Optimization of Shortest-Path Search on RDBMS-Based Graphs



Abstract
1. Introduction
2. Related Work
3. Shortest-Path Search in RDBMS
3.1. Basic Concept
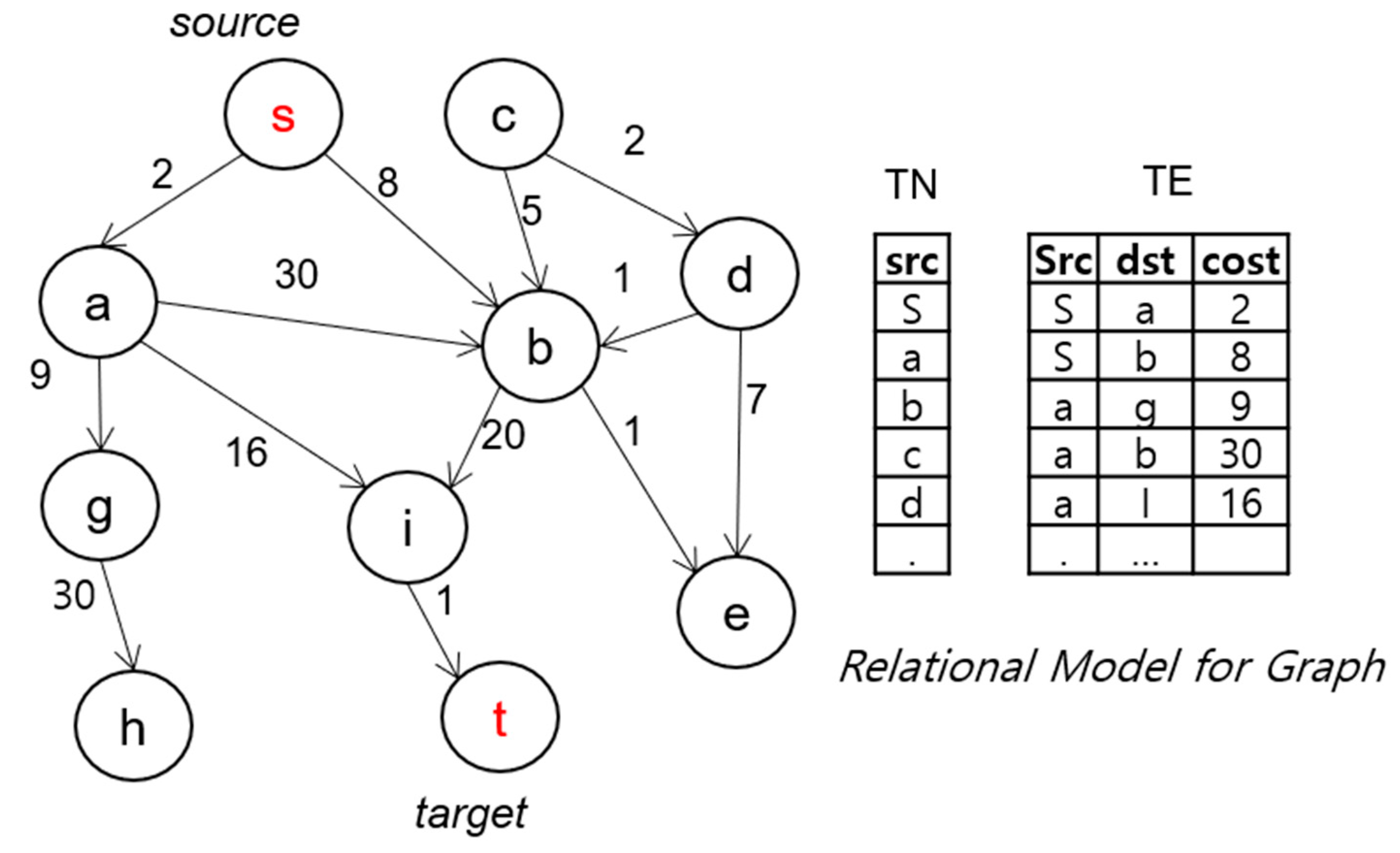
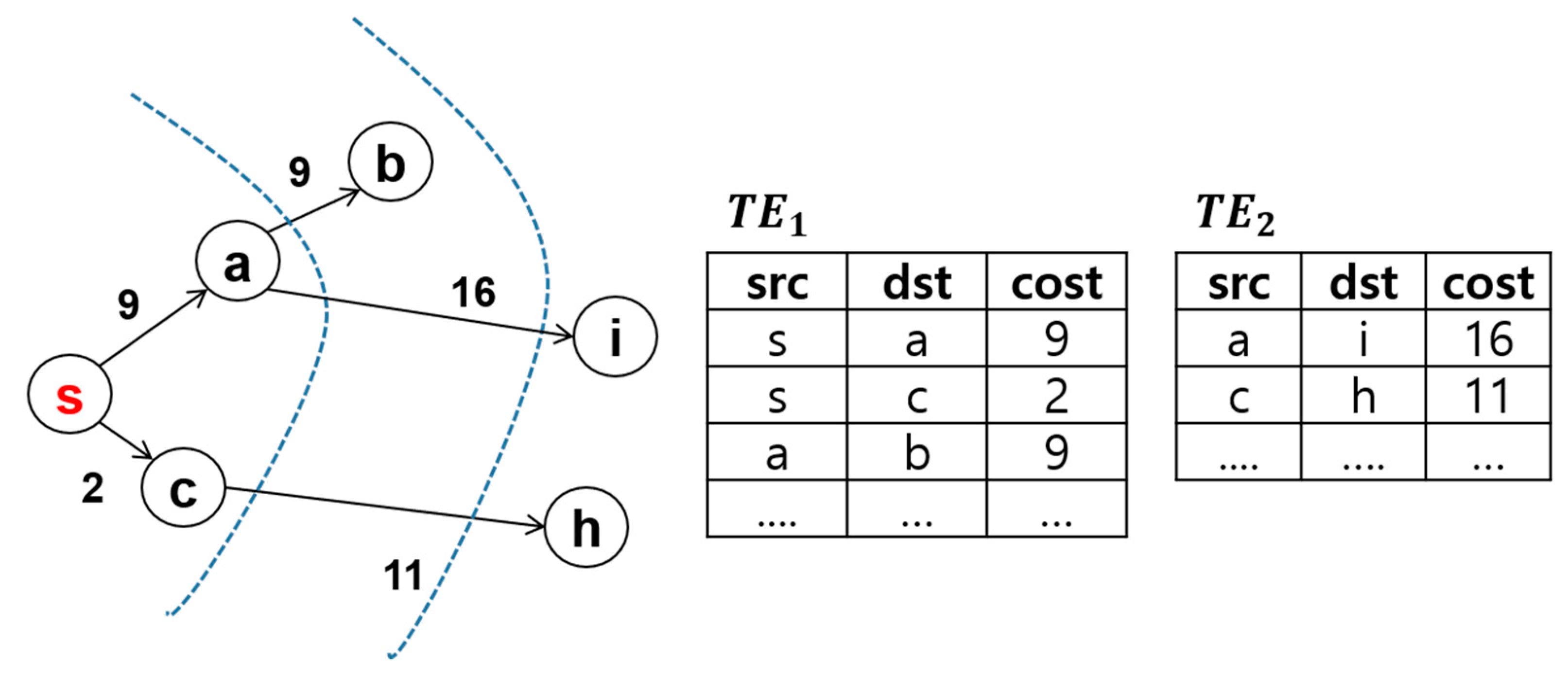
3.1.1. Graph Data Model and Concept Definition
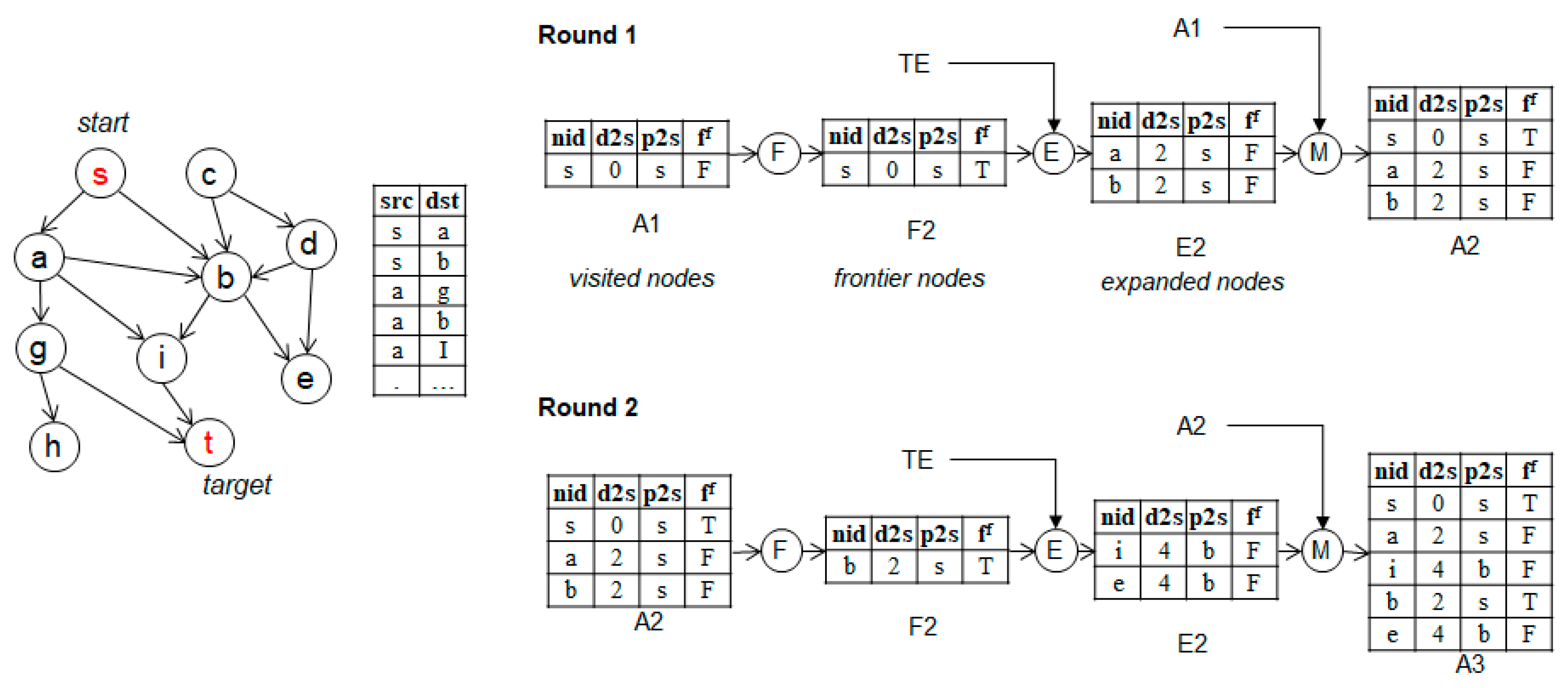
3.1.2. Basic FEM
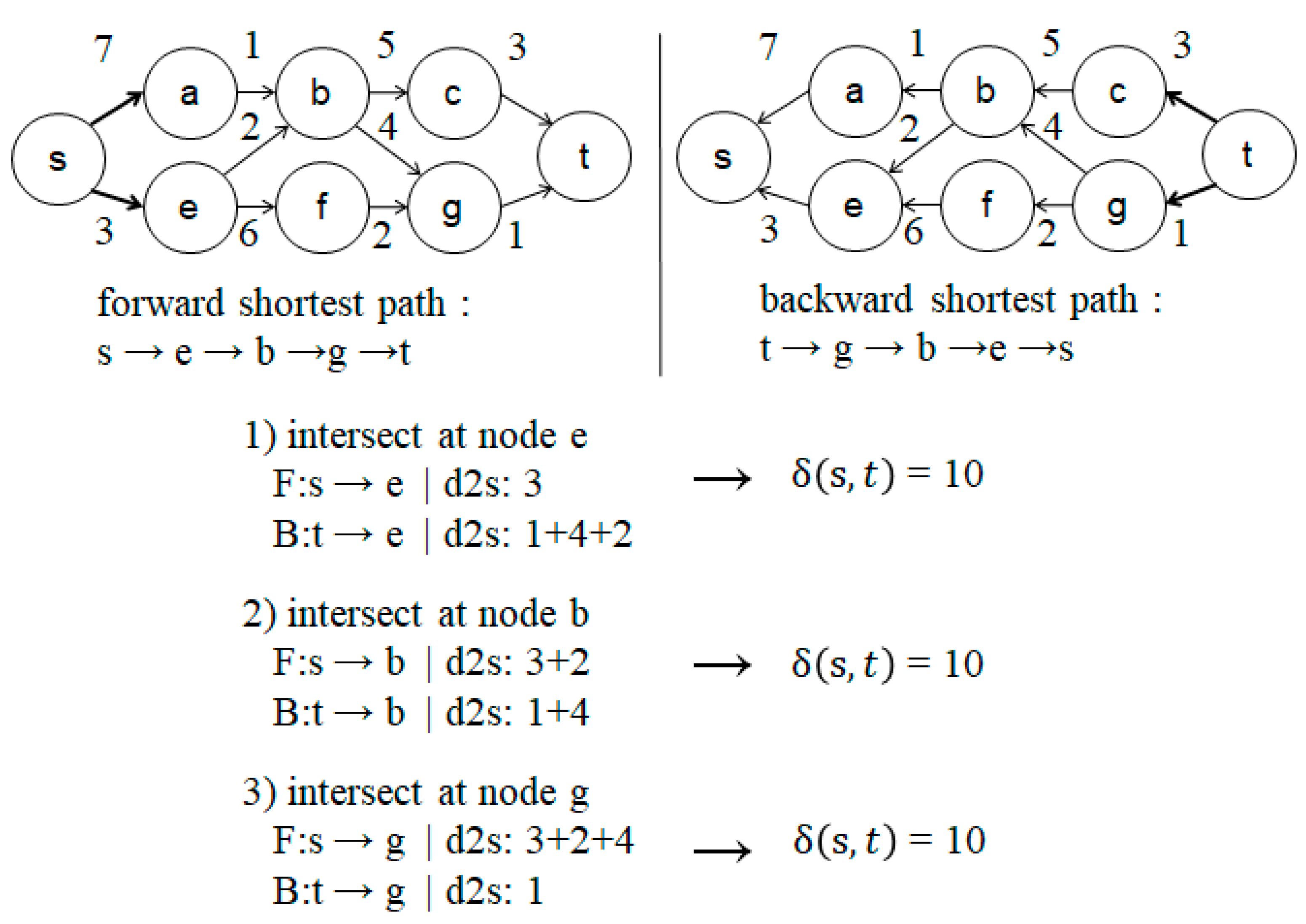
3.1.3. Limitations of Basic FEM
3.2. Optimization Techniques for Improving the Shortest Path Search
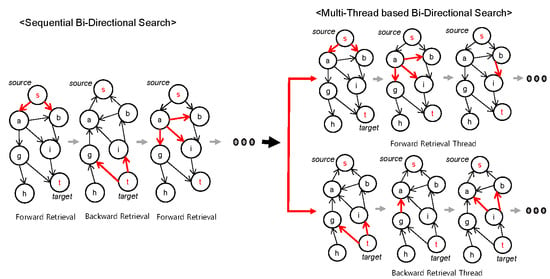
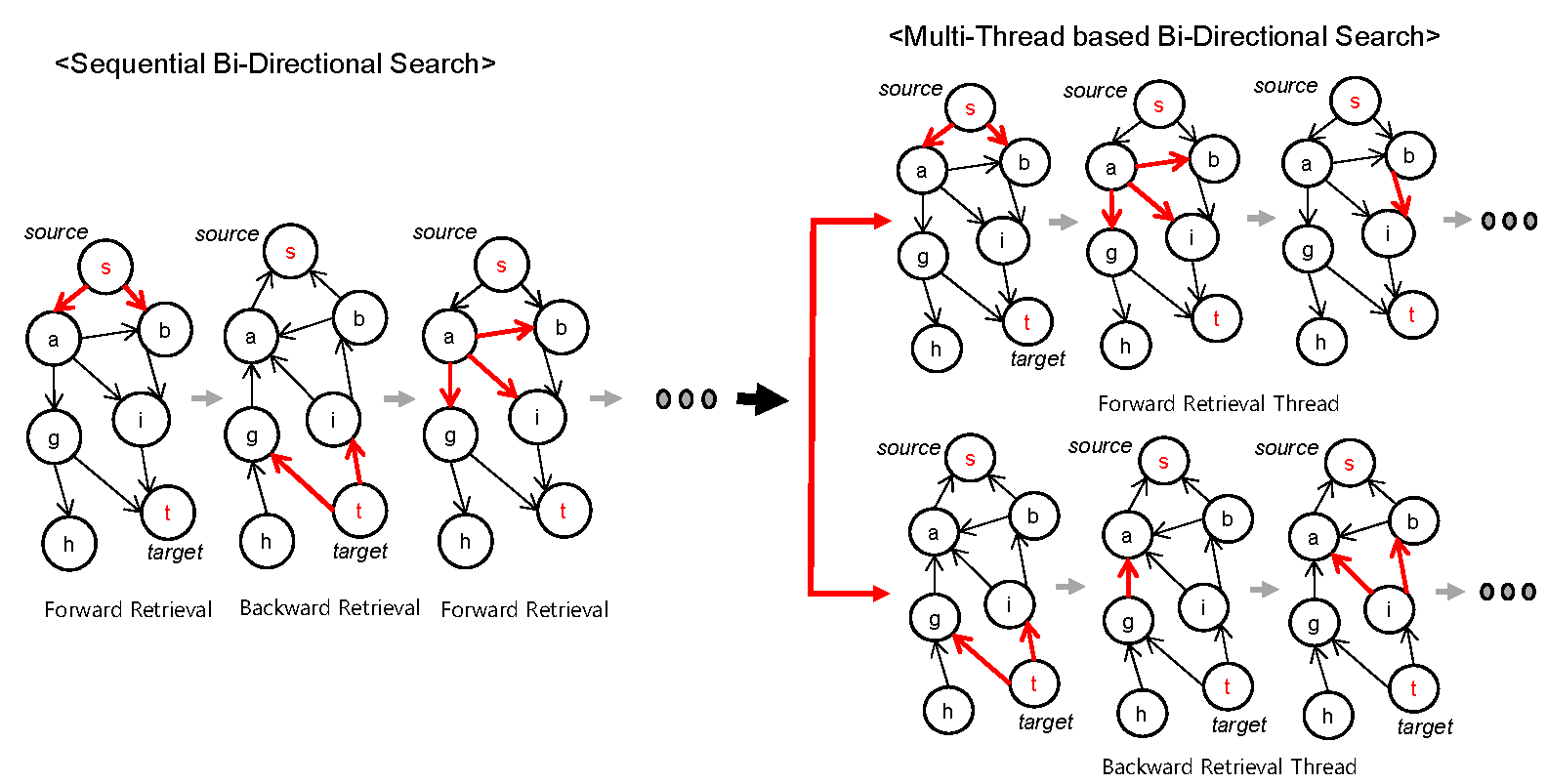
