Association Mapping between Candidate Gene SNP and Production and Oil Quality Traits in Interspecific Oil Palm Hybrids

 , and
, and
Abstract
1. Introduction
2. Results
2.1. Phenotype Analysis
2.2. Genotype Analysis
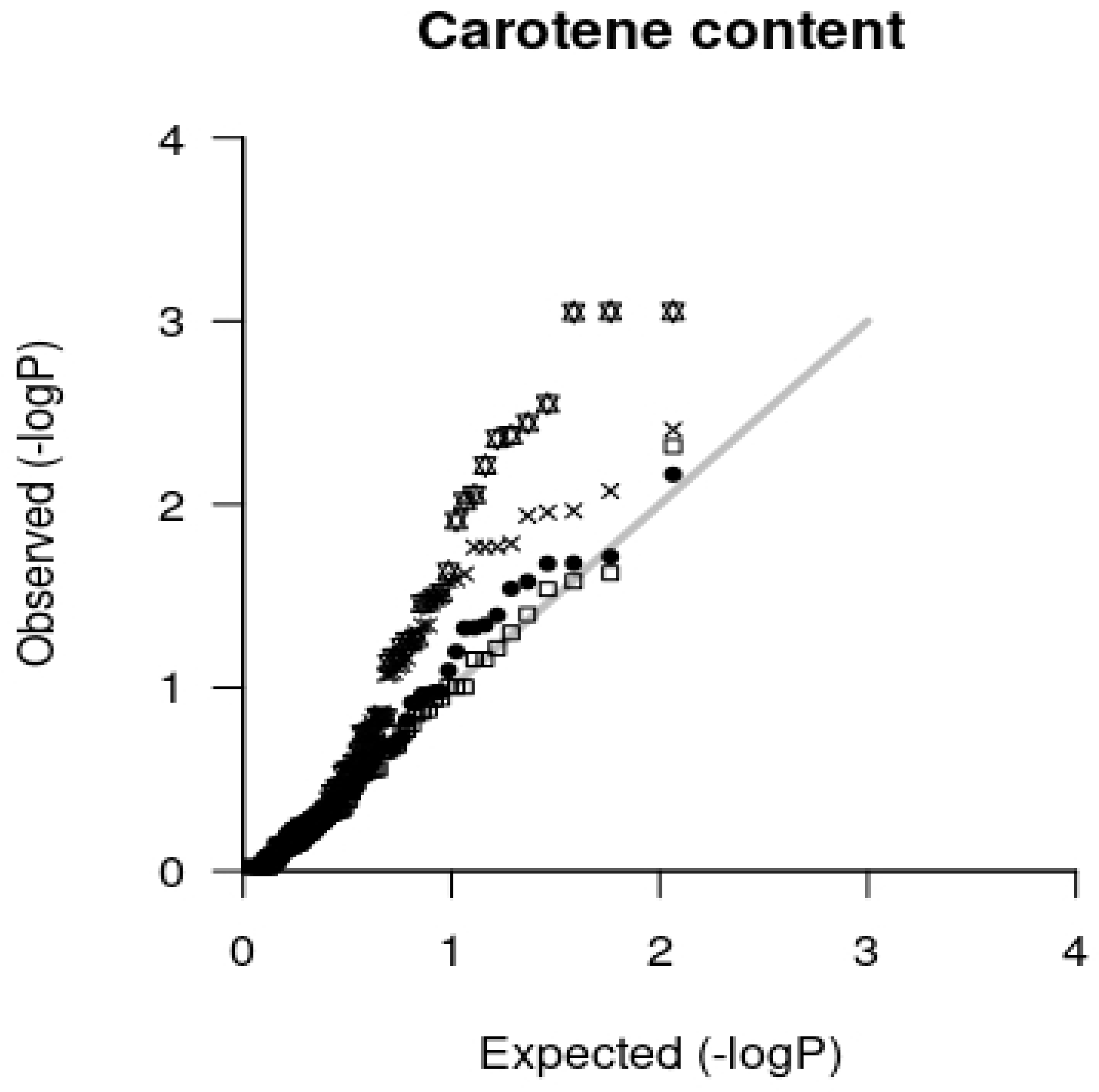
2.3. Association Analysis
3. Discussion
3.1. Phenotypic Data Analysis
3.2. SNP Detection and Genetic Diversity Analysis
3.3. Association Mapping Results
4. Material and Methods
4.1. Plant Material
4.2. Candidate Gene (CG) Selection
4.3. Trait Recording
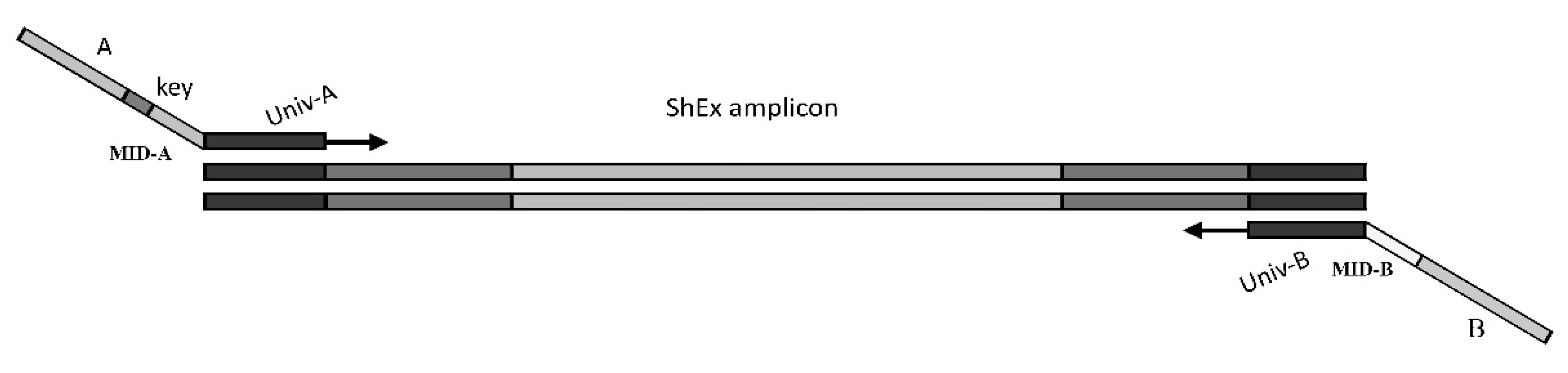
4.4. DNA Extraction and Library Construction
4.5. Sequence Processing and Association Analysis
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Seto, K.C.; Reenberg, A. Rethinking Global Land Use in an Urban Era An Introduction; The MIT Press: Cambridge, Massachusetts, 2016; ISBN 0000000000215. [Google Scholar]
- USDA. Oilseeds: World Markets and Trades; USDA: Washington, DC, USA, 2019. [Google Scholar]
- Food and Agriculture Organization of the United Nations FAOSTAT. Available online: http://www.fao.org/faostat/en/#data/QC/visualize (accessed on 9 January 2019).
