
Sentiment Analysis of Social Survey Data for Local City Councils


 and
and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
3. Methodology, Data, and Tools for Analysis of Social Survey Data
3.1. Methodology
- Identify data sources that can be used to provide social survey data;
- Determine and trial analysis tools on several different datasets;
- Develop a suite of apps to analyse the datasets for sentiment;
- Further develop an app that can access social media feeds to determine current sentiment using findings from the historic dataset analysis;
- Host the apps on a website for customer access;
- Compare historic sentiment results with current sentiment where possible, and thus demonstrate that this approach can provide useful results for a local city council.
3.2. Council Datasets from Social Surveys
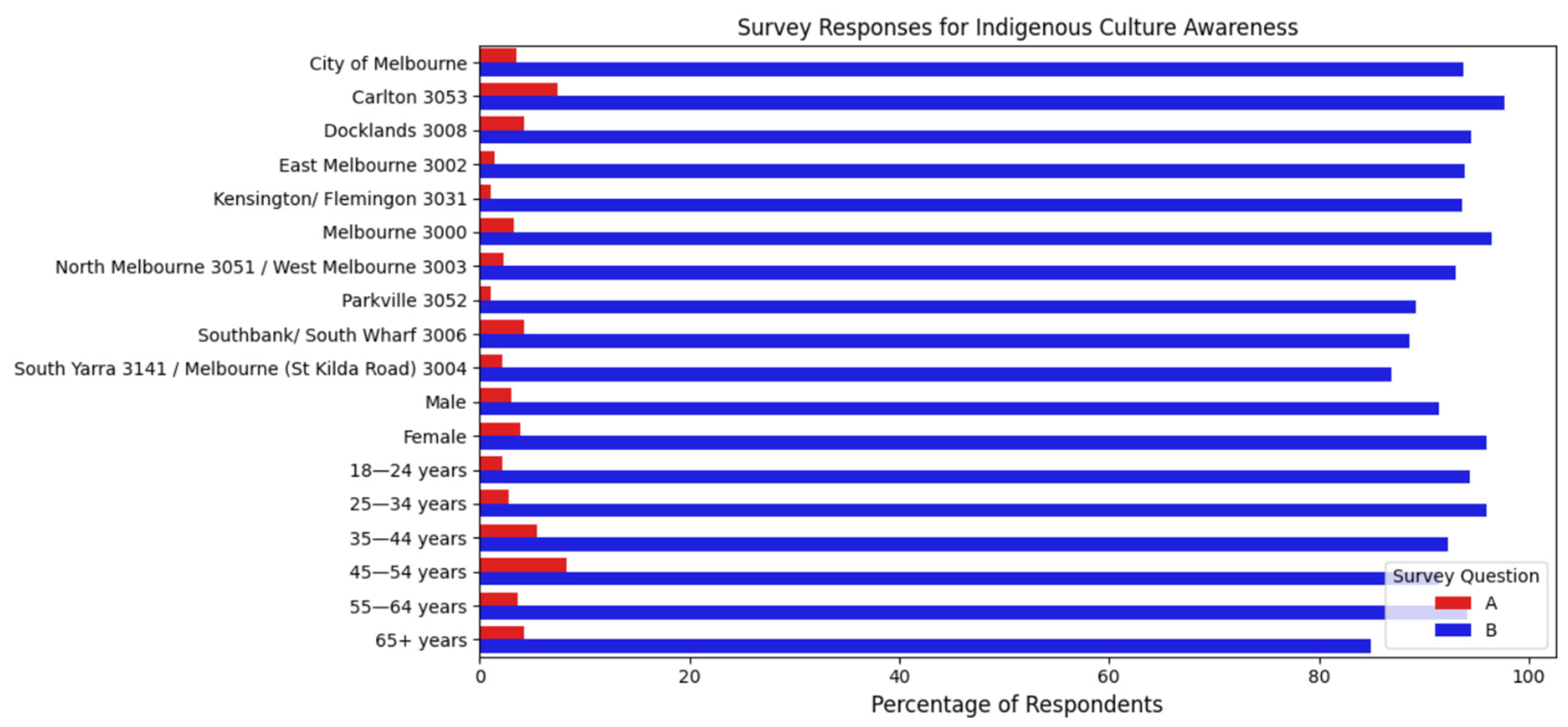
- The CoM social indicators survey that was conducted in 2018 and involved over 1200 residents. The dataset was used to measure outcomes for social indicators such as health, wellbeing, community sense, and connectedness of its citizens. The responses are quantitative in nature and thus not suitable for NLP analysis. The dataset is available online from the CoM data portal [21].
