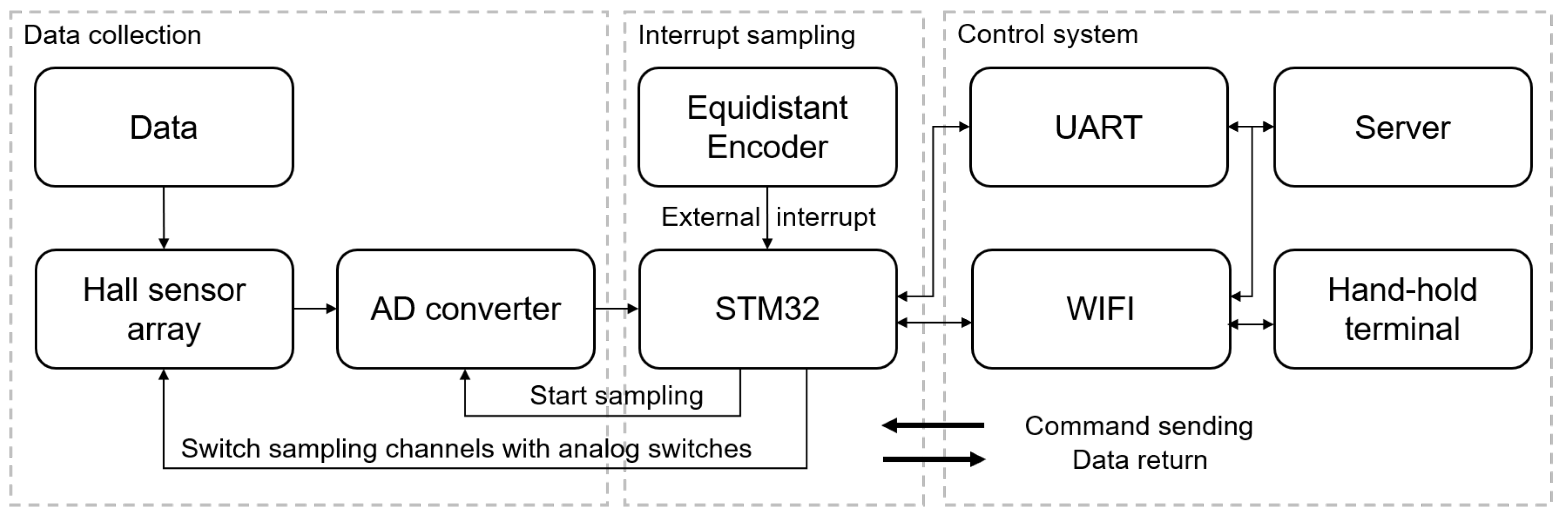
5.2. Parameters Setting
In the YOLOv9 training phase, the Stochastic Gradient Descent with Momentum (SGDM) optimization algorithm is applied, utilizing specific hyperparameters detailed in
Table 2.
Throughout training, input images undergo augmentation and resizing before being fed into the CNNs. To reduce the influence of strand-related textures, spatial filtering based on strand inclination was applied to the raw MFL images, as shown in
Figure 12c,d. The model was trained on these filtered images to preserve defect-related features while suppressing background textures. To enhance the robustness of the model, several data preprocessing and augmentation techniques were applied. First, additive Gaussian noise with zero mean and a standard deviation of
was added to the MFL signals during training to simulate real-world sensor noise. Second, to mimic partial occlusion or missing data in real scenarios, random rectangular masking was used to obscure 10–30% of the image area during augmentation. Third, beyond peak-to-peak normalization, each sensor channel was standardized using z-score normalization based on the channel’s mean and standard deviation across the dataset. This aimed to reduce hardware-specific signal variations.
Following this, predictions of bounding box information are generated based on anchor boxes. Subsequently, the loss function is employed to calculate the disparity between the predicted bounding boxes and the ground truth bounding boxes. During the testing phase, well-trained neural networks process input images with high efficiency, particularly benefiting from the one-to-one branch structure.
