

Investigating Some Issues Relating to Regime Matching

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Determining Regime Match with Two Regimes
2.1. Principles
2.2. Examples of Finding Two Regimes
2.2.1. Hamilton (1989) on High and Low Growth Rates
2.2.2. Interest Rate Rules—A Stata 14 Example
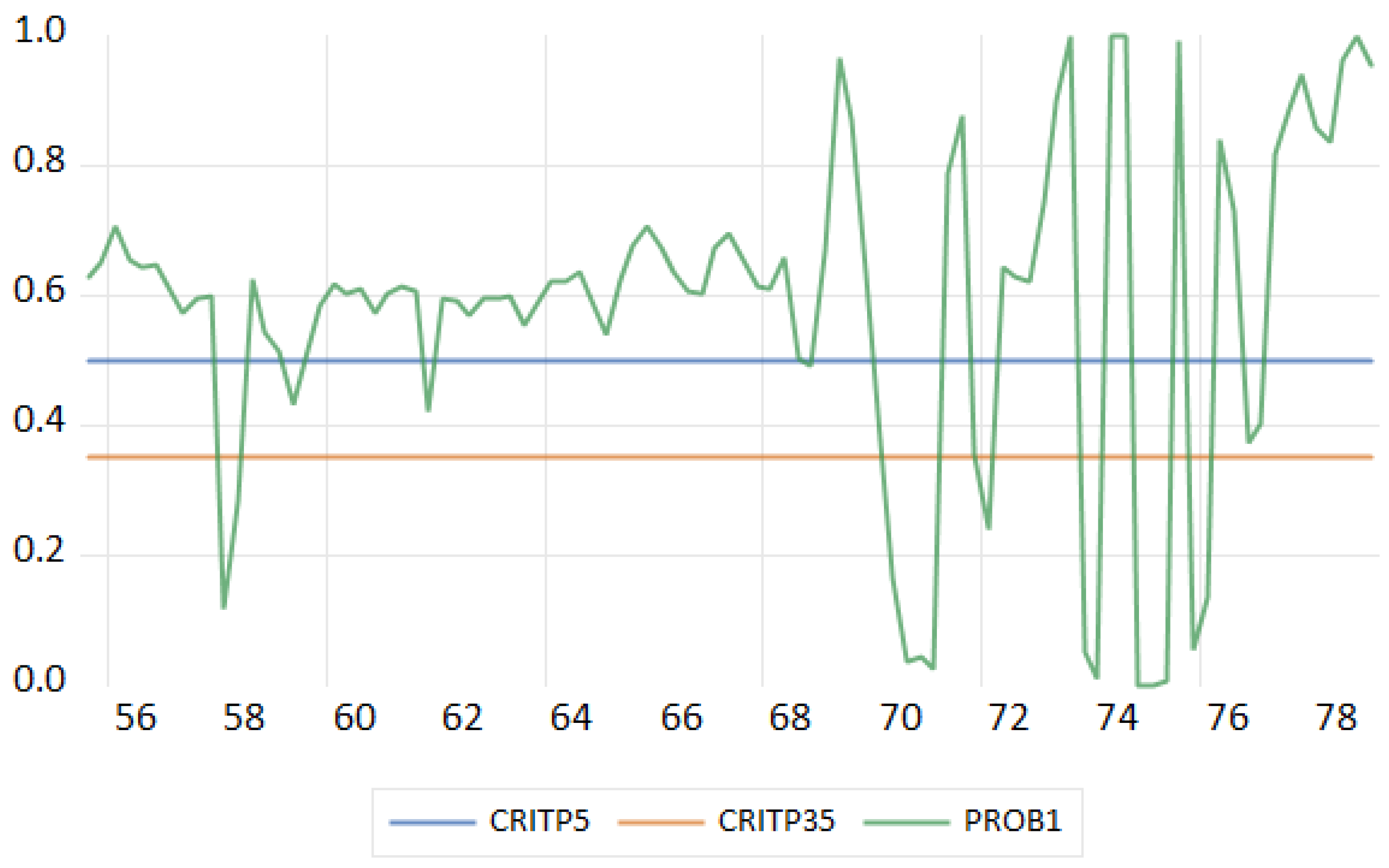
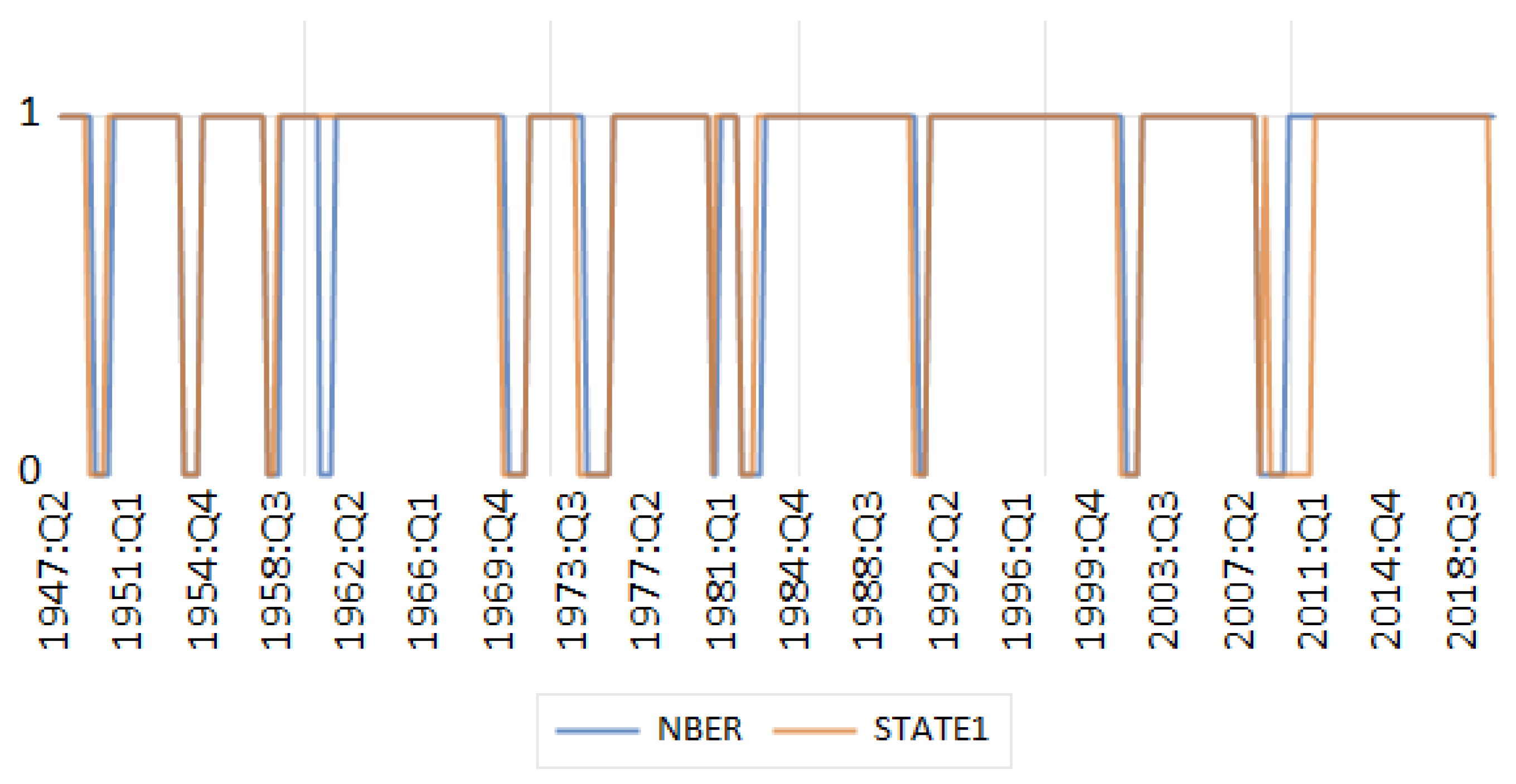
2.2.3. Romer and Romer (2020) on Upgrading NBER Recession Dates
3. Determining Regime Match with Three Regimes
3.1. Principles
3.2. Examples of Determining Three Regimes
3.2.1. Three State Interest Rate Rules—A Stata 14 Example
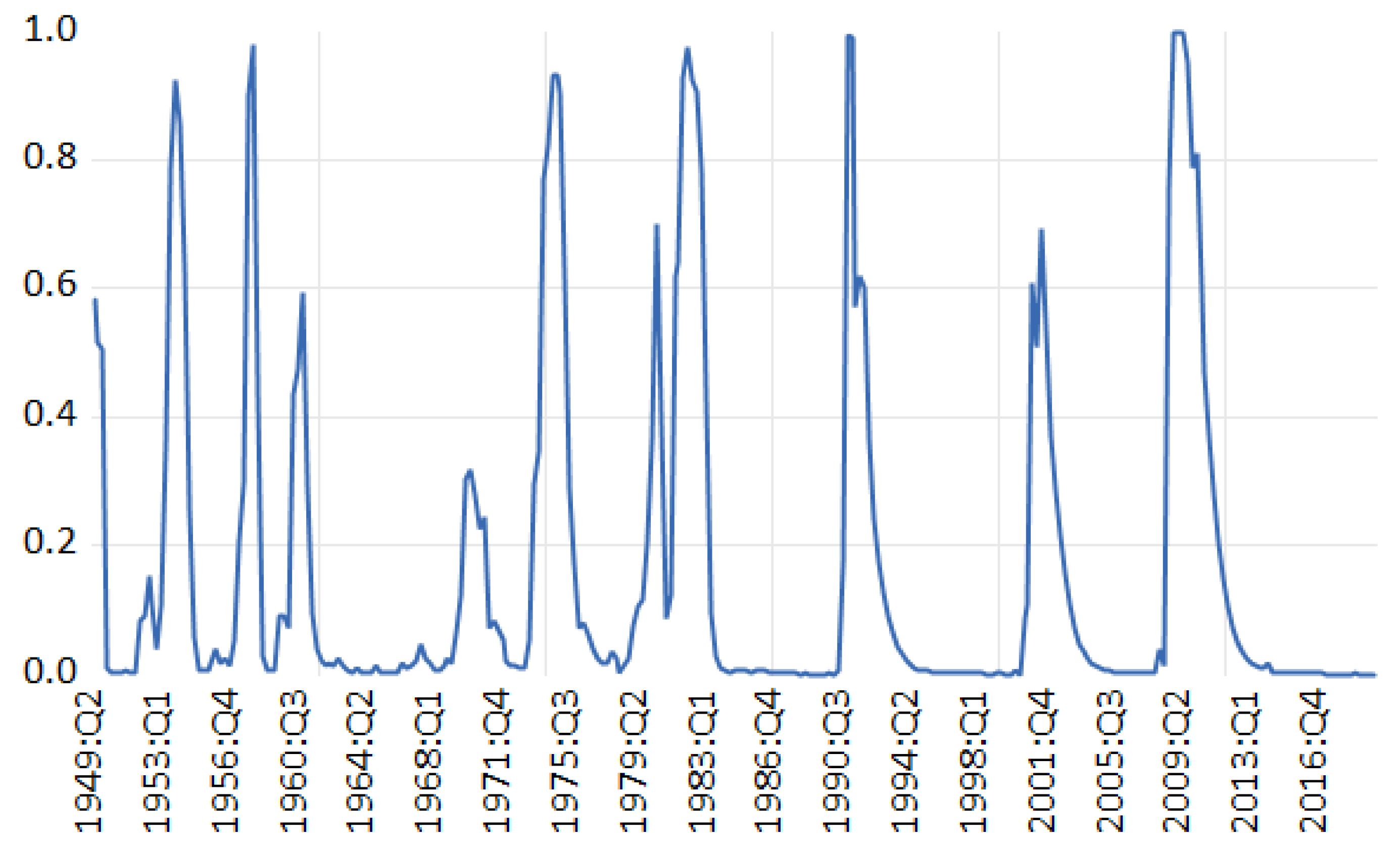
3.2.2. Three State Rule for Recession Types: Eo and Morley (2023)
4. Locating Regimes When There Are More Series than Regimes
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
| 1 | There has been work using the ROC but this requires one to introduce data that is not just that used by the MS model. Thus using the ROC one can find a value of c that matches the estimated MS regimes with something like the NBER expansion and contraction regime dates. Candelon et al. (2012) and Yang et al. (2024) do this. |
| 2 | One needs to provide exogenous process for and to do this. We fit a VAR(2) to this data for simulation purposes. |
| 3 | The estimated coefficients of the interest rate rule have the same signs for both the Stata 14 and results. With the exception of the lagged interest rate coefficient in Regime 3 they are rather similar. That is much higher for the estimates, which imply more inertia in policy. |