- The Casey Next short survey that was conducted in 2016 and a contractor report produced [22]. Over 3600 responses were collected as a combination of structured and unstructured data records that are mostly qualitative in nature. The dataset is available online from the Australian open data portal [20].
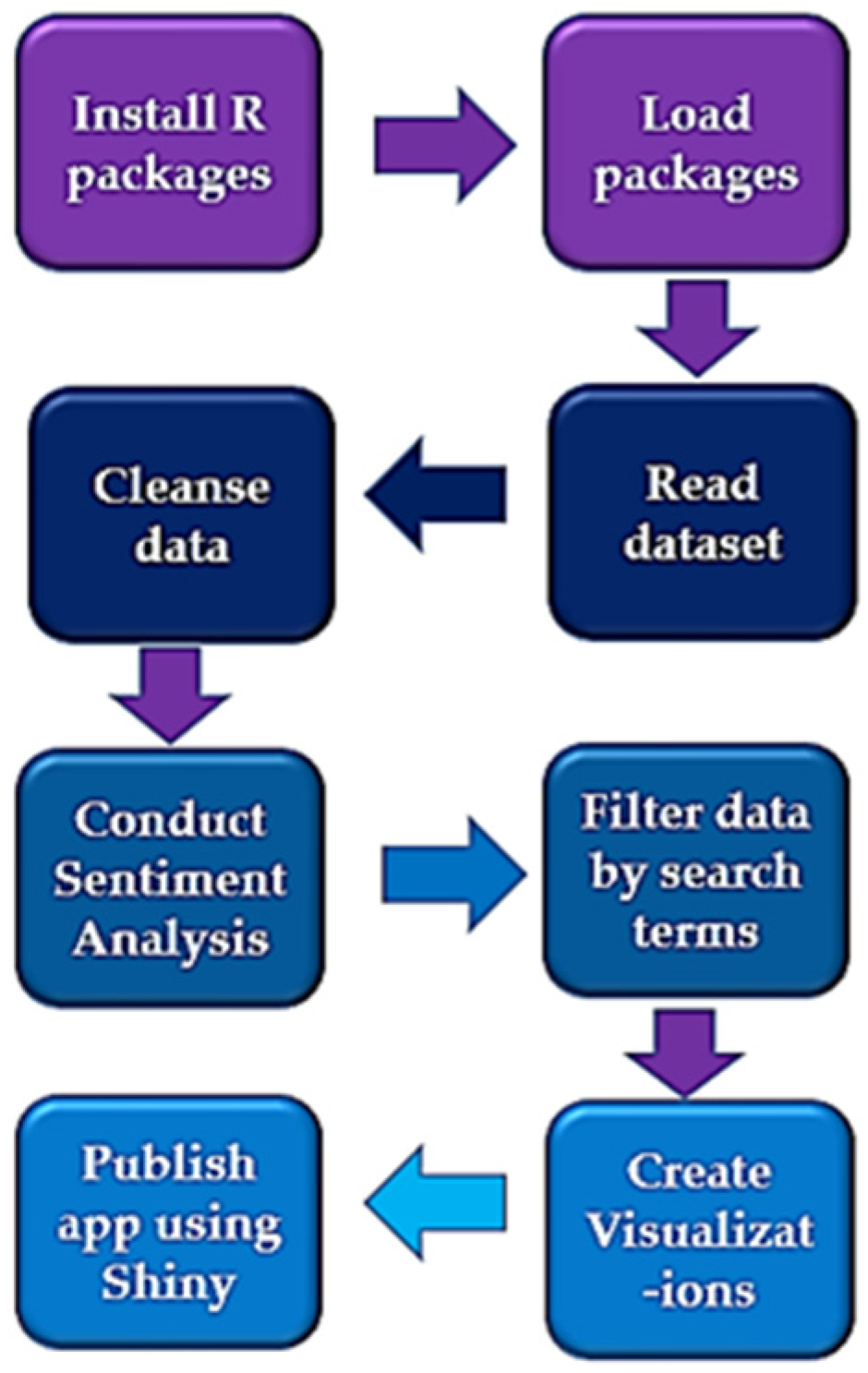
3.3. Analysis and Web Hosting Tools
4. Analysis of Data
4.1. Preliminary Analysis of City of Melbourne Social Indicators Dataset
- Participate in adequate physical activity.
