
On the Energy Behaviors of the Bellman–Ford and Dijkstra Algorithms: A Detailed Empirical Study

Abstract
1. Introduction
2. Literature Review
3. Methods, Tools, and Procedures
3.1. Methodology
- Eliminate as much of the effects due to the process used to generate the code. In particular, compilers use optimizations that may reduce the resemblance of the code to the original method. Moreover, they implement them differently. So they must be turned off as much as possible.
- Eliminate as many sources of power consumption from the run environment as possible. Modern operating systems multitask, constantly trying to do all sorts of things besides running user code. Of particular concern as noise are those that are heavy on energy.
- Use reliable, on-chip instrumentation to measure the targeted energy behaviors after eliminating hardware features that optimize or alter the natural power consumption. This empirical approach black-boxes complex behaviors and removes the need for involved modeling or complex simulations. Those methods require detailed knowledge of the processor and the memory and may not capture the whole behavior as faithfully.
3.2. Dataset Generation
- Fully dense, i.e., complete graphs, where every pair of vertices is connected, generated by setting the probability p to 1. The number of distinct edges is for a complete graph, but twice that must be created in the adjacency list of the digraph.
- Moderately dense graphs, generated by setting .
3.3. Tools and Materials
3.4. Experimental Environment and Procedures
- Open system case conditions while keeping the ambient temperature consistent under moderate air conditioning and the CPU fan turned on at a constant speed.
- Turn off hyper-threading features as it results in a more intricate power model since the extra threads consume disproportionately less power by design.
- Deactivate Turbo Boost power management to maintain the CPU’s base frequency so the results are less affected by unpredictable patterns of internal thermal variation between runs.
- Terminate unnecessary operating system processes and services to run the system with minimal resource usage.
- Introduce a cool-off period between test case trials to allow the CPU to return to a consistent initial temperature of 40 °C as reported by the system sensors tool.
- Assign core 0 to execute the experimental code and allocate other processes to cores 2, 3, 4, and 5 to prevent costly context switching. Core 1 was left idle to limit temperature effects from neighboring cores.
4. Results and Discussion
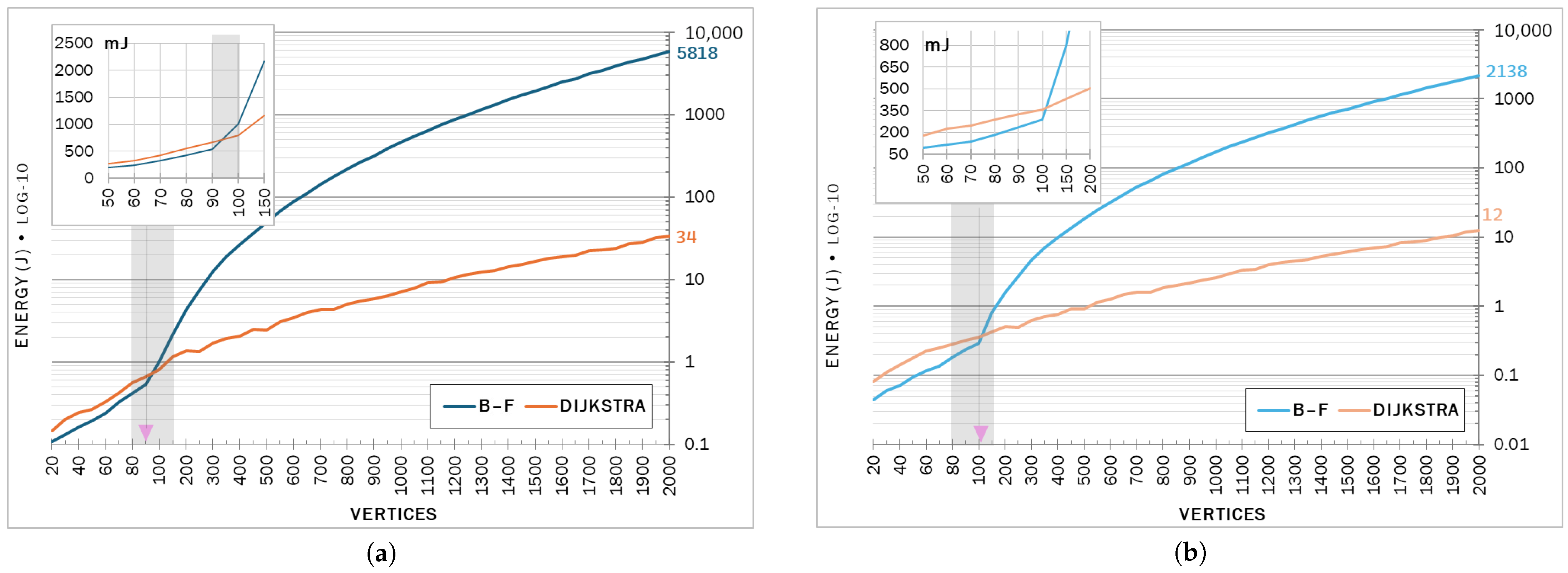
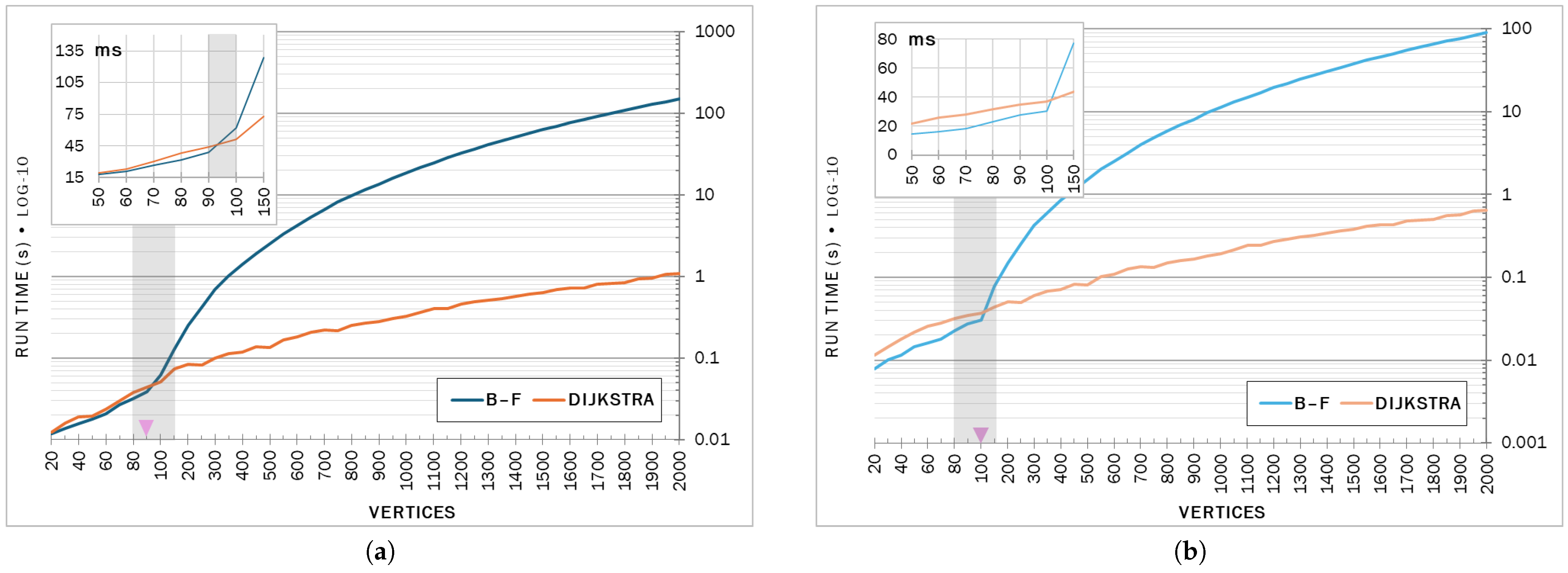
