1. Introduction
Semantic segmentation involves the allocation of a semantic label to each pixel of an image containing an object, which can deliver high-level structure information [
1]. Semantic segmentation is a crucial task in intelligent applications, such as mobile robots and autonomous driving vehicles, because it can provide an accurate understanding of a scene [
2]. Recently, significant advances have been achieved in semantic segmentation techniques of natural RGB scenes owing to the development of deep convolutional neural networks (CNNs). Deep-learning models can learn high-level abstract features from raw images with excellent performance; however, these approaches rely on large training samples [
3]. To satisfy this requirement, various public datasets have been proposed for scene labeling. For example, PASCAL VOC [
4] is a large-scale dataset used for object class recognition and contains 2913 images with pixel-level labeling with 20 classes, such as vehicles and animals. Although similar to PASCAL, ImageNet contains more than 20,000 classes and 14 million images [
5]. The COCO dataset provides more than 328,000 images with 80 classes, and the images are split into different training/validation/test datasets [
6]. More recently, the Cityscape dataset has provided a semantic understanding of urban street scenes [
7]. It contains 5000 images with dense pixel-level labeling of more than 30 classes of scenes that are commonly encountered during driving, such as vehicles, roads and fences.
Semantic segmentation can be referred to as image classification in the remote-sensing (RS) field, and it has been used in various applications such as land-cover classification, geological and environment surveys, and urban planning. [
8,
9,
10]. Deep-learning methods have been successfully adopted to solve the problem of satellite and aerial image segmentation, and they outperform original image classifiers [
11]. Various deep-learning networks have been established for semantic segmentation, and some methods have achieved good performance for RS images [
12]. Fully convolutional networks (FCNs), which were proposed by Long et al. [
13], have been used for semantic segmentation of very-high-resolution aerial images [
14,
15]. In this approach, the fully connected layer is replaced with a convolutional layer, which allows arbitrarily sized input datasets. Based on the concept of FCN, U-net was proposed by Ronneberger et al. [
16]; it uses an encoder and decoder architecture. U-net was originally designed to segment medical images, although previous studies have demonstrated that U-net can be successfully used to segment RS images [
17]. Similar to U-net, SegNet uses the encoder and decoder architecture. The encoder form is based on convolutional layers from VGG-16, and the decoder performs both upsampling and classifications [
18]. Audevert et al. [
18] demonstrated the effectiveness of using multiscale SegNet for segmenting International Society for Photogrammetry and Remote Sensing (ISPRS) datasets. Moreover, DeepLab-V3+ uses the encoder and decoder architecture with atrous convolution and fully connected conditional random fields for semantic segmentation. The DeepLab system was successfully applied to RS-images, and it could appropriately handle multiscale objects in high-resolution satellite images [