- Participate in sports and exercise activities.
- Participate in sports and exercise activities in the CoM.
- Participate in organised physical activity.
- Participate in physical activity organised by a fitness, leisure or indoor sports centre.
- Participate in physical activity organised by a sports club or association.
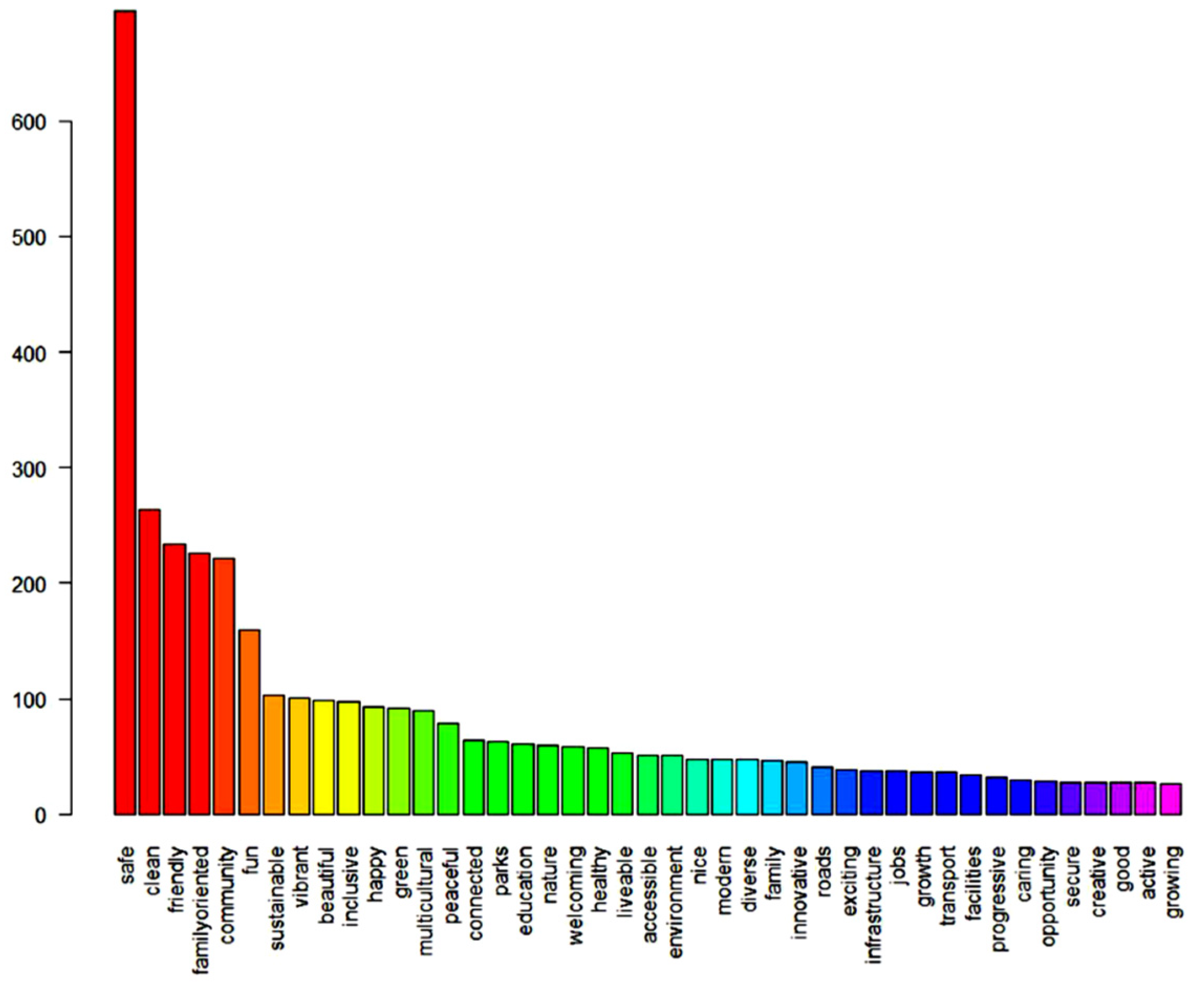
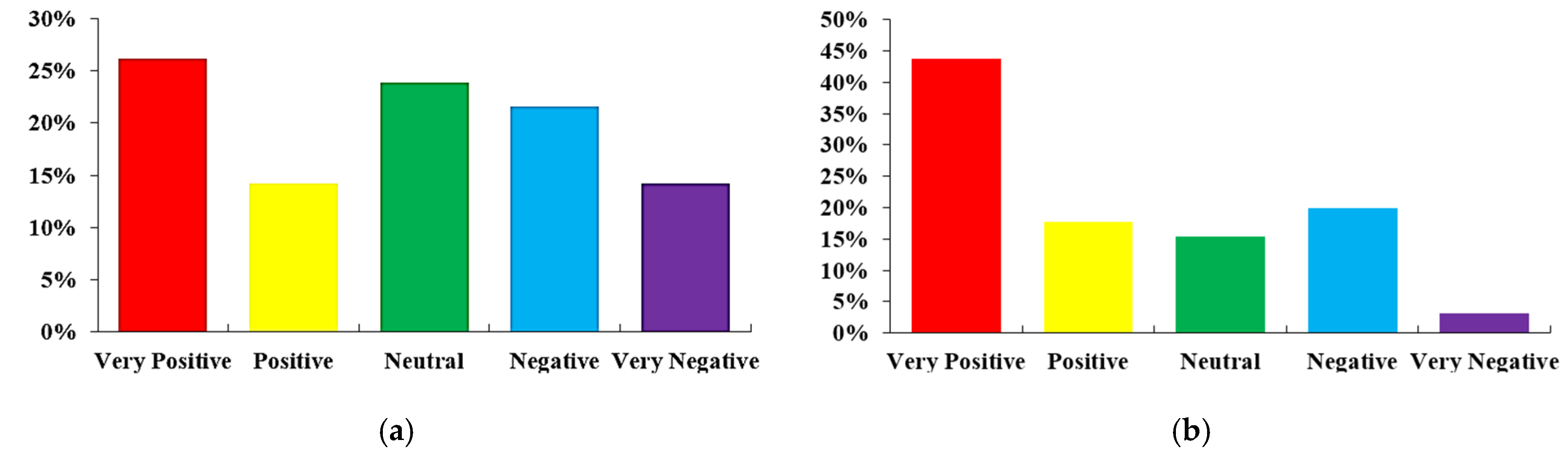
4.2. Analysis of Casey Next Dataset
- ‘What Kind of Place Would You Like Casey To Be In 2041?’
- ‘If You Could Change One Thing In Casey What Would It Be?’
- ‘Describe Your Vision For Casey In Three Words?’
- ‘What’s Most Important To You?’
