1. Introduction
Implantable and Wearable Medical Devices (IMD & WMD) are currently the new trending technologies in personal healthcare systems. They enable efficient diagnostics and easy monitoring of the patient’s health status in real-time and provide more efficient and scalable healthcare by avoiding frequent visits to the healthcare provider. These devices such as cardiovascular medical devices, neurological implants and infusion function medical devices can help control a broad range of body dysfunctions, like diabetes, cardiac arrhythmia, and epilepsy.
Information security is a serious challenge to all of such devices nowadays [
1]. Medical devices’ security, particularly for IMDs, is of paramount importance because attacks can be fatal. They do not only steal the private medical data, but they can also affect data integrity and control. IMDs are evolving to provide patients with maximum medical efficiency and safety. The device’s security and the medical records’ privacy are still under development. In fact, IMDs’ architectures usually have limited resources, such as the energy supply, processing power, and storage space. These may require the need of surgeries to overcome some of the limitations. For instance, if we need to resort to surgery in order to change batteries, we have to choose long-life battery types to avoid frequent surgeries. All of these disadvantages render traditional security procedures arduous to implement. Balancing security and confidentiality with the efficiency of the different components is a substantial matter for IMD technologies to advance. For this matter, similar to other systems, IMDs have the following security pillars to protect the patient against attacks:
Authentication: Authentication [
2] is one of the most common ways to secure two communicating devices. It ensures that both ends communicate with an authentic and legitimate device, not an impersonator. Authentication in IMDs may be directed in two possible ways: through a
direct authentication architecture or through an
indirect authentication architecture. The indirect scheme introduces a proxy device used to perform authentication protocols, decreasing computation cost and communication overheads in the IMD devices. To identify the device that is requesting a communication, the IMD can use shared keys (temporary or permanent), auxiliary sensors like fingerprint scanners or other biometric signal collectors to identify the unit and to ascertain its authenticity.
Cryptography: Cryptography [
3,
4] relies on shared secret keys to cipher the messages within a given communication. This prevents the understanding of the communication by external eavesdropping devices. Also, cryptography secures any system from any hijacking attempts. The adversary who intercepts a message is not able to perform any significant changes like the modification of the serial number in the aim of a spoofing attack. Nevertheless, standard encrypted communications are still vulnerable to Man-In-The-Middle (MITM) or replay attacks.
Anomaly Detection: This technique [
5] relies on the observation and the analysis of the received value by the device over time to conclude a pattern. Accordingly, the commands received by the device are estimated to be valid or invalid. For example, in the case of infusion pumps [
6], the control device monitors and analyzes the infusion rate in the human body over seven to ten days to learn the time and a dosage pattern. This learning approach helps the device to recognize any malicious abnormal command for injection. Therefore, the patient is secured from receiving lethal injections through the IMD.
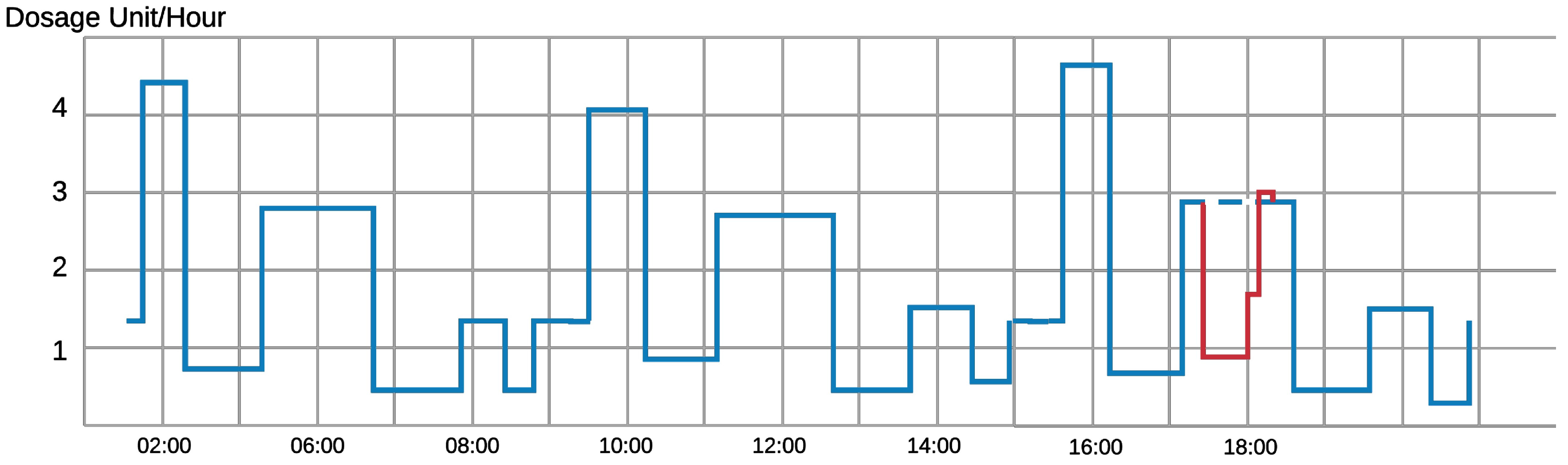
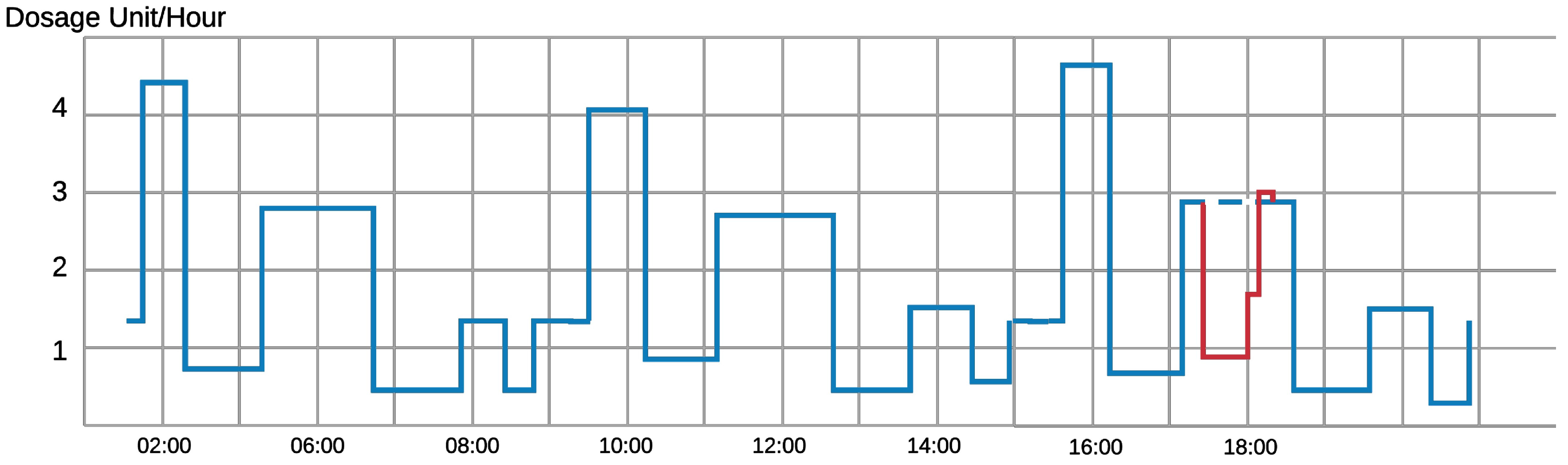
Figure 1 shows an example of a normal injection rate of an infusion device. In the first sixteen hours, we can pinpoint an injection pattern over an eight-hour period. An adversary hijacks the device and prohibits the device from injection around 6 pm (line in red). The device can detect that this prohibition is quite different from what should be injected from the device (dotted blue line) and the anomaly detection algorithm will likely disregard this command.
Jamming: Jamming attacks can be used to block any incoming packets to the IMD and block its regular work [
7]. Moreover, this technique can be used to prevent other types of attacks on the device, mainly resource depletion and denial of service attacks. Attackers can blast the device with incoming messages, that can lead to a drastic drop in the battery level and overflows of memory and storage. In such scenarios, jamming techniques can be launched from the device itself or from an annexed Wearable External Device. If the device senses the existence of these messages, jamming techniques prevent the device from receiving and treating these packets.
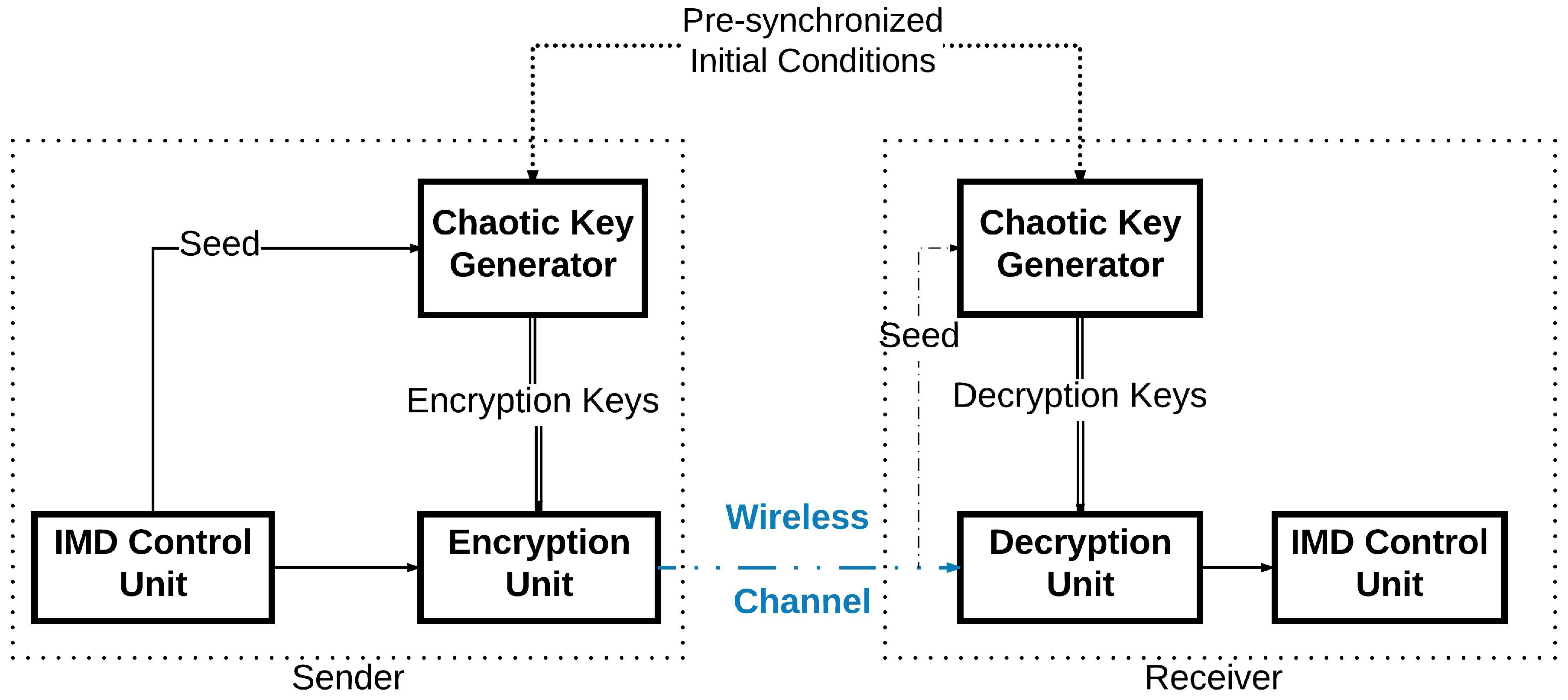
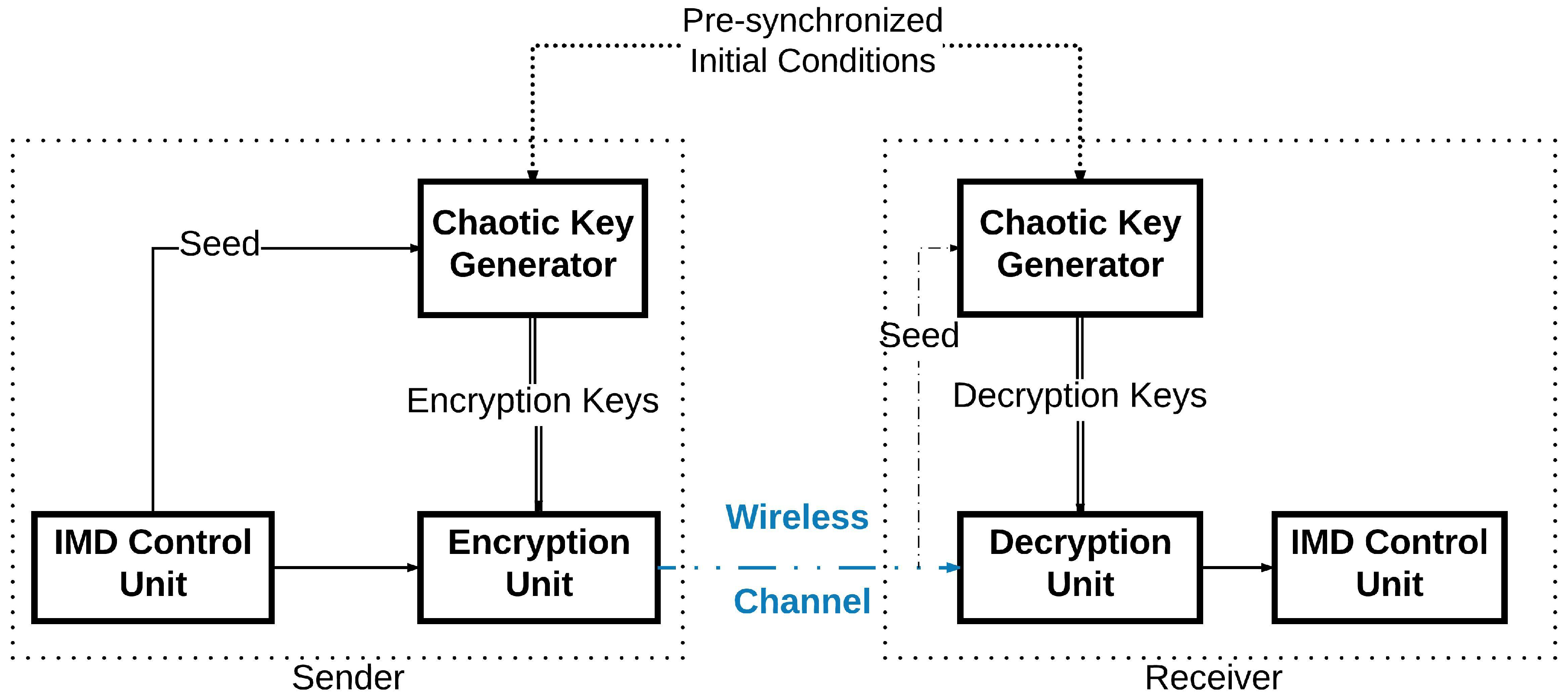
In this work, we intend to protect the IMD wireless communications through developing an efficient encryption scheme. We will design a novel technique to generate pseudo-random keys to be used as cryptographic symmetric keys similar to the work in [
8]. This key will be employed to cipher the exchanged packets between the devices used by patients and their doctors. This work does not aim specifically at a specific IMD but tackles any implantable systems that use wireless communications between its devices, e.g., an implanted pacemaker and its external monitoring device [
9]. In addition, we also present a new encryption system to protect the wireless communication between the IMDs. In the sender’s device, a key generator will generate an encryption key using a Pseudo-Random Number Generator (PRNG) based on a chaotic system [
10]. This key will be applied to cipher the message to be sent by the device. In order for the receiving device to be able to decipher the sent message, it has to generate internally the same encryption key used in the first place. The sender will not communicate the key directly on the wireless channel. The sender needs only to communicate publicly the seed used for its encryption key generation as shown in
Figure 2. Even though the seed is thought to be enough to generate the same key, the case of the chaotic system differs: the two devices use the same chaotic generator to deliver the encryption key. However, this pseudo-random generator has two inputs instead of one: the
seed and the
initial conditions. The initial conditions are already shared between the two devices through a given physical synchronization method. Therefore, when the receiver receives this seed, its internal key generator will be able to generate the right key to be used for deciphering the message it has received. Thus, the wireless communication can take place securely.
