Efficient Method for POI/ROI Discovery Using Flickr Geotagged Photos


Abstract

1. Introduction
- An efficient method of eliminating noises among collected footprints and selecting attractive footprints with a local maximum for delineating POIs and ROIs is proposed.
- An effective clustering toward pattern discovery that involves spatial and temporal properties and attributes, such as tags, with a spatial overlap (SO) algorithm is exploited. The discovered ROIs are particularly spatial overlap available that the satisfied region of ROIs can be shared for appreciating attractions.
- A POI and an ROI with peak value that indicate the most popular location and range for appreciating attractions, respectively, are uncovered.
2. Related Work
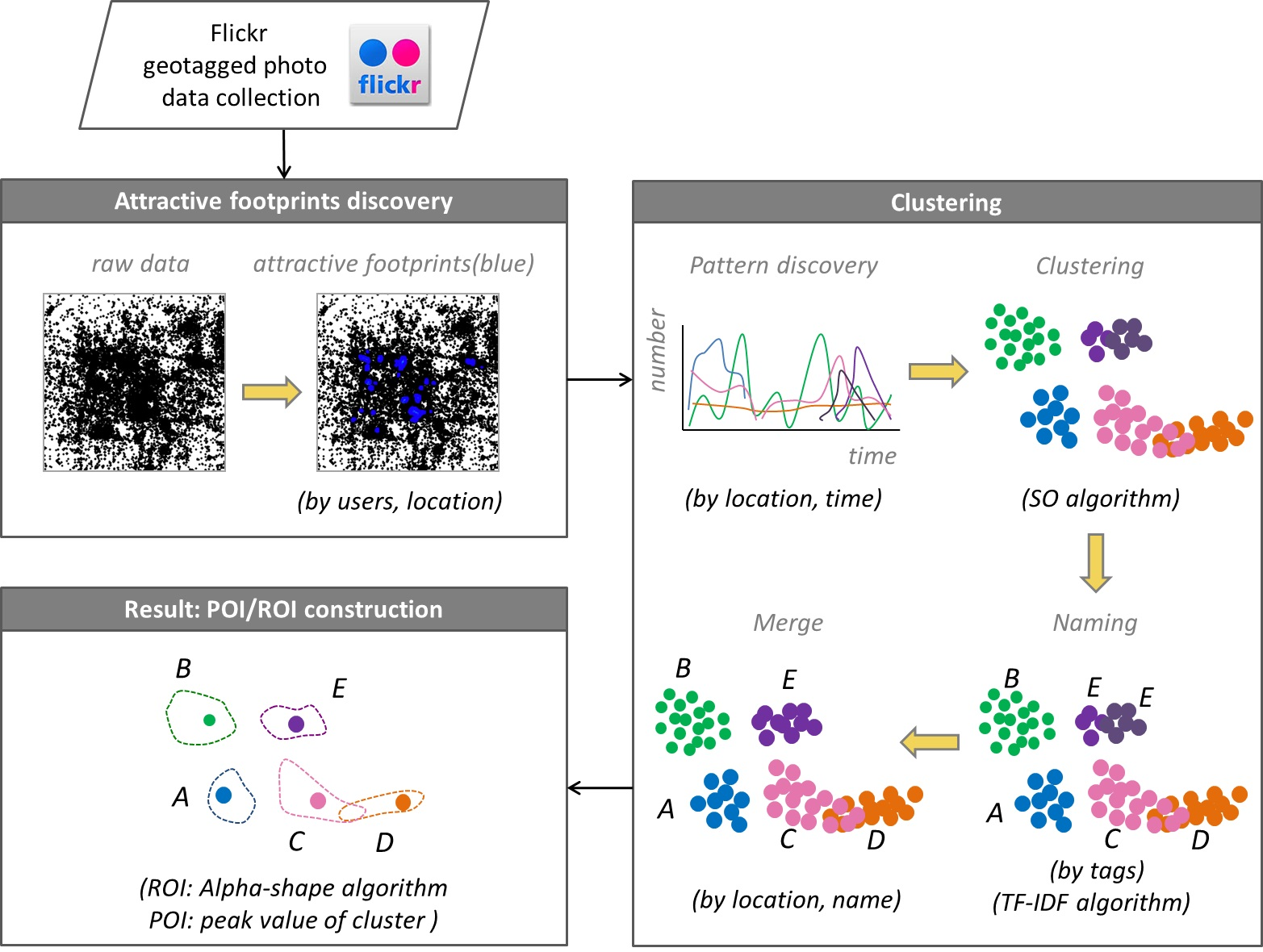
