1. Introduction
Nowadays, urban renewal has been widely performed around the globe, which could effectively relieve the shortage of urban land resources and improve urban land use efficiency [
1,
2,
3]. For instance, urban renewal in China has led to a large-scale demolition of old, low-density urban areas and urban villages over the past few decades [
2]. During the renewal process, construction sites can be a source of huge amounts of dust, which could easily be transferred to the air and water nearby, leading to severe environmental pollution.
To alleviate the accompanied dust contamination, plastic mulch has been widely utilized by local governments in China (
Figure 1). Moreover, the plastic mulch is always green, making it appear environmentally friendly. Actually, green plastic mulch is commonly made from polyethylene. Most urban renewal projects in China use the same green plastic mulch to alleviate dust contamination. After the construction process, the plastic mulch can be recycled at relevant chemical plants. Due to the stringent environmental protection regulations in China, green plastic mulch has been a must in urban renewal projects, offering an opportunity to accurately identify construction sites during urban sprawl and renewal. Therefore, it is of great significance to monitor and detect these green plastic covers (GPC), which could provide the spatial distribution of construction sites. Moreover, the detection of GPC could also help the environmental protection department with the precise control of construction dusts. However, as far as we know, there is still no report on GPC detection in the remote sensing field; therefore, we are highly motivated to propose an accurate classification method for GPC based on deep learning (DL) from VHR remotely sensed imagery.
The accurate classification of GPC is challenging for the following reasons. Firstly, the complex urban landscapes lead to a high variability of the spatial patterns of GPC. Secondly, the limited labeled data of GPC could lead to overfitting of the deep learning-based classification model. To tackle these issues, we first exploited a multi-scale deformable CNN to account for the scale and shape variability of GPC. Afterwards, we integrated unlabeled GPC samples with labeled data into a semi-supervised learning framework to increase the model’s generalization capability.
Actually, urban green plastic cover could be viewed as a specific urban land cover category. Due to its synoptic view and cost-effectiveness, remote sensing has been widely utilized for urban land use and land cover (LULC) mapping [
4,
5,
6]. Traditional methods mainly focused on the visual inspection and vectorization from VHR remotely sensed imagery. However, this is both time and labor-intensive. Therefore, how to develop an automatic urban LULC classification method has become a hot research topic [
7,
8,
9]. Early studies [
10,
11,
12,
13,
14,
15] mainly combined hand-crafted features (i.e., spectral indices, texture features) with machine learning classifiers to automatically extract a specific urban LULC type. For example, Shao et al. [
10] performed the extraction of urban impervious surface based on random forest (RF) from GaoFen-1 and Sentinel-1A imagery. Yin et al. [
11] applied both sub-pixel and super-pixel based methods for characterizing urban green space in Haidian District, Beijing. In our previous studies, we also adopted random forest and texture analysis for urban vegetation mapping [
12] and urban inundated regions extraction [
13] from unmanned aerial vehicle (UAV) remote sensing data.
Meanwhile, there are still no relevant studies on urban green plastic cover mapping from remotely sensed data. Similar research mainly consists of the detection of construction sites and urban landfill. Yu et al. [
16] proposed an unsupervised learning method for the classification of buildings under construction from multi-temporal UAV data. Silvestri et al. [
17] utilized maximum likelihood classifier (MLC) and IKONOS images to recognize the uncontrolled urban landfills. Considering that no published studies focus on green plastic cover classification, this paper could be the first attempt to solve this important and challenging issue.
