1. Introduction
Air pollution is one of the most important environmental issues in both developed and developing countries. Air pollution means the existence of one or more pollutants contaminating outdoor or indoor air in various amounts and periods which may harm human, vegetation or animal life or unexpectedly interacts with normal life or properties [
1,
2]. The distribution of air-pollution involves a complex process depending on a number of factors. In fact, air pollution prediction, which has a non-linear dynamism, is a very difficult task and requires a close understanding of the dispersion of air pollutants in the atmosphere, which involves an immense cost [
3]. In some cases, air pollution in mega cities even exceeds the standard limit which increases the concerns. For this reason, air pollution has become a problem in many cities in the world and its investigation is considered as a vital issue in urban management. The general sensitivity towards this problem has urged the officials to pass laws in order to prevent the air-pollution [
4]. One of urban managers’ objectives is to provide the citizens with the right information to make them aware of air quality rates [
5]. The pollution information includes the density of daily PM
2.5 and PM
10 pollutants which can be announced to the concerned people by city managers as a response to the air pollution [
6]. This information may assist people to avoid the polluted areas and employ public transport facilities to reduce the level of the pollution. In addition, the concerned city managers can implement the information to control the urban traffic and the responsible pollutant industries and to increase public transport facilities in order to mitigate the level of the pollution. To achieve this goal, appropriate tools need to be used to predict air pollution [
6].
According to the latest available statistics from 21 stations belonging to Tehran Air Quality Control Company (AQCC) and 16 air-pollution measurement stations belonging to the Iranian Environmental Protection Agency, PM
10 and PM
2.5 constitute the highest proportion concentration of air-pollution in Tehran. Among the pollutants such as CO, O
3, NO
2, SO
2, PM
10 and PM
2.5, PM
2.5 has the highest share. Based on the studies undertaken in 2017 by AQCC and the technical report produced on the Tehran Air Pollution Prediction System, nearly 5% of PM
2.5 pollutants are coming from neighboring populated areas laid in the west (city of Karaj, south west of Tehran (city of Shahryar), and south east of Tehran (city of Rey)). Such a percentage has been found higher in the summer time due to higher levels of wind speed in transporting the dust driven from out west and trapped in the Greater Tehran basin [
7]. The percentage presented here on PM
2.5 pollutant can be regarded, based on the AQCC expert opinion, as the highest percentage with respect to other pollutants that have been detected to be under 5%. Furthermore, the PM
2.5 detected in the winter time above is not of natural or wind-blown dust from outside deserts [
7].
PM
2.5 contaminants contain particles that are created by combustion or caused by the formation and compression of secondary particles. PM
10 particles contain particles that are 10 micrometers in diameter and smaller and can pass through the first defensive barrier (nose and throat), damage the lungs and deposition there [
8]. Studies have shown that exposure to suspended particles is associated with health effects such as cardiovascular and respiratory diseases [
9]. The World Health Organization estimates that if the average annual concentration of PM
10 is reduced from 70 μg/m
3 to 20 μg/m
3, then the associated deaths will be reduced by 15% [
10]. In fact, there is a relationship between the exposure to intense concentrations of suspended particles and the increase in daily and annual mortality, as well if the concentration of these pollutants is reduced while other factors are fixed then the associated deaths are reduced [
10]. These particles are very tiny and their damage to human health is high. In this study, PM
2.5 and PM
10 are used as pollutants to predict air pollution. Hence, air-pollution prediction is becoming one of the managerial solutions to prevent and/or mitigate its destructive implications. Therefore, it seems necessary to predict PM
10 and PM
2.5 pollutants using the appropriate methods.
In the past few decades, two general approaches of deterministic and stochastic methods have been used to predict air-pollution [
11]. Diffusion models are among the deterministic methods developed in various regions for modeling and monitoring the air pollution [
12,
13]. However, the output of these models relies on the input data, and in order to use them, it is necessary to access the data on how the pollutants disseminate and diffuse in the atmosphere [
14].
Therefore, using these models where sufficient and precise data is not accessible is problematic. Considering that the data collection needed for diffusion models is very hard and impossible at large scales, the researchers have turned to superior methods such as statistical models [
15]. Compared to the deterministic methods, statistical methods have more application in prediction of air-pollution. It is worth mentioning that factors such as air pressure, temperature, humidity, rainfall and wind affect the pollutants dissemination [
16].
A study has been conducted by [
17] with the aim of predicting the density of two pollutants (CO and NOx) in industrial locations using the autoregressive model based on artificial neural network using some meteorological parameters. As a result of performance of the proposed model, Root Mean Square Error (RMSE) for CO and NOx pollutants was 0.8445 and 0.7618, and the mean absolute error (MAE) for the pollutants was 0.1451 and 0.1598, respectively. The results show the higher importance of meteorology variables in the prediction of pollutant concentration and the efficiency of the neural network in the air pollution prediction.
The authors of [
18] introduced a model to improve the artificial neural network, which is a combination of air mass route analysis and wavelet transform. The rate of RMSE for the combinational model can be decreased by 40% on average. The study verified that especially on the days with a higher concentration of PM
2.5 often predicted for the warned threshold of the combinational models using wavelet analysis and detection rate (DR), the RMSE can reach to the average limit of 90%. This approach indicates the potential of the proposed model in air-quality prediction system in other countries.
With the aim of time series analysis in Abura region in Colombia, in different temporal scales (daily, weekly, and yearly), the geostatistical methods were suggested by [
19] so as to use the obtained information for calculation of unknown air quality values and prediction of air pollution. According to the results from the proposed method for prediction of PM
2.5 concentration on a daily basis, the amount of correlation of coefficient (R
2) that was obtained is equal to 0.55.
The authors of [
20] have used two methods of land use regression and Universal Kriging to predict the concentration of NOx in the city of Los Angeles. In addition to using the meteorological and pollutant concentration parameters, spatial parameters such as roads, population, land use and distance from the coastal regions were used. The results suggest that in prediction of NOx concentration, the universal Kriging model has more precision than land use regression. The authors of [
21] have carried out a one-year analysis of ozone concentration in the Malaga region of Spain. The multivariable regression for prediction of ozone concentration employing the meteorology parameters was employed. Diffusion models and statistical methods such as Kriging in modeling the air pollution face some limitations. The output of diffusion models is highly associated with input data and it is necessary that the data with high precision are available about the way the pollutants diffuse and disseminate in the atmosphere [
5]. Though the common statistical models of Kriging have also been used for spatial modeling of air-pollution, its ratio is constant relative to the temporal variations [
15,
22]. That is why in recent years the machine learning methods have been of interest to researchers [
5]. The authors of [
23] have employed neural networks for air-pollution prediction. The correlated parameters with the air pollutant include traffic, hours and days of week, pollutant concentration in the past 3 years, the wind speed and direction, temperature, solar radiations, rainfall, relative humidity rate and the distance from the road. The authors of [
24] have used the nonlinear autoregressive exogenous (NARX) Neural Network model for prediction of time series of ozone concentration peak. The results showed that this kind of neural network had a good performance in time series prediction of ozone concentration in Milan.
Support vector machine (SVM) and partial least square (PLS) method have been implemented for prediction of CO concentration in Rey station in Tehran [
25]. The data related to O
3, SO
2, NOx, CH
4, total hydrocarbons (THC) and meteorological data such as air pressure, temperature, wind speed and direction, and air humidity were used in a period of January 2007 to January 2011. The results verified the good accuracy of both the methods, while the combinational method of PLS-SVM is faster and better than support vector model.
The above-mentioned researches have used different machine learning algorithms which are the statistical methods for prediction of air pollution. In this research, the supervised algorithms for machine learning regression such as artificial neural network (ANN), the nonlinear autoregressive exogenous Neural Network, geographically weighted regression (GWR) and support vector regression (SVR) were used to predict PM2.5 and PM10 pollutants.
In general, two types of methods including satellite imagery and ground sensors are used to collect air pollution data. Given the cost, availability and accuracy of ground sensor data for 10 years, this type of data has been used in this research. One of the major problems of ground-based sensors is the calibration of the device. The air pollution data have been validated by Tehran Air Quality Control Company (AQCC). In spite of the above assumption, in this study, a data refinement mechanism was used to better estimate the concentration of pollutants in areas where there is a data gap or an error in the data.
To the best of our knowledge, no report is published so far regarding input data refinement for network learning, and this research seeks to improve the accuracy of these methods and select the best one for air pollution prediction. In addition, there have been few studies concerned with the identification of effective parameters in prediction of air-pollution based on statistical models, which is one of objectives of this research.
The aims of this research are as follows:
Selecting the best statistical model and its improvement for air-pollution prediction;
Selecting the best refinement method for air-pollution and meteorological data in order to predict the missed data and filter the noise of the data; and
Determination of the most influencing parameters in air pollution prediction.
To generate a dataset to be entered in the machine algorithm process, it is necessary first to interpolate the meteorological parameters for transfer of parameters from meteorology stations to air-pollution stations. Considering that there are only five meteorology stations in Tehran, the inverse distance weighting (IDW) method was assumed in this research to be suitable for interpolation of these parameters with a less number of control points.
The rest of the paper follows the materials and methods in
Section 2, the results including the data preparation and refinement and air pollution prediction are presented in
Section 3, discussion is presented in
Section 4 and finally conclusions including major results, contributions and future directions are covered in
Section 5.
2. Materials and Methods
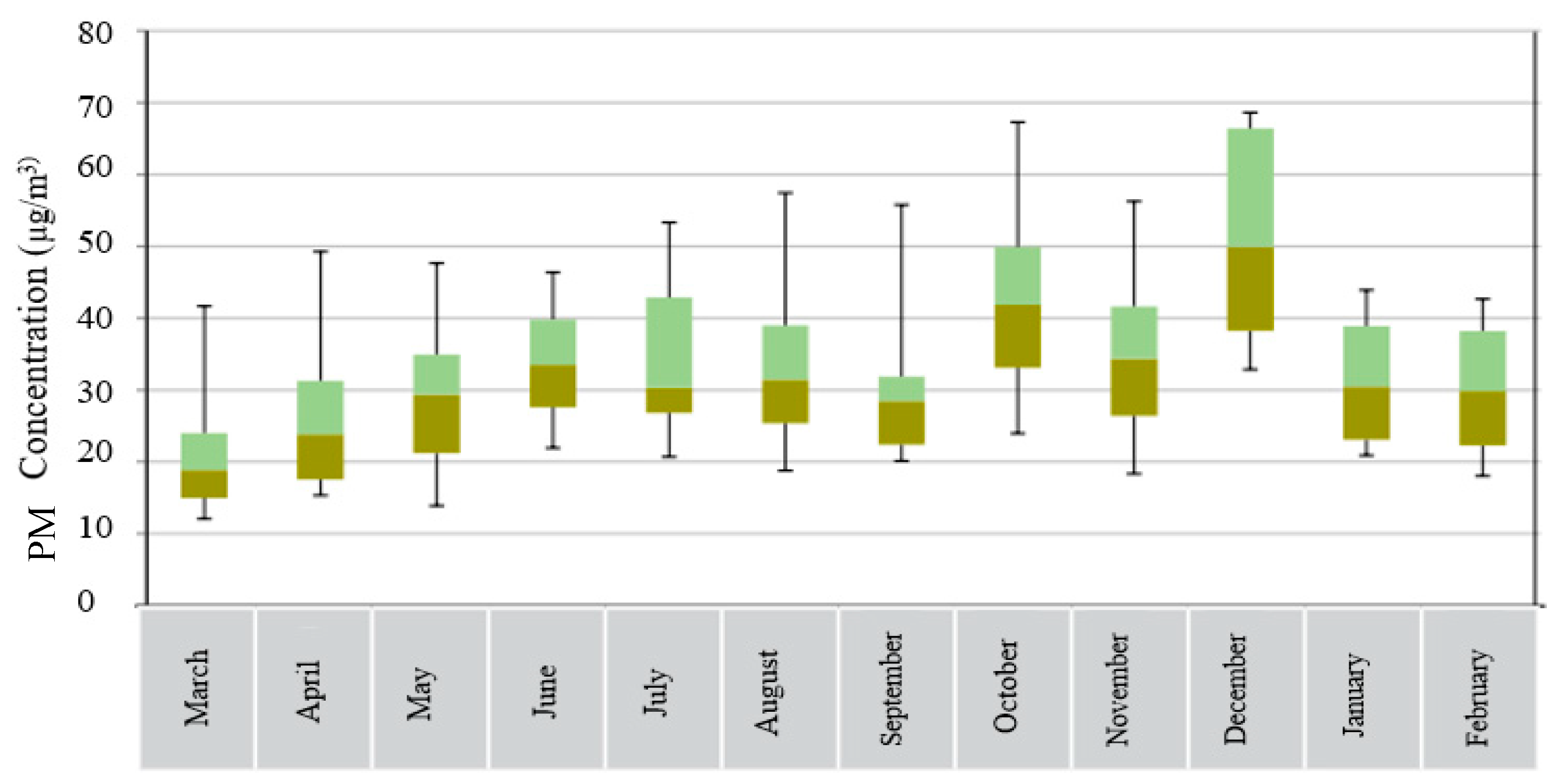
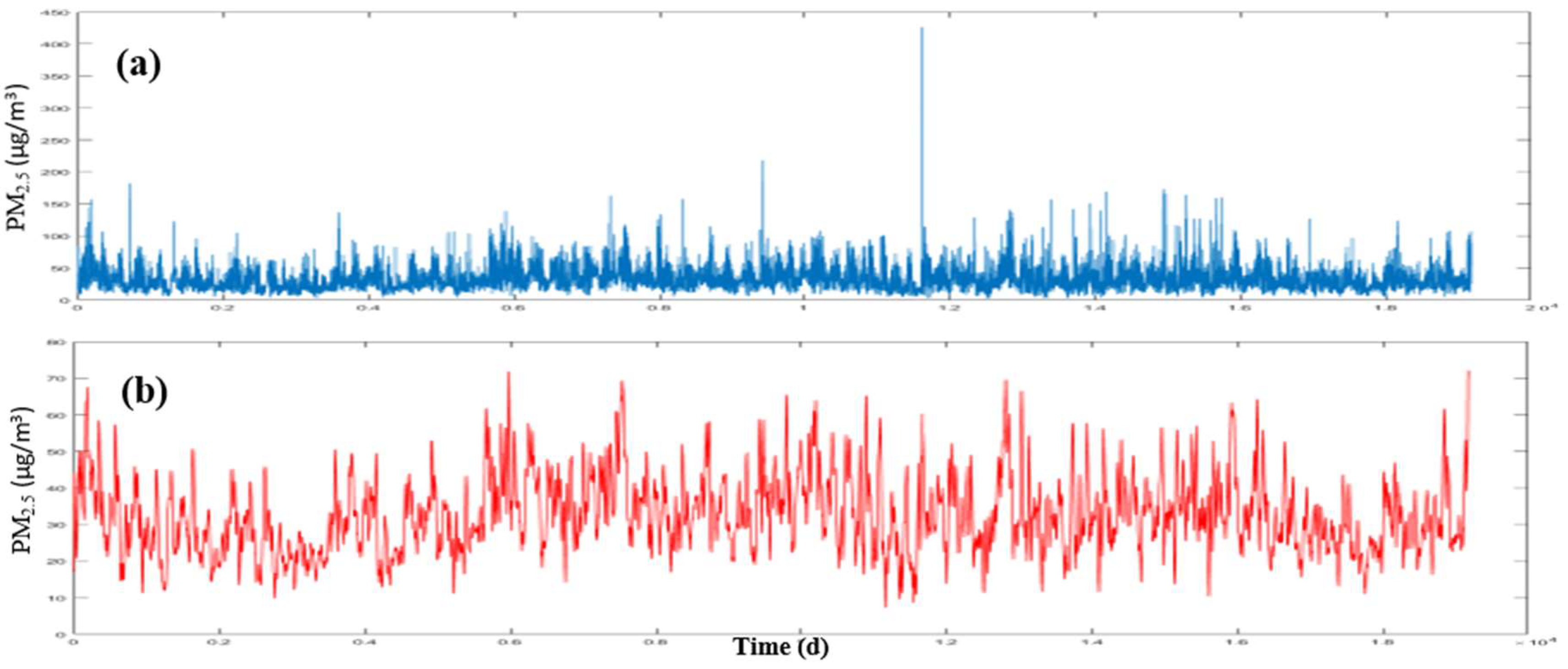
Air pollution is a phenomenon, which is affected by different factors. In order for precise prediction, right identification of these parameters influencing the air pollution is necessary. For example, one of these parameters is the month of the year where the relationship between PM
2.5 contaminant concentration and the months of the year is plotted in
Figure 1.
