Spatio-Temporal Research Data Infrastructure in the Context of Autonomous Driving

Abstract
1. Introduction
2. Overview of the Research Project and Its Requirements Concerning Data Management
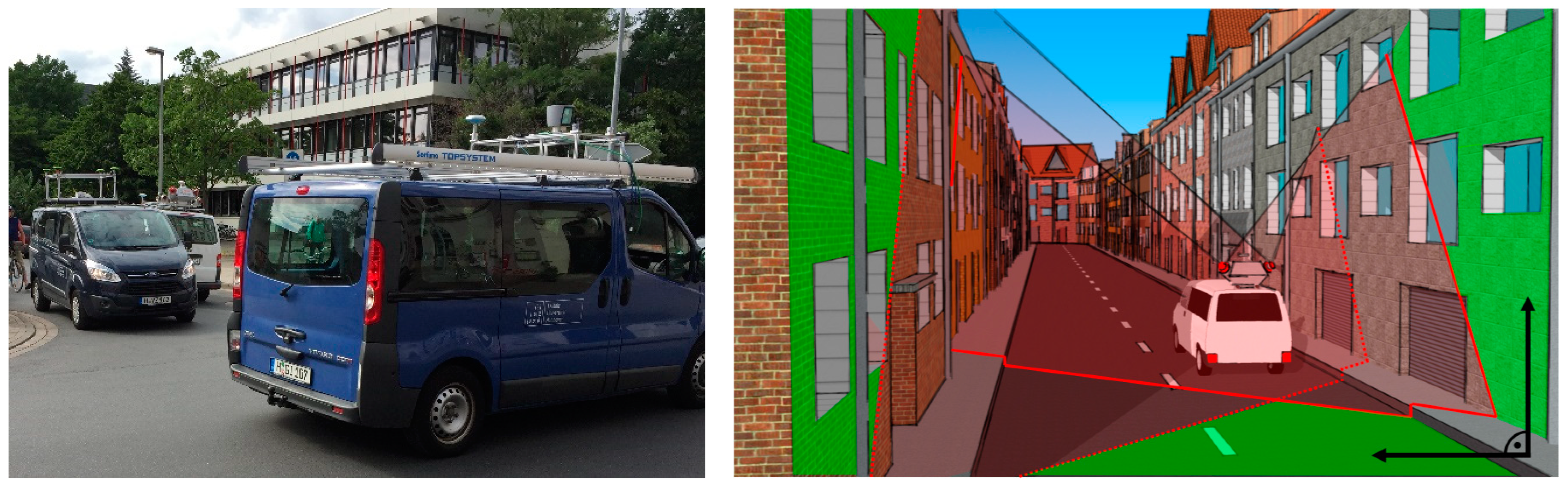
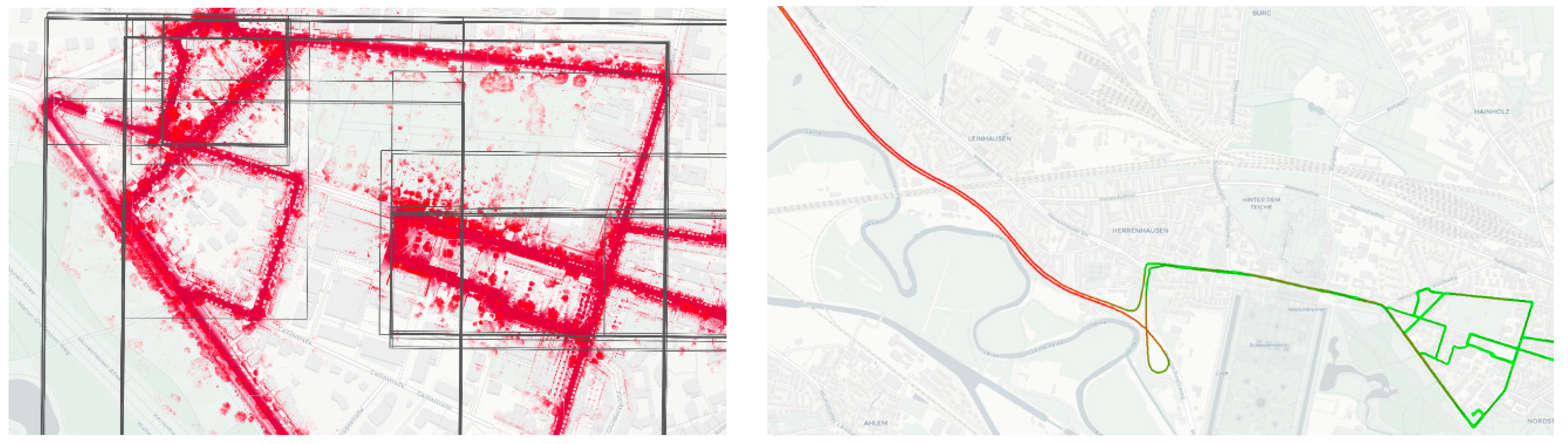
2.1. Experiments and Data
2.2. Challenges and Goals
3. Related Work
4. Proposed Data Storage Solution—System Overview
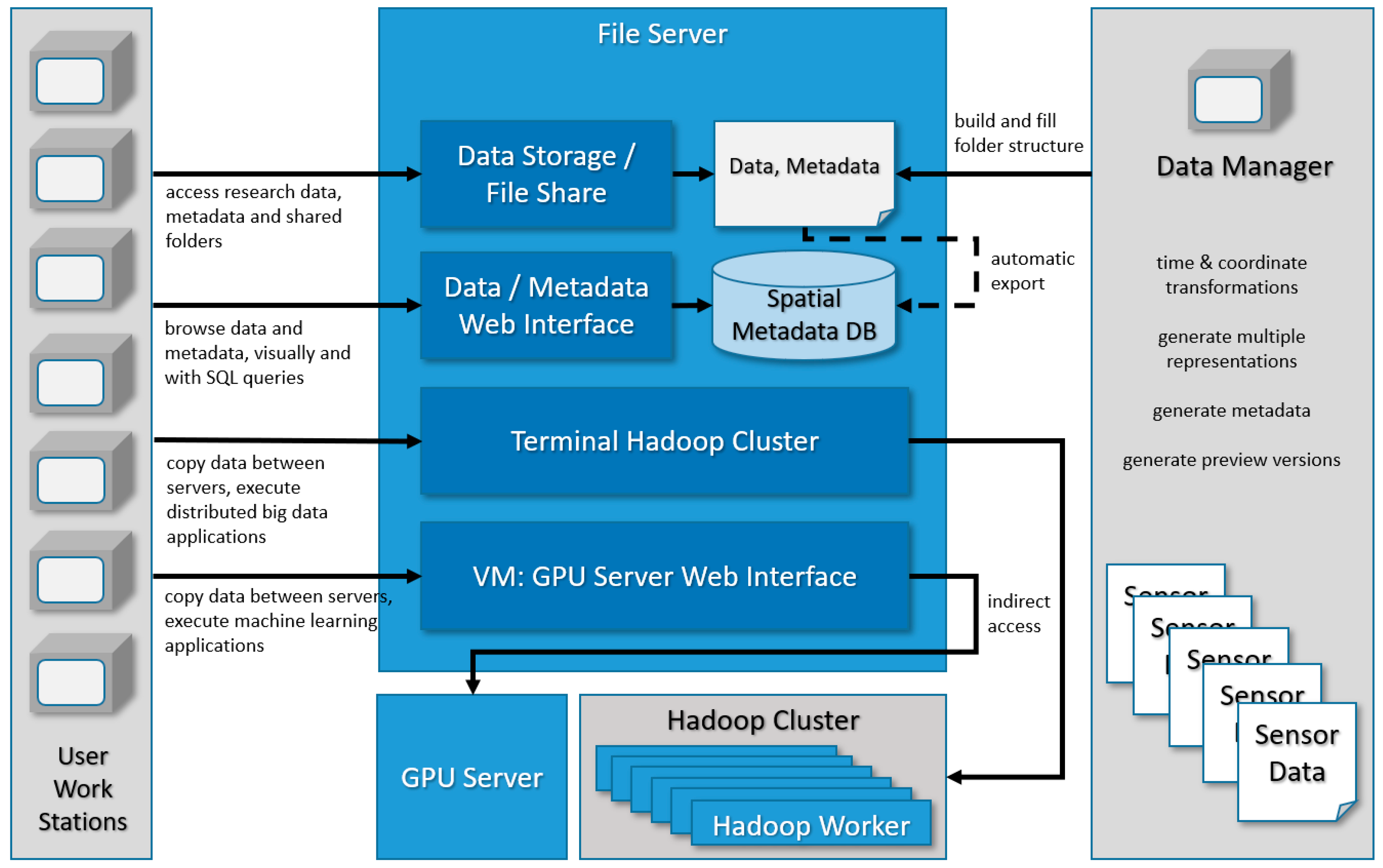
4.1. IT Infrastructure
4.2. Physical Data Storage
4.3. Metadata
4.4. Spatial Database
4.5. Web Interface and WebGIS
4.6. Hadoop Cluster/GPU Cluster
5. Data Management
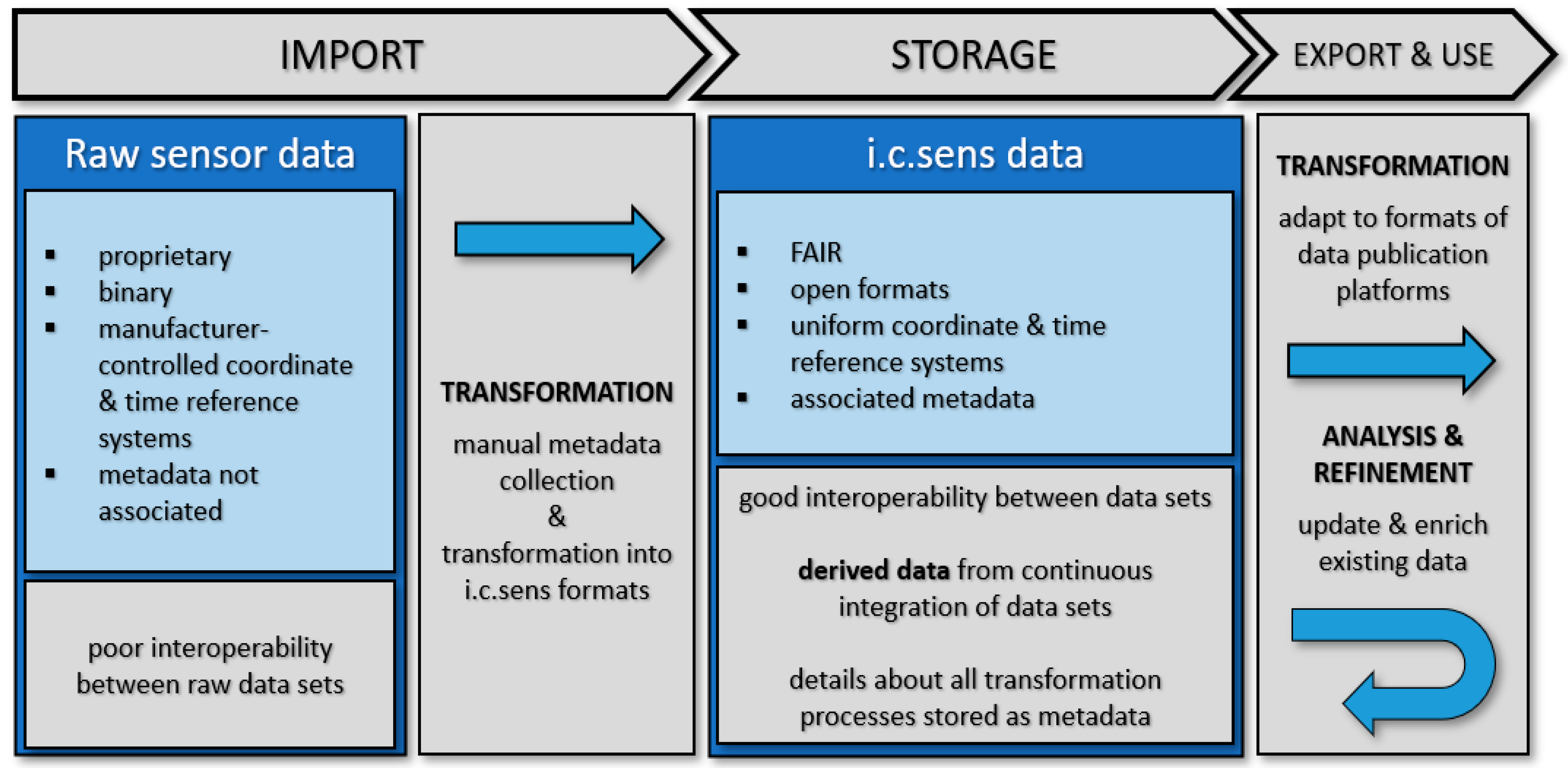
5.1. Data Preparation and Post-Processing
5.2. Data Ingestion Example
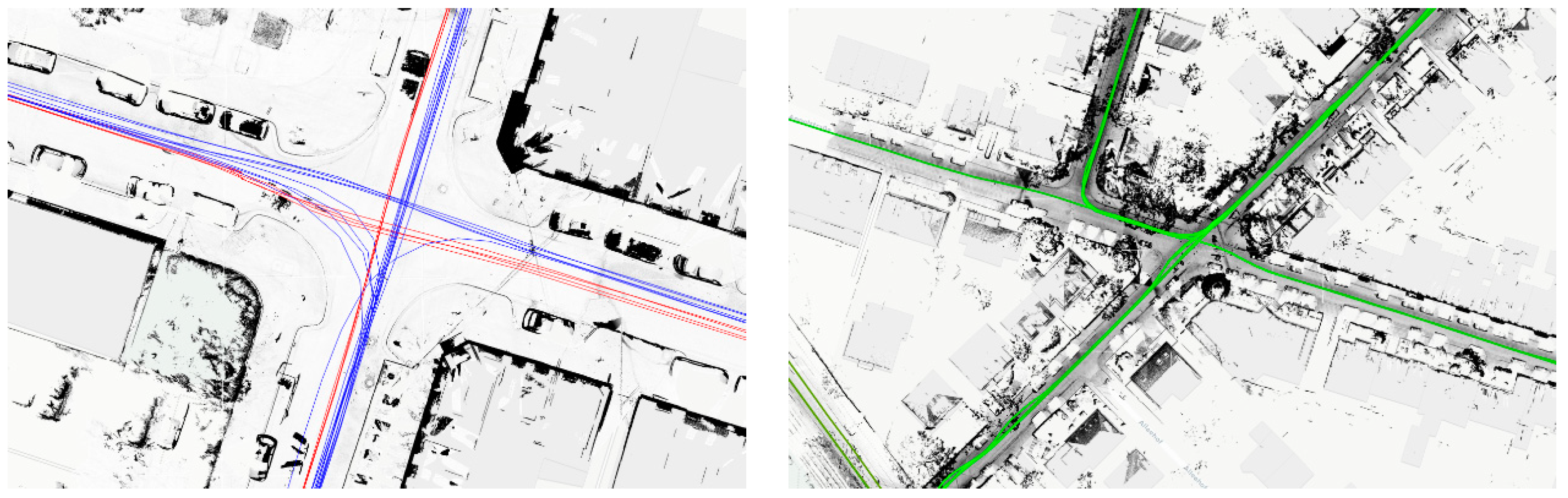
5.3. Data Usage Examples
6. Summary and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; de Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Schön, S.; Brenner, C.; Alkhatib, H.; Coenen, M.; Dbouk, H.; Garcia-Fernandez, N.; Kuntzsch, C.; Heipke, C.; Lohmann, K.; Neumann, I.; et al. Integrity and Collaboration in Dynamic Sensor Networks. Sensors 2018, 18, 2400. [Google Scholar] [CrossRef] [PubMed]
- Principles for the Handling of Research Data. Available online: https://www.mpg.de/230783/Principles_Research_Data_2010.pdf (accessed on 18 August 2020).
