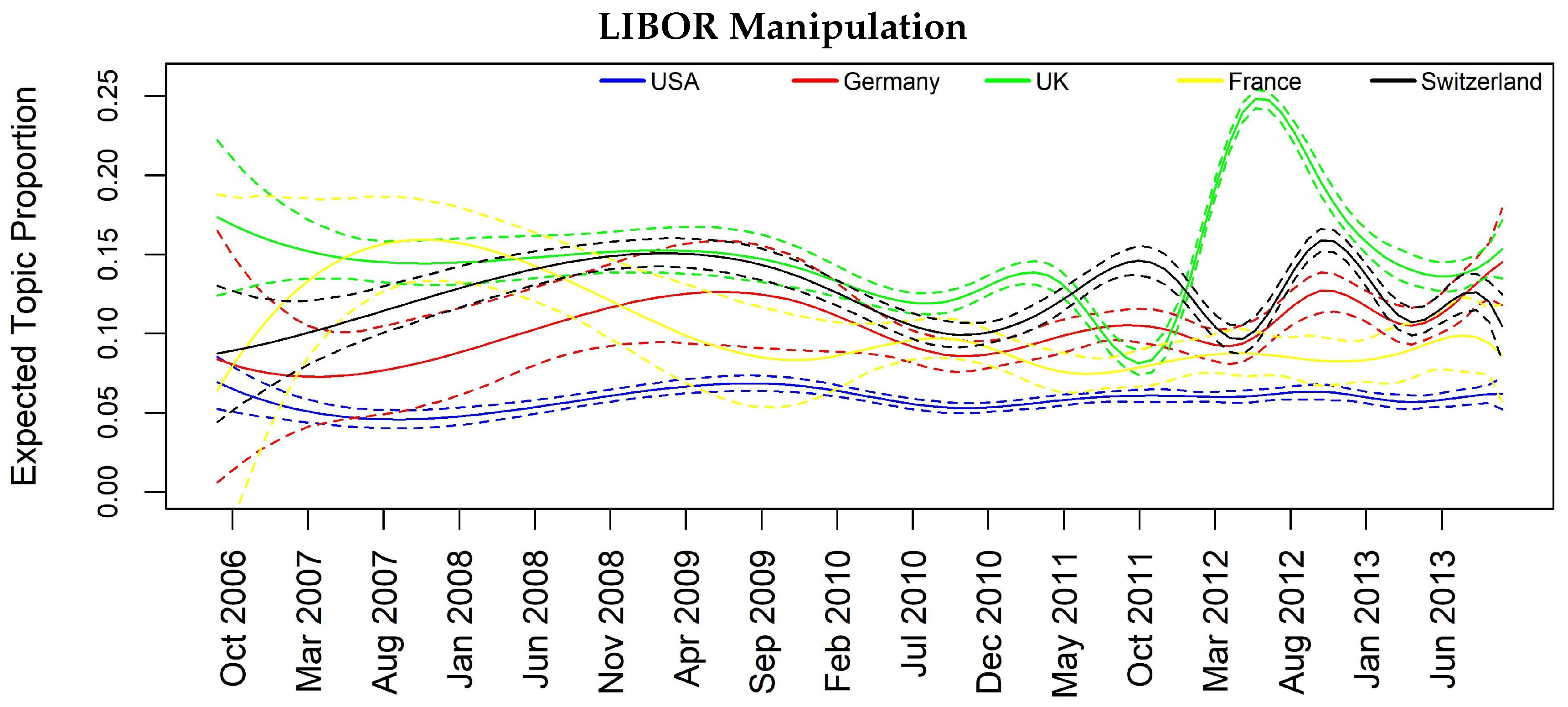
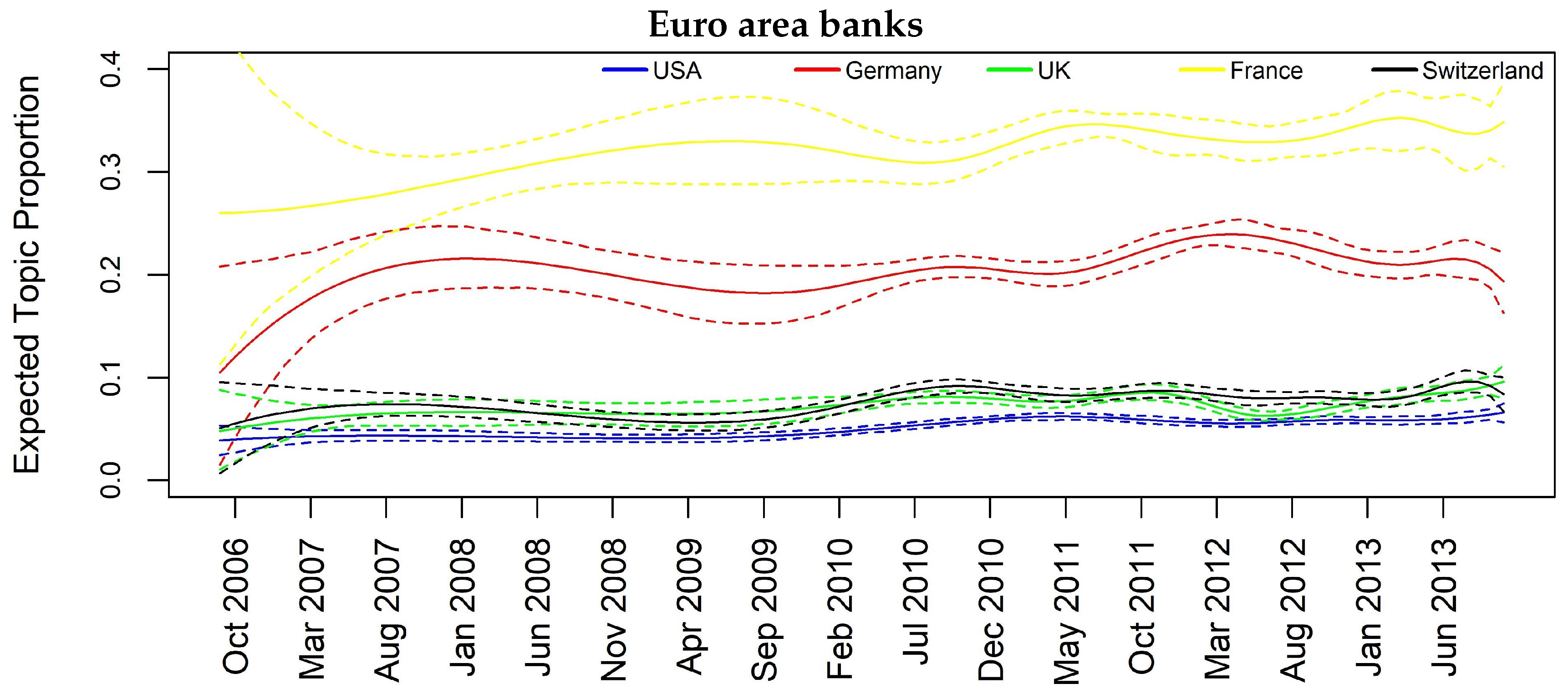
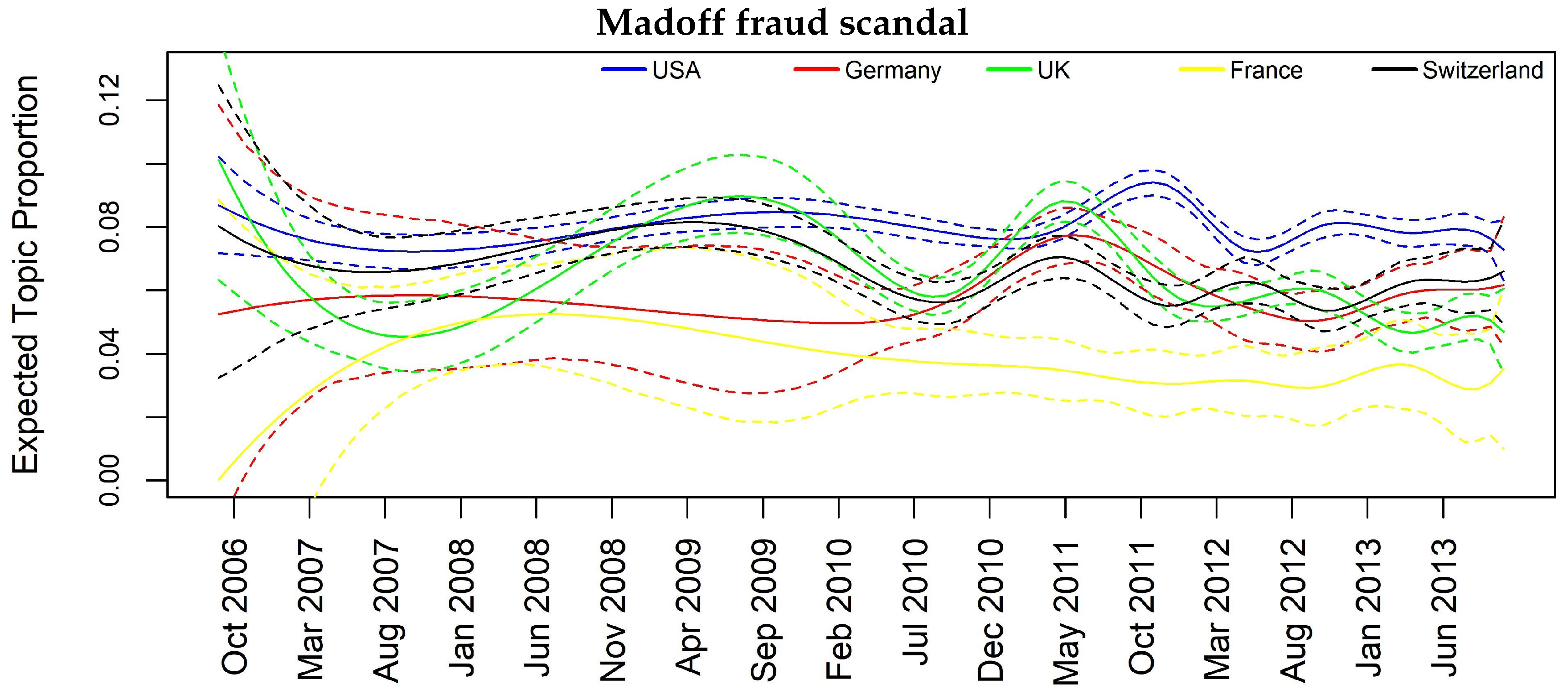
4. Results
5. Concluding Remarks
Author Contributions
Conflicts of Interest
References
- Bholat, David, Stephen Hansen, Pedro Santos, and Cheryl Schonhardt-Bailey. 2015. Text mining for central banks. In Centre for Central Banking Studies Handbook. London: Bank of England, vol. 33. [Google Scholar]
- Blei, David M., and John D. Lafferty. 2006. Correlated Topic Models. Advances in Neural Information Processing Systems 18: 1–47. [Google Scholar]
- Blei, David M., Andrew Y. Ng, and Michael I. Jordan. 2003. Latent Dirichlet allocation. JMLR 3: 993–1022. [Google Scholar]
- Bollen, Johan, Huina Mao, and Xiao-Jun Zeng. 2011. Twitter mood predicts the stock market. Journal of Computational Science 2: 1–8. [Google Scholar] [CrossRef]
- Brown, Eric D. 2012. Will Twitter make you a better investor? A look at sentiment, user reputation and their effect on the stock market. In Proceedings of the Southern Association for Information Systems Conference. Atlanta: SAIS, pp. 36–42. [Google Scholar]
- Brown, Peter F., Vincent J. Della Pietra, Peter V. deSouza, Jenifer C. Lai, and Robert L. Mercer. 1992. Class-based n-gram models of natural language. Computational Linguistics 18: 467–79. [Google Scholar]
- Cerchiello, Paola, and Paolo Giudici. 2016. How to measure the quality of financial tweets. Quality and Quantity 50: 1695–713. [Google Scholar] [CrossRef]
- Cerchiello, Paola, Giancarlo Nicola, Samuel Ronnqvist, and Peter Sarlin. 2017a. Deep Learning Bank Distress from News and Numerical Financial Data. DEM Working paper. Available online: https://arxiv.org/abs/1706.09627 (accessed on 12 Dec 2017).
