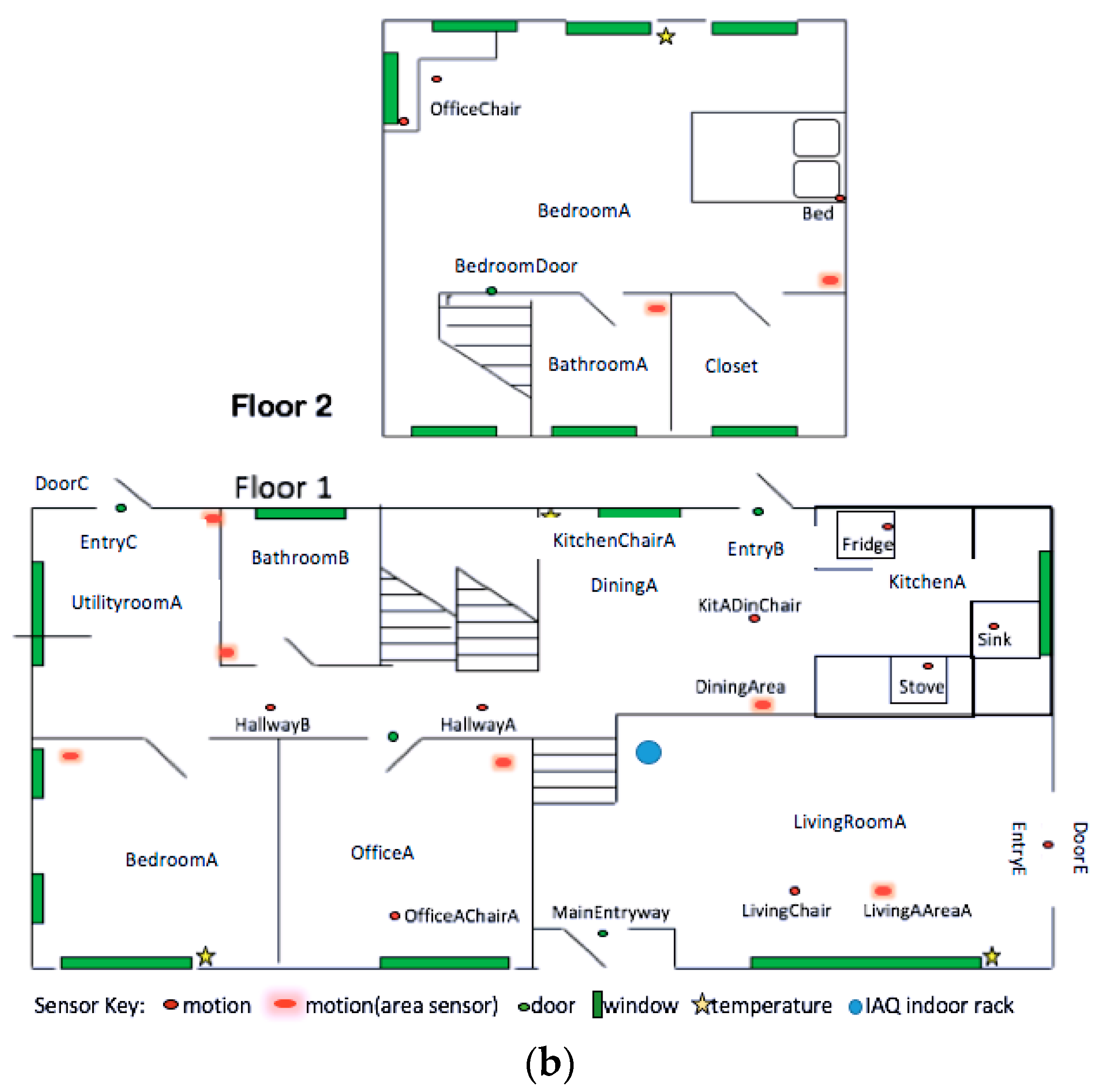
5.2. Analysis 1: AllSH_OneIAQ
Our first analysis determined the IAQ variables that were measurably impacted by captured smart home-based behavior features (AllSH_OneIAQ). To validate the overall performance of SH features and IAQ variables, we used regression to estimate the value of each dependent variable (each IAQ variable), given the independent variables (SH features). There are many techniques that have been developed for regression analysis. In our project, we performed experiments based on three algorithms: random forest (RF), linear regression (LR) and support vector regression (SVR).