According to
Figure 1, with the reduction of traffic and improvement of atmospheric conditions, the lowest monthly concentration of PM
2.5 contamination occurred in March which coincides with the New Year holidays in Iran. The monthly average of the pollutant concentration with the onset of the warm season and the occurrence of the dust phenomenon, dust has been risen in the city. Of course, the highest amounts of PM
2.5 monthly concentrations are observed in December and October, respectively, due to the air flow, the increase in atmospheric stability and the inversion of temperature, which has led to the accumulation of pollutants in the city [
7].
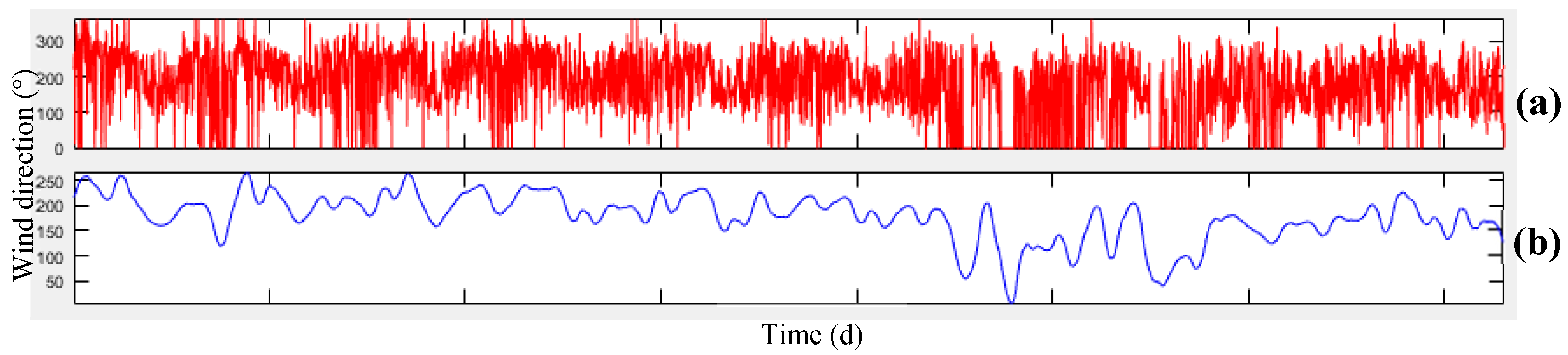
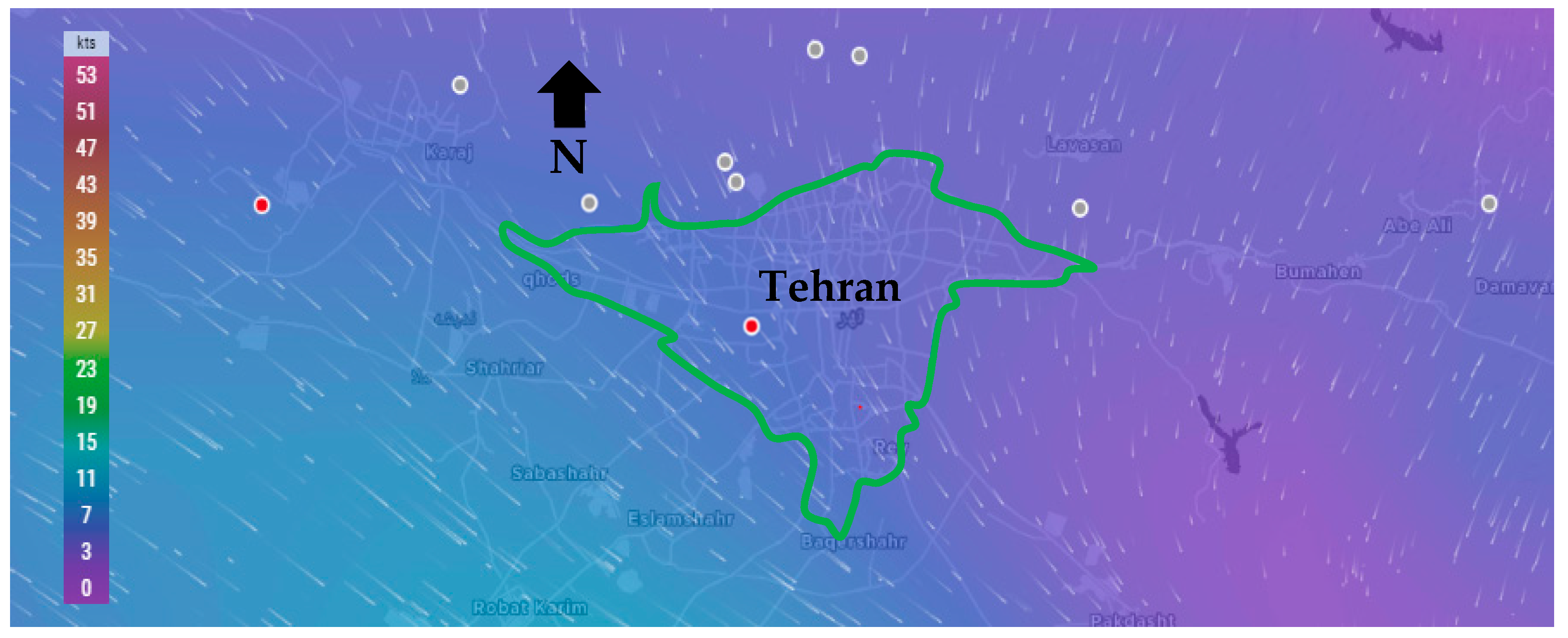
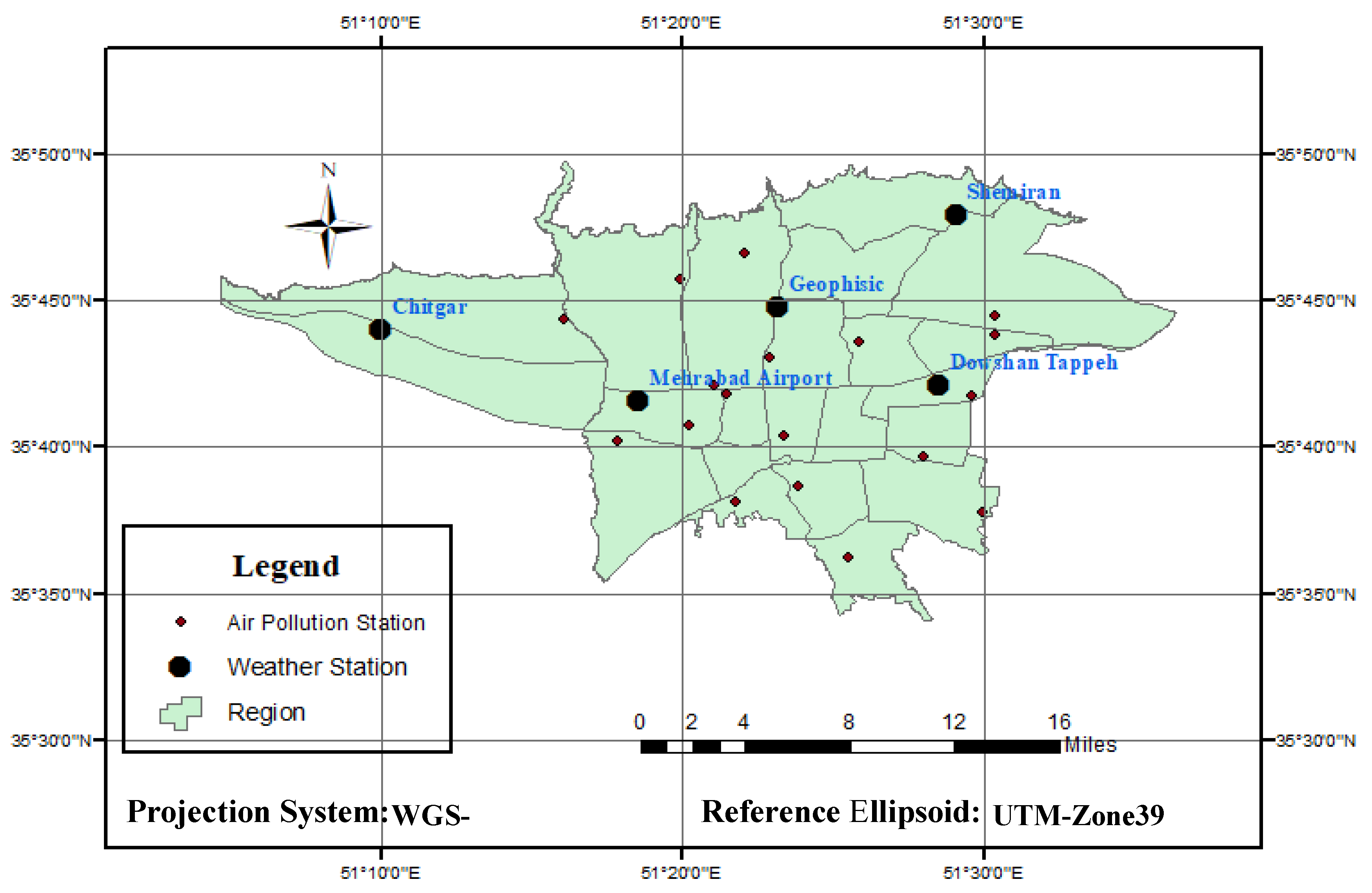
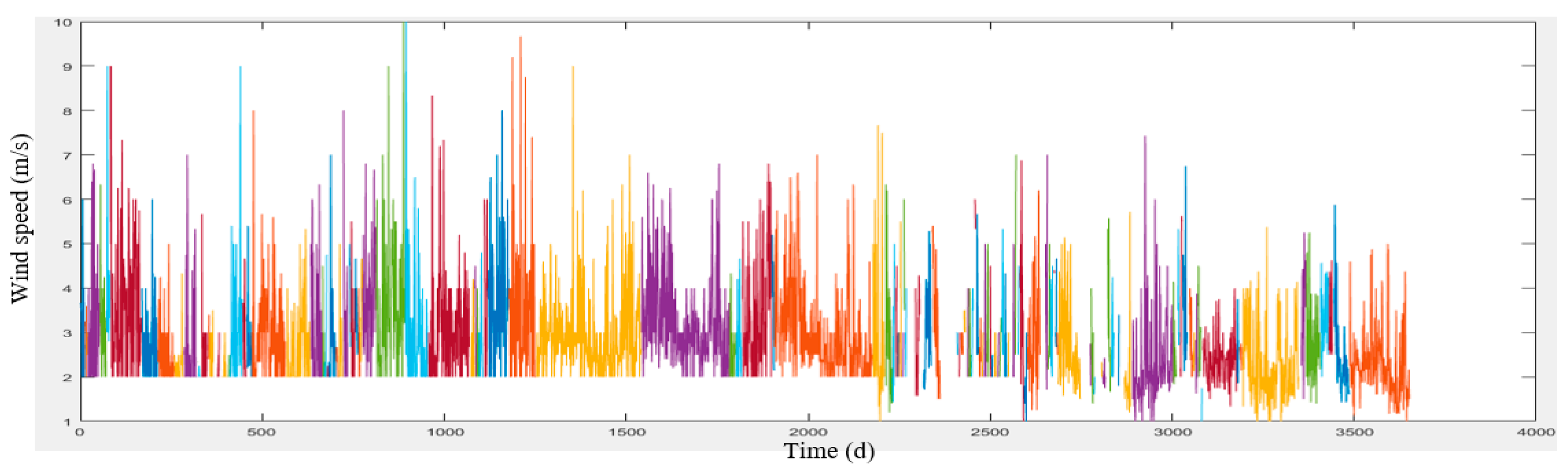
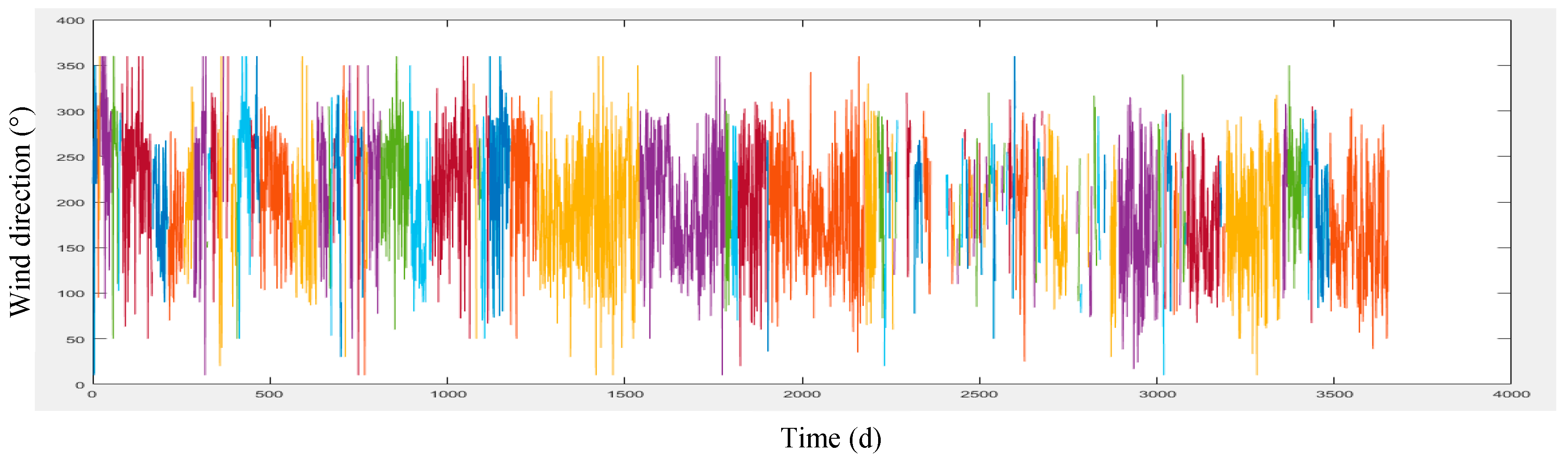
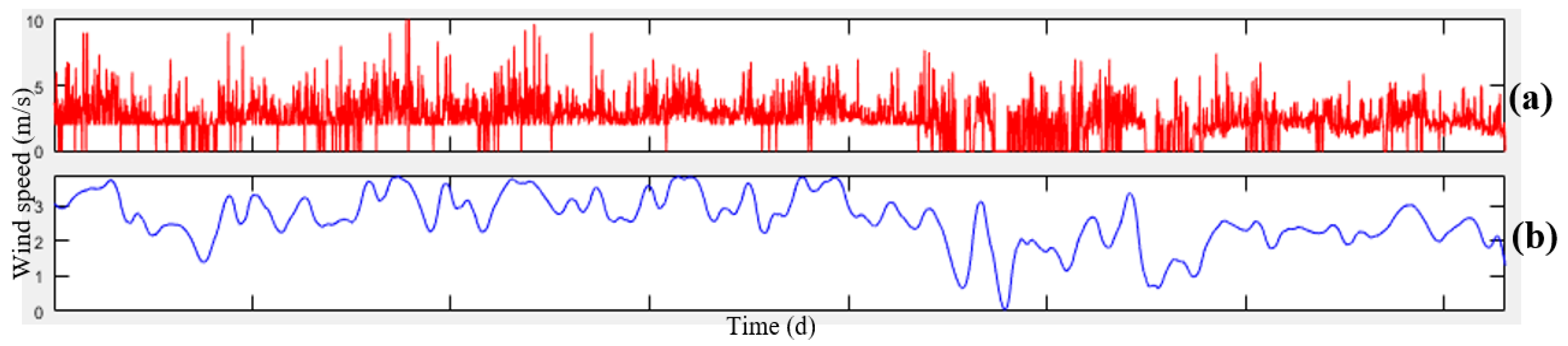
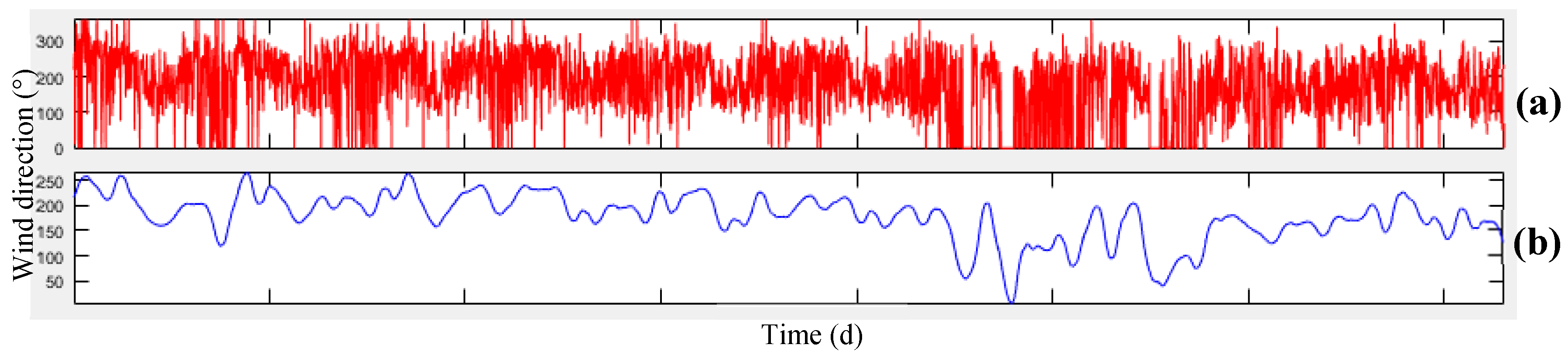