| 4 | We are grateful to James Morley for supplying programs for estimation and smoothing that handle just the pre-covid period. Because we do not use the complete data set the estimates of the parameters differ from what is in Eo and Morley (2023), although they are close. |
| 5 | Based on there was also a U shaped recession in 1982:Q2. |
| 6 | One might ask what it is that has caused the mean growth to change through the lens of the MS model. Since the mean of in an MS model at any point depends on the and the unconditional probabilities of each state, one of these has to have changed. |
| 7 | Using a wide range of starting values we got the same parameter estimates for the model. One set of starting values were those that were found when was estimated with the 40 quarter growth moving average. |
| 8 | There are more complex rules. Harding and Pagan (2006) followed some of the NBER spreadsheets to suggest that one look for whether there is a cluster of around a point t where had been produced from analyzing each of the M series. A cluster meant that for some j that was close to t. Closeness involved looking at the median distance. This is not simple to construct and one can have “tie” issues. It has been used in Harding and Pagan (2006) and also by Rodriguez Palenzuela et al. (2024). |
References
- Candelon, B., Dumitrescu, E.-I., & Hurlin, C. (2012). How to evaluate an early-warning system: Toward a unified statistical framework for assessing financial crises forecasting methods. IMF Economic Review, 60(1), 75–113. [Google Scholar] [CrossRef]
- Chahrour, R., & Jurado, K. (2022). Recoverability and expectations-driven fluctuations. The Review of Economic Studies, 89(1), 214–239. [Google Scholar] [CrossRef]
