1. Introduction
With the development of emerging technologies such as GPS, mobile communication and wireless networks, location-based social networks (LBSNs), such as Foursquare, Gowalla and Facebook, have been widely adopted worldwide. LBSNs combine social, localization and mobility functionalities, among others, to pinpoint and precisely understand locations through the mining and analysis of users’ location data. In contrast to traditional social networks, LBSNs display users’ geographical information and enrich the spatial and temporal characteristics of locations with various information drawn from users’ mobility data. Meanwhile, massive volumes of individual trajectory data are constantly being generated and are available to be extracted from LBSNs, thereby promoting research on real-time trajectory mining, user behaviour prediction, traffic analysis and location recommendation. The location-based services in LBSNs allow users to add and share locations such as restaurants, shopping malls or cinemas [
1]. One of the advantages of such geographical services is that online users can discover points of interest (POIs) for social activities occurring in the near future close to their current locations.
Since the personal trajectories formed by online users’ check-ins are closely related to their preferences at the check-in points over time, an LBSN contains not only historical check-ins as trajectory-forming sequences but also many related annotations collected by means of geographic information services [
2,
3]. Therefore, LBSN data effectively combine check-in trajectory sequences with geographical information annotated with local business activities and thus provide opportunities for researchers to derive human mobility behaviour patterns and personalized travel preferences, from which POIs can be further predicted and recommended for individuals [
4,
5,
6,
7].
POI recommendation is quite different from e-commerce recommendation, which can be performed anywhere at any time and is less strongly affected by various contextual factors. In contrast, location recommendation is relevant when people are travelling, and their travel decisions can easily be affected by various contextual factors, especially their times of travel and spatial locations. For example, in the evening, people may tend to prefer to go to a restaurant for dinner or to a bar for entertainment rather than to the library to read a book. Thus, if a person is recommended a library as a POI in the evening, they will likely not be satisfied.
Among the various factors influencing POI preferences, individuals’ psychological effects have been largely ignored in existing research on POI recommendation. For example, the preferences of an individual may be affected by personal or environmental factors, which may vary with time. Therefore, the preference of a certain user with regard to a given POI will also vary with time. Specifically, if a user wishes to go to a certain place, they may need to remember some experience concerning it and know its approximate location. Obviously, such recall of a place is similar to a recollection or memory of the user’s historical impression of that place, which is strongly related to past check-ins. In this case, we are interested in the memory-based preference derived from users’ check-ins. Consequently, in this study, we refer to classical psychological research on memory, as founded by the famous scholar Ebbinghaus. Ebbinghaus’s theory on memory can be modelled in the form of a forgetting curve, which imitates the attenuation of an individual’s memory over time [
8].
Based on the above understanding, in this paper, we propose a memory-based POI preference attenuation model for calculating the similarity of preferences between people. To achieve this objective, we first consider several essential factors: (1) the mobility trajectories of online LBSN users, which illustrate their spatial preferences regarding POIs, and (2) a memory-based preference attenuation model based on Ebbinghaus’s forgetting curve. Then, by integrating the above two factors, we define a novel measure of the similarity between online LBSN users based on the memory-based preference model. Furthermore, we propose a novel collaborative filtering model based on the proposed similarity for POI recommendation, which considers the characteristics of users’ memory-based preference attenuation. We demonstrate the effectiveness of our proposed method via 10-fold cross-validation on a real data set crawled from Foursquare. The results show that our method based on memory-based preference significantly outperforms other methods.
The organization of the paper is as follows.
Section 2 summarizes the related work.
Section 3 provides an overview of the proposed memory-based POI recommendation method.
Section 4 presents the results of an experimental evaluation of the proposed method and a corresponding parameter analysis.
Section 5 offers some further discussion and concludes the paper.
2. Related Work
2.1. Collaborative Filtering for POI Recommendation
LBSN-based POI recommendation uses such information as a user’s historical check-in records to predict the location in which the user is most likely to be interested at present and recommend that location to the user [
9]. Collaborative filtering, as a widely used basis for personalized recommendation algorithms, is also the main foundation for methods of POI recommendation and heavily relies on user–POI check-ins [
10]. The basic assumption of collaborative filtering is that the historical records of a person’s check-ins reflect their interest in POIs; thus, a user’s preferences can also be discovered from the frequencies of their visits. Therefore, if sufficient historical check-in data are available for a user, then their preferences can be predicted [
11]. Based on this assumption, in collaborative filtering methods, user preferences are typically first represented as vectors of historical visits to identify people with similar preferences; then, recommendations are provided based on the visit frequencies of similar individuals.
Collaborative filtering methods for POI recommendation can be further divided into memory-based and model-based algorithms [
10]. Memory-based algorithms include user-based and item-based collaborative filtering. In these methods, the target user’s preferences are predicted by aggregating the scores of similar users or POIs based on a similarity measure or some specific relationship [
4,
12,
13]. Related studies have captured users’ potential demands and relatively stable tastes by exploiting measurable relations between individuals and POIs from historical visits and thus have extracted preference similarities from trajectories [
2,
3,
14,
15].
Model-based algorithms recommend certain POIs to users by calculating preferences that indicate their likelihoods of visiting different POIs. These preferences are calculated by deriving a model built on the data set as a whole [
16]. Typical model-based methods include matrix factorization and Bayesian probabilistic modelling. Matrix factorization has been applied to combine geographical data with social information [
5,
6,
7]. For example, Liu et al. predicted user preferences regarding POIs by using a probabilistic factor model combining probabilistic matrix factorization with a Poisson factor model [
17]. Yin et al. proposed a probabilistic generative model for user rating profiles based on latent Dirichlet allocation [
18].
2.2. Context-Based POI Recommendation
Although the advantage of adopting collaborative filtering for POI recommendation is that there is almost no need to know any additional characteristics of the users or POIs, various related information does help to capture users’ preferences regarding POIs. Therefore, context-based POI recommendation methods have recently received considerable attention.
Context is usually defined in terms of certain descriptions of the features of the POIs visited by a user. Contextual factors have been demonstrated to exert significant influences on individuals’ preferences [
19]. For instance, environmental factors have an important impact on people’s activities and potential travel demands [
20,
21]. Considering such contextual information, such as geographic, temporal and social factors, makes it possible to capture individuals’ POI preferences to provide further information for POI recommendation.
