To verify the effectiveness of SR-SegNet proposed in this paper, experiments were carried out on Lake and River dataset. Furthermore, semantic segmentation models were used as the control groups. All experiments were evaluated based on four major metrics, including Accuracy (Ac), Dice, F1-Score (F1), and Mean intersection over union (Miou). Experimental results show that the network proposed in this paper exceeded all comparing networks on the evaluation metrics.
3.3. Experiment Setting and Training
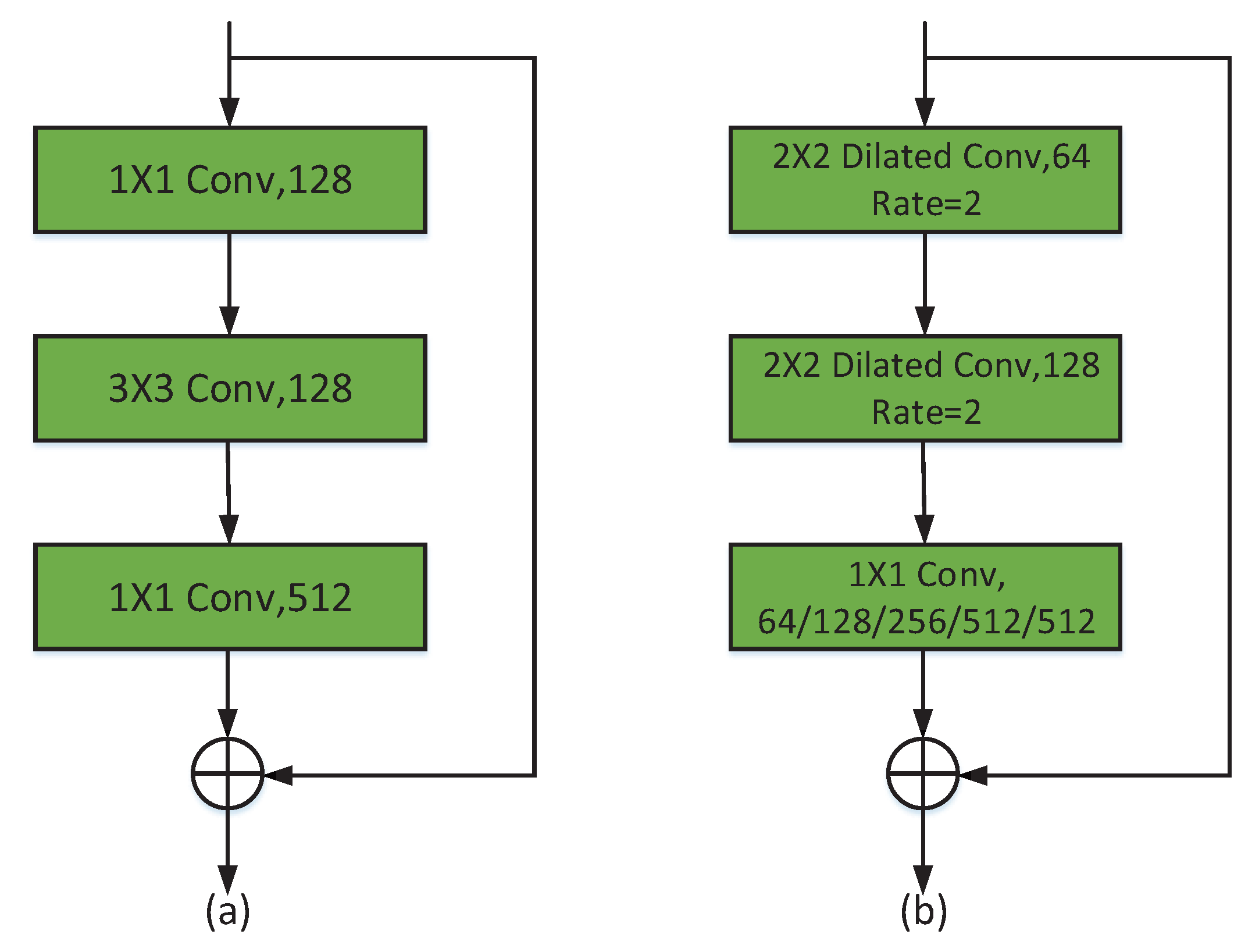
In the experiment, VGGNet was used as the backbone network, and the official VGGNet weights published by keras were used as the pre-training weights. DeconvNet, FCN32s, FCN16s, and FCN8s were selected as the comparison networks. In this paper, SR-SegNet v1 and SR-SegNet v2 are proposed. The residual block of SR-SegNet v1 did not use dilated convolutions, and the residual block of SR-SegNet v2 used 2 × 2 dilated convolutions with a dilation rate of 2. During training phase, the SGD optimizer [
38] with an initial learning rate of 0.0001 was used. The momentum was set to 0.9 and the weight decay was set to 0.0005. All models were trained for 300 epochs with a mini-batch size of 2. All experiments were carried out under windows 10 with a AMD Ryzen 7 2700 CPU (3.2 GHz), 16GB of memory (RAM), and a NVIDIA GeForce RTX 2070 (8 GB). Python 3.6 was used and the experiments were based on the keras programming framework. Furthermore, the cross entropy was used as the loss function of neural network, as shown in Equation (
9).
