
Genetic and Genomic Resources for Soybean Breeding Research

 ,
,  , , ,
, , ,  and
and 
Abstract
1. Introduction
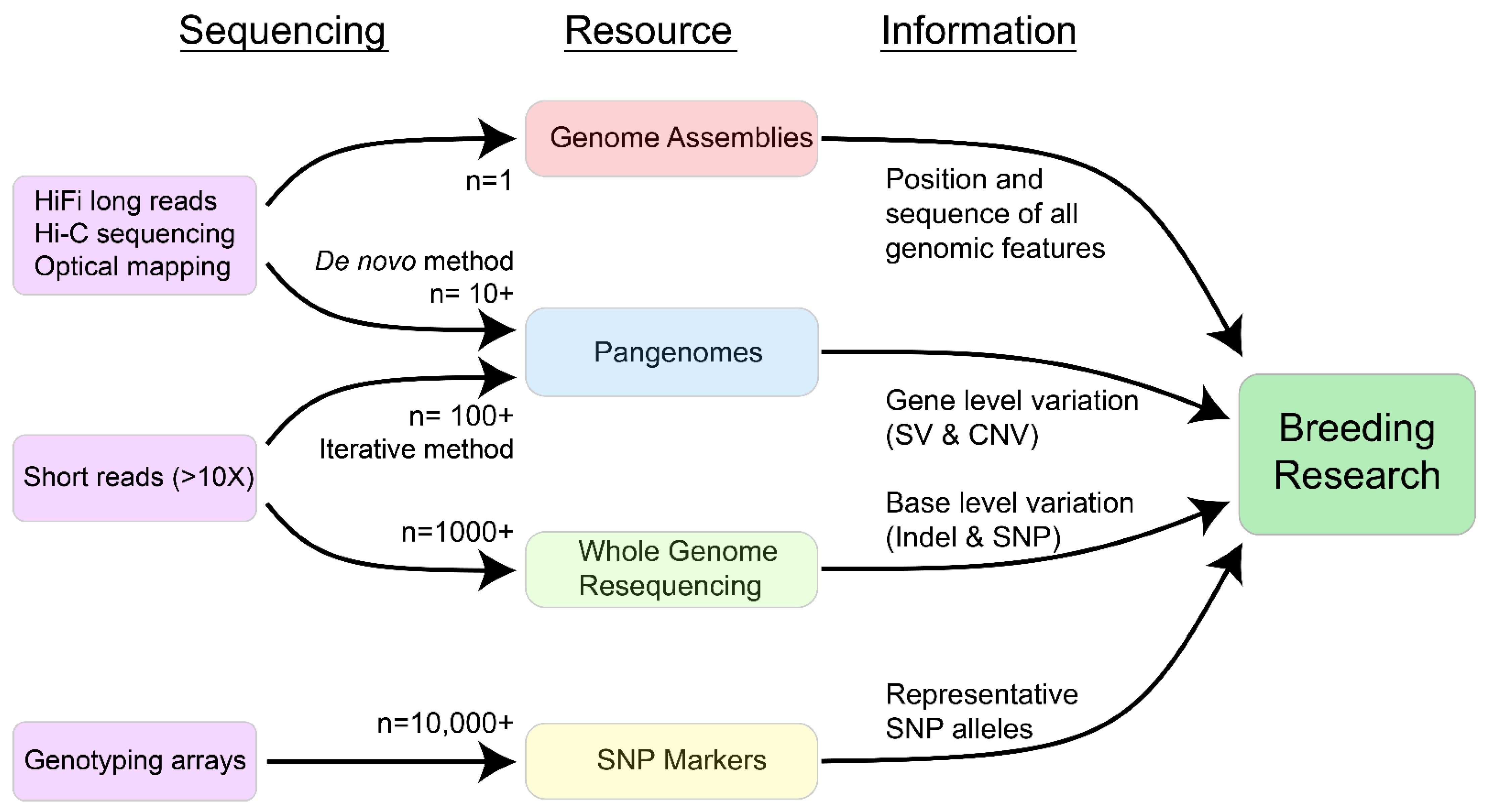
2. Main
2.1. SNP Marker Arrays
2.2. Whole-Genome Resequencing
2.3. Genome Assemblies
2.4. Pangenomes
2.5. Databases and Tools for Explorative Data Analysis
3. Conclusions and Future Perspectives in Breeding
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Doyle, J.J.; Egan, A.N. Dating the origins of polyploidy events. New Phytol. 2010, 186, 73–85. [Google Scholar] [CrossRef] [PubMed]
- Pfeil, B.; Schlueter, J.; Shoemaker, R.; Doyle, J. Placing paleopolyploidy in relation to taxon divergence: A phylogenetic analysis in legumes using 39 gene families. Syst. Biol. 2005, 54, 441–454. [Google Scholar] [CrossRef] [PubMed]
- Schmutz, J.; Cannon, S.B.; Schlueter, J.; Ma, J.; Mitros, T.; Nelson, W.; Hyten, D.L.; Song, Q.; Thelen, J.J.; Cheng, J.; et al. Genome sequence of the palaeopolyploid soybean. Nature 2010, 463, 178–183. [Google Scholar] [CrossRef] [PubMed]
- Cannon, S.B.; Shoemaker, R.C. Evolutionary and comparative analyses of the soybean genome. Breed. Sci. 2012, 61, 437–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Liu, S.; Wang, Z.; Yuan, Y.; Zhang, Z.; Liang, Q.; Yang, X.; Duan, Z.; Liu, Y.; Kong, F.; et al. Progress in soybean functional genomics over the past decade. Plant Biotechnol. J. 2022, 20, 256–282. [Google Scholar] [CrossRef]
- Syvänen, A.C. Toward genome-wide SNP genotyping. Nat. Genet. 2005, 37, S5–S10. [Google Scholar] [CrossRef]
- Song, Q.; Hyten, D.L.; Jia, G.; Quigley, C.V.; Fickus, E.W.; Nelson, R.L.; Cregan, P.B. Development and Evaluation of SoySNP50K, a High-Density Genotyping Array for Soybean. PLoS ONE 2013, 8, e54985. [Google Scholar] [CrossRef]
- Song, Q.; Hyten, D.L.; Jia, G.; Quigley, C.V.; Fickus, E.W.; Nelson, R.L.; Cregan, P.B. Fingerprinting Soybean Germplasm and Its Utility in Genomic Research. G3 Genes|Genomes|Genetics 2015, 5, 1999–2006. [Google Scholar] [CrossRef]
- Leamy, L.J.; Zhang, H.; Li, C.; Chen, C.Y.; Song, B.-H. A genome-wide association study of seed composition traits in wild soybean (Glycine soja). BMC Genom. 2017, 18, 18. [Google Scholar] [CrossRef]
- Bandillo, N.; Jarquin, D.; Song, Q.; Nelson, R.; Cregan, P.; Specht, J.; Lorenz, A. A Population Structure and Genome-Wide Association Analysis on the USDA Soybean Germplasm Collection. Plant Genome 2015, 8. [Google Scholar] [CrossRef]
- Hwang, E.-Y.; Song, Q.; Jia, G.; Specht, J.E.; Hyten, D.L.; Costa, J.; Cregan, P.B. A genome-wide association study of seed protein and oil content in soybean. BMC Genom. 2014, 15. [Google Scholar] [CrossRef] [PubMed]
- Patil, G.; Do, T.; Vuong, T.D.; Valliyodan, B.; Lee, J.-D.; Chaudhary, J.; Shannon, J.G.; Nguyen, H.T. Genomic-assisted haplotype analysis and the development of high-throughput SNP markers for salinity tolerance in soybean. Sci. Rep. 2016, 6, 19199. [Google Scholar] [CrossRef] [PubMed]
- Sharmin, R.A.; Karikari, B.; Chang, F.; Al Amin, G.M.; Bhuiyan, M.R.; Hina, A.; Lv, W.; Chunting, Z.; Begum, N.; Zhao, T. Genome-wide association study uncovers major genetic loci associated with seed flooding tolerance in soybean. BMC Plant Biol. 2021, 21, 497. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Mozzoni, L.A.; Moseley, D.; Hummer, W.; Ye, H.; Chen, P.; Shannon, G.; Nguyen, H. Genome-wide association mapping of flooding tolerance in soybean. Mol. Breed. 2019, 40, 4. [Google Scholar] [CrossRef]
- Wen, Z.; Tan, R.; Yuan, J.; Bales, C.; Du, W.; Zhang, S.; Chilvers, M.I.; Schmidt, C.; Song, Q.; Cregan, P.B.; et al. Genome-wide association mapping of quantitative resistance to sudden death syndrome in soybean. BMC Genom. 2014, 15, 809. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, A.; Mueller, D.S.; Singh, A.K. Genome-wide association and epistasis studies unravel the genetic architecture of sudden death syndrome resistance in soybean. Plant J. 2015, 84, 1124–1136. [Google Scholar] [CrossRef]
