Abstract
Smart tourism is the new frontier field of the tourism research. To solve current problems of smart tourism and tourism geographic information system (GIS), individualized tour guide route plan algorithm based on tourist sight spatial interest field is set up in the study. Feature interest tourist sight extracting matrix is formed and basic modeling data is obtained from mass tourism data. Tourism groups are determined by age index. Different age group tourists have various interests; thus interest field mapping model is set up based on individual needs and interests. Random selecting algorithm for selecting interest tourist sights by smart machine is designed. The algorithm covers all tourist sights and relative data information to ensure each tourist sight could be selected equally. In the study, selected tourist sights are set as important nodes while iteration intervals and sub-iteration intervals are defined. According to the principle of proximity and completely random, motive iteration clusters and sub-clusters are formed by all tourist sight parent nodes. Tourist sight data information and geospatial information are set as quantitative indexes to calculate motive iteration values and motive iteration decision trees of each cluster are formed, and then all motive iteration values are stored in descending order in a vector. For each cluster, there is an optimal motive iteration tree and a local optimal solution. For all clusters, there is a global optimal solution. Simulation experiments are performed and results data as well as motive iteration trees are analyzed and evaluated. The evaluation results indicate that the algorithm is effective for mass tourism data mining. The final optimal tour routes planned by the smart machine are closely related to tourists’ needs, interests, and habits, which are fully integrated with geospatial services. The algorithm is an effective demonstration of the application on mass tourism data mining.
1. Introduction
Smart tourism is the fastest growing frontier field of tourism research. The aim of smart tourism is to improve tourists’ knowledge of travel destination and help them have the best travel experience [1,2]. It is also called intelligent tourism. It uses techniques of cloud computing, Internet of Things, etc., through Internet on a portable terminal to access information about tourism resources, economy, activity, and tourists, etc., and then releases relative information for tourists [3,4,5]. According to the information, tourists can make time schedules and plan the trip before a vacation. The development of smart tourism will affect the tourism experience, management, service, and marketing [6,7]. The approach of smart tourism is to provide convenient and efficient service for tourists, build the frame of smart city and tourist sight, and finally improve the quality and level of tourism service [8,9,10,11]. Smart tourism development builds on tourism science. It takes advantage of cloud computing and artificial intelligence and combines GIS technology to distribute the most relevant tourism information on the Internet [12,13]. Of all the information, tourist sight classification, locations, distinguishing features, available transportation service around, traffic conditions, and accommodation fees are the most relevant. Through the human–computer interaction process, tourists can access tourism service information and get optimal decision support. Therefore, smart tourism is an interdisciplinary field of cloud computing, artificial intelligence, and GIS, etc., with a core aim of highly efficient tourism informationization [14,15,16] through the method of cloud computing and artificial intelligence. As its data source support is GIS service, GIS is an important prerequisite for developing smart tourism [17,18,19]. Before traveling, tourists usually make a plan including travel destinations, a time schedule, a route, accommodation, and so on in accordance with their needs and interests, travel availability, and budget, etc. These are the most concerning issue for tourists and the critical preconditions for tourists to obtain the best motive benefit satisfaction [20]. The quality of travel planning will directly influence tourists’ experiences and perceptions during the whole trip, influence the tourists’ subjective impression of the cities and destinations visited, and thus have a determined impact on the travel destination’s further marketing to attract more tourists and increase the economic benefits of tourism [21,22,23]. The more motive benefit satisfaction tourists obtain from the whole travel process, the better their perception of the travel experience and service is, and thus, the more likely they will be to positively evaluate the travel destinations. This will lead to a positive genuine evaluation on the Internet, which will promote a travel destination’s further development and economic performance [24,25]. Thus, in smart tourism supported by geospatial data and services, the aim of smart tourism is to provide tourists with smart decision support that is highly accurate, individualized, and based on tourists’ needs. It can ultimately increase the motive benefit satisfaction of tourists [26,27].
Currently, decision support for smart tourism is in the early stage of development. The techniques for developing an orientation are tourism information services and data mining. Based on mass tourism and geospatial data, tourists use smart device to select tourist sights and make tour plans by themselves. Usually, there are two modes. In the first mode, depending on the tourists’ subjective perception and knowledge of tourist sights, a tourist will refer to geospatial services and tourist sights information, in addition to other tourists’ evaluation, and extract useful information from mass tourism data [28,29,30]. By analyzing and processing the information, they form an internal perception of tourist sights and, finally, make a decision about how to travel. In the second mode, various actual and online travel agencies provide a large number of tour options for tourists. However, the two modes both have some problems. First, based on subjective perception, the routes planned by tourists are usually not the optimal one because the tourists are unfamiliar with the city or tourist sights. Meanwhile, it is difficult to extract useful and valuable information from mass tourism data as deep analysis is insufficient. The type of data is usually presented textbook-style and is crowdsourced [31,32]. An insufficient planning strategy and strong subjectivity can hardly help tourists to obtain the best motive benefit. Second, tour routes provided by travel agencies are aimed to produce a profit and may not satisfy a tourist’s individualized needs and interests [33,34,35]. Nevertheless, tourists cannot obtain the best motive benefits from a package tour. Third, mass tourism data contains high-level data and information, such that not all the information is useful and valuable. It is difficult to find valuable data and useful tourism knowledge that meets tourists’ needs and interests, while this is just the most important key to obtain the best motive benefit.
As indicated by the above analysis, this study aims to solve the problems presented; namely, that scheduled tour routes cannot meet individualized needs and interests and cannot sufficiently combine geospatial information and services. City tourist sights contain geospatial information [36,37]. We start the modeling by setting a single tourist sight as an independent object to form a feature interest tourist sight extracting matrix. A tourist sight spatial interest field model is set up based on tourists’ individualized needs and interests. According to an age index, tourists are divided into three groups, elderly group, young adult group, and children group [38,39]. The mapping relationship model between tourist sight spatial interest field model and the three groups is studied and formed. By designing and developing a smart tourist sight extracting algorithm, smart motive iteration decision trees are formed, which can help tourists to select tourist sights according to their own interests, even though they are unfamiliar with the city and tourist sights. Combining this with a geospatial service [40,41,42], we set up a smart tour guide route plan algorithm. Tour routes planned by the algorithm are related to motive iteration values. The motive iteration values along with tour routes are arranged in descending order matrix and the optimal one is provided for tourists. The method and algorithm built in the study can provide detailed decision support and tour routes for tourists according to their needs and interests and meet their satisfaction the most [43,44]. The main content of the paper is as follows.
- First, the current research status and content regarding smart tourism are analyzed. Focusing on the problems of tour route plan, we suppose that individualized tour plans combined with geospatial services are an important means to meet the motive benefit satisfaction of tourists and maximize tourism economic benefits for destinations.
- The research data resources and spatial ranges are ensured on the basis of problem analysis. According to the tourist sight distribution and geospatial information data, a tourist sight spatial interest field model is developed and its mapping relationship model for the three age groups of tourists is formed.
- A smart algorithm is designed and developed. Tourists can get hot tourist sights via smart machine according to their needs and interests. The smart machine calculates motive iteration values and, finally, outputs tour routes for tourists.
- Simulation experiment is designed. To get the best motive benefits for tourists is the core objective, and this objective is set up by a quantitative algorithm model as the dependent hypothesis variable to find out the optimal tour routes, which is iterated by several important independent variables. The independent variables are factors and disturb factors, including critical tourist sight information and GIS service information. After ensuring tourist sight spatial interest field mapping model and selecting interested tourist sights, all the factors and disturb factors are quantified and altered according to different motive iteration clusters and trees. By iterating and outputting motive iteration values, the relative tour routes are all obtained, of which the maximum iteration value route is the optimal one for tourists, and the sub-optimal ones will also be displayed for tourists to select as there are different situations and project suggestions. Finally, experiment data is analyzed and valuable knowledge on tour route is obtained. The data and knowledge can effectively help tourists to select tourist sights, plan the whole trip, and get the best motive benefit.
2. Feature Interest Tourist Sight Extracting Algorithm Based on Interest Field Mapping Model
Interest tourist sights are the basic data source to make a tour route plan and calculate motive iteration values. In a smart machine, interest tourist sights are selected automatically, and the interest tendency is the key for the machine to learn and recognize tourists’ needs. Thus, the feature interest tourist sight extracting algorithm based on interest field mapping model is set up first.
2.1. Feature Interest Tourist Sight Extracting Matrix
As to city tourism, before tourists go to an unfamiliar city, they should know about the city and tourist sights [45]. They usually select the most interested ones to visit. To obtain a data resource, the first group of definitions are discussed.
Def 1.1 Tourist sight spatial data set . Within a certain geospatial range, the set containing some popular and typical tourist sights which are selected and ensured by certain restrictive rules, is called tourist sight spatial data set .
Def 1.2 Tourist sight spatial data subset . Tourist sight spatial data set can be divided into some subsets according to different properties. Each subset is called tourist sight spatial data subset .
Def 1.3 Tourist sight spatial subset element . A single tourist sight element in any given tourist sight spatial data subset is called tourist sight subset element .
According to the definitions and properties, we set up city tourist sight spatial data set and divide tourist sights into groups, . In which, is tourist sight spatial data subset, and each subset contains tourist sight elements, . In any , a single tourist sight is coded as , . Feature interest tourist sight extracting base vector is built by tourist sight spatial subset element, , , . The maximum value of tourist sight classification and the maximum value of subset element number are used to form dimension feature interest tourist sight extracting matrix , as Formula (1). The feature interest tourist sight extracting base vector is set at each matrix row and vacant element is set by data 0. Matrix is the data resource for smart machine to select tourist sights.
2.2. Tourist Sight Spatial Interest Field Mapping Model
According to statistics for big data of various tourist sights and classifications, different tourist groups have dissimilar interest tendencies while the same group members have the similar interests [44,45,46]. The tourist sight spatial interest field is an intensity structure built on different interest degrees of tourist groups. According to the age index, tourists can be divided into the children group , , young adult group , , and the elderly group , . Based on nearly one year of tourism statistics data of a certain city, we set the total number of tourists paying a visit to all tourist sights of set as , in which the number of is , as in Formula (2).
For the tourist sight spatial data subset , is the statistics number of tourists in group who have paid a visit to the tourist sights in , . The selection of each age group for each different subset of tourist sights is independent and identically distributed [47]. The second group of definitions are discussed.
Def 2.1 Tourist sight spatial data subset visited rate . The ratio of visiting tourists’ number in group on certain tourist sight spatial data subset to the total tourists’ number of the group is called tourist sight spatial data subset visited rate , as in Formula (3). The higher the proportion is, the higher the tendency for members of the age group to visit the tourist sight subset will be.
Def 2.2 Interest field mapping model. The tourist sight spatial interest field is formed from tourist sight spatial data subset and the visited rate . The mapping relationship of the interest field and age group is called the interest field mapping model.
Def 2.3 Interest field intensity. The visited rate of age group on single sight spot spatial data subset is called the interest field intensity of subset on age group .
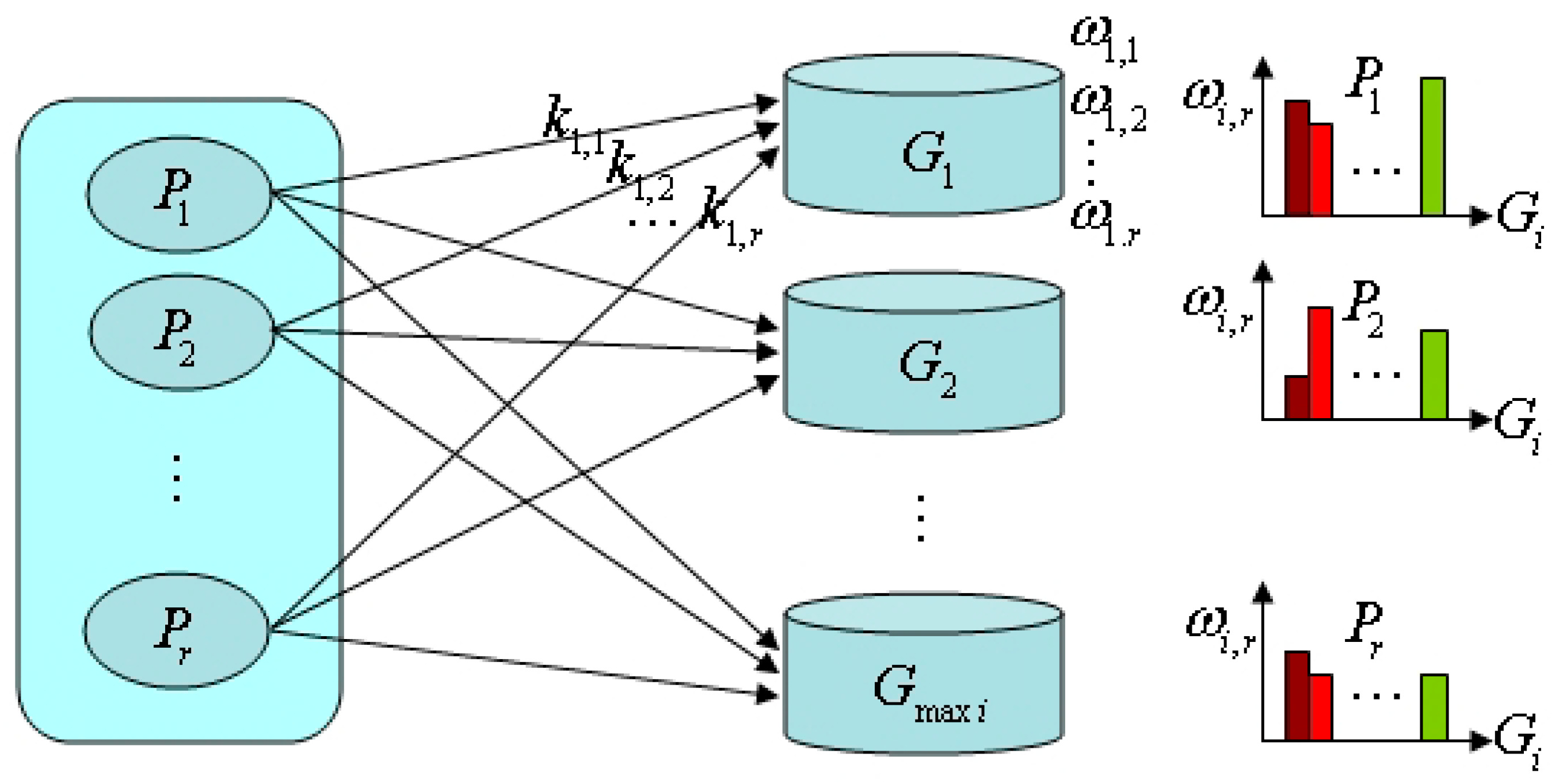
Tourist sight spatial data subset is set as object to select tourist sights and build tourist sight spatial interest field mapping model, as shown in Figure 1. Interest field intensity histogram of tourist sight spatial data subset on different age groups is shown in Figure 1 (right side). Depending on interest field intensity, the smart machine can automatically recommend tourist sight spatial data subset by the input age group.
