
Generalized Aggregation of Sparse Coded Multi-Spectra for Satellite Scene Classification



Abstract
:1. Introduction
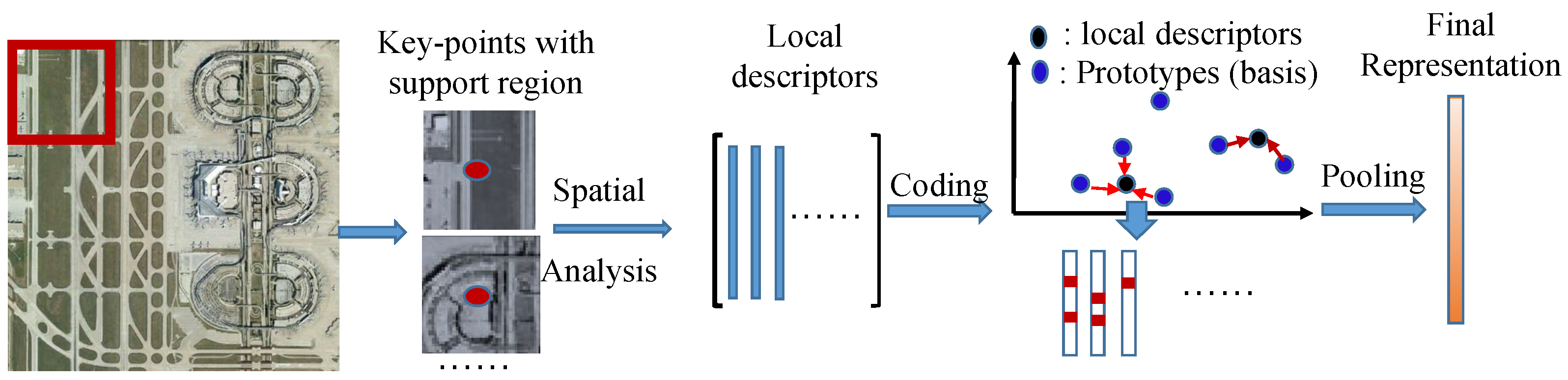
2. Related Work
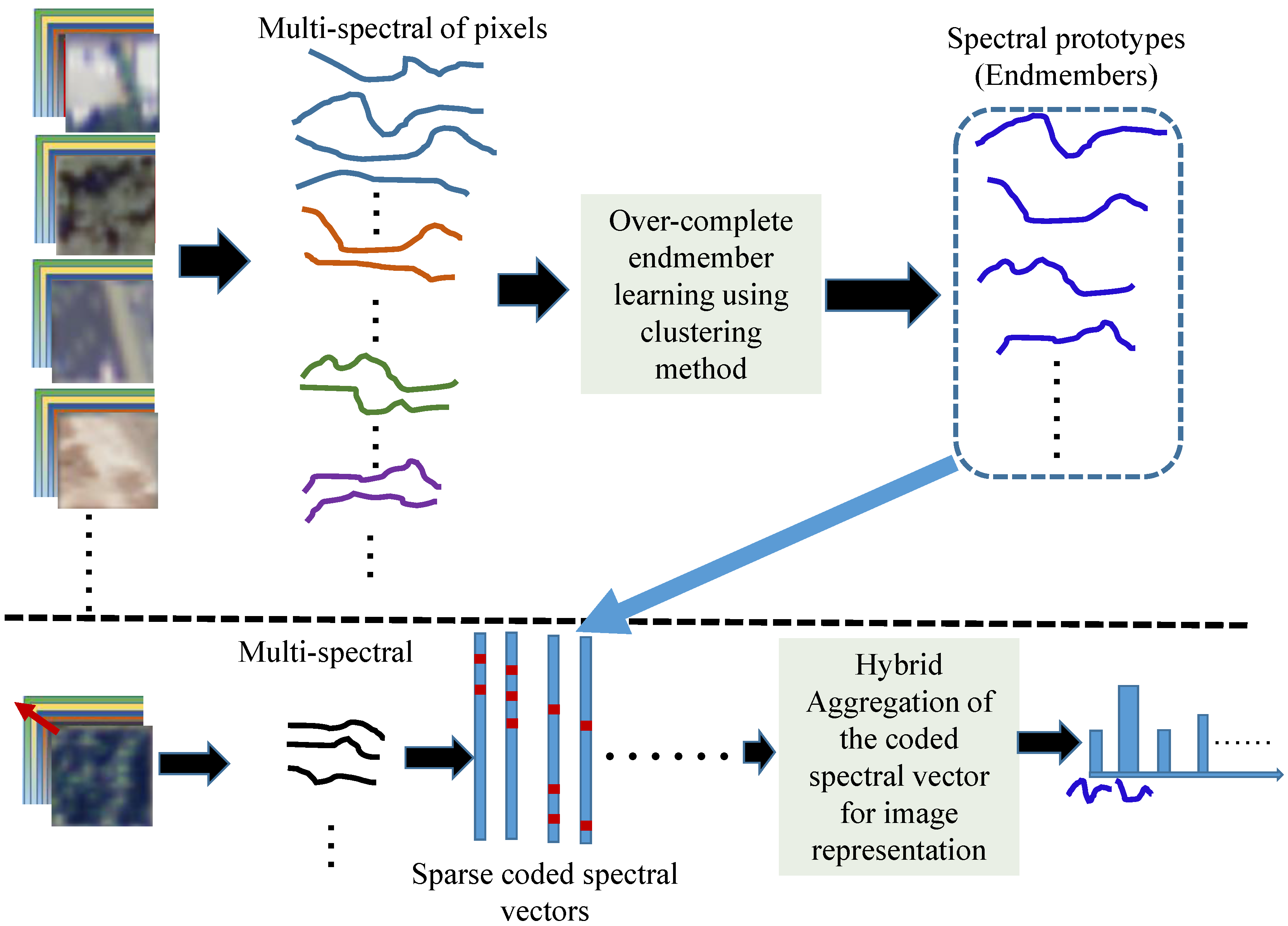
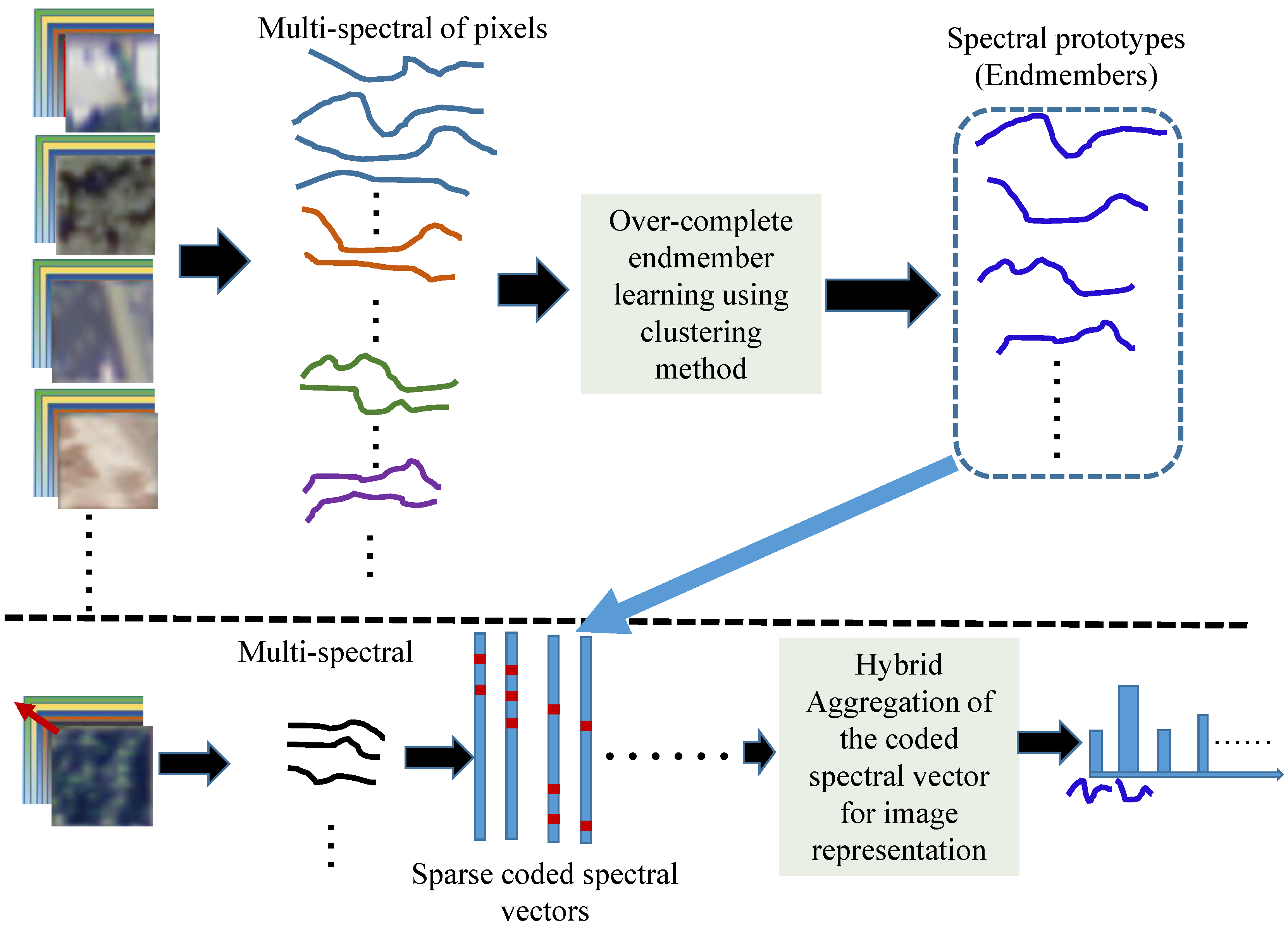
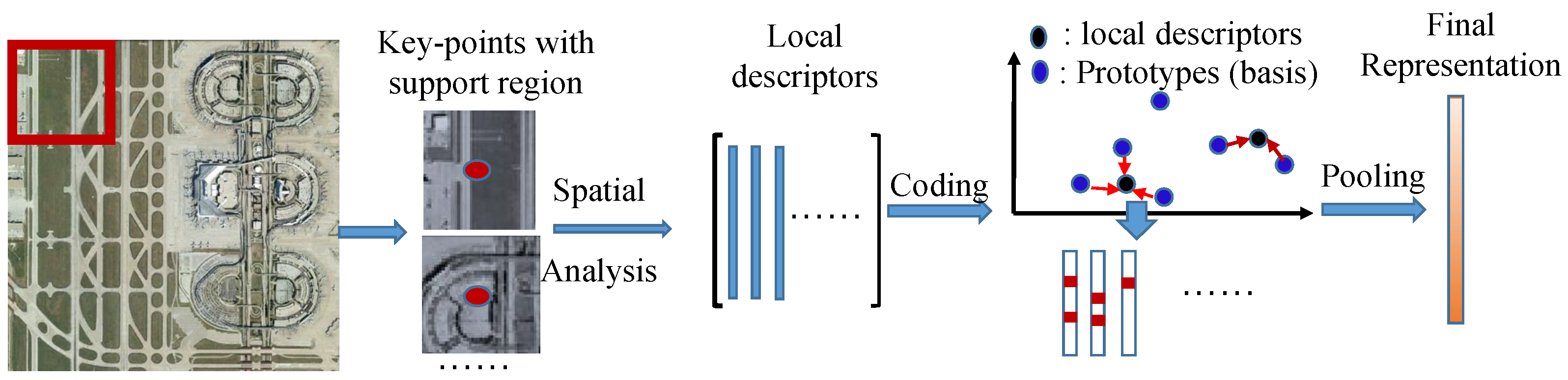
3. Generalized Aggregation of Sparse Coded Multi-Spectra
3.1. Codebook Learning and Spectral Coding Approaches
| Algorithm 1 Codebook learning of VQ method in Equation (2). | |
| Input: | |
| Output: | |
| Initialization: Randomly take K samples from for initializing : . | |
| 2: | for do |
| for do | |
| 4: | Calculate the Euclidean distance between and , and assign |
| to cluster if , | |
| end for | |
| 6: | Recalculate with the assigned samples to the k-th cluster |
| end for | |
| 8: | Repeat the above Steps 2–7 until the predefined iteration is arrived or the change of the codebook becomes small enough in two consecutive iterations. |
| Algorithm 2 Codebook learning of LcSC method in Equation (3). | |
| Input: , , , | |
| Output: | |
| 1: | Initialization:. |
| 2: | for do |
| 3: | for do |
| 4: | Calculate the control element between and using Equation (4), |
| 5: | end for |
| 6: | Normalize : ; |
| 7: | Calculate the temporary coded vector with the fixed codebook using Equation (3), |
| 8: | Refine the coded vector via selecting the atoms with the larger coded coefficients only: |
| , , and | |
| , . | |
| 9: | Update : , where and , |