5.3. Evaluation Indicator
The commonly used evaluation metrics for object detection include precision (P), recall (R), and mean Average Precision (
). Precision denotes the probability that all positive samples detected by the model are actual positive samples, while recall represents the probability that the model detects positive samples within the actual positive samples. Following standard definitions in the literature [
31], precision and recall are defined by Equations (
6) and (
7), respectively:
Here,
is the number of correctly detected defective samples,
is the number of non-defective samples falsely identified as defective,
is the number of defective samples incorrectly recognized. Furthermore,
is a comprehensive metric considering both precision (P) and recall (R). A higher
value indicates a higher detection accuracy of the model. It is defined as:
5.4. Results
As shown in
Table 3, we compare five YOLO-based detectors on our defect dataset. YOLOv9e achieves the highest recall (76.7%) and mAP@50 (75.9%), while YOLOv5 achieves the best precision (75.5%). This indicates that YOLOv9e provides more comprehensive detection coverage, whereas YOLOv5 is more conservative but confident in its predictions.
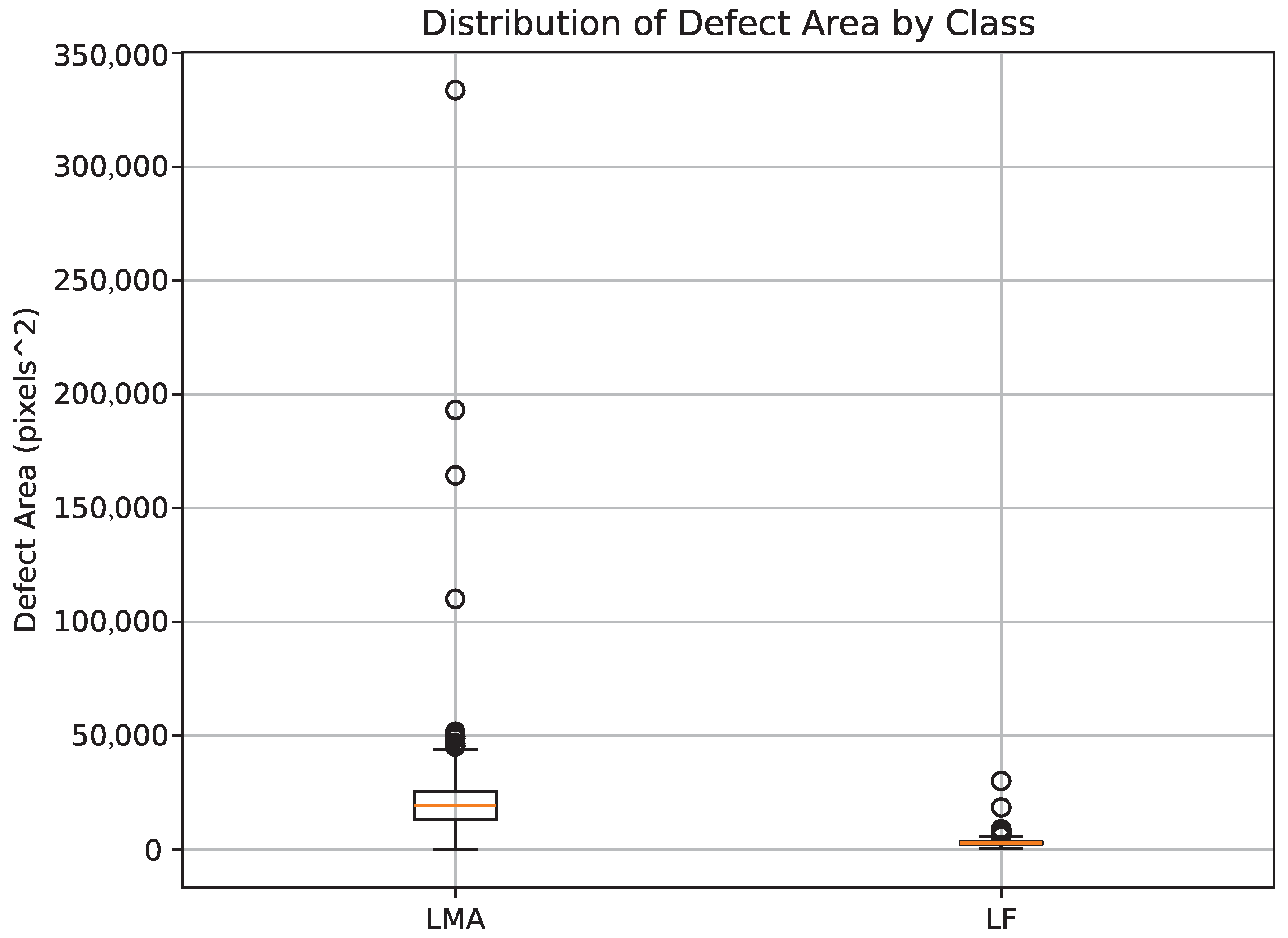
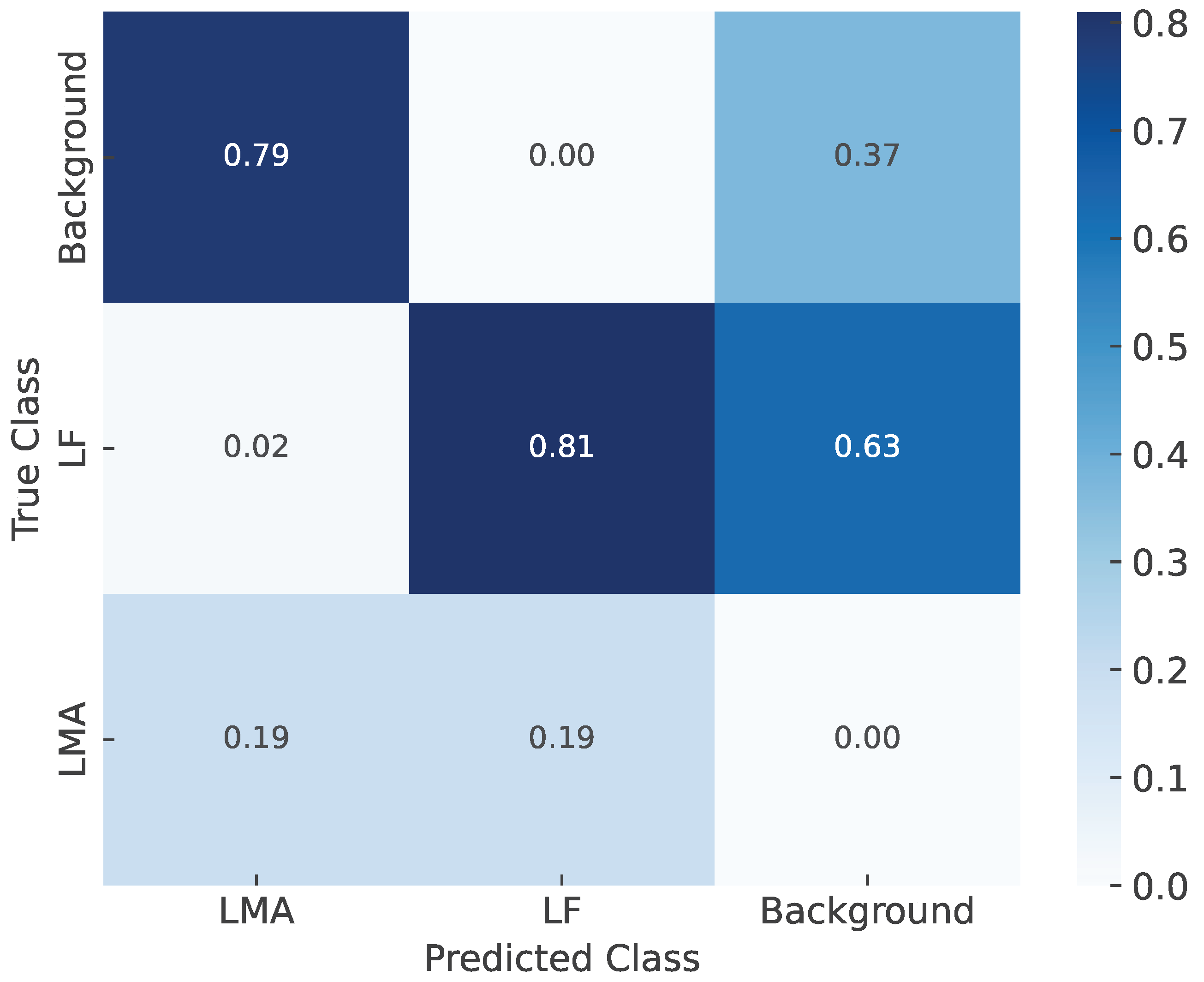
The performance gap can be attributed to the imbalance and complexity of the dataset, which contains 1678 LF and 981 LMA instances. LF defects are more frequent and typically localized, while LMA defects are more complex, spanning multiple strands with diffuse textures. YOLOv9e benefits from enhanced feature fusion and a deeper backbone, enabling better generalization across both defect types, particularly under class imbalance. In contrast, YOLOv10 