A Subject-Sensitive Perceptual Hash Based on MUM-Net for the Integrity Authentication of High Resolution Remote Sensing Images


Abstract
1. Introduction
- (1)
- We introduce the concept of subject-sensitive perceptual hash, which can be considered as a special case of the traditional perceptual hash.
- (2)
- We propose a method for constructing training sample sets to achieve subject-sensitive perceptual hash. This method can effectively use existing data sets and adjust the algorithm performance according to actual needs.
- (3)
- We propose a convolutional neural network (CNN) architecture named MUM-Net for the subject-sensitive feature extraction of HRRS images. This CNN architecture is the key to implement subject-sensitive perceptual hash.
2. Related Work
- (1)
- Most of the algorithms mentioned above use traditional feature extraction methods, which are artificially designed visual features. However, the “semantic gap” problem indicates that the content of HRRS images cannot be fully represented by visual features alone. For example, the perceptual hash authentication algorithm based on feature points can easily use “false feature points” caused by light and fog as the perceptual characteristics of remote sensing images, which greatly reduces the authentication performance of perceptual hash algorithms.
- (2)
- For specific applications of HRRS images, the robustness of existing perceptual hash authentication algorithms often has some shortcomings, as the artificially designed features cannot express more abstract high-dimensional features of the underlying features of the HRRS image, that is, the essential features of the remote sensing image in the application cannot be tapped, and the certification requirements of the HRRS image in a complex environment cannot be met.
- (3)
- The focus of HRRS image content that different types of users pay attention to is often different, which means that the perceptual hash algorithm should try to identify whether the target that the user is interested in has been tampered, while existing perceptual hash algorithms do not take this into account. For example, if the user mainly uses the information of buildings or roads in the HRRS images, the authentication algorithm should pay more attention to the addition, deletion, or change of buildings or roads in the images, and should appropriately maintain a certain degree of robustness to other categories of targets such as grasses and ponds.
3. Developed Method
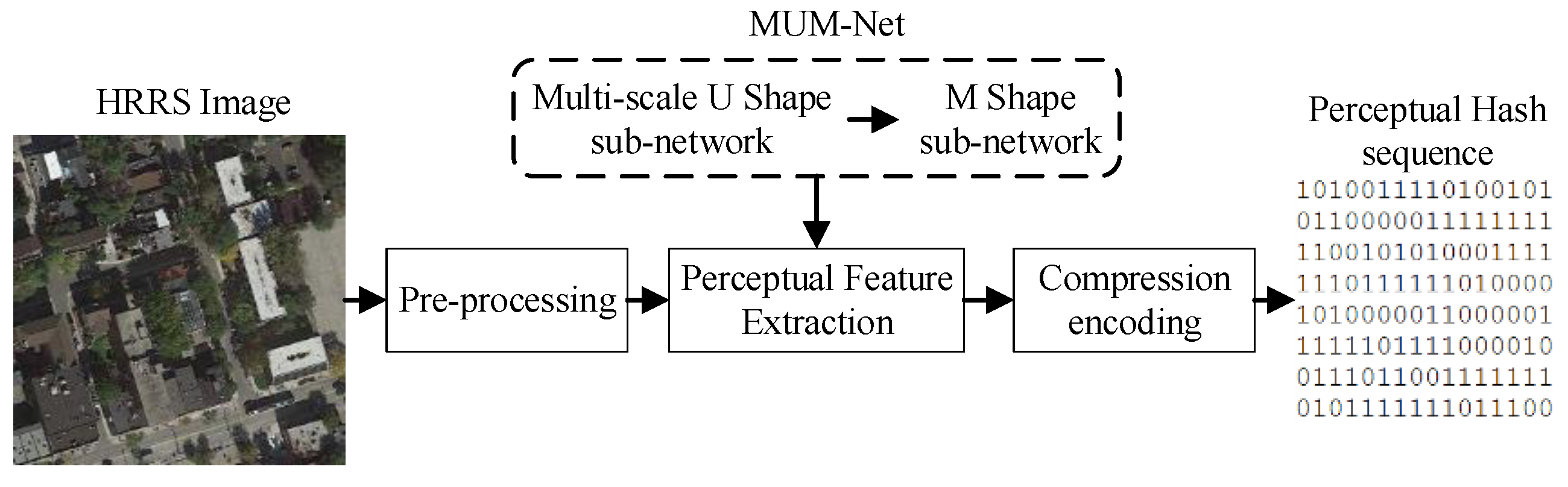
