
A Multiscale Lightweight and Efficient Model Based on YOLOv7: Applied to Citrus Orchard
 ,
,
Abstract
1. Introduction
2. Related Work
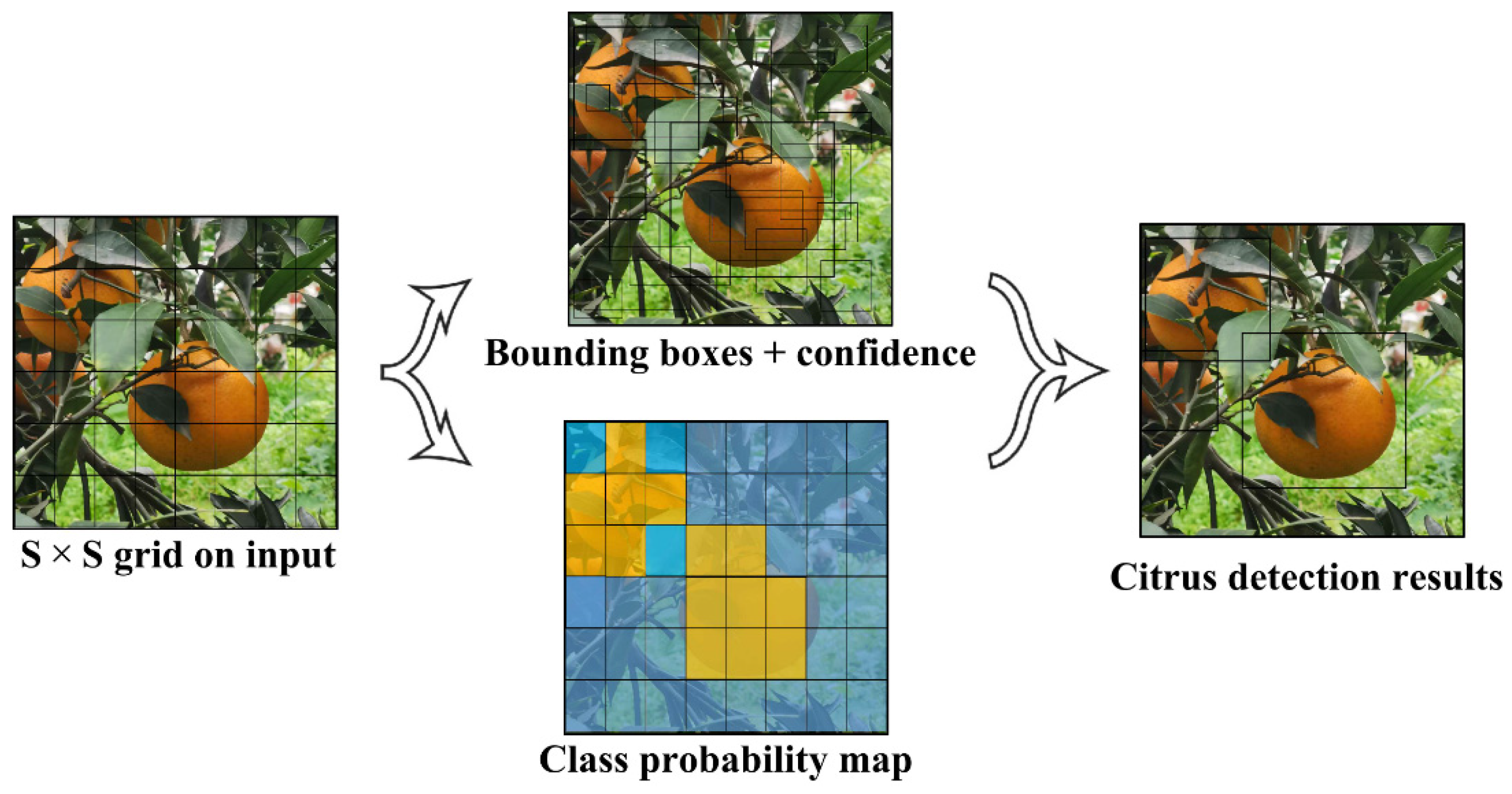
2.1. YOLOv7: Excellent Aggregator
2.2. Attention Mechanism: Selectively Paying Attention to Information
2.3. GhostConv: Lighter Convolution Module
