1. Introduction
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), which causes a cluster of respiratory tract infections called coronavirus disease 2019 (COVID-19), was first identified and characterized at the end of 2019 in China (
Zhou et al. 2020). In the early months of 2020, the virus spread worldwide; thus, on March 11, the WHO assessed that COVID-19 could be characterized as a pandemic (
World Health Organization 2020a). In Europe, the first cases were reported in Bordeaux, France, on 24 January 2020, (
Stoecklin et al. 2020). Several weeks later, on March 13, WHO remarked that Europe had become an epicenter of the pandemic with more reported cases and deaths than the rest of the world combined, apart from China (
World Health Organization 2020b). In total, between March and December 2020, the number of excess deaths in the EU compared with the 2016–2019 average reached more than half a million (
Eurostat 2020j).
Multiple studies highlighted the determinant effect of age and the presence of comorbidities on mortality rate (
Elezkurtaj et al. 2021;
Imam et al. 2020;
Mueller et al. 2020;
O’Driscoll et al. 2021;
Poblador-Plou et al. 2020). According to
Bonanad et al. (
2020), among patients aged less than 50 mortality rate was lower than 1.1% and increased exponentially after this age. The most significant increase in mortality risk compared with the immediately younger age group was observed in patients aged 60–69 (compared to 50–59). Among diseases associated with a higher risk of infection and death were respiratory diseases, diabetes, and hypertension (
Biswas et al. 2020;
Fang et al. 2020). Moreover, some studies suggested a correlation between the growth rate of SARS-CoV-2 infection and a genetic profile, particularly the distribution of the Y-chromosome haplogroup R1b (
Schillaci 2020).
Large crowds of people may facilitate the transmission of the virus.
Brown et al. (
2021) showed that shared bedrooms and bathrooms in nursing homes were associated with more extensive and deadlier COVID-19 outbreaks. Similar effects might be found in indoor settings such as large and crowded work establishments. Furthermore, people living in densely populated agglomerations with many public places might be more vulnerable to infection. Indeed, some studies indicated that population density was correlated with the basic reproductive number (R
) of SARS-CoV-2 (
Sy et al. 2021). On the contrary,
Carozzi et al. (
2022) showed that the density did not directly affect the number of cases or fatalities but the timing of the outbreaks.
Another factor that might explain the differences in the number of infections and fatalities between regions was the state’s policy concerning diagnostics, testing, and treatments. Broad access to resources such as hospitals, medical staff, and high healthcare expenditures might reduce fatality rates (
Amdaoud et al. 2021;
Coccia 2021;
Oshinubi et al. 2021). However, in the short run, it was not possible to sufficiently increase these resources. Therefore, governments imposed restrictions aimed at decreasing the number of infections. According to
Oh et al. (
2021), reductions of up to 40% in commuting mobility was associated with a reduced number of cases, especially early in the pandemic, in the majority of examined 36 (mainly OECD) countries. In the US, closing schools and colleges between March and May 2020 had a similar negative effect on COVID-19 incidence and fatality rates (
Auger et al. 2020).
Some studies indicated the importance of environmental factors on COVID-19 morbidity and mortality. For instance,
Bourdrel et al. (
2021) suggested that air pollution might be linked to an increase in COVID-19 severity through its impact on chronic disease arising from decreased immune response and thus facilitating replication of the virus and penetration of host cells. On the contrary,
Xu et al. (
2021) showed that changes in air pollution alone were insufficient to contain the spread of SARS-CoV-2, with other factors such as warmer temperatures and moderate outdoor ultraviolet exposure having greater effects.
Enforcement of the restrictions is as important as their initial imposition. Thereupon societies characterized by the high social trust may have a larger propensity to fulfill obligations and listen to medical experts’ advice. Indeed, as shown by
Amdaoud et al. (
2021), social trust was one of the key factors in reducing the fatality rate during the coronavirus pandemic. Presumably, trust in authorities may be insufficient when a large part of the society does not share the same values as policymakers. It may happen when most people are more concerned about economic damage and a breach of personal freedom than the health consequences of infection (
Szysz 2022).
The number of cases and deaths in neighboring regions were critical factors in predicting the outcome of the pandemic, and the role of this factor is growing with smaller territorial units becoming observable to the econometrician. Multiple studies conducted on different levels of regional aggregation considered such a form of possible dependence by employing spatial econometric models. In the US, the analyzes were performed, for instance, at the level of counties (
Kandula and Shaman 2021;
Sun et al. 2020), whereas in Europe at the level of states (
Sannigrahi et al. 2020), NUTS (Nomenclature of Territorial Units for Statistics) regions (
Amdaoud et al. 2021), or administrative units within a specific country (
Ehlert 2021).