Decision tree learning is one of the most popular regression learning techniques. It can naturally handle data of mixed types and missing values, which occur in all of our datasets. We choose one of the best-known learning methods: random forest learning algorithm. Using random forest, a large set of decision trees are created, each using a different set of randomly selected feature inputs. Compared with other tree learning algorithms, RF improves the prediction accuracy and the stability when the data is changed a little. However, decision trees only map the feature vector to discrete target variables, so we also considered methods that are designed to handle numeric class values.
One model that deals with numeric variables is linear regression, where a single linear formula represents the mapping from input to class values. We used the linear regression learning algorithm as our second learning method. Since our data has a large number of features, we also used a third method, the support vector regression. It is a nonlinear regression technique, which complements the linear regression method.
We evaluated the performance of all three of the above algorithms by reporting the corresponding correlation coefficients (r). In our study, we did not consider the sign of the correlation coefficient, just the absolute value. This is because we wanted to determine whether a relationship exists between the smart home features and the chemical variable features, rather than analyze the type of direction of a relationship between these two complex models. We reported correlation coefficients that are moderate or large (r ≥ 0.3). In addition, we evaluated the accuracy of our models based on 10-fold cross-validation by reporting the normalized root mean square error (NRMSE) as a performance measure.
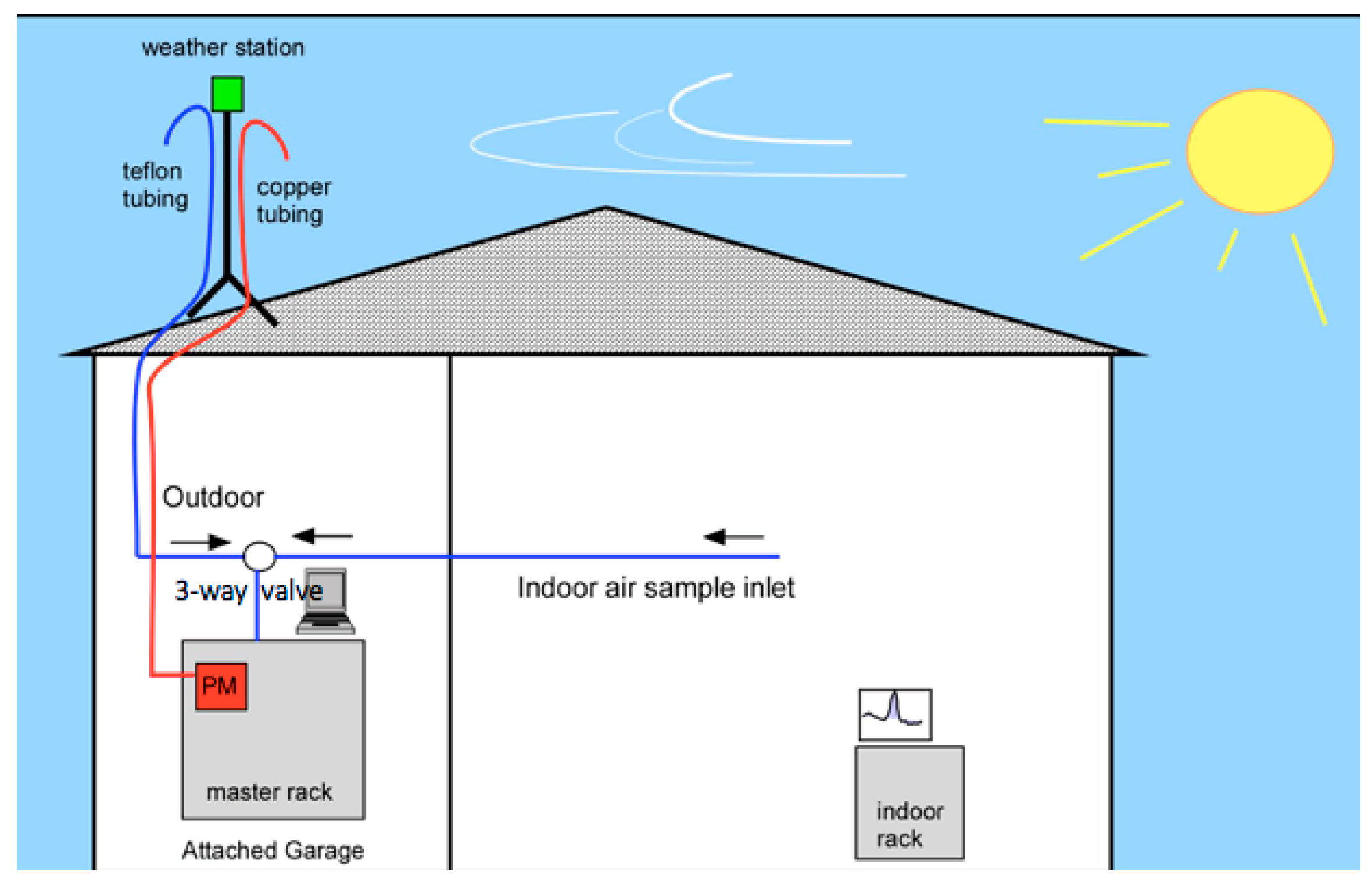
In our project, we also report the statistical significance of the observed results. We set the null hypothesis as: there is no correlation between each dependent variable and the independent variables. The corresponding alternative hypothesis is set as: there is a correlation between each dependent variable and independent variables. We then choose the value of the first type error (probability of false rejection of a true null hypothesis) as 0.05, and the value of power (the probability of correctly rejecting a false null hypothesis) as 0.9. For these parameters, the sample size should be 113. Our sample sizes for IAQ1 and IAQ2 are 620 h and 187 h respectively, which are large enough to represent subjects where the probability of correctly rejecting a false null hypothesis is greater than 0.9.