Context-based methods have obvious advantages over traditional methods by virtue of modelling various contextual factors [
19]. Based on LBSN data, recent studies have attempted to improve the accuracy and efficiency of POI recommendation by considering temporal information [
22], location tags [
23], geographic semantic information [
24] and both social and categorical correlations between people and POIs [
25,
26]. For example, Yin et al. proposed a unified probabilistic generative model, namely, the Topic-Region Model (TRM), for discovering the semantic, temporal and spatial patterns of individuals’ check-in activities and modelling their joint effects on users’ decision-making regarding POIs [
25]. Baral and Li proposed a matrix factorization method named GeoTeCS for integrating geographical, categorical, social and temporal information into a single model for POI recommendation [
5]. Hung et al. identified user communities by analysing users’ trajectories in order to predict user locations based on the similarities among the trajectories of users in the same community [
27]. Xiao et al. incorporated semantic location categories into the calculation of user similarity [
28]. Other studies have achieved improved recommendation performance by representing users’ preferences by means of semantic descriptions and similarity calculations, group preference analysis [
29] or trust relations among individuals [
30].
2.3. Temporal Factors and Ebbinghaus’s Forgetting Curve
In previous studies, temporal factors have often been considered to represent dynamic characteristics such as periodicity, non-uniformity [
31] and consecutiveness [
32]. Most previous studies have focused on periodic temporal patterns, such as hour-of-the-day and day-of-the-week patterns at a given timestamp. Some recent studies have extracted the correlations among consecutive check-ins to improve POI recommendation performance [
31]. For example, the time dimension has been divided into periodic time slots to make use of periodic temporal properties [
33]. Recent studies have modelled sequential patterns in LBSN data to capture the spatio-temporal continuity of users’ check-in behaviours for time-specific scenarios [
34].
According to the literature, individuals’ POI preferences are also associated with temporal factors, which strongly influence most of the abovementioned contextual factors [
19], as well as factors such as daily travel habits, lifestyle and characteristics of the current location and surrounding environment, which will gradually lead to changes in people’s POI preferences over time.
In reality, an individual’s memory is another important temporal factor that influences their check-in behaviours, but this factor has not been addressed in previous studies on POI recommendation. For a suitable related theory, we can refer to the well-known psychological theory developed by Ebbinghaus, namely, the forgetting curve, which represents the temporal evolution of a person’s memory. Ebbinghaus believed that the attenuation of a person’s memory is a regular but unbalanced process, as shown in
Figure 1. Initially, the forgetting speed is very fast, and it subsequently becomes increasingly slower. He hypothesized that the basal forgetting rate differs little between individuals [
35,
36]. Relevant research indicates that the forgetting curve shows an initial rapid drop, followed by a slower decrease over time; this behaviour can be simulated by an exponential function [
37].
2.4. Limitations of Existing Studies
Although previous studies have predicted individuals’ behaviours based on static preferences for POI recommendation, there has not yet been an attempt to capture dynamic changes in preference, especially in the form of attenuation over time in a manner consistent with people’s memory. Therefore, current studies lack effective methods of integrating memory-based preferences, which greatly limits the degree of intelligence that can be achieved in POI recommendation.
Since existing studies rely on the assumption that a person’s preferences remain static over time, the effects and patterns of preference changes over time related to people’s daily check-ins have been largely ignored. Specifically, an individual’s earlier check-in records should be considered to reflect less accurately their current preferences compared with recent check-in records, and thus, they should play a less important role in POI recommendation. Consequently, it is obviously unreasonable to directly use early historical data to analyse users’ travel preferences, as this will lead to a reduction in the efficiency of POI recommendation in LBSNs [