Amdaoud et al. (
2021) used the SAR model to analyze socioeconomic factors that impacted the levels of the COVID-19 death rate in different EU regions. On the other hand,
Ehlert (
2021) studied the association between different socioeconomic variables and COVID-19-related cases and deaths in German counties with SAR, SEM, and SAC models. We decided to explore these approaches by employing the SARAR model, which is a generalization of the SAR and SEM models, to analyze the numbers of COVID-19 cases and deaths in European regions.
Analyzing smaller regions may be preferred due to more insightful knowledge about differences within larger units. Moreover, a higher level of granulation allows for the production of a larger number of observations and, thus, more robust statistical analysis results. On the other hand, many variables are not available at a sufficiently small level of aggregation. Using variables from different aggregation levels simultaneously can be proposed as a compromise. In the analysis of NUTS regions, such an approach would consist of using country averages for variables unavailable at the lower level of aggregation. However, this mismatch may lead to spurious spatial autocorrelation of errors in the model.
One of the possible solutions to the problem is the so-called multiparameter, or mixed-W approach, based on using multiple spatial adjacency matrices (
Hays et al. 2009). We propose the following specification:
In this setup,
is a typical neighboring matrix, for example, based on proximity, and accounts for the spatial spread of COVID-19.
, in turn, is a matrix indicating adherence to the same country and represents the possibly omitted country-specific factors that, in a single-country study such as
Ehlert (
2021), could have been ignored. It also controls for artificial spatial autocorrelation resulting from applying country-level regressors to sub-national regions. The mixed-W approach was, for instance, used by
Lasoń and Torój (
2019) in the 2015 Polish parliamentary election study where
indicated adherence of two poviats to the same constituency, which accounts for the unobservable personal qualities of the candidates that the voters in that particular constituency are facing.
In our study, we use a similar idea (details of the model specification were described in the next section). The data covered 189 (mainly NUTS 2) regions from 19 EU countries. Some explanatory variables were aggregated at the regional level and others at the country level (see
Table 1 for details). Then, we use a mixed-W model to accommodate the spatial correlation effects stemming from the use of country-level characteristics. One can think of this empirical strategy as an alternative to a spatial multi-level model.
All in all, the study aimed to identify socio-economic and demographic factors responsible for acute differences in the increased number of deaths between the European regions, in a multi-country setup, with spatial regression models that take two types of spatial effects into account: (i) naturally arising from spatial interactions and (ii) technically arising due to inclusion of country-level characteristics that substantially extend the set of region-level characteristics. We estimated two types of spatial regression models explaining both the number of reported COVID-19 cases per 10,000 inhabitants and the percentage increase in deaths compared to the 2016–2019 average. As the study was based on cross-sectional data, we focused only on 2020 to eliminate the effect of different dynamics of vaccination between countries.