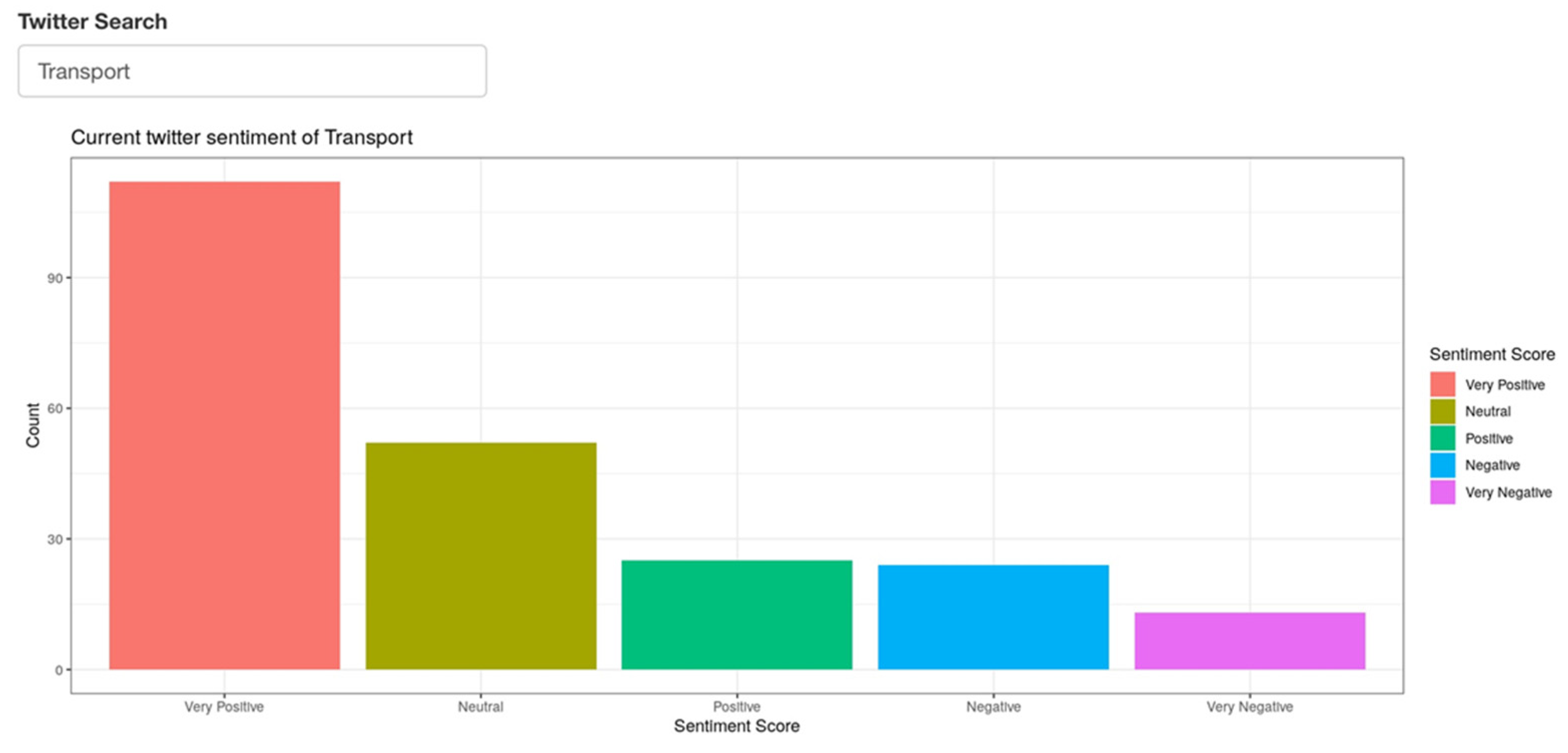
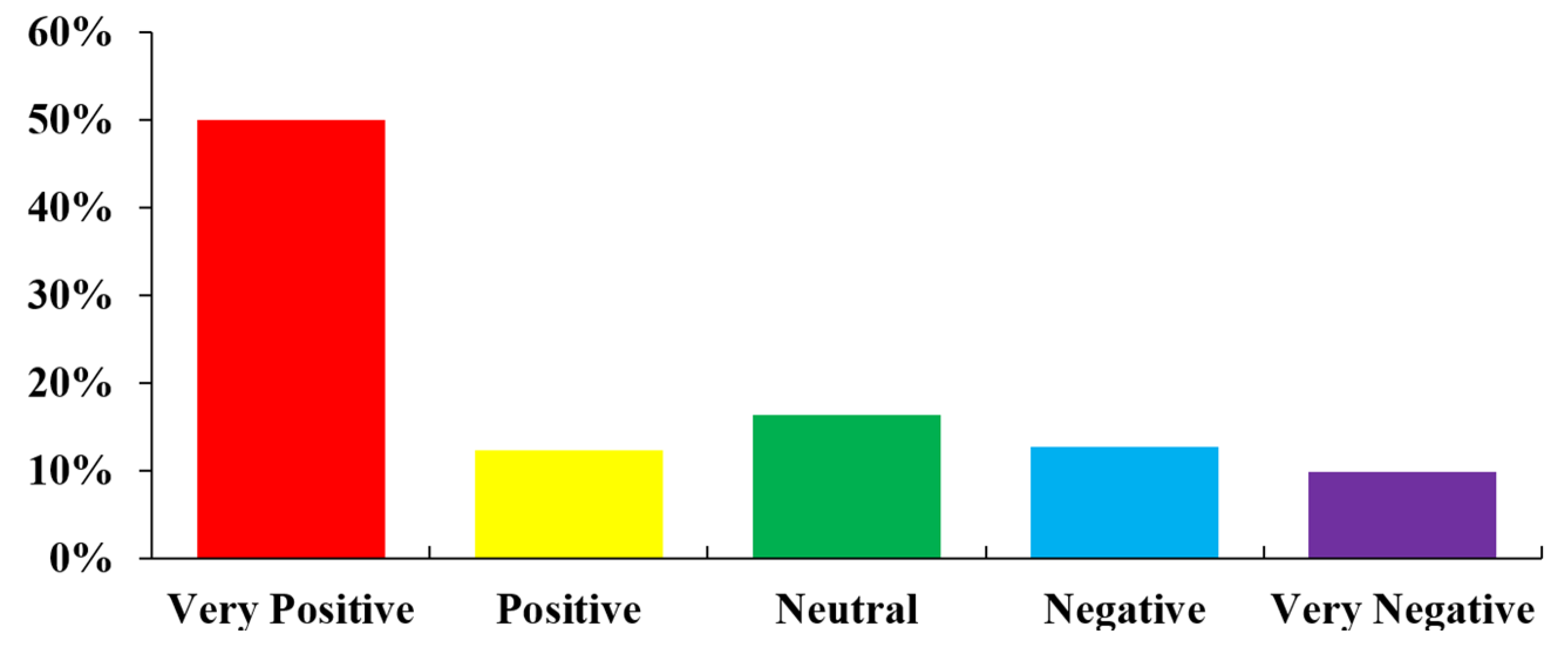
4.3. Analysis Using Social Media
5. Discussion
- consider safety, cleanliness, and family friendliness as its top priorities;
- invest further in the environment providing more parks and green spaces;
- improve transport options for their residents;
- address health and safety issues.
- expanding on the Twitter query function, which currently only takes tweets from the last 6–9 days and improving the geolocation of tweets;
- studying how sentiment changes over time;
- improving the accuracy of the sentiment analysis performed;
- building drill-down capabilities into the visualizations to promote better analysis;
- creating additional visualizations using RStudio to derive clearer insights from Twitter;
- analysing the upcoming Casey Next survey data due to be released at the end of 2021 to compare against the findings based on the 2016 survey data.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Al Nuaimi, E.; Al Neyadi, H.; Mohamed, N.; Al-Jaroodi, J. Applications of big data to smart cities. J. Internet Serv. Appl. 2015, 6, 1–15. [Google Scholar] [CrossRef]
- Mergel, I.; Rethemeyer, R.K.; Isett, K. Big data in public affairs. Public Adm. Rev. 2016, 76, 928–937. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Choppali Uand Kougianos, E. Everything you wanted to know about smart cities: The Internet of things is the backbone. IEEE Consum. Electron. Mag. 2016, 5, 60–70. [Google Scholar] [CrossRef]
- Ryan Watson Consulting Pty Ltd: Consultancy Service for Smart Cities. Available online: https://www.ryanwatsonconsulting.com.au/ (accessed on 10 November 2021).
