1. Introduction
Since the end of the 20th century, land use and land cover (LULC) maps have been extensively generated at different spatial and temporal scales. The 2000 Global Land Cover map [
1] and the 2000 CORINE Land Cover (CLC) [
2] map are two examples. Multi-temporal LULC maps can be used to monitor land changes over time, enabling the creation of indicators that can measure changes and support land management. Mapping results have a significant impact on our understandings of LULC patterns and can affect monitoring, characterization, and quantification outcomes. Nevertheless, one of the main challenges regarding LULC map production is the difficulty of distinguishing and accurately mapping land attributes.
Over the last decade, volunteered geographic information (VGI) platforms [
3], as well as other data contributed by social network communities [
4,
5], have been widely used as sources for LULC mapping and visualizations [
6,
7,
8,
9,
10,
11,
12,
13]. Crowdsourced content from online platforms, accessed, and exchanged by citizens, has emerged as a supplementary data source with significant implications for LULC database production [
14]. This nontraditional data source is not necessarily a substitute for official data, but is considered to be complementary [
15].
OpenStreetMap (OSM) is a free, open-access VGI platform to which volunteers from all over the world collaboratively contribute data, and it is a particularly promising source of information for LULC analysis [
10,
16,
17]. Several factors have been essential to its success, including its availability of up-to-date data with global coverage, improvements in data quality (mainly driven by an increase in the number of contributors over time) [
11,
18], and its extensive volume and variety of thematic attribute data [
11]. OSM therefore has the potential for use in the long-term mapping and monitoring of LULC changes [
6] and could plausibly be used to improve the production, verification, and validation of LULC maps [
6,
7,
8,
11,
19,
20,
21]. A multi-temporal trajectory can be achieved using OSM data [
22], not only for LULC mapping but also for ground-validated data creation [
19].
However, it is known that both the spatial coverage and the accuracy of OSM data are not homogeneous across all regions [
16,
23], with urban areas being likelier to have promising contributions (in both quantity and quality) than rural areas [
24,
25]. Several authors have recently highlighted quality issues on VGI platforms [
4,
26,
27,
28,
29,
30,
31,
32]. OSM data still lack formal standards, such as those established by the International Organization for Standardization (ISO) 19157: 2013 Geographic information-Data quality [
11,
33]. Five data quality criteria are commonly mentioned in the literature: (1) Completeness, (2) temporal accuracy, (3) logical consistency, (4) positional accuracy, and (5) thematic accuracy [
34,
35,
36].
The thematic accuracy [
37] of the OSM platform’s LULC mapping is currently a hot research topic [
7,
9,
10,
11,
34], and a number of studies have compared OSM data with authoritative reference data [
6,
7,
16,
33,
35,
38]. For example, two studies of mainland Portugal [
6,
7] found a total of 76.7% agreement between the data from OSM and CLC maps, with artificial surfaces, forests, and water bodies presenting promising results. Similarly, a study of Vienna [
21] compared OSM data to data from the Global Monitoring for Environment and Security Urban Atlas (GMESUA) and found an agreement rate of 76% to 91%. More recently, another comparison of OSM and GMESUA data [
8] found an agreement rate of about 90%.
Completeness accuracy [
23] is also commonly used to assess OSM data since it allows for the evaluation of territorial coverage. It has been used mainly to evaluate the completeness of OSM’s data on road networks [
22,
39,
40], buildings [
23,
41,
42], and LULC features [
6,
9,
34].
Related Works
Recent studies [
43,
44,
45] have also included OSM contributors’ update history in data quality assessments. OSM full history file stores extra information associated with data contributions, such as timestamps that provide the exact date and time of contributions [
39,
40,
41,
46]. For example, one study [
40] that assessed OSM’s road network completeness and positional accuracy using OSM data history concluded that the use of historical information improved the quality of OSM data by up to 14%. OSM data history can moreover be used for a number of different purposes [
