
OE-YOLO: An EfficientNet-Based YOLO Network for Rice Panicle Detection

Abstract
1. Introduction
2. Materials and Methods
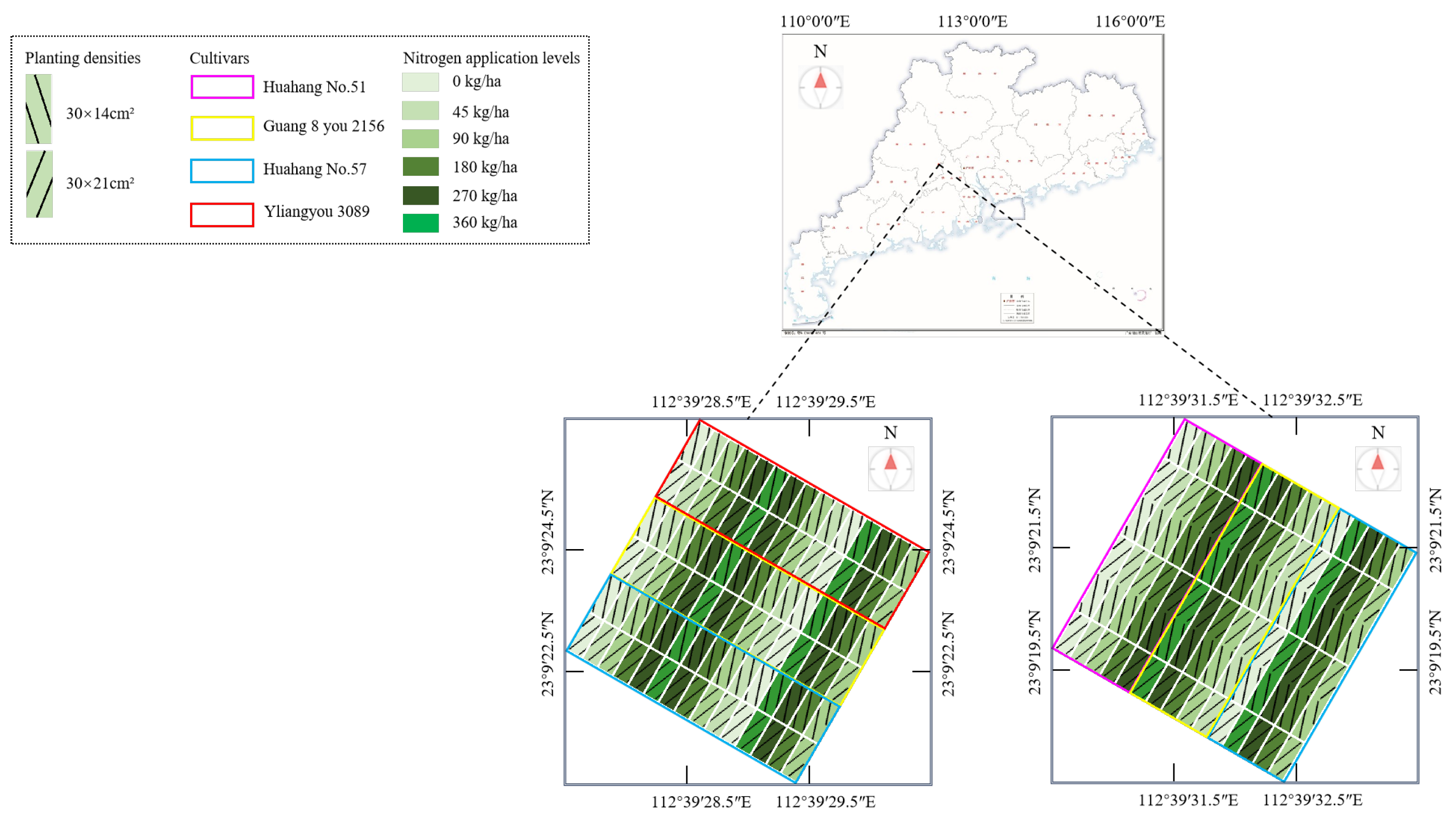
2.1. Experimental Locations
2.2. Image Preprocessing
2.3. Methods
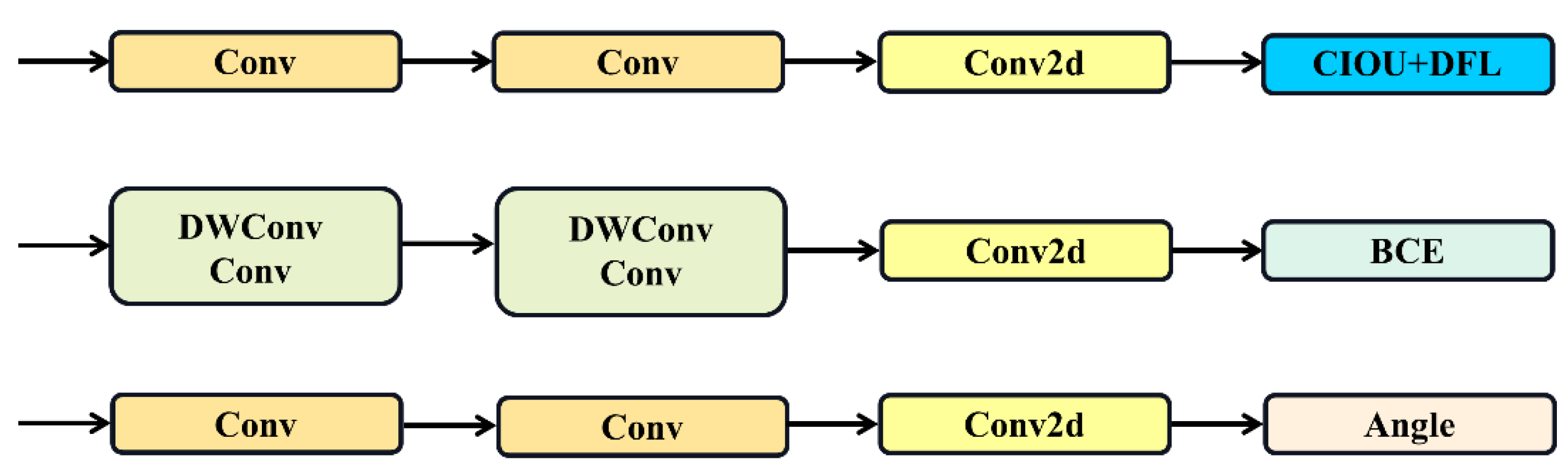
2.3.1. YOLOv11 Networks
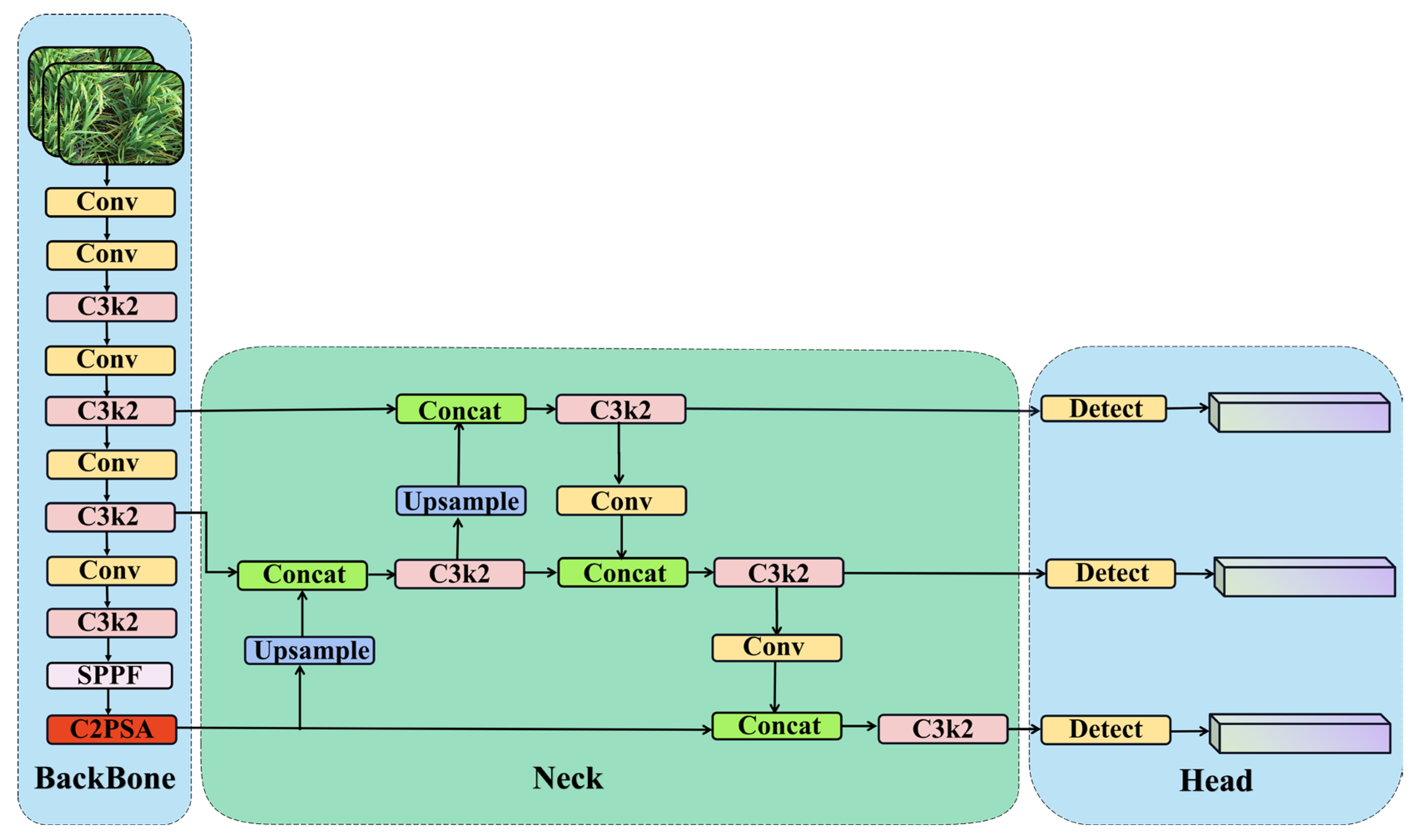