- Sundram, S.; Intan-Nur, A.M.A. South American Bud rot: A biosecurity threat to South East Asian oil palm. Crop Prot. 2017, 101, 58–67. [Google Scholar] [CrossRef]
- Pelaez, E.; Ramirez, D.; Gerardo, C. Fisiología comparada de palmas africana (Elaeis guineensis Jacq.), americana (Elaeis oleifera hbk Cortes) e híbridos (E. oleifera × E. guineensis) en Hacienda La Cabaña. Palmas 2010, 31, 29–38. [Google Scholar]
- Barba, J. Introgresión de genes E. guineensis en híbridos interespecíficos O × G para recuperar la fertilidad del polen y otras características deseables en palma de aceite. Palmas 2016, 37, 285–293. [Google Scholar]
- Torres, M.; Rey, L.; Gelves, F.; Santacruz, L. Evaluación del comportamiento de los híbridos interespecíficos Elaeis oleifera × Elaeis guineensis, en la plantación de Guaicaramo S.A. Evaluation of the Behavior of Elaeis Oleifera × Elaeis Guineensis Hybrids in Guaicaramo Plantation. Palmas 2004, 25, 350–357. [Google Scholar]
- Mohd, D.; Rajanaidu, N.; Jalani, B.S. Performance of Elaeis oleifera from Panama, Costa Rica, Colombia and Honduras in Malasya. J. Oil Palm Res. 2000, 12, 71–80. [Google Scholar]
- Cadena, T.; Prada, F.; Perea, A.; Romero, H.M. Lipase activity, mesocarp oil content, and iodine value in oil palm fruits of Elaeis guineensis, Elaeis oleifera, and the interspecific hybrid O × G (E. oleifera × E. guineensis). J. Sci. Food Agric. 2013, 93, 674–680. [Google Scholar] [CrossRef]
- Montoya, C.; Lopes, R.; Flori, A.; Cros, D.; Cuellar, T.; Summo, M.; Espeout, S.; Rivallan, R.; Risterucci, A.M.; Bittencourt, D.; et al. Quantitative trait loci (QTLs) analysis of palm oil fatty acid composition in an interspecific pseudo-backcross from Elaeis oleifera (H.B.K.) Cortés and oil palm (Elaeis guineensis Jacq.). Tree Genet. Genomes 2013, 9, 1207–1225. [Google Scholar] [CrossRef]
- Singh, R.; Tan, S.G.; Panandam, J.M.; Rahman, R.A.; Ooi, L.C.; Low, E.-T.L.; Sharma, M.; Jansen, J.; Cheah, S.-C.C. Mapping quantitative trait loci (QTLs) for fatty acid composition in an interspecific cross of oil palm. BMC Plant Biol. 2009, 9, 1–19. [Google Scholar] [CrossRef]
- Risch, N.; Merikangas, K. The future of genetic studies of complex diseases. Science 1996, 273, 1516–1517. [Google Scholar] [CrossRef]
- Augusto, A.; Garcia, F. Genetic Architecture of Quantitative Traits. Architecture 2001, 35, 303–339. [Google Scholar]
- Teh, C.K.; Ong, A.L.; Kwong, Q.B.; Apparow, S.; Chew, F.T.; Mayes, S.; Mohamed, M.; Appleton, D.; Kulaveerasingam, H. Genome-wide association study identifies three key loci for high mesocarp oil content in perennial crop oil palm. Sci. Rep. 2016, 6, 19075. [Google Scholar] [CrossRef] [PubMed]
- Kwong, Q.B.; Teh, C.K.; Ong, A.L.; Heng, H.Y.; Lee, H.L.; Mohamed, M.; Low, J.Z.B.; Apparow, S.; Chew, F.T.; Mayes, S.; et al. Development and Validation of a High-Density SNP Genotyping Array for African Oil Palm. Mol. Plant 2016, 9, 1132–1141. [Google Scholar] [CrossRef] [PubMed]
- Xia, W.; Luo, T.; Zhang, W.; Mason, A.S.; Huang, D.; Huang, X.; Tang, W.; Dou, Y.; Zhang, C.; Xiao, Y.; et al. Identification of genes affecting saturated fat acid content in Elaeis guineensis by genome-wide association analysis. BioRxiv 2018, 341347. [Google Scholar] [CrossRef]
- Corley, R.H.V.; Tinker, P.B.H. The Oil Palm; John Wiley & Sons: Hoboken, NJ, USA, 2015; ISBN 9781405189392. [Google Scholar]
- Barba, J. Oleiferas Ecuatorianas Alternativa de Manejo Agronomico para Compensar Las Perdidas Ocasionadas por la Pudricion del Cogollo en America Latina; Palmar del Río: Orellana, Ecuador, 2019; Available online: http://www.palmardelrio.com/sitio/files/oleiferasecuatorianasalternativademanejoW.pdf. (accessed on 22 February 2019).