4.1. Energy Behaviors
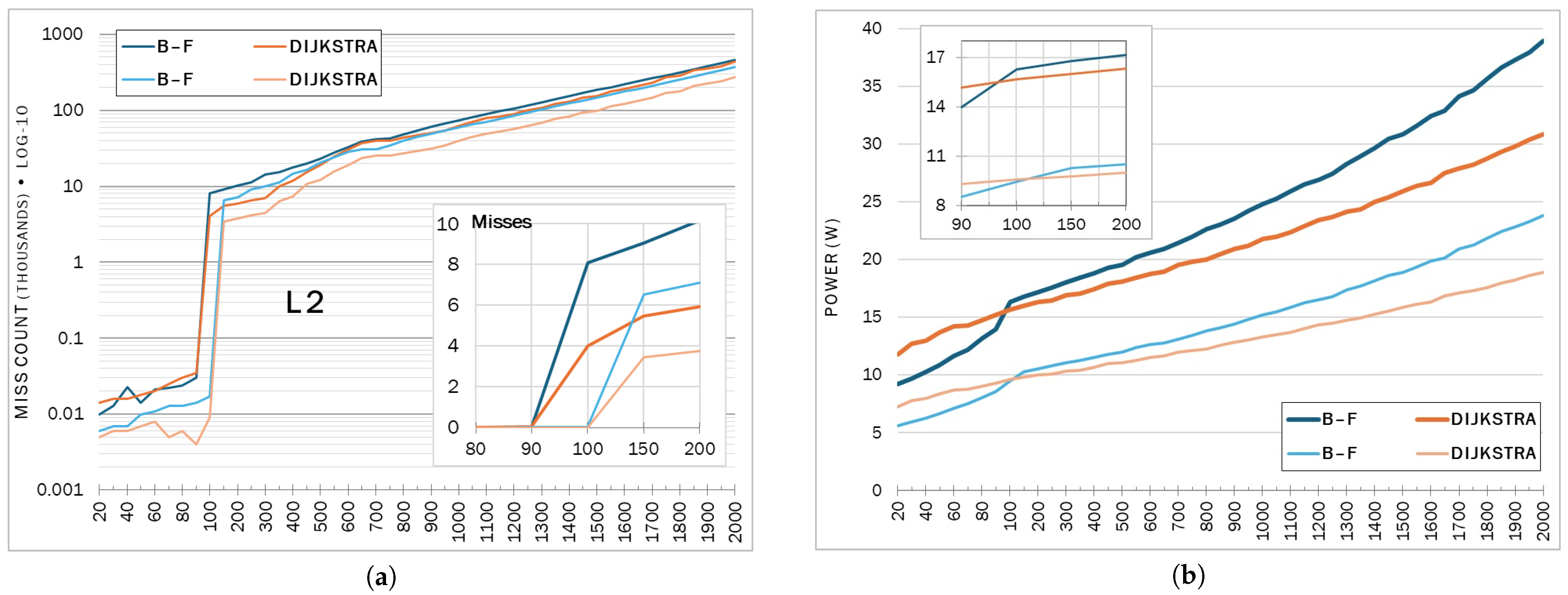
4.2. Cache Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SSSP | Single-Source Shortest Paths |
| HPC | High-Performance Computing |
| B–F | Bellman–Ford [Algorithm] |
| RAPL | Running Average Power Limit |
| FIVR | Fully Integrated Voltage Regulator |
References
- Abulnaja, O.A.; Ikram, M.J.; Al-Hashimi, M.A.; Saleh, M.E. Analyzing power and energy efficiency of bitonic mergesort based on performance evaluation. IEEE Access 2018, 6, 42757–42774. [Google Scholar] [CrossRef]
- Aljabri, N.; Al-Hashimi, M.; Saleh, M.; Abulnaja, O. Investigating power efficiency of mergesort. J. Supercomput. 2019, 75, 6277–6302. [Google Scholar] [CrossRef]
- Al-Hashimi, M.; Aljabri, N. Exploring Power Advantage of Binary Search: An Experimental Study. Int. J. Adv. Comput. Sci. Appl. 2022, 13. [Google Scholar] [CrossRef]
- Padua, D. (Ed.) Parallel Communication Models. In Encyclopedia of Parallel Computing; Springer: Berlin/Heidelberg, Germany, 2011; p. 1409. [Google Scholar]
- AbuSalim, S.W.; Ibrahim, R.; Saringat, M.Z.; Jamel, S.; Wahab, J.A. Comparative Analysis between Dijkstra and Bellman-Ford Algorithms in Shortest Path Optimization. IOP Conf. Ser. Mater. Sci. Eng. 2020, 917, 012077. [Google Scholar] [CrossRef]
- Delling, D.; Goldberg, A.V.; Nowatzyk, A.; Werneck, R.F. PHAST: Hardware-accelerated shortest path trees. J. Parallel Distrib. Comput. 2013, 73, 940–952. [Google Scholar] [CrossRef]
- Ahmad, M.; Michael, C.J.; Khan, O. A Case for a Situationally Adaptive Many-core Execution Model for Cognitive Computing Workloads. In Proceedings of the ASPLOS 2016 International Workshop on Cognitive Architectures, (CogArch), Atlanta, GA, USA, 2 April 2016. [Google Scholar]
- Lewis, R. Algorithms for Finding Shortest Paths in Networks with Vertex Transfer Penalties. Algorithms 2020, 13, 269. [Google Scholar] [CrossRef]
- Inga, E.; Inga, J.; Ortega, A. Novel Approach Sizing and Routing of Wireless Sensor Networks for Applications in Smart Cities. Sensors 2021, 21, 4692. [Google Scholar] [CrossRef]
- Sanchez, J.A.; Ruiz, P.M.; Stojmenovic, I. Energy-efficient geographic multicast routing for Sensor and Actuator Networks. Comput. Commun. 2007, 30, 2519–2531. [Google Scholar] [CrossRef]
- Schmitt, J.; Bondorf, S.; Poe, W.Y. The Sensor Network Calculus as Key to the Design of Wireless Sensor Networks with Predictable Performance. J. Sens. Actuator Netw. 2017, 6, 21. [Google Scholar] [CrossRef]
- Dljkstra, E. A Note on Two Problems in Connexion with Graphs. Numer. Math. 1959, 50, 269–271. [Google Scholar] [CrossRef]
