Geo-Tagged Social Media Data-Based Analytical Approach for Perceiving Impacts of Social Events

 , , ,
, , ,
Abstract
:1. Introduction
- (1)
- Utilizing social sensing, the proposed framework enables a combination of machine learning, natural language processing (NLP), and visualization methods to discover evidence from geo-tagged social media data that indicate the impacts of social events.
- (2)
- A topic discovery method based on Latent Dirichlet Allocation (LDA) is applied, in which a topic coherence model is used to determine the optimal number of topics hidden in the event-related information, thus obtaining a more reasonable topic clustering.
- (3)
- A social sentiment analysis is conducted to explore the impact of social events in terms of public sentiment. This analysis is based on a comparative assessment of the daily sentimental value of event-related information, event-irrelevant information, and comprehensive information.
2. Related Work
2.1. Traditional Research on the Impact of Social Events
2.2. Event-Related Research Based on Geo-Tagged Social Media Data
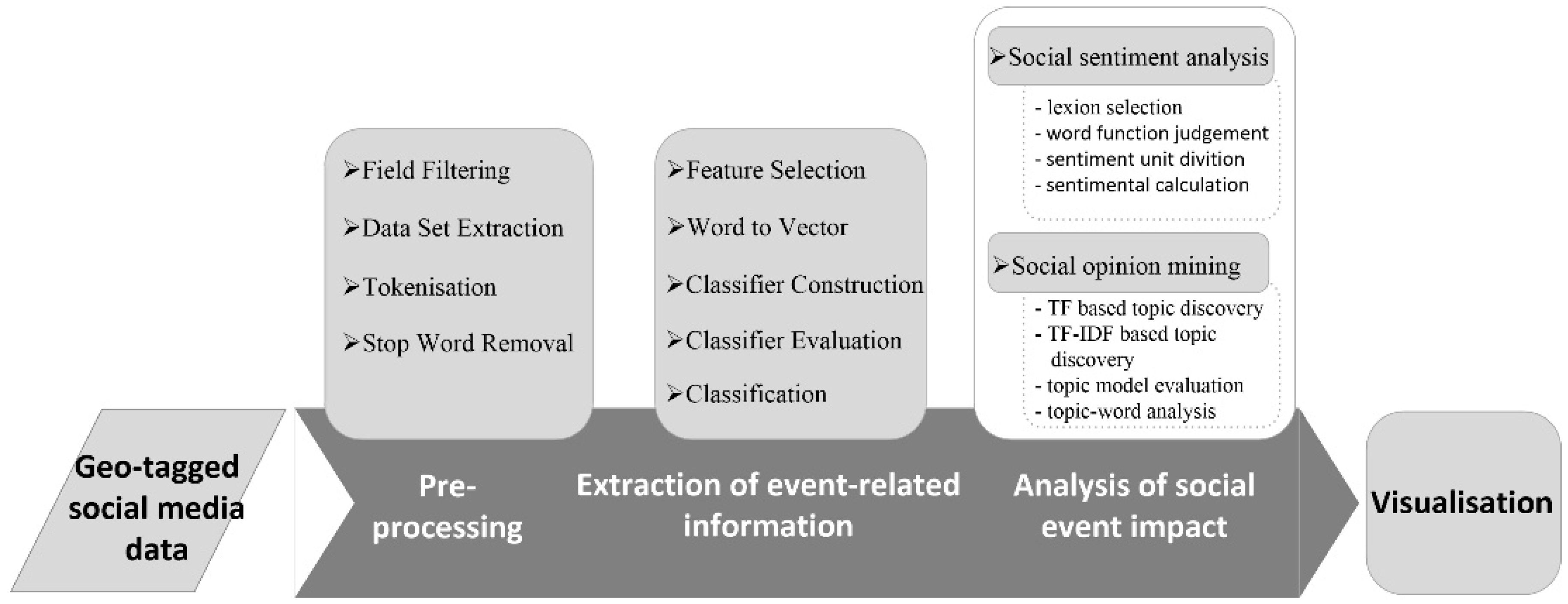
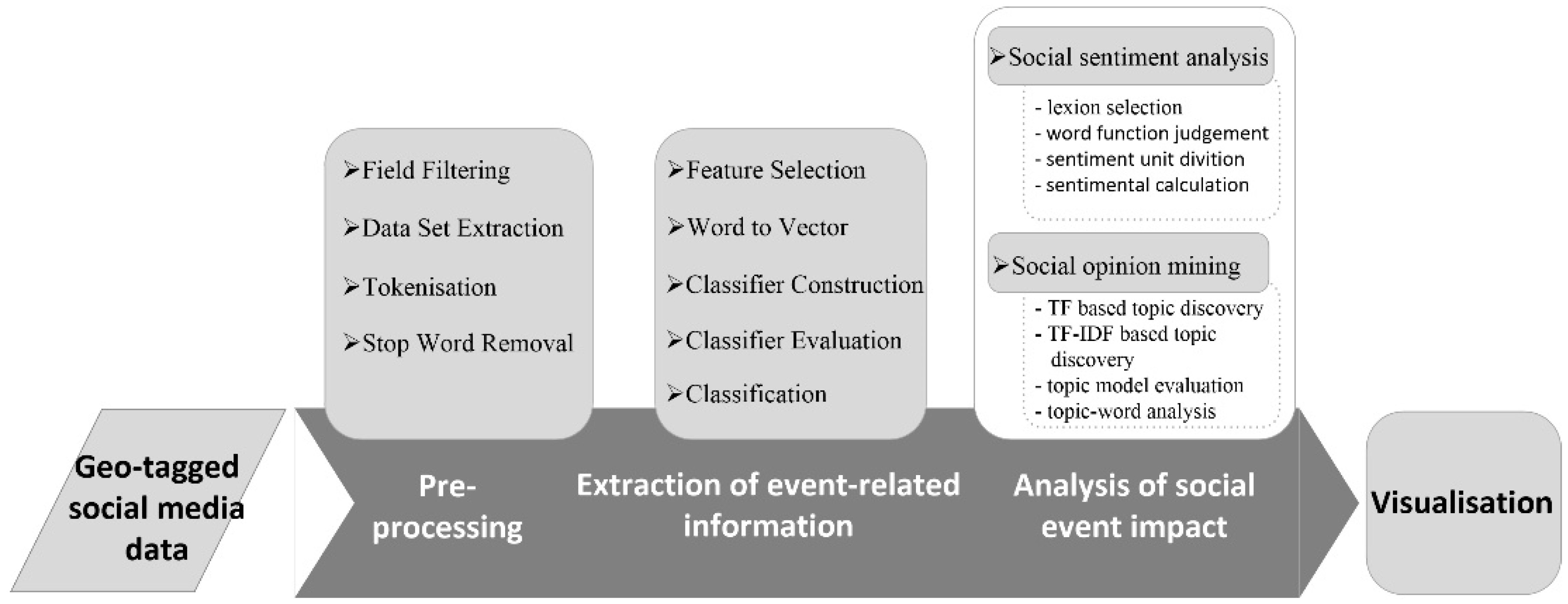
3. Methods
3.1. Preprocessing
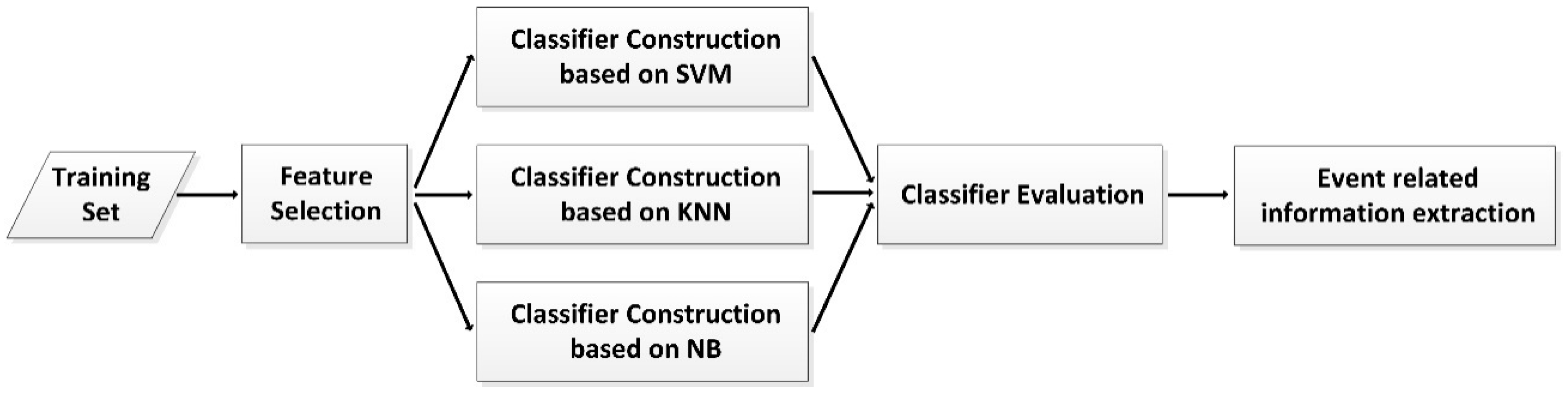
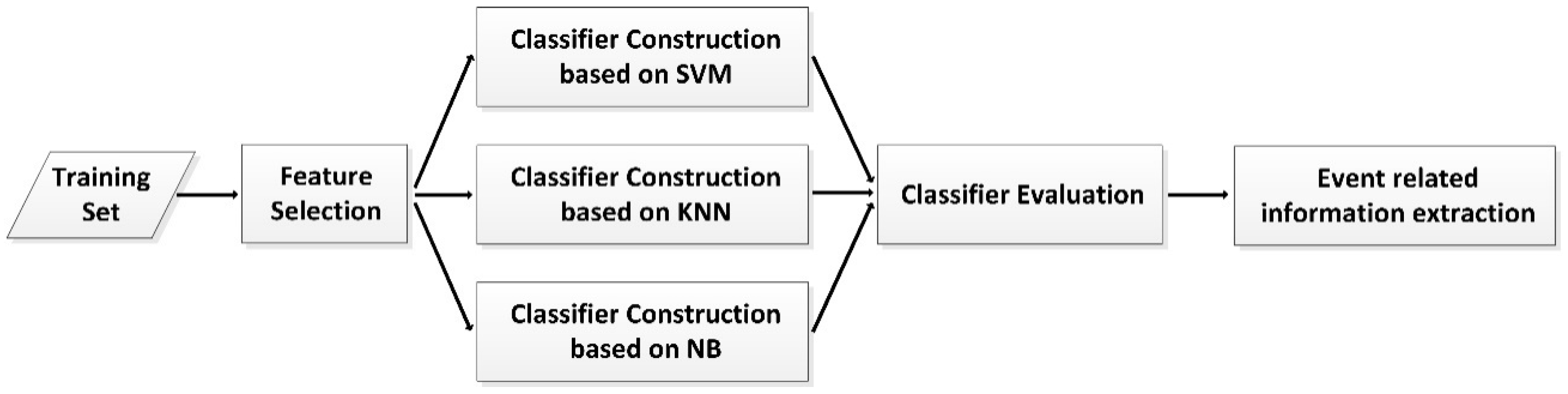
3.2. Extraction of Event-Related Information
3.3. Social Sentiment Analysis
3.4. Social Opinion Mining
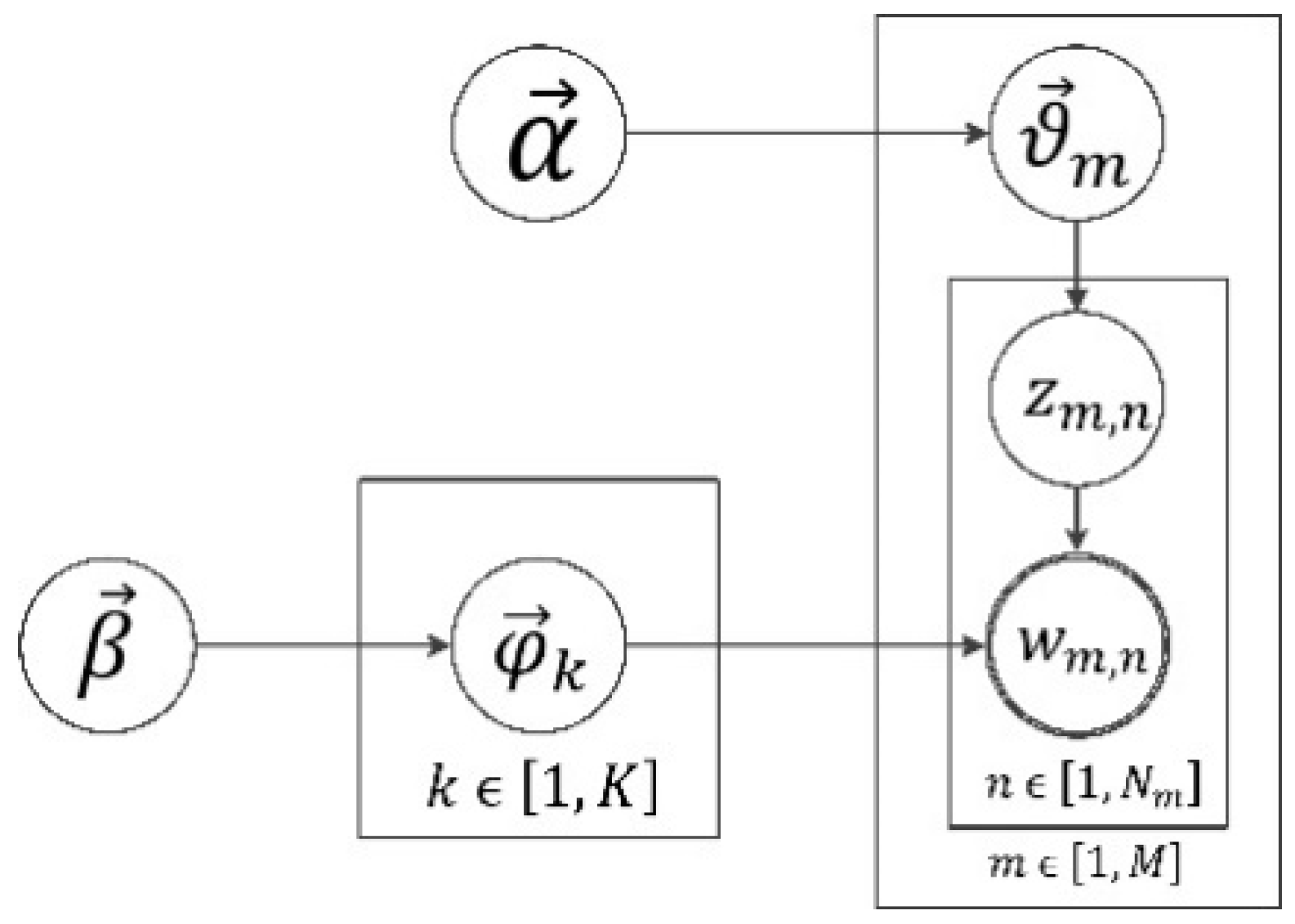
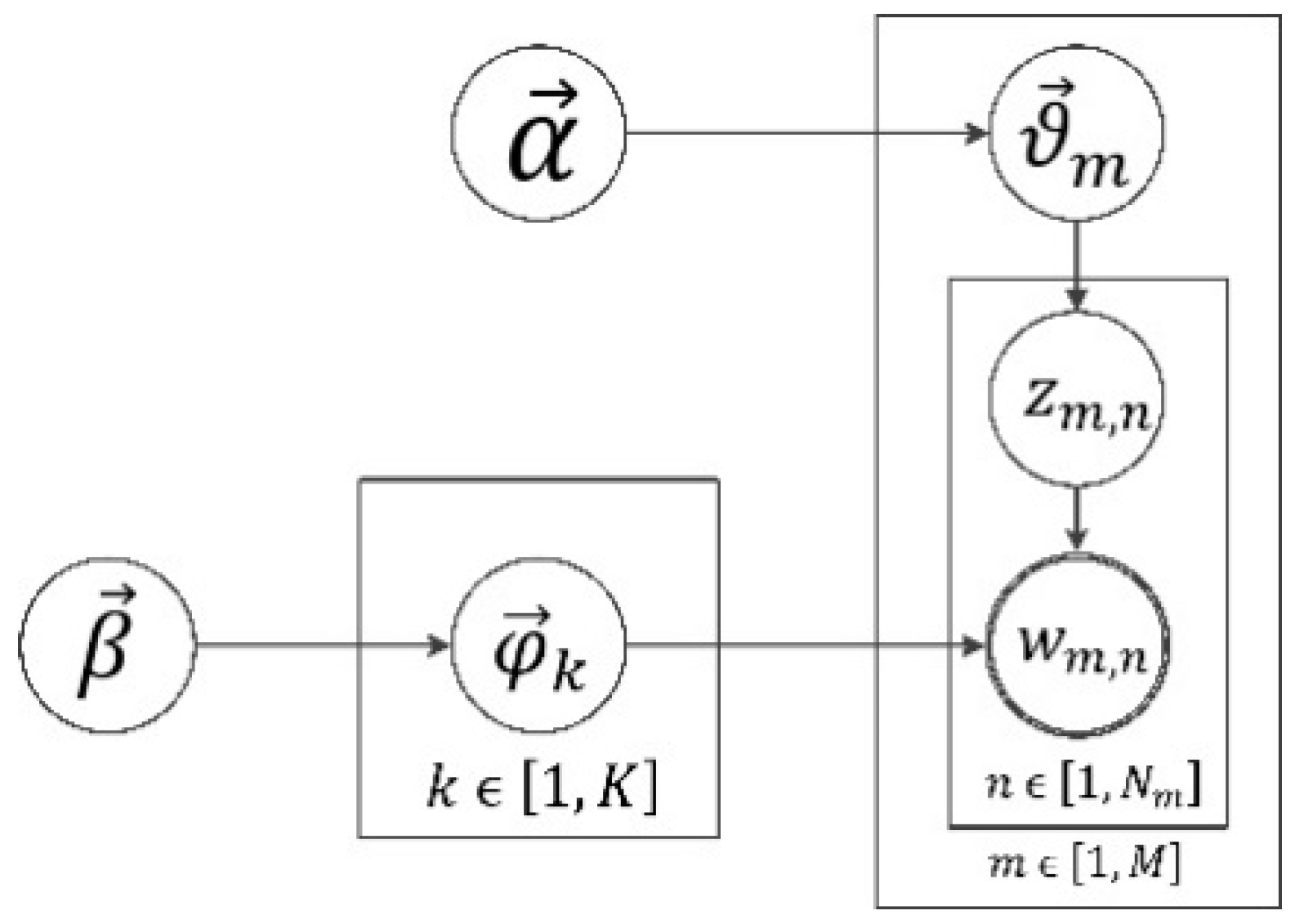
3.4.1. Topic Model: LDA
- For each document , pick a multinomial distribution from a Dirichlet distribution with parameter ;
- For each topic k =, pick a multinomial distribution from a Dirichlet distribution with parameter ;