38].
However, the question arises of how one can capture the patterns of time-related changes in preference, which are related to individuals’ subjective feelings. To answer this question, we resorted to the well-known psychological theory on memory proposed by Ebbinghaus, in which the attenuation of a person’s memory over time is represented in the form of the forgetting curve [
8,
37]. Inspired by this theory, we established a memory-based preference attenuation model to represent individuals’ preferences regarding POIs. Furthermore, we proposed a novel POI recommendation method that incorporates this memory-based preference model based on Ebbinghaus’s forgetting curve.
3. Methods
3.1. Overview of the Proposed Method
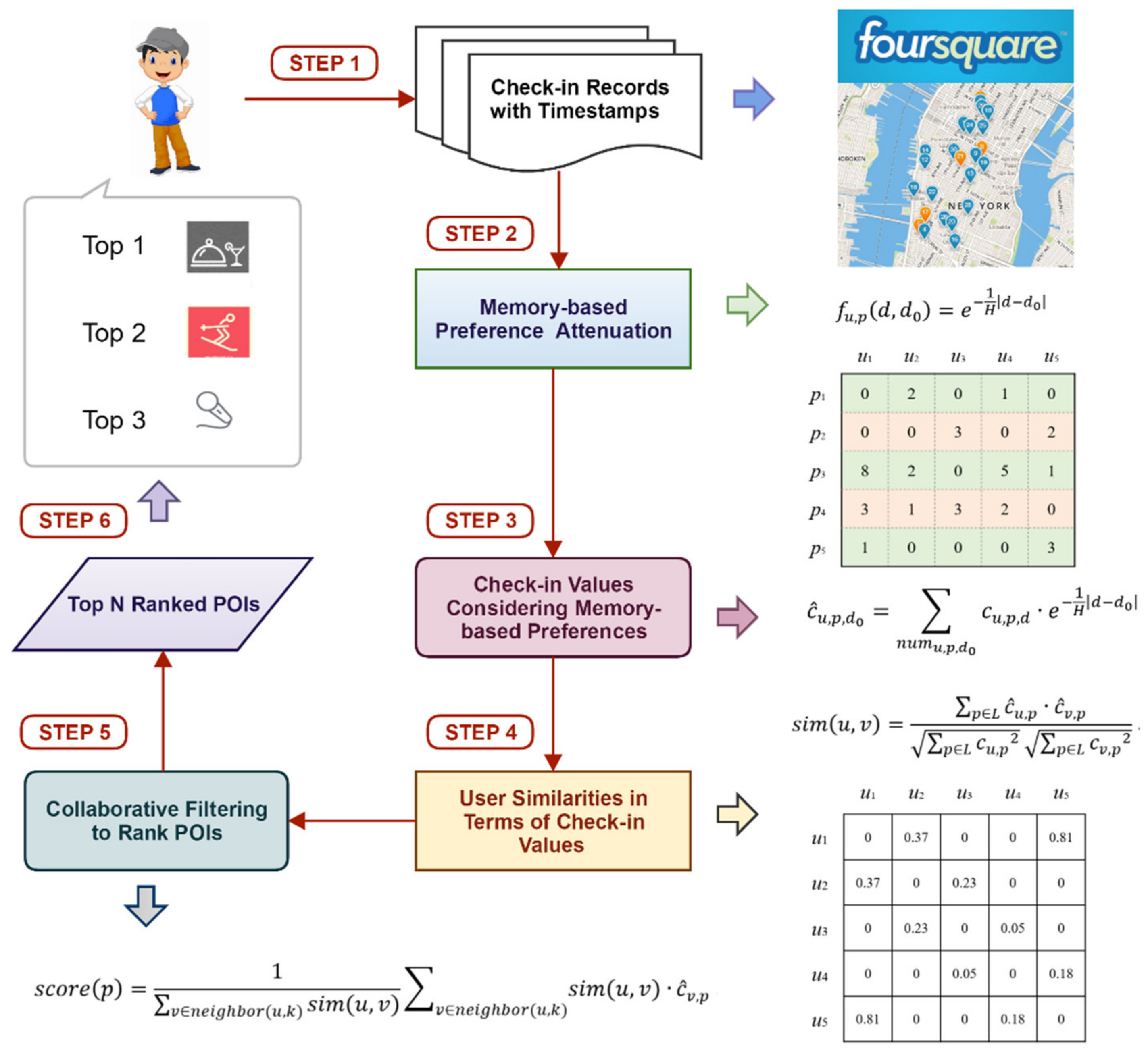
The proposed method is designed based on the understanding that an individual’s preferences regarding POIs can be represented by a forgetting curve in accordance with the memory theory of Ebbinghaus from the field of psychology. As briefly illustrated in
Figure 2 (see
Table 1 for explanations of the notations), this method is composed of six sequential steps. First, we collect historical check-ins from the LBSN website to capture individuals’ daily travel histories, with a timestamp for each check-in. Second, we introduce the memory-based preference attenuation model to describe the preference attenuation of a given individual in terms of the difference in date between the current check-in and a historical check-in at a POI. Third, for each check-in of an individual at a POI, we generate a value based on the accumulated values obtained from the proposed preference attenuation model. Fourth, we calculate the user similarity matrix for each pair of users in the LBSN in accordance with their check-in values for different POIs. Fifth, based on these similarity matrices, we adopt a collaborative filtering method to predict the levels of the user’s preference with regard to their unvisited POIs. Sixth, based on the ranked POIs for each individual, we select the top
N POIs as the recommendation list.
The detailed steps of the method are described in the following subsections. Before we present our proposed model and algorithm, essential notations are defined in
Table 1.
3.2. Memory-Based Preference Attenuation Model
Based on the Ebbinghaus forgetting curve introduced in
Section 2.3, we assume that an exponential function can be used to represent the memory-based evolution of a person’s preferences regarding POIs because the evolution of a person’s memory has been demonstrated to be similar to that of their preferences [
39].
We regard the horizontal axis of the forgetting curve as representing the difference between the current time and a previous check-in time, and we consider the memory value on the vertical axis to represent the weight of a check-in. The attenuation rate describing the change in a user’s preference regarding a certain POI between different time intervals is assumed to be similar to the forgetting process related to their memory of that POI. Thus, the preference curve is assumed to show an exponential downward trend over time; that is, the closer a previous check-in time is to the current time, the more informative it is regarding the user’s current preference. Therefore, we define a memory-based preference attenuation function that has the same form as Ebbinghaus’s forgetting curve:
where
d0 is the current check-in date and
d is a check-in date from the user’s historical records; usually, the value of
d0 should be no less than
d.
H represents a threshold on the time difference between the current date and the earliest date in the check-in records. When
d is equal to the current date
d0, the value of
f is 1, which means that no time-based decay has occurred. The greater the absolute difference is between
d and the current date
d0, the smaller the value of
f.
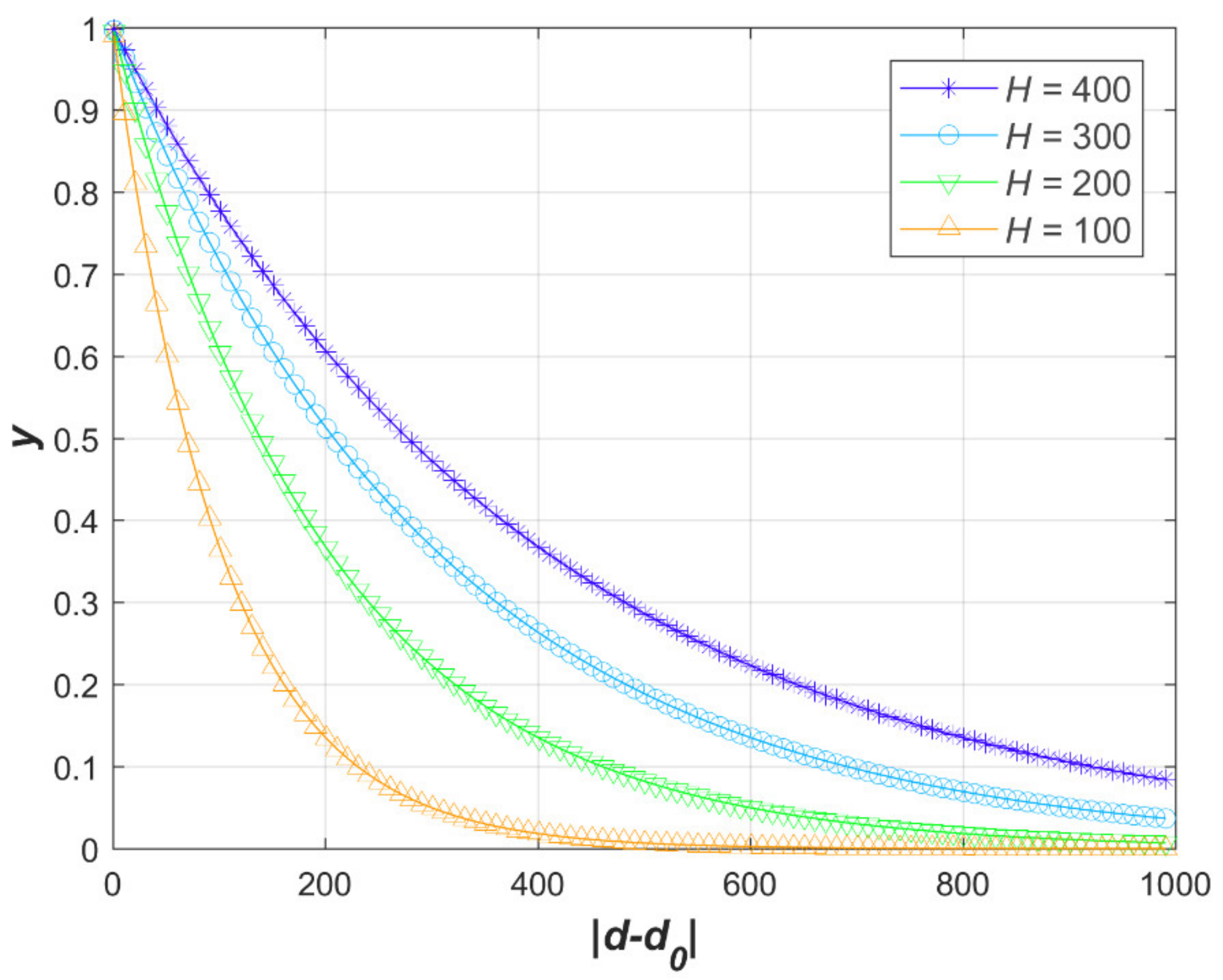
In
Figure 3, the time-related value |
d − d0| is plotted on the horizontal axis, and the vertical axis represents a time-weighted value. We observe that the smaller the time interval between the two dates
d0 and
d is, the larger the value of
. That is, we assign a higher weight to more recent check-in behaviour. Consequently, inspired by the forgetting curve, we introduce a memory-based preference attenuation function to make the value of each check-in more consistent with the dynamic changes in users’ check-in behaviour over time. Thus, we emphasize more recent check-ins while reducing the influence of earlier check-ins on POI recommendation.