| 10: | Project back to : |
| 11: | end for |
3.2. Generalized Aggregation Approach
3.3. SVM Classifier for Satellite Images
4. Experiments
4.1. Datasets
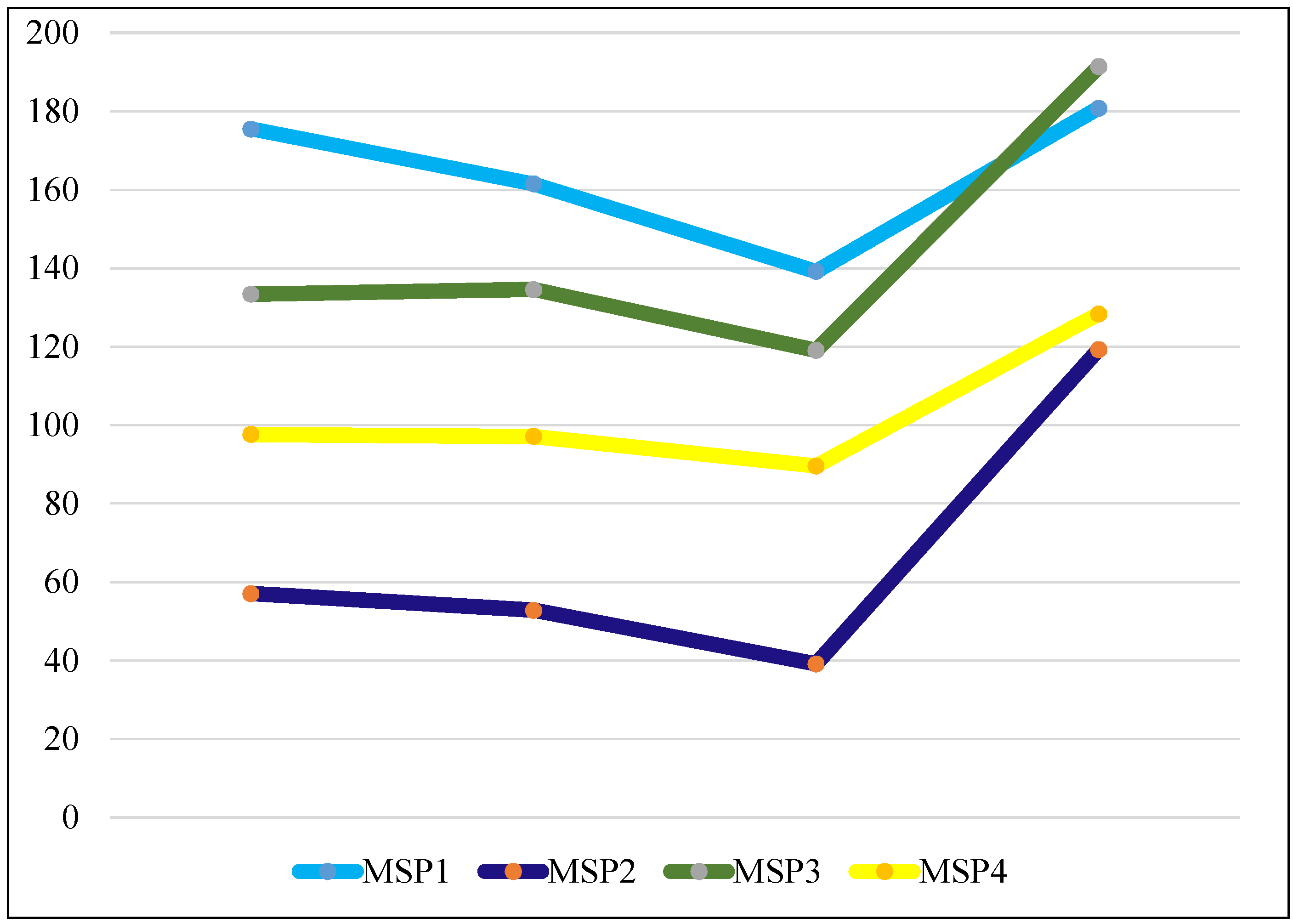
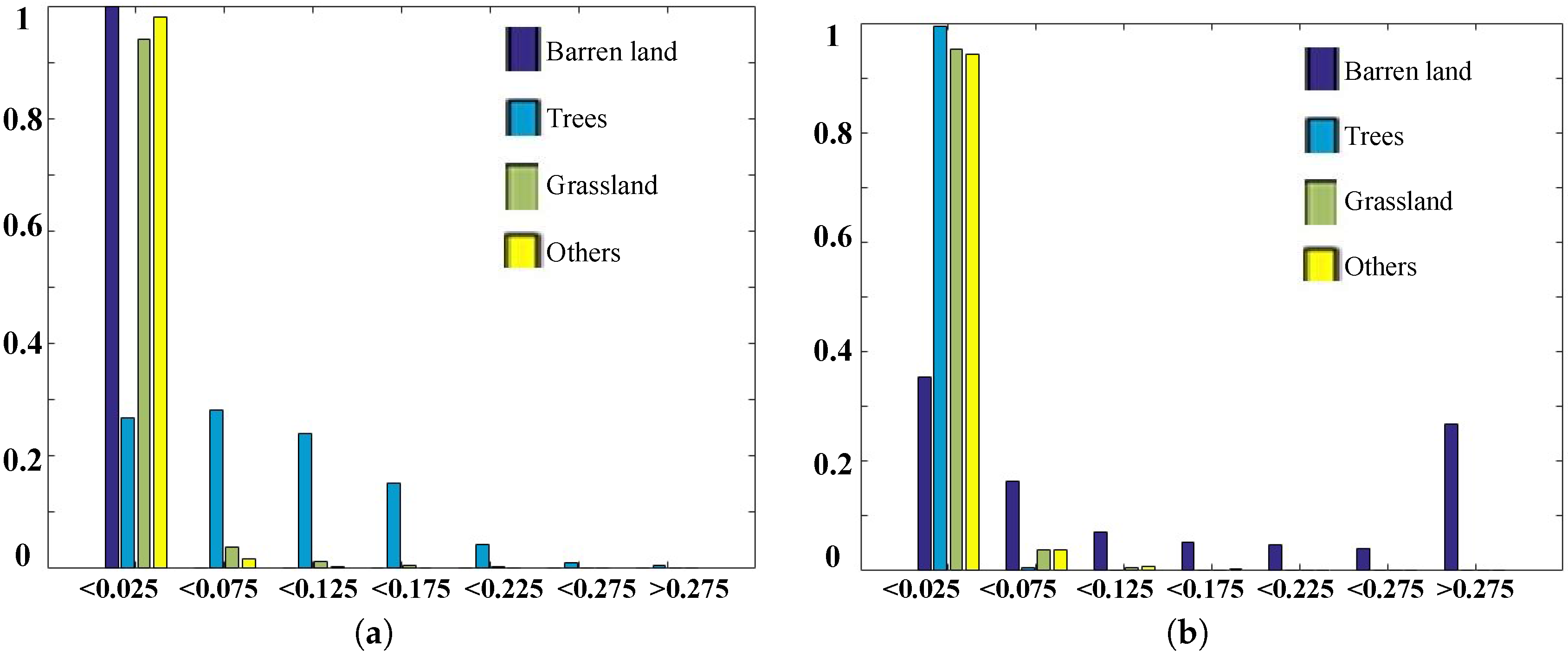
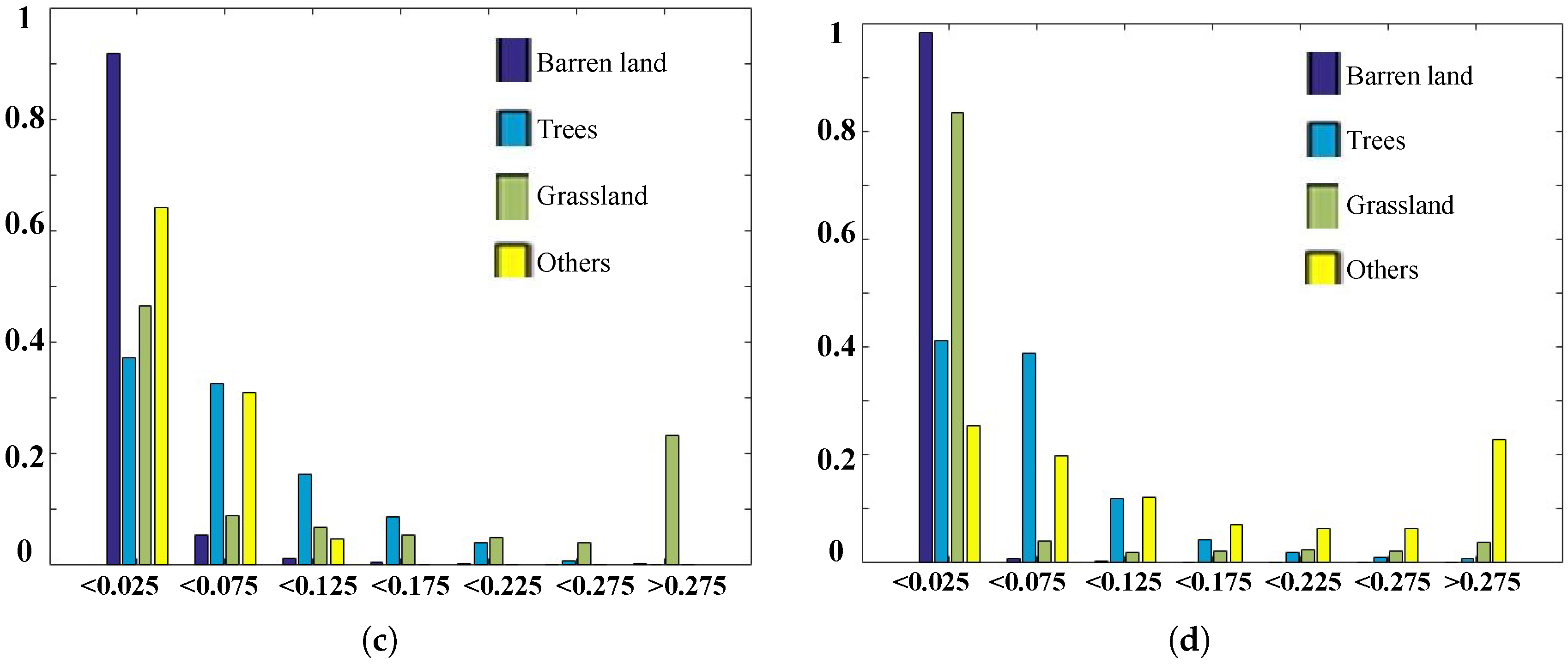
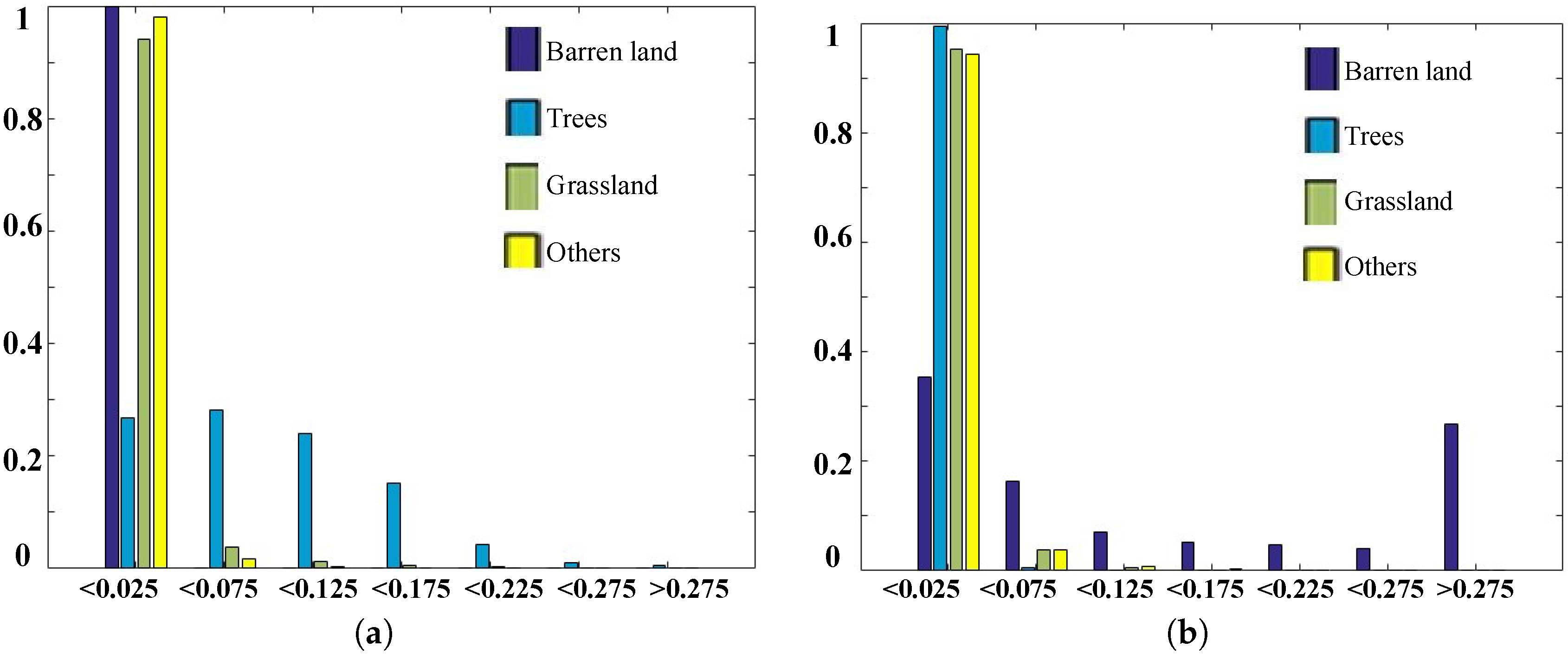
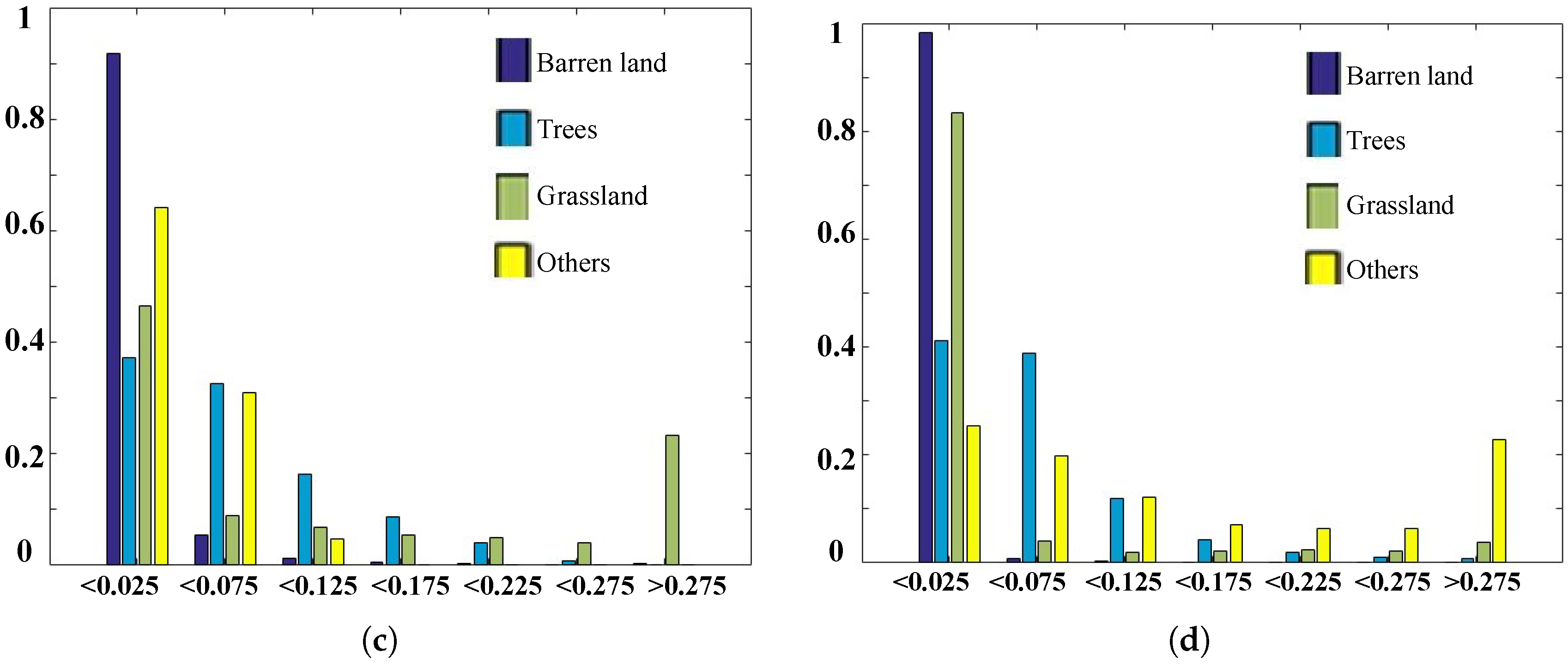
4.2. Spectral Analysis
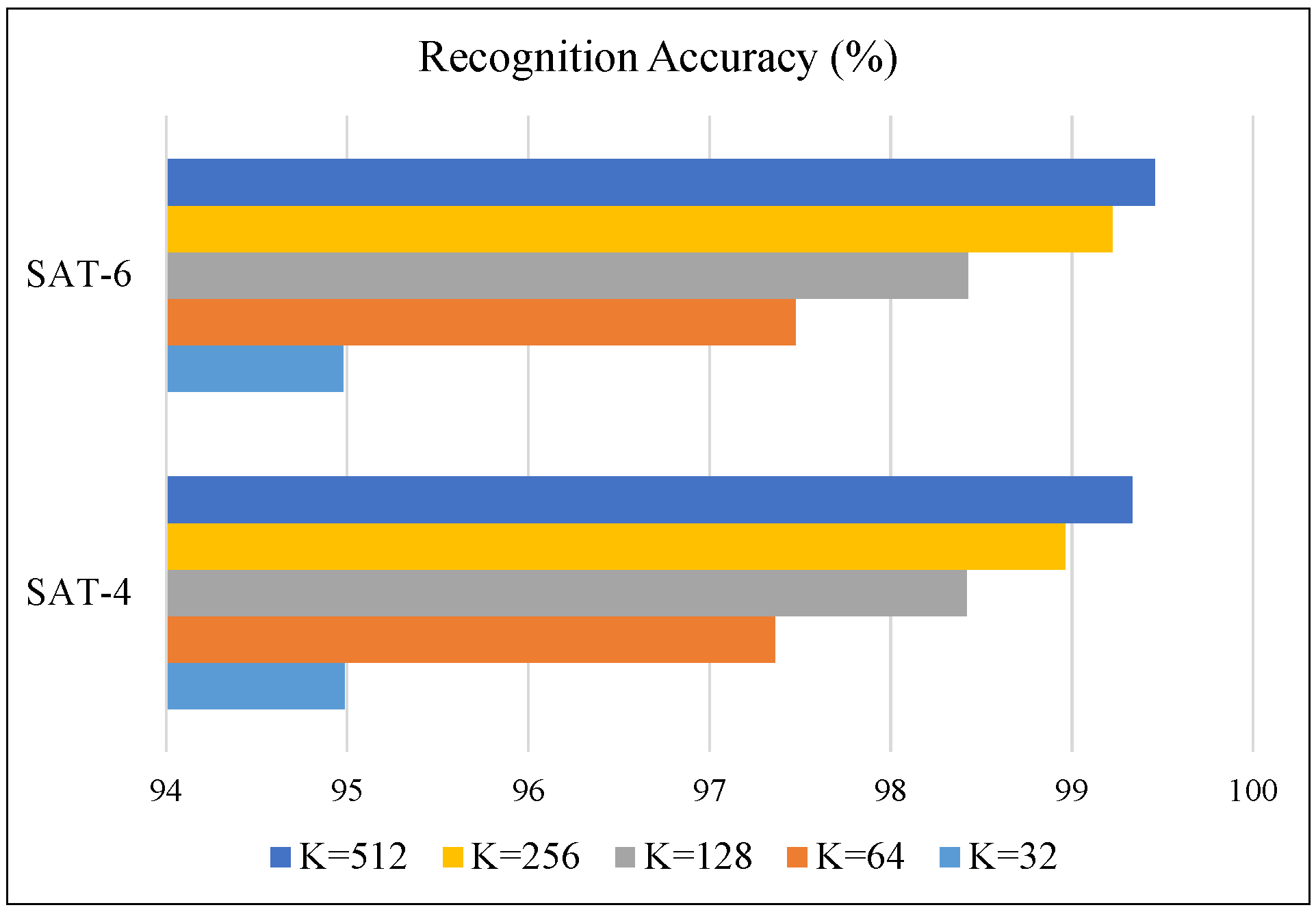
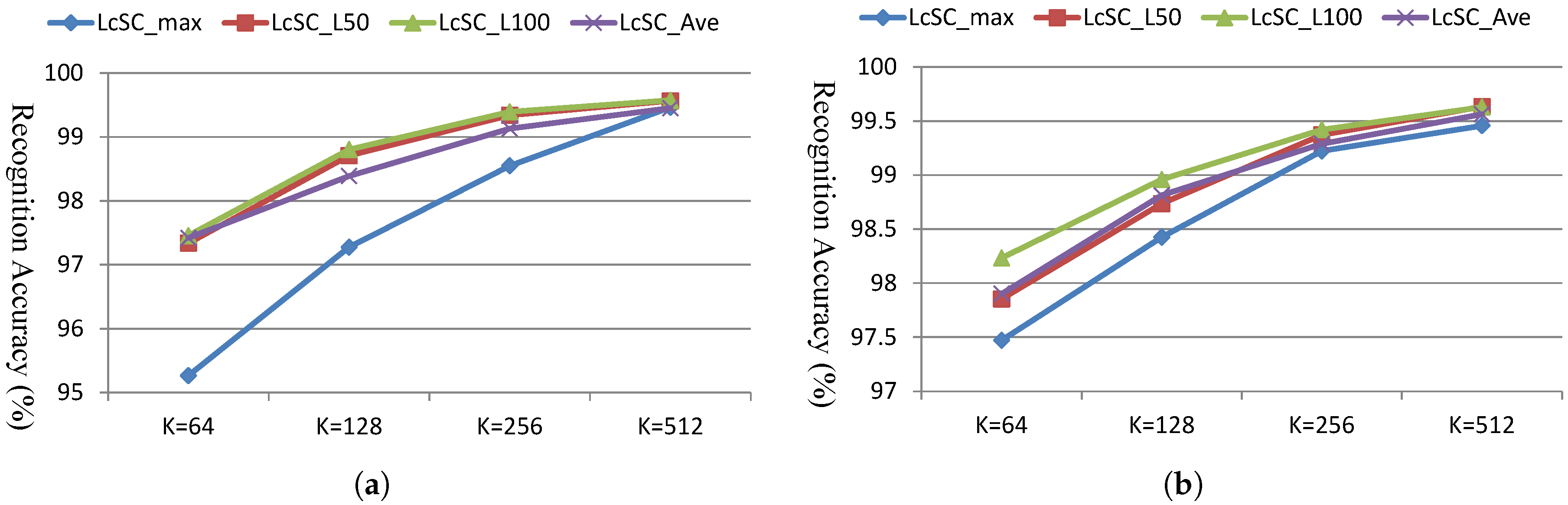
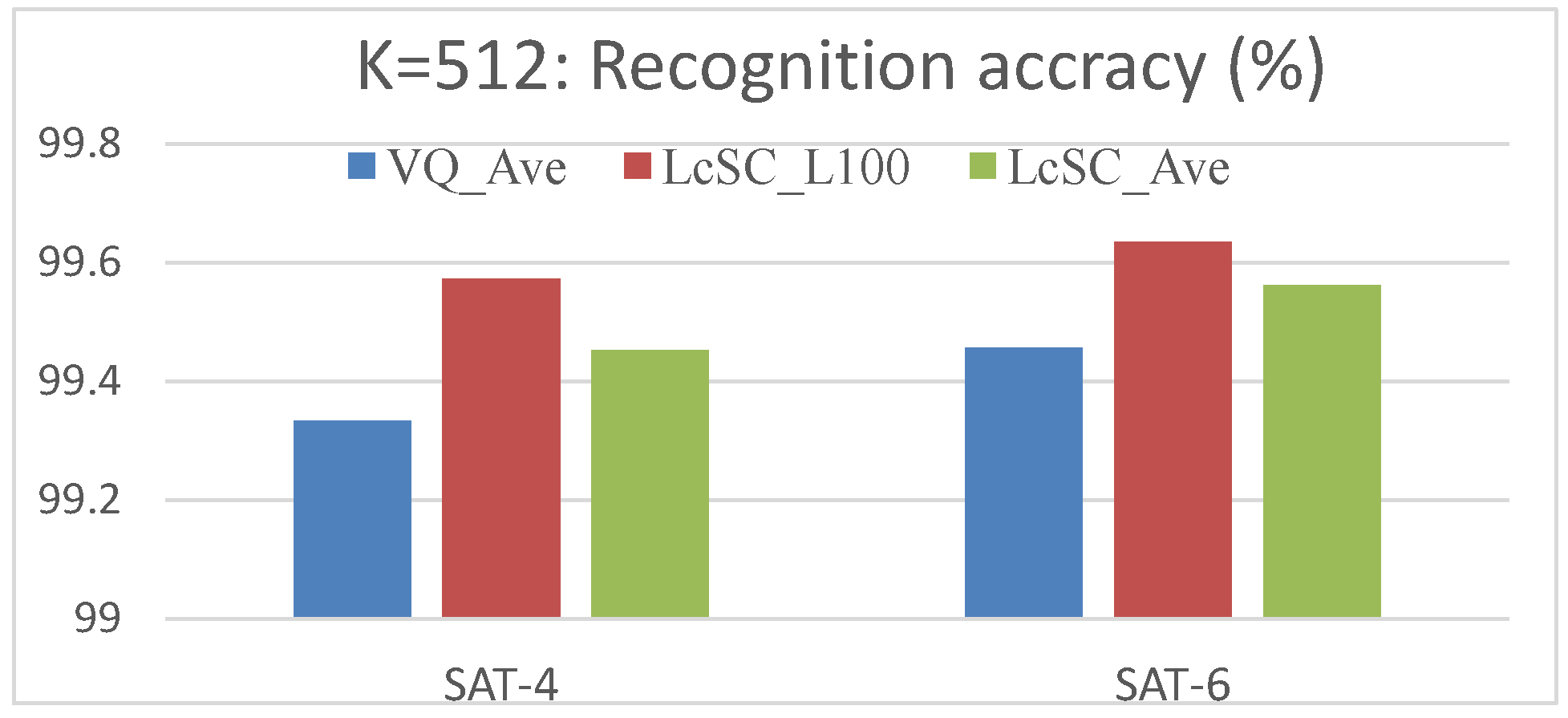
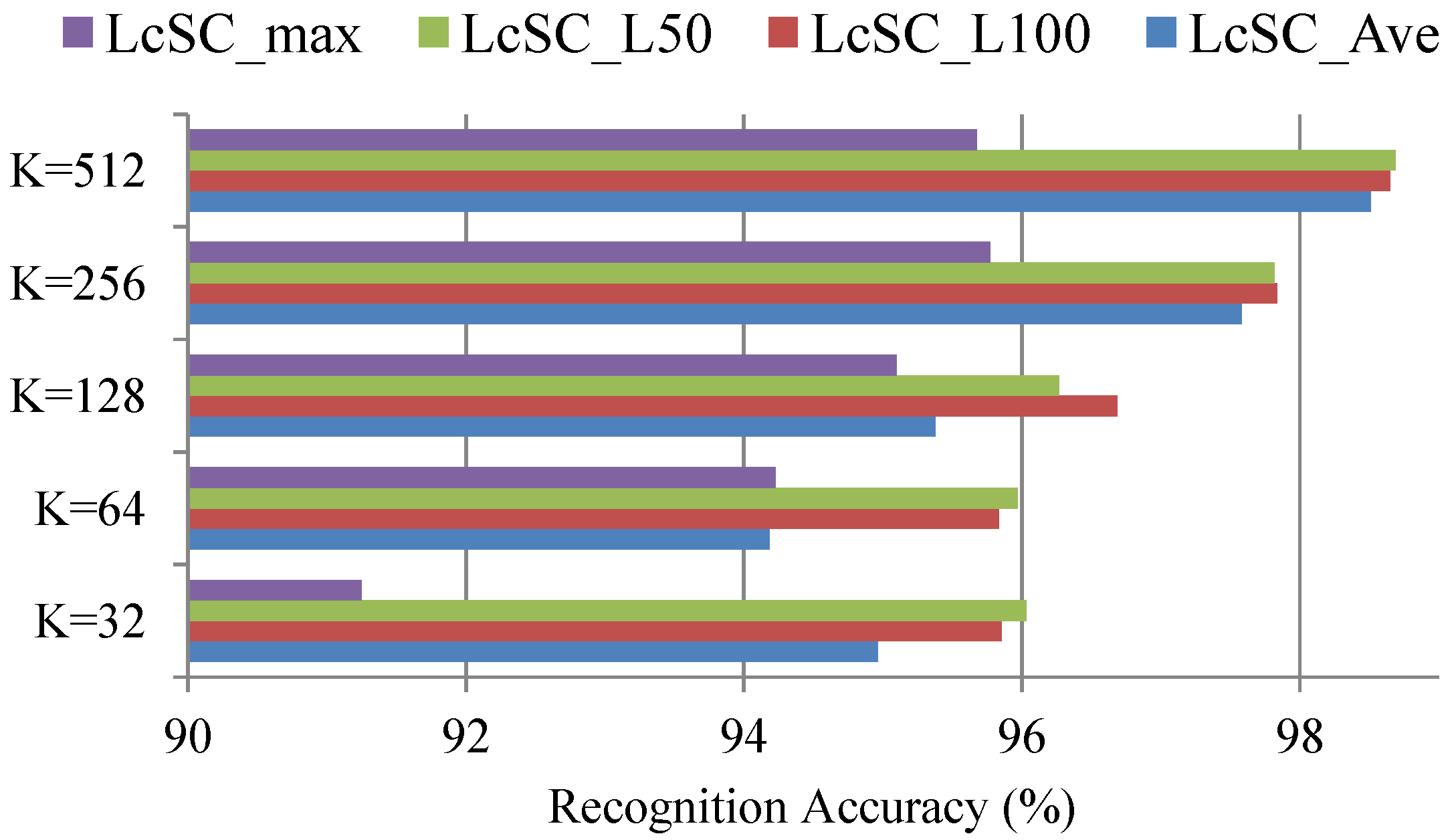
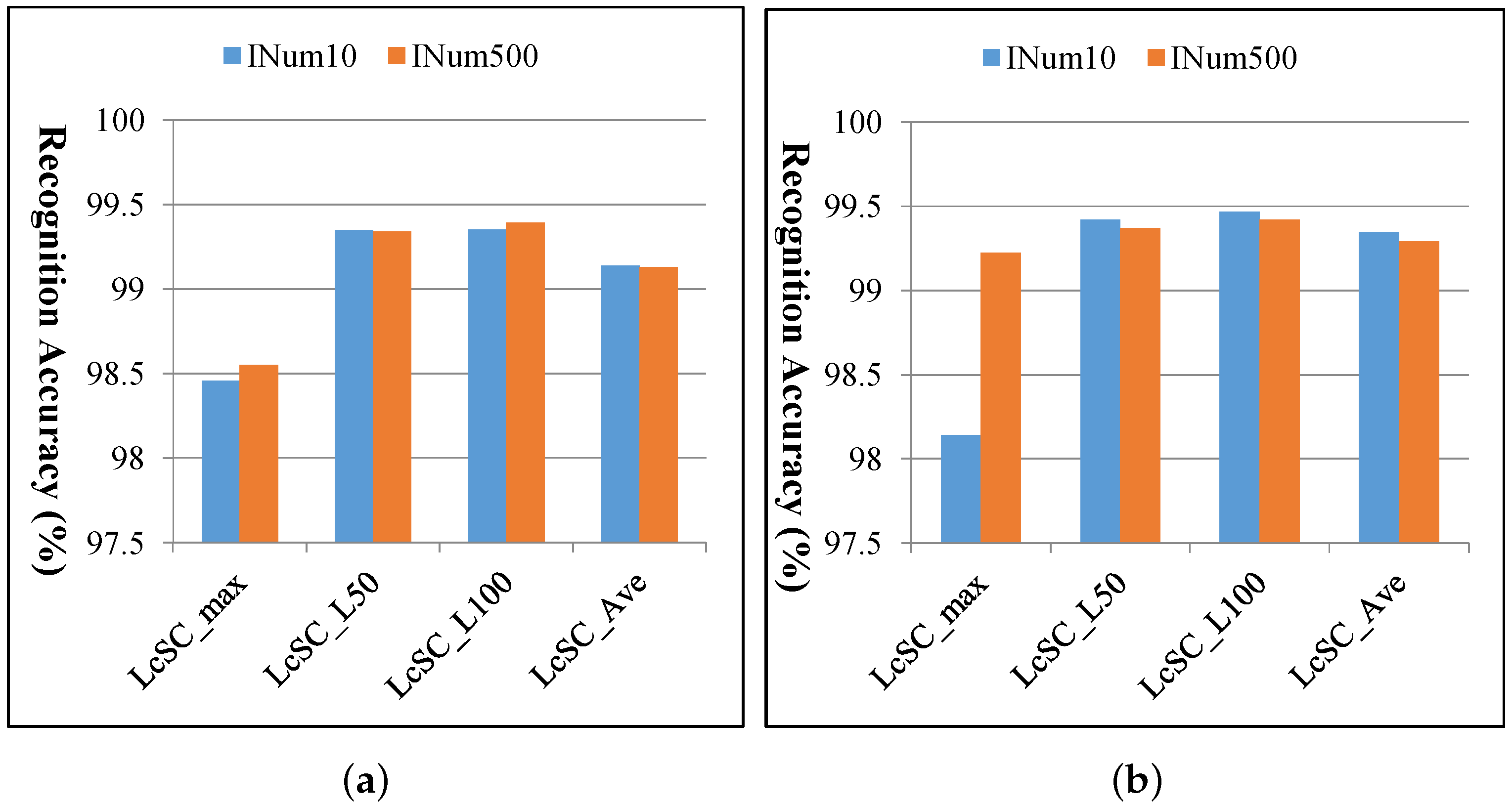
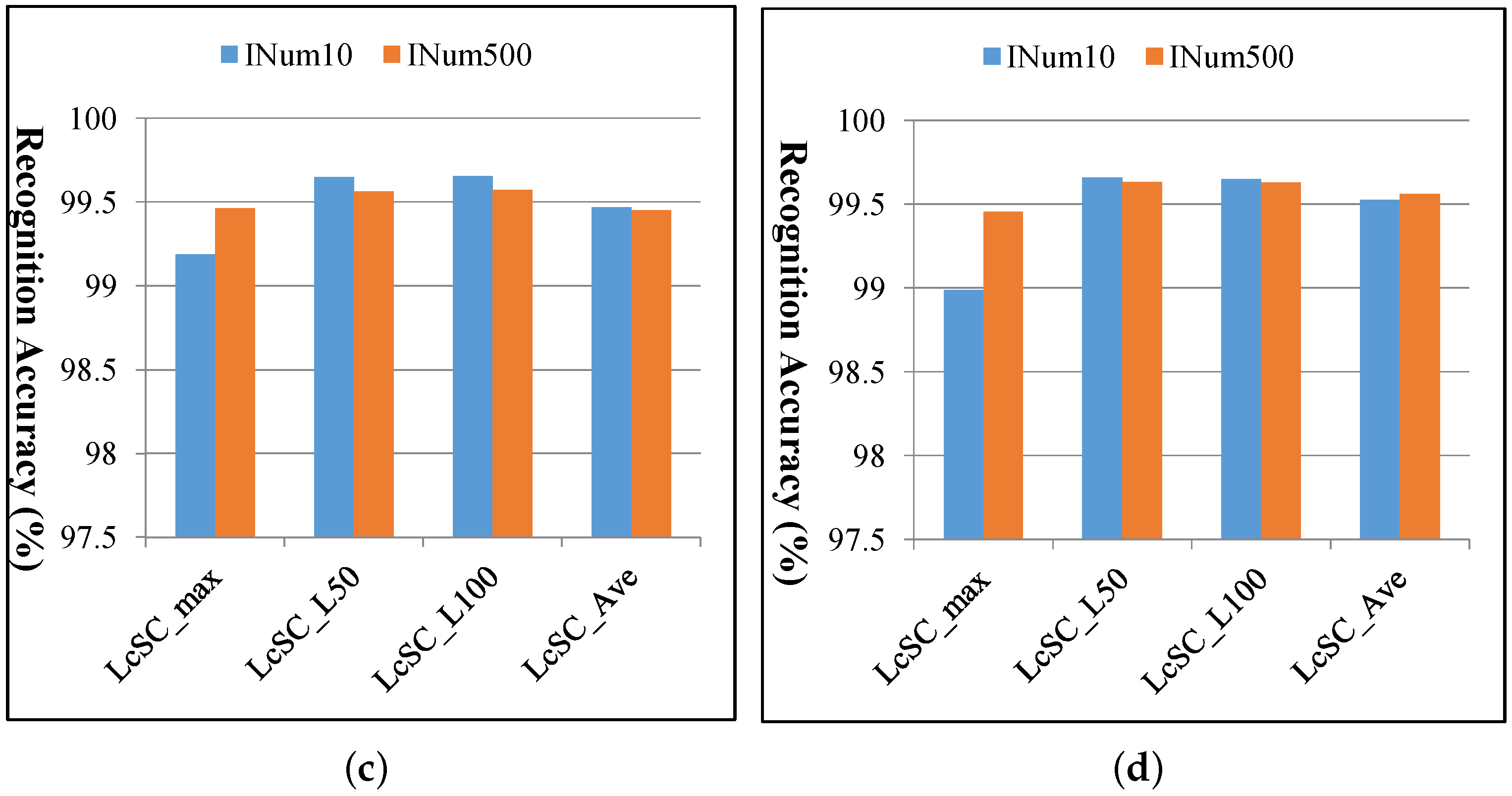
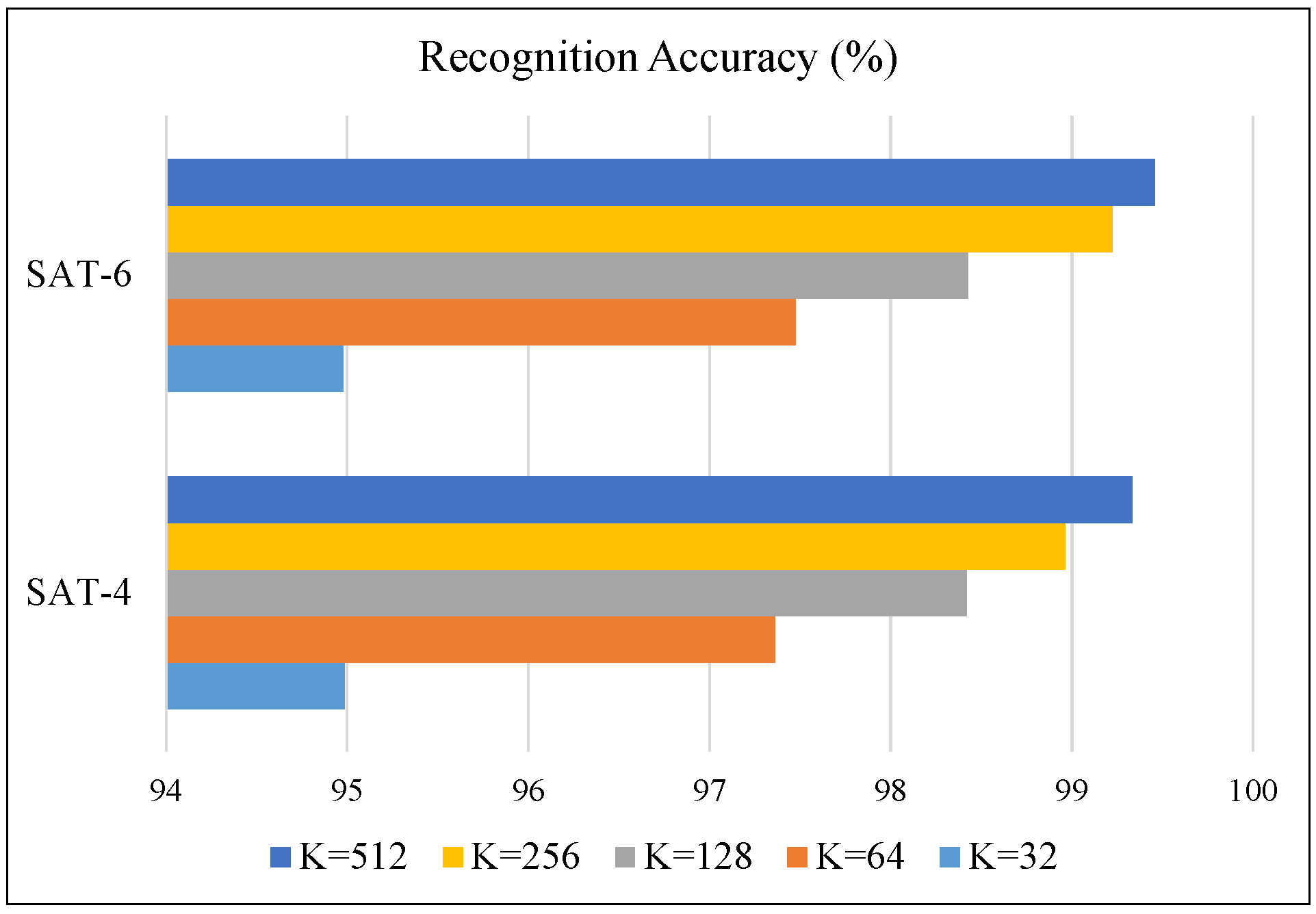
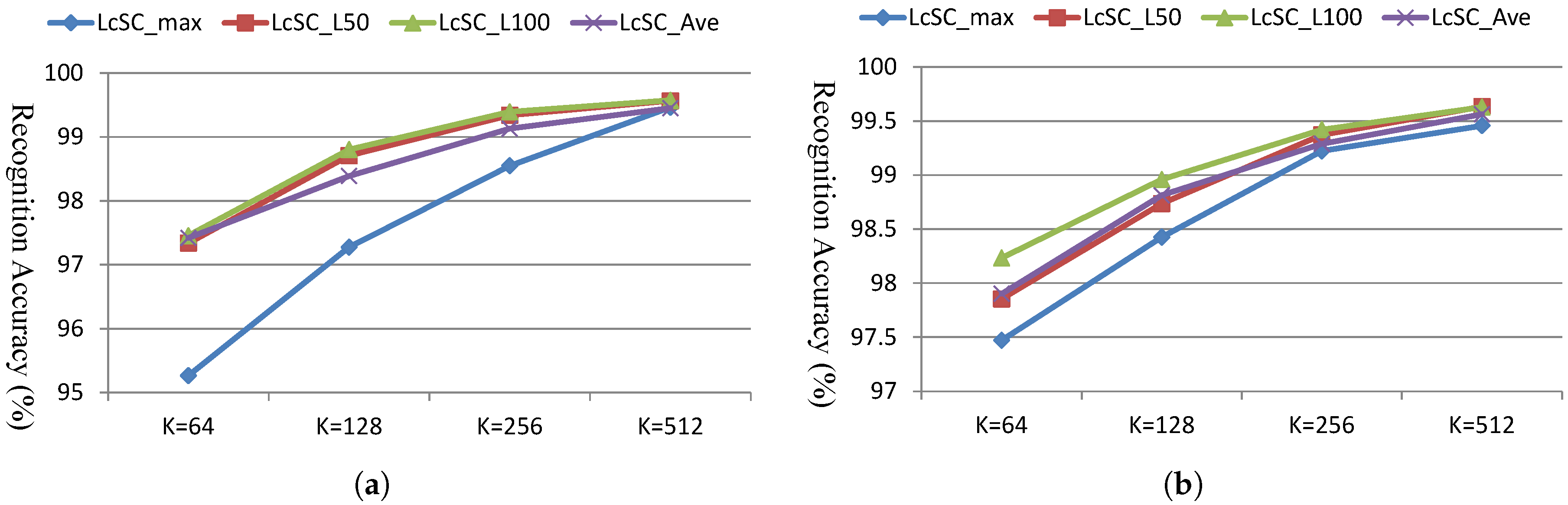
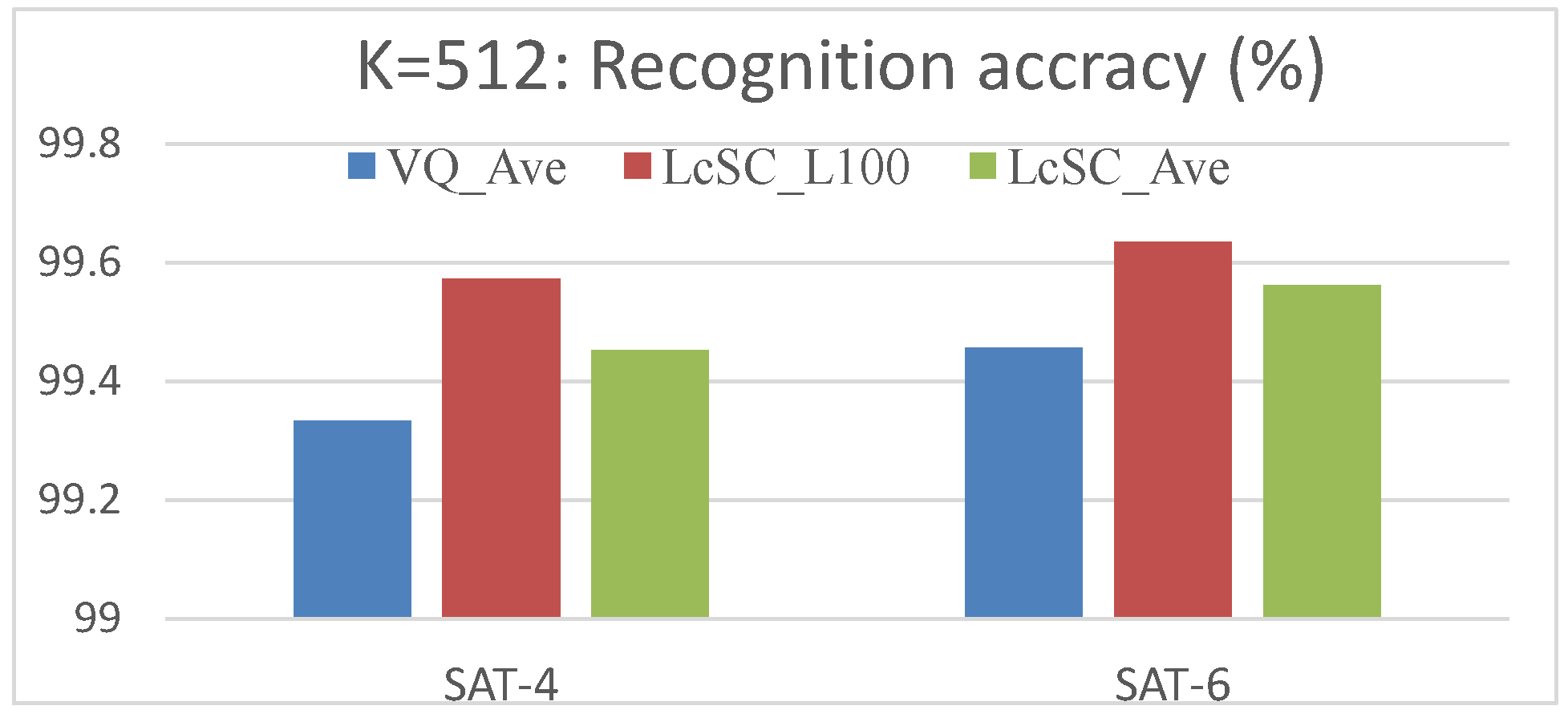
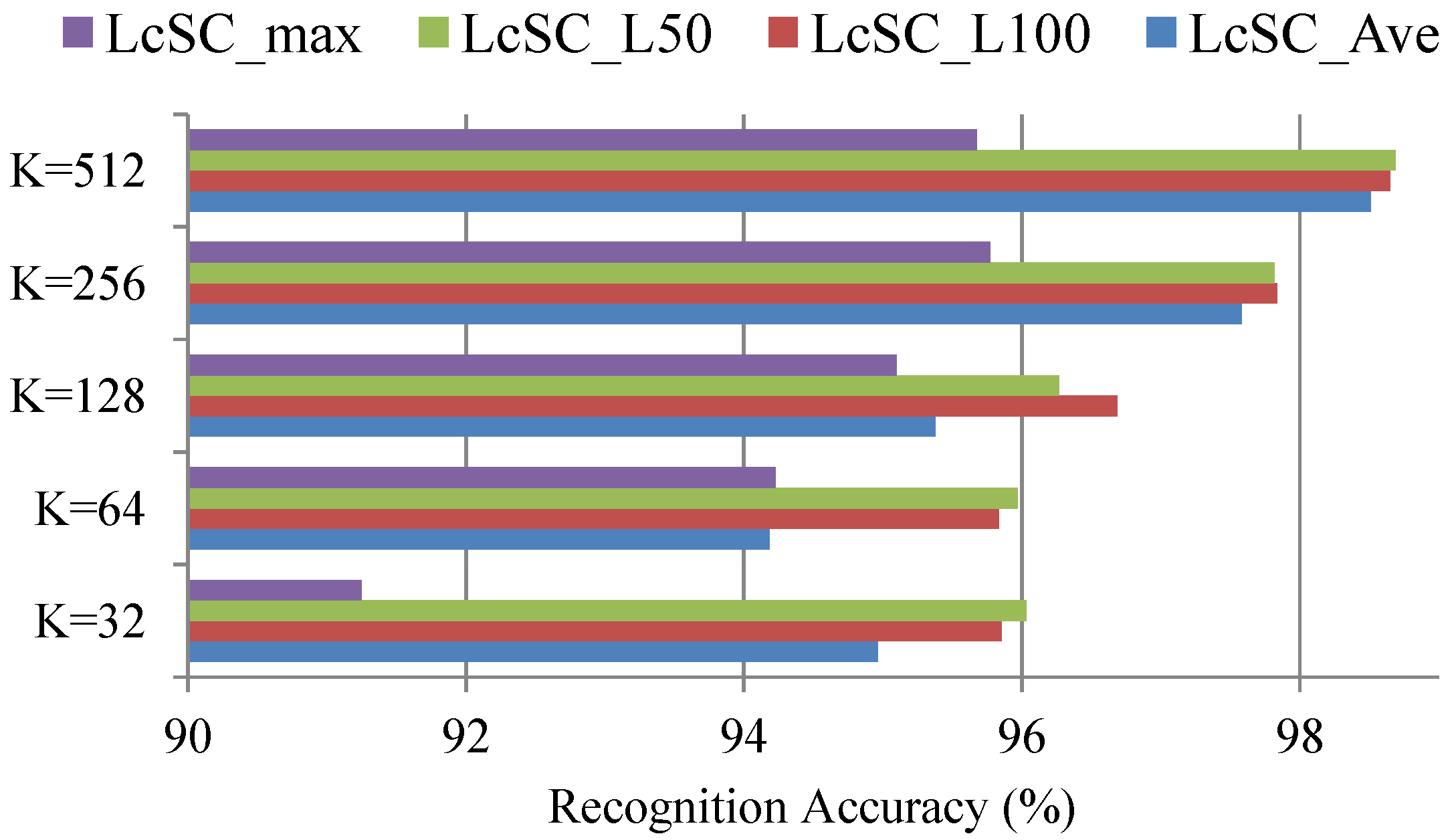
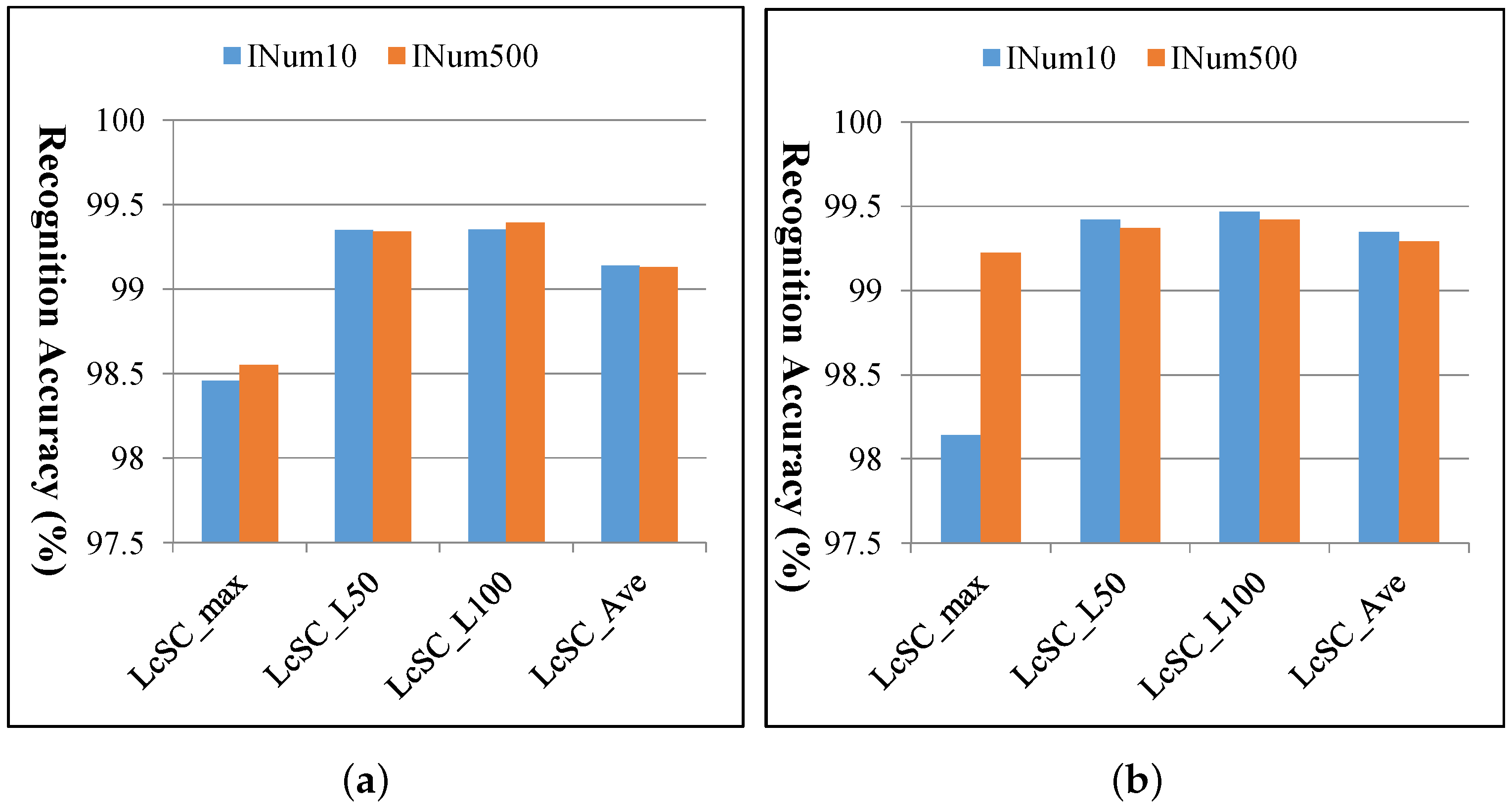
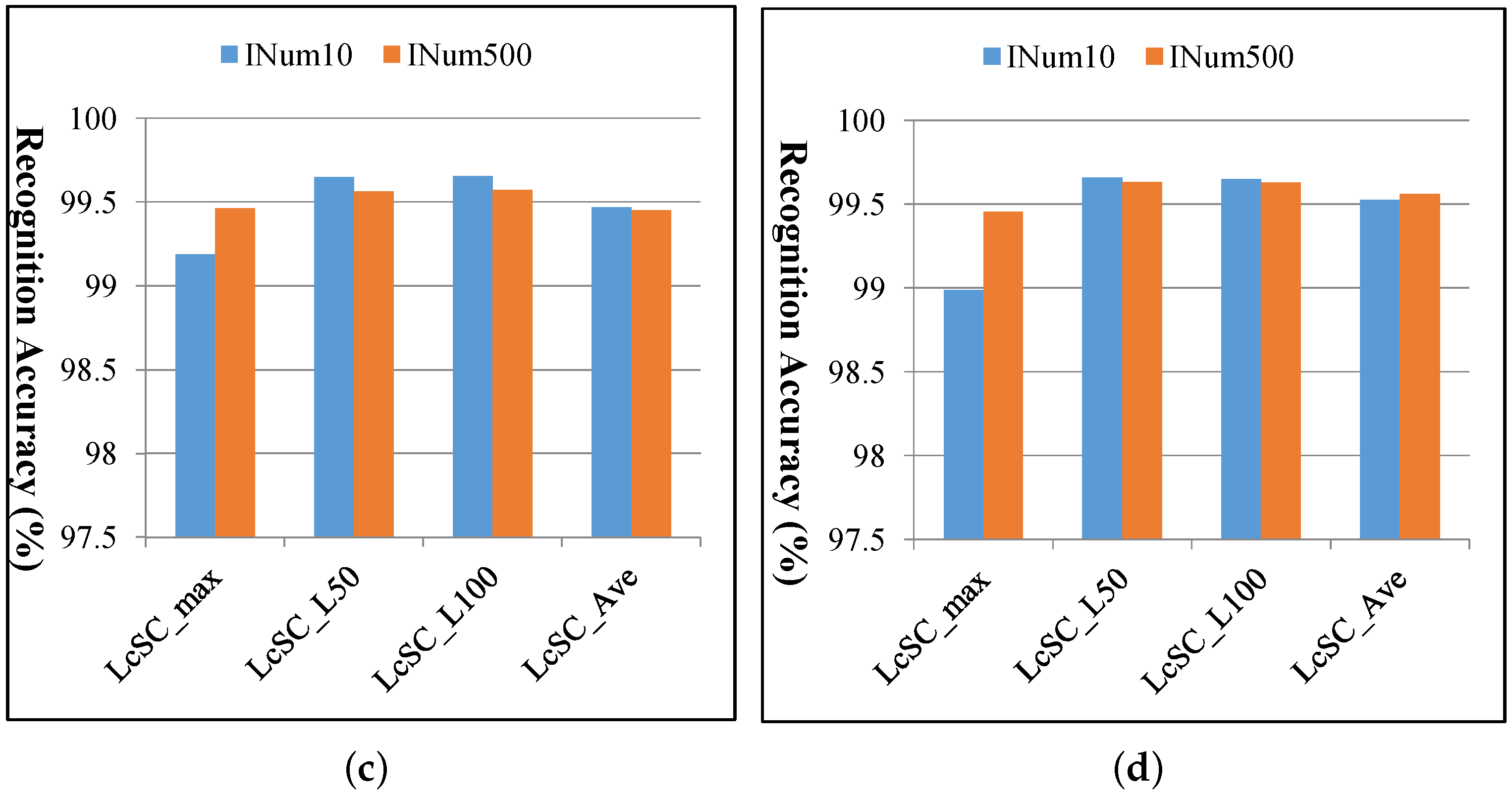
4.3. Experimental Results
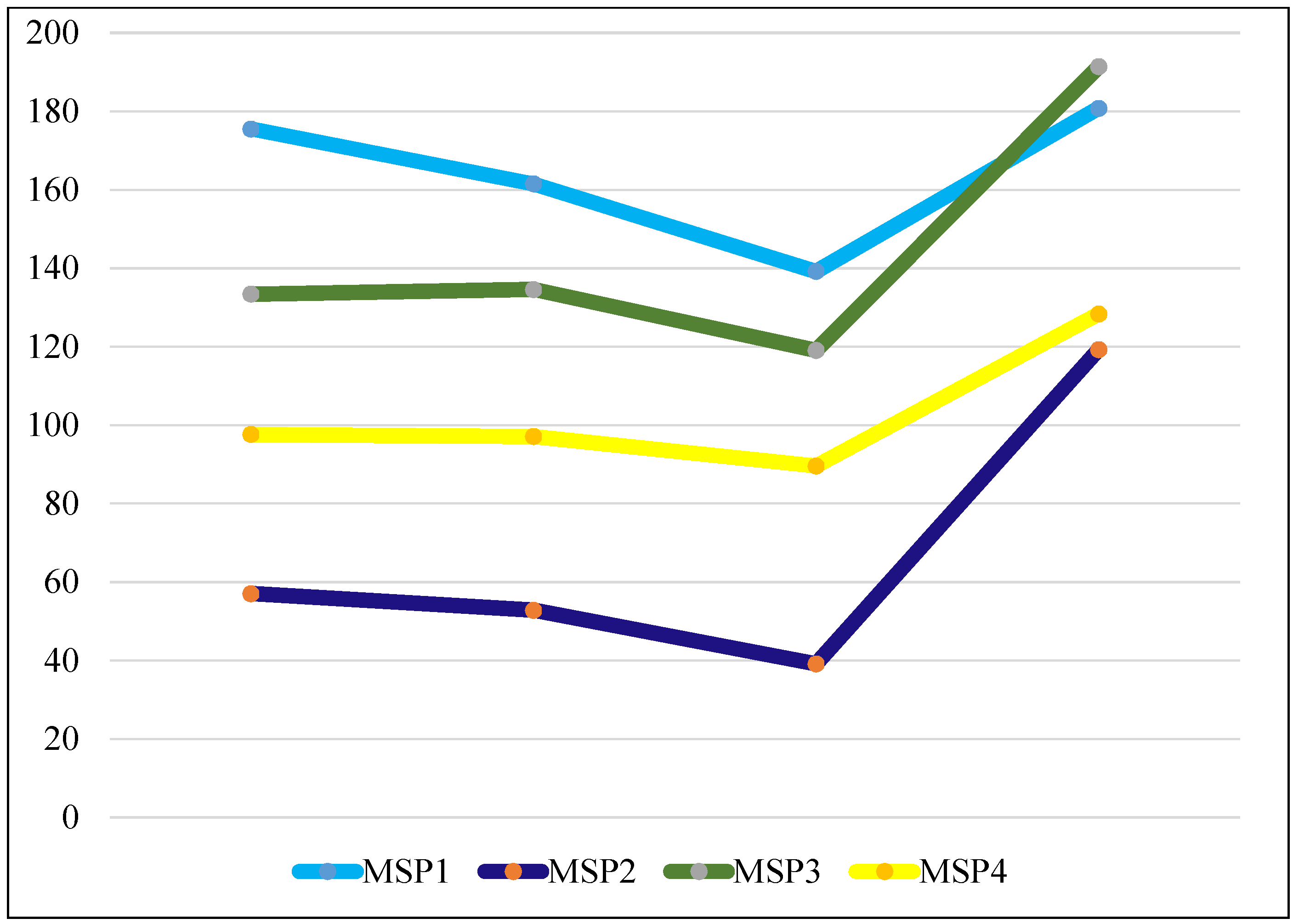
4.4. Computational Cost
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Xu, Y.; Huang, B. Spatial and temporal classification of synthetic satellite imagery: Land cover mapping and accuracy validation. Geo-Spat. Inf. Sci. 2014, 17, 1–7. [Google Scholar] [CrossRef]
- Rogan, J.; Chen, D.M. Remote sensing technology for mapping and monitoring land-cover and land-use change. Prog. Plan. 2004, 61, 301–325. [Google Scholar] [CrossRef]