x represents the sample;
p (x) and
q (x), respectively, represent two separate probability distributions of random variable
x; and
n is the number of samples.
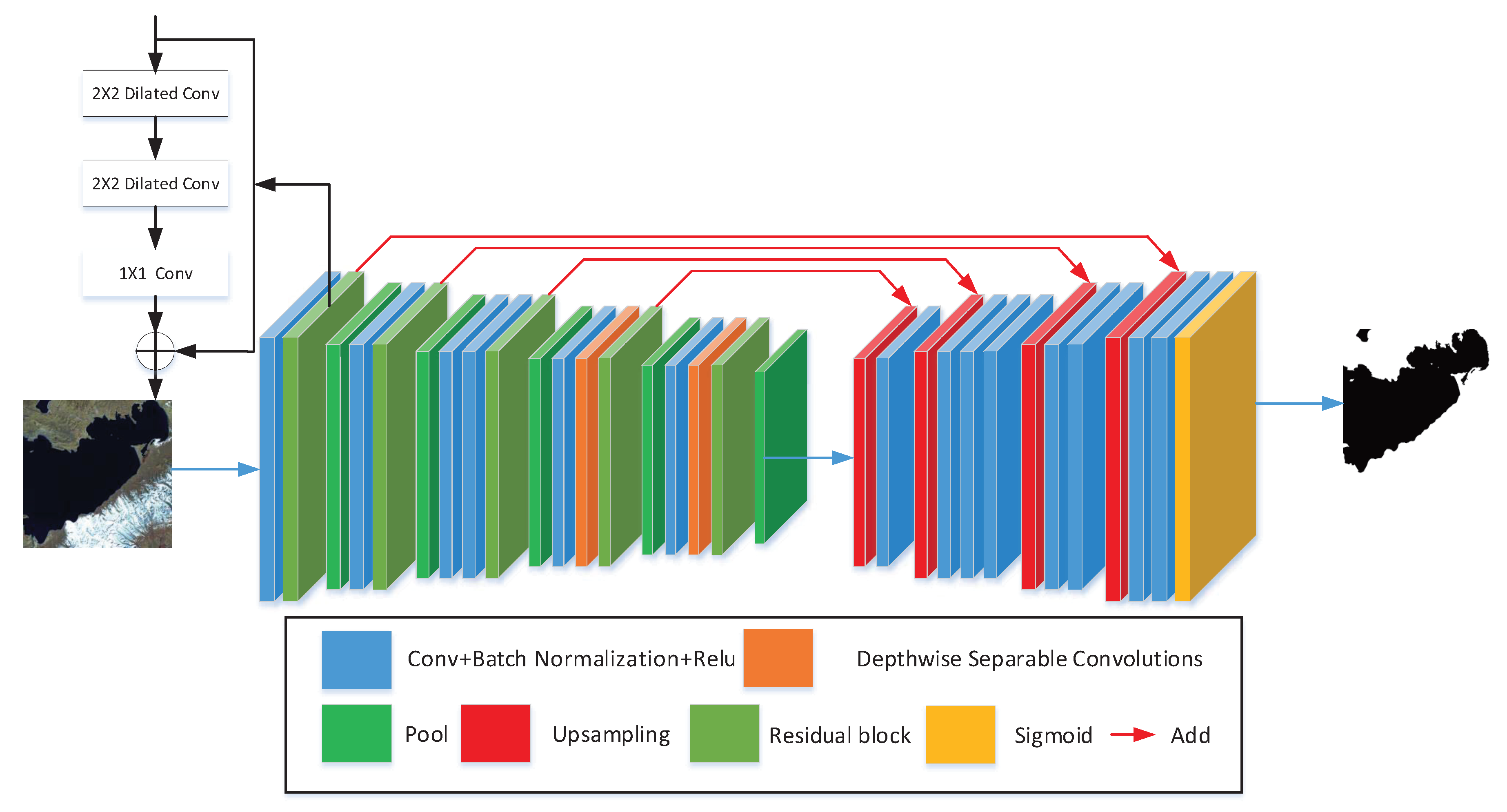
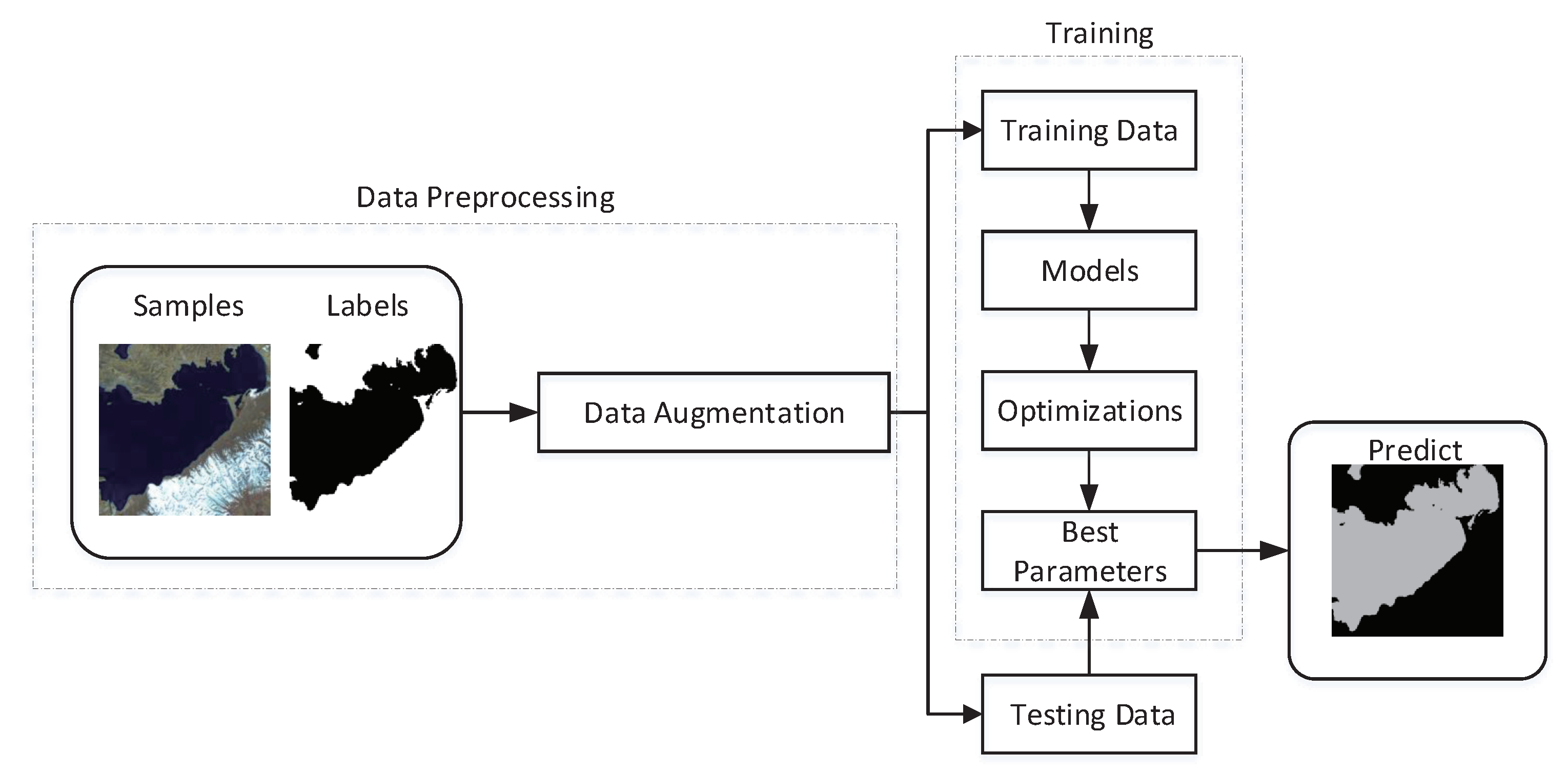
The proposed water area segmentation system is illustrated in
Figure 7. First, the Lake and River dataset was preprocessed to generate more data for neural network training through data augmentation; this technique increases the complexity of data and effectively reduces the overfitting of training [
39]. Second, the dataset was divided into training set and testing set, and the images from the training set were put into the model for training. The training procedure used the gradient descent algorithm. The labels were compared with predicted results, and the parameters were updated continuously by using back propagation and calculating the loss function [
40]. Finally, the model’s optimal parameters were saved to predict and evaluate lake and river images in the testing set.