3.3. Check-In Values with Memory-Based Preference Attenuation
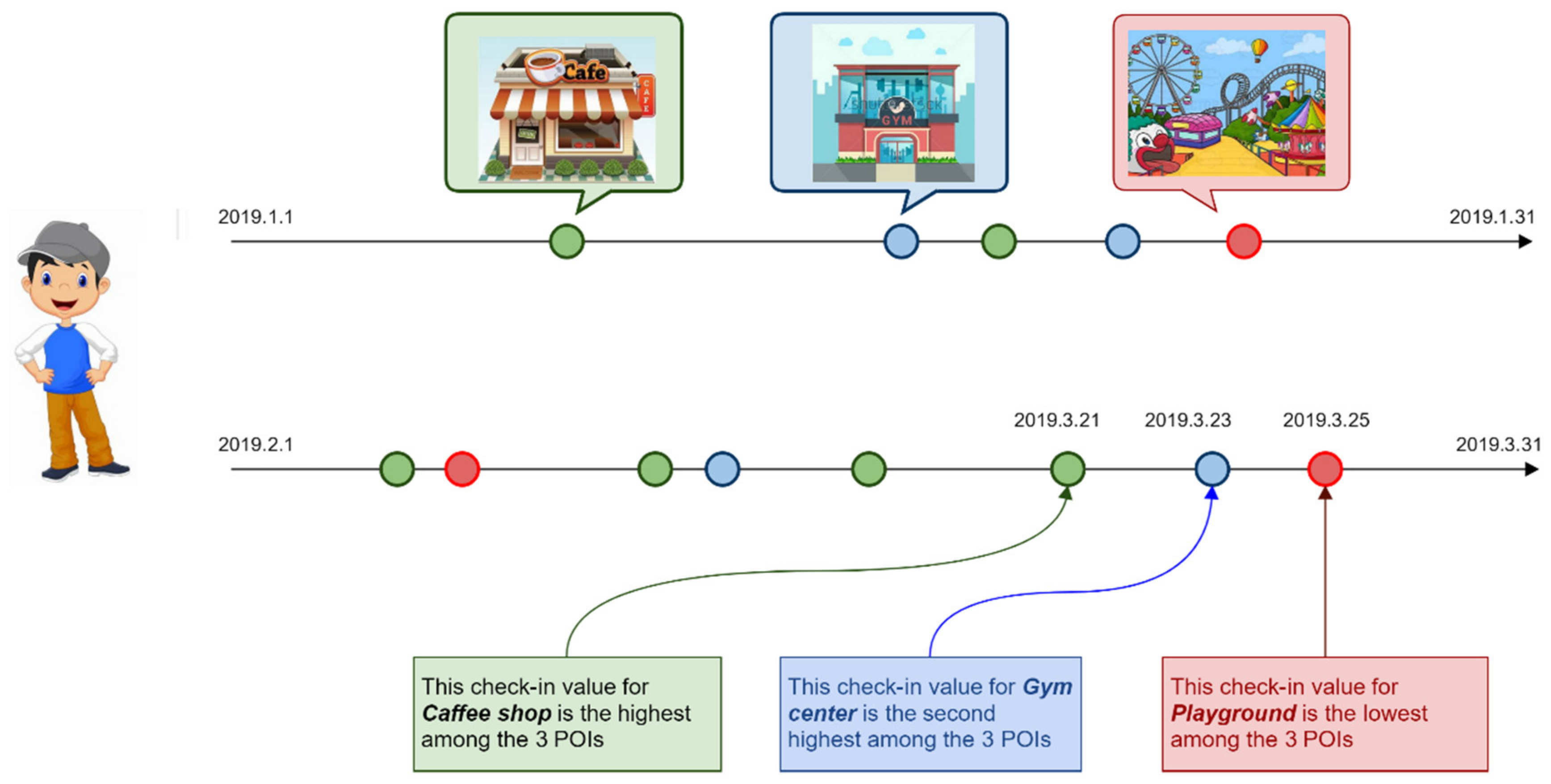
A user’s check-ins in an LBSN are composed of special places at discontinuous time points and reflect exactly the user’s daily travel destinations and interests, for purposes such as tourism, exercise and social activities. Hence, there is a strong correlation between the number of check-ins at a POI and the degree of interest of the user. That is, the more times a user
u checks in at a POI
p, the higher their interest in
p. This fact suggests that two users have common preferences if they have similar check-in histories [
13]. Therefore, to reflect the intensities of user interest in different POIs, we use the number of check-ins of user
u at POI
p rather than simply whether
u has checked in at
p. We then transform all check-ins of all users into a user–POI matrix, as follows:
To consider the influence of time-based attenuation on user preferences, it is necessary to consider the effect of time on check-in values. We can then incorporate the memory-based preference attenuation function introduced above as a weight on the preference similarity with respect to users’ timestamped POI check-ins. We adopt
cu,p,d to denote whether
u checked in at
p at time point
d and
cu,p(
d,
d0) to denote the check-in value for user
u at POI
p at time point
d with respect to an observation point
d0. We calculate
cu,p(
d,
d0) as follows:
Then, we can consider both the number of check-ins and the memory-based preference attenuation function to define the check-in value
for user
u at POI
p at the current time point
d0:
where
numu,p represents the total number of check-ins of
u at
p before the current date
d0,
cu,p,d represents whether
u checked in at
p on the date
d and
is the time attenuation factor. The recommendation effects under different thresholds
H can be tested through experiments.