2.4. Small Object Detection
3. Materials and Methods
3.1. Data Acquisition
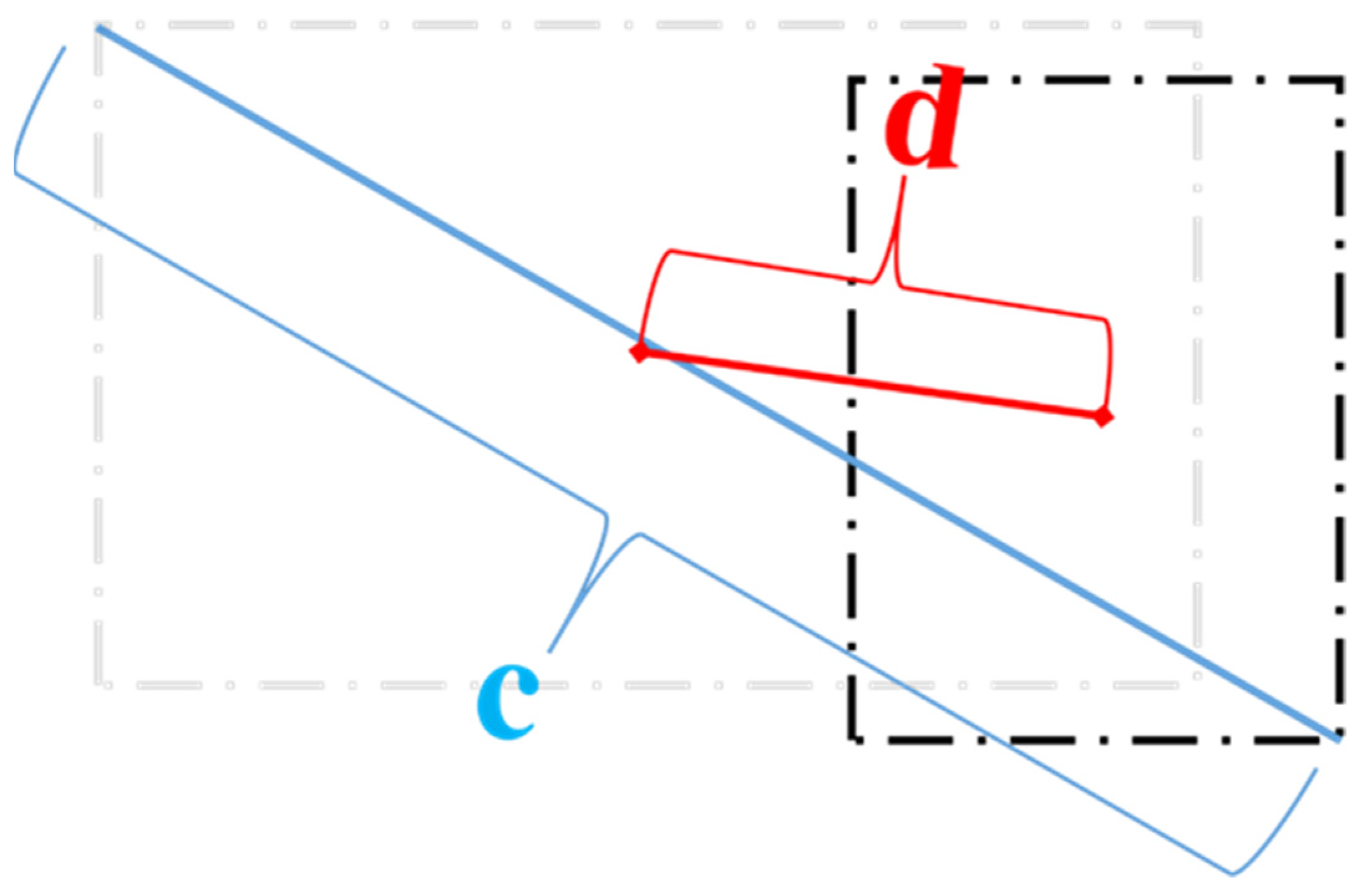
3.2. Data Preprocessing
3.3. Training Environment and Evaluation Indicators
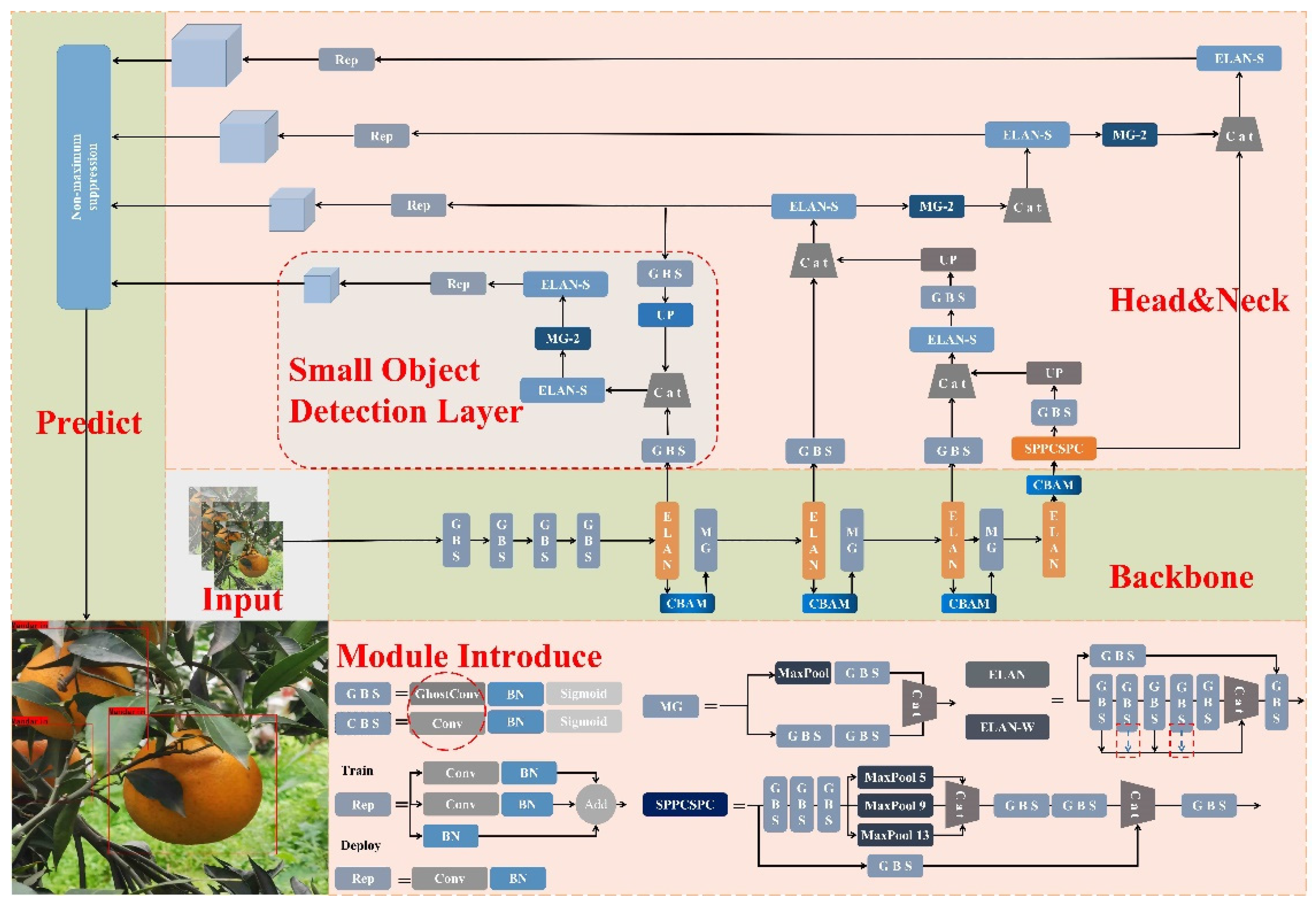
3.4. The Proposed Citrus-YOLOv7 Model
4. Results and Discussion