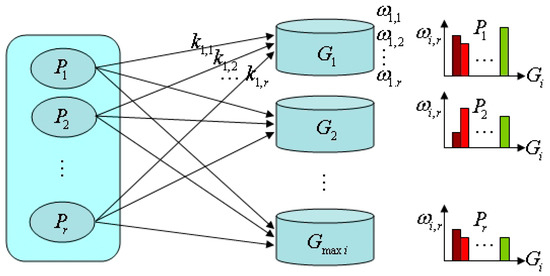
Figure 1.
Interest field mapping model and interest field intensity histogram.
2.3. Smart Tourist Sight Extracting Model
According to the built feature interest tourist sight extracting matrix, tourist sight spatial interest field mapping model, and the interest field intensity histogram [48], a smart tourist sight extracting model is developed. The distribution function of the continuous random variable is set as in Formula (4).
The continuous random variable follows a uniform distribution on the interval , denoted as . For any single value of x in the interval , the uniform distribution function yields a finite number of elements with the maximum value in the closed interval and all the elements are random [49,50,51,52]. When the randomly selected targets are tourist sights, there is a random number interval such that , and the selected random number, will be subject to integer conversion. If tourists in an age group are not familiar with tourist sights, the statistics interest field intensity is used to obtain the best motive benefits. Taking one day as the travel time, the smart tourist sight extracting algorithm model is developed as follows.
Step 1. To make the tour route planning procedure more convenient and intelligent, tourists only need to input basic personal information and the number of tourist sights, and then the smart machine will immediately plan an optimal route. Tourists only provide their gender, their age index , and the number of tourist sights to be visited. In order to have the best travel experience and avoid fatigue in one day, the number of selected tourist sight cannot exceed 5.
- (1)
- If , the system displays an alarm message. Review and input again. Cancel and log out of the system.
- (2)
- If , continue to Step.2.
Step 2. According to the index , the smart machine ensures tourist sight spatial interest subset and feature interest tourist sight extracting base vector in the sequence from the strongest interest field intensity to the weakest one.
Step 3 Smart machine ensures tourist sight element number and tourist sight spatial subset elements as follows.
- (1)
- If , arrange the related subsets in descending order. From the highest to the lowest one, one tourist sight is selected from each subset;
- (2)
- If , arrange related subsets in descending order. One tourist sight is selected from each subset;
- (3)
- If , arrange the related subsets in descending order. From the highest to the lowest one, one tourist sight is selected from each subset. Return, arrange the related subsets in descending order, and one tourist sight is selected from each subset.
Step 4 Select a tourist sight element.
- (1)
- If , for the first selected subset , smart machine invokes one time of uniform distribution function on interval and gets . Ensure there is one element tourist sight ; return, and perform the same operation on other subsets; finish, and ensure that there are m element tourist sights in total;
- (2)
- If , carry out the same operation as step (1); finish, and ensure that there are element tourist sights in total;
- (3)
- If , for the first selected subset , smart machine invokes one time of uniform distribution function on interval and gets . Ensure there is one element tourist sight ; return, and perform the same operation on other subsets, ensure there are element tourist sights; return to the first subset and perform the same operation, ensure there are element tourist sights; finish, ensure there are element tourist sights in total.
3. Smart Motive Iteration Decision Tree Algorithm
Within one day, tourists visit the selected tourist sights in a single-track and non-repetitive manner. From the initial tourist sight to the last one, any single tourist sight can only be visited once. As to the selected tourist sights, there will be kinds of tour routes for the selected tourist sights, but not all the routes are optimal. Each route has a different motive benefit value for tourists, which should be measured by a quantization method. For any one tour route, a tourist starts from the first tourist sight and travels through several city roads and road nodes and arrives at the next tourist sight. In this process, the ferry distance, road traffic conditions, the convenience of GIS services, tourists’ subjective perceptions, and so on will directly influence the motive benefit satisfaction of the tourist [53,54,55]. The motive benefit satisfaction in the previous tour interval will also influence the motive benefit satisfaction in the next tour interval. Thus, the motive iteration value of the previous tour interval is the initial value for calculating the motive iteration value of the next tour interval. Tourists travel from the first tourist sight to the last one, and in this process, the motive iteration value is monotonically increasing and thus the motive iteration function is a monotonically increasing function. For a particular tour route, each tourist sight is related to one motive iteration function value. For a different tour route, the same tourist sight may be related to different motive iteration function values as the iteration process contains different values. Thus, the ultimate output motive iteration values vary for each tour route. From the aspect of the tour route selection and motive iteration process, each tour route can form a single motive iteration decision tree. There should be a maximum value of the last tourist sight, whose decision tree and related tour route is optimal and yields the highest motive benefit value for the tourist.
3.1. Motive Interval and Motive Sub-Interval
According to the modeling concepts, the third group of definitions are discussed.
Def 3.1 Selected tourist sight set . The tourist sights selected by the smart machine which will be visited by tourists form a dataset, which is called selected tourist sight set and denoted by . The element tourist sight of set is coded as , .
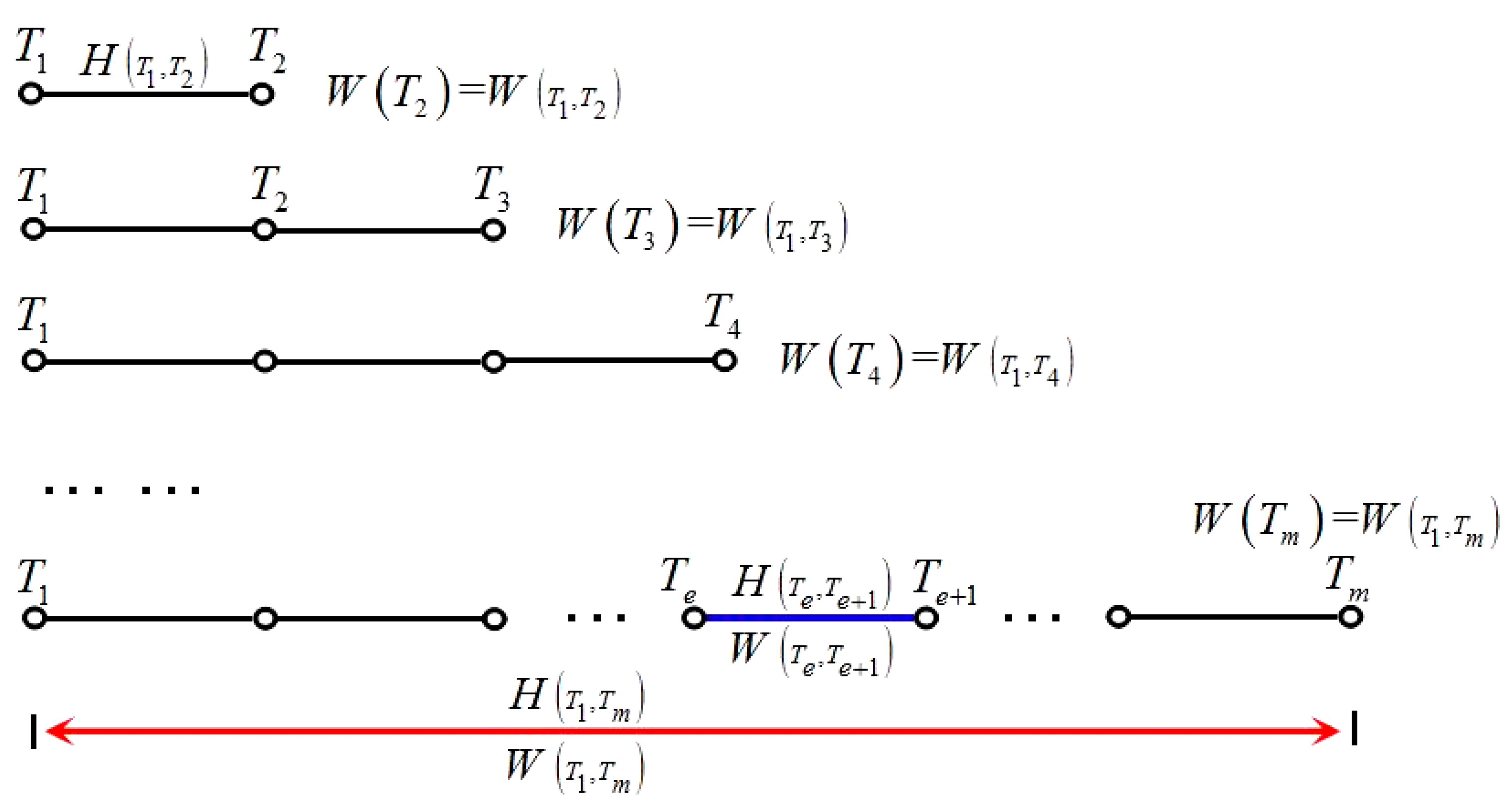
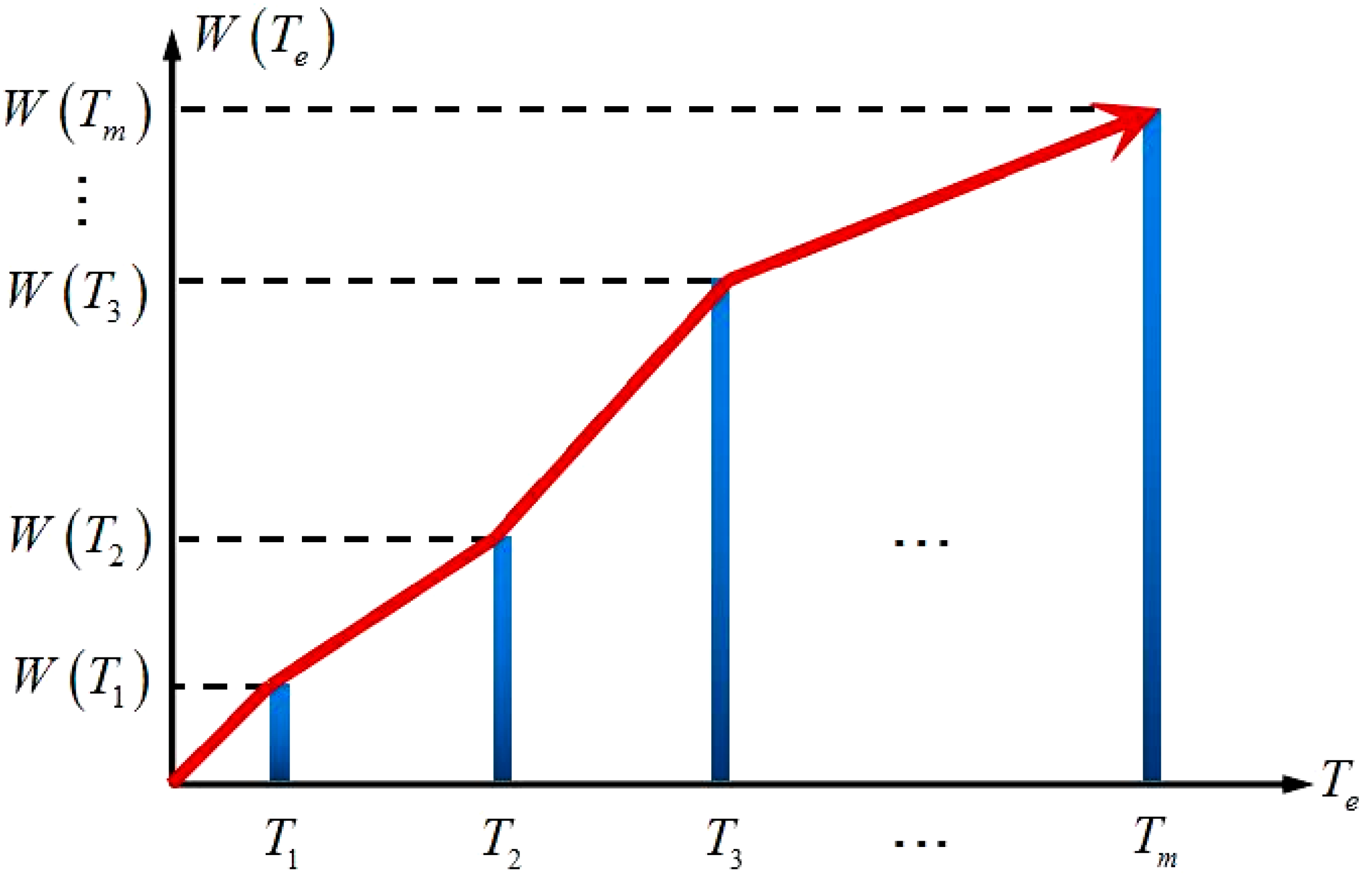
Def 3.2 Motive iteration sub-interval and sub-interval motive iteration value . Selected tourist sight set is ensured first. When tourists travel from tourist sight to the next one , the tour interval between the two tourist sights, which generates motive iteration value, is called motive iteration sub-interval . Within the sub-interval, an initial motive iteration value is set, and the smart machine calculates with indexes to output another motive iteration value, which is called sub-interval motive iteration value . The iteration value generated in the previous motive iteration sub-interval is the iteration function value on tourist sight . The value is used as the initial value to iterate the motive iteration value on tourist sight and it is the sub-interval motive iteration value on motive iteration sub-interval . This value is also the initial value of the next sub-interval. In Figure 2, the blue interval is the motive iteration sub-interval, which is related to sub-interval motive iteration value . Figure 3 shows the motive iteration function for the motive iteration sub-interval. As seen in Figure 3, is a discrete discontinuous and monotonically increasing function, and each tour route is related to a unique function .