Nien et al. [
11] explained how it is possible to realize a chaotic system to map a random sequence of numbers. They also detailed how this sequence can encrypt colored images using an XOR operation with the matrix values defining the image. This encryption was applied to digital color images in the context of internet communications, and achieved a high level of security. Bing et al. [
12] also showed how to achieve a high performance data encryption using chaotic systems for image ciphering. The chaotic carrier signal they achieved has a strong randomness, a broadband spectrum and was likely unpredictable. Octavio et al. [
13] presented in their work a very large scale integration (VLSI) implementation of a precise case of the chaotic encryption schemes. They described a system employing a Lorenz oscillator. This scheme is known for its complexity in hardware implementation, but they overcome it by developing a new Generalized Lorenz System suitable for their case. For the case of Wang et al. [
14], they realized an image encryptor based on the high-dimension Lorenz chaotic system and a perceptron model within a neural network, and proved through experimental work the high security of this algorithm and also its strong resistance to the known attack vectors. Guan et al. [
15] also introduced a similar encryption system, but they added a position shuffler and a pixel value changer in the grey-mode of an image to strengthen the security of their method. In addition, Liu et al. [
16] treated the case of image coloring encryption, where they introduced a bit-level permutation and high-dimension chaotic map to encrypt colored images. They showed afterward through experimental results and security analysis that the scheme is very effective regarding the security of the encryption. Wei et al. [
17] introduced an encryption system that has the same goal as the previous one, but uses DNA sequences for the encryption in addition to the chaotic system. Relying on the logic in the DNA sequence, they established a scheme to encode the different color layers of the image in the process. The chaotic map was mainly used to scramble the locations of the different elements. Subsequently, chaotic systems play a major role in enhancing the cryptography field.
In our previous work [
18], we developed a new way to generate secure symmetric encryption keys for the IMDs in order to cipher the wireless communication of IMDs. This scheme relies on Henon Map to generate the Pseudo-Random keys, relying on synchronized initial conditions and the cycle seed. As an extension of that work, we designed in this work the full encryption scheme for IMDs and analyzed its performances. Therefore, the main contributions in this paper can be summarized as follows:
Analysis of the new symmetric key generation scheme for wireless cryptography based on PRNG derived from a low-dimensional chaotic system.
Design of an efficient light-weight block cipher encryption scheme that uses fewer rounds than conventional encryption schemes with short-length keys.
Investigation of the encryption scheme within an on-body to off-body communication channel.
3. Key Generation
Our proposed key generation scheme will only depend on the
seed of the generator. This seed, which we will refer to as
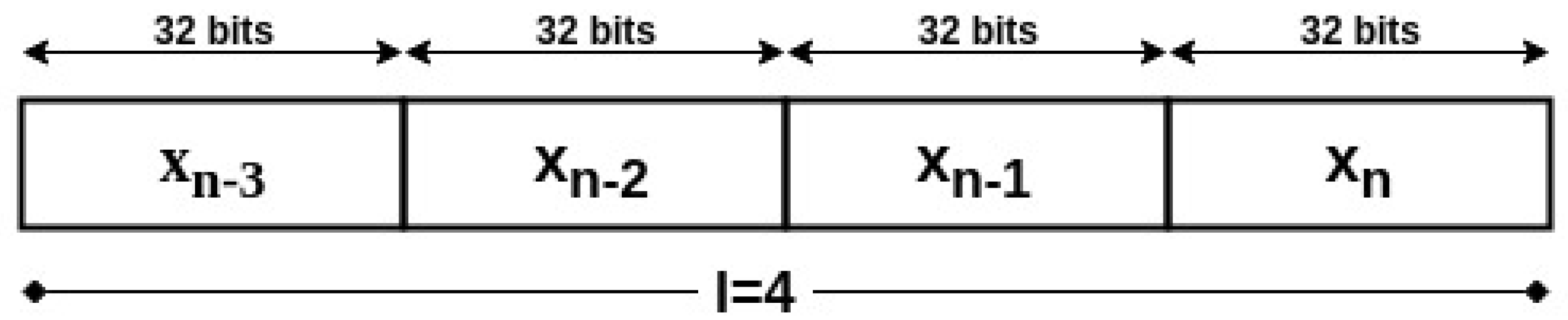