40] and allow for new perspectives on the reliability of OSM data at different scales and timeframes [
22,
40]. OSM data history is available since 2005.
In the present study, OSM data history has been accessed to generate different LULC datasets based on the contribution year (using the timestamps) in order to create regional and rural multi-temporal LULC maps. This had two primary purposes. First, we sought to evaluate the degree to which OSM datasets bounded by one-year timeframes agreed with extant authoritative datasets (i.e., CLC and the official Portuguese Land Cover Map—COS), using both completeness and thematic accuracy as quality parameters. Second, we sought to evaluate whether the OSM datasets were of sufficient quality to be used as sampling data sources for multi-temporal LULC maps. For this second assessment, we used near boundary tag accuracy (NBTA) to evaluate the fitness of the OSM data for producing training samples, by looking at the extent to which a feature’s proximity to a boundary influenced its attribute (tag) accuracy.
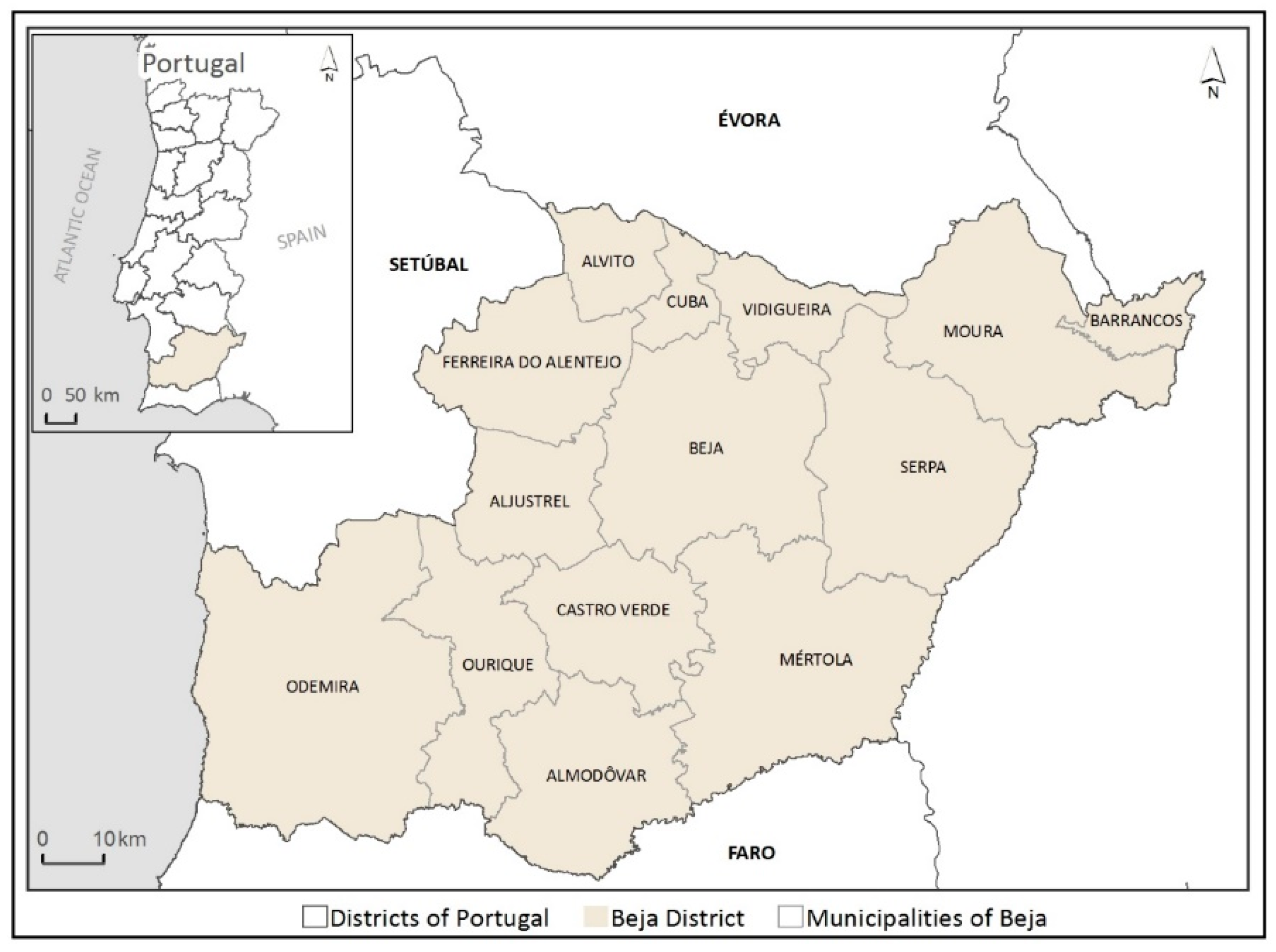
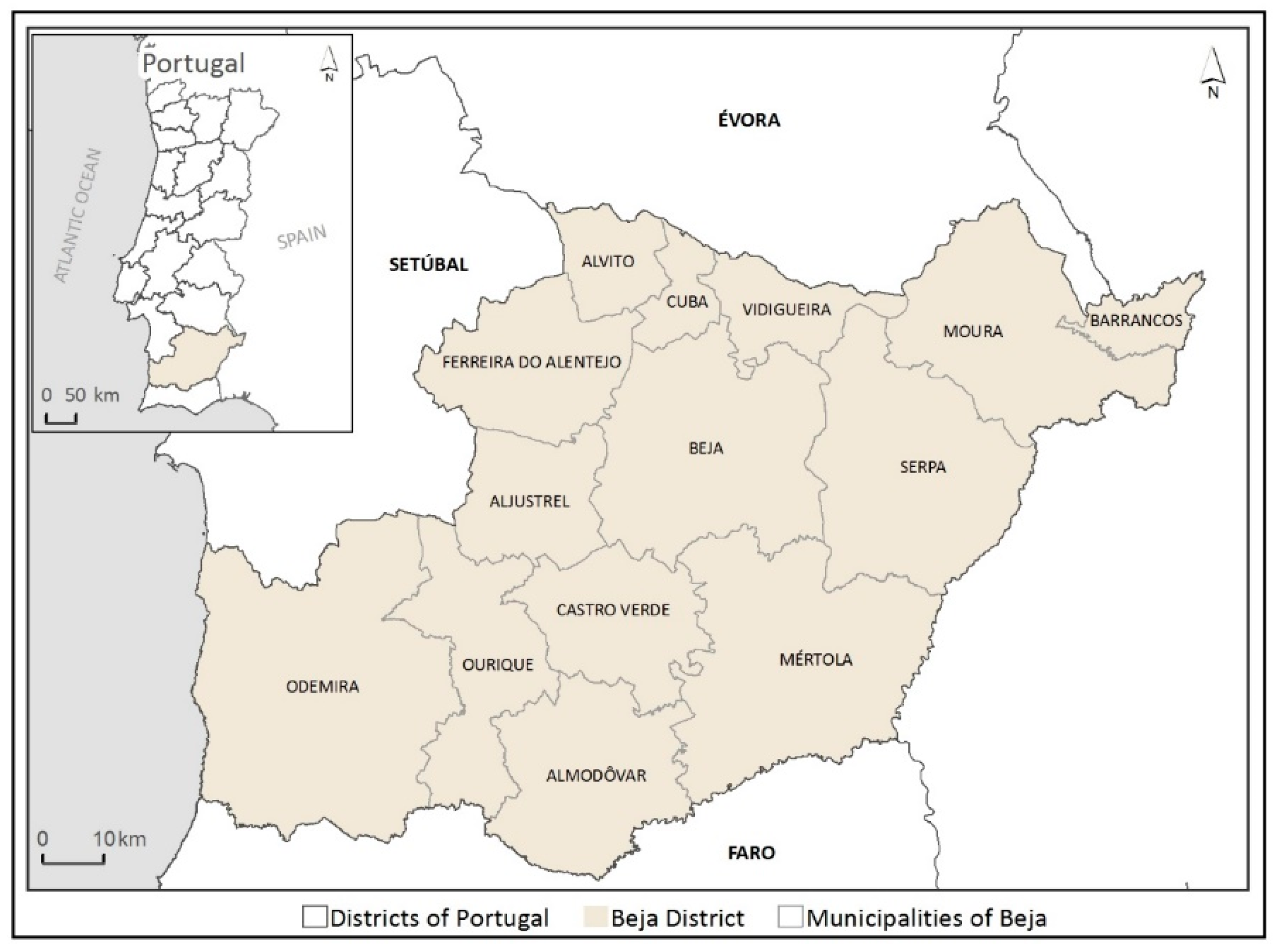
This research was conducted in the largest Portuguese district, Beja. It is a predominantly rural region with high natural and economic value, and is characterized by a mixed agro-silvo-pastoral ecosystem [
47]. In addition, the region has recently undergone rapid LULC changes [
47,
48,
49], and the limited number of references LULC data for this region emphasizes the importance of finding supplementary LULC data to support the identification and monitoring of these changes.
Our research is discussed in the rest of this paper.
Section 2 describes the study area and our data.
Section 3 details our methodology.
Section 4 presents our OSM quality results. Finally, in
Section 5 we discuss the implications and main conclusions of our results.
3. Methods
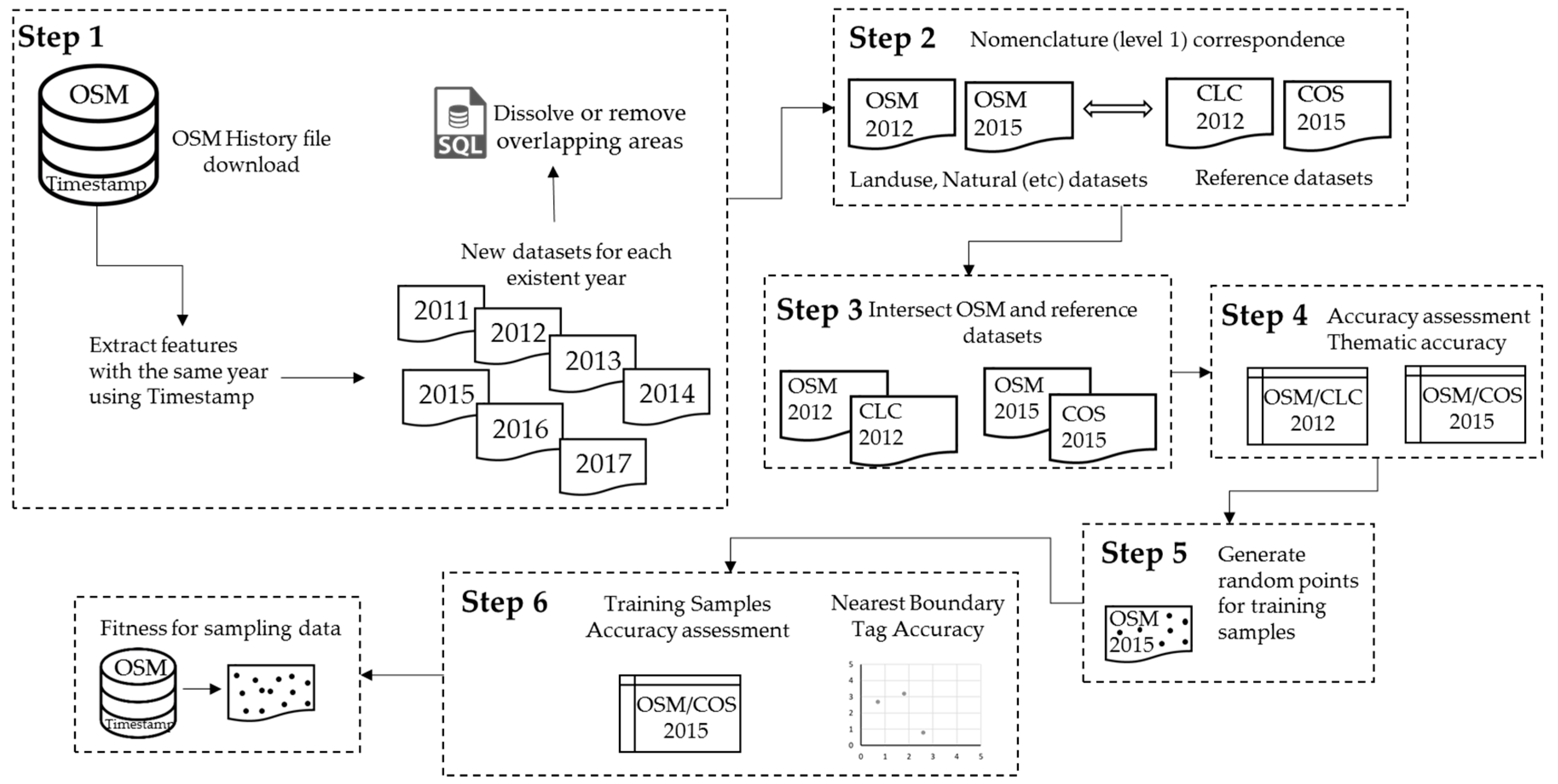
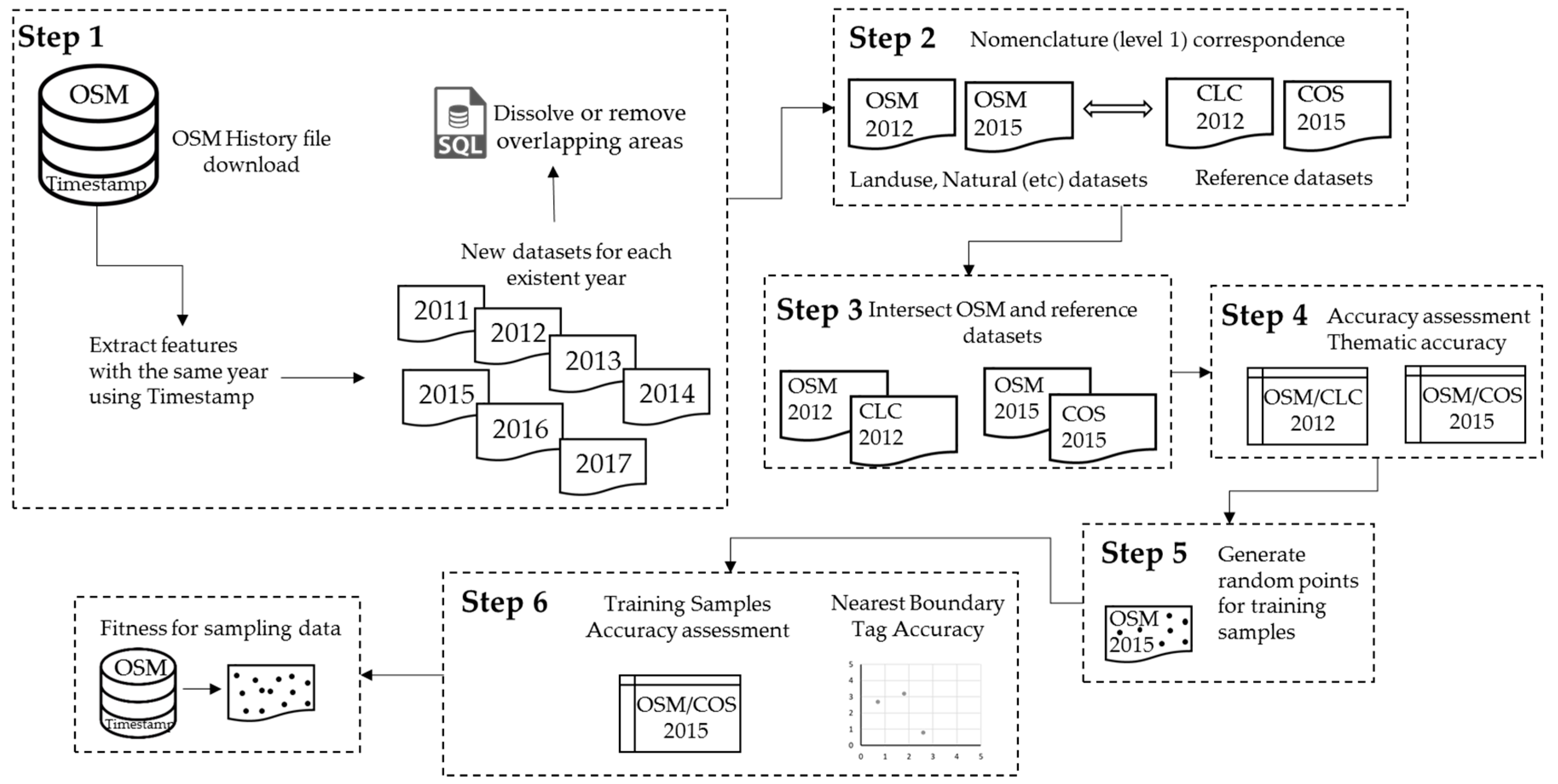
Figure 2 shows our main steps. Briefly, our first step was to download the OSM data history file and filter the contributions according to their timestamps. We obtained datasets for seven different years and resolved all logical inconsistencies, such as overlapping features. Second, we established a relationship between the OSM and CLC/COS first level of nomenclature. Third, we intersected the datasets to determine the area corresponding to the OSM dataset that matched the reference dataset. Fourth, we calculated the datasets’ completeness and thematic accuracies for 2012 and 2015. Fifth, random points were generated as training samples. Finally, in step six we calculated the NBTA for 2015.
3.1. Processing the OSM Datasets
We began by downloading from Geofabrik the latest OSM history file available at the time (7 May 2018) that covered Portugal. All OSM objects with the feature types of land use, natural features, airways, amenities, buildings, highways, historic features, leisure features, man-made features, power structures, public transportation, railroads, shops, sports, tourism, forests, and waterways were retrieved. We limited our results to features (polygons) found in the Beja district. By filtering the features by contribution year (using the timestamp data), we generated multi-temporal datasets that included only the features which were created or modified during any given year. We found contributions for seven different years (2011–2017). Since reference data for the study area only exists for 2012 (CLC) and 2015 (COS), we identified and selected all the OSM data contributions that had been created/modified in these two years (2012 and 2015) and used these two OSM datasets in our study for comparison with the reference datasets.
A common problem when processing OSM data is the presence of logical inconsistencies, such as overlapping features [
6,
9,
34,
35]. This problem is even more common when history files are used, since they contain records of every single modification. It is therefore essential to dissolve or remove the overlapping features in order to not overestimate areas and to ensure that only one attribute (tag) is kept for analysis [
6,
9,