- For the nth word in the mth document where , and
- Sample the word
- Sample the topic
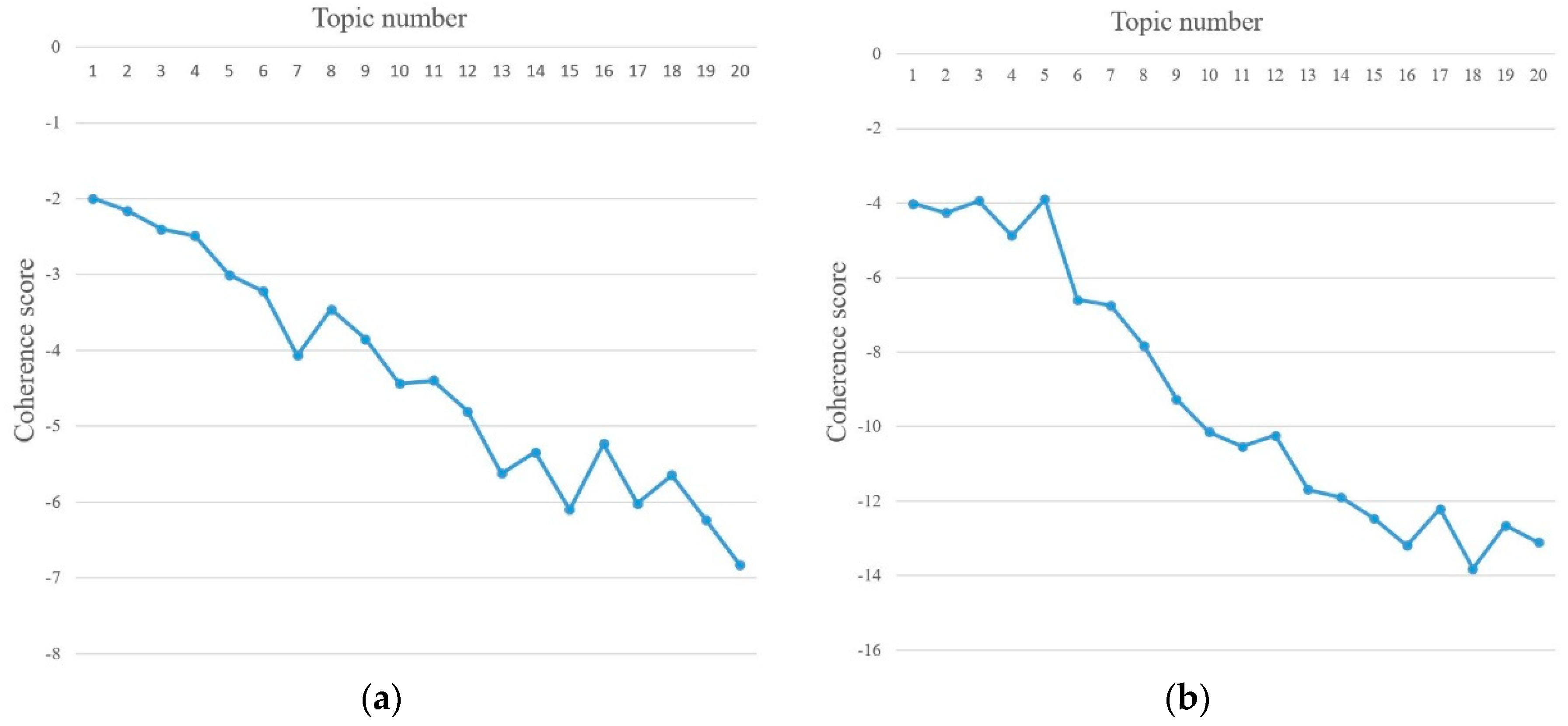
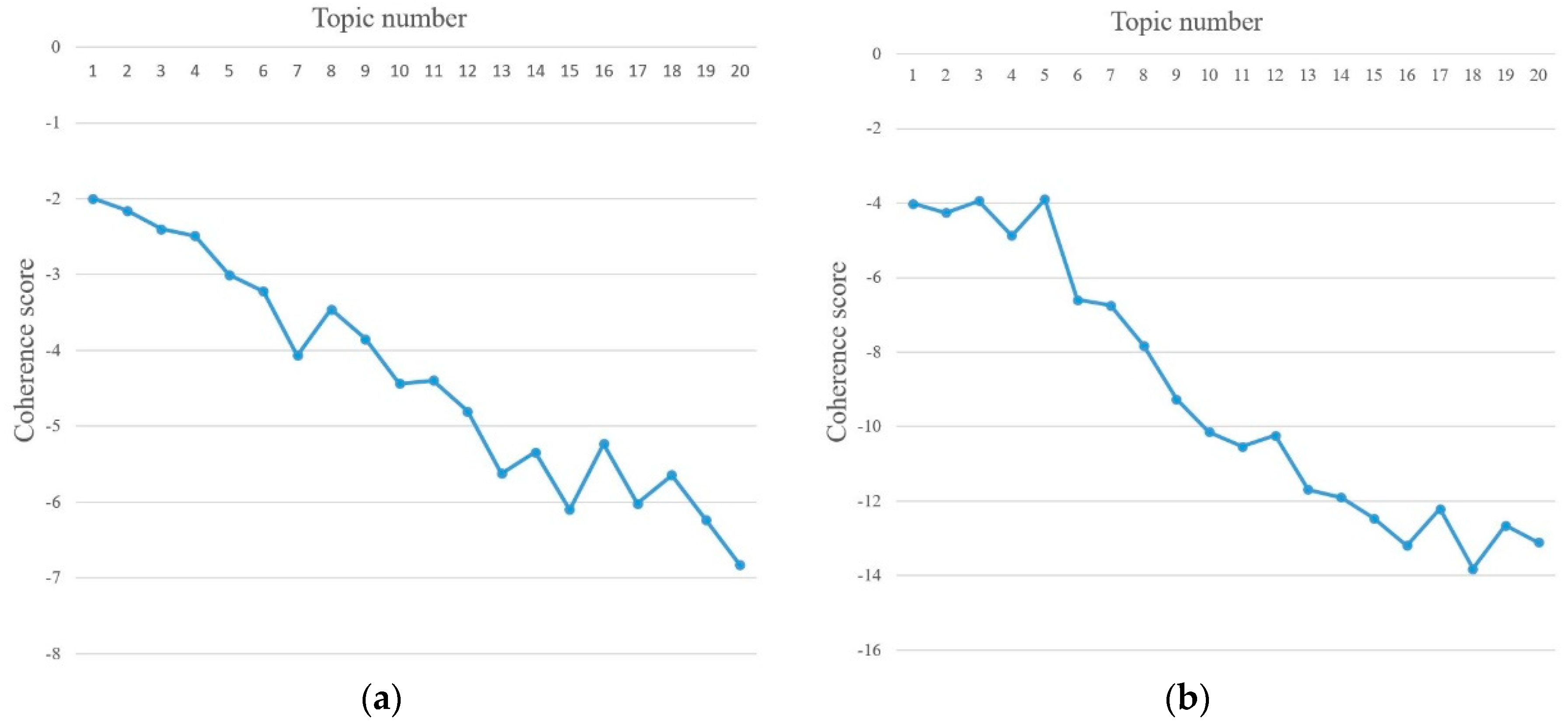
3.4.2. Topic Evaluation Based on Topic Coherence
3.5. Visualization
4. Case Study and Results
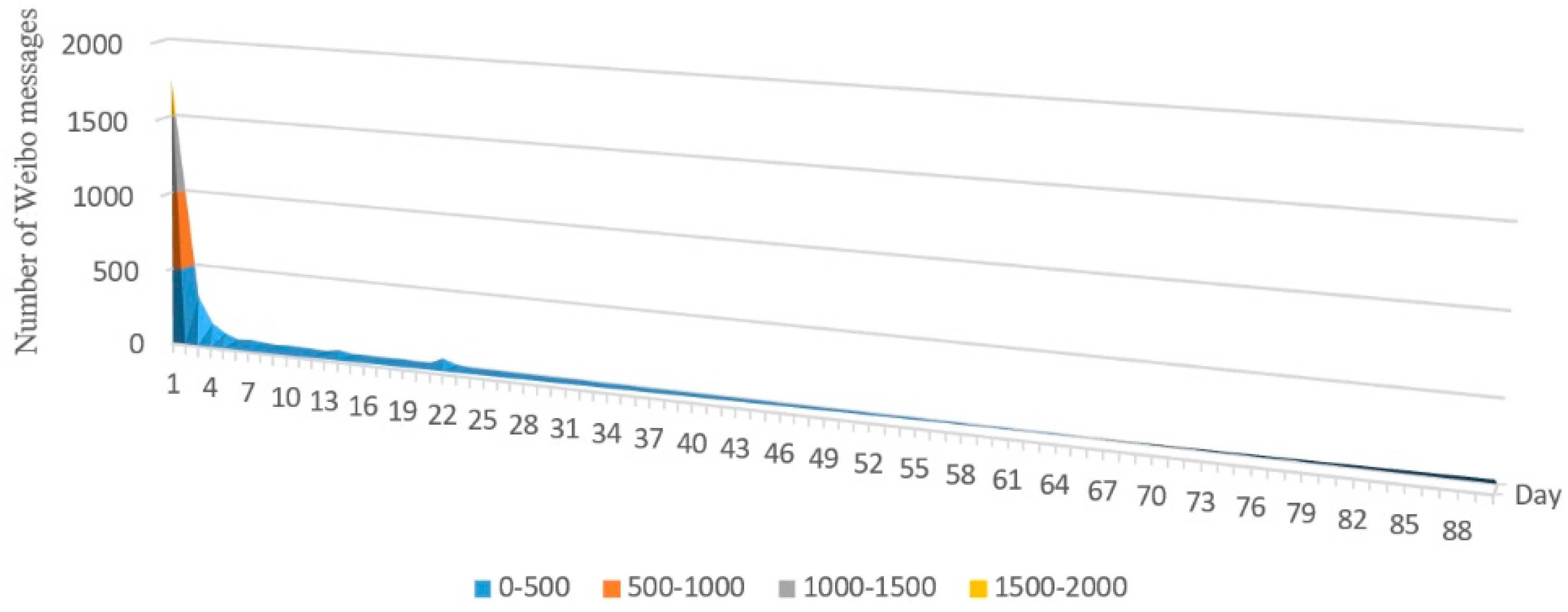
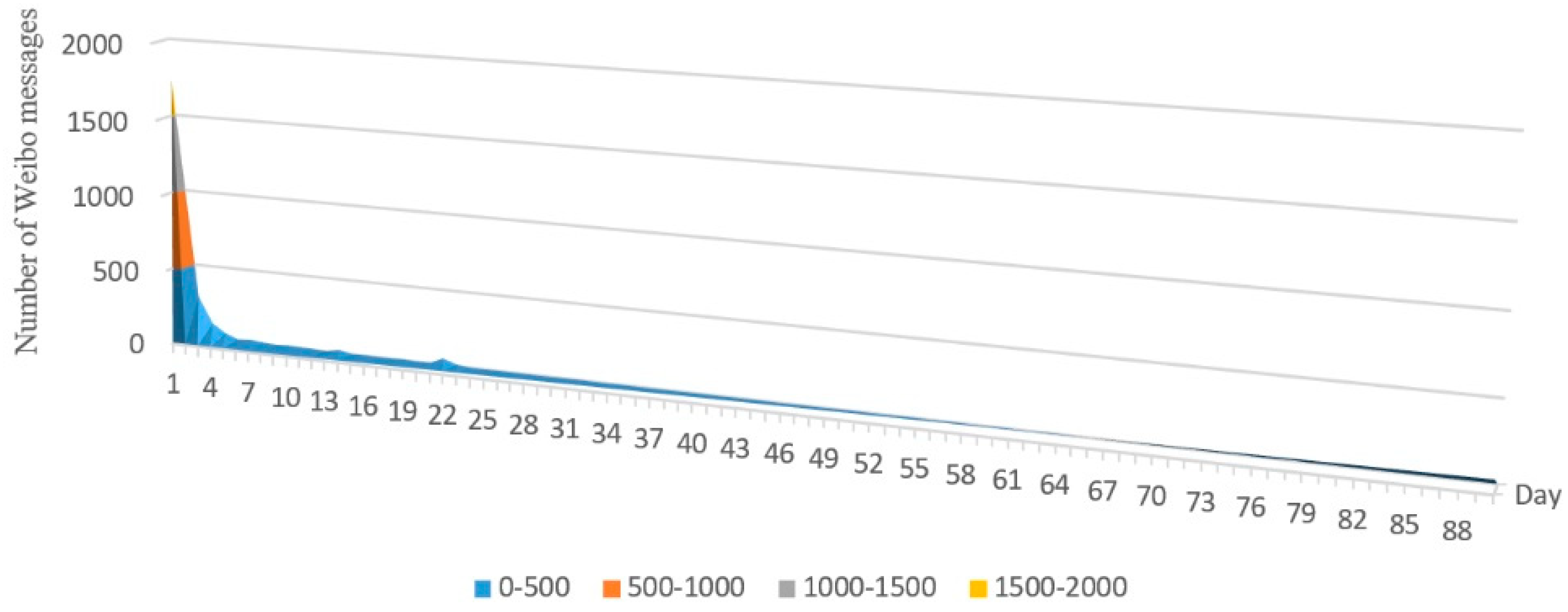
4.1. Data
4.2. Results
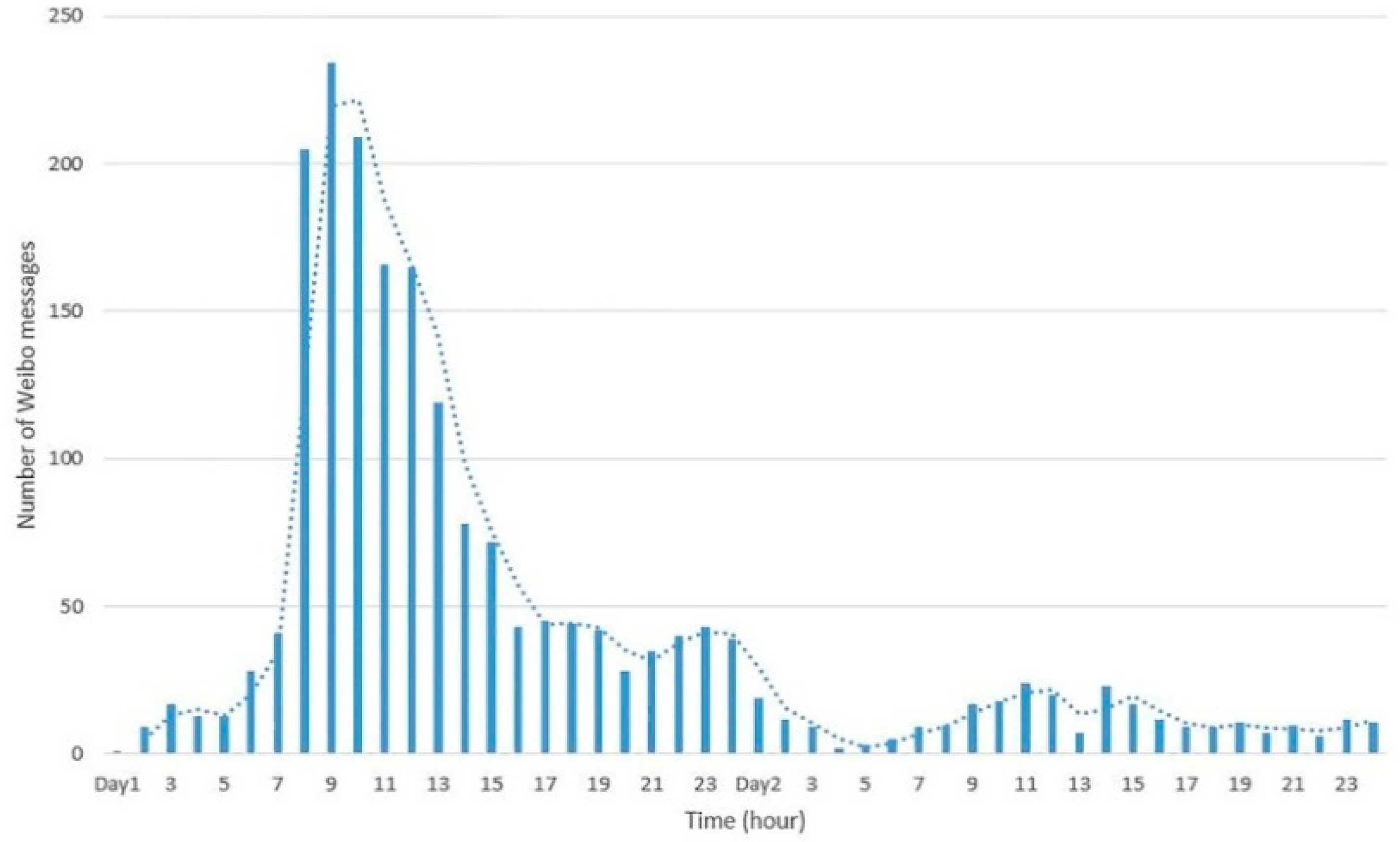
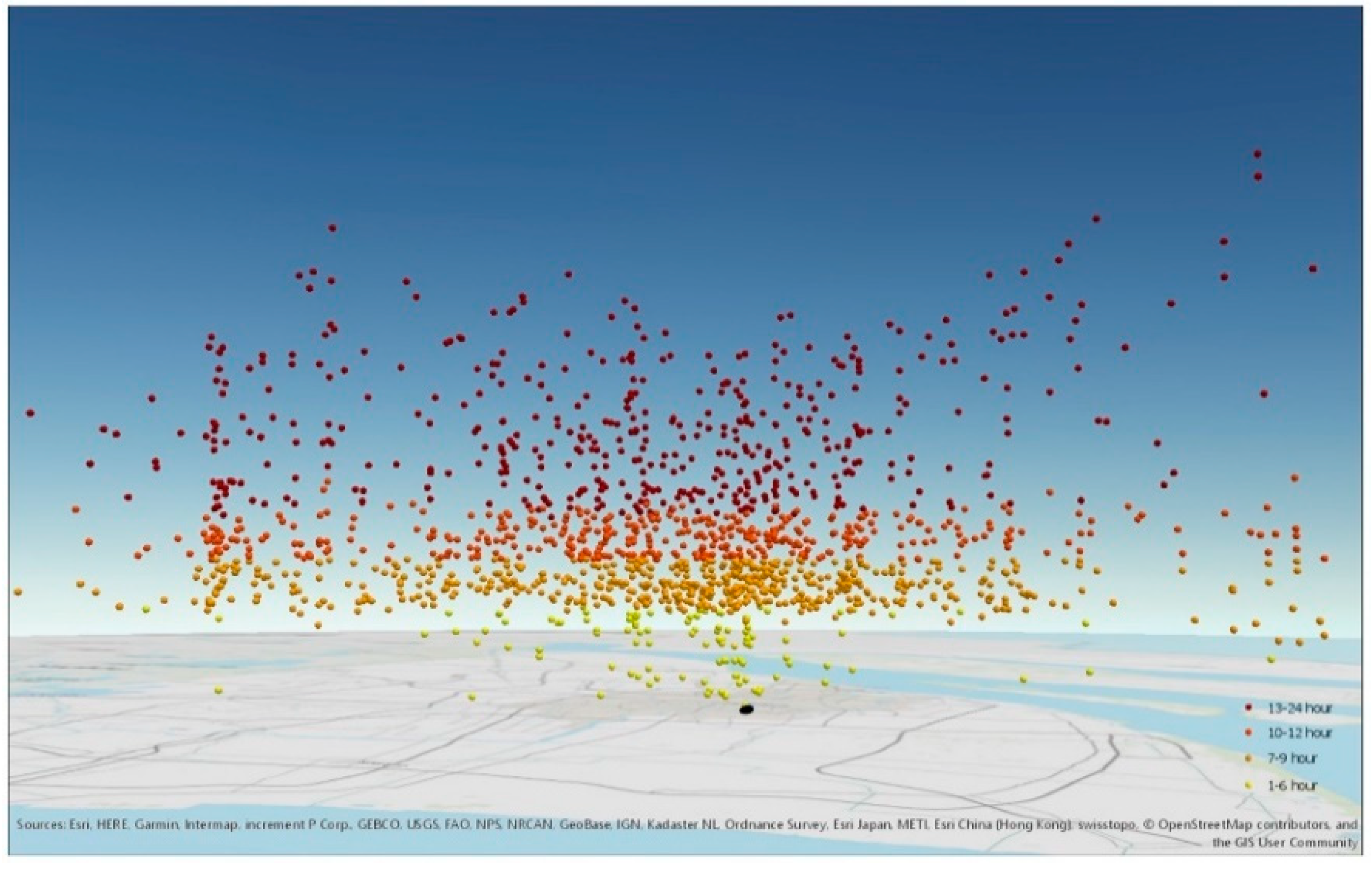
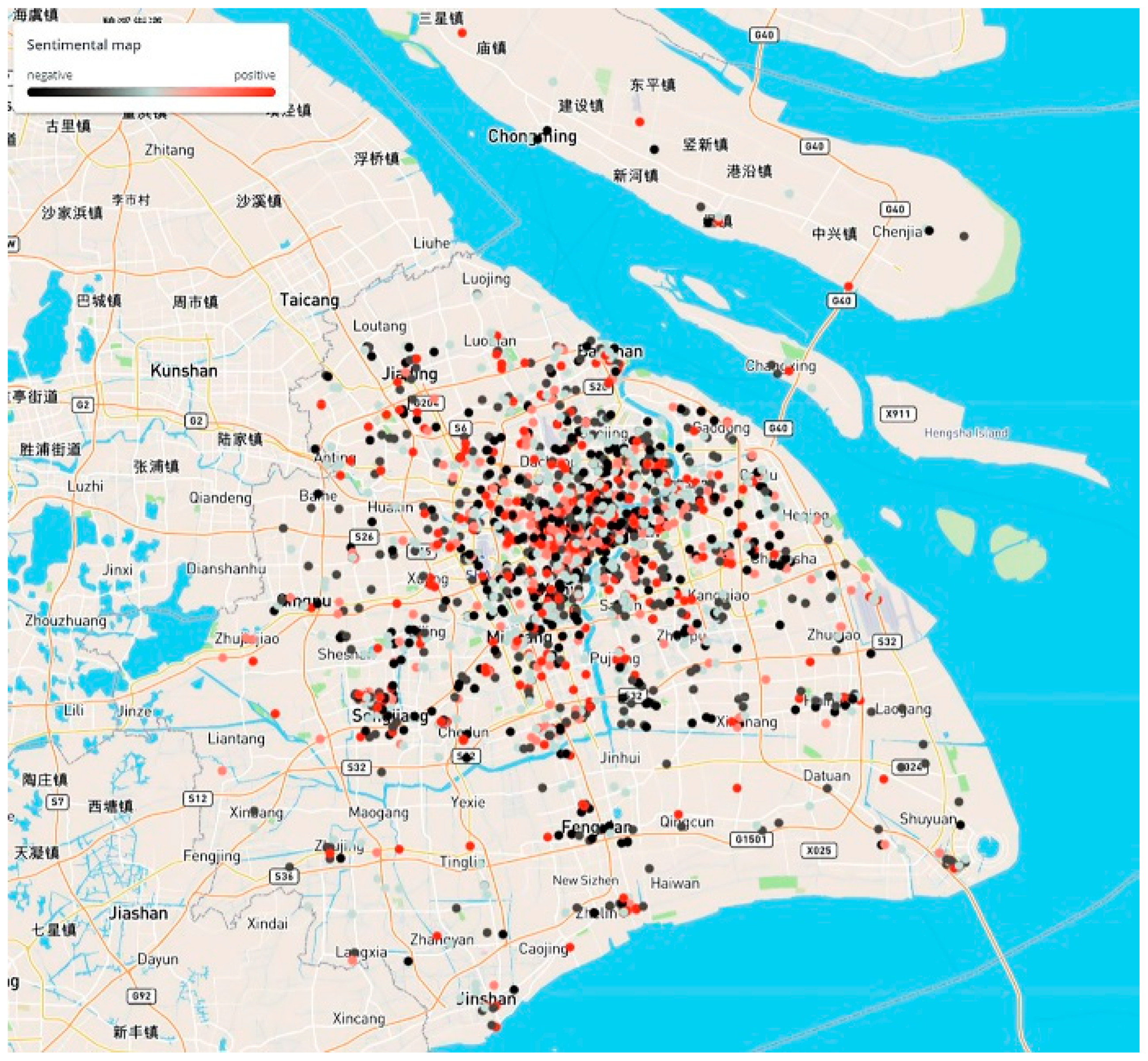
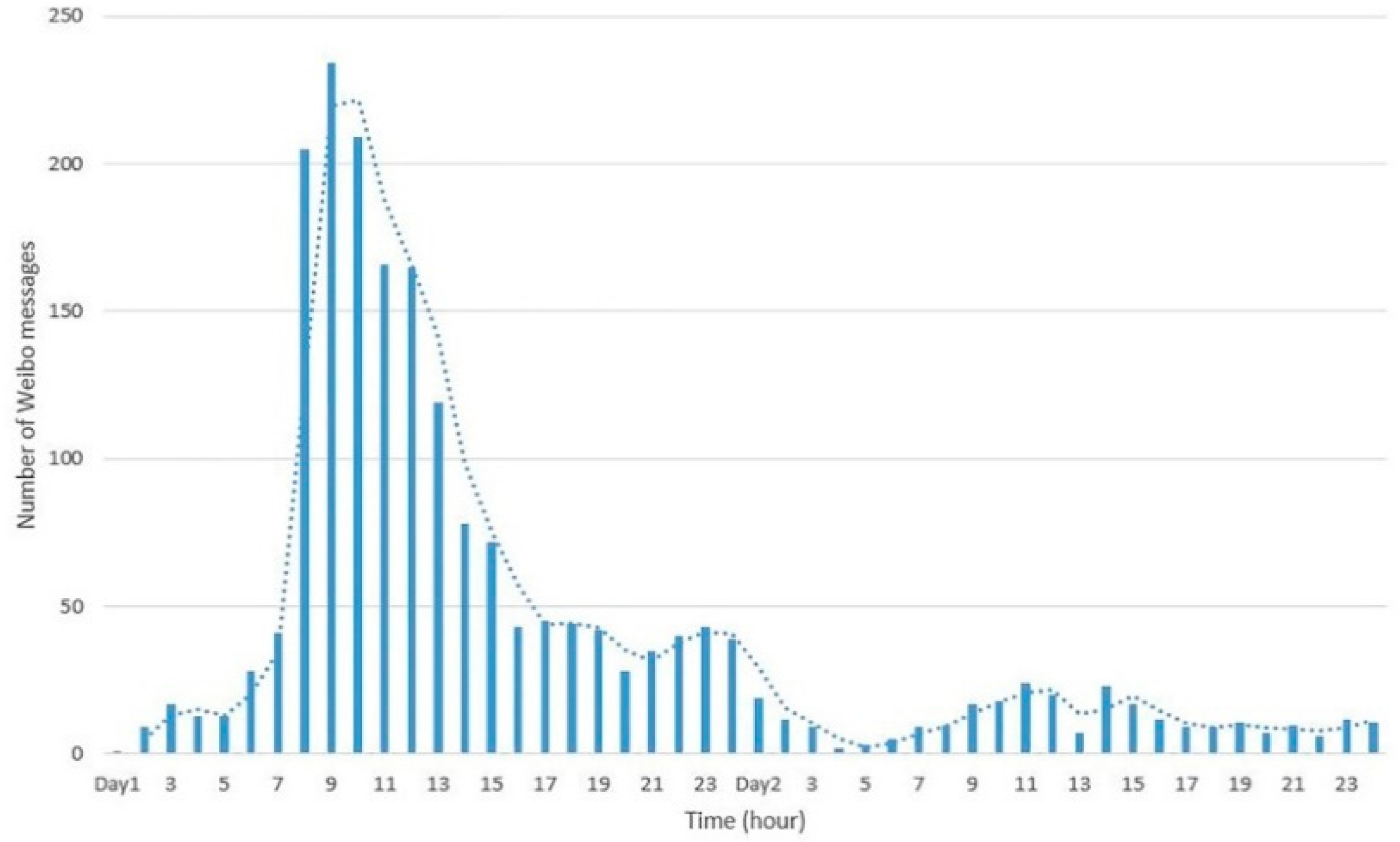
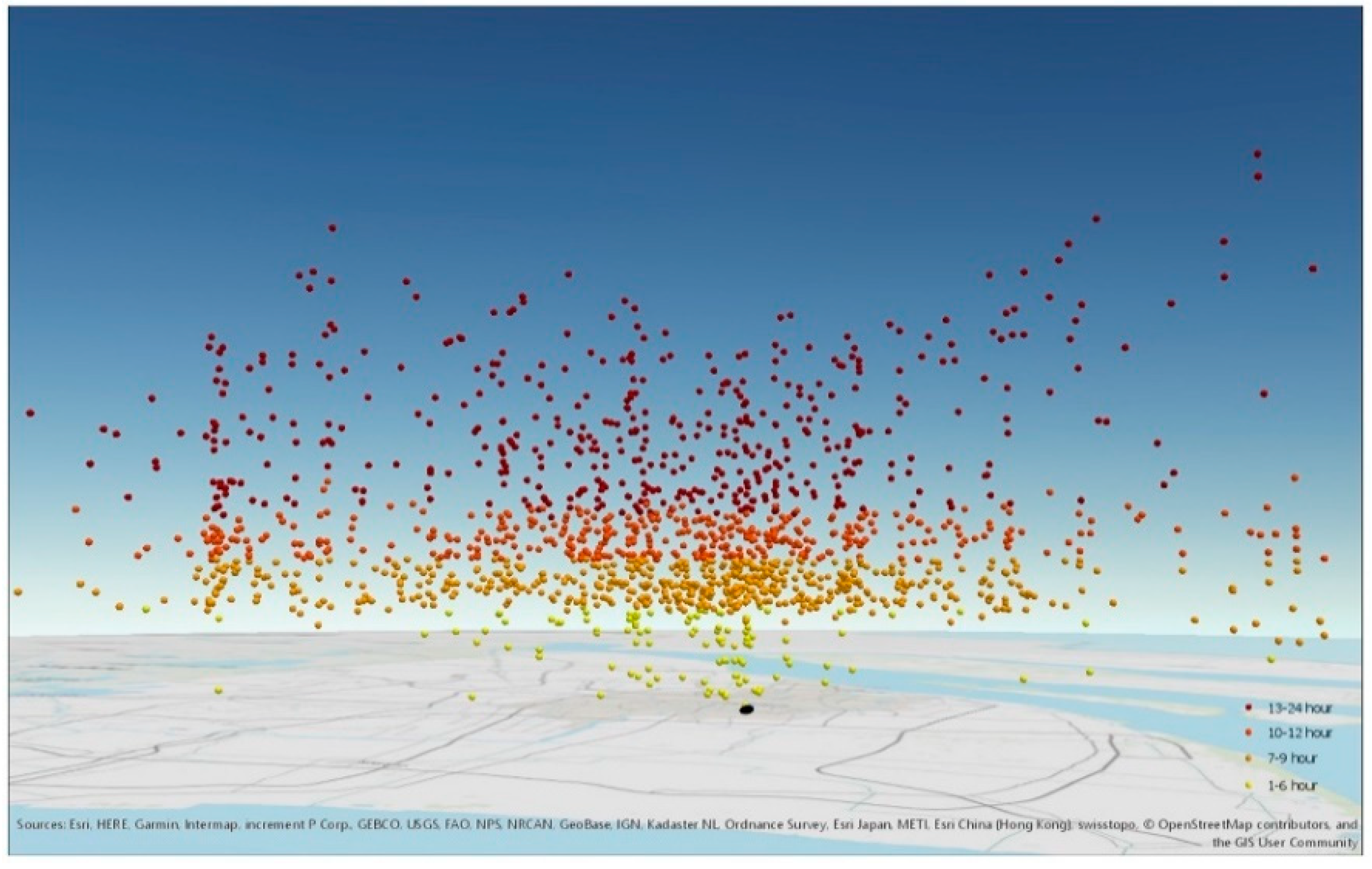
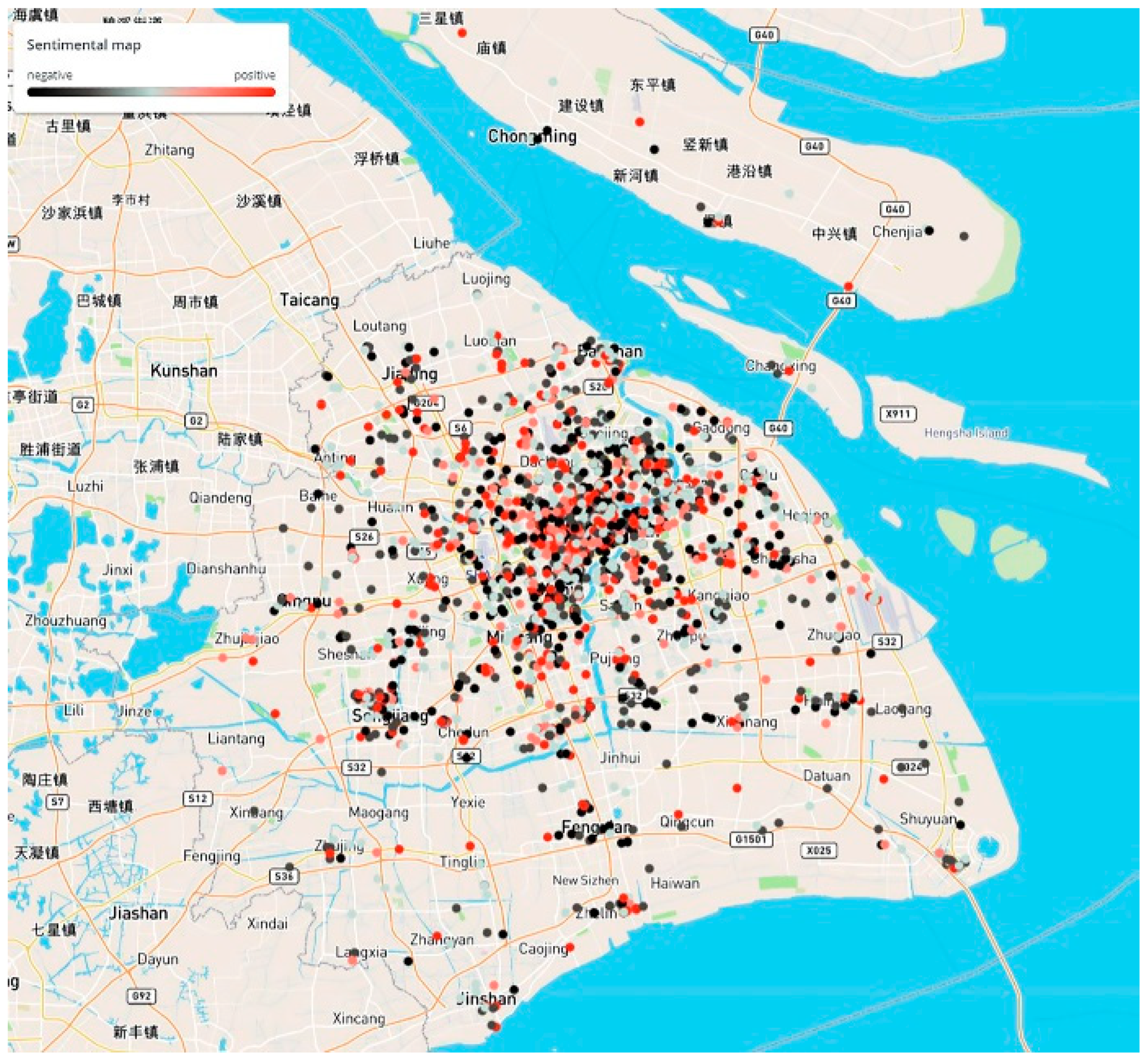
4.2.1. Extraction of Event-Related Information
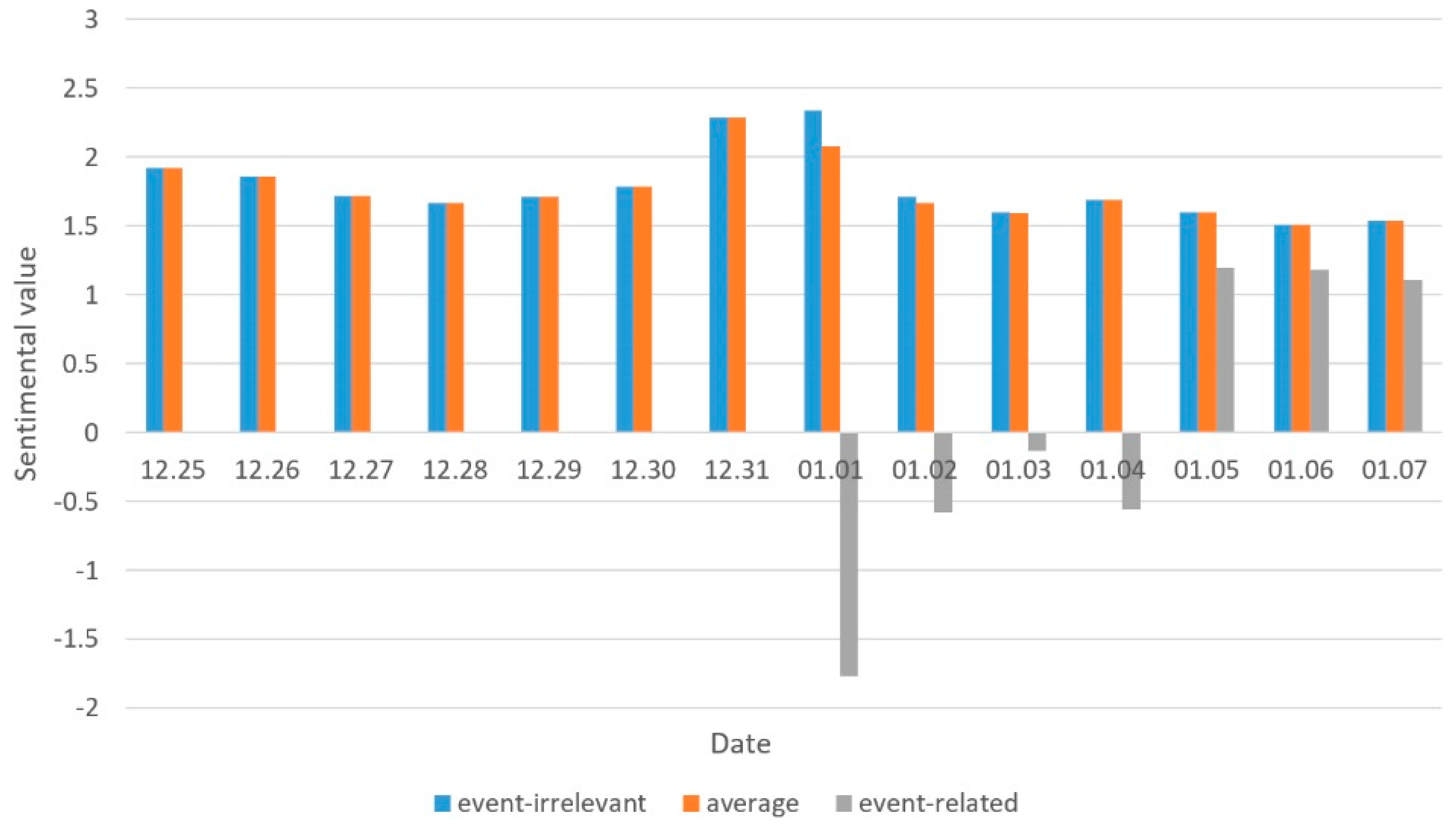
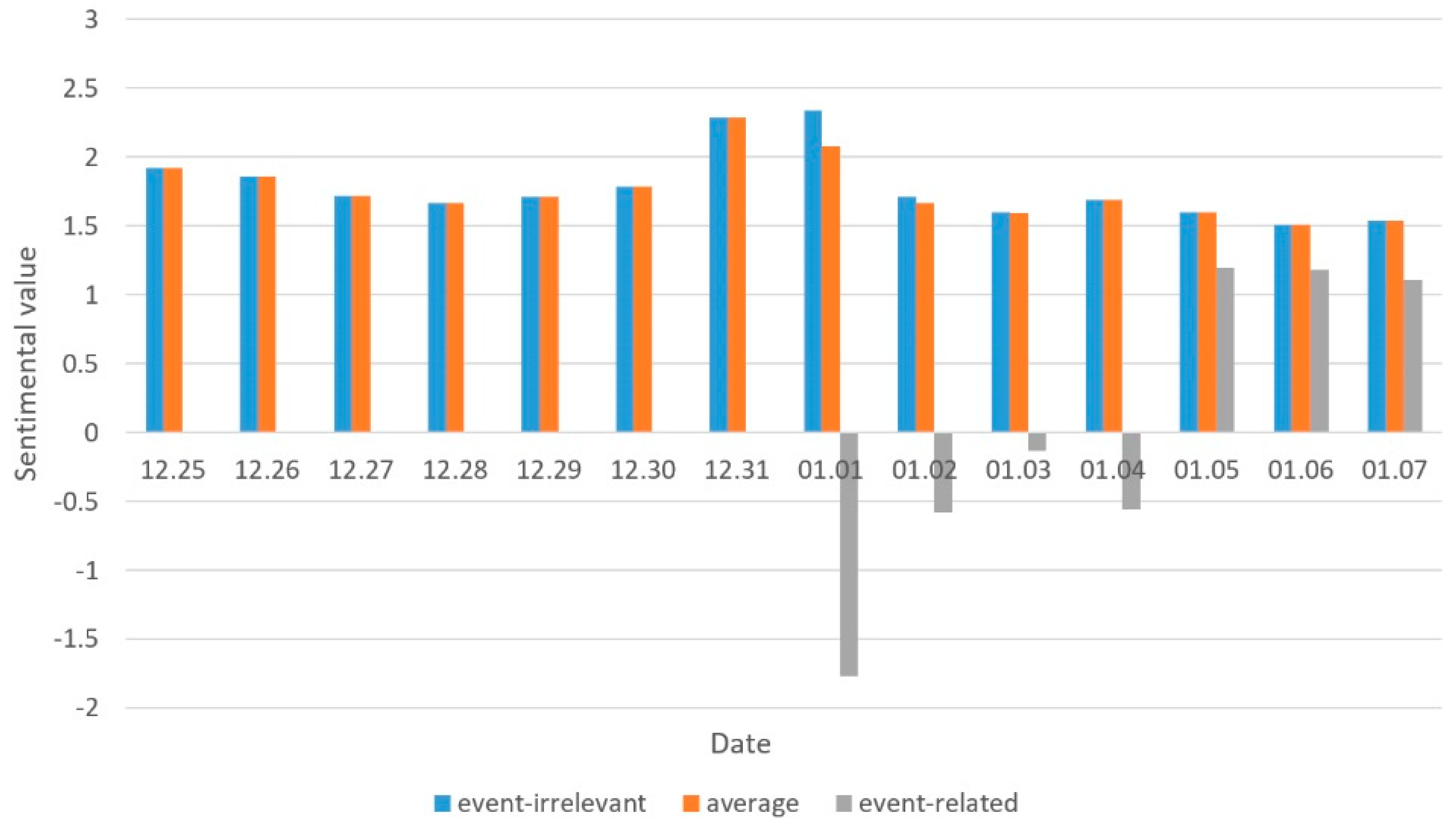
4.2.2. Social Sentiment Analysis
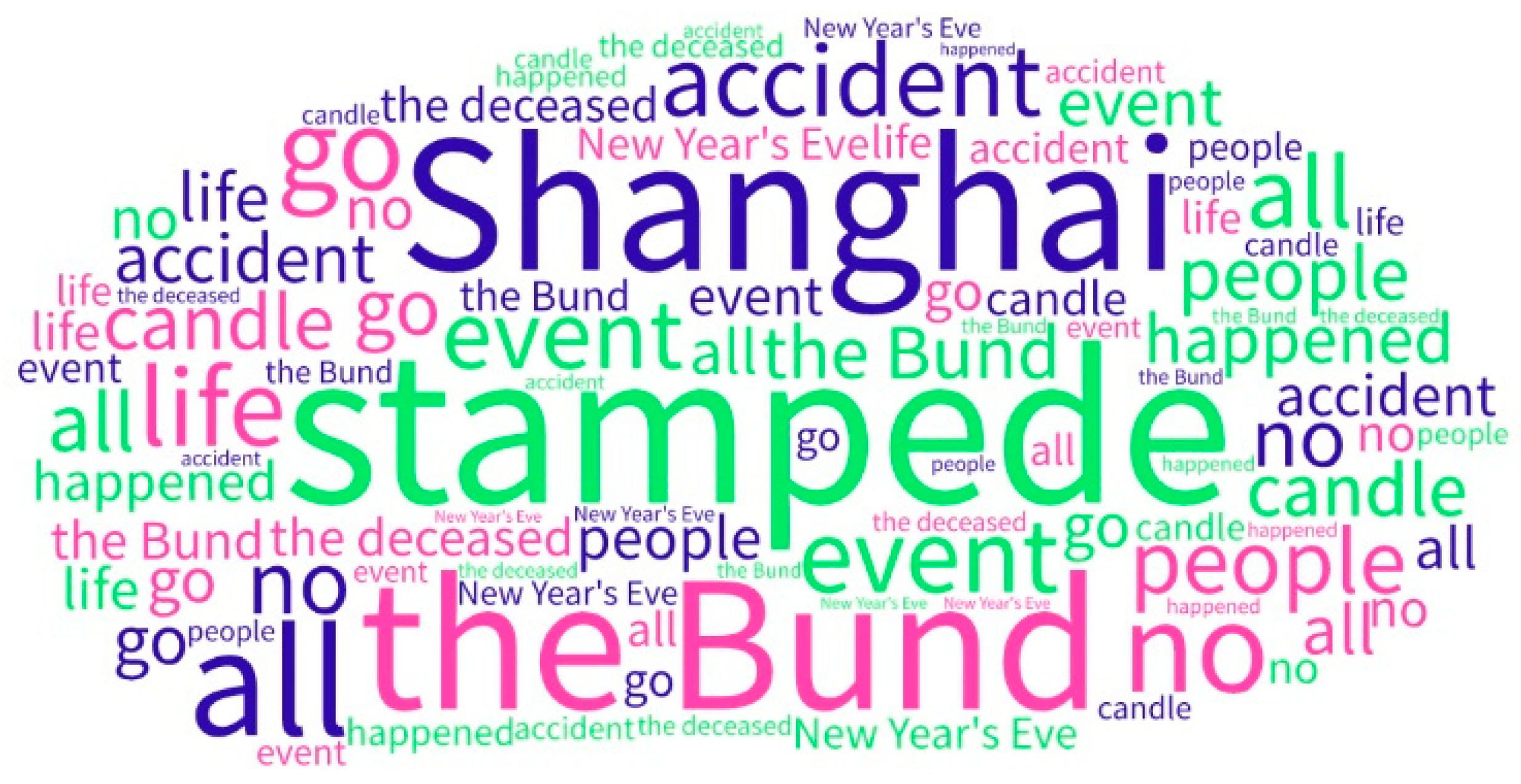
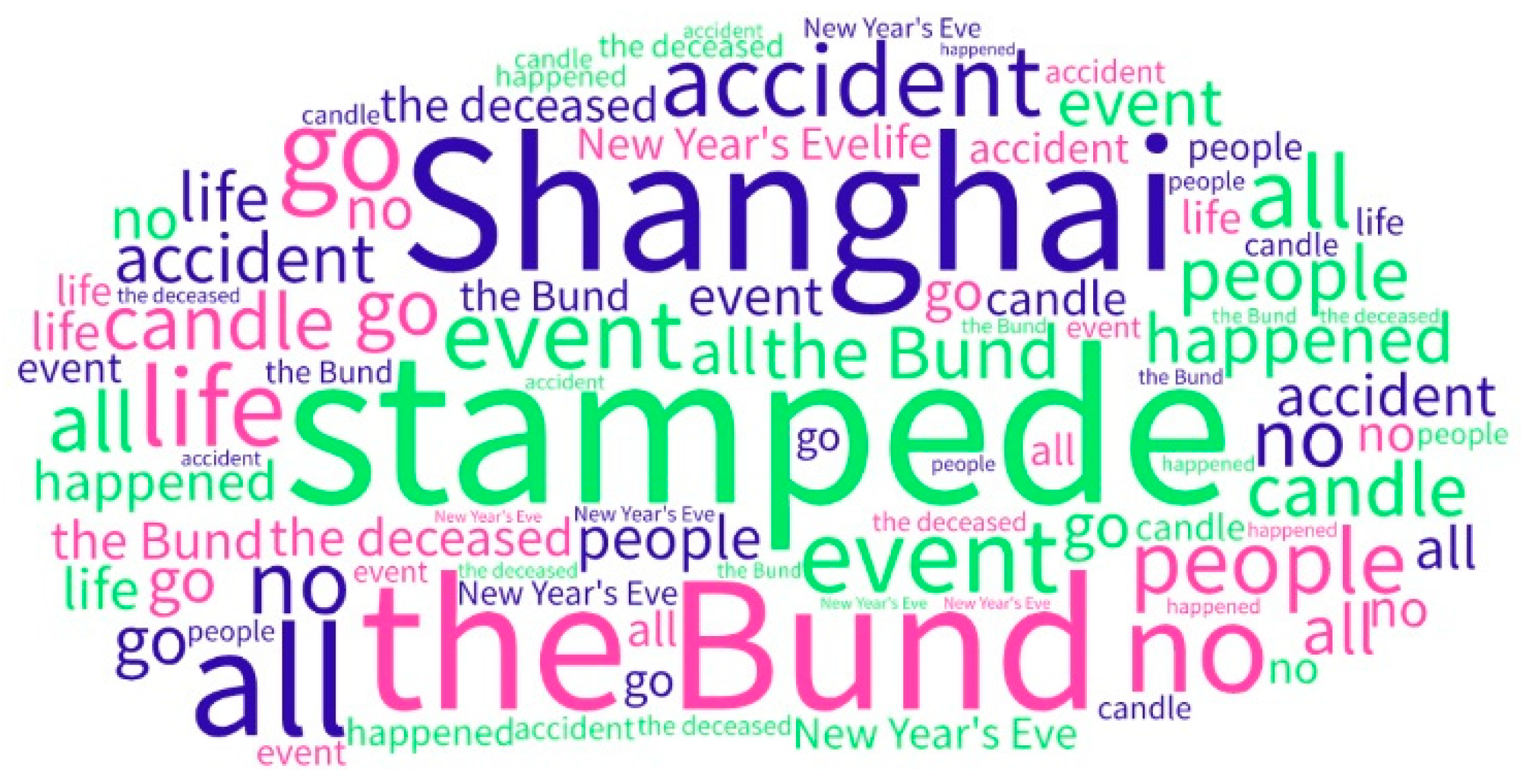