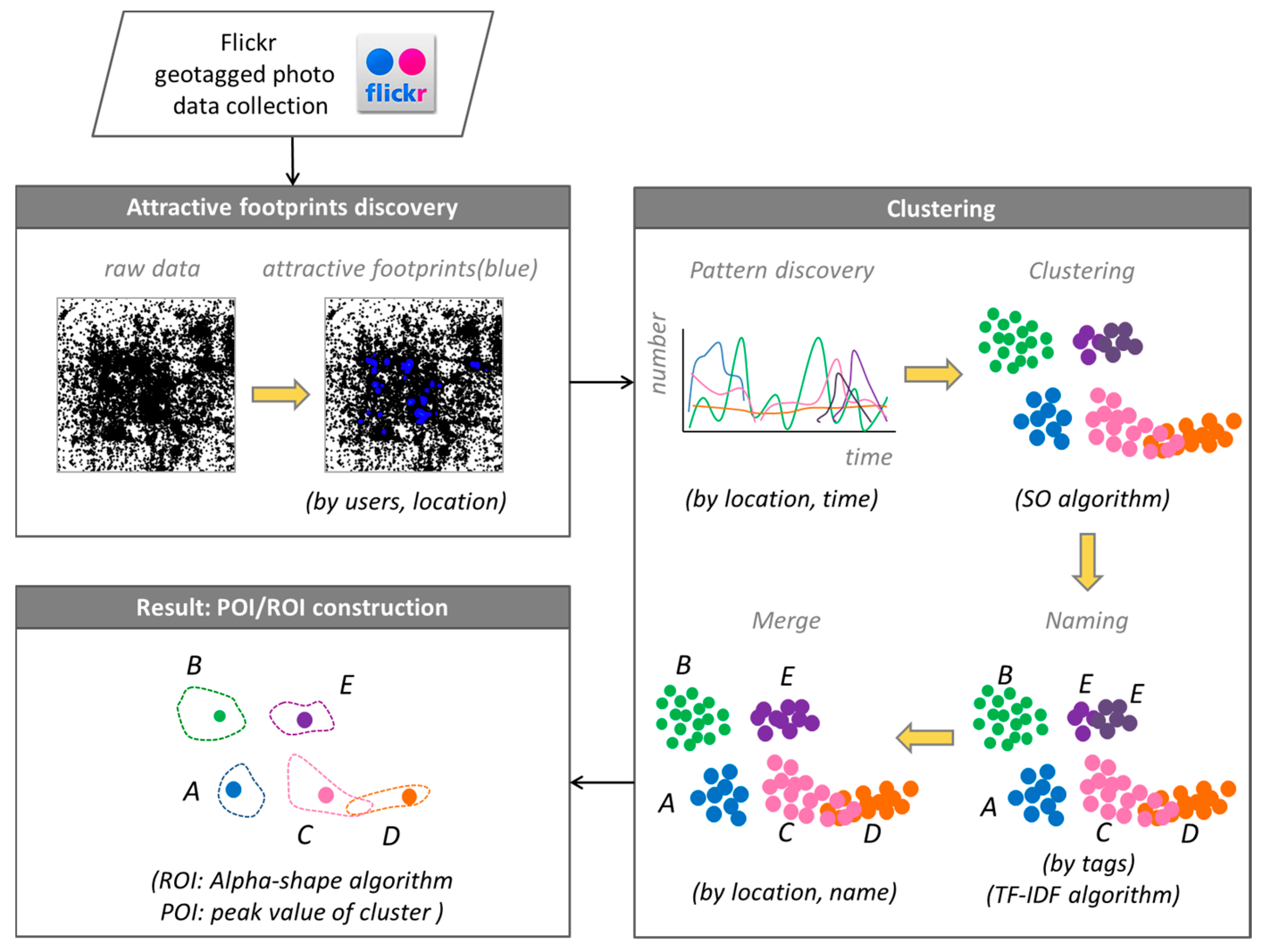
3. Method
3.1. Attractive Footprints Discovery
3.2. Clustering
3.2.1. Pattern Discovery
| Algorithm 1: Pattern discovery. |
def validation(Available_Points): #area validation
S=[]
for n in Available_Points:
m = month of n
S[m].append(n)
area=0
for s in S
area+=s.area()
return area>0
def pattern(p,r): #pattern calculation
N=Neighbours(p,r)
Available_Points=[]
for n in N: #find nearest unique users
if n.user_id not in Available_Points:
Available_Points[n.user_id]=n;
else:
if distance(p,n)<distance(p,Available_Points[n.user_id]):
Available_Points[n.user_id]=n;
if validation(Available_Points):
X = []
for n in Available_Points:
m = month of n
X[m]++ #pattern calculation based on set time
return vector_normalization(X) #pattern normalization
else:
