
Efficient Location Privacy-Preserving k-Anonymity Method Based on the Credible Chain


Abstract
:1. Introduction
2. Related Works
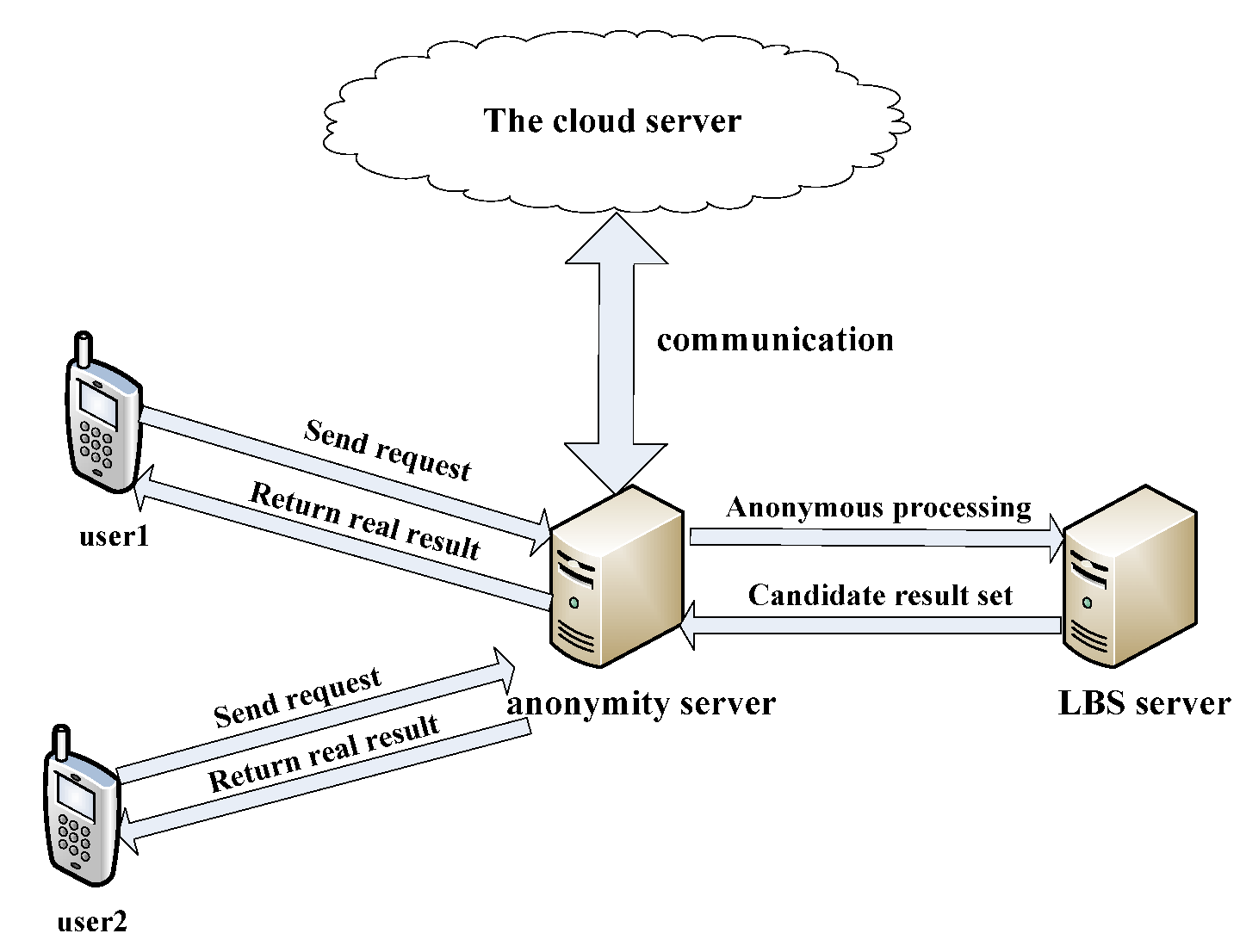
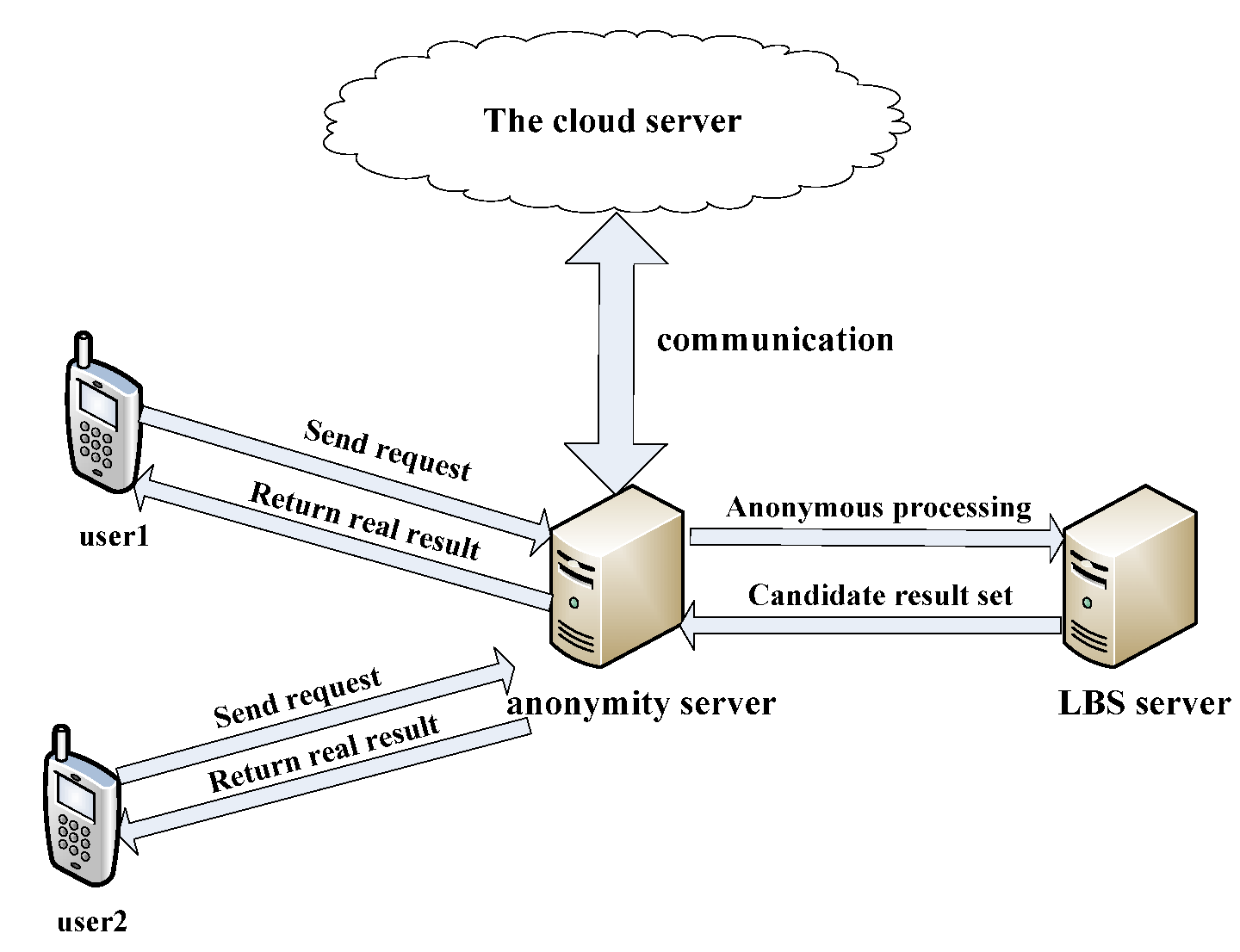
3. Systems Model
- (1)
- The quality of service (QoS).
- (2)
- When information (part of the database) disclosure occurs and LBS data are leaked, leaked information can be controlled as little as possible.
- (3)
- When location-based services are taken over by an attacker, the attacker can be misled with false data.
- (4)
- The LBS will adopt the timestamp from the received request messages to provide location services.
