1. Introduction
It has been an important task in the estimation of the transmit power and location of a node based on a set of cooperative receiver (or monitor) nodes in wireless networks. Such an estimation is particularly essential for cooperative sensing based cognitive radio (CR) [
1] networks to enable various sensing mechanisms, such as the estimation for the maximum interference-free transmit power of a frequency-agile radio in an Opportunistic Spectrum Sharing system [
2]. As pointed out in [
3], transmit power estimation is also a fundamental functional block for the detection of adverse behaviors, such as signal jamming attacks [
4] and channel capturing [
5].
As a special case of transmit power estimation, node positioning based on received signal strength observations has been extensively studied in [
6,
7,
8], where the transmit power itself is assumed known. In [
9], transmit power estimation was studied by using an ad hoc optimization method. A simple yet rough estimator was proposed by a geometrical approach with a deterministic model equation in [
3]. However, this method is not an exact way for estimation and may cause a large deviation under some circumstances. In [
2], an maximum likelihood (ML) estimation method was introduced to calculate the concerned maximum interference-free transmit power. However, the performance of ML estimation lacks relevant and comprehensive analysis. In [
10], deep theoretical results regarding the performance of ML estimation for transmit power have been established by assuming that the observation locations are random variables. The popular ML method has also been applied to [
11,
12] recently.
Specifically, we concern a wireless network consisting of a primary node, or transmit node, as well as a set of receiver nodes that are listening to the signal launched by the primary node. We assume that the primary node transmits at a constant power level during the observation period, and the receiver nodes, with their locations known previously, can exchange their respective received power information with each other [
2,
3]. The problem is estimating the transmit power and location of the primary node based on a lognormal shadowing model [
2,
13].
Mathematically, we consider an estimation issue regarding the observation model given by a lognormal shadowing model ([
2,
13]) as
where
is the path-loss exponent and
is typically a zero mean Gaussian noise
,
. There are four constant parameters in total in the model (
1), i.e., transmit power
, path-loss exponent
, and transmitter location
. The other varying variables except noise are the received power level
at the
i-th monitor node and the monitor location
,
. The estimation issue considered in the above references, e.g., [
10], are all with respect to
, i.e, path-loss exponent
is assumed known. In this paper, we consider a more general estimation issue with respect to the four parameter vector
for model (
1), based on an available data set
. In light of the fact that the observation data may be collected from a finite number of monitor locations, it is reasonably assumed that the monitor location
is deterministic, rather than random variable as in [
10].
Because of the nonlinearity of the developed models with respect to the parameters to be identified, most classic methods for linear model in [
14] are not applicable. However, the ML method is an exception, which is effective for any kind of parametric model if the distribution of noise is known. By assuming that the noise is an independent identically distributed sequence obeying
, the derived optimization objective function is a summation of the squared difference between the two sides of model Equation (
1) (discarding the noise term on the right-hand side). The optimization problem is calculated by Matlab optimization toolbox (2010b). In an iterative process, the former estimation is taken as an initial starting point for the next calculation. In this contribution, we are motivated to analyze the performance of ML-based estimation for parameter
, since the issue to find the root of the ML function is a standard optimization problem that can be solved by many mathematical or engineering software programs.
Although in practice an ML-based estimation method is usually implemented by a finite data set, there could be a concern regarding the asymptotical performance of the developed ML estimation model as the data volume
n tends to infinity. If the ML estimation is biased even when
n tends to infinity, how can one expect for the effectiveness with a fixed
n? Therefore, the major effort of this paper is to investigate the asymptotical performance of the ML estimate as
, i.e., when it succeeds and when it fails. It turns out that the monitor location set
should be rich enough in some sense to guarantee the
n-th ML estimate, denoted as
, tends to
as
. To our knowledge, a special case of this issue has been considered in [
10], where the performance of ML estimation for parameters
has been analyzed by assuming that
is a sequence of iid random variables. However, as mentioned above, it is more natural to view the receiver node locations
as deterministic values. Hence, in this paper, we will consider the performance of ML estimation for
as the number of receiver nodes
n tends to infinity by information from deterministic receive nodes.
The main contributions of this paper are as follows.
The rest of this paper is organized as follows. The proposed model and ML estimation for transmit power are presented in
Section 2. An extreme case related to consistence condition for ML estimation of transmitter power is studied in
Section 3, which may help to establish some intuitive sense for the main results of this paper. Then, as the main practical contribution of the paper, the technical mechanisms beneath the numerical experiments are demonstrated and justified in
Section 4. In
Section 5, some numerical experiments are designed to detect the performance of the ML estimate algorithm, and explained by relevant theoretical results. The main theoretical contribution is in
Section 6, where some theoretical preliminaries to be used in verification of the theoretical results in the former section are prepared. Concluding remarks of the paper are given in
Section 7.
2. Maximum Likelihood Estimation for Transmit Power in Localized Signal Strength Model
As aforementioned, we limit our discussion to Signal-Strength (SS) based localization of a single primary transmitter in the geographic coverage area [
2]. Let
denote the location of the primary transmitter. Suppose that a sequence of uncorrelated observed SS measurements,
, along with the corresponding position coordinates
, where
,
, are available. The set of observations
may be obtained in different ways. For example, consider a scenario in which
n receiver nodes, located at positions
, collect the signal strength observations
at a given time. These receiver nodes exchange their data among each other, such that at least one of these nodes receives the entire set
. Naturally, the observation set
may also be obtained by measurements from a single receiver node at
n different points in time along a trajectory as the node moves in the coverage area. In general, a given observation
may be obtained either from a measurement taken by the receiver node itself in the past, or from a measurement at another receiver node that shares the information between the two nodes. Actually, we will find below that there are a set of requirements on the number of receiver nodes and their locations that can satisfy the consistence condition of ML estimation of transmit power.