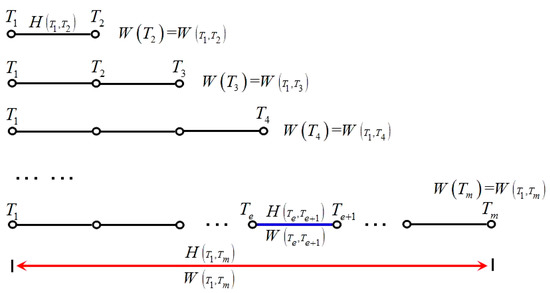
Figure 2.
Motive iteration interval, sub-interval, and relative function values.
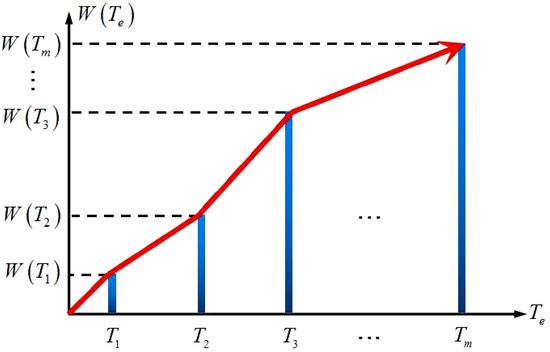
Figure 3.
Motive iteration function of a tour route.
Def 3.3 Motive iteration interval and interval motive iteration value . The sub-intervals iterate from tourist sight to and, finally, output the iteration function value on tourist sight . The whole interval from tourist sight to is called the motive iteration interval . The iteration function value on tourist sight is called the interval motive iteration value . In Figure 2, the red interval is the motive iteration interval , which is related to the interval motive iteration value .
Def 3.4 Motive iteration factor . Tourists travel from tourist sight to in motive iteration sub-interval and in the process, the sub-interval motive iteration value is mainly influenced and determined by ferry distance, road traffic, the convenience of GIS services, and tourists’ subjective perceptions. These factors are called motive iteration factors, . The most important and decisive ones are:
- The tourist sight ferry distance (km, );
- Number of nearby bus line ();
- Number of nearby subway lines ();
- Taxi fee ();
- Traffic congestion index ().
Def 3.5 Motive iteration disturbance factor . In a realistic situation, each motive iteration factor has its own factors that promote or restrain itself, and these factors are called motive iteration disturbance factors, . For each factor , the disturbance factor contains the following:
- Number of road nodes ();
- The sum of walking distance to the nearest bus station (km) and average transference time ();
- The sum of walking distance to the nearest subway station (km) and average transference time ();
- The average waiting time (h, );
- Number of roads with multiple traffic accidents, μ5(). Table 1 shows the motive iteration factor c and disturbance factor values in USD in the algorithm.
 Table 1. Motive iteration factors c and disturbance factors for the algorithm.
Table 1. Motive iteration factors c and disturbance factors for the algorithm.
Of all the factors, the average waiting time is the ratio of total waiting time to the total number of taxi stop times. During the service, a taxi may encounter traffic congestion or a red traffic light, which requires the taxi to stop and wait [56]. The total waiting time is obtained by summing all the taxi wait times.
We set initial motive iteration value on tourist sight as . Thus, the sub-interval motive iteration value is determined by motive iteration sub-interval factor , and disturbance factor follows Formula (5).
We set value , motive iteration sub-interval factor , and disturbance factor . According to the calculated increase consequence due to the motive iteration function , the recursive function Formula (6) is obtained.
According to Formula (6), when a tourist has finished visiting a tourist sight, a motive iteration value will be generated in the same time. This motive iteration value is the tourist’s satisfaction feedback for the sub-interval. It is also the critical index to evaluate the tourist’s mood, feelings, and perceptions about the travel experience, which will directly influence the satisfaction for the next sub-interval. Thus, the value is the initial motive iteration value of the next sub-interval. From the perspective of a realistic travel experience, Formula (6) accounts for the tour’s objective condition and the tourist’s subjective motive.
3.2. Motive Iteration Decision Tree Algorithm Based on M-Central Point Cluster
The selected tourist sight set elements are basic points. Apply the motive iteration algorithm to traverse all tourist sights in set . Take one certain tourist sight of set as the central point, and other tourist sights are points to be traversed. One central point can generate different tour routes, and each route is related to one unique motive iteration function value. The fourth group of definitions are discussed.
Def 4.1 Motive iteration decision tree . Tourist sight element central point is set as father node of decision tree. Other tourist sights are set as child nodes. Th child nodes expansion sequence is determined by the set T element display order and their permutations and combinations. One tour route generated by father node and its child nodes iterations relates to one decision tree; this tree is called the motive iteration decision tree . One father node and child nodes relate to decision trees, . Each decision tree relates to a unique motive iteration function value.
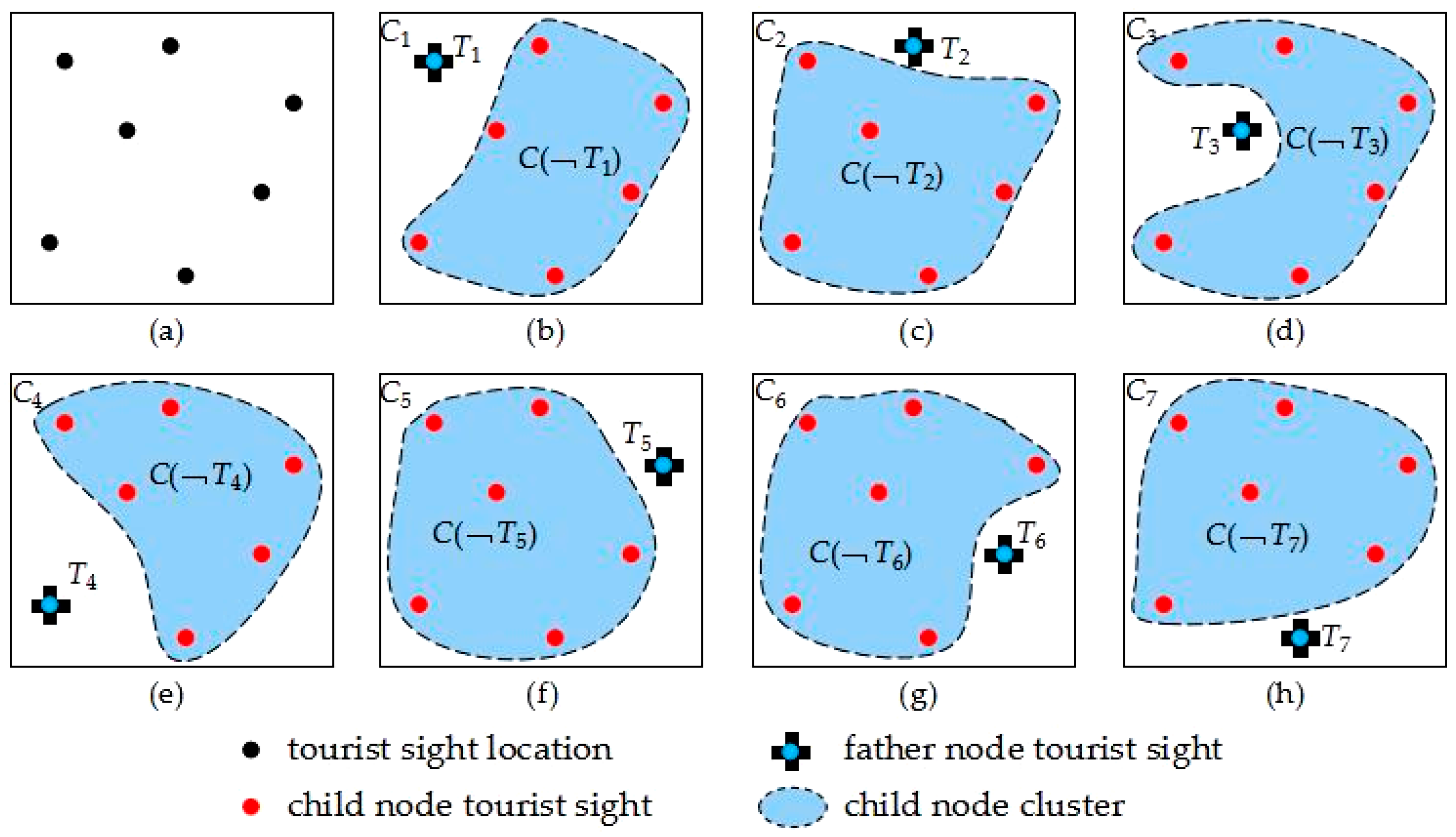
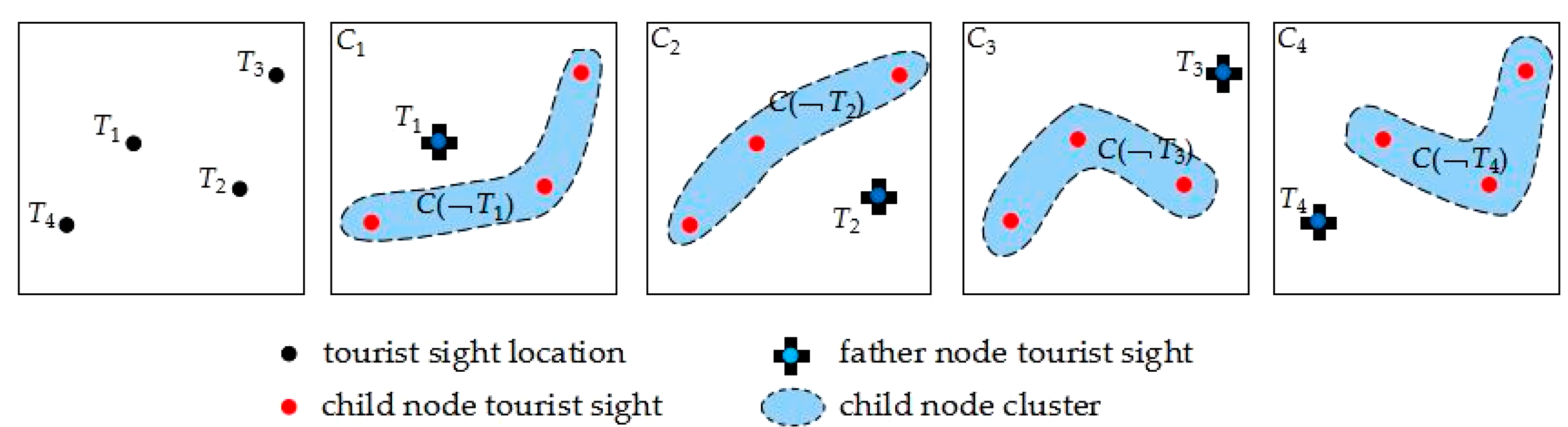
Def 4.2 Decision tree child node cluster . Tourist sight element central point is set as father node, and the other tourist sights form a cluster, which is called decision tree child node cluster [56,57,58]. Figure 4 shows all the father nodes and relative child nodes which are formed by selected tourist sight set elements. Figure 4a is tourist sight distribution. Figure 4b–h is a decision tree father node and child node cluster, , . Figure 4b shows the motive iteration decision tree formed in the way that the number one tourist sight is set as father node and the other tourist sights are set as child nodes.
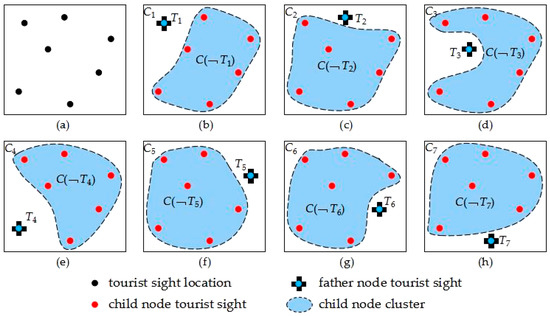
Figure 4.
Tourist sight location, father node, and child node cluster distribution.
Def 4.3 m-central point motive iteration cluster . As to one tourist sight element, tourist sight element forms motive iteration trees, and all the trees gather to one cluster, the cluster is called m-central point motive iteration cluster , . According to the definition, selected tourist sight set contains motive iteration clusters, and each cluster contains motive iteration function value.