Figure 4 illustrates a toy example of the memory-based preference value for each check-in of an individual.
3.4. User Similarities in Terms of Memory-Based Check-In Values
After considering the influence of user preference changes, we adopt the cosine method to calculate similarities based on the memory-related check-in values, such that new data are given higher weights, and we consider that the change in user travel preferences will be similar among similar users. The process of calculating the improved similarity is as follows: let
U be the set of users with check-in data, where
, and let
P be the set of check-in locations, where
.
represents the check-in value of user
u at POI
p based on the number of check-ins and the effect of the memory attenuation function. To calculate the cosine similarity
sim(
u,
v) between users
u and
v, we first construct a historical check-in vector for each user consisting of their check-in value at each POI. Then, we calculate the cosine similarity between these two vectors. Finally, the cosine similarity calculation is used to obtain the memory-based preference similarity for
u and
v:
The range of the value sim(u, v) is [0, 1]; users u and v are considered completely dissimilar to each other if sim(u, v) = 0, whereas these two users are considered completely similar to each other if sim(u, v) = 1.
3.5. POI Recommendation with the Memory-Based Similarity Model
We can now use the memory-based preference similarities between all users in an LBSN to recommend POIs at which users have not previously checked in. We first sort the similarity values calculated for the target user
u in descending order and select the
k users who are most similar to
u as the nearest neighbourhood, denoted by
neighbour(
u, k). We then adopt the weighted average method to predict the check-in value for each POI for
u and generate a recommendation list for them. In detail, for each
v neighbour(
u, k), we calculate the memory-based preference similarity between
u and
v, denoted by
sim(
u,
v). Next, we take
sim(
u,
v) as the weight of the check-in value
for each POI
p at which
v has checked in before but
u has not. For all
k users most similar to
u, we weight the check-in values for
u as follows:
. Thus, we obtain a score corresponding to
p for
u, denoted by
score(
u,
p). Finally, we rank the check-in values
score(
u,
p) for all POIs at which
u has not previously checked in in descending order to obtain the recommendation results for
u:
3.6. Methods for Comparison
For a given user, the user-based collaborative filtering method is as follows. First, the similarities between that user and all other users are calculated, and then, a prediction for a POI is produced by considering a weighted combination of the other users’ check-in records at that POI. More specifically, let
v ∈
U denote a user in the user set
U, and let
p ∈
P denote a POI in the POI set
P [
33]. We set
cv,p = 1 if
v has checked in at
p before and
cv,p = 0 otherwise. For a user
u, the recommendation score representing the likelihood that
u will check in at a POI
p that they have not visited before is computed using the following equation, where
su,v is the similarity between users
u and
v. We use the abbreviation U-CF to denote this method in the following sections.
3.7. Evaluation and Validation Methods
3.7.1. Validation Method
We partitioned the known check-ins of users at POIs into training data and test data based on the timestamps of all check-ins in ascending order. The training set consisted of the earliest 80% of the check-ins, and the test set consisted of the most recent 20% of the check-ins for all users. Users with no check-ins in the test set were removed from the data set. In addition, in the test set, we removed POIs with corresponding check-ins by users in the training set, and we used the unvisited POIs for each user to assess the effectiveness of our method.
For a given user, we collected a set of test POIs associated with that user in the test data and a set of control POIs associated with that user in neither the training data nor the test data. Then, we calculated concordance scores for both the test and control POIs and ranked each test POI against all control POIs in descending order of their scores. By repeating this ranking procedure for each user, we obtained a set of ranking lists, which we used to calculate two criteria for measuring accuracy and retrieval, as defined below.
3.7.2. Evaluation Criteria
Given a threshold L (with a default value of 10 in this paper for the calculation of all criteria), we considered a test case to be a true positive (TP) if it ranked among the top L entries in the ranking list, and we similarly considered a control case to be aalse positive (FP) if it ranked among the top L entries. Then, we calculated a criterion denoted by PRE(L) as follows: TP/(TP + FP). A method with high accuracy will tend to have a low mean relative rank and a high PRE(L). We considered a test POI to be successfully recommended if that POI was ranked among the top L entries in the ranking list. For a user u with several POIs in the test data (where the number of POIs for user u in the test data is denoted by Du), we counted the number of successful recommendations among these POIs, denoted by Ru, and calculated the fraction of successfully recommended POIs to obtain the recall for this user as follows: pu = Ru/Du. Finally, by averaging the recalls for all users with at least one POI in the test data, we obtained the overall recall under the threshold L, denoted by REC(L). In this paper, we set L = 10 for the calculation of this criterion. A method with a higher recommendation accuracy will exhibit a higher recall.
4. Results
4.1. Data Set
The data set was crawled from Foursquare, a mobile service website based on users’ location information (location-based service). Foursquare encourages users to share their real-time locations, and each check-in represents a location the corresponding user has visited at a specific time, such as a
restaurant or
attraction, as shown in
Figure 5. We focused on New York City, which is the city with the largest number of check-ins among all cities in the Foursquare data set. The data set contains five fields:
user ID,
check-in time,
check-in venue, longitude and latitude of check-in and
check-in date. We developed a Python script to crawl the related fields from Foursquare and ran the script on our computing cluster to download the data. The same computing cluster was later used to conduct the experiments.
Since we wished to study user POI preferences, we deleted locations such as
home and
company for each user. To avoid sparsity of the data set, we removed users with fewer than 10 check-ins as well as POIs with fewer than 10 check-ins. After these deletions, the data set contained 3937 users, 5766 POIs and 190,356 check-ins with dates from April 3, 2012, to September 16, 2013. The statistics of the data set are given in
Table 2.