To validate the hypothesis, we computed the correlations and NRMSE between the complete set of SH features and each predicted IAQ variable by performing the three regression learning algorithms (RF, LR, and SVR) on each house (IAQ
1 and IAQ
2), as well as on the aggregated dataset for both houses (denoted as IAQ
1_2). The results are summarized in
Table 2,
Table 3 and
Table 4. The full set of results is provided online (
http://eecs.wsu.edu/~blin).
As shown in
Table 2 and
Table 3, the majority of the IAQ variables from both IAQ
1 and IAQ
2 exhibit a relationship with the SH features, because there are over 90% IAQ variables that are highly correlated with SH features, which results in an NRSME lower than 0.12 (using random forest). Further, based on the results shown in
Table 4, we observed that the majority of IAQ variables from the aggregated dataset for both houses (IAQ
1_2) are also highly predictable from SH features (98% of the IAQ variables are highly correlated with SH features, and result in an NRSME of 0.0798 using random forest). According to this, we conclude that there is a generalized relationship between IAQ variables and SH features. Additionally, we list the correlation coefficients for IAQ variables from the aggregated dataset (IAQ
1_2) in
Table 5.
In
Table 5, we observe that there exists a relationship between human behavior and air quality inside and outside the homes. There are 16 indoor chemical variables (16 out of total 24 indoor chemical variables) that have higher correlation coefficients than those outside the house. Furthermore, there are five outdoor chemical variables (five out of 25 outdoor chemical variables) that have higher correlation coefficients than those inside the house. Thus, human behaviors have a greater impact on chemical variables measured indoors than those variables measured outdoors.
We are going to use three representative pollutants from both the indoor and outdoor categories to further interpret the results from
Table 5. We chose PM
2.5, formaldehyde, and methanol as the representatives for outdoor pollutants, VOCs released from indoor materials, and VOCs released from occupant activities.
For PM2.5, we observe that the correlation coefficient for the outdoor PM2.5 is 0.5121. This indicates that there is a correlation between outdoor PM2.5 and in-home human behaviors. Due to the wildfires, which caused heavy smoke with a large amount of outdoor PM2.5 during the experimental period, residents closed windows and doors more often than usual, and stayed at home longer than usual. In the case of the indoor PM2.5, the correlation coefficient is 0.4808, which shows that there exists a measurable relationship with human behavior, such as cooking and cleaning, and indoor PM2.5.
