Combining Design Patterns and Topic Modeling to Discover Regions That Support Particular Functionality


Abstract
:1. Introduction
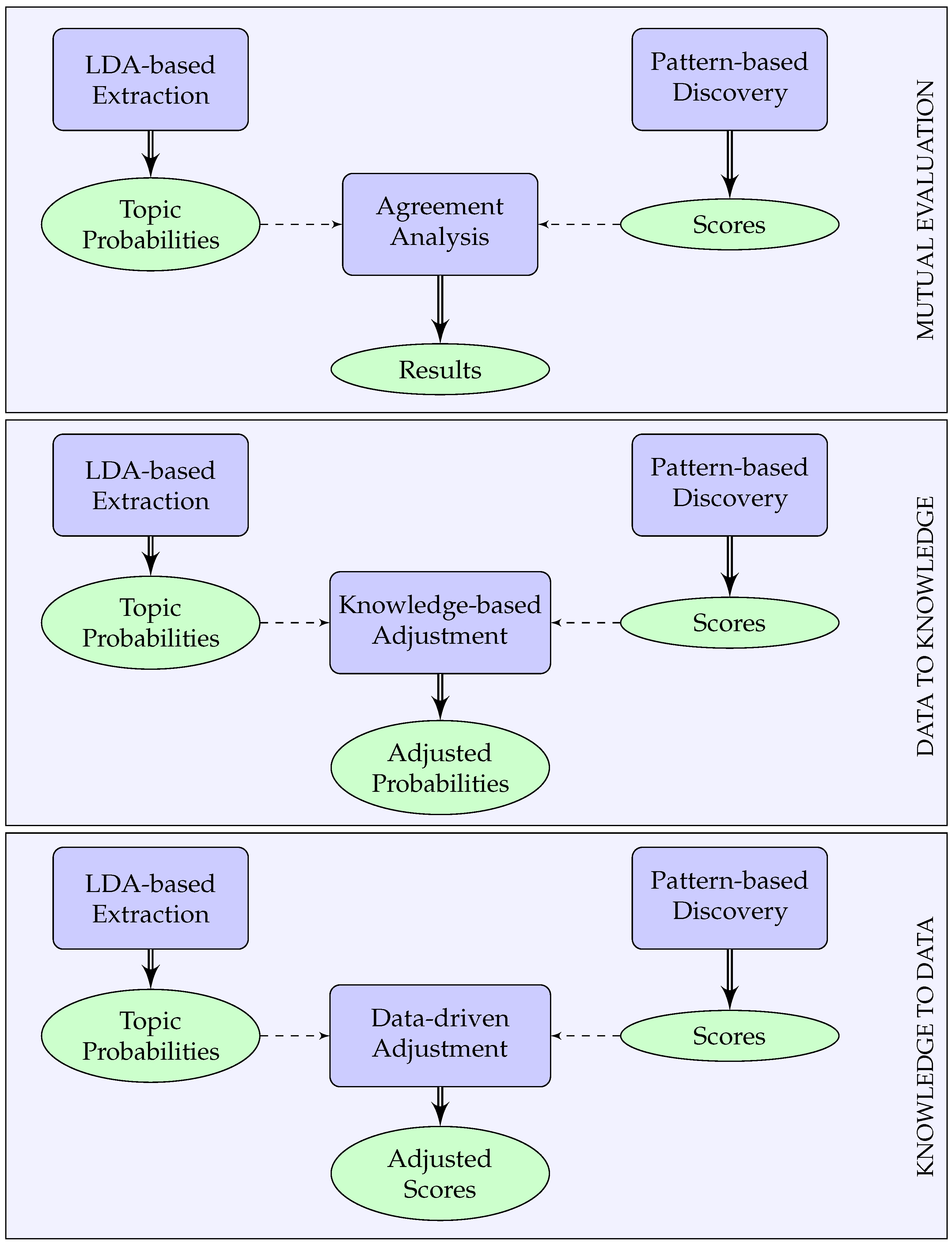
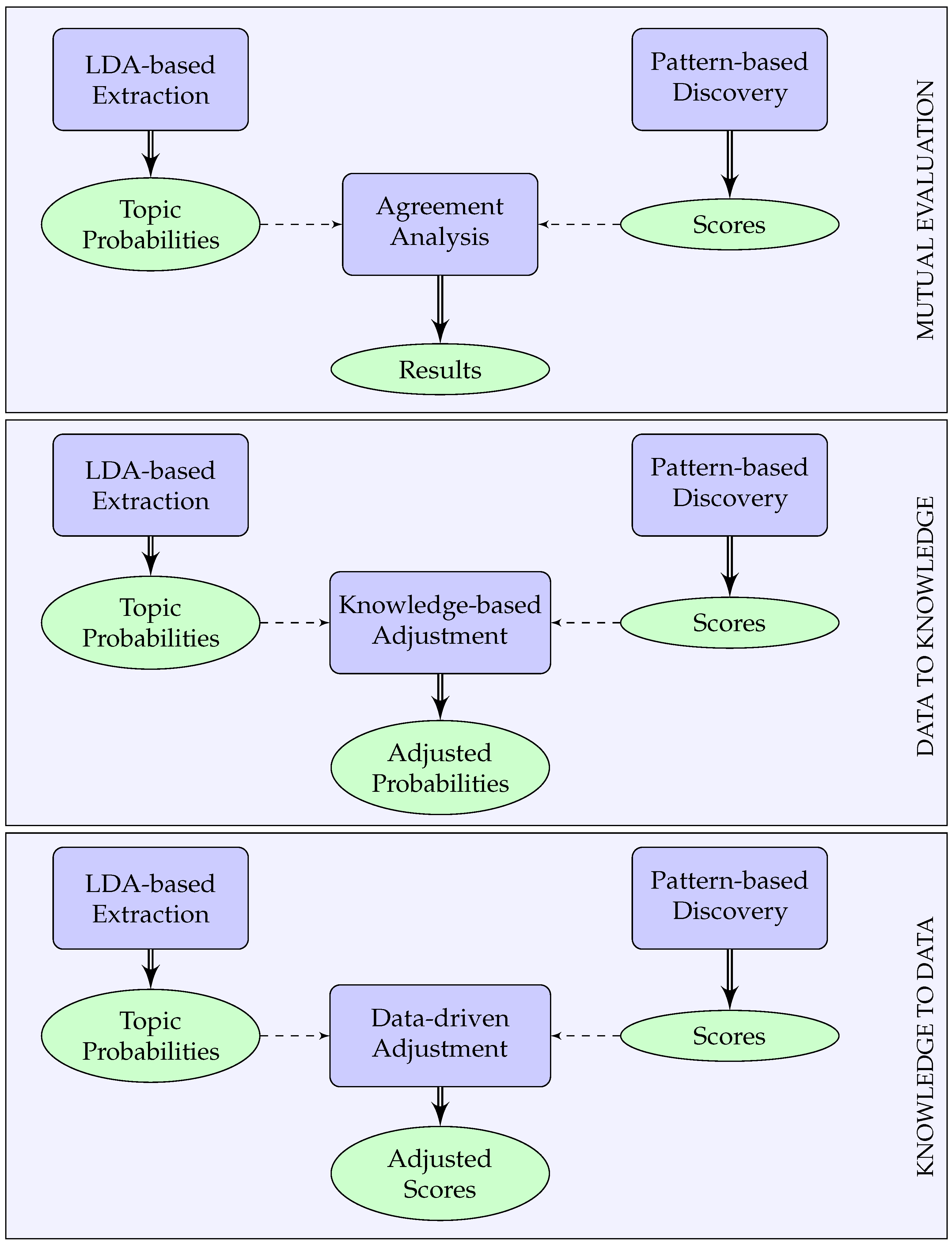
- A novel framework for discovering functional regions that combines results based on patterns and LDA topic modeling in three different ways: mutual evaluation to identify cases of significant agreement or disagreement; using pattern-based knowledge to adjust topic probabilities; and using topic probabilities to adjust pattern-based results.
- A discussion, in the context of GIS, of the benefits of combining the interpretability offered by knowledge-based techniques with the transferability and scalability of data-driven methodologies.
2. Related Work and Critical Analysis
2.1. Knowledge-Based Approaches
2.1.1. Discovering Functional Regions using Composition Patterns
2.1.2. Critical Analysis of the Pattern-Based Approach
2.2. Data-Driven Approaches
2.2.1. Functional Region Extraction from POI and Human Activity Data
2.2.2. Critical Analysis of the Topic Modeling Approach
3. Methodology
3.1. Mutual Evaluation
3.2. Data to Knowledge Fusion
3.3. Knowledge to Data Fusion
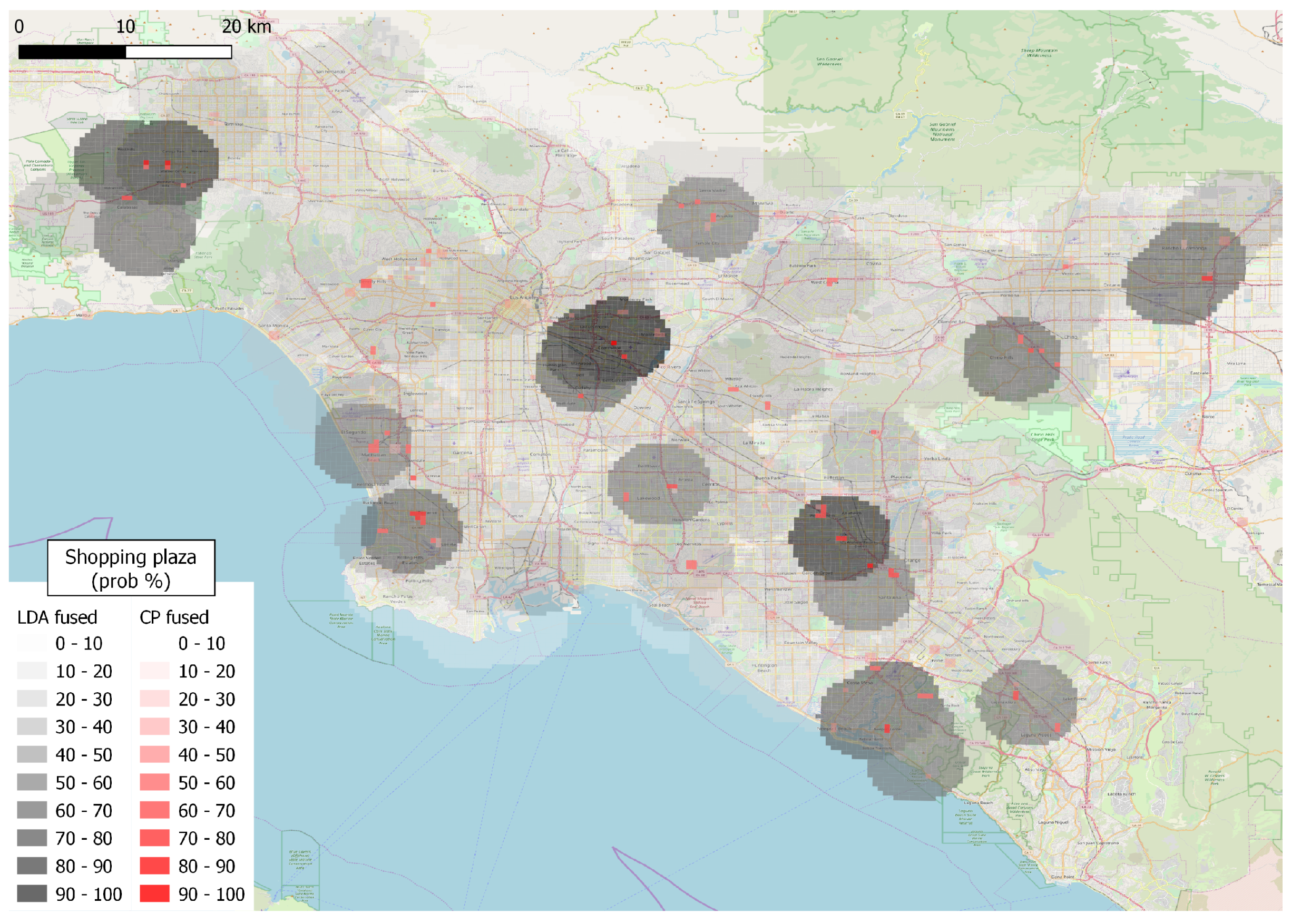
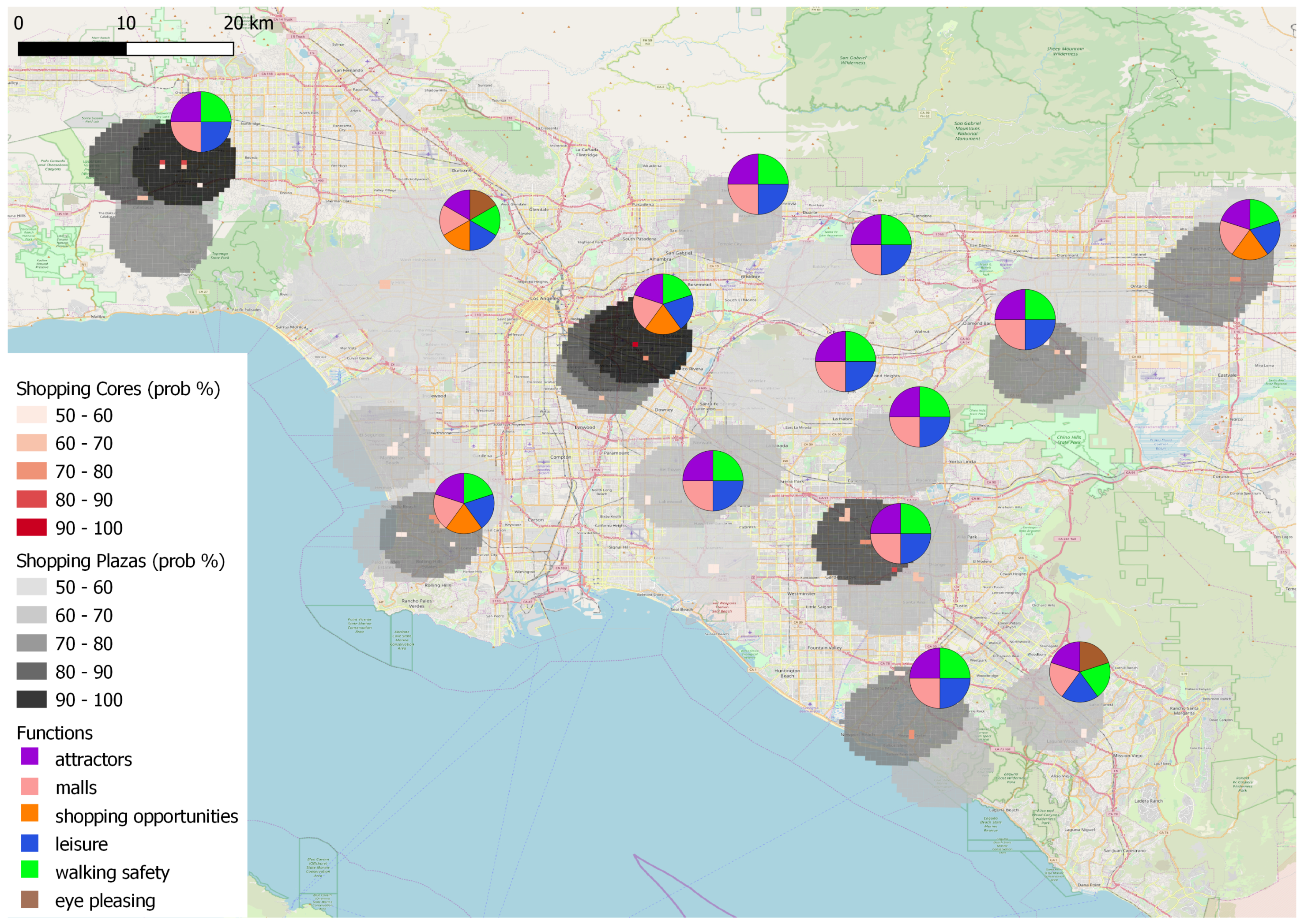
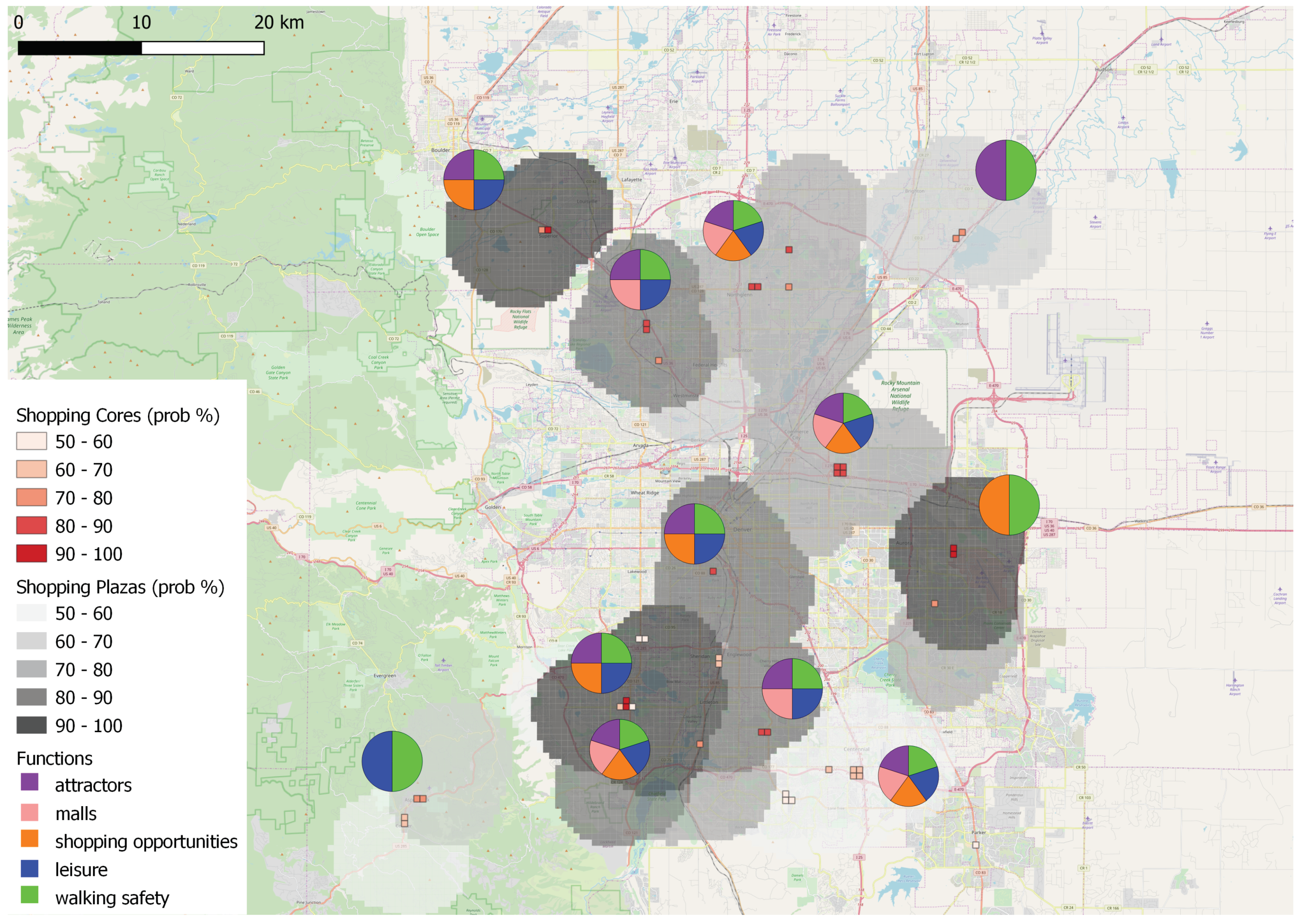
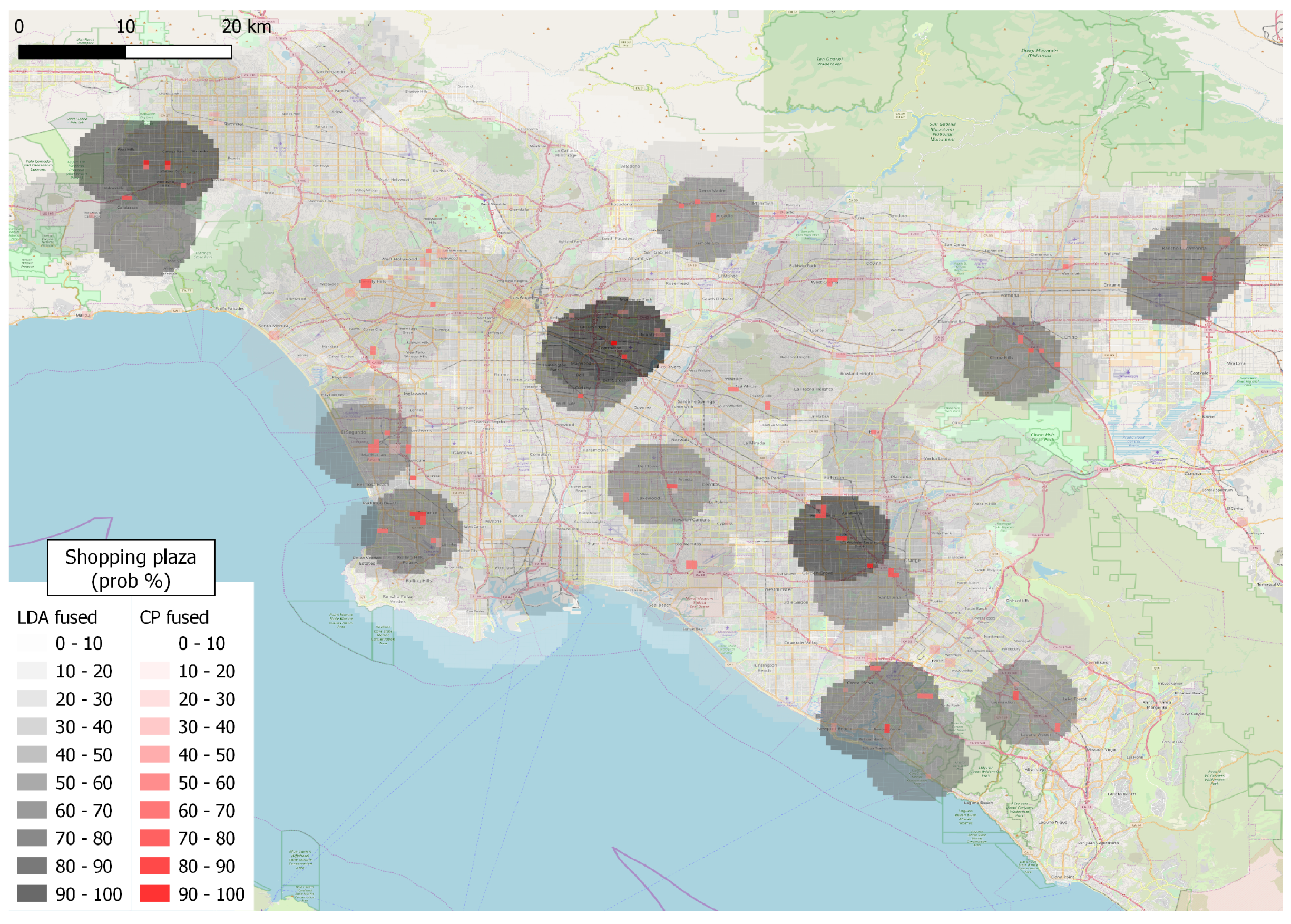
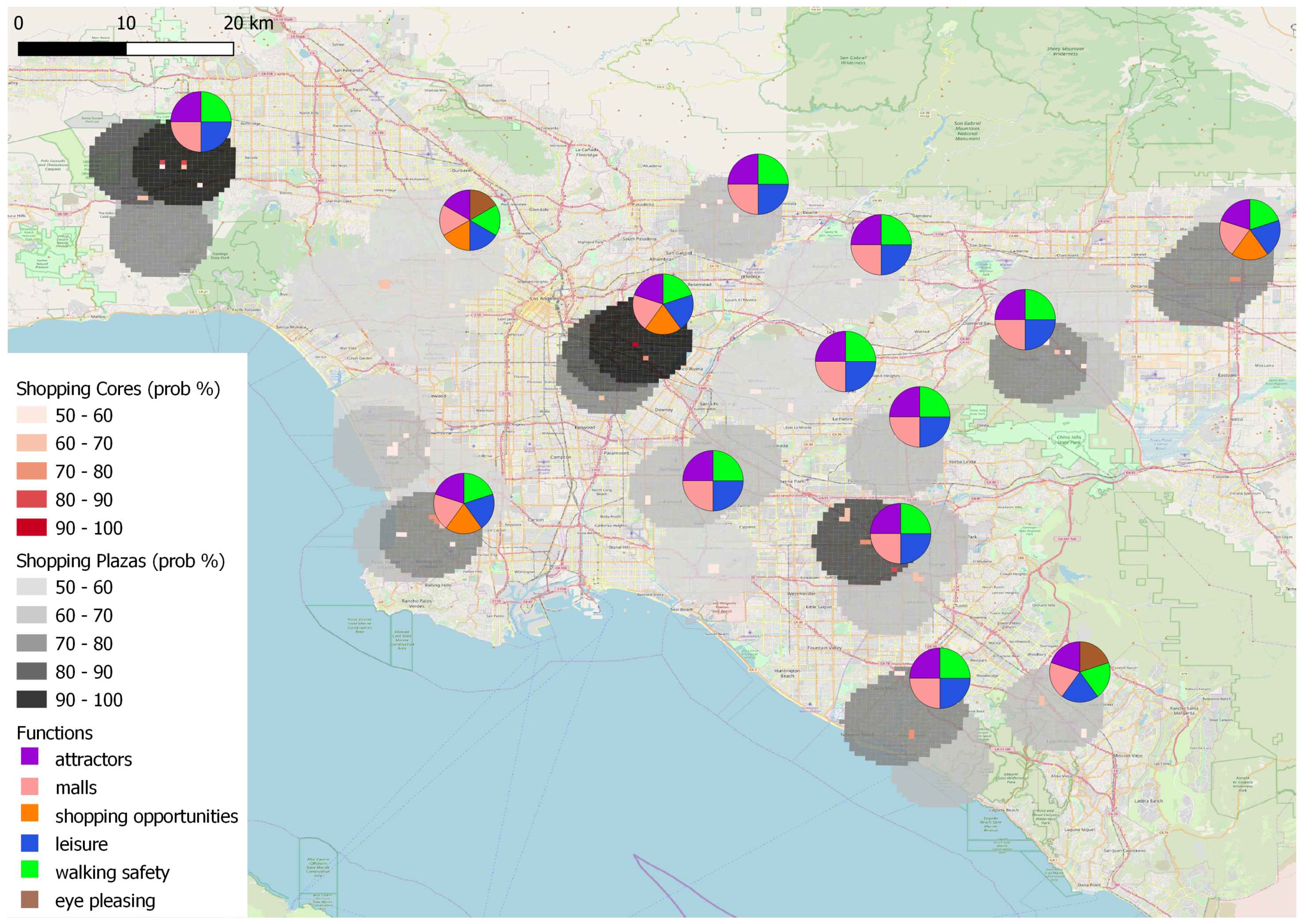
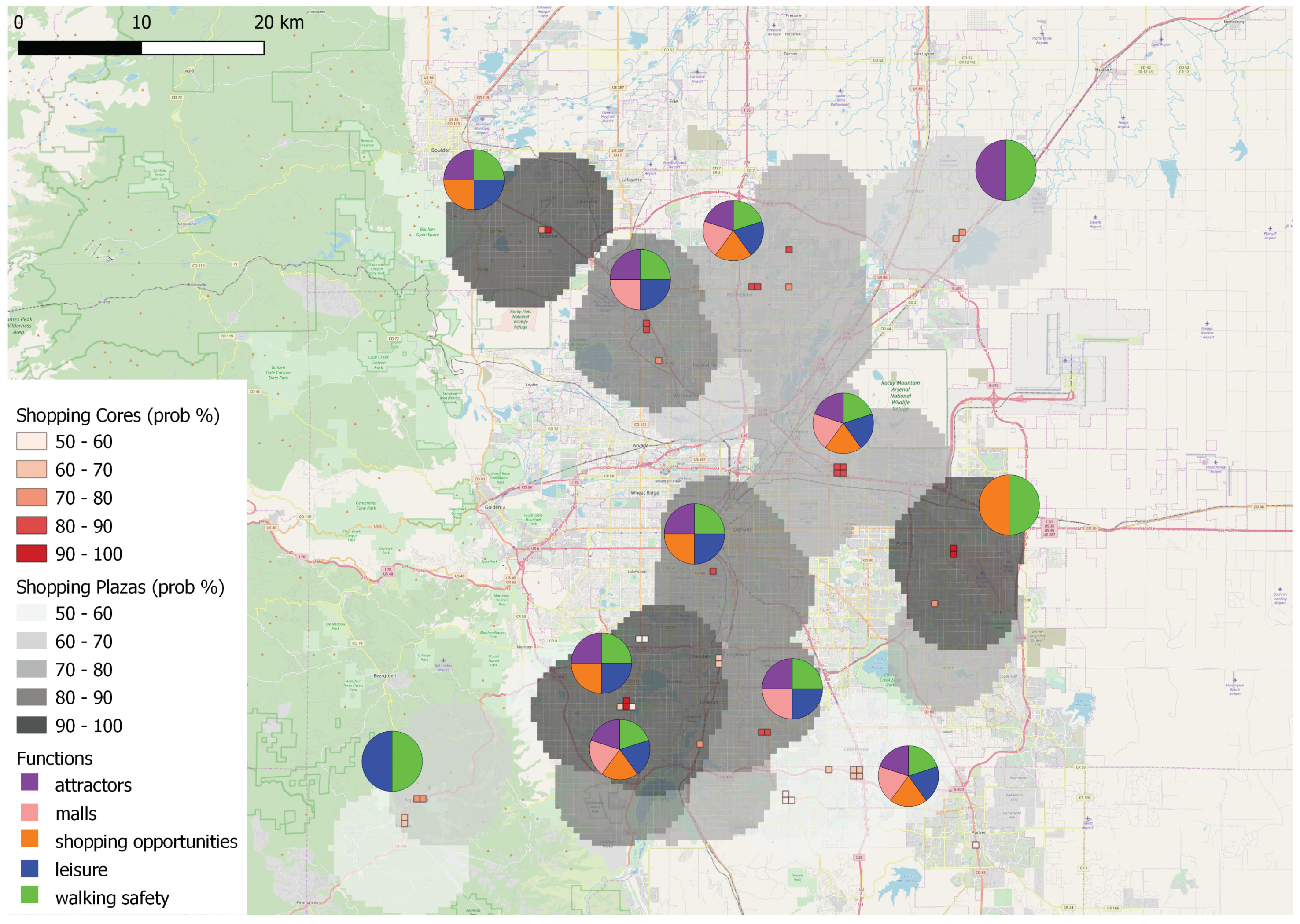
4. Demonstration and Results
4.1. Study Area and Data