- Lee, Y.-G.; Jeong, N.; Kim, J.H.; Lee, K.; Kim, K.H.; Pirani, A.; Ha, B.-K.; Kang, S.-T.; Park, B.-S.; Moon, J.-K.; et al. Development, validation and genetic analysis of a large soybean SNP genotyping array. Plant J. 2015, 81, 625–636. [Google Scholar] [CrossRef]
- Wang, J.; Chu, S.; Zhang, H.; Zhu, Y.; Cheng, H.; Yu, D. Development and application of a novel genome-wide SNP array reveals domestication history in soybean. Sci. Rep. 2016, 6, 20728. [Google Scholar] [CrossRef]
- Saleem, A.; Muylle, H.; Aper, J.; Ruttink, T.; Wang, J.; Yu, D.; Roldán-Ruiz, I. A Genome-Wide Genetic Diversity Scan Reveals Multiple Signatures of Selection in a European Soybean Collection Compared to Chinese Collections of Wild and Cultivated Soybean Accessions. Front. Plant Sci. 2021, 12. [Google Scholar] [CrossRef]
- Jeong, S.-C.; Moon, J.-K.; Park, S.-K.; Kim, M.-S.; Lee, K.; Lee, S.R.; Jeong, N.; Choi, M.S.; Kim, N.; Kang, S.-T.; et al. Genetic diversity patterns and domestication origin of soybean. Theor. Appl. Genet. 2019, 132, 1179–1193. [Google Scholar] [CrossRef]
- Jeong, N.; Kim, K.-S.; Jeong, S.; Kim, J.-Y.; Park, S.-K.; Lee, J.S.; Jeong, S.-C.; Kang, S.-T.; Ha, B.-K.; Kim, D.-Y.; et al. Korean soybean core collection: Genotypic and phenotypic diversity population structure and genome-wide association study. PLoS ONE 2019, 14, e0224074. [Google Scholar] [CrossRef] [PubMed]
- Poland, J.; Endelman, J.; Dawson, J.; Rutkoski, J.; Wu, S.; Manes, Y.; Dreisigacker, S.; Crossa, J.; Sánchez-Villeda, H.; Sorrells, M.; et al. Genomic Selection in Wheat Breeding using Genotyping-by-Sequencing. Plant Genome 2012, 5. [Google Scholar] [CrossRef]
- Zhang, J.; Song, Q.; Cregan, P.B.; Jiang, G.L. Genome-wide association study, genomic prediction and marker-assisted selection for seed weight in soybean (Glycine max). Theor. Appl. Genet. 2016, 129, 117–130. [Google Scholar] [CrossRef] [PubMed]
- Beche, E.; Gillman, J.D.; Song, Q.; Nelson, R.; Beissinger, T.; Decker, J.; Shannon, G.; Scaboo, A.M. Genomic prediction using training population design in interspecific soybean populations. Mol. Breed. 2021, 41, 15. [Google Scholar] [CrossRef]
- Song, Q.; Yan, L.; Quigley, C.; Fickus, E.; Wei, H.; Chen, L.; Dong, F.; Araya, S.; Liu, J.; Hyten, D.; et al. Soybean BARCSoySNP6K: An assay for soybean genetics and breeding research. Plant J. 2020, 104, 800–811. [Google Scholar] [CrossRef] [PubMed]
- Contreras-Soto, R.I.; de Oliveira, M.B.; Costenaro-da-Silva, D.; Scapim, C.A.; Schuster, I. Population structure, genetic relatedness and linkage disequilibrium blocks in cultivars of tropical soybean (Glycine max). Euphytica 2017, 213, 173. [Google Scholar] [CrossRef]
- Liu, Z.; Li, H.; Wen, Z.; Fan, X.; Li, Y.; Guan, R.; Guo, Y.; Wang, S.; Wang, D.; Qiu, L. Comparison of Genetic Diversity between Chinese and American Soybean (Glycine max (L.)) Accessions Revealed by High-Density SNPs. Front. Plant Sci. 2017, 8. [Google Scholar] [CrossRef]
- Happ, M.M.; Wang, H.; Graef, G.L.; Hyten, D.L. Generating High Density, Low Cost Genotype Data in Soybean [Glycine max (L.) Merr.]. G3 (Bethesda) 2019, 9, 2153–2160. [Google Scholar] [CrossRef]
- Kim, M.-S.; Lozano, R.; Kim, J.H.; Bae, D.N.; Kim, S.-T.; Park, J.-H.; Choi, M.S.; Kim, J.; Ok, H.-C.; Park, S.-K.; et al. The patterns of deleterious mutations during the domestication of soybean. Nat. Commun. 2021, 12, 97. [Google Scholar] [CrossRef]
- Torkamaneh, D.; Laroche, J.; Valliyodan, B.; O’Donoughue, L.; Cober, E.; Rajcan, I.; Vilela Abdelnoor, R.; Sreedasyam, A.; Schmutz, J.; Nguyen, H.T.; et al. Soybean (Glycine max) Haplotype Map (GmHapMap): A universal resource for soybean translational and functional genomics. Plant Biotechnol. J. 2021, 19, 324–334. [Google Scholar] [CrossRef]
- Xu, X.; Bai, G. Whole-genome resequencing: Changing the paradigms of SNP detection, molecular mapping and gene discovery. Mol. Breed. 2015, 35, 33. [Google Scholar] [CrossRef]