35]. To ensure logical consistency between the annual datasets, when overlapped features had the same attribute we dissolved the overlapping areas, while when the overlapped features’ attributes did not match the conflict areas were removed.
In addition, we examined the provenance of OSM data for our study area to confirm that there were no bulk imports from known sources (e.g., CLC; COS). In this study the polygons´ geometry for each reference dataset and both OSM datasets was compared by using the Feature Compare tool of ArcGIS 10.5 software.
3.2. Relationship between Dataset Nomenclatures
Several studies have stressed the difficulties of using datasets from different agencies due to the lack of direct relationships between their classes [
6,
9,
35,
52]. In Estima and Painho [
6], the authors attempted to reconcile the three nomenclature levels of the CLC, the OSM land use feature, and the OSM natural areas feature, based on the official descriptions of the CLC and OSM classes. Given their remarkable results, we decided to partially follow their nomenclature correspondence for the first level of the CLC and COS nomenclature, namely, (1) artificial surfaces, (2) agricultural areas, (3) forests, (4) wetlands, and (5) water (see
Table 3). For the purposes of the study, the OSM features type airways, amenities, buildings, highways, historic features, leisure features, man-made features, power structures, public transportation, railroads, shops, sports, and tourism were considered to be (1) artificial surfaces. The OSM feature type wood was classed as (3) forest, while the OSM feature type waterway was classed as (5) water.
3.3. Accuracy Assessment Criteria
3.3.1. OSM Completeness Accuracy
It can be difficult to draw definitive conclusions from OSM data due to the heterogeneity of contributions across different regions [
23]. This challenge poses particular limitations when analyzing rural areas [
16,
53]. Accordingly, the completeness accuracy criterion is commonly used to assess the quality of OSM data [
22,
34,
35]. Completeness accuracy is defined as the completeness of a dataset and measures the presence or absence of features. Typically, the total number of features is computed for point features, while for line features the total length is computed. These calculations are then compared to the reference dataset [
23]. However, for polygon features, it is assumed that the overall area of the study area is the maximum area possible, and it is therefore not necessary to compare it to reference data [
35].
In this study, completeness accuracy was calculated as a ratio of the OSM features’ overall area (
AOSM) and the total area of the study area (
ARef). It is presented here as a percentage, as described in Equation 1. A ratio of 100 means that the OSM dataset provides full coverage of the study area. This criterion was measured for all OSM dataset features for 2012 and 2015 for each LULC class.
3.3.2. OSM Thematic Accuracy
Thematic accuracy is another common criterion used to evaluate the quality of OSM dataset features in LULC mapping [
6,
7,
8,
21]. Thematic accuracy describes the accuracy of the features’ attributes (tags) by computing the differences between OSM dataset features and those of the chosen reference datasets [
35].
In this study, we used an overlap function to determine which features overlapped between the OSM datasets (2012 and 2015) and the reference datasets (CLC and COS, respectively). Following common statistical approaches [
35,
54], for each annual dataset the overlapping areas were computed in a confusion matrix, which presented the correct and incorrect mapped areas for each LULC class. The rows denote the occurrences of an actual class (OSM) and the columns denote the occurrences of reference data classes (CLC or COS). Several measures were obtained from this, including overall thematic accuracy, individual user accuracy, producer accuracy, and the Kappa index of agreement [
34,
35,
55]. The overall thematic accuracy measure provides the overall percentage of the correctly mapped OSM features by dividing the correct mapped area by the total mapped area. User accuracy measures the probability that any given LULC class from an OSM dataset will actually match the reference dataset, while producer accuracy indicates the probability that a particular LULC class from the reference dataset is classified as such in OSM [
35]. The Kappa index measures the degree of agreement between the OSM dataset and the reference dataset [
55].