It should be noted that the aforementioned studies mainly rely on hand-crafted features and machine learning approaches for urban LULC classification. However, the design of hand-crafted features relies heavily on domain expertise, which might lead to inability to discover high-level and discriminative features from remote sensing images. On the other hand, deep learning has a strong ability to extract representative multi-level features from original data instead of empirical feature design and can work in an end-to-end manner, which has led to impressive performance in the computer vison field [
18,
19,
20,
21,
22], such as in image classification [
18], object detection [
19], and semantic segmentation [
22]. More recently, deep learning, especially deep CNN, has also been successfully applied in numerous remote sensing applications [
23,
24,
25,
26,
27,
28,
29]. For instance, Huang et al. [
23] proposed a semi-transfer deep CNN for urban land use mapping, based on VHR WorldView-2 imagery, and achieved an accuracy of 91.25%. Zhang et al. [
24] proposed an object-based CNN for urban land use classification and achieved excellent classification accuracy and computational efficiency. Dong et al. [
25] exploited a hybrid approach of random forest and CNN for subtropical forest mapping, and their results indicated that the developed model could lead to an improvement in information extraction. In our previous studies [
30], we modified a two-branch CNN for urban land use mapping and found that the proposed CNN model outperforms traditional machine learning algorithms such as MLC, RF, and support vector machine (SVM). Moreover, we extended the above model to a multi-branch version for the fusion of multi-senor and multi-temporal Sentinel-1/2 imagery [
31]. All of the above studies demonstrated that CNN could provide an effective tool for remote sensing image classification. Therefore, in this study, we exploited a novel multi-scale deformable CNN to learn high-level and representative features for green plastic cover classification.
There is no denying that great improvements have been made in urban LULC mapping from remote sensing images through deep learning. However, deep learning works in an exhaustive data-driven manner, and a large number of labeled samples need to be fed into a DL model to avoid overfitting. Meanwhile, it should be noted that labeling enormous training samples is both labor-extensive and time-consuming, especially in the remote sensing and geoscience fields. Therefore, how to integrate the limited labeled samples with massive unlabeled data to improve the model’s generalization capability is a key question. Semi-supervised learning precisely provides an effective tool to tackle this issue. He et al. [
32] proposed generative adversarial network (GAN)- based, semi-supervised learning to classify hyperspectral images (HSI), while the unlabeled samples were from the GAN’s generator. Fang et al. [
33] also utilized a semi-supervised learning strategy based on several sample selection methods for HSI classification. Inspired by these studies, we also introduced a semi-supervised learning framework for the classification of urban green plastic covers based on limited well-annotated samples.
To sum up, the contributions of this study are as follows:
- (1)
For the first time, we developed a deep learning method for urban green plastic cover mapping from VHR remote sensing data, which could provide an effective tool for construction site monitoring and environmental protection.
- (2)
We exploited a multi-scale deformable CNN to tackle the variability of land object’s scales and shapes under complex urban landscapes.
- (3)
We integrated the limited labeled samples with massive unlabeled data into a semi-supervised learning framework to increase the generalization capability of the classification model for green plastic covers.
3. Methods
3.1. Overview of the Proposed Model
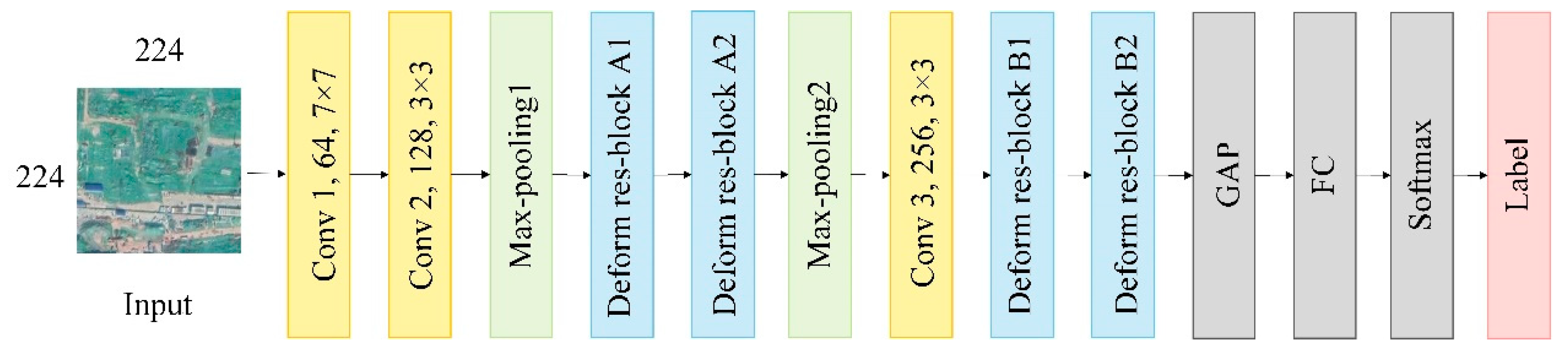
Figure 5 illustrates the overview of the proposed method for green plastic cover mapping. The input is an image patch with 224 rows and 224 columns, and the final result is a predicted land cover class. More specifically, the proposed method consists of two components: (1) Feature extraction based on a deep CNN; and (2) semi-supervised learning that integrates both labeled and unlabeled data. As for the former, we exploited a multi-scale deformable CNN to learn representative spatial features under complex urban landscapes. For the latter, the trained CNN was first utilized to endow the unlabeled data with a pseudo label. Afterwards, the most confident data were selected through top-
k ranking and added to the training set to retrain the CNN model.
