1. Introduction
The pioneering work of
Granger (
1966) demonstrated that a large number of macroeconomic time series have a typical spectral shape dominated by a peak at low frequencies. This finding suggests the presence of relatively long run information in the current level of the variables, which should be taken into account when modeling their time series evolution and can potentially be exploited to yield improved forecasts. One way to incorporate this long-run information in econometric modeling is through stochastic trends (unit roots) and/or deterministic trends. However, given that trends are slowly evolving, there is only limited information in any data set about how best to specify the trend or distinguish between alternative models of the trend. For instance, unit root tests often fail to reject a unit root despite the fact that theory does not postulate the presence of a unit root for many macroeconomic variables [see
Elliott (
2006), for further discussion of this issue]. Therefore, it appears prudent to incorporate the uncertainty arising from the presence of a stochastic trend when constructing macroeconomic forecasts. Moreover, this uncertainty is likely to be particularly important for longer horizons.
1A second source of uncertainty involved in the construction of forecasts relates to the specification of short-run dynamics driving the time series. Within an autoregressive modeling framework, this form of uncertainty can be expressed in terms of the lags of first differences of the time series being analyzed. Since the number of lags that ought to be included in the model is unknown in practice, there is a bias–variance trade-off facing the forecaster: underspecifying the number of lags would lead to biased forecasts, while including irrelevant lags would induce a higher forecast variance. The challenge therefore lies in incorporating lag order uncertainty in a manner that best addresses this trade-off.
Motivated by these considerations, this paper proposes a new multistep forecast combination approach designed for forecasting a highly persistent time series that simultaneously addresses uncertainty about the presence of a stochastic trend and uncertainty about the nature of short-run dynamics within a unified autoregressive modeling framework. Unlike extant forecast combination approaches, we develop combination forecasts based on minimizing the so-called accumulated prediction errors (APE) criterion that directly targets the asymptotic forecast risk (AFR) instead of the in-sample asymptotic mean squared error (AMSE). This is particularly relevant, since the equivalence between AFR and AMSE breaks down in a nonstationary setup. Our analysis generalizes existing results by establishing the asymptotic validity of the APE for multistep forecasts in the unit root and (fixed) stationary cases, both for models with and without deterministic trends. We further show that, regardless of the presence of a unit root, the performance of APE-weighted forecasts remains close to that of the infeasible combination forecasts which assume that the optimal (i.e., AFR minimizing) weights are known. Monte Carlo experiments are used to (i) demonstrate the finite sample efficacy of the proposed procedure relative to Mallows/Cross-Validation weighting that target the AMSE; (ii) underscore the importance of accounting for uncertainty about the stochastic trend and/or the lag order. In a pseudo out-of-sample forecasting exercise applied to US monthly macroeconomic time series, we evaluate the performance of a variety of selection/combination-based approaches at horizons of one, three, six, and twelve months. Consistent with the simulation results, the empirical analysis provides strong evidence in favor of a version of the advocated approach that simultaneously addresses stochastic trend and lag order uncertainty regardless of the forecast horizon considered.
The present study builds on previous work by
Hansen (
2010a) and
Kejriwal and Yu (
2021) who analyzed one-step ahead combination forecasts allowing for both persistence and lag order uncertainty. In particular,
Hansen (
2010a) adopted a local-to-unity framework to develop combination forecasts that combine forecasts from the restricted (i.e., imposing a unit root) and unrestricted models with the weights obtained by minimizing a one-step Mallows criterion. To address lag order uncertainty, he also proposed a general combination approach that, in addition to the restricted and unrestricted model forecasts, also combines forecasts based on different lag orders.
Kejriwal and Yu (
2021) provided theoretical justification for the general combination approach and developed improved combination forecasts that employ feasible generalized least squares (FGLS) estimates instead of ordinary least squares (OLS) estimates of the deterministic trend component.
Our paper can be viewed as extending
Hansen’s (
2010a) approach in two practically relevant directions. First, in addition to one-step ahead forecasts, we also analyze the statistical properties of multistep combination forecasts given that uncertainty regarding the presence of a stochastic trend is especially relevant over longer horizons. Second, in contrast to Mallows weighting as advocated by
Hansen (
2010a), our combination weights are obtained via the APE criterion that directly targets the AFR instead of the AMSE. Our Monte Carlo and empirical comparisons of the performance of combination forecasts based on different weighting schemes clearly illustrate the importance of directly targeting the AFR. Thus, an important implication of our study is that the preferred choice of weighting scheme when combining forecasts can critically depend on whether the variables involved are stationary or not.
The recent machine learning literature has proposed a variety of forecasting methods that exploit information in a large number of potential predictors (see, e.g.,
Masini et al. 2023, for a survey). In contrast, our study is univariate in that it only utilizes past information about the variable of interest to develop forecasts. A natural question one may ask, then, is what is the value added by our univariate forecasting approach when more sophisticated machine learning approaches are available? We offer three possible responses. First, our approach is simple to use in practice, since it only requires running OLS regressions. Second, it is transparent in that its statistical properties can be studied analytically, which can be useful for understanding the merits and limitations of the approach. Third, when evaluating the performance of machine learning methods, our preferred forecasting approach can provide a much more competitive univariate benchmark for comparison than a simple autoregressive model with a prespecified/estimated lag order which has routinely been used as the benchmark (see, e.g.,
Kim and Swanson 2018;
Medeiros et al. 2021).
The rest of the paper is organized as follows.
Section 2 provides a review of the related literature.
Section 3 presents the model and the related estimators.
Section 4 analyzes the AMSE and AFR as alternative measures of forecast accuracy.
Section 5 discusses the choice of combination weights based on the APE criterion.
Section 6 extends the analysis to allow for lag order uncertainty in the construction of the forecasts. Monte Carlo evidence, including comparisons with various existing methods, is provided in
Section 7.
Section 8 details an empirical application to forecasting US macroeconomic time series and
Section 9 concludes.
Appendix A,
Appendix B and
Appendix C contain, respectively, the proofs, details of forecasting methods considered, and additional simulation results. All computations were carried out in the 2022b version of
MATLAB (
2022).
2. Literature Review
A common practice in the economic forecasting literature is to apply a stationarity-inducing transformation (e.g., differencing or detrending) to the time series of interest and then attempt to forecast the transformed series. Consequently, most of the forecasting procedures in current use have been developed under the assumption of data stationarity. The traditional approach of
Box and Jenkins (
1970) transforms the data through differencing which amounts to modeling the low-frequency peak in the spectrum as a zero-frequency phenomenon and proceeds to forecast the transformed series using standard stationary autoregressive moving average (ARMA) models. More recently,
Stock and Watson (
2005,
2006) constructed a extensive database of 132 monthly macroeconomic time series over the period 1959-2003 and applied a variety of transformations to render them stationary before using a handful of common factors extracted from the data set using principal components as predictors (the so-called diffusion-index methodology). Similarly,
McCracken and Ng (
2016) assembled a publicly available database of 134 monthly time series referred to as FRED-MD and updated on a timely basis by the Federal Reserve Bank of St Louis. They also suggested a set of data transformations which is used to construct factor-based diffusion indexes for forecasting as well as to analyze business cycle turning points.
While convenient in practice, the approach of forecasting the transformed stationary series tends to ignore the information in the levels of the variables. In particular, it does not properly account for the uncertainty arising from the nature of the underlying trends, which can lead to poor forecasts if the trends are misspecified.
Clements and Hendry (
2001) documented, both analytically and numerically, the detrimental consequences of trend misspecification on the resulting forecasts in the presence of parameter estimation uncertainty. Specifically, they found that when the sample size increases at a faster rate than the forecast horizon, misspecifying a difference stationary process as trend stationary or vice versa yields forecast error variances of a higher order of magnitude relative to the correctly specified model. Consequently, the objective of our study is to construct forecasts of the time series in levels and explicitly model the uncertainty regarding the presence of a stochastic trend instead of transforming the time series to stationarity based on a trend specification that is determined a priori and is possibly misspecified.
Our study is closely related to the existing literature on methods for forecasting nonstationary time series.
Diebold and Kilian (
2000) showed that a unit root pretesting strategy can improve forecast accuracy relative to restricted or unrestricted estimation.
Ng and Vogelsang (
2002) found that the use of FGLS estimates of the trend component can yield superior forecasts relative to their OLS counterparts.
Turner (
2004) recommended the use of forecasting thresholds whereby the restricted (unit root) forecast is preferred on one side of these thresholds while the unrestricted (OLS) forecast is preferred on the other. His proposal was based on median unbiased estimation of the local-to-unity parameter to determine the thresholds and was shown to dominate a unit root pretesting strategy.
Ing et al. (
2012) studied the impact of nonstationarity, model complexity and model misspecification on the AFR in infinite order autoregressions.
A promising approach to addressing both stochastic trend uncertainty and lag order uncertainty is forecast combination. Introduced in the seminal work of
Bates and Granger (
1969), the idea underlying forecast combination is to exploit the bias–variance trade-off by combining forecasts from restricted (possibly subject to bias) specifications and unrestricted (possibly subject to overfitting) specifications using an appropriate choice of combination weights. A voluminous amount of literature has subsequently developed, which has analyzed the efficacy of several alternative weighting schemes for constructing the combination forecasts (see, e.g.,
Wang et al. 2022, for a recent survey).
Hansen (
2010a) proposed one-step ahead combination forecasts within an autoregressive modeling framework that accounts for both aforementioned sources of uncertainty, where the combination weights are obtained by minimizing a Mallows criterion. The Mallows criterion is designed to provide an approximately unbiased estimator of the in-sample AMSE. Hansen’s analysis showed that the unit root pretesting strategy could be subject to high forecast risk for a range of persistence levels, while his combination forecast performed favorably compared to a number of methods popular in applied work and dominated the unrestricted forecast uniformly in terms of finite sample forecast risk.
Kejriwal and Yu (
2021) proposed a refinement of
Hansen’s (
2010a) approach, which entails estimating the deterministic trend component by FGLS instead of OLS.
Tu and Yi 2017 analyzed one-step forecasting based on the Mallows averaging estimator in a cointegrated vector autoregressive model and found that it dominated the commonly used approach of pretesting for cointegration.
In a stationary setup, combination forecasts based on Mallows/cross-validation (CV) weighting typically target the AMSE, relying on its approximate equivalence with the AFR (e.g.,
Hansen 2008,
2010b;
Liao and Tsay 2020). Such equivalence, however, breaks down in a nonstationary setup.