- Kaplan, E.D.; Hegarty, C.J. Understanding GPS/GNSS: Principles and Applications, 3rd ed.; Artech House: London, UK, 2017. [Google Scholar]
- Reid, T.G.; Houts, S.E.; Cammarata, R.; Mills, G.; Agarwal, S.; Vora, A.; Pandey, G. Localization requirements for autonomous vehicles. SAE Int. J. Connect. Autom. Veh. 2019, 2, 173–190. [Google Scholar] [CrossRef]
- Schön, S. Integrity—A Topic for Photogrammetry? In The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences XLIII-B1-2020, Proceedings of the XXIV ISPRS Congress, Virtual Event, 31 August–2 September 2020; Copernicus GmbH: Göttingen, Germany, 2020; pp. 565–571. [Google Scholar]
- Voges, R.; Wieghardt, C.S.; Wagner, B. Finding Timestamp Offsets for a Multi-Sensor System Using Sensor Observations. Photogramm. Eng. Remote Sens. 2018, 84, 357–366. [Google Scholar] [CrossRef]
- Dbouk, H.; Schön, S. Reliability and Integrity Measures of GPS Positioning via Geometrical Constraints. In Proceedings of the 2019 International Technical Meeting of The Institute of Navigation, Reston, Virginia, 28–31 January 2019; pp. 730–743. [Google Scholar]