- Ford, L.R. Network Flow Theory; RAND Corporation: Santa Monica, CA, USA, 1956. [Google Scholar]
- Bellman, R. On a routing problem. Q. Appl. Math. 1958, 16, 87–90. [Google Scholar] [CrossRef]
- Sedgewick, R.; Wayne, K. Algorithms, 4th ed.; Addison-Wesley: Boston, MA, USA, 2011. [Google Scholar]
- Cormen, T.; Leiserson, C.; Rivest, R.; Stein, C. Introduction to Algorithms, 4th ed.; MIT Press: Cambridge, MA, USA, 2022. [Google Scholar]
- Moore, E. The Shortest Path through a Maze. In Proceedings of the International Symposium on the Theory of Switching; Springer: Berlin/Heidelberg, Germany, 1959; pp. 285–292. [Google Scholar]
- Kalpana, R.; Thambidurai, P. Optimizing shortest path queries with parallelized arc flags. In Proceedings of the 2011 International Conference on Recent Trends in Information Technology (ICRTIT), Chennai, India, 3–5 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 601–606. [Google Scholar]
- Zhang, W.; Chen, H.; Jiang, C.; Zhu, L. Improvement and experimental evaluation bellman-ford algorithm. In Proceedings of the 2013 International Conference on Advanced ICT and Education (ICAICTE-13), Hainan, China, 20–22 September 2013; Atlantis Press: Amsterdam, The Netherlands, 2013; pp. 138–141. [Google Scholar]
- Hajela, G.; Pandey, M. A Fine Tuned Hybrid Implementation for Solving Shortest Path Problems Using Bellman Ford. Int. J. Comput. Appl. 2014, 99, 29–33. [Google Scholar] [CrossRef]
- Abousleiman, R.; Rawashdeh, O. A Bellman-Ford approach to energy efficient routing of electric vehicles. In Proceedings of the 2015 IEEE Transportation Electrification Conference and Expo (ITEC), Chennai, India, 27–29 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–4. [Google Scholar]
- Busato, F.; Bombieri, N. An efficient implementation of the Bellman-Ford algorithm for Kepler GPU architectures. IEEE Trans. Parallel Distrib. Syst. 2015, 27, 2222–2233. [Google Scholar] [CrossRef]
- Mishra, A.; Khare, N. Power and Performance Characterization of the Dijkstra’s Graph algorithm on GPU. Int. J. Comput. Sci. Inf. Secur. 2016, 14, 858. [Google Scholar]
- Cheng, C.D. Extended Dijkstra algorithm and Moore-Bellman-Ford algorithm. arXiv 2017, arXiv:1708.04541. [Google Scholar]
- Schambers, A.; Eavis-O’Quinn, M.; Roberge, V.; Tarbouchi, M. Route planning for electric vehicle efficiency using the Bellman-Ford algorithm on an embedded GPU. In Proceedings of the 2018 4th International Conference on Optimization and Applications (ICOA), Mohammedia, Morocco, 26–27 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Abderrahim, M.; Hakim, H.; Boujemaa, H.; Touati, F. Energy-Efficient Transmission Technique based on Dijkstra Algorithm for decreasing energy consumption in WSNs. In Proceedings of the 2019 19th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Sousse, Tunisia, 24–26 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 599–604. [Google Scholar]