- Huang, X.; Feng, Q.; Qian, Q.; Zhao, Q.; Wang, L.; Wang, A.; Guan, J.; Fan, D.; Weng, Q.; Huang, T.; et al. High-throughput genotyping by whole-genome resequencing. Genome Res. 2009, 19, 1068–1076. [Google Scholar] [CrossRef] [PubMed]
- Cook, D.E.; Lee, T.G.; Guo, X.; Melito, S.; Wang, K.; Bayless, A.M.; Wang, J.; Hughes, T.J.; Willis, D.K.; Clemente, T.E.; et al. Copy Number Variation of Multiple Genes at Rhg1 Mediates Nematode Resistance in Soybean. Science 2012, 338, 1206–1209. [Google Scholar] [CrossRef] [PubMed]
- Lam, H.-M.; Xu, X.; Liu, X.; Chen, W.; Yang, G.; Wong, F.-L.; Li, M.-W.; He, W.; Qin, N.; Wang, B.; et al. Resequencing of 31 wild and cultivated soybean genomes identifies patterns of genetic diversity and selection. Nat. Genet. 2010, 42, 1053–1059. [Google Scholar] [CrossRef]
- Qi, X.; Li, M.-W.; Xie, M.; Liu, X.; Ni, M.; Shao, G.; Song, C.; Kay-Yuen Yim, A.; Tao, Y.; Wong, F.-L.; et al. Identification of a novel salt tolerance gene in wild soybean by whole-genome sequencing. Nat. Commun. 2014, 5, 4340. [Google Scholar] [CrossRef]
- Zhou, Z.; Jiang, Y.; Wang, Z.; Gou, Z.; Lyu, J.; Li, W.; Yu, Y.; Shu, L.; Zhao, Y.; Ma, Y.; et al. Resequencing 302 wild and cultivated accessions identifies genes related to domestication and improvement in soybean. Nat. Biotechnol. 2015, 33, 408–414. [Google Scholar] [CrossRef]
- Fang, C.; Ma, Y.; Yuan, L.; Wang, Z.; Yang, R.; Zhou, Z.; Liu, T.; Tian, Z. Chloroplast DNA Underwent Independent Selection from Nuclear Genes during Soybean Domestication and Improvement. J. Genet. Genom. 2016, 43, 217–221. [Google Scholar] [CrossRef]
- Maldonado dos Santos, J.V.; Valliyodan, B.; Joshi, T.; Khan, S.M.; Liu, Y.; Wang, J.; Vuong, T.D.; Oliveira, M.F.d.; Marcelino-Guimarães, F.C.; Xu, D.; et al. Evaluation of genetic variation among Brazilian soybean cultivars through genome resequencing. BMC Genom. 2016, 17, 110. [Google Scholar] [CrossRef]
- Fang, C.; Ma, Y.; Wu, S.; Liu, Z.; Wang, Z.; Yang, R.; Hu, G.; Zhou, Z.; Yu, H.; Zhang, M.; et al. Genome-wide association studies dissect the genetic networks underlying agronomical traits in soybean. Genome Biol. 2017, 18, 161. [Google Scholar] [CrossRef]
- Yang, C.; Yan, J.; Jiang, S.; Li, X.; Min, H.; Wang, X.; Hao, D. Resequencing 250 Soybean Accessions: New Insights into Genes Associated with Agronomic Traits and Genetic Networks. Genom. Proteom. Bioinform. 2021. [Google Scholar] [CrossRef]
- Torkamaneh, D.; Laroche, J.; Tardivel, A.; O’Donoughue, L.; Cober, E.; Rajcan, I.; Belzile, F. Comprehensive description of genomewide nucleotide and structural variation in short-season soya bean. Plant Biotechnol. J. 2018, 16, 749–759. [Google Scholar] [CrossRef] [PubMed]
- Valliyodan, B.; Brown, A.V.; Wang, J.; Patil, G.; Liu, Y.; Otyama, P.I.; Nelson, R.T.; Vuong, T.; Song, Q.; Musket, T.A.; et al. Genetic variation among 481 diverse soybean accessions, inferred from genomic re-sequencing. Sci. Data 2021, 8, 50. [Google Scholar] [CrossRef] [PubMed]
- Kajiya-Kanegae, H.; Nagasaki, H.; Kaga, A.; Hirano, K.; Ogiso-Tanaka, E.; Matsuoka, M.; Ishimori, M.; Ishimoto, M.; Hashiguchi, M.; Tanaka, H.; et al. Whole-genome sequence diversity and association analysis of 198 soybean accessions in mini-core collections. DNA Res. 2021, 28. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Du, H.; Li, P.; Shen, Y.; Peng, H.; Liu, S.; Zhou, G.-A.; Zhang, H.; Liu, Z.; Shi, M. Pan-genome of wild and cultivated soybeans. Cell 2020, 182, 162–176. [Google Scholar] [CrossRef] [PubMed]
- Arumuganathan, K.; Earle, E. Nuclear DNA content of some important plant species. Plant Mol. Biol. Report. 1991, 9, 208–218. [Google Scholar] [CrossRef]
- Bennett, M.; Leitch, I. Angiosperm DNA C-values database (release 8.0, Dec. 2012). Available online: http://data.kew.org/cvalues (accessed on 27 February 2022).
