1. Introduction
Crime, like any other event, always occurs at a particular place and time. Geographic information systems (GISs) have been used by law enforcement agencies (LEAs) to help their crime analysis divisions visually represent and understand crime patterns over space and time. Currently, there is a two-part classification of crimes, but only Part I offenses were used for this research since they include spatial information on where they occurred. Part I offenses include eight crime types, namely criminal homicide, rape, robbery, aggravated assault, burglary, larceny, auto theft, and arson. Based on a variety of crime theories, there are several methods that one can employ for crime analysis which aid in crime reduction efforts by LEAs, especially within high crime areas. Brantingham’s crime pattern theory deals with crime–place association that leads to the generation of these high crime areas. The theory explains that crimes are not random, and they do not occur uniformly in time, space, or society [
1]. This has led geospatial crime analysts to use spatial analysis and statistic tools to perform crime analysis and determine the high crime areas and spatial or temporal patterns. Using the Part I crimes, studies have mainly concentrated on mapping crime point density, kernel density, hot spot, and heat maps while finding correlations with the help of R and R-ArcGIS Bridge, or other statistical software [
2,
3,
4]. One of the most popular methods of the listed techniques is hot spot analysis. Hot spots are defined as smaller areas that suffer from statistically significant clusters of crime.
Hot spot policing has become a common way for police departments to prevent crime [
5]. Recently, results of studies have supported the assertion that focused police efforts on hot spots can be effective in preventing crime [
5,
6,
7,
8,
9,
10]. In a national survey sample of police departments with over 100 officers, 62% reported using crime mapping to identify crime hot spots for concentrated efforts [
11]. In 2016, 17 systematic reviews of policing performed for more than 13 years concluded that most of the effective policing strategies regarding crime control concentrated on small geographic areas [
12]. Systematic reviews are relevant because they provide an assured test of strategy effectiveness, which is an essential resource in academia, criminology, and police practitioner interests [
12]. Though current neighborhood hot spot methods fulfill their goal of visually representing crime occurrences and helping LEAs and civilians be aware of what is happening around them, they lack an accurate representation at the street level. This is because crime concentrates and is stable at a micro-scale/minimal units of geography [
13,
14,
15], and there is an increased chance to miss important crime variation in higher geographic units [
14]. When crime concentrates at certain places to form hot spots on the micro-scale such as streets, these high crime segments are called hot streets. Hot street creation often happens at the neighborhood level to provide the missing degree of high precision for observing crimes [