Another important parameter influencing the air pollution concentration is wind, which includes two components of wind speed and direction.
Figure 2 illustrates the map of the Tehran wind speed and direction and its surrounding cities.
According to
Figure 2, Tehran wind direction is from the northwest to the south-east. Therefore, the wind transfers air pollution from different parts of the city and even from cities located in the northwest of Tehran (such as Karaj) to the south and Southeast of the mega city.
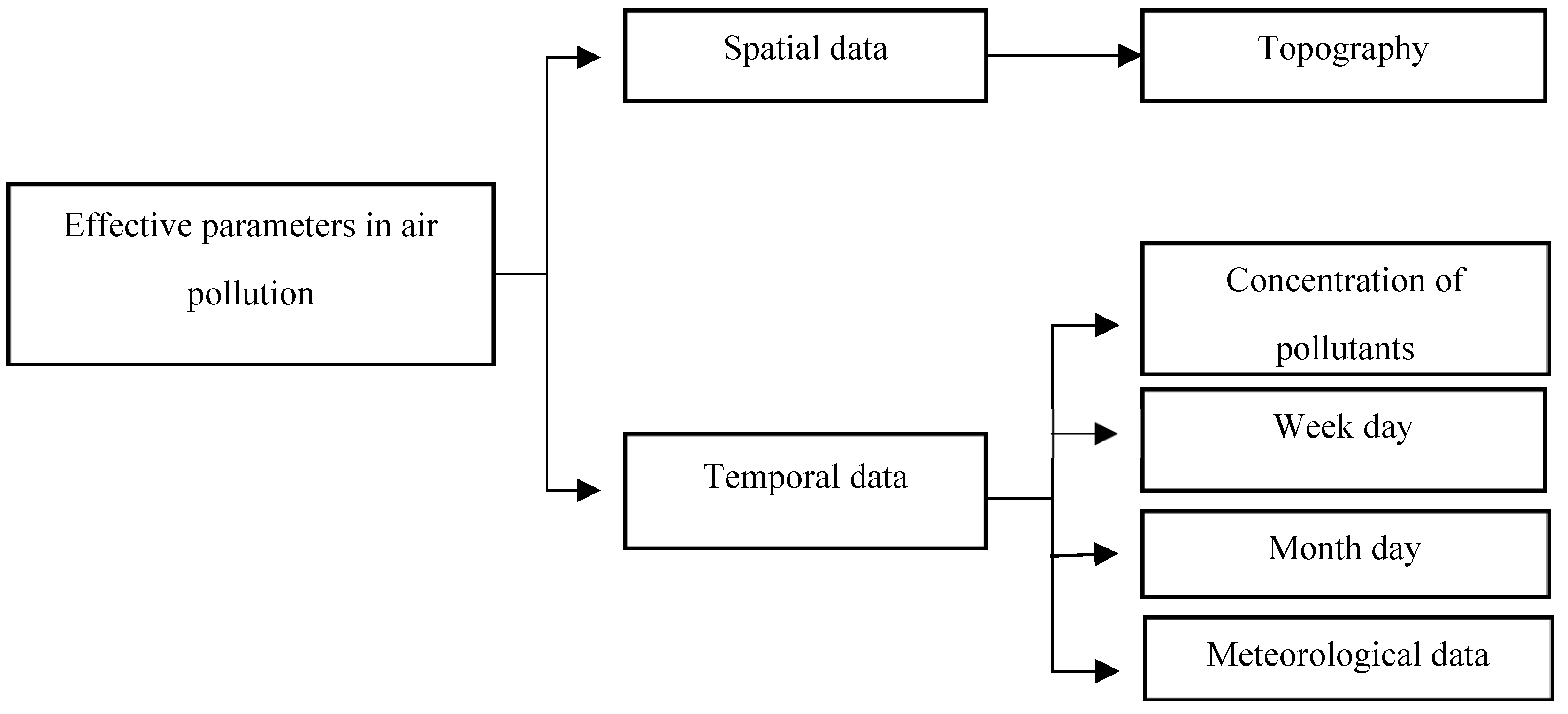
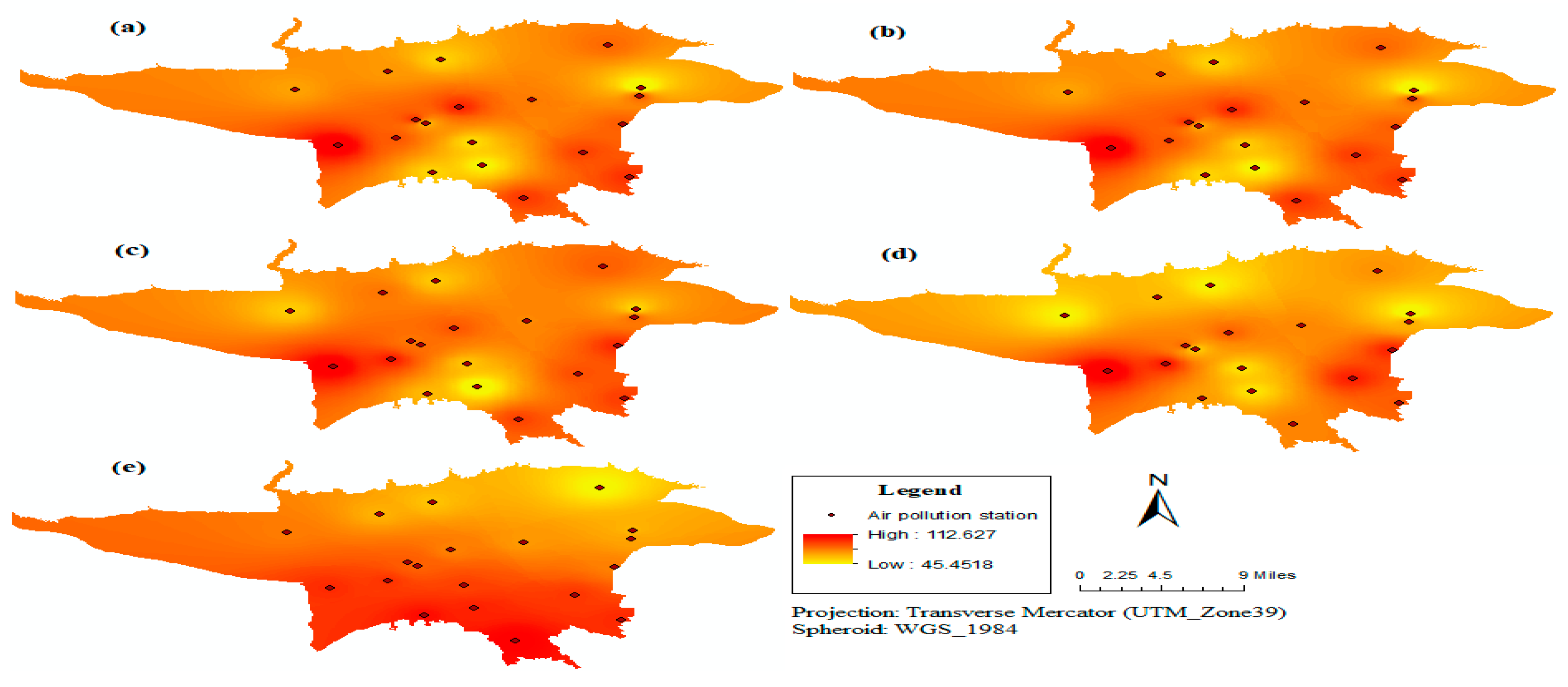
All of the influential parameters can be divided into two groups of spatial and temporal data. Temporal data refers to those data, which rapidly change in a short duration of time. Effective parameters are parameters that changes in location and time which cause changes in the concentration of air pollution.