In
Table 5, we observe that the correlation coefficient for the indoor formaldehyde is 0.9060. This large value indicates that there is a strong relationship between indoor formaldehyde and human behaviors. This is because indoor formaldehyde is mainly from indoor carpet, pressed wood products, and furniture. Indoor formaldehyde is also positively correlated with both indoor temperature and indoor humidity [
27]. Human behaviors, such as cooking, bathing, washing dishes, and opening/closing windows or doors, make a significant contribution to the temperature and humidity changes inside the house. Thus, the relationship between human behaviors and humidity generate a positive correlation with indoor formaldehyde as well. In addition, the correlation coefficient for the outdoor formaldehyde is 0.5407. Outdoor formaldehyde is mainly produced from industrial wood manufacturing [
28]. Hence, it is reasonable that the correlation coefficient is 36% lower than that for the indoor formaldehyde.
With regards to methanol, this chemical occurs either naturally in humans, animals, food, and plants, or industrially based on its use as a solvent, pesticide, and alternative fuel source [
27]. The correlation coefficient for the indoor methanol is 0.9265, which is 37% higher than that for the outdoor methanol. This makes sense, because the indoor human behaviors, such as eating, drinking, breath, and solvent, would highly impact the indoor methanol.
5.3. Analysis 2: GroupSH_InIAQ and IndivSH_InIAQ
The above regression analysis quantifies the generalized relationship between IAQ variables and SH features. After regression analysis, we performed a second analysis to determine the specific SH features that have the greatest influence both as a group and individually on the IAQ variables selected from the first analysis. Although in earlier regression analysis we validated that a generalized relationship exists between smart home features and indoor air quality chemical variables based on the aggregated dataset from the two houses, there is a tremendous diversity of specific human behaviors in each house that will affect individual IAQ variables. Thus, in this analysis, we only consider each house and do not include the aggregated dataset. Specifically, we utilize learning algorithms for three experiments (shown in
Table 6) to perform the automated selections of SH features for IAQ variables based on their ability to predict IAQ values. These three algorithms employ machine learning algorithms that only handle nominal class values. Because our data is numeric, we employ equal frequency binning to discretize the target variables by dividing the numeric range into a predetermined number (here,
n = 4) of bins.
We note that the learning algorithms used for this analysis are different from those used for the first analysis and its corresponding experiments. The classifiers in the first analysis were regression algorithms. In contrast, we now need to employ classifiers that map the feature vector to discrete-valued class labels. We utilize algorithms that are popular for feature selection, namely RF, J48 (a decision tree learner) and information gain (InfoGain). Even though decision trees are typically used for classification (as done in Analysis 1 in
Section 5.2), we also use them for feature selection in the current analysis, so as to determine which of the behavior-based attributes are most indicative of indoor air quality, and therefore exhibit the strongest relationship with indoor air quality parameters. InfoGain is used as a measure of information gain on the class that the attribute gives, so as to determine the relevance of that attribute and hence allow the elimination of attributes that are less relevant. The relevance of each attribute is evaluated by assigning a score, which is calculated as the difference in entropy with and without that attribute; afterwards, feature selection can be performed based on the scores. Entropy here measures the impurity of the sample that tells us the average number of bits needed to encode the information in the sample. Further, for classifiers RF and J48, we employ WrapperSubsetEval as an attribute evaluator, which uses a classifier to evaluate alternative attribute sets. The accuracy of the classifier for each attribute set is estimated by cross-validation.
We first perform two experiments to identify subset groups of SH features that together have the most noticeable impact on each chemical variable, and narrow down the size of the subset group to at most 15. To extend the second analysis further, we then perform a similar experiment to select individual SH features.
To be consistent with the first analysis (
Section 5.2 Analysis 1: AllSH_OneIAQ), we summarize the behavior features that show the greatest impact on the same three representative chemical variables for each house (outdoor PM
2.5, indoor formaldehyde, and indoor methanol). The feature selection summary is given in
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12, which are separated by the particular chemical variable we are analyzing. Explanations for the feature names are provided in
Table 13. The full set of results is provided online.
