Visually-Enabled Active Deep Learning for (Geo) Text and Image Classification: A Review



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Scope and Intended Audience
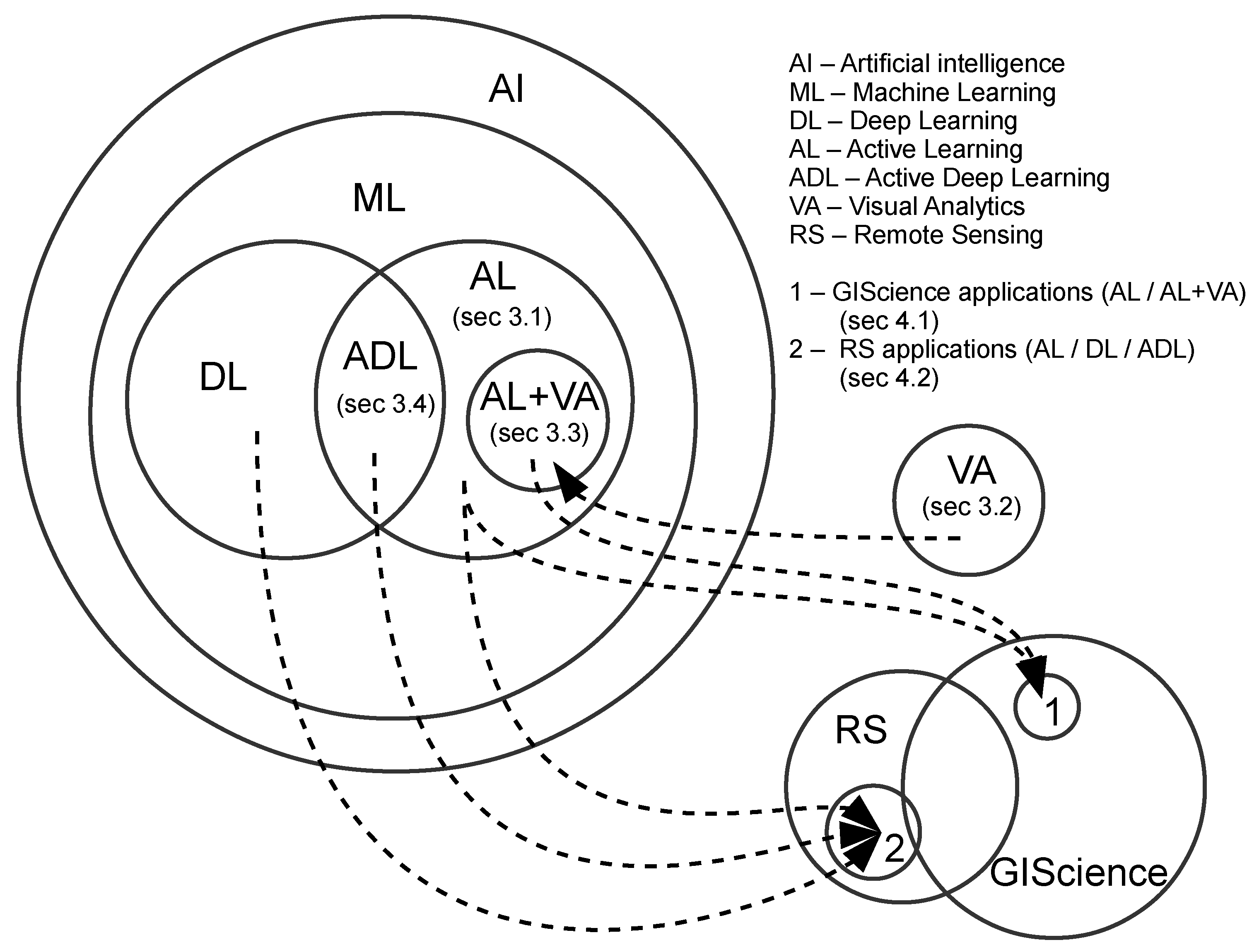
3. The State of the Art: Active Learning, Visual Analytics, and Deep Learning
3.1. Active Learning (AL)
3.1.1. What’s AL and Why AL?
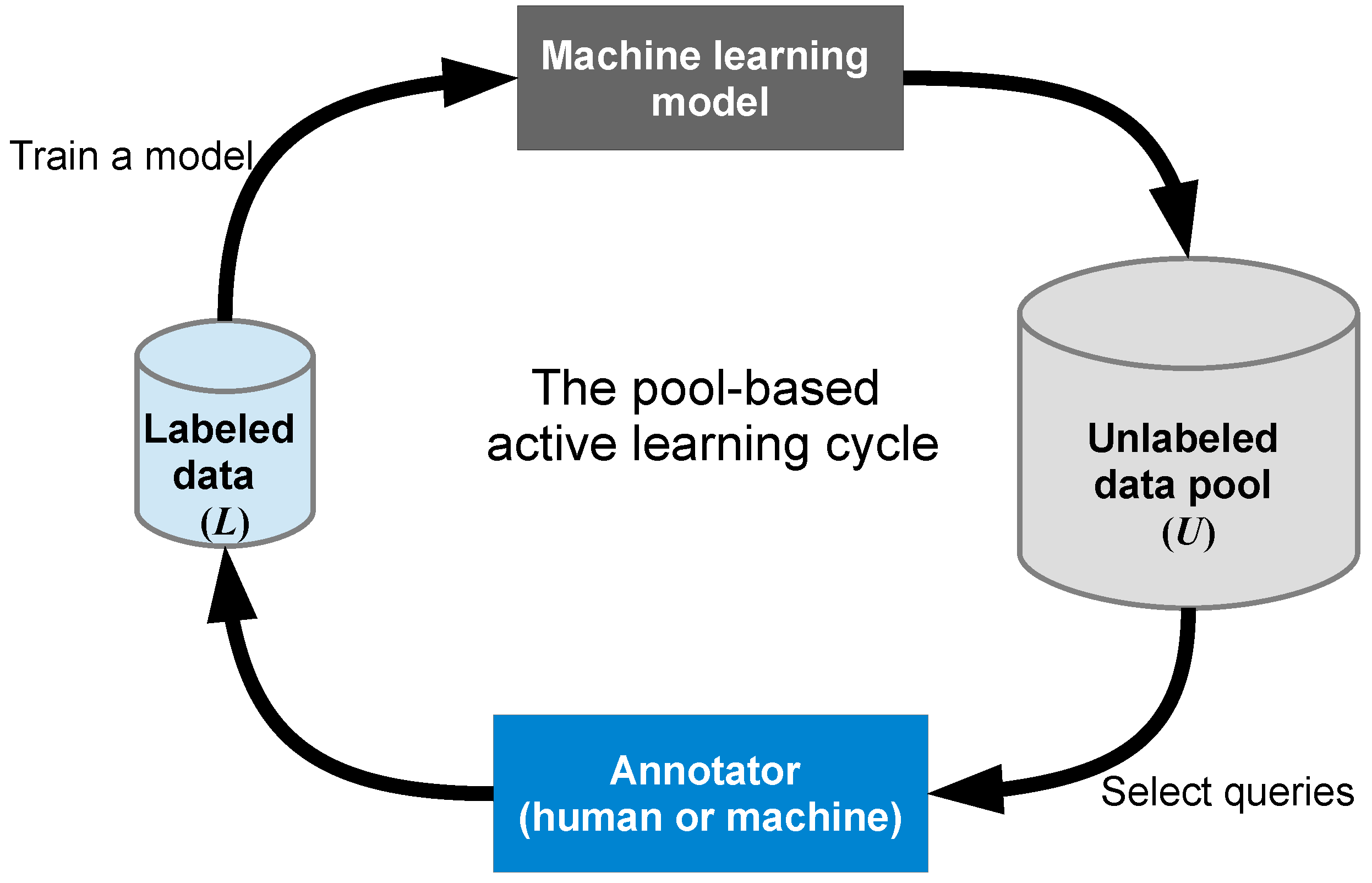
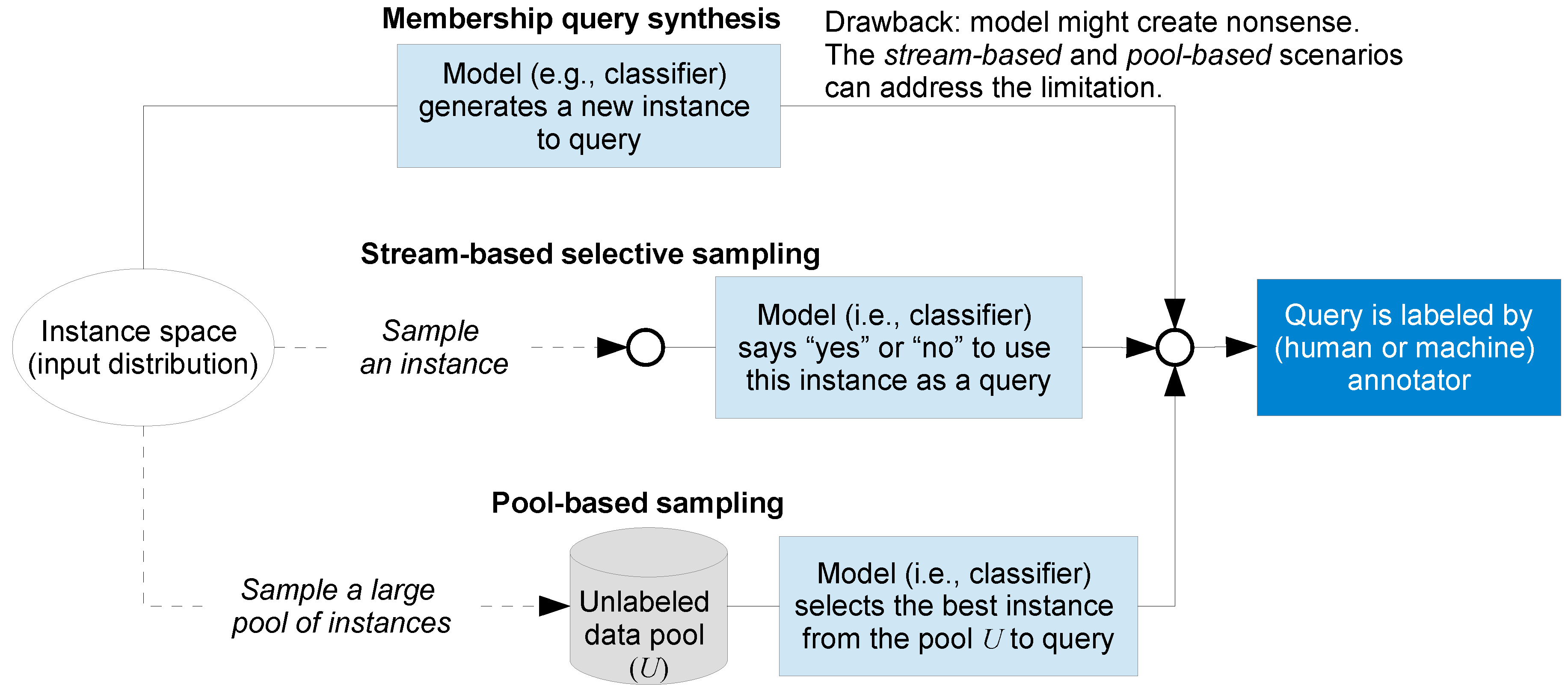
3.1.2. AL Problem Scenarios
3.1.3. AL Core Components
3.1.4. Batch-Mode AL
3.1.5. AL Query Strategies
3.1.6. Recent and Novel AL Methods
3.1.7. AL Summary and Discussion
3.2. Visual Analytics (VA) and Human-in-the-Loop
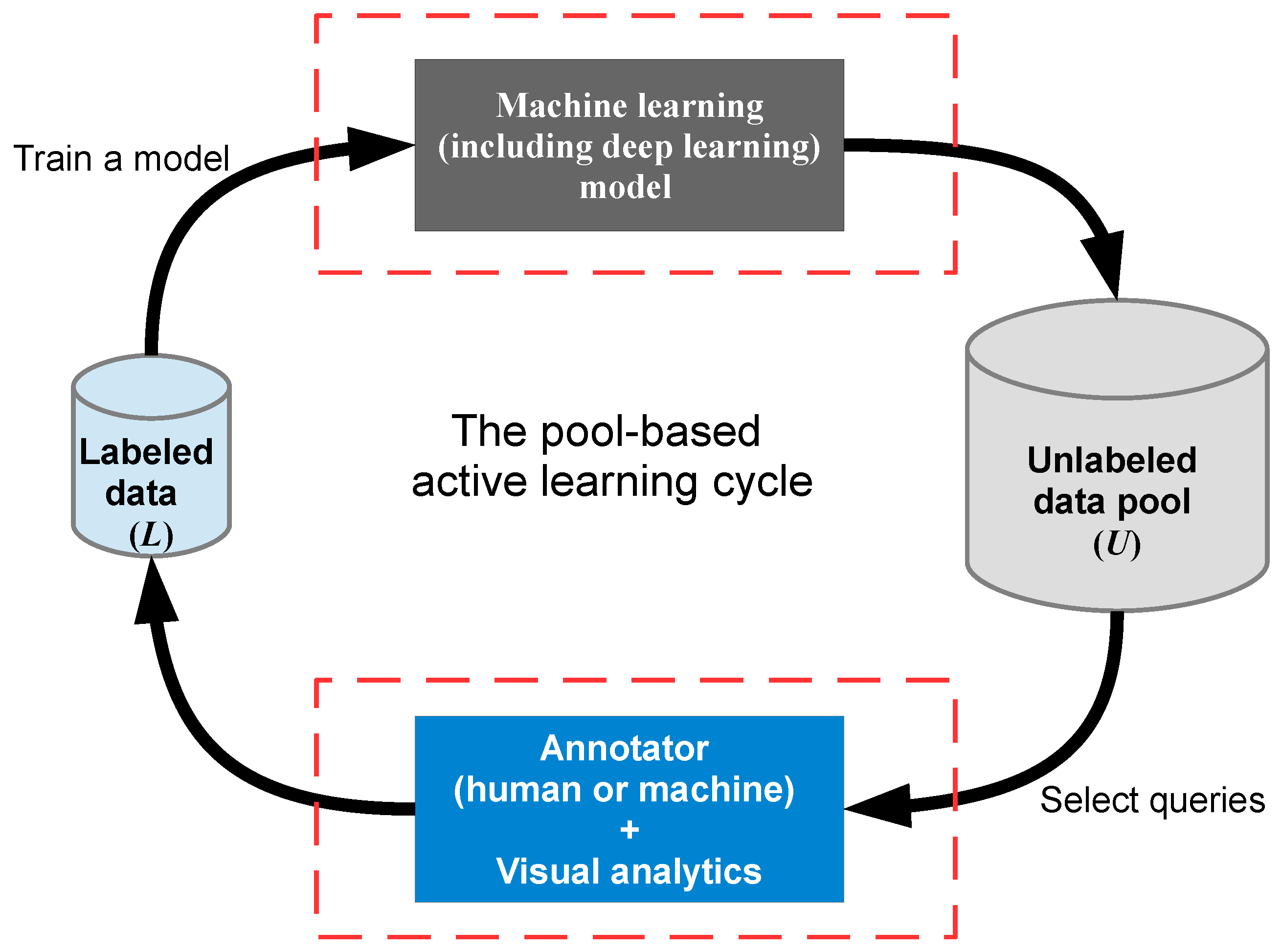
3.3. AL with VA
3.4. Active Deep Learning (ADL)
4. GIScience and RS Applications Using AL and ADL
4.1. GIScience Applications Using AL/AL with VA
4.2. RS Applications Using AL/ADL
5. Challenges and Research Opportunities
5.1. Summary and Discussion
5.2. Challenges and Research Opportunities
5.2.1. Technical Challenges and Opportunities
- Multi-label classification: Most existing multi-label classification research has been based on simple ML models (such as logistic regression [68,87], naive Bayes [68,87,145], and SVM [7,68,83,146]); but, very few on DL architectures, such as CNNs and RNNs. We need to extend the traditional ML models to DL ones for Big Data problems, because as we emphasized in Appendix A.1, DL algorithms have better scalability than traditional ML algorithms [116]. Wang et al. [147] and Chen et al. [148] have developed a CNN-RNN framework and an order-free RNN for multi-label classification for image data sets, respectively, whereas few DL based multi-label classification methods for text data have been proposed.