3.1. Overview of Developed Subject-Sensitive Perceptual Hash Algorithm
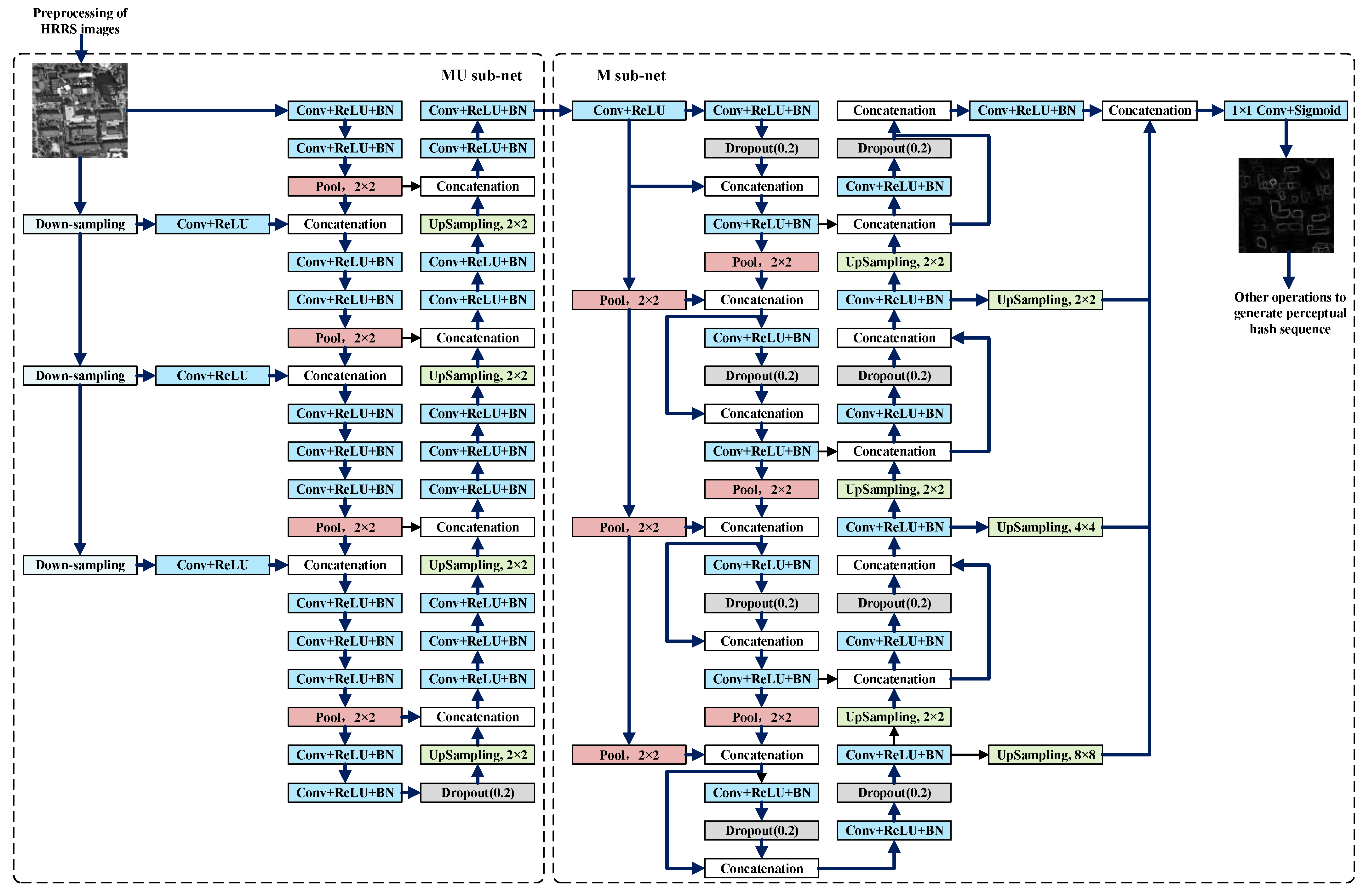
3.2. Architecture of MUM-Net
3.2.1. MU Sub-Net
3.2.2. M Sub-Net
- (1)
- A new loss function is used in M sub-net, that is, binary focal loss is used to replace the binary crossentropy used in the original M-net. This is because the training datasets we establish in Section 4.1 have the problem of an imbalance in the proportion of positive and negative samples, binary focal loss is used here to overcome this problem.
- (2)
- The input data of the M sub-net is the output of the previous sub-network, and the input of the original M-net is the fingerprint image, which determines that our M sub-network’s role is more for denoising instead of image segmentation.
3.2.3. Loss Function
3.3. Integrity Authentication Process
4. Experimental Setup
4.1. Training Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
- (1)
- Robustness. Robustness is the most significant difference between perceptual hash and cryptographic hash functions. Robustness means that the perceptual hash sequences of images with the same or similar perceptual content should be the same or similar. Suppose the original HRRS image is represented as , the HRRS image with unchanged content information is represented as , the perceptual hash function is represented as H(.), and the threshold is T, then:
- (2)
- Sensitivity to Tampering. Sensitivity to tampering, also known as “collision resistance” or ”tampering sensitivity”, means that HRRS images with different perceptual content should have different perceptual hash sequences. Suppose the HRRS image with changed content information is represented as I2, then:
- (3)
- Security. HRRS images are very likely to contain sensitive feature information, so the perceptual hash algorithm must meet security requirements. The security here mainly refers to “one-way”: the effective content information of the HRRS image cannot be obtained from the perceptual hash sequence.
- (4)
- High efficiency. High efficiency means that the perceptual hash algorithm can efficiently generate perceptual hash sequences of HRRS images and complete the corresponding authentication.
- (5)
- Tamper localization. For HRRS images with a large amount of data, “tamper localization” should also be paid attention to. This not only enables the user to quickly locate the tampered area, but also reduces the loss caused by the tampering attack, that is, only the tampered area loses its use value, and other areas will not be affected.