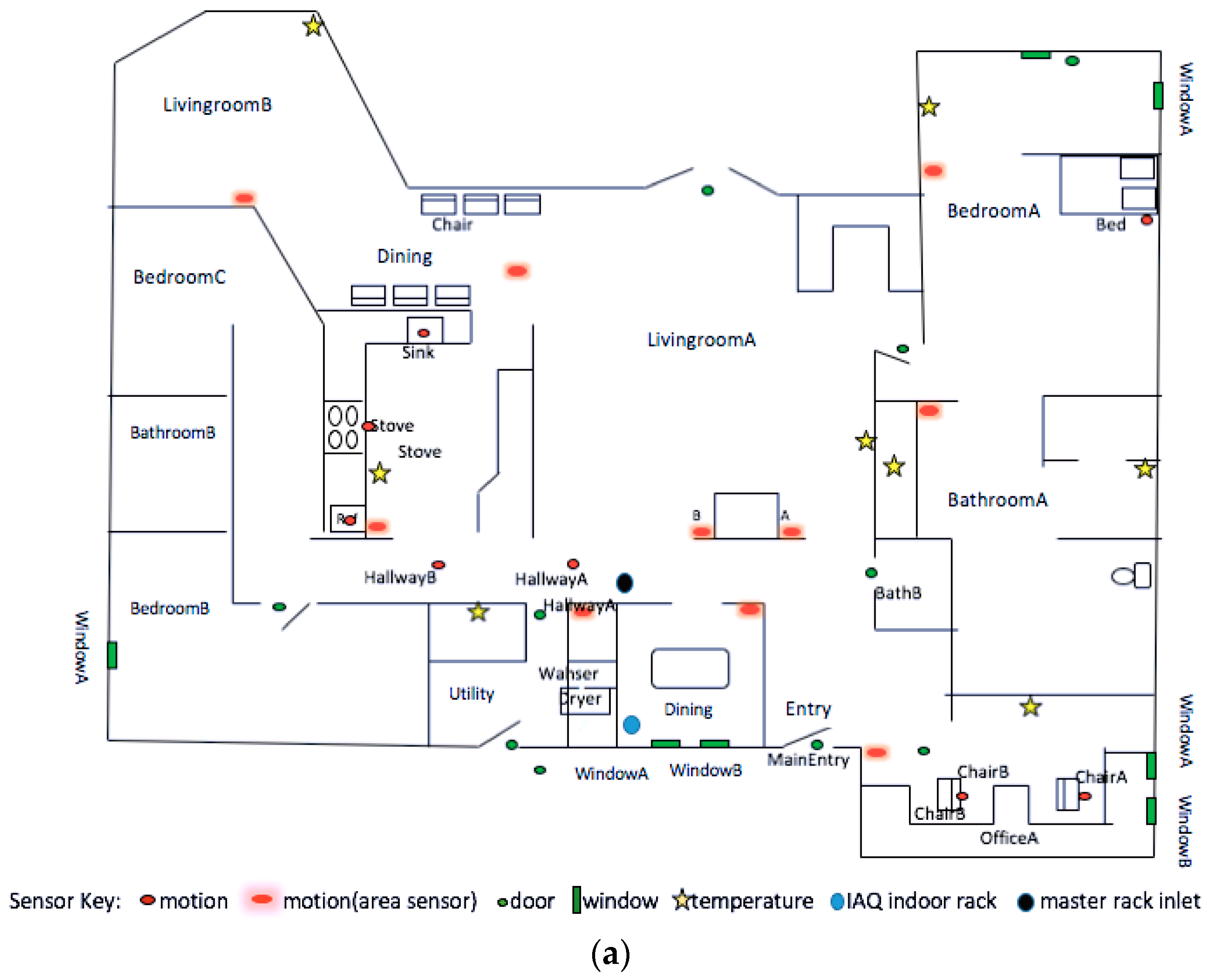
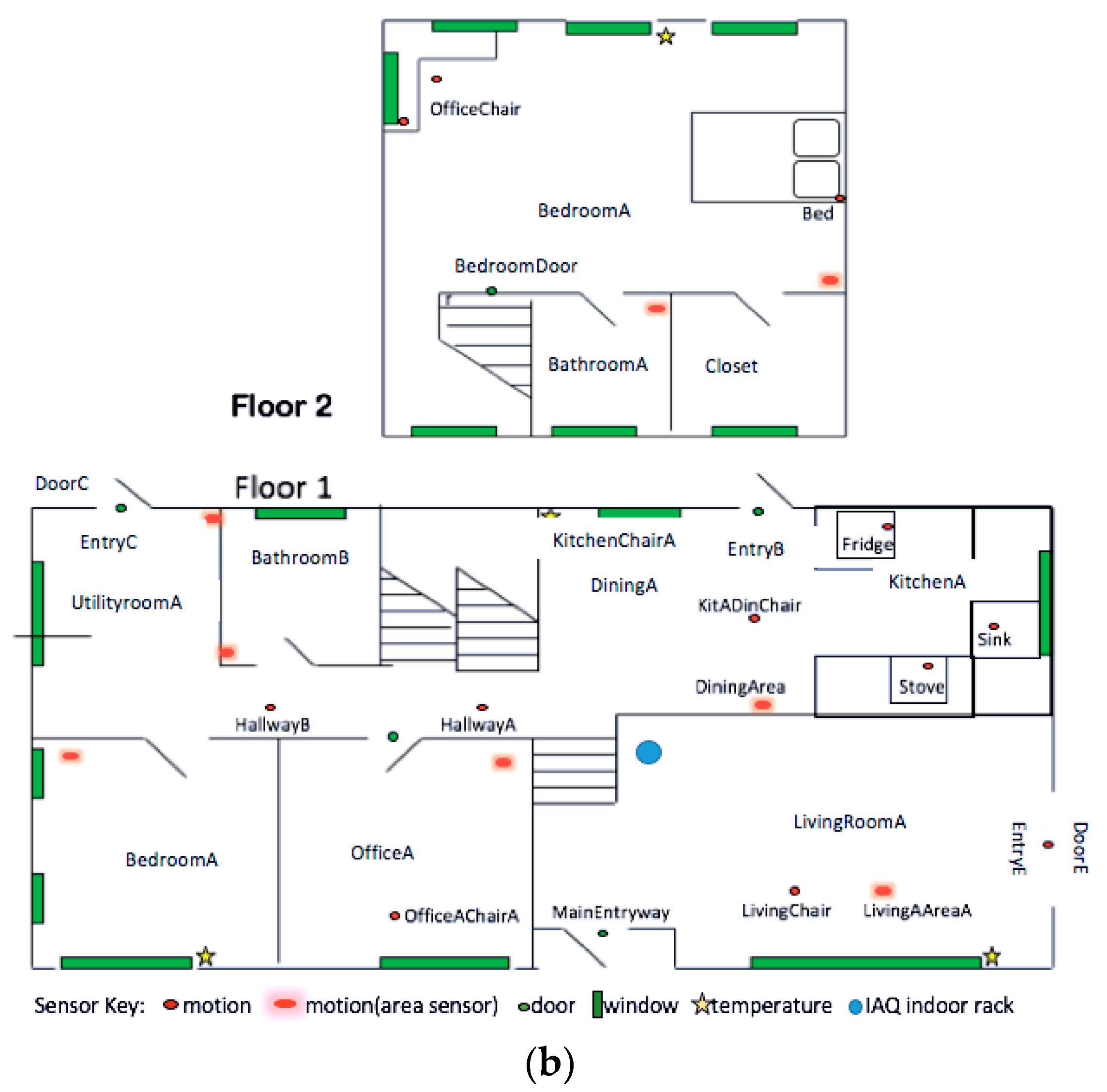
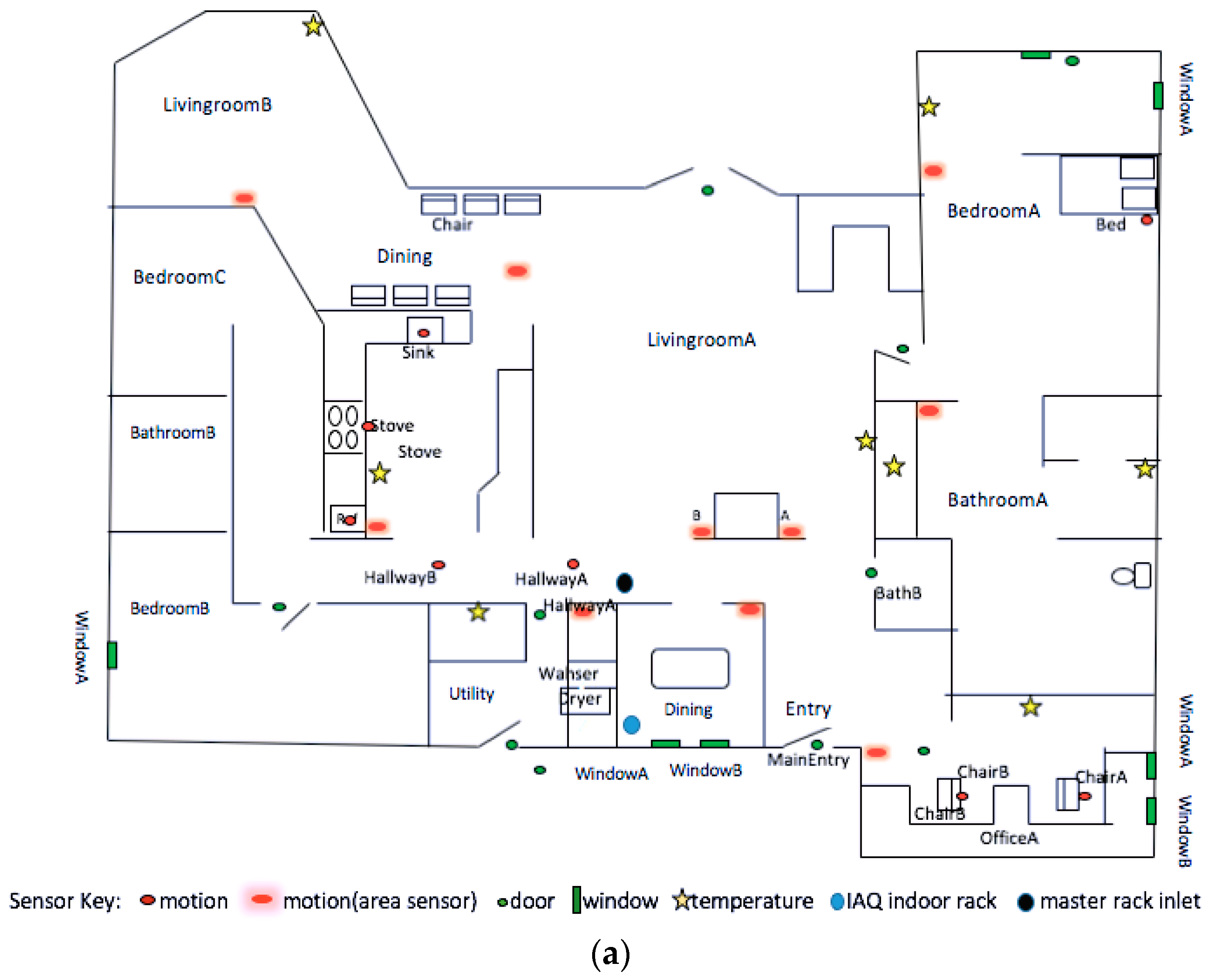
In
Table 7, we observe that for the outdoor PM
2.5 in IAQ
1, features such as temperature in the bathroom, dining room, and kitchen are highly related with outdoor PM
2.5 values. We also observe that the duration of both personal hygiene and bed-to-toilet transition are selected. This makes sense because the high-level outdoor PM
2.5 during the wildfires caused residents to stay at home longer than usual, and therefore more activities to be detected in the house than usual, especially in the bathroom, dining room, and kitchen. Similar results are found for the selected features in IAQ
2 (based on
Table 8) for the same reasons. For IAQ
2, the selected features are the temperatures in the main entryway, kitchen, master bedroom, master living room, and master office.
In
Table 9, we observe that for indoor formaldehyde in IAQ
1, the selected features are the temperatures in the master bedroom, kitchen, and stairs to the first floor, as well as the overall activity levels in the master bedroom, the secondary office, and the area of an open door in the master bedroom. This makes sense, because we know that carpet is the main source of indoor formaldehyde, and the places with carpets in IAQ
1 are the bedrooms and the secondary office, which is also located inside the master bedroom. Further, temperature and humidity in rooms with carpets have positive impacts on indoor formaldehyde levels.