3.2. Multi-Scale Deformable CNN for Feature Representation
Figure 6 and
Table 1 shows the detailed structure of the multi-scale deformable CNN for deep feature representation. Specifically, it includes several convolutional layers, max pooling layers, and deformable multi-scale residual blocks. Meanwhile, to obtain the final classification result, a global average pooling (GAP), a fully connected (FC) layer, and a Softmax layer were cascaded.
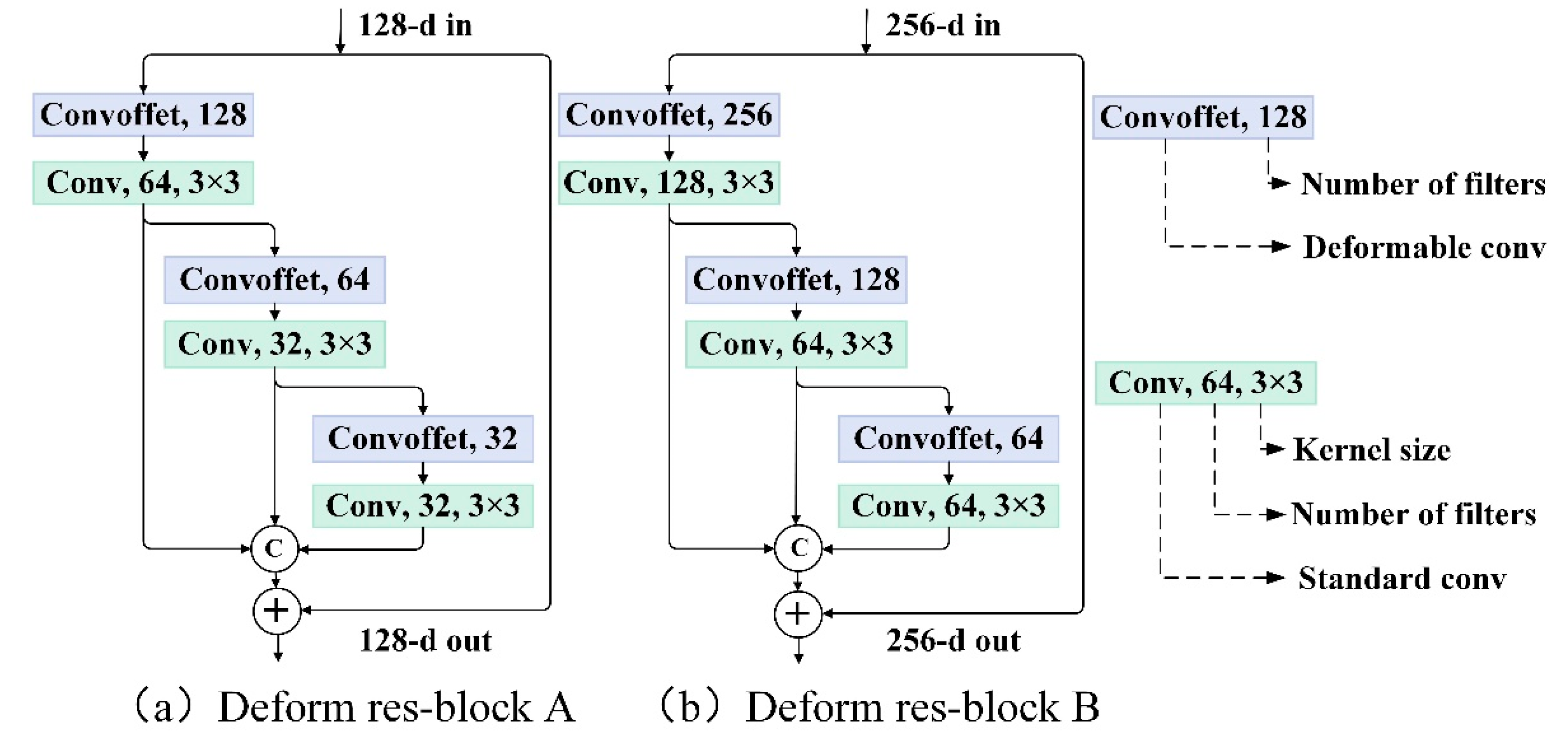
In this study, both deformable convolutions and multi-scale residual blocks were introduced into the deep CNN model for better feature representation. Through deformable convolution, the receptive field and sampling locations were trained to be adaptive to the shapes and scales of land objects, which was beneficial for extracting highly discriminative features. Meanwhile, a multi-scale residual block could extract hierarchical, multi-scale features and improve gradient flow at the same time. In addition, the integration of deformable convolutions into the multi-scale residual block could combine the merits of both modules, increasing the feature adaptability to the complex spatial patterns of urban landscapes.
Figure 7 illustrates the detailed parameters of deformable multi-scale residual blocks.
Moreover, in our previous study [
31], the multi-scale deformable CNN was proposed for spatial feature learning in a coastal wetland landscape, and showed good performance. Therefore, we also introduced it in this study when considering the spatial heterogeneity of complex urban scenarios. More details of the above model can be found in [
31].
3.3. Samples Selection for Semi-Supervised Learning