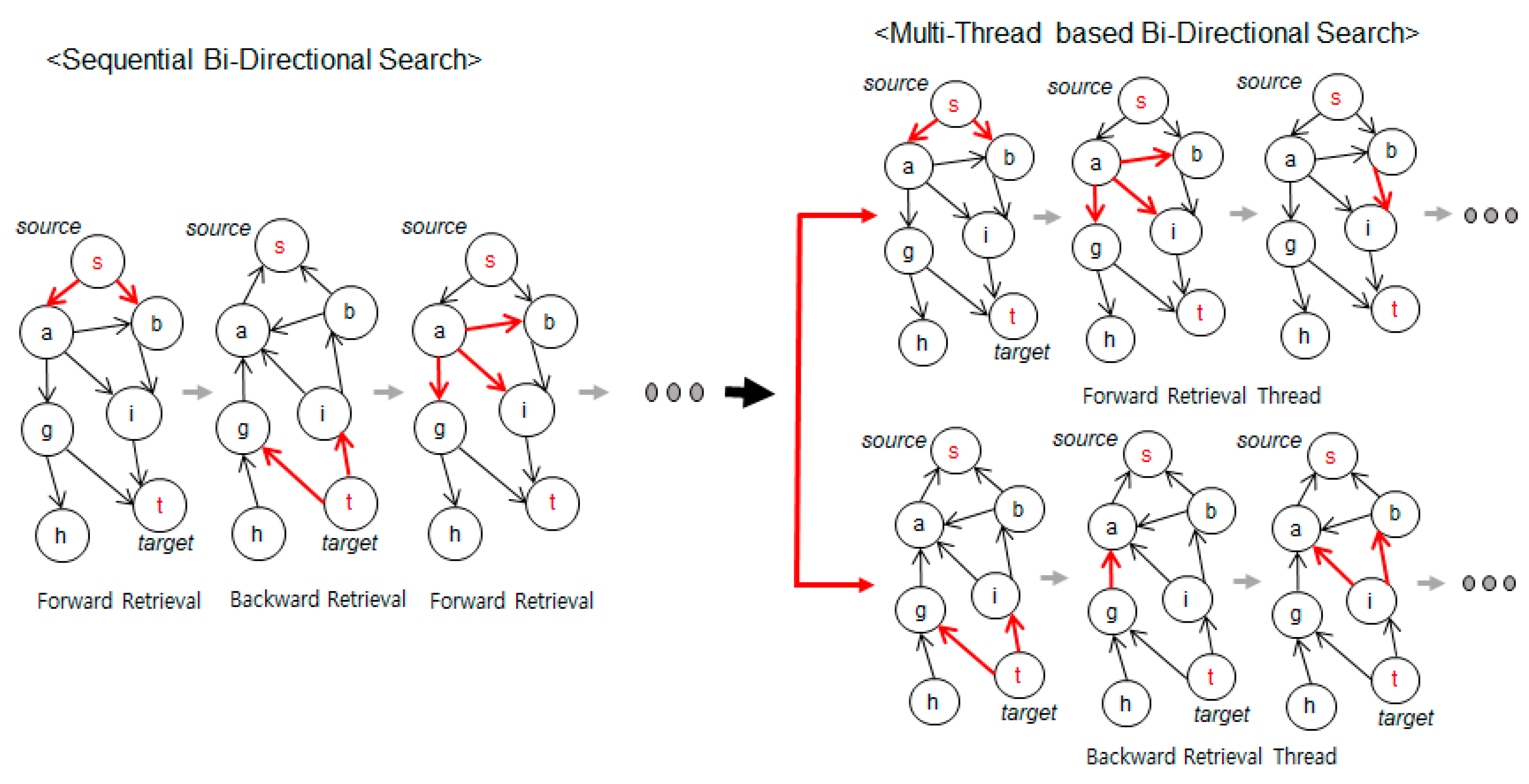
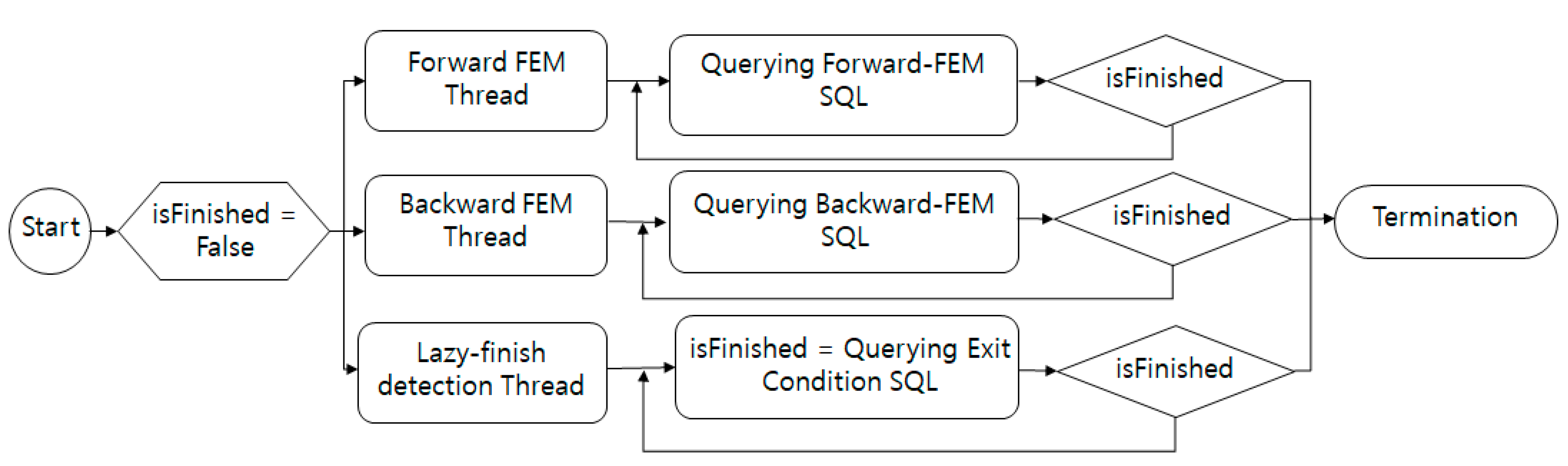
3.2.1. Multithread Bi-Directional Search
| Algorithm 1. Multithread Bi-directional Shortest Path Search |
| Input: starting node s, target node t, graph G = (V, E) Output: The shortest path between s and t. Initialize using SQL command 1 asyncCall(ForwardFEM) asyncCall(BackwardFEM) while ForwardFEM.dist + BackwardFEM.dist <= minCost do Compute minCost using SQL command 4 terminate(ForwardFEM) terminate(BackwardFEM) Return restore path Procedure