Def 4.4 Motive iteration cluster local optimal solution and global optimal solution . According to Definition 4.2, of all the motive iteration function values in one motive iteration cluster, the maximum value is called the optimal solution of the cluster, and it is also the local optimal solution of motive iteration clusters, noted as . motive iteration clusters are related to local optimal solutions, and of all the local optimal solutions, the maximum value is called global optimal solution of m motive iteration cluster.
Def 4.5 Motive iteration cluster descending sub-vector and motive iteration cluster descending vector . Each m-central point motive iteration cluster contains motive iteration decision trees and motive iteration function values. Then, motive iteration function values are set in descending order from the number one element location to No. one to get a descending order vector, it is called motive iteration cluster descending sub-vector , is vector code, , is vector element location code, and . According to the definition, motive iteration cluster local optimal solution is stored in the cluster’s number one element location of the motive iteration cluster descending sub-vector . Then, motive iteration cluster local optimal solutions are set in descending order from number one element location to number one to get a descending order vector; it is called motive iteration cluster descending vector , in which is vector element location code, . According to the definition, the motive iteration cluster global optimal solution is stored in the number one element location of motive iteration cluster descending vector .
According to the fourth group of definitions, we take selected tourist sight set containing tourist sights as basic data set. Each tourist sight sub-interval motive iteration factors and disturb factors are ensured. Motive iteration decision tree algorithm based on m-central point cluster is designed and developed.
Step 1. Empty vector and are built. empty vectors and one empty vector are built. Vector contains element locations. Vector contains element locations.
Step 2. m-central point motive iteration cluster of the number one tourist sight element is built. The number one element location tourist sight of selected tourist sight set is taken to build m-central point motive iteration cluster , which contains decision trees. Decision trees are generated by father node and child node cluster .
- (1)
- The first decision tree is built. The first decision tree starts from tourist sight , and traverses remaining tourist sights to form the first tour route;
- (2)
- Initial motive iteration function value is set. According to Formulas (5) and (6), the smart machine outputs the first decision tree’s motive iteration function value, noted as ;
- (3)
- is stored into the number one element location of vector ;
- (4)
- The second decision tree is built. The second decision tree starts from tourist sight , and traverses remaining tourist sights to form the second tour route;
- (5)
- Take step (2) initial value to iterate and output the second decision tree’s motive iteration function value, noted as ;
- (6)
- Compare and . If , the smart machine clears the number one element location , stores into the number one element location of vector , descends , and stores it into number two element location of vector ; If , smart machine keeps in the number one element location of vector , and stores into the number two element location of vector ;
- (7)
- Return to step (4). The third decision tree is built and is obtained;
- (8)
- Return to step (6), compare and other iteration values;
(I) If :
①, the smart machine clears the number one element location and the number two element location , stores into the number one element location of vector , and stores and into the number two element location and number three element location of vector respectively;
②, the smart machine clears the number two element location , keeps in the number one element location of vector , stores into the number two element location of vector , and stores into the number three element location of vector ;
③, the smart machine keeps the number one and number two element locations, and stores into the number three element location of vector ;
(II) , the method to compare and renew element location is the same as previous step (I);
Repeat sub steps (4)–(8), and motive iteration cluster descending sub-vector is obtained. The number one element location is related to local optimal solution of motive iteration cluster .
Step 3. Local optimal solution of motive iteration cluster is stored into the number one element location of vector .
Step 4. Other motive iteration clusters and local optimal solutions are generated.
- (1)
- Perform Step 2 sub step (1)-sub step (9); m-central point motive iteration cluster of the number two tourist sight element is built. Motive iteration cluster descending sub-vector and local optimal solution of motive iteration cluster are built, too;
- (2)
- Compare and . If , the smart machine clears the number one element location of vector , stores into the number one element location , stores into the number two element location ; If , the smart machine keeps in the number one element location of vector .
- (3)
- Then m-central point motive iteration cluster C3 of the number three tourist sight element is built. Motive iteration cluster descending sub-vector and local optimal solution of motive iteration cluster are built, too;
- (4)
- Compare with other local optimal solutions.
(I) :
①, the smart machine clears the number one element location and the number two element location , stores into the number one element location of vector , and stores into the number two element location and the number three element location of vector respectively;
②, the smart machine clears the number two element location , keeps in the number one element location of vector , stores into the number two element location of vector , and stores into the number three element location of vector ;
③, the smart machine keeps the number one and number two element location, and stores into the number three element location of vector ;
(II) , the method to compare and renew element location is the same as previous step (I);
Step 5. Repeat Step 4 sub step (1)-sub step (4) until motive iteration cluster descending sub-vectors and relative local optimal solutions are obtained. Output the motive iteration cluster descending vector . The number one element location is the motive iteration cluster global optimal solution .
According to Step 1~Step 5, the Algorithm 1 pseudo-code is as follows.
| Algorithm 1. The algorithm to generate and |
| 1: Set and . , , ; |
| 2: As to Cv: For , , and For , , |
| 3: As to : For , , and For , , |
| 4: Output ; |
| 5: Compare and ; |
| 6: Array in descending order from to ; |
| 7: Output and ; |
| 8: Array in descending order from to ; |
| 9: Output and |
| 10: End procedure |
The motive iteration cluster location optimal solution and the global optimal solution have practical value as smart machine has considered tourists’ individualized needs and interests.
Situation one: The principle of proximity.
After a tourist or smart machine selects tourist sights, the tourist may consider taking the whole trip starting with the nearest tourist sight, as their temporary accommodation may be close to the first tourist sight. Thus, the principle of proximity states that, the nearest tourist sight is the starting point; or if the tourist is particularly interested in a certain tourist sight, he may wish to visit that particular one first [27]. In this situation, the smart machine could only consider the decision tree, cluster, and its motive iteration cluster local optimal solution generated by tourist sight visited first.
Situation two: The principle of completely random.
After a tourist or smart machine selects tourist sights, the tourist may have no particular requirement on the tour route, and they will accept any provided tour route [45,46,47]. In this situation, the smart machine should consider motive iteration cluster global optimal solution and relative tour route first in order to best meet tourists’ best motive benefits and needs.
4. Example Simulation Experiment and Data Analysis
The research range is one particular downtown area of a city; all the factors, including disturbance factors, come from urban GIS services. The routes planned in the study are all based on city urban roads and avenues. The tourist sights selected for the original data source are all urban tourist sights which are located in the city but not in the outskirts. In one city, the factors and disturbance factors mentioned in the study are identical, and it is appropriate to use the identical factors as parameters to do the study, as different cities have different conditions. Thus, the algorithm presented in the study is suitable for a city urban tour. Taking Zhengzhou city as the data resource of tourist sight and GIS services, the basic data were sampled before the performance of example simulation experiment [2].
4.1. Data Sampling
In terms of Zhengzhou city’s urban tourist sights and GIS services, the data sampling range and objects should meet the following conditions [50,51,52,53]. (1) The research range is continuous in geographic space, and it covers all the city’s main districts. (2) The tourist sights should be representative and have a steady visitor flow volume, be well-equipped, and fully functional [56,57,58,59]. Commonly, they have a geographical advantage and convenient city service. (3) The tourist sights are independent, and do not influence each other with respect to the tour. (4) They are closely connected by a convenient urban road network. Tourists can go back and forth between two arbitrary tourist sights. According to the standard, Zhengzhou city’s third ring road, six north–south roads, and seven east–west roads are selected to form the geographic research range. Within the range, 27 tourist sights are selected as study objects. Tourist sight spatial dataset , tourist sight spatial data subset , and tourist sight spatial subset element are constructed.
According to the first group of definition and the different properties, the urban tourist sight spatial dataset contains , , and four subsets. is the park and green land set. is the amusement place set. is the venue set. is the shopping center set. The sampling data are reported in Table 2 and the tourist sight distribution is shown in Figure 5.
Table 2.
Tourist sight spatial datasets, subsets, and elements.
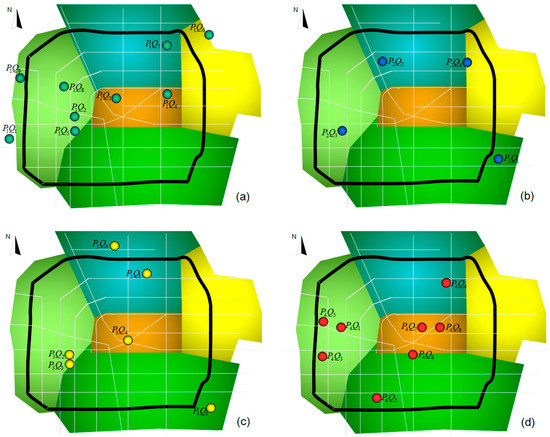
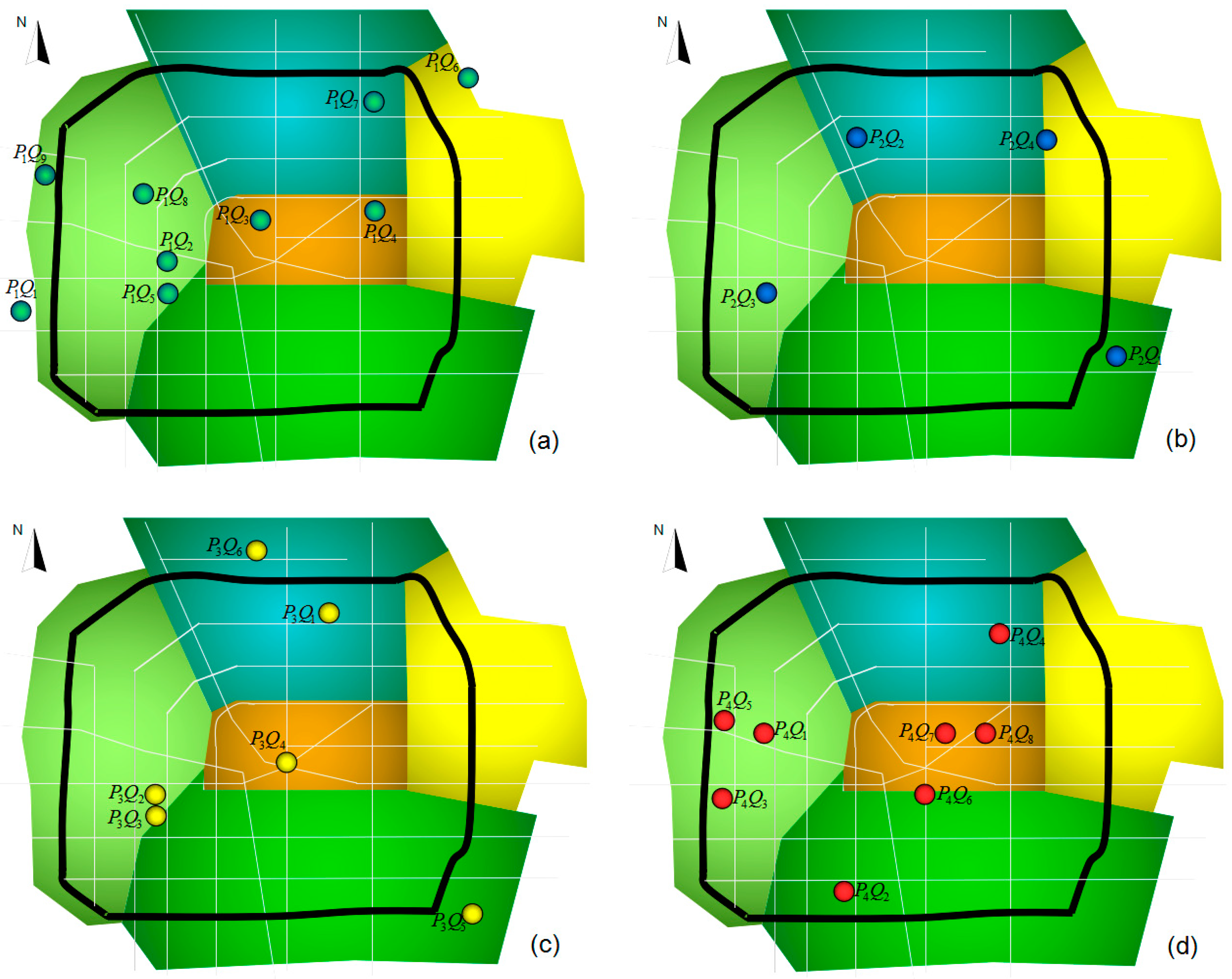
Figure 5.
Tourist sight spatial data subset element distribution. Panels (a), (b), (c) and (d) are the distributions of tourist sight spatial data subsets P1~P4. Each figure contains Zhengzhou city’s five main districts and city arterial roads. Grey roads are a north–south or east–west orientation, whereas the pitch-black road is the third ring road.
According to the data, the 4 × 9 dimension feature interest tourist sight extracting matrix is defined in Formula (7).