- Arias, D.; González, M.; Prada, F.; Ayala-Diaz, I.; Montoya, C.; Daza, E.; Romero, H.M. Genetic and phenotypic diversity of natural American oil palm (Elaeis oleifera (H.B.K.) Cortés) accessions. Tree Genet. Genomes 2015, 11, 122. [Google Scholar] [CrossRef]
- Soh, A.C.; Mayes, S.; Roberts, J.A. Oil Palm Breeding: Genetics and Genomics; CRC Press: Boca Raton, FL, USA, 2017; ISBN 9781498715447. [Google Scholar]
- Qian, F.; Korat, A.A.; Malik, V.; Hu, F.B. Metabolic Effects of Monounsaturated Fatty Acid-Enriched Diets Compared with Carbohydrate or Polyunsaturated Fatty Acid-Enriched Diets in Patients with Type 2 Diabetes: A Systematic Review and Meta-analysis of Randomized Controlled Trials. Diabetes Care 2016, 39, 1448–1457. [Google Scholar] [CrossRef] [PubMed]
- Tierney, A.C.; Roche, H.M. The potential role of olive oil-derived MUFA in insulin sensitivity. Mol. Nutr. Food Res. 2007, 51, 1235–1248. [Google Scholar] [CrossRef]
- Nesaretnam, K.; Guthrie, N.; Chambers, A.F.; Carroll, K.K. Effect of Tocotrienols on the Growth of a Human Breast Cancer Cell Line in Culture 1. Lipids 1995, 30, 1139–1143. [Google Scholar] [CrossRef]
- May, C.Y.; Nesaretnam, K. Research advancements in palm oil nutrition. Eur. J. Lipid Sci. Technol. 2014, 116, 1301–1315. [Google Scholar] [CrossRef] [PubMed]
- Guo, L.; Xia, J.; Yang, S.; Li, M.; You, X.; Meng, Z.; Lin, H. GHRH, PRP-PACAP and GHRHR Target Sequencing via an Ion Torrent Personal Genome Machine Reveals an Association with Growth in Orange-Spotted Grouper (Epinephelus coioides). Int. J. Mol. Sci. 2015, 16, 26137–26150. [Google Scholar] [CrossRef]
- Singh, D.; Singh, B.; Mishra, S.; Singh, A.K.; Singh, N.K. Candidate gene based association analysis of salt tolerance in traditional and improved varieties of rice (Oryza sativa L.). J. Plant Biochem. Biotechnol. 2019, 28, 76–83. [Google Scholar] [CrossRef]
- Singh, R.; Ong-Abdullah, M.; Low, E.T.L.; Manaf, M.A.A.; Rosli, R.; Nookiah, R.; Ooi, L.C.L.; Ooi, S.E.; Chan, K.L.; Halim, M.A.; et al. Oil palm genome sequence reveals divergence of interfertile species in Old and New Worlds. Nature 2013, 500, 335. [Google Scholar] [CrossRef] [PubMed]
- Camillo, J.; Leão, A.P.; Alves, A.A.; Formighieri, E.F.; Azevedo, A.L.S.; Nunes, J.D.; de Capdeville, G.; de Mattos, J.K.A.; Souza, M.T. Reassessment of the Genome Size in Elaeis guineensis and Elaeis oleifera, and Its Interspecific Hybrid. Genom. Insights 2014, 7, GEI-S15522. [Google Scholar] [CrossRef] [PubMed]
- Arias, D.; Ochoa, I.; Castro, F.; Romero, H. Molecular characterization of oil palm Elaeis guineensis Jacq. of different origins for their utilization in breeding programmes. Plant Genet. Resour. 2014, 12, 341–348. [Google Scholar] [CrossRef]
- Johnson, M.G.; Shaw, A.J. Genetic diversity, sexual condition, and microhabitat preference determine mating patterns in Sphagnum (Sphagnaceae) peat-mosses. Biol. J. Linn. Soc. 2015, 115, 96–113. [Google Scholar] [CrossRef]
- Ting, N.C.; Jansen, J.; Mayes, S.; Massawe, F.; Sambanthamurthi, R.; Ooi, L.C.L.; Chin, C.W.; Arulandoo, X.; Seng, T.Y.; Alwee, S.S.R.S.; et al. High density SNP and SSR-based genetic maps of two independent oil palm hybrids. BMC Genom. 2014, 15, 309. [Google Scholar] [CrossRef] [PubMed]
- Ting, N.-C.; Yaakub, Z.; Kamaruddin, K.; Mayes, S.; Massawe, F.; Sambanthamurthi, R.; Jansen, J.; Eng Ti Low, L.; Ithnin, M.; Kushairi, A.; et al. Fine-mapping and cross-validation of QTLs linked to fatty acid composition in multiple independent interspecific crosses of oil palm. BMC Genom. 2016, 17, 289. [Google Scholar] [CrossRef] [PubMed]
- Álvarez, M.F.; Angarita, M.; Delgado, M.C.; García, C.; Jiménez-Gomez, J.; Gebhardt, C.; Mosquera, T. Identification of Novel Associations of Candidate Genes with Resistance to Late Blight in Solanum tuberosum Group Phureja. Front. Plant Sci. 2017, 8, 1040. [Google Scholar] [CrossRef] [PubMed]
- Gamazon, E.R.; Wheeler, H.E.; Shah, K.P.; Mozaffari, S.V.; Aquino-Michaels, K.; Carroll, R.J.; Eyler, A.E.; Denny, J.C.; Nicolae, D.L.; Cox, N.J.; et al. A gene-based association method for mapping traits using reference transcriptome data. Nat. Genet. 2015, 47, 1091–1098. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Liu, S.; Liu, Y.; Liu, Y.; Chen, G.; Xu, J.; Deng, M.; Jiang, Q.; Wei, Y.; Lu, Y.; et al. Genome-wide association study of pre-harvest sprouting resistance in Chinese wheat founder parents. Genet. Mol. Biol. 2017, 40, 620–629. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Yan, J.; Zhao, J.; Song, W.; Zhang, X.; Xiao, Y.; Zheng, Y. Genome-wide association study (GWAS) of resistance to head smut in maize. Plant Sci. 2012, 196, 125–131. [Google Scholar] [CrossRef] [PubMed]