, represents the end of the iterations cycle of the Henon system. For security measures, the patient’s medical device will synchronize the initial conditions of the Henon equations using wired links with the trusted device. In addition, they can be pre-implemented in the system’s devices before use. Therefore, the attacker will not have the second needed input to generate the desired key, even if he/she succeeded to eavesdrop the seed. The generation of the key on the device will be simple, however, on the attacker’s device, it is going to be a complicated process. The main device will generate the seed on its side, then it will communicate it to the second end of the system. Afterwards, the encryption key will be generated independently on both sides from the communicated
to be as shown in
Figure 4. In order to reduce the computation cost of the algorithm, the data values will not be represented on the same number of bits as the key length, but on a fixed point representation of 2Q30 or 2Q14, i.e., the data has 2 bits integer and 30 bits fraction, or 2 bits integer and 14 bits fraction, respectively. This utilization of low precision among the variables of the Henon system will avoid the extra use of memory and computational resources. Hence the low resources of the device would not become a problem for the algorithm execution. The encryption key with length
m will then be the concatenation of the last binary
l values generated by the Henon equation, such that
or
.
For statistical reasons and to ensure a better security and randomness in the generated keys, the second key
Y will be the result of the XOR operation of the raw keys
X, and
Y generated from the equations as shown in
Figure 5.
The seed (or
) will be generated as a function of the system clock. Another way which is much more secure but more complex, is to use the exclusive characteristics of the wireless channel through the physical layer security to generate a common random seed based on the channel gain or phase [
26,
27,
28,
29]. Also, the manufacturer will define a non-short time lapse after which the
(seed) value will expire. When it terminates, a new request with a new value will update the Henon system’s seed of the devices. This contributes to the improvement of the system’s security while lowering the computational costs.
4. Cryptographic Unit System
Common symmetric key encryption standards like Advanced Encryption Standard [
30] use long rounds of substitution-permutation network [
31] for ciphered messages, along with long keys to enhance their security. For this reason, we design in this work a simple symmetric-key encryption scheme that is not time and memory intensive.
4.1. Diffusion and Confusion Blocks
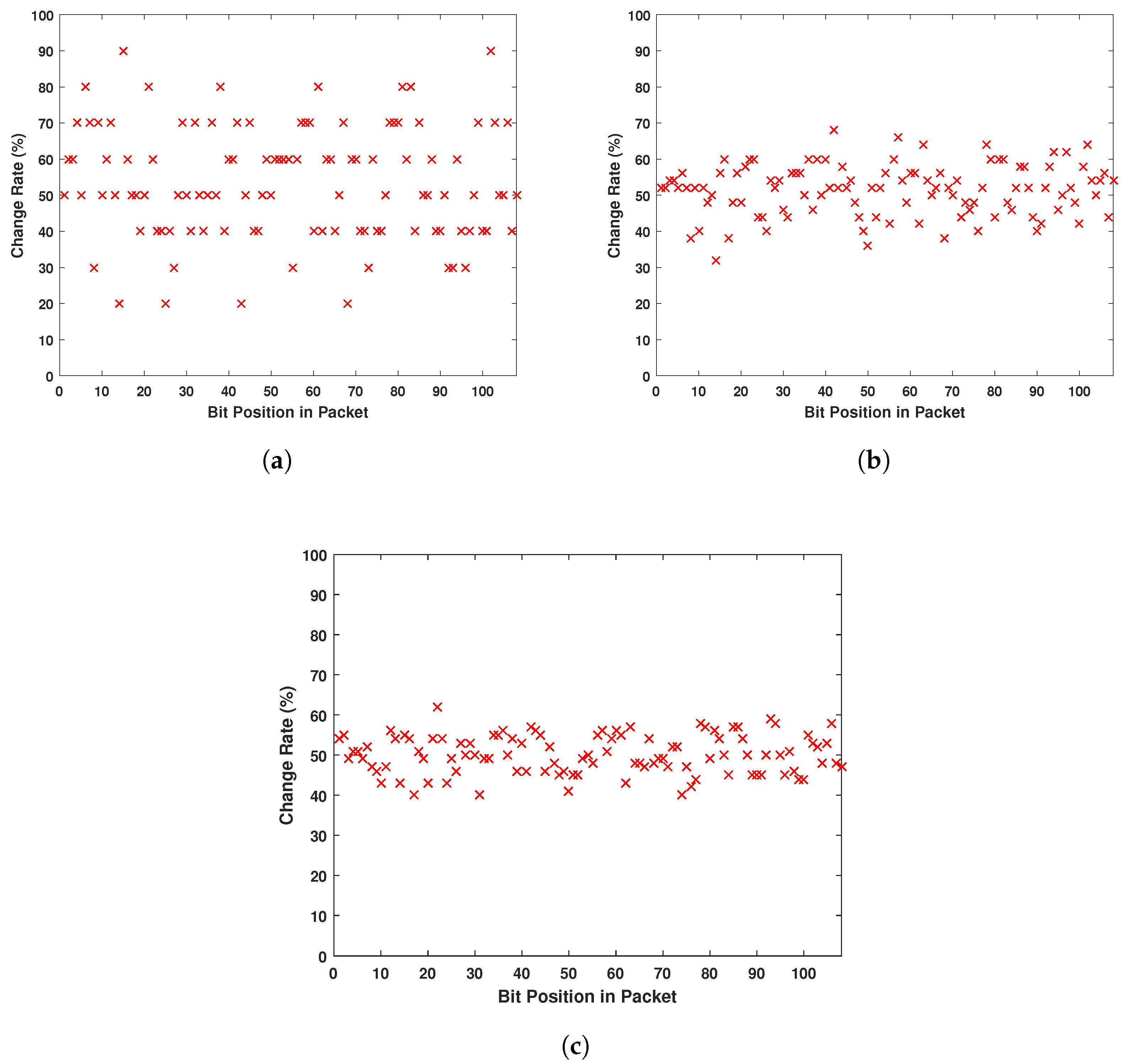
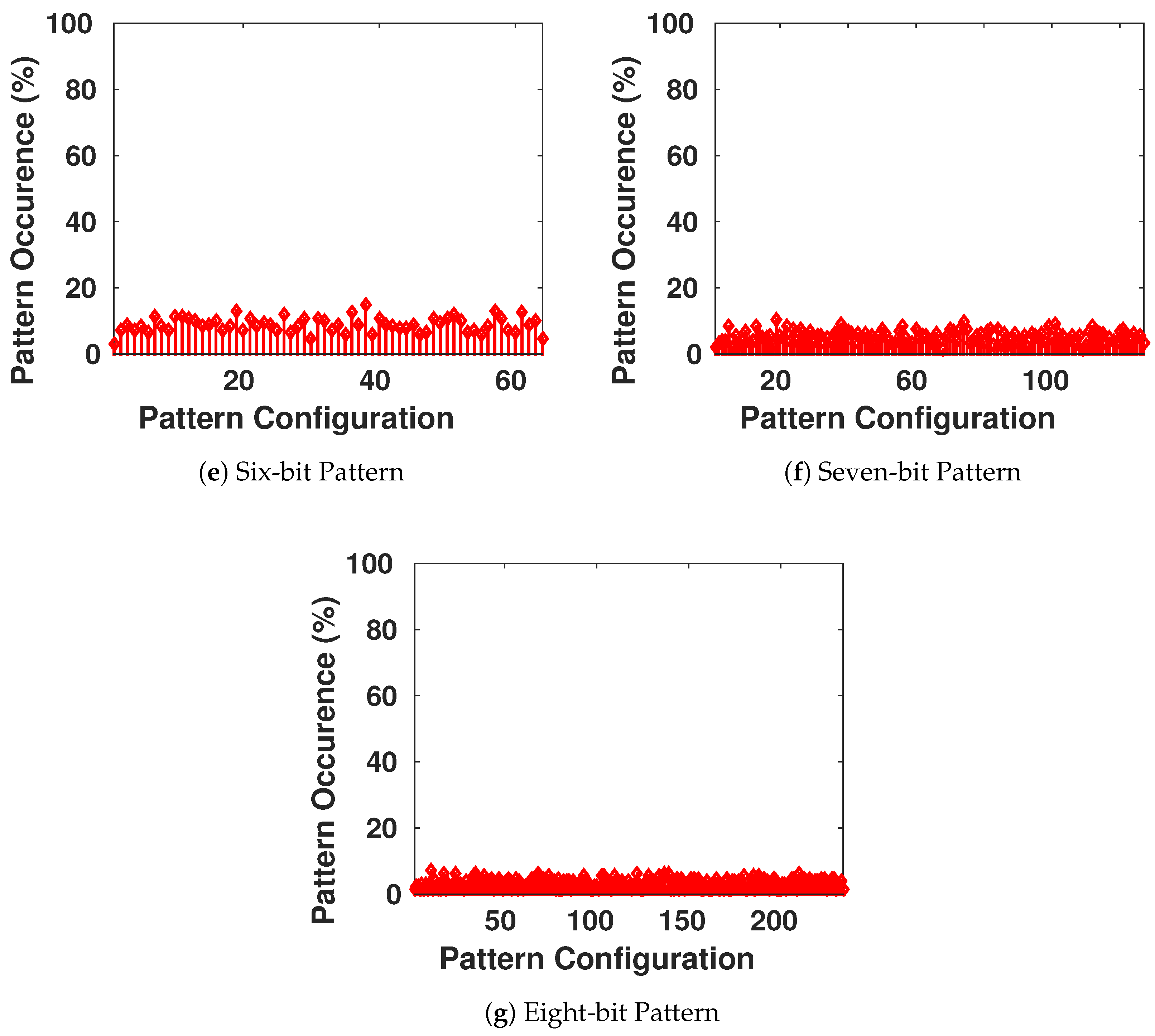
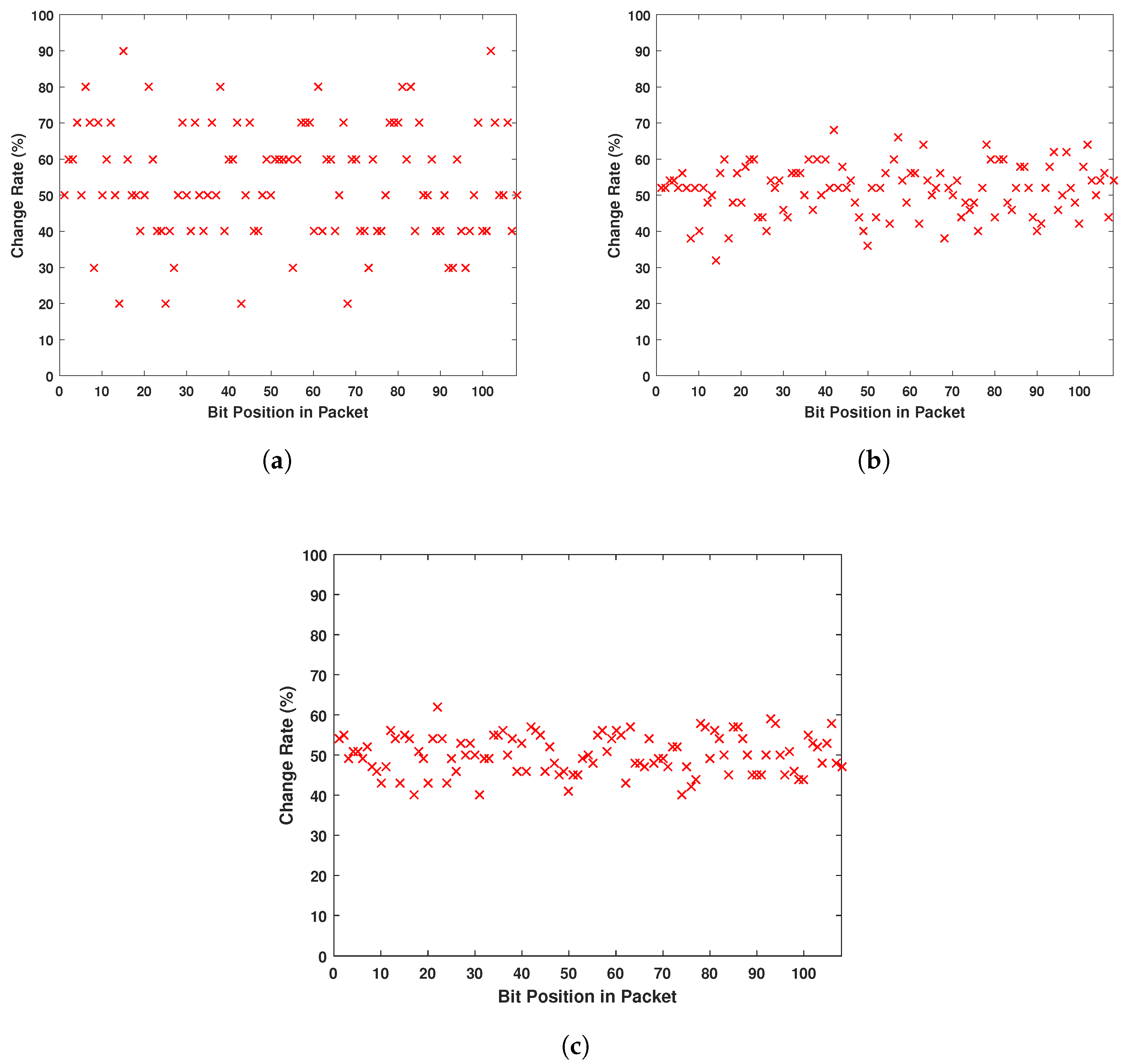
One of the main goals of encryption systems is that the output is not humanly readable. As in any electronic device, packets communicated wirelessly are a set of 1’s and 0’s. So we aim through this encryption system to prevent any eavesdropper on the communication channel from detecting patterns in different packets allowing them to understand the different parts of the message. For example, if an eavesdropper intercepts different packets and reads them [