In
Table 10, we notice that for indoor formaldehyde in IAQ
2, the selected features are temperatures in the master bathroom, kitchen, and main entry, and the duration of washing dishes. The temperature in the master bathroom could be an indication of taking a shower or running hot/cold water. Those activities in the bathroom and the duration of washing dishes may have a great contribution to the indoor humidity. In addition, the temperature feature for the main entry door is selected in IAQ
2, but not in IAQ
1. This might be because of the humidity difference during the experimental periods for the two testbeds. According to the weather station reports, for IAQ
2, the average outdoor water vapor was 10,443 parts per million (ppm) compared to 9827 ppm for IAQ
1. That is, the average humidity during the IAQ
2 experimental period was 616 ppm higher than that during the IAQ
1 period. Then, for IAQ
2, opening/closing the main entry door might allow the outdoor humidity to influence the indoor humidity.
In
Table 11, we notice that in IAQ
1, the SH features that impact indoor methanol are temperatures in the master bathroom, kitchen, living room, and utility room, and the overall activity level in the living room. This makes sense, because in the kitchen or living room, there are food, fruits, vegetables, and other foods that contain methanol [
27]. Temperatures in these rooms and the overall activity levels in the living room may indicate food processing, eating, or drinking, especially with the overly ripe or near rotting fruits or vegetables, smoked food, diet foods, or drinks with aspartame. The temperature in the utility room may indicate that the resident had been doing laundry. The liquid laundry detergents used in this process contain methanol [
28]. This also partly explains the selected SH features for indoor methanol in IAQ
2, based on
Table 12.
In
Table 12, the selected features include temperatures in the kitchen, master bathroom, and secondary living room, the overall activity levels in the dining room, and the duration of cooking and sleeping. The duration of sleeping is selected in IAQ
2 because human breath also makes a contribution to the indoor methanol. In IAQ
2, there are two adults and one child, whereas in IAQ
1 there are only two adults. The living habits of residents in these two testbeds are also different. This may be a reason that the duration of sleeping is selected in IAQ
2 instead of in IAQ
1.
After selecting subsets of SH features for each IAQ variable by RF and J48 experiments, we conducted the third experiment to find the individual SH feature that had the greatest influence on each IAQ variable. That was accomplished through utilizing attribute selection by ranking the SH attributes using their individual scores. Sample results of this analysis for the same three chemical variables are shown in
Table 14,
Table 15,
Table 16,
Table 17,
Table 18 and
Table 19. The full set of results is provided online.
In
Table 14, we notice that the majority of selected features that are strongly related with outdoor PM
2.5 are temperature variables; the top features are temperatures in the master bathroom, dining room, and kitchen. This is consistent with the results from Analysis 1, as shown in
Table 7. In addition, this experiment allows us to observe that for IAQ
1, the temperature in the master bathroom had the highest correlation with outdoor PM
2.5. This makes sense, because heavy smoke from wildfires contains elevated levels of PM
2.5. Thus, residents spend more time at home for less exposure to the outside environment.
In IAQ
2, based on
Table 15, we notice that the SH features that have the greatest impact are temperatures in the main entry, kitchen, master bedroom, and master bathroom. Moreover, the temperature in the main entry has the highest correlation with outdoor PM
2.5. This makes sense, because the temperature in the main entry might indicate opening/closing of the main door. Due to the heavy outdoor smoke, residents might open/close the main door more quickly than usual to prevent the outdoor smoke from coming into the house.
In the case of indoor formaldehyde in IAQ
1, based on
Table 16, we observe that temperature in the kitchen has the highest correlation with formaldehyde. This is because the temperature in the kitchen was very similar to temperatures throughout the whole house (in general, the difference is less than 1 Celsius, except during the cooking time), and formaldehyde is positively related to the temperature. For IAQ
2, based on
Table 17, the temperature in the master bathroom had the highest correlation with indoor formaldehyde due to the positive correlation with humidity.
Considering indoor methanol in IAQ
1, based on
Table 18, we notice that the temperature in the utility room has the highest correlation with methanol. This is because methanol is a component of the liquid laundry detergents and temperature in the utility room may indicate the residents had been doing laundry. But for IAQ
2, from
Table 19, we notice that the temperature in the secondary living room had the highest correlation with indoor methanol. That is because food and drink in the secondary living room contained methanol. Additionally, residents whose breaths have a contribution to the methanol level may spend a great deal of time in the secondary living room. Those results in the third experiment are consistent with the results from the first two experiments.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}