- Nigro, D.; Gadaleta, A.; Mangini, G.; Colasuonno, P.; Marcotuli, I.; Giancaspro, A.; Giove, S.L.; Simeone, R.; Blanco, A. Candidate genes and genome-wide association study of grain protein content and protein deviation in durum wheat. Planta 2019, 249, 1157–1175. [Google Scholar] [CrossRef] [PubMed]
- Gao, L.; Turner, M.K.; Chao, S.; Kolmer, J.; Anderson, J.A. Genome Wide Association Study of Seedling and Adult Plant Leaf Rust Resistance in Elite Spring Wheat Breeding Lines. PLoS ONE 2016, 11, e0148671. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Wilcox, P.; Telfer, E.; Graham, N.; Stanbra, L. Association of single nucleotide polymorphisms with form traits in three New Zealand populations of radiata pine in the presence of genotype by environment interactions. Tree Genet. Genomes 2016, 12, 63. [Google Scholar] [CrossRef]
- Zegeye, H.; Rasheed, A.; Makdis, F.; Badebo, A.; Ogbonnaya, F.C. Genome-Wide Association Mapping for Seedling and Adult Plant Resistance to Stripe Rust in Synthetic Hexaploid Wheat. PLoS ONE 2014, 9, e105593. [Google Scholar] [CrossRef] [PubMed]
- Pasam, R.K.; Sharma, R.; Malosetti, M.; van Eeuwijk, F.A.; Haseneyer, G.; Kilian, B.; Graner, A. Genome-wide association studies for agronomical traits in a world wide spring barley collection. BMC Plant Biol. 2012, 12, 16. [Google Scholar] [CrossRef] [PubMed]
- Solmonson, A.; Deberardinis, R.J. Lipoic acid and mitochondrial redox regulation. J. Biol. Chem. 2017, 293, 7522–7530. [Google Scholar] [CrossRef]
- Ewald, R.; Hoffmann, C.; Florian, A.; Neuhaus, E.; Fernie, A.R.; Bauwe, H. Lipoate-Protein Ligase and Octanoyltransferase Are Essential for Protein Lipoylation in Mitochondria of Arabidopsis. Plant Physiol. 2014, 165, 978–990. [Google Scholar] [CrossRef]
- Schoen, H.; Thimm, O.; Ritte, G.; Blaesing, O.; Bruynseels, K.; Hatzfeld, Y.; Frankard, V. Plants with increased yield (NUE). WO/2010/046221, 29 April 2010. [Google Scholar]
- Shintani, D.; DellaPenna, D. Elevating the vitamin E content of plants through metabolic engineering. Science 1998, 282, 2098–2100. [Google Scholar] [CrossRef]
- Benelli, G.; Pavela, R.; Petrelli, R.; Cappellacci, L.; Santini, G.; Fiorini, D.; Sut, S.; Dall’Acqua, S.; Canale, A.; Maggi, F. The essential oil from industrial hemp (Cannabis sativa L.) by-products as an effective tool for insect pest management in organic crops. Ind. Crops Prod. 2018, 122, 308–315. [Google Scholar] [CrossRef]
- Fernandes, E.S.; Passos, G.F.; Medeiros, R.; Da Cunha, F.M.; Ferreira, J.; Campos, M.M.; Pianowski, L.F.; Calixto, J.B. Anti-inflammatory effects of compounds alpha-humulene and (−)-trans-caryophyllene isolated from the essential oil of Cordia verbenacea. Eur. J. Pharmacol. 2007, 569, 228–236. [Google Scholar] [CrossRef]
- Yu, F.; Okamto, S.; Nakasone, K.; Adachi, K.; Matsuda, S.; Harada, H.; Misawa, N.; Utsumi, R. Molecular cloning and functional characterization of-humulene synthase, a possible key enzyme of zerumbone biosynthesis in shampoo ginger (Zingiber zerumbet Smith). Planta 2008, 227, 1291–1299. [Google Scholar] [CrossRef] [PubMed]
- Ames-Sibin, A.P.; Barizão, C.L.; Castro-Ghizoni, C.V.; Silva, F.M.S.; Sá-Nakanishi, A.B.; Bracht, L.; Bersani-Amado, C.A.; Marçal-Natali, M.R.; Bracht, A.; Comar, J.F. β-Caryophyllene, the major constituent of copaiba oil, reduces systemic inflammation and oxidative stress in arthritic rats. J. Cell. Biochem. 2018, 119, 10262–10277. [Google Scholar] [CrossRef] [PubMed]
- Kou, X.; Liu, C.; Han, L.; Wang, S.; Xue, Z. NAC transcription factors play an important role in ethylene biosynthesis, reception and signaling of tomato fruit ripening. Mol. Genet. Genom. 2016, 291, 1205–1217. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.-G.; Wu, B.-H.; Liu, D.-C.; Wei, Y.-M.; Gao, S.-B.; Zheng, Y.-L. Variation and their relationship of NAM-G1 gene and grain protein content in Triticum timopheevii Zhuk. J. Plant Physiol. 2013, 170, 330–337. [Google Scholar] [CrossRef]