- Garcia Fernandez, N.; Schön, S. Optimizing Sensor Combinations and Processing Parameters in Dynamic Sensor Networks. In Proceedings of the 32nd International Technical Meeting of the Satellite Division of The Institute of Navigation (ION GNSS+ 2019), Miami, FL, USA, 16–20 September 2019; pp. 2048–2062. [Google Scholar]
- Schachtschneider, J.; Schlichting, A.; Brenner, C. Assessing Temporal Behavior in LiDAR Point Clouds of Urban Environments. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2017, XLII-1/W1, 543–550. [Google Scholar] [CrossRef]
- Peters, T.; Brenner, C. Conditional Adversarial Networks for Multimodal Photo-Realistic Point Cloud Rendering. PFG 2020, 88, 257–269. [Google Scholar] [CrossRef]
- Coenen, M.; Rottensteiner, F.; Heipke, C. Precise vehicle reconstruction for autonomous driving applications. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, IV-2/W5, 21–28. [Google Scholar] [CrossRef]
- Nguyen, U.; Rottensteiner, F.; Heipke, C. Confidence-aware pedestrian tracking using a stereo camera. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, IV-2/W5, 53–60. [Google Scholar] [CrossRef]
- Gray, J.; Chaudhuri, S.; Bosworth, A.; Layman, A.; Reichart, D.; Venkatrao, M.; Pellow, F.; Pirahesh, H. Datacube: A relational aggregation operator generalizing group-by, cross-tab and sub-totals. In Proceedings of the 12th International Conference on Data Engineering, New Orleans, LA, USA, 26 February–1 March 1996; pp. 152–159. [Google Scholar]