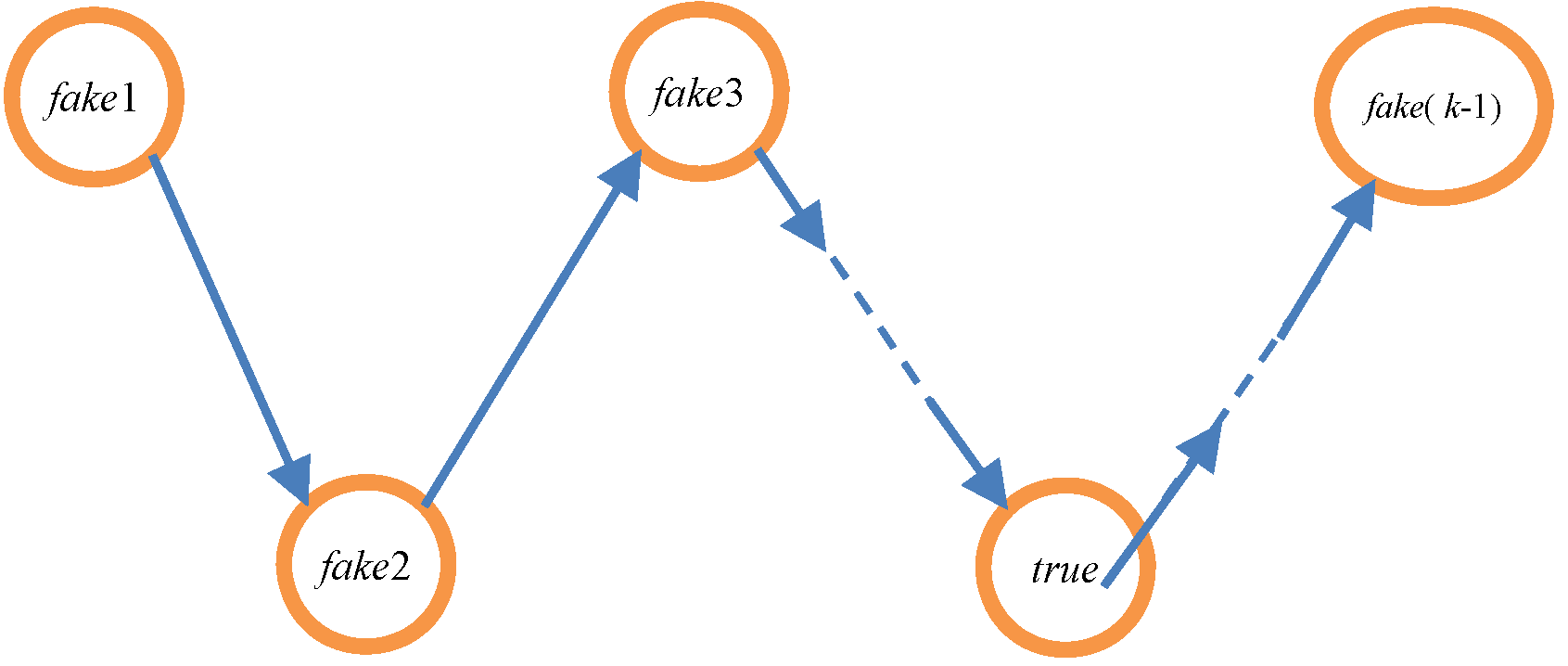
4. k-Anonymity Method Based on the Credible Chain
4.1. Preliminary Knowledge
4.2. k Value Selection
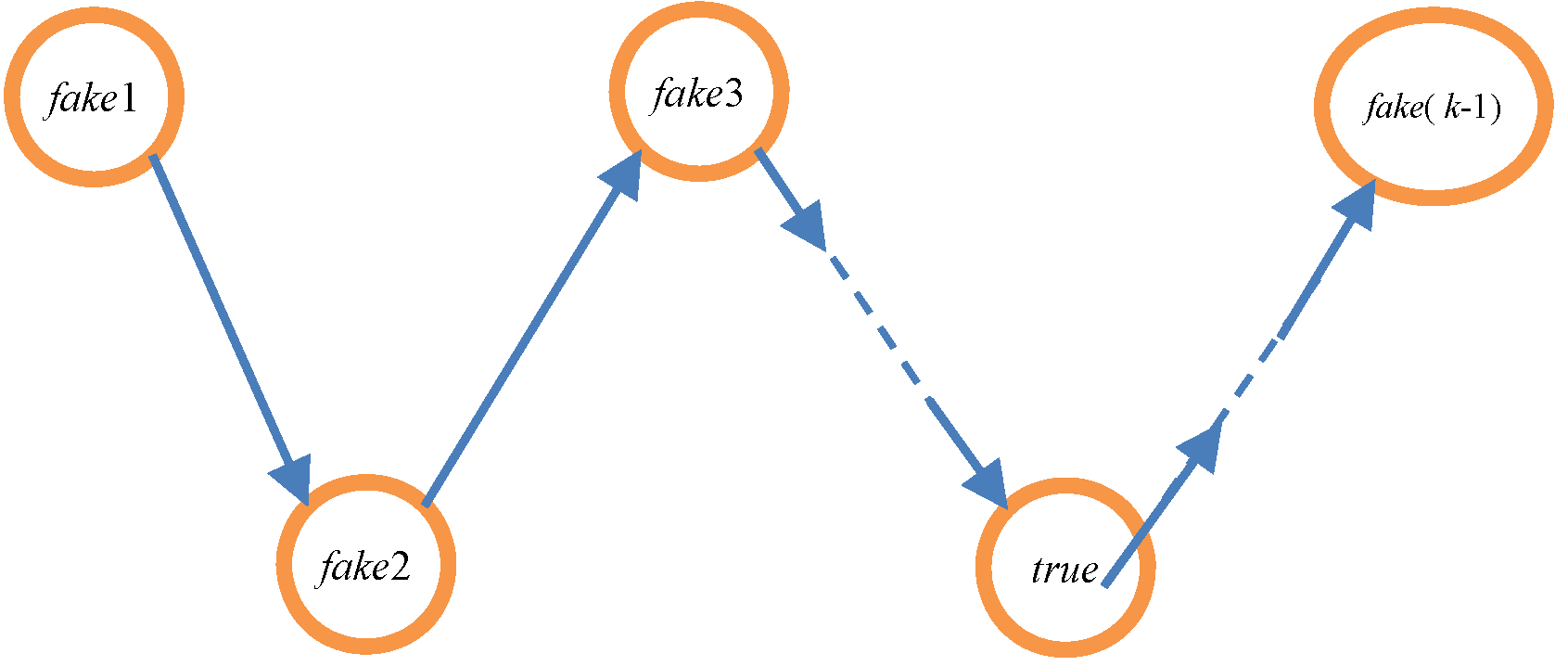
4.3. Anonymous Processing
| Algorithm 1 Make a fake trajectory |
| Input: The user’s request q Output: array P 1: q1:k−1 ← k − 1 messages selected by anonymity server 2: p1:k ← RANDOMSHUFFLE (q,q1,… ,qk−1) // The details of this step are shown in Algorithm 2 3: // The following steps are just outlines, the details of the following part are shown in Algorithm 3 4: for i = 2, 3 … k do 5: T ← NECESSARYTRAVELTIME (pi−1, pi) 6: If T ≤ 7: 8: End If 9: End for 10: Return P |
| Algorithm 2 Initial anonymous processing algorithm |
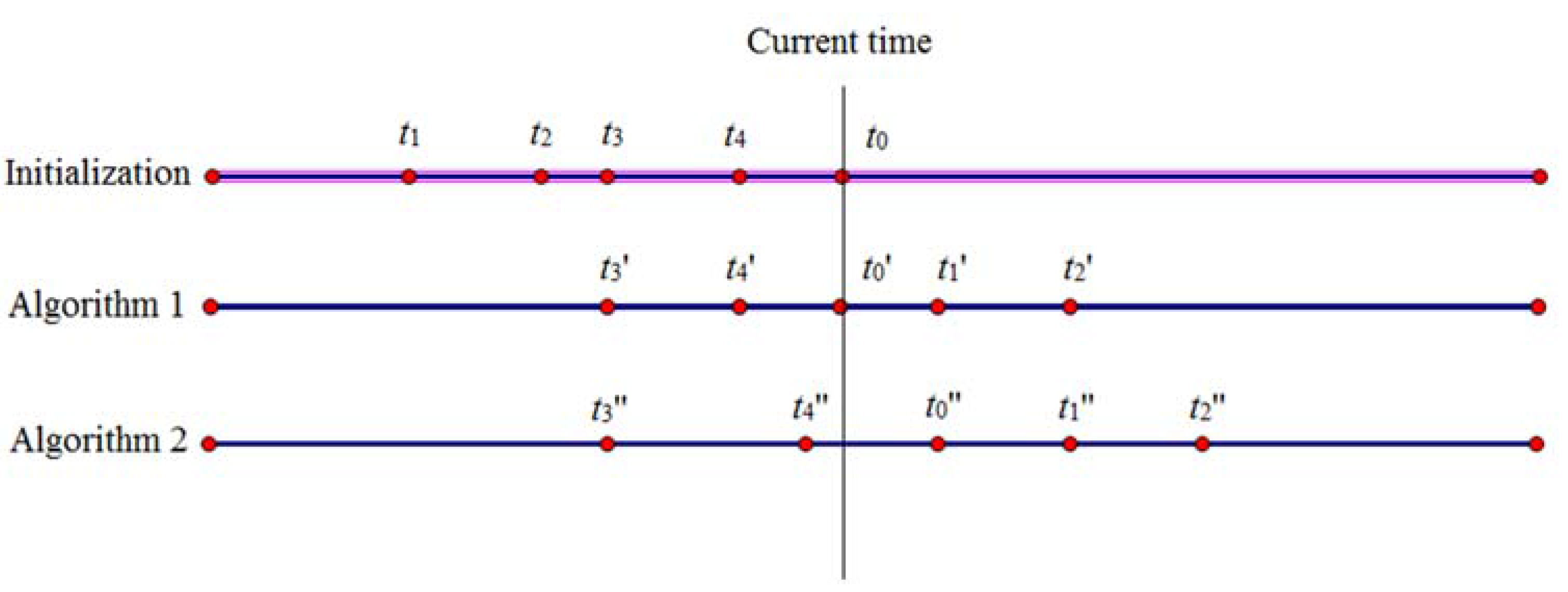
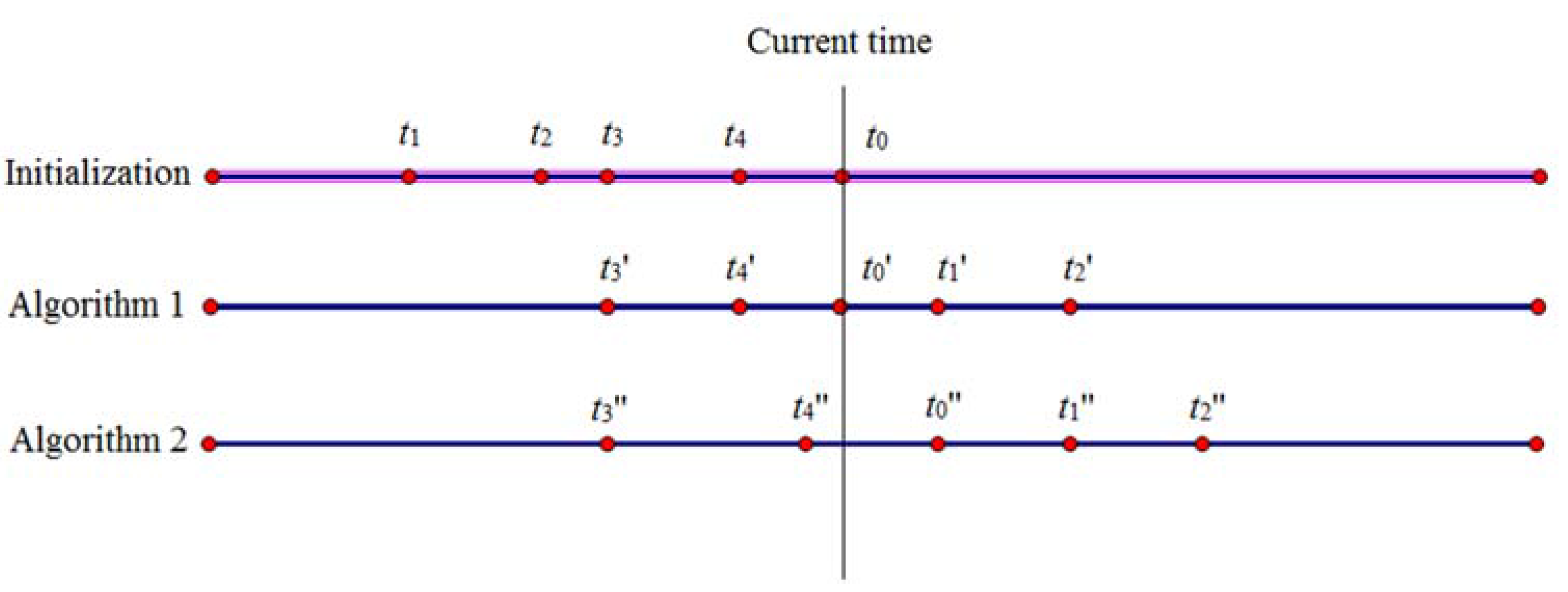
| Input: The anonymity server selects k − 1 messages from the cloud server according to s generated by the user and then places k − 1 messages and the user’s message q0 into the array Q (namely Q = {q0, q1, q2, …, qk−1}). Output: array P 11: date = q0.t // Assign q0.t (the time of the user’s request message) to the variable date. 12: i = 1 13: ∆T = max (q0-qi), i∈[1, k − 1] 14: while i ≤ k − 1 do // Update the k − 1 message selected from the cloud server in turn. 15: qi.id = q0.id 16: qi.k = q0.k 17: qi.s = q0.s 18: if qi.t∉(date − random(∆T), date) then 19: qi.t = date + random (∆T) 20: end if // Substitute date + random(∆T) for qi.t while qi.t does not fall within the range of (date − random(∆T), date). The function of random(∆T) is used to generate a random number in the range of (0, ∆T), and the random number is retained to one decimal place. 