The observation equation is given by a lognormal shadowing model ([
2,
13]) as
where noise
follows a Gaussian distribution
, and
Let us formulate below the ML estimate for
, or parameters
, based on the given observation data
. Mathematically, when the locations
are viewed as deterministic quantity, the random variable
has a Gaussian distribution
, i.e., its density is
Note that, though is a sequence of independent random variables, they have different distributions since the locations are probably different with different i.
Clearly, the corresponding ML function is
and the log ML function can be written as
which is equivalent to minimize
This turns to be a nonlinear optimization problem regarding , which can be solved by many mathematical software packages such as GAMs (General Algebraic Modeling System) and Matlab toolbox, or by designing a special program. As proposed in the Introduction, we are motivated to investigate the asymptotical performance of the ML estimate as n increases. Precisely, we are interested to know when the ML-based n-th estimate for tends to the true value as n tends to infinity.
3. Unique Solution Condition for a System of Observation Equations without Noise
In this section, we consider an extreme case related to a consistence condition for ML estimation of transmitter power, which may help to establish some intuitive sense for the main results of this paper. A similar idea can be found in the proof of Theorem 3 in [
10]. By (
2) and (
6), we have
Thus,
if there is no noise in the model Equation (
2). This further means that each term in the summation (
6) equals zero, i.e.,
We naturally want these
n equations regarding
to have a unique solution. Mathematically, the solution is not unique if we find another
such that the data set
synchronously satisfies the following
n equations:
Combining (
8) and (
9), one gets
for
, where
and
given by (
3). Thus, the solution of
n equations given by (
8) is not unique if the data set