16]. The criminology of a place has reveals many times that there are high crime streets in low-crime neighborhoods and low crime streets in high-crime neighborhoods [
17]. As a few streets contain the majority of crime, studies have shown that patrols of hot spots in those neighborhoods and the remainder of the city have resulted in reductions in crime [
5,
18]. Since there has been no easy way of delineating linear hot spots, also known as hot streets [
19], this research provides a way to efficiently replicate the creation of hot spots at a street-level as hot streets.
Currently, there are several techniques used for the identification of hot streets for policing, as no single method is sufficient and a majority of the methods are not straight forward [
19]. As seen in several examples [
4,
14,
19,
20], most of the current street analyses of crime patterns include the use of total crime count by street symbolized in several ways including point density raster attachment. There are several ways to use statistics to find spatial clusters, e.g., Moran’s I, local Moran’s I, Geary’s C, Getis Ord Gi, and Getis Ord Gi* [
3]. For a hot street analysis to be a significant measure of crime clusters like the hot spot analysis tool, it has to utilize a GIS and apply spatial statistical tests to ensure that the clustering is not a result of random chance [
21]. Currently, the local Moran’s I approach has been used to find the spatial autocorrelation between streets in order to display hot streets [
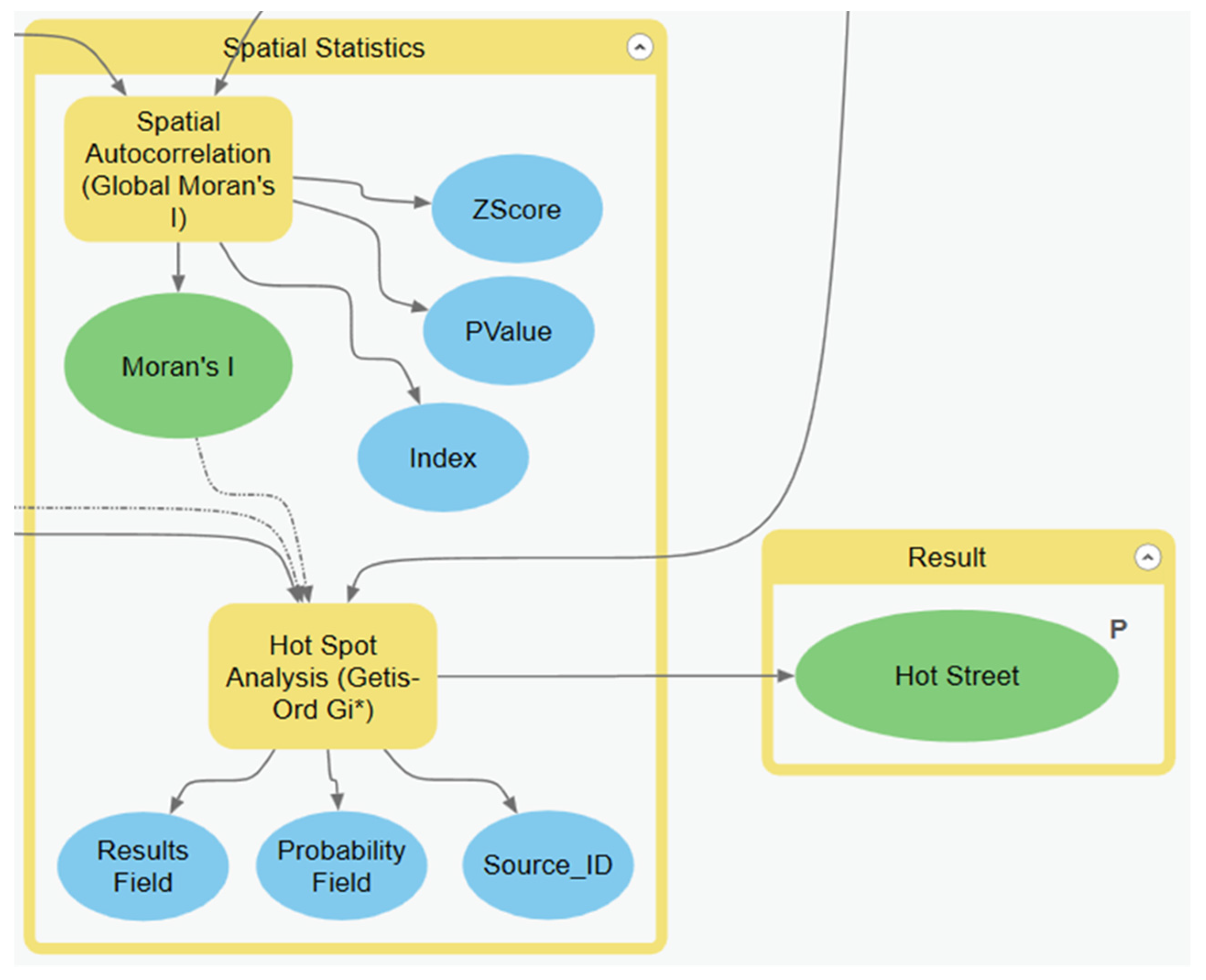
14]. This research delves into the creation of a model that uses a different correlation method called the Getis Ord Gi* statistic. The Getis Ord Gi* is a very popular statistic used in finding hot spots between polygon and point features. Both the Gi* statistic and the local Moran’s I are significant measures of local spatial clusters, but they vary in how they are calculated [
22]. For the local Moran’s I, the value for the feature (street) being analyzed is not included in the analysis, as only the value of the nearby features determine the result. The Getis Ord Gi* takes account the value of each feature, including the feature being analyzed, to find the clusters. Both methods are expected to have some similarities in the results, but there are also a few differences. By developing a method to use the Gi* statistic in this research, future work can be performed to see which methods of correlation will yield the best micro-scale results.
Though the Gi* statistic is widely used for hot spots, there are a lack of publications that utilize the statistic on the street level. There is only one methodology [
23] that describes how to utilize the Gi* statistic on the street level. This work fills the knowledge gap of hot street development through the addition of a Gi* clustering algorithm that that adds spatial statistical values. The Getis Ord Gi* statistic is used in this research because it takes account of the feature being analyzed, as well as the neighboring features, to locate where high (hot street) and low (cold street) values spatially cluster and show local dependence [