4.2. Improvement of Recommendation Performance
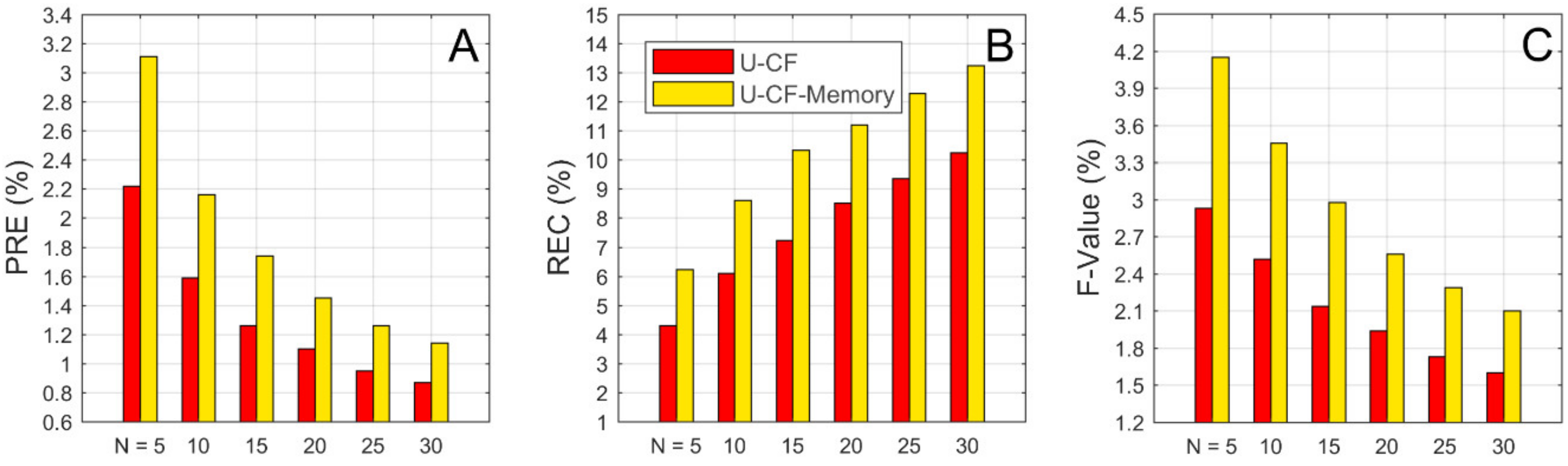
Here, the traditional user-based collaborative filtering recommendation algorithm is denoted by U-CF. Recommendation based on memory-based changes in user preference is denoted by U-CF-Memory. N values of 5, 10, 15, 20, 25 and 30 are considered.
We assessed the performance of each method using the three criteria defined in the methods section; the results are summarized in
Figure 6 and
Table 3. Our proposed method clearly outperforms U-CF. With regard to the recommendation precision (at a rank cut-off value of
N = 10), our proposed method U-CF-Memory achieves a precision (
PRE) of 2.16%, which is significantly higher than that of U-CF (1.59%), corresponding to an increase of 35.85%. In terms of the recommendation retrieval performance (at a rank cut-off value of
N = 10), U-CF-Memory achieves the higher recall (
REC), with a value of 8.61%, outperforming U-CF (6.11%) by 40.92%. With regard to the f-value, U-CF-Memory achieves a value of 3.46% (at a rank cut-off value of
N = 10), outperforming U-CF (2.52%) by 37.3%.
The above experimental results are all based on a rank cut-off value of N = 10. We also analysed the influence of different rank cut-off values (N = 5, 15, 20, 25 and 30); however, we found that the selection of the rank cut-off value did not affect our conclusion. More specifically, although the values of the evaluation criteria are different for different rank cut-off values, our method, U-CF-Memory, uniformly outperforms U-CF at all cut-off values in terms of all three criteria. Therefore, the selection of the rank cut-off value is not an important issue in regard to the comparison of the different methods.
4.3. Robustness to Parameter Values
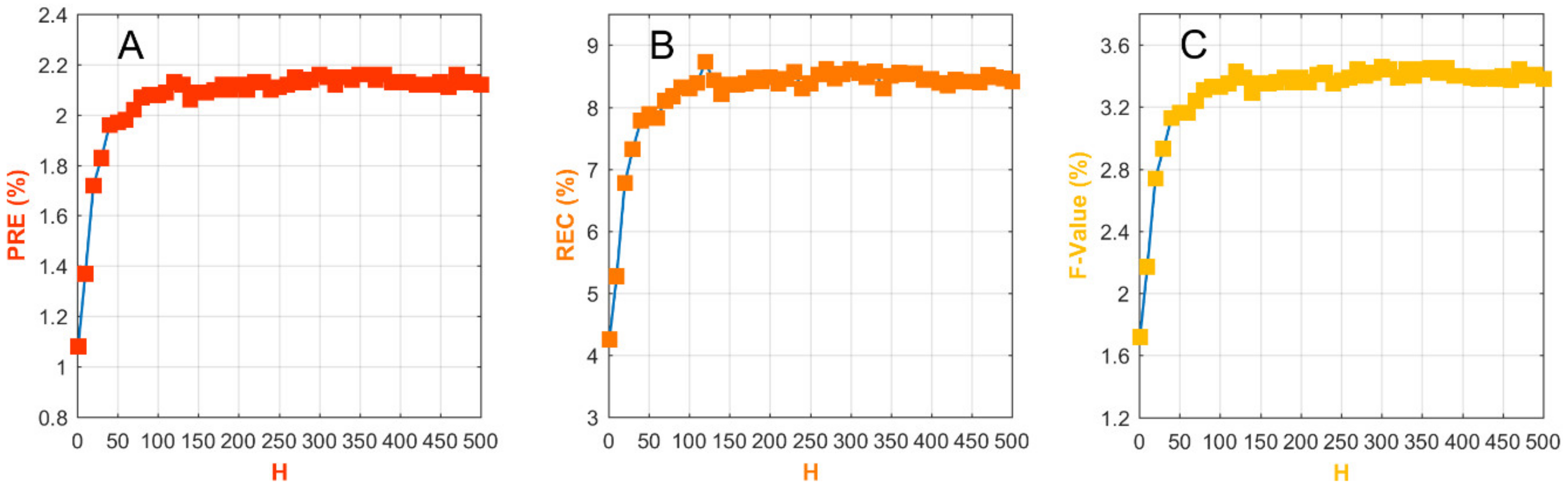
Our method has one parameter: the memory attenuation index (H). By default, this parameter is set to H = 300. However, we also assessed how the parameter H influences the performance of our proposed method.
We varied the memory attenuation index
H from 1 to 500. As shown in
Figure 7, the performance of U-CF-Memory at different values of this parameter suggests that the results are robust to this parameter over a wide range of values around the default. Taking the precision as an example, at the default value of
H, the PRE value is 2.16%. As
H decreases, the PRE value initially decreases only gradually, reaching 1.96% at
H = 40. However, when
H is less than 40, PRE decreases more dramatically with decreasing
H, reaching 1.08% at
H = 1. Thus, the curve of PRE vs. H suggests that a small value of
H is not preferred. By contrast, as
H increases towards larger values, the PRE value decreases slowly to 2.12% and then reaches a plateau, suggesting that large values of
H are preferred.