3.3.3. Near Boundary Tag Accuracy (NBTA)
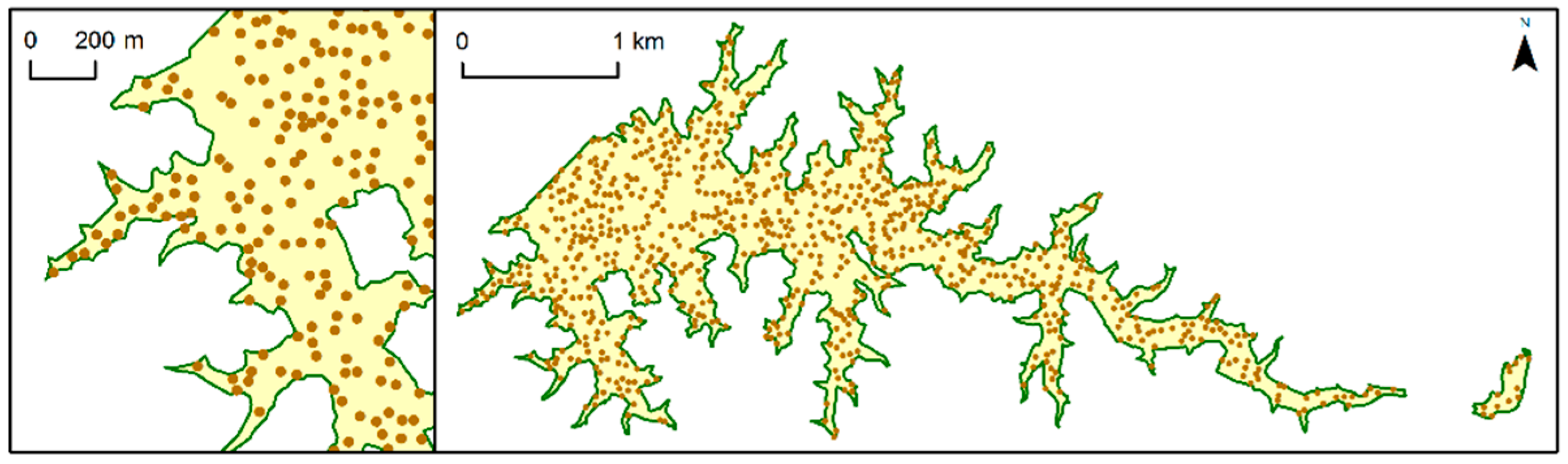
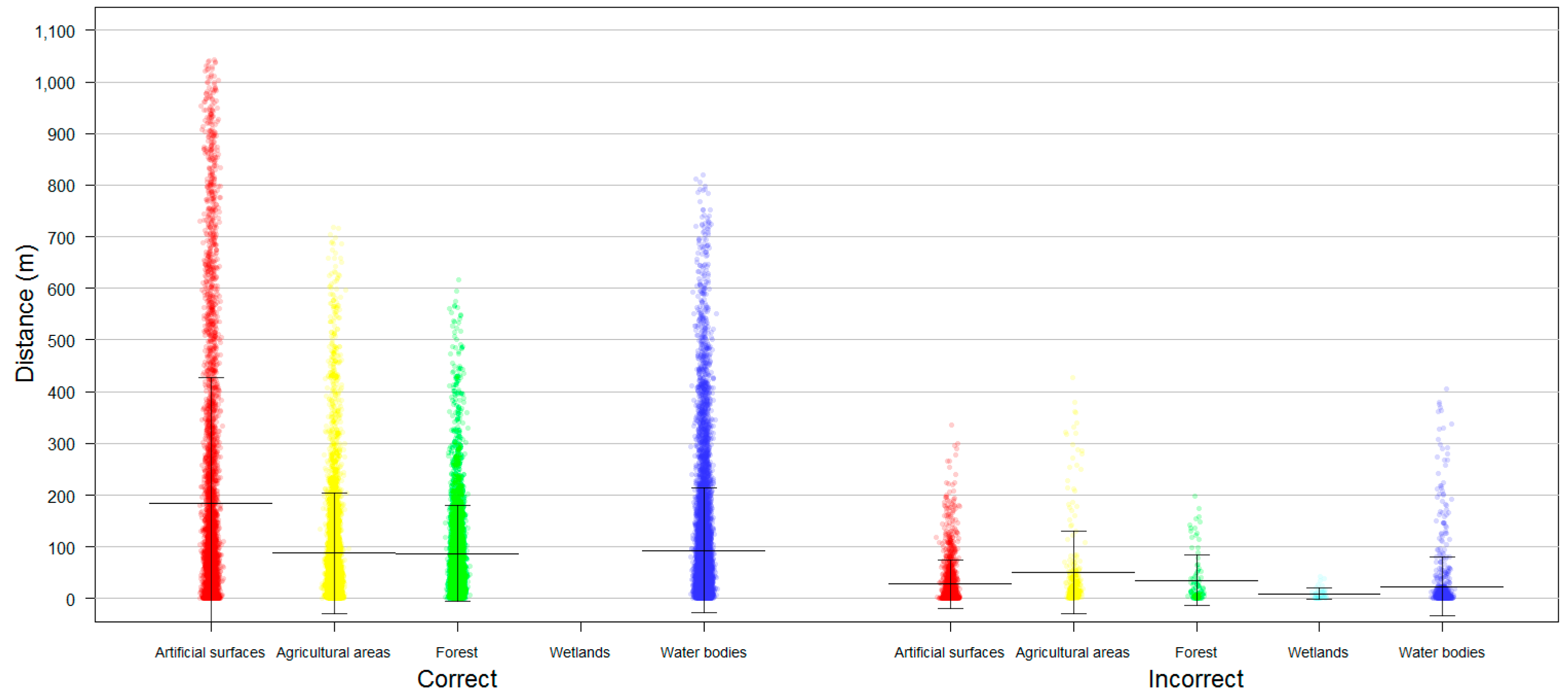
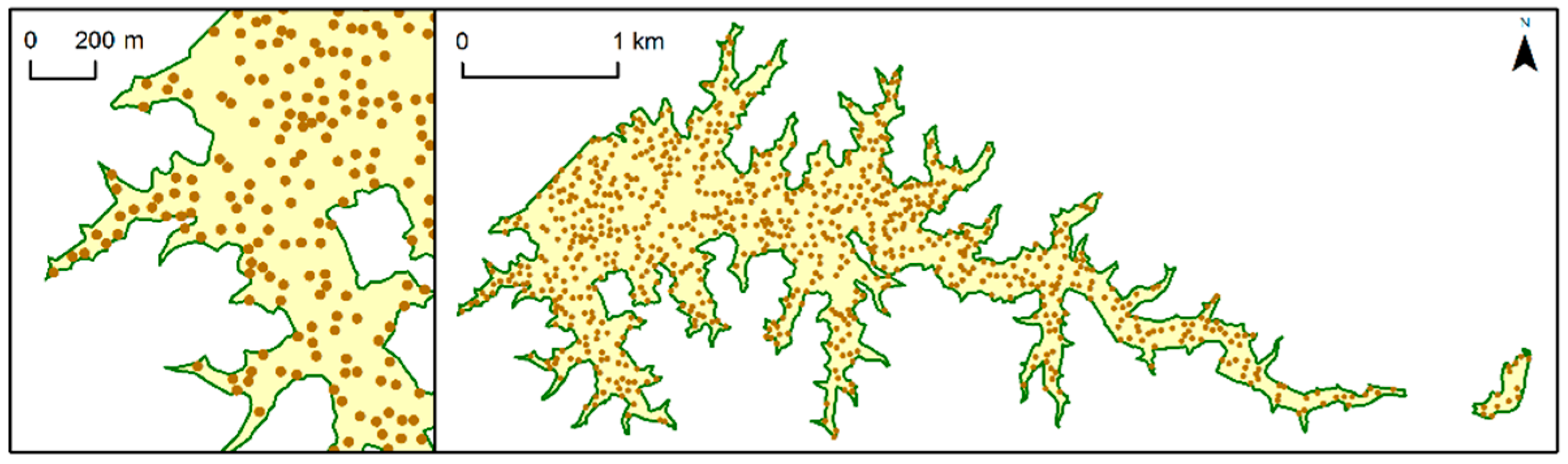
We also used NBTA to measure the fitness of the OSM data as a source of sampling data to support regional and rural LULC mapping. NBTA measures the extent to which the proximity of an OSM feature’s boundary influences the accuracy of the attribute (tag) in the training sample. We computed the NBTA for the most recent OSM dataset (2015). First, it was necessary to create training samples by generating random points inside the OSM features. Since OSM feature areas are very heterogeneous, it would be inappropriate specify an exact number of random points to be generated inside each OSM feature; instead, the total number of random points generated was proportional to the area of each OSM feature. In addition, the shortest distance allowed between any two randomly placed points was 30 m, because this is the most common spatial resolution of satellite images, such as Landsat (
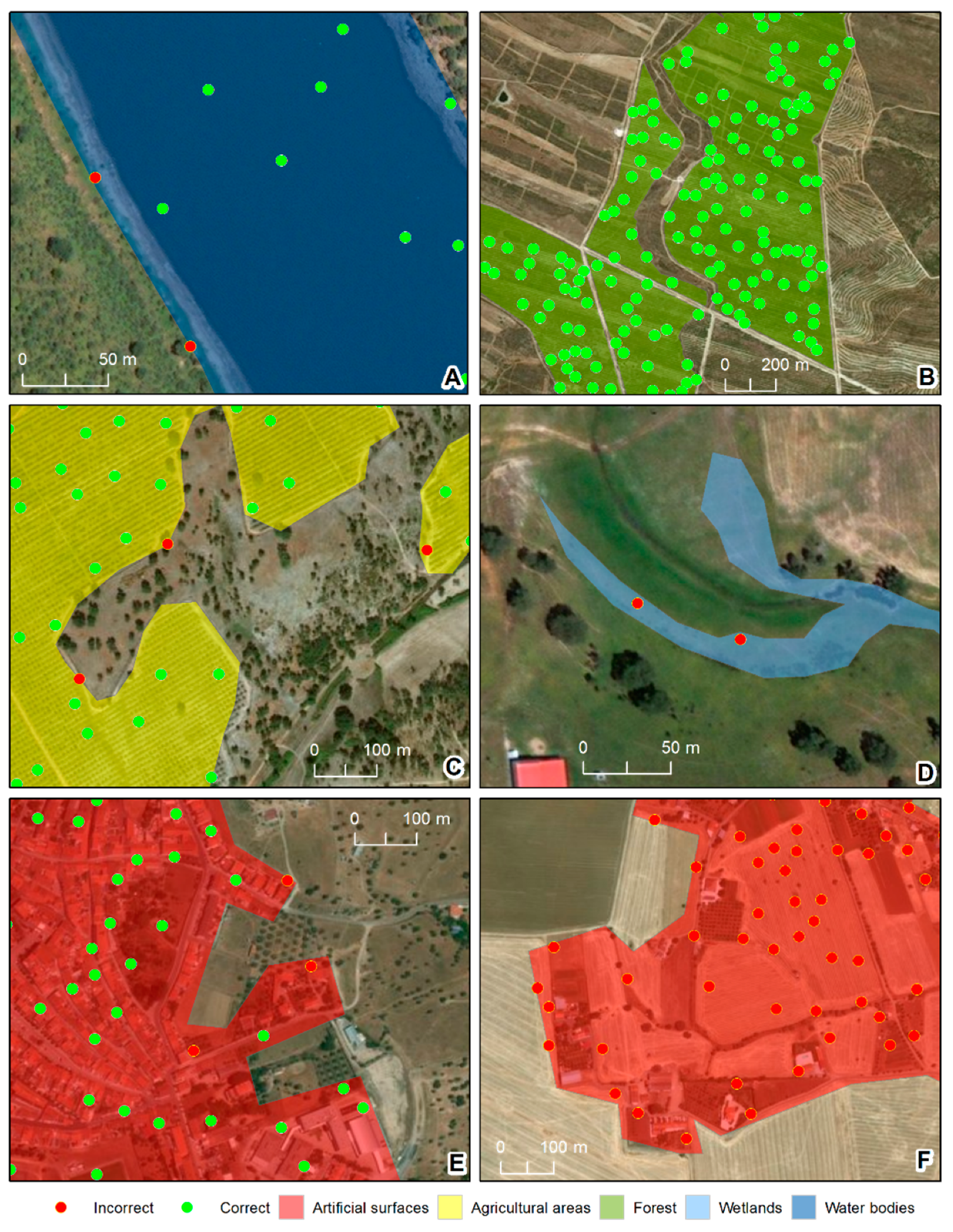
Figure 3). We used point features instead of polygon features since this minimized the effects of comparing data with different mapping scales. Each random point generated took the attribute of the corresponding OSM polygon feature.
Second, thematic accuracy was assessed following the same procedure described in
Section 3.3.2. Also, the Euclidean distance from each random point to the nearest segment of the OSM feature’s boundary was computed. The distance values (in ascending order) and the accumulated thematic accuracy were then plotted. The purpose of this process was to ascertain whether the training samples generated for each LULC class near the border of an OSM feature might be inherently less accurate.
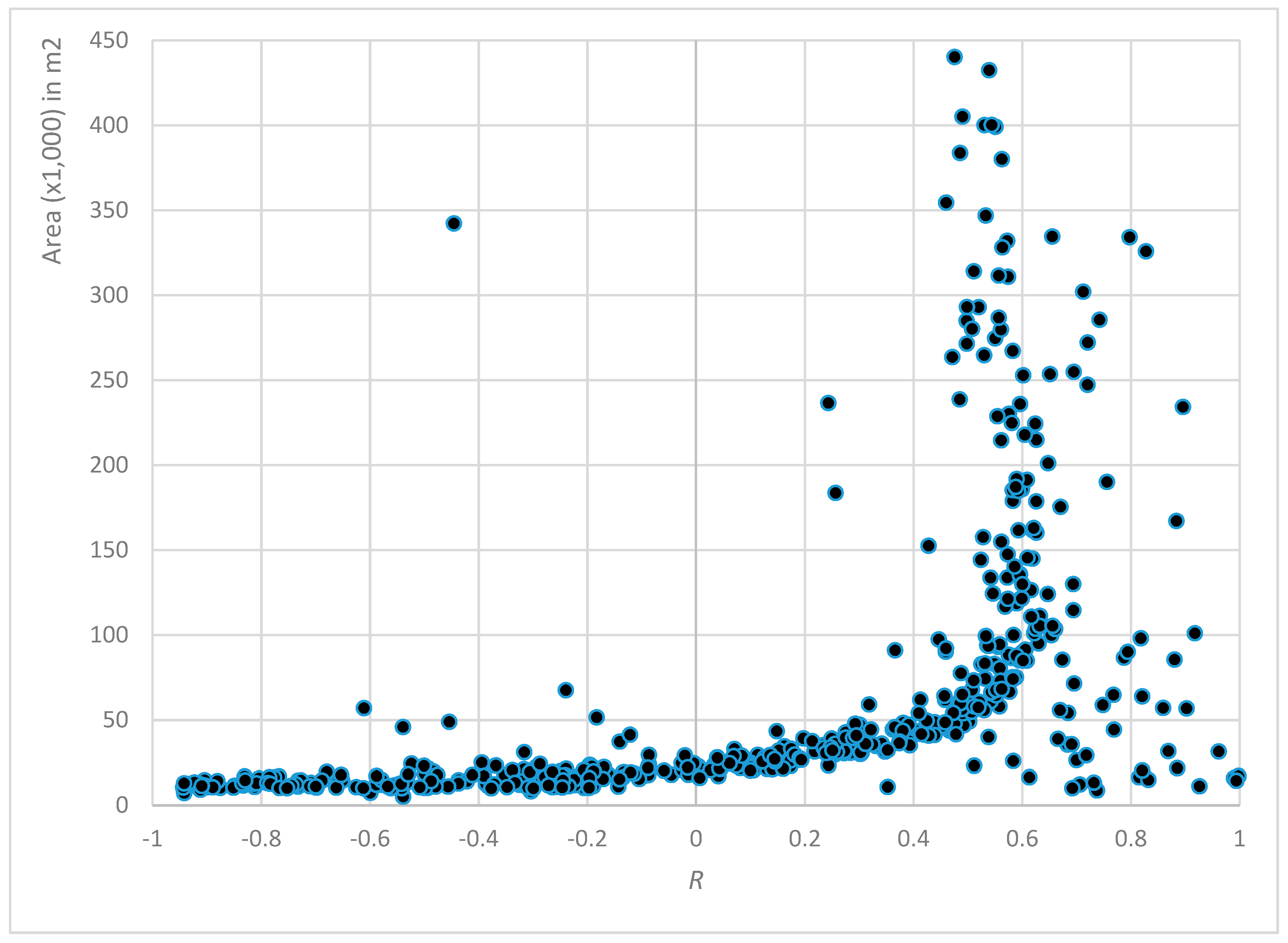
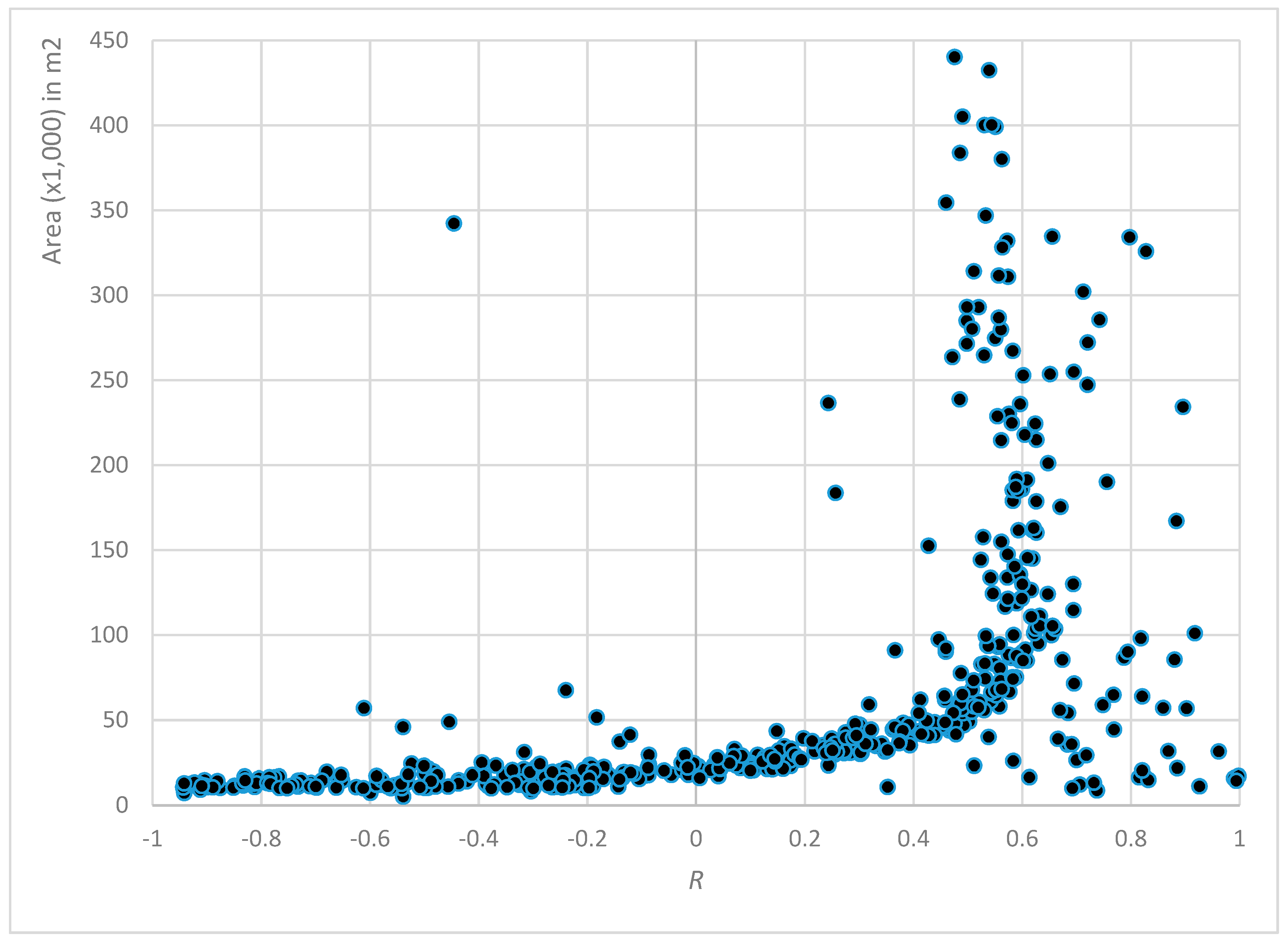
However, the relationship between the training samples accuracy and their proximity to the corresponding feature boundaries did not consider the influence of each feature area in explaining the degree of accuracy, since the distance to a feature boundary varies across feature areas. Are features with larger or smaller areas likely to have more or less accuracy? Therefore, the distance values from all training samples were standardized using the maximum and minimum distance values of the corresponding OSM feature. Similarly, the accumulated accuracy of all training samples was computed by considering each OSM feature. The relationship