21: i = i + 1 22: end while 23: P = Sort ({Q − qi}) // Place these messages from the array Q into the other array P after sorting according to the value of t. 24: Return P |
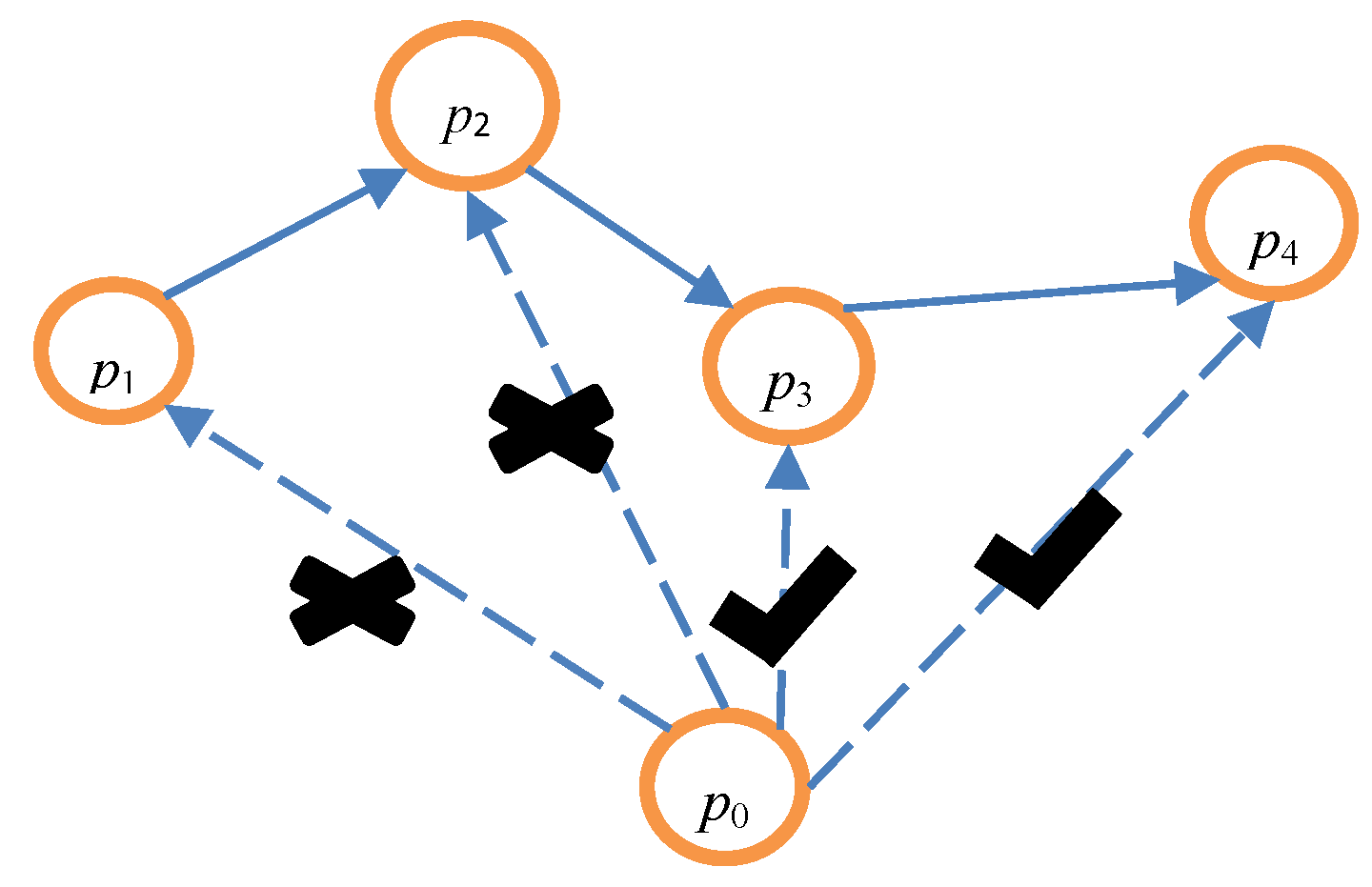
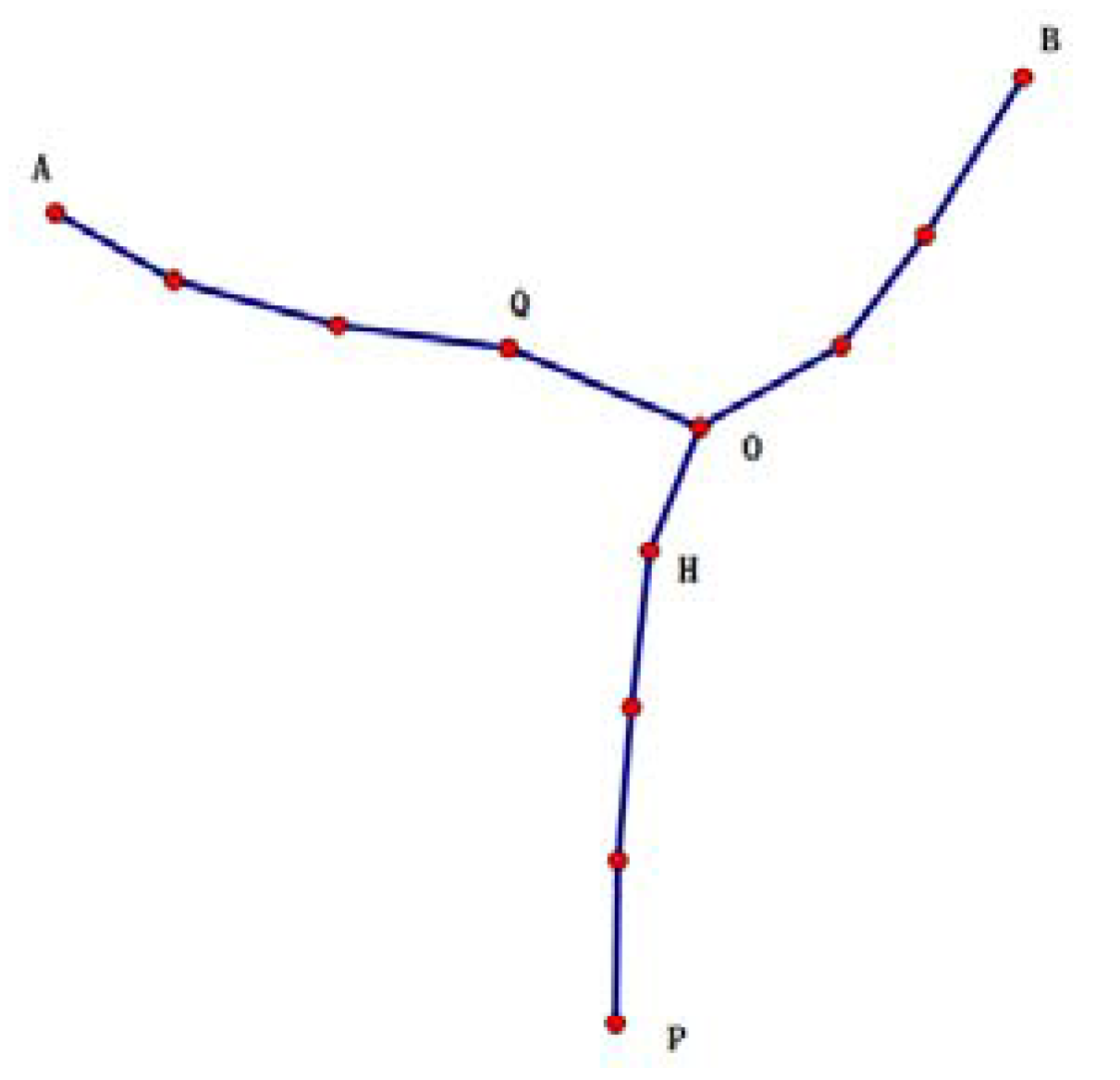
| Algorithm 3 The credible chain algorithm |
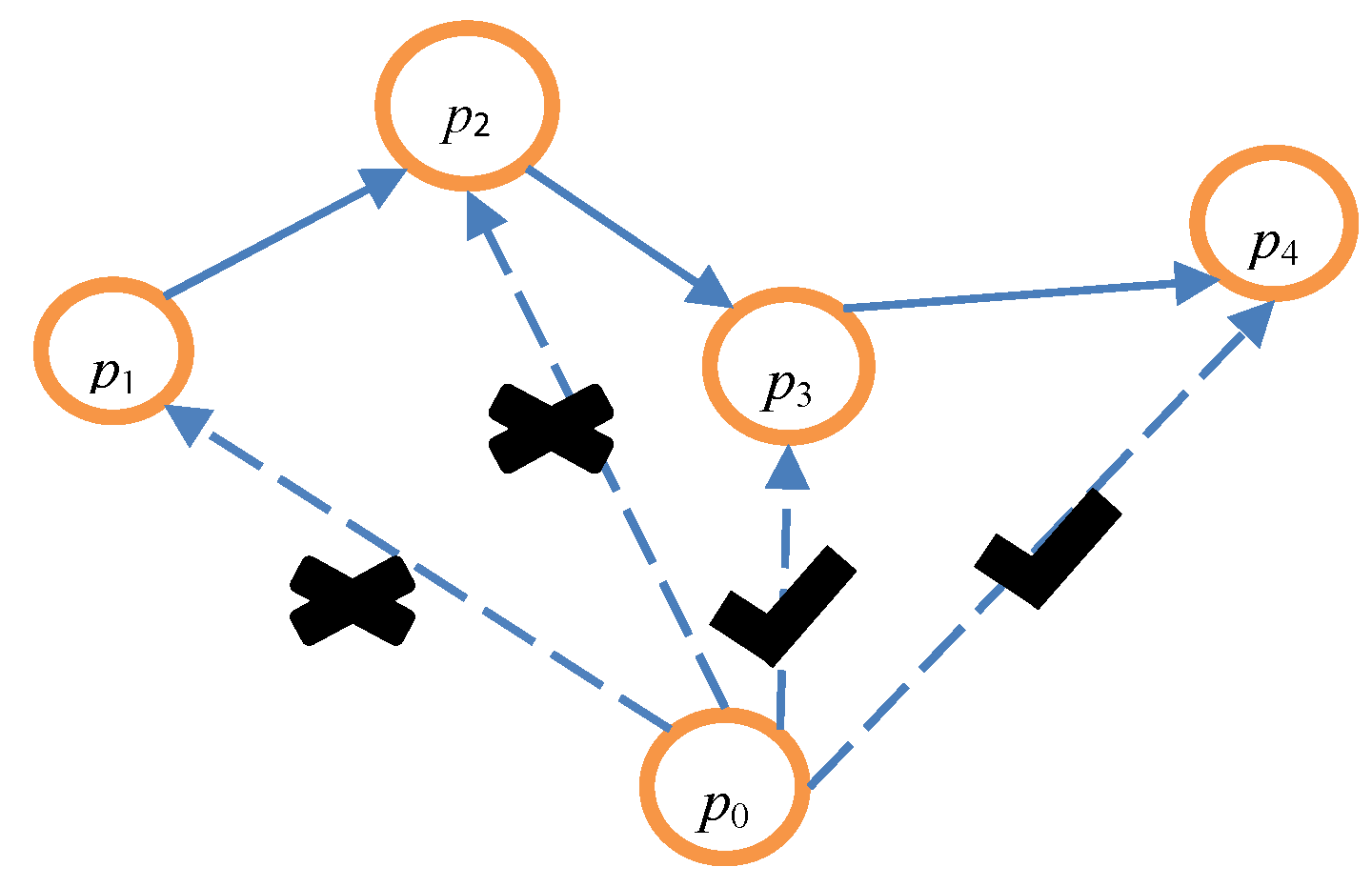
| Input: array P = {p0, p1, p2, …, pk−1}, date Output: the user’s trajectory T based on the credible chain 1: T = {p0} // Initialization should be completed before the credible chain is formed, and p0 is placed into the trajectory T. 2: if p0.t = date 3: flag = 0 // When the message p0 is exactly the user’s message, flag is set to 0. This denotes that the user’s message has been added to the credible chain. 4: else flag = 1 5: end if 6: ∆ = 0; i = 0 // ∆ is the interval between the time of the user’s request message after anonymity and the real time of the user’s request message. 7: while i ≤ k − 2 do 8: if ∆t = Si,i+1/vi,i+1 > (pi+1.t − pi.t) do // pi.loc cannot arrive at pi+1.loc. 9: if pi+1.t − ∆ = date && flag then // Judge whether pi+1 is the user’s message. 