4.2. Results Using Individual Approaches
4.3. Results of Mutual Evaluation
4.4. Results of Data to Knowledge and Knowledge to Data Fusion
4.5. Overall Results
5. Discussion
- are highly functional, also explaining which particular functions mostly contribute to this, as derived from the knowledge-based aspect;
- are popular, based on the inclusion of social media information exploited by the data-driven aspect;
- are homogeneous both in terms of the POIs included and the way they are spatially organized.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Probability | Category | Probability |
|---|---|---|---|
| shopping mall | 0.207709 | bistro | 0.000105 |
| accessories store | 0.056738 | dumpling restaurant | 0.000096 |
| chocolate shop | 0.013896 | korean restaurant | 0.000090 |
| shoe store | 0.000288 | german restaurant | 0.000080 |
| breakfast spot | 0.000282 | herbs & spices store | 0.000079 |
| gaming cafe | 0.000196 | airport terminal | 0.000078 |
| optical shop | 0.000180 | outlet store | 0.000076 |
| post office | 0.000114 |
| Variable | Component | Filter |
|---|---|---|
| Shop | ||
| Amenity | ||
| Facilities | ||
| Walkable plaza | ||
| Motorway | ||
| Service Road | ||
| Walkable | ||
| Parking place | ||
| Transportation node | ||
| Anchor Store | ||
| Mall | ||
| Attractors | ||
| Basic Shop | ||
| Special Shop | ||
| Uncommon Shop | ||
| Food court | ||
| Entertainment | ||
| Luxury services | ||
| Aesthetics |
| Functional Implications | |
|---|---|