Figure 3 illustrates the division of the employed data in the two groups of spatial and temporal data.
The parameters influencing the air pollution include topographic components (x, y, z) due to vast area of Tehran and significant height changes; meteorological components due to their direct or indirect effects on pollutant emission; week-time components, as in various days of week, the traffic in Tehran is different and accordingly the amount of pollutant concentration will be different. For example, on the weekends, Tehran experiences less traffic density; and the month of year component also due to season changes, dust, and temperature inversion leads to changes in the extent of the pollutants. On the other hand, in this research, the air pollution values of the two nearest air pollution station neighbors are used as an influential parameter in the prediction of the air pollution.
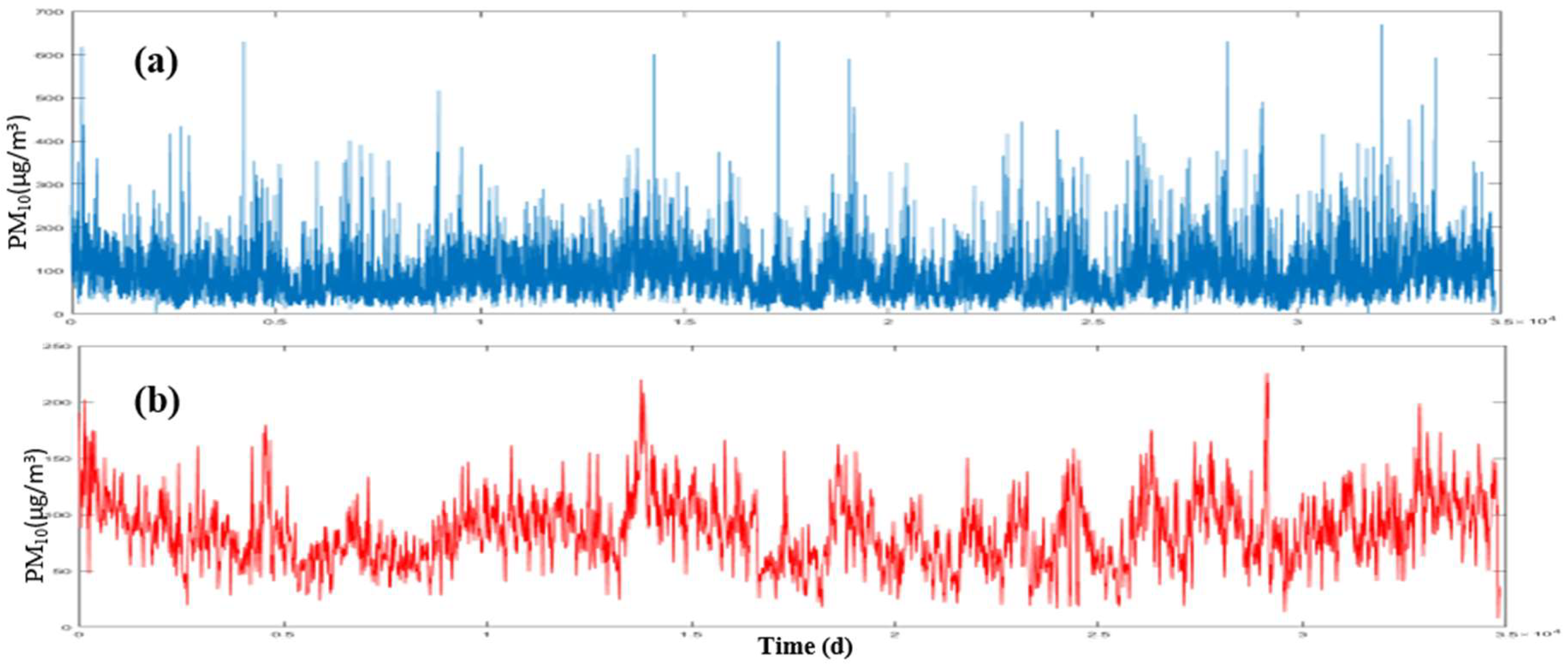
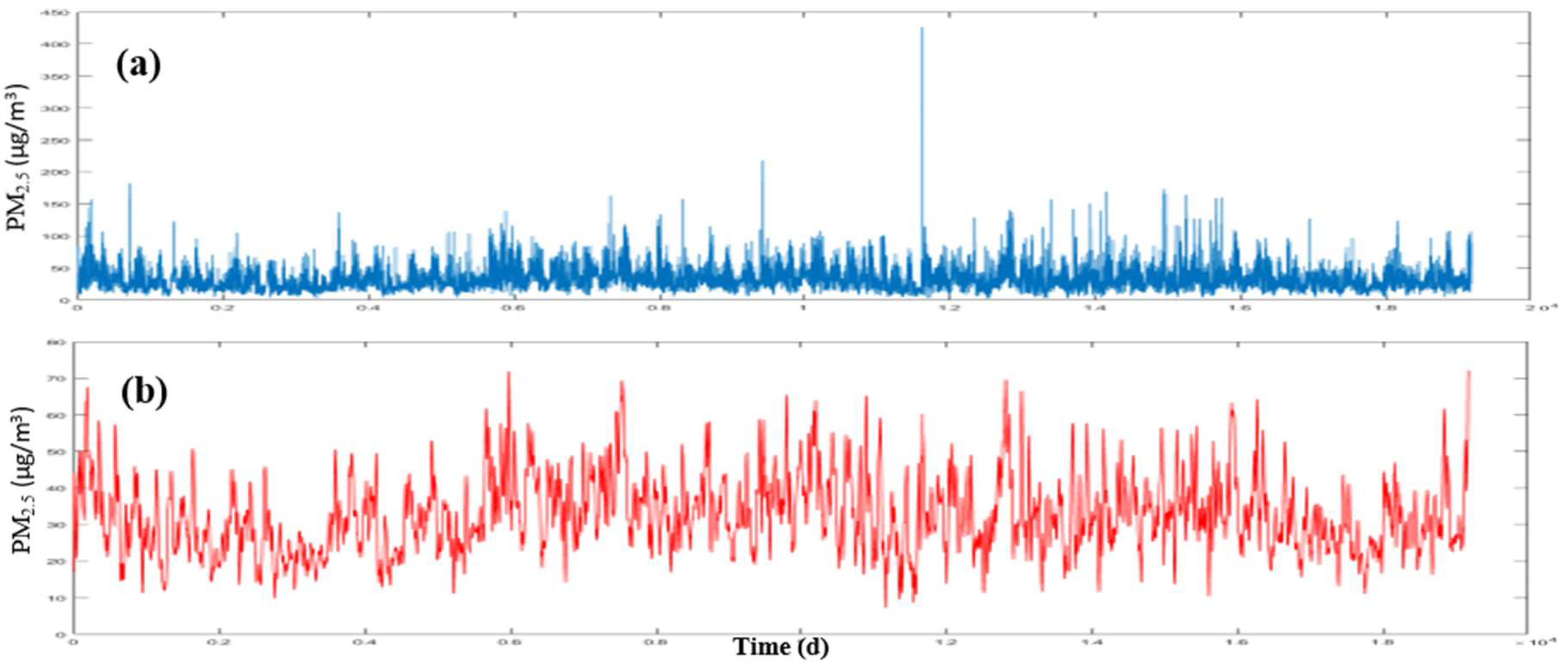
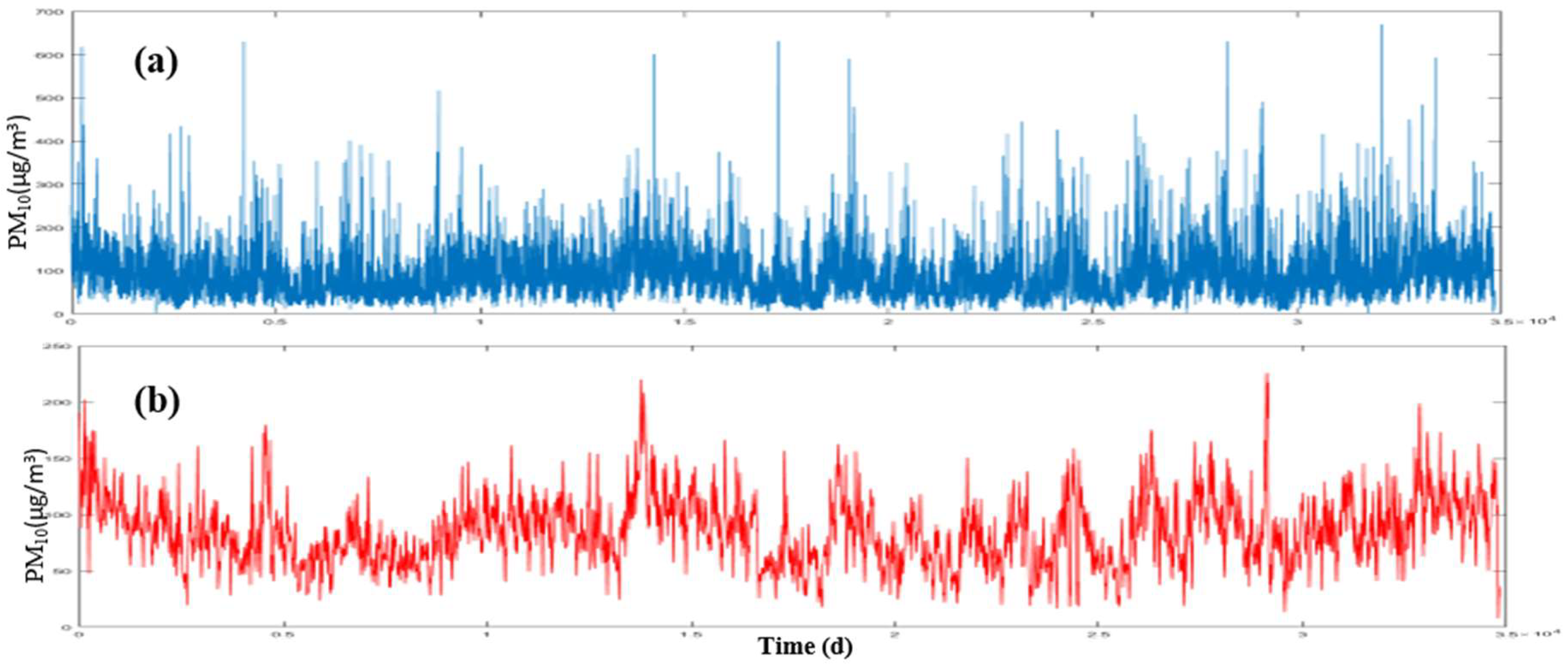
The relevant data to concentration of PM
10 and PM
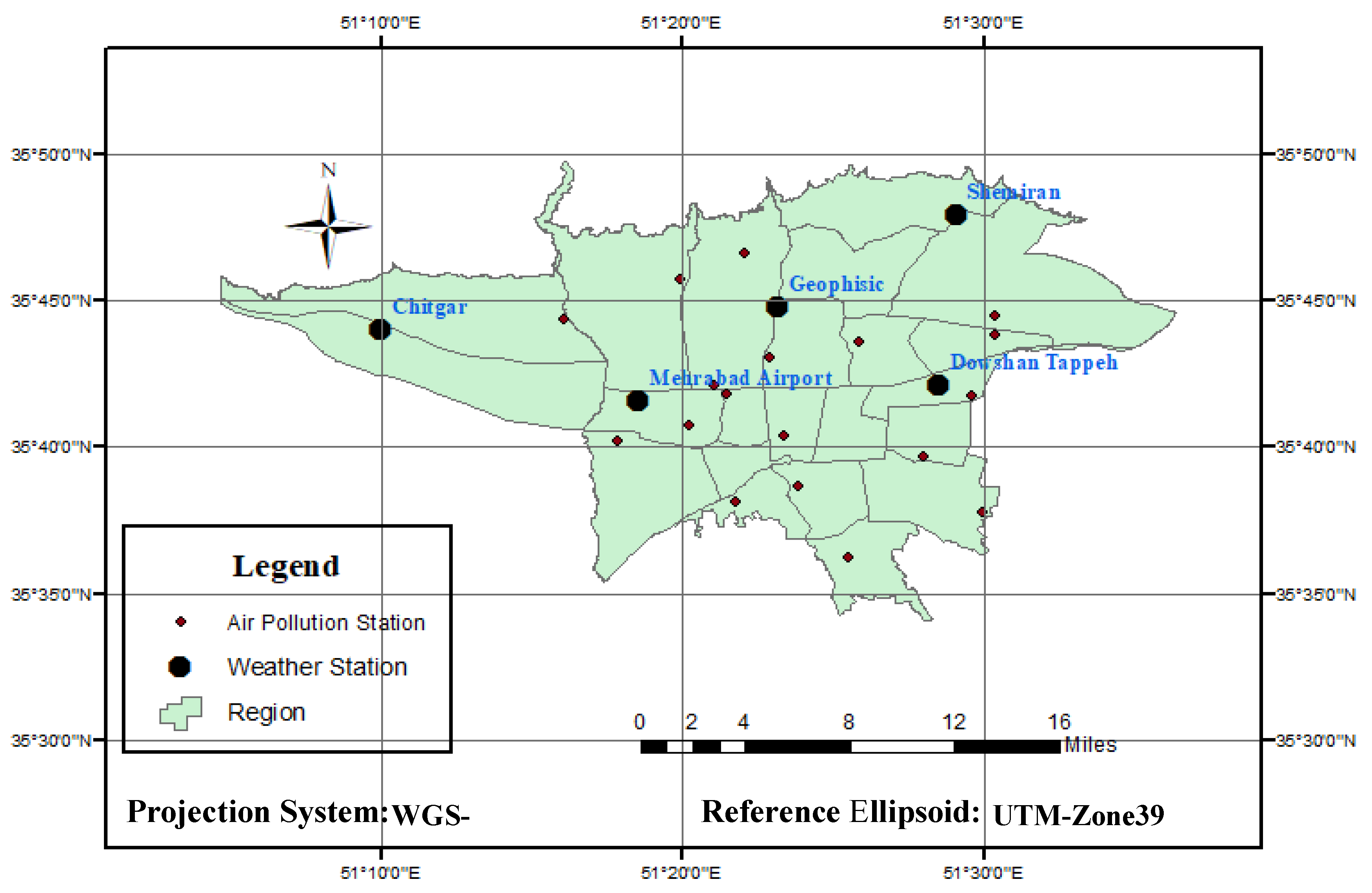
