Activity Recognition Using Gazed Text and Viewpoint Information for User Support Systems



Abstract
1. Introduction
Related Work
2. Materials and Methods
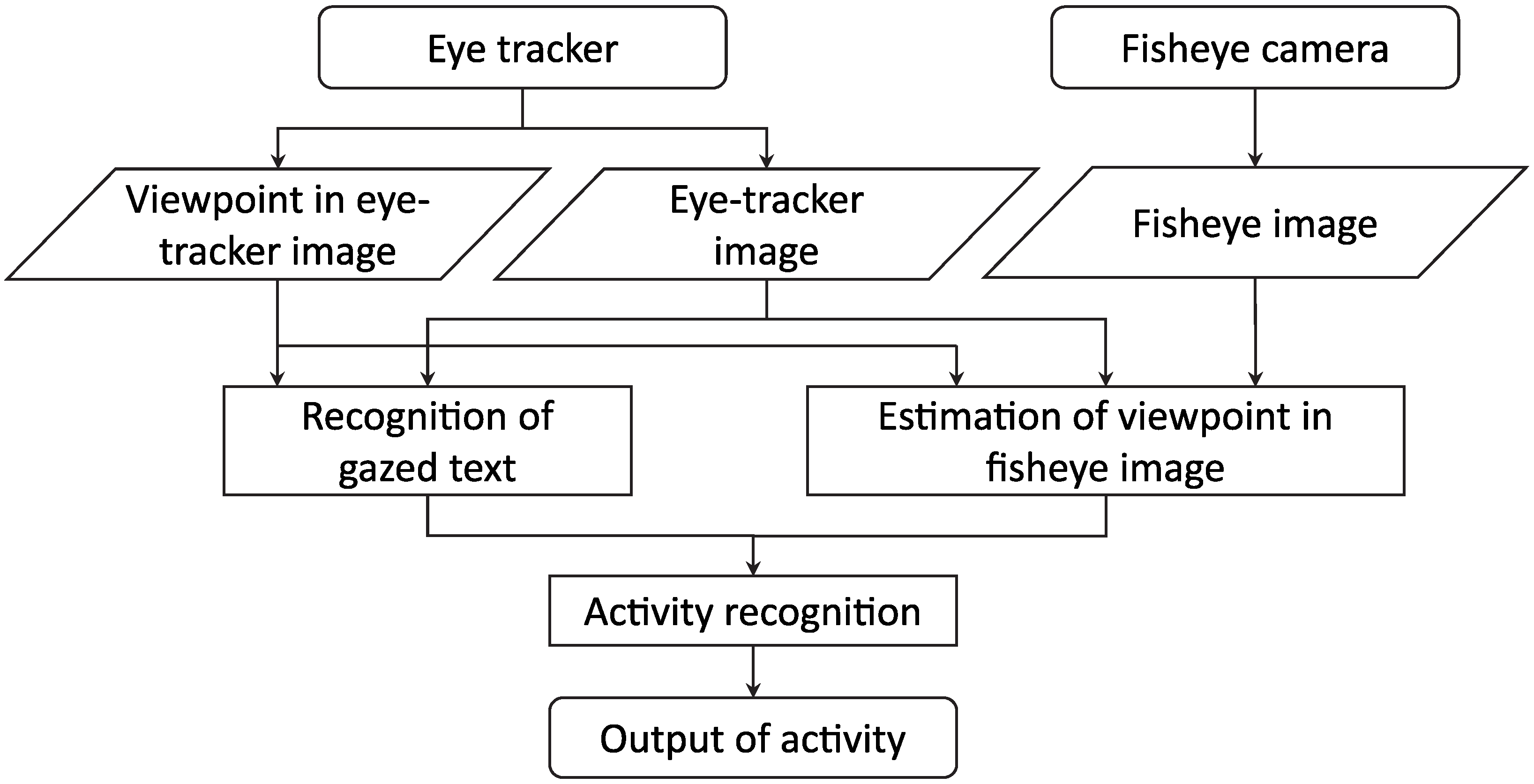
2.1. Proposed Method
2.1.1. Recognition of Gazed Text
2.1.2. Estimation of Viewpoint in the Fisheye Image
2.1.3. Activity Recognition
2.2. Experiment
2.2.1. Equipment
2.2.2. Experimental Environment
2.2.3. Training Data
- Looking at the route map to check the price,
- Looking at the route map to check the station name,
- Looking at the route map to look for guidance,
- Looking at the ticket vending machine to check the price,
- Looking at the ticket vending machine to check the station name,
- Looking at the ticket vending machine to look for guidance,
- Operating the ticket vending machine,
- Others.