2.3.2. OE-YOLO Networks Construction
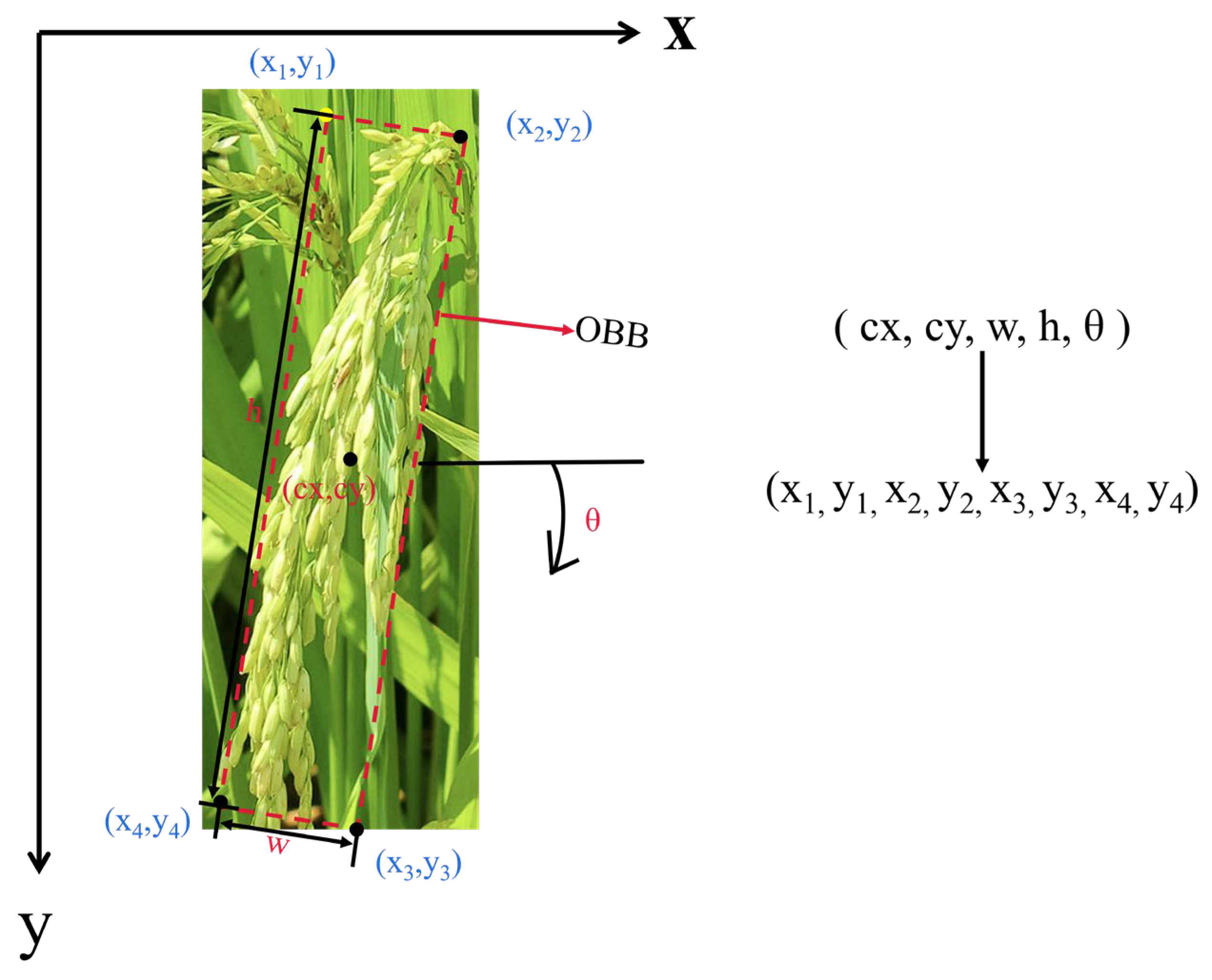
2.3.3. OBB
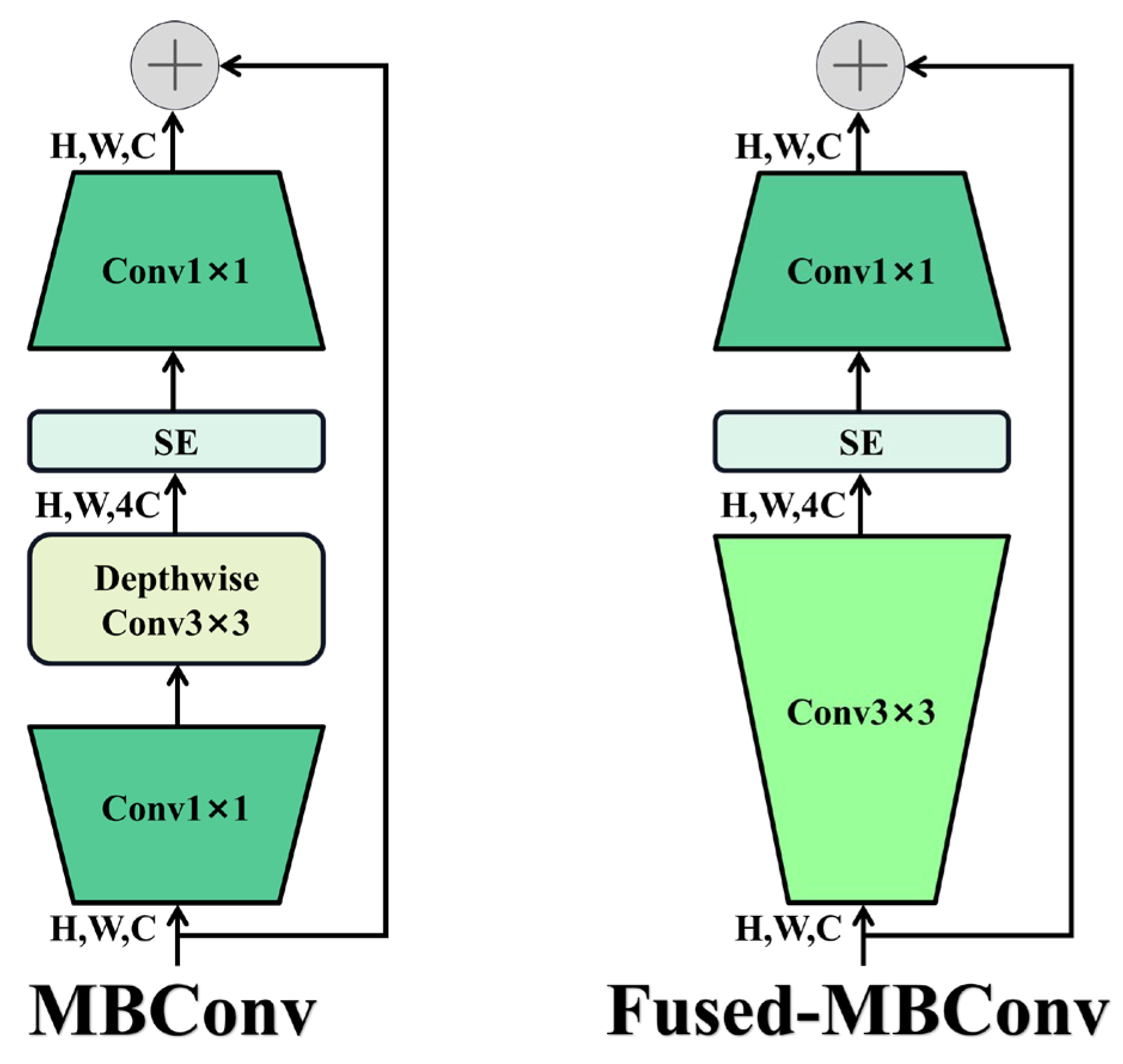
2.3.4. EfficientNetV2
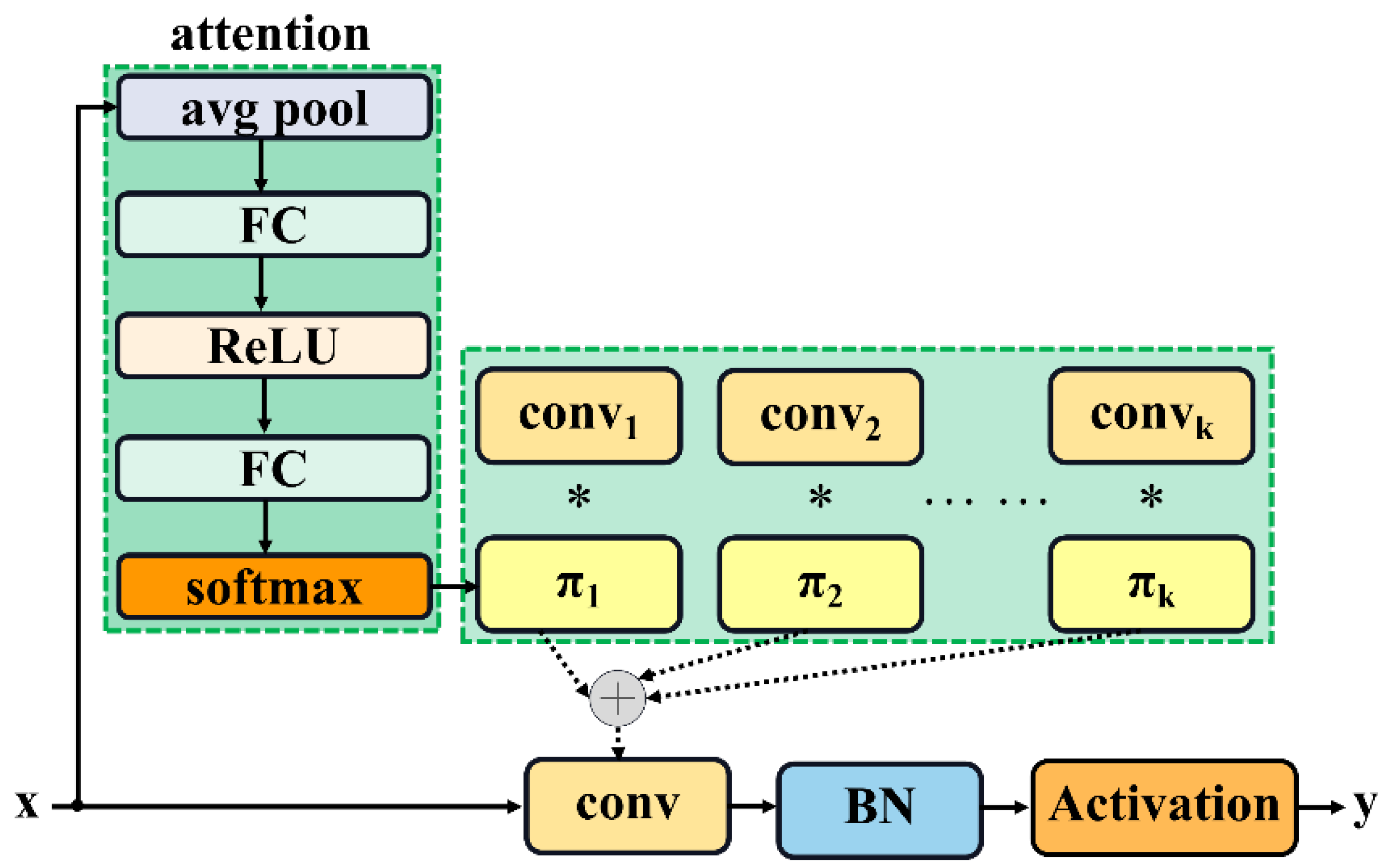
2.3.5. C3k2_DConv: Integration of Dynamic Convolution into C3k2
3. Results
3.1. Experimental Setup
3.1.1. Experimental Platform
3.1.2. Evaluation Indicators