- Song, Q.; Jenkins, J.; Jia, G.; Hyten, D.L.; Pantalone, V.; Jackson, S.A.; Schmutz, J.; Cregan, P.B. Construction of high resolution genetic linkage maps to improve the soybean genome sequence assembly Glyma1.01. BMC Genom. 2016, 17, 33. [Google Scholar] [CrossRef]
- Valliyodan, B.; Cannon, S.B.; Bayer, P.E.; Shu, S.; Brown, A.V.; Ren, L.; Jenkins, J.; Chung, C.Y.-L.; Chan, T.-F.; Daum, C.G.; et al. Construction and comparison of three reference-quality genome assemblies for soybean. Plant J. 2019, 100, 1066–1082. [Google Scholar] [CrossRef]
- Shen, Y.; Liu, J.; Geng, H.; Zhang, J.; Liu, Y.; Zhang, H.; Xing, S.; Du, J.; Ma, S.; Tian, Z. De novo assembly of a Chinese soybean genome. Sci. China Life Sci. 2018, 61, 871–884. [Google Scholar] [CrossRef]
- Shen, Y.; Du, H.; Liu, Y.; Ni, L.; Wang, Z.; Liang, C.; Tian, Z. Update soybean Zhonghuang 13 genome to a golden reference. Sci. China Life Sci. 2019, 62, 1257–1260. [Google Scholar] [CrossRef]
- Li, Y.-h.; Zhou, G.; Ma, J.; Jiang, W.; Jin, L.-g.; Zhang, Z.; Guo, Y.; Zhang, J.; Sui, Y.; Zheng, L.; et al. De novo assembly of soybean wild relatives for pan-genome analysis of diversity and agronomic traits. Nat. Biotechnol. 2014, 32, 1045–1052. [Google Scholar] [CrossRef]
- Xie, M.; Chung, C.Y.-L.; Li, M.-W.; Wong, F.-L.; Wang, X.; Liu, A.; Wang, Z.; Leung, A.K.-Y.; Wong, T.-H.; Tong, S.-W.; et al. A reference-grade wild soybean genome. Nat. Commun. 2019, 10, 1216. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Chang, S.; Hartman, G.L.; Domier, L.L. Assembly and annotation of a draft genome sequence for Glycine latifolia, a perennial wild relative of soybean. Plant J. 2018, 95, 71–85. [Google Scholar] [CrossRef] [PubMed]
- Hartman, G.; Wang, T.; Hymowitz, T. Sources of resistance to soybean rust in perennial Glycine species. Plant Dis. 1992, 76, 396–399. [Google Scholar] [CrossRef]
- Hartman, G.; Gardner, M.; Hymowitz, T.; Naidoo, G. Evaluation of perennial Glycine species for resistance to soybean fungal pathogens that cause Sclerotinia stem rot and sudden death syndrome. Crop Sci. 2000, 40, 545–549. [Google Scholar] [CrossRef]
- Horlock, C.M.; Teakle, D.; Jones, R. Natural infection of the native pasture legume, Glycine latifolia, by a mosaic virus in Queensland. Australas. Plant Pathol. 1997, 26, 115–116. [Google Scholar] [CrossRef]
- Wen, L.; Yuan, C.; Herman, T.; Hartman, G. Accessions of perennial Glycine species with resistance to multiple types of soybean cyst nematode (Heterodera glycines). Plant Dis. 2017, 101, 1201–1206. [Google Scholar] [CrossRef]
- Kim, M.-S.; Lee, T.; Baek, J.; Kim, J.H.; Kim, C.; Jeong, S.-C. Genome Assembly of the Popular Korean Soybean Cultivar Hwangkeum. bioRxiv 2021. [Google Scholar] [CrossRef]
- Bayer, P.E.; Golicz, A.A.; Scheben, A.; Batley, J.; Edwards, D. Plant pan-genomes are the new reference. Nat. Plants 2020, 6, 914–920. [Google Scholar] [CrossRef]
- Golicz, A.A.; Bayer, P.E.; Barker, G.C.; Edger, P.P.; Kim, H.; Martinez, P.A.; Chan, C.K.K.; Severn-Ellis, A.; McCombie, W.R.; Parkin, I.A.P.; et al. The pangenome of an agronomically important crop plant Brassica oleracea. Nat. Commun. 2016, 7, 13390. [Google Scholar] [CrossRef]
- Tettelin, H.; Masignani, V.; Cieslewicz, M.J.; Donati, C.; Medini, D.; Ward, N.L.; Angiuoli, S.V.; Crabtree, J.; Jones, A.L.; Durkin, A.S. Genome analysis of multiple pathogenic isolates of Streptococcus agalactiae: Implications for the microbial “pan-genome”. Proc. Natl. Acad. Sci. USA 2005, 102, 13950–13955. [Google Scholar] [CrossRef]
- Rijzaani, H.; Bayer, P.E.; Rouard, M.; Doležel, J.; Batley, J.; Edwards, D. The pangenome of banana highlights differences between genera and genomes. Plant Genome 2021, e20100. [Google Scholar] [CrossRef] [PubMed]
- Ruperao, P.; Thirunavukkarasu, N.; Gandham, P.; Selvanayagam, S.; Govindaraj, M.; Nebie, B.; Manyasa, E.; Gupta, R.; Das, R.R.; Odeny, D.A. Sorghum Pan-Genome Explores the Functional Utility for Genomic-Assisted Breeding to Accelerate the Genetic Gain. Front. Plant Sci. 2021, 12, 963. [Google Scholar] [CrossRef] [PubMed]
- Montenegro, J.D.; Golicz, A.A.; Bayer, P.E.; Hurgobin, B.; Lee, H.; Chan, C.K.K.; Visendi, P.; Lai, K.; Doležel, J.; Batley, J. The pangenome of hexaploid bread wheat. Plant J. 2017, 90, 1007–1013. [Google Scholar] [CrossRef] [PubMed]
- Hurgobin, B.; Golicz, A.A.; Bayer, P.E.; Chan, C.K.K.; Tirnaz, S.; Dolatabadian, A.; Schiessl, S.V.; Samans, B.; Montenegro, J.D.; Parkin, I.A. Homoeologous exchange is a major cause of gene presence/absence variation in the amphidiploid Brassica napus. Plant Biotechnol. J. 2018, 16, 1265–1274. [Google Scholar] [CrossRef]
- Bayer, P.E.; Scheben, A.; Golicz, A.A.; Yuan, Y.; Faure, S.; Lee, H.; Chawla, H.S.; Anderson, R.; Bancroft, I.; Raman, H.; et al. Modelling of gene loss propensity in the pangenomes of three Brassica species suggests different mechanisms between polyploids and diploids. Plant Biotechnol. J. 2021. [Google Scholar] [CrossRef] [PubMed]
- Varshney, R.K.; Roorkiwal, M.; Sun, S.; Bajaj, P.; Chitikineni, A.; Thudi, M.; Singh, N.P.; Du, X.; Upadhyaya, H.D.; Khan, A.W.; et al. A chickpea genetic variation map based on the sequencing of 3366 genomes. Nature 2021, 599, 622–627. [Google Scholar] [CrossRef]
- Gao, L.; Gonda, I.; Sun, H.; Ma, Q.; Bao, K.; Tieman, D.M.; Burzynski-Chang, E.A.; Fish, T.L.; Stromberg, K.A.; Sacks, G.L. The tomato pan-genome uncovers new genes and a rare allele regulating fruit flavor. Nat. Genet. 2019, 51, 1044–1051. [Google Scholar] [CrossRef]
