1. Introduction
Vector-based cellular automata (VCA) models extend traditional raster-based cellular automata (raster-based CA) models by using irregular vector polygons to represent actual geographic features, e.g., parcels and blocks [
1]. This extension relieves the sensitivity of a CA model to spatial resolution and breaks the limits on uniform neighborhood definition [
2,
3]. VCA models have been widely used to simulate urban dynamics, e.g., land-use and land-cover changes, urban growth [
4,
5,
6], urban planning [
7], etc. However, large-scale and highly detailed VCA/CA models usually require massive computing resources to obtain timely simulation results. Thus, researchers are turning to parallel computing to accelerate these time-consuming model simulations, e.g., programs like pRPL [
8,
9], pSLEUTH [
10], CAMEL [
11].
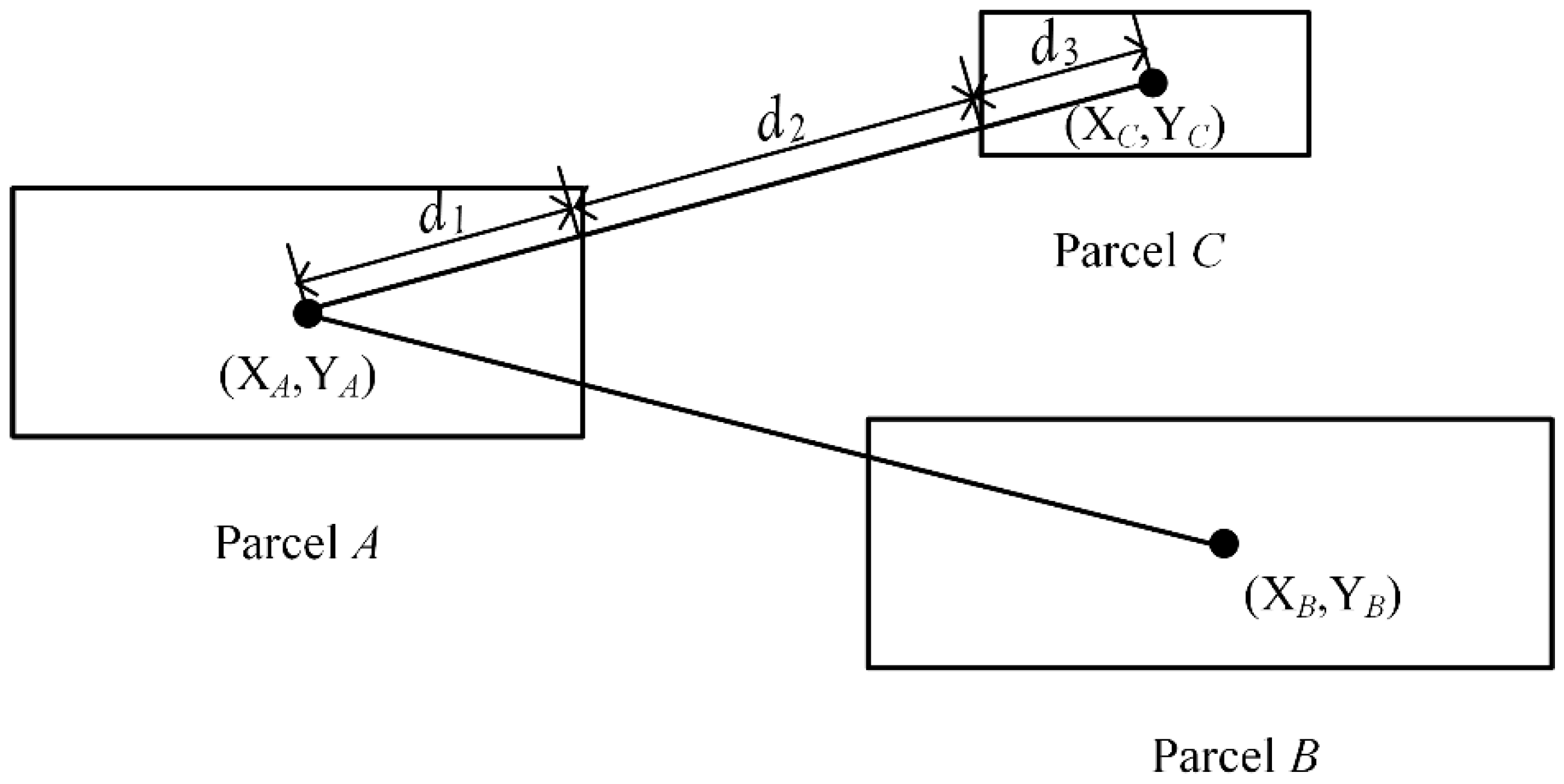
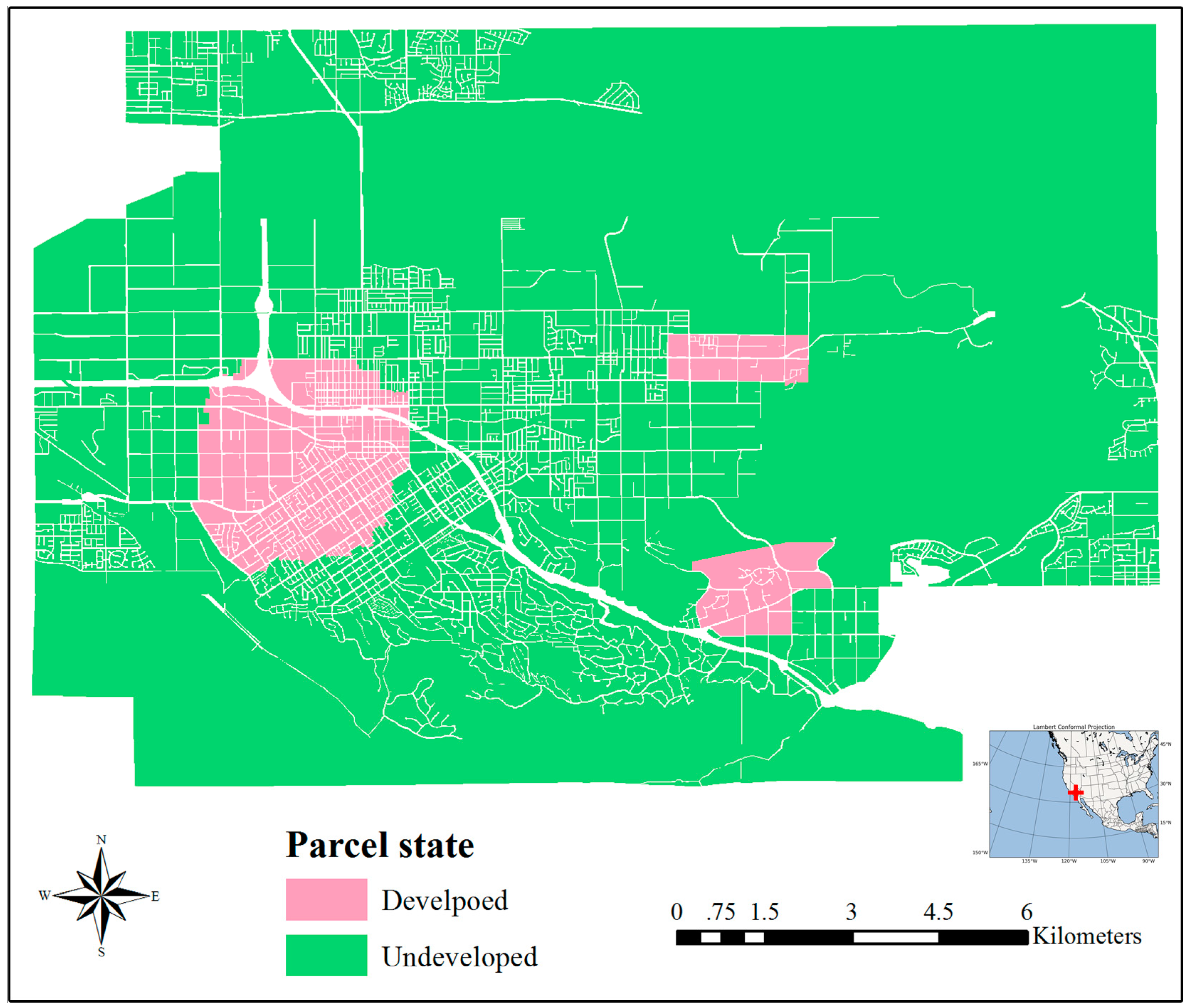
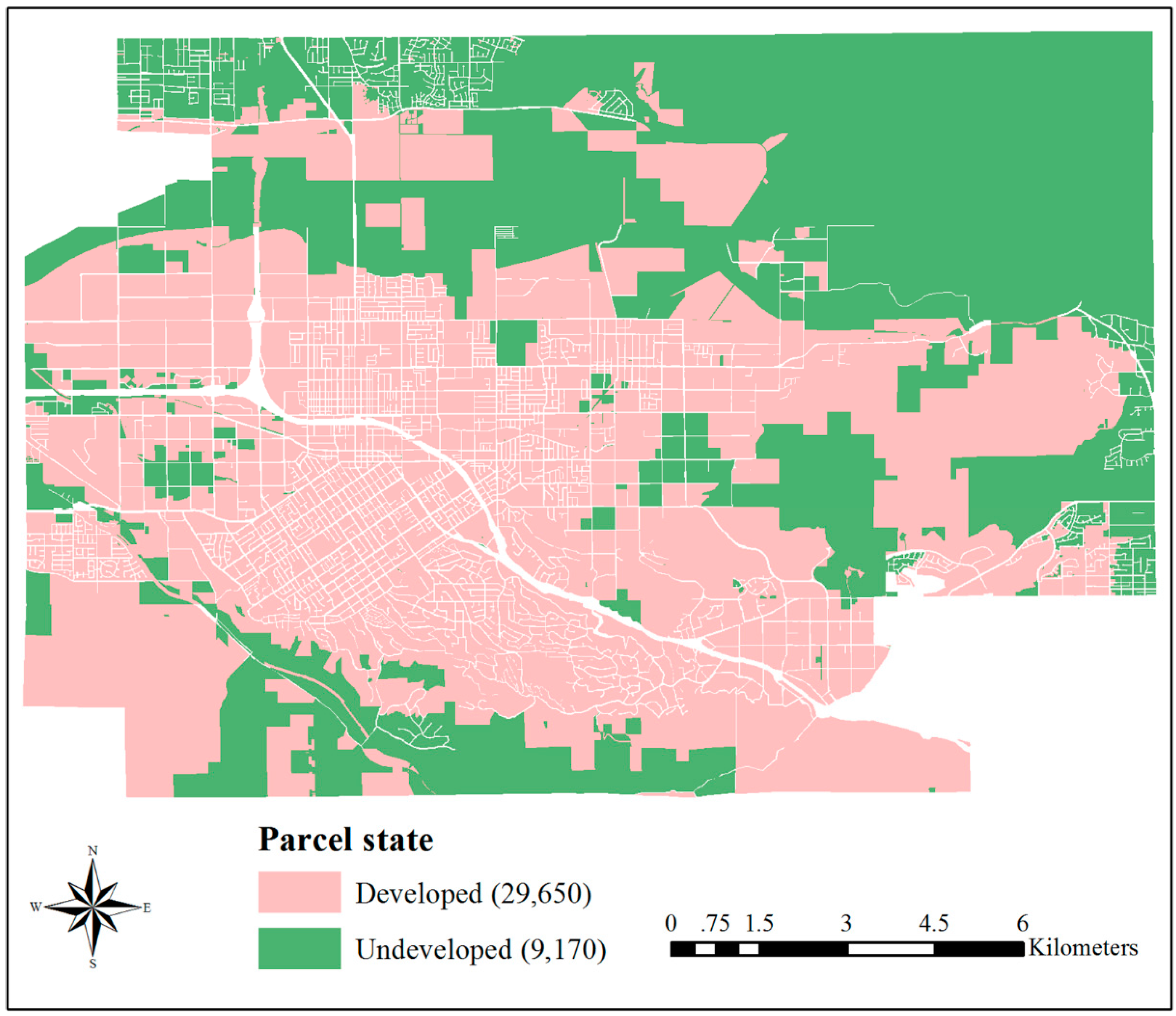