This paper is organized as follows: firstly, we discussed the dataset with particular emphasis on the level of aggregation of individual explanatory variables. Secondly, we described methods used for feature selection and estimating models. Finally, we presented and discussed the obtained results.
3. Results
3.1. Relative Number of Cases
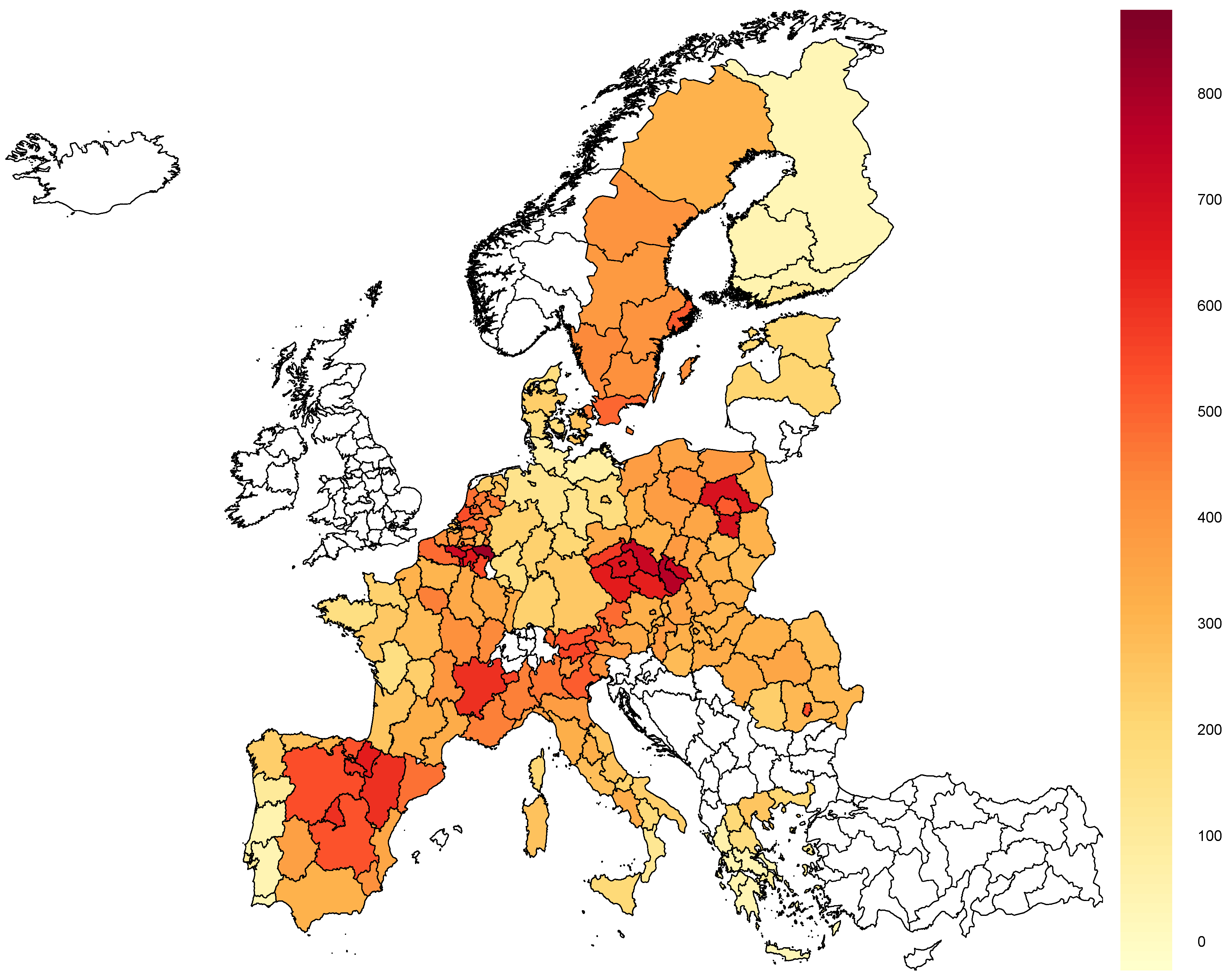
In 2020, the number of reported COVID-19 cases in the analyzed regions varied from
cases per 10,000 inhabitants in Algarve, Portugal (PT15), to 823.1 in Liège, Belgium (BE33).
Figure 1 shows that the infections were not distributed randomly but rather cluster-wise. Moreover, the differences occurred at the level of countries (e.g., compare Czechia with Finland) and regions in the same country (e.g., compare Mazovia Province with the rest of Poland or central and northern Spain with the rest of the country).
Table 4 summarizes the obtained estimates of coefficients and results of Moran’s I test. In column 1, we presented OLS estimates (non-spatial). In columns 2 and 3, the final results of the general-to-specific approach that include the component related to adherence to the same country. Finally, in columns 4 and 5, for comparison, we presented the same models as the previous two but without a component related to adherence to the same country.
In the non-spatial model, Moran’s I values are highly significant for each of the neighboring matrices (p < 10 in all cases), which indicates that accounting for spatial autocorrelation was necessary. The final models are mixed-W SARAR and mixed-W SEM. Differentiating between them depends on the chosen significance level. In the mixed-W SARAR, both and are significant at the level of 1% (p equal 0.00229 and 0.00952, respectively), while is significant at the level of 10% (p = 0.0594). In case of the mixed-W SEM, is significant at the level of 1% (p < 0.00001) and at the level of (p = 0.0103).
Moran’s I values for SARAR and SEM models with one spatial adjacency matrix indicate that they do not capture the autocorrelation stemming from the adherence to the same country (
p < 0.001 in both cases). Therefore, it clearly shows that the mixed-W approach is more appropriate for analyzing the number of cases. It is also worth noting that even though the results of Moran’s I test for the non-spatial model indicated a spatial pattern of residuals autocorrelation represented by the matrix based on distance, including the matrix based on shared borders was sufficient to account for this pattern. However, it did not work the other way around, which suggests that the actual unobserved spatial pattern is closer to the one represented by
. Nevertheless, as indicated previously, in
Appendix A.7, we showed the models with
.