- Jaiswal, R.K.; Saxena, R.; Mukherjee, S. Application of remote sensing technology for land use/land cover change analysis. J. Indian Soc. Remote Sens. 1999, 27, 123–128. [Google Scholar] [CrossRef]
- Xia, G.S.; Yang, W.; Delon, J.; Gousseau, Y.; Sun, H.; Maitre, H. Structrual High-Resolution Satellite Image Indexing. In Proceedings of the ISPRS, TC VII Symposium Part A: 100 Years ISPRS, Vienna, Austria, 5–7 July 2010; pp. 298–303. [Google Scholar]
- Jiang, Y.-G.; Ngo, C.-W.; Yang, J. Towards optimal bag-of-features for object categorization and semantic video retrieval. In Proceedings of the 6th ACM International Conference on Image and Video Retrieval, Amsterdam, The Netherlands, 9–11 July 2007; pp. 494–501. [Google Scholar]
- Jurie, F.; Triggs, B. Creating efficient codebooks for visual recognition. In Proceedings of the ICCV’05, Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; pp. 604–610. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. Packing bag-of-features. In Proceedings of the ICCV’09, 12th IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the CVPR’06, IEEE Computer Society Conference on Computer Vision, New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Yang, J.C.; Yu, K.; Gong, Y.H.; Huang, T. Linear spatial pyramid matching using sparse coding for image classification. In Proceedings of the CVPR’09, IEEE Computer Society Conference on Computer Vision, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Yu, K.; Zhang, T.; Gong, Y.H. Nonlinear learning using local coordinate coding. In Proceedings of the NIPS’09, Advances in Neural Information Processing Systems 22, Vancouver, BC, Canada, 7–10 December 2009; pp. 2223–2231. [Google Scholar]