satisfies (
10) with certain
. Conversely, if the solution is unique, the whole location set should never satisfy (
10) for any given
.
After replacing
as
in (
10), a curve is defined by equation of
as
with given parameters
,
and
. For convenience, let us call the curve given by (
11) a criterion curve with respect to
,
, and
. The class of these criterion curves can be used to to determine whether the solution of a system of
n equations given by (
8) is unique. Precisely, the condition guaranteeing uniqueness can be presented as: the data set
should not be located in any single criterion curve.
Below, we will analyze some qualities of criterion curves in detail under general setting and a special case, respectively.
3.1. Qualities of the Criterion Curve
Let us first point out a qualitative property of criterion curve given by (
11). If
, say
, we find that
This means, for any given
the criterion curve defined by (
11) is impossible to extend to infinity. However, if
, we know that the curve turns to be a circle unless
. Another immediate discovery is that the curve separates the two points
and
, due to the fact that the left-hand side of (
11) is less than its right-hand side when substituting
and
into (
11), and the inequality reversed by substituting
and
. Let us summarize these facts as a proposition below.
Proposition 1. The criterion curve defined by (11) is a straight line if and . Otherwise, it is a bounded curve. In both cases, the curve separates the two points and . By Equation (
11), a criterion curve is symmetrical to the straight line passing through points
and
. To know how many points a criterion curve intersects the mentioned straight line, let us introduce a parametrical presentation of the straight line as
where
and
. By substituting (
13) into (
11), we have
where
. It is easy to see that the Equation (
14) (with respect to
t) has at least two solutions and at most four solutions for
. If
and
