1. Introduction
Mobile edge computing (MEC) enables Internet of Things (IoT) devices with limited resources, such as computing power and energy, by providing network services at the edge of networks (i.e., on the user’s side) [
1]. Thus, it has received extensive attention and produced many works in recent years [
2,
3]. However, traditional edge computing based on terrestrial networks is unable to provide network services to users in remote areas (e.g., oceans, deserts, and forests), which occupy most of the Earth’s surface area [
4,
5]. This severely limits the realization of ubiquitous computing. Thanks to the high bandwidth and seamless coverage of low earth orbit (LEO) satellites, providing edge computing solutions to devices in remote areas via LEO satellites has become a promising proposal and research focus over the last few years [
6,
7]. Furthermore, Space-Air-Ground Integrated Network (SAGIN) integrates multi-domain network resources to enhance service capabilities and extend the range of network coverage significantly via LEO satellites. It also utilises Unmanned Aerial Vehicles (UAVs) to overcome complex terrain and provide supplementary network resources, making it a desirable architecture for providing efficient, ubiquitous network services to IoT devices in remote areas [
8,
9,
10].
Although the SAGIN architecture has the potential to provide full-area, seamless network coverage, it still faces challenges such as highly dynamic topologies and highly heterogeneous resources [
11]. Furthermore, the direct-to-cell trend means that the massive scale of IoT devices and tasks will make efficient decision-making even more challenging [
12]. This conflicts with the requirements of a space-based task offloading environment, which necessitates fast, high-performance decision-making. Traditional iteration-based heuristic algorithms cannot meet the requirements of fast responses or high-performance decision-making in constrained space-based environments. Therefore, deep reinforcement learning (DRL)-based approaches are currently demonstrating unique advantages, as they can continuously optimize decision-making strategies. By continuously engaging with environmental dynamics and monitoring system state fluctuations in real time, deep reinforcement learning can leverage its autonomous learning and policy optimization capabilities to gain a technological advantage in dynamic and uncertain edge computing environments [
13,
14].
Inspired by task offloading using deep reinforcement learning, Tang and Wong proposed a DRL-based MEC system that enables mobile devices to autonomously decide on task offloading in order to minimize long-term costs [
15]. Tang et al. presented a three-layer hierarchical computing model that integrates cloud and edge computing within a hybrid LEO satellite framework. This design enables ground users to offload tasks with the aim of reducing overall energy consumption while taking into account satellite access latency and processing resource constraints [
16]. Furthermore, to improve communication efficiency in MEC systems, Li et al. designed a resource allocation scheme that leverages DRL to jointly optimize bandwidth and transmission power [
17]. By integrating UAVs into air–ground MEC networks, Shang and Liu proposed an architecture that provides computational resources through joint optimization of user association and radio resource allocation, thereby reducing user energy consumption under stringent latency requirements [
18]. Nevertheless, these studies did not consider task queue management, which is critical to handling dynamic user demands and ensuring efficient utilization of resources. To address this, Wang et al. designed a DRL-based, drone-assisted IoT offloading strategy that optimizes bandwidth, power, and task queues under dynamic loads [
19].
The motivation for this work stems from a key limitation in existing DRL-based task offloading approaches for SAGIN systems. The relationship between task categories and resource attributes is rarely considered. Tasks with distinct processing requirements are often treated uniformly, which leads to inefficient resource utilization and increased system scheduling costs in dynamic, heterogeneous SAGIN environments. To address such an issue, we propose a DRL-based optimization framework that integrates category-attribute matching to guide intelligent task offloading decisions and minimize overall scheduling costs. Specifically, we utilise a matrix of coefficients to quantify the degree of matching between task categories and heterogeneous resources, thereby establishing explicit task–resource correlations through mathematical modelling. Virtual queues are introduced to model queue backlogs and waiting times, reflecting the impact of dynamic task arrivals. The DRL agent continuously interacts with the environment, adjusting offloading strategies based on feedback to improve adaptability and matching accuracy across diverse resource domains. Furthermore, we consider practical constraints such as limited satellite coverage duration, UAV mobility and IoT device limitations. Then, we jointly optimise bandwidth allocation, transmission power control, task queues and offloading decisions to achieve efficient, system-wide coordination. The significance of this work lies in addressing the mismatch between diverse task requirements and heterogeneous resource capabilities in SAGIN-MEC systems. By incorporating task-category and resource-attribute matching into the DRL framework, the proposed method enables more efficient offloading decisions. Combined with virtual queue modeling and joint resource control, it improves system-level adaptability and task scheduling performance under dynamic and heterogeneous conditions. Extensive experimentation demonstrates the many advantages of the proposed approach in various dynamic SAGIN scenarios.
The primary contributions of this paper can be outlined as follows:
We formulate a joint optimisation problem that incorporates the dynamic evolution of long-term task queues and the nodes’ transmission power, task-offloading strategies, and the type matching of tasks and resources. This formalization represents the relationships between these factors to improve task offload efficiency and resource utilization.
We incorporate a task–resource type matching matrix into reinforcement learning, fully utilizing the matching coefficients to reflect the compatibility between task categories and resource characteristics. This enables more optimized decision-making during task offloading, improving resource utilization and overall system performance.
We integrate a penalty mechanism into the task queue model using reinforcement learning to improve resource utilization and task scheduling efficiency. This mechanism mitigates excessive queue backlogs in dynamic SAGIN, which can lead to resource overload, high latency, and task loss. By embedding the queue length into the reward function, we dynamically guide the optimization of offloading strategies to enhance overall system performance.
The paper is set out like this:
Section 2 outlines the SAGIN-MEC system and formalizes the associated task offloading and resource allocation challenge.
Section 3 presents the algorithmic framework.
Section 4 discusses the experimental evaluation, and
Section 5 concludes the paper.
2. System Model and Problem Formulation
This section first introduces the SAGIN framework and then formulates the problem.