- Wang, J.J.; Yang, J.C.; Yu, K.; Lv, F.J.; Huang, T.; Gong, Y.H. Locality-constrained Linear Coding for Image Classification. In Proceedings of the CVPR’10, IEEE Computer Society Conference on Computer Vision, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Han, X.-H.; Chen, Y.-W.; Xu, G. High-Order Statistics of Weber Local Descriptors for Image Representation. IEEE Trans. Cybern. 2015, 45, 1180–1193. [Google Scholar] [CrossRef] [PubMed]
- Jegou, H.; Douze, M.; Schmid, C. Improving Bag-of-Features for Large Scale Image Search. Int. J. Comput. Vis. 2010, 87, 316–336. [Google Scholar] [CrossRef]
- Perronnin, F.; Sanchez, J.; Mensink, T. Improving the Fisher Kernel for Large-Scale Image Classification. In Proceedings of the ECCV2010, 11th European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 143–156. [Google Scholar]
- Han, X.-H.; Wang, J.; Xu, G.; Chen, Y.-W. High-Order Statistics of Microtexton for HEp-2 Staining Pattern Classification. IEEE Trans. Biomed. Eng. 2014, 61, 2223–2234. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhao, L.J.; Tang, P.; Huo, L.Z. Land-use scene classification using a concentric circle structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Chen, S.; Tian, Y. Pyramid of Spatial Relations for Scene-Level Land Use Classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1947–1957. [Google Scholar] [CrossRef]
