Reliability Analysis of LandScan Gridded Population Data. The Case Study of Poland



Abstract
:1. Introduction
- -
- What is the relatedness of LandScan and Polish Population Grid data?
- -
- What is the spatial pattern of highly over- and underestimated areas?
- -
- What is the relation between reliability classes and the types of built-up area and the district status?
2. Area, Materials and Methods
2.1. Overview of Polish Population
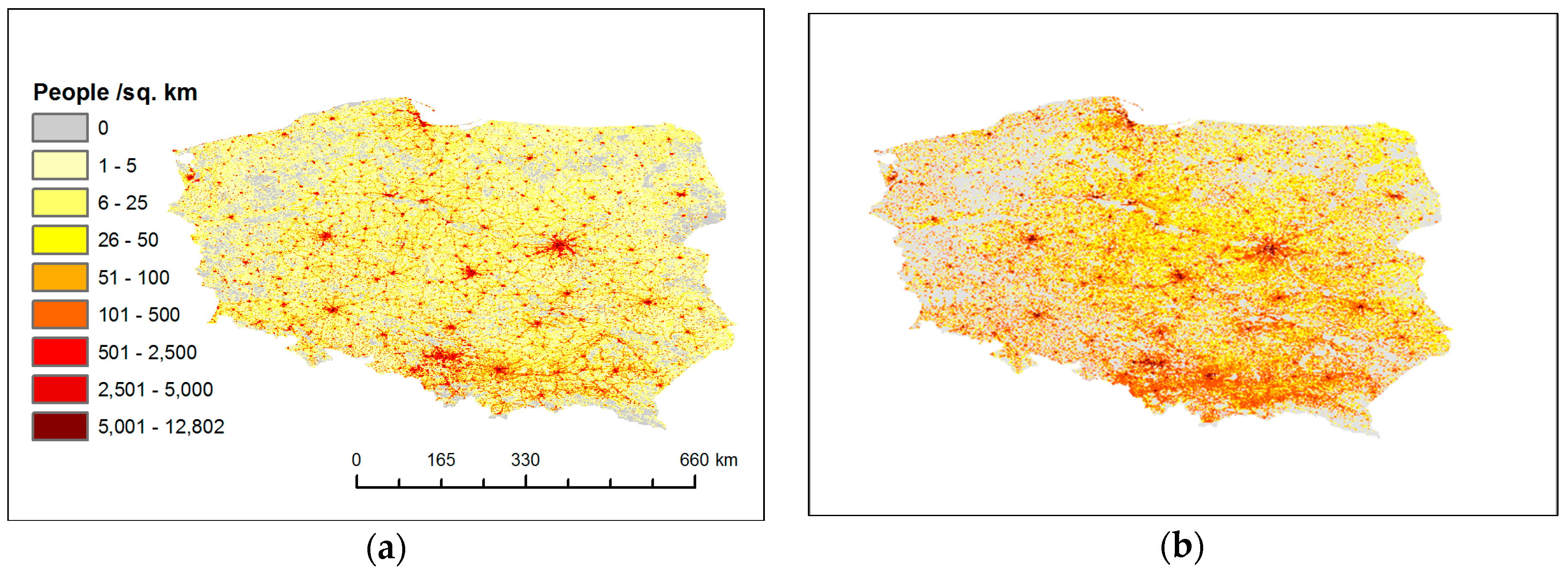
2.2. The Source Data
2.3. Methods Used
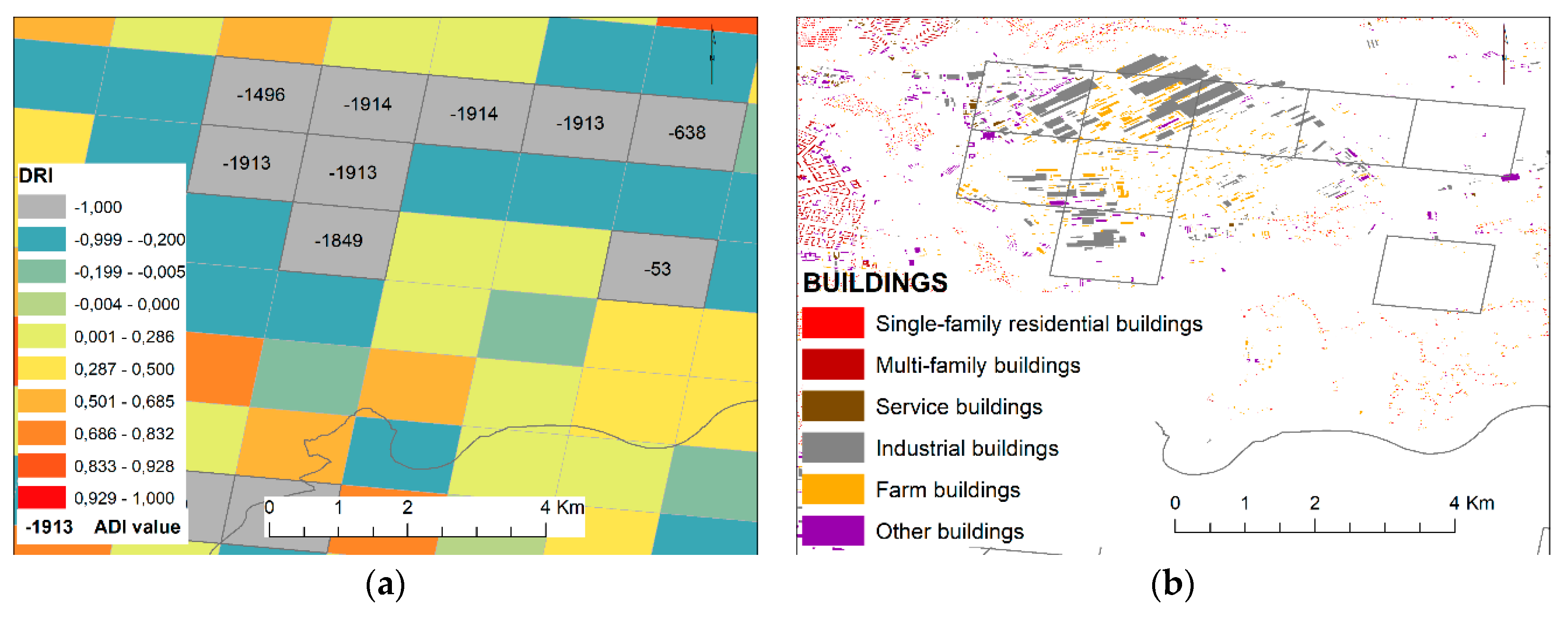
- Change in the detection approach to obtain discrepancies at the grid cell level measured by two disparity indexes. The values of these indices constituted the basis for determining the LS reliability classes.