2.1. Space-Air-Ground Integrated Network
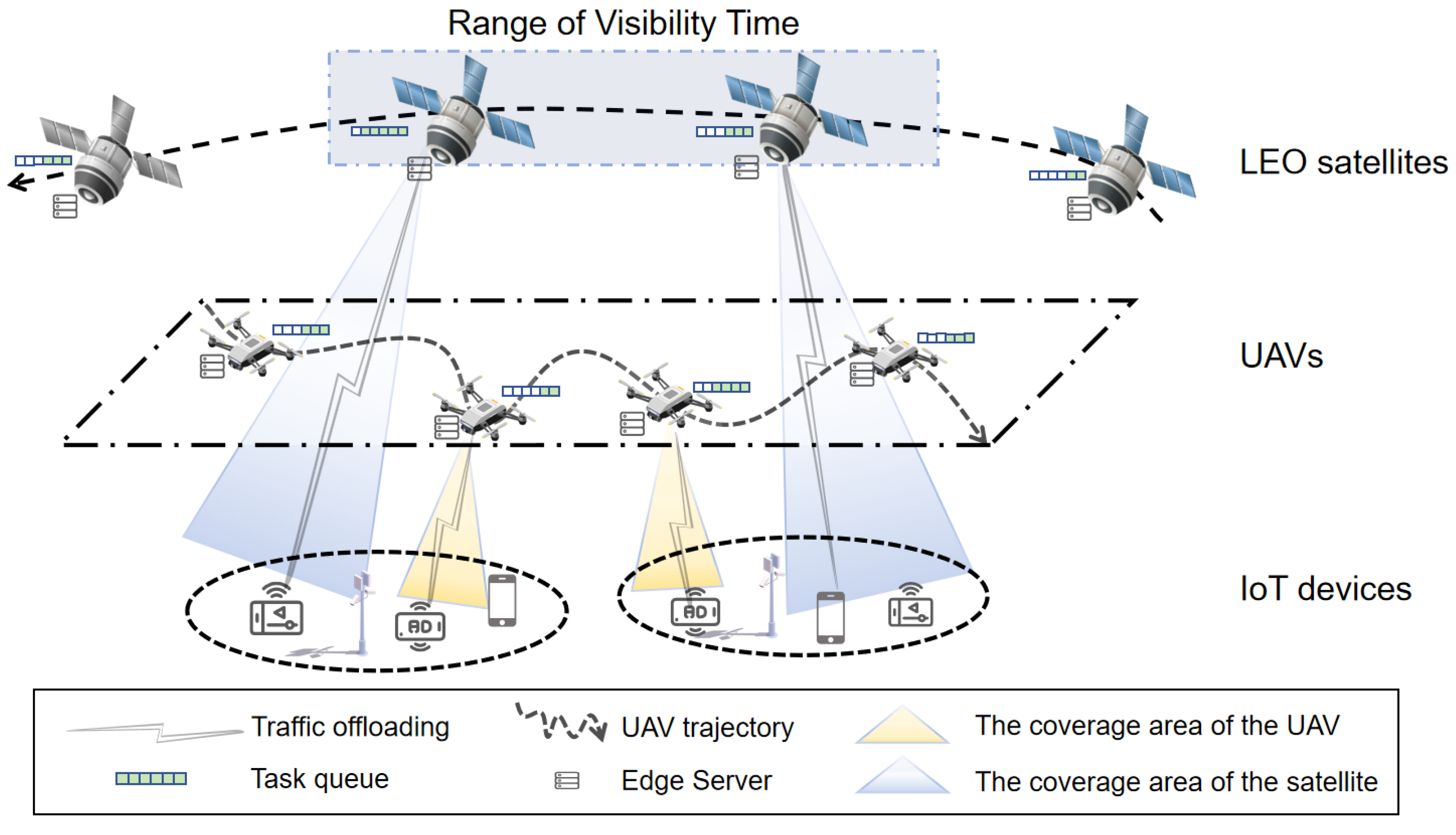
We introduce the SAGIN framework as shown in
Figure 1. The system comprises
L LEO satellites,
U UAVs, and
I IoT devices. Let
represent the set of LEO satellites,
denote the set of UAVs, and
denote the set of IoT devices acting as ground user equipment that generates computational tasks. Here,
,
, and
represent the
l-th satellite, the
u-th UAV, and the
i-th IoT device. Each IoT device, equipped with multiple transceivers, can offload tasks to a UAV or an LEO satellite via reinforcement learning–based decision-making, but only one connection is active at any time. IoT devices transmit computational tasks, while a reinforcement learning mechanism determines whether to offload them to UAVs or satellites for processing. As shown in
Figure 1, both UAVs and LEO satellites are equipped with edge servers and maintain task queues for processing offloaded computation. Satellites provide broader but time-limited coverage. The shaded regions in
Figure 1 indicate the respective coverage areas.
2.2. Task Model
To clearly describe the dynamically changing network scenario due to the random arrival of tasks, the system can be modeled by discretizing time into slots. These time slots are collectively referred to as set . At each time interval , a task arrives at the i-th IoT device, where represents the size of the task in bits, indicates the number of CPU cycles required per bit, and indicates the task categories. Task categories are defined as a set . Each represents a distinct category of tasks characterized by QoS requirements, computational properties, and resource preferences. The offloading decision for device i in time slot t is , which is either 0 or 1, where indicates assigning the task to a UAV and denotes assigning to a satellite.
Offloaded tasks accumulate in task queues
at UAVs and satellites. Let
denote a node, where
, with
representing UAVs and
representing satellites. Each node device
maintains a task queue
indicating pending tasks at time slot
t. The evolution of the task queue is influenced by tasks originating from IoT devices, with
denoting the task volume offloaded from device
i to node
n. The variable
quantifies the number of new tasks assigned to node
n at time
t, which can be calculated as follows:
where
represents the group of IoT devices that offload tasks to node
n. The task queue dynamics for a single node
n are defined as follows:
where
refers to the number of tasks executed by node
n at time
t, as determined by the node’s processing power. The aggregated task queue represents the total workload of UAVs and satellites. It is defined as the sum of individual task queues across all nodes of the same type as follows:
The dynamic updates for the aggregated task queues can be formulated as follows [
20]:
provides a system-level view of the task load across all UAVs and satellites, enabling efficient resource allocation and load balancing decisions.
2.3. Communication Model
In SAGIN, IoT devices communicate with UAVs and satellites through wireless channels. The quality of communication is determined by the channel performance, which varies depending on the node capabilities and environmental factors. This section outlines the channel gain models for ground-to-UAV and ground-to-satellite links.
2.3.1. UAV Communication Link
We consider air–ground communication channels in the Ultra High Frequency (UHF) band. Let
represent the distance from the IoT device
i to the UAV
u at time
t as follows [
21]:
We define
as the UAV’s altitude and
as its horizontal location at time
t. The variable
corresponds to the horizontal coordinates of the IoT device
i, where
i is drawn from the set
of all devices. The large-scale fading component
caused by path loss is expressed as [
22,
23]:
where
denotes the channel coefficient measured at a reference distance
, and
characterizes the signal attenuation rate over distance. To account for multipath effects, the fine-grained fading variable
H is characterized using a Rician distribution [
24]:
Here,
∂ stands for the Rician
K-factor, indicating the ratio of dominant to scattered signal power.
captures the deterministic Line-of-Sight (LoS) contribution, while
reflects the Non-Line-of-Sight (NLoS) component modeled as a Rayleigh random variable. At time slot
t, the channel gain
for the wireless connection between UAV
u and ground IoT device
i is described as [
25]:
The uplink data rate for IoT devices offloading tasks to a UAV at time
t is formulated as follows [
26]:
Here, denotes the portion of bandwidth assigned to IoT device i, while indicates the total bandwidth resource available at the UAV. The term represents the transmit power for device i, and corresponds to the background noise power. represents interference from other devices and noise.
2.3.2. Satellite Communication Link
In terrestrial IoT devices, the dimensions of the antennas can considerably influence the achievable wireless transmission rates. Because antenna size is typically inversely proportional to operating frequency, higher-frequency systems often require smaller antennas. Therefore, in satellite communication, the Ku and Ka bands are commonly used for communication between terrestrial IoT devices and satellites [
27]. The path loss
in free-space conditions is expressed as follows [
28]:
where
denotes the satellite operating frequency in MHz, and
represents the link distance between IoT device
i and satellite
l at time
t. The constant
represents the free-space path loss offset in MHz and kilometers. Environmental attenuation
accounts for factors such as rain fade and atmospheric absorption, which significantly affect channel gain, especially at higher frequencies. For simplicity,
can be modeled as a constant
, where
represents the average attenuation due to rain fade. The channel gain
for the communication link at time
t is modeled as [
29]:
Let
be the transmit gain of the satellite. At time
t, the uplink throughput achieved by IoT devices communicating with it is computed as follows:
In this equation, denotes the bandwidth allocated to IoT device i, denotes total available bandwidth of satellite l, represents transmission power allocated to device i, and indicates noise power. The term denotes interference from other devices and noise.