Hansen (
2010a) showed, within a local-to-unity framework, that the AMSEs of unrestricted as well as restricted (imposing a unit root) one-step ahead forecasts are different from the corresponding expressions for their AFR in autoregressive models (see
Section 4 for further discussion on the issue of equivalence or lack thereof).
To address the lack of equivalence between AMSE and AFR, we develop combination forecasts based on minimizing the APE criterion that directly targets the AFR instead of the AMSE. Previous work in the context of model selection has shown the APE criterion to remain valid whether the process is stationary or has a unit root. Specifically,
Ing (
2004) showed that a normalized version of the APE is almost certain to the AFR in the stationary case, while a similar result was obtained by
Ing et al. (
2009) in the unit root case. Focusing on the first-order autoregressive case and one-step ahead forecasts,
Yu et al. (
2012) extended the validity of the APE to a unit root model with a deterministic time trend. Our study extends the use of the APE criterion to construct combination forecasts in a nonstationary environment.
In summary, there is a plethora of approaches available in the literature for forecasting nonstationary time series, including model selection, pretesting, and forecast combination. Combination forecasts have often been shown to incur lower forecast risk in practice than forecasts based on model selection or pretesting. However, the existing literature has typically employed weighting schemes such as Mallows/CV weighting that have been formally justified only in a stationary framework. Our study contributes to this literature by demonstrating that when the variable of interest is potentially nonstationary, it may be desirable to construct the combination weights using an alternative approach (the APE criterion). Our findings are particularly relevant for macroeconomic applications, given that several macroeconomic time series have been documented to exhibit a degree of persistence that is difficult to distinguish from a unit root process.
3. Model and Estimation
We consider a univariate time series
generated as follows:
where
is the order of the trend component and the stochastic component
follows a finite order autoregressive process of order
process driven by the innovations
. The uncertainty about the stochastic trend is captured by the persistence parameter
that is modeled as local-to-unity with
corresponding to the unit root case and
to the stationary case. The initial observations are set at
.
2 This section treats the true lag order
as known. Lag order uncertainty is addressed in
Section 6. Our analysis is based on the following assumptions:
Assumption 1. The sequence is a martingale difference sequence with and where and is the σ-field generated by . Moreover, there exist small positive numbers and and a large positive number , such that for where and denotes the distribution of . Assumption 2. All roots of lie outside the unit circle.
The data generating process in (
1) and Assumptions 1 and 2 are adopted from
Hansen (
2010a) with an additional restriction on the distribution of
, which ensures that the sample second moments of the regressors are bounded in expectation (see
Ing et al. 2009). The difference between our modeling framework and
Ing et al. (
2009) is that they impose an exact unit root (
), while we allow
. For
, let the optimal (infeasible) mean squared error minimizing
h-step ahead forecast of
be denoted as
. It is the conditional mean of
given
, which is obtained from the following recursion (
Hamilton 1994, pp. 80–82):
with
if
and
if
and
if
. We can further rewrite (
2) as
where
if
and
with
if
.
We consider three alternative estimators of
. The first is the unrestricted estimator
obtained as
with
if
where
are the OLS estimates from the regression
Instead of using
one may consider a two-step strategy for estimating
that entails regressing
on
and obtaining the estimate
of
and the residuals
in a first step and then estimating an autoregression of order
in
to obtain the estimates of
. The forecasts are obtained from
. However, as shown in
Ng and Vogelsang (
2002), the one-step estimate
is preferable to the two-step estimate with persistent data.
The second estimator is the restricted estimator
that imposes the unit root restriction
and is obtained as
with
if
where
are the OLS estimates from the regression
Finally, the third estimator is based on taking a weighted average of the unrestricted and restricted forecasts. Letting
be the weight assigned to the unrestricted estimator, the averaging estimator is given by
The relative accuracy of the three foregoing estimators can be evaluated using the asymptotic forecast risk (AFR), which is the limit of the
h-step ahead expected squared forecast error:
In order to derive analytical expressions for the AFR, we introduce the following notation. Let
denote a standard Brownian motion on
and define the Ornstein–Uhlenbeck process
For
let
and define the stochastic processes
and the functionals
Next, note that from
we can write
where
denotes conditional expectation with respect to information at time
and the coefficients
are obtained by equating coefficients of
on both sides of the equation
where
and
. When
and
satisfies
(see
Ing et al. 2009).
Denoting
we define the following quantities:
With the above notation in place, we obtain the following result, which provides an analytical representation for the AFR of the unrestricted and restricted forecasts:
Theorem 1. Under Assumptions 1 and 2 and supwhere for some ,
(a)
(b)
Theorem 1 shows that the AFR of both the restricted and unrestricted forecasts can be decomposed into two components: the first component
depends on both the underlying stochastic/deterministic trends as well as the short-run dynamics through the coefficients
the second component
is common to the restricted and unrestricted estimators and depends on the parameters governing the short-run dynamics of the time series. The result generalizes Theorem 2 of
Hansen (
2010a) for one-step forecasts to multistep forecasts. Interestingly, when
, the AFR can be expressed as the sum of a purely nonstationary component representing the stochastic/deterministic trends (since
) and a stationary short-run component which is simply the number of first-differenced lags, i.e.,
. However, as Theorem 1 shows, when
such a stationary-nonstationary decomposition no longer holds, since both components now depend on the short-run coefficients
. Theorem 1 also generalizes Theorem 2.2 of
Ing et al. (
2009), which derived an expression for AFR assuming an exact unit root
) and no deterministic component.
The next result, which follows as a direct consequence of Theorem 1, shows that the optimal combination weight is independent of the forecast horizon and the moving average coefficients
but depends on the nuisance parameter
c:
Corollary 1. The AFR of the combination forecast is given bywith optimal (i.e., AFR minimizing) weight 4. Asymptotic Mean Squared Error and Asymptotic Forecast Risk
An alternative measure of forecast accuracy is the in-sample asymptotic mean squared error (AMSE) defined as
for the unrestricted estimator with similar expressions in place for the restricted and averaging estimators.
Hansen (
2008) established the approximate equivalence between this measure and the AFR under the assumption of strict stationarity. Accordingly, existing forecast combination approaches developed in the stationary framework are based on targeting the AMSE by appealing to its equivalence with the AFR.
Hansen (
2008) proposed estimating the weights by minimizing a
Mallows (
2000) criterion which yields an asymptotically unbiased estimate of the AMSE. Similarly,
Hansen (
2010b) demonstrated that a leave-
h-out cross validation criterion delivers an asymptotically unbiased estimate of the AMSE.
This equivalence result, however, breaks down in a nonstationary setup. For instance, when the process has a unit root with no drift and the regression does not include a deterministic component, it follows from the results in
Hansen (
2010a) that the AMSE of the one-step ahead forecast coincides with the expected value of the squared limiting Dickey–Fuller
t-statistic. This expectation has been shown to be about 1.141 by
Gonzalo and Pitarakis (
1998) and
Meng (
2005) using analytical and numerical integration techniques, respectively. In contrast,
Ing (
2001) theoretically established that the AFR of the one-step ahead forecast for the same data generating process and regression is two. More recently,
Hansen (
2010a) demonstrated the lack of equivalence within a local-to-unity framework, showing that the AMSE of unrestricted as well as restricted (imposing a unit root) one-step ahead forecasts are different from the corresponding expressions for their AFR in autoregressive models with a general lag order and a deterministically trending component. Notwithstanding this result, he suggested using a Mallows criterion to estimate the combination weights and evaluated the adequacy of the resulting combination forecast in finite samples via simulations. A similar approach was taken by
Kejriwal and Yu (
2021), who also employed Mallows weighting but estimated the deterministic component by FGLS in order to improve upon the accuracy of OLS-based forecasts.
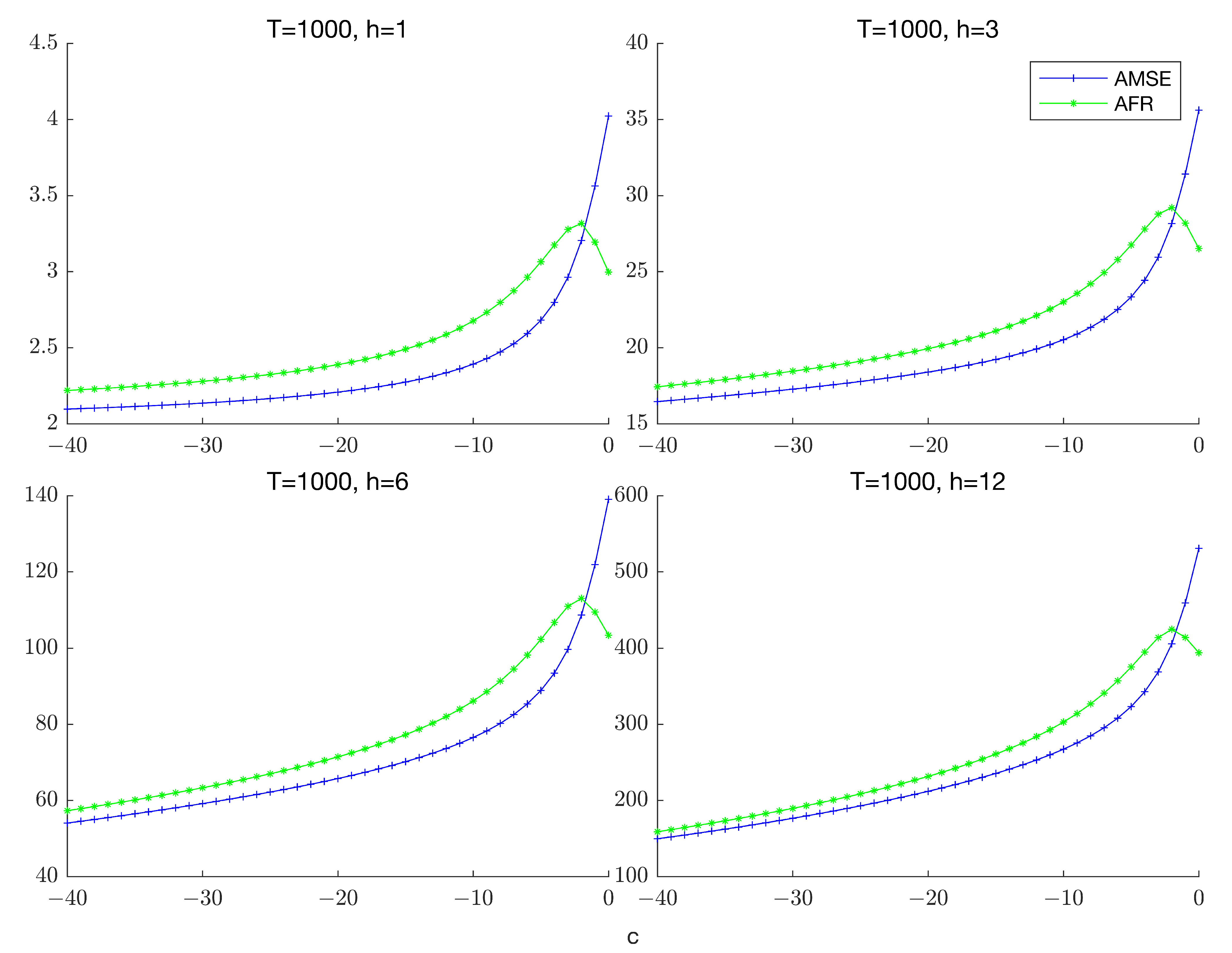
To illustrate the failure of equivalence,
Figure 1 plots the AMSE and the AFR of the unrestricted estimator for the case
and
.
