Abstract
Lychee detection and maturity classification are crucial for yield estimation and harvesting. In densely packed lychee clusters with limited training samples, accurately determining ripeness is challenging. This paper proposes a new transformer model incorporating a Kolmogorov–Arnold Network (KAN), termed GhostResNet (GRN)–KAN–Transformer, for lychee detection and ripeness classification in dense on-tree fruit clusters. First, within the backbone, we introduce a stackable multi-layer GhostResNet module to reduce redundancy in feature extraction and improve efficiency. Next, during feature fusion, we add a large-scale layer to enhance sensitivity to small objects and to increase polling of the small-scale feature map during querying. We further propose a multi-layer cross-fusion attention (MCFA) module to achieve deeper hierarchical feature integration. Finally, in the decoding stage, we employ an improved KAN for the classification and localization heads to strengthen nonlinear mapping, enabling a better fitting to the complex distributions of categories and positions. Experiments on a public dataset demonstrate the effectiveness of GRN-KANformer. Compared with the baseline, GFLOPs and parameters of the model are reduced by 8.84% and 11.24%, respectively, while mean Average Precision (mAP) metrics mAP50 and mAP50–95 reach 94.7% and 58.4%, respectively. Thus, it lowers computational complexity while maintaining high accuracy. Comparative results against popular deep learning models, including YOLOv8n, YOLOv12n, CenterNet, and EfficientNet, further validate the superior performance of GRN-KANformer.
1. Introduction
Lychee is a high-value subtropical fruit, and China accounts for about half of the world’s production [1]. During the ripening period, accurate lychee detection and maturity classification are essential for yield estimation and harvesting [2,3,4,5]. However, because lychee orchards in some regions are small and unevenly distributed, both yield estimation and harvesting face substantial challenges. Figure 1 shows an example of lychee recognition by computer vision and its robotic picking. Existing mechanical harvesters often fail to localize fruit precisely, missing small, densely clustered lychees or mistakenly grasping leaves instead, which limits yield estimation and robotic harvesting efficiency and degrades fruit quality. Therefore, developing efficient and intelligent systems for lychee localization and maturity classification is key to enhancing production efficiency and fruit quality.

Figure 1.
Example of lychee recognition and robotic picking: (a) lychee detection by computer vision; (b) robotic picking.
As the agricultural workforce continues to shrink, manual yield estimation and harvesting in complex terrains become impractical, while vision-guided robotic methods are emerging as promising alternatives [6]. Early studies applied traditional computer vision to fruit detection. Díaz et al. [7] classified four olive varieties using contour segmentation and Mahalanobis distance-based classification, achieving fast and efficient sorting in an automated system. Bulanon et al. [8] adopted an automatic thresholding algorithm based on red-channel color-difference histograms, which improved apple segmentation accuracy and recognition rates. Some researchers segmented lychee using color thresholds [9,10], while others localized fruit by extracting fruit edges for segmentation [11]. Subsequent work introduced machine learning keypoint matching to replace purely hand-crafted methods [12]. With the rise of deep learning in the past decade, a larger body of fruit detection research leveraged learned features rather than hand-engineered descriptors, thereby mitigating the limitations of traditional methods under complex illumination and cluttered backgrounds [13,14,15]. Deep learning detectors can be broadly categorized into two families. The first comprises two-stage methods that first generate proposals and then classify and refine them, typically more accurate but slower, such as the R-CNN family [16,17,18] and SPP-Net [19]. For example, Gao et al. [20] used Faster R-CNN to detect and classify apples under different growth conditions, achieving an average classification accuracy of 87.9%. Yu et al. [21] employed Mask R-CNN to segment strawberries, compute the peduncle from the mask, and determine the picking point by extending 13–20 mm upward, with a mean localization error of 1.2 mm. The second family consists of one-stage methods that directly perform classification and regression on feature maps, represented by SSD [22] and the YOLO series [23]. Wang et al. [24] improved the YOLOv5s backbone with ShuffleNet and incorporated a CBAM module in the feature fusion stage, yielding robust accuracy across diverse scenes. Liang et al. [25] proposed a UAV-based approach for lychee ripeness classification that integrates multiple optimization modules into YOLOv8, reaching an average accuracy of 87.7%. Many of these studies emphasize lightweight modules to boost efficiency. For instance, Xie et al. [26] added a P2 small object detection layer to YOLOv8 and designed a lightweight mixed local channel attention module, improving detection of low-quality lychees in orchard environments. Other studies enhance accuracy through attention mechanisms. Peng et al. [27] added a small object detection layer for UAV imagery and introduced an efficient channel attention-enhanced YOLOv8, improving robustness and accuracy for field lychee recognition and yield estimation. In addition, many studies have applied deep learning-based object detection methods in precision agriculture. Allmendinger et al. [28] compared the performance of several state-of-the-art object detection models for real-time and accurate weed detection. The results demonstrated that the YOLO series achieved superior real-time performance, whereas Transformer-based models exhibited higher detection accuracy. Cardellicchio et al. [29] trained an improved YOLO11 model and then applied incremental transfer learning to fine-tune the model for data under different representation conditions, thereby enhancing inference speed and reducing variance.
Despite these advances, designing models that simultaneously improve efficiency and maintain accuracy for detection and maturity classification of small and densely packed fruits remains challenging [30]. Some researchers have specifically targeted field fruit image analysis. James et al. [31] developed a semantic segmentation framework for fruits using transfer learning, enabling accurate segmentation with only a small number of labeled images. Shrawne et al. [32] explored fruit detection using an Eager model with a ResNet-50 backbone under various single- and multi-class settings. Others have investigated dense and small fruit detection [33,34,35]. Tu et al. [36] proposed an improved multi-scale fast region-based CNN and used an RGB-D camera to capture images of passion fruit; the method performed well when more than 80 fruits were present in dense scenes. Lu et al. [37] introduced an effective SOD head for early-stage small fruits, yielding more accurate and stable predictions. Lin et al. [38] presented an improved YOLOv8 in which the detection head was replaced by RT-DETR and CIoU was refined with Focaler-IoU, enhancing detection of occluded small pineapples.
