
Deepfake Image Classification Using Decision (Binary) Tree Deep Learning


Abstract
1. Introduction
Key Contributions
2. Related Works
2.1. Deep-Learning-Based Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Core Innovation | Acc. (%) | Generalization | Key Limitations |
|---|---|---|---|---|
| Pan, D. et al. [32] | Hybrid CNN-LSTM with Efficient NetB4/Inception V3 | 91–98 | Low | High cross-dataset variability, struggles with temporal inconsistencies |
| Rana and Sung [31] | Deepfake stack ensemble (multiple DL models) | 99.65 | Moderate | High GPU memory demand, overfits to training artifacts |
| CNN-GMM [36] | GMM probability layer replaces FC layers | 96 | Low | Sensitive to class imbalances, low computational efficiency |
| Afchar et al. [16] | MesoInception-4 for mid-level artifacts | 98 | Moderate | Fails on low-resolution inputs, limited to specific forgery types |
| Sabir et al. [37] | Recurrent CNN for temporal analysis | 94.3–96.9 | High | Weakness in frame-level manipulation detection, high latency |
| Our Method | Binary tree fusion of ViT + CNNs | 97.25 | High | Initial setup required if the method needs to be scaled |
2.2. Benchmark Datasets and Evaluation
- Accuracy: This measures the overall correctness of the model as the ratio of correct predictions to total predictions;
- F1-Score: The harmonic mean of precision and recall, useful in imbalanced classes;