3. Results and Discussion
3.1. Experimental Results
3.2. Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Polana, R.; Nelson, R. Recognizing activities. In Proceedings of the 12th International Conference on Pattern Recognition, Jerusalem, Israel, 9–13 October 1994; Volume 1, pp. 815–818. [Google Scholar]
- Yamashita, T.; Yamauchi, Y.; Fujiyoshi, H. A single framework for action recognition based on boosted randomized trees. IPSJ Trans. Comput. Vision Appl. 2011, 3, 160–171. [Google Scholar] [CrossRef]
- Chen, O.T.-C.; Tsai, C.-H.; Manh, H.H.; Lai, W.-C. Activity recognition using a panoramic camera for homecare. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance, Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Gárate, C.; Zaidenberg, S.; Badie, J.; Brémond, F. Group tracking and behavior recognition in long video surveillance sequences. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications, Lisbon, Portugal, 5–8 January 2014. [Google Scholar]
- Ouchi, K.; Doi, M. Smartphone-based monitoring system for activities of daily living for elderly people and their relatives etc. In Proceedings of the 2013 ACM Conference on Pervasive and Ubiquitous Computing Adjunct Publication, Zurich, Switzerland, 8–12 September 2013; pp. 103–106. [Google Scholar]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional neural networks for human activity recognition using mobile sensors. In Proceedings of the 2014 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar]
- Pham, C. MobiRAR: real-time human activity recognition using mobile devices. In Proceedings of the 2015 Seventh International Conference on Knowledge and Systems Engineering, Ho Chi Minh City, Vietnam, 8–10 October 2015; pp. 144–149. [Google Scholar]
- Xu, H.; Liu, J.; Hu, H.; Zhang, Y. Wearable sensor-based human activity recognition method with multi-features extracted from Hilbert-Huang transform. Sensors 2016, 16, 2048. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.-C.; Yen, C.-Y.; Chang, L.-H.; Hsieh, C.-Y.; Chan, C.-T. Wearable sensor-based activity recognition for housekeeping task. In Proceedings of the 2017 IEEE 14th International Conference on Wearable and Implantable Body Sensor Networks, Eindhoven, Netherlands, 9–12 May 2017; pp. 67–70. [Google Scholar]
- Rezaie, H.; Ghassemian, M. An adaptive algorithm to improve energy efficiency in wearable activity recognition systems. IEEE Sens. J. 2017, 17, 5315–5323. [Google Scholar] [CrossRef]
- Twomey, N.; Diethe, T.; Fafoutis, X.; Elsts, A.; McConville, R.; Flach, P.; Craddock, I. A comprehensive study of activity recognition using accelerometers. Informatics 2018, 5, 27. [Google Scholar] [CrossRef]
- Wang, Y.; Cang, C.; Yu, H. A review of sensor selection, sensor devices and sensor deployment for wearable sensor-based human activity recognition systems. In Proceedings of the 10th International Conference on Software, Knowledge, Information Management & Applications, Chengdu, China, 15–17 December 2016; pp. 250–257. [Google Scholar]
- Kanade, T.; Hebert, M. First-person vision. Proc. IEEE. 2012, 100, 2442–2453. [Google Scholar] [CrossRef]
- Yan, Y.; Ricci, E.; Liu, G.; Sebe, N. Egocentric daily activity recognition via multitask clustering. IEEE Trans. Image Process. 2015, 24, 2984–2995. [Google Scholar] [CrossRef] [PubMed]
- Abebe, G.; Cavallaro, A. A long short-term memory convolutional neural network for first-person vision activity recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1339–1346. [Google Scholar]
- Noor, S.; Uddin, V. Using context from inside-out vision for improved activity recognition. IET Comput. Vision 2018, 12, 276–287. [Google Scholar] [CrossRef]
- Nguyen, T.-H.-C.; Nebel, J.-C.; Florez-Revuelta, F. Recognition of activities of daily living with egocentric vision: A review. Sensors 2016, 16, 72. [Google Scholar] [CrossRef] [PubMed]
- Smith, R. An overview of the Tesseract OCR engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition, Parana, Brazil, 23–26 September 2007; pp. 629–633. [Google Scholar]