- Cerchiello, Paola, Paolo Giudici, and Giancarlo Nicola. 2017b. Twitter data models for bank risk contagion. Neurocomputing 264: 50–6. [Google Scholar] [CrossRef]
- Chawla, Nitesh, Zhi Da, Jian Xu, and Mao Ye. 2016. Information Diffusion on Social Media: Does It Affect Trading, Return, and Liquidity? Working paper. Available online: https://ssrn.com/abstract=2935138 (accessed on 12 Dec 2017).
- Cho, Kyunghyun, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. Paper presented at the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, October 25–29. [Google Scholar]
- Clark, Alexander. 2003. Combining distributional and morphological information for part of speech induction. Paper presented at EACL, Budapest, Hungary, April 12–17. [Google Scholar]
- Collobert, Ronan, Jason Weston, Leon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa. 2011. Natural Language Processing (Almost) from Scratch. Journal of Machine Learning Research 12: 2493–537. [Google Scholar]
- Deerwester, Scott, Susan T. Dumais, George W. Furnas, Thomas K. Landauer, and Richard Harshman. 1990. Indexing by Latent Semantic Analysis. Journal of the American Society for Information Science 41: 391–407. [Google Scholar] [CrossRef]
- Ding, Xiao, Yue Zhang, Ting Liu, and Junwen Duan. 2015. Deep Learning for Event-Driven Stock Prediction. Paper presented at the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires, Argentina, July 25–31. [Google Scholar]
- Eisenstein, Jacob, Amr Ahmed, and Eric P. Xing. 2011. Sparse additive generative models of text. Paper presented at 28th International Conference on Machine Learning, Bellevue, WA, USA, June 28–July 2. [Google Scholar]
- Giannini, Robert C., Paul J. Irvine, and Tao Shu. 2013. Do Local Investors Know More? A Direct Examination of Individual Investors’ Information Set. Working paper. Available online: http://www.utahwfc.org/uploads/ 2014_08_2.pdf (accessed on 12 Dec 2017).
- Granger, C. W. J. 1969. Investigating Causal Relations by Econometric Models and Cross-spectral Methods. Econometrica 37: 424–38. [Google Scholar] [CrossRef]
- Girolami, Mark, and Ata Kaban. 2003. On an Equivalence between PLSI and LDA. Paper presented at 26th annual international ACM SIGIR conference on Research and development in informaion retrieval, Toronto, Canada, July 28–August 1; pp. 433–4. [Google Scholar]
- Hochreiter, Sepp, and Jurgen Schmidhuber. 1997. Long Short-Term Memory. Neural Computation 9: 1735–80. [Google Scholar] [CrossRef] [PubMed]
- Hofmann, Thomas. 1999. Probabilistic Latent Semantic Indexing. Paper presented at 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, August 11–19; pp. 50–7. [Google Scholar]
- Hokkanen, Jyry, Tor Jacobson, Cecilia Skingsley, and Markus Tibblin. 2015. The Riksbanks future information supply in light of Big Data. In Economic Commentaries. Stockholm: Sveriges Riksbank, vol. 17. [Google Scholar]
- Kalchbrenner, Nal Kalchbrenner, Edward Grefenstette, and Phil Blunsom. 2014. A Convolutional Neural Network for Modelling Sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguisti, Baltimore, MD, USA, June 23–25. [Google Scholar]
- Landauer, Thomas K., Peter W. Foltz, and Darrell Laham. 1998. Introduction to Latent Semantic Analysis. Discourse Processes 25: 259–84. [Google Scholar] [CrossRef]
- Malo, Pekka, Ankur Sinha, Pyry Takala, Pekka Korhonen, and Jyrki Wallenius. 2014. Good debt or bad debt: Detecting semantic orientations in economic texts. Journal of the Association for Information Science and Technology 65: 782–96. [Google Scholar] [CrossRef]
- Martin, Sven, Jörg Liermann, and Hermann Ney. 1998. Algorithms for bigram and trigram word clustering. Speech Communication 24: 19–37. [Google Scholar] [CrossRef]
- Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. Paper presented at Workshop at International Conference on Learning Representations, Scottsdale, Arizona, May 2nd-4th. [Google Scholar]
- Mimno, David, and Andrew McCallum. 2008. Topic Models Conditioned on Arbitrary Features with Dirichlet-Multinomial Regression. In Proceedings of the Twenty-Fourth Conference on Uncertainty in Artificial Intelligence (UAI2008), Helsinki, Finland, July 9–12. [Google Scholar]
- Mittal, Anshul, and Arpit Goel. 2012. Stock Prediction Using Twitter Sentiment Analysis. Working Paper. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.375.4517&rep=rep1&type=pdf (accessed on 12 Dec 2017).
- Nann, Stefan, Jonas Krauss, and Detlef Schoder. 2013. Predictive Analytics On Public Data—The Case Of Stock Markets. ECIS 2013 Completed Research. 102. Available online: ttps://aisel.aisnet.org/ecis2013_cr/102 (accessed on 12 Dec 2017).
- Nyman, Rickard, David Gregory, Sujit Kapadia, Paul Ormerod, David Tuckett, and Robert Smith. 2015. News and Narratives in Financial Systems: Exploiting Big Data for Systemic Risk Assessment. Available online: https://www.norges-bank.no/contentassets/49b4dce839a7410b9a7f66578da8cf74/papers/smith.pdf (accessed on 12 Dec 2017).
- Oliveira, Nuno, Paulo Cortez, and Nelson Area. 2013. On the predictability of stock market behaviour using stock twits sentiment and posting volume. In Progress in Artificial Intelligence. EPIA 2013. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer, vol. 8154, pp. 355–65. [Google Scholar]
- Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation. Paper presented at the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, October 25–29; pp. 1532–43. [Google Scholar]
- Putthividhya, Duangmanee (Pew), Hagai T. Attias, and Srikantan Nagarajan. 2009. Independent Factor Topic Models. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, Quebec, Canada, June 14–18; pp. 833–40. [Google Scholar]
- Rönnqvist, Samuel, and Peter Sarlin. 2017. Bank distress in the news: Describing events through deep learning. Neurocomputing 264: 57–70. [Google Scholar] [CrossRef]
- Ranco, Gabriele, Darko Aleksovski, Guido Caldarelli, Miha Grčar, and Igor Mozetič. 2015. The Effects of Twitter Sentiment on Stock Price Returns. PLoS ONE 10: e0138441. [Google Scholar] [CrossRef] [PubMed]
- Rao, Tushar, and Saket Srivastava. 2012. Twitter sentiment analysis: How to hedge your bets in the stock markets. Available online: https://arxiv.org/abs/1212.1107 (accessed on 12 Dec 2017).
- Roberts, Margaret E., Brandon M. Stewart, and Dustin Tingley. 2016a. Navigating the Local Modes of Big Data: The Case of Topic Models. In Data Analytics in Social Science, Government, and Industry. New York: Cambridge University Press. [Google Scholar]
- Roberts, Margaret E., Brandon M. Stewart, and Edoardo M. Airoldi. 2016b. A model of text for experimentation in the social sciences. Journal of the American Statistical Association 111: 988–1003. [Google Scholar] [CrossRef]
- Sims, Christopher A. 1972. Money, Income and Causality. American Economic Review 62: 540–52. [Google Scholar]
- Socher, Richard, Jeffrey Pennington, Eric H. Huang, Andrew Y. Ng, and Christopher D. Manning. 2011. SemiSupervised Recursive Autoencoders for Predicting Sentiment Distributions. Paper presented at the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP), Edinburgh, UK, July 27–31. [Google Scholar]
- Socher, Richard, Alex Perelygin, Jean Y. Wu, Jason Chuang, Christopher D. Manning, Andrew Y. Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. Paper presented at Empirical Methods in Natural Language Processing (EMNLP 2013), Seattle, WA, USA, October 18–21; pp. 1631–42. [Google Scholar]
- Soo, Cindy K. 2013. Quantifying Animal Spirits: News Media and Sentiment in the Housing Market. Ross School of Business Paper No. 1200. Available online: https://aisel.aisnet.org/ecis2013_cr/102 (accessed on 12 Dec 2017).
- Sprenger, Timm O., and Isabell M. Welpe. 2010. Tweets and Trades: The Information Content of Stock Microblogs (November 1, 2010). Available online: http://dx.doi.org/10.2139/ssrn.1702854 (accessed on 12 Dec 2017).