3.2. Experimental Result
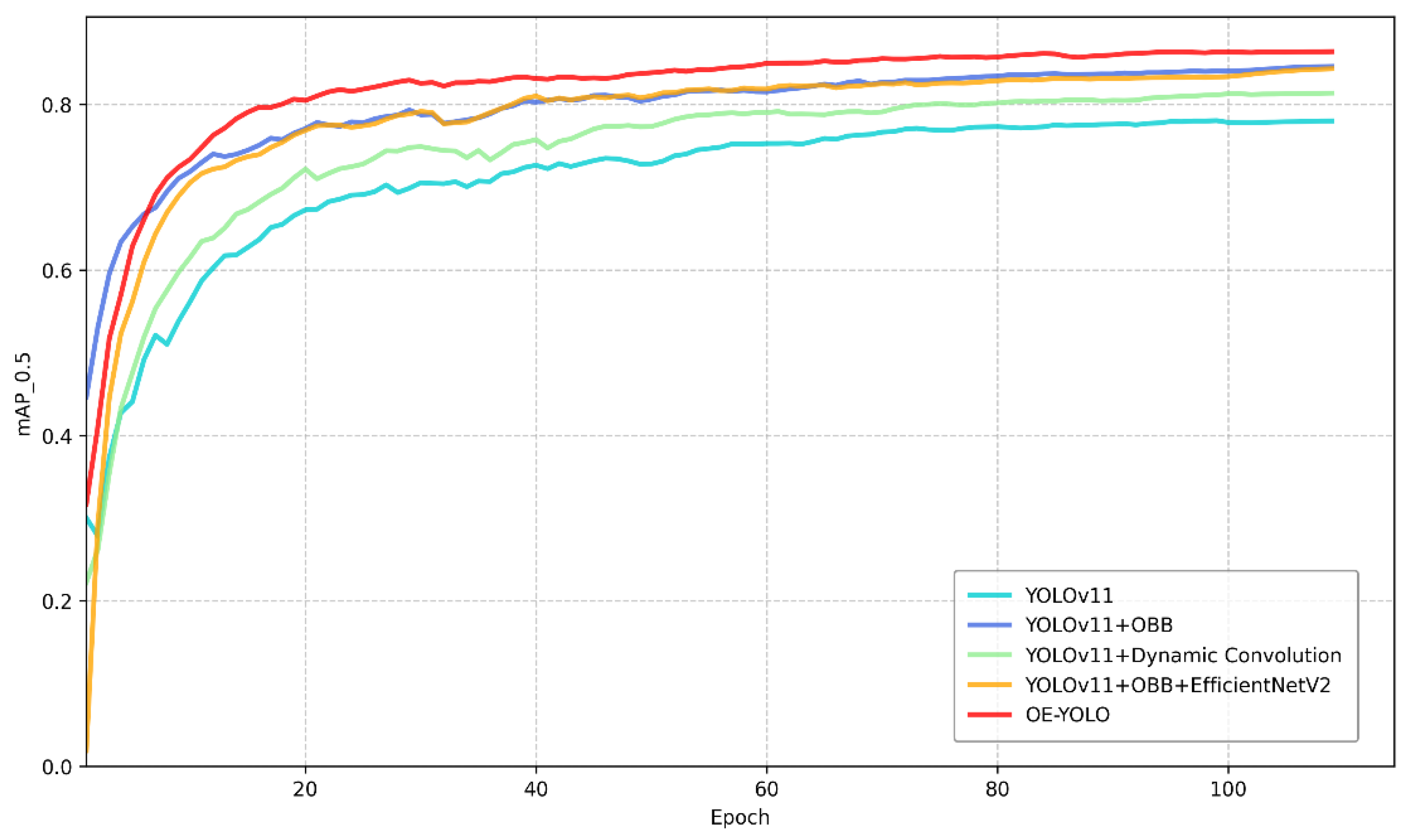
3.2.1. Ablation Studies
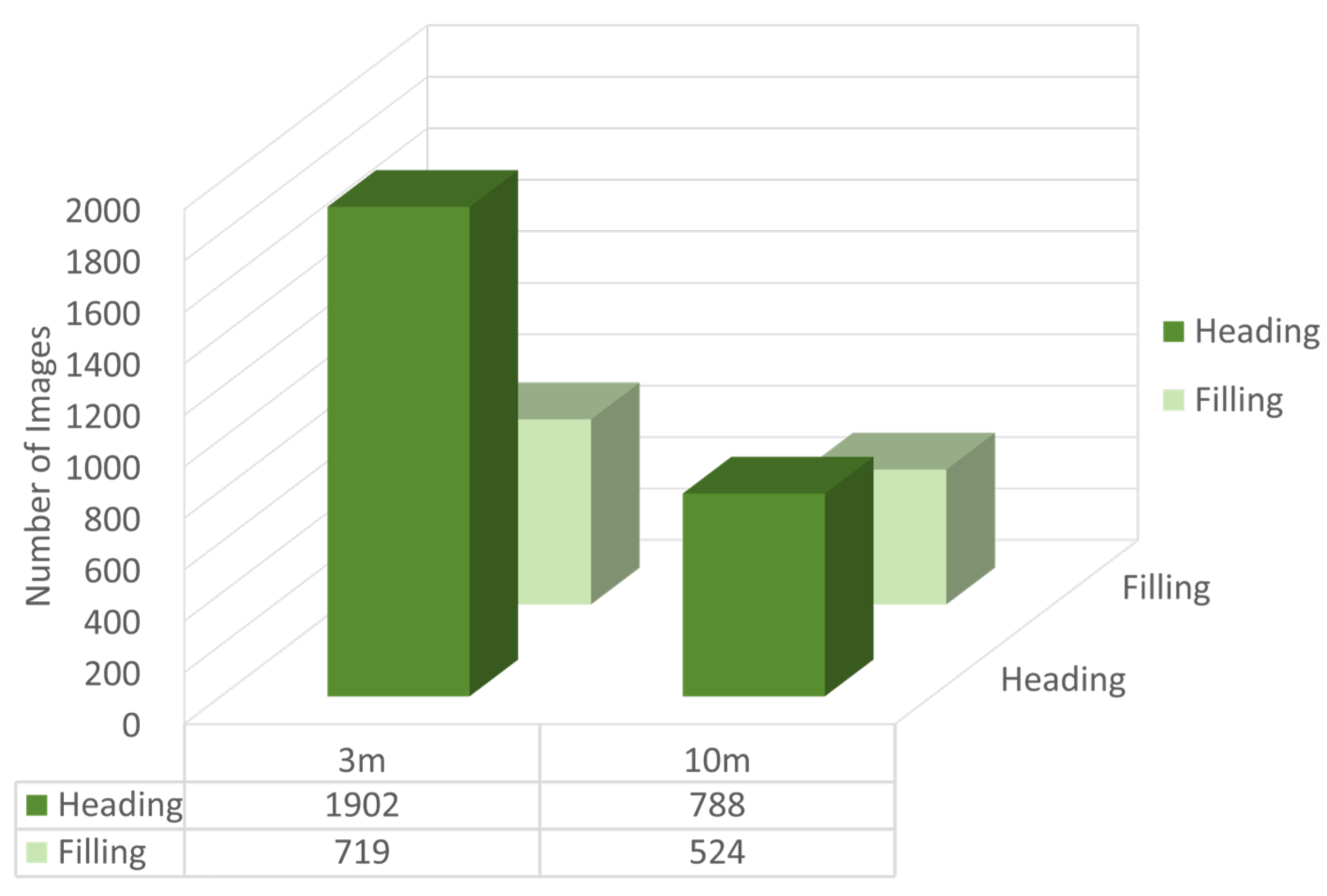
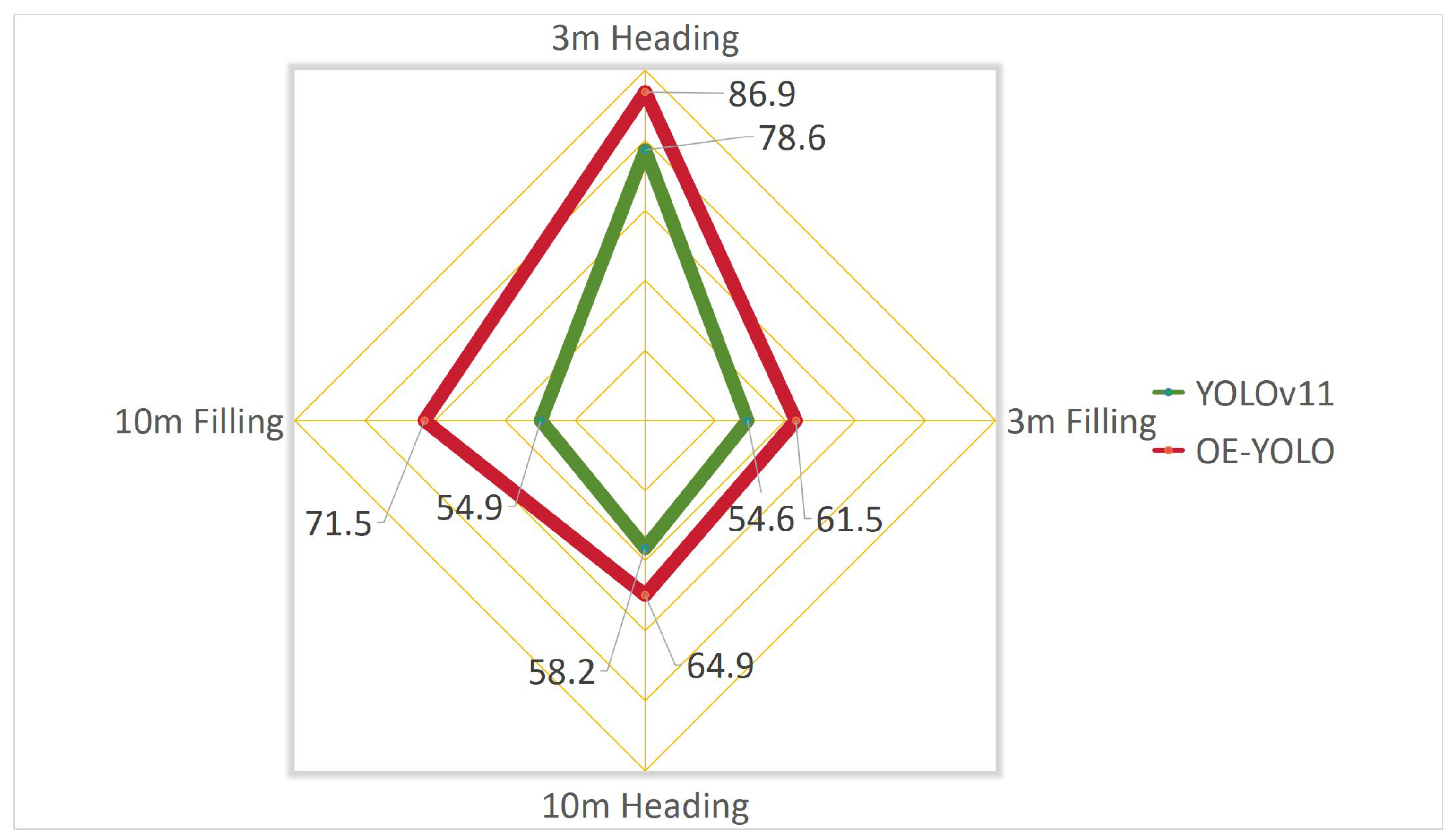
3.2.2. Detection Effectiveness at Various Growth Stages and Flight Heights
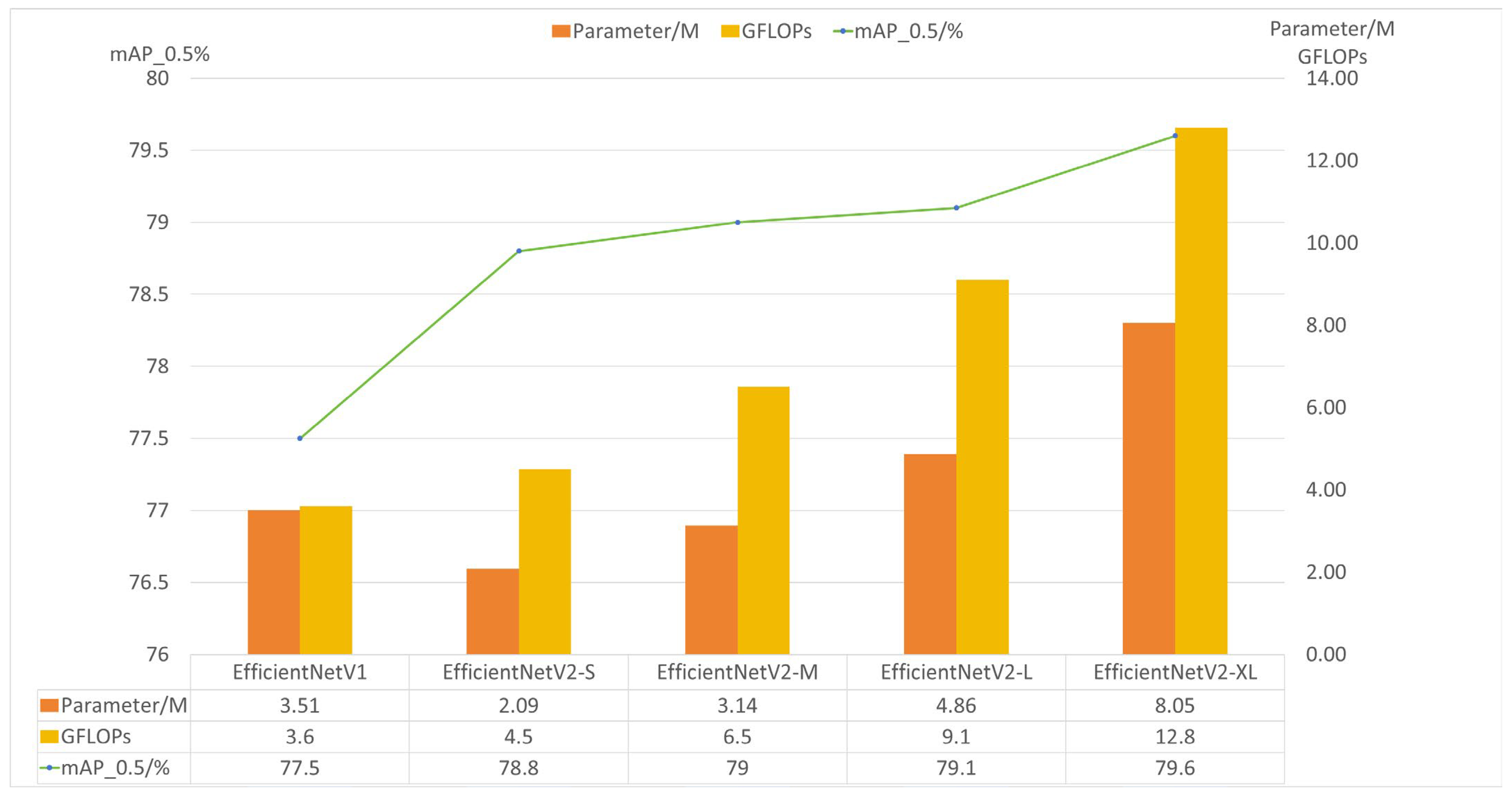
3.2.3. Experimental Analysis of EfficientNetV2 Backbone Selection
