pyjeo: A Python Package for the Analysis of Geospatial Data


Abstract
1. Introduction
2. Design of Pyjeo
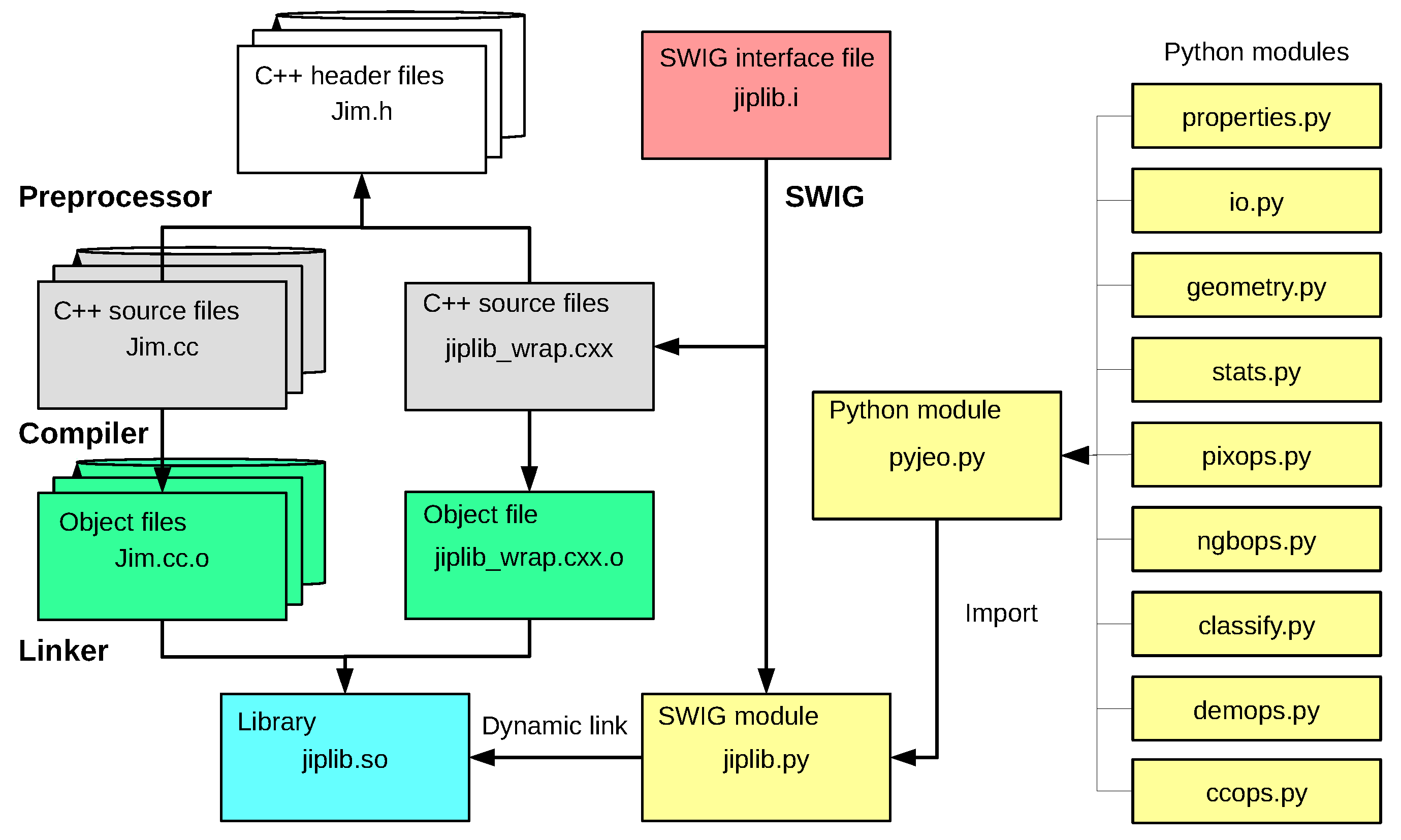
2.1. From C/C++ to Python
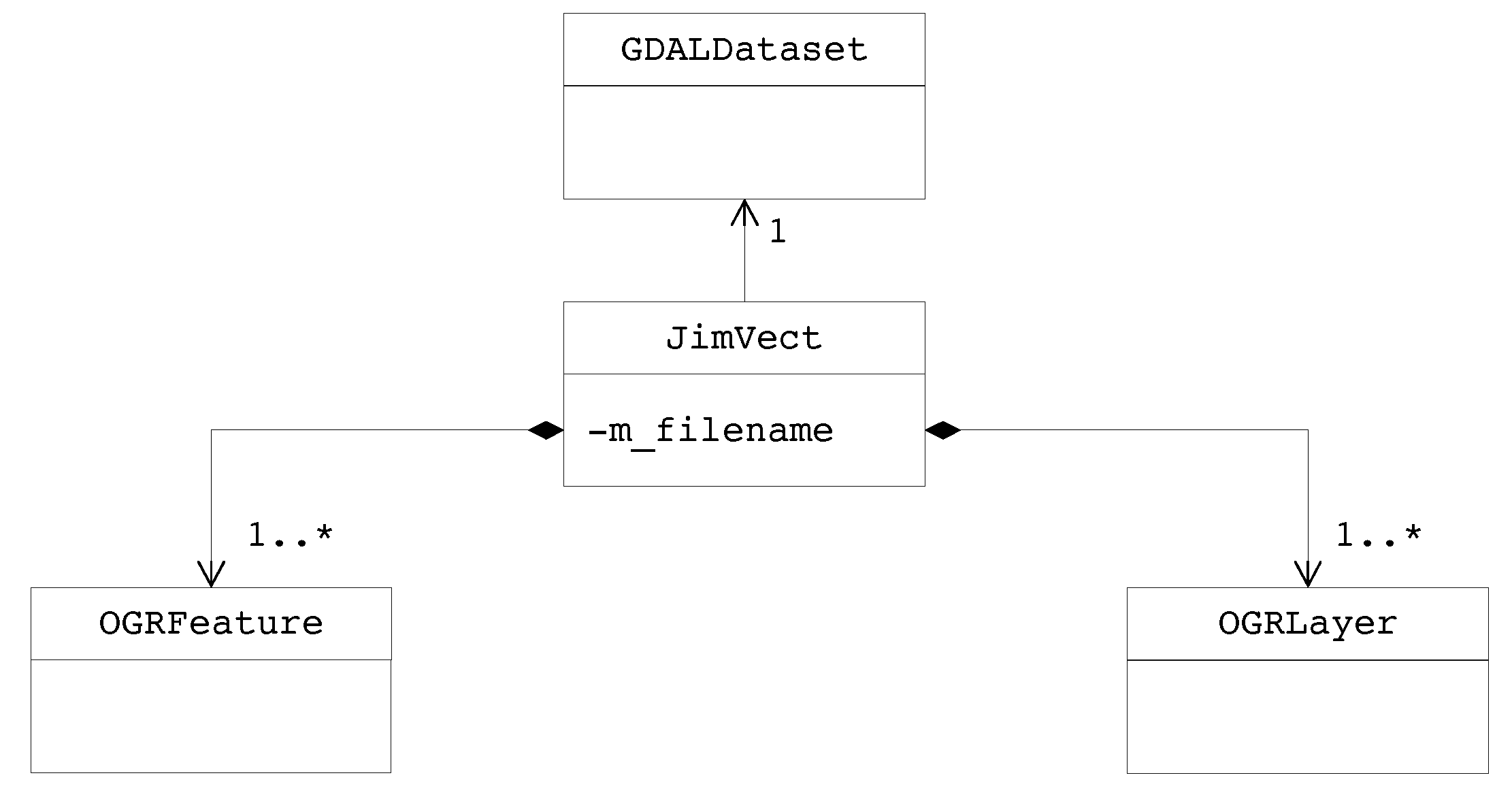
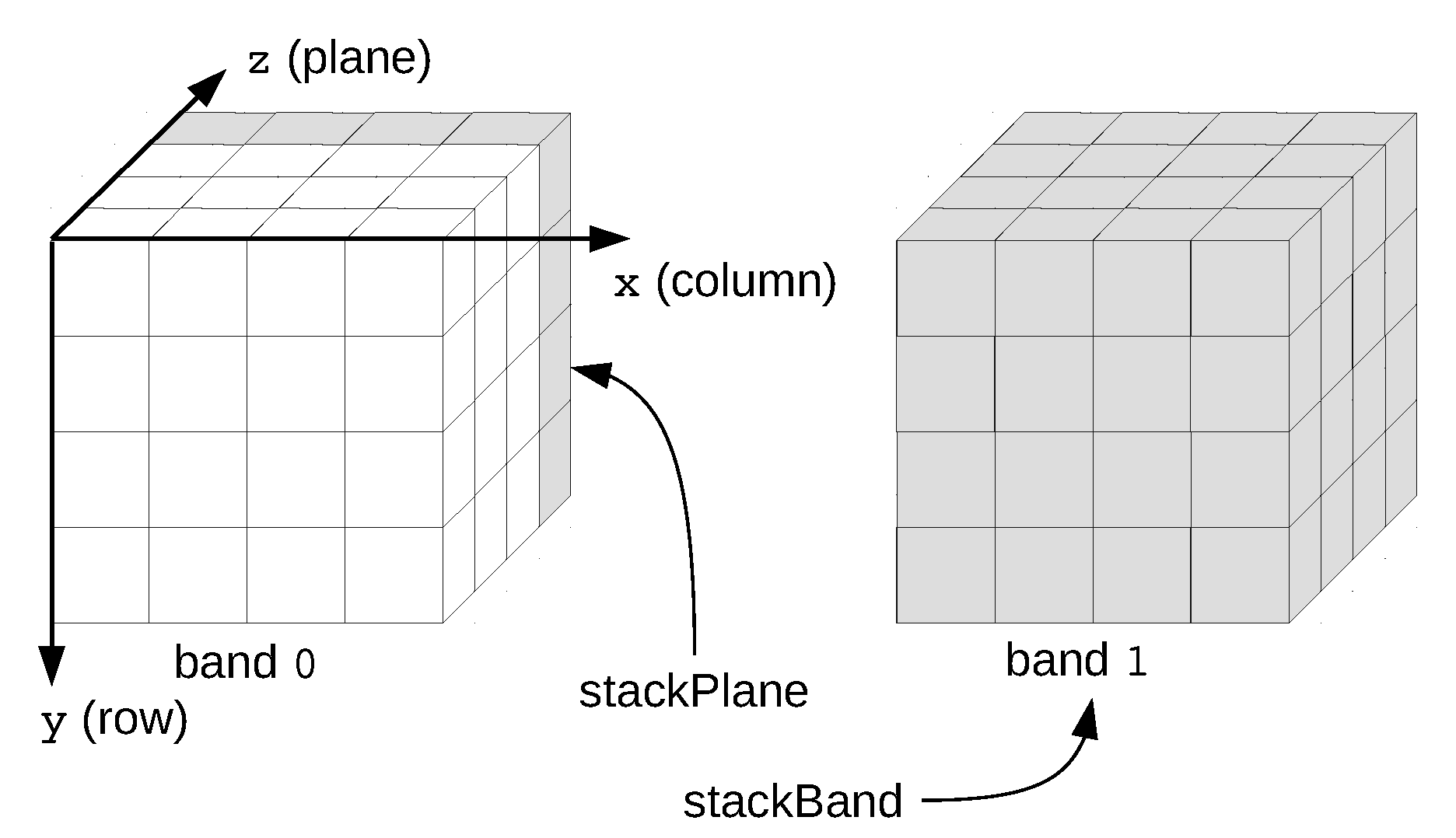
2.2. Data Model
2.3. Integrating Pyjeo for Big Data Analytics
3. Use Cases
3.1. Large-Scale Processing with Pyjeo in Jeo-Batch

3.2. Interactive Processing with Pyjeo in JEO-Lab

4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bakillah, M.; Liang, S. Open Geospatial Data, Software and Standards; Springer: Berlin, Germany, 2016. [Google Scholar]
- Easterbrook, S. Open code for open science? Nat. Geosci. 2014, 7, 779–781. [Google Scholar] [CrossRef]
- Neteler, M.; Mitasova, H. Open Source GIS: A GRASS GIS Approach; The Springer International Series in Engineering and Computer Science; Springer: New York, NY, USA, 2013. [Google Scholar]
- Rupnik, E.; Daakir, M.; Deseilligny, M.P. MicMac—A free, open-source solution for photogrammetry. Open Geospat. Data, Softw. Stand. 2017, 2, 14. [Google Scholar] [CrossRef]
- Grizonnet, M.; Michel, J.; Poughon, V.; Inglada, J.; Savinaud, M.; Cresson, R. Orfeo ToolBox: Open source processing of remote sensing images. Open Geospat. Data Softw. Stand. 2017, 2, 15. [Google Scholar] [CrossRef]