4.2.3. Social Opinion Mining
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| WTI | West Texas Intermediate |
| VSM | Vector Space Model |
| TF | Term Frequency |
| SVM | Support Vector Machine |
| NB | Naive Bayes |
| MultinomialNB | Naive Bayes classifier for multinomial models |
| BernoulliNB | Naive Bayes classifier for multivariate Bernoulli models |
| RBF | Radial Basis Function |
| KNN | K-Nearest Neighbors |
| PLSA | Probabilistic Latent Semantic Analysis |
| LDA | Latent Dirichlet Allocation |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise |
References
- Getz, D.; Page, S.J. Event Studies: Theory, Research and Policy for Planned Events, 3rd ed.; Routledge: London, UK, 2016; pp. 1–21. ISBN 978-1-138-89916-2. [Google Scholar]
- Liu, Y.; Liu, X.; Gao, S.; Gong, L.; Kang, C.; Zhi, Y.; Chi, G.; Shi, L. Social sensing: A new approach to understanding our socioeconomic environments. Ann. Assoc. Am. Geogr. 2015, 105, 512–530. [Google Scholar] [CrossRef]
- Shi, Z.Z. Intelligence Science, 2nd ed.; World Scientific Publishing Company: Singapore, 2012; pp. 135–166. ISBN 981-4360-77-5. [Google Scholar]
- Valkanas, G.; Gunopulos, D. How the live web feels about events. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 639–648. [Google Scholar]
- Ali, R.; Solis, C.; Salehie, M.; Omoronyia, I.; Nuseibeh, B.; Maalej, W. Social sensing: When users become monitors. In Proceedings of the 19th ACM SIGSOFT symposium and the 13th European Conference on Foundations of Software Engineering, Szeged, Hungary, 5–9 September 2011; ACM: New York, NY, USA, 2011; pp. 476–479. [Google Scholar]
- Ohmann, S.; Jones, I.; Wilkes, K. The perceived social impacts of the 2006 Football World Cup on Munich residents. J. Sport Tour. 2006, 11, 129–152. [Google Scholar] [CrossRef]