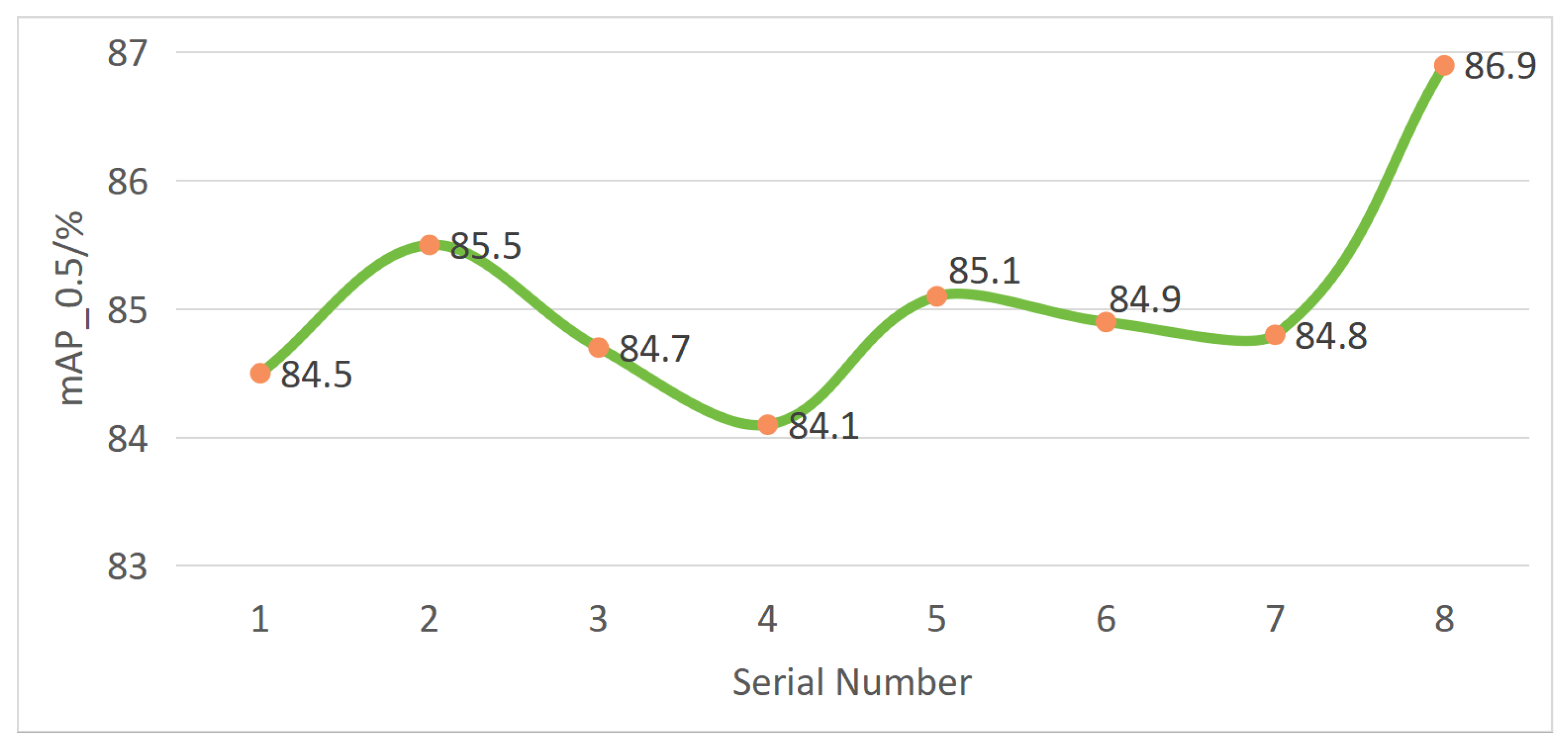
3.2.4. Experiment on C3k2_DConv Placement Strategies
3.2.5. Comparison of Different Models
4. Discussion
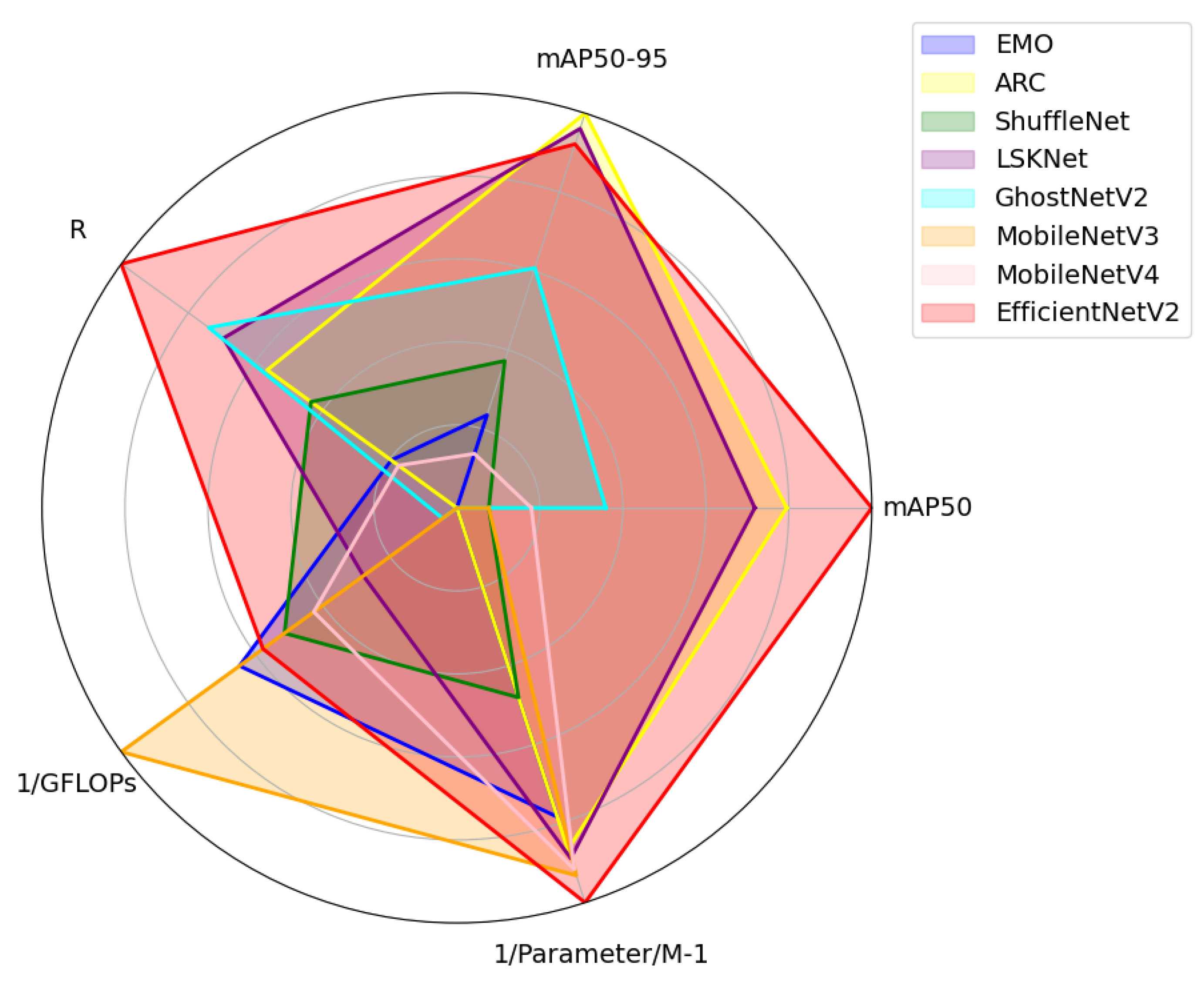
4.1. Discussion on Backbone Architecture Selection
4.2. Visualizing OE-YOLO’s Superiority in Rice Panicle Detection: Insights from Grad-CAM Heatmaps