| 1 | The datasets are available on the github of Philippe Remy at https://github.com/philipperemy/financial-news-dataset and have been retrieved and appropriately collected using Python. |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bank | # of Sentences | Country |
|---|---|---|
| Bank of America | 19,203 | USA |
| Goldman Sachs | 16,258 | USA |
| Citigroup | 15,446 | USA |
| UBS | 13,414 | Switzerland |
| Barclays | 11,434 | UK |
| Morgan Stanley | 11,162 | USA |
| HSBC | 8693 | UK |
| Deutsche Bank | 7471 | Germany |
| Credit Suisse | 6385 | Switzerland |
| Wells Fargo | 4876 | USA |
| Bank of China | 3416 | China |
| Societe Generale | 2463 | France |
| BNP Paribas | 2012 | France |
| Royal Bank of Scotland | 1943 | UK |
| Standard Chartered | 1813 | UK |
| Commerzbank | 1512 | Germany |
| BNY Mellon | 1427 | USA |
| Credit Agricole | 1195 | France |
| Banco Santander | 1023 | Spain |
| State Street | 926 | USA |
| Sumitomo Mitsui | 900 | Japan |
| JP Morgan | 755 | USA |
| Industrial and Commercial Bank of China | 732 | China |
| BBVA | 718 | Spain |
| Lloyds Bank | 648 | UK |
| China Construction Bank | 387 | China |
| ING Bank | 110 | Netherlands |
| Unicredit | 94 | Italy |
| Dexia Group | 2 | Belgium |
| Total | 136,418 |
| Country | # of Sentences |
|---|---|
| USA | 70,053 |
| UK | 24,531 |
| Switzerland | 19,799 |
| Germany | 8983 |
| France | 5670 |
| China | 4535 |
| Spain | 1741 |
| Japan | 900 |
| Netherlands | 110 |
| Italy | 94 |
| Belgium | 2 |
| Total | 136,418 |
| # of Topics | Time (s) |
|---|---|
| 5 | 371 |
| 10 | 522 |
| 12 | 685 |
| 15 | 543 |
| 25 | 1155 |
| 35 | 6667 |
| Monthly Aggregation | Weekly Aggregation | |||
|---|---|---|---|---|
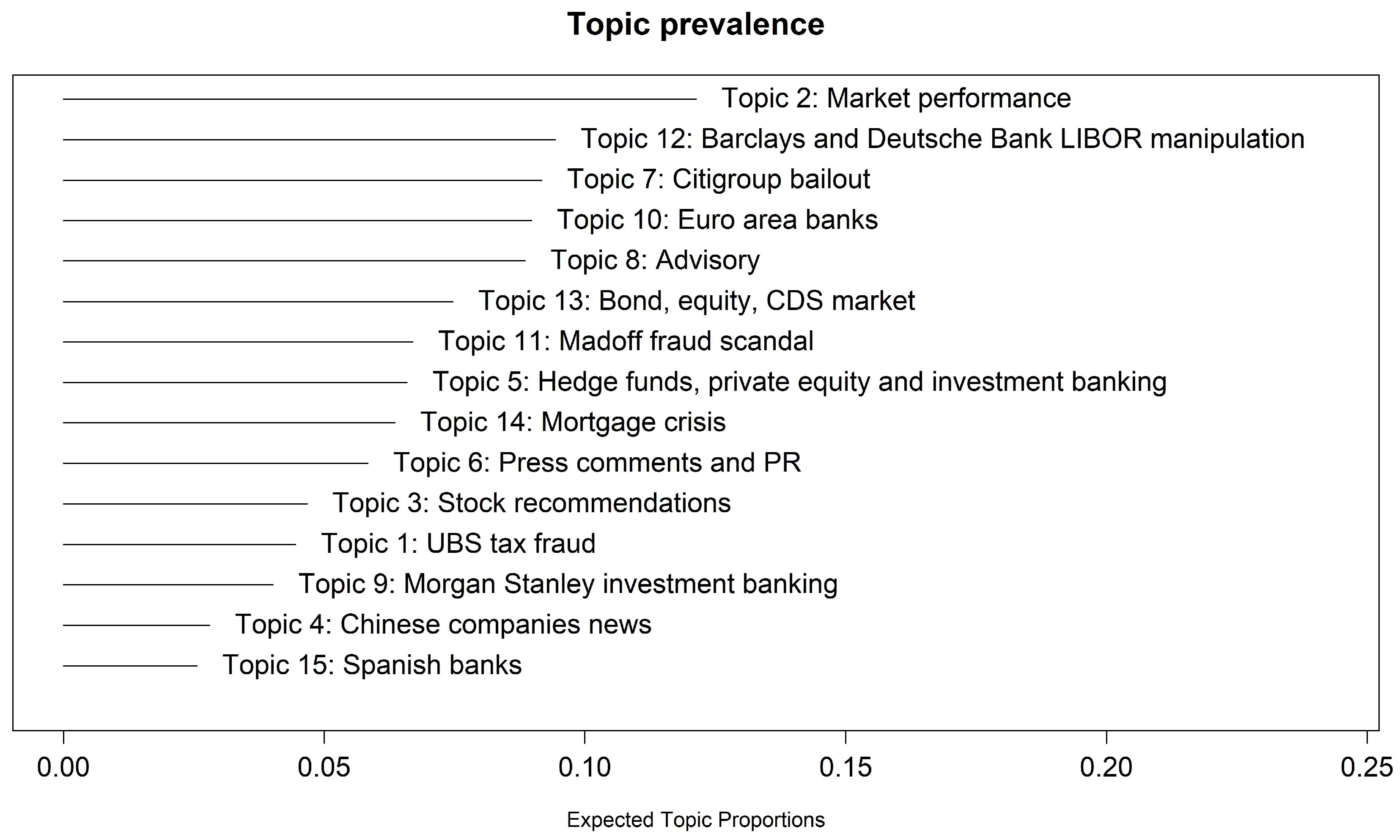
| Topic Title | 10 Topics | 12 Topics | 15 Topics | 15 Topics |
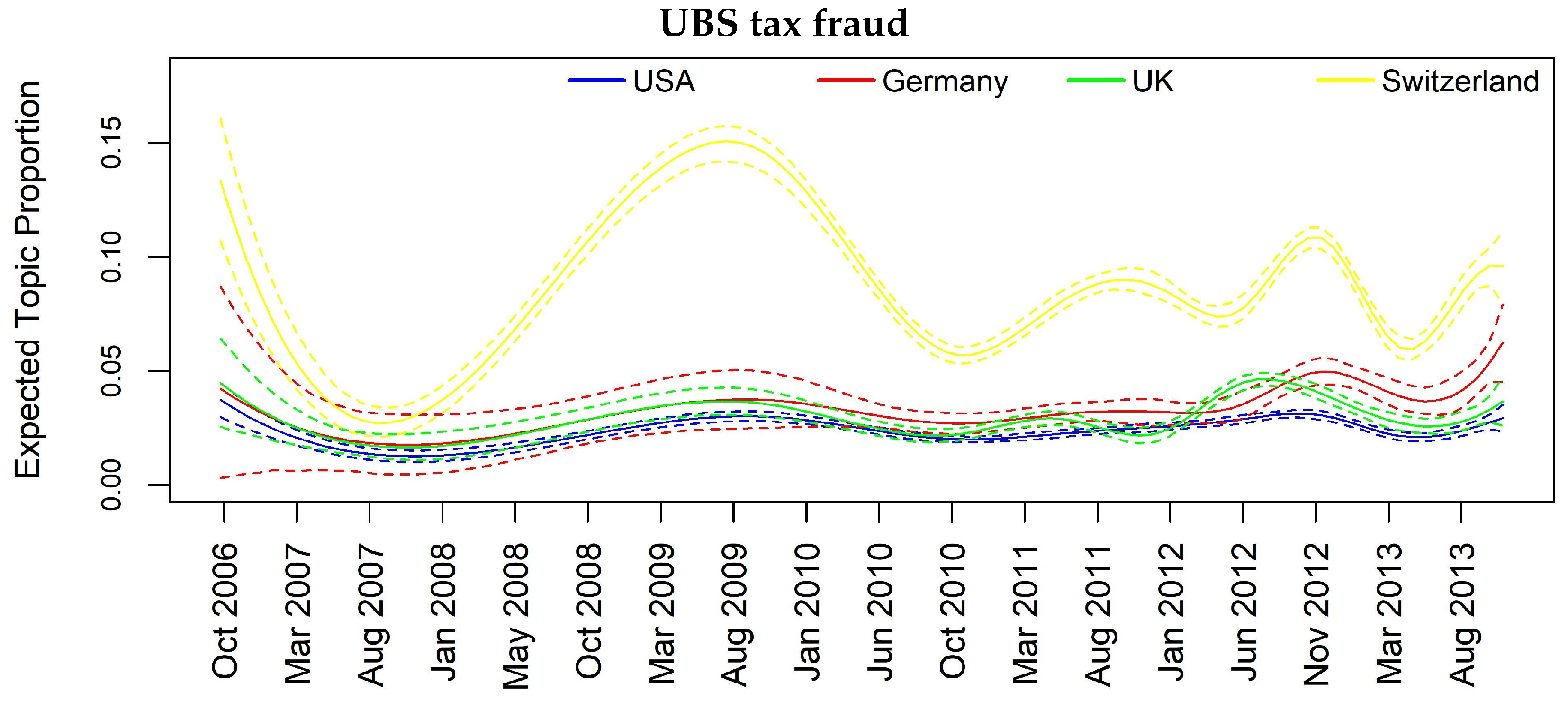
| UBS tax fraud scandal | Y | Y | Y | Y |
| Market performance | Y | Y | Y | Y |
| Stock recommendation | Y | Y | Y | Y |
| Chinese companies news | Y | Y | Y | - |