- Cheriyadat, A. Unsupervised Feature Learning for Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Saliency-Guided Unsupervised Feature Learning for Scene Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.; Wang, Z.; Huang, X.; Zhang, L.; Sun, H. Unsupervised Feature Learning via Spectral Clustering of Multidimensional Patches for Remotely Sensed Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the MM2014, 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlssonand, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land Use Classification in Remote Sensing Images by Convolutional Neural Networks. arXiv 2015. [Google Scholar]
- Penatti, O.A.B.; Nogueira, K.; Santos, J.A.D. Do Deep Features Generalize from Everyday Objects to Remote Sensing and Aerial Scenes Domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Hu, F.; Xia, G.; Hu, J.W.; Zhang, L.P. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Basu, S.; Ganguly, S.; Mukhopadhyay, S.; Dibiano, R.; Karki, M.; Nemani, R. DeepSat—A Learning framework for Satellite Imagery. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015. [Google Scholar]
- Ma, Z.; Wang, Z.P.; Liu, C.X.; Liu, X.Z. Satellite imagery classification based on deep convolution network. Int. J. Comput. Autom. Control Inf. Eng. 2016, 10, 1055–1059. [Google Scholar]
- WWW2. NAIP. Available online: http://www.fsa.usda.gov/Internet/FSA$_$File/naip$_$2009$_$info$_$final.pdf (accessed on 16 March 2017).
- Zhong, Y.F.; Fei, F.; Liu, Y.F.; Zhao, B.; Jiao, H.Z.; Zhang, L.P. SatCNN: Satellite image dataset classification using agile convolutional neural networks. Remote Sens. Lett. 2017, 8, 136–145. [Google Scholar] [CrossRef]
- Adams, J.B.; Smith, M.O.; Johnson, P.E. Spectral mixture modeling: A new analysis of rock and soil types at the Viking Lander 1 site. J. Geophys. Res. 1986, 91, 8098–8112. [Google Scholar] [CrossRef]
- Settle, J.; Drake, N. Linear mixing and the estimation of ground cover proportions. Int. J. Remote Sens. 1993, 14, 1159–1177. [Google Scholar] [CrossRef]
- Plaza, A.; Martinez, P.; Perez, R.; Plaza, J. A quantitative and comparative analysis of endmember extraction algorithms from hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2004, 42, 650–663. [Google Scholar] [CrossRef]
- Du, Q.; Raksuntorn, N.; Younan, N.; King, R. End-member extraction for hyperspectral image analysis. Appl. Opt. 2008, 47, 77–84. [Google Scholar] [CrossRef]
- Chang, C.-I.; Wu, C.-C.; Liu, W.; Ouyang, Y.-C. A new growing method for simplex-based endmember extraction algorithm. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2804–2819. [Google Scholar] [CrossRef]
- Zare, A.; Gader, P. Hyperspectral band selection and endmember detection using sparsity promoting priors. IEEE Trans. Geosci. Remote Sens. 2008, 5, 256–260. [Google Scholar] [CrossRef]