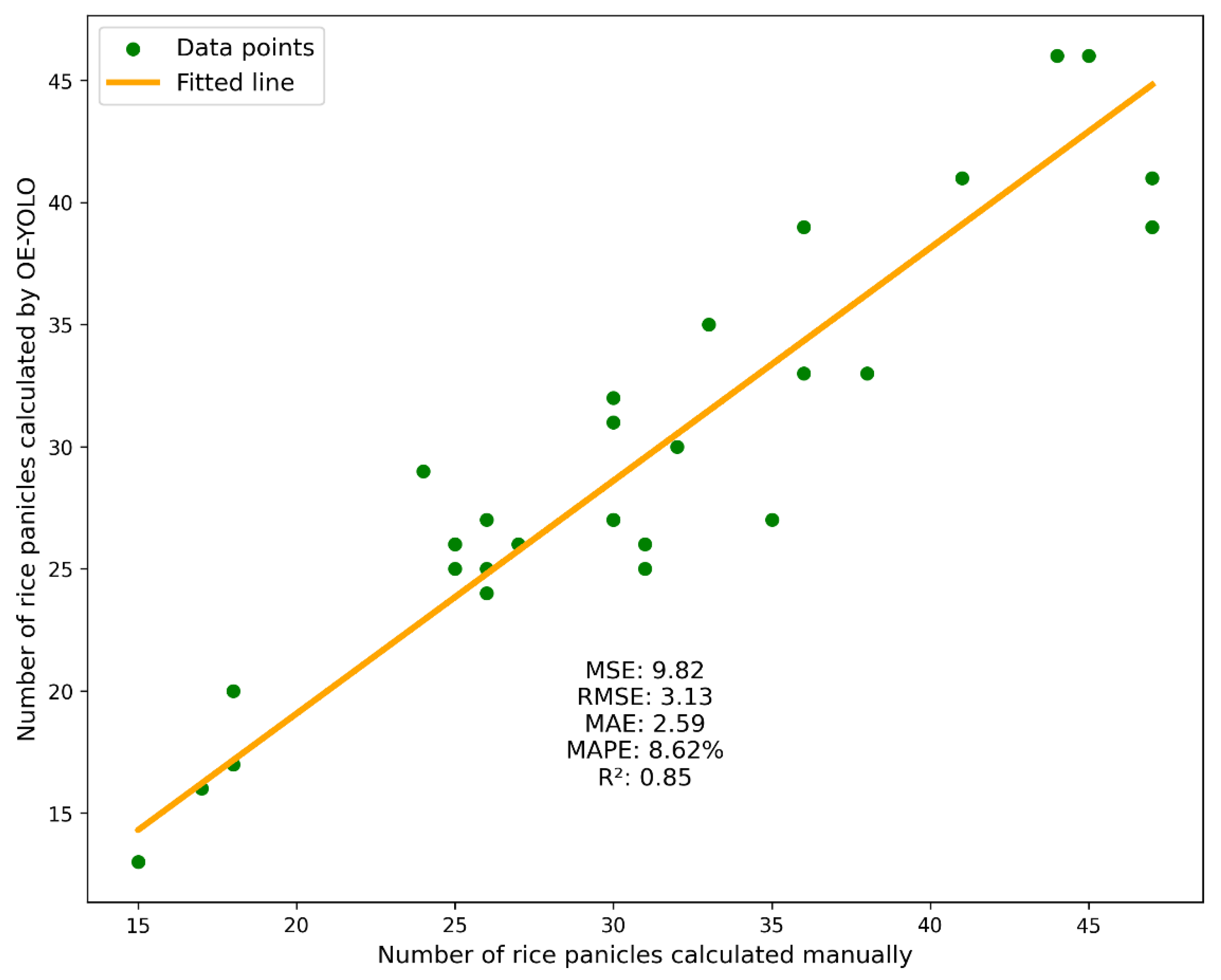
4.3. Application of Rice Panicle Counting
4.4. Broader Impact
4.5. Limitations and Future Work
- (1)
- Generalizing OE-YOLO’s architecture for cross-crop adaptability via meta-learning techniques, particularly for morphologically similar cereals like wheat and barley;
- (2)
- Implementing edge-device optimization strategies to deploy lightweight variants on agricultural robots for in-field, low-latency monitoring;
- (3)
- Developing laser-augmented UAV platforms to correlate flight altitude with multi-modal sensor data, establishing real-time yield estimation frameworks through adaptive sensor fusion.