, it has just one solution
; and it has two solutions for
. Hence, there are three different structures for the criterion curves if
; and two different structures if
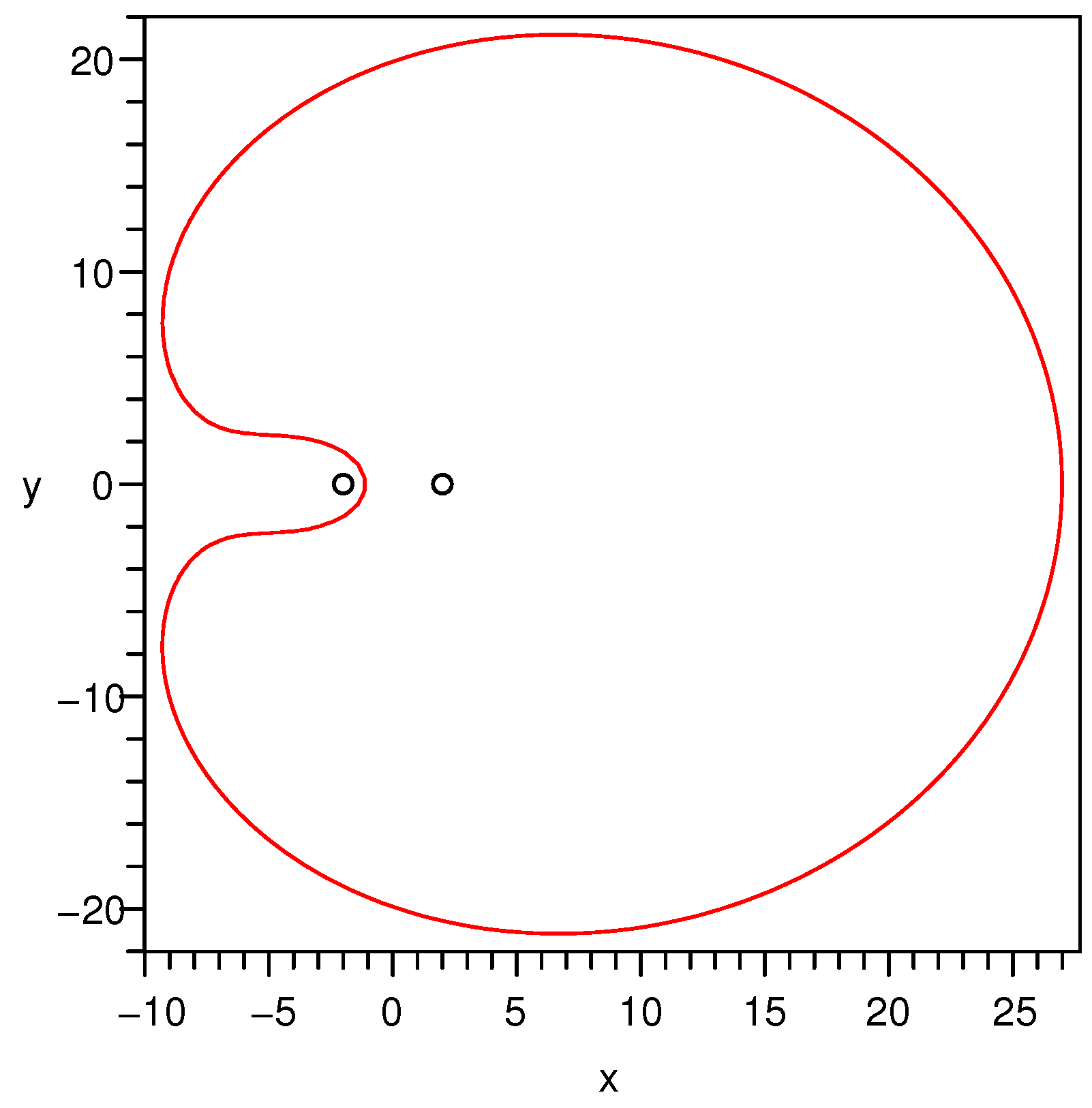
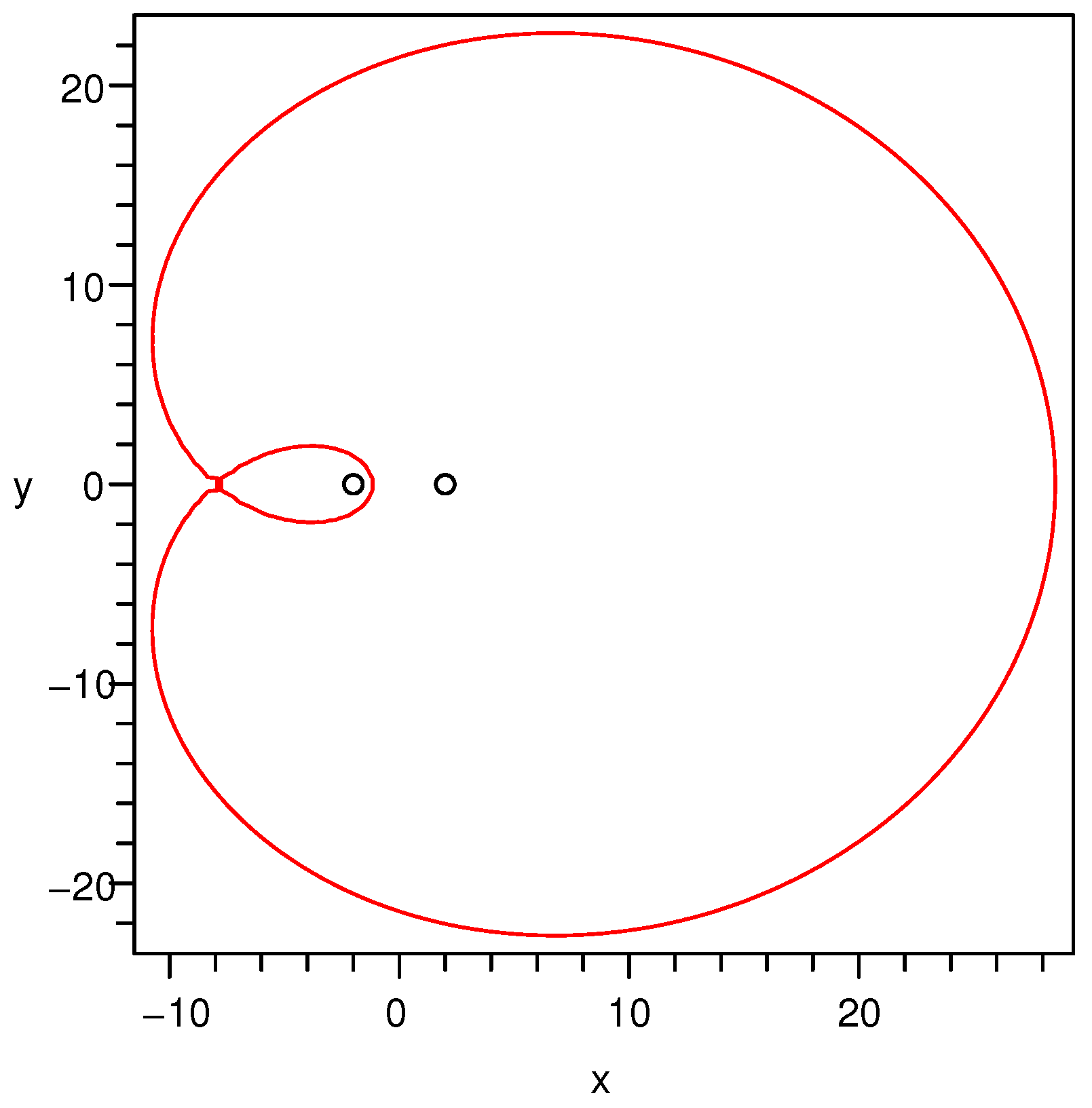
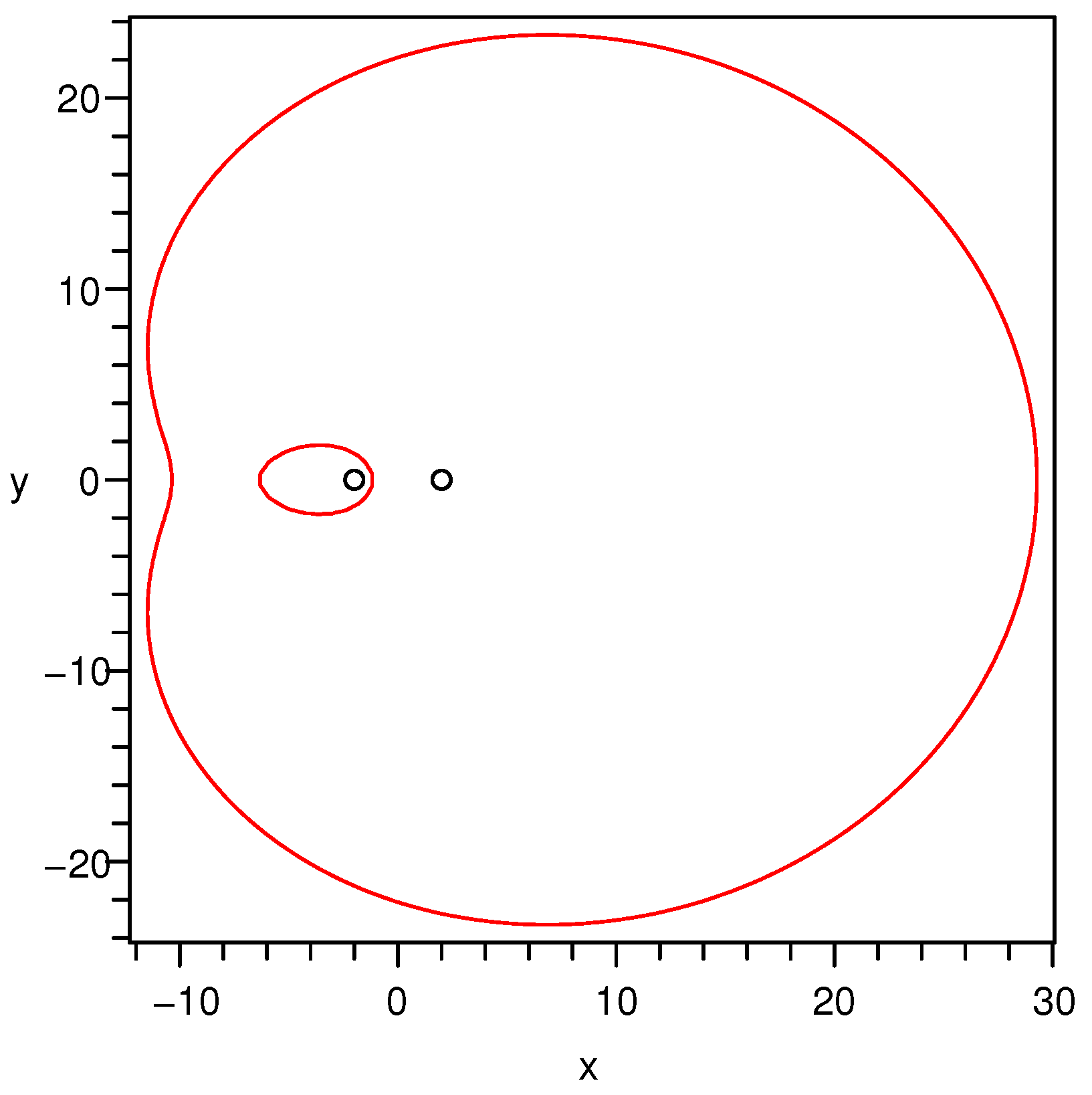
. Let us check it by numerical experiments. By setting
,
,
,
, we plot graphs of the criterion curves for
respectively in
Figure 1,
Figure 2 and
Figure 3. The reason why
selects these three values is that, under the given parameter setting,
is found numerically at a critical point corresponding to the critical curve among the other two kinds of curves. Thus, the other two values
and
from both sides of the critical value are chosen to show the bifurcation phenomenon.
The latter case will be analyzed extensively in the next subsection, so we just summarize the case below.
Proposition 2. For , the criterion curves defined by Equation (11) can be divided into 3 kinds of curves according to the number of intersecting points of a criterion curve and the straight line determined by the two points and , i.e., the number of roots of Equation (14). Specifically, the three cases are as follows: - (a)
If the number is 2, the curve is a closed connected curve. A typical graph of this case is shown in Figure 1; - (b)
If the number is 3, the curve is a closed connected curve. A typical graph of this case is shown in Figure 2; - (c)
If the number is 4, the curve is two separated curves. A typical graph of this case is shown in Figure 3.
3.2. Qualities of the Criterion Curve if Is Known
If the path-loss exponent
is known, i.e., in this case, the ML estimation is proposed for
as in [
10], by a similar reasoning process, we have the criterion curve as
with given parameters
,
and
.
Clearly, the curve is a straight line when
, and a circle when
. Though these basic facts have been discovered in [
10], we describe some more general and deeper qualities in the following propositions.