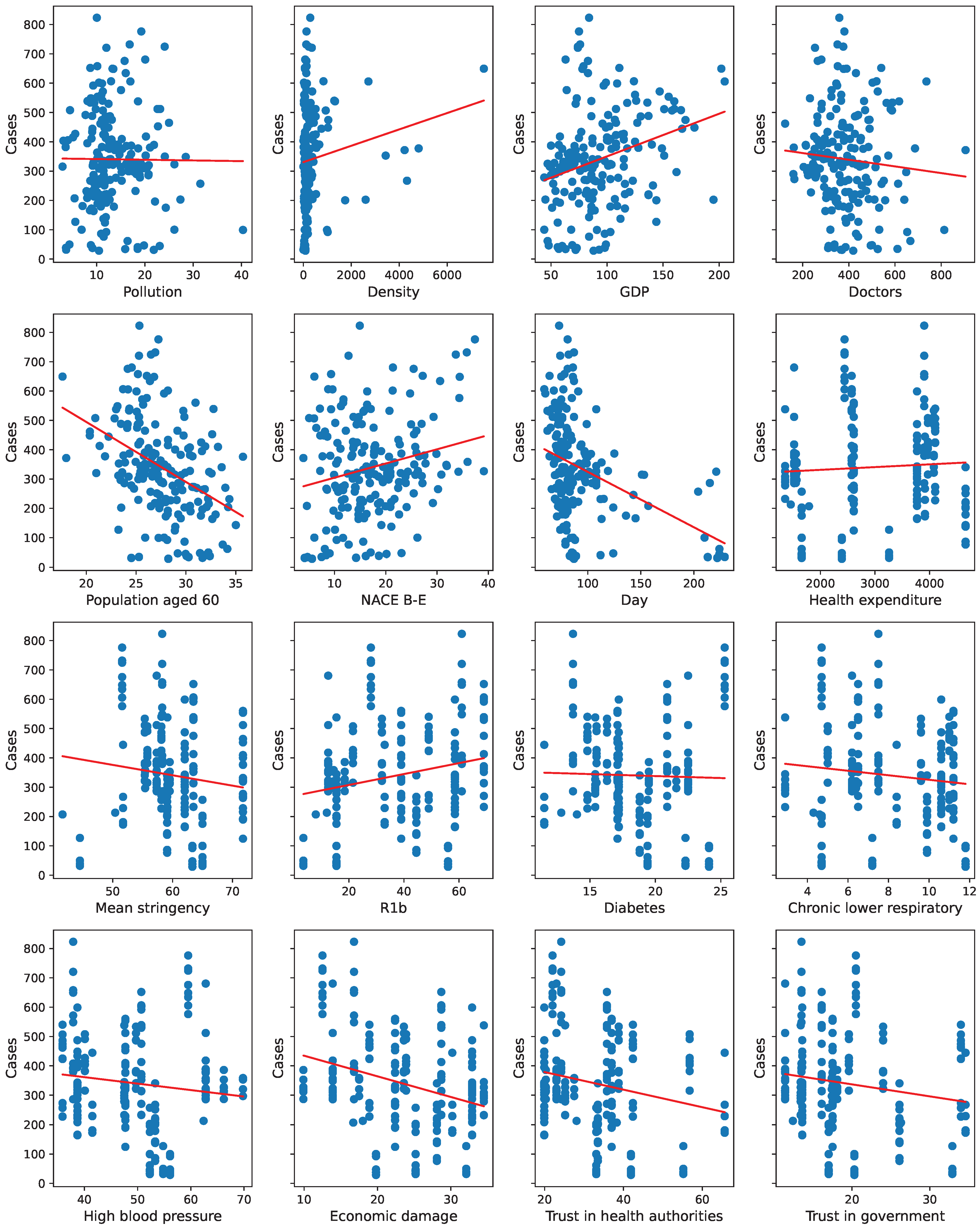
The share of the population aged 60 or over and the share of the elderly suffering from high blood pressure and chronic lower respiratory disease indicate how large part of the population was most at risk of severe COVID-19. Each of these variables was negatively correlated with the number of cases that might be caused by multiple factors. Firstly, older people are usually less mobile than the young, so they are less prone to be infected. Secondly, older people, especially those with comorbidities, could be more afraid of the outcomes of infection, and therefore, they could try to keep a social distance. Finally, some restrictions imposed by governments aimed at protecting the most prone to the severe course of the disease might be at least partially effective. Interestingly, the percentage of diabetics was not significant in any of the models with spatial components. These results align with the explanatory data analysis shown in
Appendix A.2.
From behavioral variables, only Economic Damage is significant and, as anticipated, negatively correlated with the number of cases in each specification. It was created based on the questionnaire, and different ways of aggregating the responses were possible (see
Appendix A.1). However, the significance of this variable was insensitive to the use of other aggregation methods (see
Appendix A.4).
Finally,
Table 5 presents standardized regression coefficients, computed as
(SD—standard deviation,
—
k-th explanatory variable,
y—explained variable), interpretable as coefficients in
Table 4 obtained after variable standardization. It allows for comparing the effects of one standard deviation increase on the dependent variable across regressors. One can conclude that, in quantitative terms, the Economic damage, followed by High blood pressure and R1b, contributed to the cross-regional variation in Cases to the greatest extent, whereas the contributions of Diabetes and Trust in health authorities remained most limited.