Recent studies show that the Kolmogorov–Arnold Network (KAN) has stronger nonlinear expressivity than multi-layer perceptions (MLPs) [39], markedly improving interpretability, computational efficiency, and adaptability for complex function approximation, as well as parameter efficiency and scalability across time series forecasting, computational biomedicine, and graph learning [40,41,42]. Zhang et al. [43] combined the adaptive nonlinearity of KAN with deep convolution operations, achieving strong performance in remote sensing segmentation with only 1% labeled data. Other work suggests that KAN may also improve detection. For example, Zhan et al. [44] fused spatial channel KAN attention into residual networks to form a Kolmogorov–Arnold Attention Network (KAAN), outperforming state-of-the-art methods on Market-1501, MSMT17, and VeRi-776 for object re-identification. Zhang et al. [45] combined KANConv with C2f to mitigate global feature loss from max pooling, thereby improving both accuracy and interpretability for defect recognition. Inspired by these studies, we propose a GhostResNet–KAN–Transformer (GRN-KANformer) network to address fruit detection and ripeness classification of densely distributed small lychees. The main contributions are as follows:
- A KAN-enhanced Transformer model (GRN-KANformer) is developed for dense small lychee detection and maturity classification in the field.
- Multiple enhancements for Transformer are proposed: a stackable, dynamic lightweight GhostResNet is incorporated; a small object detection layer is added to the hybrid encoder, enabling feature extraction from dense small lychees; an efficient channel attention mechanism is introduced for cross-level multi-scale fusion, reducing interference and strengthening lychee-specific feature extraction.
- An improved KAN module is incorporated into the detection head, enhancing detection capability without significant increases in model complexity.
- GRN-KANformer has been validated using a public lychee dataset and it outperforms multiple popular deep learning models.
2. Proposed Method
As shown in Figure 2, the proposed GRN-KANformer is built upon the Real-Time Detection Transformer (RT-DETR) [44], with improvements made to the three main components of the network—the backbone, neck, and head—to enhance detection performance for densely distributed small lychees. In the backbone, a lightweight GhostResNet bottleneck is employed to reduce computational complexity. In the feature encoder, we introduce a small-object feature extraction layer (S2), which is a convolutional layer followed by the S3 and S4 convolutional layers. After passing through the S5 convolutional layer, Attention-based Intra-scale Feature Interaction (AIFI) performs intra-scale interactions on S5 using a single-scale Transformer encoder to obtain F5. The original CCFF is then replaced by a Mixed Cross-layer Fusion Attention (MCFA) module, which more effectively extracts and fuses salient features while enhancing feature representation capability. A channel attention mechanism is incorporated to focus on lychees of varying maturity levels, and the final MCFA layer fuses shallow and intermediate features to better capture fine details. Finally, in the Transformer detection head, the linear head is replaced with an improved KAN, which introduces nonlinearity at minimal computational cost and helps distinguish overlapping lychees.
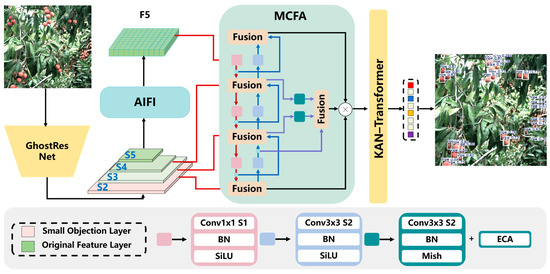
Figure 2.
The overall architecture of the proposed GRN-KANformer. (AIFI: Attention-based Intra-scale Feature Interaction; MCFA: multi-layer cross-fusion attention; BN: batch normalization; ECA: efficient channel attention; SiLU and Mish are activation functions; details of other notations are described in RT-DETR [46]).
2.1. GhostResNet Block
In on-tree lychee images, densely packed regions are typically small and often partially occluded. We combined the ideas of GhostNet [47] and ResNet [48] to design a stackable multi-layer parameterizable lightweight module named GhostResNet block (GRN), as shown in Figure 3. The first GhostCBS performs rapid downsampling and initial feature extraction, which is crucial for handling high-resolution images. Subsequent stages stack multiple GRNs to progressively deepen the network and extract increasingly abstract features.
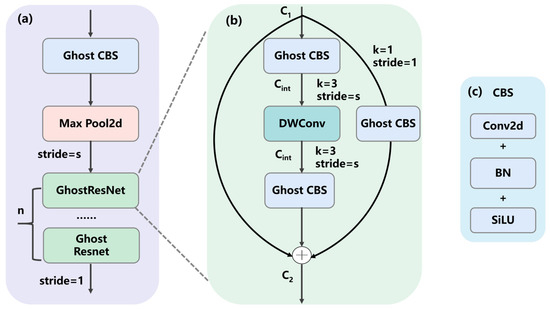
Figure 3.
(a) The GhostResNet (GRN) block; (b) details of GRN sub-module; (c) details of the CBS sub-module. (s: user-defined stride; n: the number of stacked GRN layers; C1 and C2: the input and output channel counts, respectively; Cint: the channel width after dimensionality reduction).
2.1.1. GhostResNet (GRN)
Mainstream CNNs exhibit substantial redundancy in intermediate feature maps when processing fruit images. We therefore design a lightweight module by combining two complementary primitives, GhostConv and depthwise separable convolution (DWConv) [49]. In GhostCBS, standard convolutions are replaced with GhostConv to reduce the number of filters required to generate feature maps, and identity mappings run in parallel with linear transformations to preserve intrinsic lychee features. Batch normalization (BN) and ReLU nonlinearity are applied after each layer, except that ReLU is omitted after the second Ghost module. Concretely, GhostCBS is used in the first layer and in the shortcut, dramatically reducing computation and network parameters; a 3 × 3 DWConv is employed in the second layer, while a residual shortcut connection aligns output dimensions and enables effective extraction of spatial features from lychee images.
2.1.2. Dimensionality Reduction Hyperparameter
As shown in Figure 3, GRN includes a hyperparameter, Ratio, which allows fine control over model width and capacity. For mobile deployment, a smaller Ratio (e.g., 0.125) yields an ultra-lightweight model, whereas on servers a larger Ratio (e.g., 0.5) can improve performance. By first reducing and then restoring channel dimensionality via the Ratio setting, the intermediate channels are greatly compressed, enabling the most compute-intensive 3 × 3 DWConv to operate on a very small channel width. This flexible model scaling enlarges the effective context and makes the detector more sensitive to edge textures of small lychees.