- Weber, A.; Kreuzer, M.; Knoll, A. A generalized Bellman-Ford algorithm for application in symbolic optimal control. In Proceedings of the 2020 European Control Conference (ECC), St. Petersburg, Russia, 12–15 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2007–2014. [Google Scholar]
- Rai, A. A Study on Bellman Ford Algorithm for Shortest Path Detection in Global Positioning System. Int. J. Res. Appl. Sci. Eng. Technol. 2022, 10, 2118–2126. [Google Scholar] [CrossRef]
- Alqurashi, F.S.; Al-Hashimi, M. An Experimental Approach to Estimation of the Energy Cost of Dynamic Branch Prediction in an Intel High-Performance Processor. Computers 2023, 12, 139. [Google Scholar] [CrossRef]
- Alsari, S.; Al-Hashimi, M. Investigation of Energy and Power Characteristics of Various Matrix Multiplication Algorithms. Energies 2024, 17, 2225. [Google Scholar] [CrossRef]
- Leskovec, J.; Krevl, A. Stanford Large Network Dataset Collection. 2014. Available online: https://snap.stanford.edu/data/ (accessed on 16 May 2024).
- Erdös, P.; Rényi, A. On random graphs I. Publ. Math. Debr. 1959, 6, 290–297. [Google Scholar] [CrossRef]
- rustworkx.directed_gnp_random_graph—rustworkx 0.14.2—rustworkx.org. Available online: https://www.rustworkx.org/apiref/rustworkx.directed_gnp_random_graph.html (accessed on 19 April 2024).
- Treinish, M.; Carvalho, I.; Tsilimigkounakis, G.; Sá, N. rustworkx: A High-Performance Graph Library for Python. J. Open Source Softw. 2022, 7, 3968. [Google Scholar] [CrossRef]
- Halim, S.; Halim, F. Competitive Programming 3: The New Lower Bound of Programming Contests (Handbook for ACM ICPC and IOI Contestants), 3rd ed.; Lulu: Morrisville, NC, USA, 2013; Available online: https://www.lulu.com/shop/steven-halim/competitive-programming-3/paperback/product-21059906.html?srsltid=AfmBOorJsTa4w9IgGZY55WuEr31nMr0pAoiUc2H62IFIXLNYeawPcofb&page=1&pageSize=4 (accessed on 9 October 2024).
- C++ Containers Library: std::priority_queue. Available online: https://en.cppreference.com/w/cpp/container/priority_queue (accessed on 20 June 2024).
- Free Software Foundation. A GNU Manual (3.10 Options That Control Optimization). 2017. Available online: https://gcc.gnu.org/onlinedocs/gcc-7.5.0/gcc/Optimize-Options.html (accessed on 26 April 2024).
- Perf Wiki—perf.wiki.kernel.org. Available online: https://perf.wiki.kernel.org/ (accessed on 4 December 2023).