- Precision: The ratio of true positives to all positive predictions, emphasizing the cost of false positives;
- Recall: Also known as sensitivity, this measures the model’s ability to identify all relevant cases;
- AUC-ROC: This represents the trade-off between the true positive and false positive rates across different thresholds [42].
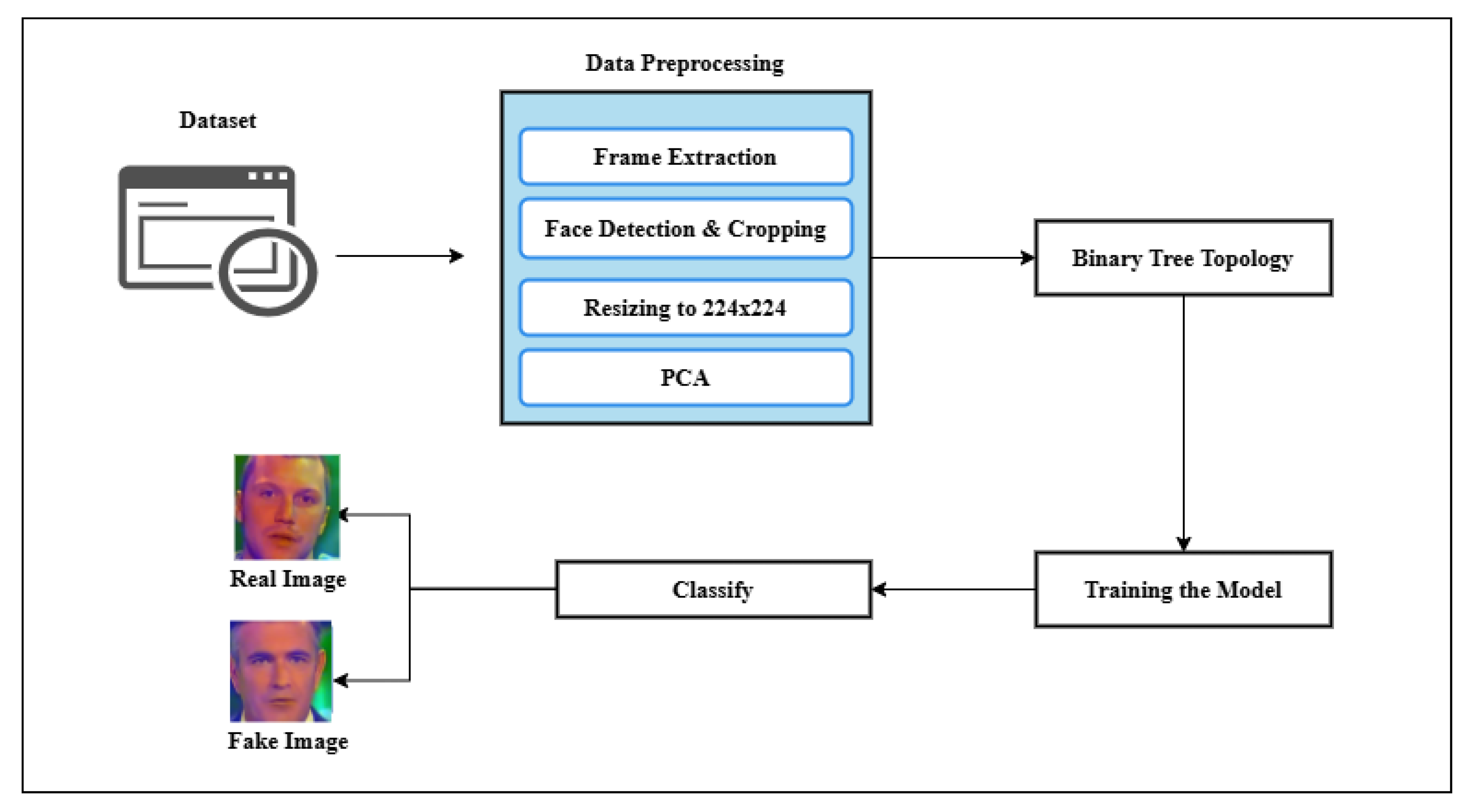
3. Methodology
3.1. Problem Definition
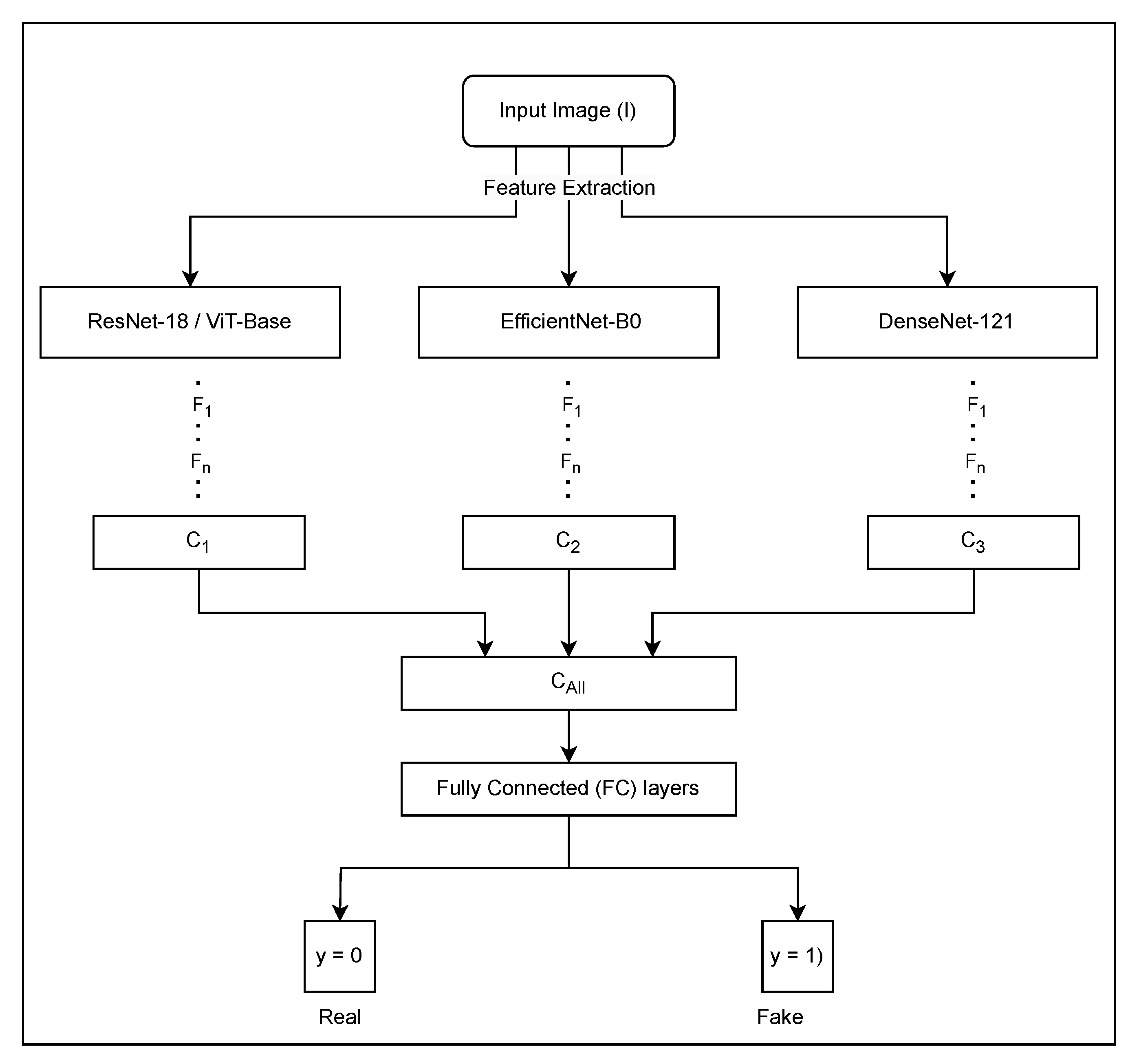
3.2. Choice of Models
3.3. The Model Architecture
3.3.1. Binary Tree Topology
3.3.2. The Proposed Framework Algorithm
| Algorithm 1 Deepfake detection framework. |
|
3.3.3. Model Ensembling
3.3.4. Integration with the Dataset
3.4. The Algorithm: Training and Snapshot Ensembling
| Algorithm 2 The algorithm initializes the model parameters, iterates through epochs with loss computation and updates, and periodically captures model snapshots. Learning rate adjustments optimize the performance, while ensembling enhances the generalization and mitigates overfitting. |
|
4. Experimental Settings
5. Evaluation Metrics
- Accuracy: Accuracy measures the proportion of correctly classified samples out of the total samples. It is defined aswhere TP, TN, FP, and FN represent true positives, true negatives, false positives, and false negatives, respectively. Accuracy provides a high-level overview of the model’s performance but may be less informative for imbalanced datasets.