| Hedge Funds, Private Equity and Inv. Banking | Y | Y | Y | Y |
| Press comments and PR | Y | Y | Y | Y |
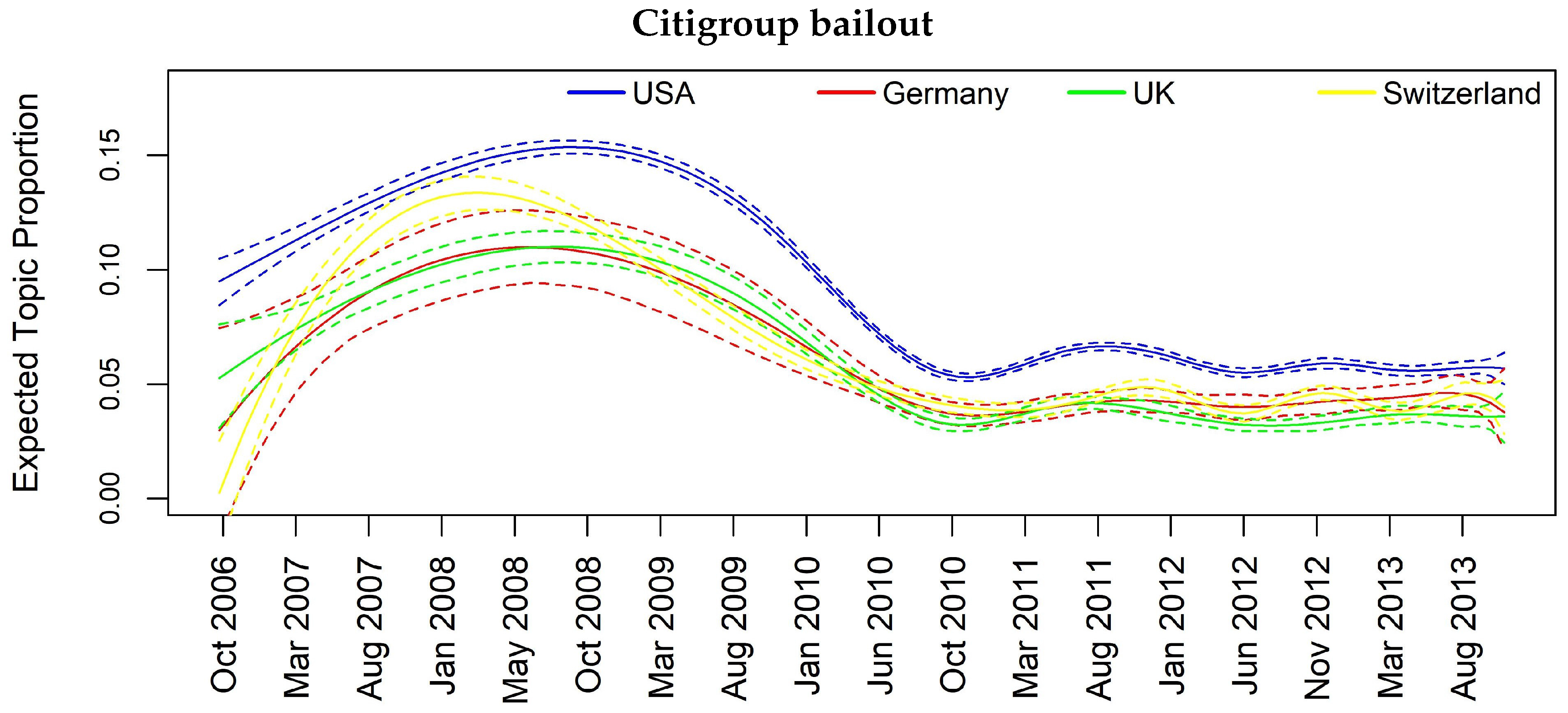
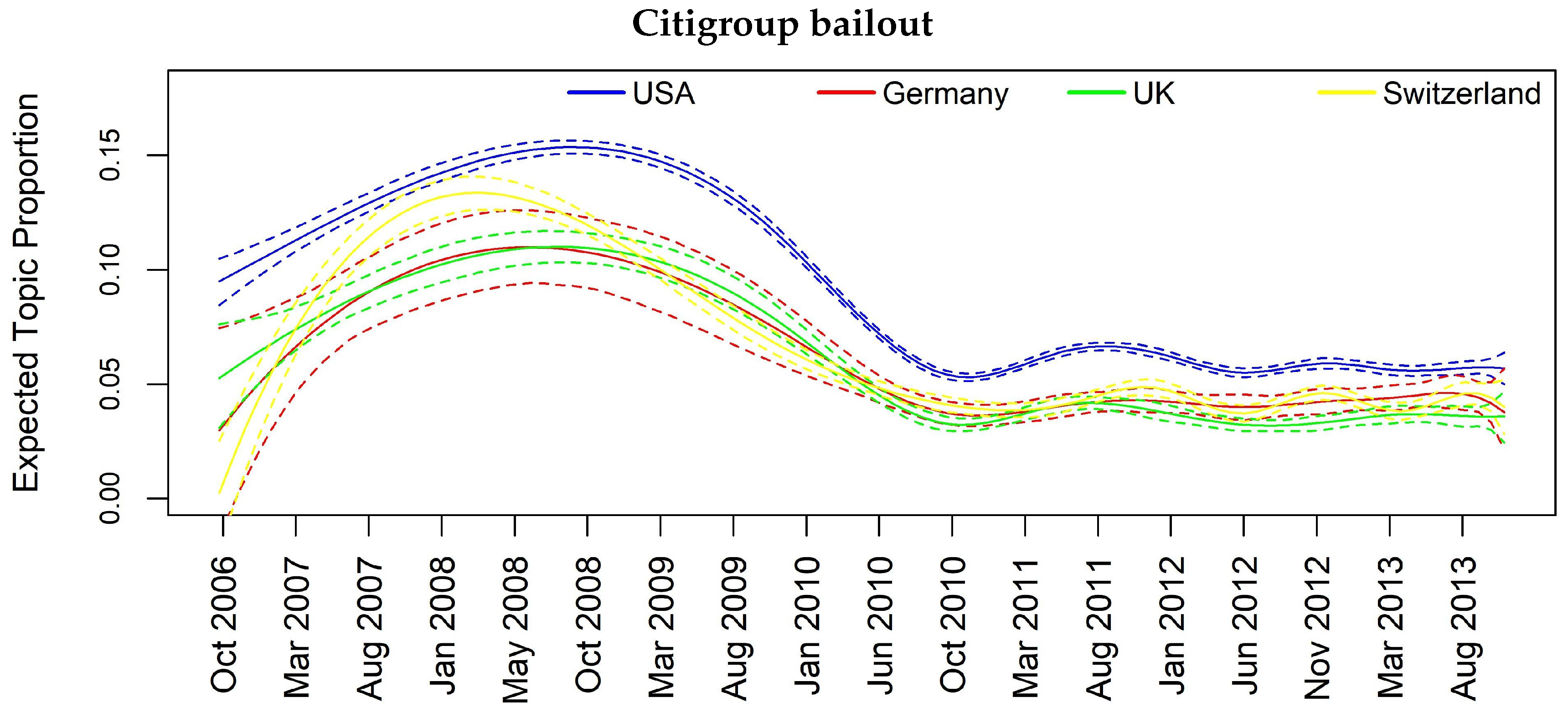
| Citigroup bailout | Y | Y | Y | Y |
| Advisory | - | - | Y | - |
| Morgan Stanley Investment Banking | Y | Y | Y | Y |
| Euro area banks | Y | Y | Y | - |
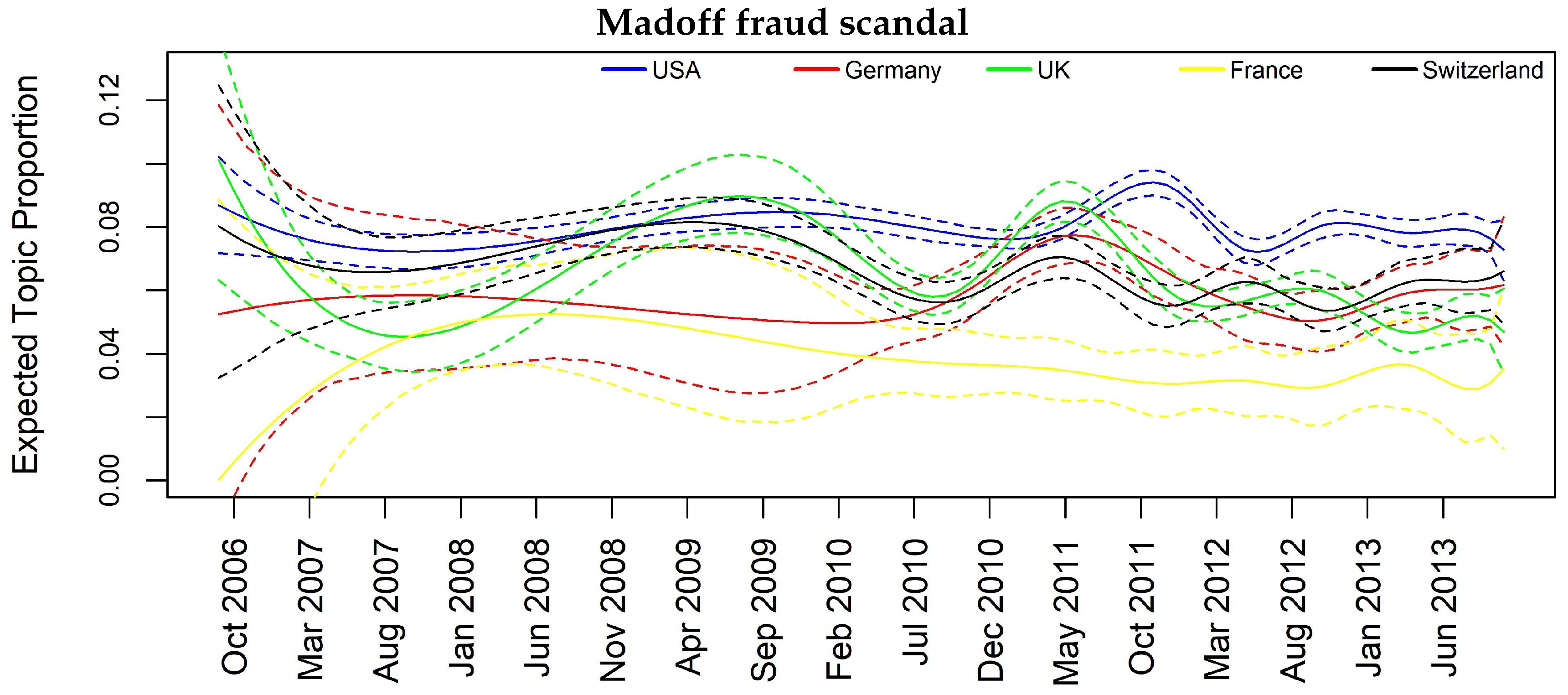
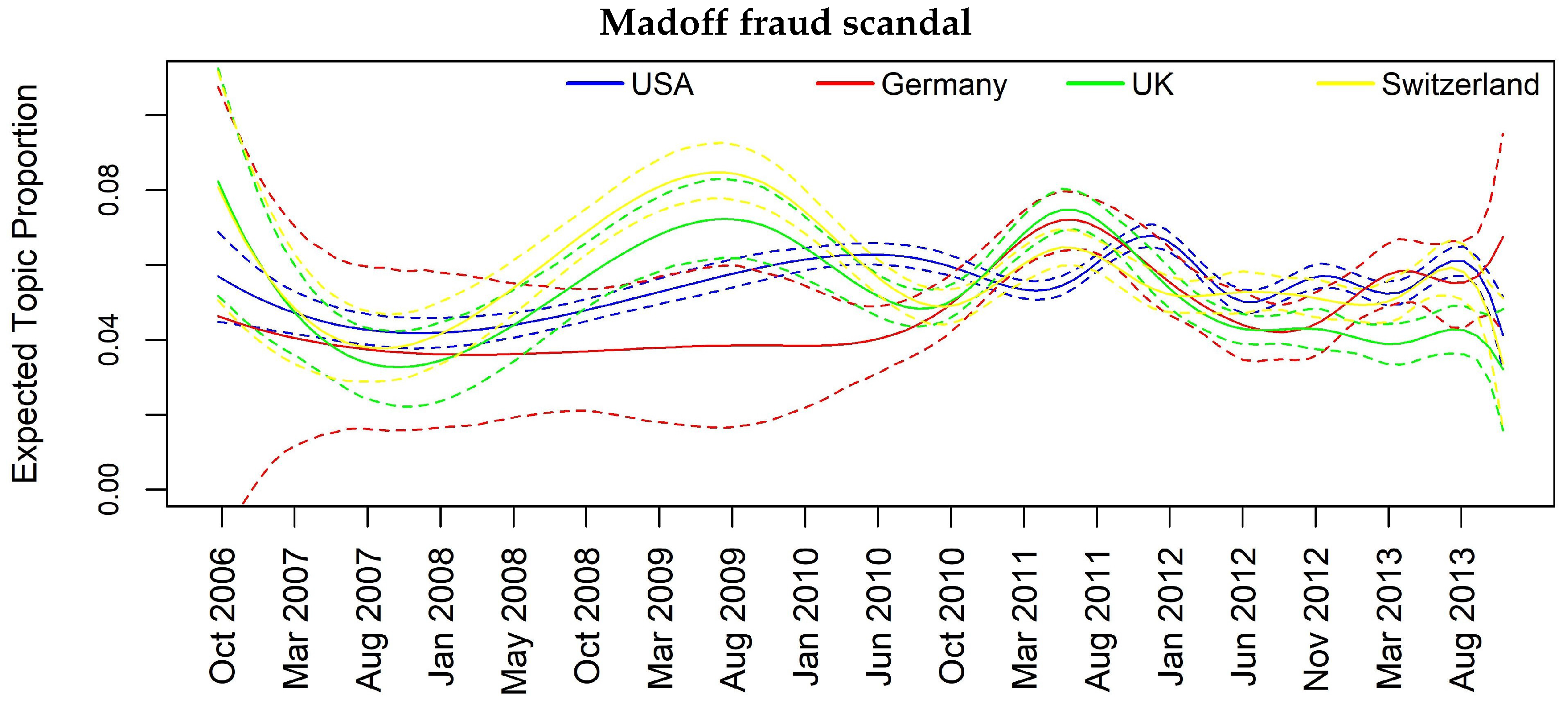
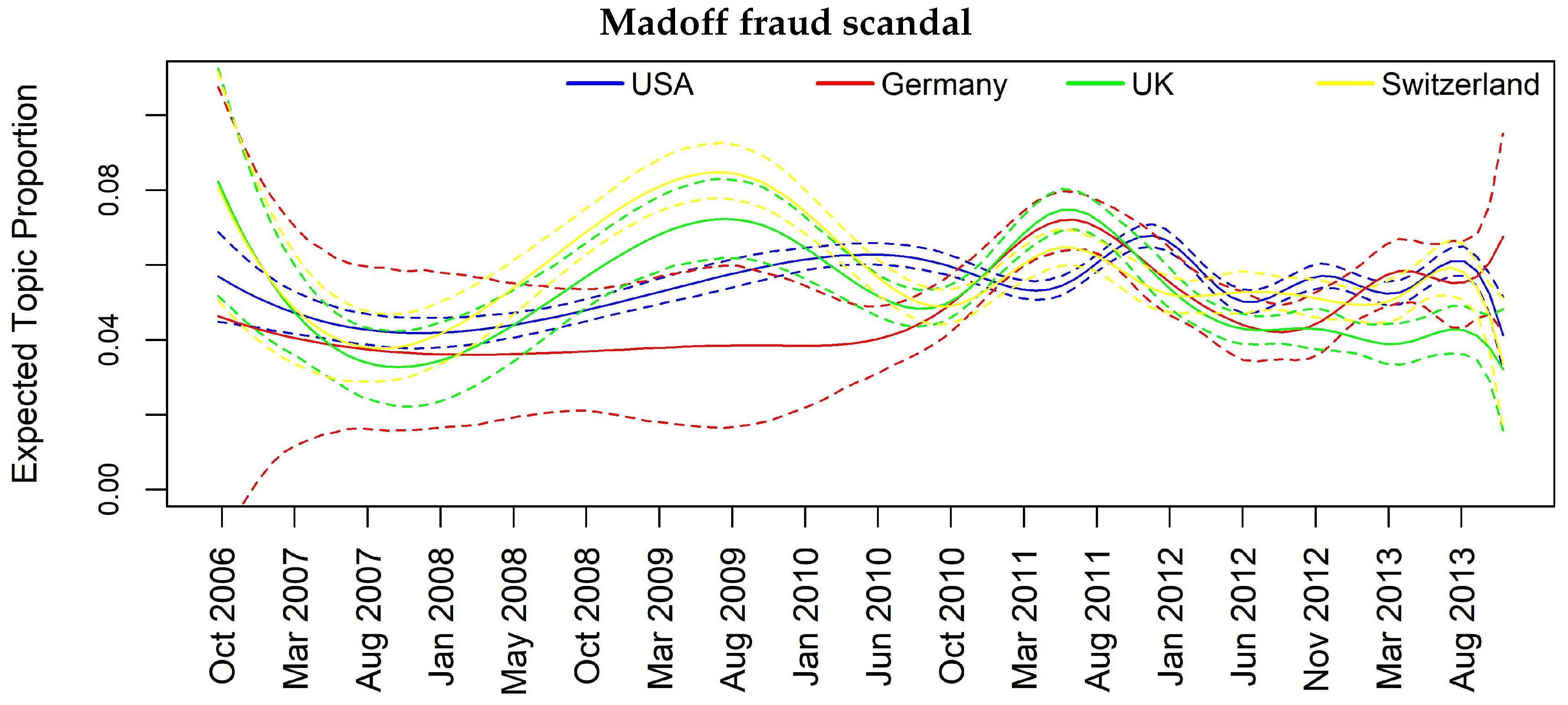
| Madoff scandal | - | - | Y | Y |
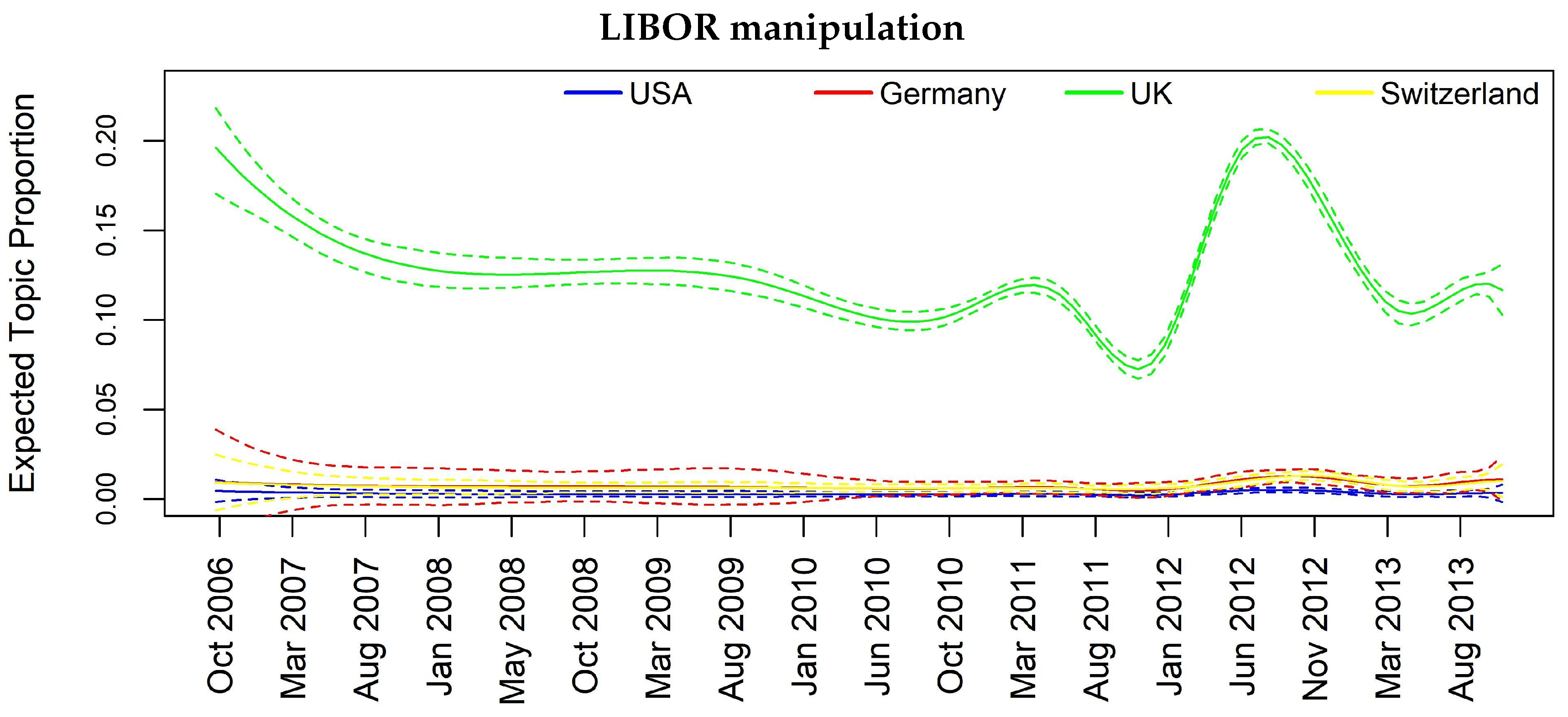
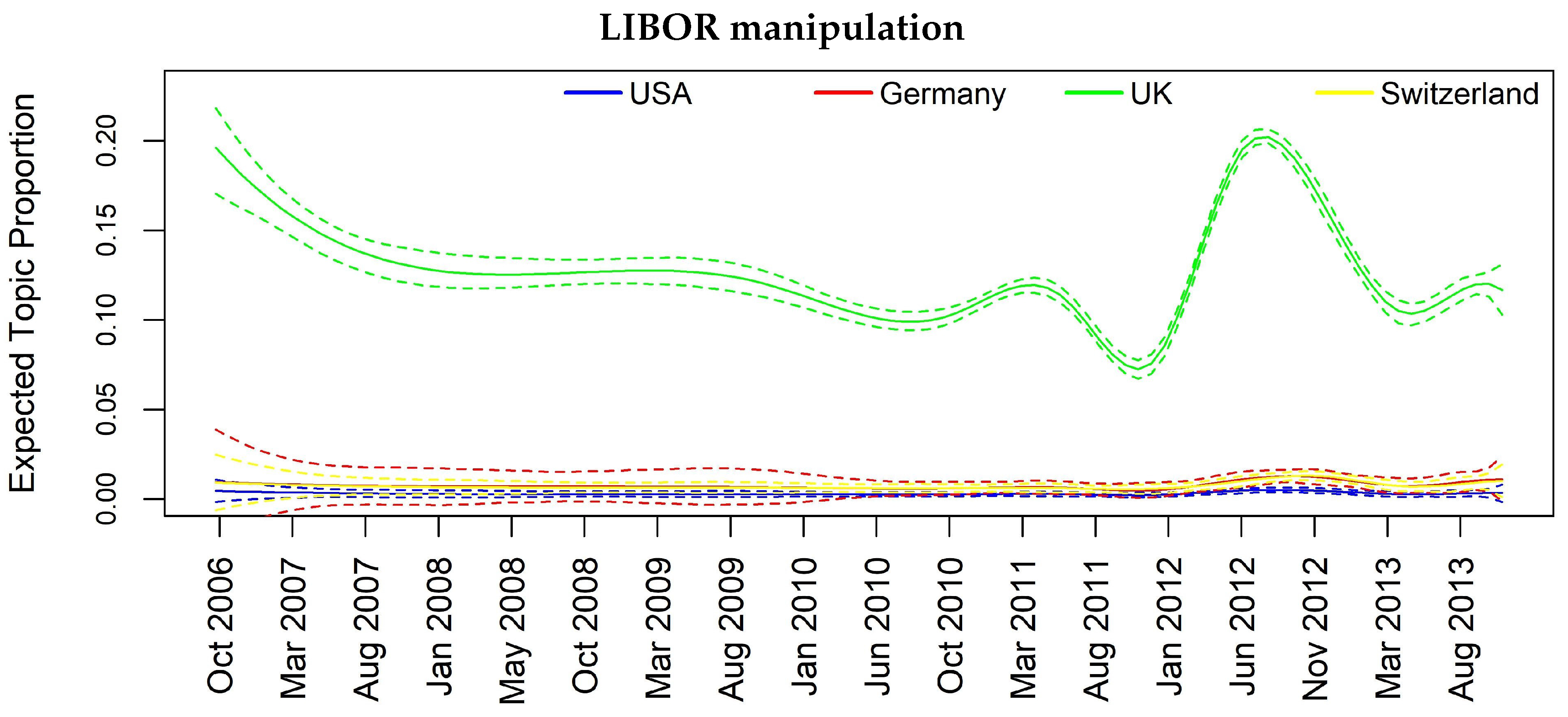
| Barclays and Deutsche B. LIBOR manipulation | Y | Y | Y | Y |
| Bond, Equity, and CDS markets | - | - | Y | Y |
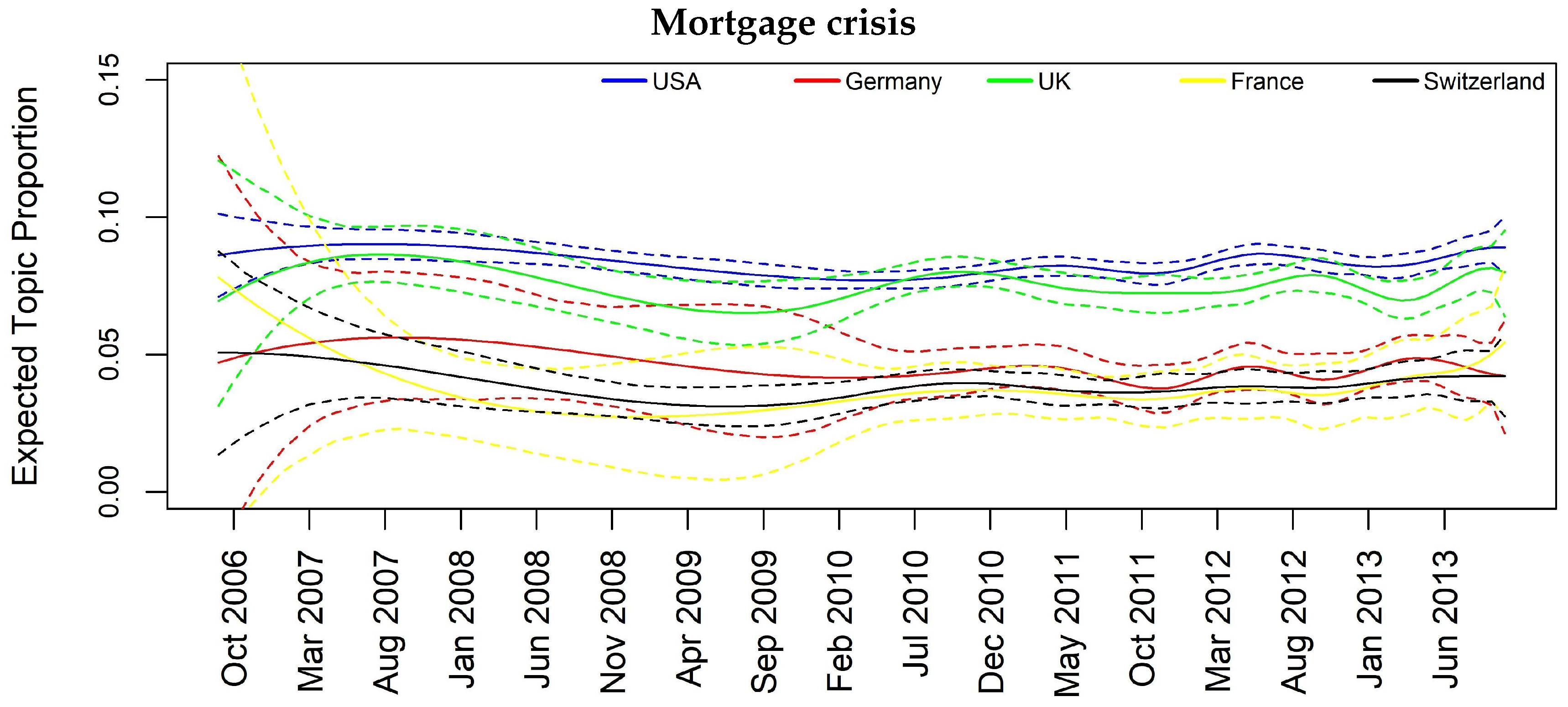
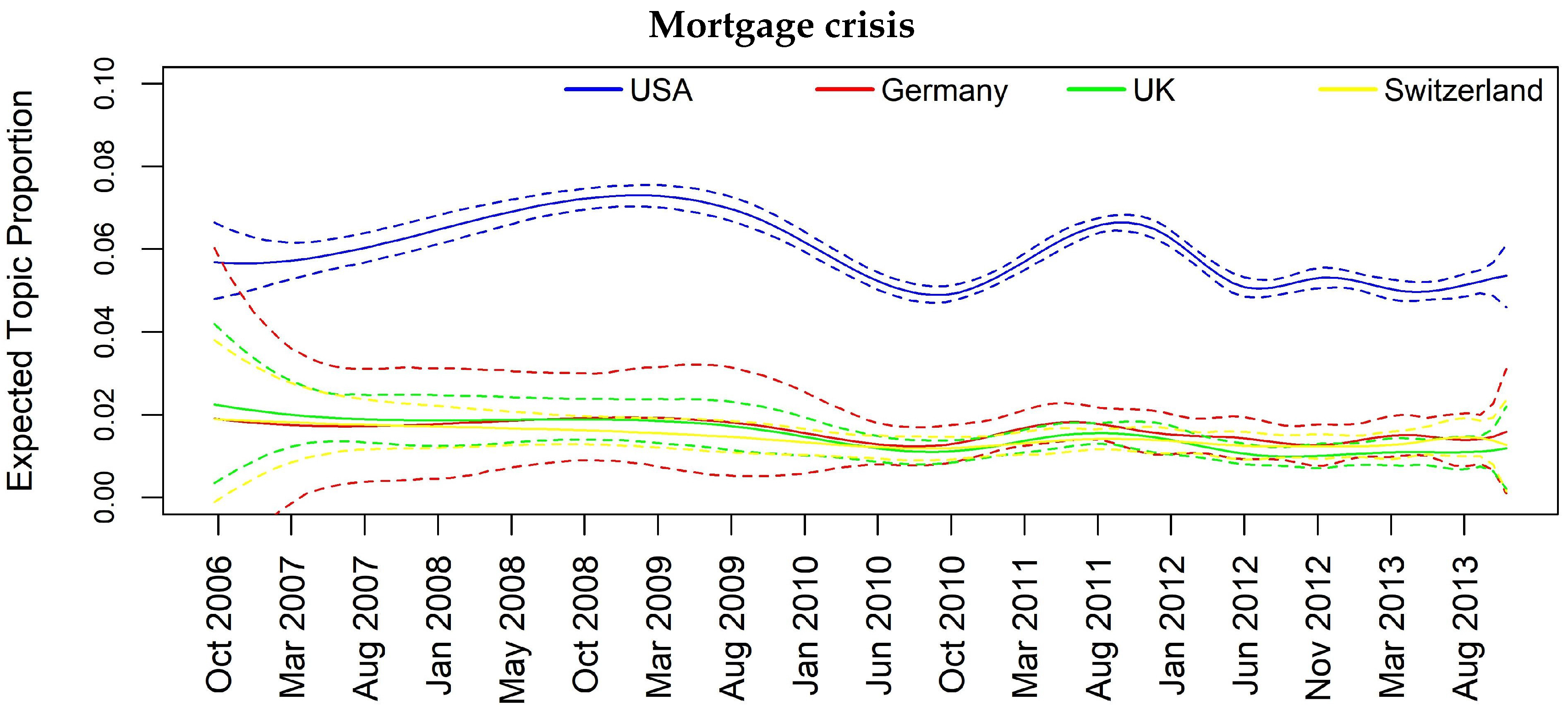
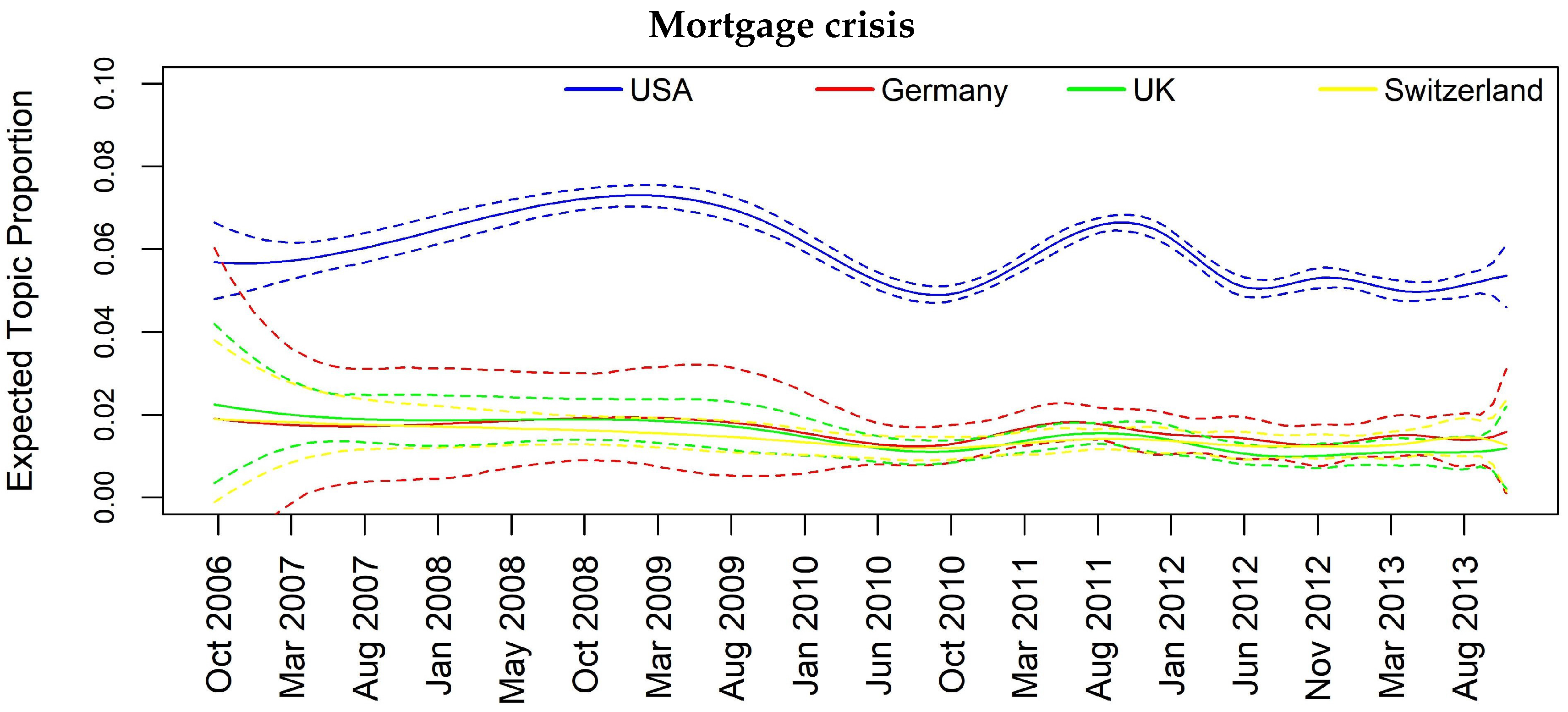
| Mortgage crisis | - | Y | Y | Y |
| Spanish banks | - | - | Y | - |
| General view on the economy | - | Y | - | - |
| Insider trading investigation | - | - | - | Y |
| Wells Fargo-Wachovia acquisition | - | - | - | Y |
| Bank management changes | - | - | - | Y |
| US banks stocks performance | - | - | - | Y |
| Topic | Words |
|---|---|
| Topic 1 | FREX: charg, justic, guilti, account, ubsn, evas, plead, prosecut, crimin, hide, depart, evad, client, indict, california, avoid, wealthi, adoboli, involv, ubsnvx |
| Topic 2 | FREX: gain, percent, cent, cmci, lost, ralli, advanc, drop, materi, sinc, jump, return, slip, tumbl, climb, slid, compil, rose, close, bloomberg |
| Topic 3 | FREX: sumitomo, mitsui, suiss, csgn, scotland, neutral, credit, lloy, spectron, neutral, rbsl, royal, icap, mizuho, csgnvx, maker, suisse , outperform, baer |
| Topic 4 | FREX: elec, cosco, sino, comm, lung, chem, pharm, fook, sang, shougang, yuexiu, sinotran, picc, swire, people , intl, emperor, shui, citic, hang |
| Topic 5 | FREX: sach, goldman, groupinc, blankfein, sachs , gupta, rajaratnam, sachsgroup, corzin, paulson, vice, wall, rajat, tourr, presid, warren, buffett, obama, hathaway, gambl |