32], conventionally he/she will know that any message will start with similar headers allocated in the first four or maybe eight bits. Moreover, he/she can notice that packets sent from the same device all have the same set of exactly sixteen bits in the middle. The eavesdropper can conclude then that this is the ID number of the device. On the other hand, a simple XOR operation or a simple bit permutation does not prevent this problem. This bit flipping just makes the analysis harder, as the eavesdropper can deduct from a simple change of a set of bits the original bit location. Once deciphered, the attacker is able to modify the packets and reuse them for his/her own purposes. For this reason, our encryption system focuses on two main properties of secure ciphers [
33]:
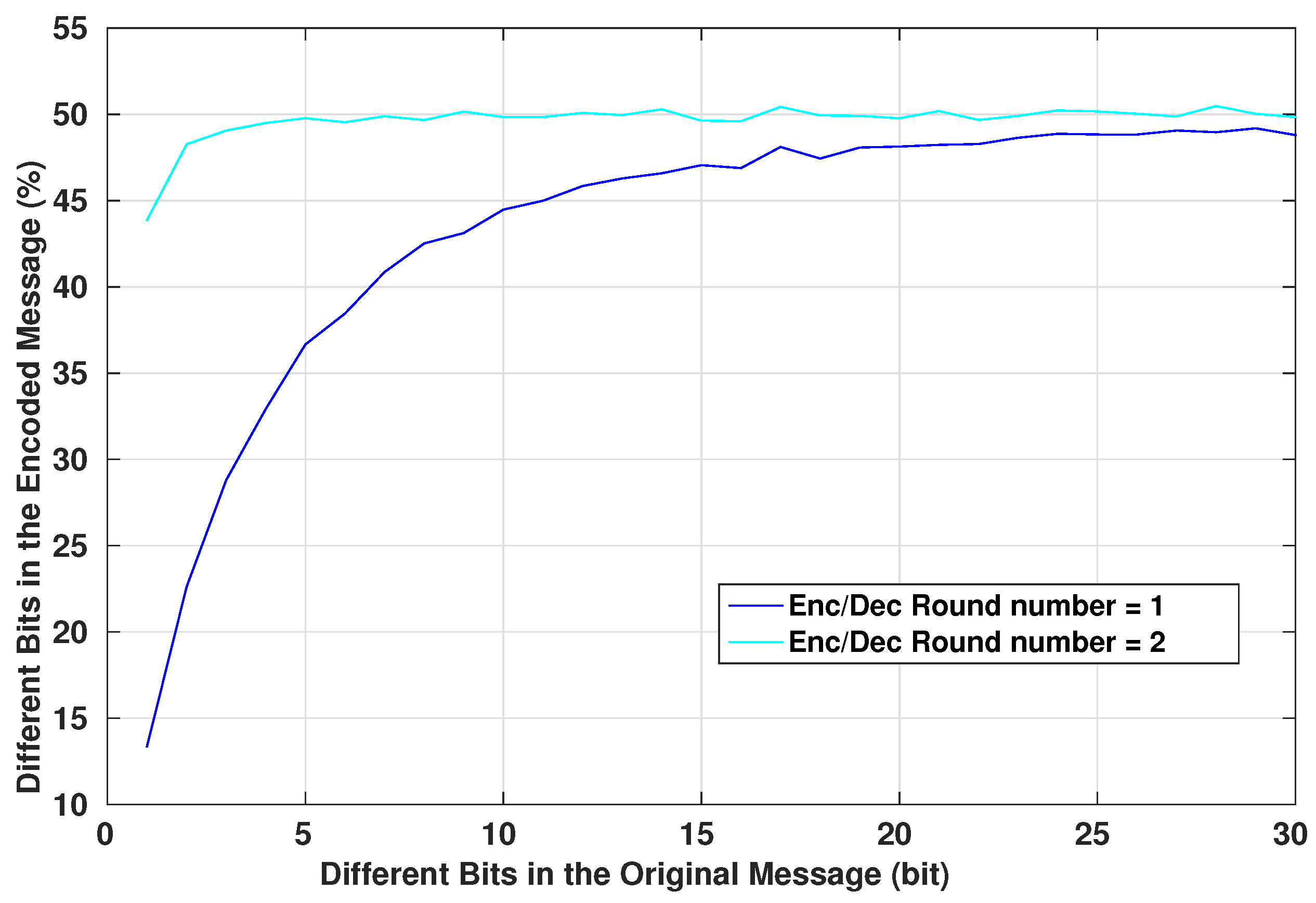
Confusion: which is the property of drastically modifying data from the input to the output. In other words, each bit of the ciphertext should depend on several parts of the system.
Diffusion: which is the property responsible for changing many different bits of the output when a single bit of the input is modified.
The combination of these two properties decreases the chance of statistical attacks and analysis to break the cipher.
4.2. Cryptographic Unit
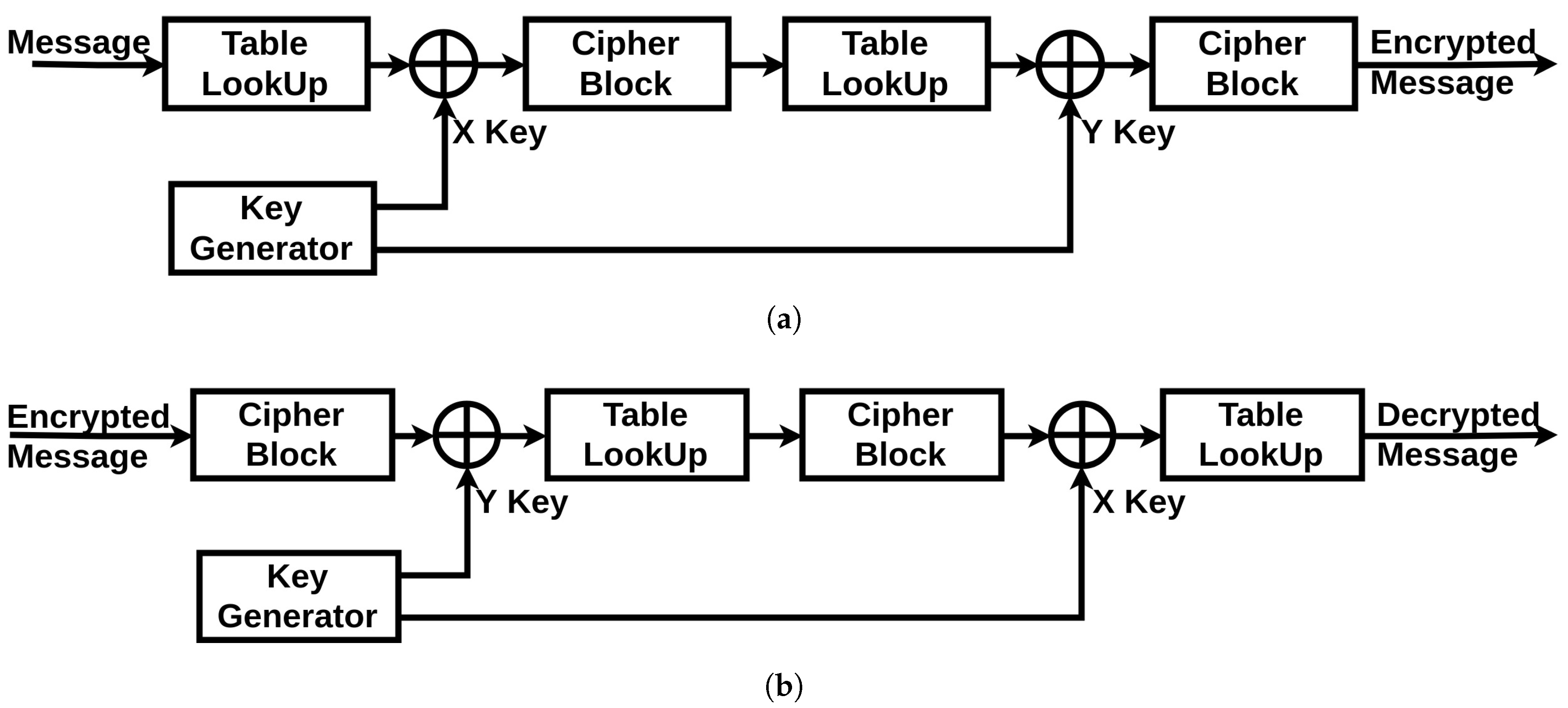
The cryptographic unit is composed of three parts: an XOR operator (a simple operator to hide the communication from simple eavesdropping), a Table LookUp unit and a Cipher block unit (described in
Section 4.3.1 and
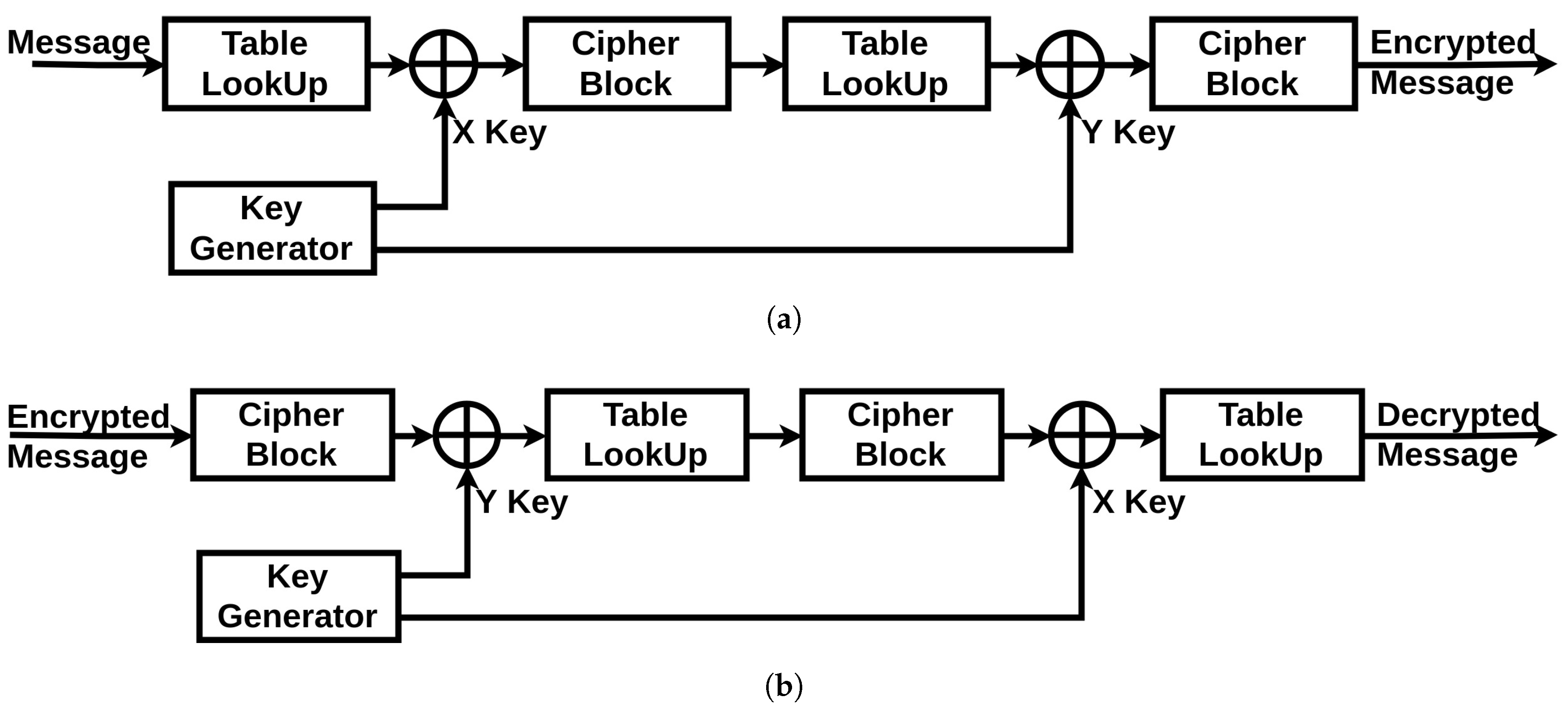
Section 4.3.2). Additionally, it has two inputs incoming from the chaotic generator: the X Key and the Y key. The full scheme of both of the encryption and decryption systems is shown in
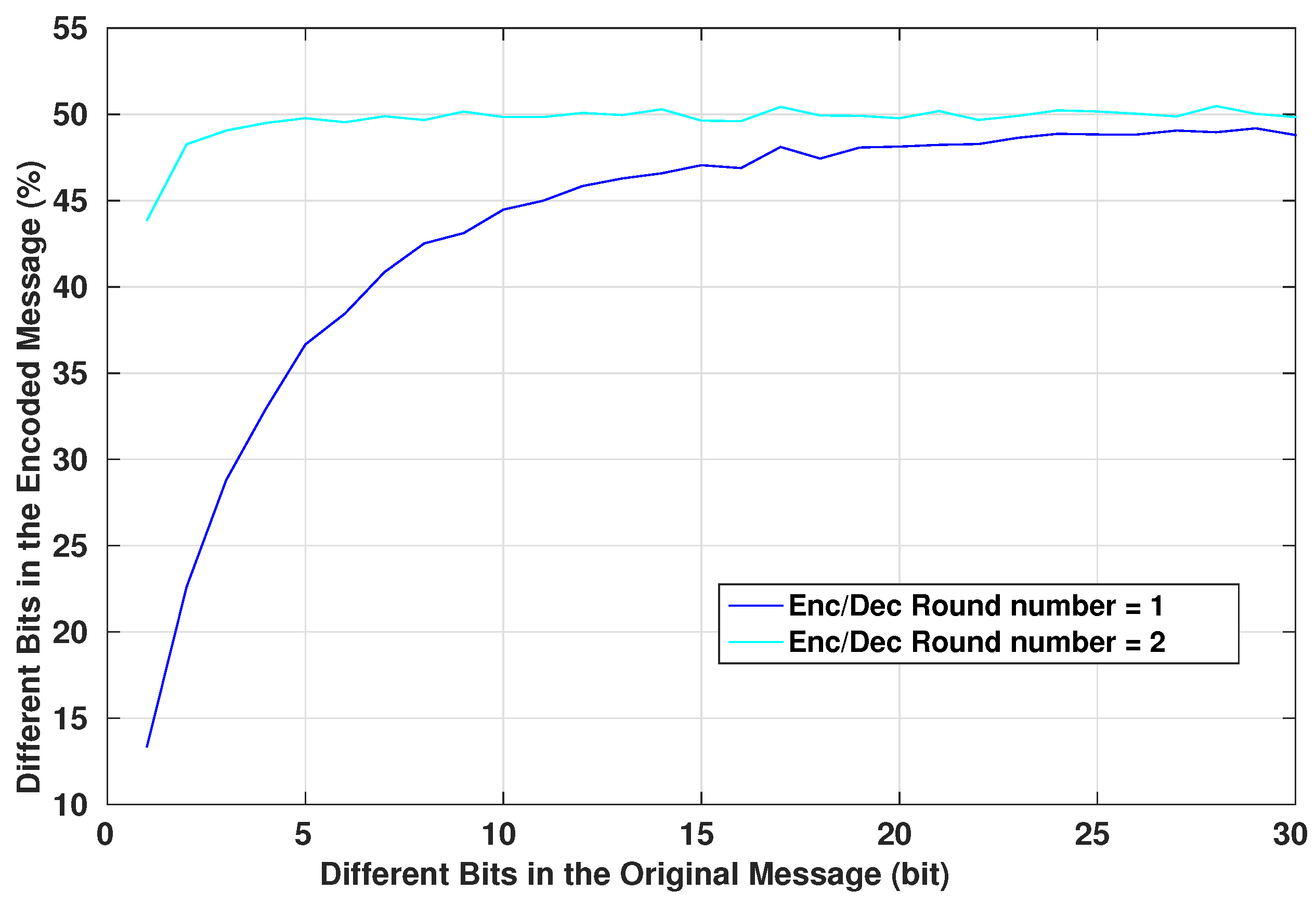
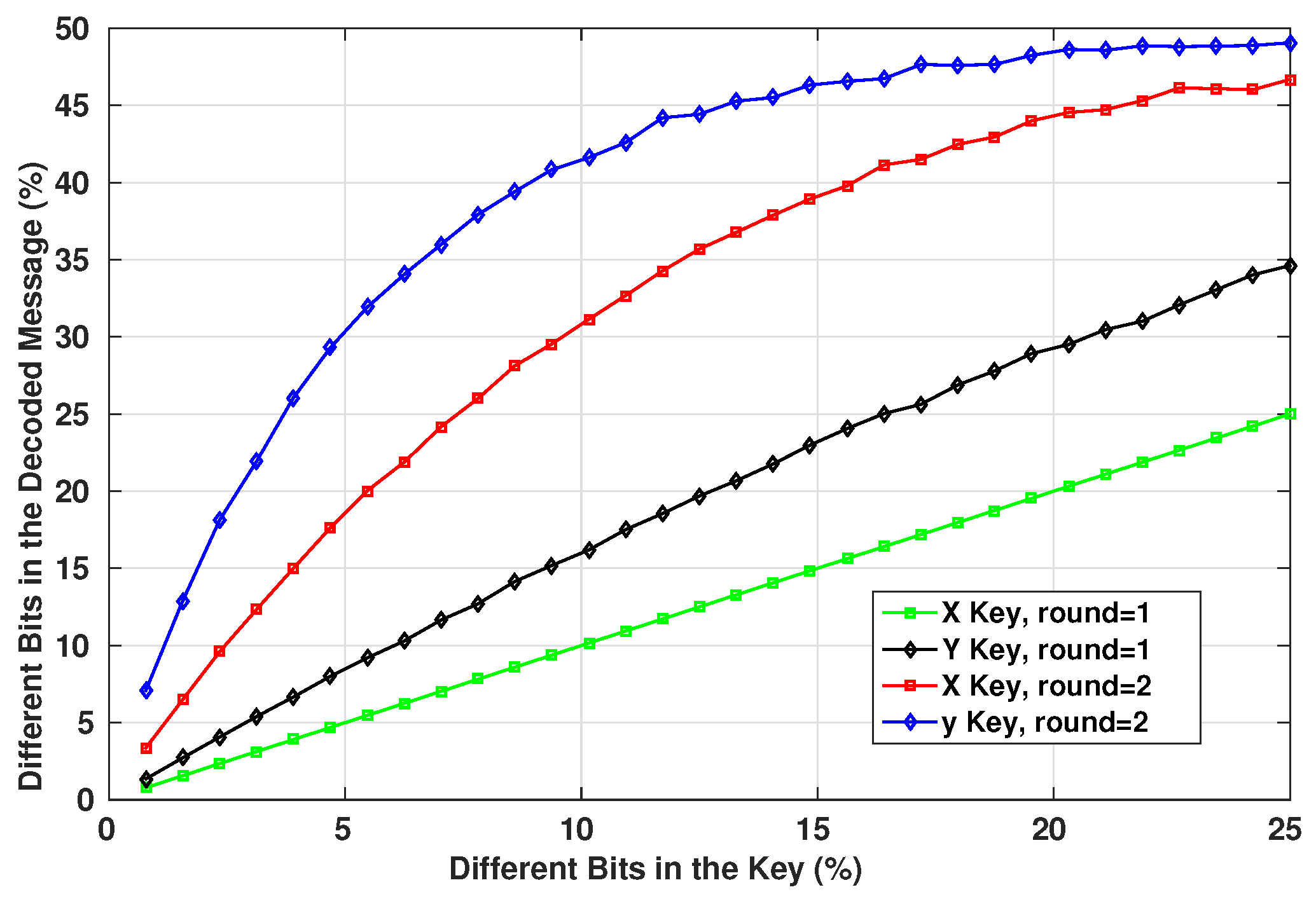
Figure 6. The original message generated by the device starts by passing through the Table LookUp unit that shuffles the bits. Then, the result is operated with an XOR operation with the X Key. Next, the signal passes through the Cipher block unit. The resulted message re-enter again through the same units in the same order, only this time the XOR operation is achieved with the Y Key. Finally, the encrypted message is generated. The two times reinstantiation of the blocks is the minimal scheme to guarantee a robust cryptographic result. For medical systems with robust computational resources, a loop can be introduced into the system to increase the complexity of the encrypted message.
For the decryption unit, the received encrypted message will get through the same units in a reverse order: the Cipher block is now used in its decryption mode, the Table LookUp unit will reorder the bits in their original positions according to the same function it has in memory (which is synchronized with the order stored in the sending device), and for the XOR operations with the encryption keys, we can get the original message by reapplying the same encryption key as a second operator. This is where the necessity of having the same encryption key on both sides is critical. If there is a looping function in the original encryption unit, the decryption unit should be synchronized with the same number of loops in its algorithm. Therefore, we can regain the original message sent by the first device.