3 The figure clearly illustrates that while the two measures of forecast accuracy follow a similar path for
c sufficiently far from zero, they tend to diverge as the process becomes more persistent. This pattern remains robust across different forecast horizons and suggests that a forecast combination approach that directly targets AFR instead of AMSE can potentially generate more accurate forecasts of highly persistent time series when forecast risk is used as a metric for forecast evaluation.
5. Choice of Combination Weights
The optimal combination forecast
is infeasible in practice, since the weight
depends on the unknown local-to-unity parameter
that is not consistently estimable. Given the lack of equivalence between AMSE and AFR for nonstationary time series as discussed in the previous section, we pursue an alternative approach to estimating the combination weights that directly targets the AFR, which is a more direct and practical measure of forecast accuracy than AMSE. In particular, the estimated weight
is obtained by minimizing the so-called accumulated prediction errors (APE) criterion defined as
with respect to
where
is the
h-step ahead combination forecast based only on data up to period
i, and
denotes the smallest positive number such that the forecasts
and
are well defined for all
. The solution is given by
The APE criterion with
was first introduced by
Rissanen (
1986) in the context of model selection.
Wei (
1987) derived the asymptotic properties of APE in general regression models and specialized his results to stationary and nonstationary autoregressive processes with
.
Ing (
2004) demonstrated the strong consistency of the APE-based lag order estimator in stationary autoregressive models for
. In particular, he showed that a normalized version of the APE is almost certain to converge to the AFR in large samples.
Ing et al. (
2009) extended the analysis to autoregressive processes with a unit root. The results in
Wei (
1987),
Ing (
2004) and
Ing et al. (
2009) all relied on the law of iterated logarithm which ensures that, in large samples, APE is almost certain to be equivalent to
times the AFR. It is, however, important to note that while this convergence result holds pointwise for
, it does not hold uniformly over
. In particular, it does not hold in the local-to-unity setup considered in this paper for
.
4 Nevertheless, the following result shows that the APE criterion remains asymptotically valid in the current framework at the two limits of
which represent the unit root and fixed stationary cases:
Theorem 2. For a given let . Under Assumptions 1 and 2 and supfor some ,
(a) For
(b)
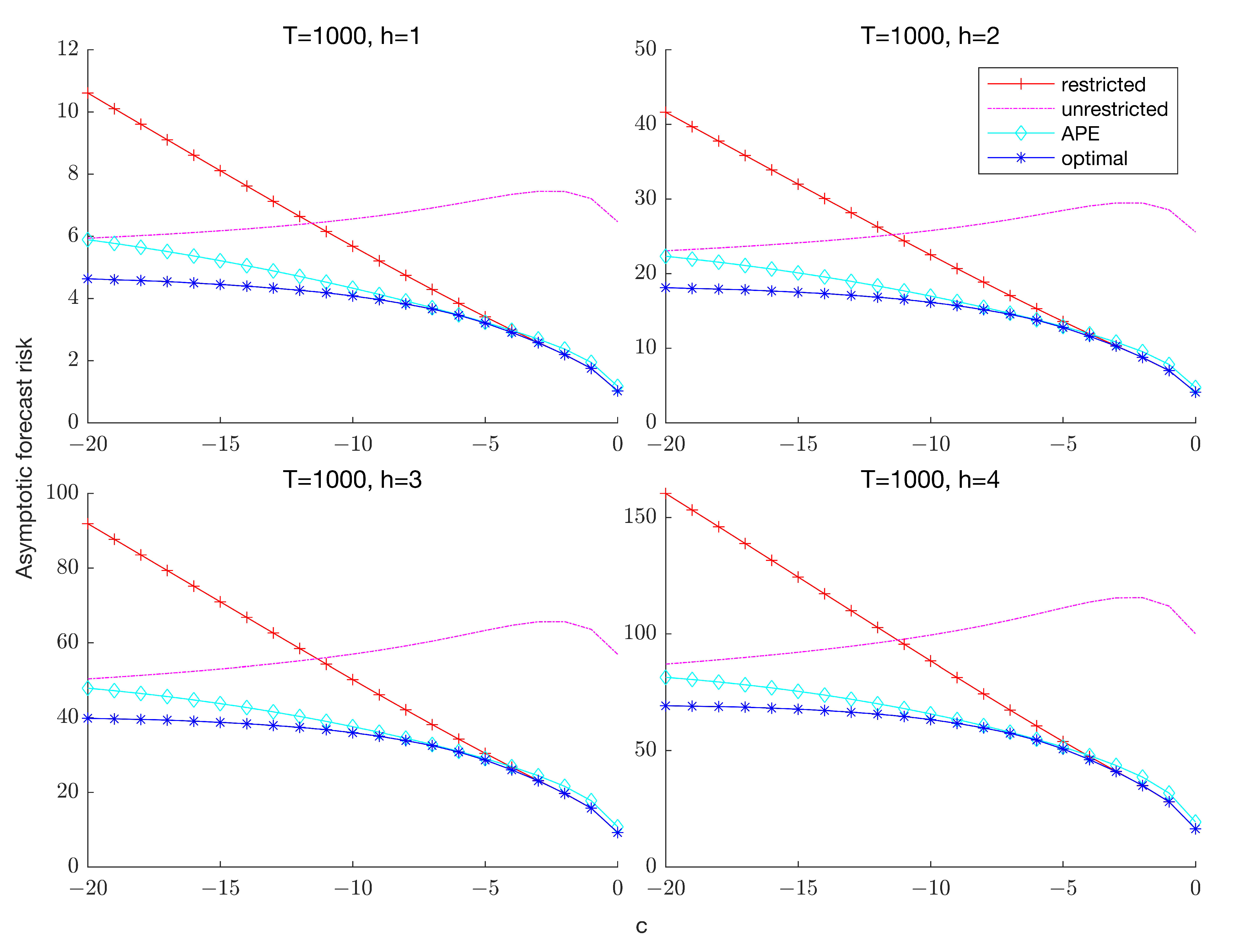
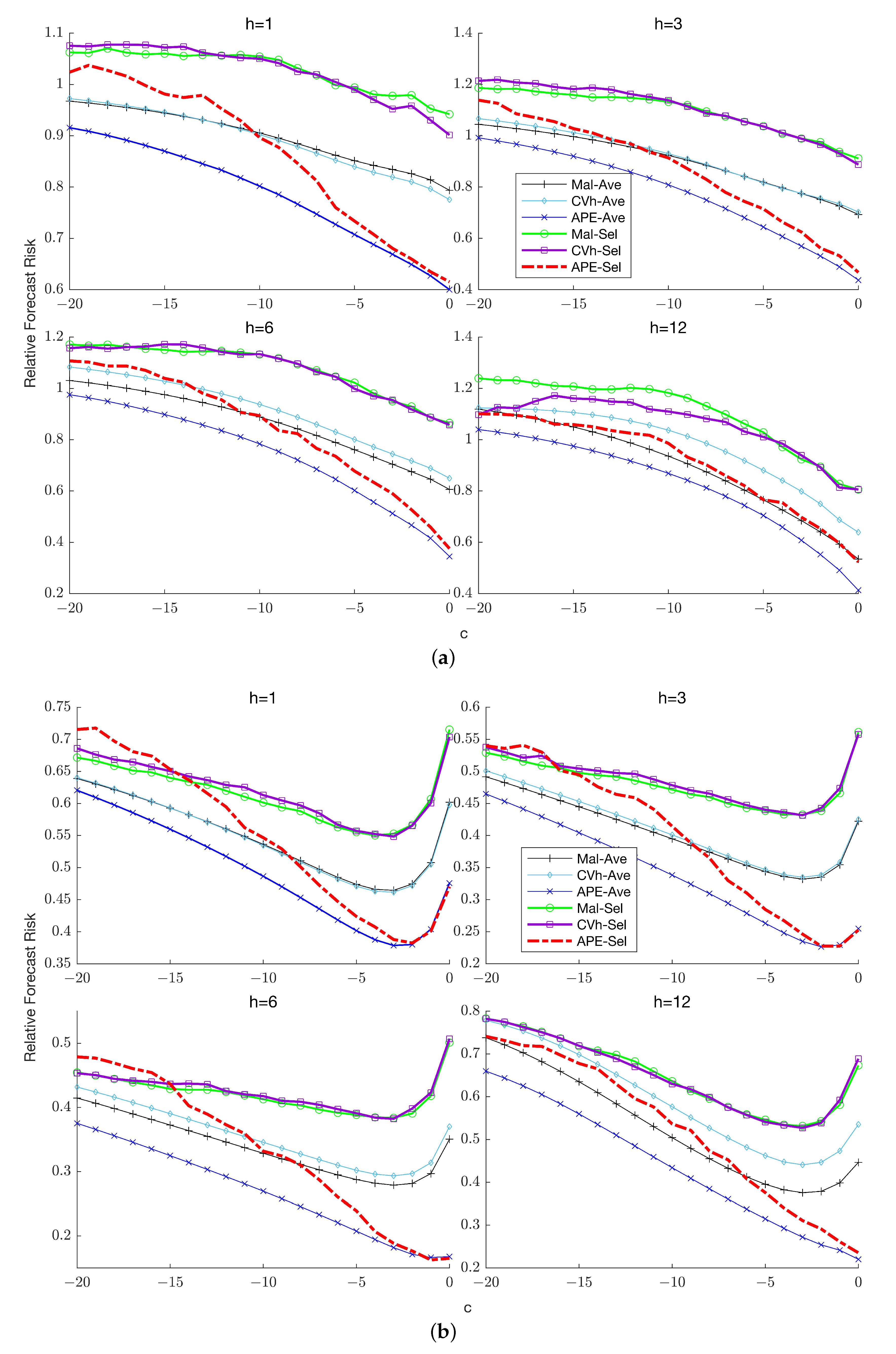
Remark 1. In a similar vein, Hansen (2010a) developed feasible combination weights by evaluating the Mallows criterion at the two limits of given that the criterion depends on and is therefore infeasible in practice. Thus, while his analysis demonstrated that the infeasible Mallows criterion is an asymptotically unbiased estimate of the AMSE for any the feasible version of the criterion remains valid only in the two limit cases. When estimation is performed using FGLS instead of OLS, Kejriwal and Yu (2021) showed that the infeasible Mallows criterion also depends on the parameter in (1) which governs the short-run dynamics. Evaluating the criterion at the two limits, however, eliminates the dependence on both nuisance parameters. Figure 2 plots the AFR of the optimal (infeasible) and APE-based combination forecasts for
and
.