3.2. Deaths Increase
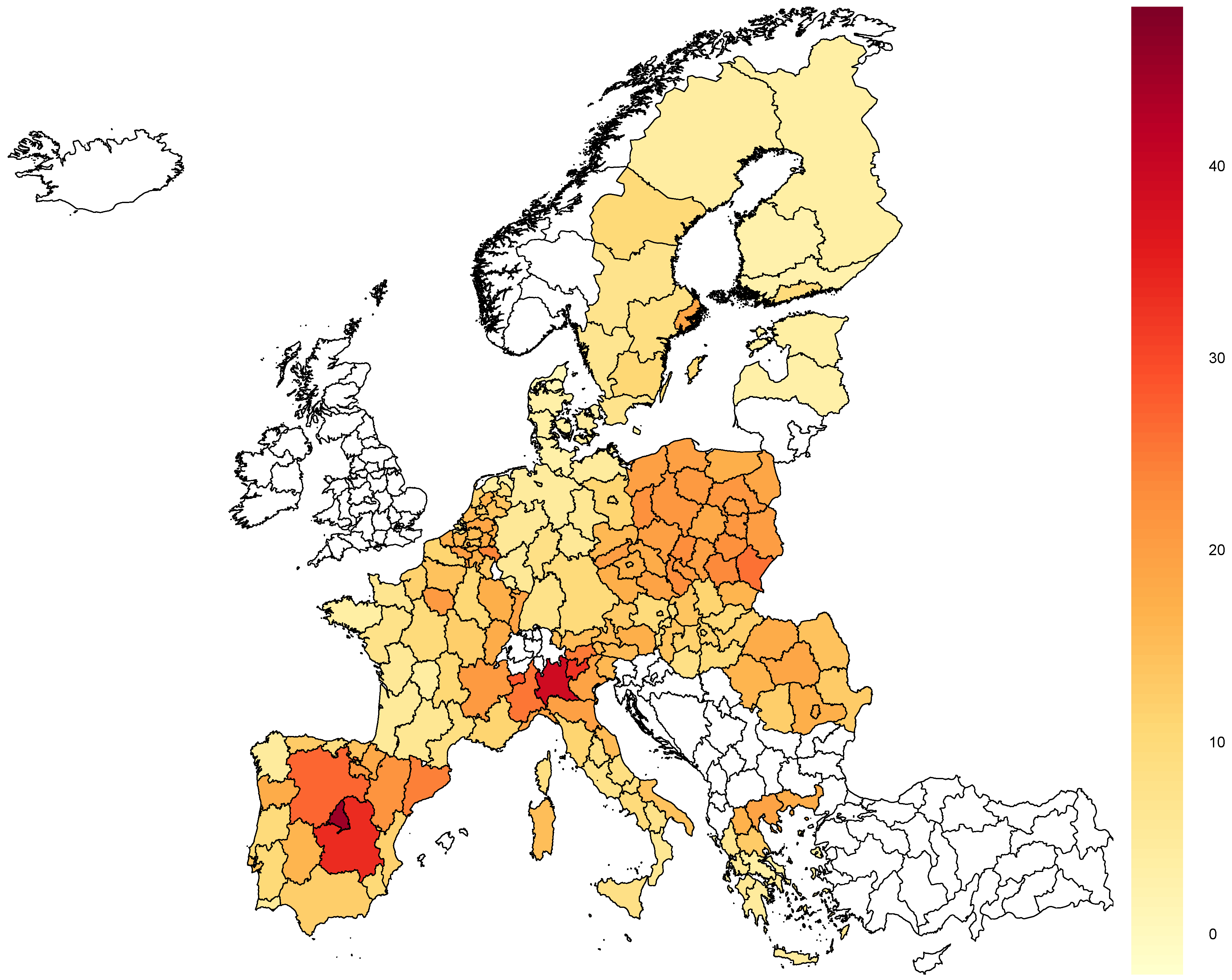
Similarly to the number of cases, the percentage of deaths increase varied significantly across European countries and regions in the same country (see
Figure 2). The smallest increase, which amounted to only around 1%, was recorded in Nordjylland, Denmark (DK05), while the largest was in Madrid, Spain (ES30), and equaled about 45%.
In
Table 6, we presented the estimation results with three models. Column 2 summarizes the results of the general-to-specific approach. Contrary to the number of reported cases, a classic SEM model without another adjacency matrix was sufficient to capture each type of spatial autocorrelation. Nevertheless, in column 3, we presented the corresponding model with two neighboring matrices. Additionally, in column 1, we included the OLS estimates.
Moran’s I statistics for the simple linear model without spatial components indicate spatial autocorrelation related to each of the three analyzed matrices (p < 0.0001 for every matrix). However, including is sufficient for capturing the whole autocorrelation of residuals (p > 0.18 for each of the three matrices in Moran’s I test for the SEM model).