2.4. Computation Model
In heterogeneous edge computing environments, tasks
arriving at the
i-th IoT device at time
t are characterized by their task categories
. The task categories vector is defined as follows:
where
K is the number of predefined task categories, such as computation-intensive, parallel computing, or real-time signal processing types.
Each UAV or satellite node consists of multiple heterogeneous computing devices, such as a Central Processing Unit (CPU), Graphics Processing Unit (GPU), Field Programmable Gate Array (FPGA), and other specialized processors. Let the set of all computing resource characteristics supported by these heterogeneous devices be denoted as follows
:
where each
represents a distinct type of computing resource, and
z denotes the total number of computing resource characteristics in the system.
To represent the availability of each resource characteristic at different nodes, we define a binary resource characteristics indicator matrix , where n is the total number of nodes that include UAVs and satellites. The nodes indexed from 1 to j correspond to UAVs, while the nodes indexed from to n correspond to satellites. The i-th row of the matrix corresponds to node i, and the z-th column corresponds to the type of computing resources .
The matrix is formally defined as:
Each element in the matrix represents a binary indicator of whether node n supports the type of computation resource at time t. Specifically, indicates that node n is equipped with resource characteristics , enabling it to execute tasks that rely on this type of hardware. In contrast, implies that the node lacks this resource.
The UAV and satellite nodes consist of multiple individual devices. Each node
n that can represent a UAV or a satellite has a corresponding resource vector
, which characterizes its computational, memory, and communication capabilities. For the
n-th node, the resource vector is as follows:
where
k represents the number of resource characteristics, and each
,
, describes a specific resource characteristic of the corresponding node.
To evaluate the compatibility between a task
and the computational resources of a specific node
n, we define a compatibility coefficient
, which quantifies the suitability of offloading the task to the node device
n. The coefficient is calculated as follows:
where
represents the task categories vector,
denotes the resource vector of node device
n, and
is a weight matrix. The weight matrix
M adjusts the relative importance of different task categories and resource characteristics, ensuring that the compatibility calculation aligns with the specific requirements of the application scenario.
The transmission delay
for node device
n is calculated using the transmission rate as follows:
where
is the data size of task
, and
is the transmission rate between IoT device
i and node
n.
The computation delay
for node device
n is adjusted by the adaptability coefficient
as follows:
where
denotes the computation intensity of the task, and
denotes the computational capacity of node device
n.
The total time delay
for node
n consists of transmission and computation components as follows:
The energy utilization of IoT device
i comprises transmission, computation, and idle energy consumption. The amount of energy consumed during data transmission to node
n is calculated as follows:
where
refers to the transmit power of device
i when communicating with node
n.
The computation related energy for device
i is given by the following:
where
is the processing power of node
n.
The idle energy consumption is computed as follows:
where
refers to the standby power of device
i, and
denotes the duration for which device
i remains inactive. The total energy expenditure of device
i in interaction with node
n is as follows:
2.5. Problem Formulation
We construct an optimization task
aiming to lower scheduling costs in SAGIN by accounting for the following three main criteria: latency, energy, and queue size. The weights
,
, and
determine their relative impact. The formulation of
is presented as follows:
The objective is the average cost across all tasks, nodes, and time slots. Constraint ensures that the offloading decision is binary, indicating the task is executed locally or offloaded. Constraint limits bandwidth usage to the maximum available bandwidth. Constraint restricts task completion time to the node’s available processing time. Constraint ensures energy consumption does not exceed the device’s maximum capacity. Constraint limits the queue length to avoid excessive backlog at each node. These constraints regulate delay, resource usage, and system balance under heterogeneous network conditions.
It is important to clarify the nature of the proposed optimization problem
in terms of convexity and computational complexity. The problem involves discrete decision variables
, which represent binary offloading choices. Due to the presence of such integer variables, problem
falls into the category of Mixed-Integer Linear Programming (MILP). MILP problems are known to be non-convex and NP-hard, meaning that they cannot, in general, be solved efficiently to global optimality using conventional convex optimization techniques [
30,
31]. This non-convexity arises not from the objective function or constraint linearity, but from the discrete nature of the decision space introduced by integer variables. To address this challenge, we propose a DRL-based solution framework in
Section 3. This framework is specifically designed to efficiently handle the high-dimensional and discrete decision space of MILP-type problems, such as ours, and reduce the computational burden associated with classical optimization solvers.
3. Algorithm Design
3.1. Markov Transformation
Considering the optimization problem
, the long-term objectives need to be integrated and treated in a multi-step decision-making framework. We can transform it into a Markov decision process (MDP) problem, which is typically defined by a four-tuple (S, A, P, R) [
32]. The elements of (S, A, P, R) are defined as follows:
State: At time t, the system state comprises various elements that reflect the system’s condition as follows:
Action: The control input at slot t includes the following: .
State Transition: Given the current state and action , the system’s evolution to the next state occurs with the following probability:
Reward: To reduce the cumulative cost in the SAGIN architecture, the immediate reward at time t is expressed as follows: .