2.2. Addition of the S2 Small Object Detection Layer
Most lychees occupy only a small fraction of the image. Prior studies have shown that adding a higher-resolution feature map in the backbone improves small object detection [26,27]. Inspired by this, we modify the feature extractor in RT-DETR by adding a small object detection layer (Figure 4). Figure 4a shows the original RT-DETR feature hierarchy; Figure 3b illustrates the design of the added S2 layer. The S2 feature map is 320 × 320 × 256, providing a smaller effective receptive field and relatively richer positional cues, thereby enhancing detection of small objects. Afterwards, we augment the corresponding positional encoding with new query indices aligned to the features extracted at S2. To ease object querying, we adopt uncertainty minimization query selection [46], which explicitly models and optimizes epistemic uncertainty to capture the joint latent variables of encoder features and thus supply high-quality queries to the decoder. Specifically, the feature uncertainty integrates discrepancies between the predictive distributions of localization and classification, as expressed in Equations (1) and (2).
where denotes the joint uncertainty metric, the decoder output feature, the predictive distribution of the localization branch, and the predictive distribution of the classification branch.
where is the total loss; and are the localization branch loss and the classification loss induced by the joint uncertainty metric.
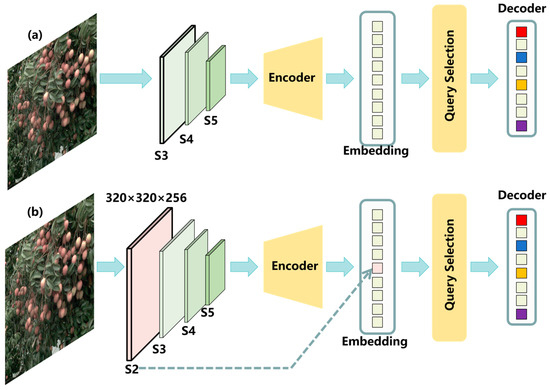
Figure 4.
Design of the S2 small object detection layer: (a) original RT-DETR architecture; (b) RT-DETR with the added S2 small object detection layer.
2.3. Multi-Layer Cross-Feature Fusion with Efficient Channel Attention
Recent studies indicate that cross-feature fusion and attention mechanisms improve fruit detection accuracy. Chai et al. [50] enhanced YOLO for cherry tomato detection using feature fusion mechanisms, achieving significant gain over the baseline model. Yan et al. [51] addressed bagged pear detection under various occlusions by introducing multi-scale cross-modal feature fusion and a cost-sensitive classification loss, improving mAP50 by 3.6% relative to the classic YOLOv10m. Xu et al. [52] proposed a passion fruit yield estimation method that combines a density-aware attention mechanism with cross-scale feature fusion; orchard experiments showed superior identification accuracy, small fruit detection, and duplicate suppression, substantially enhancing reliability and practicality. Inspired by these findings, we design a multi-layer cross-fusion attention module that further strengthens the RT-DETR’s capacity to extract and fuse heterogeneous features (Figure 5). Layer 1 fuses deep F5, mid-level S4, shallow S3, and small object S2 features. Layer 2 continues feature extraction and performs cross-scale fusion of F5, P4, and P3 from Layer 1. Layer 3 refines B2 and B3 from Layer 2, fuses them with efficient channel attention (ECA) [53] to obtain M3 and M4, and then re-fuses with B2. The final layer unifies the mid-scale features into Y34 and forms a three-path concatenation with B5 and P2.
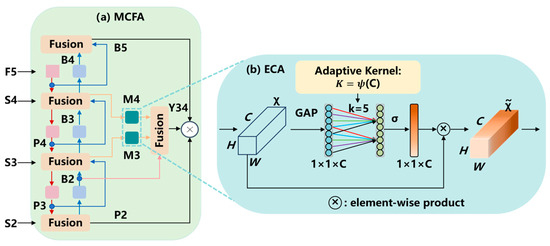
Figure 5.
(a) The structure of the multi-layer cross-fusion attention (MCFA) model; (b) the structure of the efficient channel attention (ECA) module. (GAP: global average pooling; details of other notations are described in RT-DETR [46]).
To further enhance high-level feature fusion for maturity classification, we employ ECA in the third fusion layer. As shown in Figure 5b, it captures local cross-channel interactions by considering each channel and its neighboring channels, an approach proven to be both efficient and effective. It uses a 1D convolution to avoid dimensionality reduction, providing an efficient mechanism for cross-channel interaction.
2.4. KAN-Enhanced Detection Head
On-tree lychees often occur in clusters with severe occlusions, which demands stronger nonlinearity for both detection and classification. Recent studies have shown that combining an improved KAN with a Transformer yields promising results [54]. Specifically, three strategies are adopted to overcome the large parameter count and low computational efficiency of conventional KANs: (a) using rational functions as basis functions; (b) sharing function coefficients and basis functions across groups; and (c) a variance-preserving initialization to keep activation variance consistent across layers. The main formulations of the improved KAN are as follows:
where is the ith output feature sequence, LN denotes layer normalization, and MSA multi-head self-attention.
As shown in Figure 6, the improved KAN architecture uses three differently colored dashed boxes to denote distinct parameter groups. Within each group, all edges (i.e., connections from input channels to output channels) share a single learnable nonlinear basis function, , rather than assigning a separate set of functions to every edge as in the original KAN. Moreover, all input channels within the same group (i.e., multiple inputs) share the same across all outgoing edges. The right panel of Figure 5 illustrates one exemplar activation profile for a group. The rational polynomial basis functions are given as follows:
where is the scaling factor, and and denote the polynomial coefficients, which are learned end-to-end.
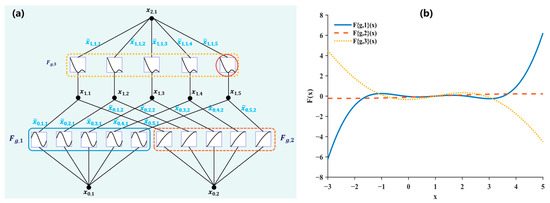
Figure 6.
(a) Illustration of the modified KAN architecture; (b) an example of individual activation function, as indicated by the red circle in (a).