24]. In addition to previous work, this study uses modified procedures and provides a model for others.
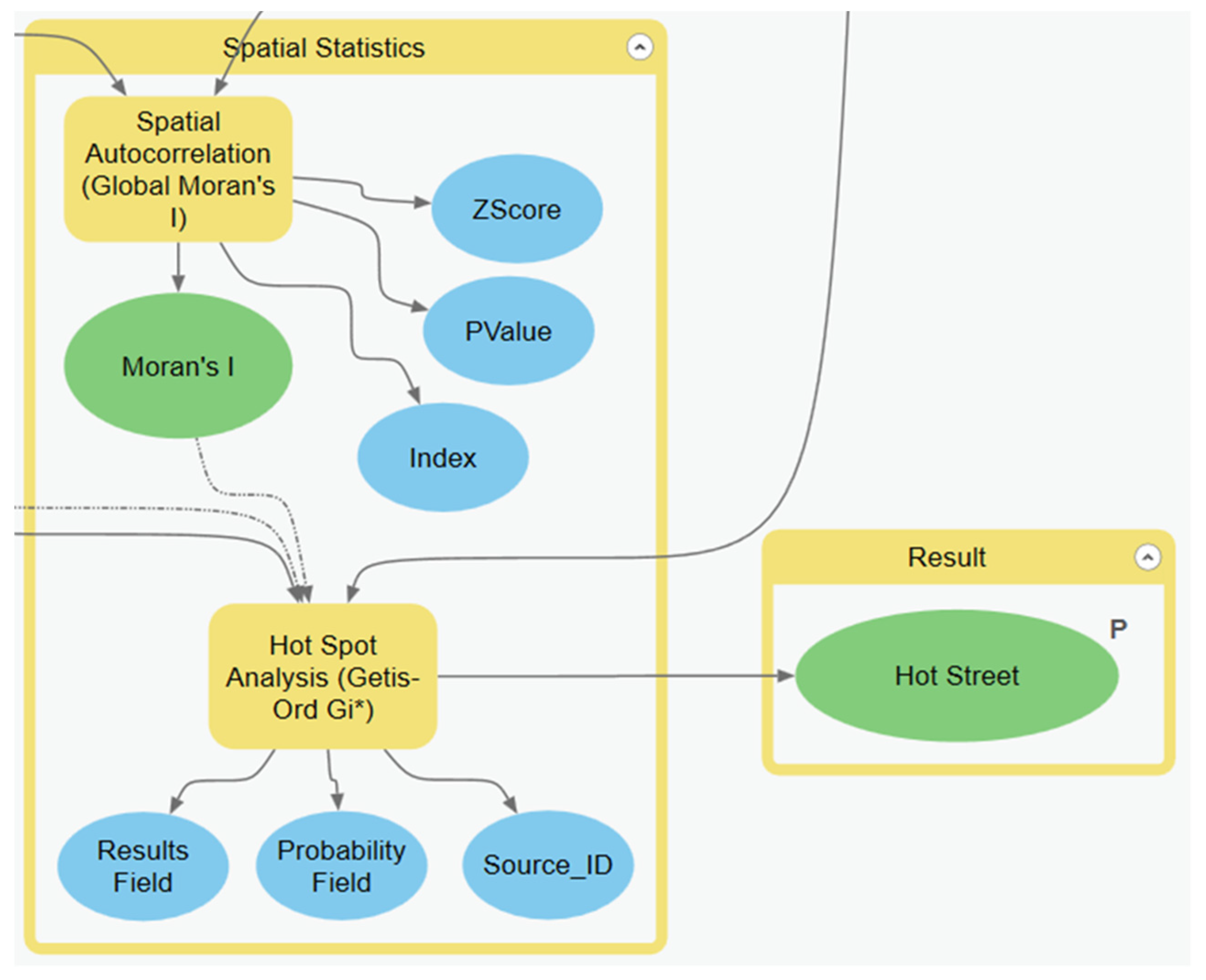
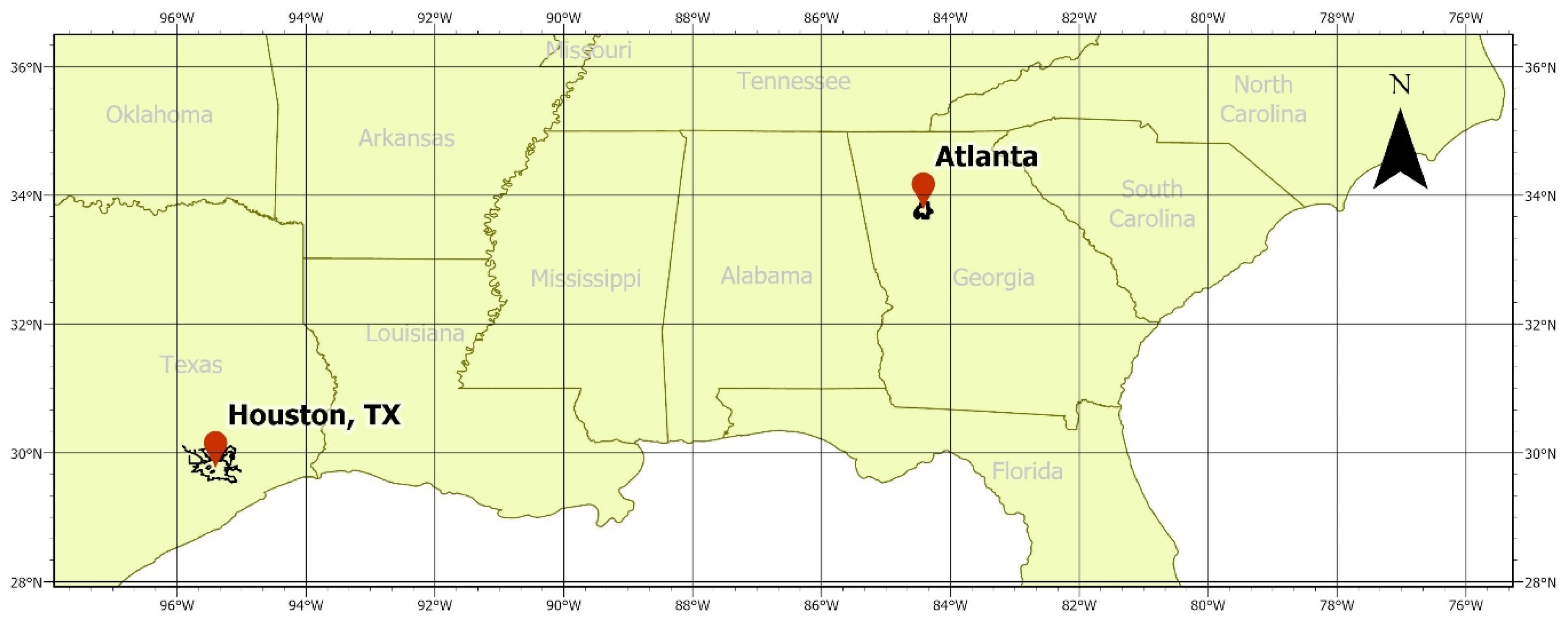
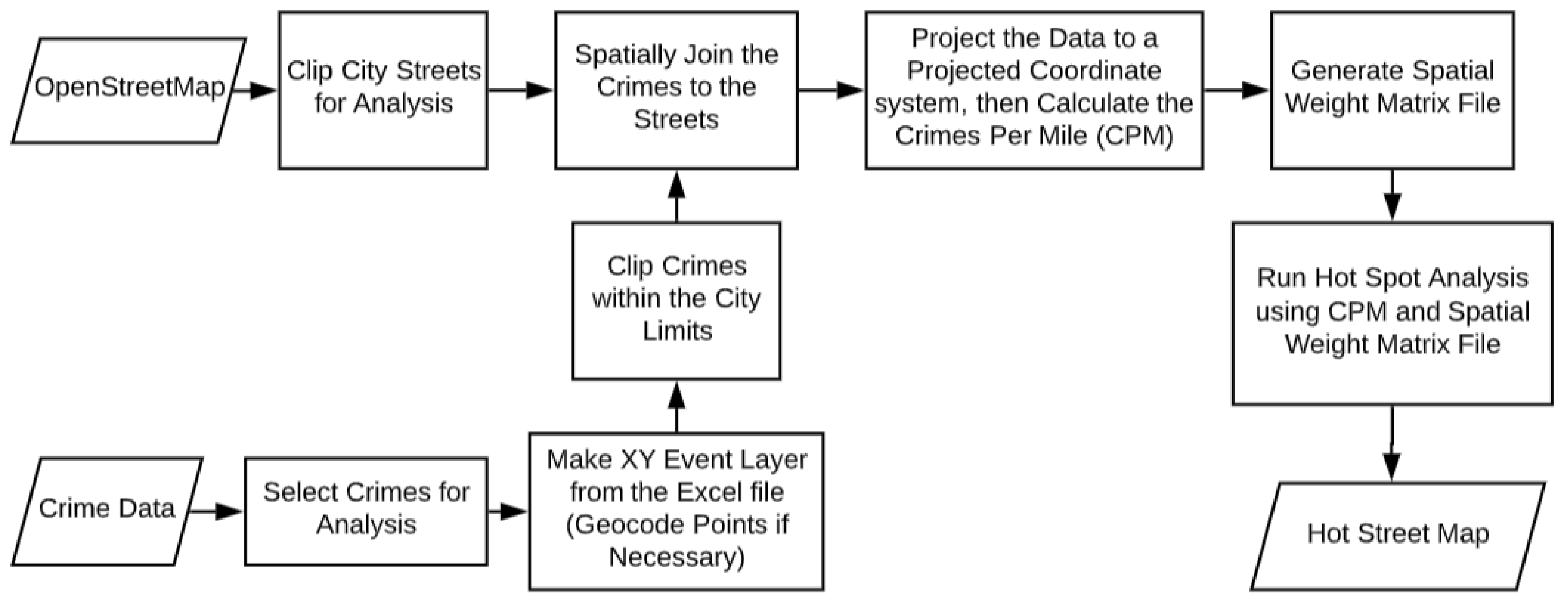
The primary research goal is to further studies on the creation of hot streets within a GIS through the development of an efficient model that uses the Getis Ord Gi* statistic. The Getis Ord Gi* delineates statistically significant spatial clusters once the crimes are attached to the nearest streets. This method should provide LEAs with a more in-depth and geographically localized result. The hot streets model created in this work is used at multiple scales within the study areas of Atlanta, Georgia and Houston, Texas to examine street-level relationships of crime. Clusters of high and low values were visualized and statistical significance was determined through the z-scores and
p-values that display spatial clusters of streets with high and low occurrences of crime. This research presents an automated model for achieving the set goal, enabling people of all experiences and levels to perform analysis. The resulting method could lead to safer travel for civilians, reduced crime along the streets within those hot spot areas, and more precise street segments within regions for police intervention, and better allocation of police resources [
14].
4. Discussion
The model was successful in providing an effective way to evaluate linear spatial clusters and hot streets. The modifiable areal unit problem (MAUP) must be considered here because different aggregation schemes yield different results despite using the same analysis and data [
34]. Results that are valid for the street-level crime study may be more accurate than broader area aggregation techniques. Despite the MAUP problem, different results are often valid because different analyses seek to answer different questions on a variety of scales. Hence, practitioners should be aware of this issue and select an appropriate scale of analysis for their analysis when utilizing this model.
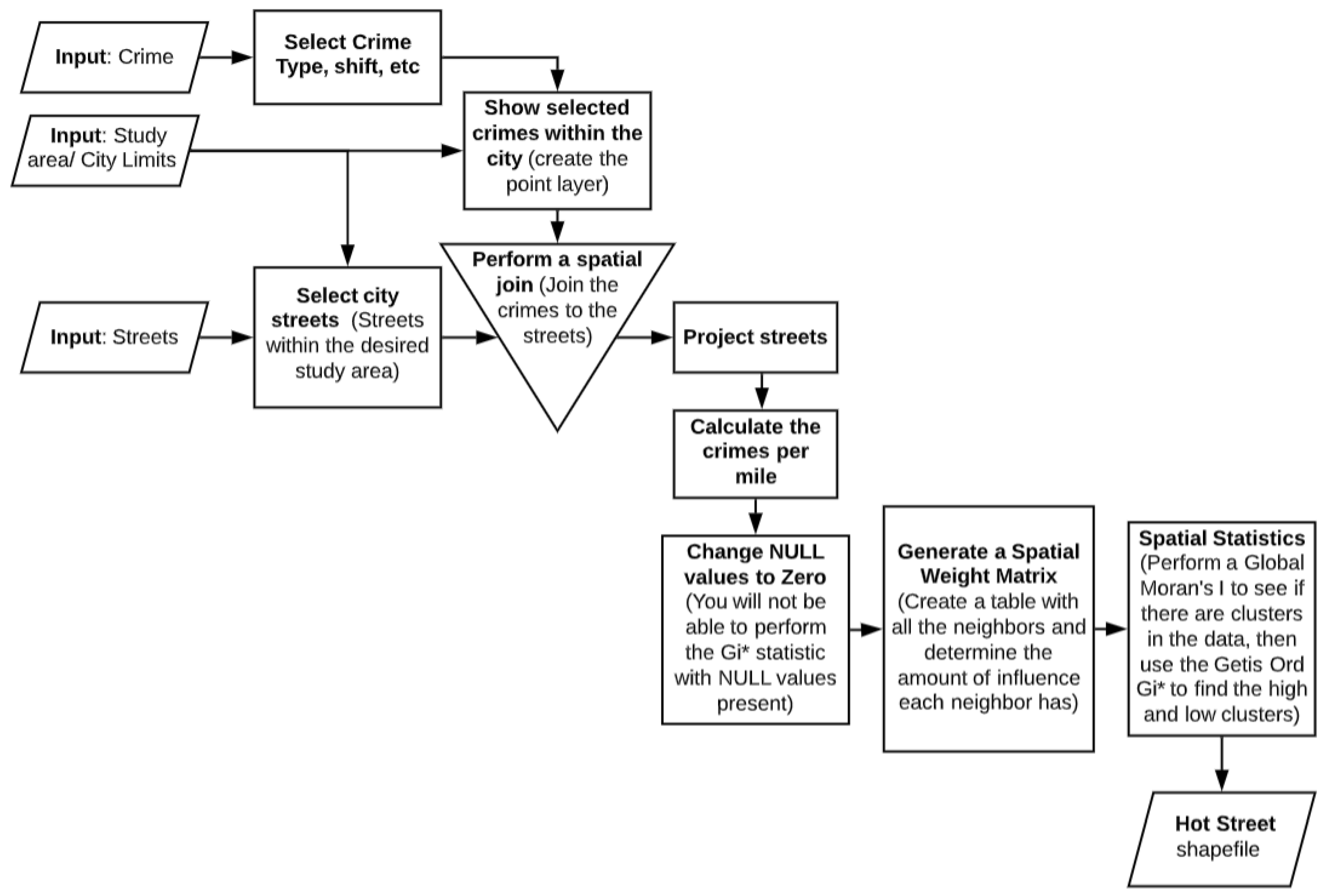
4.1. Model
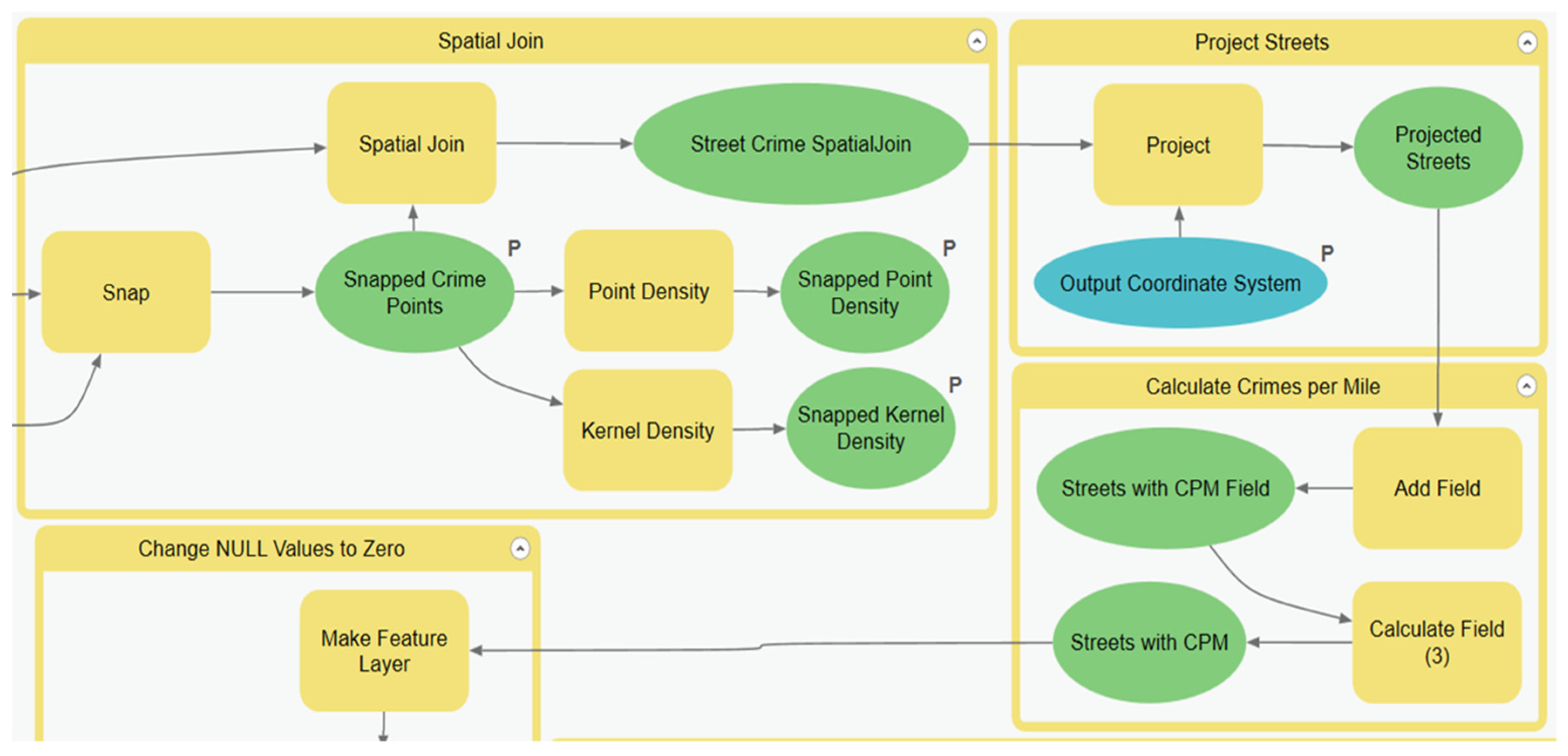
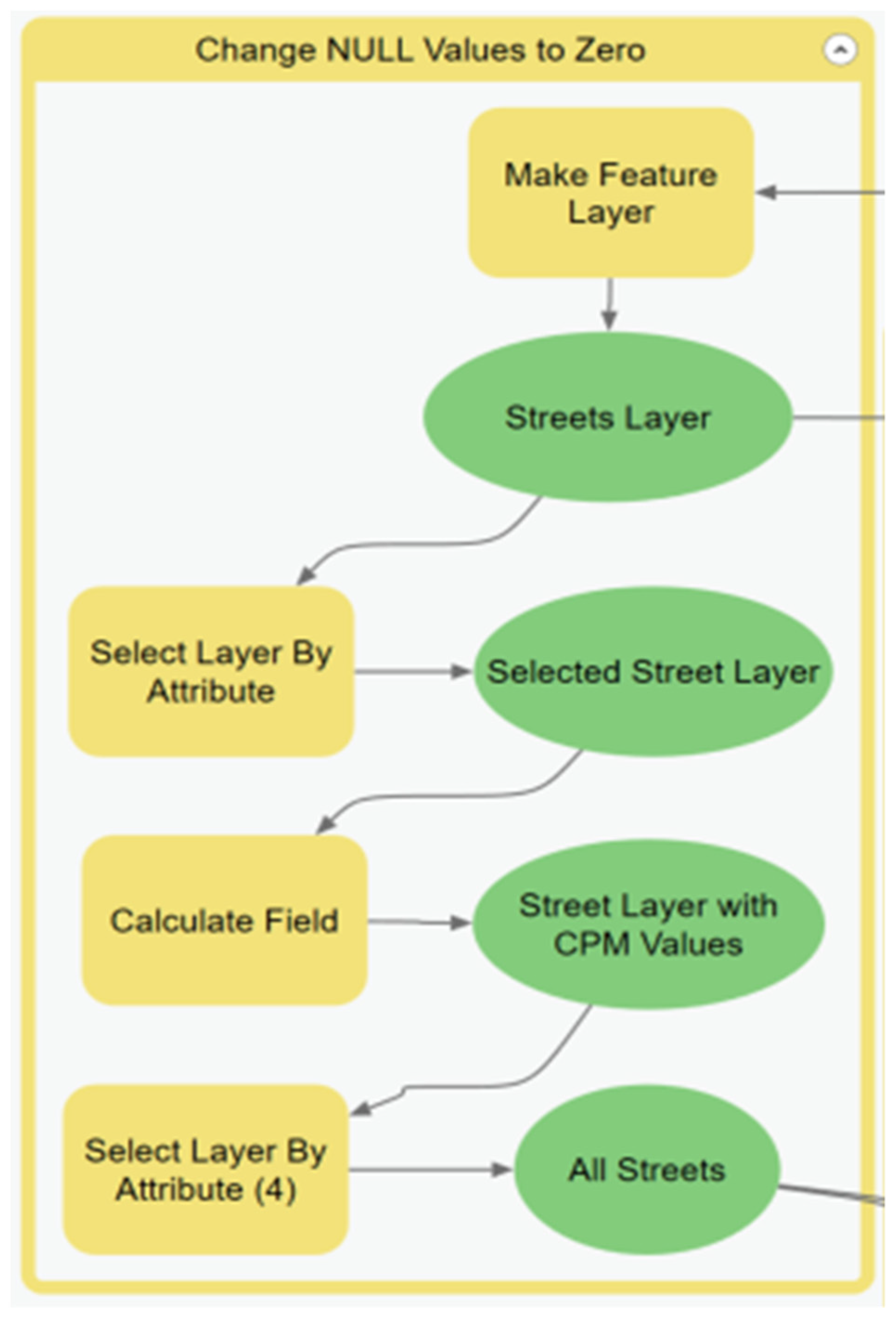
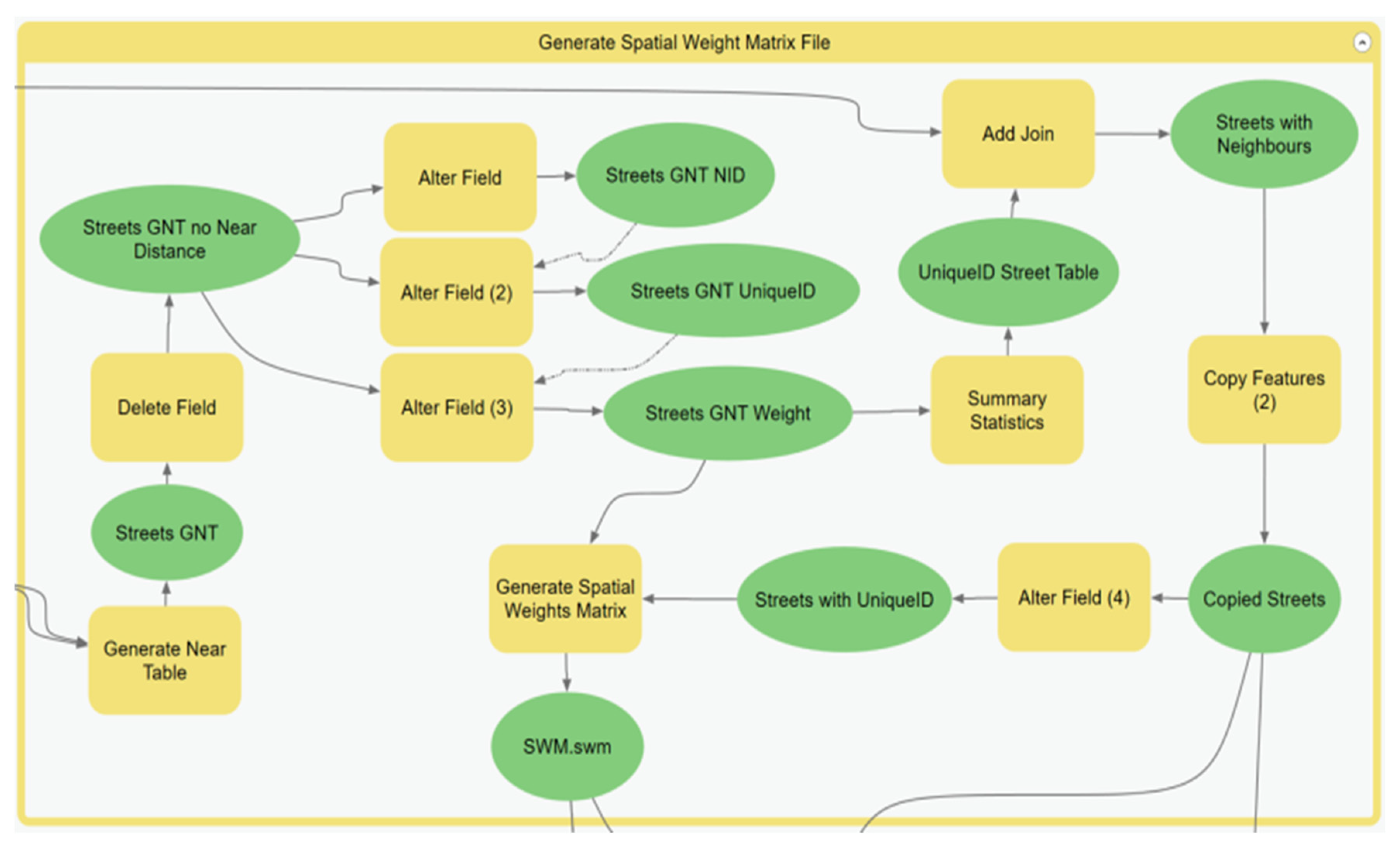
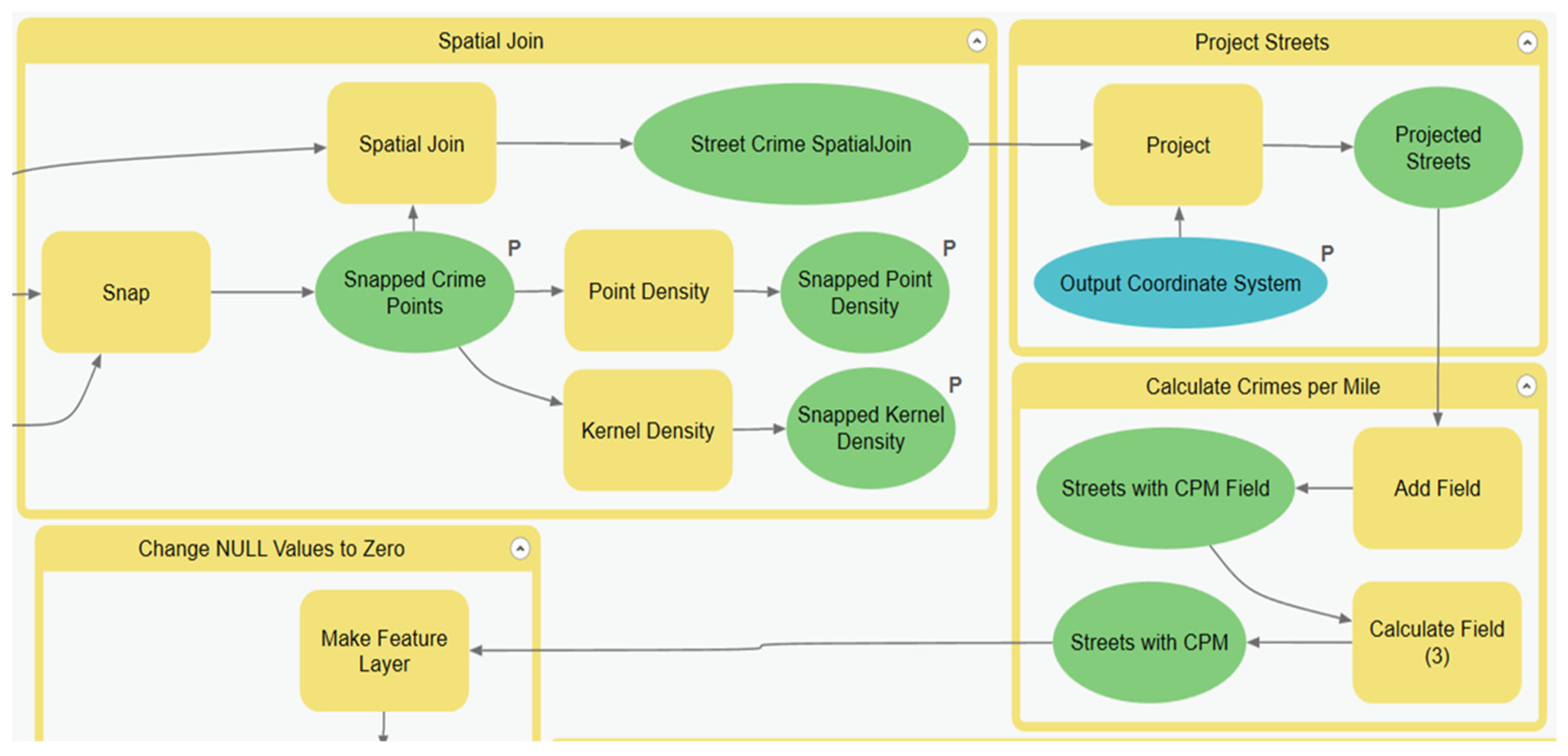
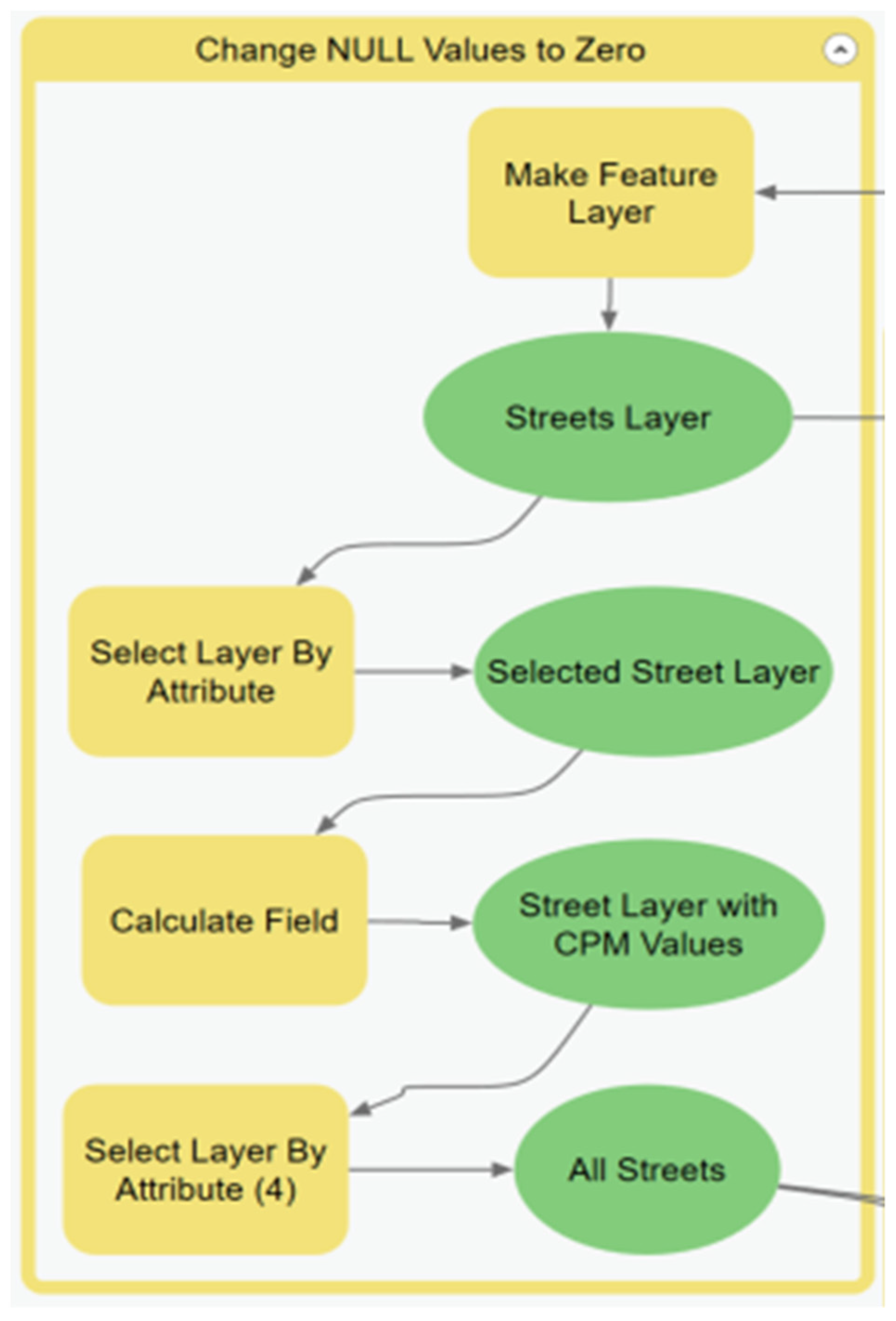
Through the course of developing this model, it was discovered that it could easily be replicated at different scales within different GISs by using the model flowcharts as a guide. After the initial run, the model can be optimized by removing processes that will produce the same result. The sub-model that can be changed is the Generate Spatial Weight Matrix (SWM) sub-model. The sub-model can be removed once the SWM file is created because the table will remain the same if the street layer and the scale of analysis is the same.