- Hübner, S.; Bercovich, N.; Todesco, M.; Mandel, J.R.; Odenheimer, J.; Ziegler, E.; Lee, J.S.; Baute, G.J.; Owens, G.L.; Grassa, C.J.; et al. Sunflower pan-genome analysis shows that hybridization altered gene content and disease resistance. Nat. Plants 2019, 5, 54–62. [Google Scholar] [CrossRef]
- Zhao, J.; Bayer, P.E.; Ruperao, P.; Saxena, R.K.; Khan, A.W.; Golicz, A.A.; Nguyen, H.T.; Batley, J.; Edwards, D.; Varshney, R.K. Trait associations in the pangenome of pigeon pea (Cajanus cajan). Plant Biotechnol. J. 2020, 18, 1946–1954. [Google Scholar] [CrossRef]
- Li, J.; Yuan, D.; Wang, P.; Wang, Q.; Sun, M.; Liu, Z.; Si, H.; Xu, Z.; Ma, Y.; Zhang, B.; et al. Cotton pan-genome retrieves the lost sequences and genes during domestication and selection. Genome Biol. 2021, 22, 119. [Google Scholar] [CrossRef]
- Zhao, Q.; Feng, Q.; Lu, H.; Li, Y.; Wang, A.; Tian, Q.; Zhan, Q.; Lu, Y.; Zhang, L.; Huang, T.; et al. Pan-genome analysis highlights the extent of genomic variation in cultivated and wild rice. Nat. Genet. 2018, 50, 278–284. [Google Scholar] [CrossRef] [PubMed]
- Garrison, E.; Sirén, J.; Novak, A.M.; Hickey, G.; Eizenga, J.M.; Dawson, E.T.; Jones, W.; Garg, S.; Markello, C.; Lin, M.F. Variation graph toolkit improves read mapping by representing genetic variation in the reference. Nat. Biotechnol. 2018, 36, 875–879. [Google Scholar] [CrossRef] [PubMed]
- Torkamaneh, D.; Lemay, M.-A.; Belzile, F. The pan-genome of the cultivated soybean (PanSoy) reveals an extraordinarily conserved gene content. Plant Biotechnol. J. 2021. [Google Scholar] [CrossRef] [PubMed]
- Bayer, P.E.; Valliyodan, B.; Hu, H.; Marsh, J.I.; Yuan, Y.; Vuong, T.D.; Patil, G.; Song, Q.; Batley, J.; Varshney, R.K. Sequencing the USDA core soybean collection reveals gene loss during domestication and breeding. Plant Genome 2021, e20109. [Google Scholar] [CrossRef] [PubMed]
- Hu, Z.; Sun, C.; Lu, K.-c.; Chu, X.; Zhao, Y.; Lu, J.; Shi, J.; Wei, C. EUPAN enables pan-genome studies of a large number of eukaryotic genomes. Bioinformatics 2017, 33, 2408–2409. [Google Scholar] [CrossRef] [PubMed]
- Hyten, D.L.; Song, Q.; Zhu, Y.; Choi, I.-Y.; Nelson, R.L.; Costa, J.M.; Specht, J.E.; Shoemaker, R.C.; Cregan, P.B. Impacts of genetic bottlenecks on soybean genome diversity. Proc. Natl. Acad. Sci. USA 2006, 103, 16666–16671. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, Y.; Wang, X.; Li, X.; Hu, J.; Fan, L.; Landis, J.B.; Cannon, S.B.; Grimwood, J.; Schmutz, J.; Jackson, S.A.; et al. Phylogenomics of the genus Glycine sheds light on polyploid evolution and life-strategy transition. Nat. Plants 2022, 8, 233–244. [Google Scholar] [CrossRef]
- Joshi, T.; Patil, K.; Fitzpatrick, M.R.; Franklin, L.D.; Yao, Q.; Cook, J.R.; Wang, Z.; Libault, M.; Brechenmacher, L.; Valliyodan, B.; et al. Soybean Knowledge Base (SoyKB): A web resource for soybean translational genomics. BMC Genom. 2012, 13, S15. [Google Scholar] [CrossRef]
- Brown, A.V.; Conners, S.I.; Huang, W.; Wilkey, A.P.; Grant, D.; Weeks, N.T.; Cannon, S.B.; Graham, M.A.; Nelson, R.T. A new decade and new data at SoyBase, the USDA-ARS soybean genetics and genomics database. Nucleic Acids Res. 2021, 49, D1496–D1501. [Google Scholar] [CrossRef]
- Karikari, B.; Wang, Z.; Zhou, Y.; Yan, W.; Feng, J.; Zhao, T. Identification of quantitative trait nucleotides and candidate genes for soybean seed weight by multiple models of genome-wide association study. BMC Plant Biol. 2020, 20, 404. [Google Scholar] [CrossRef]
- Rolling, W.; Lake, R.; Dorrance, A.E.; McHale, L.K. Genome-wide association analyses of quantitative disease resistance in diverse sets of soybean [Glycine max (L.) Merr.] plant introductions. PLoS ONE 2020, 15, e0227710. [Google Scholar] [CrossRef] [PubMed]
- Klein, A.; Houtin, H.; Rond-Coissieux, C.; Naudet-Huart, M.; Touratier, M.; Marget, P.; Burstin, J. Meta-analysis of QTL reveals the genetic control of yield-related traits and seed protein content in pea. Sci. Rep. 2020, 10, 15925. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Zhang, Z.; Wei, J.; Ling, Y.; Xu, W.; Su, Z. SFGD: A comprehensive platform for mining functional information from soybean transcriptome data and its use in identifying acyl-lipid metabolism pathways. BMC Genom. 2014, 15, 271. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Gao, Y.; Yang, Z.; Yang, W.; Yang, Y.; Gong, J.; Yang, Q.-Y.; Niu, X. Plant-ImputeDB: An integrated multiple plant reference panel database for genotype imputation. Nucleic Acids Res. 2021, 49, D1480–D1488. [Google Scholar] [CrossRef]
- Alkharouf, N.W.; Matthews, B.F. SGMD: The Soybean Genomics and Microarray Database. Nucleic Acids Res. 2004, 32, D398–D400. [Google Scholar] [CrossRef][Green Version]
- Du, J.; Grant, D.; Tian, Z.; Nelson, R.T.; Zhu, L.; Shoemaker, R.C.; Ma, J. SoyTEdb: A comprehensive database of transposable elements in the soybean genome. BMC Genom. 2010, 11, 113. [Google Scholar] [CrossRef]
- Katayose, Y.; Kanamori, H.; Shimomura, M.; Ohyanagi, H.; Ikawa, H.; Minami, H.; Shibata, M.; Ito, T.; Kurita, K.; Ito, K.; et al. DaizuBase, an integrated soybean genome database including BAC-based physical maps. Breed. Sci. 2012, 61, 661–664. [Google Scholar] [CrossRef][Green Version]
- Dai, X.; Zhuang, Z.; Boschiero, C.; Dong, Y.; Zhao, P.X. LegumeIP V3: From models to crops—an integrative gene discovery platform for translational genomics in legumes. Nucleic Acids Res. 2021, 49, D1472–D1479. [Google Scholar] [CrossRef]