3.4. Result Analysis
The experiments prove that the proposed SR-SegNet v1 and SR-SegNet v2 in this paper reduce the number of parameters by 65% and 71%, respectively, compared with the classical SegNet, and the training speed of v1 is improved by more than 10%. In addition, the Miou of v2 is improved by 2.37%. The results are shown in
Table 2 and
Table 3.
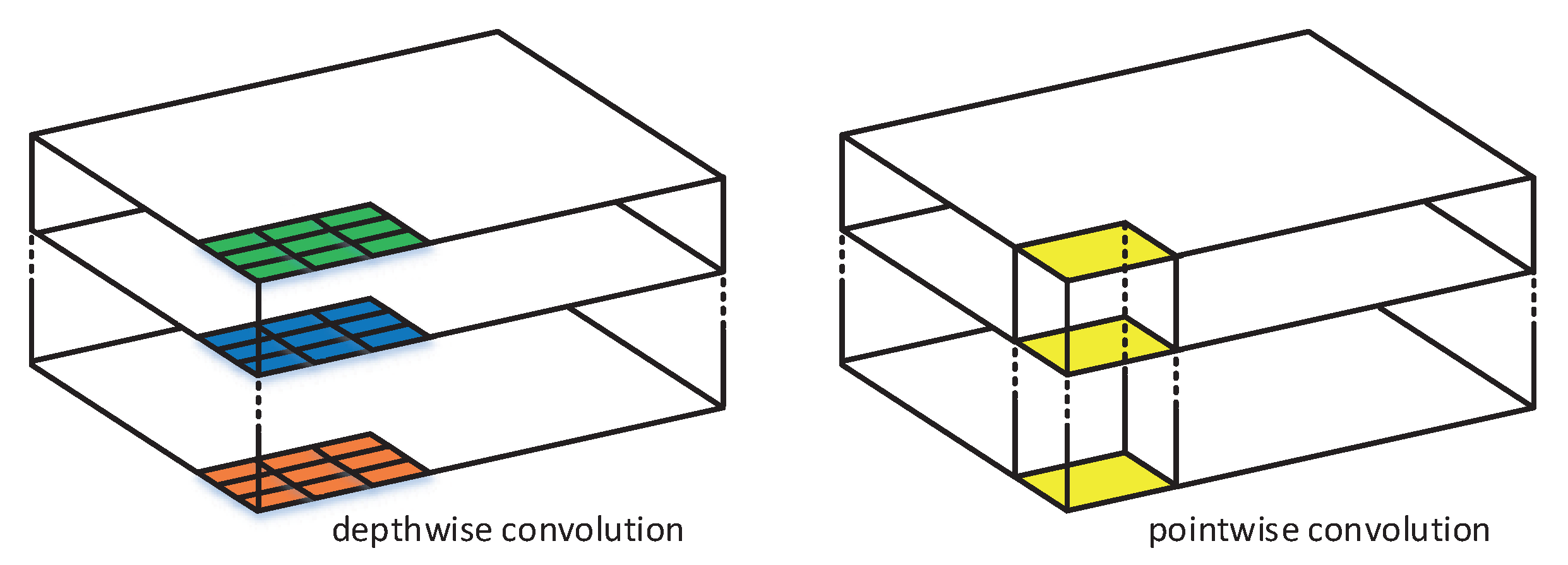
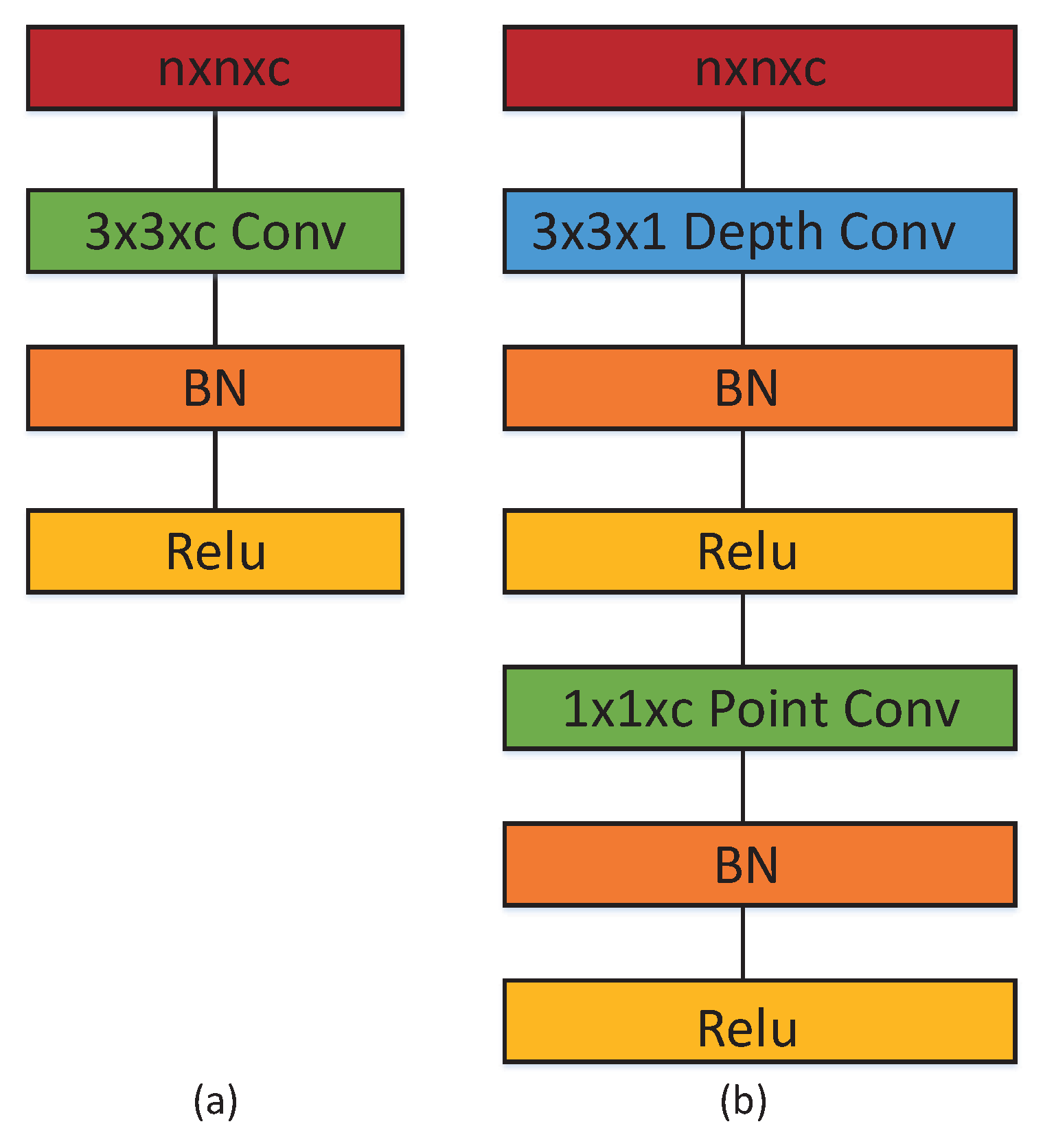
Because the classical SegNet uses a lot of convolution kernels, it generates a large number of parameters, making the model difficult to train and converge. In this paper, two improved networks are proposed. For the convolution layer, we use depthwise separable convolutions instead of standard convolutions, which greatly decreases the parameter numbers, shortens the training time, and makes the model easier to converge. Besides, the information loss caused by using this technique is at an acceptable level. In the experiment, the parameter numbers of SR-SegNet v1 is decreased by 71% and its training time is reduced by 18.3%. To compensate for the information loss caused by the usage of depthwise separable convolutions, we introduce dilated convolutions into the modified residual block and propose SR-SegNet v2. SR-SegNet v2’s parameter number is slightly increased compared with SR-SegNet v1, and its training time is reduced by 7.7% compared with the classical SegNet.
To compare the performance of each model, we tested every model under the same conditions.
Table 3 shows the segmentation metrics of each model on the testing set. It can be seen that the metrics of SegNet are superior to those of FCN and DeconvNet. Compared with FCN8s, SegNet’s Ac, Dice, F1 and Miou are 4.88%, 17.2%, 7.83%, and 1.32% higher, respectively. Compared to the classical SegNet, SR-SegNet v2 yields a higher F1 by 0.1% (0.9949 vs. 0.9939), a higher Dice by 1.2% (0.9437 vs. 0.9317), and a higher Miou by 2.37% (0.9322 vs. 0.9085).