- Hierarchical classification: As Silla et al. [149] pointed out in their survey about hierarchical classification (Appendix A.4.4) across different application domains, flat classification (Appendix A.4.4) has received much more attention in areas such as data mining and ML. However, many important real-world classification problems are naturally cast as hierarchical classification problems, where the classes to be predicted are organized into a class hierarchy (e.g., for geospatial problems, feature type classification provides a good example)—typically a tree or a directed acyclic graph (DAG). Hierarchical classification algorithms, which utilize the hierarchical relationships between labels in making predictions, can often achieve better prediction performance than flat approaches [150,151]. Thus, there is a clear research challenge to develop new approaches that are flexible enough to handle hierarchical classification tasks, in particular, the integration of hierarchical classification with single-label classification and with multi-label classification (i.e., HSC and HMC), respectively.
- Stream-based selective sampling AL: As introduced in Section 3.1.2 and discussed in [26,56], most AL methods in the literature use a pool-based sampling scenario; only a few methods have been developed for data streams. The stream-based approach is more appropriate for some real world scenarios, for example, when memory or processing power is limited (mobile and embedded devices) [26], crisis management during disaster leveraging social media data streams, or monitoring distributed sensor networks to identify categories of events that pose risks to people or the environment. To address the challenges of the rapidly increasing availability of geospatial streaming data, a key challenge is to develop more effective AL methods and applications using a stream-based AL scenario.
- Intergration of different AL problem scenarios: As introduced in Section 3.1.2, among the three main AL problem scenarios, pool-based sampling has received substantial development. But, there is a potential to combine scenarios to take advantage of their respective strengths (e.g., use of real instances that humans are able to annotate for the pool-based sampling and efficiency of membership query synthesis). In early work in this direction, Hu et al. [152] and Wang et al. [49] have combined membership query synthesis and pool-based sampling scenarios. The conclusion, based on their experiments on several real-world data sets, showed the strength of the combination against pool-based uncertainty sampling methods in terms of time complexity. More query strategies (Section 3.1.5) and M&DL architectures need to be tested to demonstrate the robustness of the improvement of the combination.
- Intergration of VA with AL/ADL: As Biewald explained in [14], human-in-the-loop computing is the future of ML. Biewald emphasized that it is often very easy to get a ML algorithm to 80% accuracy whereas almost impossible to get an algorithm to 99%; the best ML models let humans handle that 20%, because 80% accuracy is not good enough for most real world applications. To integrate human-in-the-loop methodology into ML architectures, AL is the most successful “bridge” [11,13,56,65,115], and VA can further enhance and ease the human’s role in the human-machine computing loop [4,5,11,24,25]. Intergrating the strengths of AL (especially ADL) and VA will raise the effectiveness and efficiency to new levels (Section 3.1, Section 3.2, Section 3.3 and Section 3.4). Bernard et al. [11] provided solid evidence to support this thread of research (Section 3.3).
5.2.2. Challenges and Opportunities from Application Perspective (for GIScience and RS Audience)
- Geospatial image based applications: Based on the advances achieved in M&DL, many promising geospaital applications using big geospatial image data sets are becoming possible. Diverse GIScience and RS problems can benefit from the methods we reviewed in this paper, potential applications include: land use and land cover classification [165,166], identification and understanding of patterns and interests in urban environments [167,168], and geospatial scene understanding [169,170] and content-based image retrieval [136,171]. Another important research direction is image geolocalization (prediction of the geolocation of a query image [172]), see [173] for an example of DL based geolocalization using geo-tagged images, which did not touch on AL or VA.
- Geospatial text based applications: GIR and spatial language processing have potential application to social media mining [174] in domains such as emergency management. There have already been some successful examples of DL classification algorithms being applied to tackling GIScience problems relating to crisis management, sentiment analysis, sarcasm detection, and hate speech detection in tweets; see: [162,175,176,177,178].A review of the existing geospatial semantic research can be found in [179], but neither DL or AL, nor VA are touched upon in that review. Thus, the research topics and challenges discussed there can find potential solutions using the methods we have investigated in this paper. For example, the methods we investigated here will be useful for semantic similarity and word-sense disambiguation, which are the important components of GIR [180]. Through integrating GIR with VA, AL and/or ADL, domain experts can play an important role into the DL empowered computational loop for steering the improvement of the machine learner’s performance. Recently, Adams and McKenzie [181] used character-level CNN to classify multilingual text, and their method can be improved using the “tool sets” we investigated in this paper. Some specific application problems for which we believe that VA-enabled ADL has the potential to make a dramatic impact are: identification of documents (from tweets, through news stories, to blogs) that are “about” places; classification of geographic statements by scale; and retrieval of geographic statements about movement or events.
- Geospatial text and image based applications: Beyond efforts to apply AL and related methods to text alone, text-oriented applications can be expanded with the fusion of text and geospatial images (e.g., RS imagery). See Cervone et al. [182] for an example in which RS and social media data (specifically, tweets and Flickr images) are fused for damage assessment during floods. The integration of VA and AL/ADL should also be explored as a mechanism to generate actionable insights from heterogeneous data sources in a quick manner.Deep learning shines where big labeled data is available. Thus, existing research in digital gazetteer that used big data analytics (see [183] for an example, where neither DL or AL, nor VA was used) can also be advanced from the methods reviewed in this paper. More specifically, for example, the method used in [183]—place types from (Flickr) photo tags, can be extended and enriched by image classification and recognition from the geospatial image based applications mentioned above.
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| VA | Visual Analytics |
| AL | Active Learning |
| ADL | Active Deep Learning |
| AI | Artificial Intelligence |
| ML | Machine Learning |
| DL | Deep Learning |
| M&DL | Machine Learning and Deep Learning |
| GIScience | Geographical Information Science |
| RS | Remote Sensing |
| VIL | Visual-Interactive Labeling |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| GRU | Gated Recurrent Unit |
| RBM | Restricted Boltzmann Machines |
| DBN | Deep Belief Network |
| MLP | MultiLayer Perceptron |
| SVM | Support Vector Machine |
| EM | Expectation–Maximization |
| KL divergence | Kullback-Leibler divergence |
| DAG | Directed Acyclic Graph |
| NLP | Natural Language Processing |
| NER | Named Entity Recognition |
| GIR | Geographic Information Retrieval |
| VGI | Volunteered Geographic Information |
| OSM | OpenStreetMap |
| QBC | Query-By-Committee |
| OVA/OAA/OVR | One-Vs-All / One-Against-All / One-Vs-Rest |
| OVO/OAO | One-Vs-One / One-Against-One |
| KNN | K-Nearest Neighbors |
| PCA | Principal Component Analysis |
| HMC | Hierarchical Multi-label Classification |
| HSC | Hierarchical Single-label Classification |
| IEEE VAST | The IEEE Conference on Visual Analytics Science and Technology |
Appendix A. Essential Terms and Types of Classification Tasks
Appendix A.1. Machine Learning and Deep Learning
Appendix A.2. Types of Learning Methods
Appendix A.2.1. Supervised Learning
Appendix A.2.2. Unsupervised Learning
Appendix A.2.3. Semi-Supervised Learning
Appendix A.2.4. Brief Discussion of Learning Types
Appendix A.3. Classifier
Appendix A.4. Types of Classification Tasks

Appendix A.4.1. Binary Classification
Appendix A.4.2. Multi-Class Classification
Appendix A.4.3. Multi-Label Classification
Appendix A.4.4. Hierarchical Classification
Appendix A.4.5. Evaluation Metrics for Classification Tasks
Appendix A.5. Text and Image Classifications
Appendix A.6. Word Embedding
References
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv, 2016; arXiv:1603.04467. [Google Scholar]
- Domingos, P. The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World; Basic Books: New York, NY, USA, 2015. [Google Scholar]
- Karpathy, A.; Johnson, J.; Fei-Fei, L. Visualizing and understanding recurrent networks. arXiv, 2015; arXiv:1506.02078. [Google Scholar]
- Sacha, D.; Sedlmair, M.; Zhang, L.; Lee, J.A.; Weiskopf, D.; North, S.; Keim, D. Human-centered machine learning through interactive visualization: Review and Open Challenges. In Proceedings of the ESANN 2016 Proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Liu, S.; Wang, X.; Liu, M.; Zhu, J. Towards better analysis of machine learning models: A visual analytics perspective. Vis. Inf. 2017, 1, 48–56. [Google Scholar] [CrossRef]
- Ming, Y.; Cao, S.; Zhang, R.; Li, Z.; Chen, Y.; Song, Y.; Qu, H. Understanding Hidden Memories of Recurrent Neural Networks. arXiv, 2017; arXiv:1710.10777. [Google Scholar]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A survey of active learning algorithms for supervised remote sensing image classification. IEEE J. Sel. Top. Signal Process. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Nalisnik, M.; Gutman, D.A.; Kong, J.; Cooper, L.A. An interactive learning framework for scalable classification of pathology images. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 928–935. [Google Scholar]
- Sharma, M.; Zhuang, D.; Bilgic, M. Active learning with rationales for text classification. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 441–451. [Google Scholar]
- Holzinger, A. Interactive machine learning for health informatics: When do we need the human-in-the-loop? Brain Inf. 2016, 3, 119–131. [Google Scholar] [CrossRef] [PubMed]
- Bernard, J.; Hutter, M.; Zeppelzauer, M.; Fellner, D.; Sedlmair, M. Comparing Visual-Interactive Labeling with Active Learning: An Experimental Study. IEEE Trans. Vis. Comput. Graph. 2018, 24, 298–308. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A review. arXiv, 2017; arXiv:1710.03959. [Google Scholar]
- Kucher, K.; Paradis, C.; Sahlgren, M.; Kerren, A. Active Learning and Visual Analytics for Stance Classification with ALVA. ACM Trans. Interact. Intell. Syst. 2017, 7, 14. [Google Scholar] [CrossRef]
- Biewald, L. Why Human-in-the-Loop Computing Is the Future of Machine Learning. 2015. Available online: https://www.computerworld.com/article/3004013/robotics/why-human-in-the-loop-computing-is-the-future-of-machine-learning.html (accessed on 10 November 2017).