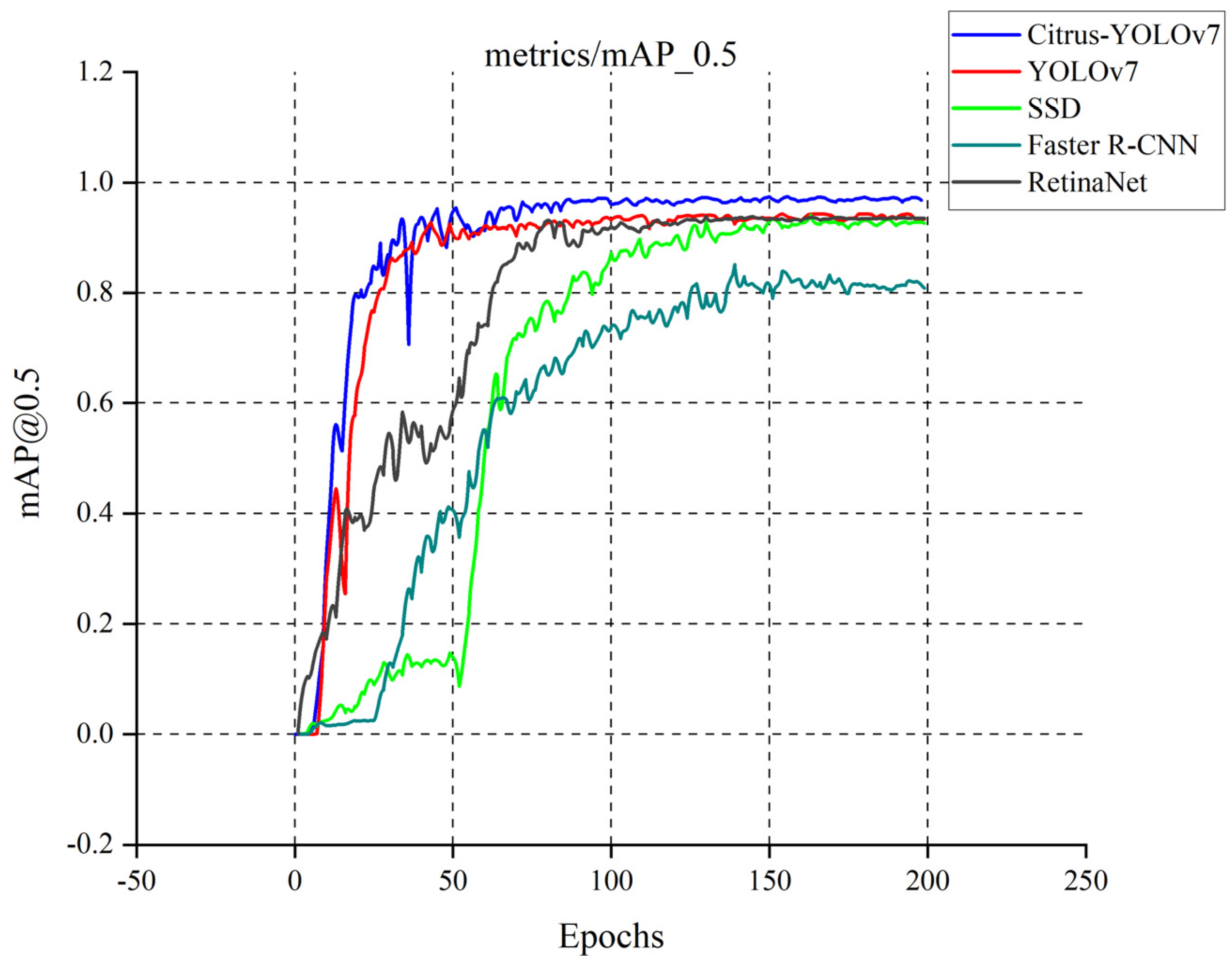
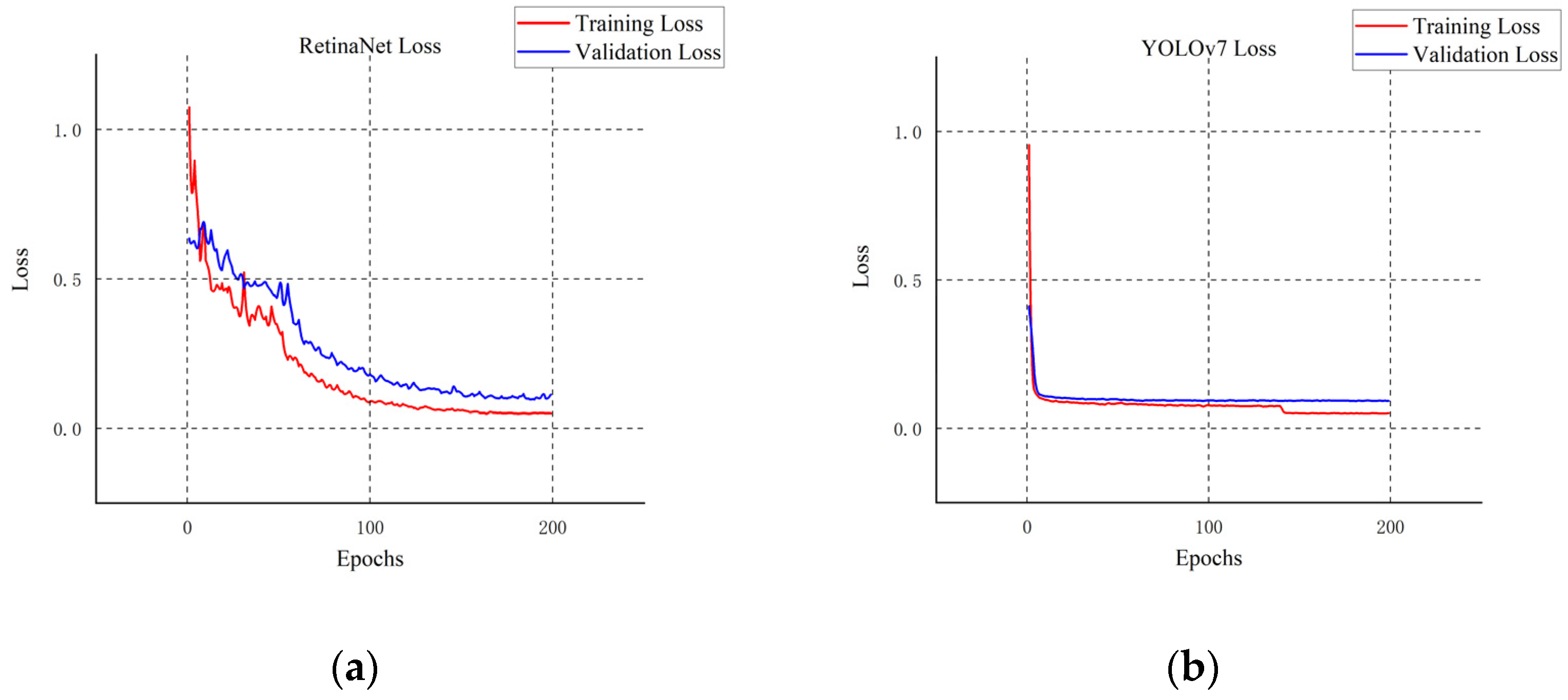
4.1. Comparison of the Overall Accuracy of Network Models
4.2. Comparison of Network Model Detection Speed
4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Deng, X.; Yang, X.; Yamamoto, M.; Biswas, M.K. Chapter 3—Domestication and history. In The Genus Citrus; Talon, M., Caruso, M., Gmitter, F.G., Eds.; Woodhead Publishing: Cambridge, UK, 2020; pp. 33–55. [Google Scholar]
- Mekouar, M.A. 15. Food and Agriculture Organization of the United Nations (FAO). Yearb. Int. Environ. Law 2017, 29, 448–468. [Google Scholar] [CrossRef]
- Sebastian, K. Atlas of African Agriculture Research & Development; : 2014. IFPRI Books: Washington, DC, USA, 2014. [Google Scholar]
- World Production of Citrus Fruits in 2020, by Region. Available online: https://www.statista.com/statistics/264002/production-of-citrus-fruits-worldwide-by-region/ (accessed on 10 July 2022).