return null
def patternDiff(a,b): #pattern difference calculation
Pdiff=[]
for m in range(1,12)
Pdiff[m]=|a.XN[m]-b.XN[m]|
return vector_normalization(Pdiff) #pattern difference normalization
def findSimlarPatternPoints(p,afs): #find points with similar pattern
S=[]
for q in afs:
if q.XN!=null:
PdiffN=patternDiff(p.XN,q.XN)
if PdiffN<=T2:
S.append(q)
return S
def main: #main function
for p in afs:
p.XN=pattern(p,r)
for p in afs:
if p.XN !=null:
p.S=findSimlarPatternPoints(p,afs)
|
3.2.2. Clustering with a Spatial Overlap Algorithm (SO Algorithm)
| Algorithm 2: Clustering with a SO algorithm. |
def clustering:
sortByPeakValue(afs) #order by peakValue DESC of afs
unmark_all(afs) #unmark all point of afs
clusters=[]
for p in afs
if p.XN!=null and is_unmark(p):
cluster=[] #create new cluster
cluster.append(p)
for q in p.S #PdiffN<=T2
if is_unmark(q):
cluster.append(q)
PdiffN=patternDiff(p.XN,q.XN)
if PdiffN<=T2-T3:
mark(q)
clusters.append(cluster)
return clusters
|
3.2.3. Naming
3.2.4. Merge
3.3. POI and ROI Determination
4. Implementation
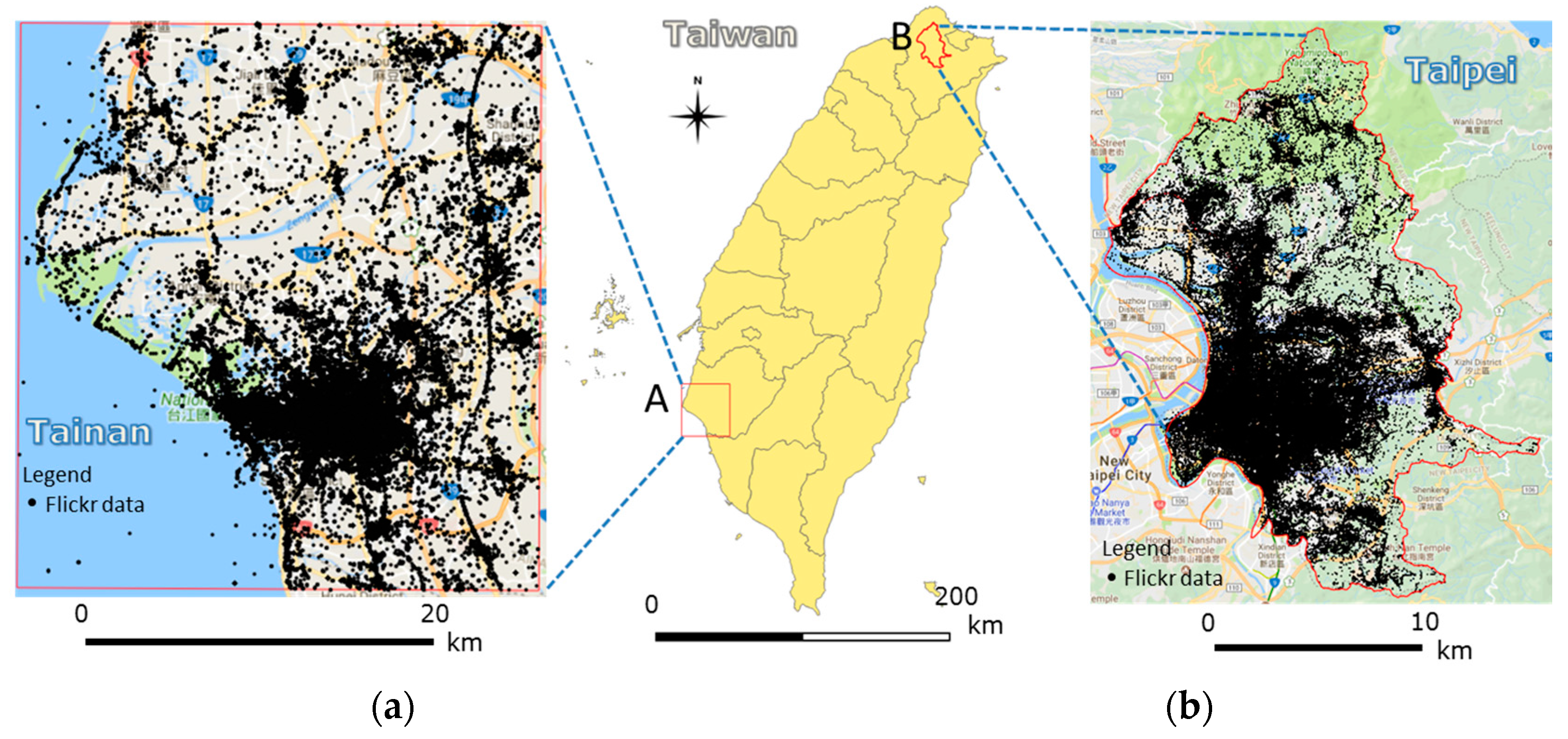
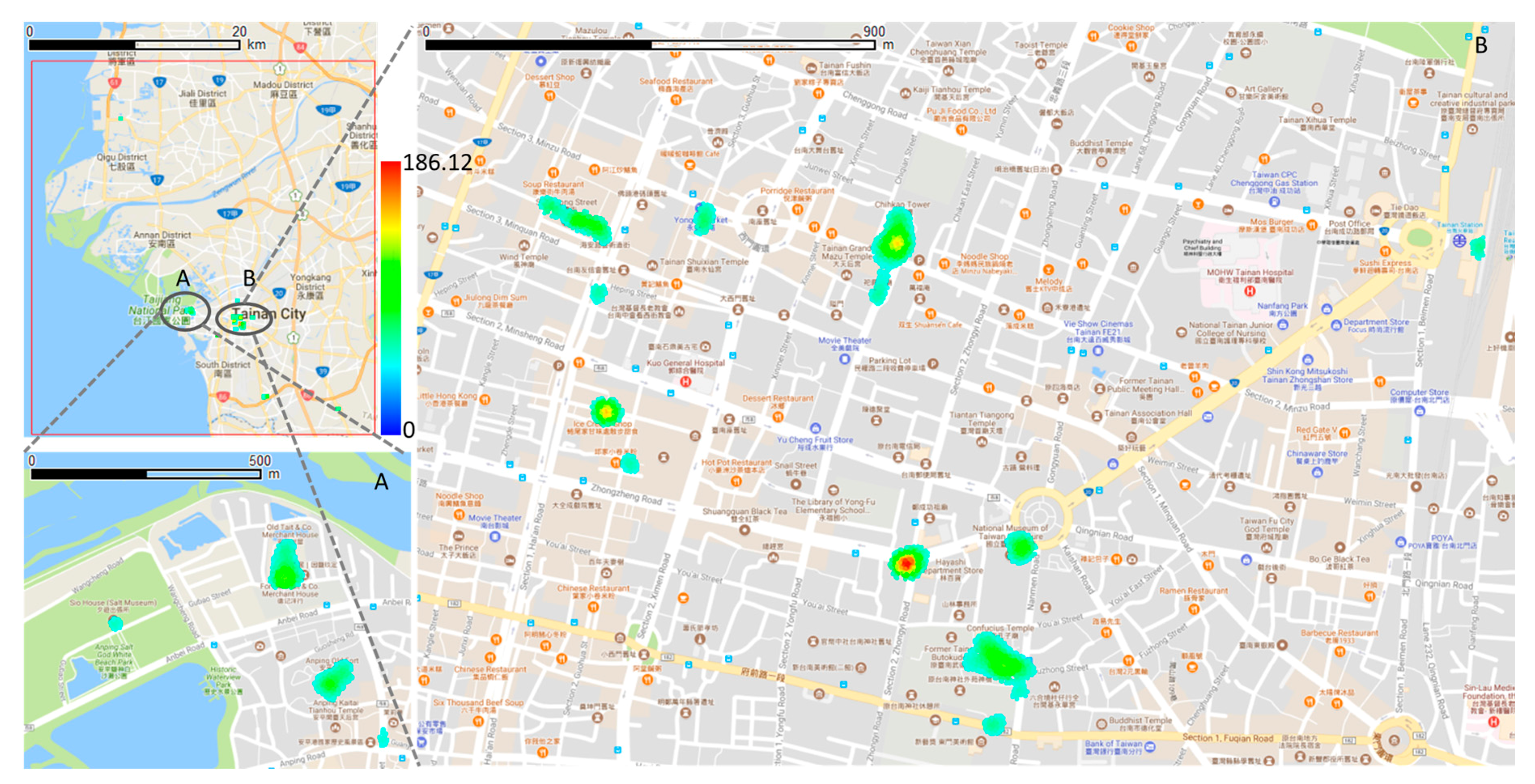
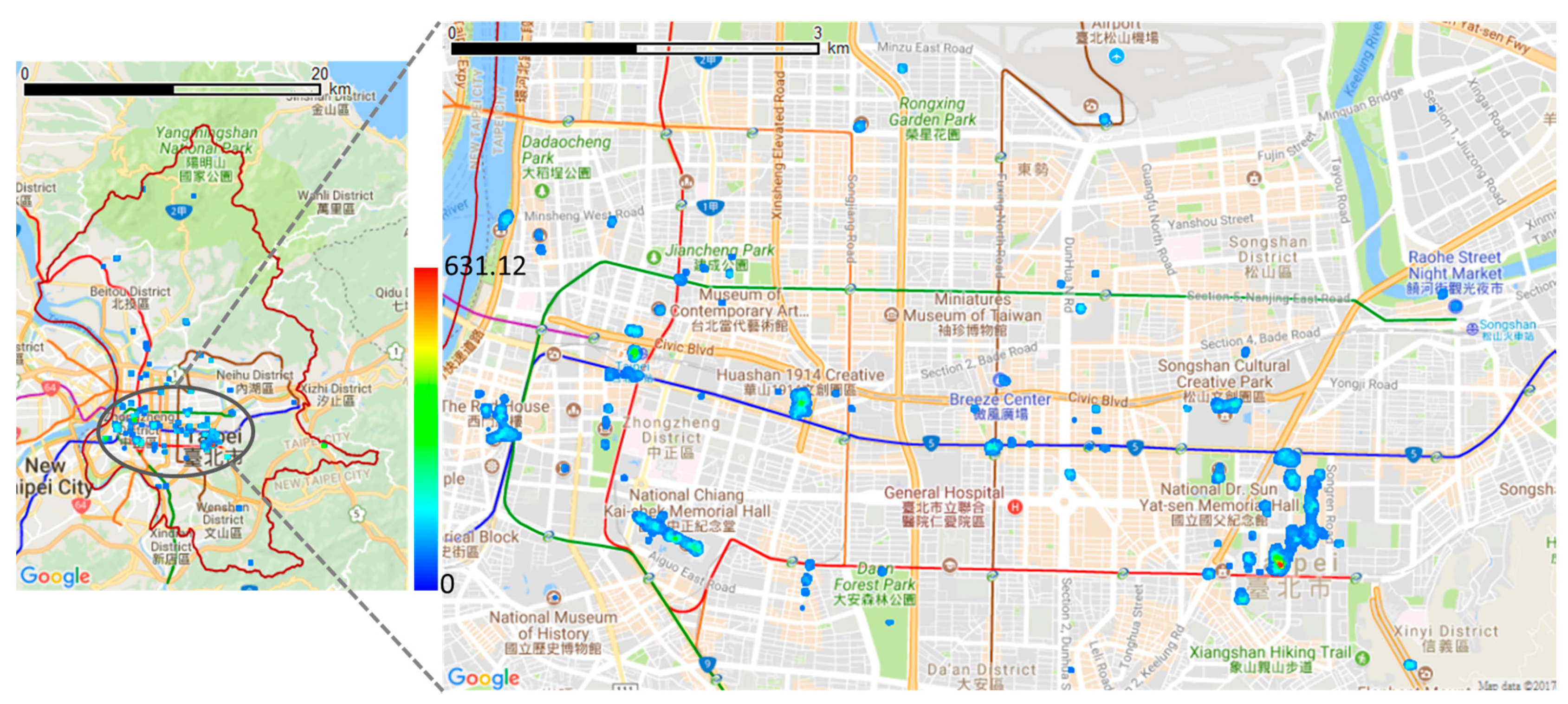
4.1. Study Areas and Materials
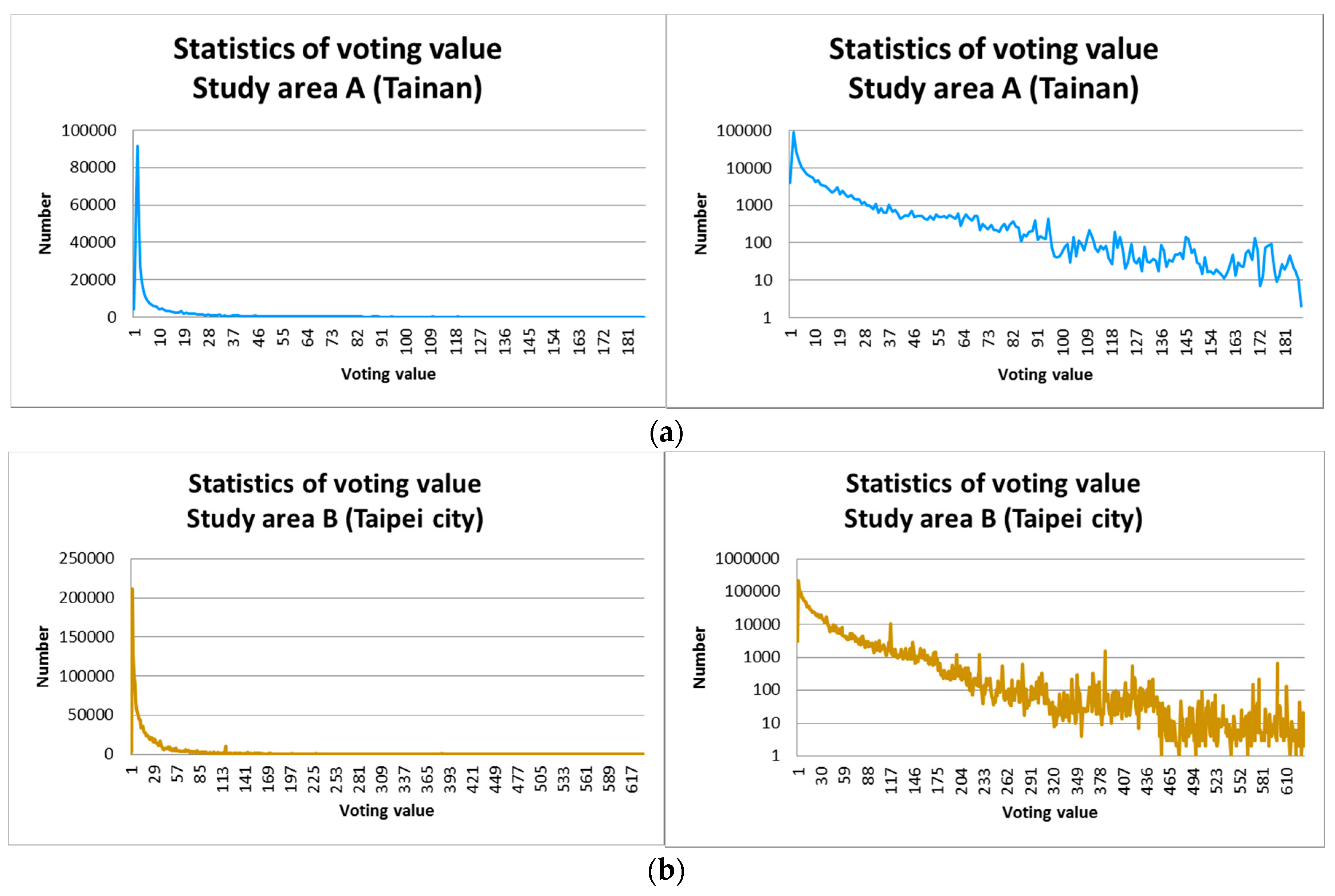
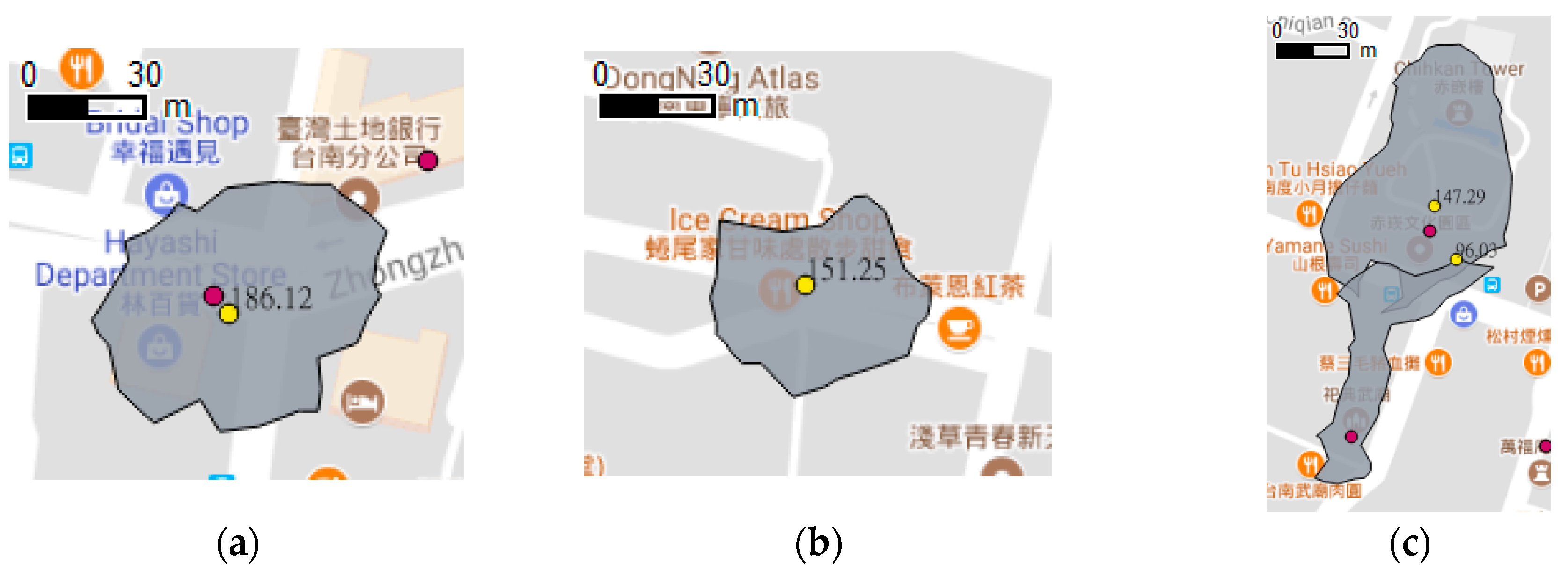
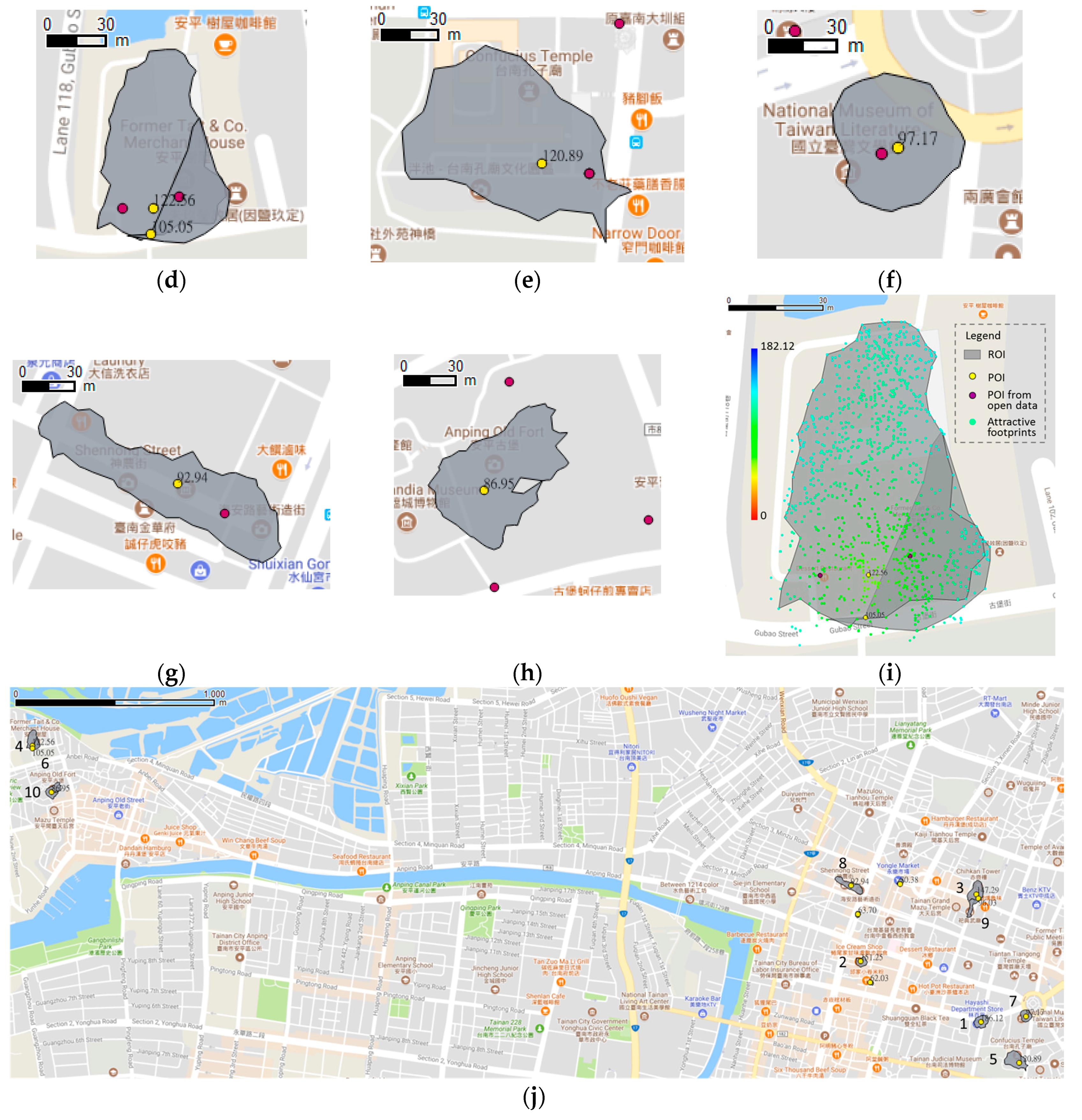
4.2. Result
4.3. Discussion and Evaluation
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Flickr: Find Your Inspiration. Available online: https://www.flickr.com/ (accessed on 20 October 2017).