- Okazaki, N.; Tsujii, J. Simple and efficient algorithm for approximate dictionary matching. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; pp. 851–859. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vision Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Mori, T.; Tonomura, M.; Ohsumi, Y.; Goto, S.; Ikenaga, T. High quality image correction algorithm with cubic interpolation and its implementations of dedicated hardware engine for fish-eye lens. J. Inst. Image Electron. Eng. Jpn. 2007, 36, 680–687. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Devices | Target Activities |
|---|---|---|
| Polana [1] | Fixed camera | walking, running, swinging, skiing, exercising, and jumping |
| Yamashita [2] | Fixed camera | walking, picking, bending, boxing, clapping, waving, jogging, running, and walking |
| Chen [3] | Fixed camera | standing, walking, sitting, falling, and watching television |
| Ouchi [5] | Wearable sensor | washing dishes, ironing, vacuuming, brushing teeth, drying hair, shaving, flushing the toilet, and talking |
| Zeng [6] | Wearable sensor | jogging, walking, ascending stairs, descending stairs, sitting, and standing |
| Pham [7] | Wearable sensor | running, walking, sitting, standing, jumping, kicking, going-up stairs, going down-stairs, laying, and unknown activities |
| Xu [8] | Wearable sensor | lying, sitting, standing, walking, running, cycling, nordic walking, watching television, computer work, driving a car, ascending stairs, descending stairs, vacuuming, ironing, folding laundry, house cleaning, playing soccer, and rope jumping |
| Liu [9] | Wearable sensor | hanging clothes, folding clothes, wiping furniture, sweeping floor, mopping floor, vacuuming floor, scrubbing floor, digging, filling, moving items (on the floor), moving items (upstairs), and moving items (downstairs) |
| Rezaie [10] | Wearable sensor | standing, sitting, lying down, brushing, eating, walking, and running |
| Twomey [11] | Wearable sensor | walking, ascending stairs, descending stairs, sitting, standing, lying down, working at computer, walking and talking, standing and talking, sleeping, etc. |
| Yan [14] | Wearable camera | reading a book, watching a video, copying text from screen to screen, writing sentences on paper, and browsing the internet |
| Abebe [15] | Wearable camera | going upstairs, running, walking, sitting/standing, and static |
| Noor [16] | Wearable camera | reaching, sprinkling, spreading, opening, closing, cutting, etc. |
| Element | Meaning |
|---|---|
| x | x-coordinate of the viewpoint location in the fisheye image |
| y | y-coordinate of the viewpoint location in the fisheye image |
| n | number of characters in the gazed text |
| t | average of character codes in the gazed text |
| d | distance between the viewpoint and the gazed text |
| c | category of the gazed text |
| Category | Texts |
|---|---|
| Guidance | Touch the button, Tozai Line, Nanboku Line,... |
| Station name | Aobayama, Sendai, International Center,... |
| Price | 200, 250, 300,... |
| Subject | Number of Frames | Number of Correctly Recognized Frames | Accuracy |
|---|---|---|---|
| 1 | 903 | 668 | 74.0% |
| 2 | 620 | 403 | 65.0% |
| 3 | 750 | 558 | 78.4% |
| 4 | 717 | 462 | 64.4% |
| 5 | 441 | 344 | 78.0% |
| 6 | 1314 | 1141 | 86.9% |
| Total | 4745 | 3576 | 75.4% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chiba, S.; Miyazaki, T.; Sugaya, Y.; Omachi, S. Activity Recognition Using Gazed Text and Viewpoint Information for User Support Systems. J. Sens. Actuator Netw. 2018, 7, 31. https://doi.org/10.3390/jsan7030031
Chiba S, Miyazaki T, Sugaya Y, Omachi S. Activity Recognition Using Gazed Text and Viewpoint Information for User Support Systems. Journal of Sensor and Actuator Networks. 2018; 7(3):31. https://doi.org/10.3390/jsan7030031
Chicago/Turabian StyleChiba, Shun, Tomo Miyazaki, Yoshihiro Sugaya, and Shinichiro Omachi. 2018. "Activity Recognition Using Gazed Text and Viewpoint Information for User Support Systems" Journal of Sensor and Actuator Networks 7, no. 3: 31. https://doi.org/10.3390/jsan7030031
APA StyleChiba, S., Miyazaki, T., Sugaya, Y., & Omachi, S. (2018). Activity Recognition Using Gazed Text and Viewpoint Information for User Support Systems. Journal of Sensor and Actuator Networks, 7(3), 31. https://doi.org/10.3390/jsan7030031