- Appel, M.; Pebesma, E. On-Demand Processing of Data Cubes from Satellite Image Collections with the gdalcubes Library. Data 2019, 4, 92. [Google Scholar] [CrossRef]
- Strobl, P.; Baumann, P.; Lewis, A.; Szantoi, Z.; Killough, B.; Purss, M.; Craglia, M.; Nativi, S.; Held, A.; Dhu, T. The six faces of the data cube. In Proceedings of the BiDS’17, Toulouse, France, 28–30 November 2017; pp. 32–35. [Google Scholar] [CrossRef]
- Soille, P.; Burger, A.; De Marchi, D.; Kempeneers, P.; Rodriguez, D.; Syrris, V.; Vasilev, V. A Versatile Data-Intensive Computing Platform for Information Retrieval from Big Geospatial Data. Future Gener. Comput. Syst. 2018, 81, 30–40. [Google Scholar] [CrossRef]
- Nissen, S. Implementation of a Fast Artificial Neural Network Library (FANN); Report; Department of Computer Science, University of Copenhagen (DIKU): København, Denmark, 2003; Volume 31, p. 29. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM TRansactions Intell. Syst. Technol. 2011, 2, 27:1–27:27. [Google Scholar] [CrossRef]
- McInerney, D.; Kempeneers, P. Pktools. In Open Source Geopspatial Tools; Blasius, B., Lahoz, W., Solomatine, D.P., Eds.; Earth Systems Data and Models; Springer: Cham, Switzerland, 2014; Chapter 12; pp. 173–197. [Google Scholar] [CrossRef]
- Soille, P. Constrained connectivity for hierarchical image partitioning and simplification. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1132–1145. [Google Scholar] [CrossRef] [PubMed]
- Beazley, D.M. Automated scientific software scripting with SWIG. Future Gener. Comput. Syst. 2003, 19, 599–609. [Google Scholar] [CrossRef]
- Pesaresi, M.; Syrris, V.; Julea, A. A New Method for Earth Observation Data Analytics Based on Symbolic Machine Learning. Remote Sens. 2016, 8. [Google Scholar] [CrossRef]
- Soille, P. Morphological Carving. Pattern Recognit. Lett. 2004, 25, 543–550. [Google Scholar] [CrossRef]
- Soille, P. Optimal removal of spurious pits in grid digital elevation models. Water Resour. Res. 2004, 40, W12509. [Google Scholar] [CrossRef]
- Soille, P.; Gratin, C. An efficient algorithm for drainage networks extraction on DEMs. J. Vis. Commun. Image Represent. 1994, 5, 181–189. [Google Scholar] [CrossRef]
- Vincent, L.; Soille, P. Watersheds in digital spaces: an efficient algorithm based on immersion simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 583–598. [Google Scholar] [CrossRef]