- (6)
- Compactness: The perceptual hash sequence should be as compact as possible.
5. Results and Analysis
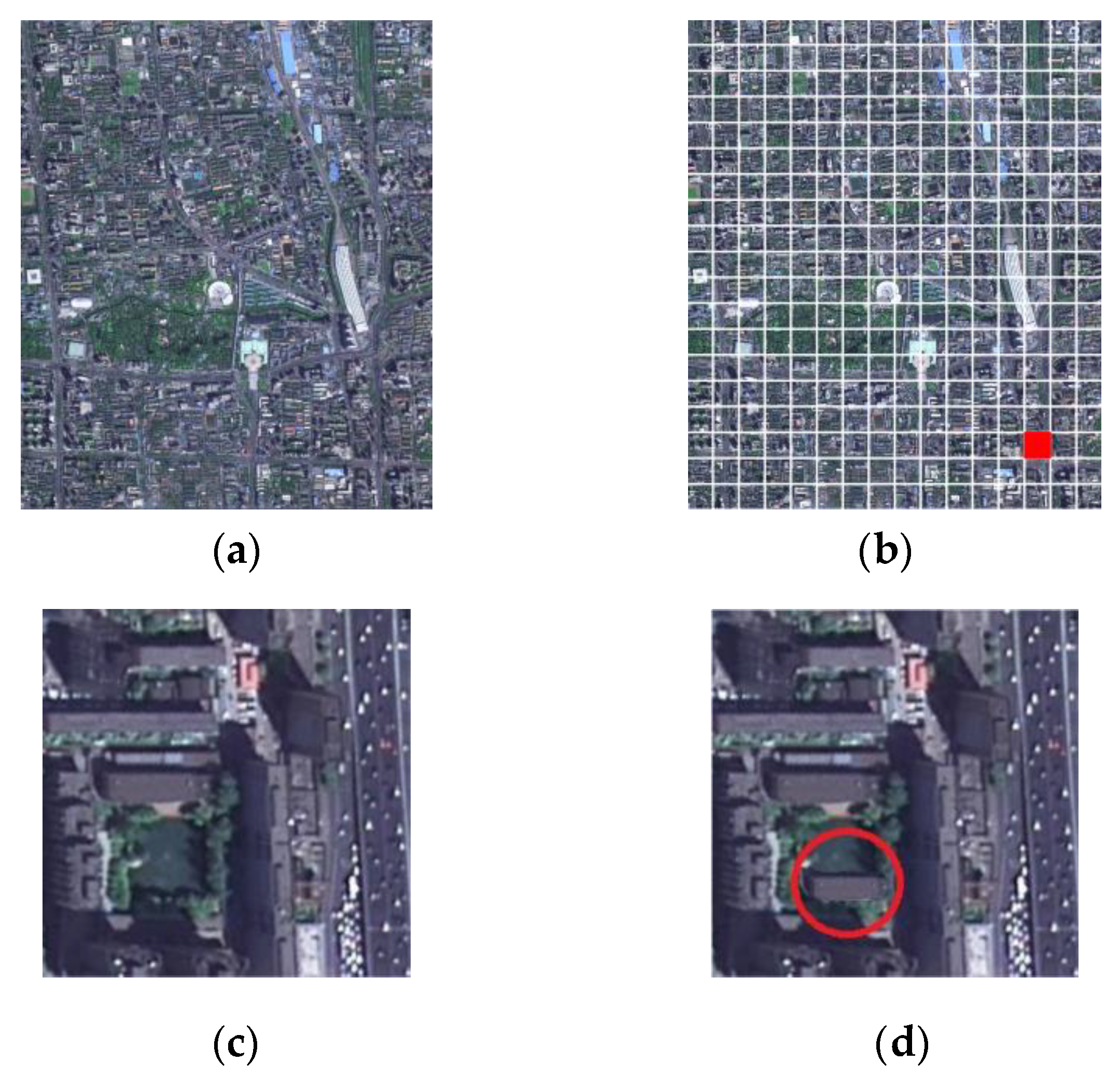
5.1. Examples of Integrity Authentication
- (1)
- The method based on DCT: the original image is normalized to a size of 64 × 64 pixels, and then DCT transformation is performed to extract low frequency coefficients for quantization. During the authentication process, the threshold is set to 0.02.
- (2)
- The method based on SIFT: First, extract the SFIT feature points of the original image, and then, uniformly select 128 feature points for quantization according to the position information. During the authentication process, the threshold is set to 0.01.
- (3)
- The method based on wavelet transform: the original image is normalized to a size of 64 × 64 pixels, and then DWT transform is performed to extract low frequency coefficients for quantization. During the authentication process, the threshold is set to 0.02.
- (4)
- The method based on SVD: the original image is normalized to a size of 64 × 64 pixels, and then SVD transformation is performed to extract singular values as perceptual features for quantization. During the authentication process, the threshold is set to 0.01.
- (1)
- In the case of using the same training sample data set of this paper and adopting the same algorithm flow, the methods based on deep learning models such as U-net, M-net and MultiResUNet are all “subject-sensitive” to a certain extent. In other words, subject-sensitive perceptual hash can be achieved based on deep learning.