5 For comparison, the unrestricted and restricted forecasts are also presented. As expected, the forecast risk of the restricted estimator increases with
, while the risk function of the unrestricted estimator is relatively flat as a function of
c. Regardless of the forecast horizon, the feasible combination forecast maintains a risk profile close to that of the optimal forecast. In particular, the risk of the APE-weighted forecast is uniformly lower than that of the unrestricted estimator across values of
, as well as lower than that of the restricted estimator unless
is very close to zero. These results suggest that the loss in forecast accuracy due to the unknown degree of persistence is relatively small when constructing the combination weights based on the APE criterion. In
Section 7 and
Section 8, we conduct extensive comparisons of the APE-based combination forecasts with both the Mallows and cross-validation based combination forecasts.
6. Lag Order Uncertainty
This section extends the preceding analysis to the case where the lag order
is unknown. In order to accommodate lag order uncertainty, the set of models on which the combination forecast is based needs to be expanded to include models with different lag orders. Such a forecast can potentially trade off the misspecification bias inherent from the omission of relevant lags against the problem of overfitting induced by the inclusion of unnecessary lags.
Kejriwal and Yu (
2021) showed that the essence of this trade-off can be captured analytically by adopting a local asymptotic framework in which the coefficients of the short-run dynamics lie in a
-neighborhood of zero in addition to the
parameterization for the persistence parameter as specified in
Specifically, we make the following assumption as in
Kejriwal and Yu (
2021):
Assumption 3. We assume that where is fixed and independent of T.
Assumption 3 ensures that the squared misspecification bias from omitting relevant lags is of the same order as the sampling variance introduced by estimating additional lags. Modeling as fixed would make the bias due to misspecification diverge with the sample size and thus leave no scope for exploiting the trade-off between inclusion and exclusion of lags when constructing the combination forecasts.
We include sub-models with
with the corresponding restricted and unrestricted forecasts given by
and
, respectively. Let
if
and zero otherwise. Define
where
is an
vector of zeros. Further, let
The following result derives the AFR of the forecasts in the presence of lag order uncertainty:
Theorem 3. Under Assumptions 1–3 and supwhere for some ,
(a)
(b)
Theorem 3 shows that large sample forecast accuracy now depends on an additional misspecification component [] emanating from the omission of relevant lags. The larger the magnitudes of the coefficients corresponding to the omitted lags, the larger the contribution of this component to the forecast risk. Moreover, under Assumption 3, varies with for but is constant for all . Similarly, varies with for but is constant thereafter. Thus, the forecast horizon only makes a limited contribution to the two short-run components of the asymptotic forecast risk. Another notable feature of Theorem 3 is that, in contrast to the case where the lag order is assumed known (Theorem 1), the contribution of the trend component is now proportional to the square of the forecast horizon. This difference is due to the fact that the coefficients for all since for by virtue of Assumption 3.
We consider two types of combination forecasts. The first is a “partial averaging” forecast that only addresses lag order uncertainty by averaging over the
unrestricted forecasts:
The weights
are obtained by minimizing the APE criterion
where
. We refer to (
6) as the APE-based partial averaging (APA) forecast.
The second forecast is a “general averaging” forecast that accounts for both persistence and lag order uncertainty and thus combines the forecasts from all
sub-models:
The weights
are obtained by minimizing a generalized APE criterion of the form
where
. We refer to
as the APE-based general averaging (AGA) forecast. Comparing the APA and AGA forecasts will serve to isolate the effects of the two sources of uncertainty on forecast accuracy.
The following result establishes the limiting behavior of the APE criterion in the presence of lag-order uncertainty:
Theorem 4. Let . Under Assumptions 1–3 and supfor some ,
(a) For
(b)
Theorem 4 shows that while APE captures the components of AFR that are attributable to persistence uncertainty and estimation of the short-run dynamics, it does not account for lag-order uncertainty in the limit. As shown in the proof of Theorem 4, this is because the former two components grow at a logarithmic rate while the bias component due to lag order misspecification is bounded [i.e., ]. Nonetheless, given that the logarithmic function is slowly varying, it can be expected that in small samples, the APE is still effective at capturing the bias that occurs due to misspecification of the number of lags. Indeed, as shown subsequently in the simulations, the APE criterion offers considerable improvements over its competitors, even under lag-order misspecification.
7. Monte Carlo Simulations
This section reports the results of a set of Monte Carlo experiments designed to (1) evaluate the finite sample performance of the proposed approach relative to extant approaches; (2) quantify the importance of accounting for each source of uncertainty in terms of its effect on finite sample forecast risk.
Section 7.1 lays out the experimental design.
Section 7.2 details the different forecasting procedures included in the analysis.
Section 7.3 and
Section 7.4 present the results. Results are obtained for
For brevity, we report the results only for
. The results for
are qualitatively similar, although the improvements offered by the proposed approach are more pronounced for
than
The full set of results is available upon request.
7.1. Experimental Design
We adopt a design similar to that in
Hansen (
2010a) and
Kejriwal and Yu (
2021) to facilitate direct comparisons. The data generating process (DGP) is based on (1) and specified as follows: (a) the innovations
(b) the trend parameters are set at
(c) the true lag order
with
for
and
. The maximum number of first-differenced lags included is set at
The sample size is set at
. The local-to-unity parameter
c varies from
to 0, implying
ranging from 0.8 to 1 for
and
ranging from 0.9 to 1 for
. At each
c value, the finite-sample forecast risk
is computed for all estimators considered, where
. All experiments are based on 10,000 Monte Carlo replications.
We report two sets of results. The first assumes k is known, thereby allowing us to demonstrate the effect of persistence uncertainty on forecast accuracy while abstracting from lag order uncertainty. The second allows to be unknown and facilitates the comparison between forecasts that address both forms of uncertainty with those that only account for lag order uncertainty.
7.2. Forecasting Methods
The benchmark forecast in both the known and unknown lag cases is calculated from a standard autoregressive model of order
estimated by OLS:
When the number of lags is assumed to be known (
Section 7.3), we compare a set of six forecasting methods: (1) Mallows selection (Mal-Sel); (2) Cross-validation selection (CVh-Sel); (3) APE selection (APE-Sel); (4) Mallows averaging (Mal-Ave); (5) Cross-validation averaging (CVh-Ave); (6) APE averaging (APE-Ave). With an unknown number of lags, the following six methods are compared
6: (1) Mallows partial averaging (MPA); (2) Cross-validation partial averaging (CPA); (3) APE partial averaging (APA); (4) Mallows general averaging (MGA); (5) Cross-validation general averaging (CGA); (6) APE general averaging (AGA). For brevity, a detailed description of these methods is not presented here but is included in
Appendix B.
Both the APE selection and combination forecasts require a choice of
. To our knowledge, no data-dependent methods for choosing
are available in the existing literature. We therefore examined the viability of alternative choices via simulations. Specifically, for each persistence level (value of
c), we computed the minimum forecast risk over all values of
in the range
with a step-size of 5 (assuming a known number of lags
k). While no single value was found to be uniformly dominant across persistence levels/horizons,
turned out to be a reasonable choice overall.