4.3. Featured Blocks
To ensure the properties discussed in the previous paragraph, our system includes the following blocks:
4.3.1. Table LookUp
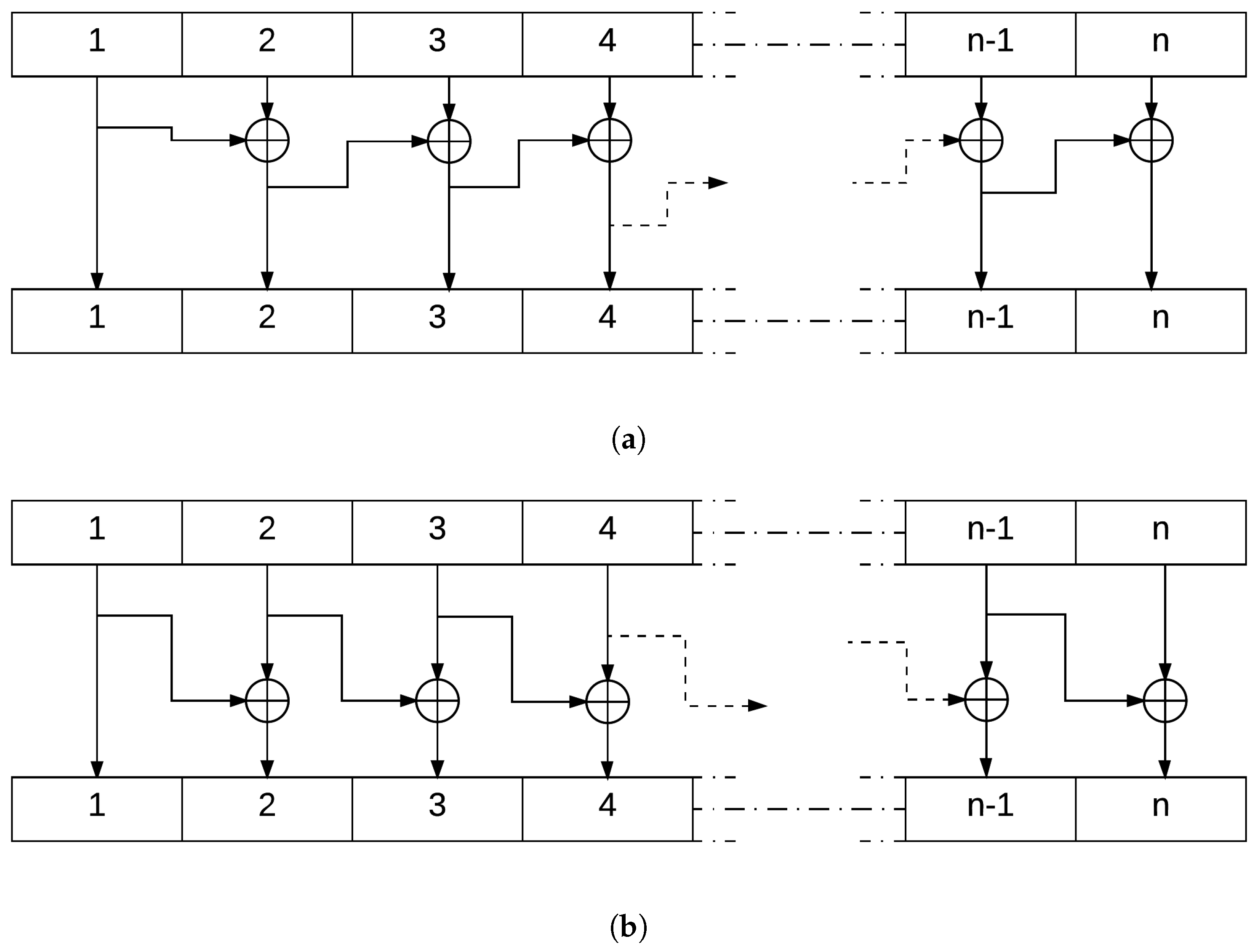
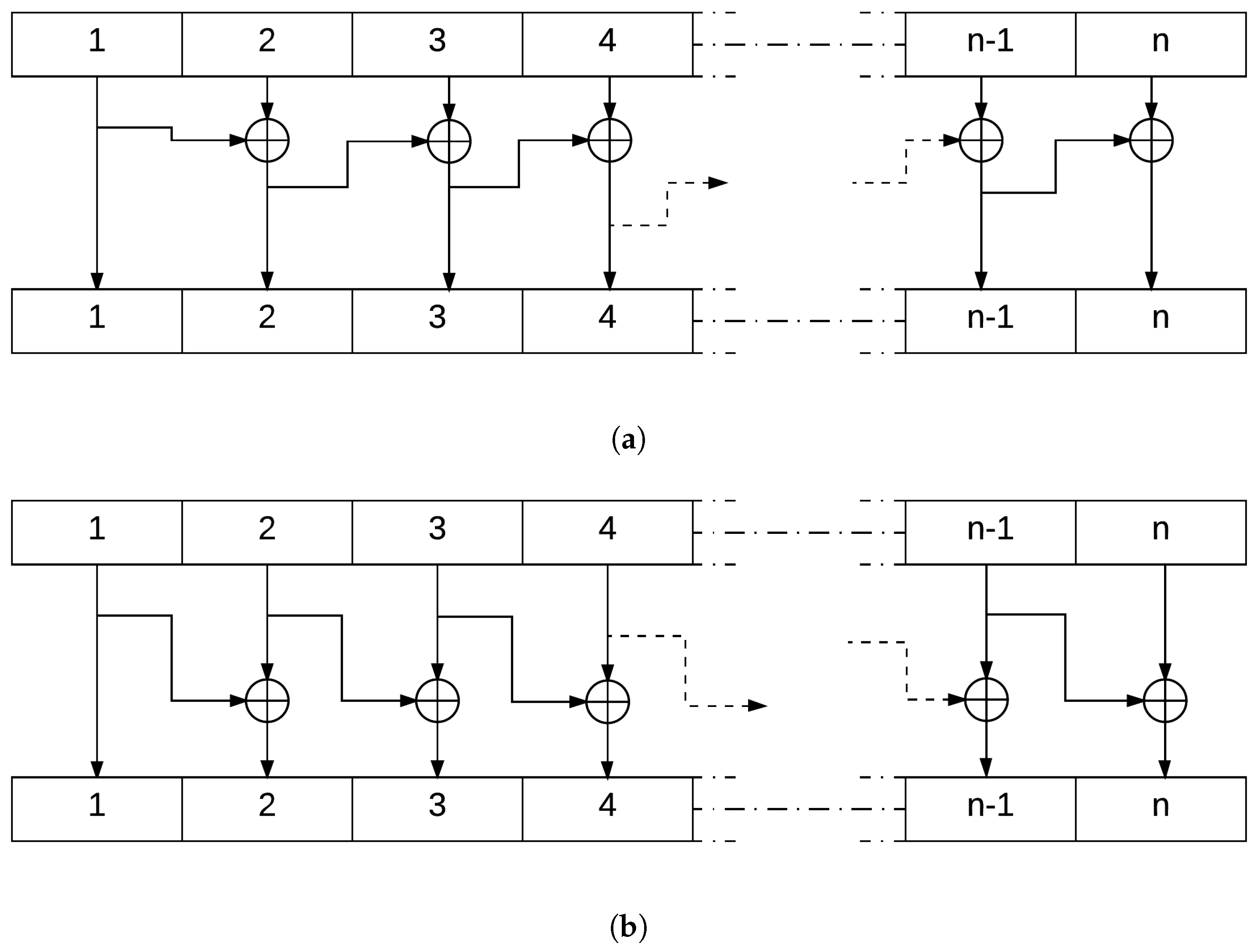
The objective of this block in the encryption system is to shuffle the different bits in the packet with the single knowledge of the device and the ones synchronized with it. This shuffle will transfer according to a reversible process
F each
i-th bit to the index
j such that
This shuffle operation will prohibit an eavesdropper from pinpointing the different original bits of the packet to decipher the role of each set of bits in the packets. For example, if an adversary intercepts a packet wirelessly and wants to resend it to the device after changing the ID number within the packet, he/she is unable to know which set of bits in the packet represents the ID tag. This Table LookUp process will enhance the confusion and diffusion characteristics of the full encryption system.
4.3.2. Cipher Block
This block of the encryption system uses the XOR function to generate an output message block where each bit depends on more than one bit from the input. This function is simple to implement and is not of high complexity. Its property where
is the key to decrypt the ciphered text after going through this block.
Figure 7 explains in detail this operation.
5. Communication Protocol
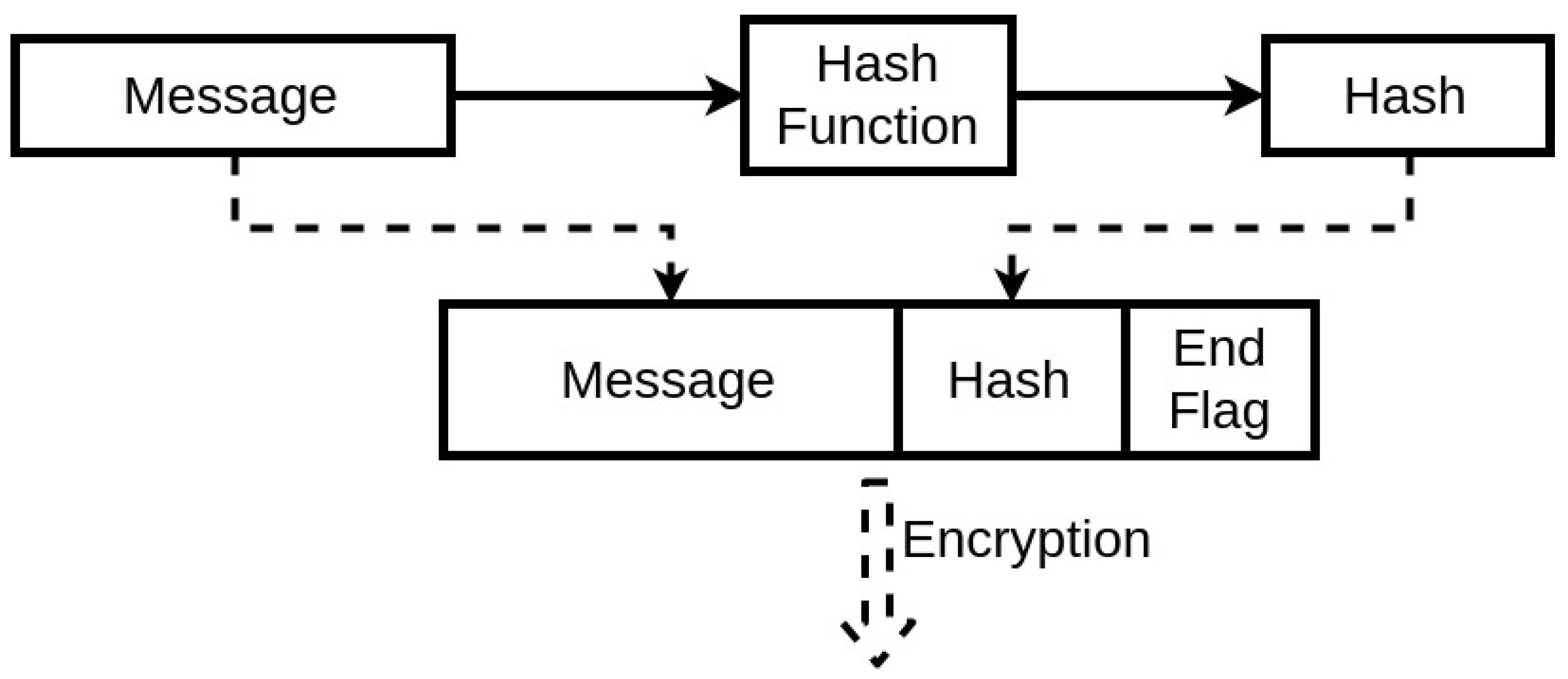
The first fundamental step for two devices to communicate securely using wireless communication with this protocol is to have synchronized initial conditions for the chaotic equations. If possible, the best approach to execute this is to synchronize it through a physical connection, as it is the most secure communication method. An alternative is to have these variables already be defined during the manufacturing process. Also, this synchronization applies to the case of the Table LookUp of the encryption unit. The device then starts with a communication request. This request identifies the sender and asks to receive the seed to start the encrypted communication. There is no threat in this step, as even if through spoofing, a third party receiving the seed from the asked device would not be able to establish a secure communication due to the lack of the initial conditions of the chaotic system. Afterwards, the second device generates a seed with its internal algorithm and sends it to the other end. When both devices have the shared seed, they can both use their implemented chaotic system to generate the same pseudo-random key. Therefore, a secure communication can be established. This process will protect the IMDs as it will ensure an encrypted communication, at the same time, the threat of achieving the encryption key by an external third-party is diminished. The devices have individual systems to generate this key, while the process itself has a low cost in the memory and computation process. This prevents the devices from sharing the key wirelessly and insecurely, and also can be programmed to change the encryption key at any needed time. The exchanged messages will include in their segments a Hash [
34] segment (
Figure 8) that can be simply generated using, for instance, a cyclic redundancy check algorithm [
35].
This Hash ensures the integrity of the exchanged message, thus guaranteeing that the message is not modified and the encryption key used is the same one on both ends. The seed is designed to expire. Therefore, there will be a periodic update of the seed. This expiration period will depend mainly on the system, to be a trade-off between performance and security. When the seed expires, the device should request again from the system a seed to be able to maintain the communication. This constant change is resource-friendly regarding the IMD capacities. Also, it ensures that an external party cannot uncover it for two main reasons. First, only one input is being communicated publicly. Second, avoiding the use of the same encryption key will prevent an attacker from analyzing the wireless communication statistically and concluding the possibilities of the key to exploit them. This is where the use of a low dimensional chaotic system is beneficial.