10: ∆ = pi.t + ∆t − date 11: end if 12: pi+1.t = pi.t + ∆t // pi+1.t is updated to guarantee that pi.loc can arrive at pi+1.loc. 13: end if 14: add (pi+1) // pi.loc can arrive at pi+1.loc, illustrating that P{X(ti+1) = qi+1.loc | X(ti) = qi .loc} ≠ 0. Hence, pi+1 should be added to the trajectory T. 15: delete (pi+1) // pi+1 should be removed from the array P. 16: when pi+1.t − ∆ = date, then // Determine whether pi+1 is the user’s message. 17: flag = 0; // if the user’s message has been added to the credible chain, and flag should be set to 0. 18: end if 19: i = i + 1 20: end while 21: Return T |
4.4. Inquiry Processing
5. Privacy Metrics
6. Experimental Analysis
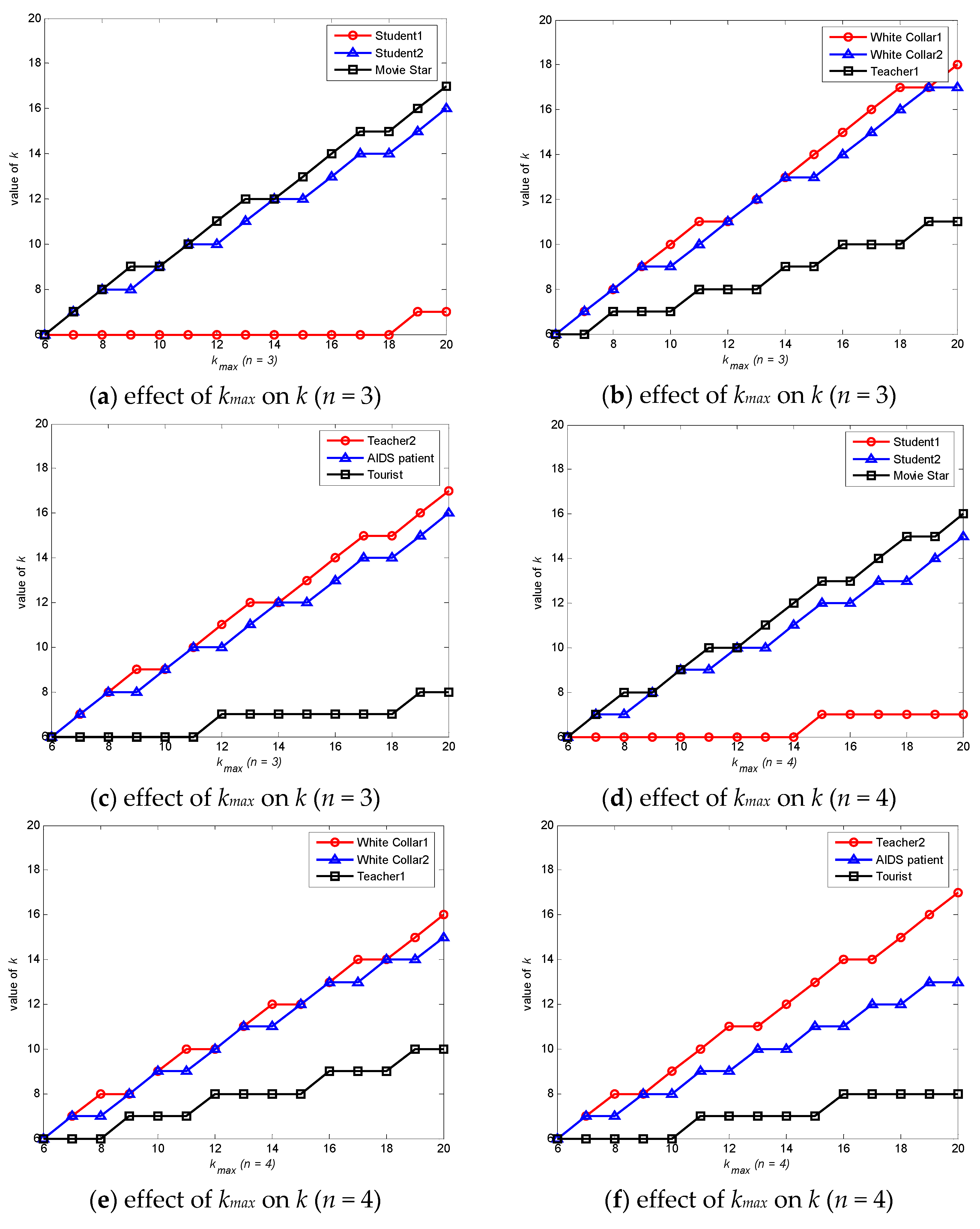
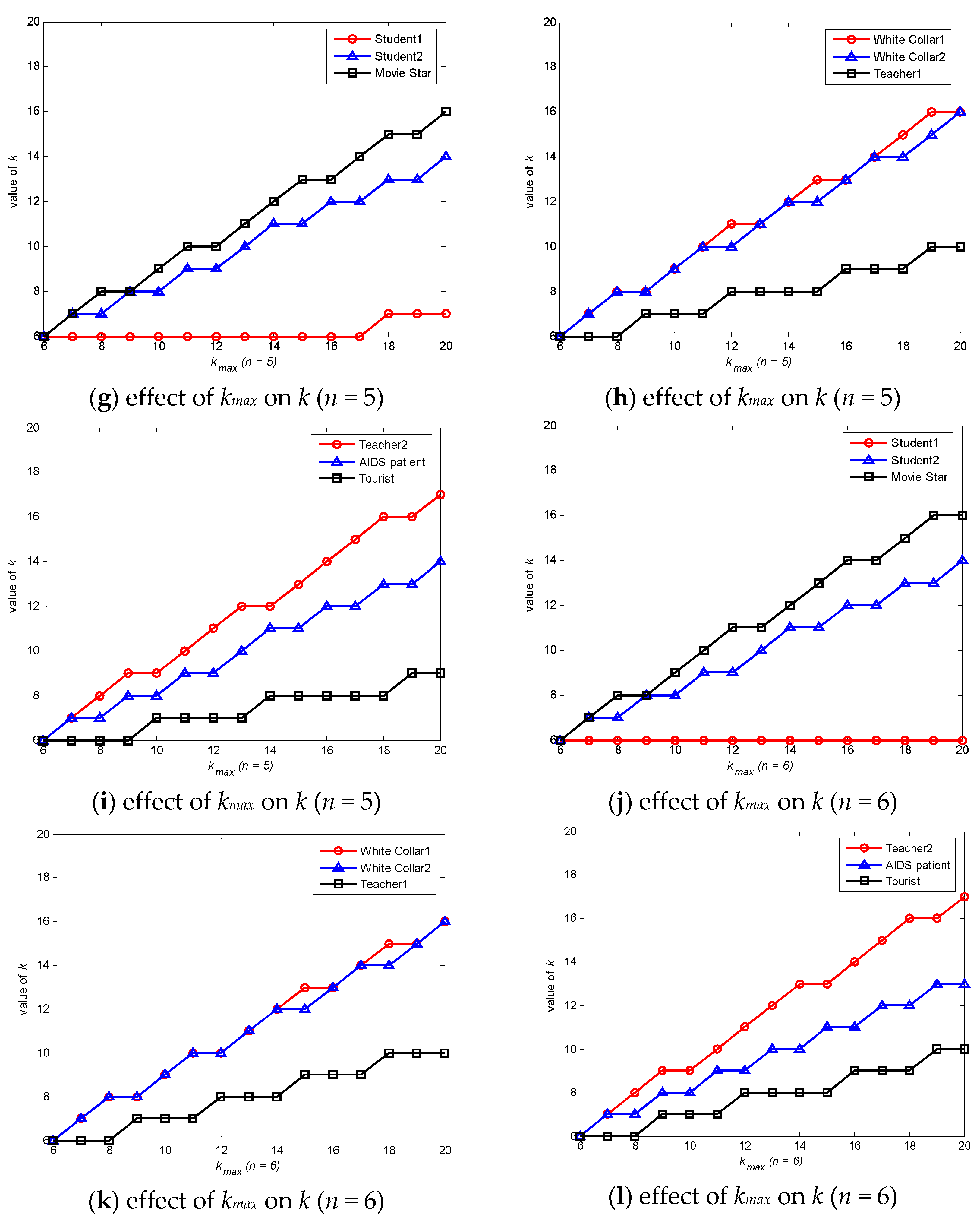
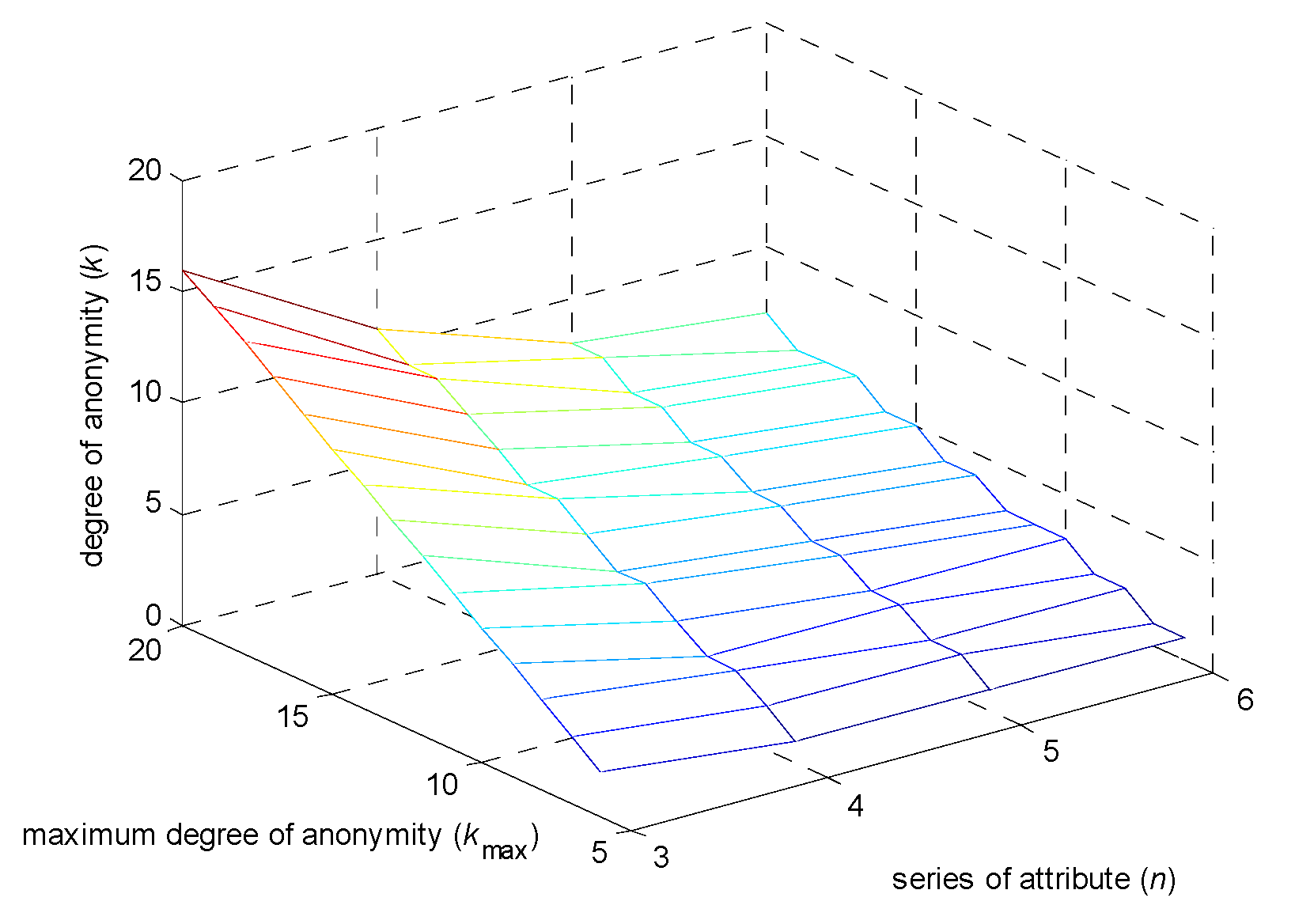
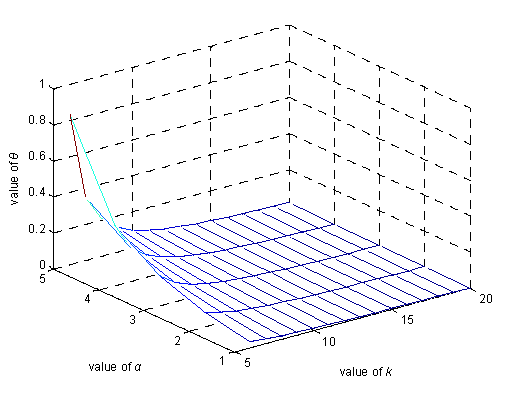
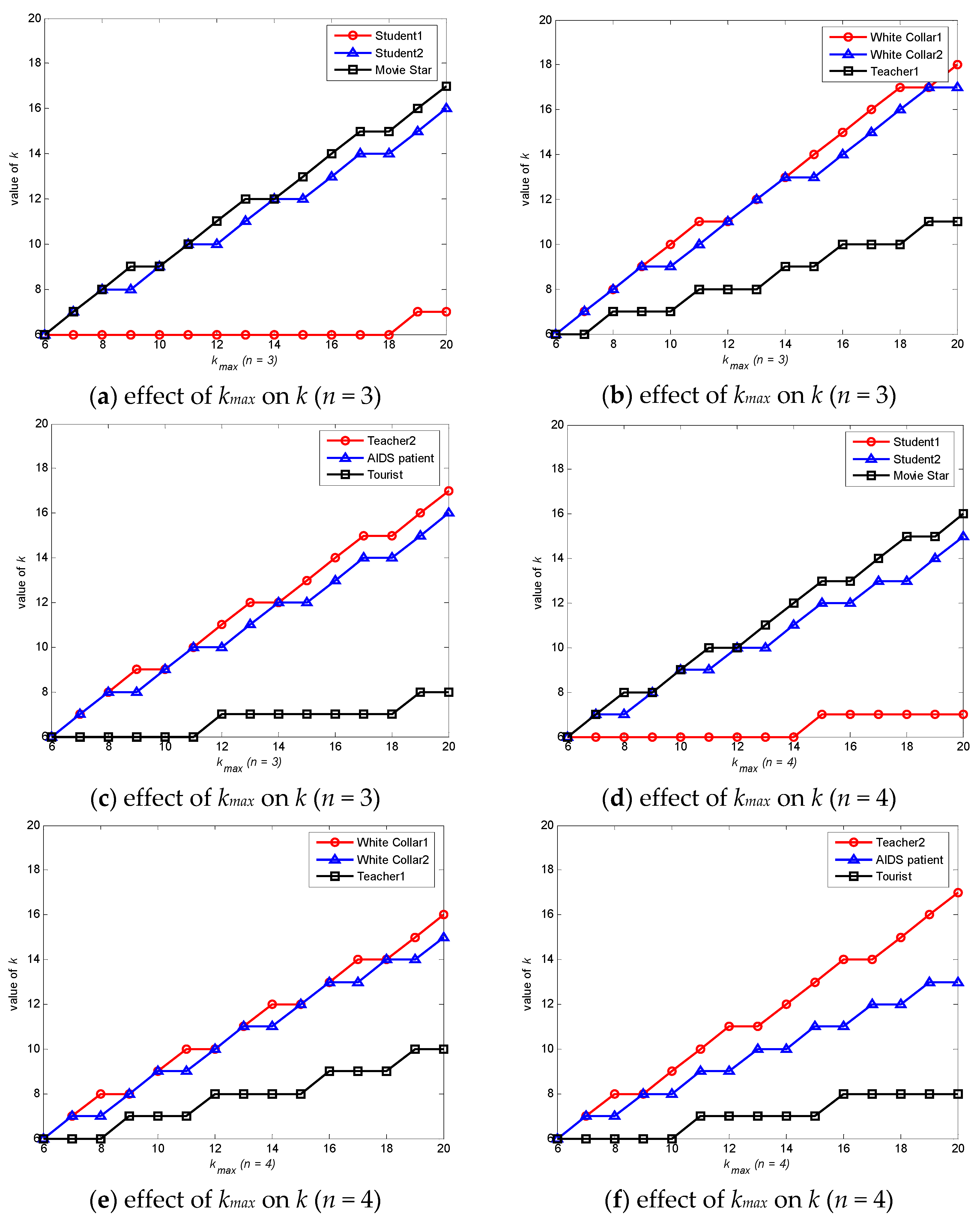
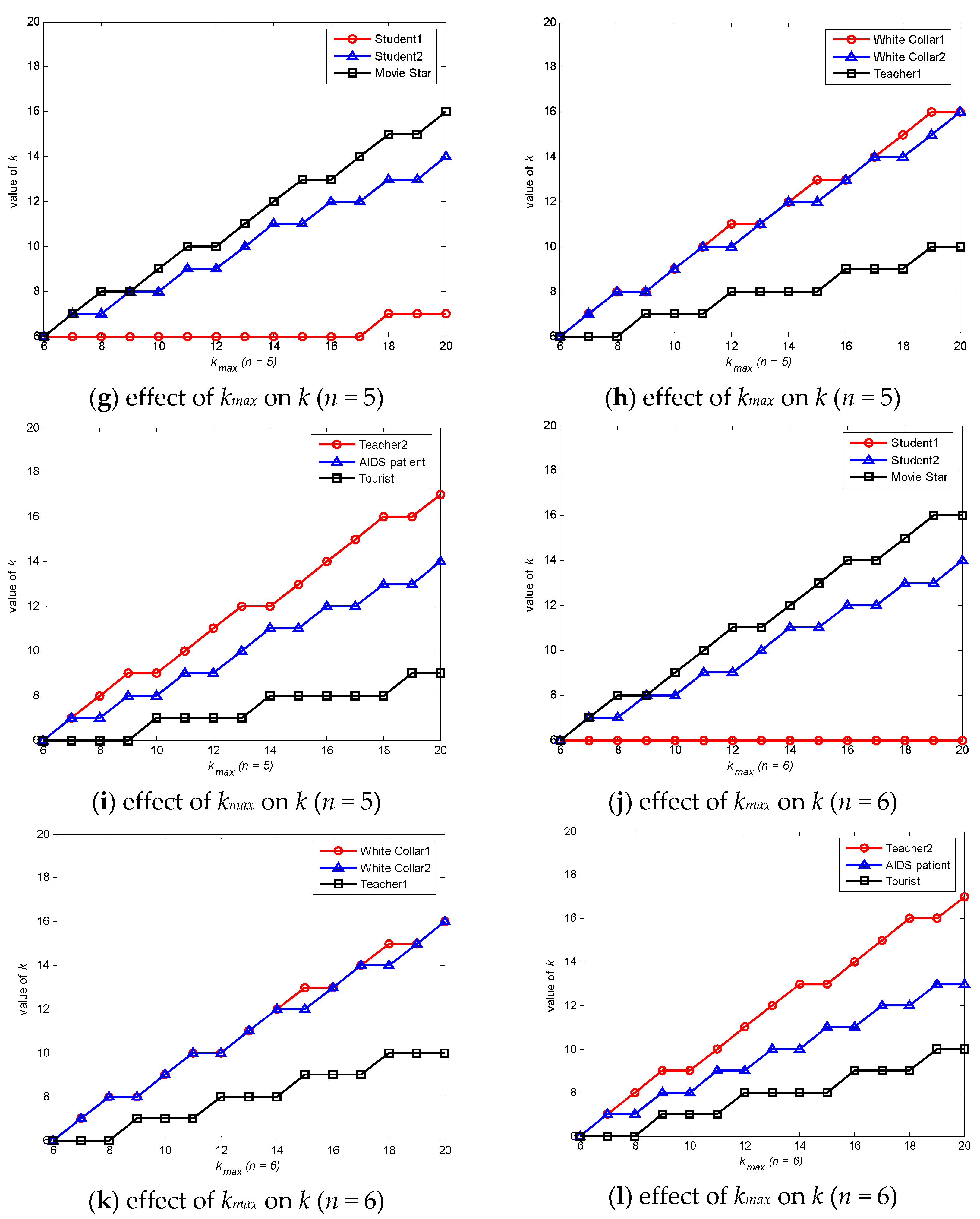
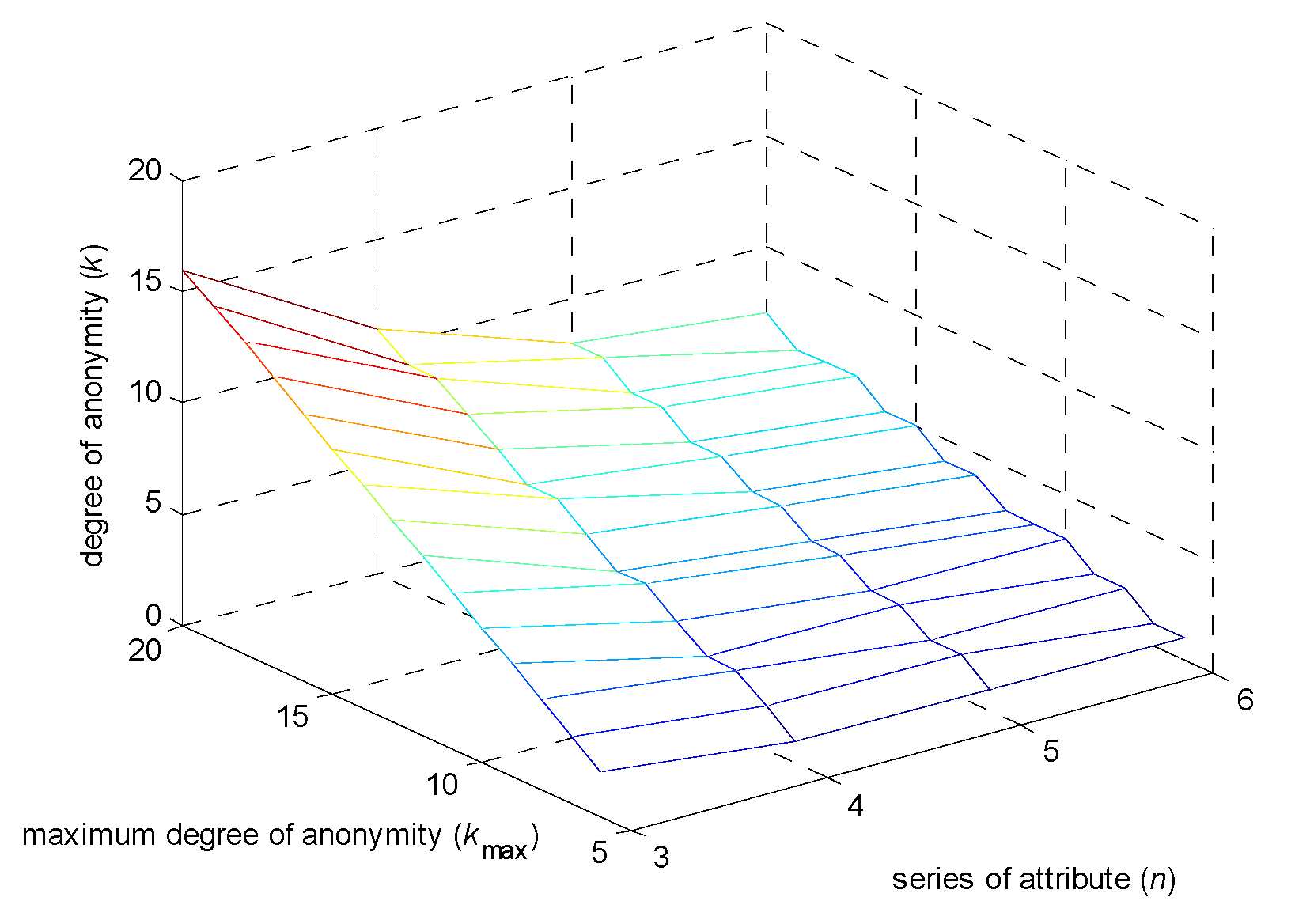
6.1. Degree of Anonymity Analysis
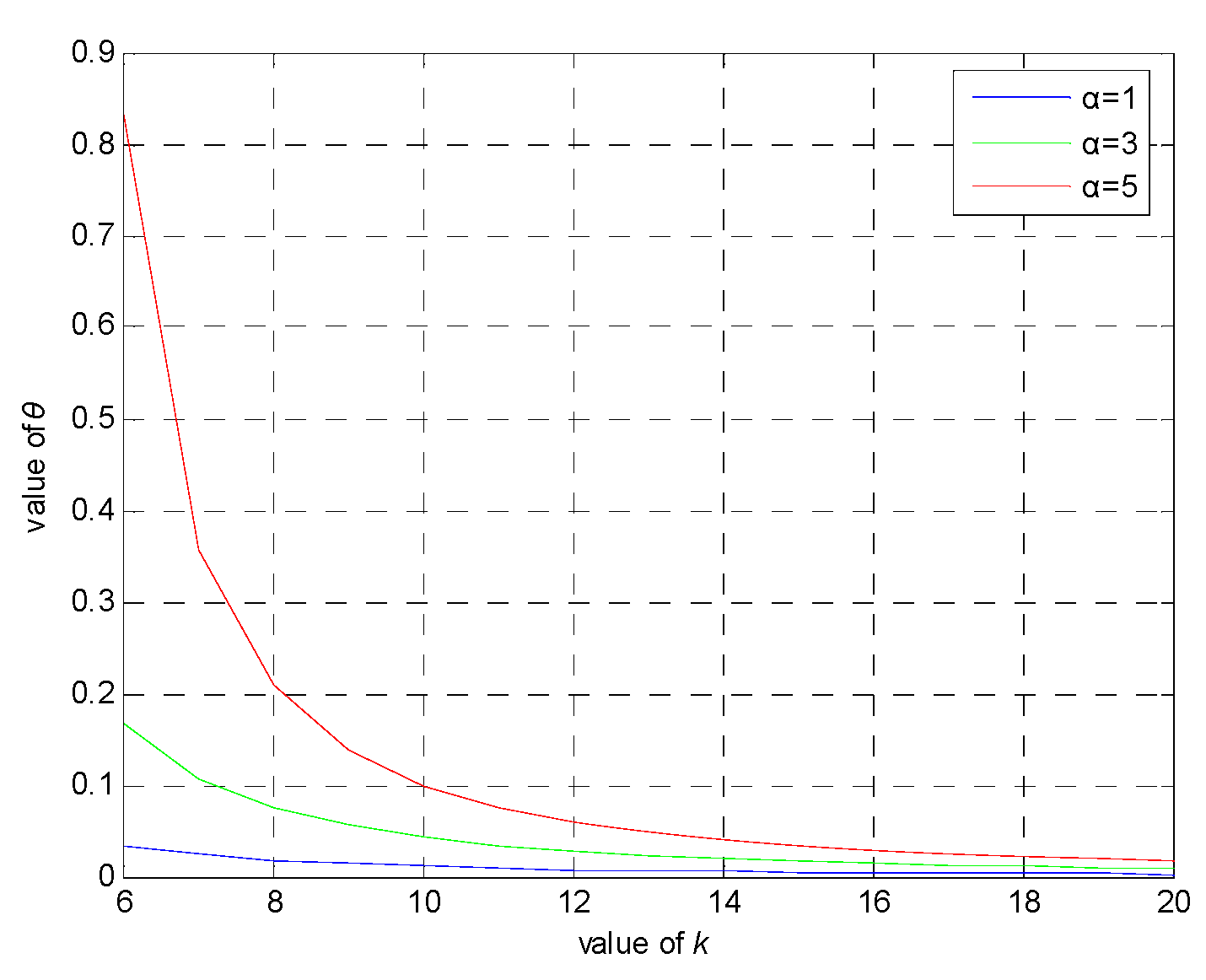
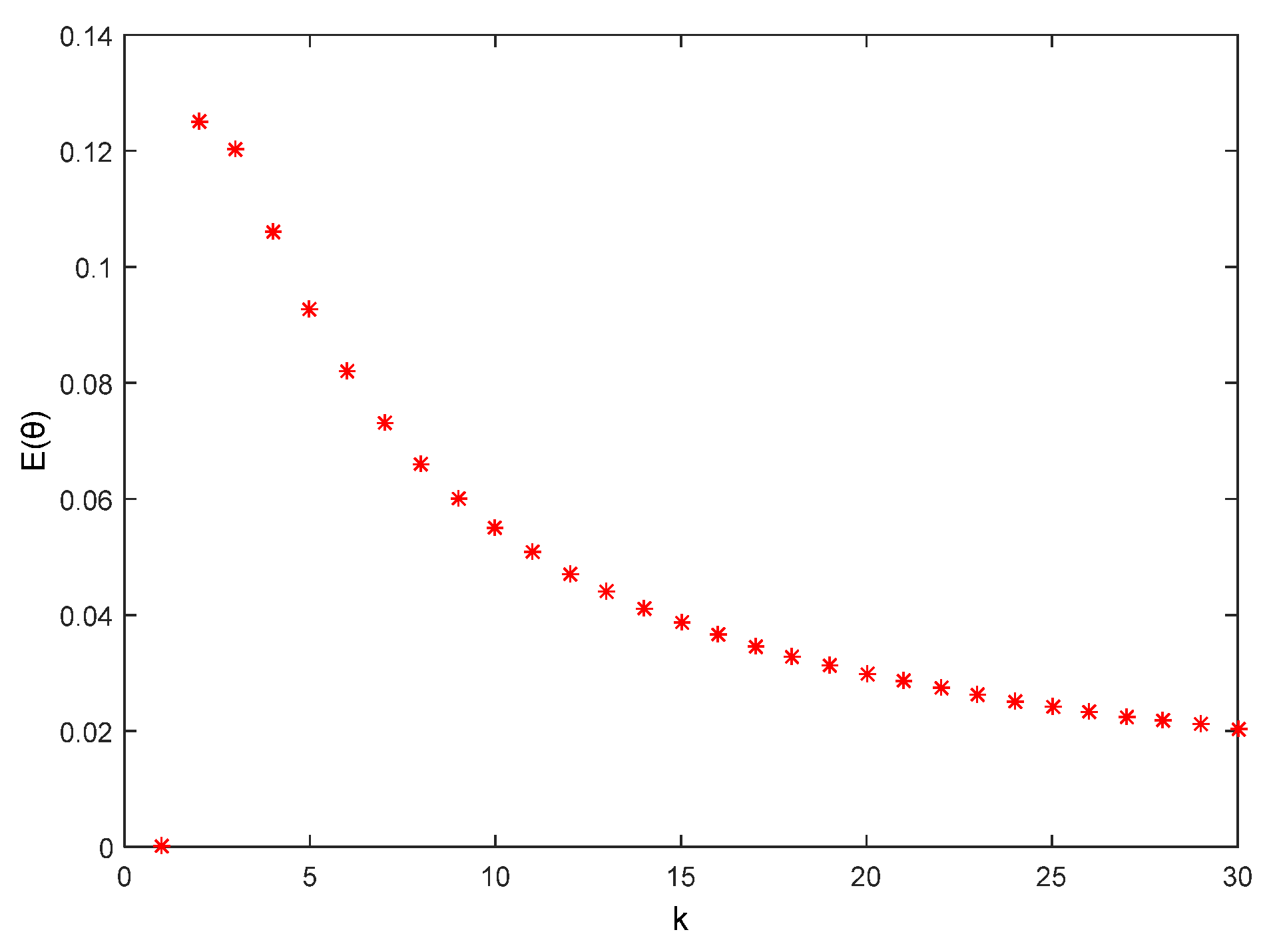
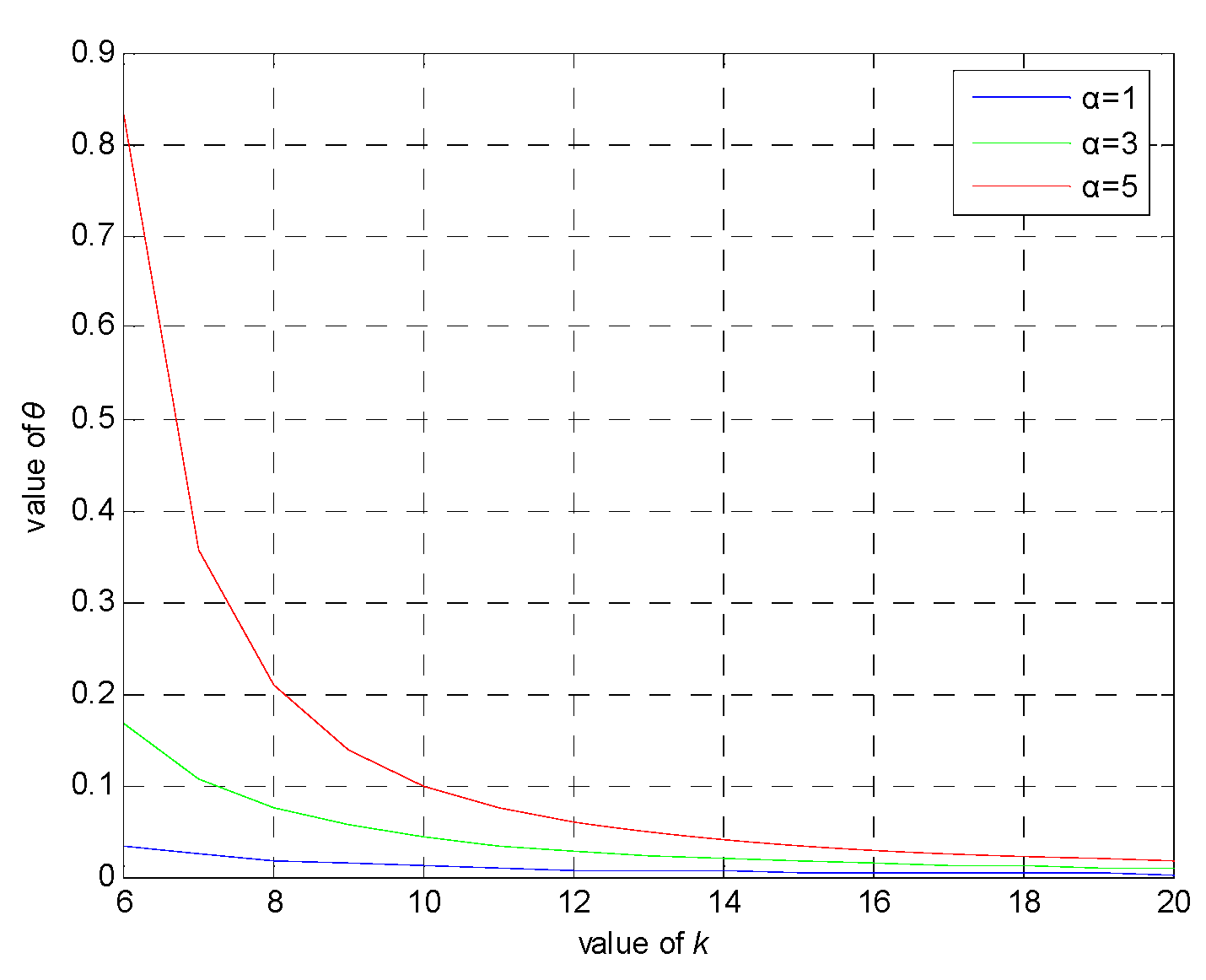
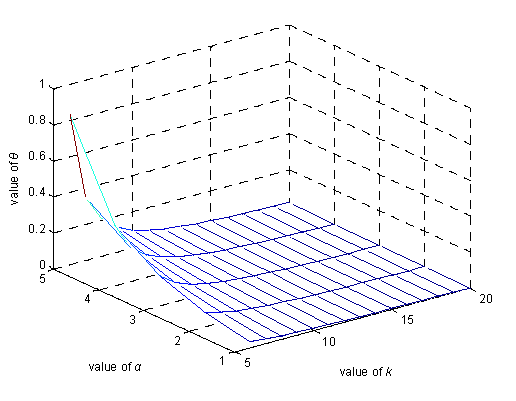
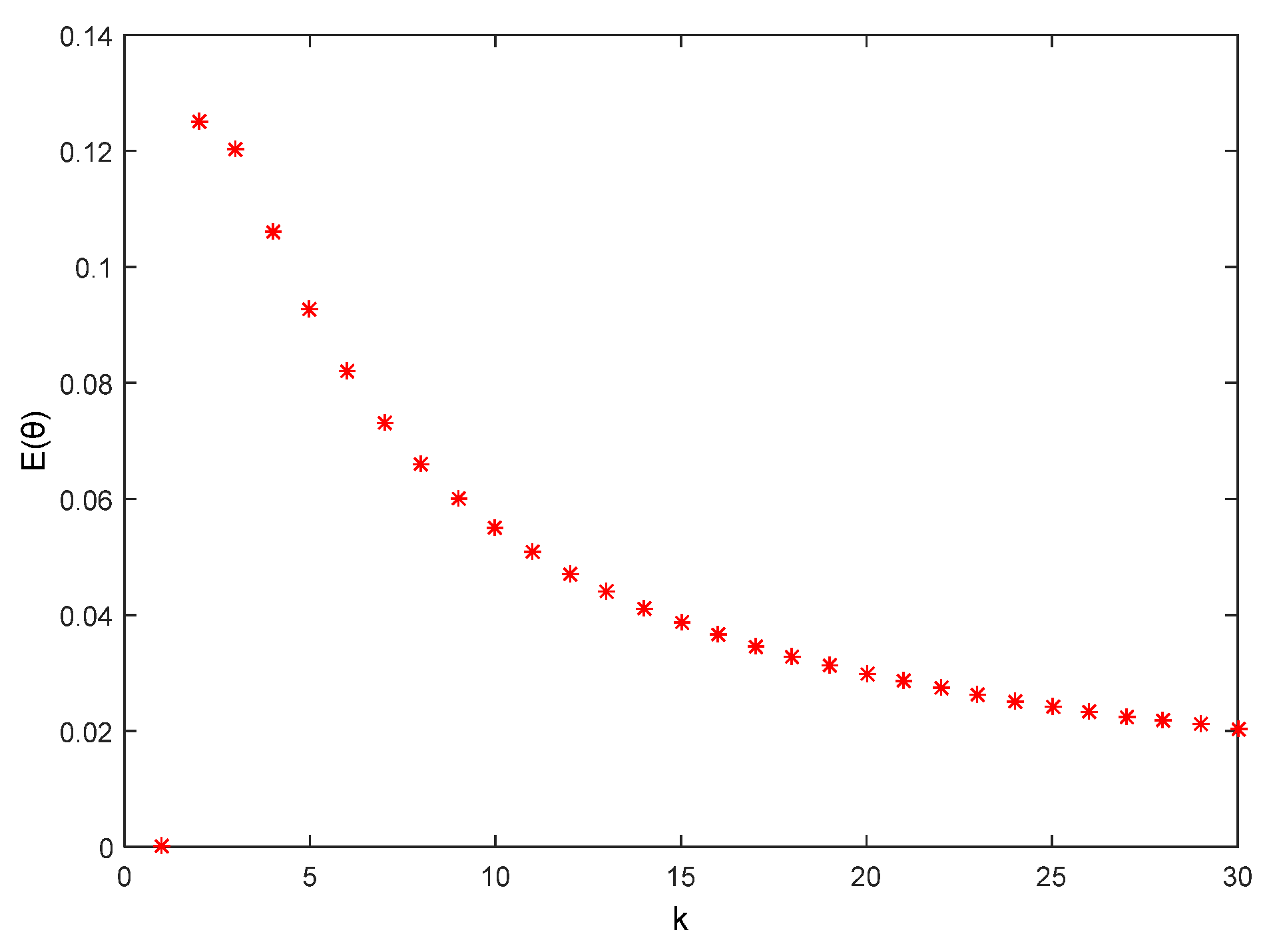
6.2. θ Privacy Analysis
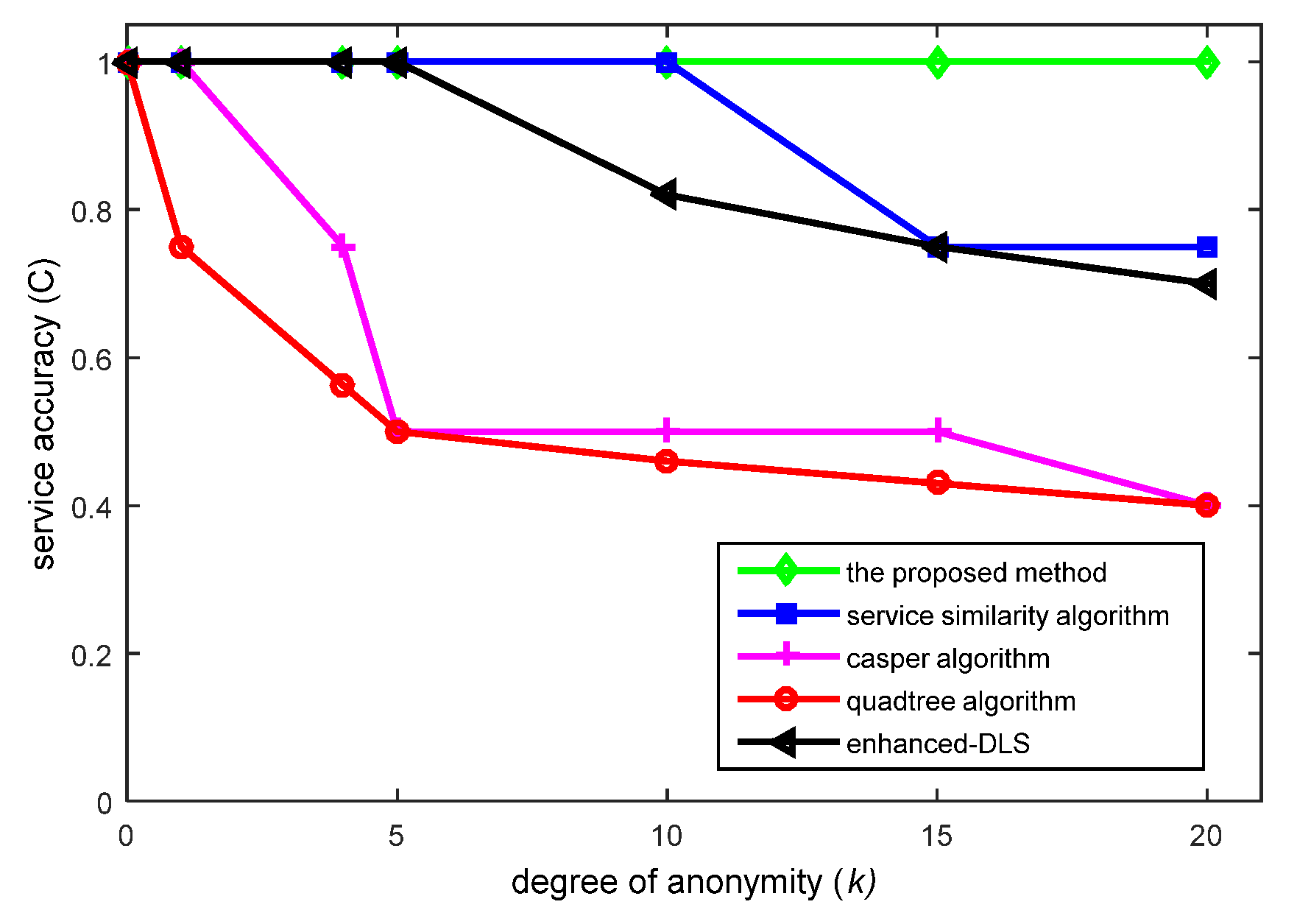
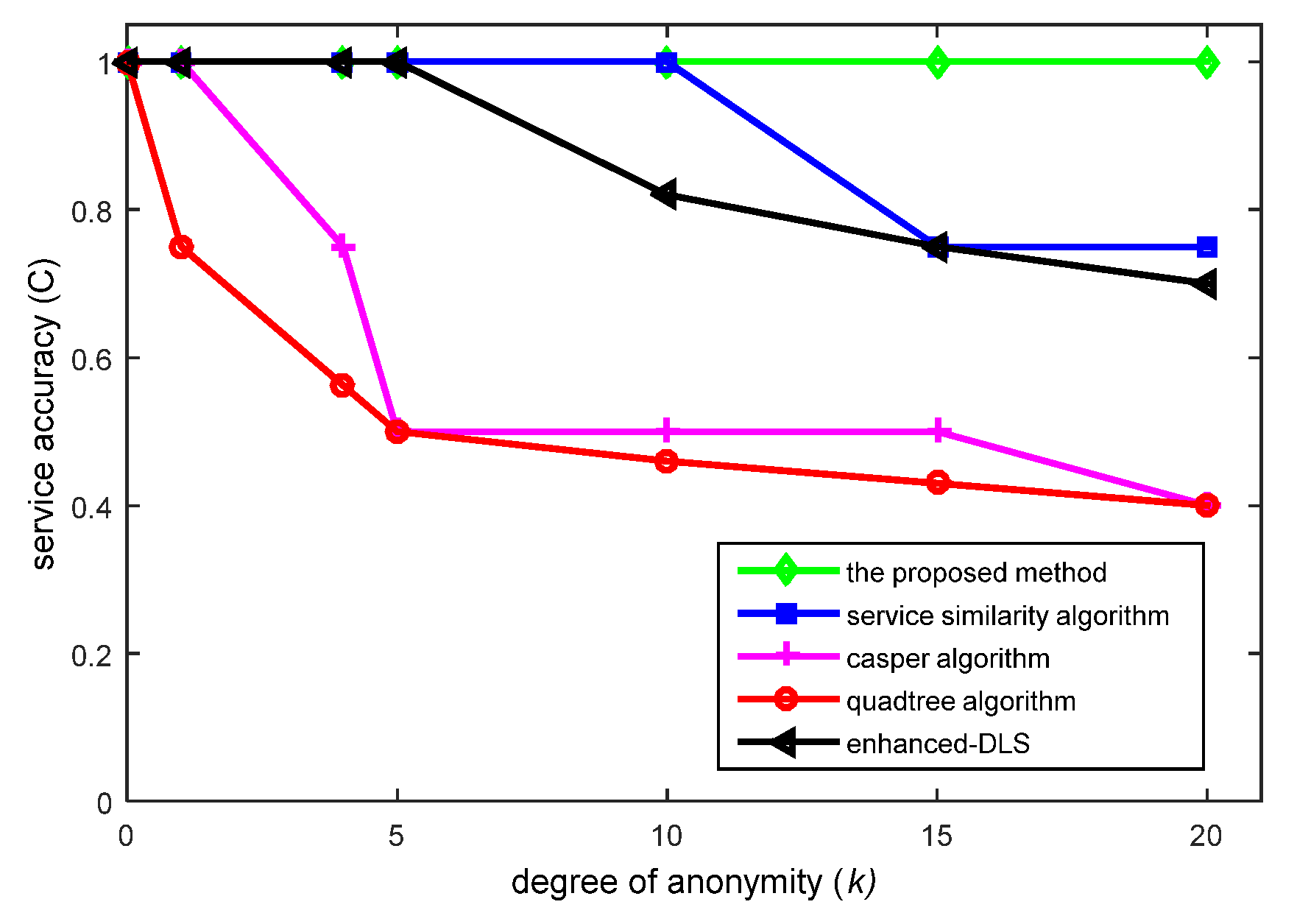
6.3. Quality of Service (QoS) Analysis
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lu, W.; Feng, M.X. Location privacy preservation in big data era: A survey. J. Softw. 2014, 4, 693–712. [Google Scholar]
- Jia, J.; Zhang, F. Non-deterministic k-anonymity algorithm based untrusted third party for location privacy protection in LBS. Int. J. Secur. Appl. 2015, 9, 387–400. [Google Scholar] [CrossRef]