Proposition 3. When , the circle defined by Label (15) is centered atwith radius , i.e., times the distance between and . While , the straight line defined by (15) is perpendicular to the line connecting and and containing their midpoint. In the circle case, the radius tends to infinity when tends to 1, which also means the circle turns out to be a straight line.
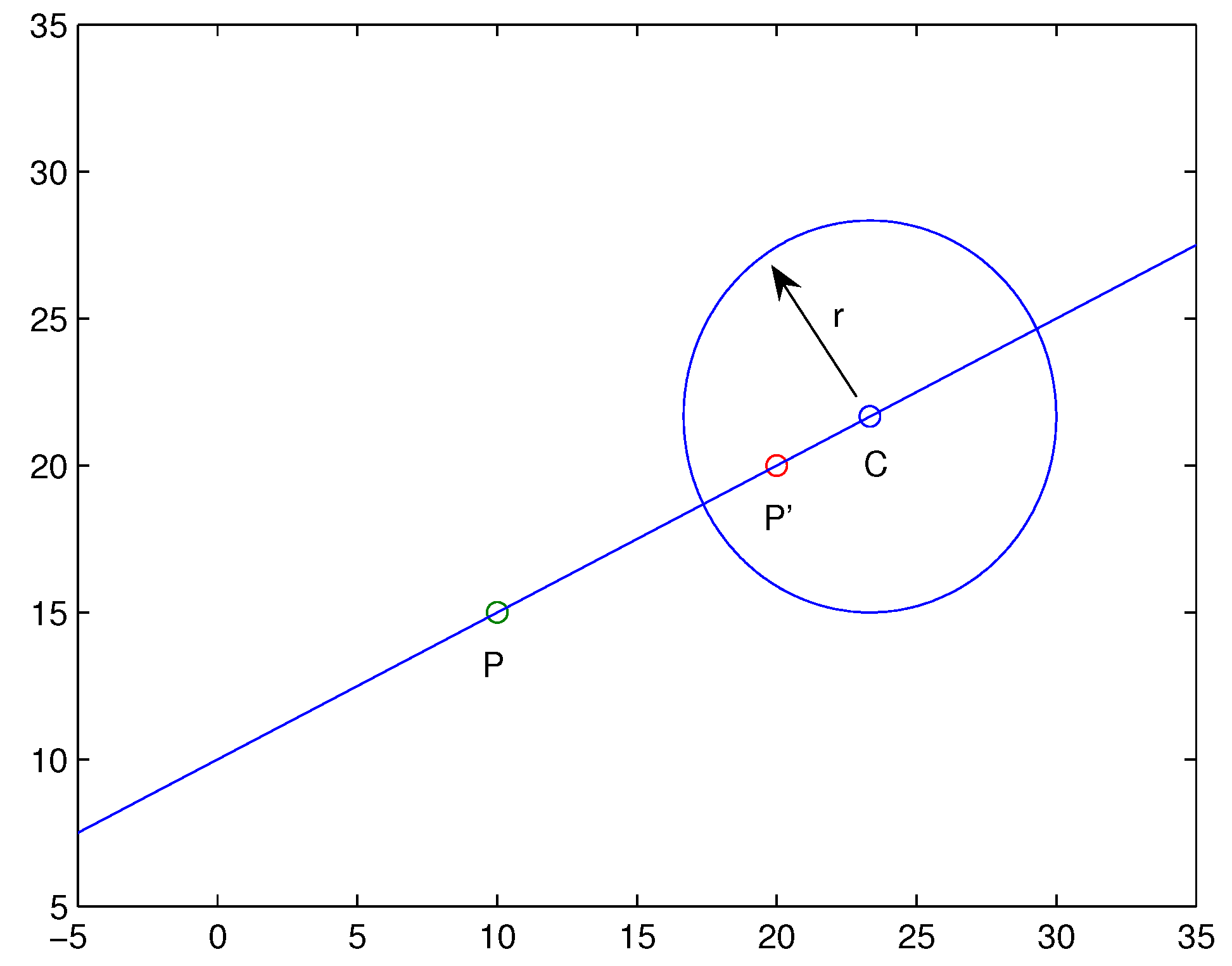
With
and
fixed, an important topic is checking whether a given circle is a criterion curve, and, if it is, how we can find the corresponding
. As shown in
Figure 4, given the point
P and a circle centered at
C with radius
r, it is important to figure out whether the circle is a criterion curve, and what
is at this moment.
Let us change the Formula (
16) into a vector form:
Hence,
, shown in
Figure 4, can be calculated from (
18) directly if
,
P and
C are known.
Let us deduce a formula to calculate
from given information: points
P and
C, and circle radius
r. In the case of
, shown in
Figure 4, by the aforementioned fact, it follows that
and
derived by (
17). Thus, from (
19) and (
20), we derive
and thus
Similar results can be derived in the case .
Therefore, now we can calculate
by Formulas (
18) to (
22) when
, i.e.,
. In the case
, or
, we know that the corresponding curve should be a straight line rather a circle. Thus, if a given circle contains the point
P, it is impossible to be a criterion curve. Let us summarize these facts as a proposition below.
Proposition 4. Assuming points and , and a circle centered at C with radius are given, then the following assertions hold:
(i) If the circle contains point P, i.e., , then the circle is not a criterion curve. Moreover, a straight line traversing through P is not a criterion curve.
(ii) If , then the circle is a criterion curve, and the corresponding in (15) can be calculated as:with . Another obvious fact is that, under case (ii) of Proposition 4, the circle contains either one of
P and
, and the other is out of the circle, as shown in
Figure 4. This also serves as an explanation as to why it fails to be a criterion curve if a circle contains
P itself. Moreover, three noncollinear points are not located in any criterion curve, if the circle determined by the three points contains
P.