- Weighted F1 score: The F1 score offers the harmonic mean of precision and recall, making it a robust metric for evaluating models in scenarios where the class distributions are imbalanced. We compute the weighted F1 score to account for class imbalances:Here, precision and recall are defined asThe weighted F1 score ensures that the model’s performance on both real and fake image classes is fairly represented.
- Confusion matrix: The confusion matrix provides a detailed breakdown of the model’s predictions, showing the distribution of TPs, TNs, FPs, and FNs. This granular analysis is instrumental in identifying specific error patterns, such as the tendency to misclassify fake images as real or vice versa.
The Dataset and Computational Resources
6. Results
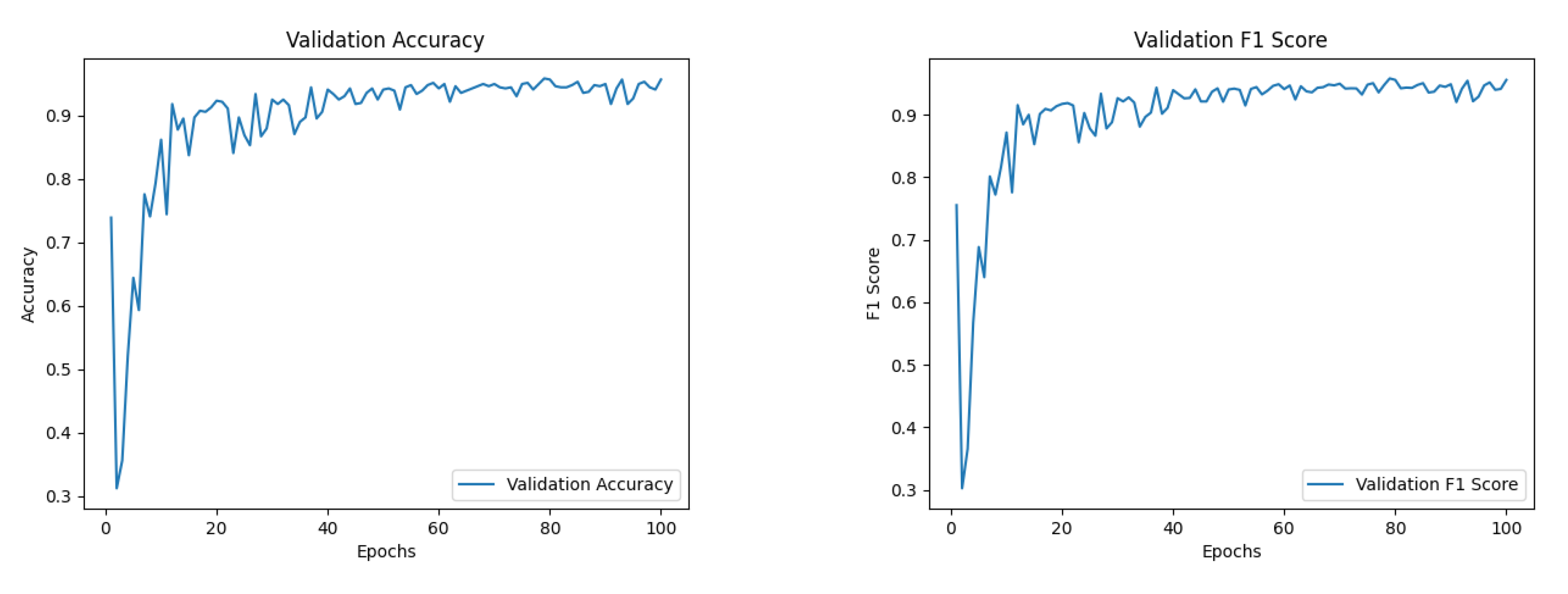
6.1. The Performance of Our Models
The Impact of Snapshot Ensembling on Deepfake Detection
6.2. A Comparative Analysis with the State-of-the-Art Methods
6.3. Analysis of the Computational Complexity
6.4. Insights from Comparative Models
- Rana et al. [52]’s ensemble achieves 99.65% accuracy but requires three-model execution (Xception × 3), resulting in 7.8× higher FLOPs than those of our CNNs-Ensemble (38.9G vs. 5.0G FLOPs);
- Afchar et al. [16]’s MesoNet achieves 98%’s MesoNet achieves 98% accuracy on their custom deepfake dataset but shows a degraded performance on compressed videos (93.5% at H.264 level 23), while our model maintains 95.53% accuracy across compression artifacts;