- Kraak, M.-J. The space-time cube revisited from a geovisualization perspective. In Proceedings of the 21st International Cartographic Conference, Durban, South Africa, 10–16 August 2003; pp. 1988–1995. [Google Scholar]
- OpenCV. Available online: https://opencv.org/ (accessed on 18 August 2020).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 18 August 2020).
- Point Cloud Library. Available online: http://pointclouds.org/ (accessed on 18 August 2020).
- Konkol, M.; Kray, C. In-depth examination of spatiotemporal figures in open reproducible research. Cartogr. Geogr. Inf. Sci. 2018, 46, 412–427. [Google Scholar] [CrossRef]
- Miller, E. An introduction to the resource description framework. Bull. Am. Soc. Inf. Sci. 1998, 25, 15–19. [Google Scholar]
- Weibel, S. The Dublin Core: A simple content description model for electronic resources. Bull. Am. Soc. Inf. Sci. Technol. 1997, 24, 9–11. [Google Scholar] [CrossRef]
- Dublin Core Metadata for Resource Discovery. Available online: https://tools.ietf.org/html/rfc2413 (accessed on 18 August 2020).
- ISO 19115-1:2014: Geographic Information—Metadata—Part1: Fundamentals. Available online: https://www.iso.org/standard/53798.html (accessed on 18 August 2020).