ForwardFEM() while true do Find the frontier node in Forward using SQL command 2 if frontier == null then Break Dist = frontier.d2s Expand and Merge paths using SQL command 3 Procedure BackwardFEM() while true do Find the frontier node in Backward using SQL command 2 if frontier == null then Break Dist = frontier.d2s Expand and Merge paths using SQL command 3 Procedure asynchCall(Method) |
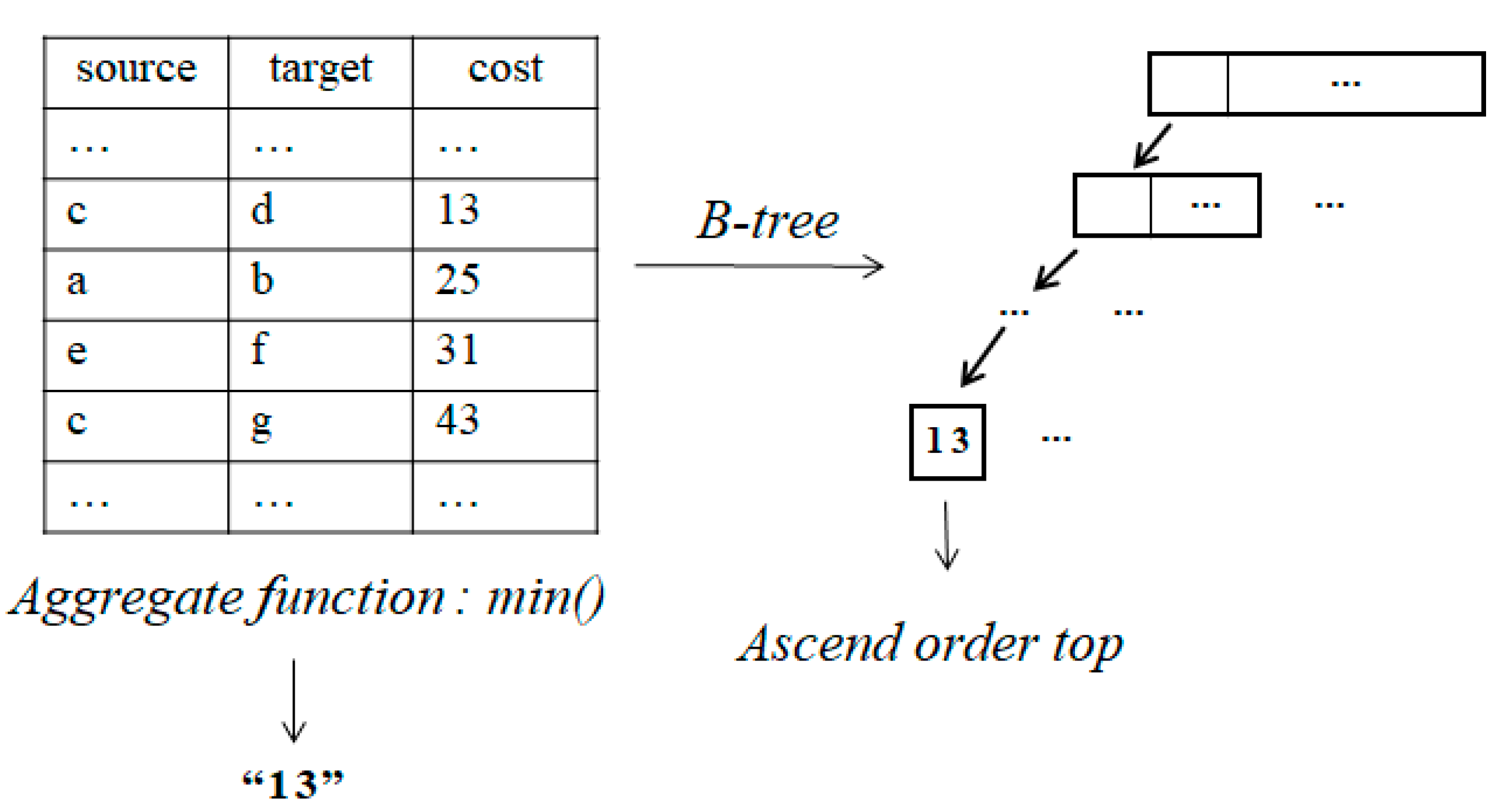
3.2.2. B-Tree Indexing on the Visited-Node Table
| SELECT top 1 nid from TA where ff = 0 and d2s = (SELECT min(d2s) from TA where ff = 0) |