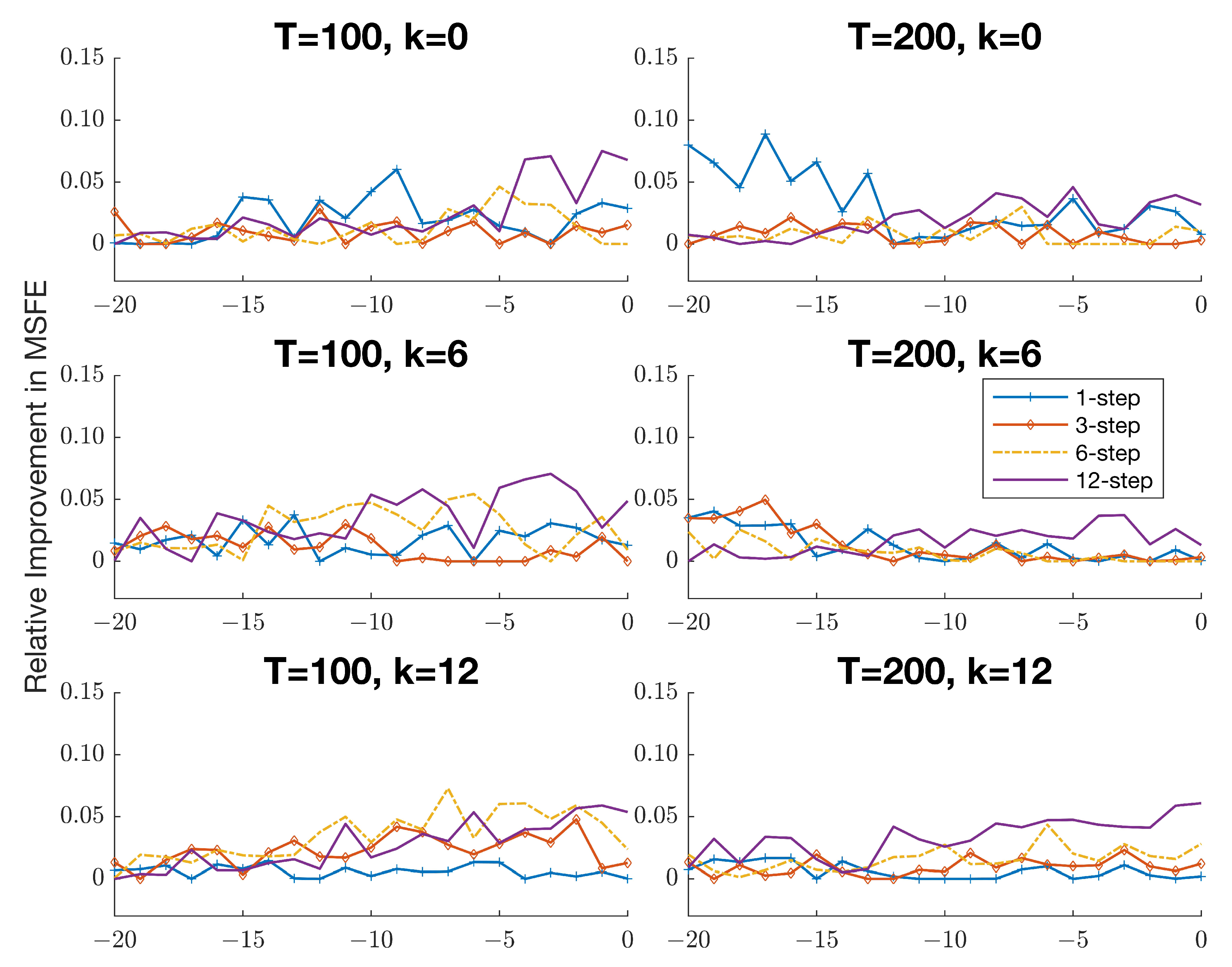
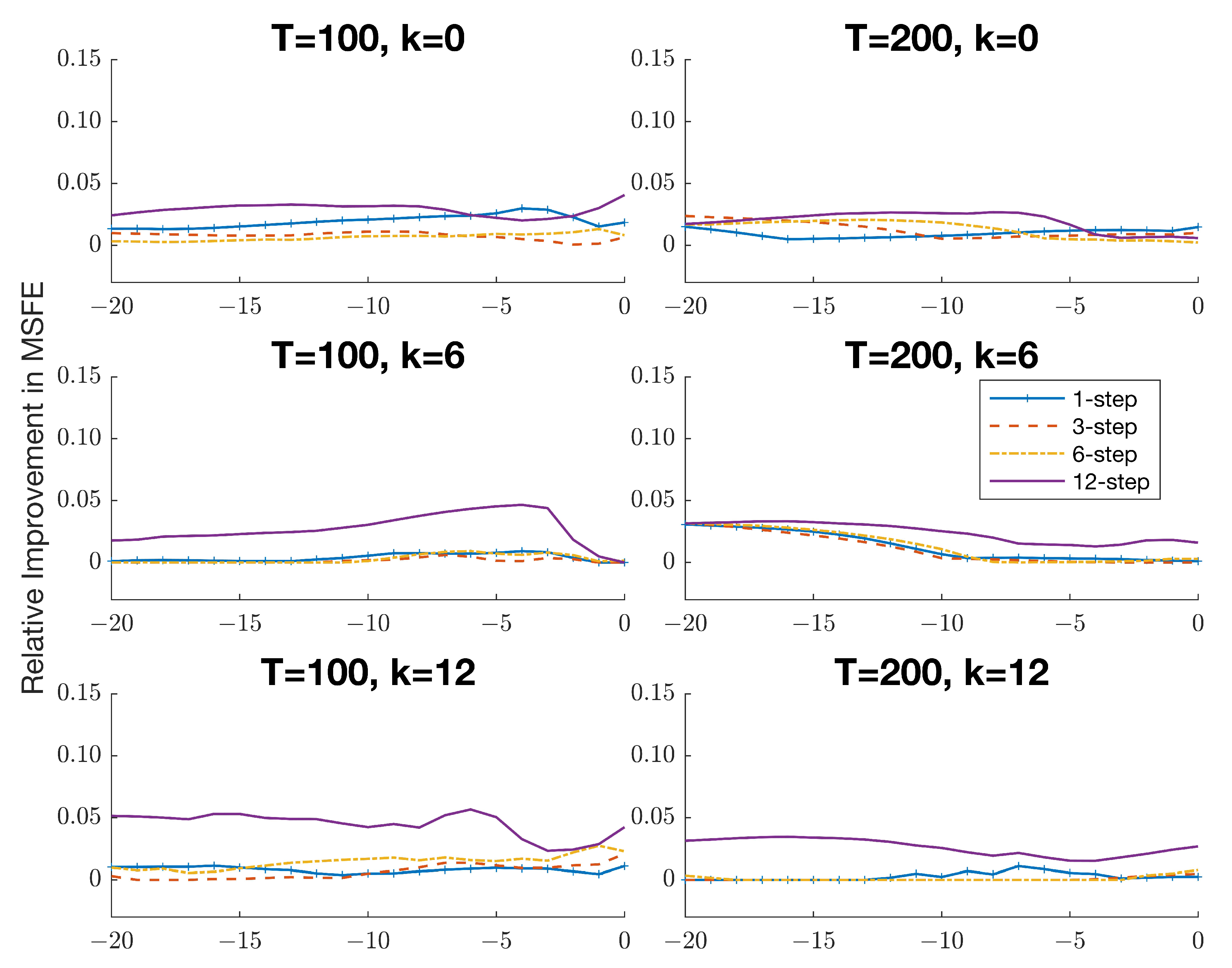
7 To justify this choice,
Figure A1 in
Appendix C plots the difference between the optimal forecast risk and the risk of the APE selection forecasts for
expressed as a percentage of the forecast risk for
. The corresponding results for the APE combination forecasts are presented in
Figure A2. It is evident that using
entails only a marginal increase in forecast risk (at most 5%) for the combination forecasts over the optimal forecast risk across different persistence levels and horizons. In contrast, the optimal choice of
for the selection forecasts is somewhat more unstable and appears to depend more heavily on the forecast horizon and the level of persistence. This robustness in behavior provides additional motivation for employing a combination approach to forecasting in practice.
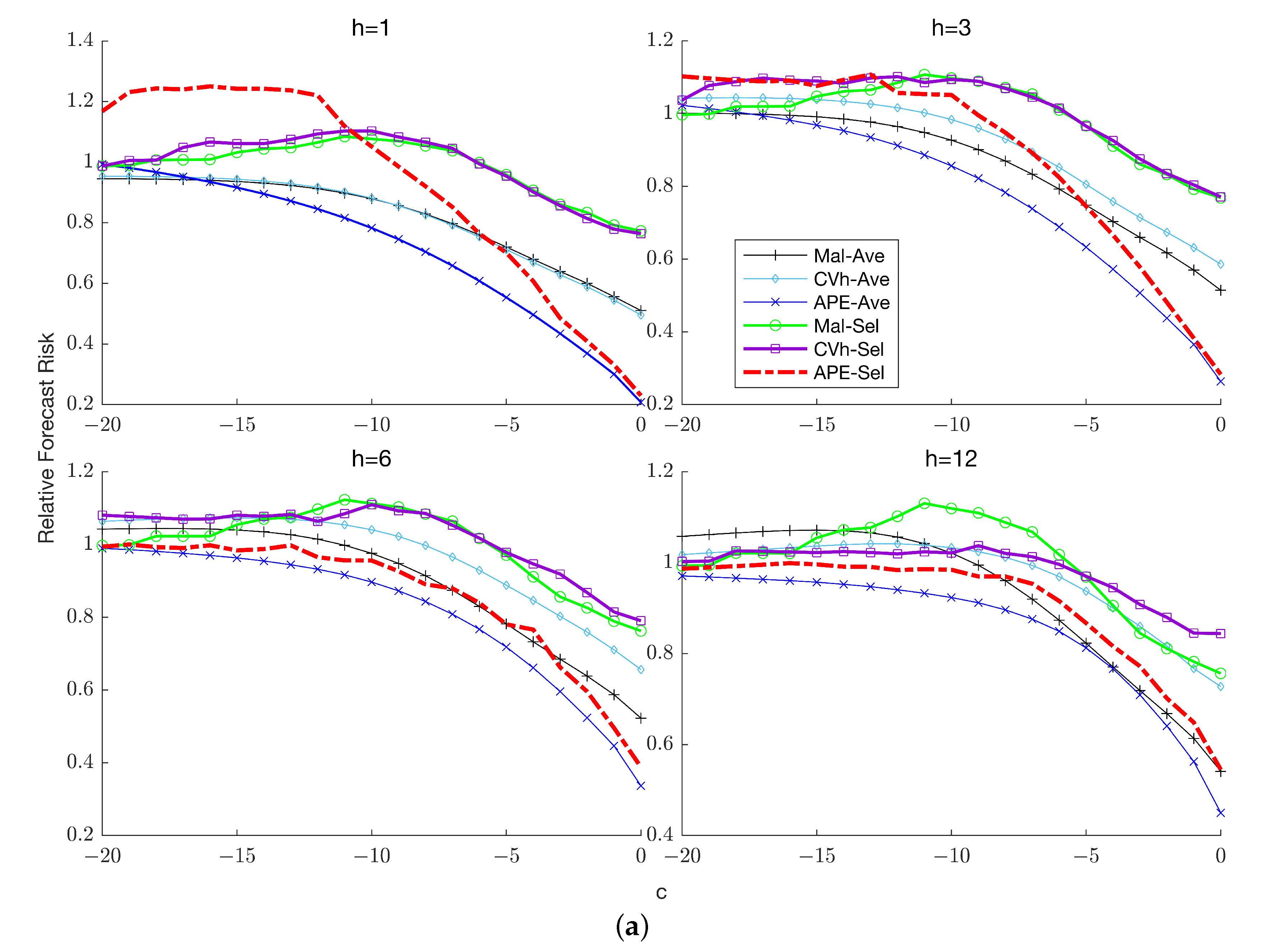
7.3. Forecast Risk with Known Lag Order
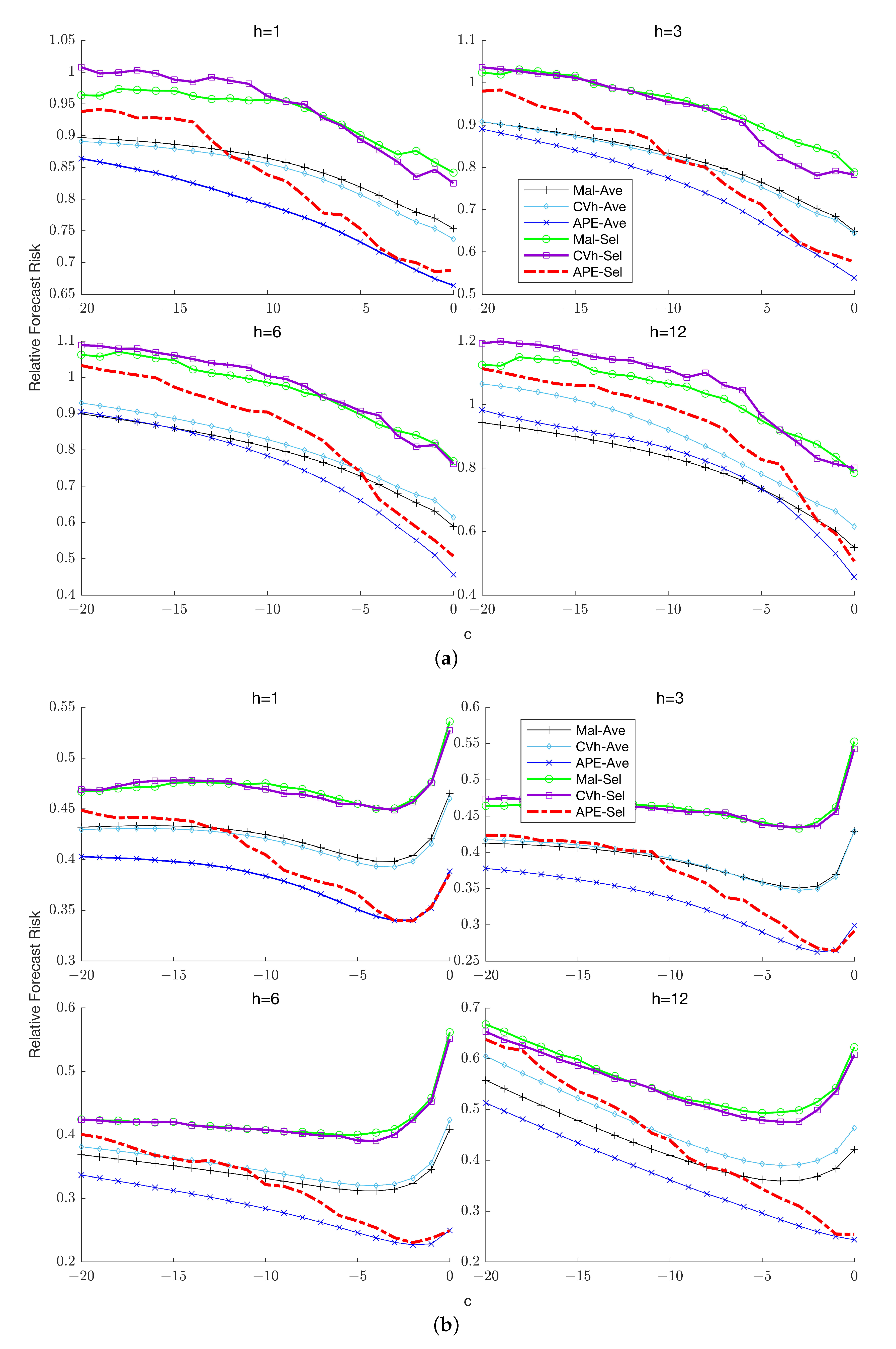
Figure 3a,b,
Figure 4a,b and
Figure 5a,b plot the risk of the six methods relative to the benchmark. First, we consider the case
. Several features of the results are noteworthy.