between a feature’s boundary proximity and its thematic accuracy is denoted by the Pearson correlation coefficient (R), which was calculated separately for each OSM feature. OSM features with fewer than three training samples were excluded from the analysis (20% of all polygons, for 2015), because when n = 2 the R coefficient would always be −1 or +1, except in the improbable circumstance that both y-values perfectly matched.
5. Discussion and Conclusions
Over the last decade, OSM data have emerged as a supplementary source of data for LULC mapping, mainly due to improvements in the quality of OSM data [
22]. LULC map accuracy assessments are extremely important since they measure the quality of the LULC map and allow for improvements in analysis reliability [
7,
9,
10,
11,
34]. However, the main focus of most LULC mapping applications that use OSM data has been on urban areas and at local scales, and some studies have emphasized the OSM data’s lack of homogeneity, both in terms of its spatial coverage and in terms of its accuracy from region to region [
16,
23]. The present study therefore proposed a methodology for creating different OSM datasets based on each OSM data contribution year, and used completeness and thematic accuracy assessments to evaluate the degree to which the OSM datasets agreed with the reference ones. In addition, we proposed NBTA as a criterion with which to evaluate the quality of OSM data as a sampling data source for multi-temporal LULC maps.
5.1. Completeness and Thematic Accuracy Assessment
Completeness accuracy and thematic accuracy are the two criteria that are most frequently mentioned to assess the quality of OSM data [
6,
7,
9,
10,
11,
23,
34,
41,
42]. In particular, some authors have emphasized the importance of using completeness accuracy as a quality measurement since OSM data’s territorial coverage can be extremely variable between locations [
22,
34,
35], which can in turn limit the ability to draw any widely applicable conclusions [
23]. Other studies have also cited a lack of OSM data contributions in rural areas [
24,
25] which we also confirmed in this study: At the time we downloaded the OSM data for the Beja district, the contribution area over all seven years (2011–2017) was less than 12% of the total Beja area. In spite of the increase year after year, the area covered in 2012 alone was less than 1% of the total Beja area, and in 2015 was still only about 1%. Thus, it is worth noting the increase in total coverage area between 2015–2016 (+1.7%) and 2016–2017 (+3.1%), which indicates an increase in volunteer participation in this region and suggests a potential for continued increases in subsequent years.