2.5 pollutants were obtained from AQCC during 2006 to 2016. The concentration of these pollutants is collected on a daily basis and delivered by the company (
http://airnow.tehran.ir/home/dataarchive.aspx). Tehran municipality has 41 stations for measuring air pollution managed and controlled by Iranian Environmental Protection Agency and AQCC. As this research needs daily data which are unavailable for all the stations, only the data related to 24 stations have been used.
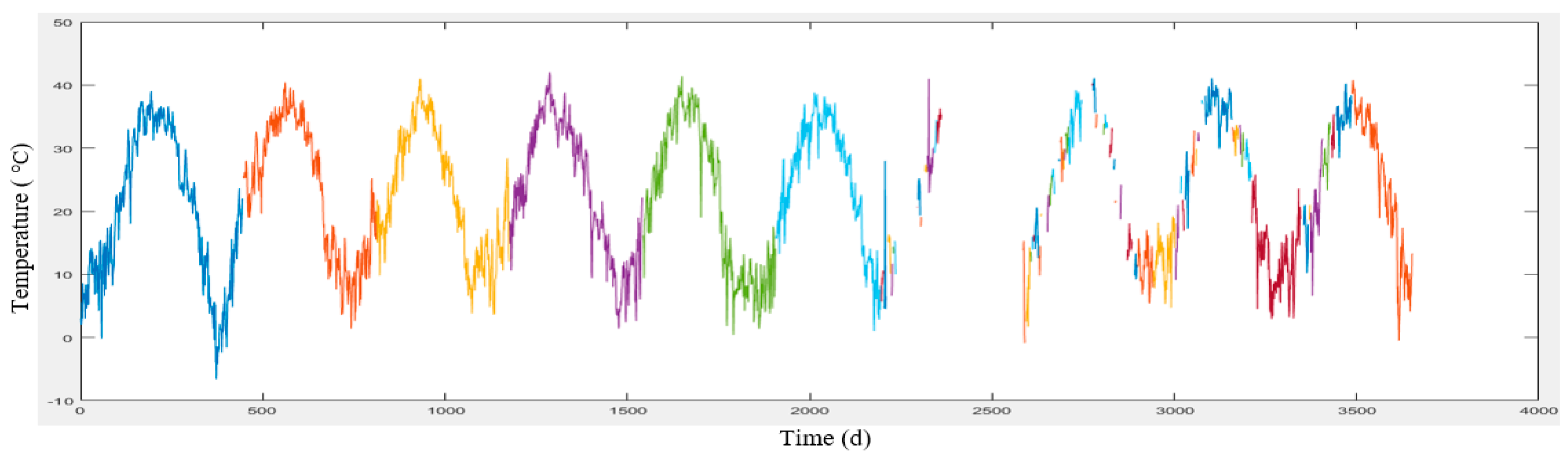
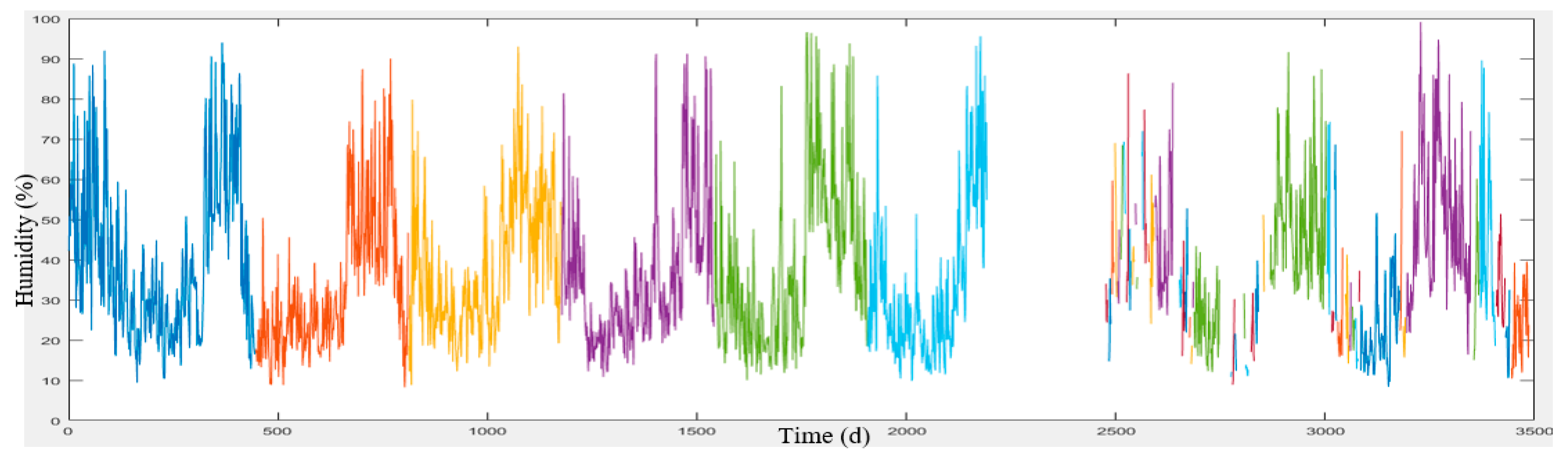
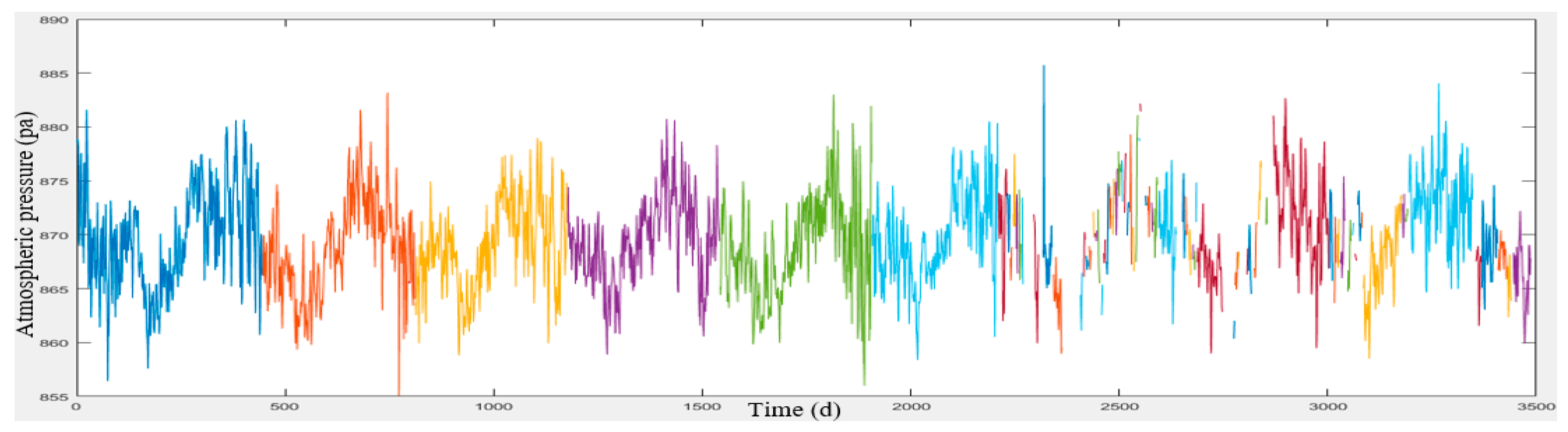
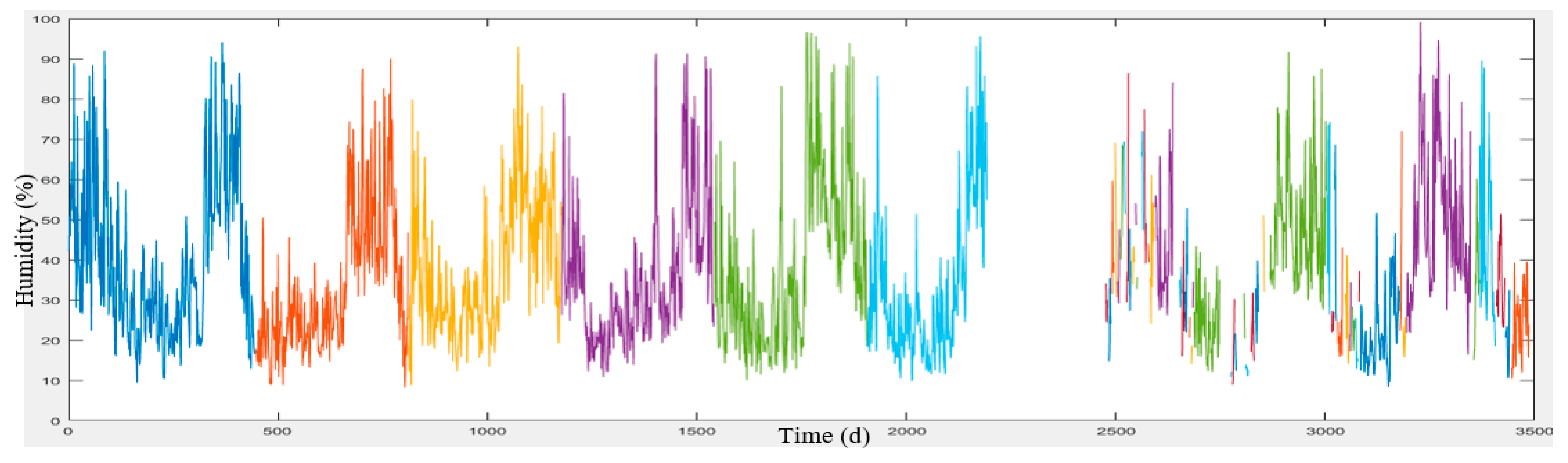
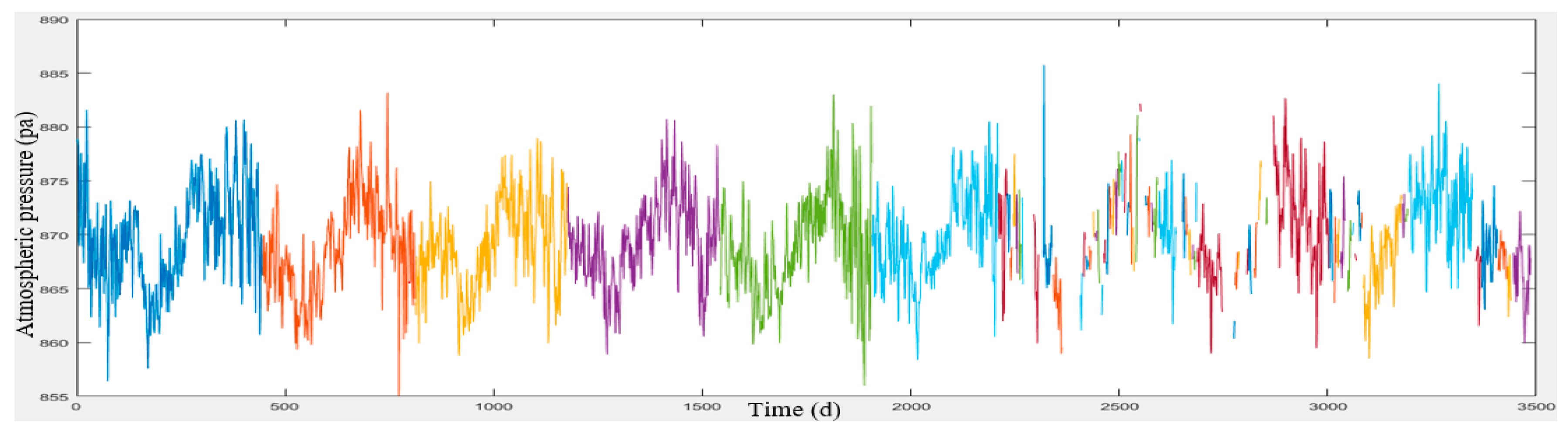
Meteorological data was provided by Iran Meteorological Organization in a 10-year period (2006 to 2016) from the Shemiran, Dowshan-Tappeh, Chitgar, Mehrabad Airport and Geophysics stations (
http://irimo.ir/eng/index.php) which are presented in
Section 3. These data include the maximum and minimum temperatures, wind speed and direction and humidity which have been collected on a daily basis. The meteorological and air pollution data have been quality controlled by the concerned organizations.