The data-driven nature of deep learning calls for a massive number of high-quality labeled samples to maintain the model’s generalization capability. However, in the field of remote sensing and geoscience, manually labeling sufficient samples is infeasible due to both the high labor intensity and the low efficiency. Semi-supervised learning, on the other hand, aims to learn from both labeled and unlabeled data, providing a favorable strategy to address the insufficient training data issue, and can achieve satisfactory accuracy with the mining of a massive number of unlabeled samples. Therefore, we resorted to deep semi-supervised learning and proposed a two-step strategy to select the most confident unlabeled samples for model retraining.
Before the description of the two-step strategy for unlabeled samples selection, we first introduce the details of the labeled data. To begin with, we annotated 700 samples for each category, including both GPC and non-GPC, to construct the initial labeled pool. The labeled samples were randomly divided into two parts: 300 for the training set and 400 for the testing set. Meanwhile, 90% of the training set was employed to train the CNN, while the remaining 10% were used as a validation set to evaluate the performance during training.
The proposed two-step strategy for semi-supervised learning was as follows. In the first step, the trained CNN was used to predict samples from the unlabeled pool to derive the posterior probability. Only the unlabeled samples with a probability exceeding 0.5 would be selected and assigned with a predicted category (namely, pseudo-labeled samples). However, these pseudo-labeled samples may be unreliable. If we directly added all these samples into the labeled pool to retrain the CNN model, the performance would not always increase due to additional noise.