- Gruber, T.; Eitzinger, J.; Hager, G.; Wellein, G. Likwid. Version V5 2022, 2, 20. [Google Scholar]
- Saini, S.; Hood, R.; Chang, J.; Baron, J. Performance evaluation of an Intel Haswell-and Ivy Bridge-based supercomputer using scientific and engineering applications. In Proceedings of the 2016 IEEE 18th International Conference on High Performance Computing and Communications; IEEE 14th International Conference on Smart City; IEEE 2nd International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Sydney, NSW, Australia, 12–14 December 2016; IEEE: Sydney, NSW, Australia, 2016; pp. 1196–1203. [Google Scholar]
- Khan, K.N.; Hirki, M.; Niemi, T.; Nurminen, J.K.; Ou, Z. RAPL in Action: Experiences in Using RAPL for Power measurements. ACM Trans. Model. Perform. Eval. Comput. Syst. (TOMPECS) 2018, 3, 1–26. [Google Scholar] [CrossRef]
- Theis, T.N.; Wong, H.S.P. The End of Moore’s Law: A New Beginning for Information Technology. Comput. Sci. Eng. 2017, 19, 41–50. [Google Scholar] [CrossRef]
- TOP500: The List Highlights—June 2024. Available online: https://top500.org/lists/top500/2024/06/highs/ (accessed on 20 June 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Year | Algorithm(s) | Focus | Contribution | Study Method |
|---|---|---|---|---|---|
| Kalpana & Thambidurai [18] | 2011 | Dijkstra | Runtime | Significantly enhanced runtime and vertex visit count of Dijkstra’s algorithm. | Experimental (empirical data, code timers) |
| Zhang et al. [19] | 2013 | Dijkstra, Bellman–Ford | Runtime | Bellman–Ford was exceptionally efficient on grid maps, reducing processing time. | Experimental (data collected from simulation) |
| Hajela & Pandey [20] | 2014 | Bellman–Ford | Runtime | Achieved a 2.88x acceleration for SSSP and 3.3x for APSP problems. | Experimental (empirical data, code timers) |
| Abousleiman & Rawashdeh [21] | 2015 | Bellman–Ford | Energy | Optimized energy consumption for electric vehicle journeys. | Experimental (data collected from simulation) |
| Busato & Bombieri [22] | 2015 | Bellman–Ford | Runtime | Optimized Bellman–Ford for faster execution on Kepler GPU structures. | Experimental (emprical data, code timers) |
| Mishra & Khare [23] | 2016 | Dijkstra | Power | Identified optimal frequency pairs for power or performance gain. | Experimental (empirical data, physical power meter) |
| Cheng [24] | 2017 | Dijkstra, Bellman–Ford | Efficiency | Introduced extended algorithms solving GSSSP efficiently under specific conditions. | Math/modeling |
| Schambers et al. [25] | 2018 | Bellman–Ford | Energy | Generated energy-efficient routes with Bellman–Ford while maintaining performance standards. | Experimental (data collected from simulation) |
| Abderrahim et al. [26] | 2019 | Dijkstra | Energy | Minimized energy consumption in WSNs using clustering and relay selection. | Experimental (data collected from simulation) |
| Weber et al. [27] | 2020 | Bellman–Ford | Runtime | Effectively handled negative cost values and parallel execution. | Math/modeling |
| Rai [28] | 2022 | Bellman–Ford, Dijkstra | Runtime | Highlighted Bellman–Ford’s versatility in handling negative weights, but with higher time complexity. | Math/modeling |