The REC metric exhibits a pattern similar to that of PRE. However, these two retrieval measures (i.e., the recall and precision) show different unimodal patterns, with a single peak occurring around the default value of H. Taking the recall as an example, at the default value of H, the REC value is 8.61%. As H decreases, the REC value initially decreases slowly, reaching 7.78% at H = 40. When H is less than 40, REC decreases at a much faster rate to 4.25% at H = 1. By contrast, as H increases towards large values, REC decreases at a slower rate, reaching 8.41% at H = 500.
Taking all these criteria into consideration, we conclude that U-CF-Memory is robust to the memory attenuation index H when it takes values larger than the default (300). Larger H values will result in only a minor loss in recommendation accuracy and thus are acceptable in most cases. However, smaller H values will, in general, lead to a dramatic loss in recommendation performance.
5. Discussion and Conclusions
In this paper, we proposed a novel method of generating personalized recommendations by exploring the effects of memory-based attenuation of preferences regarding POIs in a user-based collaborative filtering framework. We demonstrated the superior performance of our method compared with the existing approach by means of systematic validation experiments and comprehensive evaluation criteria. The main contributions of our work can be summarized as follows. First, the results of our method demonstrate that making use of the time series of check-in values instead of only summary statistics (e.g., check-in counts) can enable a more effective utilization of the data, thereby greatly improving the recommendation performance. Second, the results of our method show that weighting the check-in values using a memory-based attenuation mechanism is an effective means of using such data. Specifically, this sophisticated formulation, motivated by the memory theory of Ebbinghaus from the field of psychology, emphasizes check-in values that are closer to each other in the time series and thus leads to superior performance. Third, our method utilizes a collaborative filtering framework to make recommendations while considering the user similarities derived from the proposed memory-based mechanism and thus combines advantages of both collaborative filtering (e.g., a low computational burden) and the memory-based attenuation formulation (e.g., more precise user similarity matrices).
Our method has the following limitations. First, although we have presented comprehensive simulation experiments to assess the influence of the parameter H, a theoretical analysis of the optimal value of this parameter remains to be conducted. One possible approach is to convert the adjusted user similarity matrix into a complex network and then study how the global properties of this network (e.g., the degree distribution and the scale-free property) change with the parameter H. However, the main difficulty in this approach is that the conversion of the user similarity matrix into a network may itself require certain threshold values, which may be controversial. Second, the proposed method lacks a means of location analysis. The memory-based preference mechanism for POI recommendation can be further extended in terms of locations. Different locations have different characteristics, such as categories, visual features, recommendations by individuals, related activities and geographical features. Naturally, we may ask whether these characteristics exert any distinctive influence on the attenuation of individuals’ preferences among different locations. If so, the question arises of which characteristics affect these differences in attenuation most significantly. To further investigate these questions, we will need to incorporate additional information about specific locations, and we may need to cluster location information to reveal the fundamental rules governing the attenuation of individuals’ preferences regarding POIs. We may then incorporate any resulting findings into our POI recommendation method.
Certainly, the proposed method can be further investigated from the following perspectives. First, although our method in its current form is designed on the basis of the user-based collaborative filtering framework, the basic idea of our method could be straightforwardly incorporated into item-based collaborative filtering approaches by simply applying the memory-based preference attenuation function to the POI similarities derived from check-in data. It would also not be difficult to incorporate our idea into content-based methods by using the proposed preference function to adjust the POI similarities calculated based on the analysis of POI contents. Second, although most current collaborative filtering methods primarily use historical data to calculate user similarity scores, it has become increasingly feasible to incorporate users’ social networks and social tagging systems into a collaborative filtering framework to enhance the derivation of user similarities. Intuitively, information such as the preferences of friends and the correlations of social tags between friends should be beneficial in helping a POI recommender system to overcome known issues such as data sparsity and the cold-start problem. One of our future research directions will be the integration of such valuable information into the proposed method.
Based on the outstanding performance of our method, we expect that it can be incorporated into a variety of applications, including but not limited to the recommendation of POIs, bookmarks, news and academic resources. Of particular interest would be the incorporation of our method into the study of social networks. For example, the recommendation of friends has now become a common functionality in most instant messaging applications for smart phones. The adaptation of our approach for such a scenario could result in a method capable of recommending an appropriate list of friends.
Author Contributions
Conceptualization, M.G.; methodology, M.G.; validation, M.G., L.G.; formal analysis, M.G.; data curation, M.G.; writing—original draft preparation, M.G. and L.G.; writing—review and editing, M.G.; visualization, M.G.; supervision, M.G.; funding acquisition, M.G..
Funding
This work was partially supported by the National Natural Science Foundation of China under Grant Nos. 71871019 and 71471016 and by the Fundamental Research Funds for the Central Universities under Grant No. FRF-TP-18-013B1.