- (2)
- Although the method based on MultiResUNet has good robustness, the tampering sensitivity is insufficient, and malicious tampering cannot be well detected, such as tampering in Figure 9g; the tampering sensitivity of the method based on M-net has increased, but it is still insufficient, if the threshold is set smaller, there is still the possibility of missed detection of malicious tampering, such as the tampering of Figure 9g; U-net-based method has insufficient robustness, and it is too sensitive to subject unrelated changes, such as Figure 9e,f. Although this is not necessarily a bad thing, it means that the “subject-sensitive” of U-net-based method is insufficient; the perceptual hash algorithm based on MUM-Net has a better “subject sensitivity” and can maintain a better balance between algorithm robustness and tampering sensitivity. In short, the perceptual hash algorithm based on MUM-Net has better subject-sensitive characteristics.
5.2. Performance of Perceptual Robustness
5.3. Performance of Sensitivity to Tampering
5.4. Analysis of Algorithm Security
- (1)
- Due to the complex multi-layer nonlinear network structure, it is difficult to interpret convolutional neural networks from visual semantics [68,69]. Although the interpretable difficulty of a deep learning model is a disadvantage in other deep learning fields, the difficulty of interpretation can well guarantee the security of the algorithm, that is, even in the case of obtaining a hash sequence, it is difficult to obtain the input HRRS image in reverse.
- (2)
- The algorithm uses the AES algorithm to encrypt the perceptual features in the compression coding stage, and the security of AES has long been widely recognized. Therefore, the application of the AES algorithm further strengthens the security of the algorithm.
5.5. Tampering Location Analysis
6. Discussion
- (1)
- Robustness. The sample learning ability of MultiResUnet is the strongest among all models. Most of the edge features it extracts are the edges of buildings, so the perceptual hash algorithm based on MultiResUnet is the most robust. MUM-Net is more robust than M-net and U-net, while M-net is better than U-net. From Table 3, Table 4, Table 5 and Table 6, we can get the following robustness ranking:MultiResUnet > MUM-Net > M-net >U-net
- (2)
- Tampering sensitivity. Although robustness is the biggest advantage of perceptual hash over cryptographic hash, if the sensitivity of tampering is insufficient, it means that perceptual hash cannot detect possible malicious tampering, and it will not be able to meet the requirements of integrity authentication. Although most of the edges detected by MultiResUnet are the edges of buildings, many relevant edges are missed, which is very detrimental to its tampering sensitivity. From Table 7, Table 8, Table 9 and Table 10, we can draw the conclusion that MultiResUnet’s tampering sensitivity is the worst among all models, and M-net also has similar problems. The sensitivity of U-net is the best, even stronger than MUM-Net. Therefore, we can rank the tampering sensitivity as follows:U-net > MUM-Net > M-net > MultiResUnet
- (3)
- Security and tampering positioning. Since the algorithm processes adopted by each deep learning model are similar, but differ in the perceptual feature extraction stage, there is not much difference in the security and tampering positioning of MUM-Net, U-net, M-net and MultiResUnet.
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-Aware Network for the Extraction of Buildings from Aerial Images. Remote Sens. 2020, 12, 2161. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, W.; Yu, H.; Zhang, H.; Xia, G.S. Detecting Power Lines in UAV Images with Convolutional Features and Structured Constraints. Remote Sens. 2019, 11, 1342. [Google Scholar] [CrossRef]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Wang, Y.D.; Li, Z.W.; Zeng, C.; Xia, G.S.; Shen, H.F. An Urban Water Extraction Method Combining Deep Learning and Google Earth Engine. IEEE J. Select. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 768–781. [Google Scholar] [CrossRef]
- Tavakkoli Piralilou, S.; Shahabi, H.; Jarihani, B.; Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Aryal, J. Landslide Detection Using Multi-Scale Image Segmentation and Different Machine Learning Models in the Higher Himalayas. Remote Sens. 2019, 11, 2575. [Google Scholar] [CrossRef]