| Topic 6 | FREX: spokesman, comment, charlott, spokeswoman, immedi, carolina-bas, tocom, bacn, countrywid, north, avail, lewi, moynihan, confirm, carolina, declin, respond, corp, repres, america |
| Topic 7 | FREX: bailout, citigroup, pandit, sharehold, prefer, receiv, vikram, troubl, citigroup, announc, rescu, common, taxpay, worth, subprim, crisi, dividend, loss, plan, shed |
| Topic 8 | FREX: advis, hire, head, team, familiar, privat, wealth, manag, appoint, deal, equiti, arrang, advisori, co-head, counsel, person, barclay, financ, dbkgnde, advic |
| Topic 9 | FREX: stanley, morgan, stanley , smith, barney, gorman, mack, ventur, facebook, estat, bear, fuel, brokerag, underwrit, real, stearn, crude, commod, brent, healthcar |
| Topic 10 | FREX: societ, pariba, commerzbank, euro, estim, profit, quarter, french, general, forecast, itali, greek, half, predict, germany , technic, germani, greec, socgen, incom |
| Topic 11 | FREX: case, mellon, truste, southern, district, york, suit, bankruptci, mortgage-back, claim, stempel, oblig, collater, file, madoff, lehman, picard, jonathan, rakoff, manhattan |
| Topic 12 | FREX: libor, manipul, diamond, regul, scandal, told, wrote, think, confer, fine, ubss, gruebel, respons, lawmak, event, england, polici, hsbcs, complianc |
| Topic 13 | FREX: basi, point, markit, itraxx, percentag, yield, basispoint, swap, spread, preliminari, manufactur, extra, read, managers , tokyo, demand, releas, bond, econom, narrow |
| Topic 14 | FREX: fargo, charter, chase, well, standard, jpmorgan, jpmn, home, wfcn, build, korea, portfolio, loan, francisco-bas, origin, size, mutual, small, fargo , india |
| Topic 15 | FREX: banco, santand, bbva, bilbao, peso, spain , argentaria, spanish, chile, vizcaya, brazil, latin, mexico, spain, brasil, follow, mover, brazilian, mexican |
| Topic | Words |
|---|---|
| Topic 1 | FREX: level, drop, highest, advanc, materi, month, march, sinc, price, measur, gain, builderswel, climb, sector, sentiment, slip, rose, lowest, carri, match |