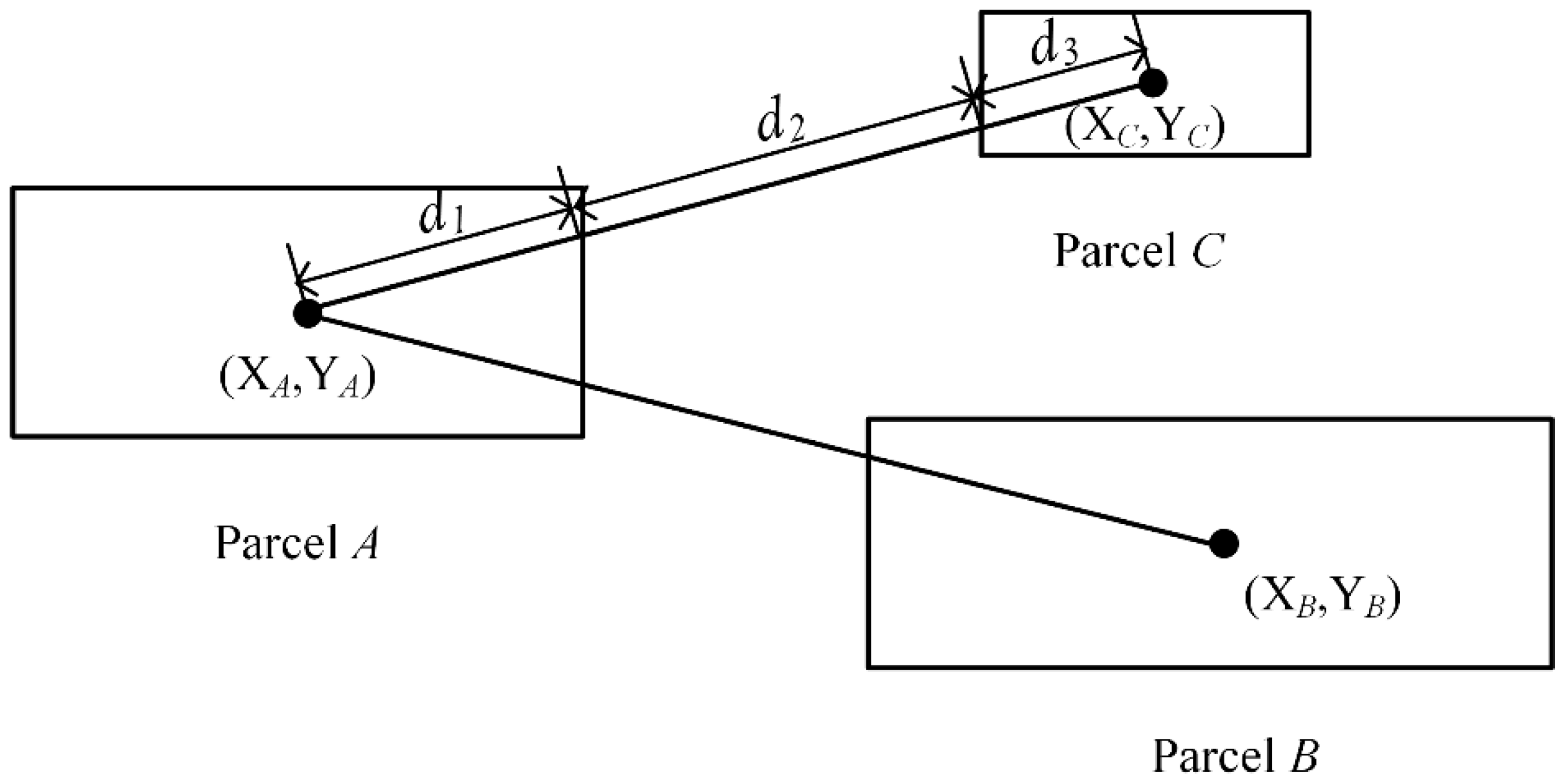
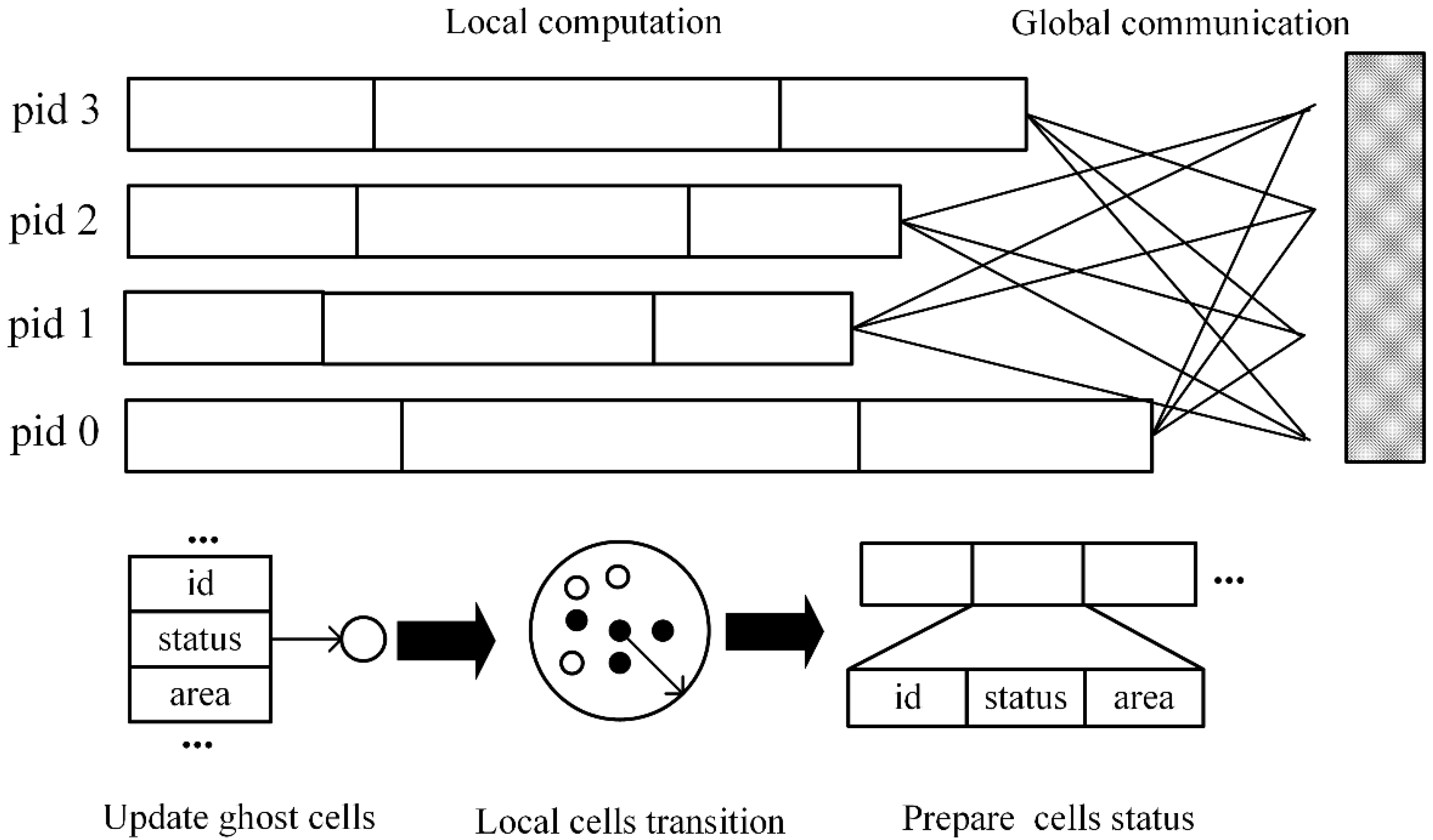
In a given VCA model, irregular parcel polygons evolve through a number of discrete time steps following a set of transition rules based on the states of neighboring parcels. Thus, a basic parallel VCA (pVCA) task is equivalent to the corresponding polygon parcel. The computation of one pVCA task includes neighbor search and parcel status transition, and the amount is generally proportional to the area of a parcel.