| Functions | Logical Formula |
| (Walkability) | |
| (Shopping Experience) | |
| (Shopping Variety) | |
| (Sh. Attractiveness) | |
| (Sh. Orientation) | |
| (Special Goods) | |
| (Compatible Components) | |
| (Shopping Opportunities) | |
| (Leisure) | |
| (Entertainment) | |
| (Luxury Services) | |
| (Access to Drivers) | |
| (Access to Non-drivers) | |
| (Walking Safety) | |
| (Well-Organized) | |
| (Visually Pleasing) | |
| Scoring Function | |
References
- Hartshorne, R. Perspective on the Nature of Geography; Rand McNally: Chicago, IL, USA, 1959. [Google Scholar]
- Tuan, Y.F. Space and Place: Humanistic Perspective. In Philosophy in Geography; Springer: Dordrecht, The Netherlands, 1979; pp. 387–427. [Google Scholar]
- Goodchild, M.F. Geographical information science. Int. J. Geogr. Inf. Syst. 1992, 6, 31–45. [Google Scholar] [CrossRef]
- Brown, L.A.; Holmes, J. The delimitation of functional regions, nodal regions, and hierarchies by functional distance approaches. J. Reg. Sci. 1971, 11, 57–72. [Google Scholar] [CrossRef]
- OECD. Redefining “Urban”: A New Way to Measure Metropolitan Areas; OECD Publishing: Paris, France, 2012. [Google Scholar] [CrossRef]
- Hill, L.L. Core elements of digital gazetteers: Placenames, categories, and footprints. In Proceedings of the International Conference on Theory and Practice of Digital Libraries, Lisbon, Portugal, 18–20 September 2000; Springer: Berlin, Germany, 2000; pp. 280–290. [Google Scholar]