In our methodology, we have only included features which were created or modified during any given year and this has influenced the low value of data for each annual dataset. Nevertheless, we decided to follow this approach, because OSM data can be updated daily, either by image interpretation, or by importing data (e.g., CLC, GPS devices). In the case of image interpretation, the satellite layer of Bing Maps is used as the background image in OSM edits. Thus, the contribution is influenced by the user’s personal knowledge, as well as by the background image used at the time of OSM data capture. Our purpose in doing was to attempt to reduce errors, as we could not know if features that were not updated by users were still valid, no longer present, or if it was merely that no user had elected to update that feature during that time period. Furthermore, the assessment of the provenance of OSM data for our study area reveals a low probability of bulk imports, since less than 0.1% of matching was obtained.
High agreement between OSM data and reference data have been found in a number of studies [
6,
7,
8,
21]. In this study, we also have found high thematic accuracy values for both the 2012 and 2015 datasets (77.3% and 91.9%, respectively), signaling a significant improvement in the quality of the data between 2012 and 2015. Nevertheless, the literature has mainly attributed quality improvements to increases in contributors over time [
11,
18] and we believe that differences between the two reference datasets we used (CLC for 2012 and COS for 2015) may also help to explain the substantial improvements in our thematic accuracy findings for 2012 and 2015. The different cartographic properties of the CLC and COS, such as their scale and spatial resolution [
56], may help to explain their different findings. The COS dataset has a minimum mapping unit (MMU) of 1 ha and a spatial resolution of 0.5 m, compared to the 25 ha and 20 m of the CLC; as such, the CLC dataset has greater polygon generalization than the COS. These comparisons provide a brief glimpse of some differences in reported results quality when LULC datasets with different cartographic properties are compared [
57,
58], and could explain the different accuracy values for each LULC class here, as represented by the form and area of each feature of OSM data.