3.2. TM-DDPG Based Offloading Algorithm
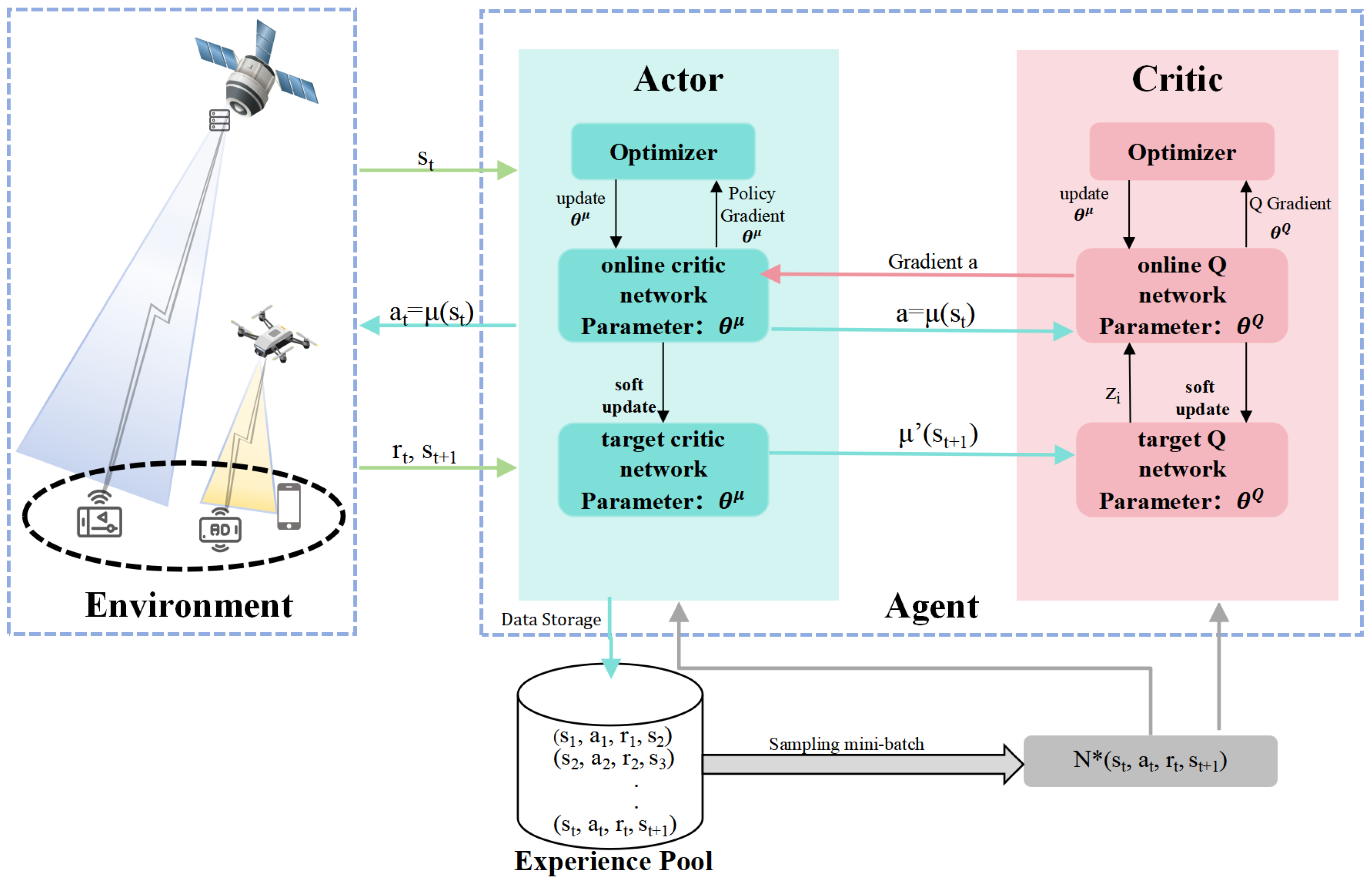
As shown in
Figure 2, the agent in the type matching enhanced deep deterministic policy gradient (TM-DDPG) algorithm comprises the following two neural networks: an actor and a critic, parameterized by
and
, respectively. The actor network interaction with the SAGIN environment results in the current state,
being obtained. Based on this state, an appropriate action,
, is selected. The selected action then generates the next state
. The reward received by the agent
R is recorded in the experience replay buffer to facilitate subsequent learning and optimization. The actor network’s parameter set, denoted by the symbol
, is iteratively optimized based on the collected experiences through the process of gradient updating.
Meanwhile, the actor network’s target network selects the corresponding action based on the next state output by the current network and updates the target network’s parameter set accordingly. To evaluate the effectiveness of the policy, the critic network calculates the Q-value for the given state and action combination (S, A). Then it updates the parameter set of the current network , based on this Q-value. Using the current state and action, the critic target network derives the target Q-value and correspondingly refines its parameters . The Q-value represents the total expected return that the agent will receive by performing a specific action in a particular state. It depends not only on the immediate reward, but also on the expectation of rewards in the future.
The Q-value update follows the principle of the Bellman equation, expressed as follows:
Here,
refers to the highest estimated Q-value following action
in state
, while
indicates the present value estimate for the current state-action pair. The critic network is gradually refined by reducing the discrepancy between this estimate and the target Q-value. The TM-DDPG algorithm guides the actor network toward an optimal policy for maximizing long-term returns. To this end, the parameters
are optimized by maximizing the corresponding policy objective function, as follows:
Here,
N denotes the total number of data samples. The critic network’s goal is to train an optimal value function by reducing the loss function to update the current network parameters
. The loss function is defined as follows: Where
is the update coefficient. The TM-DDPG algorithm demonstrates significant advantages in the task offloading problem within the SAGIN edge computing environment. It can handle complex continuous action spaces and dynamically adjust policies to cope with time-varying network environments. It demonstrates significant advantages in latency optimization and energy consumption reduction. TM-DDPG optimizes the policy (actor) and the value function (critic) through the agent–critic structure of the agent network. This structure improves learning efficiency and enables agents to adapt quickly to dynamic network environments. TM-DDPG optimizes the immediate reward at each time step and considers the long-term task offloading returns, thereby improving the system’s overall performance. Therefore, when addressing the task offloading problem in the SAGIN environment, TM-DDPG can achieve efficient, flexible, and intelligent offloading decisions while meeting the optimization objectives.
where
is the target Q-value, and
is the current Q-value. The agent updates the target network parameter set using a soft update method. This method smoothly adjusts the target network parameters towards the current ones, preventing sudden changes and ensuring stable training as follows:
To evaluate the computational overhead of the TM-DDPG algorithm, we analyze the complexity of its core learning components—the actor and critic networks, as described in Algorithm 1. These networks take the global state vector
as input, which is formed by concatenating the local observations from all IoT devices. Each per-device state
, where
denotes the state dimension and
K is the number of predefined task categories. Given
I IoT devices, the total input dimension becomes
. We denote by
the number of hidden layers in each neural network and by
H the number of neurons per hidden layer. Suppose the training is performed using a batch size of
J. Then, the computational complexity of a single training iteration is approximately
. Let
Z denote the total number of training episodes. Then the overall time complexity of TM-DDPG is
[
33].
| Algorithm 1 M-DDPG algorithm in the SAGIN scenario |
- 1:
Initialize experience replay buffer and network parameters for the user terminal agent: , , , ; - 2:
for to M do - 3:
Initialize SAGIN environment parameters and construct an integrated space-air-ground task offloading network; - 4:
Initialize the agent’s state ; - 5:
for to T do - 6:
Derive action from state using the policy output of the Actor network; - 7:
Perform to transition to and receive instantaneous reward ; - 8:
Save the tuple into the experience memory; - 9:
if t thenhe experience buffer is not full - 10:
Continue interactions; - 11:
else - 12:
Randomly sample from the experience buffer; - 13:
Compute the target value; - 14:
Compute the critic network loss function and update the critic network parameters ; - 15:
Update the actor network parameters to maximise the policy objective function; - 16:
end if - 17:
end for - 18:
Soft update the target network parameters and ; - 19:
end for
|
In addition to time complexity, we also analyze the space complexity of the TM-DDPG algorithm. The primary contributor to memory consumption is the experience replay buffer used to store transitions for training. Each transition takes up space. Therefore, the overall memory complexity of the replay buffer is , where W denotes the buffer size. Additionally, the actor and critic networks require memory for storing their parameters. Each network has approximately parameters. Since both actor and critic (along with their target networks) are maintained, the total parameter memory cost becomes . Combining both parts, the total space complexity is , where the replay buffer typically dominates.