Acknowledgments
We acknowledge Xi Sun for the technical support of related computation and validation of the method.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gao, H.; Tang, J.; Hu, X.; Liu, H.; Gao, H. Content-aware point of interest recommendation on location-based social networks. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; AAAI Press: Menlo Park, CA, USA, 2015. [Google Scholar]
- Al-Shamri, M.Y.H. User profiling approaches for demographic recommender systems. Knowl.-Based Syst. 2016, 100, 175–187. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, J.; Zhu, F.; Wang, X. Factored similarity models with social trust for top-N item recommendation. Knowl.-Based Syst. 2017, 122, 17–25. [Google Scholar] [CrossRef]
- Zhang, J.D.; Chow, C.Y. CoRe: Exploiting the personalized influence of two-dimensional geographic coordinates for location recommendations. Inf. Sci. 2015, 293, 163–181. [Google Scholar] [CrossRef]
- Baral, R.; Li, T. Exploiting the roles of aspects in personalized POI recommender systems. Data Min. Knowl. Discov. 2018, 32, 320–343. [Google Scholar] [CrossRef]
- Cheng, C.; Yang, H.; King, I.; Lyu, M.R. A Unified Point-of-Interest Recommendation Framework in Location-Based Social Networks. ACM Trans. Intell. Syst. Technol. 2016. [Google Scholar] [CrossRef]
- Gao, R.; Li, J.; Li, X.; Song, C.; Zhou, Y. A personalized point-of-interest recommendation model via fusion of geo-social information. Neurocomputing 2018, 273, 159–170. [Google Scholar] [CrossRef]
- Zeng, L.; Lin, L. An interactive vocabulary learning system based on word frequency lists and Ebbinghaus’ curve of forgetting. In Proceedings of the 2011 Workshop on Digital Media and Digital Content Management, Hangzhou, China, 11–15 May 2011. [Google Scholar]
- Liu, B.; Fu, Y.; Yao, Z.; Xiong, H. Learning geographical preferences for point-of-interest recommendation. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1043–1051. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl.-Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Mathew, W.; Raposo, R.; Martins, B. Predicting future locations with hidden Markov models. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 911–918. [Google Scholar]
- Sarwat, M.; Levandoski, J.J.; Eldawy, A.; Mokbel, M.F. LARS*: An efficient and scalable location-aware recommender system. IEEE Trans. Knowl. Data Eng. 2014, 26, 1384–1399. [Google Scholar] [CrossRef]
- Ye, M.; Yin, P.; Lee, W.C.; Lee, D.L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 325–334. [Google Scholar]
- Lee, W.P.; Ma, C.Y. Enhancing collaborative recommendation performance by combining user preference and trust-distrust propagation in social networks. Knowl.-Based Syst. 2016, 106, 125–134. [Google Scholar] [CrossRef]
- Liu, S.; Li, G.; Tran, T.; Jiang, Y. Preference relation-based markov random fields for recommender systems. Mach. Learn. 2017, 106, 547. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Liu, B.; Xiong, H.; Papadimitriou, S.; Fu, Y.; Yao, Z. A general geographical probabilistic factor model for point of interest recommendation. IEEE Trans. Knowl. Data Eng. 2015, 27, 1167–1179. [Google Scholar] [CrossRef]
- Yin, H.; Cui, B.; Zhang, C.; Hu, Z.; Chen, L. Modeling Location-Based User Rating Profiles for Personalized Recommendation. ACM Trans. Knowl. Discov. Data 2015, 9, 19. [Google Scholar] [CrossRef]
- Stefanidis, K.; Pitoura, E. Fast contextual preference scoring of database tuples. In Proceedings of the 11th International Conference on Extending Database Technology: Advances in Database Technology, EDBT’08, Nantes, France, 25–30 March 2008. [Google Scholar]
- Subbu, K.P.; Vasilakos, A.V. Big Data for Context Aware Computing-Perspectives and Challenges. Big Data Res. 2017, 10, 33–43. [Google Scholar] [CrossRef]
- Mallat, N.; Rossi, M.; Tuunainen, V.K.; Öörni, A. The impact of use context on mobile services acceptance: The case of mobile ticketing. Inf. Manag. 2009, 46, 190–195. [Google Scholar] [CrossRef]
- Sahoo, N.; Singh, P.V.; Mukhopadhyay, T. A Hidden Markov Model for Collaborative Filtering. Mis Q. 2012, 36, 1329–1356. [Google Scholar] [CrossRef]
- Jiang, S.; Qian, X.; Shen, J.; Fu, Y.; Mei, T. Author topic model-based collaborative filtering for personalized POI recommendations. IEEE Trans. Multimed. 2015, 17, 907–918. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, Y.L.; Nie, L.; Gao, Y.; Nie, W.; Zha, Z.J.; Chua, T.S. Semantic-based location recommendation with multimodal venue semantics. IEEE Trans. Multimed. 2015, 17, 409–419. [Google Scholar] [CrossRef]
- Yin, H.; Sun, Y.; Cui, B.; Chen, L. LCARS: A Location-Content-Aware Recommender System. In Proceedings of the Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 221–229. [Google Scholar]
- Zhang, J.-D.; Chow, C.-Y. GeoSoCa: Exploiting Geographical, Social and Categorical Correlations for Point-of-Interest Recommendations. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2013; pp. 443–452. [Google Scholar]
- Hung, C.-C.; Chang, C.-W.; Peng, W.-C. Mining trajectory profiles for discovering user communities. In Proceedings of the 2009 International Workshop on Location Based Social Networks, LBSN 2009, Seattle, WA, USA, 3 November 2009; pp. 1–8. [Google Scholar]
- Xiao, X.; Zheng, Y.; Luo, Q.; Xie, X. Finding similar users using category-based location history. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3 November 2010; pp. 442–445. [Google Scholar]
- Logesh, R.; Subramaniyaswamy, V.; Vijayakumar, V.; Li, X. Efficient User Profiling Based Intelligent Travel Recommender System for Individual and Group of Users. Mob. Netw. Appl. 2018, 1–16. [Google Scholar] [CrossRef]
- Logesh, R.; Subramaniyaswamy, V. A Reliable Point of Interest Recommendation based on Trust Relevancy between Users. Wirel. Pers. Commun. 2017, 97, 2751–2780. [Google Scholar] [CrossRef]
- Gao, H.; Tang, J.; Hu, X.; Liu, H. Exploring Temporal Effects for Location Recommendation on Location-based Social Networks. In Proceedings of the Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; ACM: New York, NY, USA, 2013; pp. 93–100. [Google Scholar]
- Huang, L.; Ma, Y.; Liu, Y.; Sangaiah, A.K. Multi-modal Bayesian embedding for point-of-interest recommendation on location-based cyber-physical-social networks. Futur. Gener. Comput. Syst. 2017. [Google Scholar] [CrossRef]
- Quan, Y.; Gao, C.; Ma, Z.; Sun, A.; Magnenat-Thalmann, N.; Gurvich, A.; Yakovlev, A.; Yurikova, A.; Nosov, A.; Starkov, K.; et al. Time-aware point-of-interest recommendation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; 2013; pp. 10–14. [Google Scholar]
- Ding, R.; Chen, Z.; Member, S.; Li, X. Spatial-Temporal Distance Metric Embedding for Time-Specific POI Recommendation. IEEE Access 2018, 6, 67035–67045. [Google Scholar] [CrossRef]
- Averell, L.; Heathcote, A. The form of the forgetting curve and the fate of memories. J. Math. Psychol. 2011, 55, 25–35. [Google Scholar] [CrossRef]
- Loftus, G.R. Observations: Evaluating forgetting curves. J. Exp. Psychol. Learn. Mem. Cogn. 1985, 11, 397–406. [Google Scholar] [CrossRef]
- Murre, J.M.J.; Dros, J. Replication and analysis of Ebbinghaus’ forgetting curve. PLoS ONE 2015, 10, e0120644. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Liu, Y.; Aberer, K.; Miao, C. Personalized point-of-interest recommendation by mining users’ preference transition. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management (CIKM ’13), San Francisco, CA, USA, 27 October–1 November 2013; ACM: New York, NY, USA, 2013. [Google Scholar]
- Park, S.M.; Baik, D.K.; Kim, Y.G. Sentiment user profile analysis based on forgetting curve in mobile environments. In Proceedings of the 2016 IEEE 15th International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Palo Alto, CA, USA, 22–23 August 2016; pp. 207–211. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}