- Our ViT-CNNs outperforms MesoNet in its feature learning capacity (97.25% vs. 98%) with only 20.8 GFLOPs vs. MesoNet’s 1.3 GFLOPs, demonstrating a better accuracy–computation balance for modern needs.
7. Discussion
7.1. The Effectiveness of the Binary Tree Topology
7.2. Real-World Deployment Considerations
7.3. Challenges and Limitations
8. Conclusions
9. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ViT | Vision Transformer |
| CNN | Convolutional Neural Network |
References
- Lange, R.D.; Chattoraj, A.; Beck, J.M.; Yates, J.L.; Haefner, R.M. A confirmation bias in perceptual decision-making due to hierarchical approximate inference. PLoS Comput. Biol. 2021, 17, e1009517. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar]
- Nguyen, T.T.; Nguyen, Q.V.H.; Nguyen, D.T.; Nguyen, D.T.; Huynh-The, T.; Nahavandi, S.; Nguyen, T.T.; Pham, Q.V.; Nguyen, C.M. Deep learning for deepfakes creation and detection: A survey. Comput. Vis. Image Underst. 2022, 223, 103525. [Google Scholar]
- Gupta, G.; Raja, K.; Gupta, M.; Jan, T.; Whiteside, S.T.; Prasad, M. A Comprehensive Review of DeepFake Detection Using Advanced Machine Learning and Fusion Methods. Electronics 2023, 13, 95. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. Available online: https://papers.nips.cc/paper_files/paper/2014/hash/f033ed80deb0234979a61f95710dbe25-Abstract.html (accessed on 28 March 2025).