- GIS and spatial incremental statistics approach to analyse the spatial pattern of the population reliability classes expressed by the Spatial Contiguity Index (SCI) index and Average Nearest Neighbour (ANN) ratio.
- Statistical approach to investigate the concentration of reliability classes presented by statistical measure of concentration and dispersion, relations between reliability classes and built-up areas and the type of administrative units.
3. Results
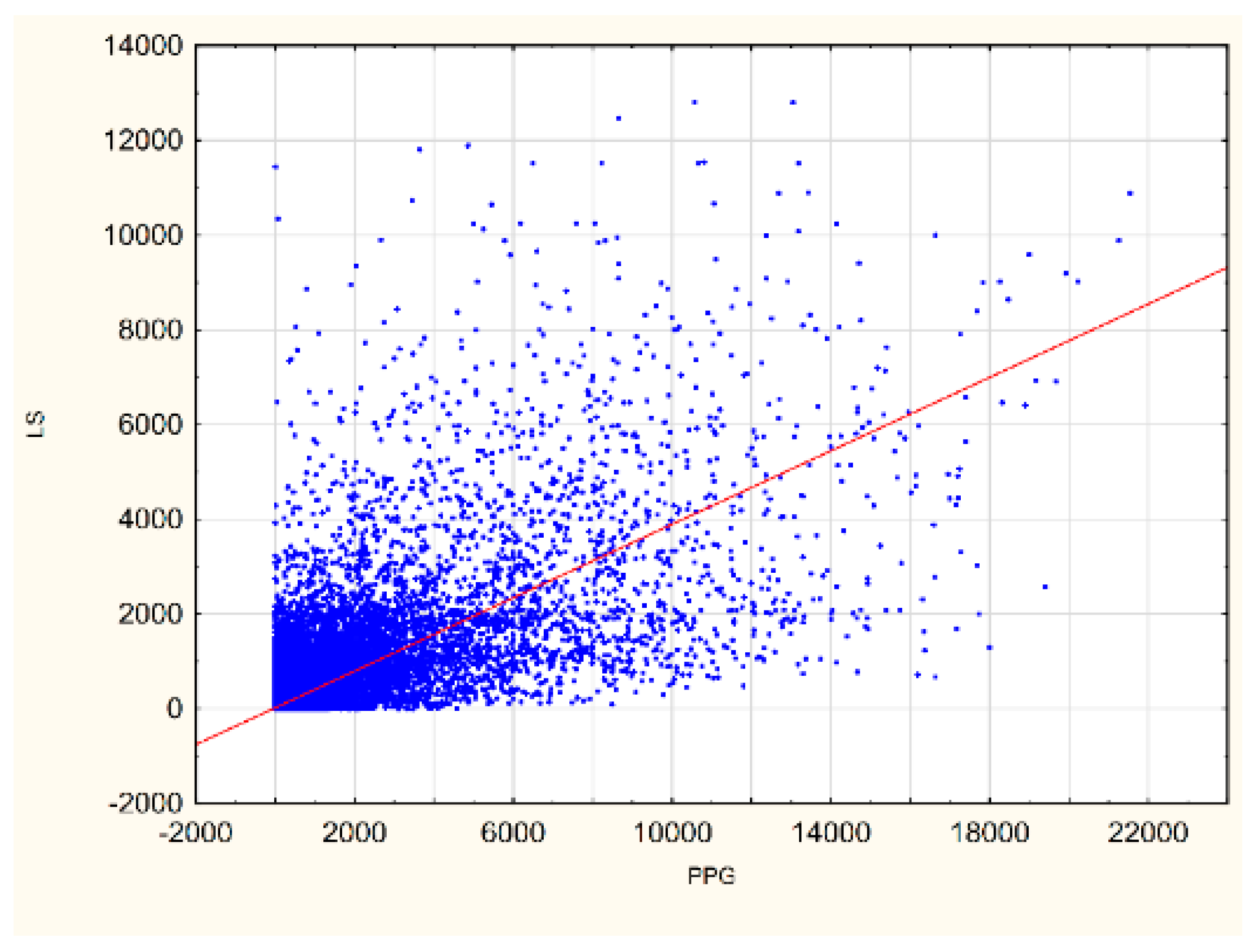
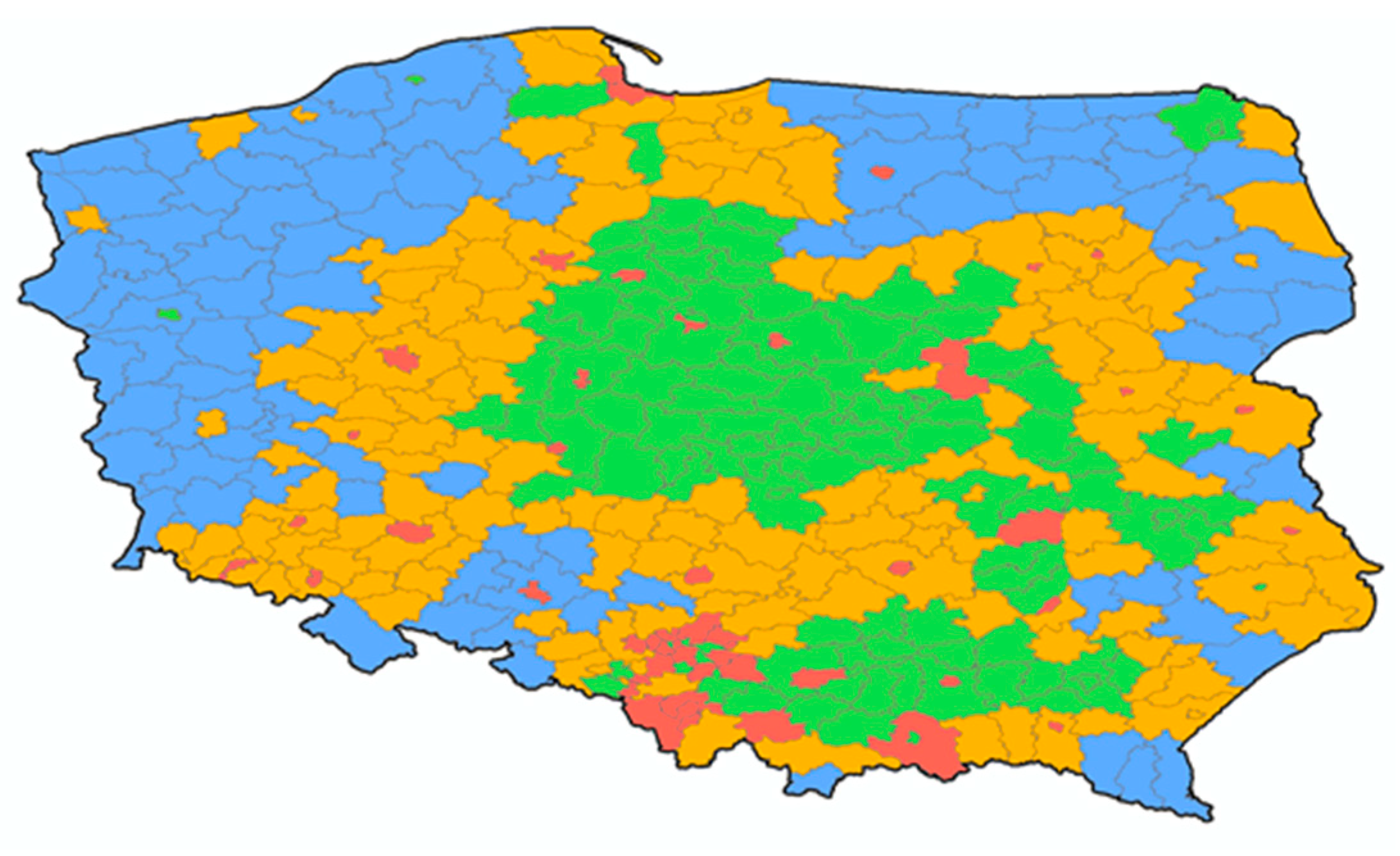
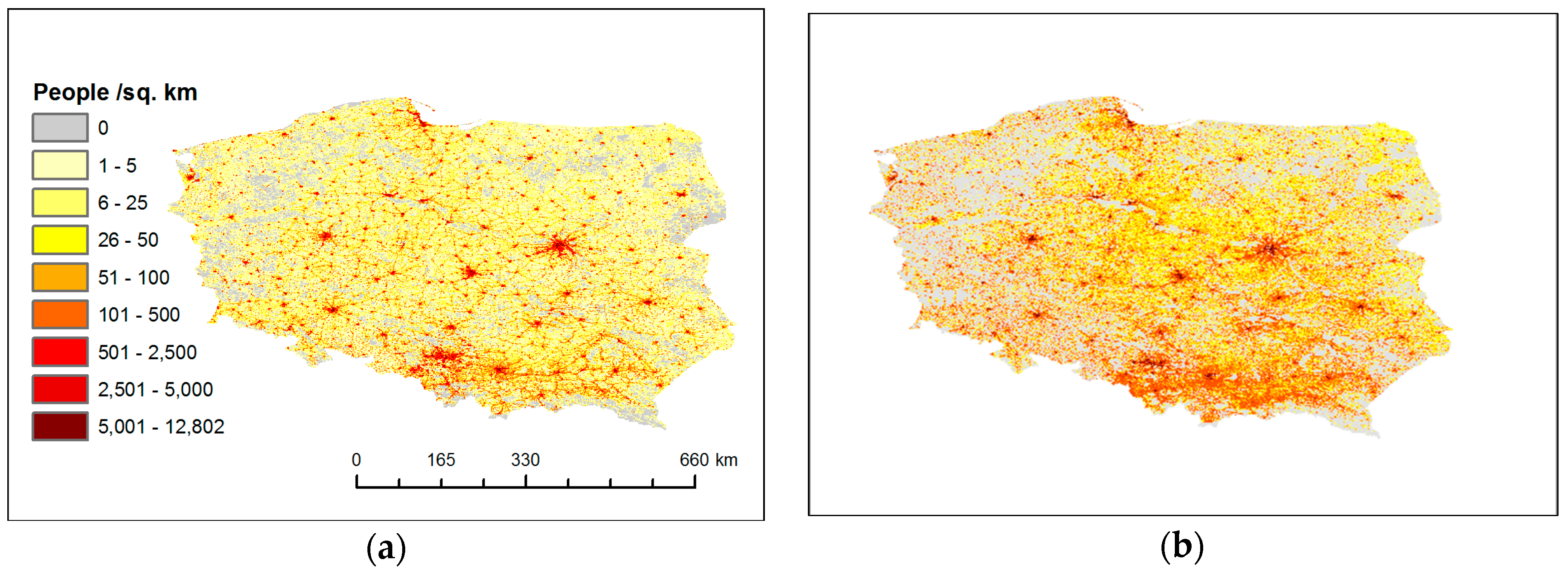
3.1. Relatedness of LandScan and Polish Population Grid Data
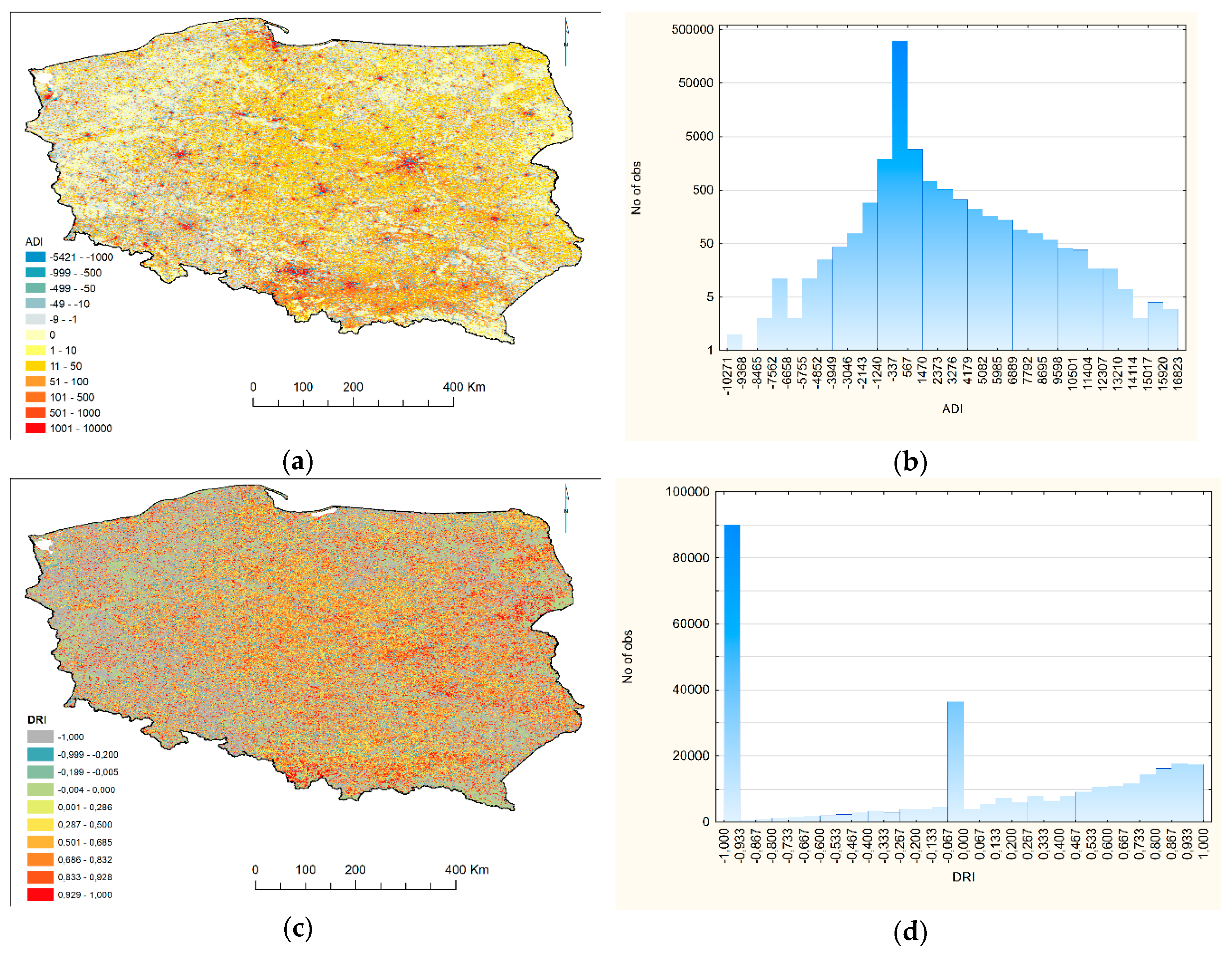
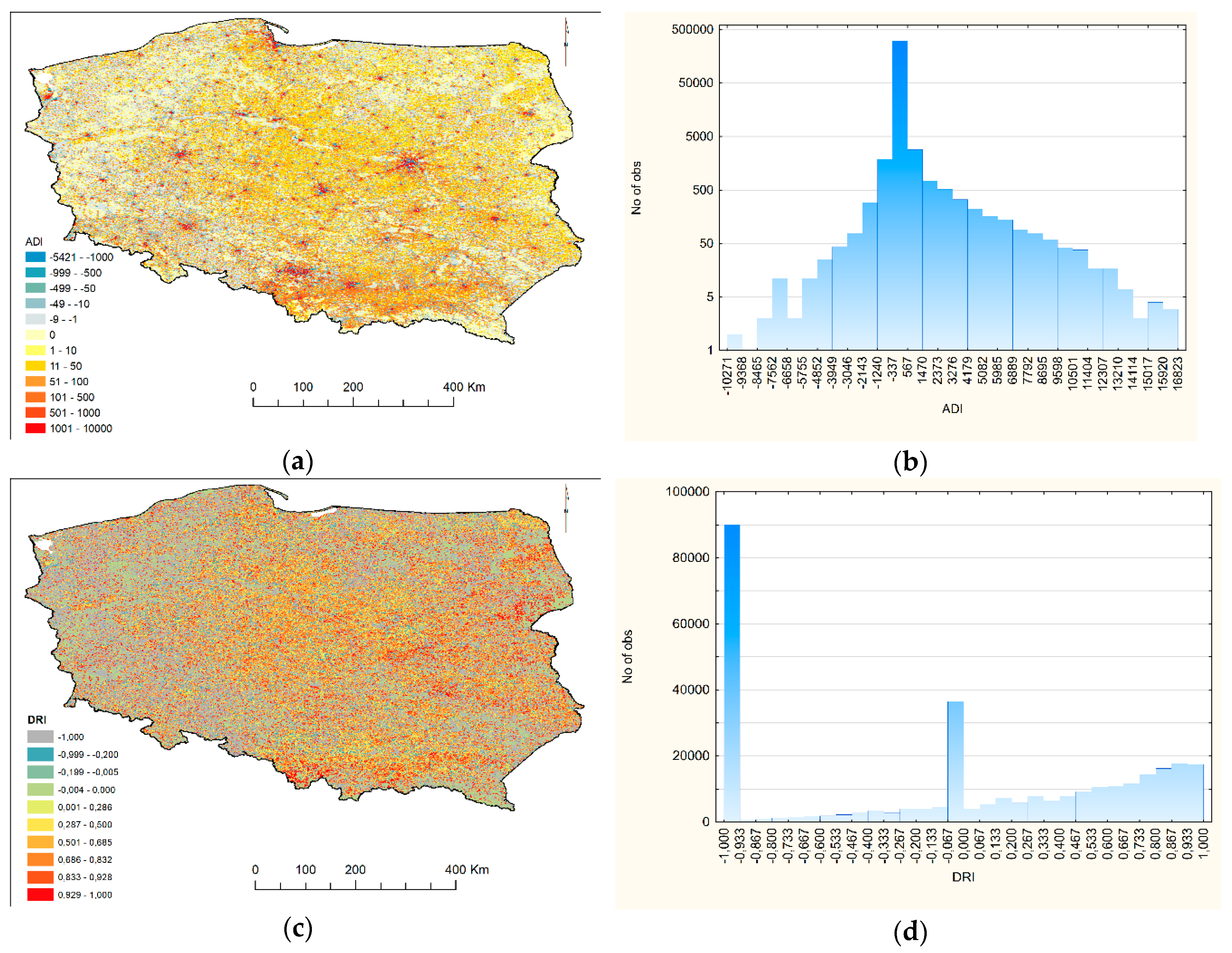
3.1.1. Reliability of LandScan Data
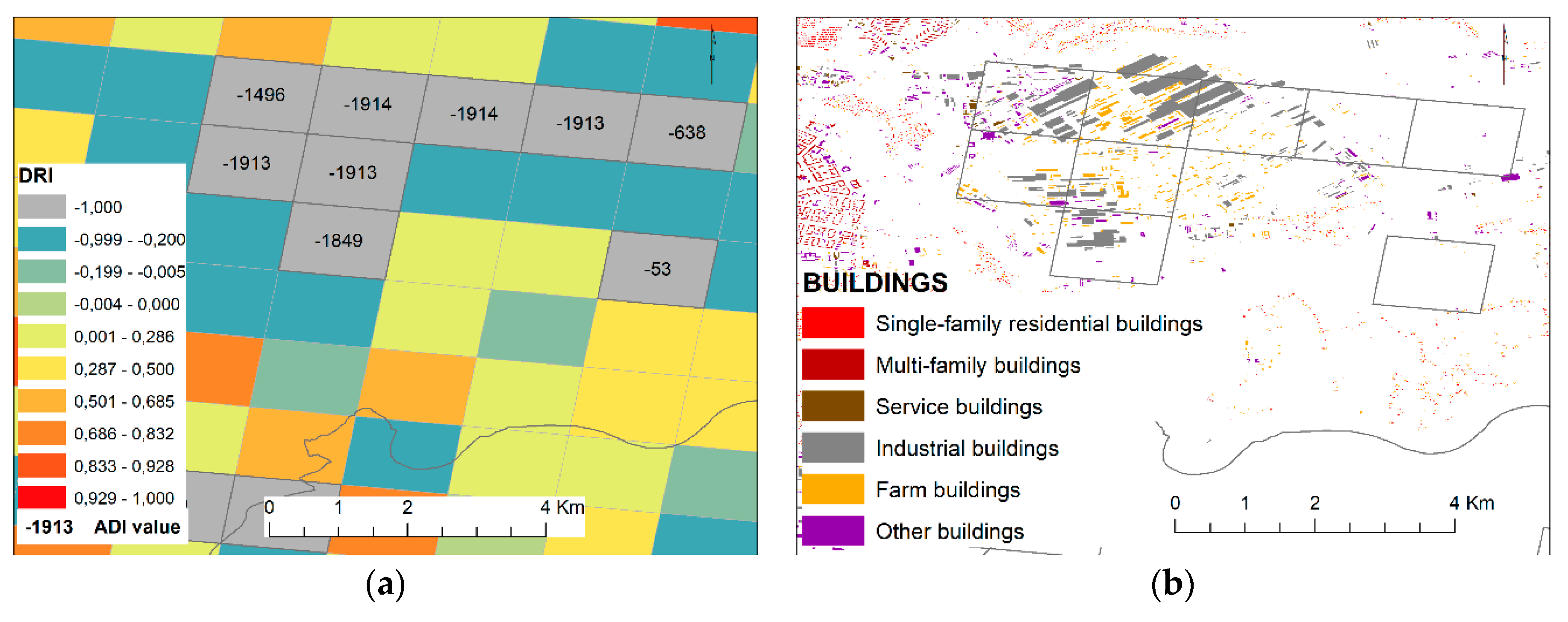