- Purves, R.S.; Clough, P.; Jones, C.B.; Arampatzis, A.; Bucher, B.; Finch, D.; Fu, G.; Joho, H.; Syed, A.K.; Vaid, S.; Yang, B. The design and implementation of SPIRIT: A spatially aware search engine for information retrieval on the Internet. Int. J. Geogr. Inf. Sci. 2007, 21, 717–745. [Google Scholar] [CrossRef]
- Papadakis, E.; Blaschke, T. Place-based GIS: Functional Space. In Proceedings of the 4th AGILE PhD School, Leeds, UK, 30 October–2 November 2017; Comber, L., Malleson, N., Eds.; CEUR: Aachen, Germany, 2017; Volume 2208. [Google Scholar]
- Boegl, K.; Adlassnig, K.P.; Hayashi, Y.; Rothenfluh, T.E.; Leitich, H. Knowledge acquisition in the fuzzy knowledge representation framework of a medical consultation system. Artif. Intell. Med. 2004, 30, 1–26. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; ACM: New York, NY, USA, 2012; pp. 186–194. [Google Scholar]
- Adams, B.; Janowicz, K. Thematic signatures for cleansing and enriching place-related linked data. Int. J. Geogr. Inf. Sci. 2015, 29, 556–579. [Google Scholar] [CrossRef]
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]
- Hobel, H.; Fogliaroni, P.; Frank, A.U. Deriving the Geographic Footprint of Cognitive Regions. In Selected papers of the 19th AGILE Conference on Geographic Information Science, Helsinki, Finland, 14–17 June 2016; Sarjakoski, T., Santos, M.Y., Sarjakoski, L.T., Eds.; Lecture Notes in Geoinformation and Cartography; Springer International Publishing: Cham, Switzerland, 2016; pp. 67–84. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Papadakis, E.; Resch, B.; Blaschke, T. Composition of Place: Towards a Compositional View of Functional Space. Cartogr. Geogr. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Janowicz, K.; Keßler, C. The role of ontology in improving gazetteer interaction. Int. J. Geogr. Inf. Sci. 2008, 22, 1129–1157. [Google Scholar] [CrossRef]
- Scheider, S.; Purves, R. Semantic Place Localization from Narratives. In Proceedings of the First ACM SIGSPATIAL International Workshop on Computational Models of Place, Orlando, FL, USA, 5–8 November 2013; Scheider, S., Adams, B., Janowicz, K., Vasardani, M., Winter, S., Eds.; ACM: New York, NY, USA, 2013; pp. 16–16. [Google Scholar] [CrossRef]
- MacEachren, A.M. Leveraging Big (Geo) Data with (Geo) Visual Analytics: Place as the Next Frontier. In Spatial Data Handling in Big Data Era: Select Papers from the 17th IGU Spatial Data Handling Symposium 2016; Zhou, C., Su, F., Harvey, F., Xu, J., Eds.; Springer Singapore: Singapore, 2017; pp. 139–155. [Google Scholar] [CrossRef]
- Scheider, S.; Janowicz, K. Place reference systems. Appl. Ontol. 2014, 9, 97–127. [Google Scholar] [CrossRef]
- Papadakis, E.; Resch, B.; Blaschke, T. A Function-based model of Place. In International Conference on GIScience Short Paper Proceedings; California Digital Library: Oakland, CA, USA, 2016. [Google Scholar]