19].
Generally, to compensate for the current lack of large datasets, semantic segmentation of RS-images using deep-learning methods with pretrained networks has been applied to natural RGB-image datasets such as ImageNet and PASCAL VOC [
20,
21]. However, unlike natural RGB-images, RS-images contain several types of low-resolution objects that are irregularly shaped, which impact subsequent object classifications [
12]. Furthermore, as RS-images are acquired from a bird’s eye perspective, the objects lie within a flat two-dimensional (2D) plane where only the top of the objects is observed [
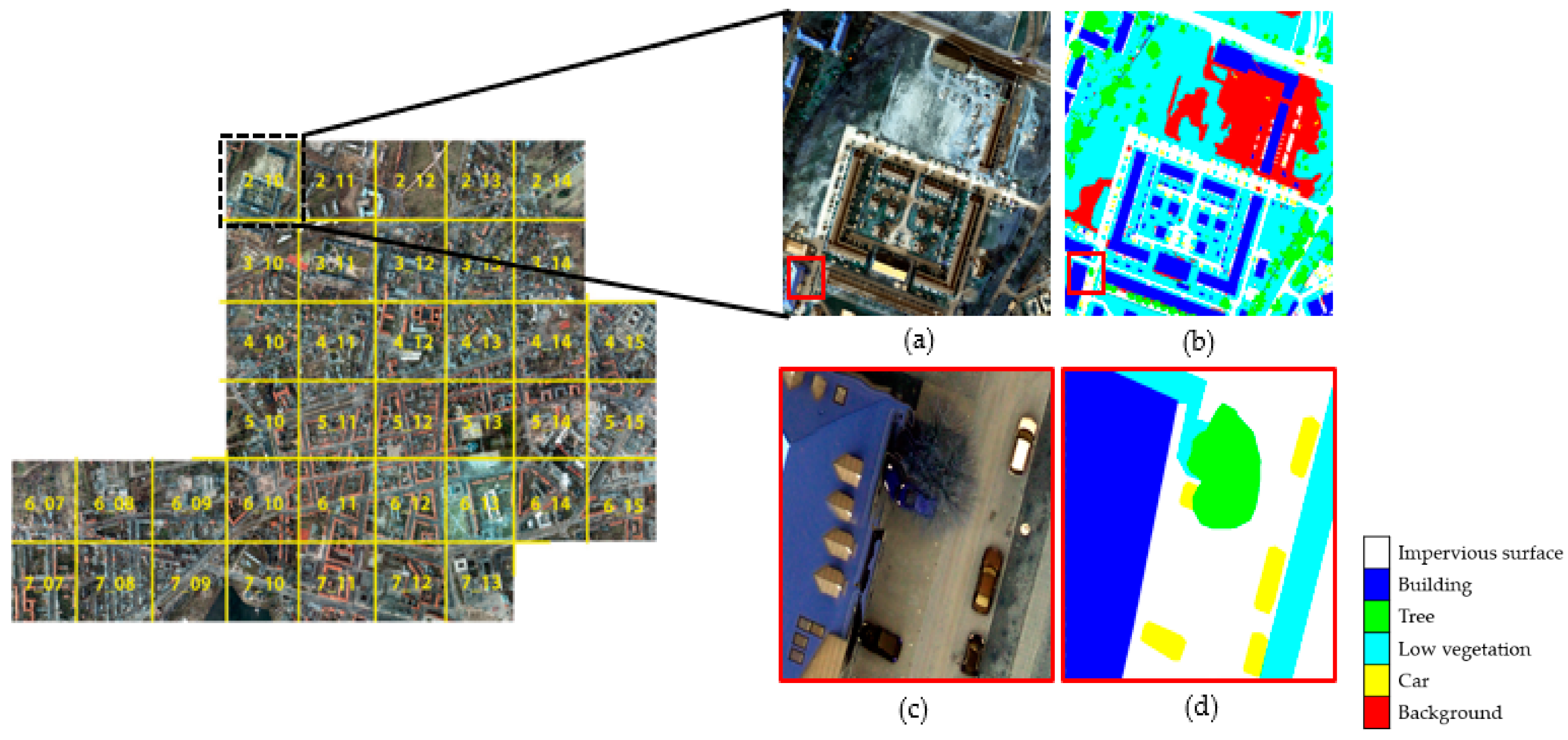
22]. Additionally, constructing a large-scale RS-image dataset is more difficult than using natural RGB-images, and creating data labels for RS-images obtained from various sensors is time consuming. Indeed, various errors can be introduced due to factors such as relief displacement caused by differences in elevation and shadows in the RS-images. Moreover, it can be difficult to define meaningful classes in a scene in case of numerous surface materials. However, despite these difficulties, large-scale RS public datasets have recently been released. For example, ISPRS provided the benchmark Vaihingen/Germany and Potsdam/Germany datasets containing 33 images with three-band infrared, red, and green (IRRG) and 38 images with four-band infrared, red, green, and blue (IRRGB), respectively, with pixel-level labeling maps comprising five classes and digital elevation models [
23]. Moreover, Zurich [
24] and Kaggle [
25] challenges yielded very-high-resolution satellite images, namely, Quickbird and Worldview-3, respectively, which contain labeling maps with 8–10 classes.
The need for research capable of learning images with different characteristics increases at once with the increase in the big datasets acquired by various sensors. However, when using heterogeneous datasets, it is difficult to account for the differences in the characteristics of input images and class types. For instance, Meletis et al. [
26] used the heterogeneous Cityscape and German traffic sign detection benchmark datasets [
27] for semantic segmentation of street scenes. The considered datasets were different; however, they contained semantically connected classes. These authors constructed a hierarchy of classifiers using hierarchical training and inference rules using the semantic relationships between the labels of each dataset. Ghassemi et al. [
28] designed an encoder and decoder network for satellite image segmentation of heterogeneous datasets. They used active learning, wherein a trained network was refined using a few sample images in the heterogeneous training and test datasets, and their method improved the network’s performance with minimal human intervention. Several studies have been conducted using heterogeneous datasets with similar types of images and labels; however, very few studies have employed natural RGB- and RS-image datasets. For the segmentation of RS-images, there were cases in which pre-trained segmentation networks from natural-image datasets, such as ImageNet, were used as initial values of the segmentation network for RS-images, but the research on directly learning RS and natural RGB-images together is insufficient [
3,
29].