3.1.2. Relatedness with Built-Up Areas and District Status
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pirowski, T.; Bartos, K. Detailed mapping of the distribution of a city population based on information from the national database on buildings. Geodetski Vestnik 2018, 62, 458–471. [Google Scholar] [CrossRef]
- Gregory, I.N.; Marti-Henneberg, J.; Tapiador, F.J. Modelling long-term pan-European population change from 1870 to 2000 by using geographical information systems. J. R. Stat. Soc. 2010, 173, 31–50. [Google Scholar] [CrossRef]
- Bielecka, E. A dasymetric density population map of Poland. In Proceedings of the ICC/ICA Conference in a Coruna, Barcelona, Spain, 9–16 July 2005. [Google Scholar]
- Balk, D.; Yetman, G. The Global Distribution of Population: Evaluating the Gains in Resolution Refinement; Center for International Earth Science Information Network (CIESIN), Columbia University: New York City, NY, USA, 2005; Available online: http://beta.sedac.ciesin.columbia.edu/gpw/docs/gpw3_documentation_final.pdf (accessed on 20 May 2018).
- Hay, S.I.; Noor, A.M.; Nelson, A.; Tatem, A.J. The accuracy of human population maps for public health application. Trop. Med. Int. Health 2005, 10, 1073–1086. [Google Scholar] [CrossRef] [PubMed]
- CESIN—Center for International Earth Science Information Network Columbia University. Gridded Population of the World, Version 4 (GPWv4): Data Quality Indicators, Beta Release; NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA, 2015. [Google Scholar] [CrossRef]
- Doxsey-Whitfield, E.; MacManus, K.; Adamo, S.B.; Pistolesi, L.; Squires, J.; Borkovska, O.; Baptista, S.R. Taking Advantage of the Improved Availability of Census Data: A First Look at the Gridded Population of the World, Version 4. Appl. Geogr. 2015, 1, 226–234. [Google Scholar] [CrossRef]
- Balk, D.L.; Deichmann, G.; Yetman, F.; Pozzi, S.; Hay, I.; Nelson, A. Determining Global Population Distribution: Methods, Applications and Data. Adv. Parasitol. 2006, 62, 119–156. [Google Scholar] [CrossRef]
- Dobson, J.; Bright, E.; Coleman, P.; Durfee, R.; Worley, B. A Global Population database for Estimating Populations at Risk. Photogramm. Eng. Remote Sens. 2000, 66, 849–857. [Google Scholar]
- Bhaduri, B.; Bright, E.; Coleman, P. Development of a high resolution population dynamics model. Paper Presented at Geocomputation, Ann Arbor, MI, USA, 1–3 August 2005; Available online: http://www.geocomputation.org/2005/Abstracts/Bhaduri.pdf (accessed on 20 May 2018).