- Grant, D.; Nelson, R.T.; Cannon, S.B.; Shoemaker, R.C. SoyBase, the USDA-ARS soybean genetics and genomics database. Nucleic Acids Res. 2010, 38, D843–D846. [Google Scholar] [CrossRef]
- Goodstein, D.M.; Shu, S.; Howson, R.; Neupane, R.; Hayes, R.D.; Fazo, J.; Mitros, T.; Dirks, W.; Hellsten, U.; Putnam, N.; et al. Phytozome: A comparative platform for green plant genomics. Nucleic Acids Res. 2012, 40, D1178–D1186. [Google Scholar] [CrossRef]
- Ma, X.; Yan, H.; Yang, J.; Liu, Y.; Li, Z.; Sheng, M.; Cao, Y.; Yu, X.; Yi, X.; Xu, W.; et al. PlantGSAD: A comprehensive gene set annotation database for plant species. Nucleic Acids Res. 2021. [Google Scholar] [CrossRef] [PubMed]
- Dong, Q.; Schlueter, S.D.; Brendel, V. PlantGDB, plant genome database and analysis tools. Nucleic Acids Res. 2004, 32, D354–D359. [Google Scholar] [CrossRef]
- Deshmukh, R.; Rana, N.; Liu, Y.; Zeng, S.; Agarwal, G.; Sonah, H.; Varshney, R.; Joshi, T.; Patil, G.B.; Nguyen, H.T. Soybean transporter database: A comprehensive database for identification and exploration of natural variants in soybean transporter genes. Physiol. Plant. 2021, 171, 756–770. [Google Scholar] [CrossRef] [PubMed]
- Jin, J.; Lu, P.; Xu, Y.; Tao, J.; Li, Z.; Wang, S.; Yu, S.; Wang, C.; Xie, X.; Gao, J.; et al. PCMDB: A curated and comprehensive resource of plant cell markers. Nucleic Acids Res. 2021. [Google Scholar] [CrossRef] [PubMed]
- Ha, J.; Jeon, H.H.; Woo, D.U.; Lee, Y.; Park, H.; Lee, J.; Kang, Y.J. Soybean-VCF2Genomes: A database to identify the closest accession in soybean germplasm collection. BMC Bioinform. 2019, 20, 384. [Google Scholar] [CrossRef] [PubMed]
- Zeng, S.; Škrabišová, M.; Lyu, Z.; Chan, Y.O.; Bilyeu, K.; Joshi, T. SNPViz v2.0: A web-based tool for enhanced haplotype analysis using large scale resequencing datasets and discovery of phenotypes causative gene using allelic variations. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Korea, 16–19 December 2020; pp. 1408–1415. [Google Scholar]
- Xu, Y.; Guo, M.; Liu, X.; Wang, C.; Liu, Y. SoyFN: A knowledge database of soybean functional networks. Database 2014, 2014. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.; Hwang, S.; Lee, I. SoyNet: A database of co-functional networks for soybean Glycine max. Nucleic Acids Research 2017, 45, D1082–D1089. [Google Scholar] [CrossRef]
- Wang, J.; Hossain, M.S.; Lyu, Z.; Schmutz, J.; Stacey, G.; Xu, D.; Joshi, T. SoyCSN: Soybean context-specific network analysis and prediction based on tissue-specific transcriptome data. Plant Direct 2019, 3, e00167. [Google Scholar] [CrossRef]
- Ruprecht, C.; Proost, S.; Hernandez-Coronado, M.; Ortiz-Ramirez, C.; Lang, D.; Rensing, S.A.; Becker, J.D.; Vandepoele, K.; Mutwil, M. Phylogenomic analysis of gene co-expression networks reveals the evolution of functional modules. Plant J. 2017, 90, 447–465. [Google Scholar] [CrossRef]
- Tavakolan, M.; Alkharouf, N.W.; Khan, F.H.; Natarajan, S. SoyProDB: A database for the identification of soybean seed proteins. Bioinformation 2013, 9, 165–167. [Google Scholar] [CrossRef]
- Yang, J.; Liu, Y.; Yan, H.; Tian, T.; You, Q.; Zhang, L.; Xu, W.; Su, Z. PlantEAR: Functional Analysis Platform for Plant EAR Motif-Containing Proteins. Front. Genet. 2018, 9. [Google Scholar] [CrossRef] [PubMed]
- Close, T.J.; Wanamaker, S.; Roose, M.L.; Lyon, M. HarvEST. In Plant Bioinformatics: Methods and Protocols; Edwards, D., Ed.; Humana Press: Totowa, NJ, USA, 2007; pp. 161–177. [Google Scholar]
- Ke, T.; Yu, J.; Dong, C.; Mao, H.; Hua, W.; Liu, S. ocsESTdb: A database of oil crop seed EST sequences for comparative analysis and investigation of a global metabolic network and oil accumulation metabolism. BMC Plant Biol. 2015, 15, 19. [Google Scholar] [CrossRef] [PubMed]
- Hisano, H.; Sato, S.; Isobe, S.; Sasamoto, S.; Wada, T.; Matsuno, A.; Fujishiro, T.; Yamada, M.; Nakayama, S.; Nakamura, Y.; et al. Characterization of the Soybean Genome Using EST-derived Microsatellite Markers. DNA Res. 2007, 14, 271–281. [Google Scholar] [CrossRef] [PubMed]
- Umezawa, T.; Sakurai, T.; Totoki, Y.; Toyoda, A.; Seki, M.; Ishiwata, A.; Akiyama, K.; Kurotani, A.; Yoshida, T.; Mochida, K.; et al. Sequencing and Analysis of Approximately 40 000 Soybean cDNA Clones from a Full-Length-Enriched cDNA Library. DNA Res. 2008, 15, 333–346. [Google Scholar] [CrossRef] [PubMed]
- Seethepalli, A.; Guo, H.; Liu, X.; Griffiths, M.; Almtarfi, H.; Li, Z.; Liu, S.; Zare, A.; Fritschi, F.B.; Blancaflor, E.B.; et al. RhizoVision Crown: An Integrated Hardware and Software Platform for Root Crown Phenotyping. Plant Phenomics 2020, 2020, 3074916. [Google Scholar] [CrossRef] [PubMed]
- Seethepalli, A.; York, L. RhizoVision explorer—interactive software for generalized root image analysis designed for everyone. Zenodo 2020. [Google Scholar] [CrossRef]
- Xavier, A.; Hall, B.; Hearst, A.A.; Cherkauer, K.A.; Rainey, K.M. Genetic Architecture of Phenomic-Enabled Canopy Coverage in Glycine max. Genetics 2017, 206, 1081–1089. [Google Scholar] [CrossRef]
- Silva, L.C.C.; da Matta, L.B.; Pereira, G.R.; Bueno, R.D.; Piovesan, N.D.; Cardinal, A.J.; God, P.I.V.G.; Ribeiro, C.; Dal-Bianco, M. Association studies and QTL mapping for soybean oil content and composition. Euphytica 2021, 217, 24. [Google Scholar] [CrossRef]
- Bhat, J.A.; Yu, D. High-throughput NGS-based genotyping and phenotyping: Role in genomics-assisted breeding for soybean improvement. Legume Sci. 2021, 3, e81. [Google Scholar] [CrossRef]