Following the idea of replacing MLPs with a nonlinear alternative, we substitute the linear layers in the detection head with a KANLinear operator. Because these linear layers govern both bounding box regression and class prediction, replacing them with KANLinear promotes a more unified vector representation and better fits complex nonlinear distributions, yielding more accurate lychee bounding boxes and maturity classifications.
3. Experimental Results
To validate the effectiveness of the proposed GRN-KANformer and assess its performance, we conducted experiments using a public lychee dataset characterized by small and densely distributed fruits. We also compare it against several state-of-the-art deep learning models (RT-DETR, YOLOv5, YOLOv8, YOLOv12, CenterNet, and EfficientNet). Performance was comprehensively evaluated in terms of precision, recall, computational complexity (GFLOPs), and model parameter size.
3.1. Dataset and Experimental Settings
In the lychee harvesting literature, most studies are based on single-fruit detection and classification [4,12,26]. The dataset originated from our previous work; details of image acquisition are provided in [55]. Images have a resolution of 1024 × 1280 and are annotated with three maturity levels: unripe, semi-ripe, and ripe. As illustrated in Figure 6a, red boxes indicate the definition of small lychee. We computed bounding box pixel areas and defined a small lychee as one with an area < 1600 px (≈0.12% of the full image). We defined dense scenes as those in which lychee annotations constitute > 30% of all annotations in an image. From the on-tree lychee dataset, we selected 225 images that meet these criteria, forming our dense and small lychee image subset.
The generalization ability of a dataset greatly impacts the performance of the trained deep learning model. To achieve good generalization, the validation error must continue to decrease as the training error decreases. Data augmentation is a powerful method to accomplish this. It generates more comprehensive data samples, thereby minimizing the gap between the training set, validation set, and test set [56]. Geometric transformations of images often preserve annotations because they only alter the positions of key features, making the transformation functions relatively safe [57]. In this work, we applied scaling, cropping, random rotation, horizontal and vertical flipping, and center cropping. Real-world data are rarely perfect [58]; when neural networks are evaluated using real data, noise can degrade accuracy and lead to poor generalization. Robustness can be improved by augmenting the data with various types of noise. In our case, Gaussian, Salt and Pepper, and Poisson noises, which are common in real images, were used to enhance the dataset. Since images are typically encoded as tensors with three dimensions—height, width, and channel—performing data augmentation in the color channel space is another effective strategy. Through basic matrix operations, RGB values can be scaled to increase or decrease image brightness [59]. Random brightness, contrast, and saturation adjustments were applied to generate new images distinct from the originals. Visualization examples of the augmented data are shown in Figure 7b.

Figure 7.
(a) Illustration of small lychees (those in red bounding boxes) defined in the current study; (b) examples of different image augmentation methods.
After data augmentation, the dataset comprises a total of 1125 images with 15,344 annotations. Following a 9:1:1 split ratio, it is divided into a training set (900 images, 12,448 annotations), a validation set (110 images, 1460 annotations), and a test set (115 images, 1436 annotations).
The proposed algorithm was developed based on the Ultralytics library [60] (version 8.3.179), Python (version 3.10.18), and PyTorch (version 2.8.0). All experiments were conducted on a workstation equipped with an Intel i7 CPU (Santa Clara, CA, USA) and an NVIDIA GeForce RTX 4090 GPU (Santa Clara, CA, USA). During training, all images were resized to 640 × 640 pixels. The batch size was set to 16, and the training was performed for 1000 epochs with an early stopping patience of 100 epochs (training terminated if no significant improvement was observed). The initial learning rate was set to 0.01 and decayed to 1% of its initial value. The Stochastic Gradient Descent (SGD) [45] was used as the optimizer with a momentum of 0.937. The weight decay coefficient was set to 0.0005 to regularize the model parameters. All other hyperparameters were kept at their default values.
3.2. Evaluation Metrics
We use per-class and overall precision (P), recall (R), and mean Average Precision (mAP50) as the basic metrics. We also report mAP50–95, i.e., the average mAP over IoU thresholds from 0.50 to 0.95 in steps of 0.05, which provides a more comprehensive assessment. The formulas for per-class P/R/AP/mAP are given in Equations (6) and (7), and those for overall P/R/AP/mAP are given in Equations (8) and (9).
where index i indicates the class; , , and represent the true positives, false positives, and false negatives; and and are consecutive recall levels.
where denotes the number of maturity levels.
3.3. Selecting the Dimensionality Reduction Hyperparameter
As discussed above, the GRN block includes a hyperparameter Ratio that controls the channel widths of the second and third layers within the block, thereby governing model size and computational cost. We conducted a hyperparameter study on Ratio. The base model is RT-DETR–ResNet50 (DETR-Res50). Its five ResNet backbone stages are replaced with GRN blocks, using the same Ratio in all stages. We evaluate three settings: 0.125, 0.25, and 0.5. The comparative results are summarized in Table 1.

Table 1.
Comparison of models with varying Ratio values. Bold text represents the best result for the metric.
All new configurations yield fewer parameters than the original DETR-Res50, with the maximum and minimum reductions being 46.37% and 29.32%, respectively, confirming the effectiveness of GRN as a lightweight backbone block. Aggregating across overall and per-class metrics, Ratio = 0.25 (GRN0.25) attains the largest number of best scores and is therefore adopted as the default setting for subsequent experiments.
3.4. Ablation Experiments
To assess the contribution of each component in GRN-KANformer, we conducted a series of ablation studies by removing one or more modules from the full model. The baseline is the DETR-Res50, and all ablations are performed to incrementally add components to the baseline to verify the effectiveness of each module. The ablation configurations are summarized in Table 2, and the evaluation follows the overall (all-class) metrics defined in Equations (8) and (9). Specifically, we begin with the baseline; then, we add, in turn, the S2 small object detection layer, the MCFA module, the GRN0.25 lightweight module, and the KAN-based improved detection head.
Table 2.
Ablation results. Best results are in bold; second-best are underlined. (Paras: parameters.)