- Liang, C.; Wang, Y.; Zhu, Y.; Tang, J.; Hu, B.; Liu, L.; Ou, S.; Wu, H.; Sun, X.; Chu, J.; et al. OsNAP connects abscisic acid and leaf senescence by fine-tuning abscisic acid biosynthesis and directly targeting senescence-associated genes in rice. Proc. Natl. Acad. Sci. USA 2014, 111, 10013–10018. [Google Scholar] [CrossRef] [PubMed]
- Nuruzzaman, M.; Sharoni, A.M.; Kikuchi, S. Roles of NAC transcription factors in the regulation of biotic and abiotic stress responses in plants. Front. Microbiol. 2013, 4, 248. [Google Scholar] [CrossRef]
- López de Armentia, A. Mapeo por Asociación Mediante Genes Candidatos en Palmera de Aceite Africana (E. guineensis Jacq.). Ph.D. Thesis, UPV/EHU, Vitoria-Gasteiz, Spain, 2017. [Google Scholar]
- García, J.A.; Yáñez, E.E. Aplicación de la metodología alterna para análisis de racimos y muestreo de racimos en tolva. Palmas 2000, 21, 303–311. [Google Scholar]
- AOCS. AOCS Official Method Ce 1h-05. In Official Methods and Recommended Practices of the AOCS; AOCS: Urbana, IL, USA, 2017. [Google Scholar]
- AOCS. AOCS Official Method Da 15-48. In Official Methods and Recommended Practices of the AOCS; AOCS: Urbana, IL, USA, 2017. [Google Scholar]
- AOCS. AOCS Official Method Ce 5c-93. In Official Methods and Recommended Practices of the AOCS; AOCS: Urbana, IL, USA, 2017. [Google Scholar]
- AOCS. AOCS Official Method Ce 8-89. In Official Methods and Recommended Practices of the AOCS; AOCS: Urbana, IL, USA, 2017. [Google Scholar]
- Siew, W.L.; Tang, T.S. PORIM p2.6 Method. In PORIM Test Methods; Malaysian Oil Palm Board (MPOB): Kuala Lumpur, Malaysia, 1995; p. 181. [Google Scholar]
- Untergasser, A.; Cutcutache, I.; Koressaar, T.; Ye, J.; Faircloth, B.C.; Remm, M.; Rozen, S.G. Primer3-new capabilities and interfaces. Nucleic Acid Res. 2012, 40, e115. [Google Scholar] [CrossRef] [PubMed]
- Thermo Fisher Scientific Multiple Primer Analyzer. Available online: https://www.thermofisher.com/es/es/home/brands/thermo-scientific/molecular-biology/molecular-biology-learning-center/molecular-biology-resource-library/thermo-scientific-web-tools/multiple-primer-analyzer.html (accessed on 28 August 2019).
- South Green Collaborators. The South Green portal: A comprehensive resource for tropical and Mediterranean crop genomics. Curr. Plant Biol. 2016, 7–8, 6–9. [Google Scholar]
- Flutre, T.; Gay, L.; Rode, N. GitHub. Available online: https://github.com/timflutre/quantgen/blob/master/demultiplex.py (accessed on 22 July 2019).
- Martin, M. Cutadapt removes adapter sequences from high-throughput sequencing reads. EMBnet. J. 2011, 17, 10–12. [Google Scholar] [CrossRef]
- Soriano, A.; Guitton, P.; Mournet, P. Workflow-Snakemake-Capture. Available online: https://github.com/SouthGreenPlatform/Workflow-snakemake-capture (accessed on 22 July 2019).
- Li, H.; Durbin, R. Fast and accurate long-read alignment with Burrows–Wheeler transform. Bioinformatics 2010, 26, 589–595. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R. 1000 Genome Project Data Processing Subgroup the Sequence Alignment/Map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [PubMed]
- Picard Tools—By Broad Institute. Available online: https://broadinstitute.github.io/picard/index.html (accessed on 30 August 2018).
- McKenna, A.; Hanna, M.; Banks, E.; Sivachenko, A.; Cibulskis, K.; Kernytsky, A.; Garimella, K.; Altshuler, D.; Gabriel, S.; Daly, M.; et al. The Genome Analysis Toolkit: A MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 2010, 20, 1297–1303. [Google Scholar] [CrossRef] [PubMed]
- Danecek, P.; Auton, A.; Abecasis, G.; Albers, C.A.; Banks, E.; Depristo, M.A.; Handsaker, R.E.; Lunter, G.; Marth, G.T.; Sherry, S.T.; et al. The variant call format and VCFtools. Bioinformatics 2011, 27, 2156–2158. [Google Scholar] [CrossRef] [PubMed]
- Jombart, T. Adegenet: A R package for the multivariate analysis of genetic markers. Bioinformatics 2008, 24, 1403–1405. [Google Scholar] [CrossRef] [PubMed]
- Goudet, J.; Jombart, T.; Goudet, M.J. Package “hierfstat”: Estimation and Tests of Hierarchical F-Statistics. 2015. Available online: https://rdrr.io/cran/hierfstat/ (accessed on 22 February 2019).
- Paradis, E.; Jombart, T.; Brian, K.; Schliep, K.; Winter, D.; Kamvar, Z.N. Package “pegas”: Population and Evolutionary Genetics Analysis System. 2018. Available online: https://cran.r-project.org/web/packages/pegas/index.html (accessed on 22 February 2019).