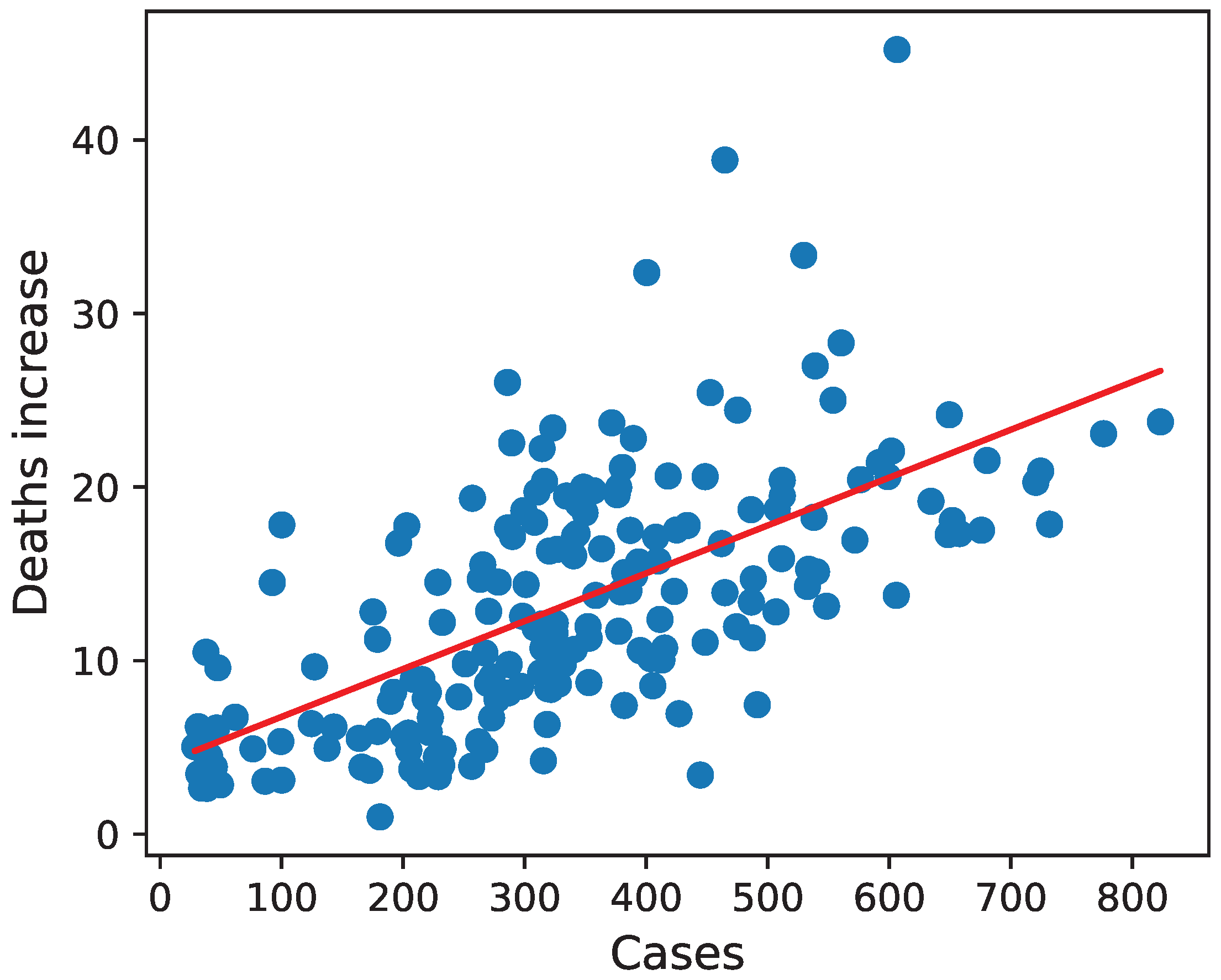
The coefficient estimate for the number of cases shows that each reported infection per 10,000 inhabitants was associated with an average increase in deaths in 2020 by 0.026 percentage points (with a 95% confidence interval equal ).