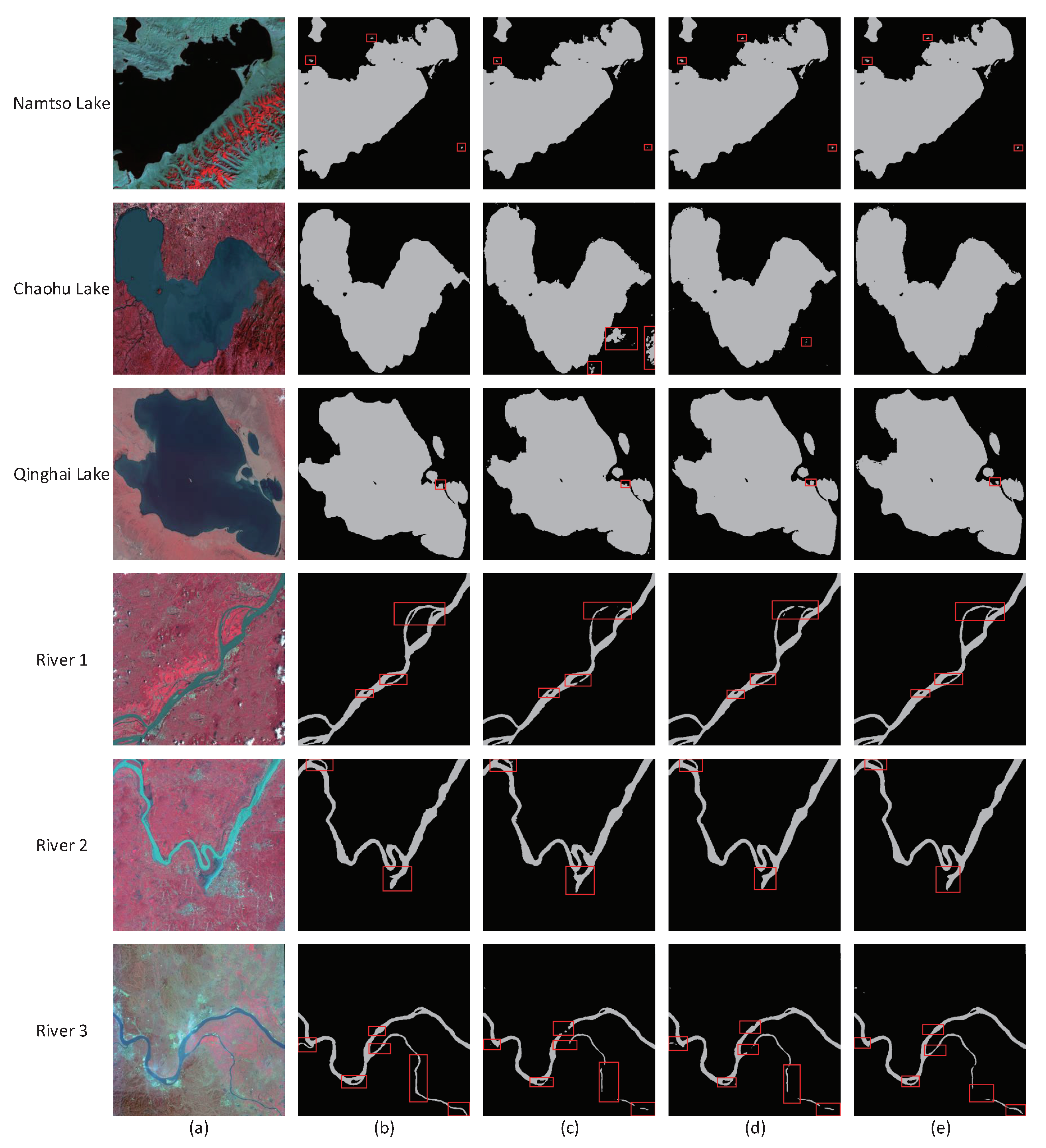
To further demonstrate the generalization performance of the network, the network trained using the Namsto Lake dataset was used to identify other lakes. In
Figure 8, the first row is Namtso Lake, the second row is Chaohu Lake, and the third row is Qinghai Lake. It can be seen in
Figure 8 that FCN and DeconvNet both adopt a simple encoding–decoding structure, and thus they could only identify the edge of the target very generally. The image spatial information is ignored in the extraction by FCN and DeconvNet, and thus neither extraction of lake boundary is fine enough. SR-SegNet can extract the lake location and boundary information better. In
Figure 8f, it can be seen that SegNet has a better segmentation ability for all three lakes, but the details of the lakes are not extracted correctly, and the non-lake parts of Chaohu Lake are misidentified. Note that SR-SegNet can effectively solve the problem of network degradation and small lake recognition.