4. Evaluation Methodology
5. Results and Discussion
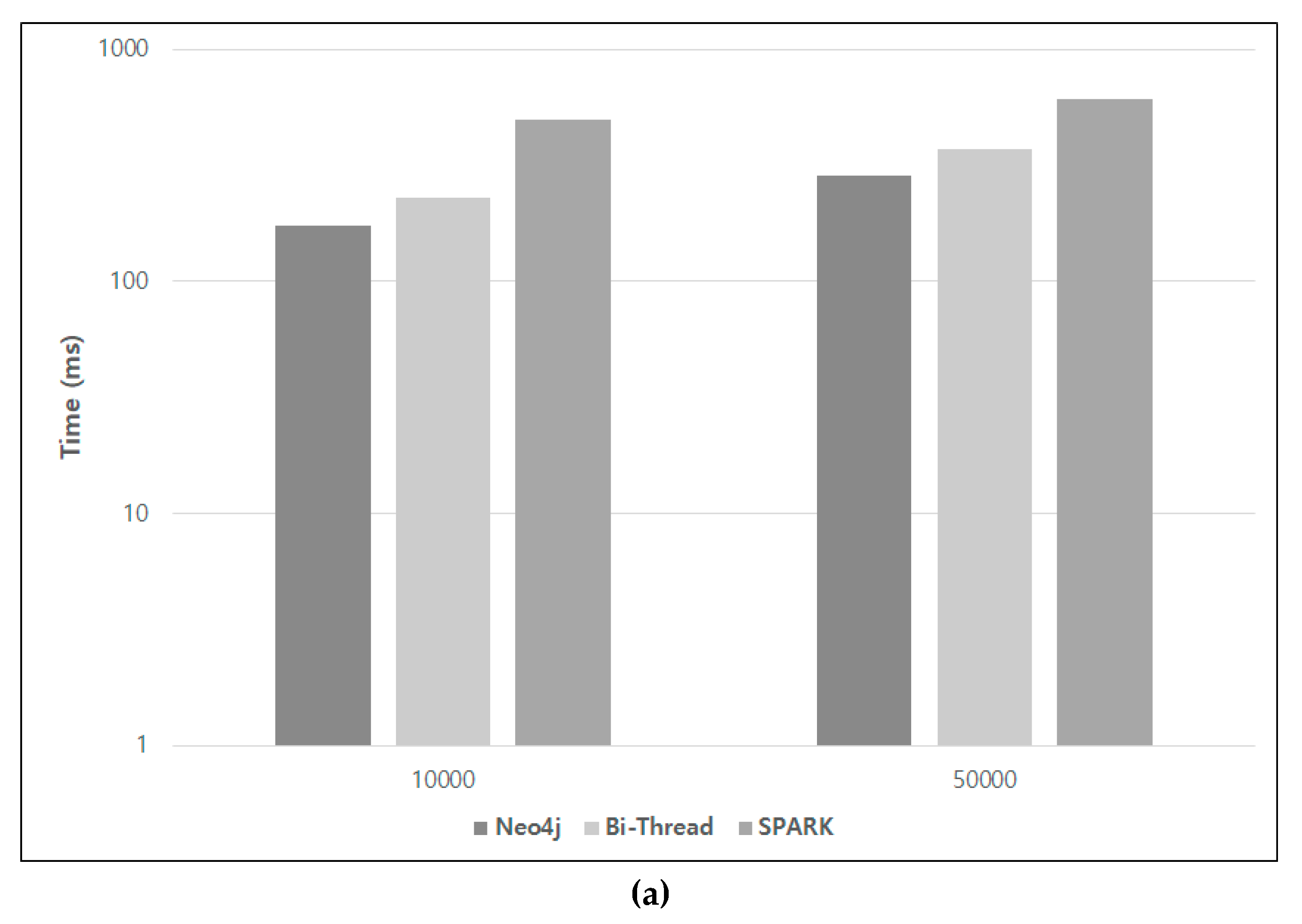
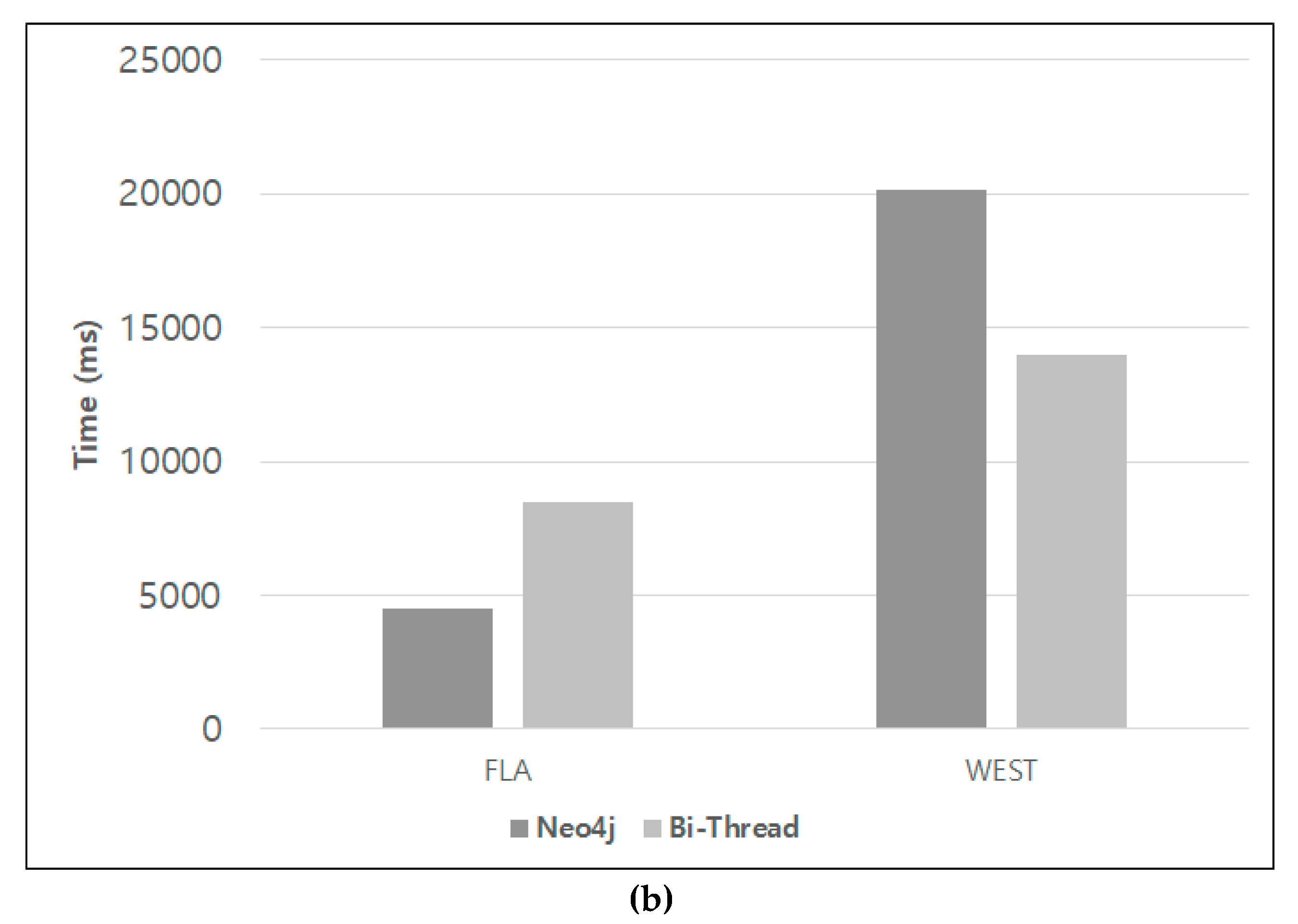
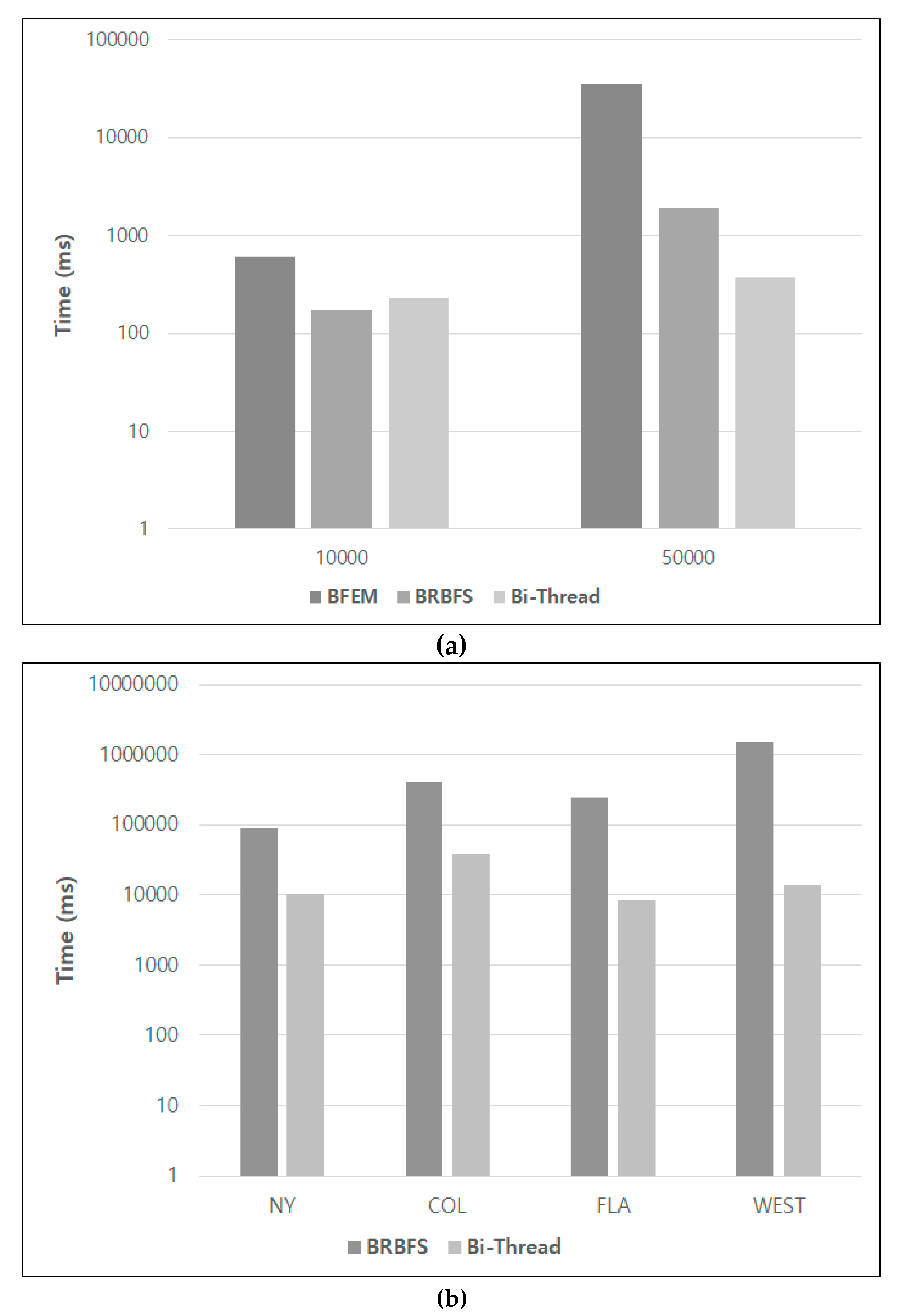
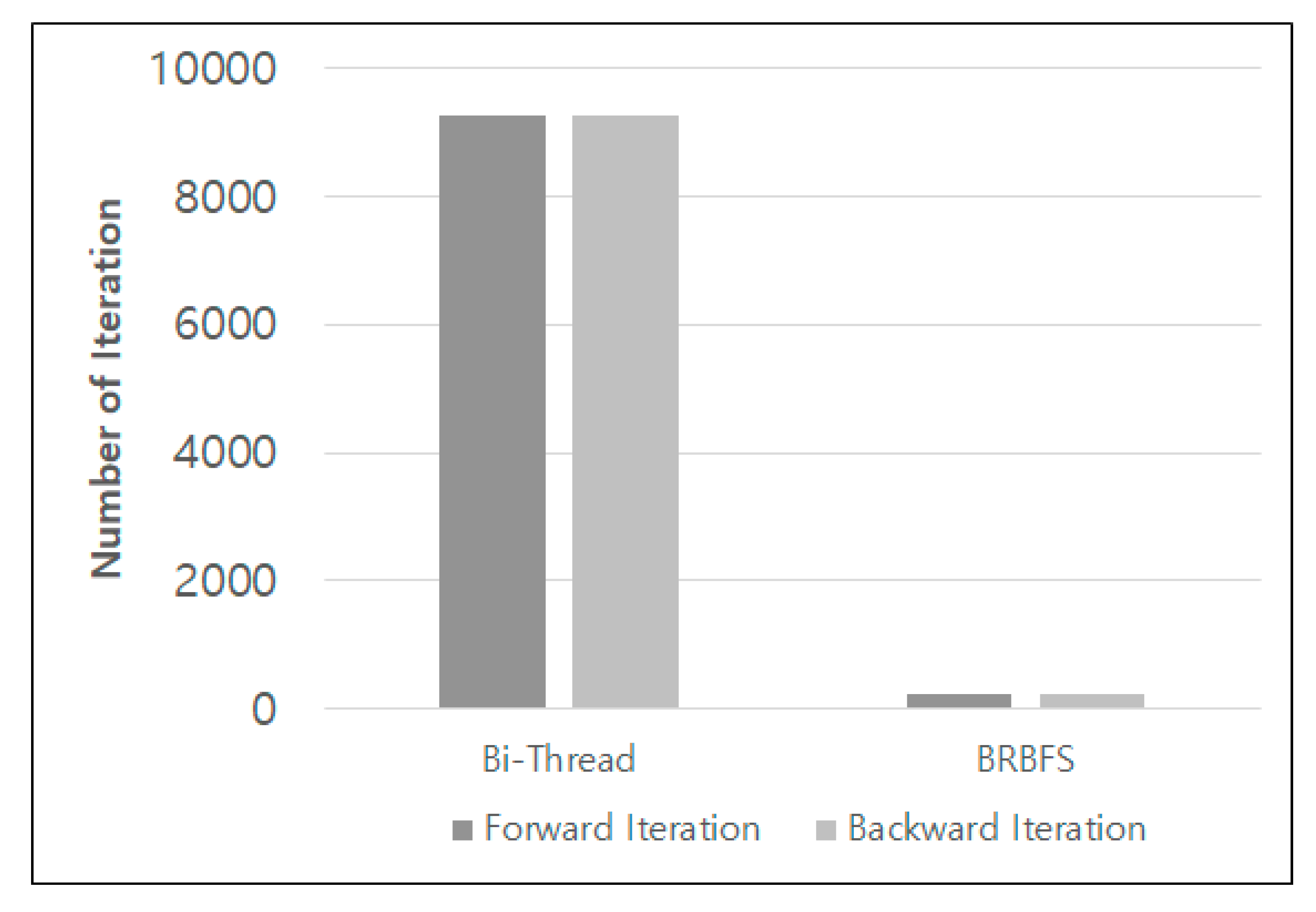
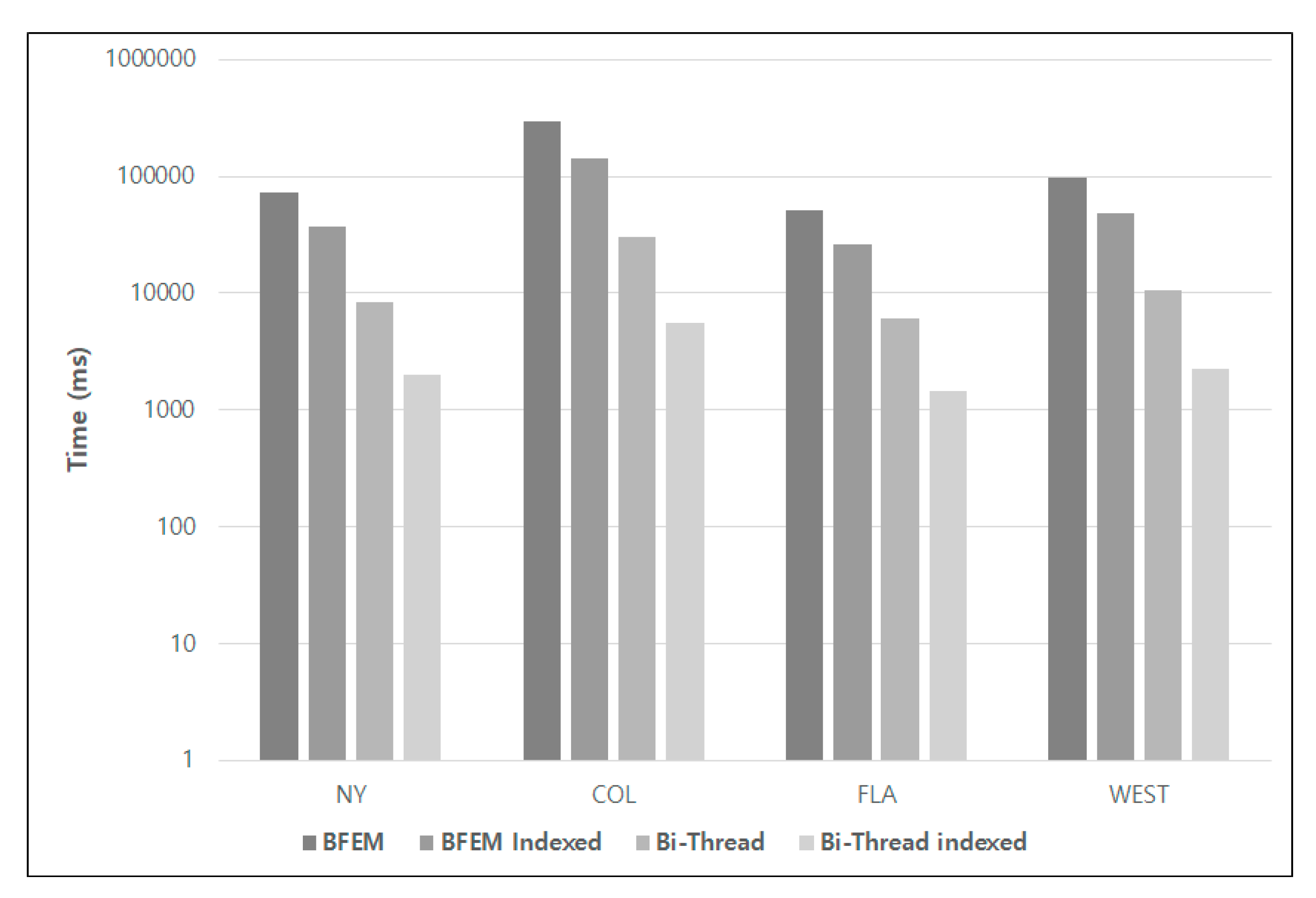
5.1. Performance Evaluation
5.2. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
| // SQL command 1 insert into ta(nid,d2s,p2s,fwd,f) values (s,0,s,1,false) insert into ta2(nid,d2s,p2s,fwd,f) values (t,0,t,1,false) // SQL command 2 nid,d2s := select nid,d2s from ta WHERE