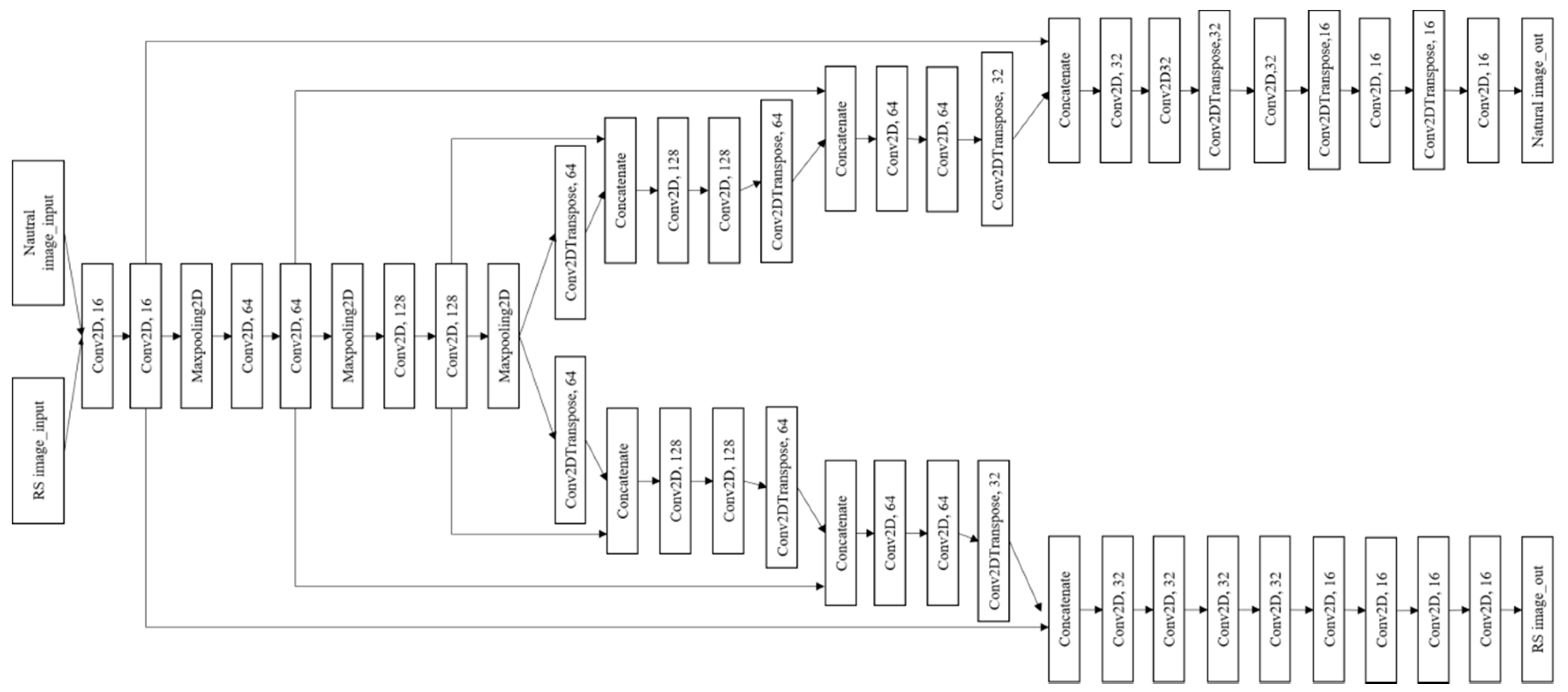
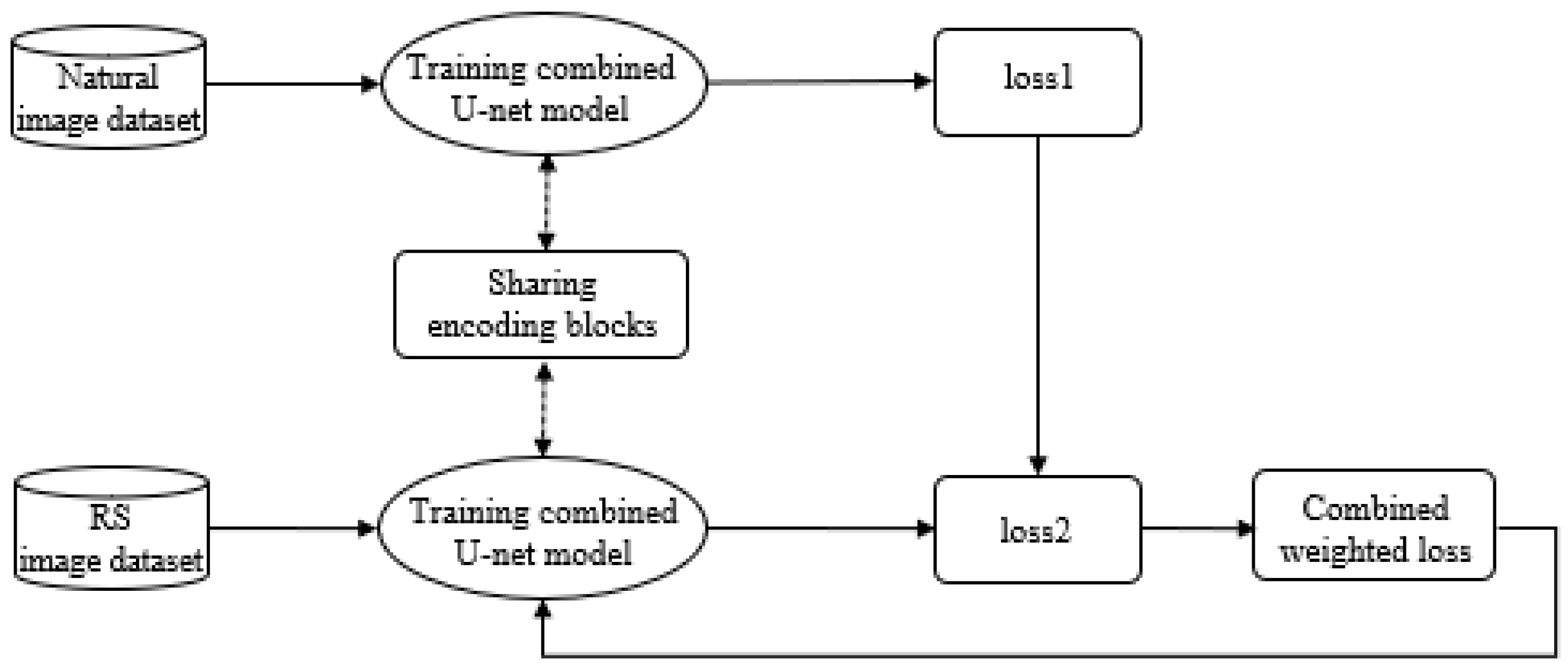
To address this paucity of research, we analyze the possibility of sharing networks of heterogeneous datasets and identify the impact of learning using the combined weighted loss function between two networks trained on different datasets to overcome the limitations imposed by a lack of training datasets. In this study, aerial and road-view image datasets were used to evaluate the proposed method. Finally, it is expected that the proposed method can be applied to not only segmentation tasks of aerial images, but also the segmentation or object detection of street-view image on web sites and scanned floorplans. The remainder of this paper is organized as follows. The architecture of the proposed method is presented in
Section 2, and the datasets and environmental conditions for the experiments are described in
Section 3 and
Section 4. The results and discussion are provided in
Section 5 and
Section 6, respectively, and the conclusions are drawn in
Section 7.