To ensure the reliability of the pseudo-labeled samples, we introduced a second step for unlabeled data selection. We calculated the similarities between each pseudo-labeled sample and all labeled samples, which are measured by the Euclidean distance:
where
and
denote the
i-th unlabeled and
j-th labeled sample, respectively;
represents the similarity metric; and
stands for the deep feature expression. Afterwards, we sorted the labeled pool by descending order of the above similarities. If the top-
k training samples have the same category as the pseudo-labeled sample, then this pseudo-labeled sample was regarded as reliable and could be added to the labeled pool for CNN retraining [
29]. In addition, we analyzed the impact of value
k in top-
k on GPC classification; the results are shown in
Section 4.4.
3.4. Details of Network Training
Although the number of training samples could be increased by means of semi-supervised learning, we still adopted the data augmentation technique to further boost the generalization capability and decrease the risk of overfitting. Specifically, all the initial labeled samples were rotated 90, 180, or 270° and flipped up and down.
All the weights of the proposed CNN model were initialized with
He normalization [
35], and all biases were initially set to 0. For optimizing weights and biases to improve classification performance, an Adam optimizer [
36] was used with an initial learning rate of 10
−4. An early-stopping technique was adopted to select the best model. Cross-entropy loss [
37] was adopted, whose expression is as follows:
where
L denotes cross-entropy loss;
stands for the probability predicted by the model;
yi denotes the ground truth; and
N refers to the number of classes.
The training procedure included the following steps:
- (1)
Firstly, the backbone, i.e., the multi-scale deformable CNN was trained using only the initial labeled data.