- Douwes-Schultz, D., Schmidt, A. M., Shen, Y., & Buckeridge, D. (2023). A three-state coupled Markov switching model for COVID-19 outbreaks across Quebec based on hospital admissions. arXiv, arXiv:2302.02488. [Google Scholar]
- Eo, Y., & Morley, J. (2022). Why has the US economy stagnated since the Great Recession? Review of Economics and Statistics, 104(2), 246–258. [Google Scholar] [CrossRef]
- Eo, Y., & Morley, J. (2023). Does the Survey of Professional Forecasters help predict the shape of recessions in real time? Economics Letters, 233, 111419. [Google Scholar] [CrossRef]
- Hamilton, J. D. (1989). A new approach to the economic analysis of nonstationary time series and the business cycle. Econometrica, 57(2), 357–384. [Google Scholar] [CrossRef]
- Harding, D., & Pagan, A. (2006). Synchronization of cycles. Journal of Econometrics, 132(1), 59–79. [Google Scholar] [CrossRef]
- Harding, D., & Pagan, A. (2016). The econometric analysis of recurrent events in macroeconomics and finance. Princeton University Press. [Google Scholar]
- Krolzig, H.-M., & Toro, J. (2005). Classical and modern business cycle measurement: The European case. Spanish Economic Review, 7, 1–21. [Google Scholar] [CrossRef]
- Martínez-Beneito, M. A., Conesa, D., López-Quílez, A., & López-Maside, A. (2008). Bayesian Markov switching models for the early detection of influenza epidemics. Statistics in Medicine, 27(22), 4455–4468. [Google Scholar] [CrossRef] [PubMed]
- Pagan, A., & Robinson, T. (2022). Excess shocks can limit the economic interpretation. European Economic Review, 145, 104120. [Google Scholar] [CrossRef]