- Bernard, J.; Zeppelzauer, M.; Sedlmair, M.; Aigner, W. A Unified Process for Visual-Interactive Labeling. In Proceedings of the 8th International EuroVis Workshop on Visual Analytics (Eurographics Proceedings), Barcelona, Spain, 12–13 June 2017. [Google Scholar]
- Andrienko, G.; Andrienko, N.; Keim, D.; MacEachren, A.M.; Wrobel, S. Challenging problems of geospatial visual analytics. J. Vis. Lang. Comput. 2011, 22, 251–256. [Google Scholar] [CrossRef]
- Wang, D.; Shang, Y. A new active labeling method for deep learning. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 112–119. [Google Scholar]
- Huang, L.; Matwin, S.; de Carvalho, E.J.; Minghim, R. Active Learning with Visualization for Text Data. In Proceedings of the 2017 ACM Workshop on Exploratory Search and Interactive Data Analytics, Limassol, Cyprus, 13 March 2017; pp. 69–74. [Google Scholar]
- Han, J.; Miller, H.J. Geographic Data Mining and Knowledge Discovery; CRC Press: Boca Raton, FL, USA, 2001. [Google Scholar]
- Miller, H.J.; Han, J. Geographic Data Mining and Knowledge Discovery, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Keim, D.A.; Kriegel, H.P. Visualization techniques for mining large databases: A comparison. IEEE Trans. Knowl. Data Eng. 1996, 8, 923–938. [Google Scholar] [CrossRef]
- MacEachren, A.M.; Wachowicz, M.; Edsall, R.; Haug, D.; Masters, R. Constructing knowledge from multivariate spatiotemporal data: integrating geographical visualization with knowledge discovery in database methods. Int. J. Geogr. Inf. Sci. 1999, 13, 311–334. [Google Scholar] [CrossRef]
- Guo, D.; Mennis, J. Spatial data mining and geographic knowledge discovery—An introduction. Comput. Environ. Urban Syst. 2009, 33, 403–408. [Google Scholar]
- Fayyad, U.M.; Wierse, A.; Grinstein, G.G. Information vIsualization in Data Mining and Knowledge Discovery; Morgan Kaufmann: San Francisco, CA, USA, 2002. [Google Scholar]
- Settles, B. Active Learning Literature Survey; Computer Sciences Technical Report 1648; University of Wisconsin: Madison, WI, USA, 2010. [Google Scholar]
- Settles, B. Active learning. Synth. Lect. Artif. Intell. Mach. Learn. 2012, 6, 1–114. [Google Scholar] [CrossRef]
- Settles, B. From theories to queries: Active learning in practice. In Proceedings of the Active Learning and Experimental Design Workshop In Conjunction with AISTATS 2010, Sardinia, Italy, 16 May 2011; pp. 1–18. [Google Scholar]
- Olsson, F. A Literature Survey of Active Machine Learning in the Context of Natural Language Processing; Swedish Institute of Computer Science: Kista, Sweden, 2009. [Google Scholar]
- Wang, M.; Hua, X.S. Active learning in multimedia annotation and retrieval: A survey. ACM Trans. Intell. Syst. Technol. 2011, 2, 10. [Google Scholar] [CrossRef]
- Muslea, I.; Minton, S.; Knoblock, C. Selective sampling with naive cotesting: Preliminary results. In Proceedings of the ECAI 2000 Workshop on Machine Learning for Information Extraction, Berlin, Germany, 21 August 2000. [Google Scholar]
- Peltola, T.; Soare, M.; Jacucci, G.; Kaski, S. Interactive Elicitation of Knowledge on Feature Relevance Improves Predictions in Small Data Sets. In Proceedings of the 22nd International Conference on Intelligent User Interfaces, Limassol, Cyprus, 13–16 March 2017. [Google Scholar]
- Xiao, T.; Xia, T.; Yang, Y.; Huang, C.; Wang, X. Learning from massive noisy labeled data for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2691–2699. [Google Scholar]
- Turney, P.D. Types of cost in inductive concept learning. arXiv, 2002; arXiv:cs/0212034. [Google Scholar]
- Weiss, G.M.; Provost, F. Learning when training data are costly: The effect of class distribution on tree induction. J. Artif. Intell. Res. 2003, 19, 315–354. [Google Scholar]
- Kittur, A.; Chi, E.H.; Suh, B. Crowdsourcing user studies with Mechanical Turk. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Florence, Italy, 5–10 April 2008; pp. 453–456. [Google Scholar]
- Paolacci, G.; Chandler, J.; Ipeirotis, P.G. Running experiments on amazon mechanical turk. Judgm. Decis. Mak. 2010, 5, 411–419. [Google Scholar]
- Buhrmester, M.; Kwang, T.; Gosling, S.D. Amazon’s Mechanical Turk: A new source of inexpensive, yet high-quality, data? Perspect. Psychol. Sci. 2011, 6, 3–5. [Google Scholar] [CrossRef] [PubMed]
- Cohn, D.; Atlas, L.; Ladner, R. Improving generalization with active learning. Mach. Learn. 1994, 15, 201–221. [Google Scholar] [CrossRef]
- Zhao, L.; Sukthankar, G.; Sukthankar, R. Incremental relabeling for active learning with noisy crowdsourced annotations. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust (PASSAT) and 2011 IEEE Third Inernational Conference on Social Computing (SocialCom), Boston, MA, USA, 9–11 October 2011; pp. 728–733. [Google Scholar]
- Yan, Y.; Fung, G.M.; Rosales, R.; Dy, J.G. Active learning from crowds. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 1161–1168. [Google Scholar]
- Joshi, A.J.; Porikli, F.; Papanikolopoulos, N. Multi-class active learning for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2372–2379. [Google Scholar]
- Domingos, P. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef]
- Chen, W.; Fuge, M. Active Expansion Sampling for Learning Feasible Domains in an Unbounded Input Space. arXiv, 2017; arXiv:1708.07888. [Google Scholar]
- Angluin, D. Queries and concept learning. Mach. Learn. 1988, 2, 319–342. [Google Scholar] [CrossRef]
- Angluin, D. Queries revisited. In Algorithmic Learning Theory; Springer: Berlin/Heidelberg, Germany, 2001; pp. 12–31. [Google Scholar]
- King, R.D.; Whelan, K.E.; Jones, F.M.; Reiser, P.G.; Bryant, C.H.; Muggleton, S.H.; Kell, D.B.; Oliver, S.G. Functional genomic hypothesis generation and experimentation by a robot scientist. Nature 2004, 427, 247–252. [Google Scholar] [CrossRef] [PubMed]
- King, R.D.; Rowland, J.; Oliver, S.G.; Young, M.; Aubrey, W.; Byrne, E.; Liakata, M.; Markham, M.; Pir, P.; Soldatova, L.N.; et al. The automation of science. Science 2009, 324, 85–89. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Hu, X.; Yuan, B.; Lu, J. Active learning via query synthesis and nearest neighbour search. Neurocomputing 2015, 147, 426–434. [Google Scholar] [CrossRef]
- Chen, L.; Hassani, S.H.; Karbasi, A. Near-Optimal Active Learning of Halfspaces via Query Synthesis in the Noisy Setting. AAAI, 2017; arXiv:1603.03515. [Google Scholar]
- Baum, E.B.; Lang, K. Query learning can work poorly when a human oracle is used. In Proceedings of the International Joint Conference on Neural Networks, Beijing, China, 3–6 November 1992; Volume 8, pp. 335–340. [Google Scholar]
- He, J. Analysis of Rare Categories; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Atlas, L.E.; Cohn, D.A.; Ladner, R.E. Training connectionist networks with queries and selective sampling. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 26–29 November 1990; pp. 566–573. [Google Scholar]