- Xu, L.; Chen, Y.Y.; Pan, J.W.; Gap, A. Multi-Structure Joint Decision-Making Approach for Land Use Classification of High-Resolution Remote Sensing Images Based on CNNs. IEEE Access. 2020, 8, 42848–42863. [Google Scholar] [CrossRef]
- Xu, S.H.; Mu, X.D.; Ke, B.; Wang, X.R. Dynamic Monitoring of Military Position based on Remote Sensing Image. Remote Sensing Technol. Appl. 2014, 29, 511–516. [Google Scholar]
- Zhang, C.; Wei, S.; Ji, S.; Lu, M. Detecting Large-Scale Urban Land Cover Changes from Very High Resolution Remote Sensing Images Using CNN-Based Classification. ISPRS Int. J. Geo-Inf. 2019, 8, 189. [Google Scholar] [CrossRef]
- Li, J.; Pei, Y.; Zhao, S.; Xiao, R.; Sang, X.; Zhang, C. A Review of Remote Sensing for Environmental Monitoring in China. Remote Sens. 2020, 12, 1130. [Google Scholar] [CrossRef]
- Niu, X.M.; Jiao, Y.H. An Overview of Perceptual Hashing. Acta Electron. Sin. 2008, 36, 1405–1411. [Google Scholar]
- Qin, C.; Sun, M.; Chang, C.C. Perceptual hashing for color images based on hybrid extraction of structural features. Signal. Process. 2018, 142, 194–205. [Google Scholar] [CrossRef]
- Ding, K.M.; Yang, Z.D.; Wang, Y.Y.; Liu, Y.M. An improved perceptual hash algorithm based on u-net for the authentication of high-resolution remote sensing image. Appl. Sci. 2019, 9, 2972. [Google Scholar] [CrossRef]
- Zhang, X.G.; Yan, H.W.; Zhang, L.M.; Wang, H. High-Resolution Remote Sensing Image Integrity Authentication Method Considering Both Global and Local Features. ISPRS Int. J. Geo-Inf. 2020, 9, 254. [Google Scholar] [CrossRef]
- Ding, K.M.; Zhu, Y.T.; Zhu, C.Q.; Su, S.B. A perceptual Hash Algorithm Based on Gabor Filter Bank and DWT for Remote Sensing Image Authentication. J. China Railw. Soc. 2016, 38, 70–76. [Google Scholar]
- Du, L.; Ho, A.T.S.; Cong, R. Perceptual hashing for image authentication: A survey. Sig. Process. Image Commun. 2020, 81, 115713. [Google Scholar] [CrossRef]
- Tang, Z.J.; Huang, Z.Q.; Zhang, X.Q.; Lao, H. Robust image hashing with multidimensional scaling. Sig. Process. 2017, 137, 240–250. [Google Scholar] [CrossRef]
- Yan, C.P.; Pun, C.M.; Yuan, X.C. Quaternion-based image hashing for adaptive tampering localization. IEEE Trans. Inform. Forens. Secur. 2016, 11, 2664–2677. [Google Scholar] [CrossRef]
- Lv, X.; Wang, Z.J. Perceptual image hashing based on shape contexts and local feature points. IEEE Trans. Inform. Forens. Secur. 2012, 7, 1081–1093. [Google Scholar] [CrossRef]
- Liu, Z.Q.; Li, Q.; Liu, J.R.; Peng, X.Y. SIFT based image hashing algorithm. Chin. J. Sci. Instrum. 2011, 32, 2024–2028. [Google Scholar]
- Monga, V.; Evans, B.L. Perceptual image hashing via feature points: Performance evaluation and tradeoffs. Ieee Trans. Image Process. 2006, 15, 3452–3465. [Google Scholar] [CrossRef] [PubMed]
- Khelifi, F.; Jiang, J. Analysis of the security of perceptual image hashing based on non-negative matrix factorization. Ieee Sig. Process. Lett. 2009, 17, 43–46. [Google Scholar] [CrossRef]
- Liu, H.; Xiao, D.; Xiao, Y.P.; Zhang, Y.S. Robust image hashing with tampering recovery capability via low-rank and sparse representation. Multimed. Tools Appl. 2016, 75, 7681–7696. [Google Scholar] [CrossRef]
- Sun, R.; Zeng, W. Secure and robust image hashing via compressive sensing. Multimed. Tools Appl. 2014, 70, 1651–1665. [Google Scholar] [CrossRef]
- Tang, Z.J.; Zhang, X.Q.; Huang, L.Y.; Dai, Y.M. Robust image hashing using ring-based entropies. Sig. Process. 2013, 93, 2061–2069. [Google Scholar] [CrossRef]
- Chen, Y.; Yu, W.; Feng, J. Robust image hashing using invariants of Tchebichef moments. Optik 2014, 125, 5582–5587. [Google Scholar] [CrossRef]
- Sajjad, M.; Haq, I.U.; Lloret, J.; Ding, W.P.; Muhammad, K. Robust image hashing based efficient authentication for smart industrial environment. Ieee Trans. Industr. Informat. 2019, 15, 6541–6550. [Google Scholar] [CrossRef]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep Transfer Learning for Few-Shot SAR Image Classification. Remote Sens. 2019, 11, 1374. [Google Scholar] [CrossRef]
- Fang, B.; Kou, R.; Pan, L.; Chen, P. Category-Sensitive Domain Adaptation for Land Cover Mapping in Aerial Scenes. Remote Sens. 2019, 11, 2631. [Google Scholar] [CrossRef]