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv 2022, arXiv:2112.10752. [Google Scholar]
- Dimensions. Dimensions Scholarly Database. 2025. Available online: https://www.dimensions.ai/resources/dimensions-scientific-research-database/ (accessed on 28 March 2025).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Nichol, A.; Dhariwal, P. GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv 2021, arXiv:2112.10741. [Google Scholar]
- Afchar, D.; Nagrani, A.; Zheng, C.; Smeureanu, R.; Sattar, M.A. MesoNet: A Compact Facial Video Forgery Detection Network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Vijayakumar, A.; Vairavasundaram, S. Yolo-based object detection models: A review and its applications. Multimed. Tools Appl. 2024, 83, 83535–83574. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Khan, A.; Khattak, M.U.; Dawoud, K. Object detection in aerial images: A case study on performance improvement. In Proceedings of the 2022 International Conference on Artificial Intelligence of Things (ICAIoT), Istanbul, Turkey, 29–30 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–9. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2307–2311. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Khan, A.; AlBarri, S.; Manzoor, M.A. Contrastive self-supervised learning: A survey on different architectures. In Proceedings of the 2022 2nd International Conference on Artificial Intelligence (ICAI), Islamabad, Pakistan, 30–31 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Dong, F.; Zou, X.; Wang, J.; Liu, X. Contrastive learning-based general Deepfake detection with multi-scale RGB frequency clues. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 90–99. [Google Scholar]
- Rajesh, N.; Prajwala, M.; Kumari, N.; Rayyan, M.; Ramachandra, A. Hybrid Model for Deepfake Detection. In Proceedings of the 3rd International Conference on Machine Learning, Advances in Computing, Renewable Energy and Communication: MARC 2021, Ghaziabad, India, 10–11 December 2021; Springer: Singapore, 2022; pp. 639–649. [Google Scholar]
- Agarwal, S.; Varshney, L.R. Limits of deepfake detection: A robust estimation viewpoint. arXiv 2019. arXiv 2019, arXiv:1905.03493. [Google Scholar]
- Haliassos, A.; Mira, R.; Petridis, S.; Pantic, M. Leveraging real talking faces via self-supervision for robust forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14950–14962. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8261–8265. [Google Scholar]
- Li, Y.; Chang, M.C.; Lyu, S. In ictu oculi: Exposing ai created fake videos by detecting eye blinking. In Proceedings of the 2018 IEEE International workshop on information forensics and security (WIFS), Hong Kong, China, 11–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Chandrasegaran, K.; Tran, N.T.; Binder, A.; Cheung, N.M. Discovering transferable forensic features for cnn-generated images detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 671–689. [Google Scholar]
- Khalid, H.; Woo, S.S. Oc-fakedect: Classifying deepfakes using one-class variational autoencoder. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 656–657. [Google Scholar]
- Caldelli, R.; Galteri, L.; Amerini, I.; Del Bimbo, A. Optical Flow based CNN for detection of unlearnt deepfake manipulations. Pattern Recognit. Lett. 2021, 146, 31–37. [Google Scholar]
- Alnafea, R.M.; Nissirat, L.; Al-Samawi, A. CNN-GMM approach to identifying data distribution shifts in forgeries caused by noise: A step towards resolving the deepfake problem. PeerJ Comput. Sci. 2024, 10, e1991. [Google Scholar]
- Sabir, E.; Cheng, J.; Jaiswal, A.; AbdAlmageed, W.; Masi, I.; Natarajan, P. Recurrent Convolutional Strategies for Face Manipulation Detection in Videos. arXiv 2019, arXiv:1905.00582. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The deepfake detection challenge (dfdc) dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2889–2898. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Dietterich, T.G. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference on Machine Learning, Garda, Italy, 28 June–1 July 1996; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1996; pp. 148–156. [Google Scholar]
- Shaaban, M.A.; Akkasi, A.; Khan, A.; Komeili, M.; Yaqub, M. Fine-Tuned Large Language Models for Symptom Recognition from Spanish Clinical Text. arXiv 2024, arXiv:2401.15780. [Google Scholar]
- Khan, A.; Shaaban, M.A.; Khan, M.H. Improving Pseudo-labelling and Enhancing Robustness for Semi-Supervised Domain Generalization. arXiv 2024, arXiv:2401.13965. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Rana, M.S.; Sung, A.H. Deepfakestack: A deep ensemble-based learning technique for deepfake detection. In Proceedings of the 2020 7th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2020 6th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), New York, NY, USA, 1–3 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 70–75. [Google Scholar]
- Agnihotri, A. DeepFake Detection using Deep Neural Networks. Ph.D. Thesis, National College of Ireland, Dublin, Ireland, 2021. Available online: https://norma.ncirl.ie/5131/1/ambujagnihotri.pdf (accessed on 18 December 2024).