- Freitas Moreira, F.; Rojas de Oliveira, H.; Lopez, M.A.; Abughali, B.J.; Gomes, G.; Cherkauer, K.A.; Brito, L.F.; Rainey, K.M. High-Throughput Phenotyping and Random Regression Models Reveal Temporal Genetic Control of Soybean Biomass Production. Front. Plant Sci. 2021, 12. [Google Scholar] [CrossRef]
- Jaiswal, P.; Avraham, S.; Ilic, K.; Kellogg, E.A.; McCouch, S.; Pujar, A.; Reiser, L.; Rhee, S.Y.; Sachs, M.M.; Schaeffer, M.; et al. Plant Ontology (PO): A controlled vocabulary of plant structures and growth stages. Comp. Funct. Genom. 2005, 6, 388–397. [Google Scholar] [CrossRef] [PubMed]
- Cooper, L.; Meier, A.; Laporte, M.-A.; Elser, J.L.; Mungall, C.; Sinn, B.T.; Cavaliere, D.; Carbon, S.; Dunn, N.A.; Smith, B.; et al. The Planteome database: An integrated resource for reference ontologies, plant genomics and phenomics. Nucleic Acids Res. 2018, 46, D1168–D1180. [Google Scholar] [CrossRef] [PubMed]
- Papoutsoglou, E.A.; Faria, D.; Arend, D.; Arnaud, E.; Athanasiadis, I.N.; Chaves, I.; Coppens, F.; Cornut, G.; Costa, B.V.; Ćwiek-Kupczyńska, H.; et al. Enabling reusability of plant phenomic datasets with MIAPPE 1.1. New Phytol. 2020, 227, 260–273. [Google Scholar] [CrossRef] [PubMed]
- Cortés, A.J.; Blair, M.W. Genotyping by Sequencing and Genome-Environment Associations in Wild Common Bean Predict Widespread Divergent Adaptation to Drought. Front. Plant Sci. 2018, 9, 128. [Google Scholar] [CrossRef]
- Cortés, A.J.; Monserrate, F.A.; Ramírez-Villegas, J.; Madriñán, S.; Blair, M.W. Drought Tolerance in Wild Plant Populations: The Case of Common Beans (Phaseolus vulgaris L.). PLoS ONE 2013, 8, e62898. [Google Scholar] [CrossRef]
- López-Hernández, F.; Cortés, A.J. Last-Generation Genome–Environment Associations Reveal the Genetic Basis of Heat Tolerance in Common Bean (Phaseolus vulgaris L.). Front. Genet. 2019, 10. [Google Scholar] [CrossRef]
- Buitrago-Bitar, M.A.; Cortés, A.J.; López-Hernández, F.; Londoño-Caicedo, J.M.; Muñoz-Florez, J.E.; Muñoz, L.C.; Blair, M.W. Allelic Diversity at Abiotic Stress Responsive Genes in Relationship to Ecological Drought Indices for Cultivated Tepary Bean, Phaseolus acutifolius A. Gray, and Its Wild Relatives. Genes 2021, 12, 556. [Google Scholar] [CrossRef]
- McClean, P.E.; Lavin, M.; Gepts, P.; Jackson, S.A. Phaseolus vulgaris: A Diploid Model for Soybean. In Genetics and Genomics of Soybean; Stacey, G., Ed.; Springer: New York, NY, USA, 2008; pp. 55–76. [Google Scholar]
- Shi, A.; Gepts, P.; Song, Q.; Xiong, H.; Michaels, T.E.; Chen, S. Genome-Wide Association Study and Genomic Prediction for Soybean Cyst Nematode Resistance in USDA Common Bean (Phaseolus vulgaris) Core Collection. Front. Plant Sci. 2021, 12, 624156. [Google Scholar] [CrossRef]
- Cortés, A.J.; López-Hernández, F.; Osorio-Rodriguez, D. Predicting Thermal Adaptation by Looking Into Populations’ Genomic Past. Front. Genet. 2020, 11. [Google Scholar] [CrossRef]
- Schrider, D.R.; Kern, A.D. Supervised Machine Learning for Population Genetics: A New Paradigm. Trends Genet. 2018, 34, 301–312. [Google Scholar] [CrossRef]
- Varshney, R.K.; Bohra, A.; Roorkiwal, M.; Barmukh, R.; Cowling, W.A.; Chitikineni, A.; Lam, H.-M.; Hickey, L.T.; Croser, J.S.; Bayer, P.E.; et al. Fast-forward breeding for a food-secure world. Trends Genet. 2021, 37, 1124–1136. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Data Type | Database | Description | Website | |
|---|---|---|---|---|
| Genome and genetic data | SFGD—Soybean Functional Genomics Database | Integration-friendly genome, transcriptome and protein data for the functional characterization of soybean pathways. Has a dataset, focused on soybean acyl–lipid pathways | http://bioinformatics.cau.edu.cn/SFGD/, accessed on 15 October 2021 | [84] |
| Plant-Impute DB | Database for genotype imputation using high-quality reference panels | https://gong_lab.hzau.edu.cn/Plant_imputeDB/, accessed on 15 October 2021 | [85] | |
| GmHapMap—Haplotype Map | Haplotype map constructed using genome sequence data from 1007 soybean accessions, with 4.3 M SNPs identified | https://soybase.org/projects/SoyBase.C2020.01.php, accessed on 15 October 2021 | [30] | |
| SoyKB—Soybean knowledge base | Soybean data hub with genomic and genetic information linked to external datasets | https://soykb.org/, accessed on 15 October 2021 | [79] | |
| SGMD—Soybean genomics and microarray database | Integrated view of the interaction of soybean with the soybean cyst nematode and contains genomic, EST and microarray data with embedded analytical tools, allowing the correlation of soybean ESTs with their gene expression profiles | https://www.hsls.pitt.edu/obrc/index.php?page=URL1096997457, accessed on 15 October 2021 | [86] | |
| SoyTEdb—Soybean Transposable Element database | Database of transposable elements identified by genetic and physical maps based on the Glyma1.01 assembly | https://www.soybase.org/soytedb/, accessed on 15 October 2021 | [87] | |
| DAIZUbase | Genome visualization and data mining tools (Gbrownse, Unifiedmap, Geneviewer and BLAST) | https://daizubase.daizu.dna.affrc.go.jp/, accessed on 15 October 2021 | [88] | |
| LegumeIP V3 | Translational genomics, offering tools to analyze gene expression data and pathway analysis | https://www.zhaolab.org/LegumeIP/gdp/, accessed on 15 October 2021 | [89] | |
| SoyBase | Integrates genetic and genomic data, including QTLs and GWAS for several hybrid lines. Facilitates BLAST using soybean pangenome of all cultivars within the database | https://soybase.org/soyseq/, accessed on 15 October 2021 | [80,90] | |