The full hot street model can take a considerable amount of time to run, depending on the input parameters of each sub-model. The streets appear to be the primary input that determines the run time of the model. The city of Atlanta had approximately 40,000 streets in the data, and the city of Houston had approximately 120,000 streets. Houston had about three times the number of streets in Atlanta, and the run time from
Table 1 shows a three-times increase in the run time. The streets took time to process when linking them with crimes and calculating the crimes per street segment. Overall, within ModelBuilder, the median time of the entire model when using the Generate Near Table tool to create the spatial weight matrix (SWM) file was 4 min 31 s. When the Summarize Nearby tool was used to create the spatial weight input table, the runtime for the same scale of analysis was increased by approximately 25 min to bring the full model runtime to an average of 30 min. When more complex distance units such as the travel time were used, the time could scale up to an hour or more for the first run. It is recommended that if the Summarize Nearby tool is used, the spatial weight matrix should be prebuilt using ranges of drive time or distance, e.g., 5, 15, or 30 min.
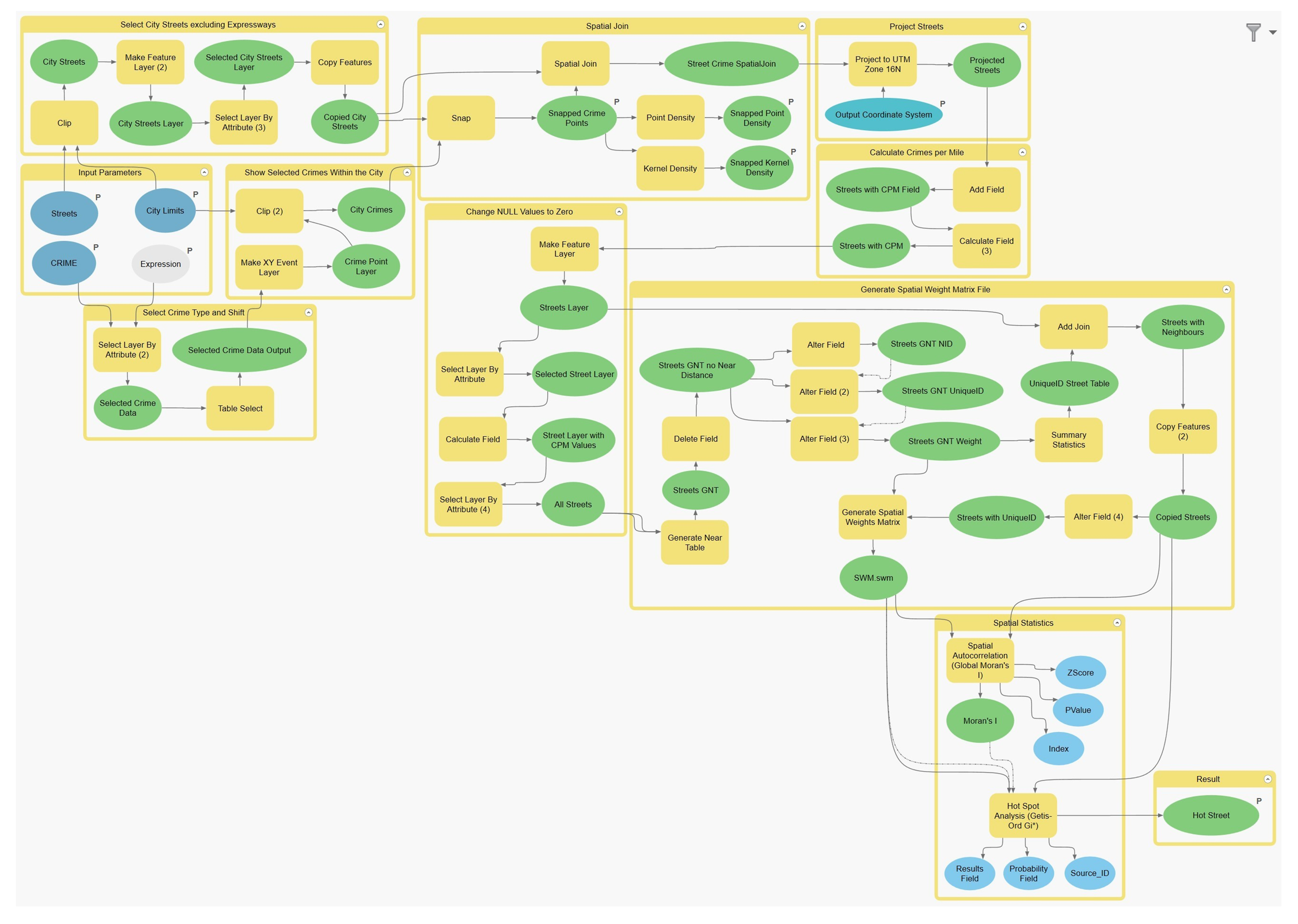
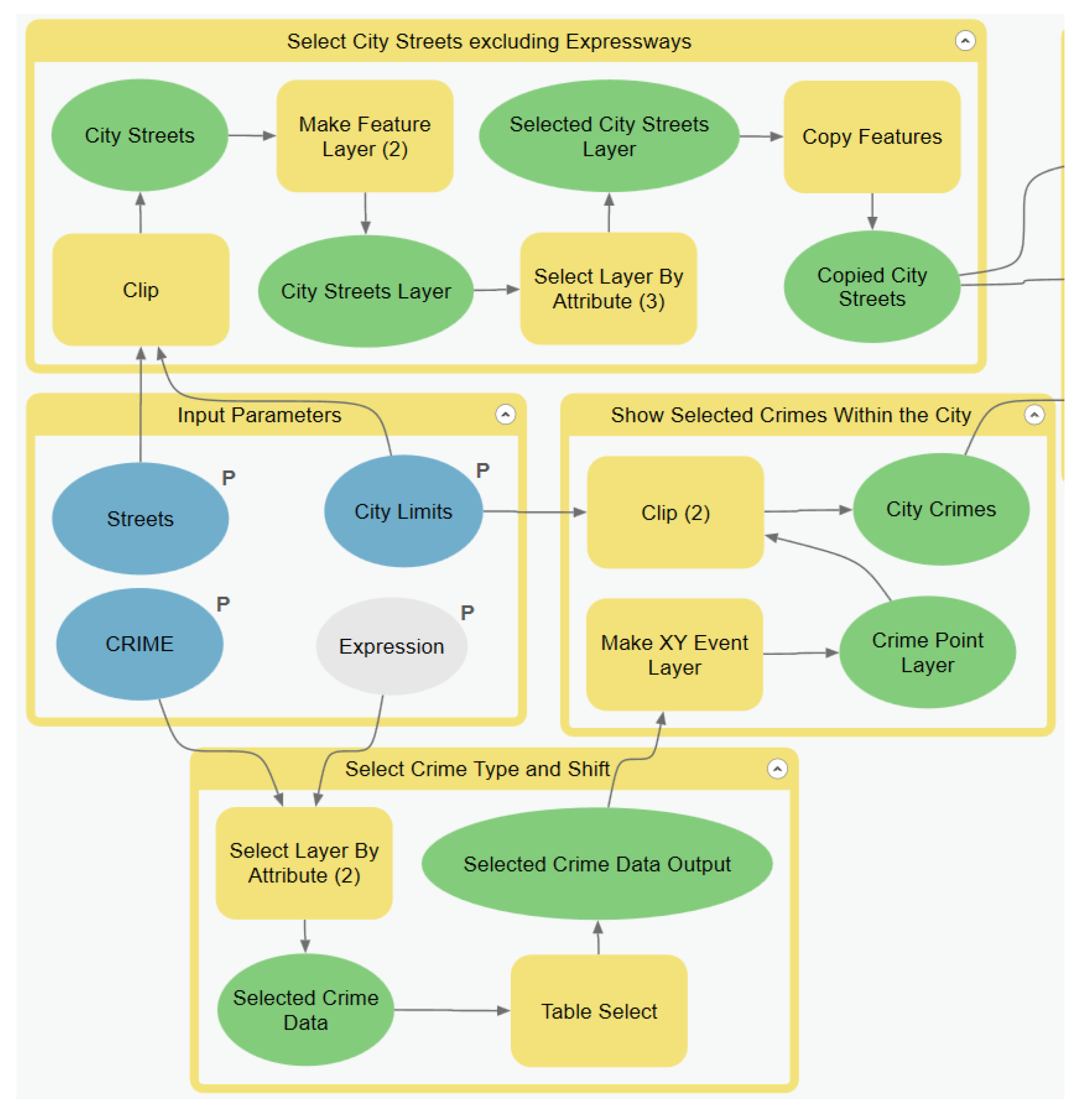
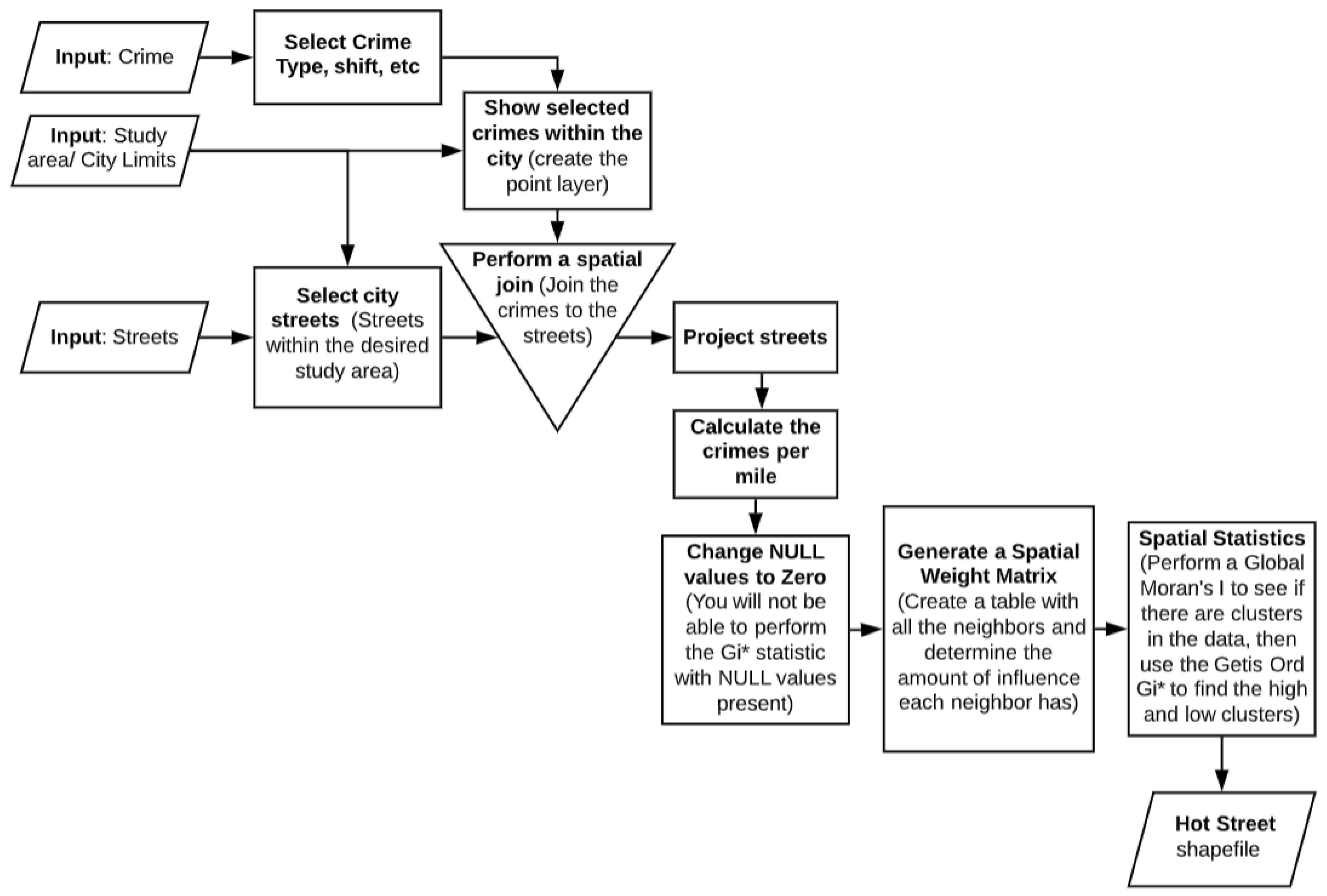
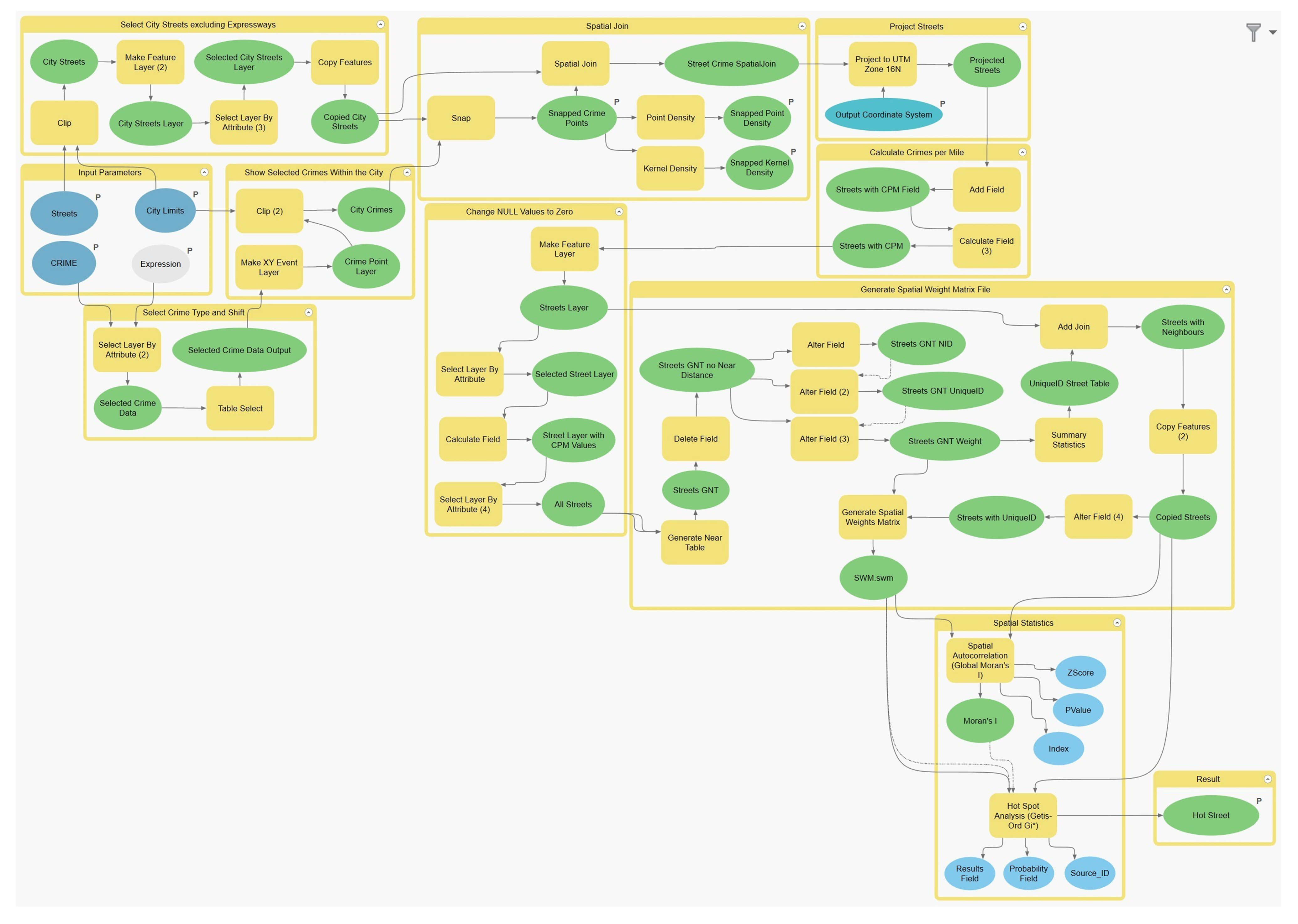
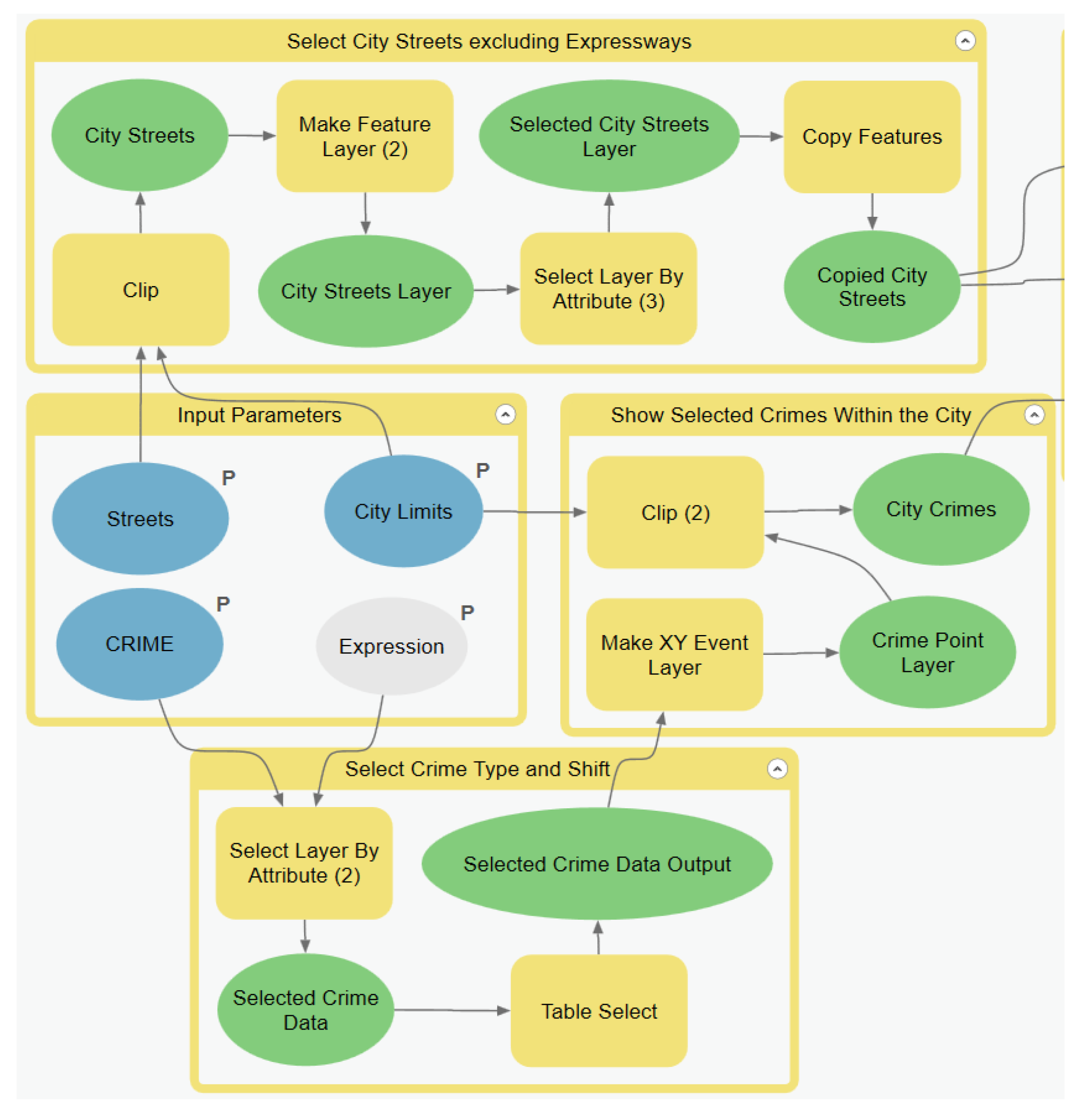
If an error occurs, two processes in two separate sub-models would most likely be the source. The first is properly locating the data points via the Make XY Event Layer found within the Show Selected Crimes Within the City sub-model (see
Appendix A). The crime data might not have the proper field name, and the GIS thus may not be able to create the point layers for future tasks. The next process is joining the crime data points to the streets via the Spatial Join tool within the Spatial Join sub-model (see
Appendix A). The Spatial Join tool should be cross-checked to ensure that the output fields that sum the count of crimes per street layer is connected to the proper fields in the data layer.