4. Experimental Conditions
To demonstrate the effectiveness of the proposed method, several experiments were conducted to compare the segmentation results of the Potsdam images. SegNet, DeepLab-V3+, and simplified U-net, which followed the RS-image path in the combined U-net model, were used to segment the Potsdam dataset with its original four bands. In addition, the Potsdam dataset was trained with only RGB bands using the simplified U-net model to compare with the combined U-net model, which only deals with the RGB bands in the Potsdam images to share convolutional layers. We randomly selected a subset of images from the Potsdam dataset to train the networks. In particular, 1600 images were used as training data, and 400 and 150 images were used as validation and test data, respectively. Finally, the combined U-net model trained the Potsdam dataset with different two conditions. In Case 1, the same number of training datasets of Cityscape dataset was used. Moreover, we varied the number of Cityscape images to confirm the effect of the Cityscape dataset size when training using the combined U-net model. In Case 2, 3000, 550, and 300 images from the Cityscape dataset were used as training, validation, and test data, respectively. Further, to provide larger weights to the Potsdam dataset, (the weight of loss in RS-image path) and (the weight of loss in natural-image path) were set as 0.8 and 0.2, respectively.
The combined U-net model was trained on the free Google Colaboratory (Colab) platform [
32]. The final epoch was set to 1000 of Adam with a learning rate of
. Considering the available memory on Colab, the batch size was set to 4. The two inputs had the same size (256
256
3); hence, we could share the weights in the initial layers. Moreover, 256
256
3 is a suitable size when using limited training resources such as RAMs and GPUs. Therefore, the original 6000
6000
4 Potsdam images were divided into smaller samples of 256
256
3, and the Cityscape images were rescaled to 256
256
3. In particular, in the second path of the combined U-net, as the six decoding block ends output a feature map of size 1024
2048
16, this feature map was scanned using a 1
1 2D convolution filter to generate output maps of size 1024
2048
5 to match the shape of the labels. We did not rescale the label images to obtain the same size as the input images because rescaling would lead to a loss of class information, which in turn would yield a distorted output. Thus, we decided to match the output of the Cityscape path with the size of the original label size (i.e., 1024
2048) to keep the class information untouched.
5. Results
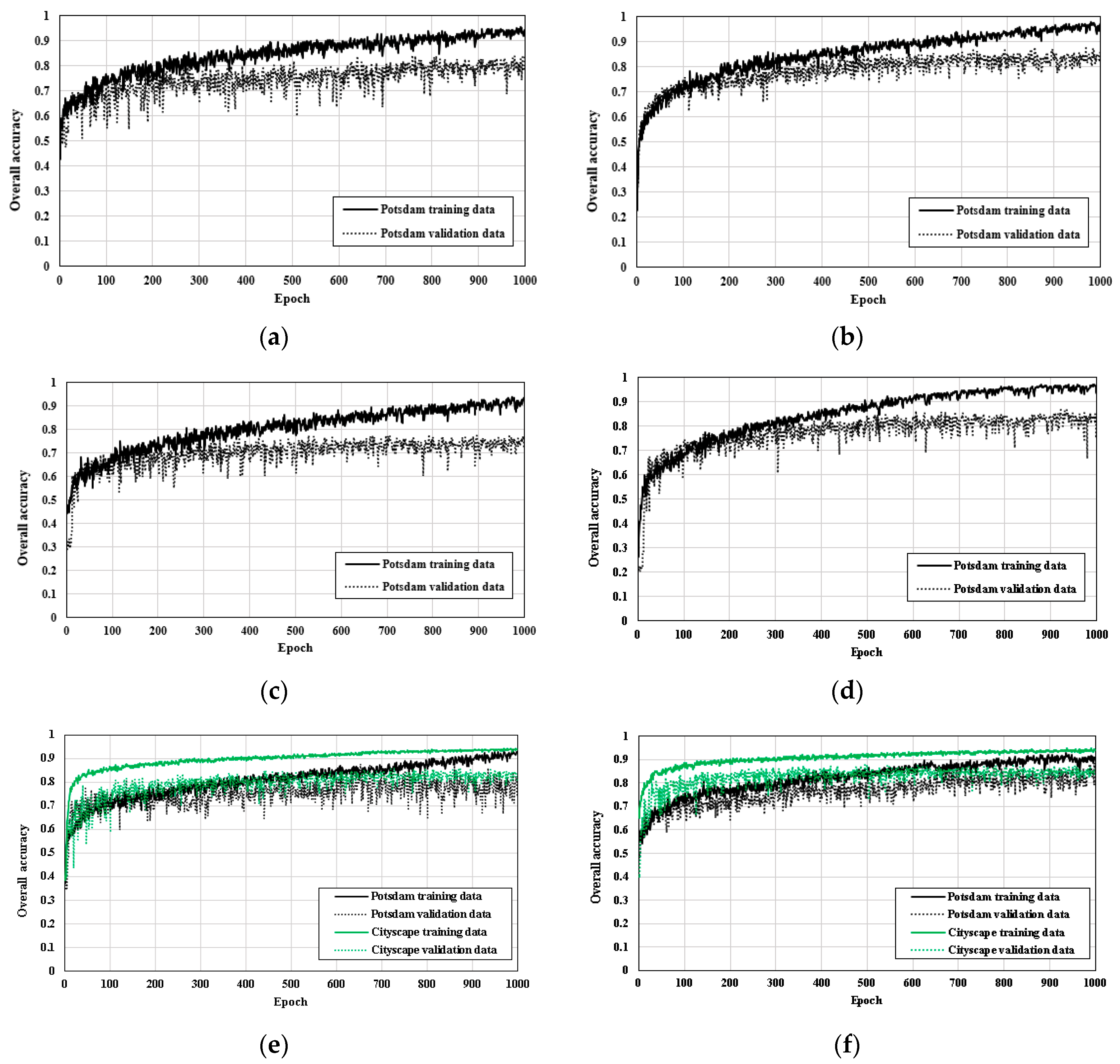
Figure 6 shows the learning graphs of the OA of the training and validation sets for the six aforementioned cases. Since a limited number of images were used for training, there was a difference in the OA between the training and validation sets. When a model has high training and low validation accuracies, this case is probably known as overfitting. Since only a part of the Potsdam dataset was used for training, insufficient training data can sometimes lead to overfitting problems [
33]. DeepLab-V3+ showed a higher OA for the validation set in comparison with the SegNet and simplified U-net models (
Figure 6b). Also, the difference in the OAs between the validation and training sets was less than when using the SegNet model. In the case of the simplified U-net model, when training was performed by only using the RGB bands of the Potsdam images, the OA of the validation set was lower than when using the original four bands (