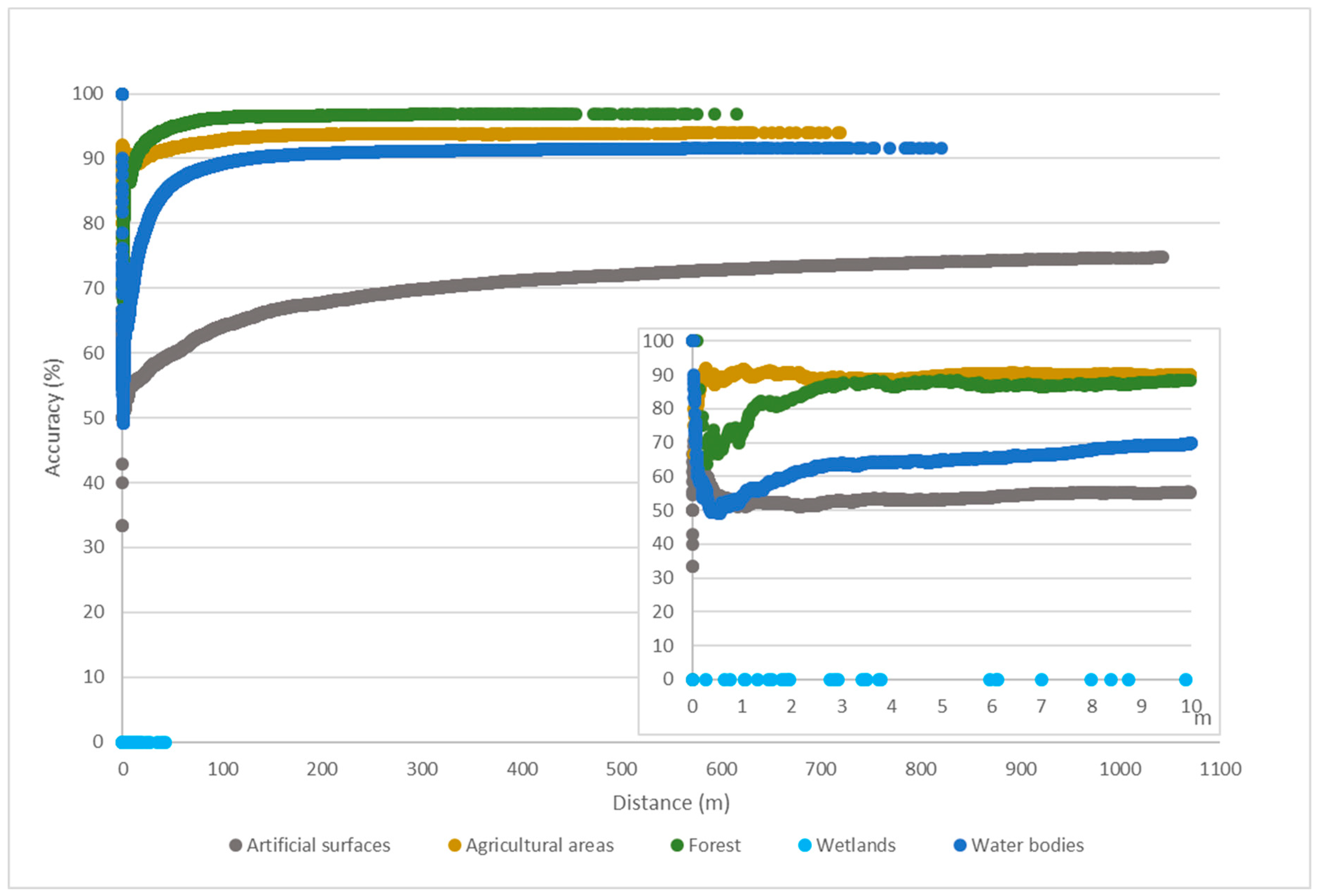
5.2. NBTA Accuracy Assessment
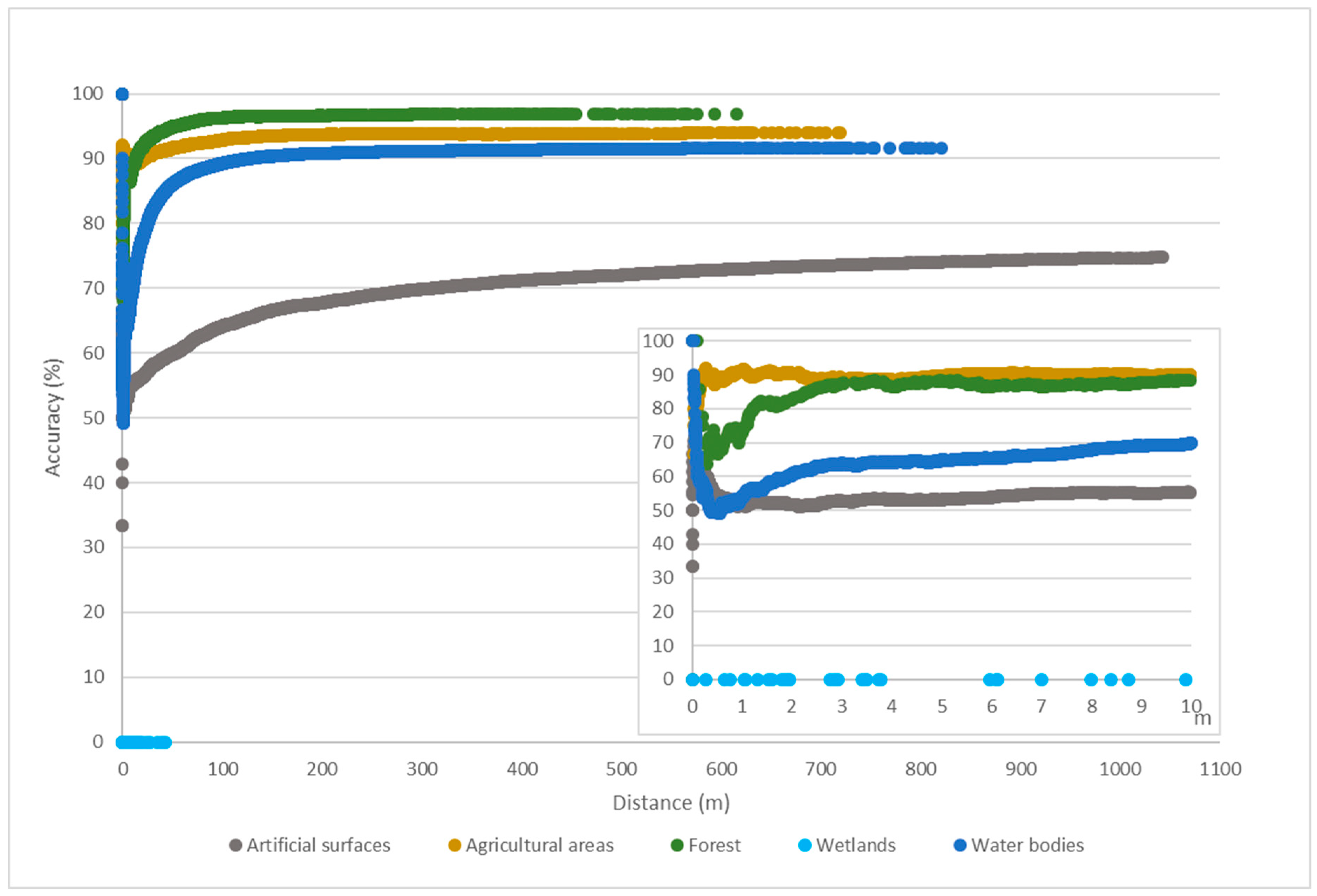
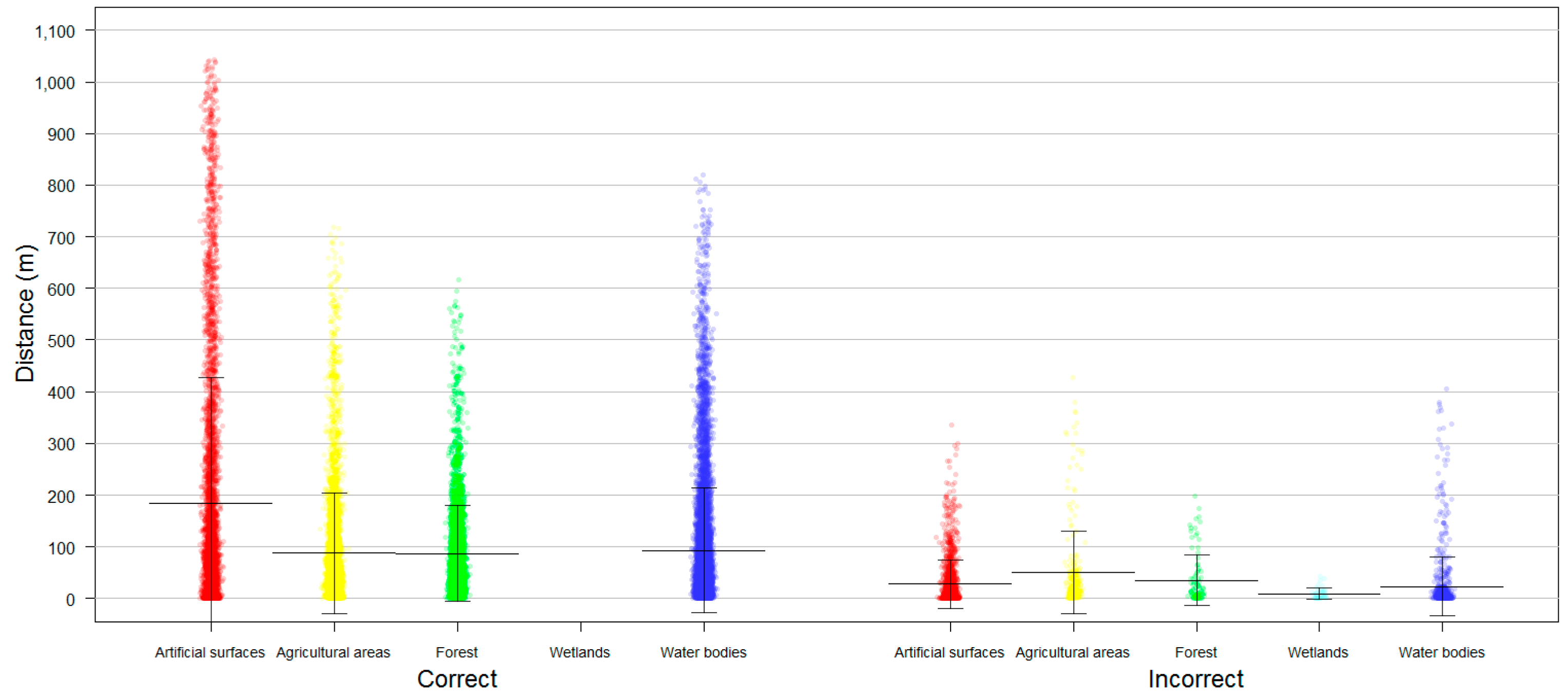
We introduced NBTA as a method to evaluate whether the quality of OSM data is suitable for it to be used as a sampling data source for LULC mapping. As expected, training samples closer to feature boundaries had higher levels of uncertainty. However, the degree of uncertainty varied significantly for each LULC class.