- Dagan, I.; Engelson, S.P. Committee-based sampling for training probabilistic classifiers. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; pp. 150–157. [Google Scholar]
- Yu, H. SVM selective sampling for ranking with application to data retrieval. In Proceedings of the Eleventh ACM SIGKDD International Conference On Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 354–363. [Google Scholar]
- Pohl, D.; Bouchachia, A.; Hellwagner, H. Batch-based active learning: Application to social media data for crisis management. Expert Syst. Appl. 2018, 93, 232–244. [Google Scholar] [CrossRef]
- Fujii, A.; Tokunaga, T.; Inui, K.; Tanaka, H. Selective sampling for example-based word sense disambiguation. Comput. Linguist. 1998, 24, 573–597. [Google Scholar]
- Lewis, D.D.; Gale, W.A. A sequential algorithm for training text classifiers. In Proceedings of the 17th annual international ACM SIGIR Conference On Research and Development in Information Retrieval, Dublin, Ireland, 3–6 July 1994; pp. 3–12. [Google Scholar]
- Settles, B.; Craven, M. An analysis of active learning strategies for sequence labeling tasks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 1070–1079. [Google Scholar]
- Huang, S.J.; Jin, R.; Zhou, Z.H. Active learning by querying informative and representative examples. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–11 December 2010; pp. 892–900. [Google Scholar]
- Du, B.; Wang, Z.; Zhang, L.; Zhang, L.; Liu, W.; Shen, J.; Tao, D. Exploring representativeness and informativeness for active learning. IEEE Trans. Cybern. 2017, 47, 14–26. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Chen, T. An active learning framework for content-based information retrieval. IEEE Trans. Multimed. 2002, 4, 260–268. [Google Scholar] [CrossRef]
- Tur, G.; Hakkani-Tür, D.; Schapire, R.E. Combining active and semi-supervised learning for spoken language understanding. Speech Commun. 2005, 45, 171–186. [Google Scholar]
- Liu, Y. Active learning with support vector machine applied to gene expression data for cancer classification. J. Chem. Inf. Comput. Sci. 2004, 44, 1936–1941. [Google Scholar] [CrossRef] [PubMed]
- Júnior, A.S.; Renso, C.; Matwin, S. ANALYTiC: An Active Learning System for Trajectory Classification. IEEE Comput. Graph. Appl. 2017, 37, 28–39. [Google Scholar] [CrossRef] [PubMed]
- Hoi, S.C.; Jin, R.; Zhu, J.; Lyu, M.R. Batch mode active learning and its application to medical image classification. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 417–424. [Google Scholar]
- Hoi, S.C.; Jin, R.; Zhu, J.; Lyu, M.R. Semisupervised SVM batch mode active learning with applications to image retrieval. ACM Trans. Inf. Syst. 2009, 27, 16. [Google Scholar] [CrossRef]
- Sharma, M.; Bilgic, M. Evidence-based uncertainty sampling for active learning. Data Min. Knowl. Discov. 2017, 31, 164–202. [Google Scholar] [CrossRef]
- Freund, Y.; Seung, H.S.; Shamir, E.; Tishby, N. Selective sampling using the query by committee algorithm. Mach. Learn. 1997, 28, 133–168. [Google Scholar] [CrossRef]
- Seung, H.S.; Opper, M.; Sompolinsky, H. Query by committee. In Proceedings of the fIfth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 287–294. [Google Scholar]
- McCallumzy, A.K.; Nigamy, K. Employing EM and pool-based active learning for text classification. In Proceedings of the International Conference on Machine Learning (ICML), Madison, WI, USA, 24–27 July 1998; pp. 359–367. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Pereira, F.; Tishby, N.; Lee, L. Distributional clustering of English words. In Proceedings of the 31st Annual Meeting on Association for Computational Linguistics, Columbus, OH, USA, 22–26 June 1993; pp. 183–190. [Google Scholar]
- Scheffer, T.; Decomain, C.; Wrobel, S. Active hidden markov models for information extraction. In International Symposium on Intelligent Data Analysis; Springer: Berlin/Heidelberg, Germany, 2001; pp. 309–318. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Brinker, K. Incorporating diversity in active learning with support vector machines. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 59–66. [Google Scholar]
- Dagli, C.K.; Rajaram, S.; Huang, T.S. Leveraging active learning for relevance feedback using an information theoretic diversity measure. Lect. Notes Comput. Sci. 2006, 4071, 123. [Google Scholar]
- Wu, Y.; Kozintsev, I.; Bouguet, J.Y.; Dulong, C. Sampling strategies for active learning in personal photo retrieval. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 529–532. [Google Scholar]
- Nguyen, H.T.; Smeulders, A. Active learning using pre-clustering. In Proceedings of the twenty-first International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 79. [Google Scholar]
- Qi, G.J.; Song, Y.; Hua, X.S.; Zhang, H.J.; Dai, L.R. Video annotation by active learning and cluster tuning. In Proceedings of the Computer Vision and Pattern Recognition Workshop, New York, NY, USA, 17–22 June 2006; p. 114. [Google Scholar]
- Ayache, S.; Quénot, G. Evaluation of active learning strategies for video indexing. Signal Process. Image Commun. 2007, 22, 692–704. [Google Scholar] [CrossRef][Green Version]
- Seifert, C.; Granitzer, M. User-based active learning. In Proceedings of the 2010 IEEE International Conference on Data Mining Workshops (ICDMW), Sydney, Australia, 13 December 2010; pp. 418–425. [Google Scholar]
- Patra, S.; Bruzzone, L. A batch-mode active learning technique based on multiple uncertainty for SVM classifier. IEEE Geosci. Remote Sens. Lett. 2012, 9, 497–501. [Google Scholar] [CrossRef]
- Xu, Z.; Akella, R.; Zhang, Y. Incorporating diversity and density in active learning for relevance feedback. In ECiR; Springer: Berlin/Heidelberg, Germany, 2007; Volume 7, pp. 246–257. [Google Scholar]
- Wang, M.; Hua, X.S.; Mei, T.; Tang, J.; Qi, G.J.; Song, Y.; Dai, L.R. Interactive video annotation by multi-concept multi-modality active learning. Int. J. Semant. Comput. 2007, 1, 459–477. [Google Scholar] [CrossRef]
- Blake, C.L.; Merz, C.J. UCI Repository of Machine Learning Databases; University of California: Irvine, CA, USA, 1998. [Google Scholar]
- Ramirez-Loaiza, M.E.; Sharma, M.; Kumar, G.; Bilgic, M. Active learning: An empirical study of common baselines. Data Min. Knowl. Discov. 2017, 31, 287–313. [Google Scholar] [CrossRef]
- Cook, K.A.; Thomas, J.J. Illuminating The Path: The Research and Development Agenda for Visual Analytics; IEEE Computer Society Press: Washington, DC, USA, 2005. [Google Scholar]
- Lu, Y.; Garcia, R.; Hansen, B.; Gleicher, M.; Maciejewski, R. The State-of-the-Art in Predictive Visual Analytics. Comput. Graph. Forum 2017, 36, 539–562. [Google Scholar] [CrossRef]
- Ma, Y.; Xu, J.; Wu, X.; Wang, F.; Chen, W. A visual analytical approach for transfer learning in classification. Inf. Sci. 2017, 390, 54–69. [Google Scholar] [CrossRef]