underperforms across all metrics, likely due to insufficient feature resolution or limited adaptability to structural variation. YOLOv11 slightly outperforms YOLOv8 but does not surpass YOLOv9e, indicating that the ability to capture fine-scale textures and semantic cues remains critical for defect detection. These results highlight the importance of model architecture capacity and robustness to data distribution when deploying models for industrial inspection. Additionally, the confusion matrix illustrating classification outcomes for LMA, LF, and background classes is shown in
Figure 14. The detection precision for LF defects is 81%, with 2% misclassified as LMA and 63% incorrectly identified as background, indicating substantial confusion with background regions. For LMA defects, the detection precision is 79%, with 37% misclassified as background. Interestingly, despite their larger spatial extent, LF defects show a higher false background rate, which may be attributed to their weaker texture contrast and smaller region size, making them more prone to being submerged in noisy background features. In contrast, LMA defects, although semantically more complex, may retain salient structures that the model can effectively learn. The background class itself suffers from severe misclassification, highlighting the challenge of effectively separating defect regions from complex backgrounds. To provide a more quantitative view of class-wise detection behavior,
Table 4 summarizes the True Positive Rate (TPR), False Positive Rate (FPR), and False Negative Rate (FNR) for the LF and LMA classes. TPR and FNR values are derived directly from the confusion matrix. Since the dataset lacks explicit annotations for background regions, FPR