- Pires de Lima, R.; Marfurt, K. Convolutional Neural Network for Remote-Sensing Scene Classification: Transfer Learning Analysis. Remote Sens. 2020, 12, 86. [Google Scholar] [CrossRef]
- Weinstein, B.G.; Marconi, S.; Bohlman, S.; Zare, A.; White, E. Individual Tree-Crown Detection in RGB Imagery Using Semi-Supervised Deep Learning Neural Networks. Remote Sens. 2019, 11, 1309. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of Different Machine Learning Methods and Deep-Learning Convolutional Neural Networks for Landslide Detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Jiang, C.; Pang, Y. Perceptual image hashing based on a deep convolution neural network for content authentication. J. Electron. Imag. 2018, 27, 1–11. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Adiga, V.; Sivaswamy, J. FPD-M-net: Fingerprint Image Denoising and Inpainting Using M-Net Based Convolutional Neural Networks. Arxiv Comp. Vis. Pattern Recog. 2019, 51–61. [Google Scholar]
- Ibtehaz, N.; Rahman M, S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Net. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Bengio, Y.; LeCun, Y. Scaling learning algorithms towards AI. Large-Scale Kern. Mach. 2007, 34, 1–41. [Google Scholar]
- Xia, X.; Kulis, B. W-net: A deep model for fully unsupervised image segmentation. arXiv 2017, arXiv:1711.08506. [Google Scholar]
- Li, X.L.; Wang, Y.Y.; Tang, Q.S.; Fan, Z.; Yu, J.H. Dual U-Net for the Segmentation of Overlapping Glioma Nuclei. Ieee Access 2019, 7, 84040–84052. [Google Scholar] [CrossRef]
- Francia, G.A.; Pedraza, C.; Aceves, M.; Tovar-Arriaga, S. Chaining a U-Net with a Residual U-Net for Retinal Blood Vessels Segmentation. IEEE Access. 2020, 8, 38493–38500. [Google Scholar] [CrossRef]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3735–3739. [Google Scholar]
- Zhang, J.W.; Jin, Y.Z.; Xu, J.L.; Xu, X.W.; Zhang, Y.C. MDU-Net: Multi-scale Densely Connected U-Net for biomedical image segmentation. arXiv 2018, arXiv:1812.00352. [Google Scholar]
- Ren, W.Q.; Pan, J.S.; Zhang, H.; Cao, X.C.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks with holistic edges. Int. J. Comp. Vis. 2020, 128, 240–259. [Google Scholar] [CrossRef]
- Villamizar, M.; Canévet, O.; Odobez, J.M. Multi-scale sequential network for semantic text segmentation and localization. Recognit. Lett. 2020, 129, 63–69. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Ji, B.; Ren, J.J.; Zheng, X.J.; Tan, C.; Ji, R.; Zhao, Y.; Liu, K. A multi-scale recurrent fully convolution neural network for laryngeal leukoplakia segmentation. Process. Control. 2020, 59, 101913. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Ding, K.M.; Zhu, C.Q.; Lu, F.Q. An adaptive grid partition based perceptual hash algorithm for remote sensing image authentication. Wuhan Daxue Xuebao 2015, 40, 716–720. [Google Scholar]
- Ji, S.P.; Wei, S.Y. Building extraction via convolutional neural networks from an open remote sensing building dataset. Acta Geod. Et Cartogr. Sinica. 2019, 48, 448–459. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhang, Y.D.; Tang, S.; Li, J.T. Secure and Incidental Distortion Tolerant Digital Signature for Image Authentication. J. Comput. Sci. Technol. 2007, 22, 618–625. [Google Scholar] [CrossRef]
- Fang, W.; HU, H.M.; Hu, Z.; Liao, S.C.; Li, B. Perceptual hash-based feature description for person re-identification. Neurocomputing 2018, 272, 520–531. [Google Scholar] [CrossRef]
- Wang, H.; Wang, H.X. Perceptual Hashing-Based Image Copy-Move Forgery Detection. Secur. Commun. Netw. 2018, 2018, 1–11. [Google Scholar] [CrossRef]
- Singh, K.M.; Neelima, A.; Tuithung, T.; Singh, K.M. Robust Perceptual Image Hashing using SIFT and SVD. curr. Sci. 2019, 8, 117. [Google Scholar]
- Ouyang, J.L.; Liu, Y.Z.; Shu, H.Z. Robust Hashing for Image Authentication Using SIFT Feature and Quaternion Zernike Moments. Multimed. Tool Appl. 2017, 76, 2609–2626. [Google Scholar] [CrossRef]
- Lu, C.S.; Liao, H.Y.M. Structural digital signature for image authentication: An incidental distortion resistant scheme. Ieee Trans. Multimed. 2003, 5, 161–173. [Google Scholar]