4. Performance Evaluation
In this section, we extend the analysis by introducing three additional reinforcement learning variants for comparison. Non-DDPG refers to the original Deep Deterministic Policy Gradient algorithm without type-matching. TM-TD3 denotes the type-matching-enhanced Twin Delayed Deep Deterministic Policy Gradient (TD3). Non-TD3 represents the standard TD3 algorithm without the type-matching mechanism. These variants are included to assess the generalization capability of the type-matching design across different algorithmic frameworks and to evaluate its contribution beyond DDPG-based methods.
The algorithms in this paper are implemented in a Python 3.11 environment and run on a Windows 10 system equipped with an NVIDIA RTX 4090Ti GPU and 16GB RAM. Additionally, the deep reinforcement learning environment is based on Pytorch 2.2.2 and Numpy 1.26.4.
Table 1 summarizes the primary simulation parameters employed in the SAGIN-MEC scenario, which involves communications among satellites, UAVs, and IoT devices. The parameters include communication frequencies and bandwidths for both satellite and UAV links, energy and transmission power constraints of IoT devices and UAVs, channel characteristics such as rain attenuation and fading factors, task data sizes, and the velocity range of UAVs. These settings define the network conditions under which the proposed framework is evaluated. Some representative parameter configurations for the SAGIN-MEC environment are listed in the table below [
34].
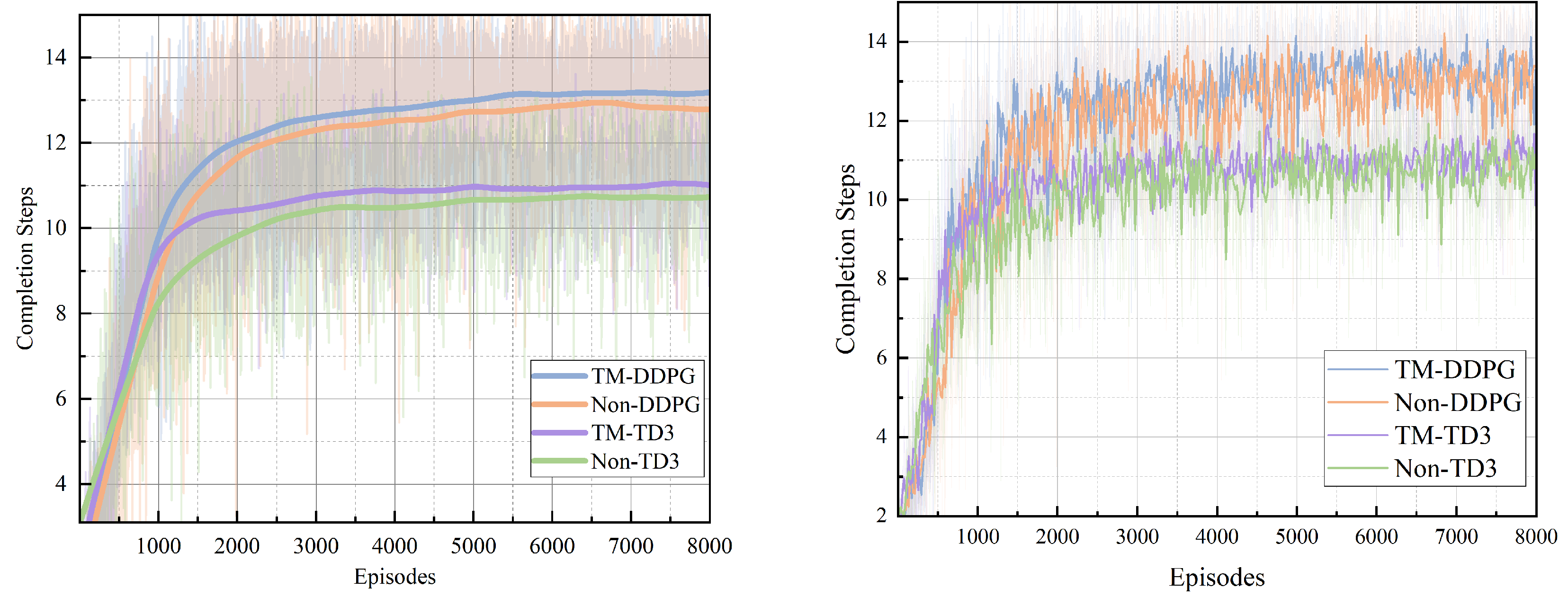
Figure 3 illustrates the learning performance of four reinforcement learning algorithms over 8000 training episodes, where the x-axis represents the number of episodes and the y-axis denotes the average task completion steps per episode. Higher values indicate more efficient task execution under the learned policy. The figure compares TM-DDPG, Non-DDPG, TM-TD3, and Non-TD3 to evaluate the effectiveness of the proposed TM enhancement. TM-DDPG demonstrates the most rapid convergence, achieving stable performance above 13 steps after approximately 2000 episodes. This indicates that the TM mechanism enables the agent to quickly adapt to environment dynamics and effectively learn optimal offloading strategies. TM-TD3 also benefits from the enhancement, converging more slowly but maintaining a clear performance margin over Non-TD3 throughout training. Non-DDPG exhibits relatively stable convergence and performs competitively, but consistently lags behind TM-DDPG in both convergence speed and final task completion steps. Non-TD3 shows the slowest learning progress and the lowest asymptotic performance, with significant variance across episodes. TM-TD3 achieves modest improvement, confirming that TM contributes positively across different algorithmic frameworks. The shaded regions around each curve represent the variance over repeated runs, reflecting learning stability. TM-based approaches not only improve mean performance but also reduce fluctuation during training, which is crucial in dynamic environments. Overall, the results validate that task–resource matching significantly enhances both learning efficiency and policy robustness, particularly within the DDPG framework. To provide a clearer view of training stability and short-term variance, we additionally present the right subfigure in
Figure 3, which depicts the same metric using a sliding window of 20 episodes. The shaded areas represent variability during training. Compared to Non-TM variants, TM-based algorithms not only demonstrate improved average performance but also significantly reduce variance, which is crucial in dynamic environments. These results confirm that task–resource matching enhancement contributes to both learning efficiency and robustness across different DRL frameworks.