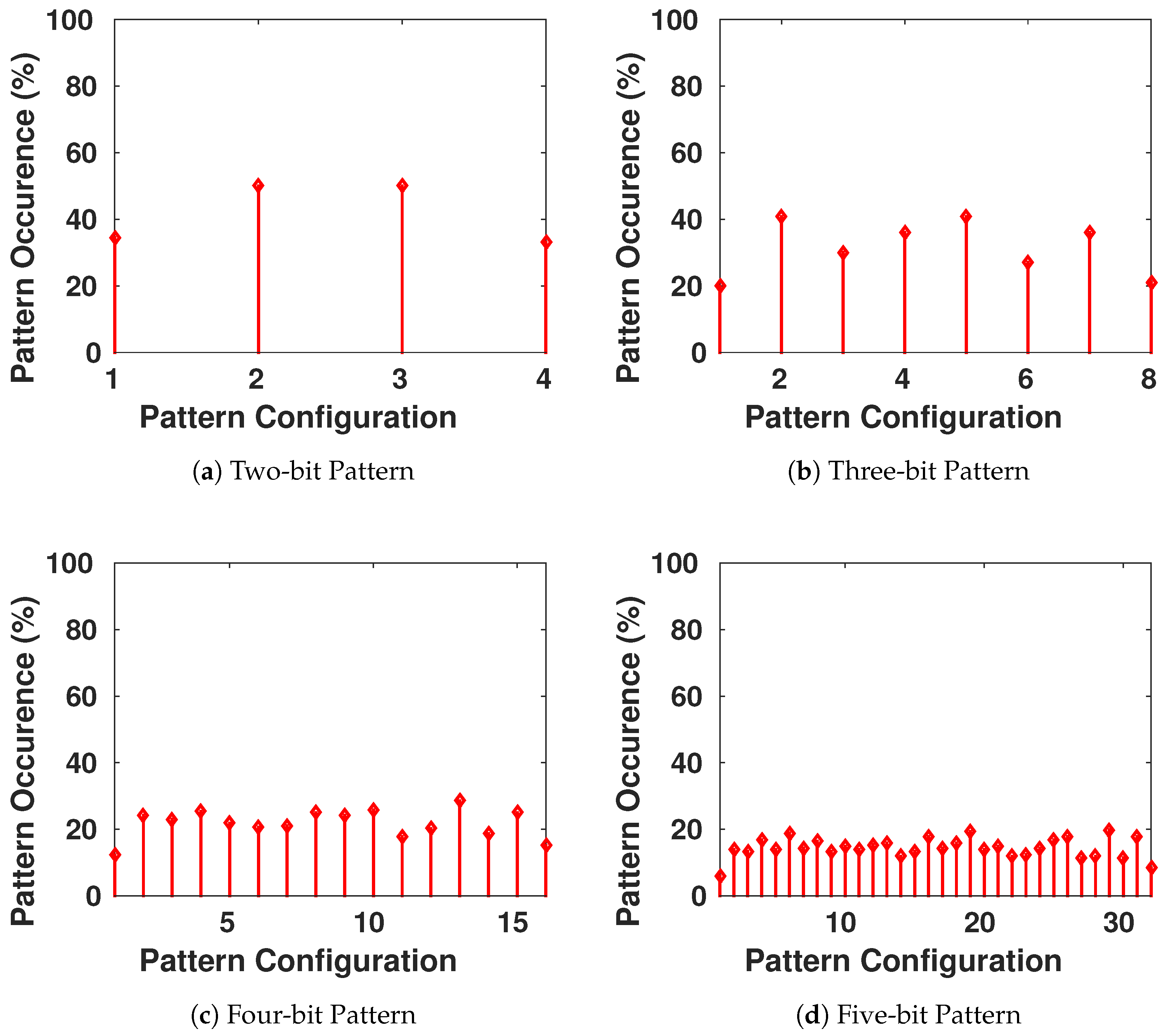
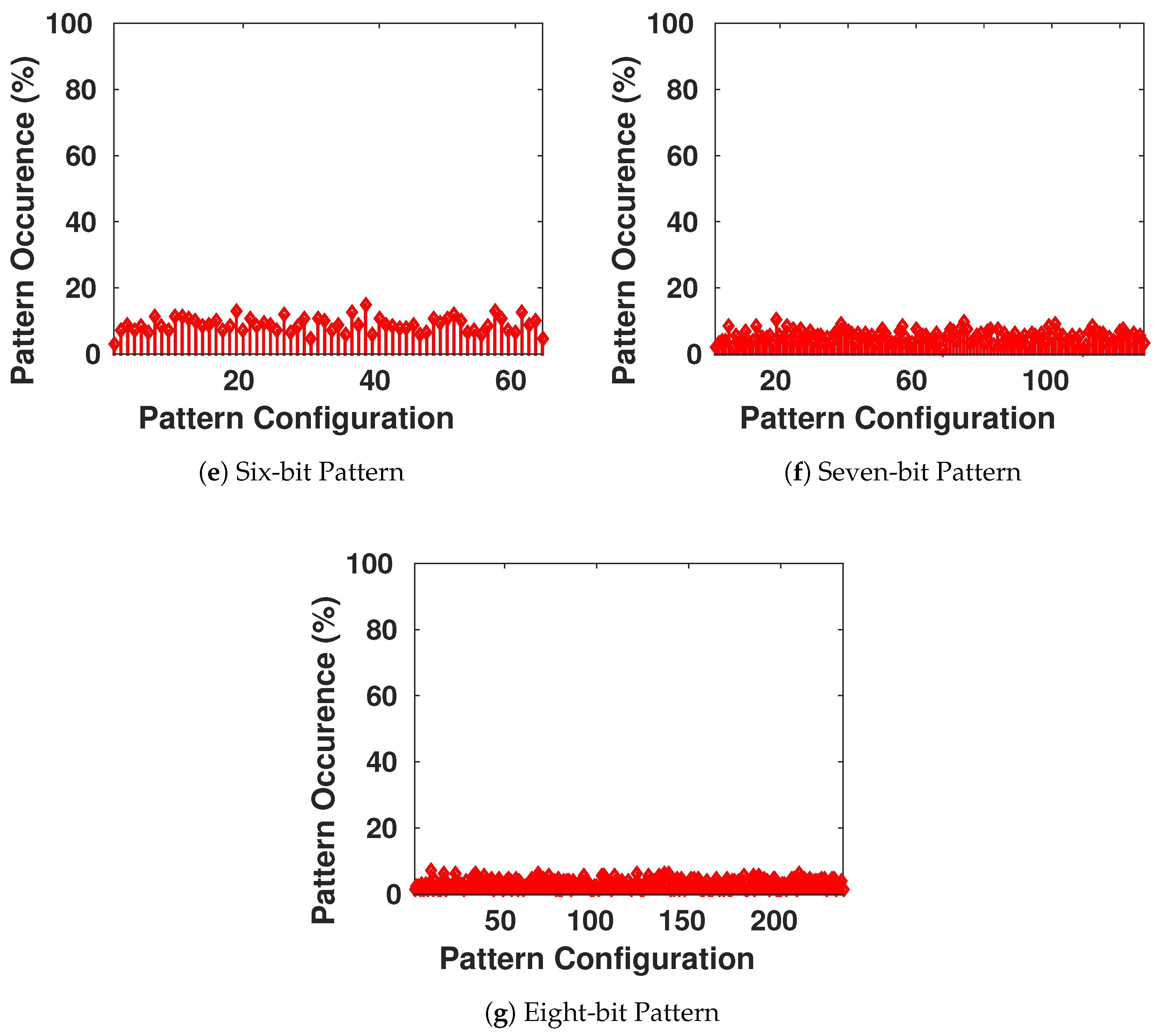
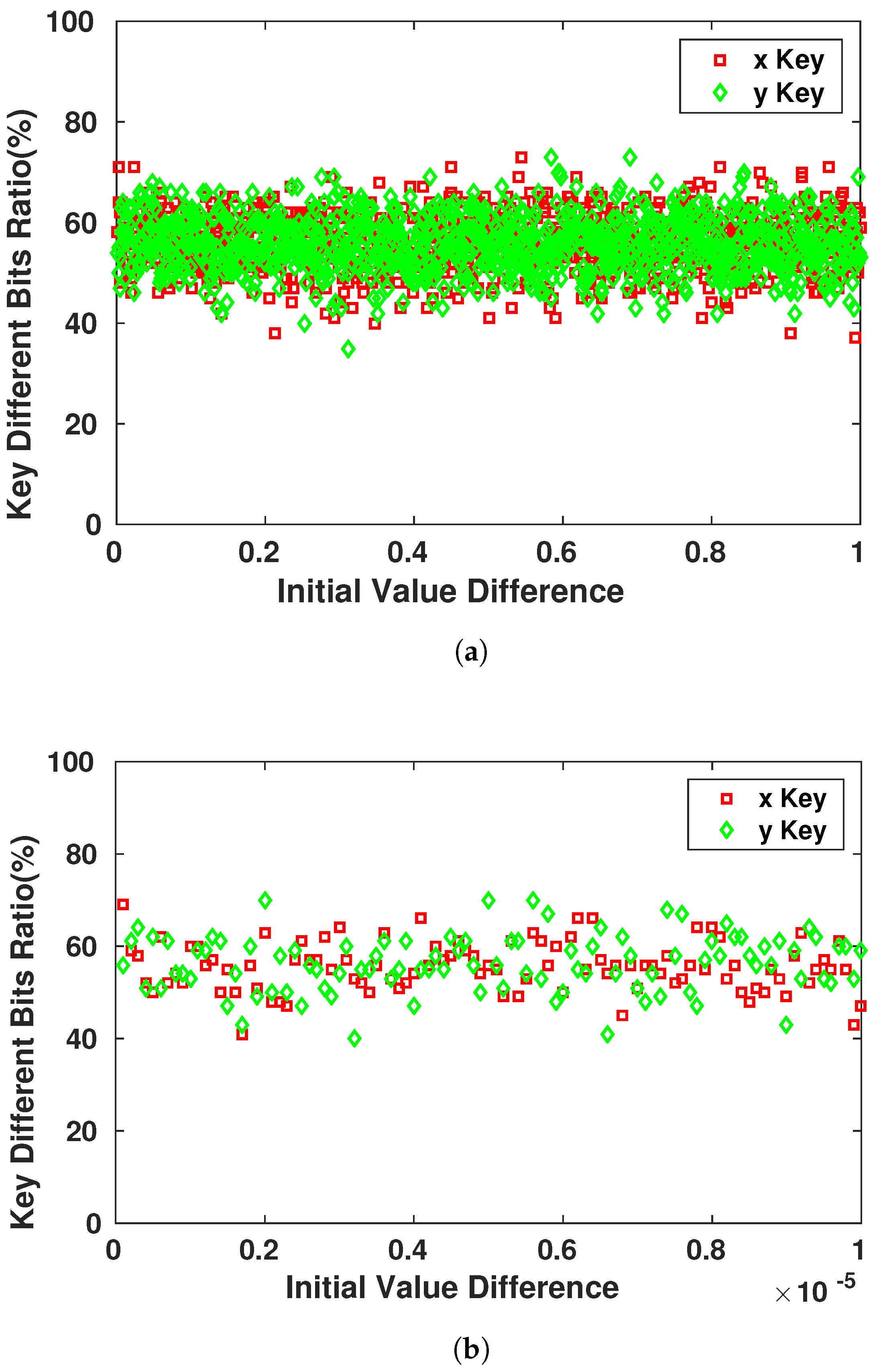
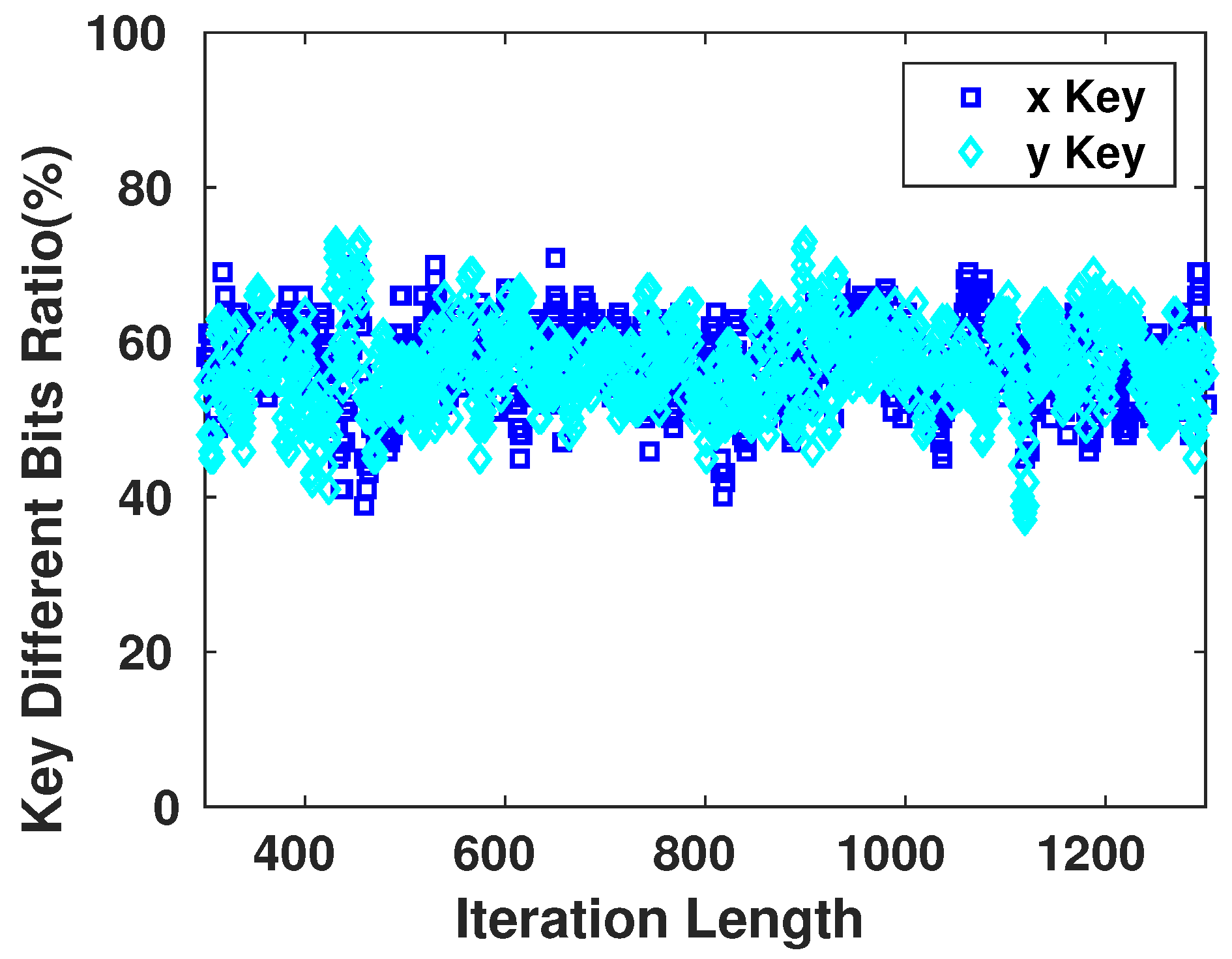
6. Statistical Tests
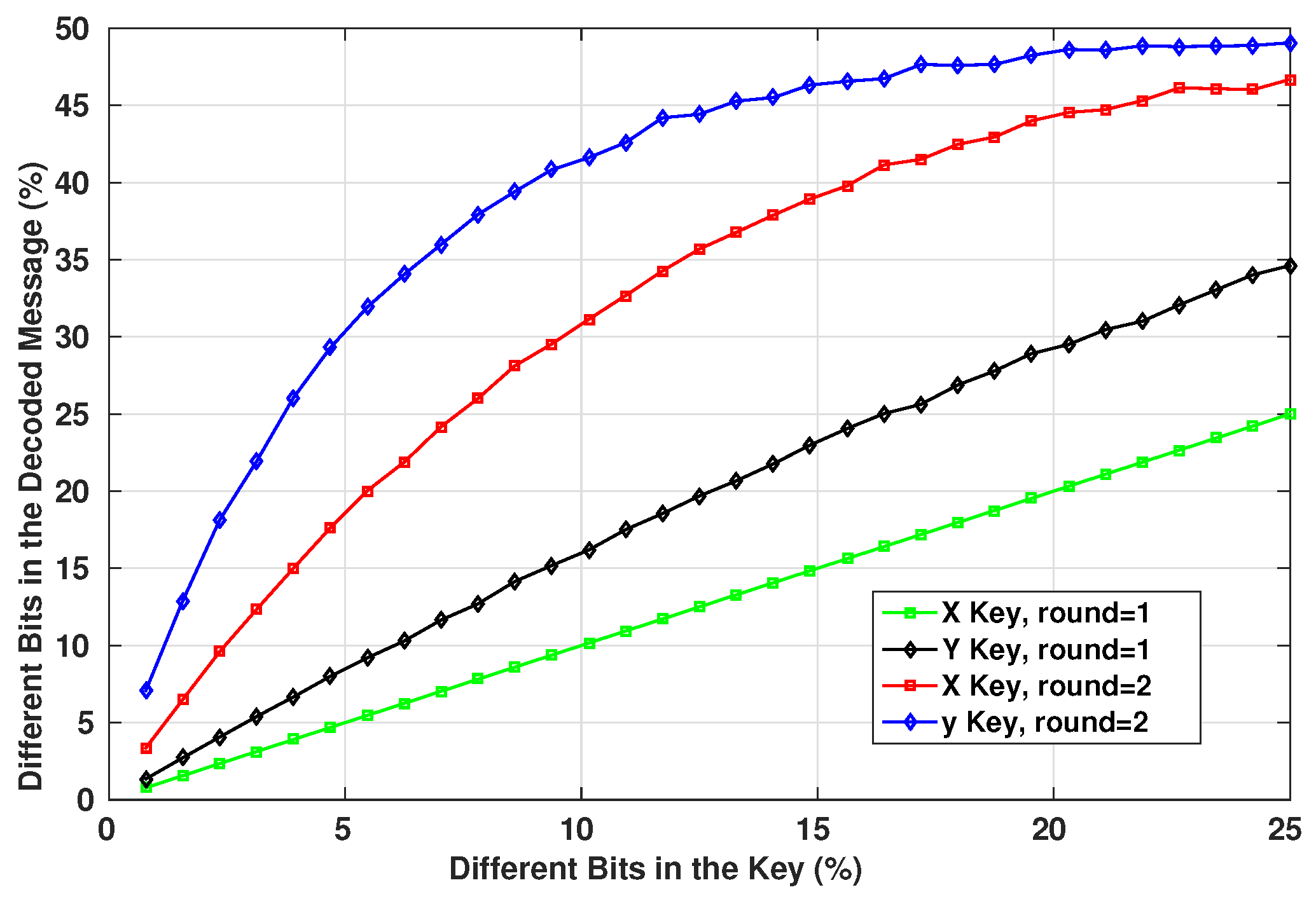
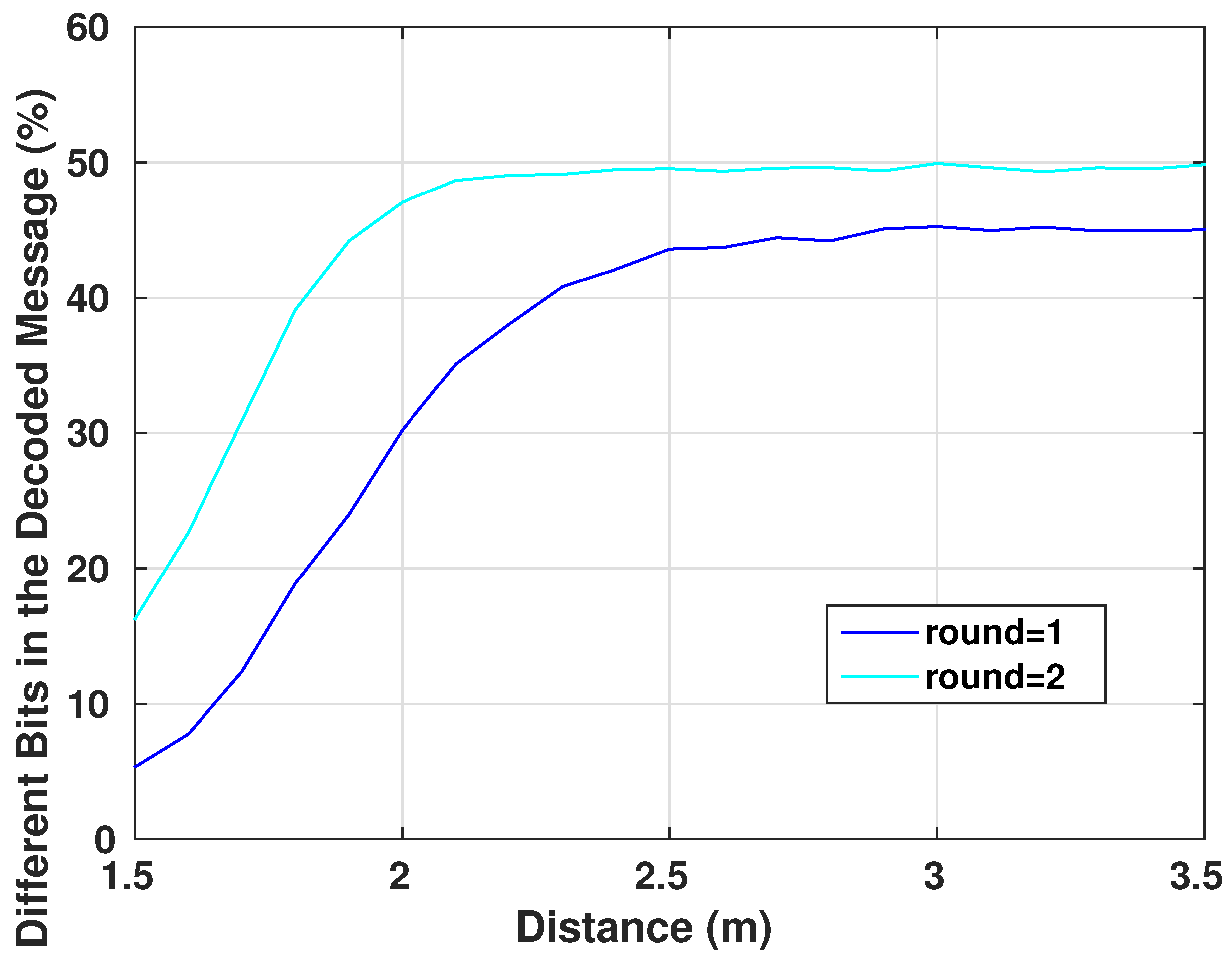
The security aspects of any encryption system relate highly to the key used in encrypting/decrypting the communicated messages [
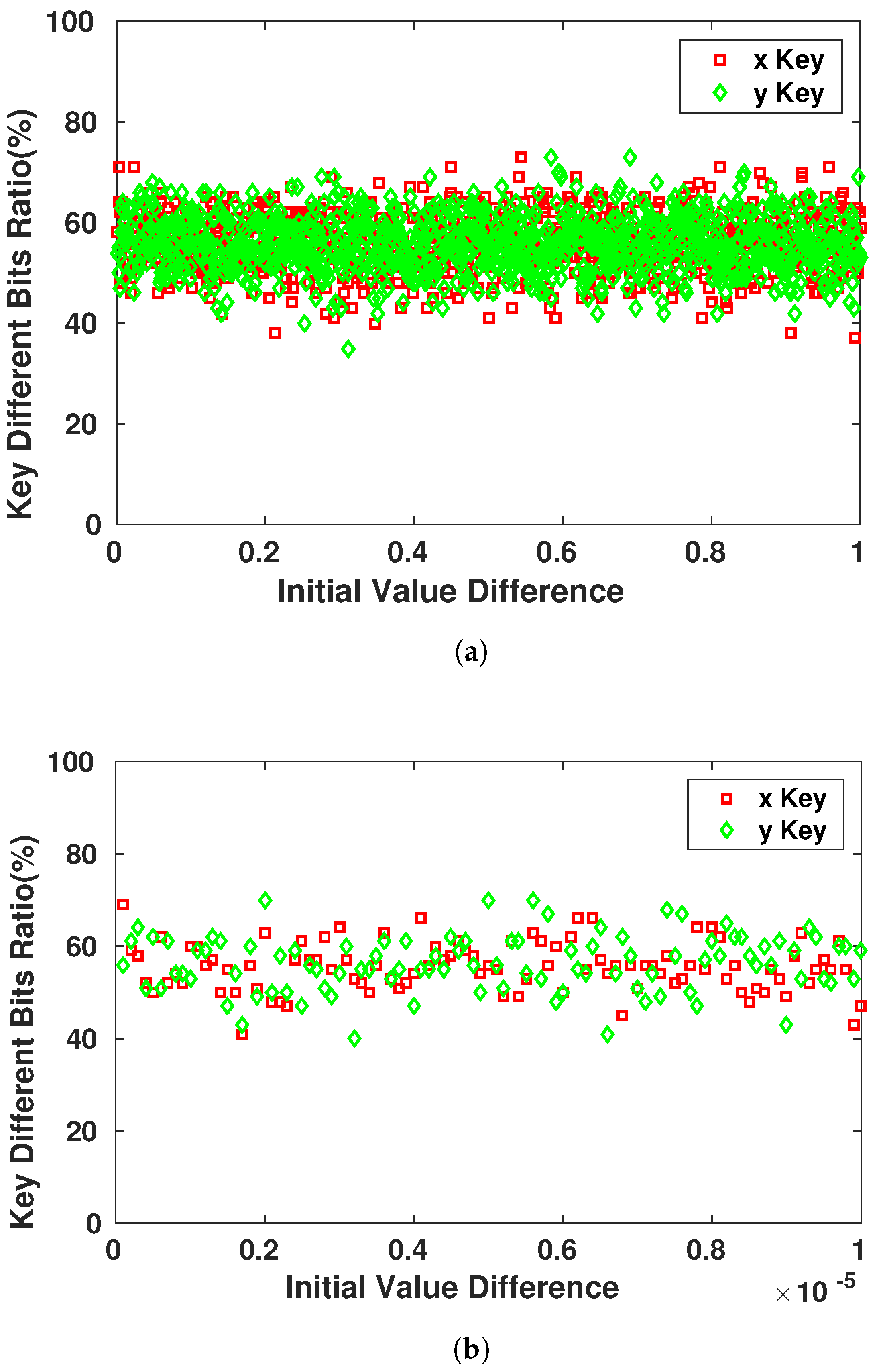
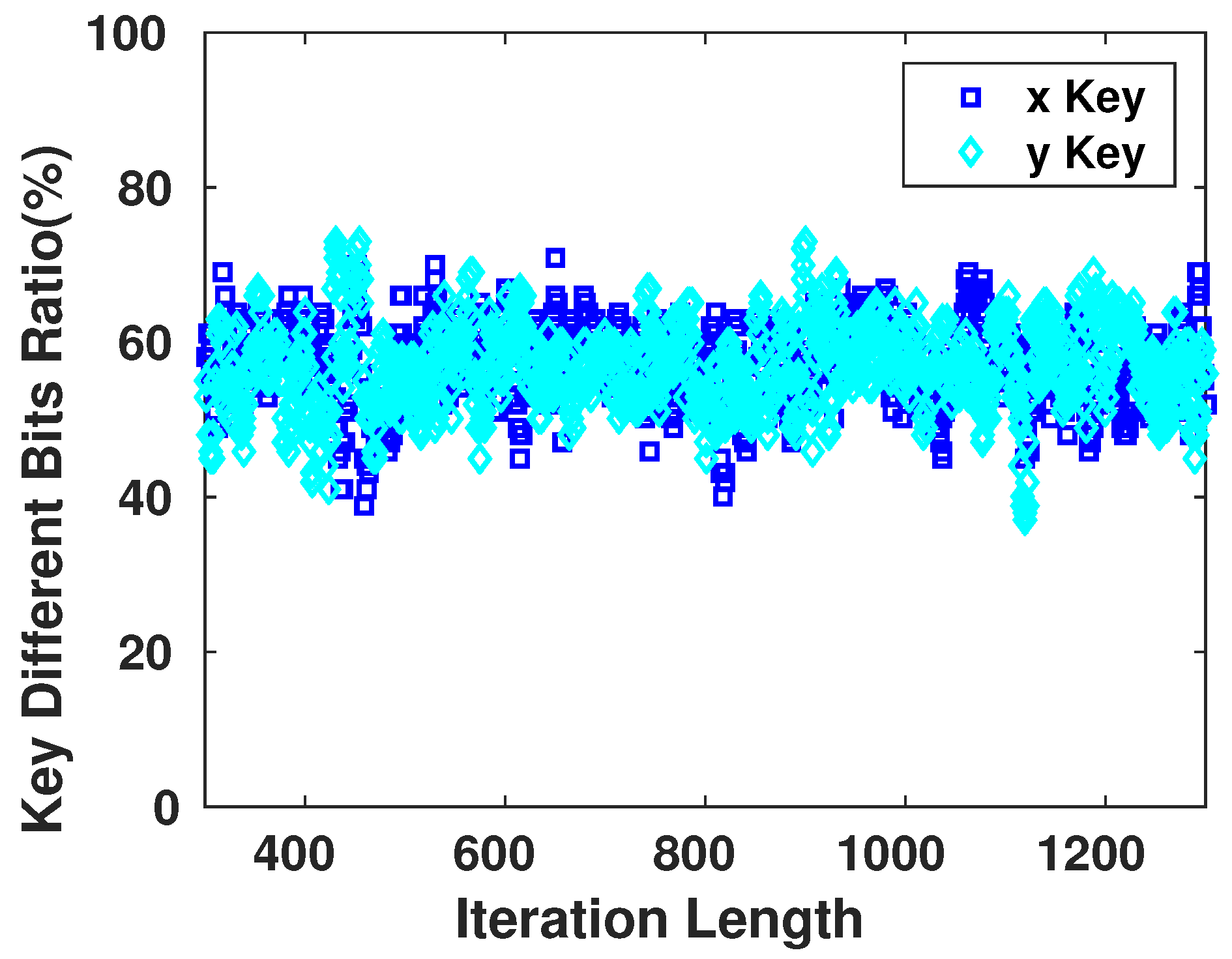
8]. As the encryption scheme that will be used in our work is symmetric, once the adversary possesses the key, the device becomes vulnerable to multiple types of attacks. Therefore, the key generator should perform like a truly random generator so it cannot be predicted by a third party using statistical or probabilistic approaches. Moreover, pseudo-random numbers generated for cryptographic applications must be unpredictable: if the initial conditions are unknown, the next output bit in the sequence generated cannot be foreseen by the adversary even if he/she possesses any knowledge of the previous random numbers in the sequence.
A set of statistical tests for the randomness of number sequences is described by The National Institute of Standards and Technology (NIST) [
36] to ensure that the given random or pseudo-random generator can be used for cryptographic purposes. The described procedures aim to detect any deviation of a given binary sequence from being random which can be due to a poorly designed generator.