- Raj, A.; Stephens, M.; Pritchard, J.K. fastSTRUCTURE: Variational inference of population structure in large SNP data sets. Genetics 2014, 197, 573–589. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhang, Z. GAPIT Version 3: An Interactive Analytical Tool for Genomic Association and Prediction. Draft, Bioinformatics. 2018. Available online: https://www.researchgate.net/publication/329829469_GAPIT_Version_3_An_Interactive_Analytical_Tool_for_Genomic_Association_and_Prediction (accessed on 20 July 2019).
- Benjamini, Y.; Hochberg, Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J. R. Stat. Soc. Ser. B 1995, 57, 289–300. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Origin: | Coari × LaMé | Taisha × Avros (RGS) | Taisha × Avros (Oleoflores) | Taisha × Econa | Taisha × Yangambi | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Production Traits | Mean Value | Level | Mean Value | Level | Mean Value | Level | Mean Value | Level | Mean Value | Level |
| BN (nº) * | 52.49 | B | 39.81 | C | 63.00 | A | 32.75 | C | 40.10 | BC |
| BW (kg) | 9.44 | B | 11.04 | B | 13.22 | A | 9.81 | B | 9.91 | B |
| BY (kg) * | 501.67 | B | 469.32 | B | 845.66 | A | 334.30 | B | 444.75 | B |
| OilfM (%) | 34.69 | A | 28.99 | B | 29.31 | B | 24.74 | C | 28.71 | BC |
| OildM (%) * | 65.23 | A | 51.20 | B | 53.70 | B | 45.69 | C | 51.14 | BC |
| OilB (%) | 22.66 | A | 17.38 | BC | 19.67 | B | 14.09 | C | 17.04 | BC |
| Oil Quality Traits | ||||||||||
| Sat (%) * | 32.07 | B | 37.91 | A | 38.64 | A | 39.39 | A | 40.00 | A |
| Mono-Un (%) * | 56.06 | A | 48.74 | B | 46.54 | B | 46.66 | B | 46.05 | B |
| Poly-Un (%) | 12.35 | C | 13.01 | BC | 14.31 | A | 13.68 | AB | 13.62 | AB |
| OA (%) * | 54.84 | A | 47.21 | B | 44.84 | B | 44.98 | B | 44.16 | B |
| IV (cg/g) * | 68.87 | A | 63.25 | B | 63.56 | B | 61.97 | B | 61.62 | B |
| SSS (%) * | 1.08 | - | 1.48 | - | 1.12 | - | 1.18 | - | 1.64 | - |
| SUS (%) * | 17.76 | B | 24.38 | A | 25.41 | A | 25.80 | A | 25.99 | A |
| SUU (%) | 35.82 | A | 31.95 | B | 31.40 | B | 31.77 | B | 29.44 | B |
| UUU (%) * | 21.06 | A | 12.01 | B | 10.28 | B | 10.23 | B | 9.90 | B |
| Tocph (ppm) * | 164.37 | C | 247.15 | AB | 198.63 | BC | 290.47 | A | 255.70 | AB |
| Alpha (ppm) * | 115.22 | B | 178.43 | A | 130.78 | B | 211.37 | A | 203.34 | A |
| Delta (ppm) * | 40.28 | - | 44.17 | - | 40.93 | - | 54.31 | - | 43.10 | - |
| Gamma (ppm) * | 39.49 | - | 46.64 | - | 47.29 | - | 47.35 | - | 42.15 | - |
| Toc3 (ppm) | 874.15 | C | 1087.74 | B | 1338.07 | A | 1159.80 | AB | 1065.70 | BC |
| Alpha3 (ppm) | 203.71 | C | 313.70 | B | 396.75 | A | 320.28 | AB | 314.24 | AB |
| Delta3 (ppm) * | 66.96 | B | 98.57 | B | 143.11 | A | 95.68 | B | 80.82 | B |
| Gamma3 (ppm) | 605.39 | B | 675.47 | B | 806.15 | A | 743.84 | AB | 670.64 | B |
| Toc (ppm) | 1038.52 | B | 1334.90 | A | 1543.12 | A | 1450.27 | A | 1321.40 | AB |
| Car (ppm) * | 785.89 | BC | 832.09 | B | 671.91 | C | 900.20 | AB | 1068.65 | A |
| Inter-Cross Fst Value | Taisha × Yangambi | Taisha × Ekona | Taisha × Avros (Oleoflores) | Taisha × Avros (RGS) | Coari × La Mé |
|---|---|---|---|---|---|
| Taisha × Yangambi | - | 0.028876 | 0.055139 | 0.068303 | 0.10416 |
| Taisha × Ekona | - | - | 0.051121 | 0.064635 | 0.083617 |
| Taisha × Avros (Oleoflores) | - | - | - | 0.10259 | 0.10992 |
| Taisha × Avros (RGS) | - | - | - | - | 0.012305 |
| Intra-Cross Fis Values | −0.7447191 | −0.69170213 | −0.72402062 | −0.46477064 | −0.46522124 |
| Production Traits | GLM_PCA | GLM_Q | MLM_PCA+K | MLM_Q+K |
|---|---|---|---|---|