- Rew, R.; Davis, G. NetCDF: An interface for scientific data access. IEEE Comput. Graph. Appl. 1990, 10, 76–82. [Google Scholar] [CrossRef]
- Meyer, B. Object-Oriented Software Construction; Prentice Hall: New York, NY, USA, 1988; Volume 2. [Google Scholar]
- Pebesma, E.; Wagner, W.; Soille, P.; Kadunc, M.; Gorelick, N.; Schramm, M.; Verbesselt, J.; Reiche, J.; Appel, M.; Dries, J.; et al. openEO: An open API for cloud-based big Earth Observation processing platforms. In Proceedings of the EGU General Assembly Conference Abstracts, Vienna, Austria, 8–13 April 2018; Volume 20, p. 4957. [Google Scholar]
- Thain, D.; Tannenbaum, T.; Livny, M. Distributed computing in practice: the Condor experience. Concurr. Comput. Pract. Exp. 2005, 17, 323–356. [Google Scholar] [CrossRef]
- De Marchi, D.; Soille, P. Advances in interactive processing and visualisation with JupyterLab on the JRC Big Data Platform (JEODPP). In Proceedings of the BiDS’19, Munich, Germany, 19–21 February 2019; pp. 45–48. [Google Scholar] [CrossRef]
- Kempeneers, P.; Soille, P. S2MOSAIC L2A 2017. 2019. Available online: http://data.europa.eu/89h/cbf1016c-2970-477a-9533-4ac8e10abb92 (accessed on 16 October 2019).