The baseline achieves a precision of 0.760, a recall of 0.816, and mAPs of 0.823 (mAP50l) and 0.512 (mAP50–95). After adding the S2 small-object module (+S2), GFLOPs and parameters increase by 6.13% and 0.67%, respectively, yet both precision and recall improve substantially; mAP50 and mAP50–95 rise to 0.832 (≈+1.09%) and 0.526 (≈+2.73%), indicating more accurate bounding box localization. Incorporating the MCFA further lifts recall to 0.850, with mAP50 and mAP50-95 reaching 0.893 and 0.562, i.e., gains of approximately 8.51% and 9.77% over the baseline. Stacking five GRN (0.25) lightweight blocks in the backbone reduces GFLOPs and parameters by 36.78% and 40.69%, confirming its positive effect on model compactness. With the KANLinear detection head added, both localization and classification improve markedly: precision and recall reach 0.863 and 0.885 (relative gains of 13.55% and 8.46% vs. baseline), while mAP50 and mAP50-95 attain 0.947 and 0.584 (improvements of 15.07% and 14.06%). Meanwhile, GFLOPs and parameters drop to 114.5 and 37.228, reductions of 8.84% and 11.24%. Overall, the results show a favorable balance between improved accuracy and the lightweight design.
To analyze which image regions are influenced by each component, we conducted a Gradient-weighted Class Activation Mapping (Grad-CAM) heatmap comparison for the ablation settings (Figure 8) [61]. Grad-CAM visualizes the regions a CNN attends to when making a specific decision by producing a heatmap that highlights areas most critical to the prediction. The baseline exhibits focused attention on most targets but also allocates attention to some non-lychee regions. After adding MCFA, S2, and KAN, the attention over small lychees becomes progressively more accurate and concentrated. In particular, the S2 and KAN modules sharpen the attention distribution on small fruits, yielding the most optimal focus across targets and notably improving detection under heavy occlusion.

Figure 8.
Comparison of heatmaps for ablation experiments: (a) ground truth; and heatmaps for (b) baseline (DETR-Res50), Grad-CAM extracted from the 22nd RepC3 layer; (c) +S2, Grad-CAM extracted from the 1st Conv layer; (d) +MCFA, Grad-CAM extracted from the 21st, 30th, and 36th RepC3 layers; (e) +GRN0.25, Grad-CAM extracted from the 4th GRN layer; (f) +KAN (full model), Grad-CAM extracted from the 1st S2 layer and the 21st, 30th, and 36th RepC3 layers.
GRN-KANformer is compared with other popular deep learning model, DETR-Res50, YOLOv5n [62], YOLOv8n [63], YOLOv12n [64], Fast R-CNN [17], CenterNet [65], and EfficientNet [66]. The quantitative results are summarized in Table 3.
Table 3.
Comparison with other models. P: precision; R: recall; Paras: parameters. Best results are in bold; second-best are underlined.
3.5. Comparison with State-of-the-Art Deep Learning Models
GRN-KANformer delivers substantial gains over the baseline and the classic two-stage detector (Fast R-CNN) on nearly all key metrics. Compared to Fast R-CNN, it improves precision, recall, mAP50, and mAP50–95 by 19.20%, 11.74%, 17.93%, and 15.42%, respectively. Even against the second-best models in each metric, it maintains a favorable margin: compared with YOLO12n, precision and mAP50 increase by 0.35% and 6.29%, respectively; compared to CenterNet, the gain in recall is 4.61%; and compared to YOLOv5n, mAP50–95 increases by 5.61%. In terms of computational efficiency, compared with Fast R-CNN and DETR-Res50, it achieves higher accuracy while reducing parameters by 8.8–28.9% and GFLOPs by 10–11.2%, indicating a good accuracy–efficiency balance. Compared to ultra-lightweight YOLO variants and EfficientNet, it trades a larger model size and computing cost for 5–12% absolute accuracy gains. Figure 9 compares the precision–recall curves at IoU = 0.50 for the models.
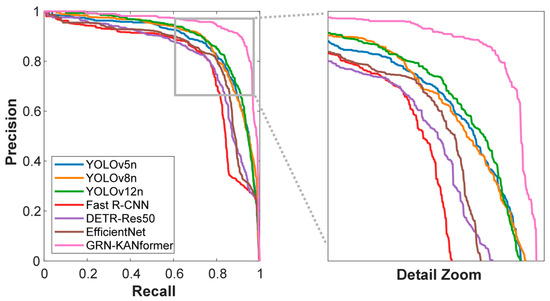
Figure 9.
Precision–recall curves of different deep learning models.
Figure 10 visualizes detection results in dense small lychee scenes. Red circles mark missed detections, and red triangles indicate inaccurate localization. The compared methods exhibit varying degrees of incomplete detection, frequently missing small or overlapping objects and yielding suboptimal boundary. By contrast, GRN-KANformer detects dense small lychees more accurately, achieves notably higher recall for small and partially occluded fruits, and produces predicted boxes with high overlap to the ground truth (GT).

Figure 10.
Visualization of lychee detection by different deep learning models: (a) ground truth; (b–i) results from YOLOv5n, YOLOv8n, YOLOv12n, Fast R-CNN, CenterNet, EfficientNet, DETR-Res50, and GRN-KANformer, respectively. Red circles mark missed detections, and red triangles indicate inaccurate localization.
Figure 11 shows the per-class maturity classification results. Although the YOLO family is generally robust, it still exhibits noticeable bias between semi-ripe and ripe, with visible misclassifications as ripe. The results from DETR-Res50 suggests that query-based decoding helps with fine-grained boundaries, yet extremely similar appearances still require priors or strengthened local attention. CenterNet, EfficientNet, and Fast R-CNN display more pronounced one-way confusion for semi-ripe, indicating limited capture of multi-scale contextual and small lychee details. By contrast, GRN-KANformer shows negligible misses for unripe fruits, and its correct semi-ripe and ripe classifications rank the highest, reflecting stronger boundary discrimination and fewer misclassifications between adjacent ripeness levels.
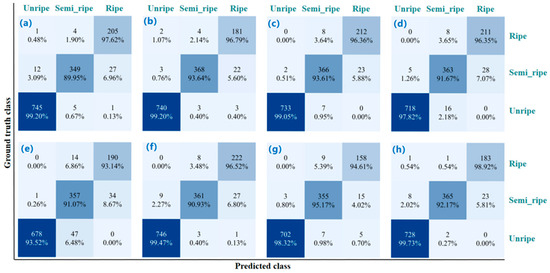
Figure 11.