- Miller, C.; Nagy, Z.; Schlueter, A. A review of unsupervised statistical learning and visual analytics techniques applied to performance analysis of non-residential buildings. Renew. Sustain. Energy Rev. 2018, 81, 1365–1377. [Google Scholar] [CrossRef]
- Sacha, D.; Zhang, L.; Sedlmair, M.; Lee, J.A.; Peltonen, J.; Weiskopf, D.; North, S.C.; Keim, D.A. Visual interaction with dimensionality reduction: A structured literature analysis. IEEE Trans. Vis. Comput. Graph. 2017, 23, 241–250. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Stoffel, A.; Behrisch, M.; Mittelstadt, S.; Schreck, T.; Pompl, R.; Weber, S.; Last, H.; Keim, D. Visual analytics for the big data era—A comparative review of state-of-the-art commercial systems. In Proceedings of the 2012 IEEE Conference on Visual Analytics Science and Technology (VAST), Seattle, WA, USA, 14–19 October 2012; pp. 173–182. [Google Scholar]
- Keim, D.; Andrienko, G.; Fekete, J.D.; Gorg, C.; Kohlhammer, J.; Melançon, G. Visual analytics: Definition, process, and challenges. Lect. Notes Comput. Sci. 2008, 4950, 154–176. [Google Scholar]
- Thomas, J.J.; Cook, K.A. A visual analytics agenda. IEEE Comput. Graph. Appl. 2006, 26, 10–13. [Google Scholar] [CrossRef] [PubMed]
- Ellis, G.; Mansmann, F. Mastering the information age solving problems with visual analytics. Eurographics 2010, 2, 5. [Google Scholar]
- Robinson, A.C.; Demšar, U.; Moore, A.B.; Buckley, A.; Jiang, B.; Field, K.; Kraak, M.J.; Camboim, S.P.; Sluter, C.R. Geospatial big data and cartography: Research challenges and opportunities for making maps that matter. Int. J. Cartogr. 2017, 1–29. [Google Scholar] [CrossRef]
- Endert, A.; Hossain, M.S.; Ramakrishnan, N.; North, C.; Fiaux, P.; Andrews, C. The human is the loop: New directions for visual analytics. J. Intell. Inf. Syst. 2014, 43, 411–435. [Google Scholar] [CrossRef]
- Gillies, M.; Fiebrink, R.; Tanaka, A.; Garcia, J.; Bevilacqua, F.; Heloir, A.; Nunnari, F.; Mackay, W.; Amershi, S.; Lee, B.; et al. Human-Centred Machine Learning. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 3558–3565. [Google Scholar]
- Knight, W. The Dark Secret at the Heart of AI - MIT Technology Review. 2017. Available online: https://www.technologyreview.com/s/604087/the-dark-secret-at-the-heart-of-ai (accessed on 10 November 2017).
- Tamagnini, P.; Krause, J.; Dasgupta, A.; Bertini, E. Interpreting Black-Box Classifiers Using Instance-Level Visual Explanations. In Proceedings of the 2nd Workshop on Human-In-the-Loop Data Analytics, Chicago, IL, USA, 14 May 2017; p. 6. [Google Scholar]
- Sacha, D.; Sedlmair, M.; Zhang, L.; Lee, J.A.; Peltonen, J.; Weiskopf, D.; North, S.C.; Keim, D.A. What You See Is What You Can Change: Human-Centered Machine Learning By Interactive Visualization. Neurocomputing 2017, 268, 164–175. [Google Scholar] [CrossRef]
- Wongsuphasawat, K.; Smilkov, D.; Wexler, J.; Wilson, J.; Mané, D.; Fritz, D.; Krishnan, D.; Viégas, F.B.; Wattenberg, M. Visualizing Dataflow Graphs of Deep Learning Models in TensorFlow. IEEE Trans. Vis. Comput. Graph. 2018, 24, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Alsallakh, B.; Jourabloo, A.; Ye, M.; Liu, X.; Ren, L. Do Convolutional Neural Networks Learn Class Hierarchy? IEEE Trans. Vis. Comput. Graph. 2018, 24, 152–162. [Google Scholar] [CrossRef] [PubMed]
- Amershi, S.; Cakmak, M.; Knox, W.B.; Kulesza, T. Power to the people: The role of humans in interactive machine learning. AI Mag. 2014, 35, 105–120. [Google Scholar] [CrossRef]
- Kim, B. Interactive and Interpretable Machine Learning Models for Human Machine Collaboration. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2015. [Google Scholar]
- Sharma, M. Active Learning with Rich Feedback. Ph.D. Thesis, Illinois Institute of Technology, Chicago, IL, USA, 2017. [Google Scholar]
- Heimerl, F.; Koch, S.; Bosch, H.; Ertl, T. Visual classifier training for text document retrieval. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2839–2848. [Google Scholar] [CrossRef] [PubMed]
- Höferlin, B.; Netzel, R.; Höferlin, M.; Weiskopf, D.; Heidemann, G. Inter-active learning of ad-hoc classifiers for video visual analytics. In Proceedings of the 2012 IEEE Conference on Visual Analytics Science and Technology (VAST), Seattle, WA, USA, 14–19 October 2012; pp. 23–32. [Google Scholar]
- Settles, B. Closing the loop: Fast, interactive semi-supervised annotation with queries on features and instances. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Scotland, UK, 27–31 July 2011; pp. 1467–1478. [Google Scholar]
- Huang, L. Active Learning with Visualization. Master’s Thesis, Dalhousie University, Halifax, NS, Canada, 2017. [Google Scholar]
- Jean, S.; Cho, K.; Memisevic, R.; Bengio, Y. On using very large target vocabulary for neural machine translation. arXiv, 2015; arXiv:1412.2007v2. [Google Scholar]
- Jean, S.; Firat, O.; Cho, K.; Memisevic, R.; Bengio, Y. Montreal Neural Machine Translation Systems for WMT’15. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisboa, Portugal, 17–18 September 2015; pp. 134–140. [Google Scholar]
- Monroe, D. Deep learning takes on translation. Commun. ACM 2017, 60, 12–14. [Google Scholar] [CrossRef]
- Zhao, W. Deep Active Learning for Short-Text Classification. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2017. [Google Scholar]
- Ng, A. What Data Scientists Should Know about Deep Learning (See Slide 30 of 34). 2015. Available online: https://www.slideshare.net/ExtractConf (accessed on 15 October 2017).
- LeCun, Y.; Cortes, C.; Burges, C. MNIST handwritten Digit Database. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 18 October 2017).
- Gal, Y.; Islam, R.; Ghahramani, Z. Deep Bayesian Active Learning with Image Data. arXiv, 2017; arXiv:1703.02910. [Google Scholar]
- Wang, K.; Zhang, D.; Li, Y.; Zhang, R.; Lin, L. Cost-effective active learning for deep image classification. IEEE Trans. Circ. Syst. Video Technol. 2017, 27, 2591–2600. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on Challenges in Representation Learning; ICML: Atlanta, GA, USA; Volume 3, p. 2.
- Chen, B.C.; Chen, C.S.; Hsu, W.H. Cross-age reference coding for age-invariant face recognition and retrieval. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 768–783. [Google Scholar]
- Griffin, G.; Holub, A.; Perona, P. Caltech-256 Object Category Dataset. 2007. Available online: http://resolver.caltech.edu/CaltechAUTHORS:CNS-TR-2007-001 (accessed on 20 October 2017).
- Huijser, M.W.; van Gemert, J.C. Active Decision Boundary Annotation with Deep Generative Models. arXiv, 2017; arXiv:1703.06971. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Goodfellow, I. Generative Adversarial Networks for Text. 2016. Available online: https://www.reddit.com/r/MachineLearning/comments/40ldq6/generative_adversarial_networks_for_text/ (accessed on 15 October 2017).