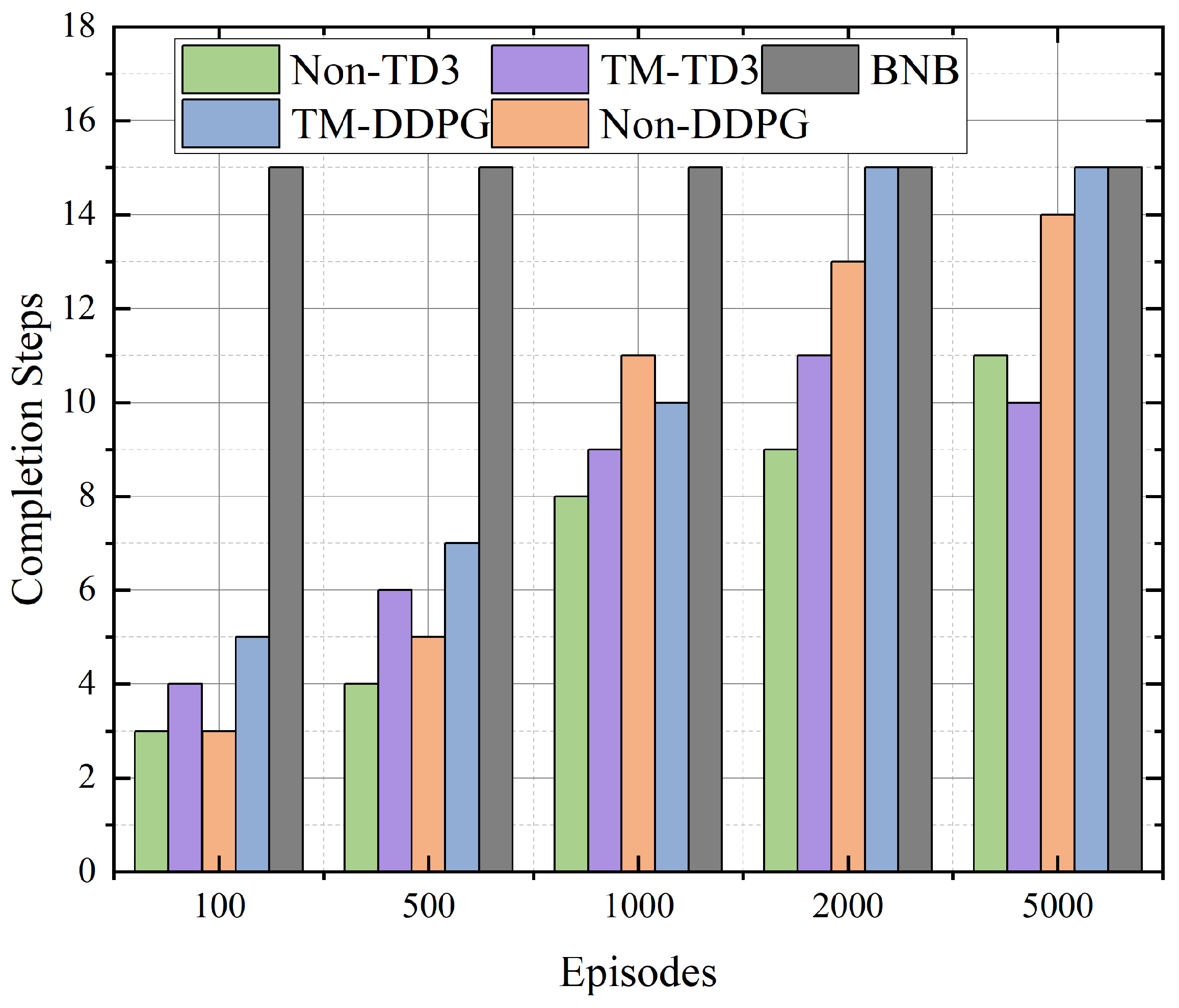
Figure 4 presents the task completion steps of different methods over training episodes, while learning-based approaches improve over time, the Branch-and-Bound (BNB) method achieves the highest number of completion steps. However, BNB is a deterministic optimization algorithm with exponential time complexity. Its performance comes at the cost of substantial computational overhead, making it unsuitable for large-scale or time-constrained environments. In contrast, the proposed TM-DDPG offers a favorable trade-off between performance and efficiency, enabling practical deployment in dynamic offloading scenarios.
Figure 5 shows the training reward curves of TM-DDPG, Non-DDPG, TM-TD3, and Non-TD3 over 8000 episodes. The reward is computed as a weighted combination of task latency, energy consumption, and queue length, reflecting the quality of each offloading decision. Higher reward values indicate more efficient and balanced task execution. TM-DDPG achieves the highest reward and exhibits rapid convergence within the first 1500 episodes, followed by stable performance with low variance. TM-TD3 also shows continuous improvement and maintains a moderate advantage over Non-TD3 throughout training, though it converges more slowly and reaches a slightly lower peak than TM-DDPG. Non-DDPG gradually increases but plateaus at a lower level, indicating less efficient policy learning. Non-TD3 demonstrates high fluctuation and limited reward gain, suggesting instability and poorer decision-making capability. The shaded regions around each curve represent the variance across multiple runs, indicating learning stability. TM-enhanced algorithms not only reach higher reward levels but also reduce variance, which is critical in dynamic environments. These results validate the effectiveness of the task–resource matching mechanism in improving policy quality and training stability, with particularly significant gains observed under the DDPG framework.
Figure 6 presents the reward distributions of TM-DDPG, Non-DDPG, TM-TD3, and Non-TD3 during the first 100 training episodes. Each boxplot illustrates the distribution of episode rewards using the interquartile range, with whiskers indicating the minimum and maximum observed values. Higher median rewards and narrower boxes indicate better and more consistent performance. TM-DDPG achieves a significantly higher median reward and a tighter distribution than Non-DDPG, suggesting that the task–resource matching (TM) mechanism enables faster policy adaptation and more effective early-stage decision-making. In contrast, TM-TD3 shows a lower median and wider spread than Non-TD3, indicating unstable learning and greater variability. This may result from the interaction between TD3’s delayed policy updates and the TM mechanism, which could disrupt learning in the early phase. Overall, the TM mechanism enhances early performance in DDPG but introduces instability when combined with TD3.
Figure 7 shows the reward distributions over the final 100 episodes after training convergence. TM-DDPG consistently outperforms all other variants, achieving the highest median reward with minimal variance, reflecting robust policy stability and superior decision quality. Non-DDPG follows with slightly lower rewards and a wider spread. TM-TD3 achieves a modest improvement over Non-TD3 in both median and variability, but the gap between the two is smaller compared to the DDPG variants. Both TD3-based algorithms exhibit greater variance than DDPG-based ones, indicating less stable convergence behavior. These results demonstrate that the TM mechanism significantly improves long-term performance in DDPG, while its effect on TD3 is limited and less reliable.