- Buskirk, T.; Kirchner, A.; Eck, A.; Signorino, C. An Introduction to Machine Learning Methods for Survey Researchers. Surv. Pract. 2018, 11, 1–10. [Google Scholar] [CrossRef]
- Ramirez, C.M.; Abrajano, M.A.; Alvarez, R.M. Using Machine Learning to Uncover Hidden Heterogeneities in Survey Data. Sci. Rep. 2019, 9, 16061. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Hovy, E. Reflections on sentiment/opinion analysis. In A Practical Guide to Sentiment Analysis; Springer: Berlin/Heidelberg, Germany, 2017; pp. 41–59. [Google Scholar]
- Khan, J.; Jeong, B.S.; Lee, Y.K.; Alam, A. Sentiment analysis at sentence level for heterogeneous datasets. In Proceedings of the Sixth International Conference on Emerging Databases: Technologies, Applications, and Theory, Jeju Island, Korea, 17–19 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 159–163. [Google Scholar]
- Naldi, M. A review of sentiment computation methods with R packages. arXiv Prepr. 2019, arXiv:1901.08319 2019. Available online: https://arxiv.org/pdf/1901.08319.pdf (accessed on 2 June 2021).
- Mohey El-Din, D. Enhancement Bag-of-Words Model for Solving the Challenges of Sentiment Analysis. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 244–252. [Google Scholar] [CrossRef][Green Version]
- Jurek, A.; Mulvenna, M.D.; Bi, Y. Improved lexicon-based sentiment analysis for social media analytics. Secur. Inform. 2015, 4, 9. [Google Scholar] [CrossRef]
- Peng, S.; Yu, S.; Mueller, P. Social networking big data: Opportunities, solutions, and challenges. Future Gener. Comput. Syst. 2018, 86, 1456–1458. [Google Scholar] [CrossRef]
- Stastita Research Department. Social Media-Statistics & Facts. 2021. Available online: https://www.statista.com/topics/1164/social-networks/ (accessed on 3 January 2022).
- Tsapatsoulis, N.; Djouvas, C. Opinion Mining from Social Media Short Texts: Does Collective Intelligence Beat Deep Learning? Front. Robot. AI 2018, 5, 138. [Google Scholar] [CrossRef] [PubMed]
- Shah, S.; Kumar, K.; Sarvananguru, R. Sentimental Analysis of Twitter Data using Classifier Algorithms. Int. J. Electr. Comput. Eng. (IJECE) 2016, 6, 357–366. [Google Scholar] [CrossRef]
- Yigitcanlar, T.; Kankanamge, N.; Vella, K. How Are Smart City Concepts and Technologies Perceived and Utilized? A Systematic Geo-Twitter Analysis of Smart Cities in Australia? J. Urban Technol. 2021, 28, 135–154. [Google Scholar] [CrossRef]
- Sv, P.; Ittamalla, D.R. An analysis of attitude of general public toward COVID-19 crises–sentimental analysis and a topic modeling study. Inf. Discov. Deliv. 2021; ahead-of-print. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public Perception of the COVID-19 Pandemic on Twitter: Sentiment Analysis and Topic Modeling Study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef] [PubMed]
- Kankanamge, N.; Yigitcanlar, T.; Goonetilleke, A.; Kamruzzaman, M. Determining disaster severity through social media analysis: Testing the methodology with South East Queensland Flood tweets. Int. J. Disaster Risk Reduct. 2019, 42, 101360. [Google Scholar] [CrossRef]
- Government of Australia. Australian Government Open Data Portal. Available online: https://data.gov.au/ (accessed on 10 November 2021).
- City of Melbourne. Social Indicators for City of Melbourne Residents. 2018. Available online: https://data.melbourne.vic.gov.au/People/Social-Indicators-for-City-of-Melbourne-Residents-/n9ie-cp6t (accessed on 10 November 2021).
- Capire. Casey Next. 2017. Available online: https://capire.com.au/projects/public-policy/casey-next/ (accessed on 2 June 2021).
- City of Casey. Managing Our Growth. Available online: https://www.casey.vic.gov.au/managing-our-growth (accessed on 4 June 2021).
- RStudio: Open Source & Professional Software for Data Science Teams. 2020. Available online: https://rstudio.com (accessed on 10 November 2021).