- Zortea, M.; Plaza, A. A quantitative and comparative analysis of different implementations of N-FINDR: A fast endmember extraction algorithm. IEEE Trans. Geosci. Remote Sens. 2009, 6, 787–791. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. SURF: Speeded Up Robust Features. Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Ishii, T.; Edgar, S.-S.; Iizuka, S.; Mochizuki, Y.; Sugimoto, A.; Ishikawa, H.; Nakamura, R. Detection by classification of buildings in multispectral satellite imagery. In Proceedings of the International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) SAT-4 | ||||||
| (%) | Barren Land | Trees | Grassland | Others | ||
| Barren land | 99.404 | 0 | 0.554 | 0.042 | ||
| Trees (linear) | 0 | 99.97 | 0.035 | 0 | ||
| Grassland | 0.407 | 0.061 | 99.515 | 0.017 | ||
| Others | 0.034 | 0.003 | 0.003 | 99.961 | ||
| (b) SAT-6 | ||||||
| (%) | Building | Barren Land | Trees | Grassland | Road | Water |
| Building | 100 | 0 | 0 | 0 | 0 | 0 |
| Barren land | 0 | 99.134 | 0 | 0.866 | 0 | 0 |
| Trees | 0 | 0 | 99.894 | 0.106 | 0 | 0 |
| Grassland | 0.008 | 0.802 | 0.143 | 99.047 | 0 | 0 |
| Road | 0 | 0 | 0 | 0 | 100 | 0 |
| Water | 0 | 0 | 0 | 0 | 0 | 100 |
| Methods | SAT-4 | SAT-6 |
|---|---|---|
| DBN [29] | 81.78 | 76.41 |
| CNN [29] | 86.83 | 79.06 |
| SDAE [29] | 79.98 | 78.43 |
| Semi-supervised [29] | 97.95 | 93.92 |
| DCNN [30] | 98.408 | 96.037 |