values are estimated under the assumption that the number of background instances is approximately equal to the total number of defect instances. This assumption enables approximate evaluation of how often background regions are incorrectly detected as defects. The estimated FPRs, 48% for LMA and 32% for LF, further support the observation that background confusion remains a critical challenge in defect localization.
To evaluate the generalization ability and robustness of our model under different data splits, we conducted a three-fold cross-validation. As shown in
Table 5, the model consistently achieves high performance across all folds, with an average precision of 74.9%, recall of 75.9%, and mAP@50 of 73.5%. These results indicate that the model is not overfitting to a particular data split and maintains stable performance, thereby justifying the validity of the reported results.
5.5. Ablation Study
In this experiment, we investigate the impact of different learning rates on the performance of YOLOv9e for defect detection.
Table 6 presents results across various learning rates (0.008, 0.006, 0.002, 0.001, and 0.010), with the best values in each metric highlighted in bold. The results show that a learning rate of 0.002 yields the best overall performance in terms of mAP@50 (75.9%) and mAP@50:95 (35.0%), indicating that a lower learning rate facilitates better detection precision and generalization. In particular, for LMA defects, this setting achieves the highest mAP@50:95 (46.2%), likely due to the complex textures and varied scales of LMA defects, which require the model to capture subtle multi-scale features. A lower learning rate helps stabilize training, allowing the model to better handle these characteristics.