| Legume Federation | Visualization of genotype comparison, genome context viewer, gene annotation and visualiz+ation, synteny, QTLS and genetic markers search. SNPs and GWAS results available | https://www.legumefederation.org/en/tools/, accessed on 15 October 2021 | ||
| Phytozome | Up-to-date repository of genome assemblies and annotation. Useful BLAST functionality between species | http://www.phytozome.net/soybean, accessed on 15 October 2021 | [91] | |
| PlantGSAD v2 | Numerous gene set annotations, including metabolic pathways and customized SEA annotations and integrated visualization features | http://systemsbiology.cau.edu.cn/PlantGSEAv2/, accessed on 15 October 2021 | [92] | |
| PlantGDB | Soybean genome and annotation tools for comparative genomics | https://www.plantgdb.org/GmGDB/, accessed on 15 October 2021 | [93] | |
| SoyTB—Transporter | Comparative analysis of transporter genes in 47 plant genomes and transcriptomes | http://artemis.cyverse.org/soykb_dev/SoyTD/, accessed on 15 October 2021 | [94] | |
| PCMDB—Plant cell markers database | Cell markers from 6 plant species to label 263 cell types across 22 tissues | www.tobaccodb.org/pcmdb/, accessed on 15 October 2021 | [95] | |
| SoyVCF 2 Genomes | Compares the user-supplied genomic data in the database for the identification of the closest soybean relative in a 222 germplasm collection | http://pgl.gnu.ac.kr/soy_vcf2genome/, accessed on 15 October 2021 | [96] | |
| SNPViz v2.0 | Web-based tool for the visualization of large-scale haplotype blocks with detailed SNPs and indels grouped by their chromosomal coordinates, along with their overlapping gene models, phenotype to genotype accuracies, Gene Ontology (GO) annotations, protein families (Pfam) annotations, genomic variant annotations and their functional effects | http://soykb.org/SNPViz2/, accessed on 15 October 2021 | [97] | |
| Functional networks, and co-expression data | SoyFN—Soybean Functional Networks | Gene and miRNA interaction database built into functional networks, with KEGG pathways and Gene Ontology annotations | https://nclab.hit.edu.cn/SoyFN, accessed on 15 October 2021 | [98] |
| SoyNet | Searchable network of soybean genes for network-based functional predictions | https://www.inetbio.org/soynet/, accessed on 15 October 2021 | [99] | |
| SoyCSN—context-specific network | Computational pipeline to analyze, annotate, retrieve and visualize context-specific network at the transcriptome and interactome levels—based on the Soybean Gene Atlas project | http://soykb.org/SoyCSN, accessed on 15 October 2021 | [100] | |
| PlaNet | Platform of web-based tools for the visualization of whole-genome co-expression networks in multiple species, including soybean | http://aranet.mpimp-golm.mpg.de/, accessed on 15 October 2021 | [101] | |
| Protein-related data | SoyProDB—Soybean Seed Protein Database | Identification of soybean seed proteins from 2D-PAGE gels | http://bioinformatics.towson.edu/Soybean_Seed_Proteins_2D_Gel_DB/Home.aspx, accessed on 15 October 2021 | [102] |
| PlantEAR | Database of EAR motif-containing proteins across 71 species | http://structuralbiology.cau.edu.cn/plantEAR/, accessed on 15 October 2021 | [103] | |
| Expressed sequence tag (EST) | HarvEST | EST data filtered using the soybean genome assembly Glyma1 | https://harvest.ucr.edu/, accessed on 15 October 2021 | [104] |
| OcsESTdb—oil crop seed EST database | EST libraries of four oilseed species with annotated sequences | http://ocri-genomics.org/ocsESTdb/, accessed on 15 October 2021 | [105] | |
| Soybean Marker database | Linkage map of soybean genome and genetic markers | http://marker.kazusa.or.jp/Soybean/, accessed on 15 October 2021 | [106] | |
| Rsoy—Riken Soybean | cDNA sequences for the functional analysis of genomic features | http://spectra.psc.riken.jp/menta.cgi/rsoy/index, accessed on 15 October 2021 | [107] | |
| Manual and image phenotype | RhizoVision Crown | Crown root images and phenotypic measurements of 187 soybean lines. Additionally, it offers a tool for root phenotyping | https://zenodo.org/record/5121845#.YYzkYJvmiV4, accessed on 15 October 2021 | [108,109] |
| SoyNAM | Phenotype and genotype data from 5555 SoyNAM lines, available through the R package NAM | https://CRAN.R-project.org/package=NAM, accessed on 15 October 2021 | [110] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petereit, J.; Marsh, J.I.; Bayer, P.E.; Danilevicz, M.F.; Thomas, W.J.W.; Batley, J.; Edwards, D. Genetic and Genomic Resources for Soybean Breeding Research. Plants 2022, 11, 1181. https://doi.org/10.3390/plants11091181
Petereit J, Marsh JI, Bayer PE, Danilevicz MF, Thomas WJW, Batley J, Edwards D. Genetic and Genomic Resources for Soybean Breeding Research. Plants. 2022; 11(9):1181. https://doi.org/10.3390/plants11091181
Chicago/Turabian StylePetereit, Jakob, Jacob I. Marsh, Philipp E. Bayer, Monica F. Danilevicz, William J. W. Thomas, Jacqueline Batley, and David Edwards. 2022. "Genetic and Genomic Resources for Soybean Breeding Research" Plants 11, no. 9: 1181. https://doi.org/10.3390/plants11091181
APA StylePetereit, J., Marsh, J. I., Bayer, P. E., Danilevicz, M. F., Thomas, W. J. W., Batley, J., & Edwards, D. (2022). Genetic and Genomic Resources for Soybean Breeding Research. Plants, 11(9), 1181. https://doi.org/10.3390/plants11091181