ta.d2s=(select min(d2s) from ta where f=false) and f=false update ta set f = true where ta.nid = nid // SQL command 3 INSERT INTO ta(nid, d2s, p2s, fwd, f) (SELECT tid as nid, cost+? as d2s, ? as p2s, ? as fwd, false as f FROM TE WHERE fid=?) ON CONFLICT(nid) DO UPDATE SET d2s=excluded.d2s, p2s=excluded.p2s, fwd=excluded.fwd,f=excluded.f WHERE ta.d2s>excluded.d2s // SQL command 4 select min(TF.d2s+TB.d2s) from ta as TF, ta2 as TB where TF.nid = TB.nid |
References
- Dijkstra, E.W. A note on two problems in connection with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Gao, J.; Zhou, J.; Yu, J.X.; Wang, T. Shortest path computing in relational DBMSs. IEEE Trans. Knowl. Data Eng. 2013, 26, 997–1011. [Google Scholar]
- Hong, J.; Park, K.; Han, Y.; Rasel, M.K.; Vonvou, D.; Lee, Y.K. Disk-based shortest path discovery using distance index over large dynamics graphs. Inf. Sci. 2017, 382, 201–215. [Google Scholar] [CrossRef]
- Wagner, D.; Willhalm, T. Speed-up techniques for shortest-path computations. In Annual Symposium on Theoretical Aspects of Computer Science; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- De Leo, D.; Boncz, P. Extending SQL for computing shortest paths. In Proceedings of the Fifth International Workshop on Graph Data-management Experiences and Systems, Chicago, IL, USA, 14–19 May 2017; ACM: New York, NY, USA, 2017. [Google Scholar]
- Greco, S.; Molinaro, C.; Pulice, C.; Quintana, X. All-pairs shortest distances maintenance in relational DBMSs. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 215–222. [Google Scholar]
- Neo4J. Available online: http://neo4j.org/ (accessed on 28 August 2019).