- Sweeney, L. K-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 5, 557–570. [Google Scholar] [CrossRef]
- Gruteser, M.; Grunwal, D. Anonymous usage of location-based services through spatial and temporal cloaking. In Proceedings of the 1st International Conference on Mobile Systems, Applications, and Services (MobiSys’03), San Francisco, CA, USA, 5–8 May 2003; pp. 163–168. [Google Scholar]
- Gedik, B.; Liu, L. A customizable k-anonymity model for protecting location privacy. In Proceedings of the 25th IEEE International Conference on Distributed Computing Systems (ICDCS’05), Columbus, OH, USA, 6–10 June 2005; pp. 620–629. [Google Scholar]
- Bamba, B.; Liu, L.; Pesti, P.; Wang, T. Supporting anonymous location queries in mobile environments with privacy grid. In Proceedings of the 17th International World Wide Web Conference (WWW’08), Beijing, China, 21–25 April 2008; pp. 237–246. [Google Scholar]
- Jagwani, P.; Kaushik, S. K-anonymity based on fuzzy spatio-temporal context. In Proceedings of the 2014 IEEE 15th International Conference on Mobile Data Management (MDM’14), Brisbane, Australia, 14–18 July 2014; pp. 15–18. [Google Scholar]
- Mokbel, M.F.; Chow, C.Y.; Aref, W.G. Casper: Query processing for location services without compromising privacy. ACM Trans. Database Syst. 2016, 4, 24–48. [Google Scholar]