| CPU | Intel Xeon E5-2680v3 (2.50 GHz, 12-Core) |
|---|---|
| Cache Memory | L1/core: 32 KiB data, 32 KiB instruction |
| L2/core: 256 KiB | |
| L3: 30 MiB (20-way) | |
| Main Memory | 8 GB DDR4-2133 |
| OS | Linux 64-bit (Lubuntu 18.04.6 LTS) |
| Compiler | GNU Compiler Collection 7.5.0 |
| Profiler | perf 4.9 |
| Vertices | Fully Dense (Complete) | Moderately Dense | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Edges | Energy (J) | Power (W) | Edges | Energy (J) | Power (W) | |||||||
| B–F | Dijkstra | B–F | Dijkstra | % Adv | B–F | Dijkstra | B–F | Dijkstra | % Adv | |||
| 10 | 90 | 0.08 | 0.13 | 8.6 | 11.2 | 31.2 | 53 | 0.03 | 0.06 | 5.3 | 6.9 | 31.0 |
| 20 | 380 | 0.11 | 0.15 | 9.2 | 11.8 | 28.4 | 227 | 0.04 | 0.08 | 5.6 | 7.2 | 28.4 |
| 30 | 870 | 0.13 | 0.20 | 9.7 | 12.7 | 30.6 | 521 | 0.06 | 0.11 | 6.0 | 7.8 | 30.6 |
| 40 | 1560 | 0.16 | 0.24 | 10.3 | 13.0 | 26.5 | 925 | 0.07 | 0.14 | 6.3 | 8.0 | 26.4 |
| 50 | 2450 | 0.19 | 0.27 | 10.9 | 13.7 | 26.1 | 1454 | 0.10 | 0.18 | 6.7 | 8.4 | 25.8 |
| 60 | 3540 | 0.24 | 0.33 | 11.7 | 14.2 | 21.8 | 2120 | 0.12 | 0.22 | 7.2 | 8.7 | 21.8 |
| 70 | 4830 | 0.33 | 0.43 | 12.2 | 14.3 | 17.1 | 2866 | 0.13 | 0.25 | 7.5 | 8.8 | 17.1 |
| 80 | 6320 | 0.42 | 0.56 | 13.1 | 14.7 | 11.9 | 3785 | 0.18 | 0.29 | 8.1 | 9.0 | 12.0 |
| 90 | 8010 | 0.54 | 0.67 | 14.0 | 15.2 | 8.7 | 4754 | 0.24 | 0.32 | 8.6 | 9.3 | 8.6 |
| 100 | 9900 | 1 | 0.80 | 16.3 | 15.7 | −3.7 | 5932 | 0.29 | 0.36 | 9.5 | 9.6 | 1.6 |
| 150 | 22,350 | 2 | 1 | 16.8 | 16.0 | −4.9 | 13,385 | 1 | 0.43 | 10.3 | 9.8 | −4.9 |
| 200 | 39,800 | 4 | 1 | 17.2 | 16.3 | −5.0 | 23,841 | 2 | 1 | 10.5 | 10.0 | −4.9 |
| 250 | 62,250 | 7 | 1 | 17.6 | 16.4 | −6.5 | 37,282 | 3 | 0.5 | 10.8 | 10.1 | −6.5 |
| 300 | 89,700 | 13 | 2 | 18.0 | 16.9 | −5.9 | 53,755 | 5 | 1 | 11.0 | 10.4 | −6.0 |
| 350 | 122,150 | 19 | 2 | 18.4 | 17.0 | −7.5 | 73,202 | 7 | 1 | 11.3 | 10.4 | −7.5 |
| 400 | 159,600 | 27 | 2 | 18.8 | 17.4 | −7.3 | 95,606 | 10 | 1 | 11.5 | 10.7 | −7.4 |
| 450 | 202,050 | 37 | 2 | 19.3 | 17.9 | −7.1 | 121,036 | 14 | 1 | 11.8 | 11.0 | −7.0 |
| 500 | 249,500 | 49 | 2 | 19.6 | 18.1 | −7.7 | 149,430 | 18 | 1 | 12.0 | 11.1 | −7.7 |
| 550 | 301,950 | 68 | 3 | 20.2 | 18.4 | −8.8 | 180,880 | 25 | 1 | 12.4 | 11.3 | −8.7 |
| 600 | 359,400 | 87 | 3 | 20.6 | 18.8 | −8.9 | 215,251 | 32 | 1 | 12.6 | 11.5 | −8.8 |
| 650 | 421,850 | 111 | 4 | 20.9 | 19.0 | −9.2 | 252,806 | 41 | 1 | 12.8 | 11.6 | −9.1 |
| 700 | 489,300 | 143 | 4 | 21.4 | 19.6 | −8.7 | 293,051 | 52 | 2 | 13.1 | 12.0 | −8.7 |
| 750 | 561,750 | 178 | 4 | 21.9 | 19.8 | −9.7 | 336,645 | 65 | 2 | 13.4 | 12.1 | −9.7 |
| 800 | 639,200 | 221 | 5 | 22.6 | 20.0 | −11.5 | 383,059 | 81 | 2 | 13.8 | 12.3 | −11.4 |
| 850 | 721,650 | 268 | 5 | 23.0 | 20.5 | −11.0 | 428,357 | 98 | 2 | 14.1 | 12.5 | −10.9 |
| 900 | 809,239 | 315 | 6 | 23.5 | 20.9 | −11.0 | 484,763 | 116 | 2 | 14.4 | 12.8 | −11.1 |
| 950 | 901,550 | 391 | 6 | 24.2 | 21.2 | −12.3 | 540,280 | 144 | 2 | 14.8 | 13.0 | −12.2 |
| 1000 | 999,000 | 466 | 7 | 24.8 | 21.7 | −12.3 | 598,440 | 171 | 3 | 15.2 | 13.3 | −12.3 |
| 1050 | 1,101,450 | 548 | 8 | 25.3 | 22.0 | −13.0 | 653,798 | 201 | 3 | 15.5 | 13.5 | −13.0 |
| 1100 | 1,208,900 | 644 | 9 | 25.9 | 22.4 | −13.6 | 717,578 | 237 | 3 | 15.9 | 13.7 | −13.7 |