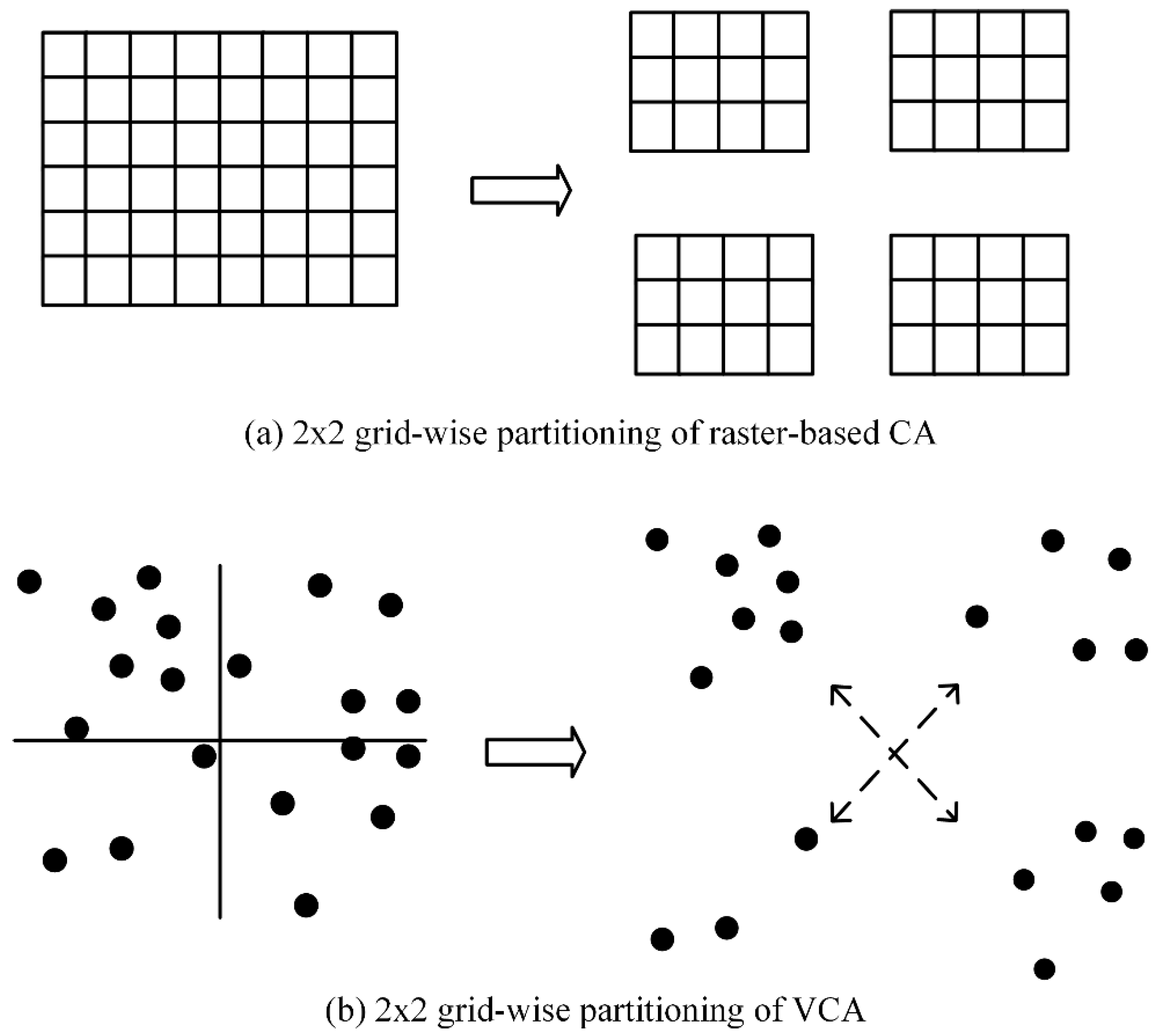
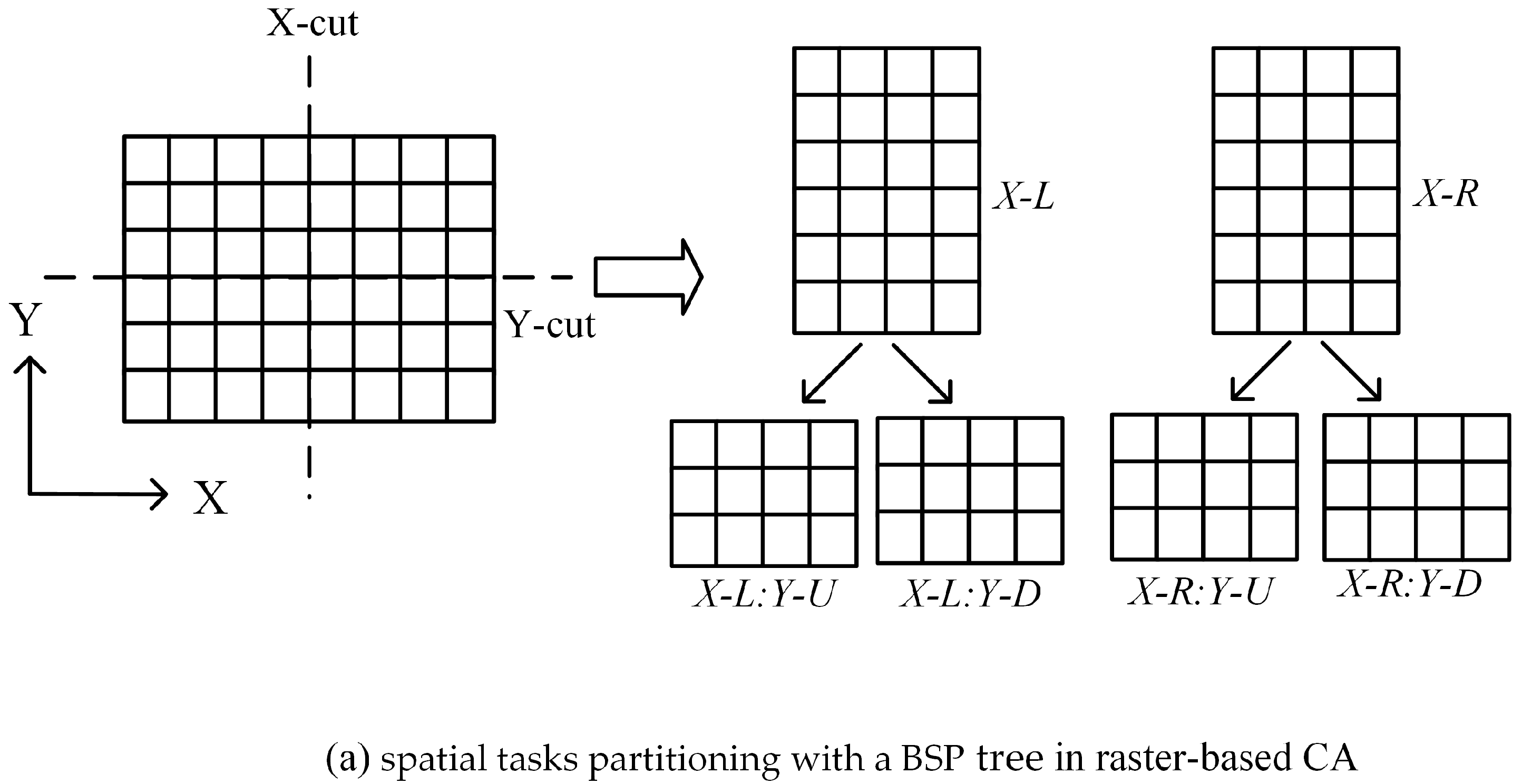
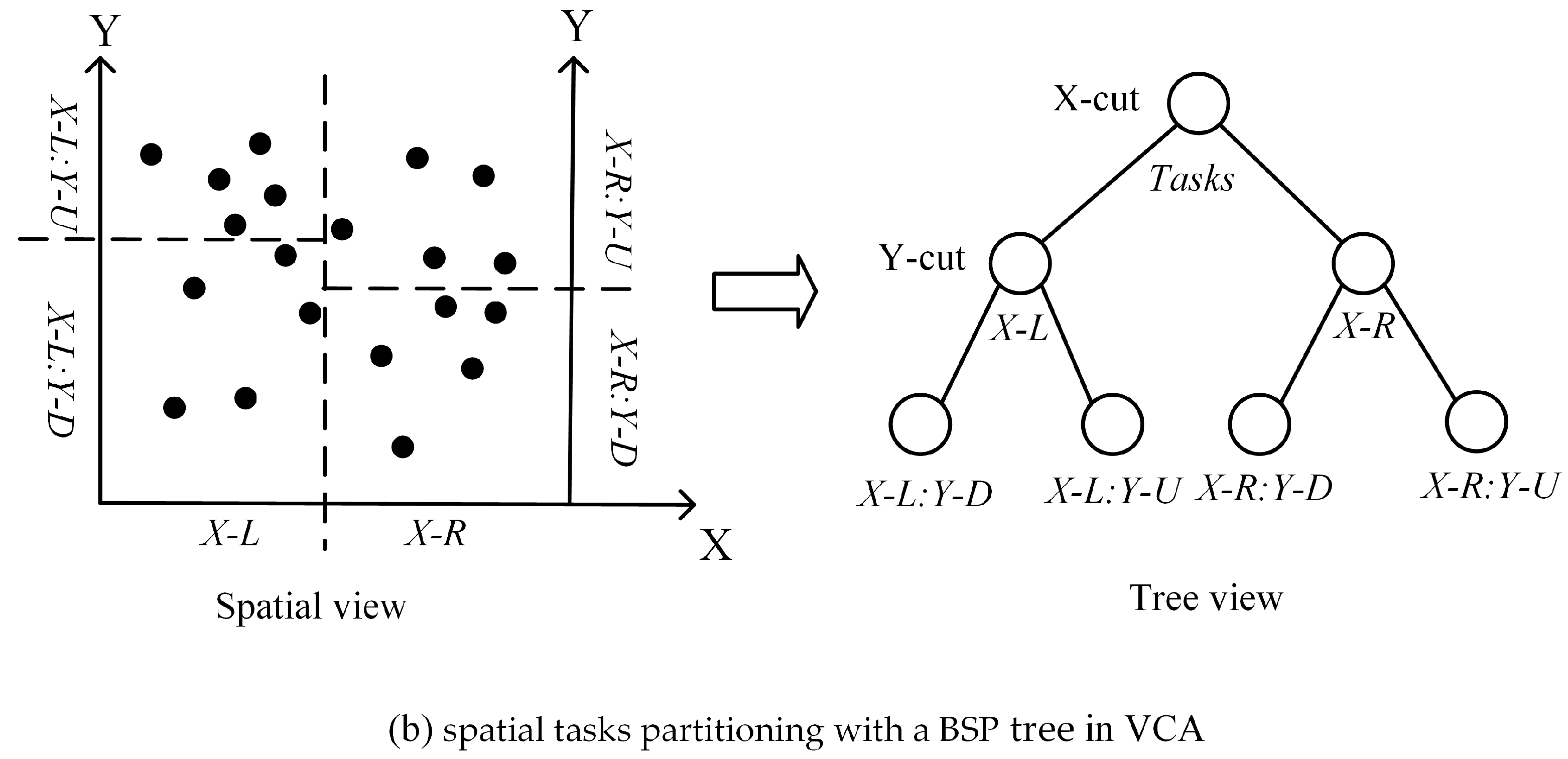
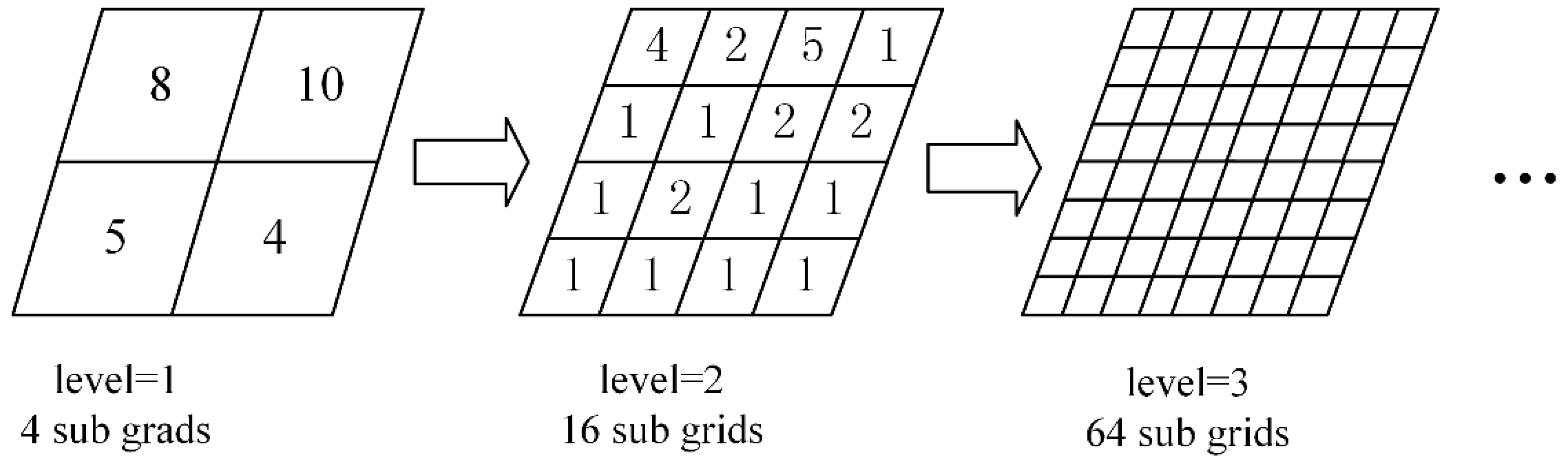
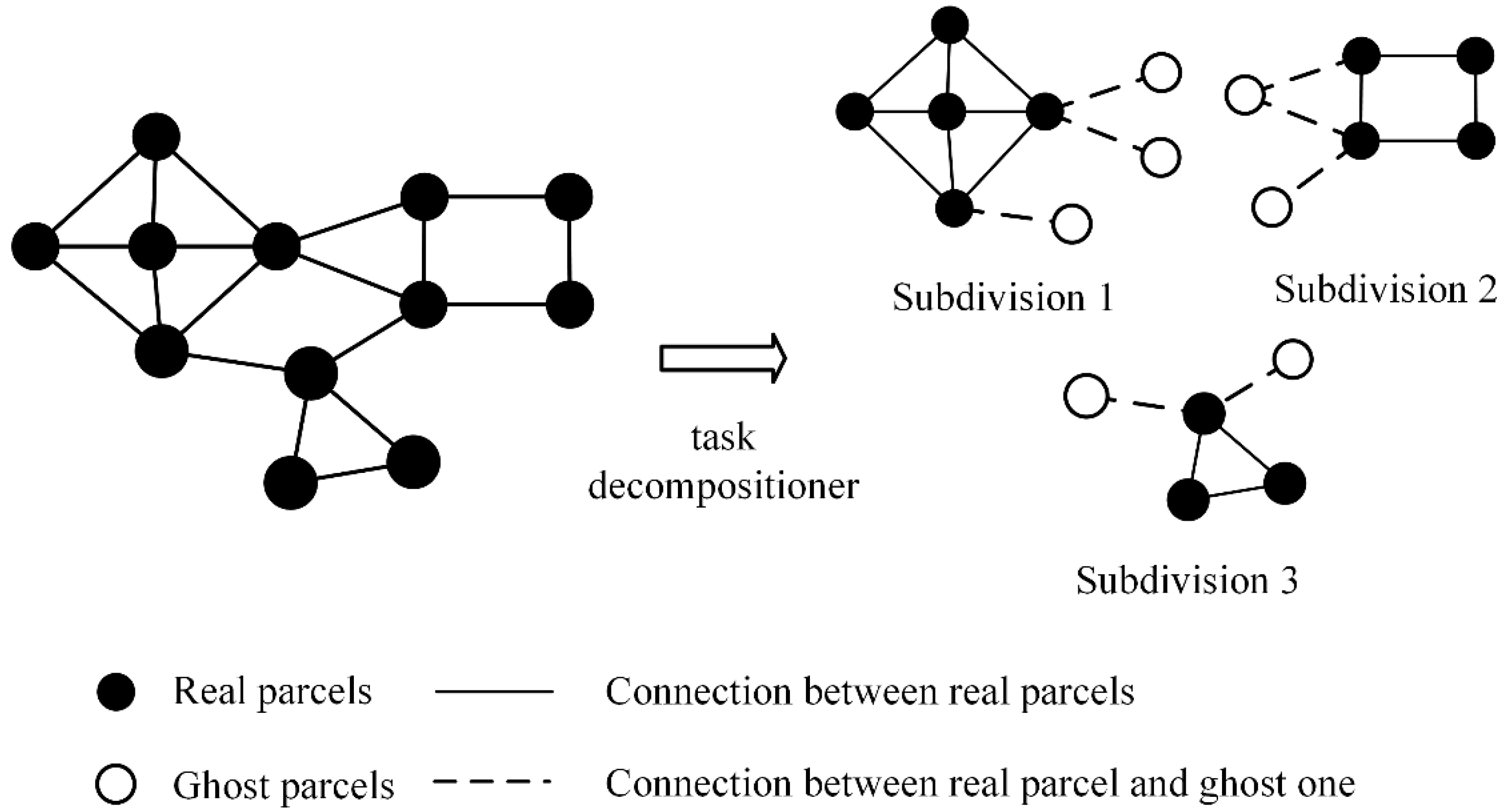
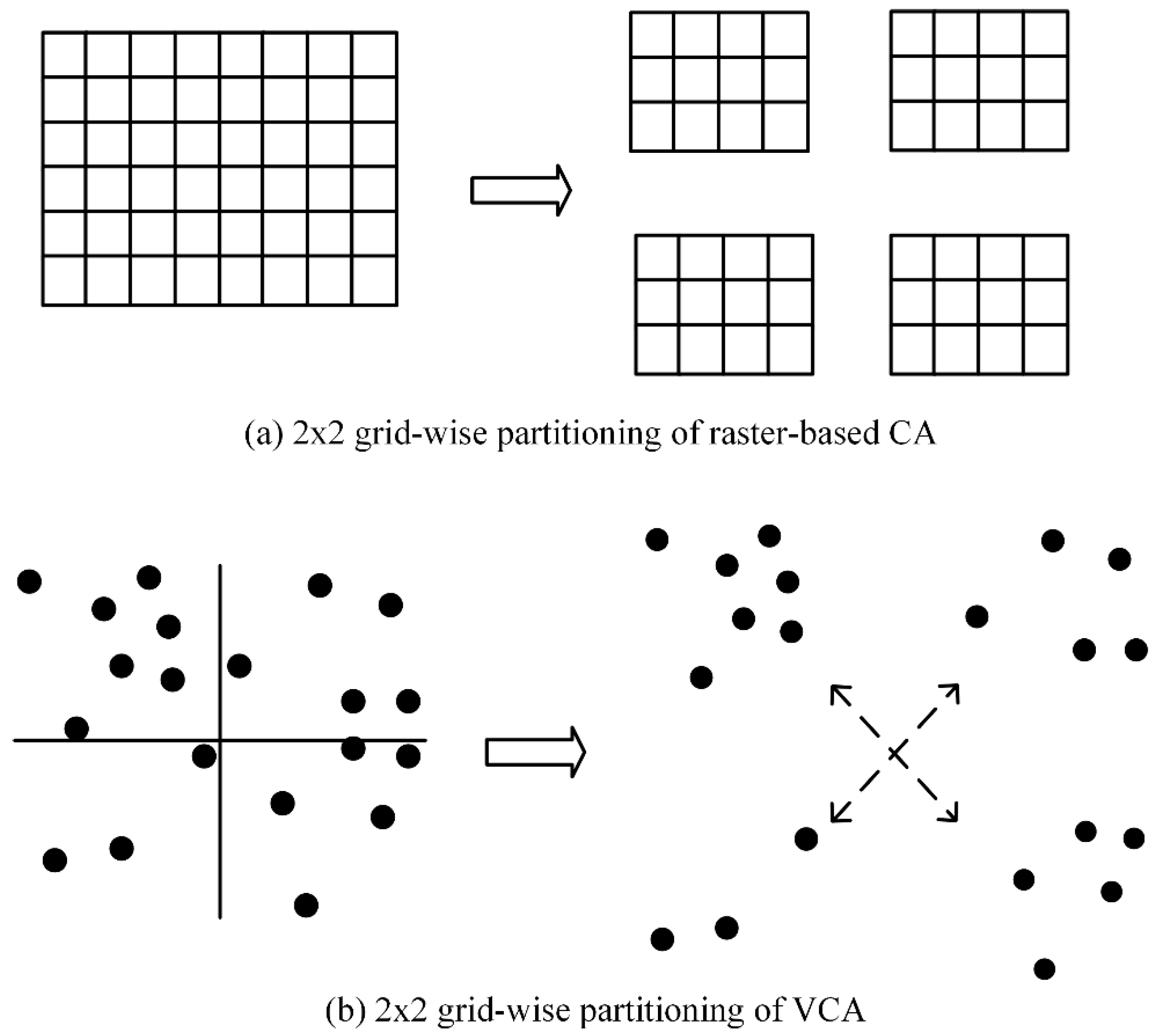
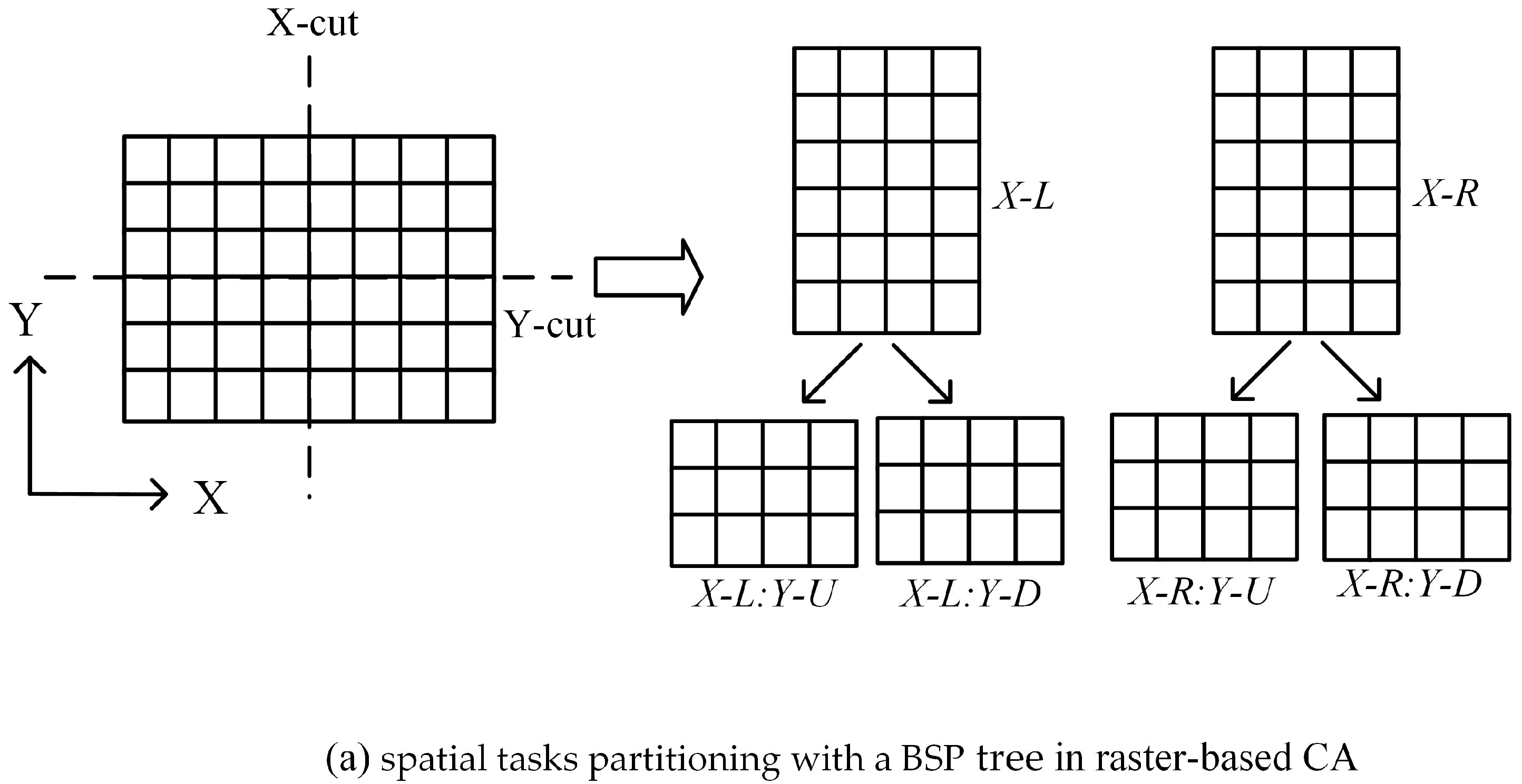
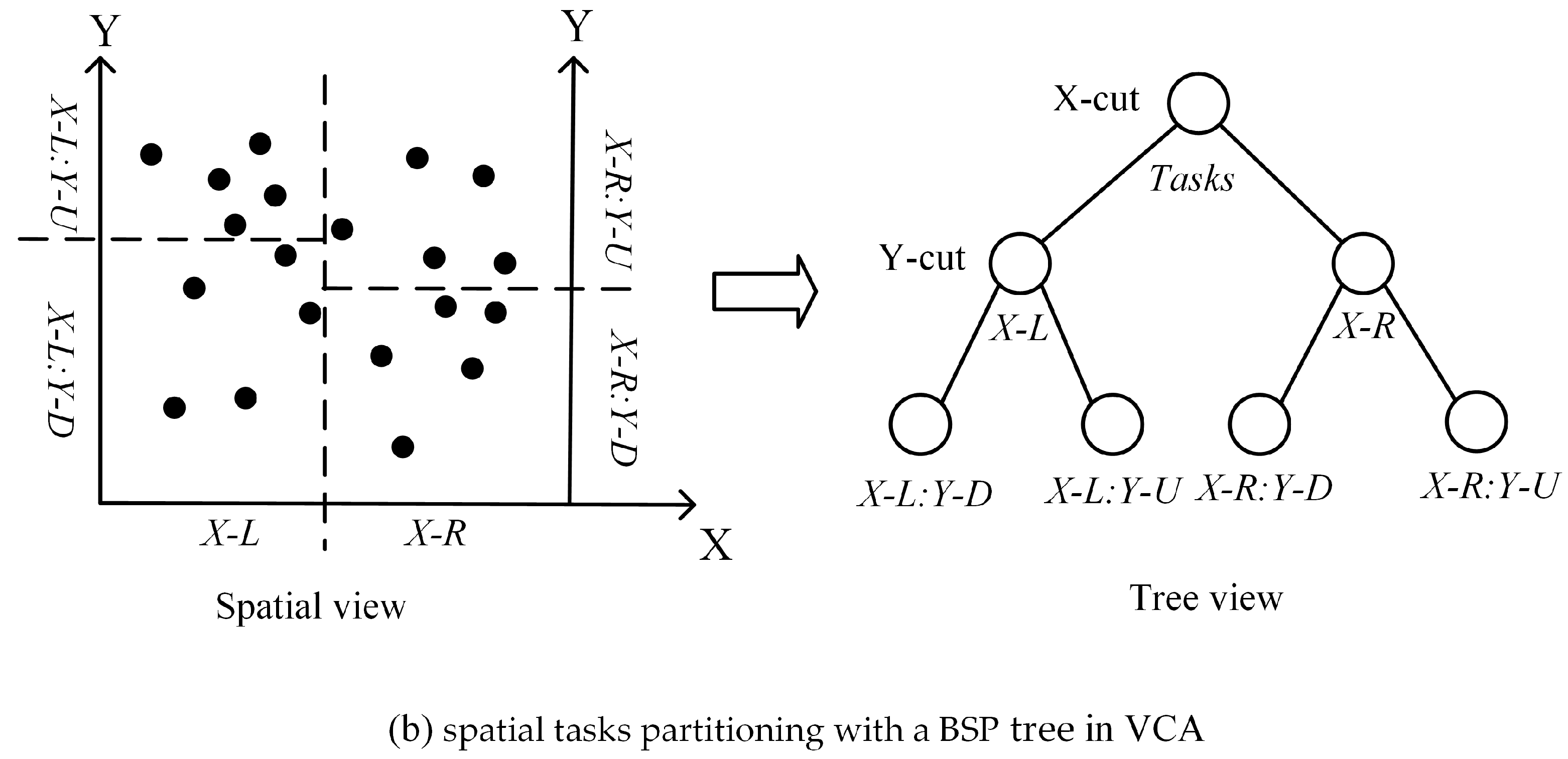
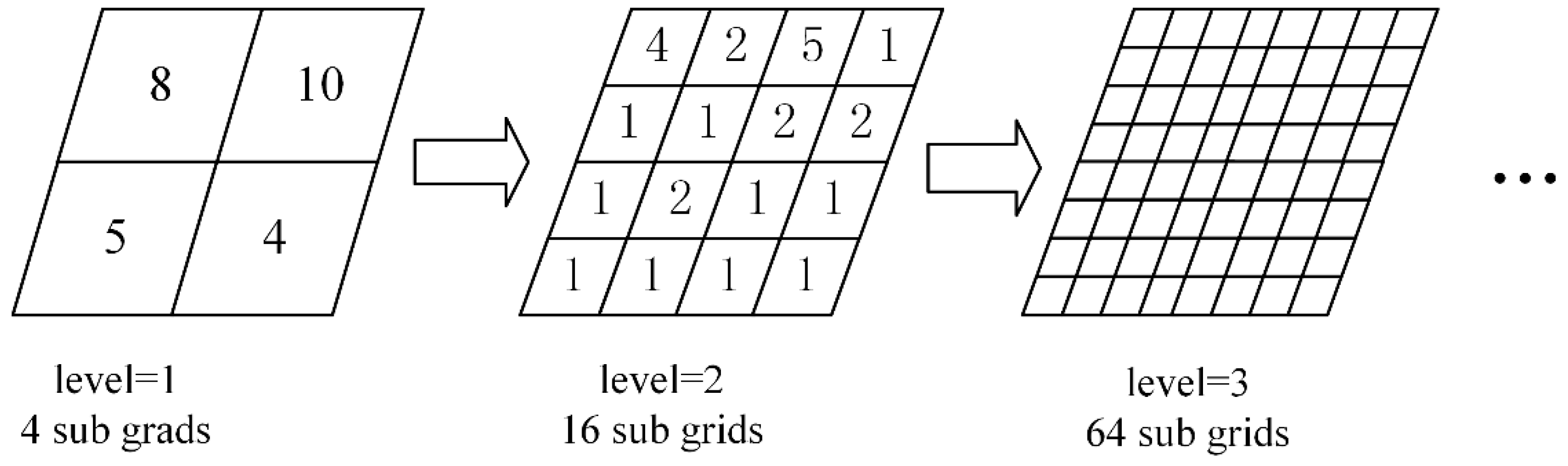
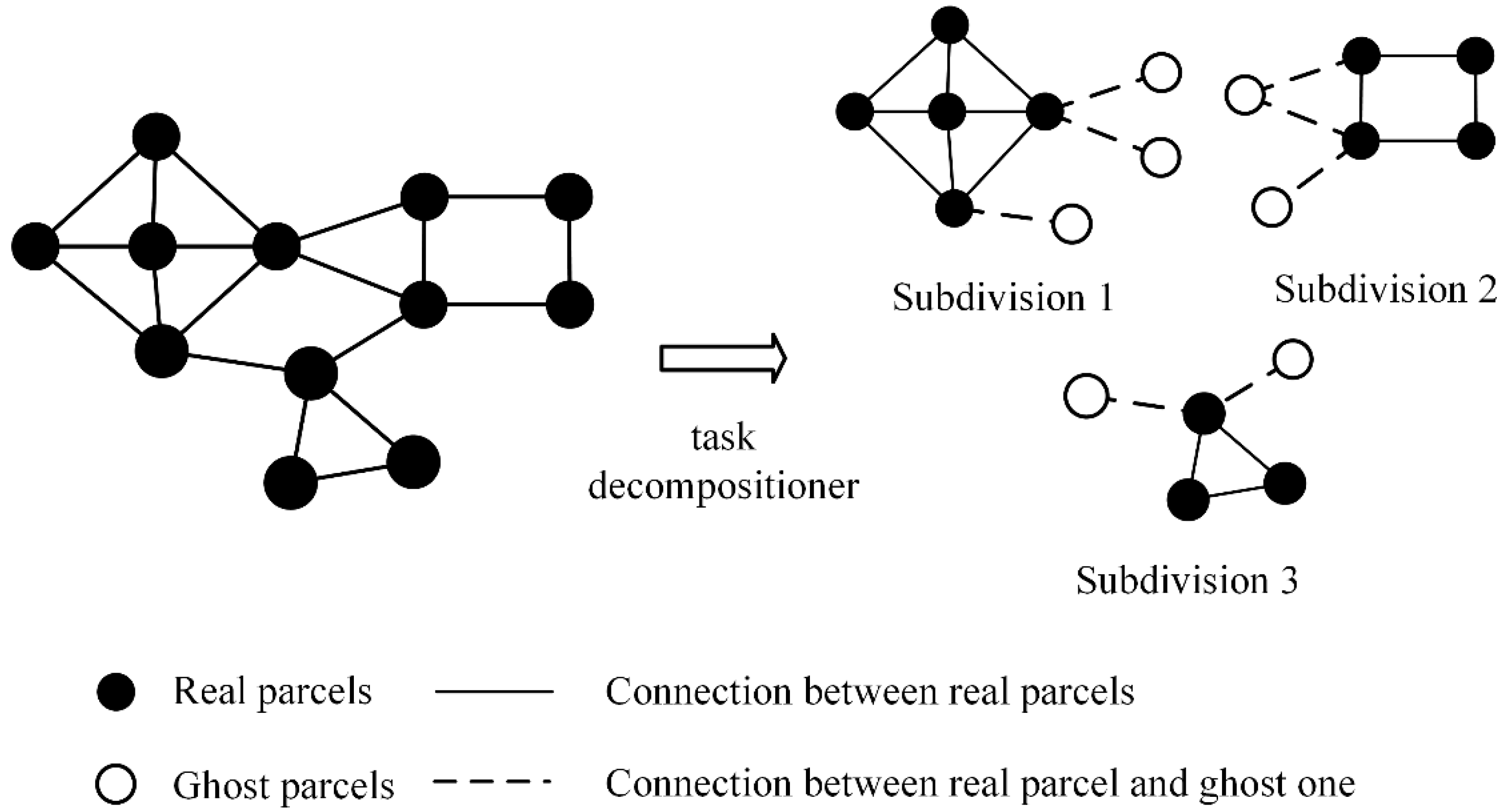
The task decomposition in pVCA models can be formulated as typical space partitioning problems. There is a growing collection of space partitioning algorithms, which can be