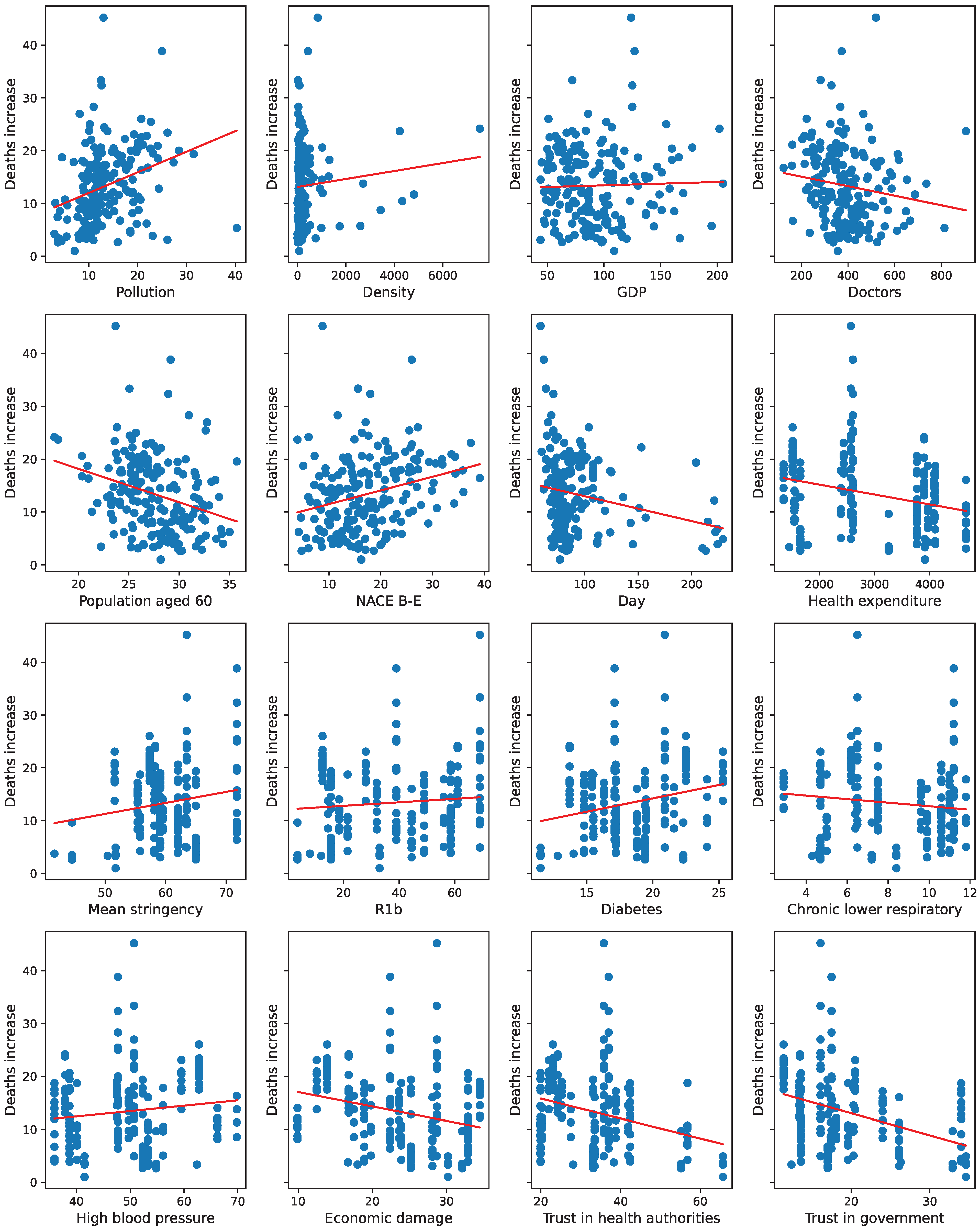
Interestingly, the number of people with diabetes and average exposure to air pollution were significant in the non-spatial model but not in spatial ones. The lack of a correlation between air pollution and the number of COVID-19 fatalities is contrary to some ecological studies (
Comunian et al. 2020;
Prinz and Richter 2022). When air pollution is dropped from the analysis, no other variable emerges as additionally relevant, not least the population density.
Mean stringency is significant and positively correlated with deaths increase in all shown models. Probably, it is because the countries affected by the pandemic the most imposed stricter restrictions than the others. The impact of individual restrictions on the number of cases and fatalities is hard to assess in a cross-sectional analysis like this. Although we tried the instrumental variable approach, described in detail in
Appendix A.6, we recommend using panel analysis based on country-level data. Therefore, a far-fetched conclusion should not be drawn based on this positive correlation.
As can be concluded from the standardized regression coefficients in
Table 7, the dominant contributor to explaining the cross-regional variation in the death count was the number of Cases, whereas the lowest contributions came from the number of Doctors, Pollution intensity, as well as diabetes incidence rate.
All the models for the deaths increase included Cases as one of the explanatory variables. Although this approach allows disaggregating the effect of COVID-19 on mortality into two separate channels, it does not allow for assessing the net effect of factors impacting both the number of cases and deaths per case. Therefore, we estimated different models for deaths increase without including Cases. The results are shown in
Appendix A.8.
3.3. Models Based on the Whole Set of Predictors
A high correlation with other predictors could cause the significance of some variables in the models presented so far. To confirm that it did not happen, we estimated models with similar specifications to the previous ones but on the whole set of predictors. However, the number of regressors is quite large compared to the number of observations. Therefore, all the estimates presented in this subsection should be treated as complements of the previous two and not be interpreted separately.
We presented the estimation results in
Table 8. To analyze infection incidence, we estimated mixed-W SEM and mixed-W SARAR as well as SEM for deaths increase. In the case of the number of reported cases, except R1b, all the significant variables in spatial models with preselected predictors are still significant at 10%. Furthermore, none of the variables rejected by BMA is significant in these settings.