- Zhou, S.; Chen, Q.; Wang, X. Active deep learning method for semi-supervised sentiment classification. Neurocomputing 2013, 120, 536–546. [Google Scholar] [CrossRef]
- Zhang, Y.; Lease, M.; Wallace, B. Active Discriminative Text Representation Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–9 February 2017; pp. 3386–3392. [Google Scholar]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Mitra, P.; Shankar, B.U.; Pal, S.K. Segmentation of multispectral remote sensing images using active support vector machines. Pattern Recognit. Lett. 2004, 25, 1067–1074. [Google Scholar] [CrossRef]
- Rajan, S.; Ghosh, J.; Crawford, M.M. An active learning approach to hyperspectral data classification. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1231–1242. [Google Scholar] [CrossRef]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.F.; Emery, W.J. Active learning methods for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2218–2232. [Google Scholar] [CrossRef]
- Demir, B.; Persello, C.; Bruzzone, L. Batch-mode active-learning methods for the interactive classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1014–1031. [Google Scholar] [CrossRef]
- Patra, S.; Bruzzone, L. A fast cluster-assumption based active-learning technique for classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1617–1626. [Google Scholar] [CrossRef]
- Stumpf, A.; Lachiche, N.; Malet, J.P.; Kerle, N.; Puissant, A. Active learning in the spatial domain for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2492–2507. [Google Scholar] [CrossRef]
- Ferecatu, M.; Boujemaa, N. Interactive remote-sensing image retrieval using active relevance feedback. IEEE Trans. Geosci. Remote Sens. 2007, 45, 818–826. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.; Zhang, H.; Eom, K.B. Active deep learning for classification of hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 712–724. [Google Scholar] [CrossRef]
- Chen, J.; Zipf, A. DeepVGI: Deep Learning with Volunteered Geographic Information. In Proceedings of the 26th International Conference on World Wide Web Companion. International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 April 2017; pp. 771–772. [Google Scholar]
- LeCun, Y. LeNet-5, Convolutional Neural Networks 2015. Available online: http://yann.lecun.com/exdb/lenet/ (accessed on 18 October 2017).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Mooney, P.; Minghini, M. A review of OpenStreetMap data. In Mapp. Citiz. Sens.; Ubiquity Press: London, UK, 2017; pp. 37–59. [Google Scholar] [CrossRef]
- McCallum, A. Multi-label text classification with a mixture model trained by EM. AAAI Workshop Text Learn. 1999, 1–7. Available online: https://mimno.infosci.cornell.edu/info6150/readings/multilabel.pdf (accessed on 17 November 2017).
- Godbole, S.; Sarawagi, S. Discriminative methods for multi-labeled classification. Adv. Knowl. Discov. Data Min. 2004, 22–30. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. Cnn-rnn: A unified framework for multi-label image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2285–2294. [Google Scholar]
- Chen, S.F.; Chen, Y.C.; Yeh, C.K.; Wang, Y.C.F. Order-free rnn with visual attention for multi-label classification. arXiv, 2017; arXiv:1707.05495. [Google Scholar]
- Silla, C.N., Jr.; Freitas, A.A. A survey of hierarchical classification across different application domains. Data Min. Knowl. Discov. 2011, 22, 31–72. [Google Scholar] [CrossRef]
- Ghazi, D.; Inkpen, D.; Szpakowicz, S. Hierarchical versus flat classification of emotions in text. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, USA, 5 June 2010; pp. 140–146. [Google Scholar]
- Bi, W.; Kwok, J.T. Mandatory leaf node prediction in hierarchical multilabel classification. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 2275–2287. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Wang, L.; Yuan, B. Querying representative points from a pool based on synthesized queries. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012; pp. 1–6. [Google Scholar]
- Raad, M. A nEw Business Intelligence Emerges: Geo.AI. 2017. Available online: https://www.esri.com/about/newsroom/publications/wherenext/new-business-intelligence-emerges-geo-ai/ (accessed on 17 November 2017).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Manning, C.D. Computational linguistics and deep learning. Comput. Linguist. 2015, 41, 701–707. [Google Scholar] [CrossRef]
- Knight, W. AI’s Language Problem—MIT Technology Review. 2016. Available online: https://www.technologyreview.com/s/602094/ais-language-problem (accessed on 15 November 2017).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Xia, J.; Wang, F.; Zheng, X.; Li, Z.; Gong, X. A novel approach for building extraction from 3D disaster scenes of urban area. In Proceedings of the 2017 25th International Conference on Geoinformatics, Buffalo, NY, USA, 2–4 August 2017; pp. 1–4. [Google Scholar]
- Bejiga, M.B.; Zeggada, A.; Nouffidj, A.; Melgani, F. A convolutional neural network approach for assisting avalanche search and rescue operations with uav imagery. Remote Sens. 2017, 9, 100. [Google Scholar] [CrossRef]
- Badjatiya, P.; Gupta, S.; Gupta, M.; Varma, V. Deep learning for hate speech detection in tweets. In Proceedings of the 26th International Conference on World Wide Web Companion. International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 April 2017; pp. 759–760. [Google Scholar]
- Andriole, S. Unstructured Data: The Other Side of Analytics. 2015. Available online: http://www.forbes.com/sites/steveandriole/2015/03/05/the-other-side-of-analytics (accessed on 20 October 2017).
- Hahmann, S.; Burghardt, D. How much information is geospatially referenced? Networks and cognition. Int. J. Geogr. Inf. Sci. 2013, 27, 1171–1189. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv, 2015; arXiv:1508.00092. [Google Scholar]
- Tracewski, L.; Bastin, L.; Fonte, C.C. Repurposing a deep learning network to filter and classify volunteered photographs for land cover and land use characterization. Geo-Spat. Inf. Sci. 2017, 20, 252–268. [Google Scholar] [CrossRef]
- Hu, Y.; Gao, S.; Janowicz, K.; Yu, B.; Li, W.; Prasad, S. Extracting and understanding urban areas of interest using geotagged photos. Comput. Environ. Urban Syst. 2015, 54, 240–254. [Google Scholar] [CrossRef]
- Albert, A.; Kaur, J.; Gonzalez, M.C. Using convolutional networks and satellite imagery to identify patterns in urban environments at a large scale. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1357–1366. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 487–495. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Wan, J.; Wang, D.; Hoi, S.C.H.; Wu, P.; Zhu, J.; Zhang, Y.; Li, J. Deep learning for content-based image retrieval: A comprehensive study. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 157–166. [Google Scholar]
- Lin, T.Y.; Belongie, S.; Hays, J. Cross-view image geolocalization. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 891–898. [Google Scholar]
- Lin, T.Y.; Cui, Y.; Belongie, S.; Hays, J. Learning deep representations for ground-to-aerial geolocalization. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5007–5015. [Google Scholar]
- Zafarani, R.; Abbasi, M.A.; Liu, H. Social Media Mining: An Introduction; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Nguyen, D.T.; Mannai, K.A.A.; Joty, S.; Sajjad, H.; Imran, M.; Mitra, P. Rapid Classification of Crisis-Related Data on Social Networks using Convolutional Neural Networks. arXiv, 2016; arXiv:1608.03902. [Google Scholar]
- Nguyen, D.T.; Al-Mannai, K.; Joty, S.R.; Sajjad, H.; Imran, M.; Mitra, P. Robust Classification of Crisis-Related Data on Social Networks Using Convolutional Neural Networks. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media (ICWSM), Montreal, QC, Canada, 15–18 May 2017; pp. 632–635. [Google Scholar]
- Severyn, A.; Moschitti, A. Twitter sentiment analysis with deep convolutional neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 959–962. [Google Scholar]
- Poria, S.; Cambria, E.; Hazarika, D.; Vij, P. A deeper look into sarcastic tweets using deep convolutional neural networks. arXiv, 2016; arXiv:1610.08815. [Google Scholar]
- Hu, Y. Geospatial semantics. arXiv, 2017; arXiv:1707.03550v2. [Google Scholar]
- Janowicz, K.; Raubal, M.; Kuhn, W. The semantics of similarity in geographic information retrieval. J. Spat. Inf. Sci. 2011, 2011, 29–57. [Google Scholar] [CrossRef]
- Adams, B.; McKenzie, G. Crowdsourcing the Character of a Place: Character-Level Convolutional Networks for Multilingual Geographic Text Classification. Trans. GIS 2018. [Google Scholar] [CrossRef]
- Cervone, G.; Sava, E.; Huang, Q.; Schnebele, E.; Harrison, J.; Waters, N. Using Twitter for tasking remote-sensing data collection and damage assessment: 2013 Boulder flood case study. Int. J. Remote Sens. 2016, 37, 100–124. [Google Scholar] [CrossRef]
- Gao, S.; Li, L.; Li, W.; Janowicz, K.; Zhang, Y. Constructing gazetteers from volunteered big geo-data based on Hadoop. Comput. Environ. Urban Syst. 2017, 61, 172–186. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 10 October 2017).