4.2. Hot Streets Results
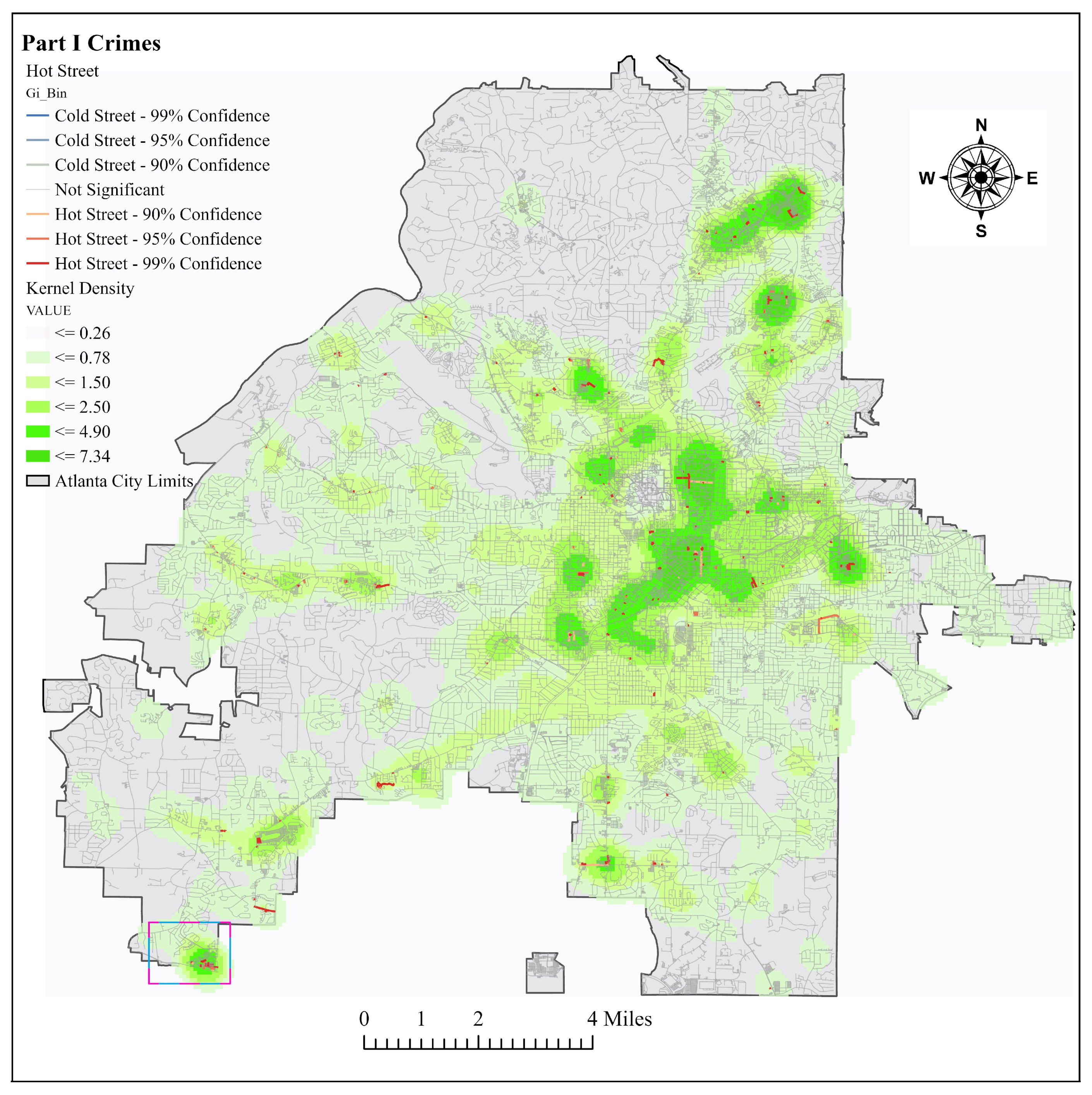
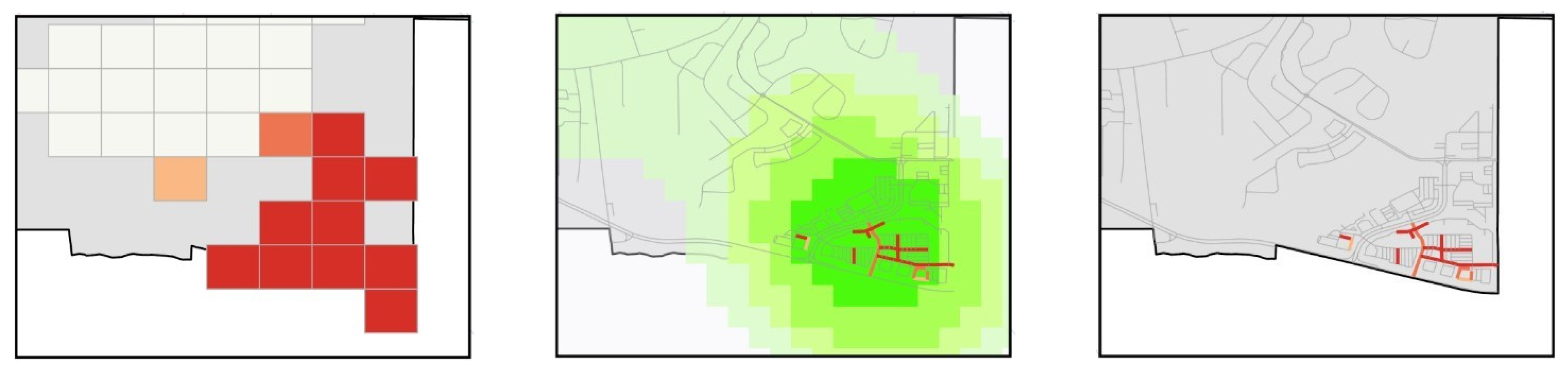
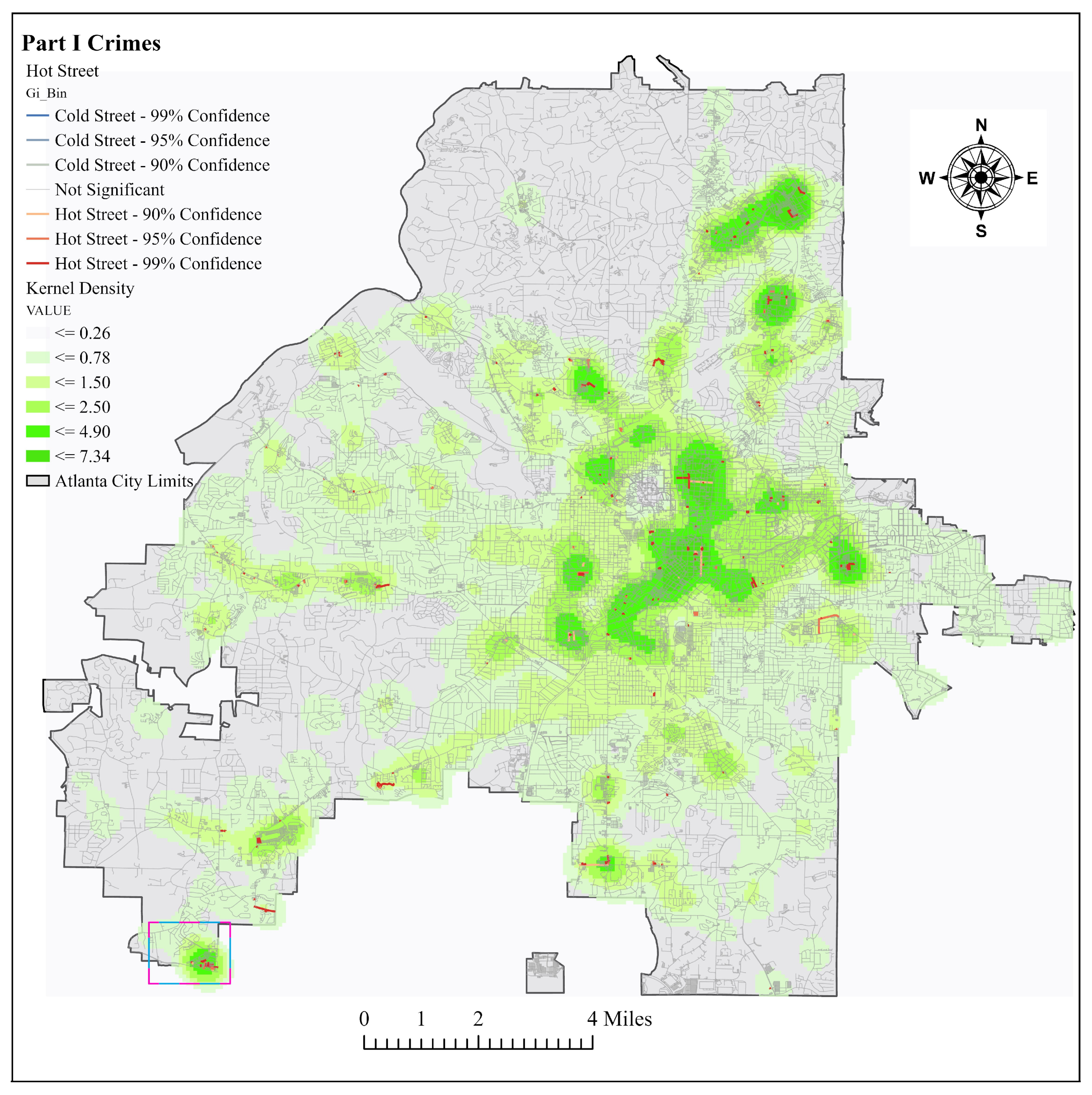
The model was run multiple times, but only seven runs were described here. Most of the crime points appear to be clustered at the eastern part of downtown Atlanta, north-east of the city, and the southwest. At the current scale of analysis, which included only intersecting streets, no cold streets were found. Other runs performed at the early stages of the model, which did not take account of street connectivity and used only Euclidean distance, did display cold spots. Thus, it is safe to anticipate that cold spots will appear once the scale of analysis is increased. Additionally, no cold spots existed for some of the runs when using the Optimized Hot Spot tool, which picks the best aggregation levels to show maximum clustering. Therefore, the authors are not overtly concerned that at the current scale of analysis no cold streets were delineated.
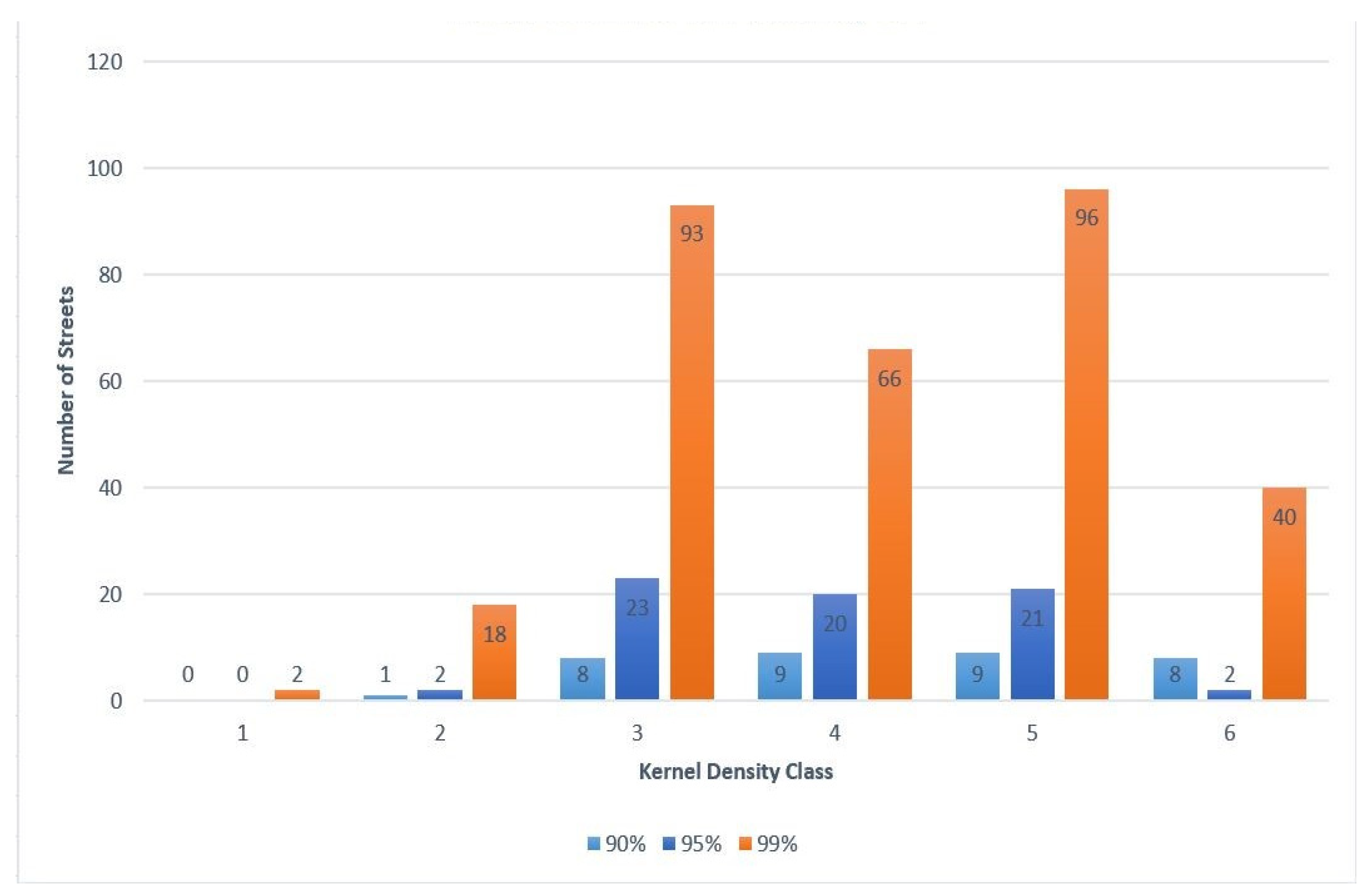
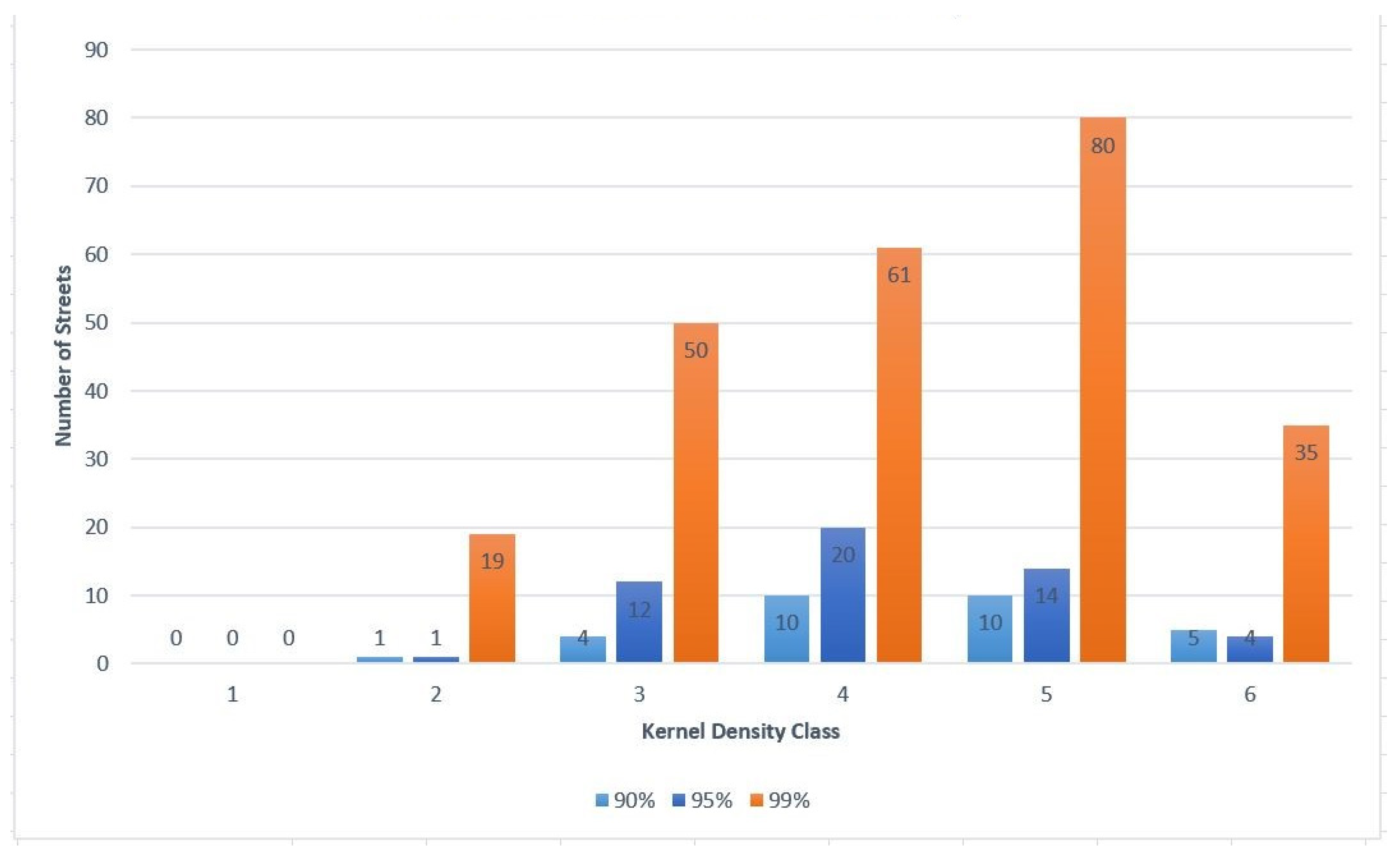