- Fredline, E.; Faulkner, B. Variations in residents’ reactions to major motorsport events: Why residents perceive the impacts of events differently. Event Manag. 2001, 7, 115–125. [Google Scholar] [CrossRef]
- Fredline, E.; Faulkner, B. Residents’ reactions to the staging of major motorsport events within their communities: A cluster analysis. Event Manag. 2001, 7, 103–114. [Google Scholar] [CrossRef]
- José Miguel, P.M. Do Football Victories Affect Social Unrest? Evidence from Africa. Master’s Thesis, Pontificia Universidad Católica de Chile, Santiago, Chile, 2017. [Google Scholar]
- Scholtens, B.; Peenstra, W. Scoring on the stock exchange? The effect of football matches on stock market returns: An event study. Appl. Econ. 2010, 41, 3231–3237. [Google Scholar] [CrossRef]
- Barreda, A.A.; Zubieta, S.; Chen, H.; Cassilha, M.; Kageyama, Y. Evaluating the impact of mega-sporting events on hotel pricing strategies: The case of the 2014 FIFA World Cup. Tour. Rev. 2014, 72, 184–208. [Google Scholar] [CrossRef]
- Healy, A.J.; Malhotra, N.; Mo, C.H. Irrelevant events affect voters’ evaluations of government performance. Proc. Natl. Acad. Sci. USA 2010, 107, 12804–12809. [Google Scholar] [CrossRef] [PubMed]
- Crude Oil Market and Geopolitical Events: An Analysis Based on Information-Theory-Based Quantifiers. Available online: https://arxiv.org/abs/1704.04442 (accessed on 20 February 2018).
- America Rebounds: A National Study of Public Response to the September 11th Terrorist Attacks. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.458.6605&rep=rep1&type=pdf (accessed on 20 November 2017).