| Topic 2 | FREX: goldman, sach, sachs, gupta, groupinc, rajaratnam, sachsgroup, street, rajat, blankfein, warren, wall, procter, corzin, tourr, hathaway, ex-goldman, paulson, galleon, inca |
| Topic 3 | FREX: north, countrywid, charlott, bofa, bacn, mortgag, carolina-bas, loan, fanni, merger, moynihan, america, lewi, carolina, freddi, corp, america, brian, repurchas, grayson |
| Topic 4 | FREX: declin, comment, spokesman, spokeswoman, tocom, confirm, duval, mark, e-mail, mari, contact, declinedto, spokesmen, retreat, hasn, york-bas, onth, bloomberg, cohen, interview |
| Topic 5 | FREX: court, district, judg, manhattan, case, dismiss, file, appeal, southern, suit, bankruptci, truste, complaint, claim, -cv-, suprem, rakoff, lawsuit, commiss, mortgage-back |
| Topic 6 | FREX: fargo, well, wachovia, call, avail, repres, wfcn, didn, hour, francisco-bas, bancorp, farg, francisco, respond, request, stumpf, protest, reach, messag, wasn |
| Topic 7 | FREX: bailout, post, billion, announc, result, writedown, troubl, rescu, sheet, book, common, crisi, balanc, prefer, addit, expens, loss, inject, profit, exposur |
| Topic 8 | FREX: execut, chief, chairman, offic, vice, obama, peter, vikram, presid, replac, join, appoint, co-head, left, secretari, univers, board, rubin, pandit, member |
| Topic 9 | FREX: barclay, barc, libor, barclays, barcl, pound, manipul, british, diamond, barclaysplc, brit, britain, absa, plc, penc, fine, interbank, submiss, uk, million-pound |
| Topic 10 | FREX: came, guilti, adoboli, ubss, investig, plead, client, regulatori, indict, requir, arrest, view, complianc, unauthor, banker, hide, desk, ubsnvx, ubs, wealthi |
| Topic 11 | FREX: close, cent, stock, share, afternoon, friday, earli, near, thursday, higher, discount, volum, nyse, tuesday, option, nasdaq, morn, jump, trade, tumbl |
| Topic 12 | FREX: wealth, estat, divis, hedg, manag, focus, oper, invest, busi, fund, investment-bank, unit, privat, main, overse, small, foreign, blackrock, branch, smaller |