- Hobel, H.; Abdalla, A.; Fogliaroni, P.; Frank, A.U. A Semantic Region Growing Algorithm: Extraction of Urban Settings. In Proceedings of the 18th AGILE Conference on Geographic Information Science, Lisbon, Portugal, 9–12 June 2015; Bação, F., Santos, M.Y., Painho, M., Eds.; Lecture Notes in Geoinformation and Cartography. Springer International Publishing: Cham, Switzerland, 2015; pp. 19–33. [Google Scholar]
- Liu, X.; Andris, C.; Rahimi, S. Place niche and its regional variability: Measuring spatial context patterns for points of interest with representation learning. Comput. Environ. Urban Syst. 2019, 75, 146–160. [Google Scholar] [CrossRef]
- Tao, H.; Wang, K.; Zhuo, L.; Li, X. Re-examining urban region and inferring regional function based on spatial-temporal interaction. Int. J. Digital Earth 2019, 12, 293–310. [Google Scholar] [CrossRef]
- Su, S.; Lei, C.; Li, A.; Pi, J.; Cai, Z. Coverage inequality and quality of volunteered geographic features in Chinese cities: Analyzing the associated local characteristics using geographically weighted regression. Appl. Geogr. 2017, 78, 78–93. [Google Scholar] [CrossRef]
- Noulas, A.; Scellato, S.; Mascolo, C.; Pontil, M. Exploiting Semantic Annotations for Clustering Geographic Areas and Users in Location-based Social Networks. In Proceedings of the 2011 Workshop on the Social Mobile Web, Barcelona, Spain, 21 July 2011; AAAI: Menlo Park, CA, USA, 2011; Volume WS-11-02. [Google Scholar]
- Zhou, X.; Zhang, L. Crowdsourcing functions of the living city from Twitter and Foursquare data. Cartogr. Geogr. Inf. Sci. 2016, 43, 393–404. [Google Scholar] [CrossRef]