- Kisilevich, S.; Keim, D.; Andrienko, N.; Andrienko, G. Towards acquisition of semantics of places and events by multi-perspective analysis of geotagged photo collections. In Geospatial Visualisation; Springer: Berlin, Germany, 2013; pp. 211–233. [Google Scholar]
- Dunkel, A. Visualizing the perceived environment using crowdsourced photo geodata. Landsc. Urban Plan. 2015, 142, 173–186. [Google Scholar] [CrossRef]
- Kennedy, L.; Naaman, M.; Ahern, S.; Nair, R.; Rattenbury, T. How Flickr Helps Us Make Sense of the World: Context and Content in Community-Contributed Media Collections; ACM: New York, NY, USA, 2007; pp. 631–640. [Google Scholar]
- Li, L.; Goodchild, M.F. Constructing Places from Spatial Footprints; ACM: New York, NY, USA, 2012; pp. 15–21. [Google Scholar]
- Li, S.; Dragicevic, S.; Castro, F.A.; Sester, M.; Winter, S.; Coltekin, A.; Pettit, P.; Jiang, B.; Haworth, J.; Stein, A.; et al. Geospatial big data handling theory and methods: A review and research challenges. ISPRS J. Photogramm. Remote Sens. 2016, 115, 119–133. [Google Scholar] [CrossRef]
- Korakakis, M.; Spyrou, E.; Mylonas, P.; Perantonis, S.J. Exploiting social media information toward a context-aware recommendation system. Soc. Netw. Anal. Min. 2017, 7, 42. [Google Scholar] [CrossRef]
- Hu, Y.; Gao, S.; Janowicz, K.; Yu, B.; Li, W.; Prasadd, S. Extracting and understanding urban areas of interest using geotagged photos. Comput. Environ. Urban Syst. 2015, 54, 240–254. [Google Scholar] [CrossRef]
- Terminology-POI WG Terminology Glossary. Available online: https://www.w3.org/2010/POI/wiki/Terminology (accessed on 14 February 2017).