- Bhaduri, B.; Bright, E.; Coleman, P.; Urban, M. LandScan USA: A high-resolution geospatial and temporal modeling approach for population distribution and dynamics. Geojournal 2007, 69, 103–117. [Google Scholar] [CrossRef]
- Calka, B.; Nowak Da Costa, J.; Bielecka, E. Fine scale population density data and its application in risk assessment. Geomat. Nat. Hazards Risk 2017, 8, 1440–1455. [Google Scholar] [CrossRef]
- Linard, C.; Kabaria, C.W.; Gilbert, M.; Tatem, A.J.; Gaughan, A.E.; Stevens, F.R.; Sorichetta, A.; Noor, A.M.; Snow, R.W. Modelling changing population distributions: An example of the Kenyan Coast, 1979–2009. Int. J. Digit. Earth 2017, 10, 1017–1029. [Google Scholar] [CrossRef]
- Deville, P.; Linard, C.; Martine, S.; Gilbert, M.; Stevens, F.R.; Gaughan, A.E.; Blondel, V.D.; Tatem, A.J. Dynamic population mapping using mobile phone data. Proc. Natl. Acad. Sci. USA 2014, 111, 15888–15893. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Peng, Z.; Wu, H.; Jiao, H.; Yu, Y. Exploring Urban Spatial Feature with Dasymetric Mapping Based on Mobile Phone Data and LUR-2SFCAe Method. Sustainability 2018, 10, 2432. [Google Scholar] [CrossRef]
- Pesaresi, M.; Ehrlich, D.; Ferri, S.; Florczyk, A.J.; Freire, S.; Halkia, S.; Julea, A.M.; Kemper, T.; Soille, P.; Syrris, V. Operating Procedure for the Production of the Global Human Settlement Layer from Landsat Data of the Epochs 1975, 1990, 2000, and 2014; EUR 27741 EN; Publications Office of the European Union: Ispra, Italy, 2016. [Google Scholar] [CrossRef]
- Sabesan, A.; Abercrombie, K.; Ganguly, A.R.; Bhaduri, B.; Bright, E.A.; Coleman, P.R. Metrics for the comparative analysis of geospatial datasets with applications to high-resolution grid-based population data. GeoJournal 2007, 69, 81–91. [Google Scholar] [CrossRef]
- Bai, Z.; Wang, J.; Wang, M.; Gao, M.; Sun, J. Accuracy Assessment of Multi-Source Gridded Population Distribution Datasets in China. Sustainability 2018, 10, 1363. [Google Scholar] [CrossRef]
- Available online: http://www.fao.org/docrep/009/a0310e/A0310E07.htm (accessed on 10 September 2018).
- Merkens, J.-L.; Vafeidis, A.T. Using information on settlement patterns to improve the spatial distribution of population in coastal impact assessments. Sustainability 2018, 10, 3170. [Google Scholar] [CrossRef]
- Tatem, A.J.; Gaughan, A.E.; Stevens, F.R.; Patel, N.N.; Jia, P.; Pandey, A.; Linard, C. Quantifying the effects of using detailed spatial demographic data on health metrics: A systematic analysis for the AfriPop, AsiaPop, and AmeriPop projects. Lancet N. Am Ed. 2013, 381, S142. [Google Scholar] [CrossRef]
- Ma, Y.; Xu, W.; Zhao, X.; Li, Y. Modeling the Hourly Distribution of Population at a High Spatiotemporal Resolution Using Subway Smart Card Data: A Case Study in the Central Area of Beijing. ISPRS Int. J. Geo-Inf. 2017, 6, 128. [Google Scholar] [CrossRef]
- Mondal, P.; Tatem, A.J. Uncertainties in Measuring Populations Potentially Impacted by Sea Level Rise and Coastal Flooding. PLoS ONE 2012, 7, e48191. [Google Scholar] [CrossRef]
- Azar, D.; Engstrom, R.; Graesser, J.; Comenetz, J. Generation of fine-scale population layers using multi-resolution satellite imagery and geospatial data. Remote Sens. Environ. 2013, 130, 219–232. [Google Scholar] [CrossRef]
- Nowak Da Costa, J.; Bielecka, E.; Calka, B. Uncertainty quantification of the Global Rural-Urban Mapping Project over Polish census data. In Proceedings of the Environmental Engineering 10th International Conference, Vilnius, Lithuania, 27–28 April 2017. [Google Scholar] [CrossRef]
- Hall, O.; Stroh, E.; Paya, F. From census to grids: Comparing gridded population of the world with Swedish census records. Open Geogr. J. 2012, 5, 1–5. [Google Scholar] [CrossRef]
- Palczynska, P. Analysis of the Reliability of Global Population Density Data in Poland. Master’s Thesis, Military University of Technology, Warsaw, Poland, 2016. [Google Scholar]
- GUS. Ludność w Gminach Według Stanu w Dniu 31.12.2011 r.—Bilans Opracowany w Oparciu o Wyniki NSP 2011; Główny Urząd Statystyczny: Warsaw, Poland, 2012.