- Zhang, Q.H.; Xing, P.F.; Huang, Y.B.; Dong, R.H.; Yang, Z.P. An efficient speech perceptual hashing authentication algorithm based on DWT and symmetric ternary string. Int. J. Informat. Comm. Technol. 2018, 12, 31–50. [Google Scholar]
- Yang, Y.; Zhou, J.; Duan, F.; Liu, F.; Cheng, L.M. Wave atom transform based image hashing using distributed source coding. J. Inf. Secur. Appl. 2016, 31, 75–82. [Google Scholar] [CrossRef]
- Neelima, A.; Singh, K.M. Perceptual Hash Function based on Scale-Invariant Feature Transform and Singular Value Decomposition. Comput. J. 2018, 59, 1275–1281. [Google Scholar] [CrossRef]
- Kozat, S.S.; Venkatesan, R.; Mihcak, M.K. Robust perceptual image hashing via matrix invariants. In Proceedings of the 2004 International Conference on Image Processing (ICIP), Singapore, 24–27 October 2004; pp. 3443–3446. [Google Scholar]
- Ding, K.; Meng, F.; Liu, Y.; Xu, N.; Chen, W. Perceptual Hashing Based Forensics Scheme for the Integrity Authentication of High Resolution Remote Sensing Image. Information 2018, 9, 229. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.W.; Hu, F.; Shi, B.G.; Bai, X.; Zhong, Y.F.; Zhang, L.P. AID: A Benchmark Dataset for Performance Evaluation of Aerial Scene Classification. Ieee Trans. Geo. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhu, Q.Q.; Zhong, Y.F.; Zhao, B.; Xia, G.S.; Zhang, L.P. Bag-of-Visual-Words Scene Classifier With Local and Global Features for High Spatial Resolution Remote Sensing Imagery. IEEE Geo. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Dai, D.; Yang, W. Satellite Image Classification via Two-Layer Sparse Coding With Biased Image Representation. IEEE Geo Remote Sens. Lett. 2011, 8, 173–176. [Google Scholar] [CrossRef]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digital Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Xiong, H.K.; Gao, X.; Li, S.H.; Xu, Y.H.; Wang, Y.Z.; Yu, H.Y.; Liu, X.; Zhang, Y.F. Interpretable, structured and multimodal deep neural networks. Recogn Artif. Intell. 2018, 31, 1–11. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tampering Test | Algorithm Based on DCT | Algorithm Based on SIFT | Algorithm Based on DWT | Algorithm Based on SVD | Algorithm in [13] | Algorithm in [62] | This Algorithm (T = 0.02) | This Algorithm (T = 0.01) |
|---|---|---|---|---|---|---|---|---|
| Lossy compressed image | 0.045 unpassed | 0.02 unpassed | 0.017 passed | 0.008 passed | 0.021 unpassed | 0.15 unpassed | 0.009 passed | 0.009 passed |
| Noise added image | 0.011 passed | 0.008 passed | 0.015 passed | 0.006 passed | 0.017 passed | 0.14 unpassed | 0.015 passed | 0.015 unpassed |
| subject unrelated tampering one | 0.000 passed | 0.005 passed | 0.008 passed | 0.002 passed | 0.022 unpassed | 0.11 unpassed | 0.013 passed | 0.013 unpassed |
| subject unrelated tampering two | 0.016 passed | 0.008 passed | 0.014 passed | 0.006 passed | 0.025 unpassed | 0.12 unpassed | 0.007 passed | 0.007 passed |
| subject unrelated tampering three | 0.033 unpassed | 0.012 unpassed | 0.019 passed | 0.008 passed | 0.030 unpassed | 0.14 unpassed | 0.016 passed | 0.016 unpassed |
| subject related tampering one | 0.031 unpassed | 0.020 unpassed | 0.022 unpassed | 0.014 unpassed | 0.032 unpassed | 0.24 unpassed | 0.026 unpassed | 0.026 unpassed |
| subject related tampering two | 0.026 unpassed | 0.019 unpassed | 0.018 passed | 0.015 unpassed | 0.035 unpassed | 0.22 unpassed | 0.024 unpassed | 0.024 unpassed |
| subject related tampering three | 0.052 unpassed | 0.035 unpassed | 0.027 unpassed | 0.019 unpassed | 0.043 unpassed | 0.25 unpassed | 0.045 unpassed | 0.045 unpassed |
| subject related tampering four | 0.068 unpassed | 0.044 unpassed | 0.051 unpassed | 0.025 unpassed | 0.048 unpassed | 0.27 unpassed | 0.051 unpassed | 0.051 unpassed |
| Tampering Test | Algorithm Based on U-Net | Algorithm Based on M-Net | Algorithm Based on MultiResUnet | Algorithm Based on Our Model |
|---|---|---|---|---|
| Lossy compressed image | 0.021 | 0.014 | 0.0039 | 0.011 |
| Noise added pictures | 0.015 | 0.013 | 0.0026 | 0.012 |
| subject unrelated tampering one | 0.016 | 0.014 | 0.014 | 0.014 |
| subject unrelated tampering two | 0.082 | 0.019 | 0.005 | 0.011 |
| subject unrelated tampering three | 0.076 | 0.018 | 0.009 | 0.016 |
| subject related tampering one | 0.109 | 0.012 | 0.008 | 0.033 |