- Yong, Y.A.; Cheng, L.Y.; Feng, M.J.; Li, X. Location privacy-preserving method of k-anonymous based on service similarity. J. Commun. 2014, 11, 162–169. [Google Scholar]
- Niu, B.; Li, Q.H.; Zhu, X.Y.; Cao, G.H.; Li, H. Achieving k-anonymity in privacy-aware location-based services. In Proceedings of the 33rd IEEE International Conference on Computer Communications (INFOCOM’14), Toronto, ON, Canada, 27 April–2 May 2014; pp. 754–762. [Google Scholar]
- Chow, C.Y.; Mokbel, M.F.; Li, X. A peer-to-peer spatial cloaking algorithm for anonymous location-based services. In Proceedings of the 14th Annual ACM International Symposium on Advances in Geographic Information Systems (GIS’ 06), Virginia, VA, USA, 10–11 November 2006; pp. 171–178. [Google Scholar]
- Chow, C.Y.; Mokbel, M.F.; Li, X. Spatial cloaking for anonymous location-based services in mobile peer-to-peer environments. Geoinformatica 2011, 2, 351–380. [Google Scholar] [CrossRef]
- Zakhary, S.; Radenkovic, M.; Benslimane, A. The quest for location-privacy in opportunistic mobile social networks. In Proceedings of the 2013 IEEE 9th International Conference on Wireless Communications and Mobile Computing (IWCMC’13), Cagliari, Italy, 1–5 July 2013; pp. 667–673. [Google Scholar]
- Gheorghita, M.O.; Solanas, A.; Forne, J. Location privacy in chain-based protocols for location-based services. In Proceedings of the 2008 IEEE 3rd International Conference on Digital Telecommunications (ICDT’08), Bucharest, Romania, 29 June–5 July 2008; pp. 64–69. [Google Scholar]