- Śleszynski, P. Delimitation of the Functional Urban Areas around Poland’s Voivodship Capital Cities. Przeglad Geograficzny 2013, 85, 173–197. [Google Scholar] [CrossRef]
- Korcelli, P.; Grochowski, M.; Kozubek, E.; Korcelli-Olejniczak, E.; Werner, P. Development of Urban-Rural Regions: From European to Local Perspective; Monografie IGiPZ PAN No 14; PAN IGiPZ: Warszawa, Poland, 2012. [Google Scholar]
- Migacz, T.M. Geostatistics Portal—A platform for statistical data geovisualization. Stat. J. IAOS 2015, 31, 463–470. [Google Scholar] [CrossRef]
- GUS. Available online: https://geo.stat.gov.pl/imap/?locale=en (accessed on 18 January 2019).
- Medynska-Gulij, B. Geovisualisation as a process of creating complementary visualisations: Static two-dimensional, surface three-dimensional, and interactive. Geod. Cartogr. 2017, 66, 89–104. [Google Scholar] [CrossRef]
- Bielecka, E.; Dukaczewski, D.; Janczar, E. Spatial Data Infrastructure in Poland—Lessons learnt from so far achievements. Geod. Cartogr. 2018, 67, 3–20. [Google Scholar] [CrossRef]
- Clark, P.J.; Evans, F.C. Distance to nearest neighbour as a measure of spatial relationships in populations. Ecology 1954, 35, 445–453. [Google Scholar] [CrossRef]
- Lai, P.; So, F.; Chan, K. Spatial Epidemiological Approaches in Disease Mapping and Analysis; Taylor & Francis Group: Boca Raton, USA, 2009. [Google Scholar]
- Calka, B. Comparing continuity and compactness of choropleth map classes. Geod. Cartogr. 2018, 67, 21–34. [Google Scholar] [CrossRef]
- Medyńska-Gulij, B. Map compiling, map reading and cartographic design in “Pragmatic pyramid of thematic mapping. Quaestiones Geographicae 2010, 29, 57–63. [Google Scholar] [CrossRef]
- Nagle, N.N.; Buttenfield, B.; Leyk, S.; Spleilman, S. Dasymetric modelling uncertainty. Ann. Assoc. Am. Geogr. 2014, 104, 80–95. [Google Scholar] [CrossRef]
- Potere, D.; Schneider, A.; Shlomo, A.; Civco, D.L. Mapping urban areas on a global scale: Which of the eight maps now available is more accurate? Int. J. Remote Sens. 2009, 30, 6531–6558. [Google Scholar] [CrossRef]
- Oyabu, Y.; Terada, M.; Yamaguchi, T.; Iwasawa, S.; Hagiwara, J.; Koizumi, D. Evaluation reliability of Mobile Spatial Statistics. NTT DOCOMOTO Tech. J. 2013, 14, 16–23. [Google Scholar]
- Aubrecht, C.; Yetman, G.; Balk, D.; Steinnocher, K. What is to be expected from broad-scale population data? Showcase accessibility model validation using high-resolution census information. In Proceedings of the 13th International Conference on Geographic Information Science, Guimarães, Portugal, 1–15 May 2010; pp. 1–7. [Google Scholar]
- Leys, C.; Ley, C.; Klein, O.; Bernard, P.; Licata, L. Detecting outliers: Do not use standard deviation around the mean, use absolute deviation around the median. J. Exp. Soc. Psychol. 2013, 49, 764–766. [Google Scholar] [CrossRef]
- Draugalis, J.R.; Plaza, C.M. Best Practices for Survey Research Reports Revisited: Implications of Target Population, Probability Sampling, and Response Rate. Am. J. Pharm. Educ. 2009, 73, 142. [Google Scholar] [CrossRef] [PubMed]
- Dygaszewicz, J. Geographical information systems in public statistics. Wiadomości Statystyczne 2011, 9, 19–31. [Google Scholar]
- Drzewiecki, W. Thorough statistical comparison of machine learning regression models and their ensembles for sub-pixel imperviousness and imperviousness change mapping. Geod. Cartogr. 2017, 66, 171–210. [Google Scholar] [CrossRef]
- Pokonieczny, K. Comparison of land passability maps created with use of different spatial data bases. Geografie 2018, 123, 317–352. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviations | GPW | GRUMP | LandScan | GHSL |
|---|---|---|---|---|
| Name | Gridded Population of the World | Global Rural-Urban Mapping Project | LandScan (LS) Global Population | Global Human Settlement Layer |
| Reference years of population estimation | 1990, 2000, 2005, 2010, prediction for 2015, 2020 | 1990, 1995, 2000 | 1998, from 2000 each year | 1975, 1990, 2000, 2014 |
| Format spatial resolution | Grid/raster, ASCII 2.5 arc-minutes 30 arc-seconds for 2010 | Grid/raster 30 arc-seconds | Grid 30 arc-seconds | TIF and OVR files 259 m, 1 km World Mollweide |
| Source and ancillary data | Data from nation census agencies, water mask, coastline | GPW, urban mask, settlement points, NOAA’s night-time lights data | Census data, roads, slope NIMA’s DTED, Global Land cover database, VMap, satellite imagery, night-time light NGDC, regional statistics | GPWv4, population censuses, Global, fine-scale satellite images, census data, volunteering geographic information sources |
| Method and algorithm | Disaggregation of national census data, smooth pycnophylactic (mass-preserving) interpolation | Disaggregation of national census data, smooth pycnophylactic (mass-preserving) interpolation | Disaggregation sub-national census counts within administrative boundary, locally adoptive ‘smart’ interpolation algorithm | Spatial data mining technologies |