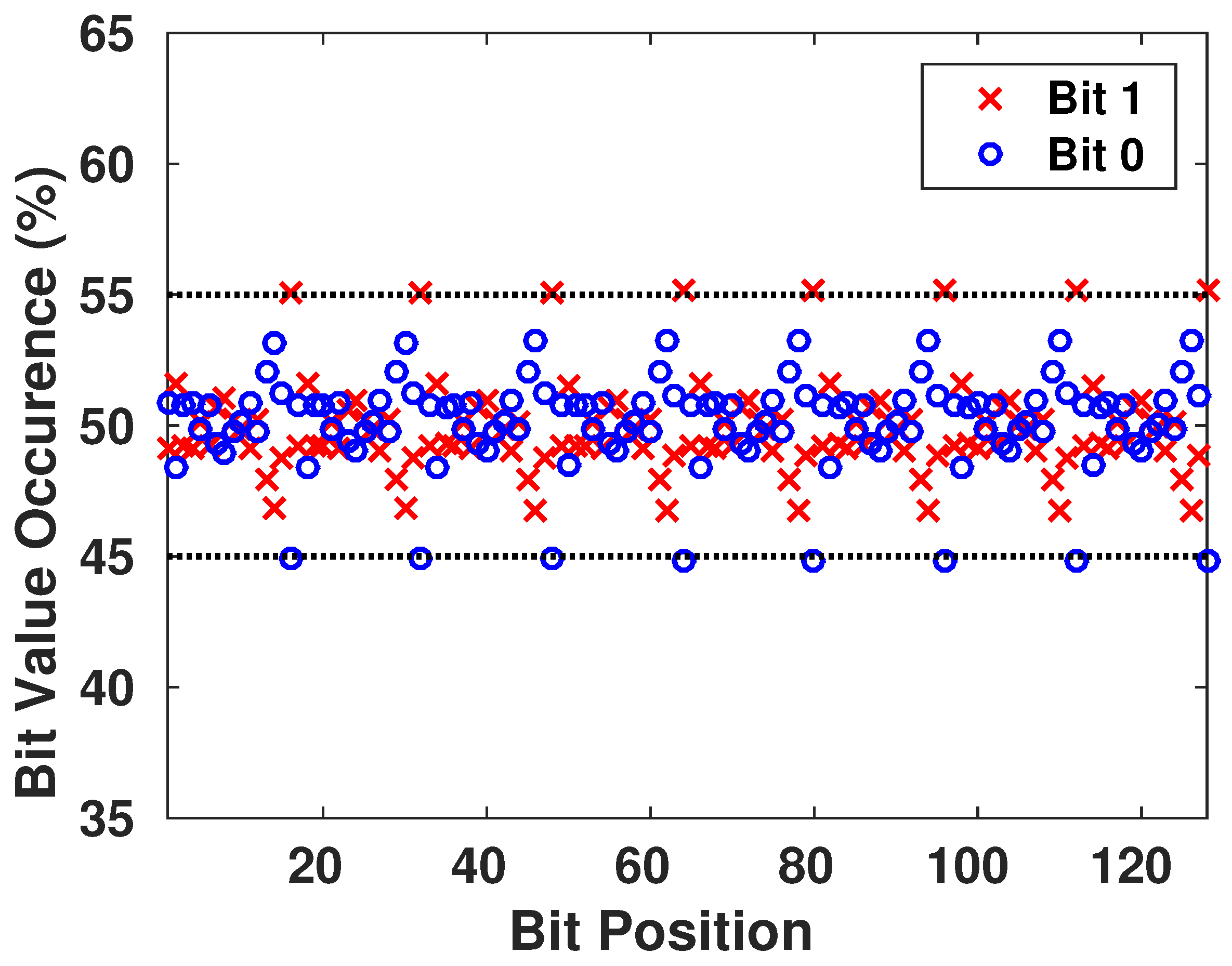
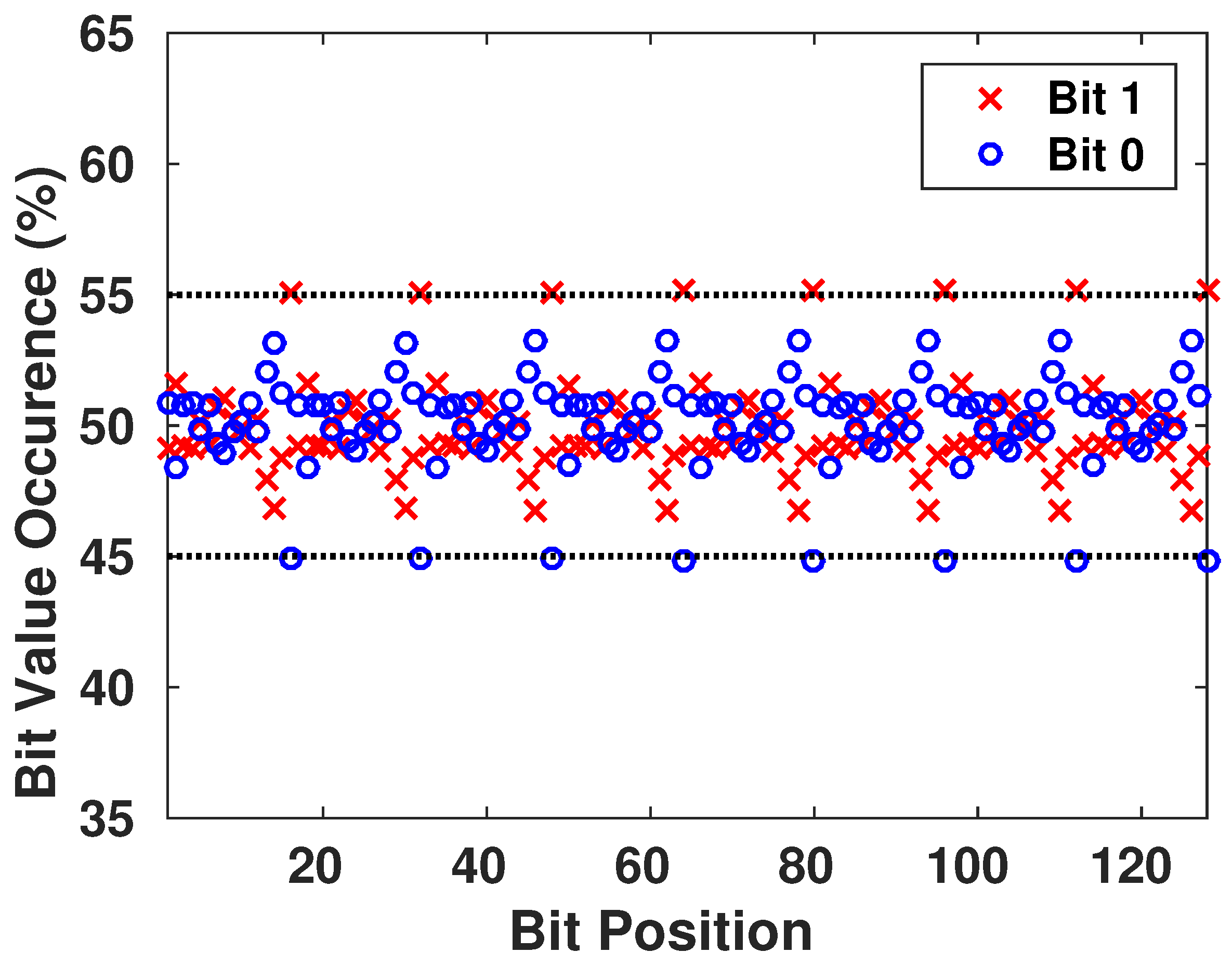
6.1. Monobit Test
This test ensures the randomness of the whole sequence by verifying if the appearance proportions of 0’s and 1’s are approximately the same. Thus, there is not a value that is more probable to appear than the other.
The test assigns a value of
to each 0 and a value of 1 to each 1 in the n-bit sequence, then it computes the sum
into
The test passes when , with being the complementary error function. The result is interpreted as follows: if in the sequence there are too many ones or too many zeros, will deviate from 0, and large values of will lead to a small value of .
6.2. Frequency Test within a Block
This test verifies the proportion of 1’s within M-bit blocks. It determines if the frequency of 1’s in the M-bit block is approximately the same as the frequency of 0, as expected from any random sequence. This test is a general form of the previous test, as the latter falls in this test when M is equal to the total length of the sequence.
The test divides the whole sequence into M-bit blocks, if there are any remaining bits, they are automatically discarded. Then, it computes the proportion
of 1’s in each block
i, and finally,
The test passes when , with N being the number of blocks in the sequence and being the incomplete gamma function. The result is interpreted nearly as the previous one: a small value of indicates that there is a large deviation from the equal proportion of 1’s and 0’s in at least one of the blocks.
6.3. Runs Test
A run is a continuous sequence of the same bit value. The run should also be bounded with a bit of the opposite value at its start and end. An example of a
bit run is:
This test verifies if the number of runs existing in the generated sequence is as expected from a random sequence. In other words, the test verifies if the oscillation between 0’s and 1’s is not too quick or too slow for a random sequence.
The test verifies this oscillation by calculating
where
The result is interpreted as follows: A small value of indicates that the oscillation between 0’s and 1’s in the sequence is too slow to be considered as a random sequence, a large value of indicates that the oscillation is being too quick for a random sequence.
6.4. Test for the Longest Run of Ones in a Block
This test ensures that the length of the longest run of 1’s within the different M-bit blocks of the generated sequence is compatible with the length of the longest run of 1’s expected in a random sequence, with M a pre-set value from the NIST.
The test will compute the longest run
k of 1’s in each block, then will categorize the block into categories
depending on the value of
k according to
Table 1.
Then it will compute the frequencies of the longest run of the blocks
= number of blocks falling in
. Afterwards, it will calculate
where
L and
N are pre-determined by the NIST as shown in
Table 2.
The test passes when . The result value being not small shows that the generated sequences have no cluster of 1’s or 0’s.
6.5. Discrete Fourier Transform (Spectral) Test
This test focuses on the peak heights of the Discrete Fourier Transform (DFT) of the generated sequence. It looks in the sequence for periodic features that contradict the assumed randomness of the bit chain.
The test assigns a value of
to each 0 and a value of 1 to each 1 in the n-bit sequence and sums it to produce a value
X, then it applies the DFT,
. Afterwards, it computes
and the peak height threshold
. Finally, it computes
, the expected theoretical number of peaks under the threshold
T, and
with
the actual number of peaks in
M that are less than the threshold
T.
The test passes when . A low value of d indicates that there were actually too many peaks in M above the threshold T.
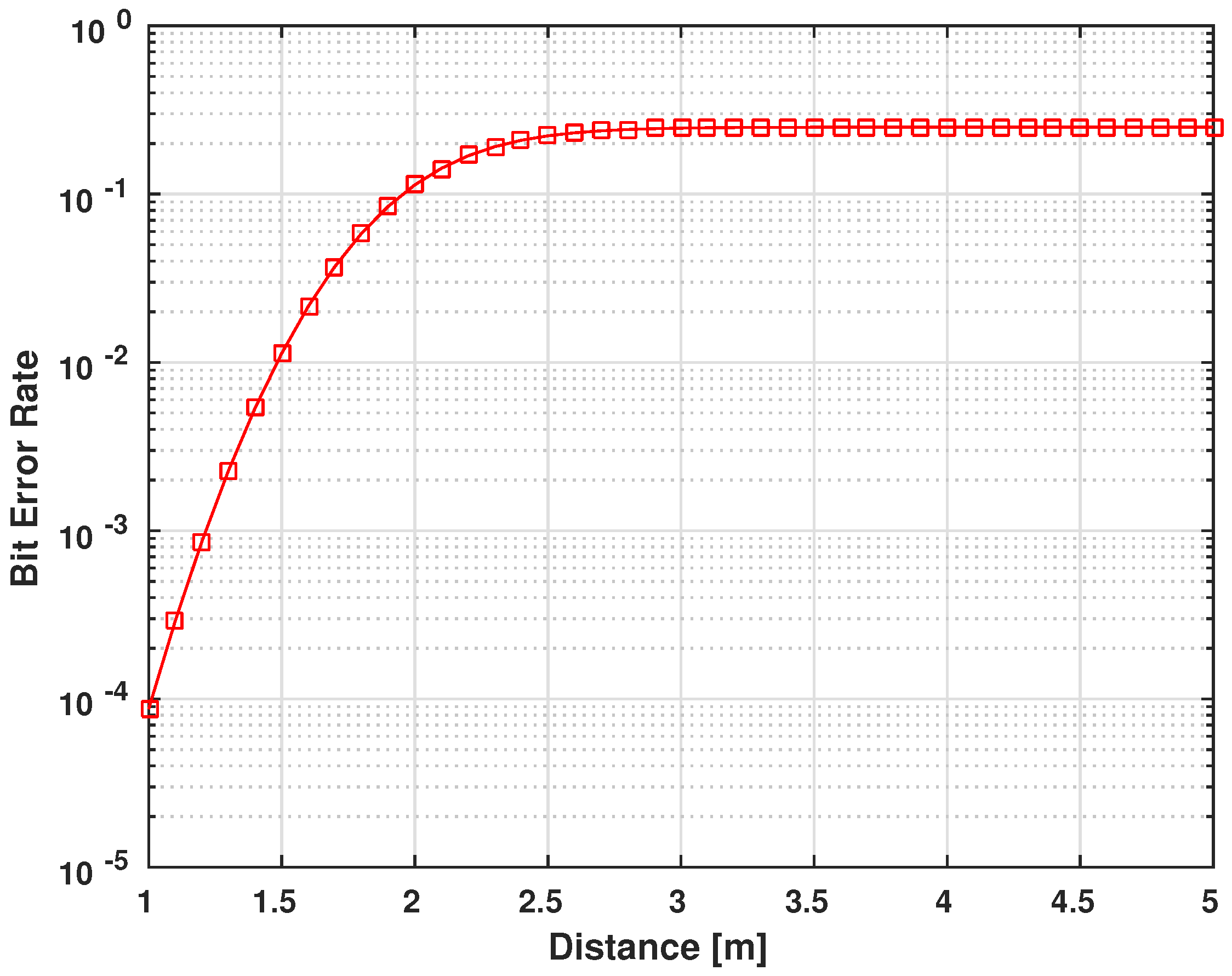
9. Hardware Implementation
Our proposed system consists of the implementation of The Henon map system to generate the random keys
x and
y. This architecture relies on fixed parameters,
a and
b and has two main blocks: the Cipher block and the Table LookUp. We simulated the proposed architecture of the encryption system, as shown in
Figure 19, for the correct functional operation with test vectors returned by a software simulation with the VHSIC Hardware Description Language (VHDL). To avoid the problem of VHDL dealing with real numbers for the Henon Map system, as mentioned in
Section 3, we implemented the system using a fixed point representation of the real numbers on 32 bits (for the 2Q30 representation) or 16 bits (for the 2Q14 representation). The system has been implemented on Xilinx Spartan-6 [
44] using a VHDL structural description. ISE Simulator (ISim) of Xilinx software tools [
45] were used to evaluate the hardware resource requirements for our encryption system. The synthesis results after analysis of our system’s implementation are displayed in
Table 5 and
Table 6, defining the hardware resources regarding Slices/Flip-Flops numbers and the speed performance. The results explain that our encryption system can be effectively implemented for low-resources IMDs. A comparable implementation of the DES algorithm is presented in
Table 7.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}