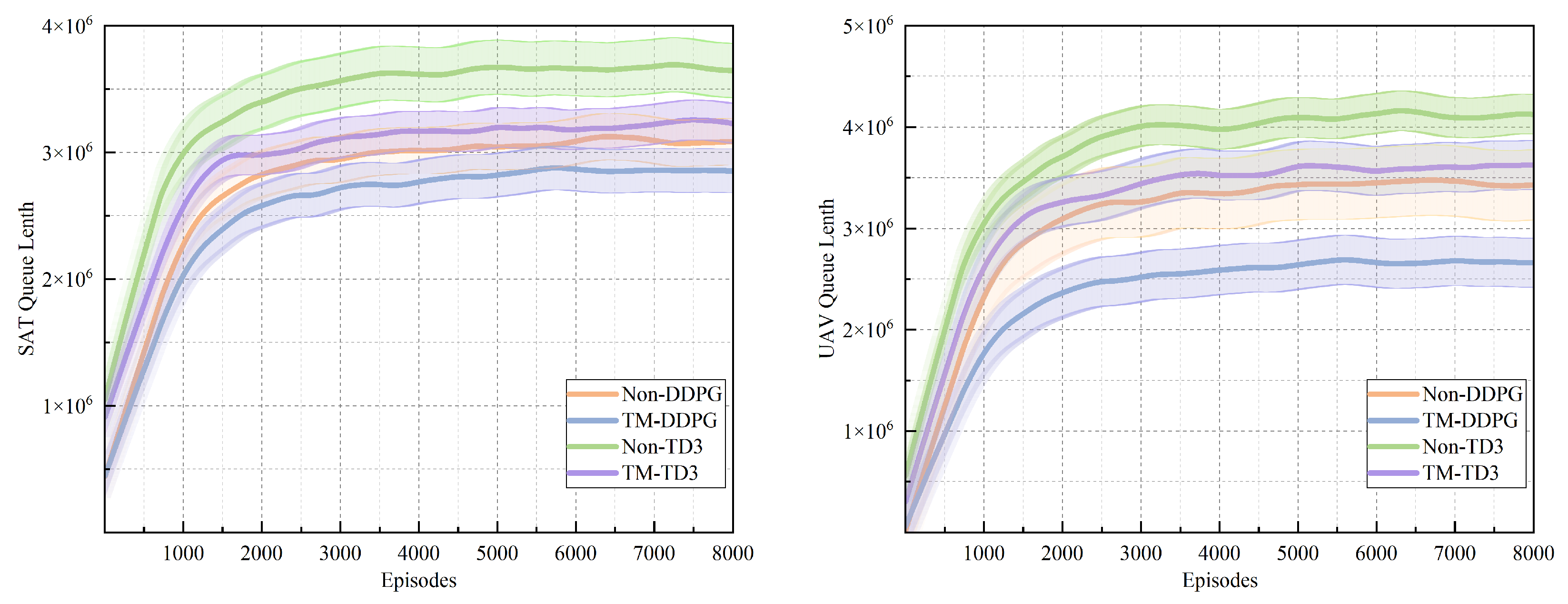
Figure 8 compares the task queue lengths of TM-DDPG, Non-DDPG, TM-TD3, and Non-TD3 on satellite and UAV nodes over 8000 training episodes. The left subfigure shows the queue length on satellite (SAT) nodes, while the right subfigure presents the same metric on UAV nodes. Queue length reflects the degree of task accumulation at each node, which is directly related to system load, latency, and congestion. All algorithms exhibit a sharp increase in queue length during the early training phase, followed by gradual stabilization as their policies converge. TM-DDPG consistently maintains the lowest queue length on both satellite and UAV nodes, indicating more effective task distribution and faster convergence. In contrast, Non-TD3 results in the highest queue length throughout training, suggesting inefficient offloading behavior and greater system pressure. TM-TD3 performs slightly better than Non-DDPG on satellites but worse on UAVs, reflecting mixed effectiveness of the task–resource matching (TM) mechanism in the TD3 framework. The variance bands surrounding each curve represent performance variability across independent runs. TM-DDPG shows both lower queue length and reduced variance, indicating more stable and balanced learning. Overall, the TM mechanism significantly improves load balancing and reduces node congestion, especially when combined with DDPG. This leads to improved system responsiveness and supports more efficient learning of offloading policies.
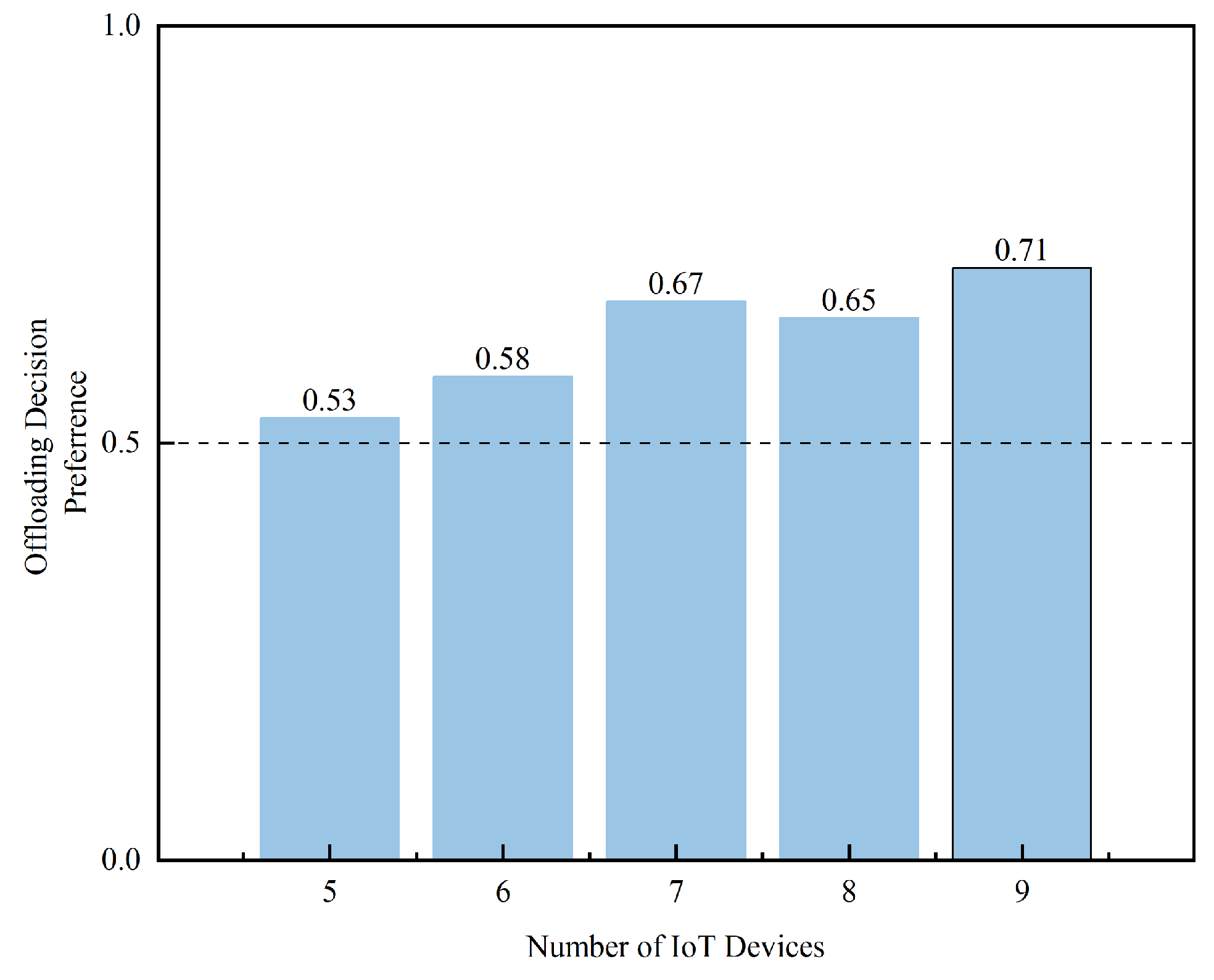
Figure 9 presents the offloading preference learned by TM-DDPG under different numbers of IoT devices, ranging from 5 to 9. The y-axis represents the proportion of offloading decisions directed toward satellite nodes, where a value above 0.5 indicates a preference for satellite over UAV offloading. As the number of IoT devices increases, the preference shifts upward from 0.53 to 0.71. This trend suggests that under higher system load, TM-DDPG increasingly favors satellite nodes due to their stronger processing capacity and higher bandwidth. Satellite links can accommodate more concurrent offloading requests and provide stable performance under traffic pressure. Importantly, the preference never reaches 1.0, indicating that UAVs are still actively selected. Their inclusion is based on real-time environmental factors such as queue length, latency, and transmission cost. TM-DDPG adapts its policy to leverage both UAV and satellite resources, achieving dynamic and balanced load distribution. The resulting strategy reflects a resource-aware and task-sensitive offloading behavior suited to heterogeneous edge environments.