Figure 6c,d). Also, the learning graph of the simplified U-net model of the training Potsdam images with its four bands showed that the OA of the training set was higher than in the other two cases with the combined U-net models; however, the OA of the validation set was relatively lower than that of the training set.
When comparing between the simplified U-net model training with original four bands and Case 1 in the combined model, it can be seen that the OAs of the validation sets of both are similar, but the OAs of the training set in Case 1 were lower than those in the simplified U-net model (
Figure 6d,e). Although the combined U-net model used for Case 1 trained the Potsdam and Cityscape datasets together, it used only the RGB-images from the Potsdam data. In contrast, the simplified U-net model also used the NIR band of the Potsdam data rather than simply using only the RGB bands, which aided the meaningful classification of objects such as trees and low vegetation that are particularly prominent at NIR wavelengths.
In Case 2 of the combined U-net model, in which the size of the Cityscape dataset was increased relative to Case 1, the OAs of the training and validation sets further improved relative to Case 1. Although the OA of the training data in Case 2 was lower than that of DeepLab-V3+ and simplified U-net, the gap in training and validation accuracy was decreased. As the amount of data in the Cityscape dataset increased, the overfitting problem was effectively reduced. For the OAs of the Cityscape dataset in Case 1 and Case 2, they showed a similar tendency; furthermore, as the amount of data increased, the validation accuracy of the Cityscape dataset improved.
Table 3 shows the average F1 scores of the five classes and the OA of the test set for the six models. The OAs of the SegNet, DeepLab-V3+, simplified U-net models with the two cases, and combined U-net models with the two cases are 0.8346, 0.8605, 0.8477, 0.7841, 0.8268 and 0.8721, respectively. Among the single models, the OA of the DeepLab-V3+ was highest, and Case 2 of the proposed combined U-net model had a higher OA than that of the DeepLab-V3+. The simplified U-net model trained using only the RGB bands of the Potsdam images had the lowest OA.
In addition, in the simplified U-net trained using original four bands, the F1 scores of the impervious surface, building, low vegetation, tree, and car classes are 0.8623, 0.8535, 0.8205, 0.8457 and 0.8123, respectively. Although Case 1 in the combined U-net model exhibited higher F1 scores for the impervious surface and building classes, it showed lower F1 scores for the vegetation and tree classes. In particular, Case 2 in the combined U-net model exhibited higher F1 scores for the impervious surface, building, and car classes. The road boundaries and car shapes were well predicted in Case 2. In order to visually analyze the segmentation results when using the combined U-net model rather than when using the simplified U-net model, we selected sites that can show the characteristics of three cases as an example, and the semantic segmentation results are shown in
Figure 7. In the simplified U-net model trained with original four bands, there were errors in classifying roads and buildings; however, compared with Cases 1 and 2, low vegetation and tree classes were effectively distinguished (
Figure 7a–j). In Case 1, materials on the roof were misclassified as car because their shape and colors were similar (
Figure 7k–o). Case 2 showed the most efficiency in classifying buildings and roads; however, it could not clearly distinguish between trees and low vegetation (
Figure 7k–u).