4. Consistence Condition for ML Estimation of Transmitter Power
In this section, we deduce the consistence condition to guarantee convergence of the ML estimate for , i.e., as . Roughly speaking, the consistence condition is that the location set should be rich enough in some sense. A criterion is given and proved.
Let us introduce the definition for consistence condition, which is a requirement for richness of the locations , as introduced in the former section. The requirement is somewhat similar to `persistence of excitation condition’ in a least squares algorithm to guarantee the convergence.
Let us introduce a limit set of a sequence of point sets in terms of standard Euclidean distance.
Definition 1. Denote a series of nonintersecting and successive index sets for the whole natural numbers as with . Let is a point set in . A point is called a limit point of the sequence of point sets , if for , there exists and such thatholds for . The set comprised of all such limit points is called the limit set of the set sequence , denoted as . For example, letting
we have its limit set to
.
Below we define the criterion curve strictly, which actually has been introduced in
Section 3.
Definition 2. A criterion curve is defined by equation of aswith given parameters , and . Remark 1. When , a criterion curve is a circle for if and a line if , as already shown in Section 3. Thus, under this setting, four noncollinear and nonconcyclic points are impossible to locate in any single criterion curve. Now, we are in a position to state a consistence result for ML estimation for transmitter power model.
Theorem 1. Suppose that the location set is in a bounded region, and denotewhere is a positive integer. If the limit set does not locate in any single criterion curve given by (24), then the ML estimation for model (2) with likelihood function given by (5) is very consistent, i.e., the estimates converge to the true vale with probability 1 as the data number tends to infinity. Proof. Theorem 3 is used to prove the above theorem. Since the model is assumed to be located in a local region, we need only to check the two conditions therein. By the likelihood function given by (
5) and density for
given by (
4), we have
where
used on the right-hand side is used to make the expressions brief. By the fact that all parameters belong to a compact set, the condition (ii) of Theorem 3 is satisfied.
The continuity of
with respect to all variables is obvious. By Remark 5, we need only to verify (
53). To show (
53) for density (
4), it is sufficient to show that, for any different
and
, there exist
s and
such that
By substituting (
4) to (
26), we have
which means that there is no criterion curve containing all points of the limit set
. In other words, this is equivalent to say that the limit set
is not located in any single criterion curve given by (
24), which finishes the proof of the theorem. ☐
Based on Theorem 1, the ML estimate for transmitter power may fail even if the number of observation tends to infinity if the whole location set belongs to a single criterion curve. Below are two typical cases when is known.
(i). The set
is located in a straight line, which means
and
in (
24). In this case, the ML estimator for location
may tend to its symmetrical point with respect to the line yet the estimate for
still works, as in Example 2. Furthermore, if the set
is asymptotically located in a straight line, the same phenomenon happens, as shown in Example 4.
(ii). The set
is located in a circle, which means
and
in (
24). In this case, the ML estimate may tend to another location
given by (
23), and estimate for
tends to
, as in Example 3.
However, even in the two cases above, it is still possible to see that the ML estimators converge to the true value because the true value are also the solution of the likelihood function.
5. Numerical Algorithm and Experiments
Let us first develop a recursive numerical algorithm to minimize
in (
6) by using Matlab code/fminsearch/. When the
n-th ML estimate for
is numerically found to be
, the next minima
for
is numerically searched based on
as:
This means the starting point of the next search is , rather than any other randomly selected value. Thus, the information obtained by the former step has been used for the next search, which may increase the effectiveness.
For simplicity, the numerical experiments below are designed to investigate the performance of ML estimation for parameters
, instead of
. Naturally, similar phenomena exist for ML estimation of
. Four numerical experiments below are designed to investigate the asymptotical performances of the ML estimation for
in model (
2) as the observation number tends to infinity. The first one achieved a successful observation while the rest three failed. The essential reason for the failure is that the likelihood function (
5), or the equivalent function
in (
6), has multiple roots when some conditions are not met. Note that, even in the three examples of failure, the ML estimation may still work since the true value is also a root of the likelihood function. It depends on the numerical algorithm to find the roots of the likelihood function.