- (4)
- Further strengthening the validation of this model, including overcoming existing limitations and improving the detection methods for rice panicles under different weather conditions and flight heights, comparing with more OBB models that can be used for real-time object detection by adjusting the high-accuracy architecture for efficient execution on resource-constrained hardware. Furthermore, developing validation of OE-YOLO on direct-seeded datasets to assess its robustness under unstructured planting patterns, expanding its practical applicability to broader agricultural practices.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Seck, P.A.; Diagne, A.; Mohanty, S.; Wopereis, M.C.S. Crops That Feed the World 7: Rice. Food Secur. 2012, 4, 7–24. [Google Scholar] [CrossRef]
- Abdullah, H.M.; Mohana, N.T.; Khan, B.M.; Ahmed, S.M.; Hossain, M.; Islam, K.S.; Redoy, M.H.; Ferdush, J.; Bhuiyan, M.A.H.B.; Hossain, M.M.; et al. Present and Future Scopes and Challenges of Plant Pest and Disease (P&D) Monitoring: Remote Sensing, Image Processing, and Artificial Intelligence Perspectives. Remote Sens. Appl. Soc. Environ. 2023, 32, 100996. [Google Scholar] [CrossRef]
- Sanaeifar, A.; Guindo, M.L.; Bakhshipour, A.; Fazayeli, H.; Li, X.; Yang, C. Advancing Precision Agriculture: The Potential of Deep Learning for Cereal Plant Head Detection. Comput. Electron. Agric. 2023, 209, 107875. [Google Scholar] [CrossRef]
- Duan, L.; Huang, C.; Chen, G.; Xiong, L.; Liu, Q.; Yang, W. Determination of Rice Panicle Numbers during Heading by Multi-Angle Imaging. Crop J. 2015, 3, 211–219. [Google Scholar] [CrossRef]
- Chaurasia, H.; Arora, A.; Raju, D.; Marwaha, S.; Chinnusamy, V.; Jain, R.; Haque, M.A. PanicleDet: A Deep Learning-Based Model for Detection of Panicle Stages in Paddy. Neural Comput. Appl. 2024, 37, 2663–2673. [Google Scholar] [CrossRef]
- Tan, S.; Lu, H.; Yu, J.; Lan, M.; Hu, X.; Zheng, H.; Peng, Y.; Wang, Y.; Li, Z.; Qi, L.; et al. In-Field Rice Panicles Detection and Growth Stages Recognition Based on RiceRes2Net. Comput. Electron. Agric. 2023, 206, 107704. [Google Scholar] [CrossRef]
- Zhou, C.; Ye, H.; Hu, J.; Shi, X.; Hua, S.; Yue, J.; Xu, Z.; Yang, G. Automated Counting of Rice Panicle by Applying Deep Learning Model to Images from Unmanned Aerial Vehicle Platform. Sensors 2019, 19, 3106. [Google Scholar] [CrossRef]
- Lan, M.; Liu, C.; Zheng, H.; Wang, Y.; Cai, W.; Peng, Y.; Xu, C.; Tan, S. RICE-YOLO: In-Field Rice Spike Detection Based on Improved YOLOv5 and Drone Images. Agronomy 2024, 14, 836. [Google Scholar] [CrossRef]
- Sun, J.; Zhou, J.; He, Y.; Jia, H.; Toroitich Rottok, L. Detection of Rice Panicle Density for Unmanned Harvesters via RP-YOLO. Comput. Electron. Agric. 2024, 226, 109371. [Google Scholar] [CrossRef]
- Liang, Y.; Li, H.; Wu, H.; Zhao, Y.; Liu, Z.; Liu, D.; Liu, Z.; Fan, G.; Pan, Z.; Shen, Z.; et al. A Rotated Rice Spike Detection Model and a Crop Yield Estimation Application Based on UAV Images. Comput. Electron. Agric. 2024, 224, 109188. [Google Scholar] [CrossRef]
- Lu, Z.; Yu, S.; Huang, K.; Yang, W. An Impurity Rate Estimation Method of Post-Harvest Sugarcane Based on Rotated Bounding Box and Binocular Vision. IEEE Access 2024, 12, 130557–130570. [Google Scholar] [CrossRef]
- Wang, C.; Liu, K.; Zou, B.; Li, M.; Yuan, H.; Peng, Q. A Rotating Object Detection Method for Greenhouses in Remote Sensing Images. In Proceedings of the 2024 IEEE International Conference on Smart City (SmartCity), Wuhan, China, 13–15 December 2024; pp. 48–55. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Jegham, N.; Koh, C.Y.; Abdelatti, M.; Hendawi, A. Evaluating the Evolution of YOLO (You Only Look Once) Models: A Comprehensive Benchmark Study of YOLO11 and Its Predecessors. arXiv 2024, arXiv:2411.00201v1. [Google Scholar]
- Llerena, J.M.; Zeni, L.F.; Kristen, L.N.; Jung, C. Gaussian Bounding Boxes and Probabilistic Intersection-Over-Union for Object Detection. arXiv 2021, arXiv:2106.06072. [Google Scholar] [CrossRef]
- Ran, Z.; Lu, C.; Hu, Y.; Yang, D.; Sun, X.; Zhima, Z. Automatic Detection of Quasi-Periodic Emissions from Satellite Observations by Using DETR Method. Remote Sens. 2024, 16, 2850. [Google Scholar] [CrossRef]
- Qin, Y.; Kou, Z.; Han, C.; Wang, Y. Intelligent Gangue Sorting System Based on Dual-Energy X-Ray and Improved YOLOv5 Algorithm. Appl. Sci. 2023, 14, 98. [Google Scholar] [CrossRef]
- Gomroki, M.; Hasanlou, M.; Reinartz, P. STCD-EffV2T Unet: Semi Transfer Learning EfficientNetV2 T-Unet Network for Urban/Land Cover Change Detection Using Sentinel-2 Satellite Images. Remote Sens. 2023, 15, 1232. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Zou, Y.; Tian, Z.; Cao, J.; Ren, Y.; Zhang, Y.; Liu, L.; Zhang, P.; Ni, J. Rice Grain Detection and Counting Method Based on TCLE–YOLO Model. Sensors 2023, 23, 9129. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Guo, J.; Wu, E. ParameterNet: Parameters Are All You Need for Large-Scale Visual Pretraining of Mobile Networks. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 15751–15761. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic Convolution: Attention Over Convolution Kernels. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11027–11036. [Google Scholar]
- Zhang, T.; Zhang, J.; Pan, P.; Zhang, X. YOLO-RRL: A Lightweight Algorithm for PCB Surface Defect Detection. Appl. Sci. 2024, 14, 7460. [Google Scholar] [CrossRef]
- Shao, Y.; Zhang, R.; Lv, C.; Luo, Z.; Che, M. TL-YOLO: Foreign-Object Detection on Power Transmission Line Based on Improved Yolov8. Electronics 2024, 13, 1543. [Google Scholar] [CrossRef]