Conversely, higher learning rates (0.008 and 0.010) result in performance degradation across all metrics, especially mAP@50:95. This suggests that excessively high learning rates may cause instability during training, impairing the model’s ability to learn fine-grained defect patterns—especially critical for LMA detection. For LF defects, which are typically smaller and more localized, a learning rate of 0.006 achieves the highest mAP@50 (69.8%), suggesting that LF detection benefits from a moderate learning rate that balances convergence speed with accuracy. The dataset used in this study consists of 1678 LF and 981 LMA instances, collected from wire ropes in a controlled laboratory setting. Variations in defect size, texture, and boundary ambiguity influence the model’s sensitivity to the learning rate. Specifically, LF defects, being smaller and more localized, may require a slightly higher learning rate to avoid overfitting and encourage faster convergence. In contrast, LMA defects, with more complex patterns, benefit from the stability provided by a lower learning rate.
Overall, the study highlights that lower learning rates, such as 0.002, tend to yield better performance for complex defects like LMA, while higher learning rates may lead to convergence issues and performance degradation. These findings emphasize the importance of choosing an appropriate learning rate based on both the defect characteristics and dataset distribution to ensure model stability and optimal detection outcomes.
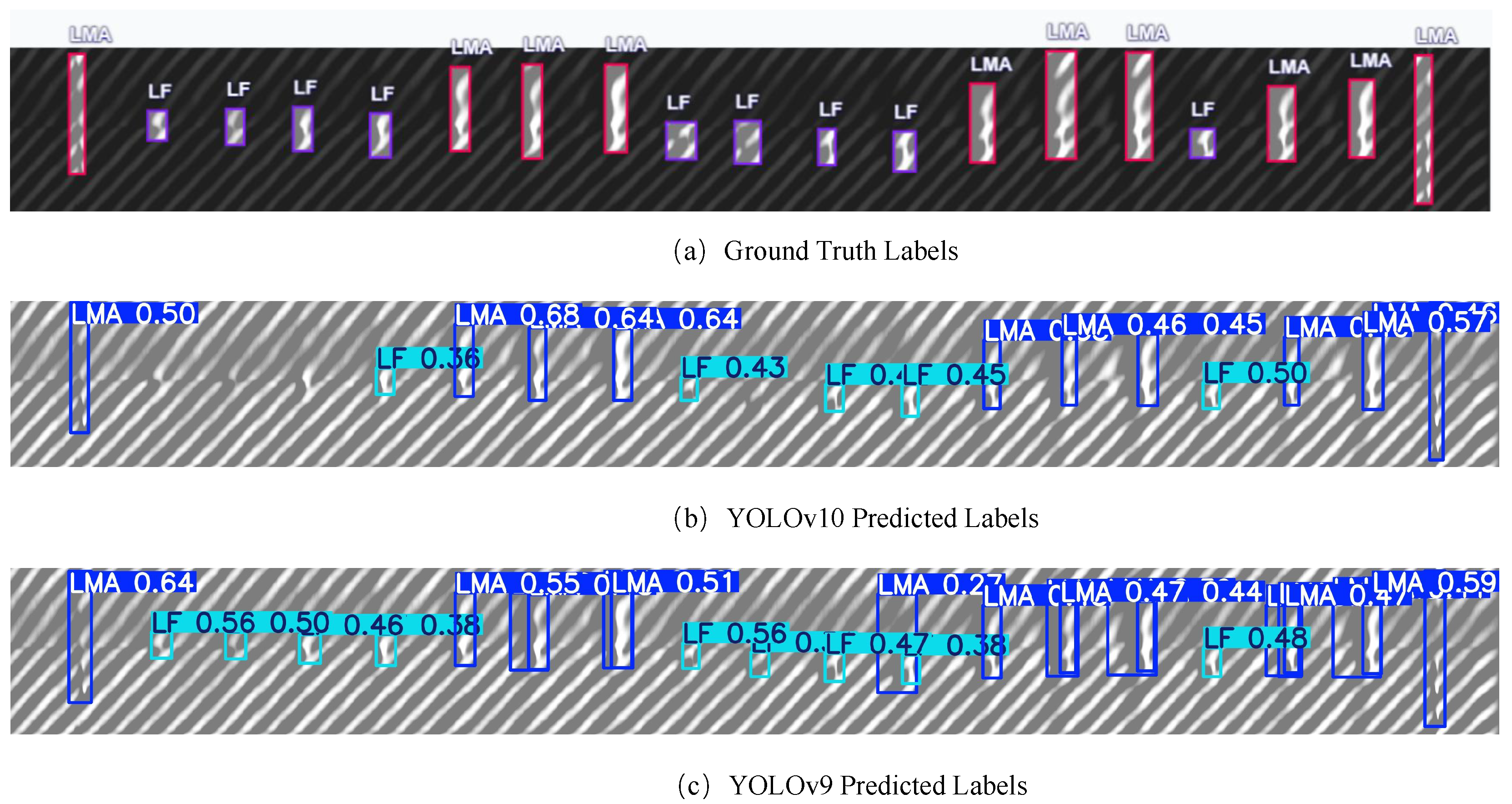