- Zhi, Y.; Li, H.; Wang, D.; Deng, M.; Wang, S.; Gao, J.; Duan, Z.; Liu, Y. Latent spatio-temporal activity structures: A new approach to inferring intra-urban functional regions via social media check-in data. Geo-Spat. Inf. Sci. 2016, 19, 94–105. [Google Scholar] [CrossRef]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability; Le Cam, L.M., Neyman, J., Eds.; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Assunção, R.M.; Neves, M.C.; Câmara, G.; Freitas, C.D.C. Efficient regionalization techniques for socio-economic geographical units using minimum spanning trees. Int. J. Geogr. Inform.Sci. 2006, 20, 797–811. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Gao, S.; Gong, L.; Kang, C.; Zhi, Y.; Chi, G.; Shi, L. Social Sensing: A New Approach to Understanding Our Socioeconomic Environments. Ann. Assoc. Am. Geogr. 2015, 105, 512–530. [Google Scholar] [CrossRef]
- Cohn, A.; Gotts, N. The ’Egg-Yolk’ Representation of Regions with Indeterminate Boundaries. In Geographic Objects with Indeterminate Boundaries; Burrough, P.A., Frank, A.U., Eds.; Taylor & Francis: London, UK, 1996; pp. 171–187. [Google Scholar]
- Mai, G.; Janowicz, K.; Hu, Y.; Gao, S.; Zhu, R.; Yan, B.; McKenzie, G.; Uppal, A.; Regalia, B. Collections of Points of Interest: How to Name Them and Why it Matters. In Proceedings of the Spatial Big Data and Machine Learning in GIScience Workshop at GIScience 2018, Melbourne, Australia, 28 August 2018; Raubal, M., Wang, S., Guo, M., Jonietz, D., Kiefer, P., Eds.; ETH: Zurich, Switzerland, 2018; pp. 29–33. [Google Scholar]