Confusion matrices of maturity classification by different deep learning models: (a–h) YOLOv5n, YOLOv8n, YOLOv12n, Fast R-CNN, CenterNet, EfficientNet, DETR-Res50, and GRN-KANformer, respectively.
To further evaluate the performance of the proposed GRN-KANformer, we conducted comparative experiments with models of similar parameter scales, including YOLOv8-s/m and YOLOv12-s/m/l. Each model was trained three times with different random seeds, and the mean and standard deviation of all metrics were reported (see Table 4 and Figure 9). GRN-KANformer achieved the best performance across all indicators—precision (0.867 ± 0.015), recall (0.883 ± 0.002), mAP50 (0.925 ± 0.002), and mAP50–95 (0.585 ± 0.003), surpassing the best YOLO baselines (YOLOv12-m, mAP50 = 0.890; YOLOv8-m, mAP50–95 = 0.559) by approximately 3.9% and 4.7%, respectively. With its higher computational complexity (114.5 GFLOPs, 37.23 M parameters) compared to YOLOv8-m (78.7 GFLOPs, 25.84 M parameters), GRN-KANformer demonstrates a good performance–complexity trade-off, exhibiting consistent convergence, low metric variance (±0.003–0.015), and strong robustness across experiments. These results confirm its enhanced accuracy, stability, and generalization capability for lychee detection tasks.
Table 4.
Experimental results of several deep learning models with comparable parameter scales under three different random seeds. The values are presented as mean ± standard deviation. Bold values represent the best results.
4. Discussion
Lychee detection and maturity classification are prerequisites for unmanned yield estimation and robotic harvesting. Prior work has addressed small fruit detection to some extent [25,33,35,37]. In this study, we modified KAN and incorporated it into a Transformer, along with other improvements, to form GRN-KANformer for the same purpose. Against seven popular deep learning models, it achieves the best results on four metrics: precision, recall, mAP50, and mAP50–95. Among the eight models, it ranks sixth in parameter size and fifth in GFLOPs, indicating that the accuracy gains come at some cost to model complexity and computational cost, though it achieves significant improvement compared to the baseline DETR-Res50. For the model to run on an edge-computing device such as in harvesting robots, this may still need further work for practical deployment.
Our results also reveal a two-sided nature of KAN: if used improperly, KAN can increase representational capacity but also inflate parameters, consistent with prior findings [41,43]. We observed that replacing MLPs with a traditional KAN in the feature extraction or fusion stages increased parameters and degraded performance, specifically when substituting the MLPs in AIFI and in the decoder FFN. Instead, replacing only the linear layers in the detection head yielded better results on small lychee images than other models. Nevertheless, performance may decline in unseen scenarios (e.g., fruit varieties absent from the training set).
It should be noted that lychees also tend to grow in bunches, but the clustering is not as obvious as grapes or cherry tomatoes. Depending on the applications, it may be desirable to detect lychees and the maturity level individually, as performed in this study in some cases; however, in other cases, it may be better to detect them and classify their maturity levels in bunches. We do not have specific data on this, but we suspect that how clustered lychees are depends on the varieties. In the case of cherry tomatoes, both approaches have been explored [67,68], while for grapes, usually detection and harvesting are carried out in bunches [69]. However, the maturity level definition is likely to be less objective in bunches than in individual fruits.
Future work will explore the following: (1) expanding and diversifying the dataset to cover lychees of different sizes, cultivars, and environmental conditions, thereby enhancing generalization and reducing overfitting, including detection and classification in both individual fruit and bunches; (2) extending the framework to other fruits (e.g., strawberries and smaller blueberries) to broaden applicability in precision agriculture; and (3) developing an integrated multi-fruit detector to reduce data collection and annotation overhead across fruit types, improve model generality, and enable more robust agricultural applications.
5. Conclusions
This study presents GRN-KANformer, a KAN-integrating transformer tailored to fruit detection and maturity classification for small and dense lychees. By stacking purpose-designed lightweight modules, adding a small object detection layer, employing multi-layer cross-fusion attention in the neck for feature extraction and integration, and enhancing the detection head with KAN, the proposed framework improves both efficiency and robustness for lychee detection and classification under limited data. Comprehensive comparative experiments validate the superiority of the model and highlight its potential for practical deployment in precision agriculture.
Author Contributions
Conceptualization, Z.Z. and Y.T.; Methodology, Z.Z. and Y.T.; Software, Z.Z., Y.W. and S.C.; Validation, Z.Z., Y.W. and S.C.; Investigation, Y.T.; Resources, Y.T.; Data curation, Y.W.; Writing—original draft, Z.Z.; Writing—review and editing, S.C., Y.W. and Y.T.; Visualization, Z.Z.; Supervision, Y.T.; Funding acquisition, Y.T. All authors have read and agreed to the published version of the manuscript.
Funding
The Shenzhen Talent Startup Funds (No. 827-000954), and Shenzhen University (No. 86902/00248).