- (2)
Next, the backbone was utilized to predict the unlabeled datasets, and only the samples that passed the two-step selection process would be added to the labeled pool with pseudo labels.
- (3)
The backbone was retrained with samples from the new labeled pool.
In addition, the deep learning library used was TensorFlow [
38]. The entire semi-supervised learning framework was conducted on the Ubuntu 18.04 operating system with Intel Xeon(R) Gold 5118 CPU and NVIDIA TITAN V with 12 GB memory.
3.5. Accuracy Assessments
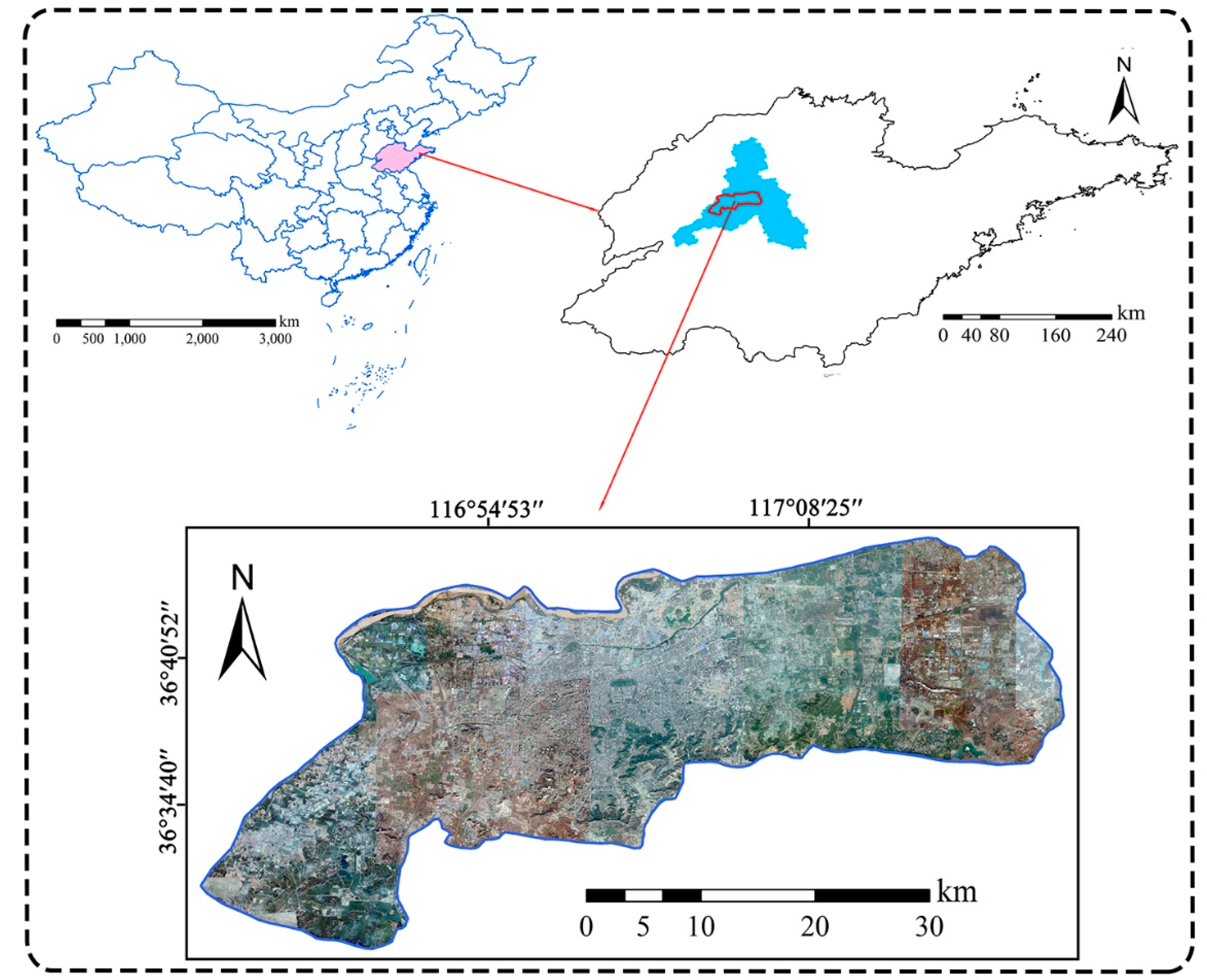
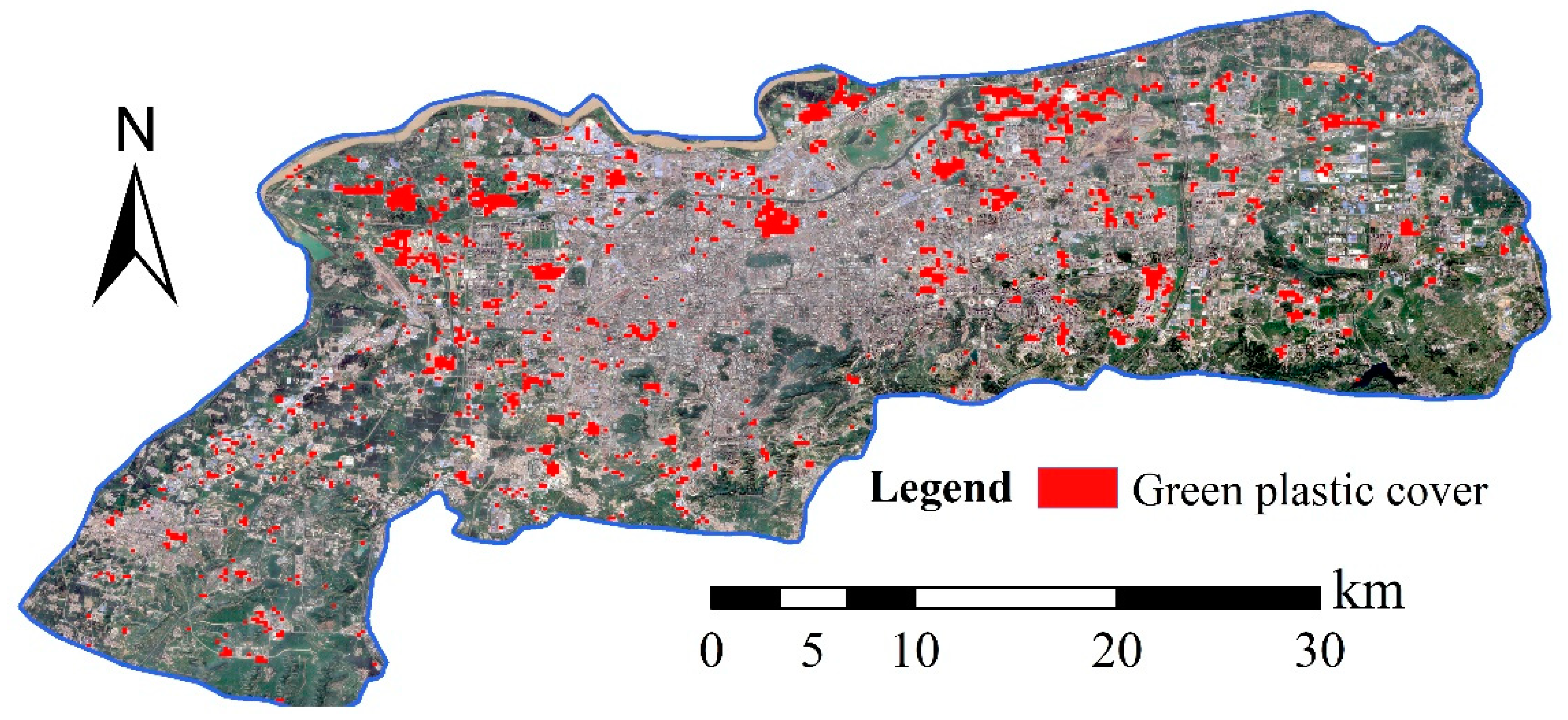
After the classification model was trained, a total of 400 testing samples were utilized to calculate the overall accuracy and confusion matrix. The following metrics were also calculated: Producer accuracy (PA), user accuracy (UA), and Kappa coefficient. Meanwhile, visual evaluation was also involved to check for obvious classification errors. In general, visual inspection is a subjective evaluation method that determines whether the classification result is good or not through comparing the green plastic cover mapping results with high-resolution images from Google Earth. Since the green plastic mulch could be identified by eye on Google Earth, we used the visual interpreted images as the “gold standard.” Moreover, we conducted field surveys in several places in Jinan to make sure that the interpreted images were correct.
We also conducted an ablation study to justify the performance of the semi-supervised learning strategy. Furthermore, a comparison with several commonly used CNN models in the computer vision field was performed to evaluate the effectiveness of the multi-scale deformable CNN in this paper.
5. Conclusions