- Brownlee, J. How to Make Predictions with Scikit-Learn. 2018. Available online: https://machinelearningmastery.com/make-predictions-scikit-learn/ (accessed on 10 November 2021).
- Kearney, M.W. R: Collecting and Analyzing Twitter Data. 2018. Available online: https://mkearney.github.io/nicar_tworkshop (accessed on 10 November 2021).
- Shiny. Available online: https://shiny.rstudio.com/ (accessed on 10 November 2021).
- Hostinger. Available online: https://www.hostinger.com/ (accessed on 10 November 2021).
- Pylvainen, I. What Are the Limits of the Shinyapps.io Free Plan? 2020. Available online: https://support.rstudio.com/hc/en-us/articles/217592947-What-are-the-limits-of-the-shinyapps-io-Free-plan- (accessed on 4 June 2021).
- Kang, H. The prevention and handling of the missing data. Korean J. Anesthesiol. 2013, 64, 402–406. [Google Scholar] [CrossRef] [PubMed]
- RDocumentation. Syuzhet. Available online: https://www.rdocumentation.org/packages/syuzhet/versions/1.0.6 (accessed on 5 June 2021).
- Rajan, V.M.; Ramanujan, A. Architecture of a Semantic WordCloud Visualization. In Second International Conference on Networks and Advances in Computational Technologies; Springer: Berlin/Heidelberg, Germany, 2021; pp. 95–106. [Google Scholar]
- Holtz, Y. The Wordcloud2 Library. 2018. Available online: https://www.r-graph-gallery.com/196-the-wordcloud2-library.html (accessed on 10 November 2021).
- Bose, S. RSentiment. 2018. Available online: https://www.rdocumentation.org/packages/RSentiment/versions/2.2.2 (accessed on 21 September 2021).
- Silge, J.; Robinson, D. Introduction to Tidytext. 2021. Available online: https://cran.r-project.org/web/packages/tidytext/vignettes/tidytext.html (accessed on 10 November 2021).
- Correll, D. Social Media Statistics Australia–September 2021. Available online: https://www.socialmedianews.com.au/social-media-statistics-australia-september-2021/ (accessed on 19 November 2021).
- Ferenstein, G. Twitter Is a Mainstream Liberal, but a Conservative Wonk. 2013. Available online: https://techcrunch.com/2013/03/05/pew-twitter-is-a-mainstream-liberal-but-a-conservative-wonk/ (accessed on 21 September 2021).
- Wahby, A.; Tibble, K.; Nitikin, L.; Lepelaar, M.; Rossouw, M. City of Casey Sentiment Analysis and Web APIs. In Student Report for Client; Swinburne University of Technology: Melbourne, Australia, 2021. [Google Scholar]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lepelaar, M.; Wahby, A.; Rossouw, M.; Nikitin, L.; Tibble, K.; Ryan, P.J.; Watson, R.B. Sentiment Analysis of Social Survey Data for Local City Councils. J. Sens. Actuator Netw. 2022, 11, 7. https://doi.org/10.3390/jsan11010007
Lepelaar M, Wahby A, Rossouw M, Nikitin L, Tibble K, Ryan PJ, Watson RB. Sentiment Analysis of Social Survey Data for Local City Councils. Journal of Sensor and Actuator Networks. 2022; 11(1):7. https://doi.org/10.3390/jsan11010007
Chicago/Turabian StyleLepelaar, Marianna, Adam Wahby, Martha Rossouw, Linda Nikitin, Kanewa Tibble, Peter J. Ryan, and Richard B. Watson. 2022. "Sentiment Analysis of Social Survey Data for Local City Councils" Journal of Sensor and Actuator Networks 11, no. 1: 7. https://doi.org/10.3390/jsan11010007
APA StyleLepelaar, M., Wahby, A., Rossouw, M., Nikitin, L., Tibble, K., Ryan, P. J., & Watson, R. B. (2022). Sentiment Analysis of Social Survey Data for Local City Councils. Journal of Sensor and Actuator Networks, 11(1), 7. https://doi.org/10.3390/jsan11010007