- Arvanitidis, P.; Economou, A.; Kollias, C. Terrorism’s effects on social capital in European countries. Public Choice 2016, 169, 231–250. [Google Scholar] [CrossRef]
- Breitsohl, J.; Garrod, B. Assessing tourists’ cognitive, emotional and behavioural reactions to an unethical destination incident. Tour. Manag. 2016, 54, 209–220. [Google Scholar] [CrossRef]
- Li, H.; Song, W.; Collins, R. Post-event visits as the sources of marketing strategy sustainability: A conceptual model approach. J. Bus. Econ. Manag. 2014, 15, 74–95. [Google Scholar] [CrossRef]
- Calabrese, F.; Pereira, F.C.; Di Lorenzo, G.; Liu, L.; Ratti, C. The geography of taste: Analyzing cell-phone mobility and social events. In Proceedings of the International Conference on Pervasive Computing, Helsinki, Finland, 17–20 May 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 22–37. [Google Scholar]
- Ratkiewicz, J.; Conover, M.; Meiss, M.R.; Gonçalves, B.; Flammini, A.; Menczer, F. Detecting and tracking political abuse in social media. In Proceedings of the International Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; AAAI: Palo Alto, CA, USA, 2011; pp. 297–304. [Google Scholar]
- Sobkowicz, P.; Kaschesky, M.; Bouchard, G. Opinion mining in social media: Modeling, simulating, and forecasting political opinions in the web. Gov. Inf. Q. 2012, 29, 470–479. [Google Scholar] [CrossRef]
- Goldthorpe, J.H. On Sociology: Numbers, Narratives, and the Integration of Research and Theory, 1st ed.; Oxford University Press: Oxford, UK, 2000; pp. 45–65. ISBN 978-0-19-829572-3. [Google Scholar]
- Savage, M.; Burrows, R. The coming crisis of empirical sociology. Sociology 2007, 41, 885–899. [Google Scholar] [CrossRef]
- Mobasheri, A.; Sun, Y.; Loos, L.; Ali, A.L. Are Crowdsourced datasets suitable for specialized routing services? Case study of OpenStreetMap for routing of people with limited mobility. Sustainability 2017, 9, 997. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Glennon, J.A. Crowdsourcing geographic information for disaster response: A research frontier. Int. J. Digit. Earth 2010, 3, 231–241. [Google Scholar] [CrossRef]
- Crooks, A.; Croitoru, A.; Stefanidis, A.; Radzikowski, J. # Earthquake: Twitter as a distributed sensor system. Trans. GIS 2013, 17, 124–147. [Google Scholar] [CrossRef]
- Krumm, J.; Horvitz, E. Eyewitness: Identifying local events via space-time signals in twitter feeds. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; ACM: New York, NY, USA, 2015. [Google Scholar]
- Sugitani, T.; Shirakawa, M.; Hara, T.; Nishio, S. Detecting local events by analyzing spatiotemporal locality of tweets. In Proceedings of the 27th International Conference on Advanced Information Networking and Applications Workshops, Barcelona, Spain, 25–28 March 2013; IEEE: New York, NY, USA, 2013; pp. 191–196. [Google Scholar]
- Cheng, X.; Yan, X.; Lan, Y.; Guo, J. Btm: Topic modeling over short texts. IEEE Trans. Knowl. Data Eng. 2014, 26, 2928–2941. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, L.; Lei, D.; Yuan, Q.; Zhuang, H.; Hanratty, T.; Han, J. Triovecevent: Embedding-based online local event detection in geo-tagged tweet streams. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017; pp. 595–604. [Google Scholar]
- Zhou, X.; Xu, C. Tracing the spatial-temporal evolution of events based on social media data. ISPRS Int. J. Geo-Inf. 2017, 6, 88. [Google Scholar] [CrossRef]
- Murzintcev, N.; Cheng, C. Disaster Hashtags in Social Media. ISPRS Int. J. Geo-Inf. 2017, 6, 204. [Google Scholar] [CrossRef]
- Yan, Y.; Eckle, M.; Kuo, C.L.; Herfort, B.; Fan, H.; Zipf, A. Monitoring and assessing post-disaster tourism recovery using geotagged social media data. ISPRS Int. J. Geo-Inf. 2017, 6, 144. [Google Scholar] [CrossRef]
- Nakaji, Y.; Yanai, K. Visualization of real-world events with geotagged tweet photos. In Proceedings of the IEEE International Conference on Multimedia and Expo Workshops (ICMEW), Melbourne, VIC, Australia, 9–13 July 2012; IEEE: New York, NY, USA, 2012; pp. 272–277. [Google Scholar]
- Gao, Y.; Wang, S.; Padmanabhan, A.; Yin, J.; Cao, G. Mapping spatiotemporal patterns of events using social media: A case study of influenza trends. Int. J. Geogr. Inf. Sci. 2018, 32, 425–449. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef] [Green Version]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Yang, L.; MacEachren, A.M.; Mitra, P.; Onorati, T. Visually-Enabled Active Deep Learning for (Geo) Text and Image Classification: A Review. ISPRS Int. J. Geo-Inf. 2018, 7, 65. [Google Scholar] [CrossRef]
- Feng, Y.; Sester, M. Extraction of pluvial flood relevant volunteered geographic information (VGI) by deep learning from user generated texts and photos. ISPRS Int. J. Geo-Inf. 2018, 7, 39. [Google Scholar] [CrossRef]
- Cambria, E.; Schuller, B.; Xia, Y.; Havasi, C. New avenues in opinion mining and sentiment analysis. IEEE Intell. Syst. 2013, 28, 15–21. [Google Scholar] [CrossRef]
- Dong, Z.; Dong, Q.; Hao, C. Hownet and its computation of meaning. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; ACL: Stroudsburg, PA, USA; pp. 53–56. [Google Scholar]
- Wang, Y.; Zhang, S.X. Research of sentiment analysis for Chinese micro-blog topic. J. Fuyang Norm. Univ. (Nat. Sci.) 2017, 34, 50–56. (In Chinese) [Google Scholar]
- Wen, Z. A Study on Negation in Modern Chinese. Ph.D. Thesis, Fudan University, Shanghai, China, 2003. (In Chinese). [Google Scholar]
- Dang, L.; Zhang, L. Method of discriminant for Chinese sentence sentiment orientation based on HowNet. Appl. Res. Comput. 2010, 27, 1370–1372. (In Chinese) [Google Scholar]
- Xu, L.; Lin, H.; Pan, Y.; Ren, H.; Chen, J. Constructing the affective lexicon ontology. J. China Soc. Sci. Tech. Inf. 2008, 27, 180–185. (In Chinese) [Google Scholar]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic latent semantic analysis. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, Stockholm, Sweden, 30 July–1 August 1999; Morgan Kaufmann Publishers: San Francisco, CA, USA, 1999; pp. 289–296. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101 (Suppl. 1), 5228–5235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parameter Estimation for Text Analysis. Available online: http://www.arbylon.net/publications/text-est.pdf (accessed on 15 November 2017).
- Röder, M.; Both, A.; Hinneburg, A. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 31 January–6 February 2015; ACM: New York, NY, USA, 2015; pp. 399–408. [Google Scholar]
- Newman, D.; Lau, J.H.; Grieser, K.; Baldwin, T. Automatic evaluation of topic coherence. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 1–6 June 2010; ACL: Stroudsburg, PA, USA, 2010; pp. 100–108. [Google Scholar]
- Zheng, Y.; Wu, W.; Chen, Y.; Qu, H.; Ni, L.M. Visual analytics in urban computing: An overview. IEEE Trans. Big Data 2016, 2, 276–296. [Google Scholar] [CrossRef]
- Tang, J.; Liu, Z.; Sun, M. A Survey of Text Visualization. J. Comput. Aided Des. Comput. Graph. 2013, 25, 273–285. (In Chinese) [Google Scholar]
- Investigation Report of 2014 Shanghai Stampede Event. Available online: http://www.shjcw.gov.cn/2015jjw/n2230/n2237/u1ai51007.html (accessed on 4 November 2017).
- Jendryke, M.; Balz, T.; Liao, M. Big location-based social media messages from China’s Sina Weibo network: Collection, storage, visualization, and potential ways of analysis. Trans. GIS 2017, 21, 825–834. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Vanderplas, J. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Joachims, T. Learning to Classify Text Using Support Vector Machines, 1st ed.; Springer: Boston, MA, USA, 2002; pp. 45–74. ISBN 978-1-4613-5298-3. [Google Scholar]
- How Spatial Aggregation Works. Available online: https://github.com/CartoDB/torque/wiki/How-spatial-aggregation-works (accessed on 2 November 2017).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Number of Records | Date | Description | |
|---|---|---|---|
| Event-related dataset | 2093 | January 2015 | Posted with event-related hashtags |
| Event-irrelevant dataset | 61,081 | 1 January 2014 | Posted in the New Year 2014 |
| Method | Parameters | Precision | Recall | F1_Score |
|---|---|---|---|---|
| MultinomialNB | alpha = 0.5 | 1.000 | 0.685 | 0.813 |
| BernoulliNB | alpha = 0.001 | 0.995 | 0.972 | 0.984 |
| KNN | K = 3, weights = Euclidean distance | 0.972 | 0.319 | 0.481 |
| SVM (Linear Kernel) | C = 1 | 0.991 | 0.995 | 0.993 |
| SVM (RBF Kernel) | C = 100, gamma = 0.01 | 0.991 | 0.995 | 0.993 |
| Topic | Topic Word Content | Interpretation | Relationship | Sentimental Value |
|---|---|---|---|---|
| 1 | candle, event, report, event investigation, happened, Shanghai, people, leader, accident, that night, all, officers, went, eat, restaurant | Local officers ate dinner at nearby restaurants during the night of the incident | Related event | −0.85 |
| 2 | report, event investigation, survey result, event, candle, strong, cancel, light show, crowd, happened, that night, people, Shanghai, all, the deceased, | Because of the stampede event, the light show was canceled in case of another security incident. | Causal relationship | −1.87 |
| 3 | survey result, leader, people, restaurant, event, die, Shanghai, district mayor, dismissed, go, Huangpu district, courage, happened, accident, the Bund, | The government handled the incident, dismissed the mayor, this may be related to a previous restaurant event | Causal relationship | −3.20 |
| 4 | accident, Shanghai, the Bund, people, event, center, crowd, happened, mad, share, quick, come to see, candle, view, all | 1. Overcrowding caused a stampede 2. The public spreads event-related information through social media | 1. Reason 2. Public concentration | −0.55 |
| 5 | candle, event, people, accident, Shanghai, all, go, the deceased, rest in peace, life, happened, the victim, strong, the Bund, silence | The reaction of the people to the incident, wishing that the dead rest in peace, hoping people can be strong | Public reaction to death people | −1.14 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, R.; Lin, D.; Jendryke, M.; Zuo, C.; Ding, L.; Meng, L. Geo-Tagged Social Media Data-Based Analytical Approach for Perceiving Impacts of Social Events. ISPRS Int. J. Geo-Inf. 2019, 8, 15. https://doi.org/10.3390/ijgi8010015
Zhu R, Lin D, Jendryke M, Zuo C, Ding L, Meng L. Geo-Tagged Social Media Data-Based Analytical Approach for Perceiving Impacts of Social Events. ISPRS International Journal of Geo-Information. 2019; 8(1):15. https://doi.org/10.3390/ijgi8010015
Chicago/Turabian StyleZhu, Ruoxin, Diao Lin, Michael Jendryke, Chenyu Zuo, Linfang Ding, and Liqiu Meng. 2019. "Geo-Tagged Social Media Data-Based Analytical Approach for Perceiving Impacts of Social Events" ISPRS International Journal of Geo-Information 8, no. 1: 15. https://doi.org/10.3390/ijgi8010015
APA StyleZhu, R., Lin, D., Jendryke, M., Zuo, C., Ding, L., & Meng, L. (2019). Geo-Tagged Social Media Data-Based Analytical Approach for Perceiving Impacts of Social Events. ISPRS International Journal of Geo-Information, 8(1), 15. https://doi.org/10.3390/ijgi8010015