This study proposed a deep semi-supervised learning framework for urban green plastic cover mapping from VHR remote sensing imagery. A multi-scale deformable CNN was exploited for discriminative feature learning in the complex urban landscapes. A two-step sample selection strategy was proposed for semi-supervised learning to identify the most reliable sample from the unlabeled pool. Experiments and an ablation study were conducted to confirm the good performance of the proposed method.
The experimental results indicate that the proposed method could classify green plastic covered regions in Jinan with a high performance. An accuracy assessment showed that the overall accuracy (OA) was 91.63% and the Kappa index was 0.8325. Moreover, a careful visual inspection showed that most of the green plastic-covered areas could be correctly identified. An ablation study showed that the semi-supervised learning strategy could increase the OA by 6.38% compared with supervised learning, indicating that the mining of the most confidential unlabeled data could effectively improve the classification accuracy. Meanwhile, the comparison with several classic CNN models in the computer vision field showed that the multi-scale deformable CNN in this study yielded the highest accuracy, justifying its effectiveness for spatial feature learning in complex urban landscapes.
Moreover, this study is the first attempt to identify green plastic cover from VHR remote sensing data based on deep learning methods, which could provide a baseline for relevant studies. Although the proposed CNN is now utilized for urban plastic-covered region recognition, it could also be applied to other applications, such as remote sensing scene understanding. In future work, we will further justify the model’s effectiveness and use semantic segmentation models to derive the exact boundaries of the green plastic covered regions.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}