6. Discussion
6.1. Comparison with Other Algorithms
Among the single models, the DeepLab-V3+ model had higher segmentation OAs for the Potsdam images than the SegNet and simplified U-net models. In particular, the simplified U-net model had the lowest OA among the other networks compared with when training with RGB-images only. This is because the segmentation accuracies of the tree and low vegetation classes were reduced when training without the NIR band. In this context, although the Potsdam dataset was trained using an identically sized Cityscape dataset in Case 1, the OA and F1 scores of the vegetation, tree, and car classes showed no improvements compared with DeepLab-V3+ and simplified U-net. The results show that training using the Potsdam data in its original four bands is more effective in classifying vegetation classes than that using just the RGB bands. This is because the NIR band is a key band for classifying trees and low vegetation; in addition, several trees and low vegetation with low reflectance had similar colors to ground and impervious surfaces in the RGB-images. However, the semantic segmentation accuracy was improved by increasing the size of the Cityscape dataset when training using the combined U-net model. In particular, the F1 scores of impervious surface, buildings, and cars improved in Case 2 relative to other networks. Furthermore, when training Potsdam using the Cityscape dataset, the overfitting problem was decreased. This is because although there are various roads, cars, and buildings in the Cityscape dataset and the shooting angle and shapes are different relative to such objects in the Potsdam images, there may be common points in terms of their color and/or relationships with the surrounding environment.
6.2. Cityscape Dataset Impact
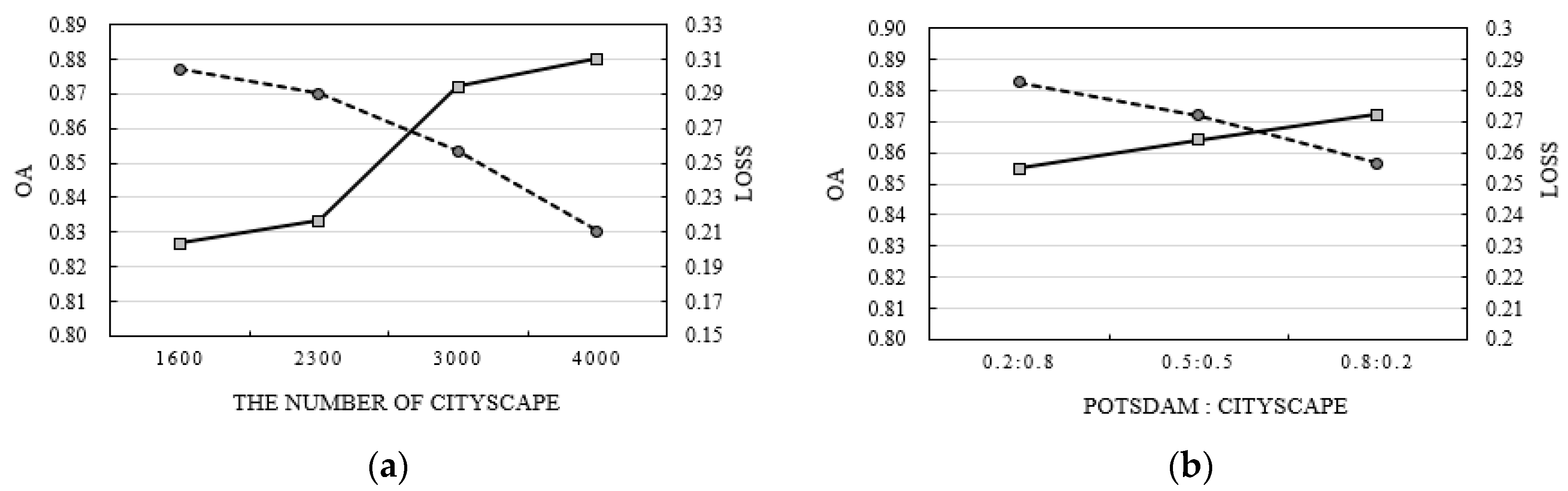
By comparing the results of Case 1 and Case 2, it was confirmed that the combined U-net model was affected by the number of Cityscapes. We varied the number of Cityscape training data and changed the weight values of the Potsdam and Cityscape datasets (
and
) (
Figure 8). When the same number of Potsdam datasets was used; for example, 1600 images were used as training data and 400 and 150 images were used as validation and test data, respectively, the accuracy of the Potsdam test data improved with the increase in the training data of the Cityscape. In particular, when the number of Cityscape images was about 2500–2900, the OA of the combined U-net model became similar to that of the single models such as SegNet, simplified U-net, and DeepLab-V3+, and the number of Cityscape images was 3000, which is about twice that of the Potsdam dataset, so the OA dramatically increased (
Figure 8a).