| BN | 0.4349 | 0.335 | 0.350 | 0.286 |
| BY | 0.369 | 0.335 | 0.298 | 0.289 |
| BW | 0.377 | 0.383 | 0.357 | 0.332 |
| OilfM | 0.294 | 0.293 | 0.294 | 0.294 |
| OildM | 0.281 | 0.285 | 0.281 | 0.327 |
| OilB | 0.331 | 0.337 | 0.303 | 0.458 |
| Oil Quality Traits | ||||
| Sat | 0.301 | 0.332 | 0.270 | 0.442 |
| Mono-Un | 0.305 | 0.352 | 0.298 | 0.317 |
| Poly-Un | 0.348 | 0.385 | 0.347 | 0.381 |
| OA | 0.333 | 0.365 | 0.323 | 0.426 |
| IV | 0.434 | 0.376 | 0.327 | 0.753 |
| SSS | 0.310 | 0.312 | 0.295 | 0.292 |
| SUS | 0.286 | 0.319 | 0.285 | 0.314 |
| SUU | 0.272 | 0.279 | 0.271 | 0.282 |
| UUU | 0.313 | 0.348 | 0.306 | 0.355 |
| Tocph | 0.333 | 0.355 | 0.323 | 0.322 |
| Alpha | 0.359 | 0.394 | 0.330 | 0.327 |
| Delta | 0.341 | 0.319 | 0.341 | 0.317 |
| Gamma | 0.265 | 0.260 | 0.265 | 0.266 |
| Toc3 | 0.315 | 0.306 | 0.315 | 0.311 |
| Alpha3 | 0.284 | 0.264 | 0.284 | 0.270 |
| Delta3 | 0.329 | 0.382 | 0.315 | 0.295 |
| Gamma3 | 0.342 | 0.339 | 0.337 | 0.333 |
| Toc | 0.325 | 0.309 | 0.325 | 0.316 |
| Car | 0.486 | 0.645 | 0.359 | 0.334 |
| CG | SNP Position | Production Traits | AM Model | p Value | %VA | Effect |
|---|---|---|---|---|---|---|
| BKACPII_1 | C10: 22949607 | BW | MLM_Q | 0.013 | 13.9 | 6.812 |
| BY | MLM_Q | 0.037 | 26.2 | 538.811 | ||
| EgNAC | C05: 40852639 | OildM | MLM_PCA | 0.044 | 18.3 | −5.524 |
| OilB | MLM_PCA | 0.046 | 8.9 | −3.256 | ||
| LIPOIC | C07: 18432097 | OilfM | GLM_Q | 0.042 | 10.9 | −2.387 |
| M2200 | C13: 12503450 | OildM | MLM_PCA | 0.009 | 19.9 | 13.384 |
| PKP-ALPHA | C01: 40816686 | OilB | MLM_PCA | 0.007 | 10.8 | −9.339 |
| SEQUI | U02: 19591286 | BW | MLM_Q | 0.015 | 14.1 | 2.319 |
| TO1 | U02: 79752170 | BN | MLM_Q | 0.020 | 24.4 | −45.134 |
| BW | MLM_Q | 0.033 | 14.8 | −6.218 | ||
| CG Name | SNP Position | Quality Traits | AM Model | p Value | %VA | Effect |
| ATAGB1_ML * | C13: 103569 | SSS | MLM_Q | 0.022 | 7.2 | −0.614 |
| Mono-Un | MLM_PCA | 0.008 | 20.4 | −5.291 | ||
| Poly-Un | MLM_PCA | 0.047 | 10.7 | 1.136 | ||
| ATP3 | U05: 50035832 | Mono-Un | MLM_PCA | 0.050 | 18.7 | −5.726 |
| Poly-Un | MLM_PCA | 0.003 | 13.7 | 2.549 | ||
| atpB | CT: 54552 | Delta | MLM_Q | 0.046 | 11.6 | −6.913 |
| BnC8_761 | C08: 4351912 | Delta3 | MLM_Q | 0.008 | 17.3 | 33.287 |
| OA | MLM_PCA | 0.025 | 20.1 | −2.488 | ||
| UUU | MLM_PCA | 0.048 | 21.8 | −2.250 | ||
| CA3 | C02: 35978226 | Delta | MLM_Q | 0.045 | 11.6 | 15.740 |
| EgNAC | C05: 40852136 | OA | MLM_PCA | 0.015 | 20.6 | 2.890 |
| Sat | MLM_PCA | 0.042 | 17.2 | −1.990 | ||
| SUS | MLM_PCA | 0.014 | 23.2 | −2.189 | ||
| SUU | MLM_PCA | 0.019 | 14.3 | 2.125 | ||
| UUU | MLM_PCA | 0.007 | 23.5 | 3.246 | ||
| C05: 40852594 | Mono-Un | MLM_PCA | 0.044 | 18.8 | 3.568 | |
| OA | MLM_PCA | 0.005 | 21.7 | 4.826 | ||
| Poly-Un | MLM_PCA | 0.010 | 12.3 | −1.310 | ||
| SUS | MLM_PCA | 0.009 | 23.6 | −3.376 | ||
| UUU | MLM_PCA | 0.003 | 24.3 | 5.081 | ||
| C05: 40852639 | Car | MLM_Q | 0.026 | 26.9 | −173.576 | |
| EOCHYB | C04: 37534489 | Alpha | MLM_Q | 0.027 | 14.6 | −50.440 |
| GLUT1 | C12: 28135330 | OA | MLM_PCA | 0.040 | 19.7 | −2.823 |
| C12: 28135361 | OA | MLM_PCA | 0.040 | 19.7 | −2.823 | |
| C12: 28135379 | OA | MLM_PCA | 0.040 | 19.7 | −2.823 | |
| HtC2_11412 | C08: 25294023 | Delta3 | MLM_Q | 0.036 | 15.7 | 27.356 |
| SUU | MLM_PCA | 0.047 | 13.4 | −1.552 | ||
| C08: 25294107 | Delta3 | MLM_Q | 0.015 | 16.7 | 29.133 | |
| SSS | MLM_Q | 0.049 | 6.1 | 0.290 | ||
| HtC2_1255C2-411 | C02: 43975856 | SSS | MLM_Q | 0.046 | 6.1 | 0.529 |
| C02: 43975982 | SSS | MLM_Q | 0.046 | 6.1 | 0.529 | |