- Cao, L.; Sun, Y.; Xu, H. Historical trajectories based location privacy protection query. In Proceedings of the IEEE 11th International Conference on Ubiquitous Intelligence and Computing (ICUIC’14), Ayodya Resort, Bali, Indonesia, 9–12 December 2014; pp. 228–235. [Google Scholar]
- Kang, D.; Jung, J.; Mun, J.; Lee, D.; Choi, Y. Efficient and robust user authentication scheme that achieve user anonymity with a Markov chain. Secur. Commun. Netw. 2016, 11, 1462–1476. [Google Scholar] [CrossRef]
- Montazeri, Z.; Houmansadr, A.; Pishro-Nik, H. Achieving Perfect Location Privacy in Markov Models Using Anonymization. 2016. Available online: http://www-unix.ecs.umass.edu/~dgoeckel/zarrin_isita.pdf (accessed on 1 December 2016).
- Wang, Y.Z.; Xie, L.; Zheng, B.H.; Lee, K.C.K. High utility k-anonymization for social network publishing. Knowl. Inf. Syst. 2016, 3, 697–725. [Google Scholar] [CrossRef]
- Dai, J.Z.; Li, Z.L. A location authentication scheme based on proximity test of location tags. In Proceedings of the 2013 1st International Conference on Information and Network Security (ICINS’13), Beijing, China, 22–24 November 2013; pp. 1–6. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User | Location | Density | Time Interval | Correlation Degree | Associated Number |
|---|---|---|---|---|---|
| Student 1 | canteen | crowded | morning | high | few |
| Student 2 | hospital | crowded | afternoon | low | numerous |