- Liu, Y.; Yuan, Y.; Gao, S. Modeling the Vagueness of Areal Geographic Objects: A Categorization System. ISPRS Int. J. Geo-Inf. 2019, 8, 306. [Google Scholar] [CrossRef]
- Papadakis, E.; Baryannis, G.; Petutschnig, A.; Blaschke, T. Function-Based Search of Place Using Theoretical, Empirical and Probabilistic Patterns. ISPRS Int. Journal Geo-Inf. 2019, 8, 92. [Google Scholar] [CrossRef]

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadakis, E.; Gao, S.; Baryannis, G. Combining Design Patterns and Topic Modeling to Discover Regions That Support Particular Functionality. ISPRS Int. J. Geo-Inf. 2019, 8, 385. https://doi.org/10.3390/ijgi8090385
Papadakis E, Gao S, Baryannis G. Combining Design Patterns and Topic Modeling to Discover Regions That Support Particular Functionality. ISPRS International Journal of Geo-Information. 2019; 8(9):385. https://doi.org/10.3390/ijgi8090385
Chicago/Turabian StylePapadakis, Emmanuel, Song Gao, and George Baryannis. 2019. "Combining Design Patterns and Topic Modeling to Discover Regions That Support Particular Functionality" ISPRS International Journal of Geo-Information 8, no. 9: 385. https://doi.org/10.3390/ijgi8090385
APA StylePapadakis, E., Gao, S., & Baryannis, G. (2019). Combining Design Patterns and Topic Modeling to Discover Regions That Support Particular Functionality. ISPRS International Journal of Geo-Information, 8(9), 385. https://doi.org/10.3390/ijgi8090385