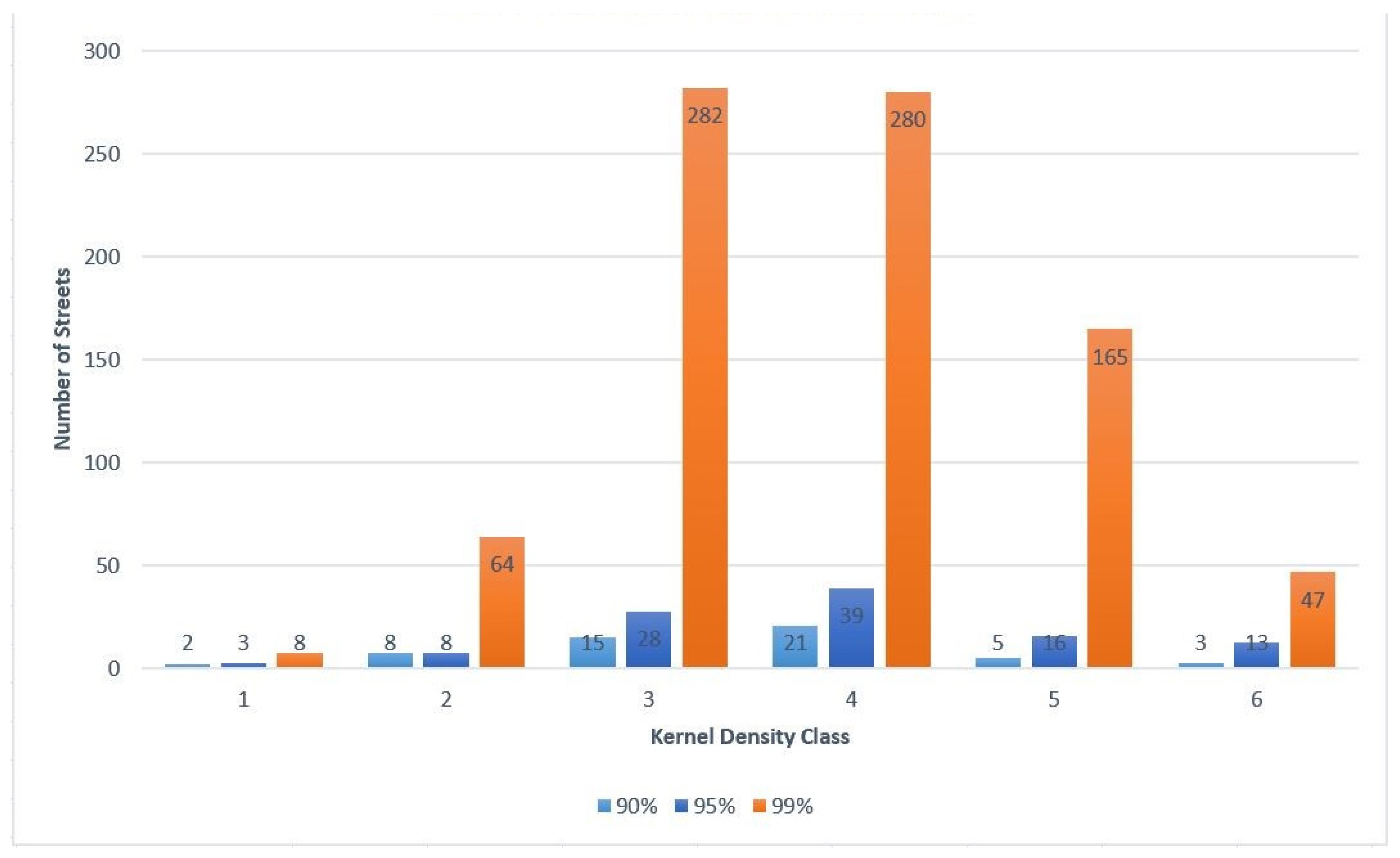
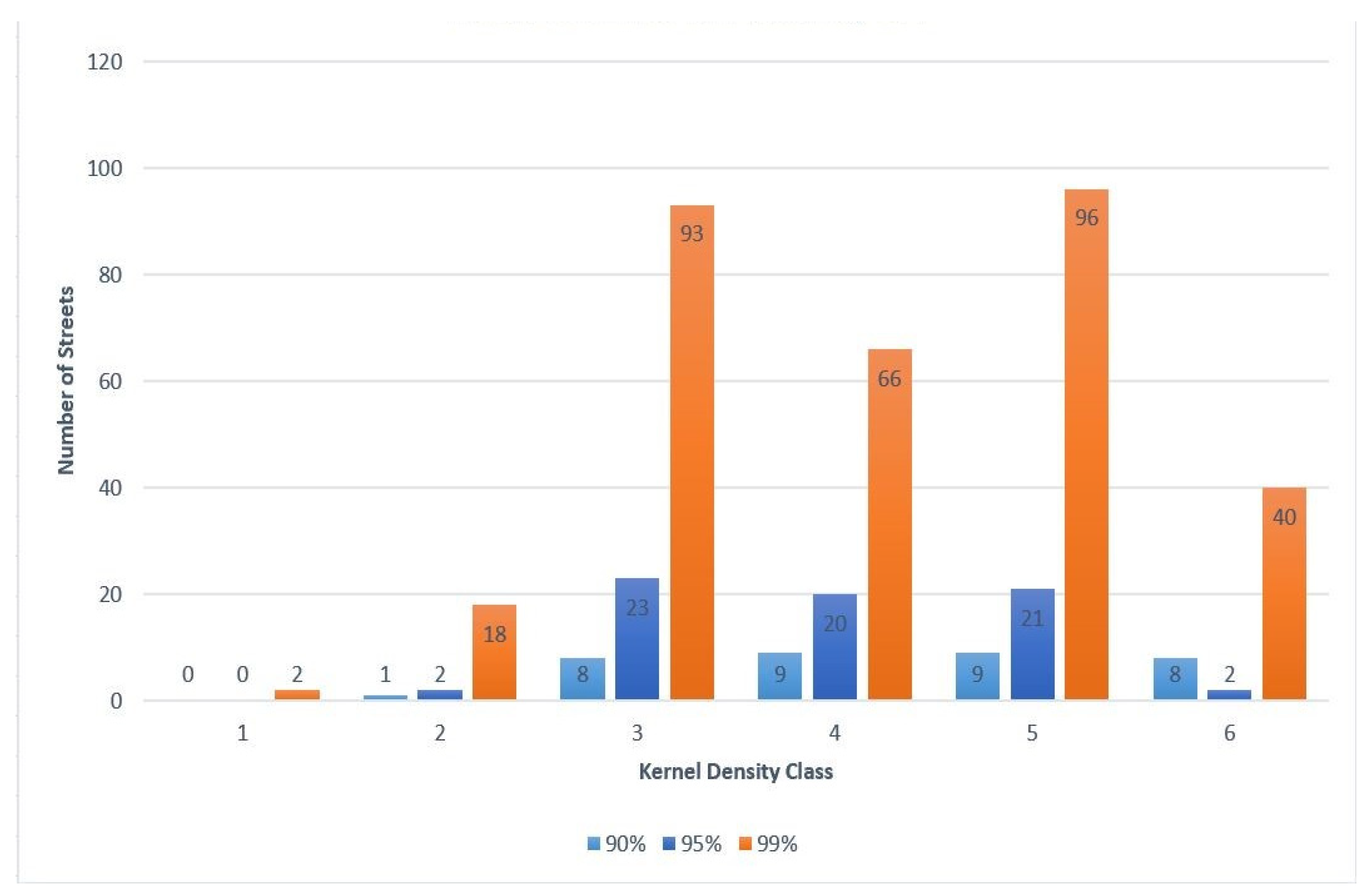
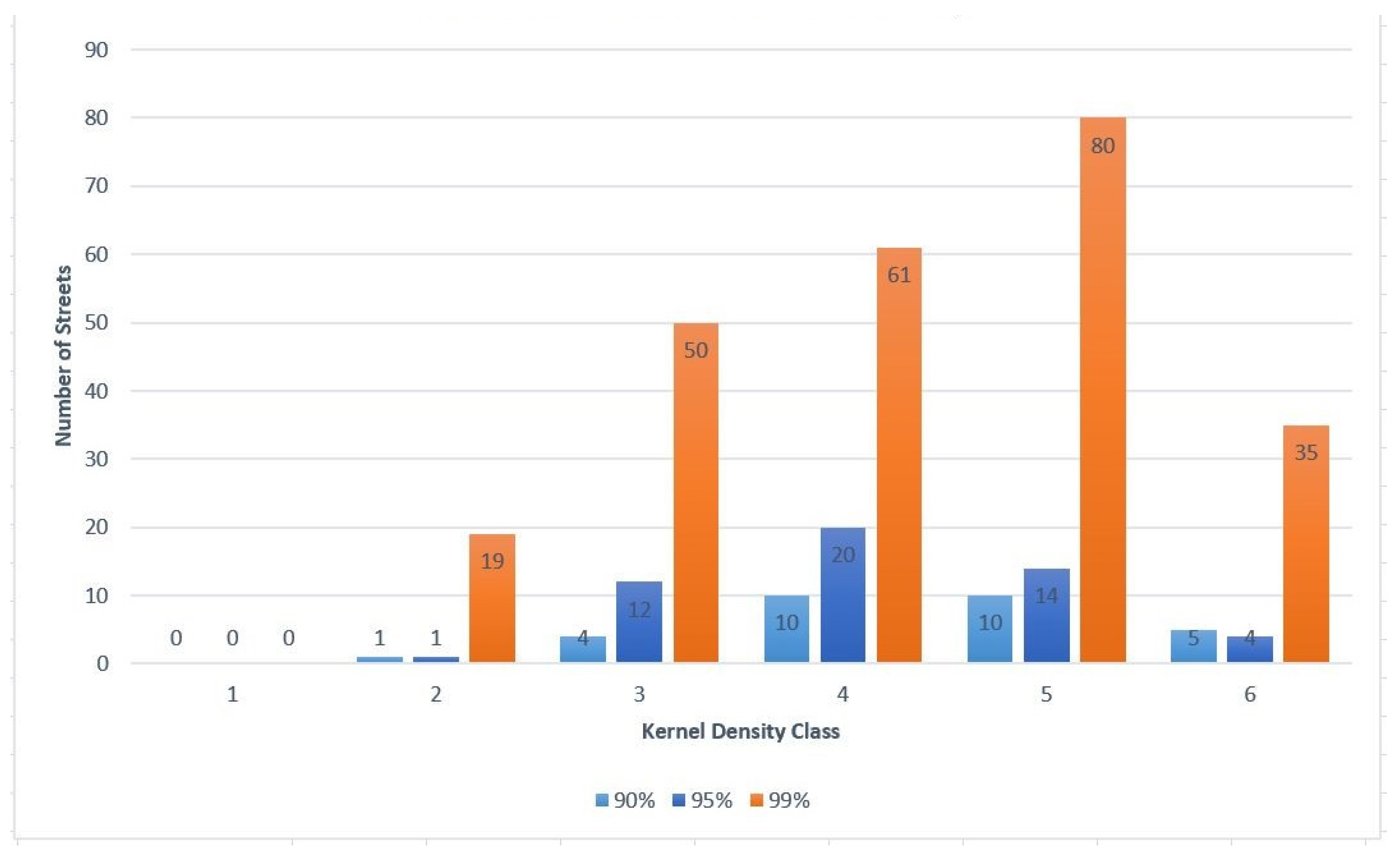
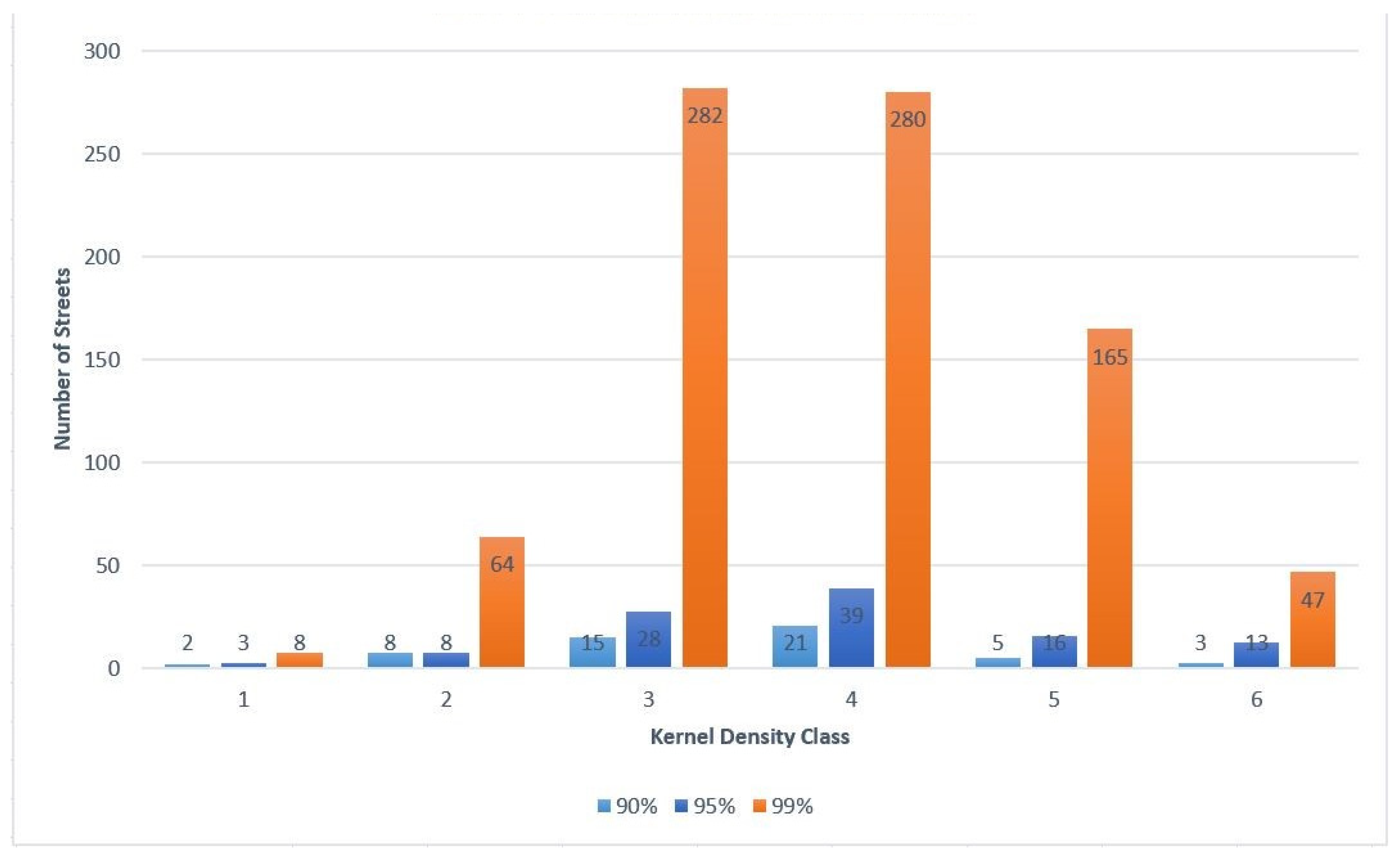
4.2.1. Hot Street Overlap with Kernel Density
For all the hot street maps created, there was an overlay with the kernel density raster layer. The kernel densities were created used the default bandwidth, which was computed with the spatial variant of Silverman’s rule of thumb [
35]. The kernel density was divided into six classes similar to the hot streets, and, before the model was run, it was expected that most of the hot streets would fall within high crime density areas. After analyzing the results from multiple runs, it appears that most of the hot streets appeared in higher density classes. The top three density classes had the most hot streets. In the lowest density class, hot streets hardly occurred. A total of 15 out of 1751 hot streets for all combined runs coincided with the lowest density class, but these streets were occasionally close to the next density class or had multiple crimes at the same street location.