| Set | Fake Images | Real Images | Total Images |
|---|---|---|---|
| Training Set | 4250 | 850 | 5100 |
| Validation Set | 970 | 194 | 1164 |
| Test Set | 485 | 97 | 582 |
| Metric | CNNs-Ensemble | ViT_CNNs-Ensemble |
|---|---|---|
| Overall Accuracy (%) | 95.53 | 97.25 |
| Precision (Fake Class) (%) | 95.99 | 98.96 |
| Recall (Fake Class) (%) | 98.76 | 97.73 |
| Precision (Real Class) (%) | 92.77 | 89.32 |
| Recall (Real Class) (%) | 79.38 | 94.85 |
| Overall Precision (%) | 95.45 | 97.35 |
| Overall Recall (%) | 89.07 | 96.29 |
| Overall F1 Score (%) | 95.39 | 97.28 |
| Time (in Hours) | 2.45 gpu | 1.90 gpu |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Without Ensemble | ||||
| Real | 0.9277 | 0.7938 | 0.8556 | 97 |
| Fake | 0.9599 | 0.9876 | 0.9736 | 485 |
| With Snapshot Ensemble | ||||
| Real | 0.94 | 0.74 | 0.83 | 97 |
| Fake | 0.95 | 0.99 | 0.97 | 485 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Without Ensemble | ||||
| Real | 0.8932 | 0.9485 | 0.9200 | 97 |
| Fake | 0.9896 | 0.9773 | 0.9834 | 485 |
| With Snapshot Ensemble | ||||
| Real | 0.93 | 0.85 | 0.88 | 97 |
| Fake | 0.99 | 0.98 | 0.98 | 485 |
| Method | Technique | Accuracy (%) |
|---|---|---|
| Pan, D. et al. [53] | Xception + MobileNet | 91–98 |
| Rana M. S. and Sung A. H. [52] | Heavy Ensemble (3 × Xception) | 99.65 |
| Afchar et al. [16] | MesoInception (Lightweight CNN) | 98 |
| Sabir et al. [37] | Recurrent CNNs + LSTM | 94.3–96.9 |
| CNN-GMM | CNN + Gaussian Mixture Model | 96 |
| Our Model (CNNs-Ensemble) | ResNet + EfficientNet + DenseNet Tree | 95.53 |
| Our Model (ViT-CNNs) | ViT + CNNs Tree | 97.25 |
| Model | FLOPs (G) | Params (M) | Inference (ms) |
|---|---|---|---|
| Xception | 16.85 | 22.9 | 34 |
| MesoNet | 1.32 | 2.1 | 12 |
| Rana et al. Rana et al. (Ensemble) [52] | 38.92 | 85.3 | 121 |
| CNNs-Ensemble | 5.0 | 25.0 | 28 |
| ViT_CNNs-Ensemble | 20.8 | 99.7 | 121 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alrajeh, M.; Al-Samawi, A. Deepfake Image Classification Using Decision (Binary) Tree Deep Learning. J. Sens. Actuator Netw. 2025, 14, 40. https://doi.org/10.3390/jsan14020040
Alrajeh M, Al-Samawi A. Deepfake Image Classification Using Decision (Binary) Tree Deep Learning. Journal of Sensor and Actuator Networks. 2025; 14(2):40. https://doi.org/10.3390/jsan14020040
Chicago/Turabian StyleAlrajeh, Mariam, and Aida Al-Samawi. 2025. "Deepfake Image Classification Using Decision (Binary) Tree Deep Learning" Journal of Sensor and Actuator Networks 14, no. 2: 40. https://doi.org/10.3390/jsan14020040
APA StyleAlrajeh, M., & Al-Samawi, A. (2025). Deepfake Image Classification Using Decision (Binary) Tree Deep Learning. Journal of Sensor and Actuator Networks, 14(2), 40. https://doi.org/10.3390/jsan14020040