Data Availability Statement
The data used in this study are publicly available, as described in reference [53], and the link is https://data.mendeley.com/datasets/6svnttj9g4/1 (accessed on 2 November 2025). The code for this study is made public at https://github.com/SeiriosLab/Lychee/tree/main/Code (accessed on 2 November 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chen, H.; Huang, H. China litchi industry: Development, achievements and problems. In Proceedings of the I International Symposium on Litchi and Longan, Guangzhou, China, 18–24 June 2000; Volume 558, pp. 31–39. [Google Scholar]
- Wang, C.; Han, Q.; Zhang, T.; Li, C.; Sun, X. Litchi picking points localization in natural environment based on the Litchi-YOSO model and branch morphology reconstruction algorithm. Comput. Electron. Agric. 2024, 226, 109473. [Google Scholar] [CrossRef]
- Li, B.; Lu, H.; Wei, X.; Guan, S.; Zhang, Z.; Zhou, X.; Luo, Y. An Improved Rotating Box Detection Model for Litchi Detection in Natural Dense Orchards. Agronomy 2023, 14, 95. [Google Scholar] [CrossRef]
- Li, T.; Cong, P.; Xu, Y.; Liang, J.; Wang, K.; Zhang, X. Target detection model for litchi picking in complex scenes. Digit. Eng. 2025, 5, 100032. [Google Scholar] [CrossRef]
- Xie, Z.; Liu, W.; Li, Y.; Du, J.; Long, T.; Xu, H.; Long, Y.; Zhao, J. Enhanced litchi fruit detection and segmentation method integrating hyperspectral reconstruction and YOLOv8. Comput. Electron. Agric. 2025, 237, 110659. [Google Scholar] [CrossRef]
- Jiao, Z.; Huang, K.; Jia, G.; Lei, H.; Cai, Y.; Zhong, Z. An effective litchi detection method based on edge devices in a complex scene. Biosyst. Eng. 2022, 222, 15–28. [Google Scholar] [CrossRef]
- Diaz, R.; Faus, G.; Blasco, M.; Blasco, J.; Molto, E. The application of a fast algorithm for the classification of olives by machine vision. Food Res. Int. 2000, 33, 305–309. [Google Scholar] [CrossRef]
- Bulanon, D.M.; Kataoka, T.; Ota, Y.; Hiroma, T. AE—Automation and emerging technologies: A segmentation algorithm for the automatic recognition of Fuji apples at harvest. Biosyst. Eng. 2002, 83, 405–412. [Google Scholar] [CrossRef]
- Guo, A.; Xiao, D.; Zou, X. Computation model on image segmentation threshold of litchi cluster based on exploratory analysis. J. Fiber Bioeng. Inform. 2014, 7, 441–452. [Google Scholar] [CrossRef]
- Xiong, J.; He, Z.; Lin, R.; Liu, Z.; Bu, R.; Yang, Z.; Peng, H.; Zou, X. Visual positioning technology of picking robots for dynamic litchi clusters with disturbance. Comput. Electron. Agric. 2018, 151, 226–237. [Google Scholar] [CrossRef]
- Xiong, J.; Lin, R.; Liu, Z.; He, Z.; Tang, L.; Yang, Z.; Zou, X. The recognition of litchi clusters and the calculation of picking point in a nocturnal natural environment. Biosyst. Eng. 2018, 166, 44–57. [Google Scholar] [CrossRef]
- Wang, C.; Tang, Y.; Zou, X.; Luo, L.; Chen, X. Recognition and matching of clustered mature litchi fruits using binocular charge-coupled device (CCD) color cameras. Sensors 2017, 17, 2564. [Google Scholar] [CrossRef] [PubMed]
- Xiao, F.; Wang, H.; Xu, Y.; Zhang, R. Fruit detection and recognition based on deep learning for automatic harvesting: An overview and review. Agronomy 2023, 13, 1625. [Google Scholar] [CrossRef]
- Zheng, Z.; Xiong, J.; Lin, H.; Han, Y.; Sun, B.; Xie, Z.; Yang, Z.; Wang, C. A method of green citrus detection in natural environments using a deep convolutional neural network. Front. Plant Sci. 2021, 12, 705737. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Zhao, W.; Wang, Y.; Yan, W.Q.; Li, Y. Lightweight and efficient deep learning models for fruit detection in orchards. Sci. Rep. 2024, 14, 26086. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Gao, F.; Fu, L.; Zhang, X.; Majeed, Y.; Li, R.; Karkee, M.; Zhang, Q. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, L.; Zhao, Y.; Xiong, Z.; Wang, S.; Li, Y.; Lan, Y. Fast and precise detection of litchi fruits for yield estimation based on the improved YOLOv5 model. Front. Plant Sci. 2022, 13, 965425. [Google Scholar] [CrossRef]
- Liang, C.; Liu, D.; Ge, W.; Huang, W.; Lan, Y.; Long, Y. Detection of litchi fruit maturity states based on unmanned aerial vehicle remote sensing and improved YOLOv8 model. Front. Plant Sci. 2025, 16, 1568237. [Google Scholar] [CrossRef]
- Xie, J.; Liu, J.; Chen, S.; Gao, Q.; Chen, Y.; Wu, J.; Gao, P.; Sun, D.; Wang, W.; Shen, J. Research on inferior litchi fruit detection in orchards based on YOLOv8n-BLS. Comput. Electron. Agric. 2025, 237, 110736. [Google Scholar] [CrossRef]
- Peng, H.; Li, Z.; Zou, X.; Wang, H.; Xiong, J. Research on litchi image detection in orchard using UAV based on improved YOLOv5. Expert Syst. Appl. 2025, 263, 125828. [Google Scholar] [CrossRef]
- Allmendinger, A.; Saltık, A.O.; Peteinatos, G.G.; Stein, A.; Gerhards, R. Assessing the capability of YOLO-and transformer-based object detectors for real-time weed detection. Precis. Agric. 2025, 26, 52. [Google Scholar]
- Cardellicchio, A.; Renò, V.; Cellini, F.; Summerer, S.; Petrozza, A.; Milella, A. Incremental learning with domain adaption for tomato plant phenotyping. Smart Agric. Technol. 2025, 12, 101324. [Google Scholar] [CrossRef]
- Ragu, N.; Teo, J. Object detection and classification using few-shot learning in smart agriculture: A scoping mini review. Front. Sustain. Food Syst. 2023, 6, 1039299. [Google Scholar] [CrossRef]
- James, J.A.; Manching, H.K.; Hulse-Kemp, A.M.; Beksi, W.J. Few-shot fruit segmentation via transfer learning. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 13618–13624. [Google Scholar]
- Shrawne, S.; Sawant, M.; Shingate, M.; Tambe, S.; Patil, S.; Sambhe, V. Fine-tuning retinanet for few-shot fruit detection. In Proceedings of the International Conference on Advanced Network Technologies and Intelligent Computing, Varanasi, India, 19–21 December 2024; pp. 124–143. [Google Scholar]