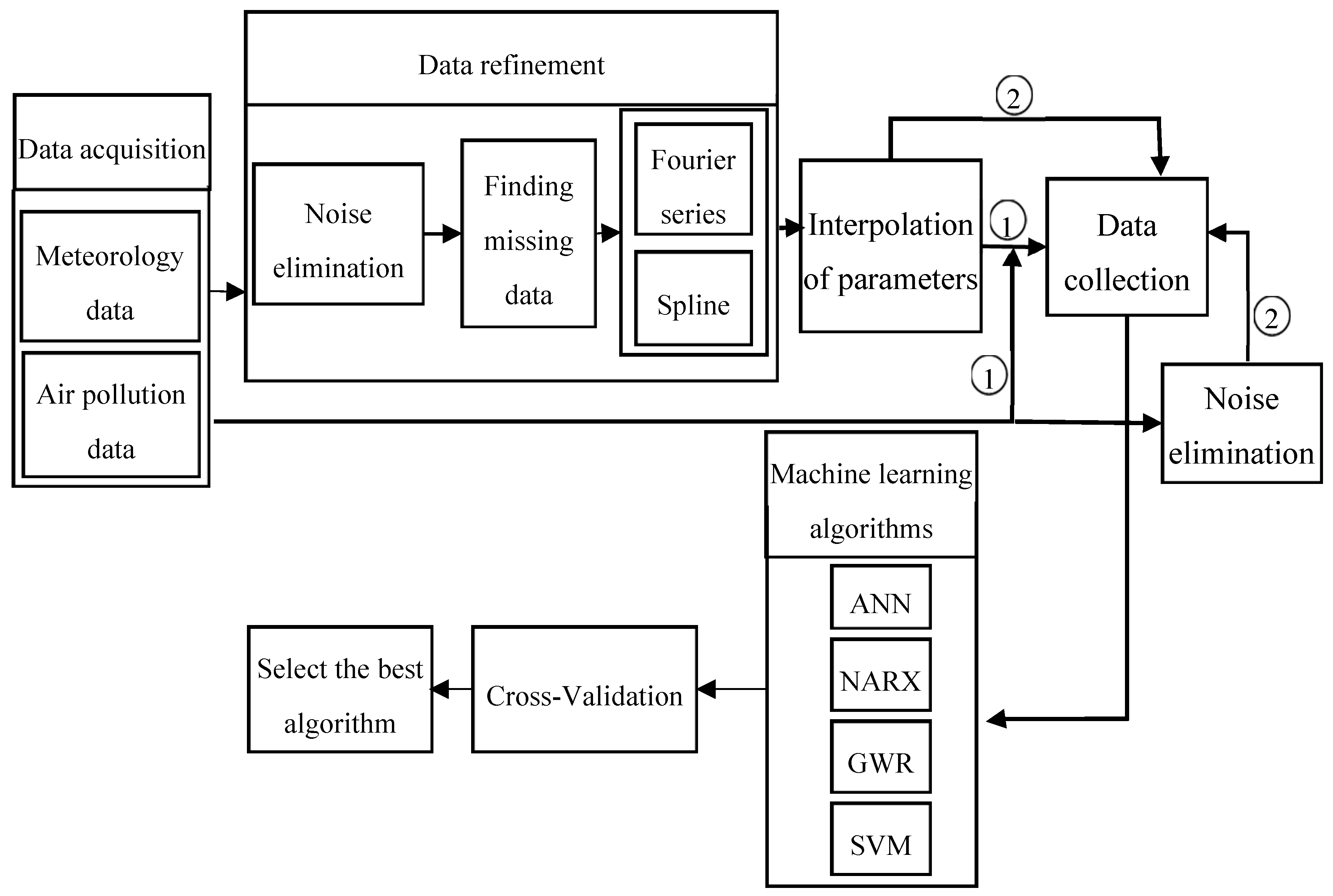
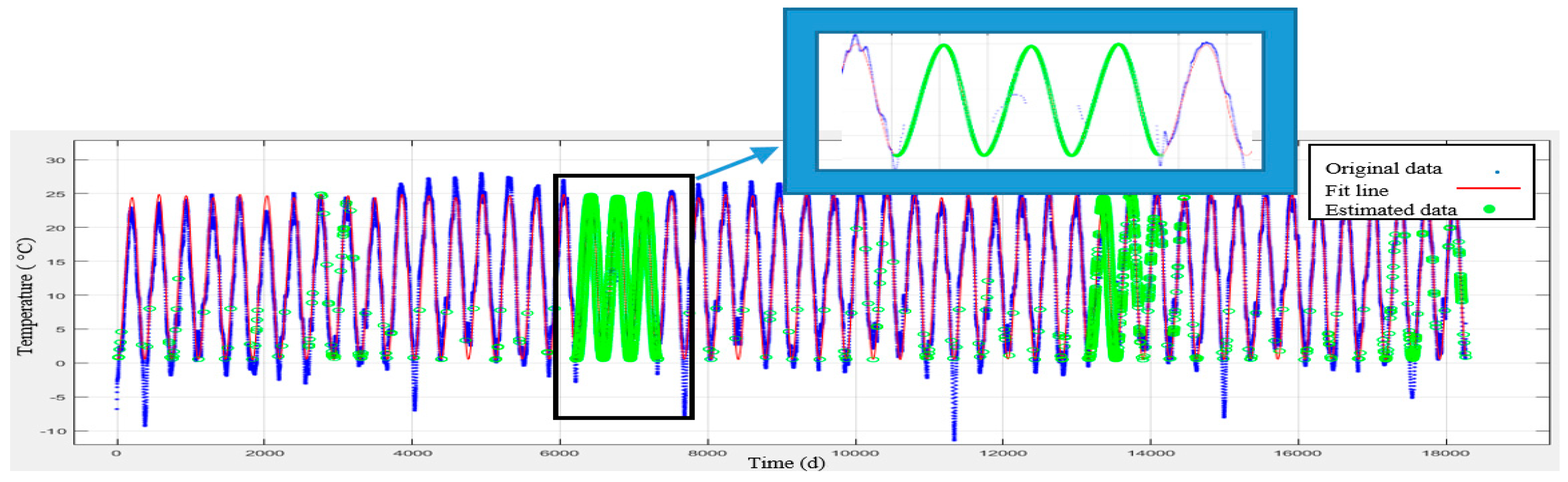
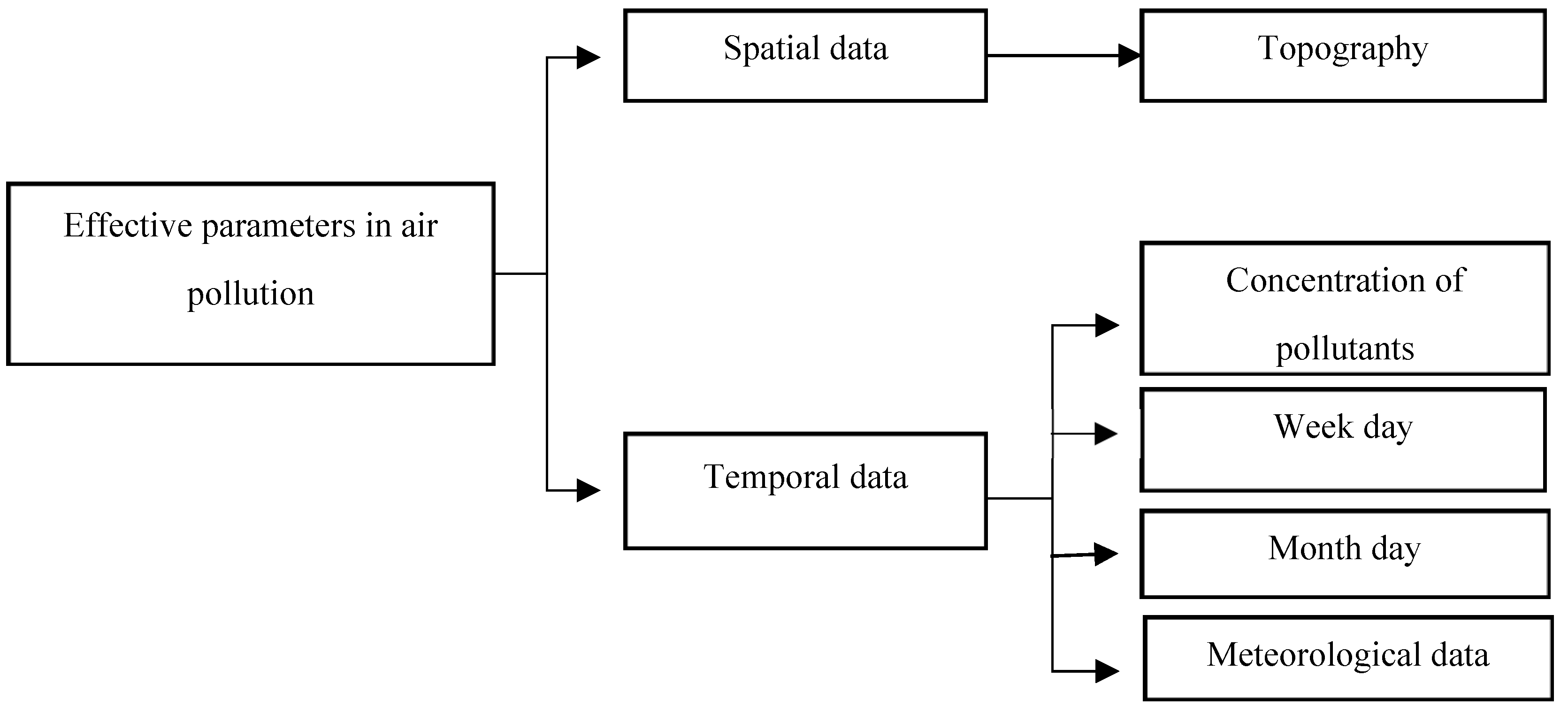
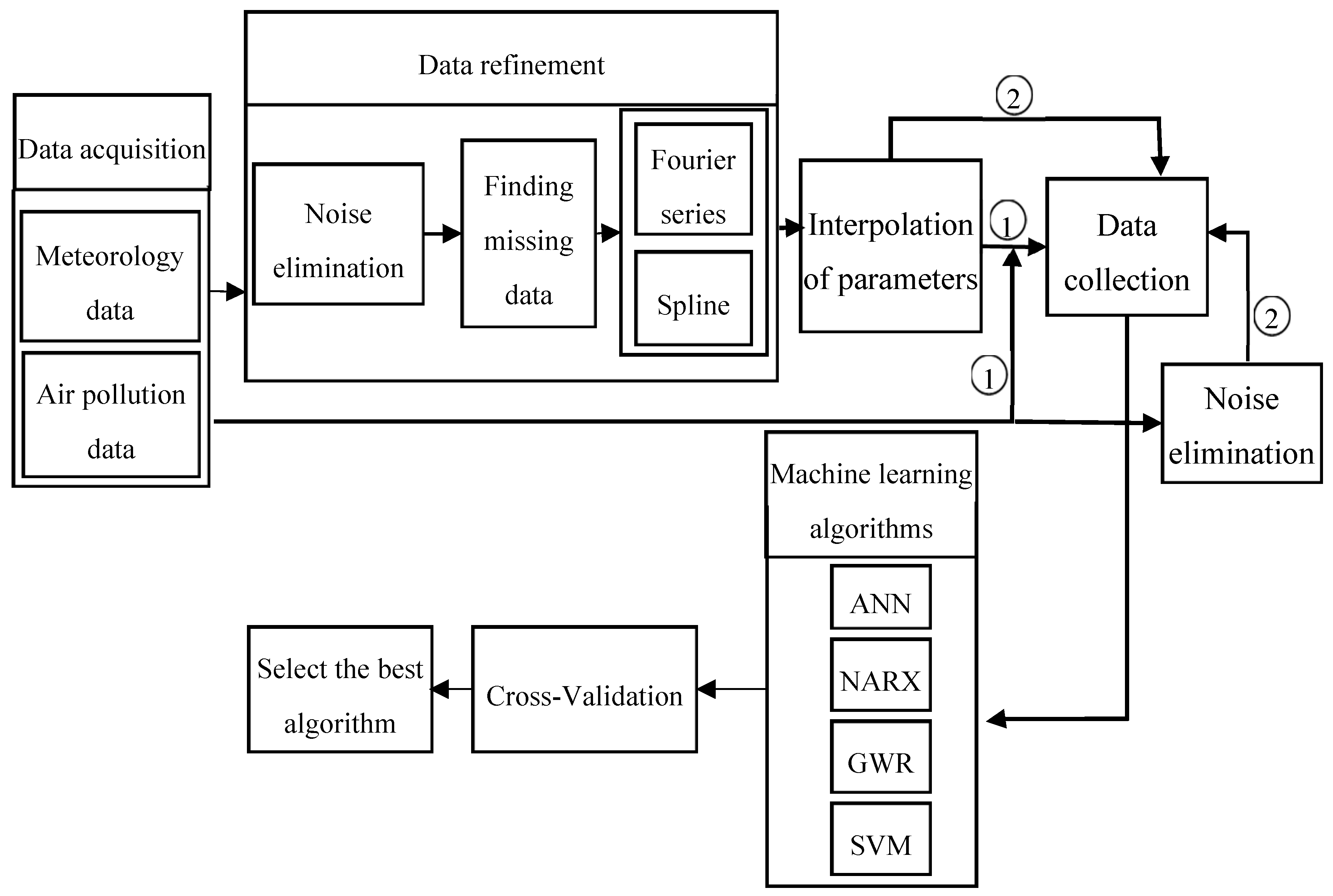
To predict the air-pollution, this research used machine learning methods such as SVR, GWR, artificial neural network, and NARX with external input. To this end, the meteorological data were employed for learning, collected from Iran Meteorological Organization during the ten year period. Given that these data were not error-free and there were lost data in these datasets for daily, weekly, and monthly durations, they were initially refined and prepared for machine learning. Afterward, all the methods were compared and the best model for air-pollution prediction was selected which is illustrated in
Figure 4.