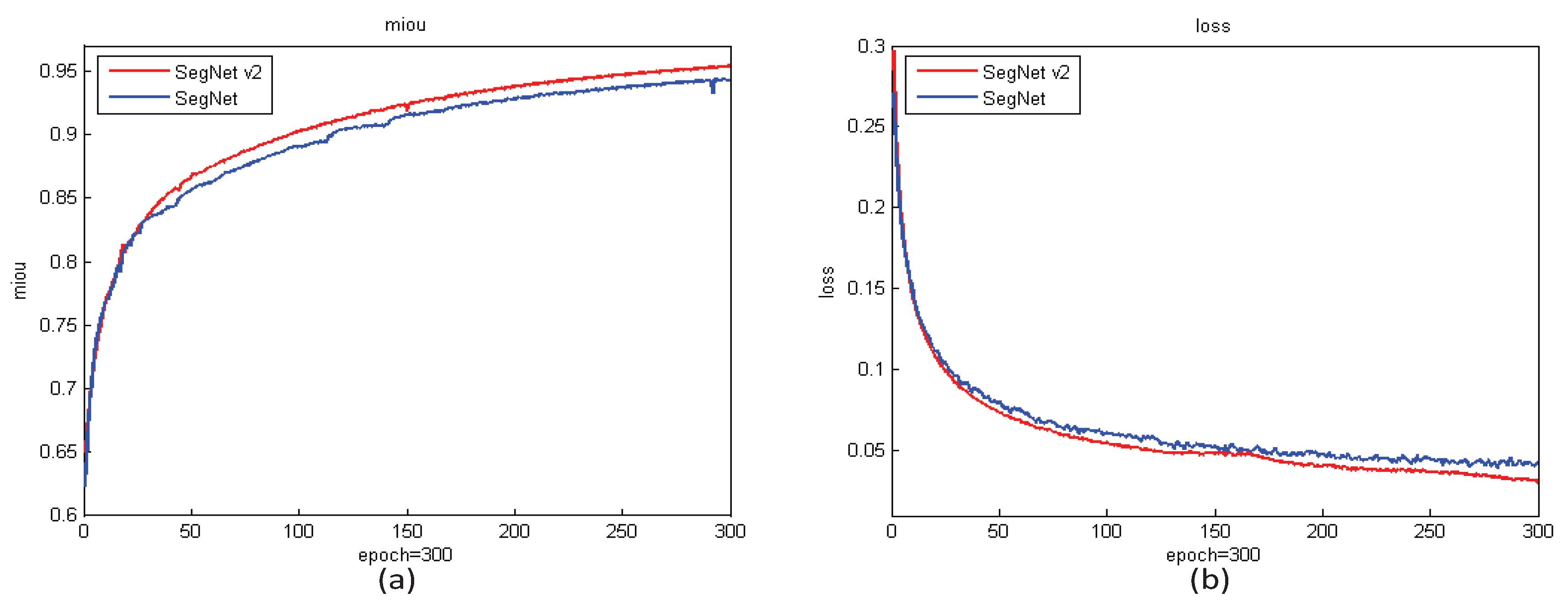
Figure 9 shows the training curves of SR-SegNet v2 and SegNet. It can be seen that SR-SegNet v2 performs better than SegNet, and its training process is smoother, whereas SegNet has many fluctuations. It is shown that the performance of the model is further improved with modified residual blocks added.
To demonstrate the superiority of the networks proposed in this paper, SegNet, SR-SegNet v1, and SR-SegNet v2 were tested and evaluated, respectively. Note that the proportion of lakes in a remote sensing image is relatively large, and the proportion of rivers in a remote sensing image is relatively small. Remote sensing images of lakes and rivers with both more positive pixels and fewer positive pixels were analyzed, respectively, in the experiment.
Table 4 shows the number of positive pixels (water body) and negative pixels (background) of six remote sensing images selected from the test images. The proportion represents the ratio of the number of positive pixels to total pixels. It can be seen that in a
pixel remote sensing image, the number of lake pixels is 6 to 10 times greater than those of rivers.