| 1150 | 1,321,350 | 750 | 9 | 26.5 | 22.9 | −13.6 | 791,382 | 276 | 3 | 16.2 | 14.0 | −13.6 |
| 1200 | 1,438,800 | 873 | 11 | 26.9 | 23.4 | −13.1 | 854,042 | 321 | 4 | 16.5 | 14.3 | −13.2 |
| 1250 | 1,561,250 | 1003 | 12 | 27.4 | 23.7 | −13.6 | 935,063 | 369 | 4 | 16.8 | 14.5 | −13.6 |
| 1300 | 1,688,700 | 1165 | 12 | 28.3 | 24.1 | −14.8 | 1,011,396 | 428 | 5 | 17.4 | 14.8 | −14.9 |
| 1350 | 1,821,150 | 1332 | 13 | 28.9 | 24.4 | −15.8 | 1,080,998 | 489 | 5 | 17.7 | 14.9 | −15.8 |
| 1400 | 1,958,600 | 1521 | 14 | 29.7 | 25.0 | −15.9 | 1,173,749 | 559 | 5 | 18.2 | 15.3 | −15.9 |
| 1450 | 2,101,050 | 1734 | 15 | 30.5 | 25.4 | −16.6 | 1,247,141 | 637 | 6 | 18.7 | 15.6 | −16.6 |
| 1500 | 2,248,500 | 1943 | 17 | 30.8 | 25.9 | −16.0 | 1,346,941 | 714 | 6 | 18.9 | 15.9 | −16.0 |
| 1550 | 2,400,950 | 2195 | 18 | 31.6 | 26.4 | −16.4 | 1,437,976 | 807 | 7 | 19.3 | 16.2 | −16.5 |
| 1600 | 2,558,400 | 2483 | 19 | 32.5 | 26.6 | −18.0 | 1,533,197 | 913 | 7 | 19.9 | 16.3 | −18.0 |
| 1650 | 2,720,850 | 2751 | 20 | 32.9 | 27.5 | −16.5 | 1,615,042 | 1011 | 7 | 20.1 | 16.8 | −16.4 |
| 1700 | 2,888,300 | 3131 | 23 | 34.1 | 27.9 | −18.2 | 1,730,900 | 1151 | 8 | 20.9 | 17.1 | −18.2 |
| 1750 | 3,060,750 | 3466 | 23 | 34.6 | 28.2 | −18.5 | 1,834,246 | 1274 | 9 | 21.2 | 17.3 | −18.5 |
| 1800 | 3,238,200 | 3878 | 24 | 35.6 | 28.7 | −19.3 | 1,922,130 | 1426 | 9 | 21.8 | 17.6 | −19.4 |
| 1850 | 3,420,650 | 4334 | 27 | 36.6 | 29.4 | −19.8 | 2,030,429 | 1593 | 10 | 22.4 | 18.0 | −19.8 |
| 1900 | 3,608,100 | 4778 | 29 | 37.3 | 29.8 | −20.2 | 2,141,696 | 1756 | 10 | 22.8 | 18.2 | −20.1 |
| 1950 | 3,800,550 | 5258 | 32 | 38.0 | 30.4 | −20.0 | 2,276,225 | 1933 | 12 | 23.3 | 18.6 | −20.0 |
| 2000 | 3998000 | 5818 | 34 | 38.9 | 30.9 | −20.7 | 2394482 | 2138 | 12 | 23.8 | 18.9 | −20.7 |
| Memory | Latency (ns) |
|---|---|
| L1 | 1.4 |
| L2 | 3.9 |
| L3 | 16.1 |
| Main | 88.6 |
| Vertices | Fully Dense (Complete) | Moderately Dense | ||||||
|---|---|---|---|---|---|---|---|---|
| L2 Miss | L3 Miss | L2 Miss | L3 Miss | |||||
| B–F | Dijkstra | B–F | Dijkstra | B–F | Dijkstra | B–F | Dijkstra | |
| 10 | 8 | 13 | 2 | 3 | 6 | 4 | 2 | 1 |
| 20 | 10 | 14 | 3 | 2 | 6 | 5 | 3 | 2 |
| 30 | 13 | 16 | 2 | 4 | 7 | 6 | 3 | 3 |
| 40 | 23 | 16 | 1 | 5 | 7 | 6 | 5 | 1 |
| 50 | 14 | 18 | 2 | 4 | 10 | 7 | 4 | 2 |
| 60 | 21 | 20 | 3 | 6 | 11 | 8 | 3 | 3 |
| 70 | 22 | 25 | 4 | 2 | 13 | 5 | 3 | 4 |
| 80 | 24 | 30 | 6 | 7 | 13 | 6 | 3 | 4 |
| 90 | 30 | 35 | 10 | 9 | 14 | 4 | 5 | 2 |
| 100 | 8077 | 4034 | 70 | 32 | 17 | 9 | 5 | 2 |
| 150 | 9070 | 5474 | 80 | 33 | 6519 | 3447 | 20 | 15 |
| 200 | 10,186 | 5929 | 82 | 34 | 7131 | 3767 | 22 | 17 |
| 250 | 11,143 | 6486 | 86 | 35 | 9128 | 4127 | 23 | 20 |
| 300 | 14263 | 7025 | 4155 | 36 | 9886 | 4457 | 30 | 24 |
| 350 | 15447 | 10,071 | 4557 | 3198 | 11,289 | 6340 | 1876 | 32 |
| 400 | 17,640 | 11,731 | 4996 | 3493 | 14,696 | 7392 | 3205 | 2189 |
| 450 | 20,145 | 15,462 | 5492 | 3830 | 16,622 | 10,644 | 3576 | 2451 |
| 500 | 22,784 | 18,879 | 6037 | 4200 | 20,507 | 11,994 | 3870 | 2688 |
| 550 | 28,109 | 24,883 | 6619 | 4605 | 23,824 | 15,819 | 4301 | 2947 |
| 600 | 32,655 | 30,340 | 7258 | 5050 | 28,317 | 18,971 | 4595 | 3232 |