As illustrated in
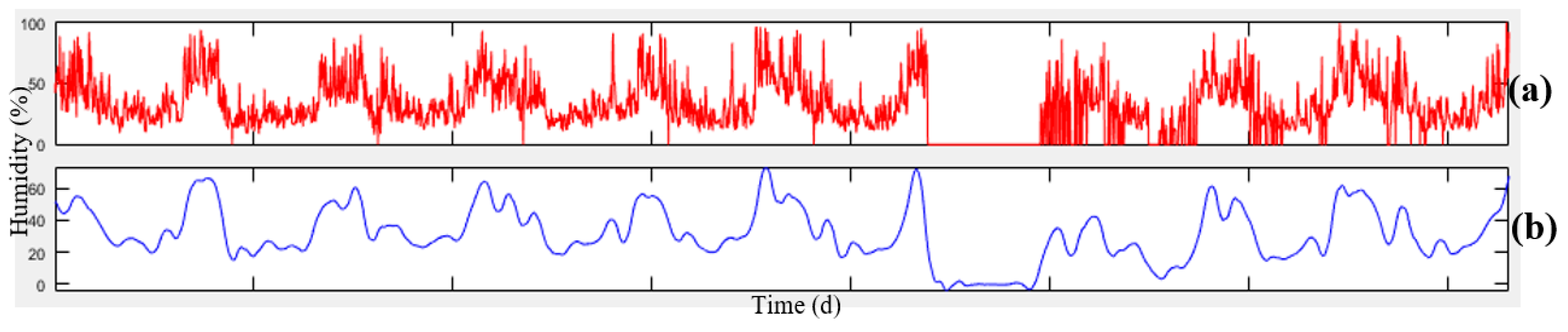
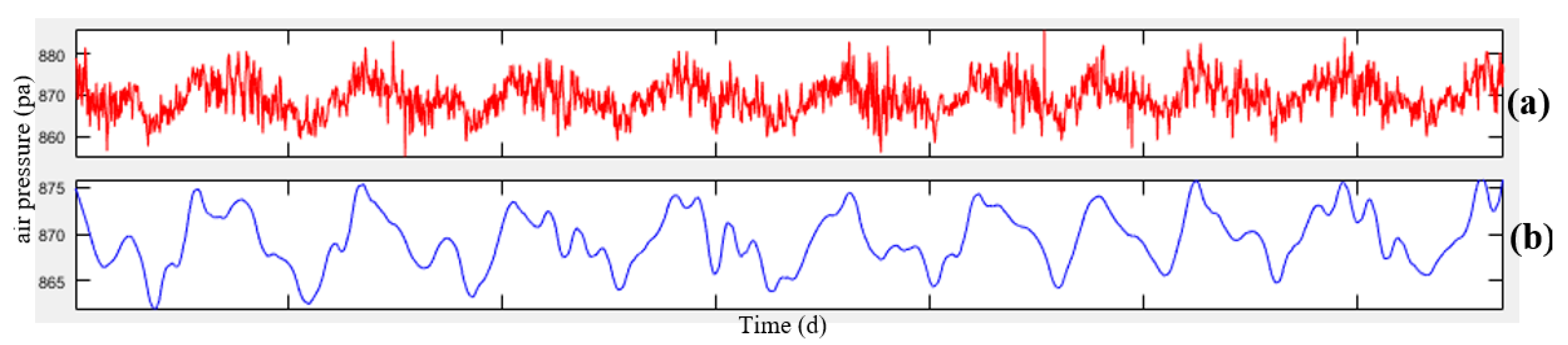
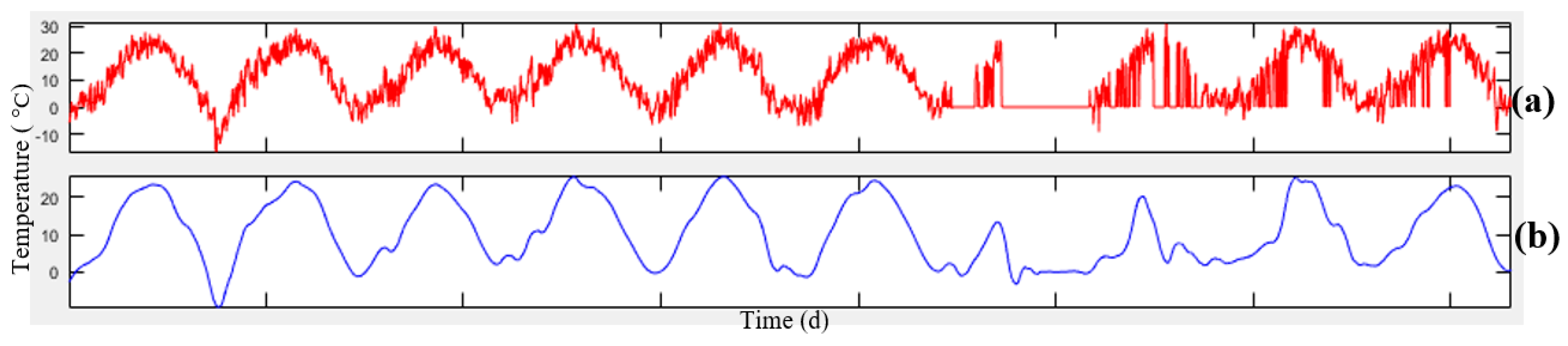
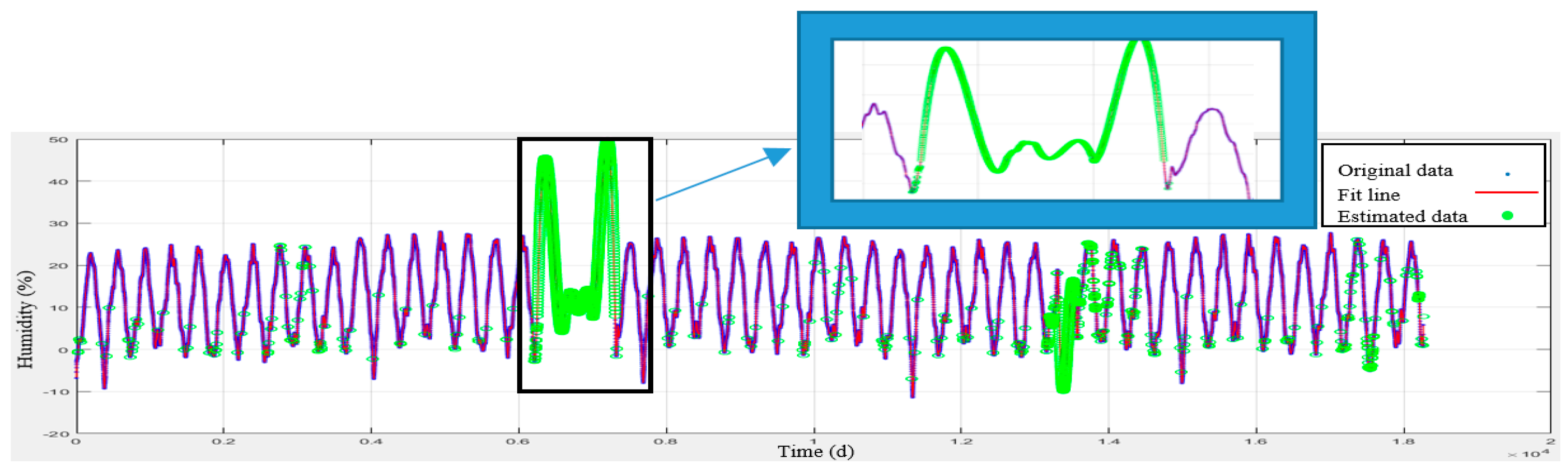
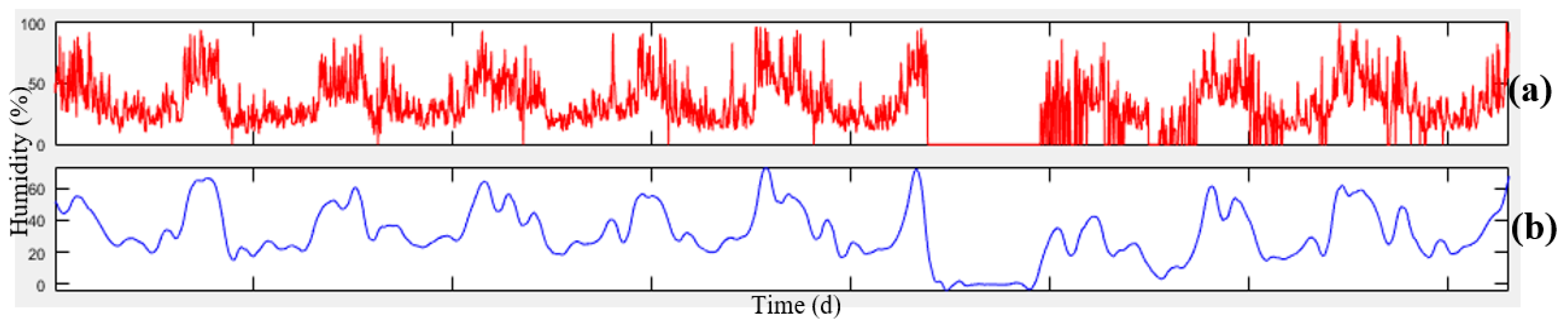
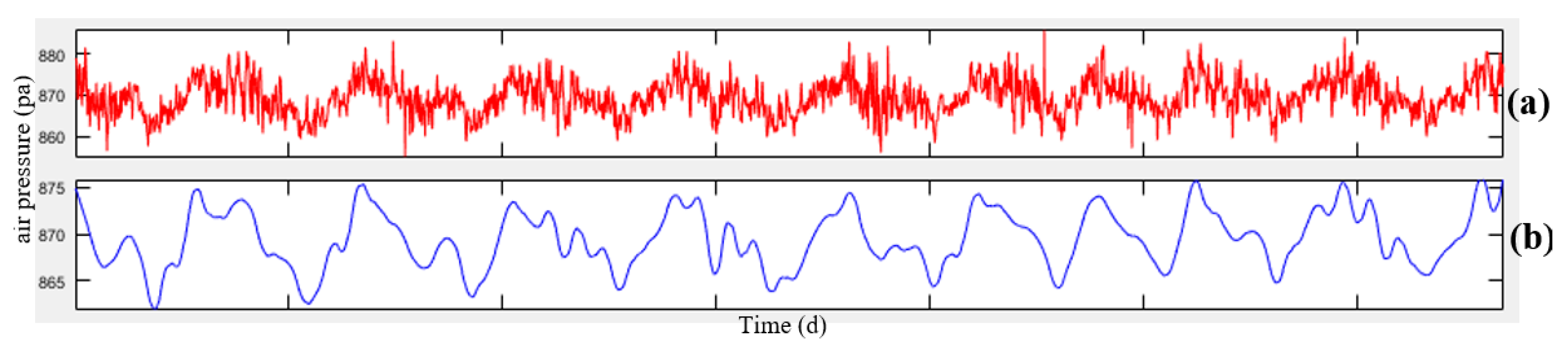
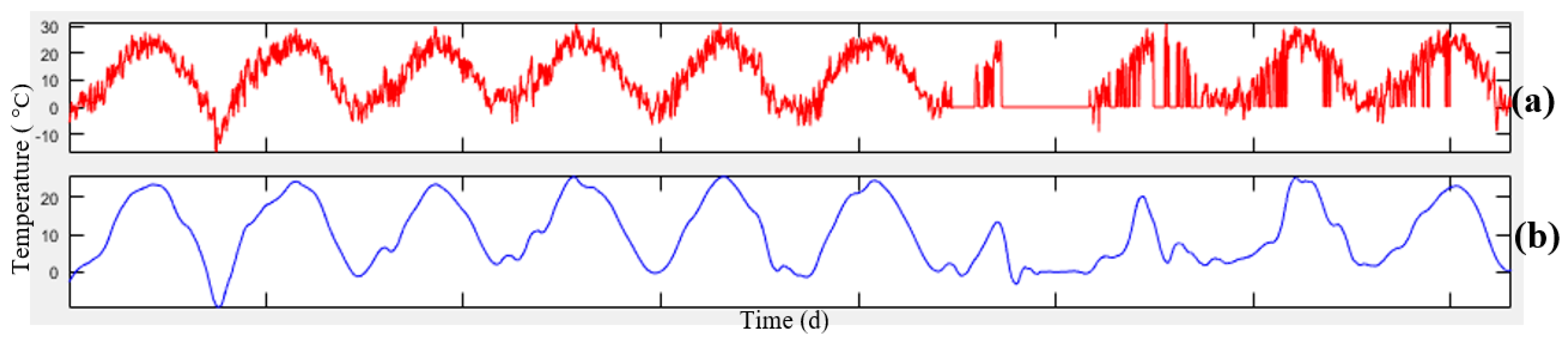
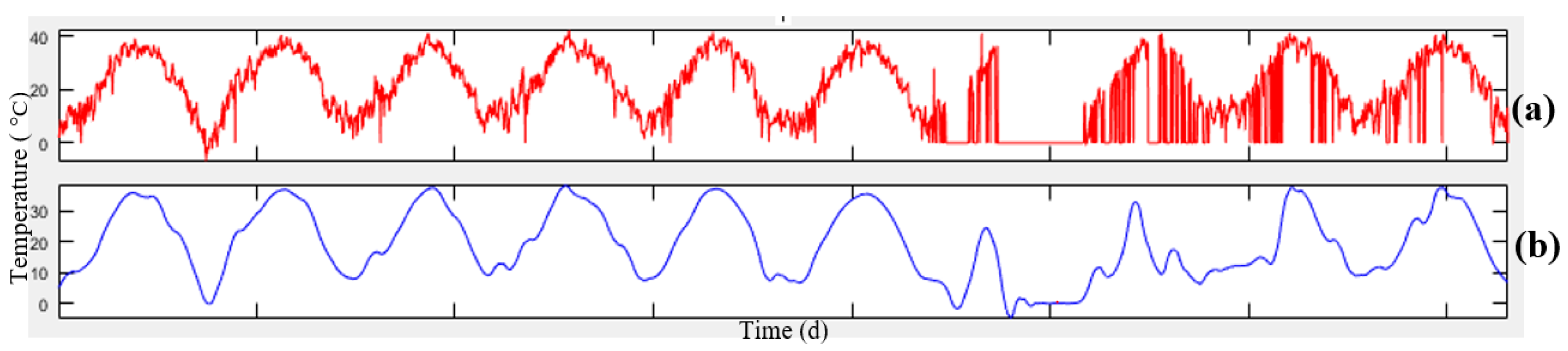
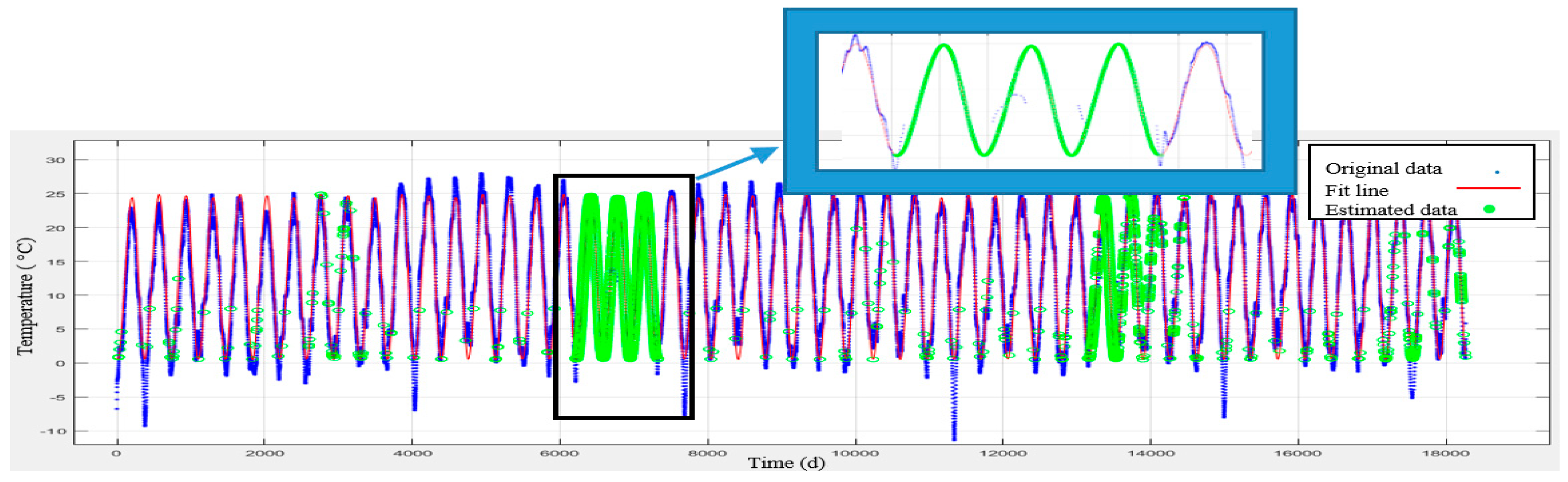
Figure 4, the data related to meteorology and air-pollution has been obtained from meteorological organization and AQCC. These data are not error-free, requiring some algorithms to remove outliers and find the lost data. For this purpose, in this research, refinement and treatment of the data were conducted in several steps. Considering that the structure of time series for air pollutants could not be modeled in a precise form, only noise deletion algorithm has been run. This research uses two datasets for prediction of air-pollution. In the first dataset, the refined meteorological data and unrefined pollutant data, and in the second database, refined meteorological data and pollutant data have been used.
In order to remove the noise in the air-pollution and meteorological data, Savitzky-Golay filter was used. Savitzky-Golay smoothing filter (also referred to as smoothing polynomial filter or Least-Squares smoothing filter) is typically used to smooth a signal with high noise which has a long frequency (without noise). This filter is better than ordinary Finite Impulse Response (FIR) filter [
26]. The Savitzky-Golay filter is optimum because it minimizes the least square error in multinomial connections to each frame of noise data [
26]. The information obtained from the meteorological organization for the 10-year data was not complete. To compensate for this data gap, this research has used Fourier series and spline multinomial approaches. Having refined the meteorological data, values of these parameters need to be obtained in air-pollution stations to use this information in predicting the air-pollution. After these steps, the two datasets provided for running the air prediction algorithms were used. This research employs SVR, NARX, ANN, and GWR for air-pollution prediction, as summarized in the following section. Finally, the results were evaluated using cross-validation and the best method for modeling the air-pollution prediction was developed.
After each of the methods is implemented and modeled, the results should be validated and compared. Therefore, in this research, two parameters of the coefficient of determination and root mean square error using cross-validation method were used to evaluate the results. The determination coefficient shows the correlation between the observed values and the calculated values which is always between 0 and 1, the value of one represents a complete correlation between the observed values and the calculated values, and the zero value represents the independence of the observed values and the values c alculated. The coefficient of determination and the root mean square error have been calculated using Equations (1) and (2) [
27,
28].
where
N is the number of observations,
is the observed parameter,
Pi is the calculated parameter,
is the mean of the observation parameter,
is the average calculation parameter,
is the standard deviation of the observations and
is the standard deviation of the calculation.
5. Conclusions