In the experiments, to give larger weights to the Potsdam dataset,
and
were fixed to 0.8 and 0.2, respectively. We examined the weight values effect through an experiment, where
was set to 0.2 and
was set to 0.8, where the weights of the two datasets were the same. In this case, the number of Potsdam and Cityscape datasets was the same as in Case 2 of the combined U-net model. As a result, with the decrease in the weight of the Potsdam dataset, the OA of the test set decreased. This is because the loss due to the Potsdam dataset was less reflected when training the combined U-net model (
Figure 8b). In particular, when
and
were set to 0.2 and 0.8, respectively, the OA was less than with the DeepLab-V3+ model.
6.3. Limitations and Future Work
Although the combined U-net model can train heterogeneous datasets, its network structure is relatively complex, and it takes a long time to perform learning processes compared with network learning with a single dataset. For example, when training the combined U-net model in Google Colab, when the batch size was set to be more than 4 (8 or 16), we faced a memory problem. Furthermore, there was a limitation in that the performance of the combined U-net model was changed according to the number of Cityscapes and weight values.
In addition, since RS-images generally have more than four bands, including the NIR band, not using the additional bands for learning with natural RGB-images can lower the segmentation accuracy of vegetation-related classes. To overcome these limitations, future work is needed to develop a method that can effectively include the NIR band of RS-images while learning with natural RGB-images. Furthermore, to examine the effect of the architecture of the combined U-net model, we plan to see how the OA of the Potsdam dataset changes when the shared phase in the encoder and decoder part of the combined U-net model is changed (e.g., non-shared encoder and shared decoder).
7. Conclusions
In this paper, we proposed the combined U-net model that can train RS-images using a natural-image dataset. The network composed of encoder and decoder blocks, and the encoder blocks were shared with the two different datasets (Potsdam and Cityscape); the network was updated using the combined weighted loss function. The results obtained from the experiments indicated that when training using the identically sized Potsdam data with RBG bands and Cityscape data, the OA was decreased compared with single models training using only the original Potsdam data. However, the accuracy of the Potsdam dataset improved with an increase in the size of the Cityscape dataset. These results show that the use of a large-scale natural-image dataset can improve the semantic segmentation accuracy of the RS-image dataset using the proposed method. The proposed method can solve the problem of insufficiently large RS-image datasets for semantic segmentation. Furthermore, this study confirms the possibility of learning heterogeneous datasets at the same time by sharing the encoder phase and generated weights from two datasets in deep learning networks. It is expected that this approach can not only be applied to segmentation tasks of aerial images but also to tasks with various purposes of using big heterogeneous datasets. For example, when using a relatively limited number of datasets such as newly constructed floorplans and street-view images on web sites for special tasks such as classification and object detection, the big datasets, such as existing scanned floorplans and satellite or unmanned aerial vehicle images which are datasets acquired from different times and sensors but with similar characteristics, can be used to solve the problem of insufficient training data in input dataset by sharing specific part of deep learning networks.
However, the computational burden of the proposed method is relatively high because the combined U-net model trains heterogeneous datasets at the same time. In addition, the segmentation accuracy can be changed according to the number of Cityscape datasets and the weight values between Potsdam and Cityscape. Also, there was a problem in that the provided information by the NIR band could not be used because only the RGB bands were used. For future work, we aim to improve the combined U-net model structure by conducting experiments in regard to including the NIR band information of the Potsdam dataset.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}