- Scott, S.; Matwin, S. Feature engineering for text classification. ICML 1999, 99, 379–388. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Anderson, M.R.; Antenucci, D.; Bittorf, V.; Burgess, M.; Cafarella, M.J.; Kumar, A.; Niu, F.; Park, Y.; Ré, C.; Zhang, C. Brainwash: A Data System for Feature Engineering. In Proceedings of the 6th Biennial Conference on Innovative Data Systems Research (CIDR ’13), Asilomar, CA, USA, 6–9 January 2013. [Google Scholar]
- Yang, L. AI vs. Machine Learning vs. Deep Learning—Deep Learning Garden. 2016. Available online: http://deeplearning.lipingyang.org/2016/11/23/machine-learning-vs-deep-learning/ (accessed on 17 October 2017).
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Herrera, F.; Charte, F.; Rivera, A.J.; Del Jesus, M.J. Multilabel Classification: Problem Analysis, Metrics and Techniques; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning; MIT press: Cambridge, MA, USA, 2012. [Google Scholar]
- Cherkassky, V.; Mulier, F.M. Learning From Data: Concepts, Theory, and Methods; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Zhu, X.; Goldberg, A.B. Introduction to semi-supervised learning. Synth. Lect. Artif. Intell. Mach. Learn. 2009, 3, 1–130. [Google Scholar] [CrossRef]
- Zhu, X. Semi-Supervised Learning Literature Survey; Computer Sciences Technical Report 1530; University of Wisconsin: Madison, MI, USA, 2005. [Google Scholar]
- Langley, P. Intelligent behavior in humans and machines. American Association for Artificial Intelligence. 2006. Available online: http://lyonesse.stanford.edu/~langley/papers/ai50.dart.pdf (accessed on 29 December 2017).
- Mitchell, T.M. The Discipline of Machine Learning; Technical Report CMU-ML-06-108; Carnegie Mellon University: Pittsburgh, PA, USA, 2006. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Gebru, T.; Krause, J.; Wang, Y.; Chen, D.; Deng, J.; Aiden, E.L.; Fei-Fei, L. Using deep learning and google street view to estimate the demographic makeup of the us. arXiv, 2017; arXiv:1702.06683. [Google Scholar]
- Kendall, A.; Cipolla, R. Geometric loss functions for camera pose regression with deep learning. arXiv, 2017; arXiv:1704.00390. [Google Scholar]
- Vandal, T.; Kodra, E.; Ganguly, S.; Michaelis, A.; Nemani, R.; Ganguly, A.R. DeepSD: Generating High Resolution Climate Change Projections through Single Image Super-Resolution. arXiv, 2017; arXiv:1703.03126. [Google Scholar]
- Aggarwal, C.C. Data Classification: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Galar, M.; Fernández, A.; Barrenechea, E.; Bustince, H.; Herrera, F. An overview of ensemble methods for binary classifiers in multi-class problems: Experimental study on one-vs-one and one-vs-all schemes. Pattern Recognit. 2011, 44, 1761–1776. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Milgram, J.; Cheriet, M.; Sabourin, R. “One against one” or “one against all”: Which one is better for handwriting recognition with SVMs? In Tenth International Workshop on Frontiers in Handwriting Recognition; Suvisoft: La Baule, France, October 2006. [Google Scholar]
- Levatić, J.; Kocev, D.; Džeroski, S. The importance of the label hierarchy in hierarchical multi-label classification. J. Intell. Inf. Syst. 2015, 45, 247–271. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Mining multi-label data. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2009; pp. 667–685. [Google Scholar]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Gibaja, E.; Ventura, S. A tutorial on multilabel learning. ACM Comput. Surv. (CSUR) 2015, 47, 52. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Matwin, S.; Nock, R.; Famili, A.F. Learning and evaluation in the presence of class hierarchies: Application to text categorization. In Canadian Conference on AI; Springer: Berlin/Heidelberg, Germany, 2006; Volume 2006, pp. 395–406. [Google Scholar]
- Vens, C.; Struyf, J.; Schietgat, L.; Džeroski, S.; Blockeel, H. Decision trees for hierarchical multi-label classification. Mach. Learn. 2008, 73, 185–214. [Google Scholar] [CrossRef]
- Bi, W.; Kwok, J.T. Multi-label classification on tree-and dag-structured hierarchies. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 17–24. [Google Scholar]
- Sapozhnikov, G.; Ulanov, A. Extracting Hierarchies from Data Clusters for Better Classification. Algorithms 2012, 5, 506–520. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, H.; Lu, B. Enhanced K-Nearest Neighbour Algorithm for Large-scale Hierarchical Multi-label Classification. In Proceedings of the Joint ECML/PKDD PASCAL Workshop on Large-Scale Hierarchical Classification, Athens, Greece, 5 September 2011. [Google Scholar]
- Vailaya, A.; Figueiredo, M.; Jain, A.; Zhang, H.J. Content-based hierarchical classification of vacation images. In Proceedings of the IEEE International Conference on Multimedia Computing and Systems, Austin, TX, USA, 7–11 June 1999; Volume 1, pp. 518–523. [Google Scholar]
- Cheong, S.; Oh, S.H.; Lee, S.Y. Support vector machines with binary tree architecture for multi-class classification. Neural Inf. Process. Lett. Rev. 2004, 2, 47–51. [Google Scholar]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Meimandi, K.J.; Gerber, M.S.; Barnes, L.E. Hdltex: Hierarchical deep learning for text classification. arXiv, 2017; arXiv:1709.08267. [Google Scholar]
- Ren, Z.; Peetz, M.H.; Liang, S.; Van Dolen, W.; De Rijke, M. Hierarchical multi-label classification of social text streams. In Proceedings of the 37th international ACM SIGIR Conference On Research & Development in Information Retrieval, Gold Coast, Australia, 6–11 July 2014; pp. 213–222. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Imran, M.; Mitra, P.; Srivastava, J. Cross-language domain adaptation for classifying crisis-related short messages. arXiv, 2016; arXiv:1602.05388. [Google Scholar]
- Stanford NER Recognizer. Available online: https://nlp.stanford.edu/software/CRF-NER.shtml (accessed on 10 October 2017).
- Stanford Named Entity Tagger. Available online: http://nlp.stanford.edu:8080/ner (accessed on 10 October 2017).
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. (CSUR) 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, X. A re-examination of text categorization methods. In Proceedings of the 22nd Annual International ACM SIGIR Conference On Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 42–49. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Baroni, M.; Dinu, G.; Kruszewski, G. Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors. ACL 2014, 1, 238–247. [Google Scholar]




© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; MacEachren, A.M.; Mitra, P.; Onorati, T. Visually-Enabled Active Deep Learning for (Geo) Text and Image Classification: A Review. ISPRS Int. J. Geo-Inf. 2018, 7, 65. https://doi.org/10.3390/ijgi7020065
Yang L, MacEachren AM, Mitra P, Onorati T. Visually-Enabled Active Deep Learning for (Geo) Text and Image Classification: A Review. ISPRS International Journal of Geo-Information. 2018; 7(2):65. https://doi.org/10.3390/ijgi7020065
Chicago/Turabian StyleYang, Liping, Alan M. MacEachren, Prasenjit Mitra, and Teresa Onorati. 2018. "Visually-Enabled Active Deep Learning for (Geo) Text and Image Classification: A Review" ISPRS International Journal of Geo-Information 7, no. 2: 65. https://doi.org/10.3390/ijgi7020065
APA StyleYang, L., MacEachren, A. M., Mitra, P., & Onorati, T. (2018). Visually-Enabled Active Deep Learning for (Geo) Text and Image Classification: A Review. ISPRS International Journal of Geo-Information, 7(2), 65. https://doi.org/10.3390/ijgi7020065