- Zhao, Y.; Gong, L.; Huang, Y.; Liu, C. A review of key techniques of vision-based control for harvesting robot. Comput. Electron. Agric. 2016, 127, 311–323. [Google Scholar] [CrossRef]
- Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar]
- Kukreja, V.; Dhiman, P. A Deep Neural Network based disease detection scheme for Citrus fruits. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020. [Google Scholar]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef]
- Darwin, B.; Dharmaraj, P.; Prince, S.; Popescu, D.E.; Hemanth, D.J. Recognition of Bloom/Yield in Crop Images Using Deep Learning Models for Smart Agriculture: A Review. Agronomy 2021, 11, 646. [Google Scholar] [CrossRef]
- Horng, G.J.; Liu, M.X.; Chen, C.C. The Smart Image Recognition Mechanism for Crop Harvesting System in Intelligent Agriculture. IEEE Sens. J. 2020, 20, 2766–2781. [Google Scholar] [CrossRef]
- Liu, G.X.; Nouaze, J.C.; Mbouembe, P.L.T.; Kim, J.H. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef]
- Qi, J.T.; Liu, X.N.; Liu, K.; Xu, F.R.; Guo, H.; Tian, X.L.; Li, M.; Bao, Z.Y.; Li, Y. An improved YOLOv5 model based on visual attention mechanism: Application to recognition of tomato virus disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Liu, Z.S.; Xiang, X.Y.; Qin, J.H.; Ma, Y.T.; Zhang, Q.; Xiong, N.N. Image Recognition of Citrus Diseases Based on Deep Learning. CMC-Comput. Mater. Contin. 2021, 66, 457–466. [Google Scholar] [CrossRef]
- Mo, J.; Ye, J.; Yang, J.; Hu, L.; Li, Q.; Yi, W.; Qiu, W. Distilled-MobileNet Model of Convolutional Neural Network Simplified Structure for Plant Disease Recognition. Smart Agric. 2021, 3, 109–117. [Google Scholar] [CrossRef]
- Bi, S.; Gao, F.; Chen, J.W.; Zhang, L. Orange target recognition based on depth convolution neural network. J. Agric. Mach. 2019, 50, 6. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv Prepr. 2022, arXiv:2207.02696. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2019. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Glenn, J. yolov5. Git Code. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 20 November 2022).
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Laker City, UT, USA, 18–22 June 2018. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H.J.A. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv Prepr. 2017, arXiv:1704.04861. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Lawrence Zitnick, C. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Yuan, J.; Hu, Y.; Yin, B.; Sun, Y. Survey of Small Object Detection Methods Based on Deep Learning; ICESC: Coimbatore, India, 2022. [Google Scholar]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.I. Small Object Detection using Context and Attention; ICAIIC: Jeju Island, Republic of Korea, 2019. [Google Scholar]
- Liu, G.; Han, J.; Image, W.R.J.; Computing, V. Feedback-Driven Loss Function for Small Object Detection. Image Vis. Comput. 2021, 111, 104197. [Google Scholar] [CrossRef]
- Tzutalin, D. LabelImg.Git Code. 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 20 November 2022).
- DeVries, T.; Vision, G.W.T.J.A.C.; Recognition, P. Improved Regularization of Convolutional Neural Networks with Cutout. In Improved Regularization of Convolutional Neural Networks with Cutout; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S. Random Erasing Data Augmentation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 13001–13008. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv Preprint 2015, arXiv:1409.1556. [Google Scholar]
- Ying, Z.; Li, G.; Ren, Y.; Wang, R.; Wang, W. A New Image Contrast Enhancement Algorithm Using Exposure Fusion Framework. In Computer Analysis of Images; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar]
- WongKinYiu. 2022. YOLOv7.Git code. Available online: https://github.com/WongKinYiu/yolov7 (accessed on 20 November 2022).