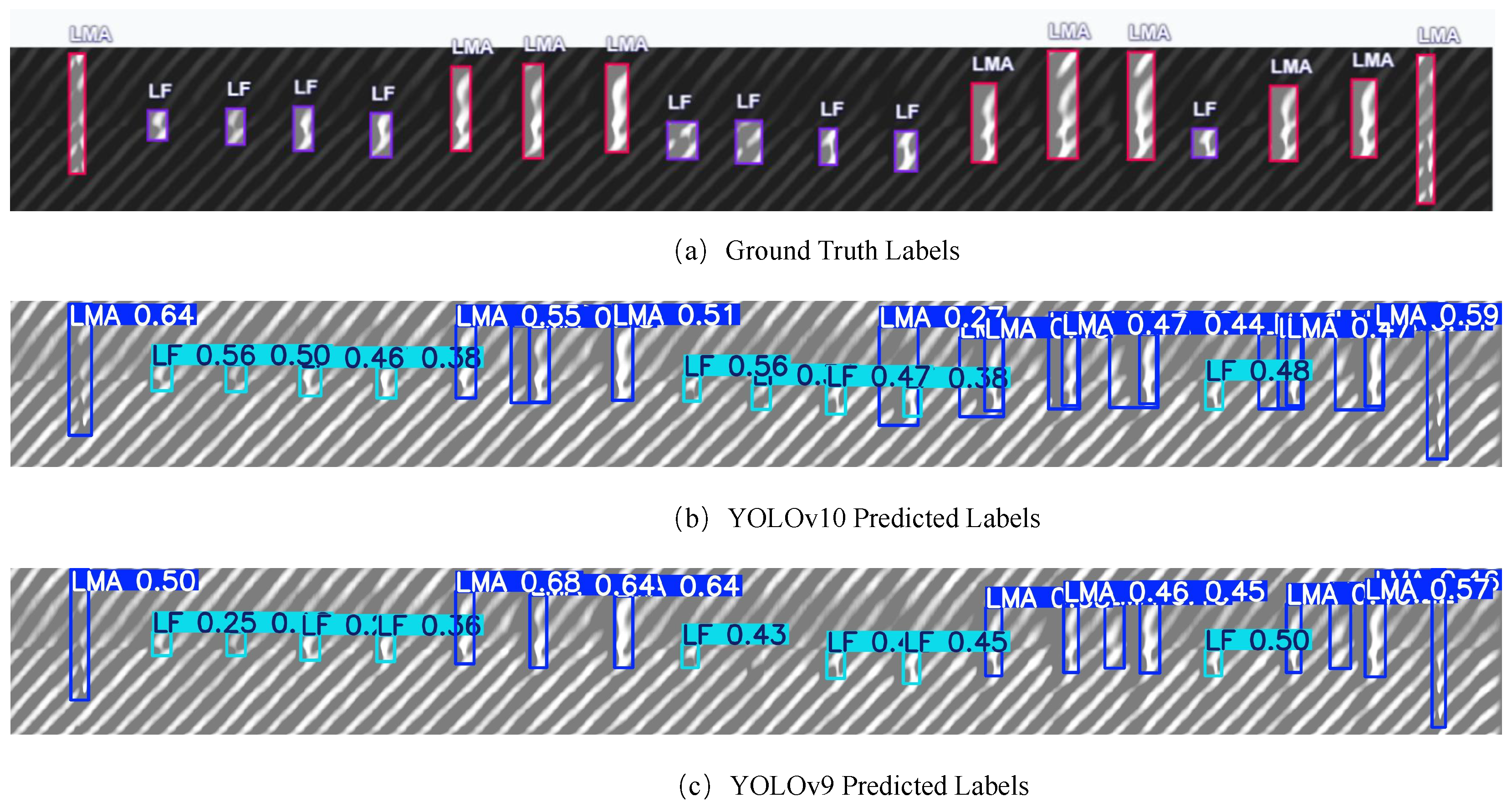
To further examine detection behavior under varying configurations, we compare YOLOv9e and YOLOv10 under different IoU and confidence thresholds, as illustrated in
Figure 15 and
Figure 16. Under default settings, YOLOv10 (
Figure 15b) performs reliably in detecting large-scale LMA defects with high confidence and minimal redundancy. However, it fails to capture many small-scale LF instances, indicating limited sensitivity to fine-grained targets. In contrast, YOLOv9e (
Figure 15c) detects most LF defects, benefiting from multi-scale feature extraction and enhanced spatial representation. Nonetheless, it suffers from redundant detections for LMA defects, especially when the defect spans a large area, resulting in overlapping bounding boxes. When the confidence threshold is reduced to 0.1 and the IoU threshold to 0.6 (
Figure 16), YOLOv10 (
Figure 16b) significantly improves its recall on LF instances, successfully capturing smaller defects. However, this improvement introduces redundant bounding boxes on LMA, mirroring the behavior of YOLOv9e under default settings. Under the same relaxed thresholds, YOLOv9e (
Figure 16c) maintains high recall for both LMA and LF while effectively suppressing redundant detections on LMA, suggesting better spatial consistency and localization precision. These observations highlight the complementary characteristics of the two detectors and demonstrate that threshold tuning plays a critical role in balancing recall and redundancy. Moreover, they emphasize the need for adaptive post-processing strategies when applying object detectors to industrial defect datasets with mixed defect sizes and ambiguous boundaries.
To justify the necessity of deep neural networks for our defect detection task, we performed a cross-series ablation study on several YOLO architectures with varying depth and capacity: YOLOv5n (Nano), YOLOv9t (Shallow), YOLOv9s (Medium), and YOLOv9e (Deep). As shown in
Table 7, the detection performance improves consistently with the depth of the model. YOLOv9e achieves the highest mAP@50 (75.9%) and recall (76.7%), significantly outperforming shallower counterparts such as YOLOv5n (70.1%, 71.9%) and YOLOv9t (70.0%, 72.7%). These results demonstrate that deeper networks are more effective in capturing complex and subtle visual patterns present in pipeline defects, particularly under challenging conditions such as noisy backgrounds and low contrast features. This supports the adoption of deep architectures not only for improved robustness, but also for their superior feature extraction capacity, which is critical for detecting small LF defects.
Furthermore, we performed an ablation study to evaluate the impact of the Auxiliary Reversible Branch (ARB) in YOLOv9e. As shown in
Table 8, removing ARB leads to a drop in both precision and mAP@50, indicating that ARB enhances the model’s ability to localize and classify defects more accurately. Interestingly, the recall slightly increases without ARB, suggesting a more aggressive detection behavior, possibly at the cost of increased false positives.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}