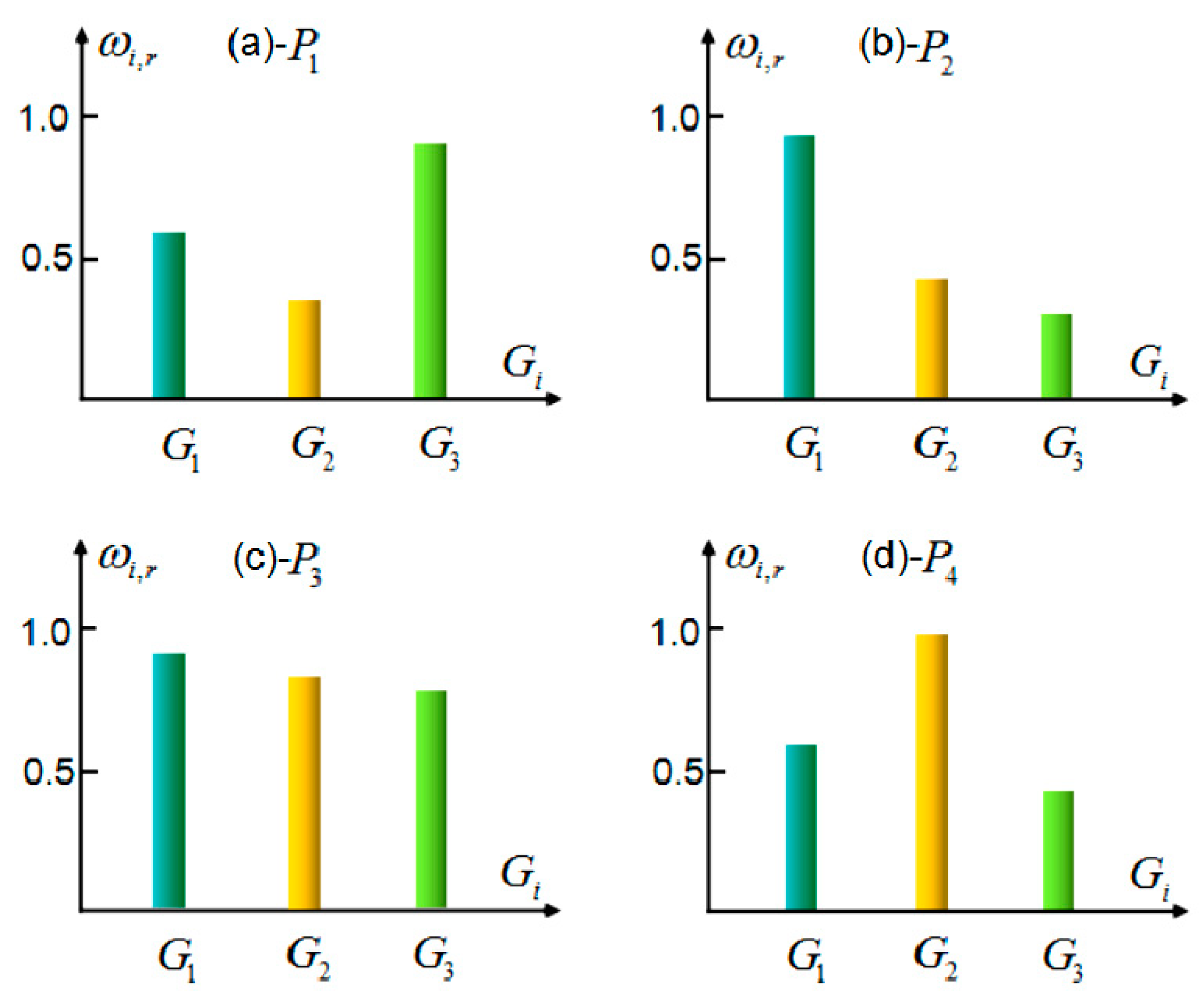
According to the second group of definition, tourist sight spatial interest field mapping model of Zhengzhou city is set up. In terms of tourist statistics, each group’s number of people is 350, ,. The visiting tourists and the visited rate for each tourist sight subset are reported in Table 3. From Figure 6, the interest field intensity for each group for each tourist sight can be analyzed, and visual graphs are obtained. Elderly people have the greatest interest in park and green land subset , followed by children, while young adults have the least interest. Children have the greatest interest in amusement place set , followed by young adults, while elderly people have the least interest. All groups have relatively identical interest in venue set . Young adults have the greatest interest in shopping center set , followed by children, while elderly people have the least interest. According to the interest field mapping model and intensity graphs, the smart machine will determine the interest tendencies and provide the proper tourist sights after the tourist input the number of tourist sight to visit.
Table 3.
The visiting tourists and visited rate for each group and tourist sight subset.
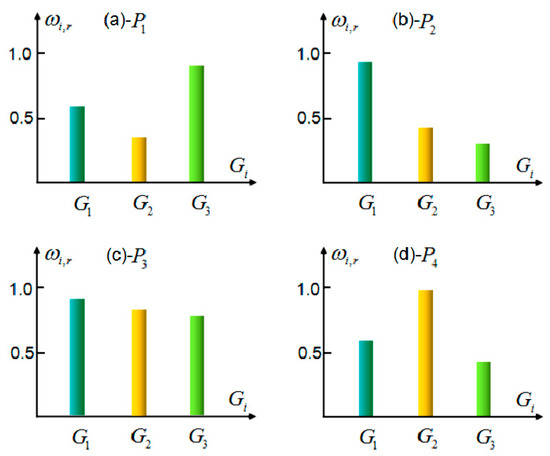
Figure 6.
Each tourist sight’s interest field intensity for each age group. (a) is the park and green land subset, (b) is the amusement place set, (c) is the venue set, and (d) is the shopping center set.
4.2. Simulation Experiment and Results Analysis
Based on the algorithm models developed and the data sampling, a simulation experiment is performed, and data result analysis is obtained.
4.2.1. Simulation Experiment
A young adult plans to have a trip in downtown of Zhengzhou city, but he is not familiar with the city. He wishes to visit four tourist sights within one day. According to his requirements, the smart machine plans a tour route for him. First, referring to the interest field mapping model and intensity, the smart machine matches the background data and determines that this tourist belongs to the young adult group and the machine determines that he may have a high level of interest tendency in tourist sights in the shopping set and venue subset but a low level of interest tendency in park and green land park. Thus, the most interested tourist sights are at the top of the priority list for the smart machine to select. Meanwhile, tourist sight repeat ability should be set to avoid the same tourist sights being selected. Meanwhile, less interested tourist sights are also considered but the least interested ones are avoided to ensure that the tourist sight selection is comprehensive and diverse. Matrix P is used as a data resource from which to extract the proper tourist sights. In the simulation experiment, the smart machine selects and recommends the following tourist sights.
- Sample 1: , , ;
- Sample 2: , , ;
- Sample 3: , , ;
- Sample 4: , , ;
- Sample 5: , .
The young adult tourist selects one of the five samples according to his own interests and needs. If he has no particular preference of the recommended samples, the smart machine will randomly select one sample for him. Take Sample 1, for instance. The smart machine provides him with one famous park, two famous venues, and one shopping mall; they are Bishagang park, Erqi memorial, Henan museum, and Zhongyuan Wanda. Store the selected tourist sight into matrix , as in Formula (7).
Tourist sights , , and are taken as father nodes, respectively, and the decision tree child node clusters and the motive iteration clusters are built as shown in Figure 7.
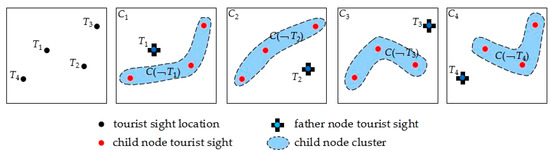
Figure 7.
Building the decision tree child node clusters and the motive iteration clusters .
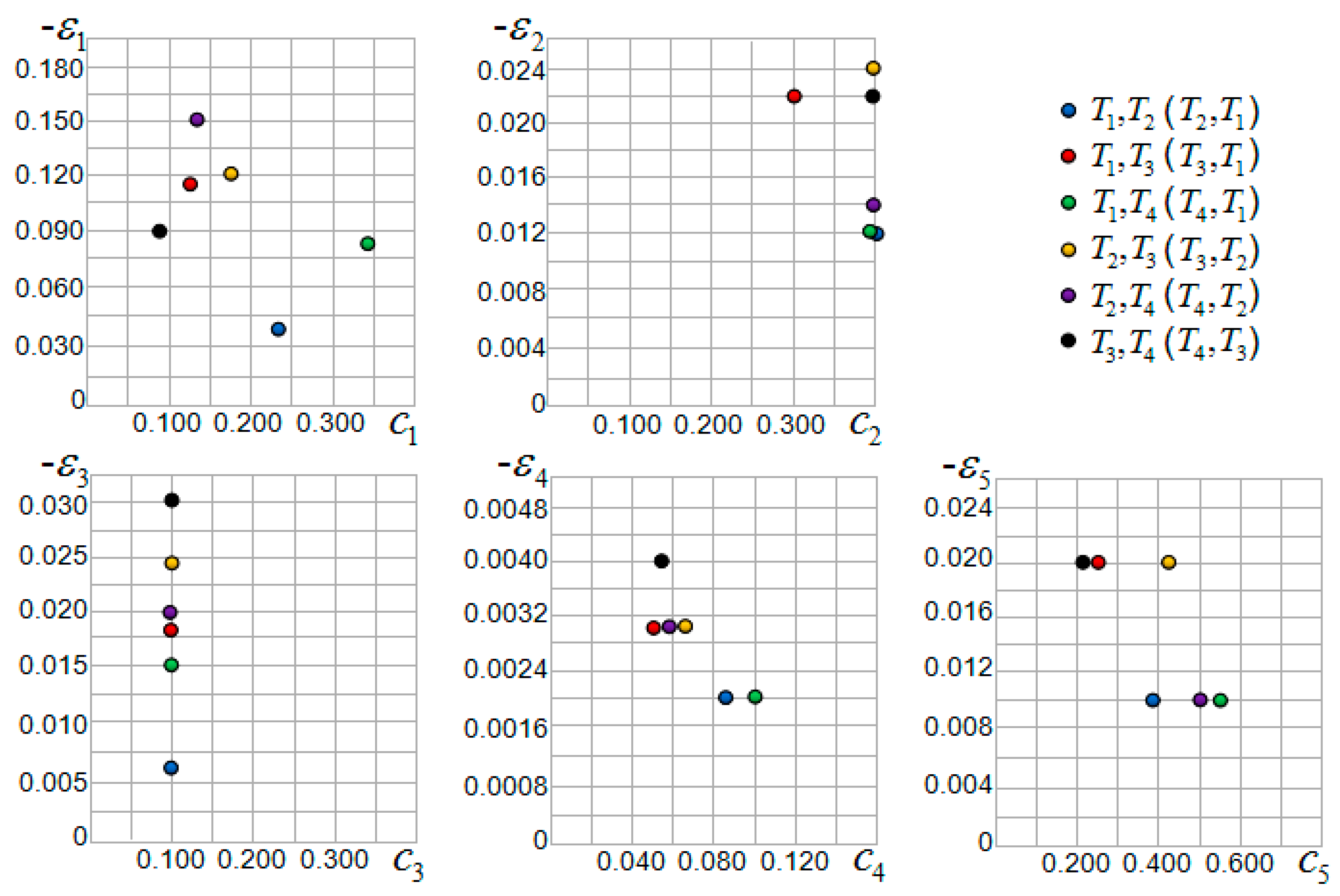
Tourist sight is taken as father node to build the decision tree and six trees are formed in total. Each decision tree contains three motive iteration sub-intervals , the corresponding three sub-interval motive iteration values , one motive iteration interval , and one interval motive iteration value . Each decision tree and sub-interval relates to the motive iteration function and function value, and the maximum value of motive iteration function relates to motive iteration cluster local optimal solution . Regarding the other tourist sights , and , the method to generate the decision tree and local optimal solution is identical. From the basic GIS service data for Zhengzhou city, the motive iteration factor and disturbance factor of each sub-interval are constructed, as Table 4 and Figure 8 indicates. In Figure 8, the abscissa is and the ordinate is . According to the algorithm in the third segment, each decision tree sub-interval motive iteration value , interval motive iteration value , motive iteration function value, and motive iteration cluster local optimal solution are obtained; the initial values are all , as Table 5 shows. Each decision tree’s sub-interval motive iteration values and interval motive iteration values are shown in Figure 9 and Figure 10.
Table 4.
The tourist sight motive iteration factors, and disturbance factors, for the simulation experiment.
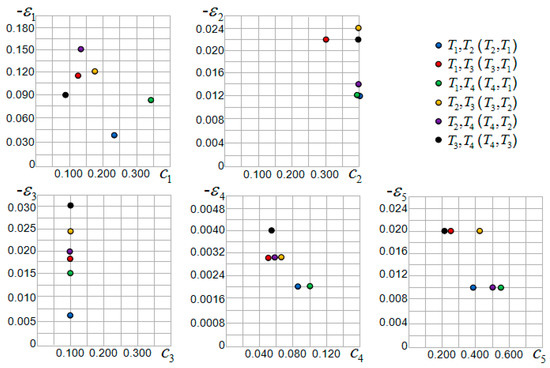
Figure 8.
Distribution of the simulation experiment tourist sight motive iteration factor and disturbance factor . To display all the data in the first quadrant, the ordinate value is set as .
Table 5.
Decision tree interval motive iteration values and global optimal solution.
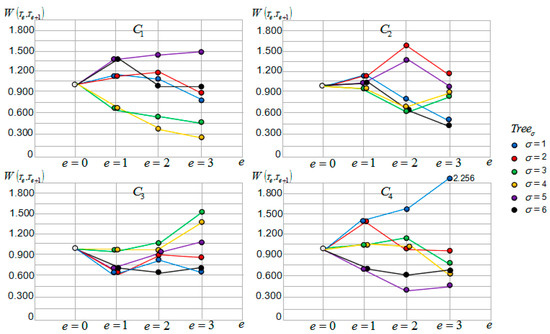
Figure 9.
Each tourist sight sub-interval motive iteration value tendency curves.
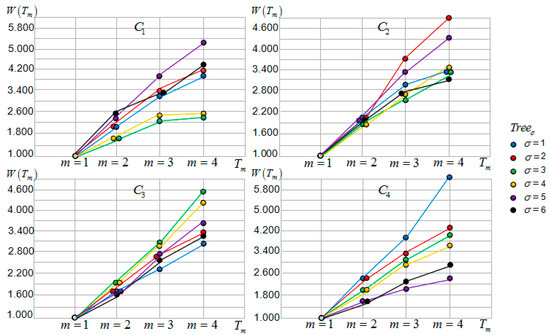
Figure 10.