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; IEEE Trans: Nashville, TN, USA, 2021. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2019, 34, 12993–13000. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Fruit Images for Object Detection. Available online: https://www.kaggle.com/datasets/mbkinaci/fruit-images-for-object-detection (accessed on 20 November 2022).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Proportion | Number of Pictures | Number of Fruits | |
|---|---|---|---|---|
| dataset | training set | 80% | 1012 | 5338 |
| validation set | 10% | 127 | 489 | |
| test set | 10% | 127 | 507 | |
| total | 100% | 1266 | 6334 |
| Models | mAP@0.5 | mAP@[0.5:0.95] | Precision | Recall | F1 |
|---|---|---|---|---|---|
| Faster R-CNN | 82.93% | 57.25% | 69.34% | 90.24% | 78.42% |
| RetinaNet | 93.67% | 67.90% | 90.77% | 92.56% | 91.66% |
| SSD | 92.81% | 65.46% | 86.12% | 89.50% | 87.78% |
| YOLOv7 | 94.64% | 69.19% | 93.69% | 91.41% | 92.54% |
| Citrus-YOLOv7 | 97.29% | 74.83% | 94.25% | 93.37% | 93.81% |
| Models | Inference Time | Parameter | FLOPs |
|---|---|---|---|
| Faster R-CNN | 195.17 ms | 136.69 M | 369.72 G |
| RetinaNet | 70.69 ms | 36.33 M | 145.34 G |
| SSD | 91.02 ms | 23.62 M | 273.17 G |
| YOLOv7 | 78.27 ms | 35.47 M | 105.11 G |
| Citrus-YOLOv7 | 69.38 ms | 24.26 M | 76.40 G |
| Methods | mAP@0.5 | F1 | Parameter | Inference Time |
|---|---|---|---|---|
| YOLOv7 | 94.64% | 92.54% | 35.47 M | 73.27 ms |
| YOLOv7 + SD | 95.05% | 92.12% | 36.00 M | 74.31 ms |
| YOLOv7 + GC | 92.73% | 90.43% | 24.89 M | 53.87 ms |
| YOLOv7 + CBAM | 95.16% | 92.62% | 34.31 M | 61.59 ms |
| YOLOv7 + SD + GC | 95.86% | 92.08% | 25.21 M | 57.53 ms |
| YOLOv7 + GC + CBAM | 96.63% | 91.97% | 23.98 M | 52.04 ms |
| YOLOv7 + SD + CBAM | 97.07% | 93.53% | 34.79 M | 66.25 ms |
| YOLOv7 + SD + GC + CBAM | 97.29% | 93.81% | 24.26 M | 69.38 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Liu, H.; Zhang, Y.; Zhang, D.; Ouyang, H.; Chen, X. A Multiscale Lightweight and Efficient Model Based on YOLOv7: Applied to Citrus Orchard. Plants 2022, 11, 3260. https://doi.org/10.3390/plants11233260
Chen J, Liu H, Zhang Y, Zhang D, Ouyang H, Chen X. A Multiscale Lightweight and Efficient Model Based on YOLOv7: Applied to Citrus Orchard. Plants. 2022; 11(23):3260. https://doi.org/10.3390/plants11233260
Chicago/Turabian StyleChen, Junyang, Hui Liu, Yating Zhang, Daike Zhang, Hongkun Ouyang, and Xiaoyan Chen. 2022. "A Multiscale Lightweight and Efficient Model Based on YOLOv7: Applied to Citrus Orchard" Plants 11, no. 23: 3260. https://doi.org/10.3390/plants11233260
APA StyleChen, J., Liu, H., Zhang, Y., Zhang, D., Ouyang, H., & Chen, X. (2022). A Multiscale Lightweight and Efficient Model Based on YOLOv7: Applied to Citrus Orchard. Plants, 11(23), 3260. https://doi.org/10.3390/plants11233260