- Kempeneers, P.; Soille, P. Optimizing Sentinel-2 image selection in a Big Data context. Big Earth Data 2017, 1, 145–158. [Google Scholar] [CrossRef]
- Mueller-Wilm, U.; Devignot, O.; Pessiot, L. Sen2Cor Configuration and User Manual; Telespazio VEGA Deutschland GmbH: Darmstadt, Germany, 2016. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- De Marchi, D.; Burger, A.; Kempeneers, P.; Soille, P. Interactive visualisation and analysis of geospatial data with Jupyter. In Proceedings of the BiDS’17, Toulouse, France, 28–30 November 2017; pp. 71–74. [Google Scholar] [CrossRef]
- Soille, P. Towards the Compositing and Mosaicing of Sentinel-2 Images Using Quality and Spatial Coherence Constraints. In Proceedings of the Sentinel-2 for Science Workshop, Casablanca, Morocco, 10–11 October 2014; ESA: Paris, France, 2014. [Google Scholar]
- Griffiths, P.; Van der Linden, S.; Kuemmerle, T.; Hostert, P. A Pixel-Based Landsat Compositing Algorithm for Large Area Land Cover Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 6, 2088–2101. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Description | SCL Code |
|---|---|---|
| 0 | Vegetation | 4 |
| 1 | Bare Soils | 5 |
| 2 | Water | 6 |
| 3 | Dark Area Pixels | 2 |
| 4 | Snow/Ice | 11 |
| 5 | Cirrus | 10 |
| 6 | Cloud Shadows | 3 |
| 7 | Clouds low probability/Unclassified | 7 |
| 8 | Clouds medium probability | 8 |
| 9 | Clouds high probability | 9 |
| 10 | Saturated/Defective | 1 |
| 11 | No Data | 0 |
| Task | Throughput | Total Processing Time |
|---|---|---|
| selection | tiles/hour/core | 20 h |
| Sen2Cor | tiles/hour/core | 50 h |
| compositing | 2 tiles/hour/core | 15 h |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kempeneers, P.; Pesek, O.; De Marchi, D.; Soille, P. pyjeo: A Python Package for the Analysis of Geospatial Data. ISPRS Int. J. Geo-Inf. 2019, 8, 461. https://doi.org/10.3390/ijgi8100461
Kempeneers P, Pesek O, De Marchi D, Soille P. pyjeo: A Python Package for the Analysis of Geospatial Data. ISPRS International Journal of Geo-Information. 2019; 8(10):461. https://doi.org/10.3390/ijgi8100461
Chicago/Turabian StyleKempeneers, Pieter, Ondrej Pesek, Davide De Marchi, and Pierre Soille. 2019. "pyjeo: A Python Package for the Analysis of Geospatial Data" ISPRS International Journal of Geo-Information 8, no. 10: 461. https://doi.org/10.3390/ijgi8100461
APA StyleKempeneers, P., Pesek, O., De Marchi, D., & Soille, P. (2019). pyjeo: A Python Package for the Analysis of Geospatial Data. ISPRS International Journal of Geo-Information, 8(10), 461. https://doi.org/10.3390/ijgi8100461