| Ours | 99.709 | 99.679 |
| CB Size | Off-Line | On-Line | ||||
|---|---|---|---|---|---|---|
| CL(s) | SVM-T(m) | FE(s) | SVM-P(s) | |||
| SAT-4 | SAT-6 | SAT-4 | SAT-6 | For one 28 × 28 image | ||
| Dict:256 | 270.40 | 393.17 | 42.62 | 9.54 | 0.024 | 0.010 |
| Dict:512 | 530.96 | 906.17 | 52.89 | 11.25 | 0.038 | 0.014 |
| Codebook Size | SAT-4 | SAT-6 | ||
|---|---|---|---|---|
| INum10 | INum500 | INum10 | INum500 | |
| K = 256 | 4.54 | 270.40 | 6.61 | 393.17 |
| K = 512 | 7.37 | 530.96 | 12.57 | 906.17 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, X.-H.; Chen, Y.-w. Generalized Aggregation of Sparse Coded Multi-Spectra for Satellite Scene Classification. ISPRS Int. J. Geo-Inf. 2017, 6, 175. https://doi.org/10.3390/ijgi6060175
Han X-H, Chen Y-w. Generalized Aggregation of Sparse Coded Multi-Spectra for Satellite Scene Classification. ISPRS International Journal of Geo-Information. 2017; 6(6):175. https://doi.org/10.3390/ijgi6060175
Chicago/Turabian StyleHan, Xian-Hua, and Yen-wei Chen. 2017. "Generalized Aggregation of Sparse Coded Multi-Spectra for Satellite Scene Classification" ISPRS International Journal of Geo-Information 6, no. 6: 175. https://doi.org/10.3390/ijgi6060175
APA StyleHan, X.-H., & Chen, Y.-w. (2017). Generalized Aggregation of Sparse Coded Multi-Spectra for Satellite Scene Classification. ISPRS International Journal of Geo-Information, 6(6), 175. https://doi.org/10.3390/ijgi6060175