| 650 | 38,813 | 37,097 | 7927 | 5551 | 30,614 | 23,556 | 5061 | 3552 |
| 700 | 41,962 | 39,446 | 8657 | 6101 | 30,762 | 25,077 | 5501 | 3904 |
| 750 | 42,165 | 40,097 | 9492 | 6663 | 34,792 | 25,508 | 6009 | 4264 |
| 800 | 47,689 | 43,795 | 10,434 | 7306 | 39,734 | 27,369 | 6662 | 4675 |
| 850 | 54,461 | 47,154 | 11,395 | 7979 | 44,938 | 29,452 | 7271 | 5106 |
| 900 | 61,595 | 50,490 | 18,129 | 8771 | 49,397 | 31,535 | 11,477 | 5613 |
| 950 | 67,705 | 53,563 | 23,322 | 12,917 | 54,298 | 34,033 | 14,766 | 8266 |
| 1000 | 74,422 | 62,573 | 25,637 | 15,592 | 59,275 | 39,465 | 16,380 | 9978 |
| 1050 | 81,245 | 70,036 | 27,996 | 17,097 | 64,736 | 44,526 | 17,888 | 10,942 |
| 1100 | 88,729 | 78,241 | 30,699 | 18,672 | 70,672 | 48,928 | 19,603 | 11,950 |
| 1150 | 96,865 | 82,150 | 33,527 | 20,524 | 77,492 | 52,228 | 21,422 | 13,135 |
| 1200 | 106,213 | 88,777 | 36,851 | 22,559 | 84,630 | 56,510 | 26,299 | 14,437 |
| 1250 | 115,996 | 99,920 | 40,507 | 24,637 | 93,025 | 62,908 | 28,364 | 17,767 |
| 1300 | 127,503 | 108,929 | 44,417 | 27,015 | 102,253 | 68,079 | 30,387 | 19,010 |
| 1350 | 140,150 | 120,196 | 48,824 | 29,695 | 112,121 | 76,417 | 32,513 | 20,341 |
| 1400 | 153,675 | 130,818 | 53,535 | 32,640 | 123,243 | 83,220 | 34,473 | 21,765 |
| 1450 | 168,919 | 147,369 | 60,795 | 35,647 | 134,545 | 93,750 | 37,202 | 23,288 |
| 1500 | 184,410 | 155,416 | 66,663 | 38,930 | 146,936 | 97,910 | 39,468 | 24,919 |
| 1550 | 201,394 | 176,144 | 72,802 | 42,687 | 161,512 | 111,853 | 42,231 | 26,663 |
| 1600 | 221,373 | 190,421 | 80,023 | 46,619 | 176,323 | 120,105 | 45,575 | 28,529 |
| 1650 | 241,672 | 212,108 | 87,962 | 51,118 | 192,563 | 134,853 | 48,350 | 30,527 |
| 1700 | 263,930 | 233,081 | 96,450 | 56,189 | 210,221 | 148,366 | 52,147 | 32,663 |
| 1750 | 288,133 | 270,908 | 106,018 | 61,763 | 231,075 | 170,976 | 55,865 | 34,950 |
| 1800 | 316,716 | 285,083 | 116,251 | 67,451 | 253,374 | 179,490 | 59,776 | 37,396 |
| 1850 | 347,279 | 334,600 | 127,781 | 74,142 | 277,824 | 210,794 | 63,960 | 40,014 |
| 1900 | 380,792 | 351,362 | 139,551 | 80,971 | 305,385 | 223,657 | 68,437 | 42,815 |
| 1950 | 418,567 | 379,312 | 152,404 | 88,785 | 335,679 | 238,961 | 73,140 | 45,812 |
| 2000 | 460,088 | 433,785 | 167,522 | 93,457 | 366,596 | 273,443 | 77,640 | 49,019 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alamoudi, O.; Al-Hashimi, M. On the Energy Behaviors of the Bellman–Ford and Dijkstra Algorithms: A Detailed Empirical Study. J. Sens. Actuator Netw. 2024, 13, 67. https://doi.org/10.3390/jsan13050067
Alamoudi O, Al-Hashimi M. On the Energy Behaviors of the Bellman–Ford and Dijkstra Algorithms: A Detailed Empirical Study. Journal of Sensor and Actuator Networks. 2024; 13(5):67. https://doi.org/10.3390/jsan13050067
Chicago/Turabian StyleAlamoudi, Othman, and Muhammad Al-Hashimi. 2024. "On the Energy Behaviors of the Bellman–Ford and Dijkstra Algorithms: A Detailed Empirical Study" Journal of Sensor and Actuator Networks 13, no. 5: 67. https://doi.org/10.3390/jsan13050067
APA StyleAlamoudi, O., & Al-Hashimi, M. (2024). On the Energy Behaviors of the Bellman–Ford and Dijkstra Algorithms: A Detailed Empirical Study. Journal of Sensor and Actuator Networks, 13(5), 67. https://doi.org/10.3390/jsan13050067