- Liu, Q.; Lv, J.; Zhang, C. MAE-YOLOv8-based small object detection of green crisp plum in real complex orchard environments. Comput. Electron. Agric. 2024, 226, 109458. [Google Scholar] [CrossRef]
- Li, T.; Chen, Q.; Zhang, X.; Ding, S.; Wang, X.; Mu, J. PeachYOLO: A lightweight algorithm for peach detection in complex orchard environments. IEEE Access 2024, 12, 96220–96230. [Google Scholar] [CrossRef]
- Zhang, N.; Cao, J. Robust Real-Time Blueberry Counting in Greenhouses Using Small-Object Detection and Mamba-Driven Multi-Step Trajectory Completion. Smart Agric. Technol. 2025, 12, 101402. [Google Scholar] [CrossRef]
- Tu, S.; Pang, J.; Liu, H.; Zhuang, N.; Chen, Y.; Zheng, C.; Wan, H.; Xue, Y. Passion fruit detection and counting based on multiple scale faster R-CNN using RGB-D images. Precis. Agric. 2020, 21, 1072–1091. [Google Scholar] [CrossRef]
- Lu, Y.; Sun, M.; Guan, Y.; Lian, J.; Ji, Z.; Yin, X.; Jia, W. SOD head: A network for locating small fruits from top to bottom in layers of feature maps. Comput. Electron. Agric. 2023, 212, 108133. [Google Scholar] [CrossRef]
- Lin, C.; Jiang, W.; Zhao, W.; Zou, L.; Xue, Z. DPD-YOLO: Dense pineapple fruit target detection algorithm in complex environments based on YOLOv8 combined with attention mechanism. Front. Plant Sci. 2025, 16, 1523552. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. Kan: Kolmogorov-arnold networks. arXiv 2024, arXiv:2404.19756. [Google Scholar] [PubMed]
- Somvanshi, S.; Javed, S.A.; Islam, M.M.; Pandit, D.; Das, S. A survey on kolmogorov-arnold network. ACM Comput. Surv. 2024, 58, 1–35. [Google Scholar] [CrossRef]
- Xie, X.; Zheng, W.; Xiong, S.; Wan, T. MTAD-Kanformer: Multivariate time-series anomaly detection via kan and transformer. Appl. Intell. 2025, 55, 796. [Google Scholar] [CrossRef]
- Wang, Z.; Zainal, A.; Siraj, M.M.; Ghaleb, F.A.; Hao, X.; Han, S. An intrusion detection model based on Convolutional Kolmogorov-Arnold Networks. Sci. Rep. 2025, 15, 1917. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Jin, Z.; Xia, Y.; Yuan, X.; Wang, Y.; Li, N.; Yu, Y.; Li, D. SS-KAN: Self-Supervised Kolmogorov-Arnold Networks for Limited data Remote Sensing Semantic Segmentation. Neural Netw. 2025, 192, 107881. [Google Scholar] [CrossRef]
- Zhan, S.; Su, J.; Liu, P.; Fu, Y.; Zhu, J. Object re-identification using Kolmogorov-Arnold attention networks. Math. Found. Comput. 2025. early access. [Google Scholar] [CrossRef]
- Zhang, Q.; Xu, X.; Wang, Z.; Wen, Y. Defect detection of PCB-AoI dataset based on improved YOLOv10 algorithm. In Proceedings of the 4th International Conference on Computer, Artificial Intelligence and Control Engineering, Heifei China, 10–12 January 2025; pp. 60–66. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Chai, S.; Wen, M.; Li, P.; Zeng, Z.; Tian, Y. DCFA-YOLO: A Dual-Channel Cross-Feature-Fusion Attention YOLO Network for Cherry Tomato Bunch Detection. Agriculture 2025, 15, 271. [Google Scholar] [CrossRef]
- Yan, S.; Hou, W.; Rao, Y.; Jiang, D.; Jin, X.; Wang, T.; Wang, Y.; Liu, L.; Zhang, T.; Genis, A. Multi-scale cross-modal feature fusion and cost-sensitive loss function for differential detection of occluded bagging pears in practical orchards. Artif. Intell. Agric. 2025, 15, 573–589. [Google Scholar] [CrossRef]
- Xu, D.; Wang, C.; Li, M.; Ge, X.; Zhang, J.; Wang, W.; Lv, C. Improving passion fruit yield estimation with multi-scale feature fusion and density-attention mechanisms in smart agriculture. Comput. Electron. Agric. 2025, 239, 110958. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Yang, X.; Wang, X. Kolmogorov-arnold transformer. arXiv 2024, arXiv:2409.10594. [Google Scholar]
- Zhang, Z.; Wang, Y.; Chai, S.; Liu, Y.; Xie, Z.; Huang, W.; Li, P.; Luo, Z.; Lu, D.; Tian, Y. An RGB-D Image Dataset for Lychee Detection and Maturity Classification for Robotic Harvesting. arXiv 2025, arXiv:2510.16800. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Yang, Z.; Sinnott, R.O.; Bailey, J.; Ke, Q. A survey of automated data augmentation algorithms for deep learning-based image classification tasks. Knowl. Inf. Syst. 2023, 65, 2805–2861. [Google Scholar] [CrossRef]
- Akbiyik, M.E. Data augmentation in training CNNs: Injecting noise to images. arXiv 2023, arXiv:2307.06855. [Google Scholar] [CrossRef]
- Ma, J.; Hu, C.; Zhou, P.; Jin, F.; Wang, X.; Huang, H. Review of image augmentation used in deep learning-based material microscopic image segmentation. Appl. Sci. 2023, 13, 6478. [Google Scholar] [CrossRef]
- Jocher, G.; Jing, Q.; Ayush, C. Ultralytics YOLO. Available online: https://github.com/ultralytics/ultralytics (accessed on 20 July 2025).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics, Version 7.0. computer software. 2020. Available online: https://ultralytics.com (accessed on 29 July 2025).
- Sohan, M.; Sai Ram, T.; Rami Reddy, C.V. A review on yolov8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Tirunelveli, India, 27–28 June 2023; pp. 529–545. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Cai, Y.; Cui, B.; Deng, H.; Zeng, Z.; Wang, Q.; Lu, D.; Cui, Y.; Tian, Y. Cherry Tomato Detection for Harvesting Using Multimodal Perception and an Improved YOLOv7-Tiny Neural Network. Agronomy 2024, 14, 2320. [Google Scholar] [CrossRef]
- Li, P.; Wen, M.; Zeng, Z.; Tian, Y. Cherry Tomato Bunch and Picking Point Detection for Robotic Harvesting Using an RGB-D Sensor and a StarBL-YOLO Network. Horticulturae 2025, 11, 949. [Google Scholar] [CrossRef]
- Wu, X.; Tian, Y.; Zeng, Z. Leff-yolo: A lightweight cherry tomato detection yolov8 network with enhanced feature fusion. In Proceedings of the International Conference on Intelligent Computing, Ningbo, China, 26–29 July 2025; pp. 474–488. [Google Scholar]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).