Figure 10 illustrates the average task latency under varying numbers of IoT devices for three different offloading strategies. The latency values are computed as the average of each node device’s local processing delay and task transmission delay, aggregated over multiple episodes after the training process has converged.The Random strategy produces the highest latency across all settings. Its delay increases rapidly as the number of devices grows and peaks at device count eight. The results suggest a lack of effective task allocation. Non-DDPG performs better than Random and keeps lower latency overall. However, its average delay continues to rise with more devices, indicating limited scalability under high load. TM-DDPG achieves the lowest latency across all tested scenarios. Its performance remains stable with minimal fluctuations. The zoomed view shows that TM-DDPG maintains low latency even as the system becomes more congested. This indicates that its offloading policy adapts well to load variations and uses available resources more efficiently.
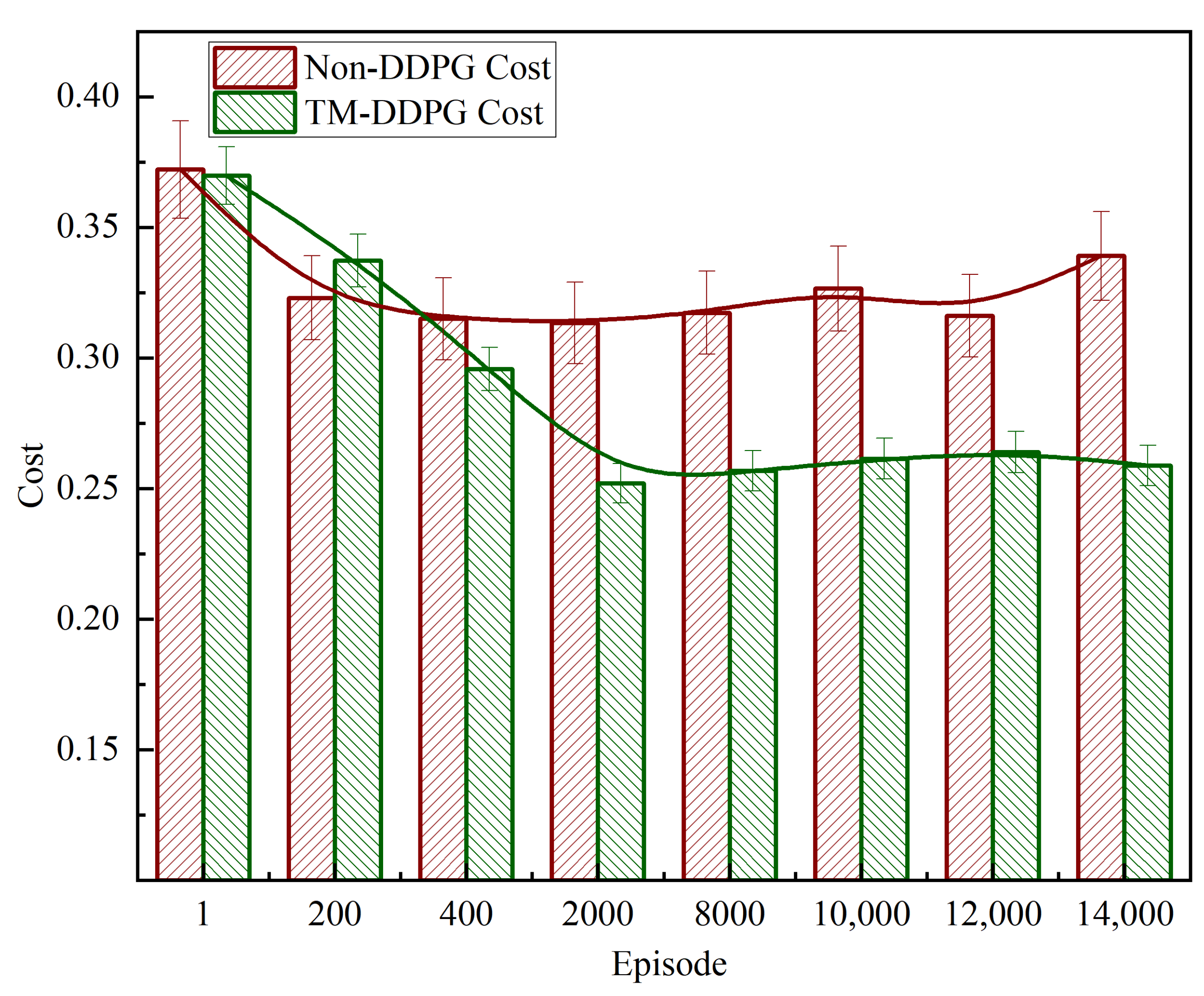
Figure 11 illustrates the cost evolution of TM-DDPG and Non-DDPG across selected training episodes. The y-axis represents the average offloading cost, which combines factors such as energy consumption, transmission delay, and task queuing time. Each bar denotes the average cost at a given episode, and the error bars represent a fixed margin added for visual comparison. The green bars correspond to TM-DDPG, while the red bars represent Non-DDPG. Additionally, smoothed trend lines are superimposed for both algorithms to highlight long-term behavior. In the early training phase (Episode 1–1000), both algorithms begin with similarly high cost levels. TM-DDPG then shows a steady downward trend, indicating effective policy learning and faster convergence. By contrast, Non-DDPG achieves partial cost reduction but fluctuates more significantly and stabilizes at a higher cost level. In the later stages (Episode 8000 onward), TM-DDPG maintains consistently lower cost values with minimal variation, demonstrating improved robustness and stable long-term performance. These results confirm that the task–resource matching enhancement enables TM-DDPG to better adapt to system dynamics and achieve superior cost-efficiency during and after convergence.
5. Conclusions
In this paper, we present a task offloading and resource allocation formulation framework tailored for dynamic and heterogeneous SAGIN environments. The framework integrates a task–resource matching matrix and reinforcement learning to optimize bandwidth, transmission power, and task queue management. The key features of the framework include a matching mechanism that matches task categories with resource characteristics, efficient dynamic queue modeling and a TM-DDPG algorithm that enables real-time optimization. Experimental results show that the proposed framework significantly outperforms existing approaches by reducing system cost, decreasing latency, and improving resource utilization. These results validate the effectiveness of the framework in addressing the challenges of task offloading in heterogeneous SAGIN.
Although this study has demonstrated favorable performance in task offloading and resource allocation, several limitations remain. The current framework does not consider UAV path planning, which is critical for practical deployment in dynamic airspace environments. Moreover, the proposed model is based on a single-agent architecture and does not account for coordination or conflict resolution among multiple agents. Realistic scenarios often involve multiple UAVs, satellites, and ground nodes, introducing more complex interactions and resource competition. Future work will consider integrating path planning into the reinforcement learning framework to enable adaptive trajectory control. Additionally, multi-agent cooperation strategies will be explored to support efficient task allocation and resource management across SAGIN, thereby enhancing the scalability and applicability of the proposed method in real-world heterogeneous environments.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}