| subject related tampering two | 0.088 | 0.072 | 0.027 | 0.064 |
| subject related tampering three | 0.095 | 0.087 | 0.078 | 0.11 |
| subject related tampering four | 0.041 | 0.062 | 0.037 | 0.085 |
| Manipulation | Algorithm Based on U-Net | Algorithm Based on M-Net | Algorithm Based on MultiResUnet | Algorithm Based on Our Model |
|---|---|---|---|---|
| TS1T | 100% | 100% | 100% | 100% |
| TSAID | 99.5% | 100% | 100% | 100% |
| TSMerced | 98.0% | 100% | 100% | 100% |
| TSRS19 | 99.5% | 99.5% | 100% | 99.5% |
| TSDOTA | 98.8% | 100% | 100% | 100% |
| TS3T | 95.8% | 99.6% | 100% | 99.8% |
| Manipulation | Algorithm Based on U-Net | Algorithm Based on M-Net | Algorithm Based on MultiResUnet | Algorithm Based on Our Model |
|---|---|---|---|---|
| TS1T | 77.0% | 86.5% | 92.0% | 89.5% |
| TSAID | 81.0% | 88.0% | 94.0% | 91.0% |
| TSMerced | 75.5% | 84.0% | 91.5% | 89.5% |
| TSRS19 | 78.5% | 87.0% | 93.0% | 90.5% |
| TSDOTA | 82.5% | 84.5% | 95.6% | 88.5% |
| TS3T | 75.1% | 86.3% | 91.6% | 90.3% |
| Manipulation | Algorithm Based on U-Net | Algorithm Based on M-Net | Algorithm Based on MultiResUnet | Algorithm Based on Our Model |
|---|---|---|---|---|
| TS1T | 81.5% | 89.0% | 94.0% | 93.0% |
| TSAID | 84.0% | 90.5% | 95.0% | 92.0% |
| TSMerced | 82.5% | 90.0% | 94.5% | 92.0% |
| TSRS19 | 82.5% | 89.0% | 95.5% | 91.5% |
| TSDOTA | 83.0% | 87.6% | 95.1% | 90.5% |
| TS3T | 79.1% | 90.2% | 94.0% | 91.9% |
| Manipulation | Algorithm Based on U-Net | Algorithm Based on M-Net | Algorithm Based on MultiResUnet | Algorithm Based on Our Model |
|---|---|---|---|---|
| TS1T | 93.0% | 94.0% | 99.0% | 97.5% |
| TSAID | 92.5% | 94.5% | 99.5% | 95.5% |
| TSMerced | 91.5% | 95.5% | 99.0% | 95.5% |
| TSRS19 | 90.5% | 94.0% | 98.5% | 95.0% |
| TSDOTA | 88.6% | 91.2% | 96.4% | 94.4% |
| TS3T | 89.5% | 92.9% | 95.5% | 94.8% |
| Threshold | Algorithm Based On U-Net | Algorithm Based on M-Net | Algorithm Based on MultiResUnet | Algorithm Based on Our Model |
|---|---|---|---|---|
| T = 0.01 | 22.5% | 34.5% | 96% | 27.5% |
| T = 0.02 | 39.0% | 45.5% | 97.5% | 40.5% |
| T = 0.03 | 53.5% | 58.0% | 100% | 51.5% |
| T = 0.05 | 84.0% | 87.0% | 100% | 76.5% |
| Threshold | Algorithm Based on U-Net | Algorithm Based on M-Net | Algorithm Based on MultiResUnet | Algorithm Based on Our Model |
|---|---|---|---|---|
| T = 0.01 | 0.0% | 1.0% | 4.5% | 0.0% |
| T = 0.02 | 6.5% | 16.5% | 24.0% | 15.0% |
| T = 0.03 | 22.0% | 28.5% | 38.0% | 26.5% |
| T = 0.04 | 31.0% | 37.0% | 52.5% | 33.0% |
| Threshold | Algorithm Based on U-Net | Algorithm Based on M-Net | Algorithm Based on MultiResUnet | Algorithm Based On Our Model |
|---|---|---|---|---|
| T = 0.01 | 0.0% | 5.0% | 11.0% | 0.5% |
| T = 0.02 | 2.5% | 7.0% | 15.0% | 3.5% |
| T = 0.03 | 6.5% | 12.5% | 25.5% | 8.0% |
| T = 0.04 | 13.5% | 20.5% | 39.0% | 15.0% |
| Threshold | Algorithm Based on U-Net | Algorithm Based on M-Net | Algorithm Based on MultiResUnet | Algorithm Based on Our Model |
|---|---|---|---|---|
| T = 0.01 | 0.0% | 1.5% | 23.0% | 1.0% |
| T = 0.02 | 9.0% | 8.5% | 38.5% | 5.5% |
| T = 0.03 | 11.0% | 10.0% | 44.5% | 9.0% |
| T = 0.04 | 12.5% | 14.0% | 56.0% | 11.5% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, K.; Liu, Y.; Xu, Q.; Lu, F. A Subject-Sensitive Perceptual Hash Based on MUM-Net for the Integrity Authentication of High Resolution Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2020, 9, 485. https://doi.org/10.3390/ijgi9080485
Ding K, Liu Y, Xu Q, Lu F. A Subject-Sensitive Perceptual Hash Based on MUM-Net for the Integrity Authentication of High Resolution Remote Sensing Images. ISPRS International Journal of Geo-Information. 2020; 9(8):485. https://doi.org/10.3390/ijgi9080485
Chicago/Turabian StyleDing, Kaimeng, Yueming Liu, Qin Xu, and Fuqiang Lu. 2020. "A Subject-Sensitive Perceptual Hash Based on MUM-Net for the Integrity Authentication of High Resolution Remote Sensing Images" ISPRS International Journal of Geo-Information 9, no. 8: 485. https://doi.org/10.3390/ijgi9080485
APA StyleDing, K., Liu, Y., Xu, Q., & Lu, F. (2020). A Subject-Sensitive Perceptual Hash Based on MUM-Net for the Integrity Authentication of High Resolution Remote Sensing Images. ISPRS International Journal of Geo-Information, 9(8), 485. https://doi.org/10.3390/ijgi9080485