Each tourist sight interval motive iteration value and function curves.
4.2.2. Data Result Analysis and Discussion
Motive Iteration Cluster and Child Node Cluster
As to Figure 7, the selected four tourist sights are set as father nodes to form child node clusters and the motive iteration cluster , respectively. Since the initial father nodes are different from each other, the child node clusters that are formed have different distribution shapes.
In terms of geographical distribution, child node clusters and formed by tourist sights and have a long zonal distribution with a large opening angle directed northwest and southeast. The child node clusters and formed by and have a comparatively short zonal distribution with a small opening angle directed southeast and northwest. Regarding the different shapes, opening angles and directions, the zonal distributions of and that account for child nodes , , and , , are relatively discrete in spatial clustering distribution. Child nodes , , and , , are relatively concentrated in spatial clustering distribution. In general, a more concentrated child cluster is much more beneficial because they have shorter times and ferry distances between tourist sights within the cluster, more convenient ferry access, lower taxi costs, and less traffic congestion, all of which contribute to generating a globally optimal solution. Regarding the iterating result, this simulation experiment’s global optimal solution appears in motive iteration cluster formed by the tourist sight father node.
Motive Iteration Factor and Disturbance Factor
Considering Table 4 and Figure 8, the motive iteration factor and disturbance factor vary in different sub-intervals. In the first group, sub-interval has the highest factor value while sub-interval has the lowest factor value. Sub-interval has the lowest value, which has the strongest disturbance influence. Sub-interval has the highest value with the weakest disturbance influence. In terms of the factor value, according to the clustering principle, sub-intervals , , and are clustered in one group, while and are clustered in another group.
In the second group, all sub-intervals factor c values are 0.400 except that of , which is 0.300. Sub-interval has the lowest value, whose disturbance influence is the strongest. Sub-intervals and have the highest value, whose disturbance influence is the weakest. Sub-intervals , , and are clustered in one group, whereas sub-intervals , and are clustered in another group.
In the third group, all sub-intervals factor values are 0.100. Sub-interval has the lowest value, whose disturbance influence is the strongest. Sub-interval has the highest value, whose disturbance influence is the weakest. Sub-intervals , , and are clustered in one group. The other two sub-intervals form two clusters.
In the fourth group, sub-interval has the lowest factor value, whereas sub-interval has the lowest factor value. Sub-intervals and have the highest value, whose disturbance influence is the weakest. Sub-interval has the lowest value, whose disturbance influence is the strongest. Sub-intervals and are clustered in one group, whereas sub-intervals , , and are clustered in another group.
In the fifth group, sub-interval has the highest factor value, whereas sub-interval has the lowest factor value. Sub-intervals , , and have the highest value, whose disturbance influence is the weakest, and they are clustered in one group. Sub-intervals , , and have the lowest value, whose disturbance influence is the strongest, and they are clustered in one group.
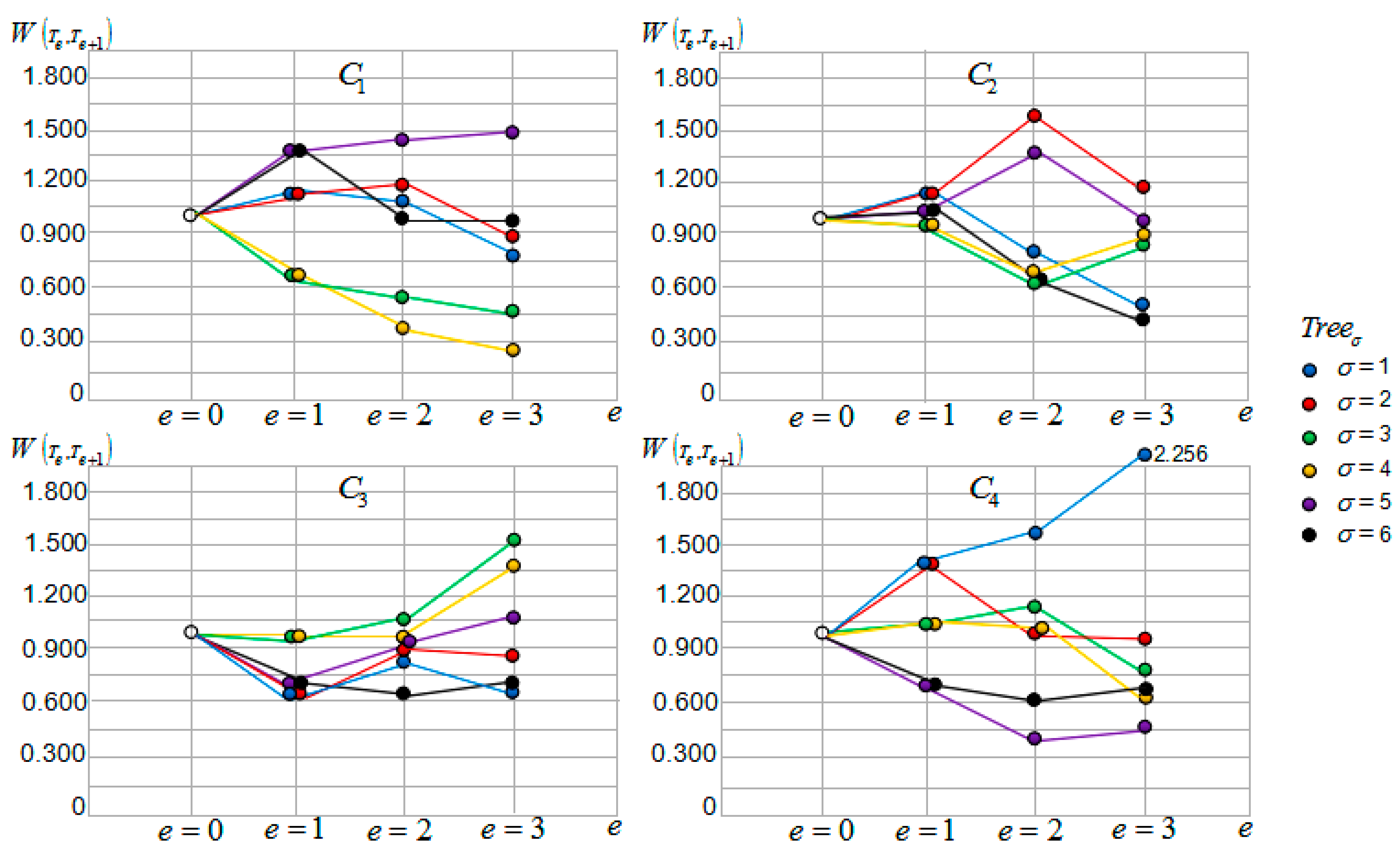
Decision Tree Sub-Interval Motive Iteration Value
As can be observed from Table 5 and Figure 9, the motive iteration clusters generated from different tourist sight father nodes have large differences in terms of the sub-interval motive iteration values, the output values, and the tendency curves. Each sub-interval’s output value is determined by the previous sub-interval, and the value fluctuates. The values randomly vary up and down with the change in tourists’ travel times and locations, which are determined by the sub-intervals initial value and factors and .
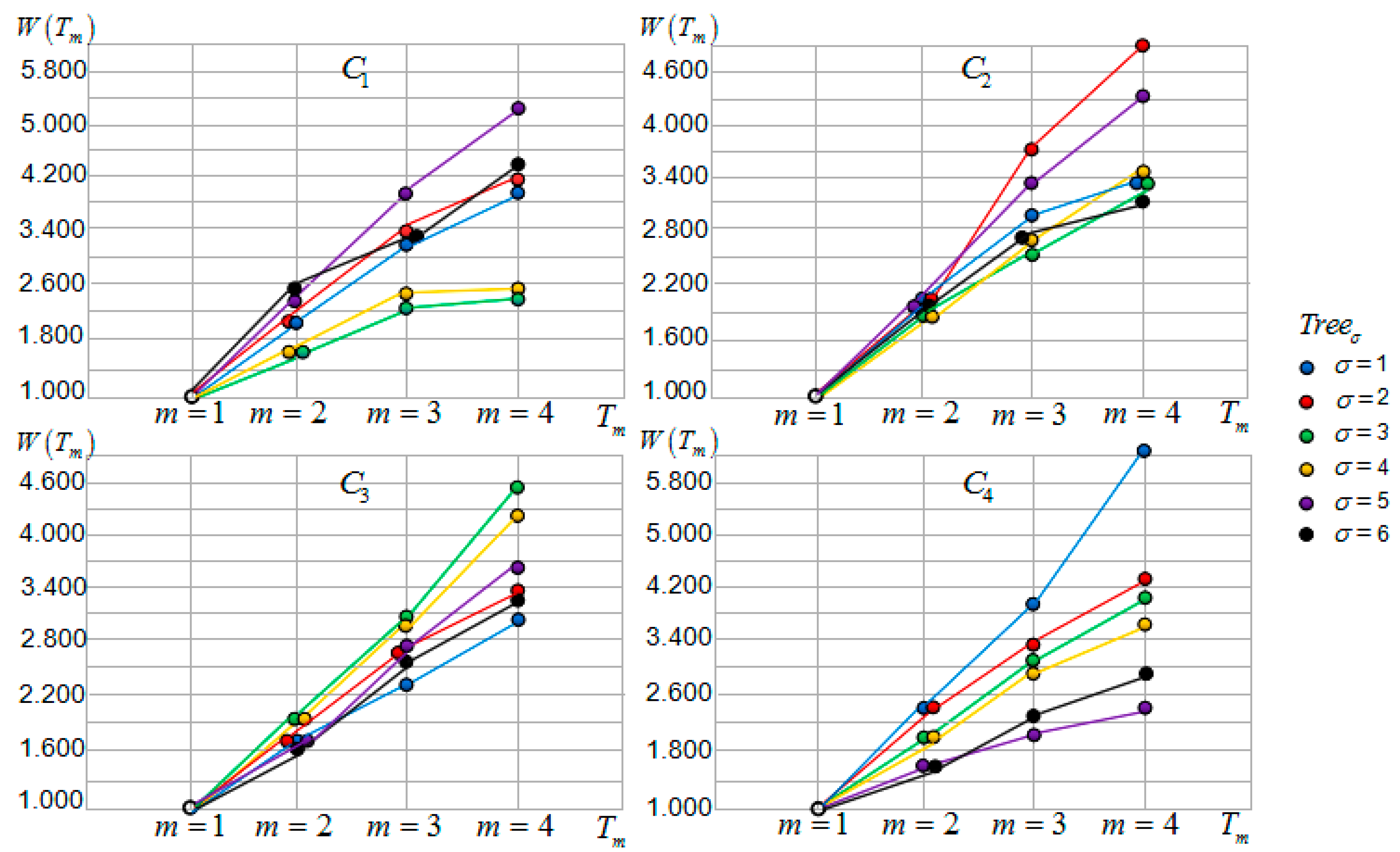
Compare the four motive iteration cluster values and the tendency curves of the cluster generated from tourist sight father node T3. These are most concentrated, which accounts for why the influence of each cluster decision tree relative tour routes on tourists is similar and in the same level. Tourists can choose any one of the tour routes and obtain the same motive benefit satisfaction.
Motive iteration cluster tendency curves for clusters , and are relatively discrete. For cluster , the tendency curves of the decision trees relative tour routes are close and can be clustered in one group, and the tendency curves of the decision trees relative tour routes are close and can be clustered in another group. The tendency curves of the decision tree relative tour route can be clustered in one group, and it has the greatest influence on tourists’ motive benefit satisfaction. Regarding cluster , the tendency curves of the decision trees relative tour routes are close and can be clustered in one group, and the tendency curves of the decision trees relative tour routes are close and can be clustered in another group. Regarding cluster , the tendency curves of the decision trees relative tour routes are close and can be clustered in one group, and the tendency curves of the decision trees relative tour routes are close and can be clustered in another group. The tendency curves of the decision tree relative tour route can be clustered in one group, and it has the greatest influence on tourists’ motive benefit satisfaction. The tour routes clustered in one group have a similar influence on tourists’ motive benefit satisfaction. Tourists may choose any one of the tour routes and obtain the same motive benefit satisfaction.
Decision Tree Interval Motive Iteration Value
Considering Table 5 and Figure 10, the motive iteration clusters generated from different tourist sight father nodes have large differences in the interval motive iteration values. In terms of output value , each motive iteration cluster’s function is monotonically increasing. Comparing four groups of motive iteration output values, the tendency curves of the cluster generated from tourist sight father node are the most concentrated, because the cluster sub-intervals’ tendency curves are the most concentrated. It also accounts for why the influence of each cluster decision tree relative tour routes for tourists is similar and in the same level. Tourists may choose any one of the tour routes and obtain the same motive benefit satisfaction. Regarding cluster C1, the tendency curves of the decision trees relative tour routes are close and can be clustered in one group, and the tendency curves of the decision trees relative tour routes are close and can be clustered in another group. The tendency curves of the decision tree relative tour route can be clustered in one group, and it has the greatest influence on tourists’ motive benefit satisfaction. Regarding cluster , the tendency curves of the decision trees relative tour routes are close and can be clustered in one group, and the tendency curves of the decision trees relative tour routes are close and can be clustered in another group. Regarding cluster , the tendency curves of the decision trees relative tour routes are close and can be clustered in one group, and the tendency curves of the decision trees relative tour routes are close and can be clustered in one group. The tendency curves of the decision tree relative tour route can be clustered in one group, and it has the greatest influence on tourists’ motive benefit satisfaction. The tour routes clustered in one group have a similar influence on tourists’ motive benefit satisfaction, and tourists may choose any one of the tour routes and obtain the same motive benefit satisfaction.