- Rodriguez Palenzuela, D., Grigoraș, V., Saiz, L., Stoevsky, G., Tóth, M., & Warmedinger, T. (2024). The euro area business cycle and its drivers. (Tech. Rep.). European Central Bank Occasional Paper No. 354. Available online: https://www.econstor.eu/handle/10419/301916 (accessed on 1 February 2025).
- Romer, C. D., & Romer, D. H. (2020). NBER recession dates: Strengths, weaknesses, and a modern upgrade. Mimeo. [Google Scholar]
- Shaby, B. A., Reich, B. J., Cooley, D., & Kaufman, C. G. (2016). A Markov-switching model for heat waves. The Annals of Applied Statistics, 10(1), 74–93. [Google Scholar] [CrossRef]
- StataCorp. (2015). Stata 14: Time series reference manual. Stata Press College Station. [Google Scholar]
- Twain, M. (1903). The jumping frog (illustrated by f. strothman). Harper and Brothers. [Google Scholar]
- Yang, L., Lahiri, K., & Pagan, A. (2024). Getting the ROC into Sync. Journal of Business & Economic Statistics, 42(1), 109–121. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hall, A.D.; Pagan, A.R. Investigating Some Issues Relating to Regime Matching. Econometrics 2025, 13, 9. https://doi.org/10.3390/econometrics13010009
Hall AD, Pagan AR. Investigating Some Issues Relating to Regime Matching. Econometrics. 2025; 13(1):9. https://doi.org/10.3390/econometrics13010009
Chicago/Turabian StyleHall, Anthony D., and Adrian R. Pagan. 2025. "Investigating Some Issues Relating to Regime Matching" Econometrics 13, no. 1: 9. https://doi.org/10.3390/econometrics13010009
APA StyleHall, A. D., & Pagan, A. R. (2025). Investigating Some Issues Relating to Regime Matching. Econometrics, 13(1), 9. https://doi.org/10.3390/econometrics13010009