| AIDS patient | hospital | crowded | morning | high | numerous |
| White collar 1 | home | sparse | morning | high | numerous |
| White collar 2 | road | sparse | night | irrelevant | numerous |
| Movie Star | market | extremely crowded | evening | low | numerous |
| Teacher 1 | campus | moderately crowded | afternoon | high | many |
| Teacher 2 | bar | crowded | night | irrelevant | many |
| Tourist | scenic area | crowded | morning | irrelevant | some |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Huang, H.; Qin, Y.; Wang, Y.; Wu, M. Efficient Location Privacy-Preserving k-Anonymity Method Based on the Credible Chain. ISPRS Int. J. Geo-Inf. 2017, 6, 163. https://doi.org/10.3390/ijgi6060163
Wang H, Huang H, Qin Y, Wang Y, Wu M. Efficient Location Privacy-Preserving k-Anonymity Method Based on the Credible Chain. ISPRS International Journal of Geo-Information. 2017; 6(6):163. https://doi.org/10.3390/ijgi6060163
Chicago/Turabian StyleWang, Hui, Haiping Huang, Yuxiang Qin, Yunqi Wang, and Min Wu. 2017. "Efficient Location Privacy-Preserving k-Anonymity Method Based on the Credible Chain" ISPRS International Journal of Geo-Information 6, no. 6: 163. https://doi.org/10.3390/ijgi6060163
APA StyleWang, H., Huang, H., Qin, Y., Wang, Y., & Wu, M. (2017). Efficient Location Privacy-Preserving k-Anonymity Method Based on the Credible Chain. ISPRS International Journal of Geo-Information, 6(6), 163. https://doi.org/10.3390/ijgi6060163