The Motive Iteration Cluster Local Optimal Solution and Global Optimal Solution
Table 5 presents the motive iteration cluster descending sub-vector and motive iteration cluster descending vector that are obtained.
- As to cluster , ;
- As to cluster , ;
- As to cluster , ;
- As to cluster , ;
- Cluster ~, .
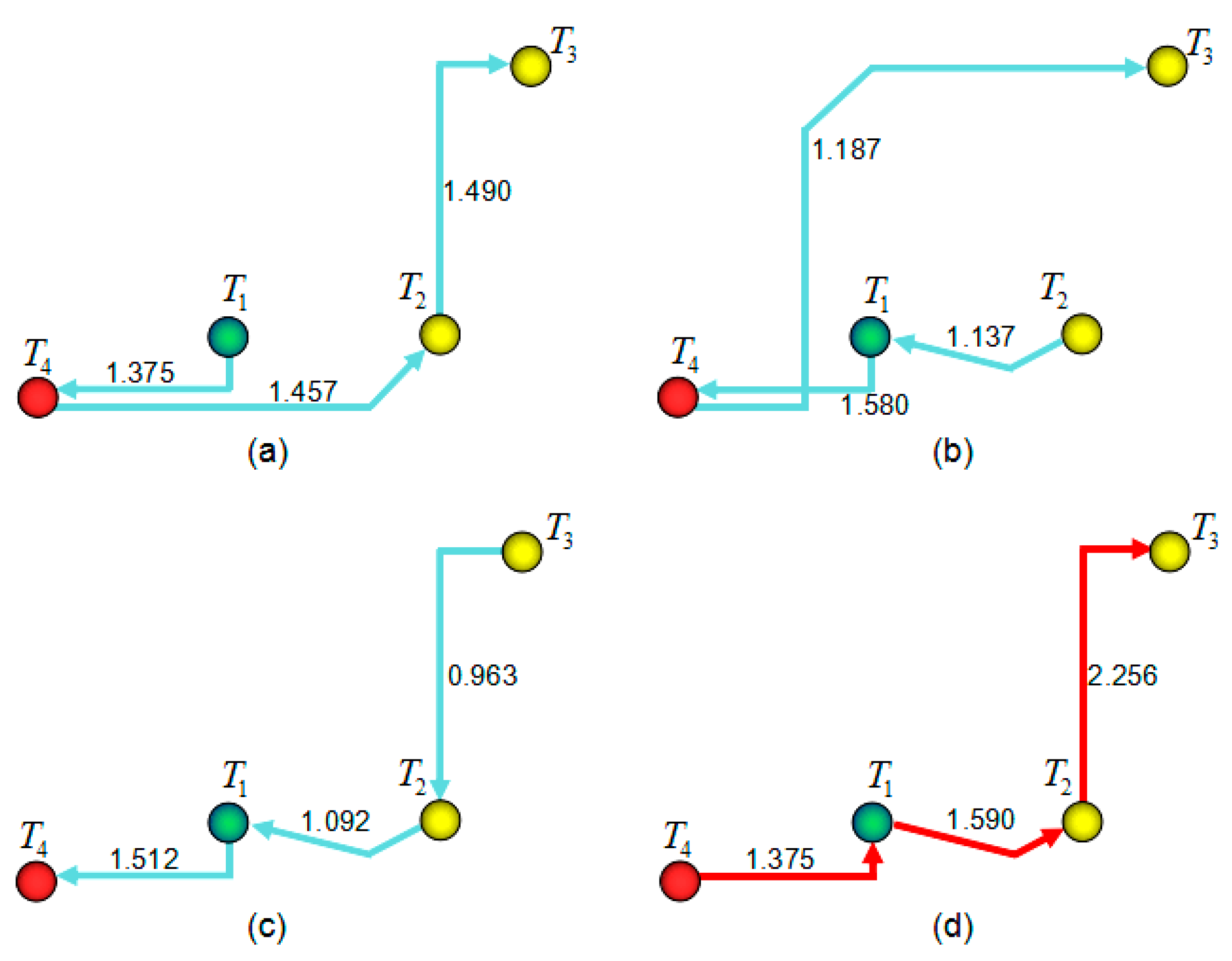
In Figure 10, the six best values of all four clusters are shown. The highest one is the cluster’s local optimal solution . In the four motive iteration clusters, the decision trees , , and motive iteration values are local optimal solutions ; they are , , and , respectively. According to the definition, motive iteration cluster global optimal solution is , it is thus whose relative tour route is the first decision tree in cluster , shown as the red route in Figure 11.
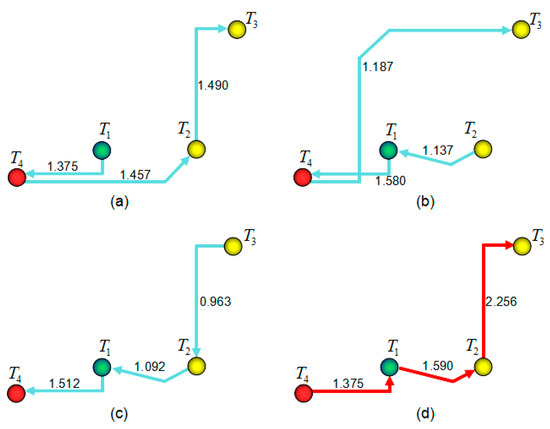
Figure 11.
Tour routes for motive iteration decision tree local optimal solutions.
The local optimal solution is the iteration value of the cluster optimal route. If tourists choose one starting tourist sight for the trip, the smart machine will output all the tour routes related to the cluster as descending sub-vector elements and highly recommends the first element tour route for tourists. Considering a tourist’s own needs and interests, they choose the tour route by themselves. For example, a tourist obtains accommodation next to the Erqi memorial and he takes this tourist sight as the starting one to visit. In this case, since the tour route is , which is Erqi memorial, Bishagang park, Zhongyuan Wanda, and Henan museum, and is the cluster’s optimal tour route, the smart machine will highly recommend it to the tourist. If tourists do not choose the starting tourist sight, the smart machine will output all the tour routes related to the cluster descending vector elements and specifically recommends the first element tour route for tourists, considering the tourist’s own needs and interests, and they choose a tour route themselves. In the simulation experiment, the smart machine highly recommends the cluster tour route which is Zhongyuan Wanda, Bishagang park, Erqi memorial, and Henan museum, the red route. Figure 11 shows the relative tour routes of the motive iteration decision tree local optimal solutions, of which the red noted route is the global optimal solution tour route. The decision tree father nodes for Figure 11a–d are tourist sights ~, respectively.
The Advantage of the Algorithm
As to the study, the algorithm designed in the paper could plan optimal tour routes for tourists and help them to get best motive benefits. Firstly, it considers tourists’ individualized needs and interests. The smart machine designed in the study can automatically select interested tourist sights and plan optimal routes according to the basic information provided by tourists, which is convenient and intelligent. The planned routes combine factors and disturb factors of GIS service, which are all genuine and precise factors tourists must consider and deal with during the whole trip. In this aspect, tourists will not plan routes by themselves; rather, all the optimal routes are planned by the smart machine. This process is better than the procedure whereby tourists find mass information on the Internet and plan routes by themselves, in which many key factors may be neglected and cannot provide the best travel experience and motive benefits. Meanwhile, the smart machine only considers tourists’ profits and interests, but travel companies mainly consider their own profits to earn more money, which will neglect tourists’ needs and interests. In all, the optimal routes of smart machine can meet the needs and interests of tourists and thus provide better information than mass tourism data on the Internet and travel companies.
5. Conclusions
Some critical issues and existing problems in smart tourism and tourism GIS are discussed and analyzed in the study. Mining the most valuable tour route knowledge from big data-level information is the key to increasing the motive benefit satisfaction. When planning a trip and tour routes, tourists are usually unfamiliar with a strange city and its tourism services information. Travel agencies provide planned tour routes for tourists to gain profits, and they insufficiently consider tourists’ needs and interests since they provide group tours with fixed schedules, offer limited ferry transportation ways, and confine the range of activities for tourists.
Referring to Reference [5]’s concept of using a scalable geospatial analysis based on cloud computing platform to detect tourism destinations, this study establishes basic city tourist sight data information and GIS data as independent variables to build a feature interest tourist sight extracting matrix, which is not scalable. Reference [5] uses a cloud computing platform, whereas this study develops a new calculating system to obtain iteration values.
Referring to Reference [17]’s concept of oriented spanning trees, this study also generates spanning trees. Reference [17] adds genetic and multi-criteria thoughts to solve the path problems; in this study, there is one criterion, which aims to determine the maximum iteration value.
Representative tourist sights and service functions are integrated and are used as a data resource to build the algorithm. The tourist sight classification is a subset, and it is an effective means to group and segment tourists’ needs and interests. It is also the basis upon which to build the tourist sight spatial interest field mapping model.
An age index is used to group tourists because this standard has broad coverage and strong representation because similarly aged people have similar interests. The developed smart tourist sight extracting algorithm model is highly random and a strict logic is used in the algorithm, covering all the tourist sights, with each tourist sight having the same probability of being selected. Considering one-day trips, in order to ensure that tourists have an enjoyable trip experience at tourist sights to obtain the best motive benefit satisfaction, the smart machine sets an upper limit for the number of selected tourist sights and then stores, manages, and plans tourist sights and tour routes accordingly.
Referring to Reference [18]’s approach to solving shortest-distance problems, in designing the algorithm and smart machine, this study supplements more details to meet a majority of the tourists’ needs. Two principles are applied; one is the principle of proximity, and the other is the principle of completely random. Considering these two principles, a smart motive iteration decision tree algorithm is designed and developed. A quantitative method is used to evaluate the motive iteration trees and tour routes generated from different tourist sight father nodes and the results are used as the basis for smart machine recommendations for tourist sights and tour routes.
Compared with Reference [39]’s application of spatial partitioning and k-means clustering, the concept of clustering is also used in this study. Reference [39] applies k-means clustering to habitat occupation in Propithecus perrieri. Similarly, the m-central point clusters are developed, where each tourist sight is used as father node to generate decision trees. When a tourist chooses situation one and starts at the closest tourist sight, only one cluster will be studied and used to determine the optimal tour route, which will decrease the cost. When a tourist chooses situation two and randomly chooses a starting tourist sight, the smart machine needs to determine the global optimal solution and recommend the best tour route for tourists.
The recommended tour routes obey the optimum principle, and individualized interests and needs are considered. In tour route planning, it avoids tourists’ subjective cognition and considers mainly individualized needs most, in addition to objective conditions. The methodology does not seek to pursuit profit as do travel agencies; instead, it is based on serving tourists. Regarding massive and big data-level tourism information, this study presents a method to access valuable and concealed tour route knowledge, which are relevant to tourists’ needs and interest. The algorithm developed in the study is practical and its performance are an effective examination of data mining in mass tourism data.
Author Contributions
This research was completed jointly by all the authors. De Zhang collected and processed the original data. Yinhu Zhan and Guanghui Feng mainly conducted and designed the experiments. Xiao Zhou performed the experiments and wrote the paper. Shaomei Li assisted with the experimental design. Xiao Zhou and Yinhu Zhan conducted the data collection and analysis.