- Geospatial Metadata Standards and Guidelines. Available online: https://www.fgdc.gov/metadata/geospatial-metadata-standards/ (accessed on 18 August 2020).
- Metadata Directory. Available online: https://rd-alliance.github.io/metadata-directory/standards/ (accessed on 18 August 2020).
- List of Metadata Standards. Available online: http://www.dcc.ac.uk/resources/metadata-standards/list/ (accessed on 18 August 2020).
- Coetzee, S.; Ivánová, I.; Mitasova, H.; Brovelli, M.A. Open Geospatial Software and Data: A Review of the Current State and A Perspective into the Future. ISPRS Int. J. Geo-Inf. 2020, 9, 90. [Google Scholar] [CrossRef]
- Breunig, M.; Bradley, P.E.; Jahn, M.; Kuper, P.; Mazroob, N.; Rösch, N.; Al-Doori, M.; Stefanakis, E.; Jadidi, M. Geospatial Data Management Research: Progress and Future Directions. ISPRS Int. J. Geo-Inf. 2020, 9, 95. [Google Scholar] [CrossRef]
- Bernard, L.; Brauner, J.; Mäs, S.; Wiemann, S. Geodateninfrastrukturen. In Geoinformatik; Sester, M., Ed.; Springer Spektrum: Berlin, Germany, 2019; pp. 91–122. [Google Scholar]
- OGC. Available online: https://www.ogc.org/ (accessed on 18 August 2020).
- Sensor Observation Service. Available online: https://www.opengeospatial.org/standards/sos/ (accessed on 18 August 2020).