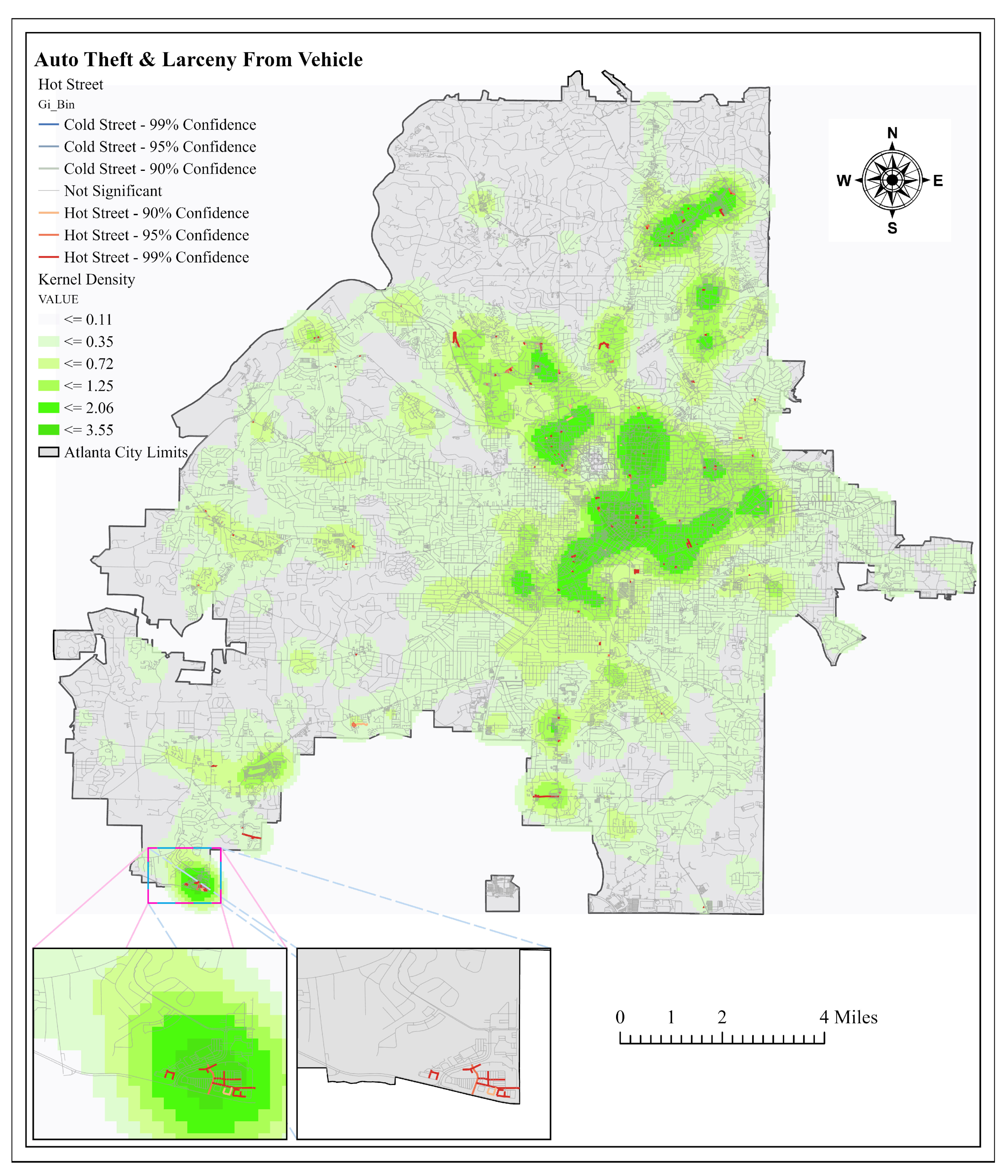
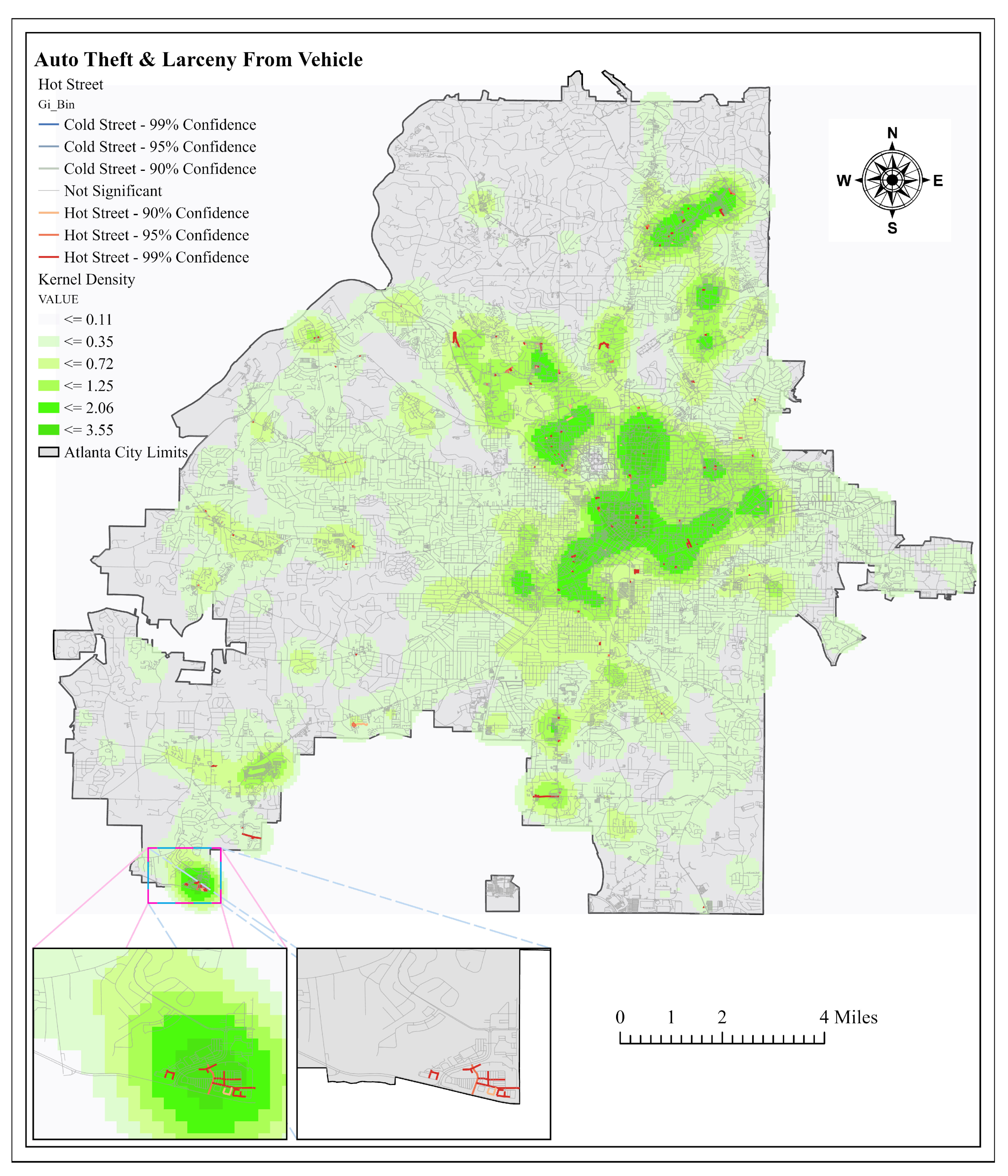
4.2.2. Atlanta Part 1 vs. Auto Theft and Vehicle Larceny
The Part I crimes were compared with street auto-related crimes to see the difference in associated street incidents. Starting with auto theft and larceny from vehicle, crimes had an 83% match accuracy of crimes to streets, instead of the 81% match seen from Part I crimes. Using the hot street mapping for auto theft and larceny from vehicle provided 8% more hot streets in the three highest density classes than Part I crimes. The increased percentage of hot streets in the higher density classes was significant because this may mean that mapping street related crimes might be the best use of the hot street model. More studies have to be performed to confirm if this holds true in multiple study areas.
4.2.3. Atlanta Part 1 vs. Houston Part 1
Atlanta and Houston Part I crimes were compared to see if there were similarities between the street classes the hot streets occur mostly in. After the analysis, the city of Atlanta had most of the hot streets within the service street class, followed by the residential street class, secondary, tertiary, and finally the primary street class. For the city of Houston, most of the crimes occurred in the secondary streets class, followed by the service, primary, tertiary, and finally the residential streets in order from the highest to lowest number of hot streets. This exemplified the issue of not being able to generalize spatial crime patterns. The same crime analysis in different cities resulted in unique spatial patterns for each locale. Crime analysts can determine particular spatial patterns and the associated street classes, and, subsequently, they are able to present more information to an administrative crime analysis unit to aid the decision-making process.
4.3. Limitations
One of the most significant limitations of this analysis was the accuracy (geographic and attribute) of the crime data provided by the police department. Most of the issues from mismatched crimes to streets resulted from crimes at intersection points or neighboring streets of buildings with exits to both roads, where the crime occurred closer to a different street than the street name given to the crime. Additionally, street segments sometimes did not have names attached to old and newer routes that may appear in police reports. There was also an issue with streets that do not intersect with any other linear feature because the street layer still needs to be properly connected.
4.4. Future Research and Recommendations
Though this model fulfilled the goal of creating an effective means to depict crime patterns for intersecting streets, there are still several improvements that can be made to the methodology. One of the recommended improvements is a larger study area than the intended focus. The study area should be increased beyond the city limits because sometimes the police respond as backup to crimes outside of, but very close to, the city limit boundary. Under this circumstance, the officer might be responsible for filing a report because no hard lines show the boundaries, especially for properties on the border. Increasing the clipped area beyond the initially intended study area or city limits and adding crimes of nearby cities associated with the street segments that cross city limits can represent more accurate patterns on the edge of town. The extent of this increase of the study area depends on the number of neighbors in the study. The streets at the edge of the initial study area should have their neighbors and associated crime included in the analysis, even if those neighbors are beyond the original study area limits.
Second, for this tool to be efficiently used by crime analysts around the United States, it needs to be integrated into the records management system (RMS) currently used by the police so that the analysis can be automated and continuously added to the automatically developed map layers. Finally, the model may also have potential applications in point-to-polyline studies such as car accident patterns. The spatial joins would be more accurate since most of the accidents occur on the road, and the model will show precisely which streets need more safety restrictions for drivers.
5. Conclusions
This study created a standardized model that police departments and civilians in different cities can adopt. This model has proven to be an efficient methodology for the identification of micro-clustering of crime, as it provides a workflow that saves time and is easily manipulated for different desired studies. Additionally, the model results provide an increased chance of catching important crime variation in smaller geographic units. In comparison to kernel density, the hot street analysis model successfully delivers a high level of precision for observing crime patterns on each street. The increased precision pinpoints the streets needed for intervention within the high crime density areas. The model also offers an increased flexibility for crime analysis teams, as it can work on several scales and in different study areas. It is important to note that broadening the number of street neighbors will lead to an increase in analysis run time. Most of the hot streets per area appeared within the higher crime densities in all study areas and presented hot streets in different street classes. Auto-related crimes displayed an increased percentage of streets in higher kernel density classes than Part I crimes. This may support the idea that the model provides more accurate results when studying auto-related events, but future tests will have to be carried out to be certain.
In the city of Atlanta, the service roads class contains over 80% of all the identified hot streets. Service roads include alleys, parking aisles, and other access roads. Based on this finding, a possible approach that can be taken by the police department is crime prevention through environmental design combined with police patrols. For the city of Houston, most crimes occur on the secondary roads. This shows that different cities display different patterns, and after crime analysts find out patterns and associated street classes, they can present more information to the administrative crime analysis unit to aid the decision-making process.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}