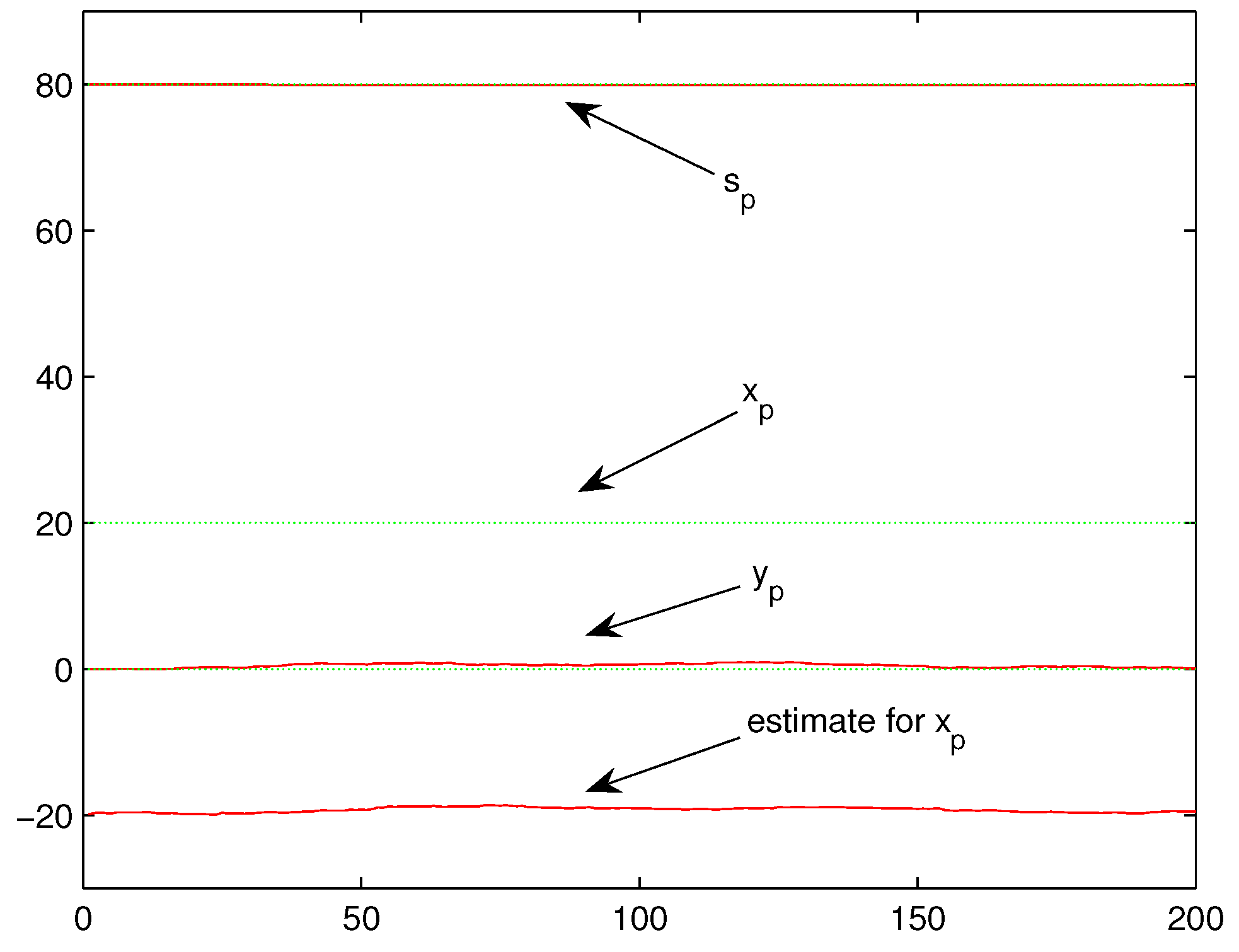
Example 1. Let , in (2) and (3), , and assume all locations are all located in the set successively infinite times. The performance has been shown in Figure 5. Clearly, the corresponding location set
in Theorem 1 is:
Hence,
is still comprised of these four noncollinear and nonconcyclic points. By Theorem 1 and Remark 1, the ML estimation for
will definitely converge to all true values as shown in
Figure 5, which coincides with the numerical experiments.
The set does not need to own four noncollinear and nonconcyclic points. As a matter of fact, consists of three noncollinear points (or three collinear points) may still work.
Example 2. Under the same setting of Example 1, expect that all locations are located in the set . The performance has been shown in Figure 6. The location set
is obviously located in a criterion curve, since they are all located in the straight line
. The corresponding
in (
15) by the fact
. In addition, the corresponding
under this case, so, by (
10),
. This means that the ML estimates for
and
have no bias, while the ML estimate for
may tend to
, which has been discovered by the experiment. By observing that the symmetric point of
with respect to the line
is
, the ML estimators for
may converge to
, yet the estimators for
and
still work, as shown in
Figure 6.
Example 3. Under the same setting of Example 1, expect that all locations are located in the setwith . The performance has been shown in Figure 7. The location set
in Example 3 is also located in a criterion curve, since they are all located in the same circle with center
with radius
, calculated by Proposition 4. The corresponding
in (
15) and the corresponding
, so, by (
10),
. This means that ML estimate for
have no bias, while ML estimates for
and
may tend to
and
respectively, which has been discovered by the experiment, as shown in
Figure 7.
Example 4. Under the same setting of Example 1, expect all locations . The performance has been shown in Figure 8. Note that the corresponding location set
in Theorem 1 is:
Clearly,
is located on line
. Thus, it is located on a single criterion curve. A similar phenomenon of Example 2 happens. By observing that the symmetric point of
with respect to the line
is
, the ML estimators for
may converge to
yet the estimators for
and
still work, as shown in
Figure 8.
It is similar to design a set of numerical experiments to make the ML estimations for all fail. The four simple examples above are just used to demonstrate some basic features of the proposed ML estimate algorithm.
6. Consistence Analysis of Maximum Likelihood Estimation
This section serves as theoretical preliminaries for the former mathematical analysis, which contains general consistence analysis for the proposed ML estimation algorithm based on independent observations with different distributions. As for independent identically distributed observation cases, we refer to Theorem 1.3.3 in Chapter 1 of book [
15]. Hence, Theorem 2 here can be taken as an extension of the counterpart in [
15]. Furthermore, we propose an easy way of checking the criterion in the following Theorem 3. On the other hand, the readers who are more concerned with practical applications are suggested to pay more attention to Theorem 3.
Although the ML method, suggested by R. A. Fisher, has attracted the interest of mathematicians in theoretical performance analysis for a long time, there are still remain open quite basic issues such as the one investigated in this paper. Thus, this section investigates the basic strong consistence for theoretical preparation.