First, the selection forecasts typically exhibit higher risk than the corresponding combination forecasts across sample sizes and horizons. Second, when the APE combination forecast is clearly the dominant method, performing discernibly better than forecasts based on either of the two competing weighting schemes. When its dominance continues except when is sufficiently large (the exact magnitude being horizon-dependent), in which case the benchmark delivers the most accurate forecasts and averaging over the restricted model becomes less attractive. Third, the relative performance of the Mallows and cross-validation weighting schemes depends on the horizon: at the two schemes yield virtually indistinguishable forecasts; when Mallows weighting yields uniformly lower risk over the parameter space; at Mallows weighting is preferred when persistence is high (close to zero) while cross-validation weighting dominates for lower levels of persistence.
In the presence of higher order serial correlation (), the superior performance of the APE combination forecast becomes even more evident: it now dominates all competing forecasts regardless of horizon and sample size. In particular, APE weighting outperforms the benchmark at all persistence levels, even at unlike the case. The intuition for this difference in relative performance between the cases with and without higher-order serial correlation is that in the former case, averaging is comparatively more beneficial, since imposing the unit root restriction can potentially reduce the estimation uncertainty associated with the coefficients of the lagged differences. This reduction in sampling uncertainty in turn engenders a reduction in the overall risk of the combination forecast relative to the unrestricted benchmark forecast. Another notable difference from the case is that while Mallows and cross-validation weighting are comparable for the former now dominates for uniformly over the parameter space.
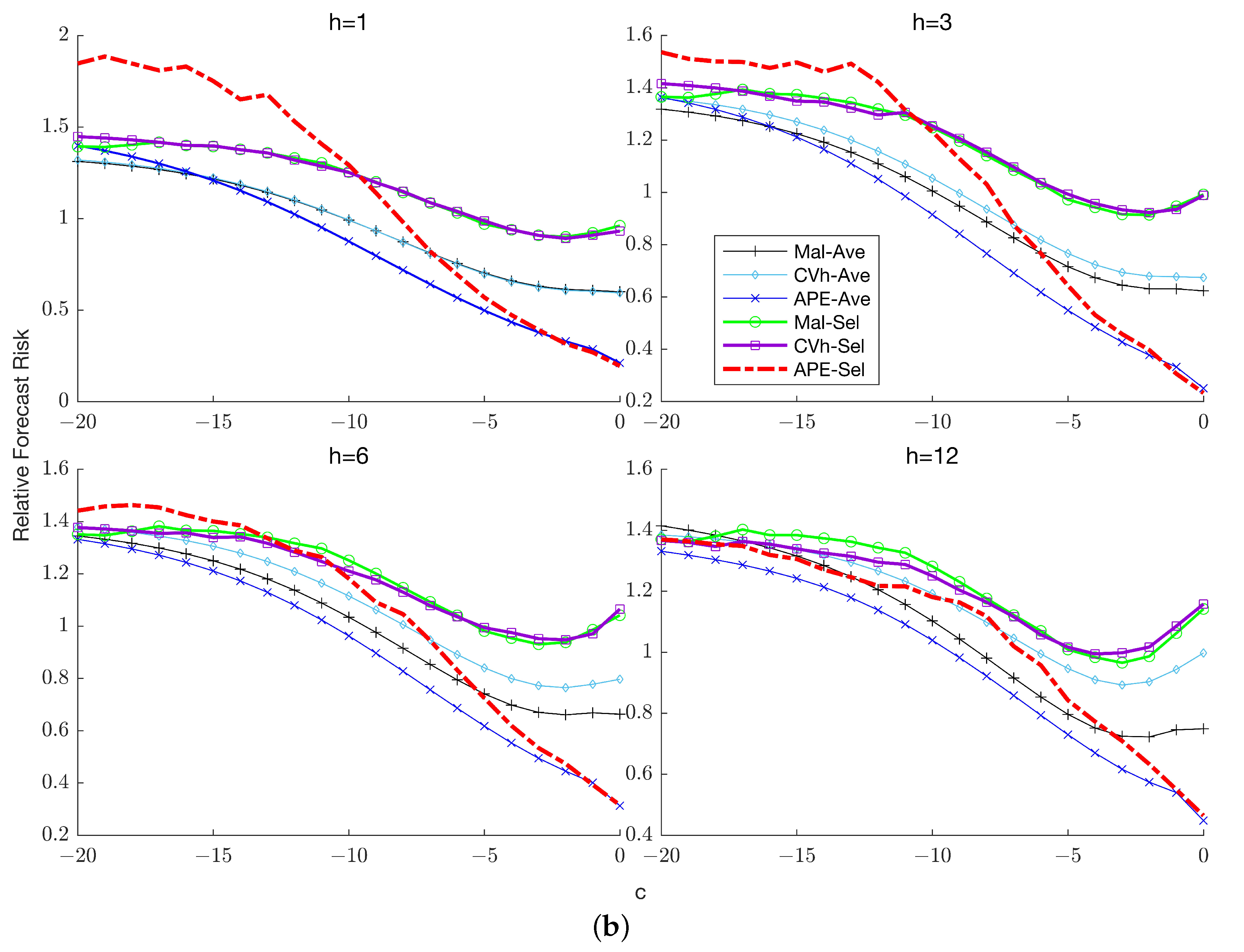
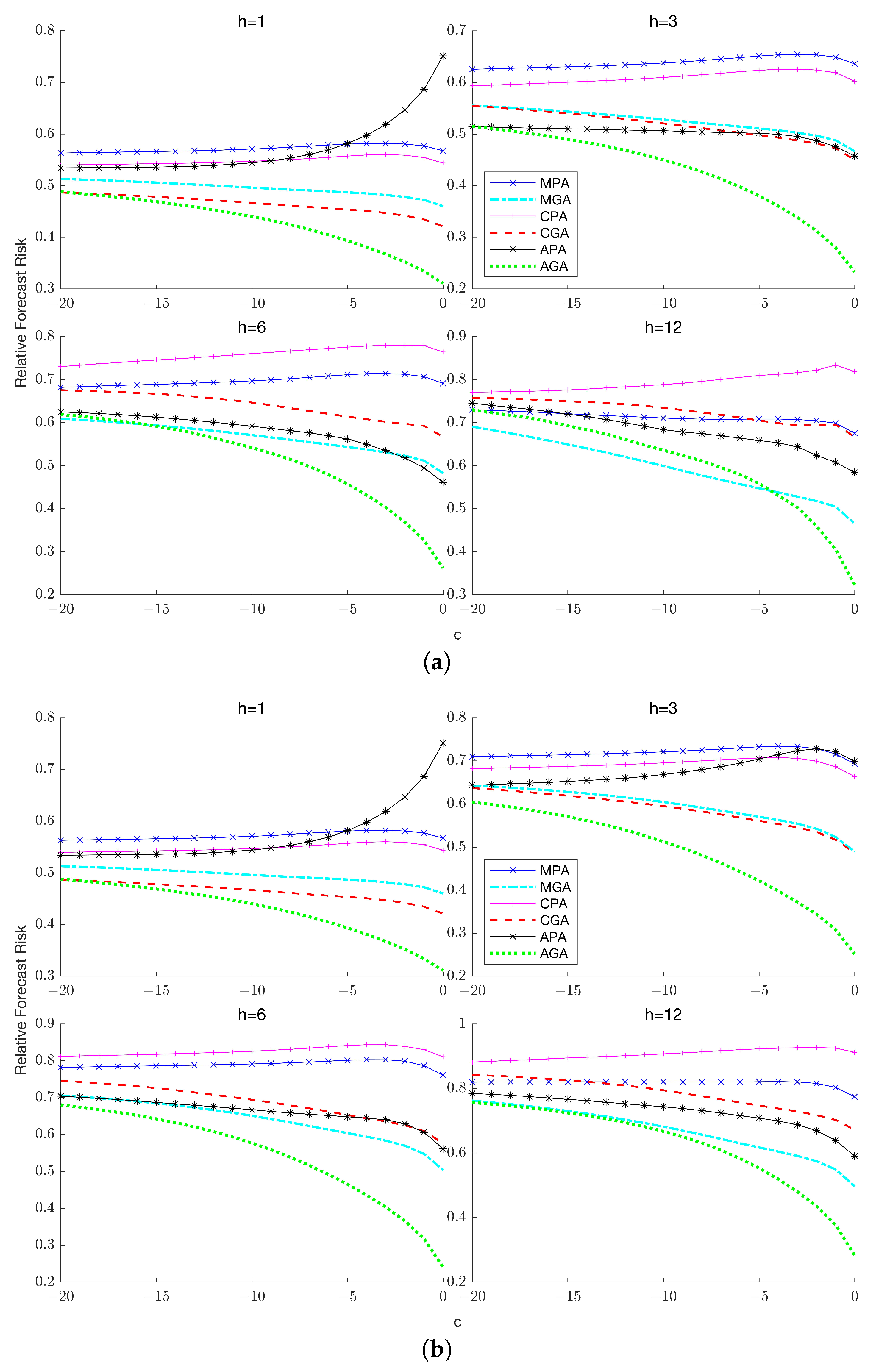
7.4. Forecast Risk with Unknown Lag Order
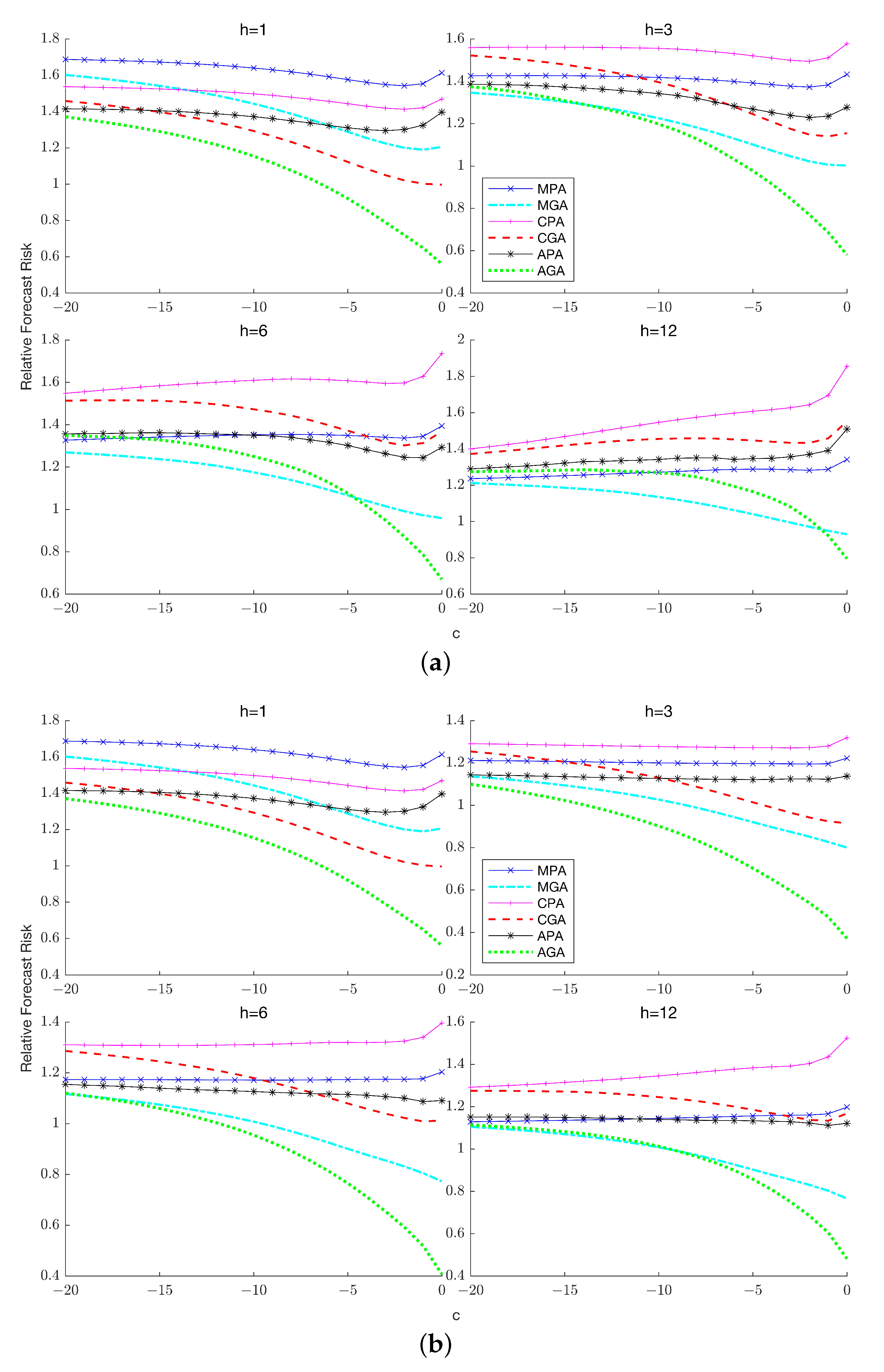
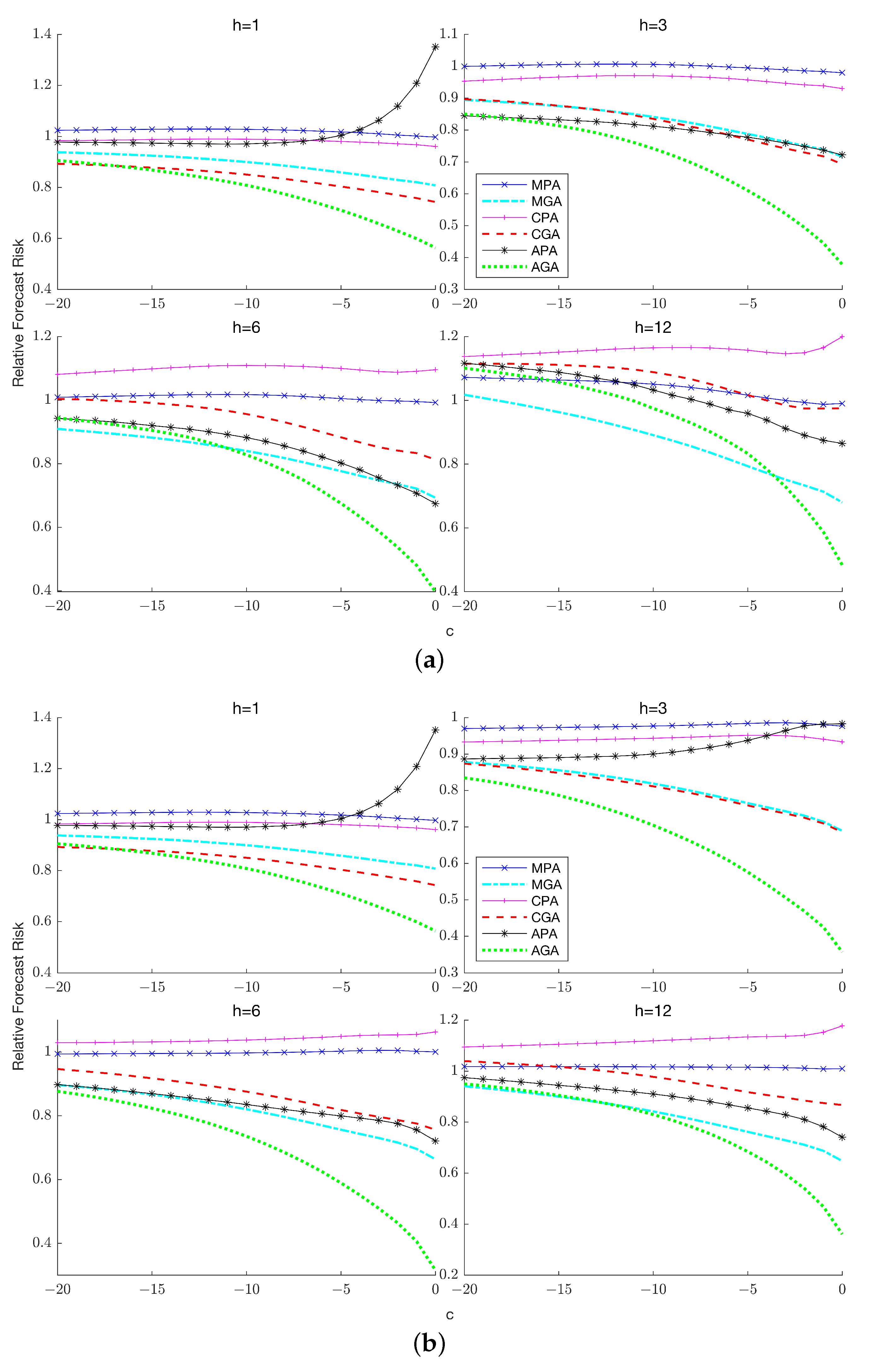
Figure 6a,b,
Figure 7a,b and
Figure 8a,b plot the relative risk of the six combination forecasts which comprise the three partial forecasts that only account for lag-order uncertainty and the three general forecasts that account for both lag-order and stochastic trend uncertainty. A clear implication of these results is that general averaging methods typically exhibit considerably lower forecast risk than partial averaging methods unless the process has relatively low persistence, in which case averaging over the unit root model increases the forecast risk incurred by the general averaging methods. The improvements offered by general averaging hold across both horizons and the number of lags
in the true DGP and become more prominent as the sample size increases.