- Miller, J.J. Graph database applications and concepts with Neo4J. In Proceedings of the Southern Associations for Information Systems Conference, Atlanta, GA, USA, 23–24 March 2013. [Google Scholar]
- Vicknair, C.; Macias, M.; Zhao, Z.; Nan, X.; Chen, Y.; Wilkins, D. A comparison of a graph database and a relational database: A data provenance perspective. In Proceedings of the 48th Annual Southeast Regional Conference, Oxford, MS, USA, 15–17 April 2010; ACM: New York, NY, USA, 2010. [Google Scholar]
- Apache Hadoop. Available online: http://hadoop.apache.org (accessed on 28 August 2019).
- Apache SPARK. Available online: http://spark.apache.org (accessed on 28 August 2019).
- Aridhi, S.; Lacomme, P.; Ren, L.; Vincent, B. A MapReduce-based approach for shortest path problem in large-scale networks. Eng. Appl. Artif. Intell. 2015, 41, 151–165. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Arfat, Y.; Mehmood, R.; Albeshri, A. Parallel shortest path graph computations of United States road network data on Apache Spark. In Proceedings of the International Conference on Smart Cities, Infrastructure, Technologies and Applications, Jeddah, Saudi Arabia, 27–29 November 2017; Springer: Chamonix, France, 2017; pp. 323–336. [Google Scholar]
- Fan, W.; Yu, W.; Xu, J.; Zhou, J.; Luo, X.; Yin, Q.; Lu, P.; Cao, Y.; Xu, R. Parallelizing sequential graph computations. ACM Trans. Database Syst. 2018, 43, 18. [Google Scholar] [CrossRef]
- Reddy, H. Pathfinding—Dijkstra’s and A* algorithm’s. Int. J. IT Eng. 2013, 1–15. Available online: http://cs.indstate.edu/hgopireddy/algor.pdf (accessed on 27 August 2019).
- Goldberg, A.V.; Harrelson, C. Computing the shortest path: A search meets graph theory. In Proceedings of the 16th Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, Vancouver, BC, Canada, 23–25 January 2005; pp. 156–165. [Google Scholar]
- Goldberg, A.V.; Werneck, R.F.F. Computing point-to-point shortest path from external memory. In Proceedings of the ALENEX/ANALCO, Vancouver, BC, Canada, 22 January 2005; pp. 26–40. [Google Scholar]
- Vaira, G.; Kurasova, O. Parallel bidirectional Dijkstra’s shortest path algorithm. In Frontiers in Artificial Intelligence and Applications; IOS Press: Amsterdam, The Nederlands, 2011; pp. 422–435. [Google Scholar]
- Powel, M.L.; Kleiman, S.R.; Barton, S.; Shan, D.; Stein, D.; Weeks, M. SunOS multi-thread architecture. In The SPARC Technical Papers; Springer: New York, NY, USA, 1991; pp. 339–372. [Google Scholar]
- Comer, D. Ubiquitous B-tree. ACM Comput. Surv. 1979, 11, 121–137. [Google Scholar] [CrossRef]
- Demetrescu, C.; Goldberg, A.V.; Johnson, D.S. Ninth DIMACS Implementation Challenge-Shortest Paths. Available online: http://www.dis.uniromal.it/~challenge9 (accessed on 30 January 2018).
- Available online: http://www.postgresql.org/docs/10/sql-explain.html (accessed on 9 October 2019).
- Ahn, J.; Lee, T.; Im, D.-H. Efficiently Answering Reachability Queries for Tree-Structured Data in Repetitive Prime Number Labeling Schemes. Appl. Sci. 2018, 8, 785. [Google Scholar] [CrossRef]
- Ahn, J. Optimization Techniques for 2-hop Labeling of Dynamic Directed Acyclic Graphs. In Proceedings of the DC@ISWC, Kobe, Japan, 18 October 2016; pp. 1–8. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Synthetic Data (Directed and Weighted) | Real Data (Undirected and Weighted) | |||||
|---|---|---|---|---|---|---|
| 10K-nodes | 50K-nodes | NY | COL | FLA | WEST | |
| # of nodes | 1K | 5K | 264K | 435K | 1.07M | 6.26M |
| # of edges | 10K | 50K | 733K | 1.05M | 2.71M | 15.24M |
| Real Data | Synthetic Data |
|---|---|
| A 1 2 2008 | 0 385 19 |
| A 2 1 2008 | 0 323 5 |
| A 3 4 395 | 0 453 20 |
| A 4 3 395 | 0 522 8 |
| (arc, start, target, weight) | (start, target, weight) |
| Query | Start(ID) | Target(ID) | # of Nodes in Path | Neo4J | Bi-Thread |
|---|---|---|---|---|---|
| Q1 | 6789 | 1049371 | 685 | 5491 | 6318 |
| Q2 | 7280 | 1194133 | 417 | 3633 | 1061 |
| Q3 | 2101844 | 7 | 524 | 4218 | 3495 |
| Q4 | 2097157 | 28 | 15 | 174 | 59 |
| Q5 | 84 | 1049935 | 94 | 747 | 183 |
| Q6 | 1333393 | 3 | 3001 | X | 769,048 |
| Q7 | 484766 | 32505 | 2371 | X | 599,902 |
| Q8 | 21 | 3841216 | 4620 | X | 2,249,322 |
| Method | Data Sets | # of FEM Iteration | Total Cost |
|---|---|---|---|
| BRBFS | 10000 | 17 | 109,346 |
| 50000 | 79 | 2,312,855 | |
| WEST | 94 | 136,980,000,000 | |
| Bi-Thread | 10000 | 35 | 114,832 |
| 50000 | 1372 | 1,353,632 | |
| WEST | 7430 | 4,265,980 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, K.; Ahn, J.; Im, D.-H. Optimization of Shortest-Path Search on RDBMS-Based Graphs. ISPRS Int. J. Geo-Inf. 2019, 8, 550. https://doi.org/10.3390/ijgi8120550
Seo K, Ahn J, Im D-H. Optimization of Shortest-Path Search on RDBMS-Based Graphs. ISPRS International Journal of Geo-Information. 2019; 8(12):550. https://doi.org/10.3390/ijgi8120550
Chicago/Turabian StyleSeo, Kwangwon, Jinhyun Ahn, and Dong-Hyuk Im. 2019. "Optimization of Shortest-Path Search on RDBMS-Based Graphs" ISPRS International Journal of Geo-Information 8, no. 12: 550. https://doi.org/10.3390/ijgi8120550
APA StyleSeo, K., Ahn, J., & Im, D.-H. (2019). Optimization of Shortest-Path Search on RDBMS-Based Graphs. ISPRS International Journal of Geo-Information, 8(12), 550. https://doi.org/10.3390/ijgi8120550