Let be a statistical experiment, which means that is a probability space for any . Let be absolutely continuous with respect to measure on and thus , i.e., something like density function. Let X be the observation data generated by a certain statistical experiment. Thus, the function can be taken as a likelihood function corresponding to the experiment and observation X. The statistic defined by
is called the ML estimator for the parameter
based on the observation
X. In the case of independent identically distributed (iid) observations,
, where
possesses the density
with respect to measure
. The ML estimator
has a simple form as
Moreover, in many applications, the likelihood function depends on some other varying quantities, e.g., the likelihood function for transmitter power model by (
5) involves
and
. This means that the ML estimator
is generally
where
is a deterministic quantity (or vector), e.g.,
in (
5). The issue to be faced now is to estimate parameter
via the available observations and the varying data
. Naturally, some restrictions upon the extra data set
are required to guarantee the consistence.
In the aforementioned iid case with likelihood function (
29), the ML estimator
is strongly consistent (see Theorem 1.3.3 in Chapter 1 of book [
15]), i.e.,
with probability 1 as
. Below, we intend to obtain a similar result by using the case with likelihood function as (
30).
Theorem 2. Let Θ be a bounded closed set in , be a continuous function of for almost all , . Let the following conditions be fulfilled with a real number :
(i) Denote a series of nonintersecting and successive index sets for the whole natural numbers as with the volume of less than or equal to a constant positive integer m. For all and all , there exists a positive number (may depend on θ, q and γ) such that(ii) For any , and , there exists a positive number (may depend on θ, q and δ) such that Then, for any fixed , the ML estimator given by (30) tends to θ as with probability 1. Let us explain the two conditions briefly here. The condition (i) requires that in any index set there is at least a density function with a different value as is changed. This means the data set should be rich enough to make density function distinguishable according to different values of . On the other hand, condition (ii) desires that the density function has certain continuity with respect to in some sense.
Remark 2. This theorem is a twofold extension of Theorem 4.3 in Chapter 1 of book [15]. Firstly, the theorem in book [15] deals with an iid likelihood function as (29), which is just a special case of (30) without in the likelihood function. Secondly, a parameter q is introduced here in the conditions (i) and (ii) to include the counterpart conditions therein as a special case of , although, is a wise choice. Remark 3. When we consider a fixed true value , the condition (i) can be reduced to . This means only the difference between (any) and (fixed) is required with .
Before prove the theorem, let us introduce an extension of Young’s inequality [
16] below and refer its proof to [
17].
Lemma 1. Suppose that , and with . Then,where the equalities hold if or . Remark 4. This lemma develops an extension of the classic Young’s inequality; see, e.g., [16],for , and with , which is a source of lots of important inequalities, e.g., Holder’s inequality and Minkowski’s inequality. A corollary from the proof is The below proof for Theorem 2 shares the main ideas of the counterpart for Theorem 4.3 in [
15].
Proof of Theorem 2. Notice that the maximum operator is taking over a finite set
in (
31) of condition (i), thus there exists an index
such that
Let
be a sphere of a small radius
located entirely in the region
. We shall estimate first
. Supposing that
is the center of
, then
We now intend to find a suitable upper bound for the expectation of the left-hand side of (
37). This can be done by considering the right-hand side in two separated nonintersecting index subsets of
i, denoted by
and
. By taking expectation over index set
for (
37), we have
Here and hereafter,
p satisfies
. By Lemma 1 and (
36), the first term of (
38) derives
By Hölder’s inequality, the second term of (
38) derives
By the inequality
and (
38)–(
40), we obtain
By taking expectation over index set
for (
37), we have
By Hölder’s inequality, the first term of (
42) is not greater than 1, and the second term of (
42) satisfies inequality (
40). Similar to (
41), we obtain
Finally, by (
41) and (
43), we have
By definition of
in (
32), it is easy to show that, e.g., see [
15],
Noticing the fact
m is a constant integer, this means
can be held if we select sufficiently small
. Thus, the right-hand side of (
44) tends exponentially to 0 as
.
Fix
and cover the exterior of the sphere
by
M spheres
, of radius
with centers
. The number
is chosen to be sufficiently small so that all the spheres will be located in the region
and so that, for all
j, the inequality
satisfied. Then, by definition of
and (
44),
Therefore,
which finishes the proof. ☐
Once the two conditions of Theorem 2 are justified, then strong consistence of ML estimation algorithm follows. However, the two conditions are inconvenient to use in applications. Below is an attempt to find a simple and applicable criterion by using the two conditions (i) and (ii) with in Theorem 2.
Theorem 3. Let Θ be a bounded closed set in , belong to a compact set, be a continuous function of , , and , and is the same notation of Theorem 2. Furthermore, if
(i′) For any different and , there exist fixed and and such that(ii′) For all , the derivative of satisfies Then, for any fixed , the ML estimator given by (30) tends to θ as with probability 1. Proof. We need only to justify that the two conditions of Theorem 2 are satisfied with . Clearly, the condition (ii′) is stronger than (ii) of Theorem 2 in view of standard Differential Mean Value Theorem with respect to . Thus, we need only to guarantee that (i′) is a special case of (i).
By (i′), continuity of
, and the fact that
is compact, for any given
, there exists a number
such that
Again, by the fact that
belongs to a compact set, there exists a closed ball (neighborhood) of
, denoted by
with
, such that
holds for any
. Clearly, this immediately implies (
31) with
which finishes the proof. ☐
By the notion introduced by Definition 1, we simplify further the condition (i′) of Theorem 3 for application.
Remark 5. By Definition 1 and continuity of density , we find a simple sufficient condition to guarantee the condition (i′) of Theorem 3 as:
(i″) For any different , there exist fixed and such that 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