- Yahoo! GeoPlanet. Available online: https://developer.yahoo.com/geo/geoplanet/ (accessed on 20 October 2017).
- Openpois. Available online: http://openpois.ogcnetwork.net/ (accessed on 20 October 2017).
- NYC OpenData. Available online: https://nycopendata.socrata.com/ (accessed on 20 October 2017).
- Tainan City POI. Available online: http://data.tainan.gov.tw/dataset/landmark2 (accessed on 20 October 2017).
- Chuang, H.-M.; Chang, C.-H.; Kao, T.-Y.; Cheng, C.-T.; Huang, Y.-Y.; Cheong, K.-P. Enabling maps/location searches on mobile devices: Constructing a POI database via focused crawling and information extraction. Int. J. Geogr. Inf. Sci. 2016, 30, 1405–1425. [Google Scholar] [CrossRef]
- Jonietz, D.; Zipf, A. Defining fitness-for-use for crowdsourced points of interest (POI). ISPRS Int. J. Geo-Inf. 2016, 5, 149. [Google Scholar] [CrossRef]
- Rousell, A.; Hahmann, S.; Bakillah, M.; Mobasheri, A. Extraction of landmarks from OpenStreetMap for use in navigational instructions. In Proceedings of the 18th AGILE International Conference on Geographic Information Science, Lisbon, Portugal, 9–12 June 2015. [Google Scholar]
- Cheng, Z.; Caverlee, J.; Lee, K.; Sui, D.Z. Exploring Millions of Footprints in Location Sharing Services. ICWSM 2011, 2011, 81–88. [Google Scholar]
- Spyrou, E.; Korakakis, M.; Charalampidis, V.; Psallas, A.; Mylonas, P. A Geo-Clustering Approach for the Detection of Areas-of-Interest and Their Underlying Semantics. Algorithms 2017, 10, 35. [Google Scholar] [CrossRef]
- Skovsgaard, A.; Jensen, C.S. A clustering approach to the discovery of points of interest from geo-tagged microblog posts. In Proceedings of the 2014 IEEE 15th International Conference on Mobile Data Management (MDM), Brisbane, Australia, 14–18 July 2014; pp. 178–188. [Google Scholar]
- Vu, D.D.; To, H.; Shin, W.-Y.; Shahabi, C. GeoSocialBound: An Efficient Framework for Estimating Social POI Boundaries Using Spatio—Textual Information; ACM: New York, NY, USA, 2016; p. 3. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, Oregon, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Kisilevich, S.; Mansmann, F.; Keim, D. P-DBSCAN: A Density Based Clustering Algorithm for Exploration and Analysis of Attractive Areas Using Collections of Geo-Tagged Photos; ACM: New York, NY, USA, 2010; p. 38. [Google Scholar]
- Twitter. Available online: https://twitter.com/ (accessed on 20 October 2017).
- Facebook. Available online: https://www.google.com.tw/ (accessed on 20 October 2017).
- Instagram. Available online: https://www.instagram.com/ (accessed on 20 October 2017).
- flickr App Garden. Available online: https://www.flickr.com/services/api/ (accessed on 20 October 2017).
- Discover the Action around You with the Updated Google Maps. Available online: https://blog.google/products/maps/discover-action-around-you-with-updated/ (accessed on 20 October 2017).
- Liu, J.; Huang, Z.; Chen, L.; Shen, H.T.; Yan, Z. Discovering Areas of Interest with Geo-Tagged Images and Check-Ins; ACM: New York, NY, USA, 2012; pp. 589–598. [Google Scholar]
- Shirai, M.; Hirota, M.; Ishikawa, H.; Yokoyama, S. A method of Area of Interest and Shooting Spot Detection using Geo-tagged Photographs. In Proceedings of the First ACM Sigspatial International Workshop on Computational Models of Place, Orlando, FL, USA, 5–8 November 2013; pp. 34–41. [Google Scholar]
- Ruiz, C.; Spiliopoulou, M.; Menasalvas, E. C-Dbscan: Density-Based Clustering with Constraints; Springer: Heidelberg, Germany, 2007; pp. 216–223. [Google Scholar]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial-temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Du, Q.; Dong, Z.; Huang, C.; Ren, F. Density-Based Clustering with Geographical Background Constraints Using a Semantic Expression Model. ISPRS Int. J. Geo-Inf. 2016, 5, 72. [Google Scholar] [CrossRef]
- Yang, Y.; Gong, Z. Identifying, Points of Interest Using Heterogeneous Features. ACM Trans. Intell. Syst. Technol. 2015, 5, 68. [Google Scholar] [CrossRef]
- Campello, R.J.; Moulavi, D.; Sander, J. Density-Based Clustering Based on Hierarchical Density Estimates; Springer: Berlin, Germany, 2013; pp. 160–172. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.-P.; Sander, J. OPTICS: Ordering Points to Identify the Clustering Structure; ACM: New York, NY, USA, 1999; pp. 49–60. [Google Scholar]
- Laptev, D.; Tikhonov, A.; Serdyukov, P.; Gusev, G. Parameter-Free Discovery and Recommendation of Areas-of-Interest; ACM: New York, NY, USA, 2014; pp. 113–122. [Google Scholar]
- Encalada, L.; Boavida-Portugal, I.; Cardoso Ferreira, C.; Rocha, J. Identifying Tourist Places of Interest Based on Digital Imprints: Towards a Sustainable Smart City. Sustainability 2017, 9, 2317. [Google Scholar] [CrossRef]
- Graham, R.L. An efficient algorith for determining the convex hull of a finite planar set. Inf. Process. Lett. 1972, 1, 132–133. [Google Scholar] [CrossRef]
- Edelsbrunner, H.; Kirkpatrick, D.; Seidel, R. On the shape of a set of points in the plane. IEEE Trans. Inf. Theory 1983, 29, 551–559. [Google Scholar] [CrossRef]
- Moreira, A.; Santos, M.Y. Concave hull: A k-nearest neighbours approach for the computation of the region occupied by a set of points. In Proceedings of the International Conference on Computer Graphics Theory and Applications (GRAPP), Barcelona, Spain, 8–11 March 2007; pp. 61–68. [Google Scholar]
- Find Your WOEID. Available online: http://www.woeidlookup.com/ (accessed on 13 March 2018).