The segmentation results of test picture are shown in
Figure 10. It can be seen that SegNet has a good segmentation ability for remote sensing images of lakes with more positive pixels. However, in the first row, the “small lake” near Namtso Lake is not recognized, proving that SegNet’s detection ability of small targets is poor. In contrast, SR-SegNet v2 solves this problem, with dilated convolutions in its modified residual blocks. This modification ensures the network’s better performance and increases the receptive field of the convolution layer. In the second row, SegNet dose not do well in Chaohu Lake’s segmentation, and there are many noises around the lake. However, the two improved networks proposed in this paper avoid degradation during training process and greatly reduce the noises, as a result of the introduction of modified residual blocks. The third row is the segmentation of Qinghai Lake; the extraction of lake boundary is not fine enough, which is also a problem to be solved in the future. It is worth noting that remote sensing images of Namtso Lake were used in training in this experiment, and remote sensing images of Qinghai Lake and Chaohu Lake were not included in the training set. However, good segmentation results for Qinghai lake and Chaohu Lake are given by SR-SegNet, which clearly proves the generalization abilities of the proposed networks.
In the experiments, it was found that river segmentation of SegNet is not as good as for the lake. This phenomenon has the following two explanations: first, the proportion of positive pixels in a river image is far less than the proportion of negative pixels; and, second, the extraction of river features is more complex than that of lake features. The classical SegNet performance degrades because there are too many deep layers, and a large number of training parameter is not helpful in dealing with complex features such as those of rivers. SR-SegNet V1 and SR-SegNet v2 are proposed to reduce the upsampling time and the training parameter number by using depth separable convolutions. At the same time, to reduce the depth of the network without affecting feature extraction, the modified residual block is introduced into the encoding stage to alleviate the problem of network degradation and extract more information. As shown in
Figure 10, SR-SegNet is more effective in river segmentation, its results are closer to the real labels, and it can extract complex features which SegNet cannot. SR-SegNet v2 adds dilated convolutions to its convolution layers to further increase its receptive field. In the segmentation of Rivers 1 and 3, SegNet doe not work well on small river detection, because it cannot extract enough spatial information. In contrast, with the introduction of modified residual blocks, our proposed method can effectively extract spatial information for small river identification. In
Figure 10, SR-SegNet v2 is able to segment River 3. As its receptive field expands, SR-SegNet v2 has a better result on river reach segmentation, and the result fully proves the effectiveness of dilated convolutions.
The model-testing times are shown in
Table 5. After introducing depthwise separable convolutions and the residual structure, the network is simplified. The average testing time of SR-SegNet v1 is 27% shorter than that of the classical SegNet. In SR-SegNet v2, with extra dilated convolutions, the network computation is increased. Therefore, its average testing speed is only about 10% faster than that of the classical SegNet.
The results of the quantitative comparison are summarized in
Table 6. In experiments on three lakes, it can be seen that SR-SegNet does not greatly outperform the classical SegNet; it only shows a small improvement. SR-SegNet v2 has a 99.56% Ac and a 94.92% Miou in the lake extraction, 0.06% and 0.35% higher than those of the classical SegNet, respectively.
However, for an image with complex rivers, where the number of positive pixels is far fewer than the number of negative pixels, the Ac and F1 of these three networks are relatively high, because there are fewer categories to classify, and the proportion of negative pixels in each image is very high. The selected Miou can distinguish all three networks more accurately. For Miou, SR-SegNet v2 hits the highest score with a gain of 2.46% compared to the classical SegNet (0.9311 vs. 0.9065) and SR-SegNet v1 achieves an improvement of 2.39% over the classical SegNet (0.9304 vs. 0.9065). The superiority of proposed networks in this paper for river extraction is thereby verified.
3.5. Verification Experiment
To further verify the generalization abilities of the models proposed in this paper, Cityscapes, a public dataset, was selected for further experiment. Due to the limitation of computer memory, this experiment did not use all categories of the Cityscapes dataset. Only four categories, namely human, car, road, and background, were selected. Then 2975 pictures were used as the training dataset and 2975 pictures as the validation dataset. With the Adam optimizer, the initial learning rate was 0.0001, the weight attenuation rate was 0.0005, the training batch batch-size was 3, and the iteration was 160 times.
The research topic of this paper is water area segmentation. To verify the generalization performance and effectiveness of the algorithms proposed in this paper, we selected a different dataset for verification. The biggest difference between the Cityscapes dataset and the water area segmentation dataset is that their objects are different, but using different objects for verification can better demonstrate the generalization performance of the networks proposed in this paper. The experimental results are shown in
Table 7. We can see that the training speed of V2 is increased by about 8.3%, and its Miou is also increased by 1.01%. Therefore, the generalization performance and effectiveness of the proposed network is verified.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}