Measurement errors have been an integrated part of observations which cause errors in the modeling and analysis processes. Similarly, the finding of this research was not free from errors. Therefore, after investigating the various methods for noise and error removal, the Savitzky–Golay filter was found to be more appropriate than other methods such as wavelet analysis. This filter cannot alone compensate for the lost data. Therefore, this research uses Fourier series and spline functions, the former being appropriate for daily and weekly lost data and the latter for the monthly lost data. The extent of the effects of these methods on the accuracy improvement of the prediction model was nearly 10–15%. The two datasets were used in this research whose difference was in refinement or non-refinement of the times series of the pollutants. In both cases, the best method for prediction of air pollution was NARX method. When the time series of the pollutants is refined, about 40% increase in R2 and 94% decrease in RMSE occurs. Considering the prior studies, this research had a minimum error in the air pollution prediction model.
The maximum prediction times were also addressed, which achieved a significant accuracy within 7 days. The results of this research are only for PM10 and PM2.5 pollutants as the main source of air pollution in Tehran. The applicable data were also collected from stations for air pollution measurement on the daily basis. Finally, using the genetic algorithm, the effective parameters in prediction of the air pollution, data for day of week, week of month, topography, wind direction, maximum temperature, and the value of pollutants for the two selected nearest neighbor air pollution stations were identified.
The major contributions of this research are as follows:
A comparative study of machine learning methods including NARX, ANN, GWR and SVR has been employed for air pollution prediction and the NARX finally selected as the optimum one.
The research has improved the efficiency of the machine learning method employed based on filtering the existing noise in both the meteorological and air pollution data as well as predicting the missed meteorological data.
This research has proposed a novel approach for air pollution prediction in urban areas based on both stationary and non-stationary pollution sources using machine learning and statistical methods.
Fourier series has been implemented for monthly missed meteorological data and spline methods employed for daily and weekly missed meteorological data.
The effective parameters for air pollution prediction have been determined in this research.
Some shortcomings of the research are as follows:
Unviability of some urban traffic data, distance from road and some more meteorological parameters related to pollution sources causes some errors in the final air pollution prediction.
As some of the air pollution data provided by the Iranian Environmental Protection Agency were heterogeneous and lack a suitable spatio-temporal structure, they have been excluded in the analysis.
The employment of Savitzky–Golay filter in some limited places where no air pollution data were available, may slightly affect the final air pollution prediction accuracy which could not be avoided due to some data scarcity. Anyway, the implementation of Fourier series and spline functions in those areas has significantly reduced the impact of the data gap.
For future research, the following recommendations are presented to enhance the quality of air pollution prediction:
This research used daily data of the pollutants. So, the quality of the proposed model can be significantly improved if hourly data is implemented
Considering the importance of air pollution problem, it is recommended that the number of air pollution measuring stations increases in Tehran so as to allow for a better fit on the air pollution prediction.
Applying more inclusive parameters such as urban traffic, distance from road and some more meteorological parameters related to pollution sources are among the important factors in modeling and prediction of urban air pollution especially in industrial cities like Tehran. In this research, due to the unavailability of the afore-mentioned data, it was impossible to apply all the influencing data in the proposed model.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}