- Li, H.; Yi, Z.; Mei, L.; Duan, J.; Sun, K.; Li, M.; Yang, W.; Wang, Y. SCFNet: Lightweight Steel Defect Detection Network Based on Spatial Channel Reorganization and Weighted Jump Fusion. Processes 2024, 12, 931. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; NanoCode012; Xie, T.; Kwon, Y.; Michael, K.; Liu, C.; Fang, J.; et al. Ultralytics/Yolov5: V6.0-YOLOv5n “Nano” Models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support; Version v6.0; CERN: Geneve, Switzerland, 2021. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3500–3509. [Google Scholar]
- Li, Z.; Hou, B.; Wu, Z.; Ren, B.; Yang, C. FCOSR: A Simple Anchor-Free Rotated Detector for Aerial Object Detection. Remote Sens. 2023, 15, 5499. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3163–3171. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align Deep Features for Oriented Object Detection. arXiv 2021, arXiv:2008.09397. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Zhang, J.; Li, X.; Li, J.; Liu, L.; Xue, Z.; Zhang, B.; Jiang, Z.; Huang, T.; Wang, Y.; Wang, C. Rethinking mobile block for efficient attention-based models. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Pu, Y.; Wang, Y.; Xia, Z.; Han, Y.; Wang, Y.; Gan, W.; Wang, Z.; Song, S.; Huang, G. Adaptive Rotated Convolution for Rotated Object Detection. arXiv 2023, arXiv:2303.07820. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.-M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 16748–16759. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetV2: Enhance Cheap Operation with Long-Range Attention. arXiv 2022, arXiv:2211.12905. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4—Universal Models for the Mobile Ecosystem. arXiv 2024, arXiv:2404.10518. [Google Scholar]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why Did You Say That? arXiv 2017, arXiv:1611.07450. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Collection Time | Growth Stage | RGB Images |
|---|---|---|---|
| EXP.1 | 17 June 2021 | Heading | 303 |
| EXP.1 | 28 June 2021 | Filling | 493 |
| EXP.1 | 24 June 2024 | Heading | 133 |
| EXP.1 | 5 July 2024 | Filling | 143 |
| EXP.2 | 18 October 2021 | Heading | 556 |
| EXP.2 | 26 October 2021 | Filling | 557 |
| Stage | Operator | Channels | Stride | Layers |
|---|---|---|---|---|
| 0 | Conv | 24 | 2 | 1 |
| 1 | Fused-MBConv1 | 24 | 1 | 2 |
| 2 | Fused-MBConv4 | 48 | 2 | 4 |
| 3 | Fused-MBConv4 | 64 | 2 | 4 |
| 4 | MBConv4, SE0.25 | 128 | 2 | 6 |
| 5 | MBConv6, SE0.25 | 160 | 1 | 9 |
| 6 | MBConv6, SE0.25 | 256 | 2 | 15 |
| 7 | Conv and Pooling and FC | 1280 | - | 1 |
| YOLOv11n | OBB | EfficientNetV2 | C3k2_DConv | mAP50/% | mAP50-95/% | Parameter/M | GFLOPs |
|---|---|---|---|---|---|---|---|
| √ | 78.6 | 42.7 | 2.58 | 6.3 | |||
| √ | √ | 84.7 | 49.8 | 2.65 | 6.6 | ||
| √ | √ | 78.8 | 49.4 | 2.09 | 4.5 | ||
| √ | √ | 81.2 | 45.2 | 2.94 | 6.2 | ||
| √ | √ | √ | 84.5 | 49.7 | 2.15 | 4.7 | |
| √ | √ | √ | √ | 86.9 | 50.6 | 2.45 | 4.8 |
| 3 m | 10 m | ||||
|---|---|---|---|---|---|
| Heading | Filling | Heading | Filling | ||
| P/% | YOLOv11 | 73.0 | 59.9 | 59.1 | 53.9 |
| OE-YOLO | 83.9 | 61.8 | 57.9 | 63.4 | |
| R/% | YOLOv11 | 72.7 | 65.2 | 62.0 | 56.5 |
| OE-YOLO | 82.8 | 76.1 | 75.3 | 73.0 | |
| Serial Number | C3k2_DConv Location for Different Size Feature Maps | Evaluation Metrics | |||||
|---|---|---|---|---|---|---|---|
| 80 × 80 | 40 × 40 | 20 × 20 | mAP50/% | mAP50-95% | Parameter/M | GFLOPs | |
| 1 | - | - | - | 84.5 | 49.7 | 2.15 | 4.7 |
| 2 | √ | 85.5 | 49.9 | 2.22 | 5.0 | ||
| 3 | √ | 84.7 | 50.0 | 2.27 | 5.3 | ||
| 4 | √ | 84.1 | 49.0 | 2.43 | 4.9 | ||
| 5 | √ | √ | 85.1 | 49.6 | 2.28 | 4.9 | |
| 6 | √ | √ | 84.9 | 50.2 | 2.44 | 4.9 | |
| 7 | √ | √ | 84.8 | 50.1 | 2.49 | 5.3 | |
| 8 | √ | √ | √ | 86.9 | 50.6 | 2.45 | 4.8 |
| Model | mAP50/% | Parameter/M | GFLOPs |
|---|---|---|---|
| YOLOv5n | 75.5 | 2.28 | 5.9 |
| YOLOv8n | 76.7 | 2.68 | 6.8 |
| YOLOv8-obb | 84.1 | 2.76 | 7.2 |
| YOLOv11n | 78.6 | 2.58 | 6.3 |
| YOLOv12n | 80.0 | 2.53 | 5.8 |
| Oriented R-CNN | 80.8 | 41.43 | 211.4 |
| R3Det_tiny | 81.1 | 37.15 | 231.9 |
| S2A-Net | 85.2 | 38.54 | 196.2 |
| FCOSR | 84.3 | 31.89 | 206.2 |
| OE-YOLO | 86.9 | 2.45 | 4.8 |
| Model | mAP50/% | mAP50-95/% | Parameter/M | GFLOPs |
|---|---|---|---|---|
| EMO | 83.0 | 47.1 | 2.84 | 4.6 |
| ShuffleNet | 83.3 | 47.8 | 3.62 | 5.0 |
| ARC | 86.1 | 51.0 | 2.68 | 7.5 |
| LSKNet | 85.8 | 50.8 | 2.64 | 5.9 |
| GhostNetV2 | 84.4 | 49.0 | 6.48 | 7.2 |
| MobileNetV3 | 83.3 | 45.9 | 2.56 | 3.8 |
| MobileNetV4 | 83.7 | 46.6 | 2.59 | 5.3 |
| EfficientNetV2 | 86.9 | 50.6 | 2.45 | 4.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Guan, M.; Chen, J.; Pan, Y.; Zheng, J.; Jin, Z.; Li, H.; Tan, S. OE-YOLO: An EfficientNet-Based YOLO Network for Rice Panicle Detection. Plants 2025, 14, 1370. https://doi.org/10.3390/plants14091370
Wu H, Guan M, Chen J, Pan Y, Zheng J, Jin Z, Li H, Tan S. OE-YOLO: An EfficientNet-Based YOLO Network for Rice Panicle Detection. Plants. 2025; 14(9):1370. https://doi.org/10.3390/plants14091370
Chicago/Turabian StyleWu, Hongqing, Maoxue Guan, Jiannan Chen, Yue Pan, Jiayu Zheng, Zichen Jin, Hai Li, and Suiyan Tan. 2025. "OE-YOLO: An EfficientNet-Based YOLO Network for Rice Panicle Detection" Plants 14, no. 9: 1370. https://doi.org/10.3390/plants14091370
APA StyleWu, H., Guan, M., Chen, J., Pan, Y., Zheng, J., Jin, Z., Li, H., & Tan, S. (2025). OE-YOLO: An EfficientNet-Based YOLO Network for Rice Panicle Detection. Plants, 14(9), 1370. https://doi.org/10.3390/plants14091370