An alternative way of explaining the impact of High blood pressure, Chronic lower respiratory disease, and Diabetes variables on the dependent ones could be based on the fact that the detectability of these diseases may depend on the healthcare system, i.e., when its quality is worse, the ‘official’ statistic underestimates the share of the chronically ill (better healthcare—more official cases of these three diseases). At the same time, it is straightforward to regard a better healthcare system dealing more efficiently with the outcomes of the COVID-19 pandemic (better healthcare—fewer deaths). Bottom line, when the three diseases in question act predominantly as a proxy for healthcare quality, a negative correlation with COVID-19 mortality arises. Nevertheless, this kind of risk should be predominantly related to the models explaining the number of deaths, and to a lesser extent—the number of cases.
On the other hand, in the case of the deaths increase model, only Cases, Day, Health expenditure, and Doctors are significant variables in both models based on the whole and the restricted sets of predictors.
The coefficients corresponding to the share of people working in the industry without construction were significantly greater than zero in each of the specifications concerning the number of cases (both with preselected and the whole sets of predictors). It could be caused by a greater chance of infection in crowded work establishments, or it was only a statistical effect stemming from mass testing campaigns in some workplaces such as mines in Silesia (
Krzysztofik et al. 2020). However, if it was only a statistical effect, the larger share of people employed in B-E sectors should inflate the number of deaths controlled by the number of cases, but this variable is insignificant in the model for the increase in deaths.
The number of days before the first cases negatively impacted the number of reported infections and the increase in the number of deaths in all models presented in the study. As far as the former, the correlation could be caused by the more extended period when people could infect. In the latter’s case, this effect is controlled by the number of cases. Therefore, the negative impact of days on the deaths increase was probably caused by the fact that countries hit by COVID-19 later had more time to stock all the necessary resources used in the treatment and prepare a better pandemic strategy.
BMA selected neither health expenditure nor the number of doctors for the model explaining the number of cases, and none of these variables were significant in the models based on the whole set of predictors, which shows that their impact on the effective detection and prevention of infections was negligible. Nevertheless, both significantly reduced fatality rates for a given number of cases.
The coefficients for GDP per capita were significantly greater than zero in all models for the number of cases and insignificant in all models for deaths increase. This conclusion may be treated as an extension of the results obtained by
Amdaoud et al. (
2021) that showed that the level of GDP per capita was associated with the increased death rates but did not distinguish the effect between the impact on the infection rate and the case fatality rate.
4. Discussion
The study identifies and distinguishes factors that explain inter- and intra-national variation in COVID-19 mortality through two different mechanisms: increased infections and fatalities per case. Identifying them allows for the prediction of the outcome of the pandemic and the imposing of appropriate countermeasures by decision-makers. Countries and regions with better quality healthcare, measured by the number of practitioners and health expenditures, could keep death rates low with a relatively high number of cases. On the other hand, entities with less developed healthcare systems could only try to decrease the number of infections. However, when imposing restrictions to reduce the number of cases, the decision-makers have to account for specific characteristics of societies that concern the population structure, employment structure, wealth, or attitudes toward these limitations.
It must be emphasized that the public health implications of this study do not generalize easily to other periods or geographic areas. From 2021 onward, the landscape has changed considerably with the increasing availability of vaccines, virus mutations (mostly towards endemization), and increasing organizational preparedness of the healthcare systems. Probably, a comparable setting in which these results apply would be an emergence of a new respiratory pathogen (or a milestone mutation of an existing one) with at least similar properties in terms of transmission and severity.
Peters (
2022) summarizes the evidence that such a scenario is non-negligible.
Our estimation results confirm that accounting for spatial autocorrelation is necessary for analyzing the outcomes of the pandemic, which is in line with
Amdaoud et al. (
2021). What is methodologically new in our study is the use of two spatial adjacency matrices simultaneously. An additional component indicating adherence to the same country is introduced mainly to enable the inclusion of variables from the higher level of aggregation. However, even with all attributes at the same level of aggregation employing this matrix may be helpful due to the possible existence of some unobserved and country-specific factors that impact the outcome of the pandemic.
The analysis in the study can be extended in several ways. Firstly, new variants of the SARS-CoV-2 may respond differently to factors that were important in the first waves of the pandemic. Therefore, further studies can include different periods. However, in this approach analyzing panel data may be more appropriate because the pace of allocation of vaccines, which is a critical factor in predicting the outcome of the pandemic from the beginning of 2021, cannot be easily aggregated with the cross-sectional data.
Secondly, as shown in the study, employing panel econometrics may also be helpful because different countries imposed various restrictions at different moments, and aggregating them into simple, cross-sectional indices seems insufficient.
Finally, all the neighboring matrices analyzed in the study are based on the geographical proximity of regions or adherence to the same country. However, as suggested by
Kandula and Shaman (
2021), using matrices that reflect the flows of people between regions can also be considered. Such matrices, however, are difficult to obtain in practice (see
Torój (
2022), Table 7 for a scarce example for NUTS-3 regions in Poland), at least not the entire Europe as in this study. One might also expect them to resemble the distance-based matrix, explored here in
Appendix A.5.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