| HtC7_9200 | C06: 41269483 | Toc | GLM_Q | 0.042 | 13.6 | 157.269 |
| Tocph | MLM_Q | 0.046 | 13.2 | 35.249 | ||
| C06: 41269559 | Car | MLM_Q | 0.005 | 28.3 | −158.848 | |
| JC35 | C13: 22806955 | Car | MLM_Q | 0.024 | 27.0 | −109.838 |
| JC55 | C05: 14759308 | IV | MLM_PCA | 0.007 | 15.1 | 7.826 |
| LIPOIC | C07: 18431998 | Gamma | GLM_Q | 0.041 | 7.0 | −7.841 |
| Mono-Un | MLM_PCA | 0.039 | 18.9 | −2.700 | ||
| OA | MLM_PCA | 0.024 | 20.2 | −2.842 | ||
| Poly-Un | MLM_PCA | 0.037 | 11.0 | 0.782 | ||
| C07: 18432097 | Gamma | GLM_Q | 0.003 | 11.6 | −11.135 | |
| Toc | GLM_Q | 0.043 | 13.5 | −184.481 | ||
| Toc3 | GLM_Q | 0.027 | 16.3 | −173.161 | ||
| Delta3 | MLM_Q | 0.033 | 16.0 | −27.292 | ||
| PAT_2 | C09: 34725045 | Alpha | MLM_Q | 0.014 | 15.5 | 49.496 |
| Delta | MLM_Q | 0.027 | 12.1 | 9.758 | ||
| Tocph | MLM_Q | 0.005 | 15.4 | 70.245 | ||
| PAT_2_ML | C02: 23775894 | Poly-Un | MLM_PCA | 0.035 | 11.0 | −0.877 |
| PAT_6 | C08: 27075521 | Car | MLM_Q | 0.040 | 26.6 | −163.806 |
| PDHB | C01: 51857834 | IV | MLM_PCA | 0.027 | 13.8 | 3.407 |
| PKP-ALPHA | C01: 40816686 | UUU | MLM_PCA | 0.034 | 22.1 | −7.962 |
| SEQUI | U02: 19591232 | Toc | GLM_Q | 0.031 | 13.9 | 260.781 |
| Toc3 | GLM_Q | 0.040 | 15.9 | 212.755 | ||
| Gamma3 | MLM_Q | 0.015 | 14.1 | 142.540 | ||
| SSS | MLM_Q | 0.028 | 6.6 | 0.504 | ||
| IV | MLM_PCA | 0.037 | 13.5 | −2.828 | ||
| Poly-Un | MLM_PCA | 0.020 | 11.6 | −1.139 | ||
| U02: 19591286 | IV | MLM_PCA | 0.020 | 14.1 | −3.630 | |
| SHELL | C02: 3078054 | Alpha | MLM_Q | 0.029 | 14.6 | 66.367 |
| Delta | MLM_Q | 0.028 | 12.1 | 17.751 | ||
| Tocph | MLM_Q | 0.019 | 14.1 | 90.283 | ||
| C02: 3078154 | Toc | GLM_Q | 0.031 | 13.9 | 213.715 | |
| Toc3 | GLM_Q | 0.046 | 15.8 | 169.457 | ||
| Alpha | MLM_Q | 0.048 | 14.2 | 37.502 | ||
| Delta3 | MLM_Q | 0.026 | 16.1 | 32.474 | ||
| Gamma3 | MLM_Q | 0.023 | 13.7 | 109.420 | ||
| Tocph | MLM_Q | 0.029 | 13.7 | 51.563 | ||
| TO1 | U02: 79752182 | Gamma3 | MLM_Q | 0.030 | 13.6 | 136.526 |
| U02: 79752184 | Gamma3 | MLM_Q | 0.030 | 13.6 | 136.526 | |
| TO3 | C03: 13885419 | Car | MLM_Q | 0.029 | 27.0 | −157.239 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Astorkia, M.; Hernandez, M.; Bocs, S.; Lopez de Armentia, E.; Herran, A.; Ponce, K.; León, O.; Morales, S.; Quezada, N.; Orellana, F.; et al. Association Mapping between Candidate Gene SNP and Production and Oil Quality Traits in Interspecific Oil Palm Hybrids. Plants 2019, 8, 377. https://doi.org/10.3390/plants8100377
Astorkia M, Hernandez M, Bocs S, Lopez de Armentia E, Herran A, Ponce K, León O, Morales S, Quezada N, Orellana F, et al. Association Mapping between Candidate Gene SNP and Production and Oil Quality Traits in Interspecific Oil Palm Hybrids. Plants. 2019; 8(10):377. https://doi.org/10.3390/plants8100377
Chicago/Turabian StyleAstorkia, Maider, Mónica Hernandez, Stéphanie Bocs, Emma Lopez de Armentia, Ana Herran, Kevin Ponce, Olga León, Shone Morales, Nathalie Quezada, Francisco Orellana, and et al. 2019. "Association Mapping between Candidate Gene SNP and Production and Oil Quality Traits in Interspecific Oil Palm Hybrids" Plants 8, no. 10: 377. https://doi.org/10.3390/plants8100377
APA StyleAstorkia, M., Hernandez, M., Bocs, S., Lopez de Armentia, E., Herran, A., Ponce, K., León, O., Morales, S., Quezada, N., Orellana, F., Wendra, F., Sembiring, Z., Asmono, D., & Ritter, E. (2019). Association Mapping between Candidate Gene SNP and Production and Oil Quality Traits in Interspecific Oil Palm Hybrids. Plants, 8(10), 377. https://doi.org/10.3390/plants8100377