Among the three weighting schemes, APE-based weights are the preferred choice except when and , where Mallows weighting turns out to be the dominant approach if persistence is relatively low. A potential explanation for this result is that with long horizons and a small sample size, the APE criterion is based on a relatively smaller number of prediction errors, which increases the sampling variability associated with the resulting weights, thereby increasing the risk of the combination forecast. As in the known lag-order case, the choice between Mallows and cross-validation weighting is horizon-dependent: when cross-validation weighting is preferred while when Mallows weighting is preferred, with the magnitude of reduction in forecast risk increasing as increases.
In summary, the results from the simulation experiments make a strong case for employing APE weights when constructing the combination forecasts and clearly highlight the benefits of targeting forecast risk rather than in-sample mean squared error. The comparison of general and partial combination forecasts also underscore the importance of concomitantly controlling for both stochastic trend uncertainty and lag-order uncertainty in generating accurate forecasts.
8. Empirical Application
This section conducts a pseudo out-of-sample forecast comparison of the different multistep forecast combination methods using a set of US macroeconomic time series. Our objectives are to empirically assess (1) the efficacy of different averaging/selection methods relative to a standard autoregressive benchmark; (2) the importance of averaging over both the persistence level and the lag order; and (3) the relative performance of alternative weight choices for constructing the combination forecasts.
Our analysis employs the FRED-MD data set compiled by
McCracken and Ng (
2016), which contains 123 monthly macroeconomic variables over the period January 1960–December 2018
8.
McCracken and Ng (
2016) suggested a set of seven transformation codes designed to render each series stationary: (1) no transformation; (2)
(3)
; (4) log
; (5)
log
; (6)
log
; (7)
. To ensure that the series fit our framework, which allows for highly persistent time series with/without deterministic trends, we adopt the following transformation codes as modified by
Kejriwal and Yu (
2021): (1’) no transformation; (2’)
; (3’)
, (4’)
; (5’)
; (6’)
; (7’)
. For series that correspond to codes (1’) and (4’), we construct the forecasts from a model with no deterministic trend (
), while for the remaining codes, we use forecasts from a model that include a linear deterministic trend (
). We also report results for eight core series as in
Stock and Watson (
2002), comprising four real and four nominal variables. As in the simulation experiments, four alternative forecast horizons are considered:
. We use a rolling window scheme with an initial estimation period of January 1960–December 1969 so that the forecast evaluation period is January 1970–December 2018 (588 observations). The size of the estimation window changes depending on the forecast horizon
h. For example, when
, the initial training sample contains 120 observations from January 1960–December 1969 while for
, it contains only 118 observations from January 1960–October 1969. This ensures that the forecast origin is January 1970 for all forecast horizons considered. We compare ten different methods in terms of the mean squared forecast error (MSFE) computed as the average of the squared forecast errors: (1) MPA: Mallows partial averaging over the number of lags only in the unrestricted model; (2) MGA: Mallows general averaging over both the unit root restriction and the number of lags; (3) CPA: leave-
h-out cross-validation (CV-
h) averaging over the number of lags only in the unrestricted model; (4) CGA: leave-
h-out cross-validation averaging over both the unit root restriction and the number of lags; (5) APA: accumulated prediction error averaging over the number of lags only in the unrestricted model; (6) AGA: accumulated prediction error averaging over both the unit root restriction and the number of lags; (7) MS: Mallows selection from all models (unrestricted and restricted) that vary with the number of lags; (8) CVhS: leave-
h-out cross-validation selection from all models (unrestricted and restricted) that vary with the number of lags; (9) APES: accumulated prediction error selection from all models (unrestricted and restricted) that vary with the number of lags; (10) AR: unrestricted autoregressive model (benchmark). The maximum number of allowable first differenced lags in each method is set at
. The benchmark forecast is computed from unrestricted OLS estimation of an autoregressive model of the form (
10) that uses 12 first-differenced lags of the dependent variable and includes/excludes a deterministic trend depending on the transformation code the series corresponds to, as discussed above.
Table 1a (
) and
Table 1b (
) report the percentages of wins and losses based on the MSFE for the 123 series. Specifically, they show the percentage of 123 series for which a method listed in a row outperforms a method listed in a column, and all other methods (last column). A summary of the results in
Table 1(a and b) is given below:
The averaging methods uniformly dominate their selection counterparts at all forecast horizons. For instance, Mallows/cross-validation averaging outperform the corresponding selection procedures in more than 90% of the series at each horizon. The performance of AGA relative to APES is relatively more dependent on the horizon, with improvements observed in 77% (65%) of the series for ), respectively.
Given a particular weighting scheme, averaging over both the unit root restriction and number of lags (general averaging) outperforms averaging over only the number of lags (partial averaging) at all horizons. For instance, when MGA (CGA, AGA) dominate MPA (CPA, APA) in 95% (81%, 79%) of the series, respectively, based on pairwise comparisons. A similar pattern is observed for multi-step forecasts.
Across all horizons, AGA emerges as the leading procedure due to its ability to deliver forecasts with the lowest MSFE among all methods for the maximum number of series (last column of
Table 1(a and b)). This approach also dominates each of the competing approaches in terms of pairwise comparisons. The APES approach ranks second among all methods so that forecasting based on the accumulated prediction errors criterion (either AGA or APES) outperforms the other approaches for more than 50% of the series over each horizon (the specific percentages are 68.3% for
; 57.7% for
55.3% for
).
Next, we examine the performance of the forecasting methods for different types of series based on their groupwise classification by
McCracken and Ng (
2016) in an attempt to uncover the extent to which the best methods vary by the type of series analyzed. In particular,
McCracken and Ng (
2016) classified the series into eight distinct groups: (1) output and income; (2) labor market; (3) housing; (4) consumption, orders and inventories; (5) money and credits; (6) interest and exchange rates; (7) prices; (8) stock market. For each of these groups,
Table 2 reports the method(s) with the lowest MSFE for the most series compared to all other competing methods. We also report the number of horizons in which (a) averaging outperforms selection and vice-versa; (b) averaging over both the unit root restriction and number of lags (general averaging—GA) methods is superior to averaging over only the number of lags (partial averaging—PA) and vice-versa; (c) each of the three weighting schemes dominates the other two. The results are consistent with those in
Table 1(a and b) and clearly demonstrate (1) the dominance of averaging over selection (with the exception of Group 3) ; (2) the benefits of accounting for both stochastic trend uncertainty and lag order uncertainty (GA) relative to only the latter (PA) for five out of the eight groups; (3) the superiority of APE weighting over the two competing weighting schemes (the exception is Group 5, where cross-validation weighting is the dominant approach).
Finally, we present a comparison of the different methods with respect to their ability to forecast the eight core series analyzed in
Stock and Watson (
2002).
Table 3 reports the MSFE of the eight methods relative to the benchmark model (
10) for four real variables (industrial production, real personal income less transfers, real manufacturing and trade sales, number of employees on nonagricultural payrolls) while
Table 4 reports the corresponding results for four nominal variables (the consumer price index, the personal consumption expenditure implicit price deflator, the consumer price index less food and energy, and the producer price index for finished goods). To assess whether the difference between the proposed methods and the benchmark model is statistically significant, we use a two-tailed Diebold–Mariano test statistic (
Diebold and Mariano 1995). A number less than one indicates better forecast performance than the benchmark and vice versa. The method with smallest relative MSFE for a given series is highlighted in bold.
Consider first the results for real variables (
Table 3). The performance of the best method is statistically significant (at the 10% level) relative to the benchmark in twelve out of the sixteen cases. Consistent with the results in
Table 1(a and b) and
Table 2, general averaging typically dominates partial averaging, the exceptions being nonagricultural employment for
industrial production at
and real manufacturing and trade sales for
where APES is the dominant procedure. The AGA approach turns out to have the highest relative forecast accuracy in 50% of all cases, with the improvements offered over rival approaches being particularly notable at
. While cross-validation weighting does not yield the best forecasting procedure in any of the cases, Mallows weighting is the preferred approach in only two cases, although the improvements are statistically insignificant. Turning to the nominal variables (
Table 4), the best method significantly outperforms the benchmark in ten cases. Again, general averaging is usually preferred to partial averaging, the exception being the case
, where APA outperforms all other methods for three of the four variables. As with the real variables, the AGA forecast is the most accurate in 50% of all cases, though the improvements are now comparable across horizons. Finally, cross-validation weighting partly redeems itself by providing the best forecast in four cases, while Mallows weighting is the preferred method in only one case.
It is useful to briefly discuss the recent, related literature to place our empirical findings in perspective.
Cheng and Hansen (
2015) conducted a comparison of several shrinkage-type forecasting approaches using 143 quarterly US macroeconomic time series (transformed to stationarity) from 1960 to 2008. Their methods included factor-augmented forecast combination based on Mallows/cross-validation/equal weights, Bayesian model averaging, empirical Bayes, pretesting and bagging. They found that while the methods were comparable at the one-quarter horizon, cross-validation weighting clearly emerged as the preferred approach at the four-quarter horizon.
Tu and Yi (
2017) found that, when forecasting US inflation one-quarter ahead, Mallows-based combination forecasts that combine forecasts from unrestricted and restricted (imposing no error correction) vector autoregressions under the assumption of cointegration dominated both unrestricted and restricted forecasts. Using the same data set as ours,
Kejriwal and Yu (
2021) compared partial and general combination forecasts using Mallows weights with forecasts based on pretesting and Mallows selection. Consistent with our results, they found that a general combination strategy that averages over both the unit root restriction and different lag orders delivered the best forecasts overall.
In summary, our empirical results were found to be consistent with the simulation results in that (1) addressing both persistence uncertainty and lag-order uncertainty are crucial for generating accurate forecasts; (2) a weighting scheme that directly targets forecast risk instead of in-sample mean squared error yields an efficacious forecast combination approach at all horizons.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}