- Keßler, C.; Maué, P.; Heuer, J.T.; Bartoschek, T. Bottom-up Gazetteers: Learning from the Implicit Semantics of Geotags; Spring: Heidelberg, Germany, 2009; pp. 83–102. [Google Scholar]
- Mummidi, L.N.; Krumm, J. Discovering points of interest from users’ map annotations. GeoJournal 2008, 72, 215–227. [Google Scholar] [CrossRef]
- Krumm, J.C.; Mummidi, L.N. Discovering Points of Interest from Users Map Annotations. U.S. Patent 8,401,771, 19 March 2013. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Rattenbury, T.; Naaman, M. Methods for extracting place semantics from Flickr tags. ACM Trans. Web 2009, 3, 1. [Google Scholar] [CrossRef]
- Hollenstein, L.; Purves, R. Exploring place through user-generated content: Using Flickr tags to describe city cores. J. Spat. Inf. Sci. 2010, 2010, 21–48. [Google Scholar]
- Lim, K.H.; Chan, J.; Leckie, C.; Karunasekera, S. Personalized trip recommendation for tourists based on user interests, points of interest visit durations and visit recency. Knowl. Inf. Syst. 2017, 1–32. [Google Scholar] [CrossRef]
- Yang, Y.; Gong, Z. Identifying Points of Interest by Self-Tuning Clustering; ACM: New York, NY, USA, 2011; pp. 883–892. [Google Scholar]
- Liu, M.; Yang, J. An improvement of TFIDF weighting in text categorization. Int. Proc. Comput. Sci. Inf. Technol. 2012, 47, 44–47. [Google Scholar]
- Google Maps. Available online: https://www.google.com.tw/maps/ (accessed on 20 October 2017).
- Yan, Y.; Eckle, M.; Kuo, C.-L.; Herfort, B.; Fan, H.; Zipf, A. Monitoring and Assessing Post-Disaster Tourism Recovery Using Geotagged Social Media Data. ISPRS Int. J. Geo-Inf. 2017, 6, 144. [Google Scholar] [CrossRef]
- Flickr APP Garden-flickr.photos.search. Available online: https://www.flickr.com/services/api/flickr.photos.search.html (accessed on 20 October 2017).
- Perry, J.W.; Kent, A.; Berry, M.M. Machine literature searching x. machine language; factors underlying its design and development. J. Assoc. Inf. Sci. Technol. 1955, 6, 242–254. [Google Scholar] [CrossRef]
- Tourism Bureau of Tainan City Government. Available online: https://www.twtainan.net/en-us (accessed on 20 October 2017).
- Department of Information and Tourism, Taipei City Government. Available online: http://english.tpedoit.gov.taipei/ (accessed on 17 January 2018).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Study Area A | Study Area B |
|---|---|---|
| Total number of photos | 276,018 | 1,956,980 |
| Percentage of photos in Taiwan | 3.44% | 24.36% |
| Distinct contributed users | 6,749 | 22,886 |
| User tags (total/distinct) | 925,761/34,140 | 2,918,749/97,803 |
| Photos with user tags | 144,249 | 406,461 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuo, C.-L.; Chan, T.-C.; Fan, I.-C.; Zipf, A. Efficient Method for POI/ROI Discovery Using Flickr Geotagged Photos. ISPRS Int. J. Geo-Inf. 2018, 7, 121. https://doi.org/10.3390/ijgi7030121
Kuo C-L, Chan T-C, Fan I-C, Zipf A. Efficient Method for POI/ROI Discovery Using Flickr Geotagged Photos. ISPRS International Journal of Geo-Information. 2018; 7(3):121. https://doi.org/10.3390/ijgi7030121
Chicago/Turabian StyleKuo, Chiao-Ling, Ta-Chien Chan, I-Chun Fan, and Alexander Zipf. 2018. "Efficient Method for POI/ROI Discovery Using Flickr Geotagged Photos" ISPRS International Journal of Geo-Information 7, no. 3: 121. https://doi.org/10.3390/ijgi7030121
APA StyleKuo, C.-L., Chan, T.-C., Fan, I.-C., & Zipf, A. (2018). Efficient Method for POI/ROI Discovery Using Flickr Geotagged Photos. ISPRS International Journal of Geo-Information, 7(3), 121. https://doi.org/10.3390/ijgi7030121