| Topic 13 | FREX: point, basi, swap, percentag, tokyo, itraxx, japan, dubai, extra, narrow, spread, sukuk, dollar, hsbcnasdaq, australia, instead, credit-default, basispoint, default, rate |
| Topic 14 | FREX: morgan, stanley, stanl, barney, mitsubishi, gorman, cyclic, smith, facebook, ventur, mack, mufg, appl, underwrit, revenu, brent, joint, healthcar, payor, cargo |
| Topic 15 | FREX: forecast, growth, predict, half, domest, three, second, project, gross, will, economi, almost, slow, spend, earn, fiscal, monetari, expect, deficit, probabl |
| Topic | China | France | Germany | Spain | Switzerland | UK | USA |
|---|---|---|---|---|---|---|---|
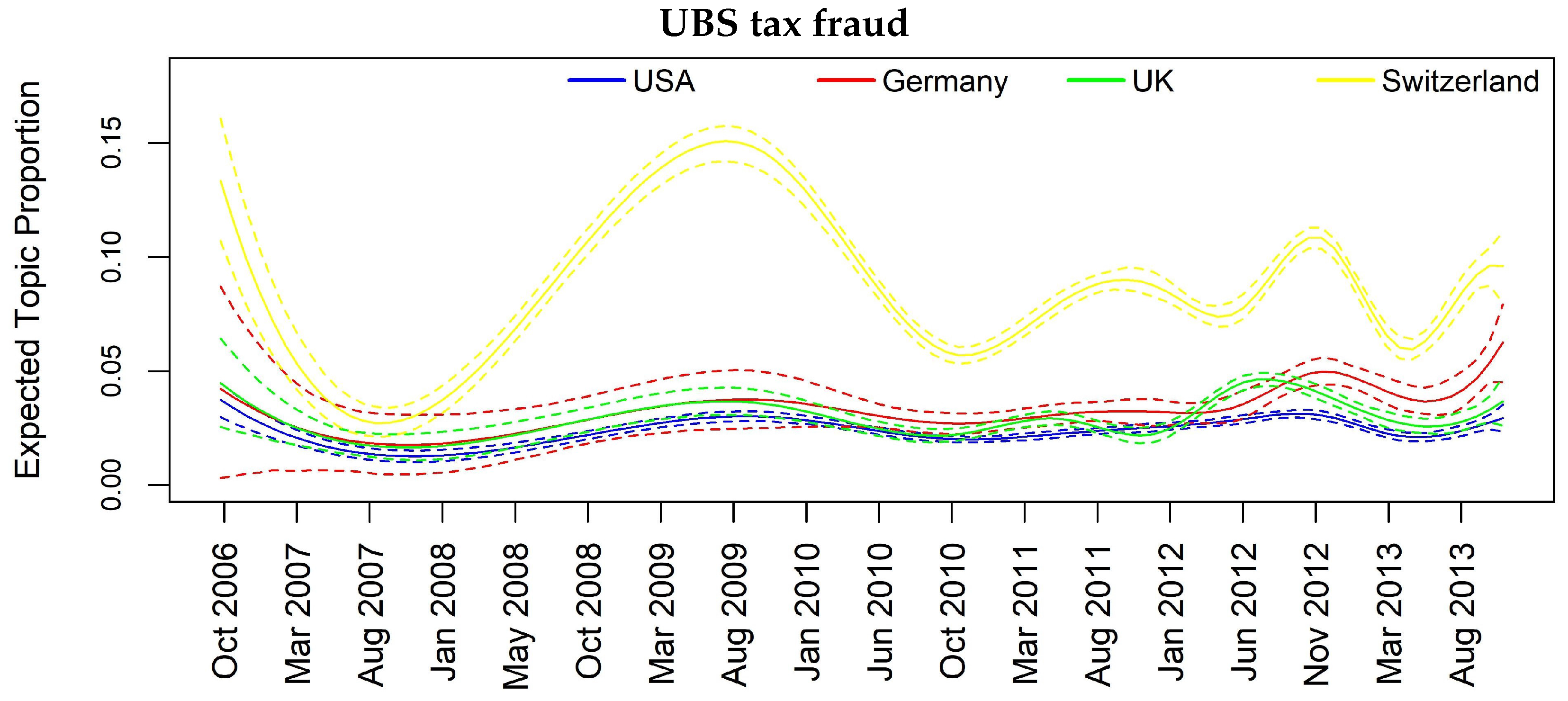
| UBS tax fraud scandal | 0.01 | 0.03 | 0.04 | 0.01 | 0.13 | 0.03 | 0.03 |
| Market performance | 0.17 | 0.11 | 0.11 | 0.12 | 0.12 | 0.10 | 0.13 |
| Stock recommend. | 0.01 | 0.05 | 0.03 | 0.01 | 0.15 | 0.06 | 0.01 |
| Chinese company news | 0.43 | 0.01 | 0.01 | 0.01 | 0.01 | 0.03 | 0.01 |
| H. Funds, Pr. Eq. and Inv. Bank. | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.12 |
| Press comments and PR | 0.02 | 0.02 | 0.03 | 0.02 | 0.03 | 0.02 | 0.09 |
| Citigroup bailout | 0.07 | 0.04 | 0.04 | 0.02 | 0.07 | 0.05 | 0.13 |
| Advisory | 0.03 | 0.07 | 0.20 | 0.03 | 0.10 | 0.14 | 0.06 |
| Morgan St. Inv. Banking | 0.00 | 0.01 | 0.01 | 0.00 | 0.01 | 0.01 | 0.07 |
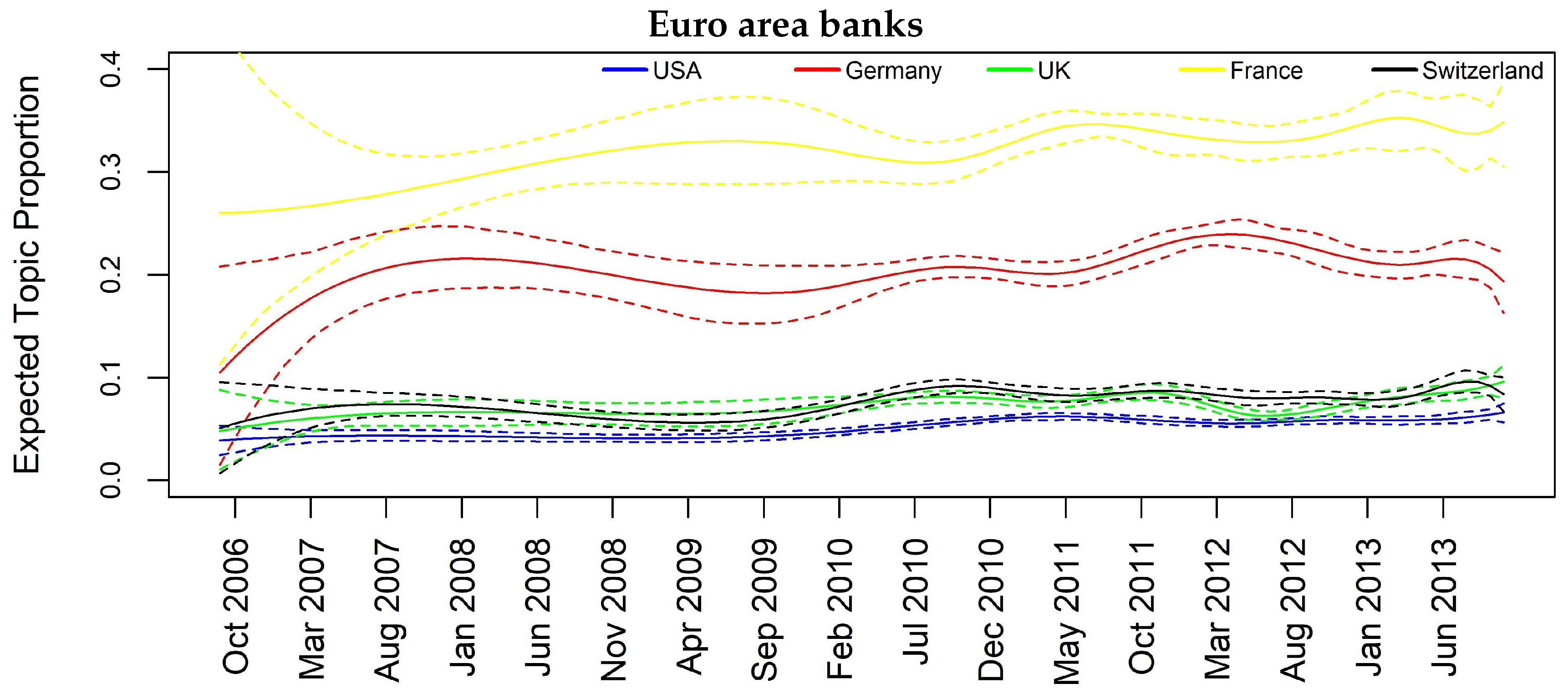
| Euro area banks | 0.07 | 0.40 | 0.24 | 0.08 | 0.08 | 0.07 | 0.05 |
| Madoff scandal | 0.02 | 0.03 | 0.06 | 0.02 | 0.06 | 0.06 | 0.08 |
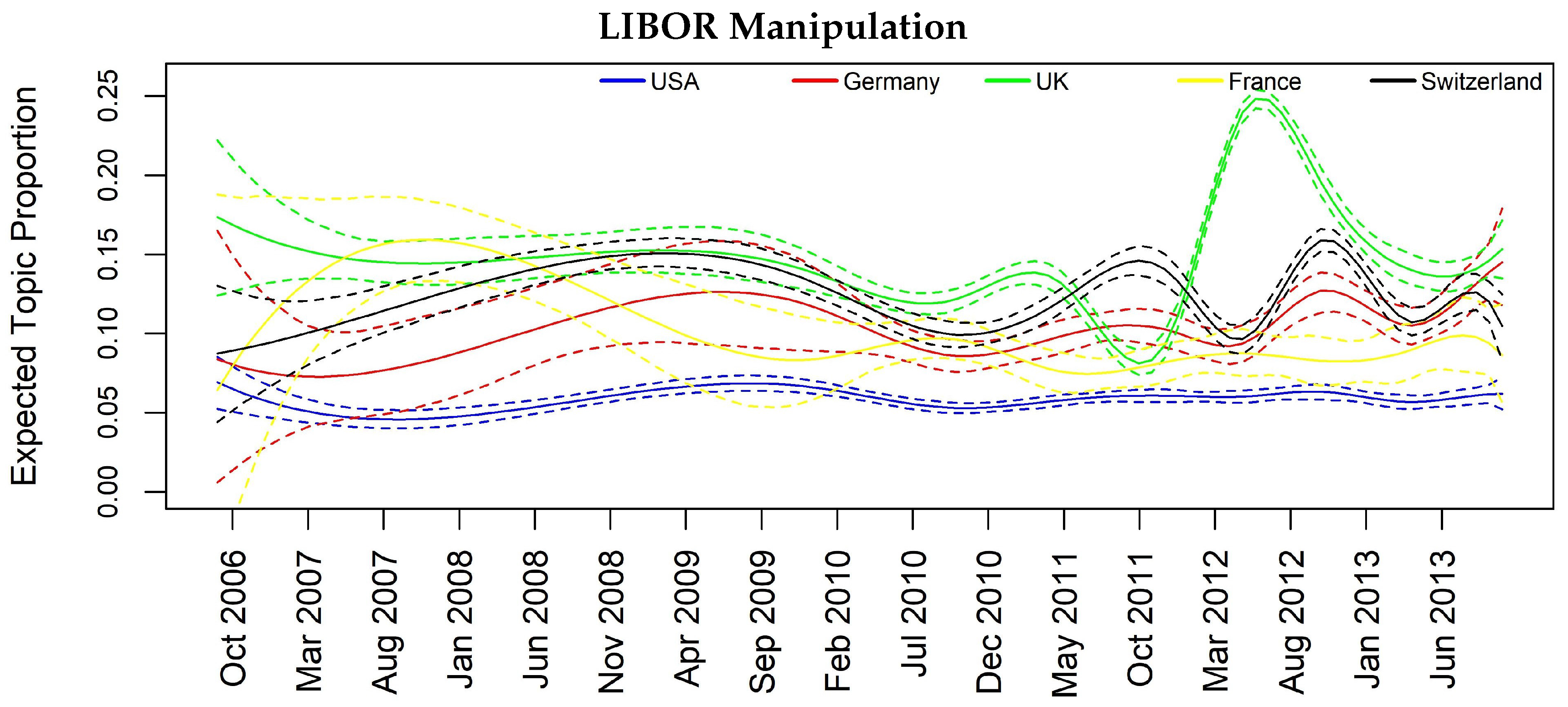
| Barclays and DB LIBOR manip. | 0.07 | 0.09 | 0.11 | 0.03 | 0.13 | 0.18 | 0.06 |
| Bond, Equity and CDS markets | 0.05 | 0.08 | 0.07 | 0.06 | 0.03 | 0.15 | 0.06 |
| Mortgage crisis | 0.04 | 0.03 | 0.04 | 0.02 | 0.03 | 0.07 | 0.08 |
| Spanish banks | 0.02 | 0.02 | 0.02 | 0.57 | 0.02 | 0.02 | 0.02 |
| UBS Tax Fraud | Significant Lag | Citigroup Bailout | Significant Lag |
| FR → USA | 1L, 2L | FR → USA | 1L, 2L |