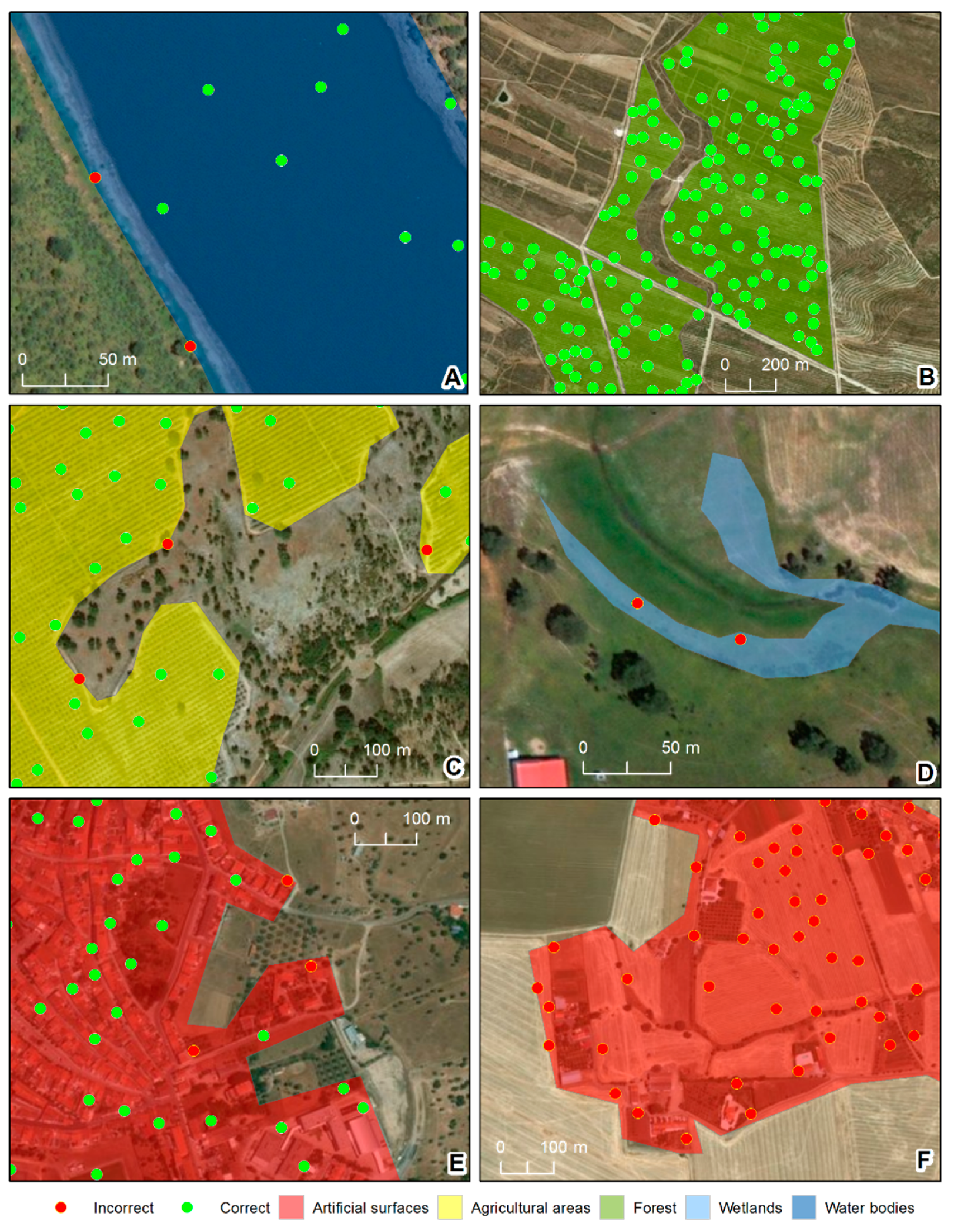
Beja is a region defined by strong processes of desertification and is dominated by large croplands with well-defined limits [
48,
49]. These characteristics help to explain why the forest and agricultural classes had the highest accuracy values, as these classes are typically represented as large homogeneous areas that are easier to map. Nevertheless, there was a slight difference between the two classes, with agricultural areas having slightly lower accuracy values than forests—perhaps due to the fact that agricultural areas, while typically defined by large crop areas, in some cases also have small spaces with trees, ponds, and houses, potentially resulting in some confusion. Contributors may have preferred to draw large features to represent the crops, ignoring the existence of small areas with different LULC types. Water features, which behave similarly, had slightly larger wrongly-classified areas, likely due to the fact that water boundaries are perennially associated with changing weather conditions.
Artificial surfaces presented two different behaviors. For consolidated urban areas, such as the region’s main town (Beja) [
49], the features behaved identically to the agricultural and forest areas. However, in more dispersed settlements (which were predominant in the Beja district), differences in interpretation of the MMU between the contributors (who were more likely to map everything in detail) and the technicians responsible for COS mapping (who were bound to the rules of cartography at a scale 1:25000) could explain the comparatively low accuracy. In addition, dispersed settlement areas demarcated by the contributors as artificial surfaces had relatively small dimensions, since contributors start considering houses far apart from each other’s as isolated elements.
Finally, the wetlands class showed a complete disagreement between the two datasets duo to semantic incoherencies. The OSM feature descriptions of wetlands suggests that this class is mainly comprised of flood zones, mostly along water lines, whereas COS defined wetlands as areas of swamps and marshes. In sum, there were three classes where discrepancies between the OSM and reference datasets were essentially geometric (forest, agricultural, and water areas), one where they were semantic (wetlands), and one where they were both semantic and geometric (artificial surfaces). This finding is shown in more detail in
Figure 7.
Some of the semantic incoherencies found in this study may be related to the used nomenclature correspondence. As some authors already have mentioned, the nomenclature harmonization between different datasets [
6,
9,
35,
52] can be a difficult process and can influence the results [
8].
Comparing the influence of each feature area on the NBTA yielded some interesting results. We found that the training samples’ accuracy was proportional to their proximity to the polygon’s boundary, but this proportionality was somewhat dependent on the area of the polygon. Features with areas >10 ha had a steady positive correlation, presenting a higher level of thematic accuracy as training samples moved away from the features’ boundaries. Looking at the descriptive statistics for each LULC class in the 2015 OSM dataset, the classes represented by these larger areas were mainly agricultural areas and forests. In features of <5 ha, this relationship between accuracy and the proximity to the polygon’s boundary was not clear, since training samples demonstrated both positive and negative correlations to boundary proximity. These areas were mainly comprised of artificial surfaces with very disparate geometries, including both large and small areas and consolidated and dispersed settlements.
5.3. Conclusions and Perspectives
OSM data history was accessed to generate LULC datasets based on the contribution year (timestamp). Two different datasets comprising all contributions made in 2012 and in 2015 were created. Although downloading the data history was straightforward, the data exploration required some Structured Query Language (SQL) knowledge in order to obtain data elements, such as timestamps, that are stored on raw packages. This may prevent or simply restrain the use of OSM data history by common users. In addition, there are several logical inconsistencies in the OSM data that need to be analyzed and resolved, which are time-consuming.
Our research was conducted at the district level in a predominantly rural region that has undergone rapid LULC changes. In rural areas, where reference data are scarce, LULC data with high accuracy, even in small quantities, will always be of significant value. Thus, OSM platforms should be seen as a valid source of data, both in the production and updating of LULC maps and as a sample source for training purposes in supervised multi-temporal remote sensing classifications. If these data are used as auxiliary data to classify satellite images, the use of timestamps to create, for example, multi-temporal year-based or month-based datasets could improve the quality of future classifications. Additional research should investigate whether the use of OSM data history and the division of features by their year of contribution influence the accuracy of OSM data, and whether they can be used as ground-truth auxiliary data. Furthermore, the present study demonstrated that OSM LULC classes (artificial surfaces, agricultural areas, forests, and water) were as accurate as the official reference dataset to which they were compared (COS 1:25 0000 map), and thus have great potential as auxiliary data for use in mapping applications. More analyses should be carried out in other regions. Ultimately, OSM data are freely available and their use is not highly time-consuming. The approach used here could therefore also be usefully applied at a larger scale (e.g., country level).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}