Funding
This research was funded by the National Natural Science Foundation of China (Grant No. 41571399, 41501446, 41771487 and 41704006), Training Program for Young Backbone Teachers of Henan Higher Education Institute (Grant No. 2017GGJS196), Henan Scientific and Technological Project (Grant No. 182102210554) and Open-end Fund of State Key Laboratory of Geo-Information Engineering (Grant No. SKLGIE2018-ZZ-6).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
| Meaning | Meaning of Subscript and Superscript | |
| tourist sight spatial data set | None | |
| tourist sight spatial data subset | r: subset number | |
| Subset element tourist sight | s: element tourist sight number in subset | |
| tourist sight classification number | None | |
| tourist sight number of the subset | r: subset number | |
| tourist sight extracting base vector | r: subset number | |
| tourist sight extracting matrix | None | |
| Age group classification | i: age group number | |
| Number of people in statistics | None | |
| Age group Gi number of people | i: age group number | |
| Age index | None | |
| Number of people visiting Gi | i: age group number r: subset number | |
| Visited rate of Pr | i: age group number r: subset number | |
| Number of tourist sight to be visited | None | |
| Selected tourist sight set | None | |
| Selected tourist sight set element | e: Selected tourist sight set number | |
| Motive iteration function | e: Selected tourist sight set number | |
| Motive iteration sub-interval | Te: Selected tourist sight set element e: Selected tourist sight set number | |
| Sub-interval motive iteration value | Te: Selected tourist sight set element e: Selected tourist sight set number | |
| Motive iteration interval | Tm: The final tourist sight to be visited | |
| Interval motive iteration value | Tm: The final tourist sight to be visited | |
| Motive iteration factor | None | |
| Specific factor | None | |
| Motive iteration disturbance factor | None | |
| Specific disturbance factor | None | |
| Motive iteration decision tree | σ: Tree number | |
| Child node cluster | Te: Selected tourist sight set element e: Selected tourist sight set number | |
| Motive iteration cluster | v: Cluster number | |
| Decision tree local optimal solution | Cv: Motive iteration cluster | |
| Decision tree global optimal solution | Cv: Motive iteration cluster | |
| Motive iteration cluster descending sub-vector | a: Motive iteration cluster descending sub-vector number | |
| Motive iteration cluster descending vector | b: Motive iteration cluster descending vector number | |
| arbitrary | None | |
| Join | None | |
| Positive integer | None | |
| Positive real number | None |
References
- Jeong, J.S.; García-Mourno, L.; Hernández-Blanco, J.; Jaraíz-Cabanillas, F.J. An operational method to supporting siting decisions for sustainable rural second home planning in ecotourism sites. Land Use Policy 2014, 41, 550–560. [Google Scholar] [CrossRef]
- Rahayuningsih, T.; Muntasib, E.K.S.H.; Prasetyo, L.B. Nature Based Tourism Resources Assessment Using Geographic Information System (GIS): Case Study in Bogor. Procedia Environ. Sci. 2016, 33, 365–375. [Google Scholar] [CrossRef]
- Balmford, A.; Beresford, J.; Green, J.; Naidoo, R.; Walpole, M.; Manica, A. A global perspective on trends in nature-based tourism. PLoS Biol. 2009, 7, e1000144. [Google Scholar] [CrossRef]
- Page, S.J. Transport and Tourism: Global Perspectives; Pearson: Harlow, UK, 2005. [Google Scholar]
- Zhou, X.; Xu, C.; Kimmons, B. Detecting tourism destinations using scalable geospatial analysis based on cloud computing platform. Comput. Environ. Urban Syst. 2015, 54, 144–153. [Google Scholar] [CrossRef]
- Cheng, T.; Haworth, J.; Wang, J. Spatio-temporal autocorrelation of road network data. J. Geogr. Syst. 2012, 14, 389–413. [Google Scholar] [CrossRef]
- Kruger, M.; Viljoen, A.; Saayman, M. Who Visits the Kruger National Park, and Why? Identifying Target Markets. J. Travel Tour. Mark. 2017, 34, 312–340. [Google Scholar] [CrossRef]
- Sakip, S.R.M.; Akhir, N.M.; Omar, S.S. Determinant Factors of Successful Public Parks in Malaysia. Proc. Soc. Behav. Sci. 2015, 170, 422–432. [Google Scholar] [CrossRef]
- Perrine, K.; Khani, A.; Ruiz-Juri, N. Map-Matching Algorithm for Applications in Multimodal Transportation Network Modeling. Transp. Res. Rec. 2015, 2537, 62–70. [Google Scholar] [CrossRef]
- Li, J.Q. Match bus stops to a digital road network by the shortest path model. Transp. Res. Part C Emerg. Technol. 2012, 22, 119–131. [Google Scholar] [CrossRef]
- Zheng, W.; Huang, X.; Li, Y. Understanding the tourist mobility using gps: Where is the next place? Tour. Manag. 2017, 59, 267–280. [Google Scholar] [CrossRef]
- World Tourism Organization. Annual Report 2015. Available online: http://cf.cdn.unwto.org/sites/all/.files/pdf/annual_report_2015_lr.pdf (accessed on 23 August 2017).
- Chen, P.; Nie, Y. Bicriterion shortest path problem with a general nonadditive cost. Transp. Res. Part B Methodol. 2013, 57, 419–435. [Google Scholar] [CrossRef]
- Huttenlocher, D.P.; Klanderman, G.A.; Rucklidge, W.J. Comparing images using the Hausdorff distance. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 850–863. [Google Scholar] [CrossRef]
- Yuan, L.; Yu, Z.; Luo, W.; Zhang, J.; Hu, Y. Clifford algebra method for network expression, computation, and algorithm construction. Math. Methods Appl. Sci. 2014, 37, 1428–1435. [Google Scholar] [CrossRef]
- Garroppo, R.G.; Giordano, S.; Tavanti, L. A survey on multi-constrained optimal path computation: Exact and approximate algorithms. Comput. Netw. 2010, 54, 3081–3107. [Google Scholar] [CrossRef]
- Liu, L.; Mu, H.; Yang, X.; He, R.; Li, Y. An oriented spanning tree based genetic algorithm for multi-criteria shortest path problems. Appl. Soft Comput. J. 2012, 12, 506–515. [Google Scholar] [CrossRef]
- Mohri, M. Semiring Frameworks and Algorithms for Shortest-Distance Problems. J. Autom. Lang. Comb. 2013, 7, 321–350. [Google Scholar]
- Yang, B.; Luan, X.; Zhang, Y. A Pattern-Based Approach for Matching Nodes in Heterogeneous Urban Road Networks. Trans. GIS 2015, 18, 718–739. [Google Scholar] [CrossRef]
- Wang, X.; Choi, T.M.; Liu, H.; Yue, X. Novel ant colony optimization methods for simplifying solution construction in vehicle routing problems. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3132–3141. [Google Scholar] [CrossRef]
- Fang, Z.; Zong, X.; Li, Q.; Li, Q.; Xiong, S. Hierarchical multi-objective evacuation routing in stadium using ant colony optimization approach. J. Transp. Geogr. 2011, 19, 443–451. [Google Scholar] [CrossRef]
- Fang, Z.; Tu, W.; Li, Q.; Shaw, S.-L.; Chen, S.; Chen, B.Y. A voronoi neighborhood-based search heuristic for distance/capacity constrained very large vehicle routing problems. Int. J. Geogr. Inf. Sci. 2013, 27, 741–764. [Google Scholar] [CrossRef]
- Szeto, W.Y.; Wang, A.B. Reliable network design under supply uncertainty with probabilistic guarantees. Transp. A Transp. Sci. 2016, 12, 504–532. [Google Scholar] [CrossRef]
- Srinivasan, K.K.; Prakash, A.A.; Seshadri, R. Finding most reliable paths on networks with correlated and shifted log–normal travel times. Transp. Res. Part B Methodol. 2014, 66, 110–128. [Google Scholar] [CrossRef]
- Tu, W.; Li, Q.; Fang, Z.; Shaw, S.-L.; Zhou, B.; Chang, X. Optimizing the locations of electric taxi charging stations: A spatial–temporal demand coverage approach. Transp. Res. Part C Emerg. Technol. 2016, 65, 172–189. [Google Scholar] [CrossRef]
- Poletti, F. Public Transit Mapping on Multi-Modal Networks. Master’s Thesis, IVT, ETH Zurich, Zurich, Switzerland, 2016. [Google Scholar]
- Daina, N.; Sivakumar, A.; Polak, J.W. Electric vehicle charging choices: Modelling and implications for smart charging services. Transp. Res. C Emerg. Technol. 2017, 81, 36–56. [Google Scholar] [CrossRef]
- Lin, C.; Choy, K.L.; Ho, G.T.S.; Chung, S.H.; Lam, H.Y. Survey of Green Vehicle Routing Problem: Past and future trends. Expert Syst. Appl. 2014, 41, 1118–1138. [Google Scholar] [CrossRef]
- Jabbarpour, M.R.; Noor, R.M.; Khokhar, R.H. Green vehicle traffic routing system using ant-based algorithm. J. Netw. Comput. Appl. 2015, 58, 294–308. [Google Scholar] [CrossRef]
- Kwon, Y.; Choi, Y.; Lee, D. Heterogeneous fixed fleet vehicle routing problem considering carbon emission. Transp. Res. D Transp. Environ. 2013, 16, 81–89. [Google Scholar] [CrossRef]
- Sundar, K.; Rathinam, S. Algorithms for Routing an Unmanned Aerial Vehicle in the Presence of Refueling Depots. IEEE Trans. Autom. Sci. Eng. 2014, 11, 287–294. [Google Scholar] [CrossRef]
- Bruglieri, M.; Pezzella, F.; Pisacane, O.; Suraci, S. A Variable Neighborhood Search Branching for the Electric Vehicle Routing Problem with Time Windows. Electron. Notes Discret. Math. 2015, 47, 221–228. [Google Scholar] [CrossRef]
- Miralinaghi, M.; Lou, Y.; Keskin, B.B.; Zarrinmehr, A.; Shabanpour, R. Refueling station location problem with traffic deviation considering route choice and demand uncertainty. Int. J. Hydrogen Energy 2017, 42, 3335–3351. [Google Scholar] [CrossRef]
- Suzuki, Y. A decision support system of dynamic vehicle refueling. Decis. Support Syst. 2009, 46, 522–531. [Google Scholar] [CrossRef]
- Nosovskiy, G.V.; Liu, D.; Sourina, O. Automatic clustering and boundary detection algorithm based on adaptive influence function. Pattern Recognit. 2008, 41, 2757–2776. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Y. A comprehensive survey of clustering algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef]
- Zhan, Q.; Deng, S.; Zheng, Z. An Adaptive Sweep-Circle Spatial Clustering Algorithm Based on Gestalt. ISPRS Int. J. Geo-Inf. 2017, 6, 272. [Google Scholar] [CrossRef]
- Wansink, B.; Ittersum, K.V. Stopping decisions of travelers. Tour. Manag. 2004, 25, 319–330. [Google Scholar] [CrossRef]
- Ross, A.C.; Lehman, S.M. Applying spatial partitioning and K-Means clustering to habitat occupation in Propithecus perrieri. Am. J. Phys. Anthropol. 2011, 144, 257. [Google Scholar]
- Grubesic, T.H.; Wei, R.; Murray, A.T. Spatial Clustering Overview and Comparison: Accuracy, Sensitivity, and Computational Expense. Ann. Assoc. Am. Geogr. 2014, 104, 1134–1155. [Google Scholar] [CrossRef]
- Papa, J.P.; Falcao, A.X.; Levada, A.L.M.; Correa, D.C.; Salvadeo, D.H.P.; Mascarenhas, N.D.A. Fast and accurate holistic face recognition using optimum-path forest. In Proceedings of the 16th International Conference on Digital Signal Processing, Santorini-Hellas, Greece, 5–7 July 2009. [Google Scholar]
- Lopes, G.; Silva, D.; Rodrigues, A.; Filho, P. Recognition of handwritten digits using the signature features and Optimum-Path Forest Classifier. IEEE Latin Am. Trans. 2016, 14, 2455–2460. [Google Scholar] [CrossRef]
- Suganuma, N.; Uozumi, T. Precise Position Estimation of Autonomous Vehicle Based on Map-Matching. In Proceedings of the Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011; pp. 296–301. [Google Scholar]
- Aeberhard, M.; Rauch, S.; Bahram, M.; Tanzmeister, G. Experience, results and lessons learned from automated driving on Germany’s highways. IEEE Intell. Transp. Syst. Mag. 2015, 7, 42–57. [Google Scholar] [CrossRef]
- Gruyer, D.; Belaroussi, R.; Revilloud, M. Accurate Lateral Positioning from Map Data and Road Marking Detection; Pergamon Press, Inc.: Tarrytown, NY, USA, 2016; Volume 43, pp. 1–8. [Google Scholar]
- Bo, T.; Khokhar, S.; Gupta, R. Turn prediction at generalized intersections. In Proceedings of the Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 1399–1404. [Google Scholar]
- Kim, J.; Jo, K.; Chu, K.; Sunwoo, M. Road-model-based and graph-structure-based hierarchical path-planning approach for autonomous vehicles. Proc. Inst. Mech. Eng. Part D 2014, 228, 909–928. [Google Scholar] [CrossRef]
- Guo, C.; Kidono, K.; Meguro, J.; Kojima, Y.; Ogawa, M.; Naito, T. A low-cost solution for automatic lane-level map generation using conventional in-car sensors. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2355–2366. [Google Scholar] [CrossRef]
- Gwon, G.-P.; Hur, W.-S.; Kim, S.-W.; Seo, S.-W. Generation of a precise and efficient lane-level road map for intelligent vehicle systems. IEEE Trans. Veh. Technol. 2017, 66, 4517–4533. [Google Scholar] [CrossRef]
- Zhang, T.; Yang, D.; Li, T.; Li, K.; Lian, X. An improved virtual intersection model for vehicle navigation at intersections. Transp. Res. Part C Emerg. Technol. 2011, 19, 413–423. [Google Scholar] [CrossRef]
- Jia, Q.; Wang, R. Automatic extraction of road networks from GPS traces. Photogramm. Eng. Remote. Sens. 2016, 82, 593–604. [Google Scholar]
- Hall, C.M.; Le-Klahn, D.T.; Ram, Y. Tourism, Public Transport and Sustainable Mobility; Channel View Publications: Bristol, UK, 2017. [Google Scholar]
- Cheng, Y.H.; Chen, S.Y. Perceived accessibility, mobility, and connectivity of public transportation systems. Transp. Res. Part A Policy Pract. 2015, 77, 386–403. [Google Scholar] [CrossRef]
- Thill, J.C. Geographic information systems for transportation in perspective. Transp. Res. Part C Emerg. Technol. 2000, 8, 3–12. [Google Scholar] [CrossRef]
- Benenson, I.; Martens, K.; Rofé, Y.; Kwartler, A. Public transport versus private car GIS-based estimation of accessibility applied to the Tel Aviv metropolitan area. Ann. Reg. Sci. 2011, 47, 499–515. [Google Scholar] [CrossRef]
- Kim, J.; Thapa, B.; Jang, S. GPS-based mobile exercise application: An alternative tool to assess spatio-temporal patterns of visitors’ activities in a National Park. J. Park Recreat. Admin. 2019, 37, 124–134. [Google Scholar] [CrossRef]
- Kang, S.; Lee, G.; Kim, J.; Park, D. Identifying the spatial structure of tourism attraction system in South Korea using GIS and network analysis: An application of anchor-point theory. J. Destin. Mark. Manag. 2018, 9, 358–370. [Google Scholar]
- Kim, J.; Nicholls, S. Influence of the measurement of distance on assessment of recreation access. Leisure Sci. 2016, 38, 118–139. [Google Scholar] [CrossRef]
- Kang, S.; Kim, J.; Nicholls, S. National tourism policy and spatial patterns of domestic tourism in South Korea. J. Travel Res. 2014, 53, 791–804. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).