- Sensor Model Language (SensorML). Available online: https://www.ogc.org/standards/sensorml/ (accessed on 18 August 2020).
- ISO 19156:2011. Available online: https://www.iso.org/standard/32574.html (accessed on 18 August 2020).
- Registry of Research Data Repositories. Available online: http://re3data.org/ (accessed on 18 August 2020).
- GeoNetwork. Available online: https://www.osgeo.org/projects/geonetwork/ (accessed on 18 August 2020).
- OSGeo. Available online: https://www.osgeo.org/ (accessed on 18 August 2020).
- MIT Geodata Repository. Available online: https://libguides.mit.edu/gis/Geodata/ (accessed on 18 August 2020).
- PANGAEA. Available online: https://www.pangaea.de/ (accessed on 18 August 2020).
- Harvard Geospatial Library. Available online: http://hgl.harvard.edu:8080/opengeoportal/ (accessed on 18 August 2020).
- The Open Archives Initiative Protocol for Metadata Harvesting. Available online: http://www.openarchives.org/OAI/openarchivesprotocol.html (accessed on 18 August 2020).
- Apache Hadoop. Available online: https://hadoop.apache.org/ (accessed on 18 August 2020).
- Heinzle, F.; Anders, K.H.; Sester, M. Pattern recognition in road networks on the example of circular road detection. In Proceedings of the 4th International Conference on Geographic Information Science, Münster, Germany, 20–23 September 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 153–167. [Google Scholar]
- PostGIS. Available online: https://postgis.net/ (accessed on 18 August 2020).
- DC/OS. Available online: https://dcos.io/ (accessed on 18 August 2020).
- ROS. Available online: https://www.ros.org/ (accessed on 18 August 2020).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EXPERIMENT_1 | ||||
| SENSOR_PLATFORM_1 | ||||
| PLATFORM_CALIBRATION_DATA: includes data from platform calibration, i.e., raw measurements and obtained transformations between sensors | ||||
| ROS_BAGS: storage for raw version of data logged by the ROS computer (includes data from stereo camera and GNSS/IMU system) as ROS bags; useable to re-create the sensor data traffic during recording | ||||
| MMS | ||||
| FULL_PROJECT: proprietary MMS storage format can be used by proprietary software to export various types of MMS-related data; this is considered the raw data for the MMS; metadata XML file | ||||
| EXPORTED_POINT_CLOUD: point cloud data in various formats, e.g., colored point cloud with absolute coordinates separated into uniform spatial grid cells to reduce file size, full (down-sampled) point cloud; metadata XML file | ||||
| EXPORTED_TRAJECTORY: export from MMS-internal GNSS as ASCII text file; metadata XML file | ||||
| STEREO_CAMERA | ||||
| STEREO_CAMERA_1 | ||||
| CAMERA_CALIBRATION_DATA: data from camera calibration, i.e., raw images and obtained (intrinsic) camera parameters | ||||
| IMAGE_DATA: includes pairs of left/right images and an ASCII table that maps timestamps to image IDs; metadata XML file | ||||
| GNSS/IMU | ||||
| GNSS/IMU_1 | ||||
| PROPRIETARY_FORMAT: original sensor-dependent format, in some cases, only useable using sensor-specific proprietary software; metadata XML file | ||||
| EXPORTED_FORMAT: export to accessible, interoperable ASCII format after export from the proprietary format using proprietary software; metadata XML file | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fischer, C.; Sester, M.; Schön, S. Spatio-Temporal Research Data Infrastructure in the Context of Autonomous Driving. ISPRS Int. J. Geo-Inf. 2020, 9, 626. https://doi.org/10.3390/ijgi9110626
Fischer C, Sester M, Schön S. Spatio-Temporal Research Data Infrastructure in the Context of Autonomous Driving. ISPRS International Journal of Geo-Information. 2020; 9(11):626. https://doi.org/10.3390/ijgi9110626
Chicago/Turabian StyleFischer, Colin, Monika Sester, and Steffen Schön. 2020. "Spatio-Temporal Research Data Infrastructure in the Context of Autonomous Driving" ISPRS International Journal of Geo-Information 9, no. 11: 626. https://doi.org/10.3390/ijgi9110626
APA StyleFischer, C., Sester, M., & Schön, S. (2020). Spatio-Temporal Research Data Infrastructure in the Context of Autonomous Driving. ISPRS International Journal of Geo-Information, 9(11), 626. https://doi.org/10.3390/ijgi9110626