| Data producer | CIESIN & CIAT | CIESIN & IFPRI & CIAT & World Bank | ORNL | European Commission Joint Research Centre (JRC) |
| Delivery policy | Creative Commons Attribution 4.0 International License | Creative Commons Attribution 4.0 International License | Available for purchase | Open and free data |
| Applications | Demonstrate the spatial relationship of human populations and the environment (e.g., pollution, diseases, biodiversity) across the globe | Delimitation of urban and rural areas | Trends and demographic changes, risk assessment, strategic planning, and sustainable development, humanitarian aid and human well-being, people exposure to different types of hazards | Crisis management, demographic trends, monitoring urban growth and degree of urbanisation |
| Number of publication in WoS/Scopus databases 1 | 17/13 | 12/11 | 66/93 | 29/40 |
| Reliability Classes | Range of ADI | Range of DRI |
|---|---|---|
| M—the most reliable | −9 ≤ ADIi ≤ 9 | −0.5 MAD < DRIi < +0.5 MAD |
| H—highly reliable | −1.0 MAD < DRIi ≤−0.5 MAD or 0.5 MAD ≤ DRIi < +1.0 MAD | |
| −1.0 MAD < ADIi ≤ −0.5 MAD or 0.5 MAD ≤ ADIi < +1.0 MAD | DRI1 = 1 or DRI1 =−1 | |
| R—reasonably reliable | ------ | −1.5 MAD < DRIi ≤ −1.0 MAD or 1.0 MAD ≤ DRIi < +1.5 MAD |
| −1.5 MAD< ADIi ≤ −1.0 MAD or 1.0 MAD≤ ADIi < +1.5 MAD | DRI1 = 1 or DRI1 =−1 | |
| P—poorly reliable | ------ | −1.5 MAD ≤ DRIi or DRIi ≥ +1.5 MAD |
| −1.5 MAD ≤ ADIi or ADIi ≥ +1.5 MAD | DRI1 = 1 or DRI1 =−1 |
| Descriptive Statistics | PPG | LS | ADI | DRI |
|---|---|---|---|---|
| Min | 0 | 0 | −10,271 | −1 |
| The first quartile (Q1) | 0 | 2 | −3.0 | −1 |
| Median | 12 | 6 | 0 | 0 |
| Mean | 123.1 | 65 | 57.6 | −0.023 |
| Mode | 0 | 0 | 0 | −1 |
| The third quartile (Q3) | 65 | 19 | 37.0 | 0.667 |
| Max | 21,531 | 12,802 | 16,823 | 1 |
| Range | 21,531 | 12,802 | 27,094 | 2 |
| Interquartile range | 65 | 17 | 40 | 1.667 |
| Percentile 10 | 0 | 0 | −16.0 | −1 |
| Percentile 90 | 187 | 100 | 115.0 | 0.882 |
| Skewness | 13.64 | 14.74 | 13.84 | −0.210 |
| Kurtosis | 236.1 | 300.0 | 286.9 | −1.462 |
| Standard deviation | 657.45 | 344.46 | 476.0 | 0.732 |
| Variance | 432,661 | 118,652 | 226,871 | 0.534 |
| Sum (number of people) | 38,492,223 | 38,414,488 | - | - |
| Reliability Classes | Grid Cells Number (%) | Level of Uncertainty | Number (%) |
|---|---|---|---|
| M—the most reliable | 177,663 (56.9) | No change Insignificant overestimation Insignificant underestimation | 144,484 (46.2) 17,504 (5.6) 15,672 (5.1) |
| H—highly reliable | 47,296 (15.1) | Low overestimation (Ho) Low underestimation (Hu) | 13,986 (4.4) 33,319 (10.7) |
| R—reasonably reliable | 74,188 (23.7) | Moderate overestimation (Ro) Moderate underestimation (Ru) | 7,476 (2.4) 66,712 (21.4) |
| P—poorly reliable | 13,318 (4.3) | High overestimation (Po) High underestimation (Pu) | 3,705 (1.2) 9,613 (3.1) |
| Reliability Class | SCI | ANN (z Score; p-value) |
|---|---|---|
| M—the most reliable | 0.33 | 1.30 (243.81; 0.0000) |
| H—highly reliable | 0.07 | 0.88 (−47.75; 0.0000) |
| R—reasonably reliable | 0.11 | 0.96 (−15.78; 0.0000) |
| P—poorly reliable | 0.05 | 0.77 (−48.64; 0.0000) |
| Share of LS Reliability Classes | Mean | Std. Dev | Min | Max | PCC Statistical Significance at p < 0.05 |
|---|---|---|---|---|---|
| The most reliable | 52.19 | 13.59 | 20.94 | 84.19 | −0.098 |
| Highly reliable | 18.04 | 7.42 | 3.14 | 46.15 | −0.355 |
| Reasonably reliable | 24.67 | 7.81 | 4.94 | 44.58 | 0.446 |
| Poorly reliable | 5.06 | 3.10 | 0.00 | 21.94 | −0.049 |
| Reliability Class | ADI Threshold | Slope | Inter-ception | R Square | Std. Error | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 6 | 9 | 12 | 15 | 18 | 21 | |||||
| M—the most reliable | 51.8 1 | 52.6 | 54.7 | 56.9 | 58.8 | 64.0 | 65.8 | 67.4 | 2.440 | 48.038 | 0.9716 | 1.104 |
| H—highly reliable | 19.3 | 18.3 | 16.8 | 15.1 | 14.1 | 11.3 | 10.4 | 9.7 | −1.474 | 20.997 | 0.9850 | 0.481 |
| R—reasonably reliable | 24.7 | 24.8 | 24.3 | 23.7 | 22.9 | 21.5 | 20.6 | 1.7 | −0.775 | 26.265 | 0.9438 | 0.500 |
| P—poorly reliable | 4.2 | 4.3 | 4.2 | 4.3 | 4.2 | 3.2 | 3.2 | 3.2 | −0.192 | 4.700 | 0.7103 | 0.324 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calka, B.; Bielecka, E. Reliability Analysis of LandScan Gridded Population Data. The Case Study of Poland. ISPRS Int. J. Geo-Inf. 2019, 8, 222. https://doi.org/10.3390/ijgi8050222
Calka B, Bielecka E. Reliability Analysis of LandScan Gridded Population Data. The Case Study of Poland. ISPRS International Journal of Geo-Information. 2019; 8(5):222. https://doi.org/10.3390/ijgi8050222
Chicago/Turabian StyleCalka, Beata, and Elzbieta Bielecka. 2019. "Reliability Analysis of LandScan Gridded Population Data. The Case Study of Poland" ISPRS International Journal of Geo-Information 8, no. 5: 222. https://doi.org/10.3390/ijgi8050222
APA StyleCalka, B., & Bielecka, E. (2019). Reliability Analysis of LandScan Gridded Population Data. The Case Study of Poland. ISPRS International Journal of Geo-Information, 8(5), 222. https://doi.org/10.3390/ijgi8050222