| FR → UK | 1L, 2L | CH → UK | 1L, 2L |
| UK → DE | 2L | FR → UK | 1L |
| UK → FR | 2L | USA → CH | 1L, 2L |
| Euro Area Banks | Significant Lag | Madoff Scandal | Significant Lag |
| CH → USA | 1L, 2L | UK → USA | 1L, 2L |
| FR → USA | 1L, 2L | CH → USA | 1L, 2L |
| USA → UK | 1L,2L | DE → UK | 2L |
| CH → UK | 1L,2L | DE → CH | 2L |
| FR → UK | 1L,2L | FRA → CH | 2L |
| FR → CH | 1L,2L | - | - |
| FR → DE | 1L,2L | - | - |
| Libor Manipulation | Significant Lag | Mortgage Crisis | Significant Lag |
| CH → USA | 2L | CH → USA | 2L |
| CH → DE | 1L | FR → UK | 2L |
| - | - | USA → CH | 1L, 2L |
| - | - | FR → CH | 2L |
| - | - | USA → FR | 1L, 2L |
| - | - | USA → DE | 1L |
| UBS Tax Fraud | Significant Lag | Citigroup Bailout | Significant Lag |
| UK → USA | 1L,2L | USA → UK | 1L |
| USA → CH | 1L,2L | USA → CH | 1L, 2L |
| USA → DE | 1L,2L | DE → UK | 1L |
| UK → DE | 2L | UK → USA | 2L |
| - | - | DE → USA | 2L |
| Mortgage Crisis | Significant Lag | Madoff Scandal | Significant Lag |
| UK → CH | 1L, 2L | CH → USA | 1L, 2L |
| CH → UK | 1L, 2L | UK → CH | 1L, 2L |
| USA → CH | 2L | USA → DE | 1L |
| - | - | UK → USA | 2L |
| - | - | DE → USA | 2L |
| - | - | UK → DE | 2L |
| Libor Manipulation | Significant Lag | Mgmt Changes | Significant Lag |
| CH → USA | 1L | - | - |
| USA → UK | 2L | - | - |
| CH → UK | 2L | - | - |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cerchiello, P.; Nicola, G. Assessing News Contagion in Finance. Econometrics 2018, 6, 5. https://doi.org/10.3390/econometrics6010005
Cerchiello P, Nicola G. Assessing News Contagion in Finance. Econometrics. 2018; 6(1):5. https://doi.org/10.3390/econometrics6010005
Chicago/Turabian StyleCerchiello, Paola, and Giancarlo Nicola. 2018. "Assessing News Contagion in Finance" Econometrics 6, no. 1: 5. https://doi.org/10.3390/econometrics6010005
APA StyleCerchiello, P., & Nicola, G. (2018). Assessing News Contagion in Finance. Econometrics, 6(1), 5. https://doi.org/10.3390/econometrics6010005