grouped according to how partitioning is conducted and classified into two categories; flat grid partitioning and hierarchical tree partitioning. Flat grid-based partitioning algorithms use a rectangular grid to partition the target space, thus directly obtaining discrete regular subdivisions. Hierarchical tree-based algorithms on the other hand, divide the target space into two or more disjoint subsets recursively, eventually producing a binary space partitioning (BSP) tree, e.g., KD-tree.
However, both flat grid-based and hierarchical tree-based algorithms are not easily applicable to pVCA task decomposition because neither the equal subdivision area nor equal task number can guarantee an equal workload. Flat grid partitioning can produce equal-area subdivisions, but the irregular shape of pVCA parcels leads to different task numbers for each subdivision. Conversely, hierarchical tree partitioning can easily produce equal task numbers by recursive division, but the workload of each subdivision is still unbalanced because of the varying computing complexity of pVCA tasks.
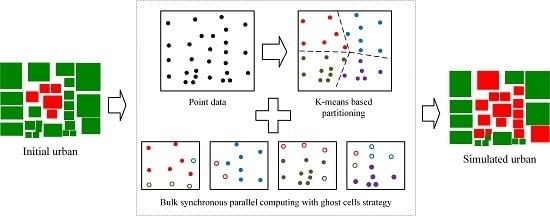
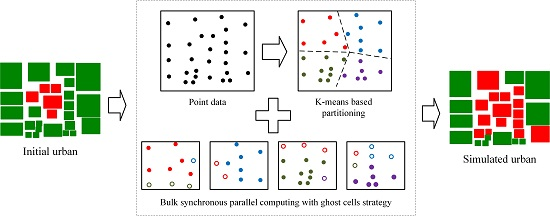
In this paper, a novel pVCA task decomposition algorithm based on general k-means clustering named KCP is proposed to overcome these drawbacks. The KCP method formulates a customized k-means clustering to cluster tasks with higher geographical proximity. This method uses parcel centroid to represent parcel polygons and defines a proximity distance combining parcel size and outer distance. Through an iterative process, the generated subdivisions will contain neighboring parcels, while, at the same time, the technique will separate large-sized parcels using the centroid distance. In this way, the KCP decomposition can take both task numbers and their computation complexity into consideration to obtain better workload balance. Since the workload of each subdivision depends on the number of allocated tasks, the computing complexity and communication overhead depend on the amount of ghost parcels, the NSD-PA (normalized standard deviation of the area of parcels), NSD-PN (normalized standard deviation of the number of parcels), and the number of total ghost agents that are applied to indicate local workload balance and the communication overhead.
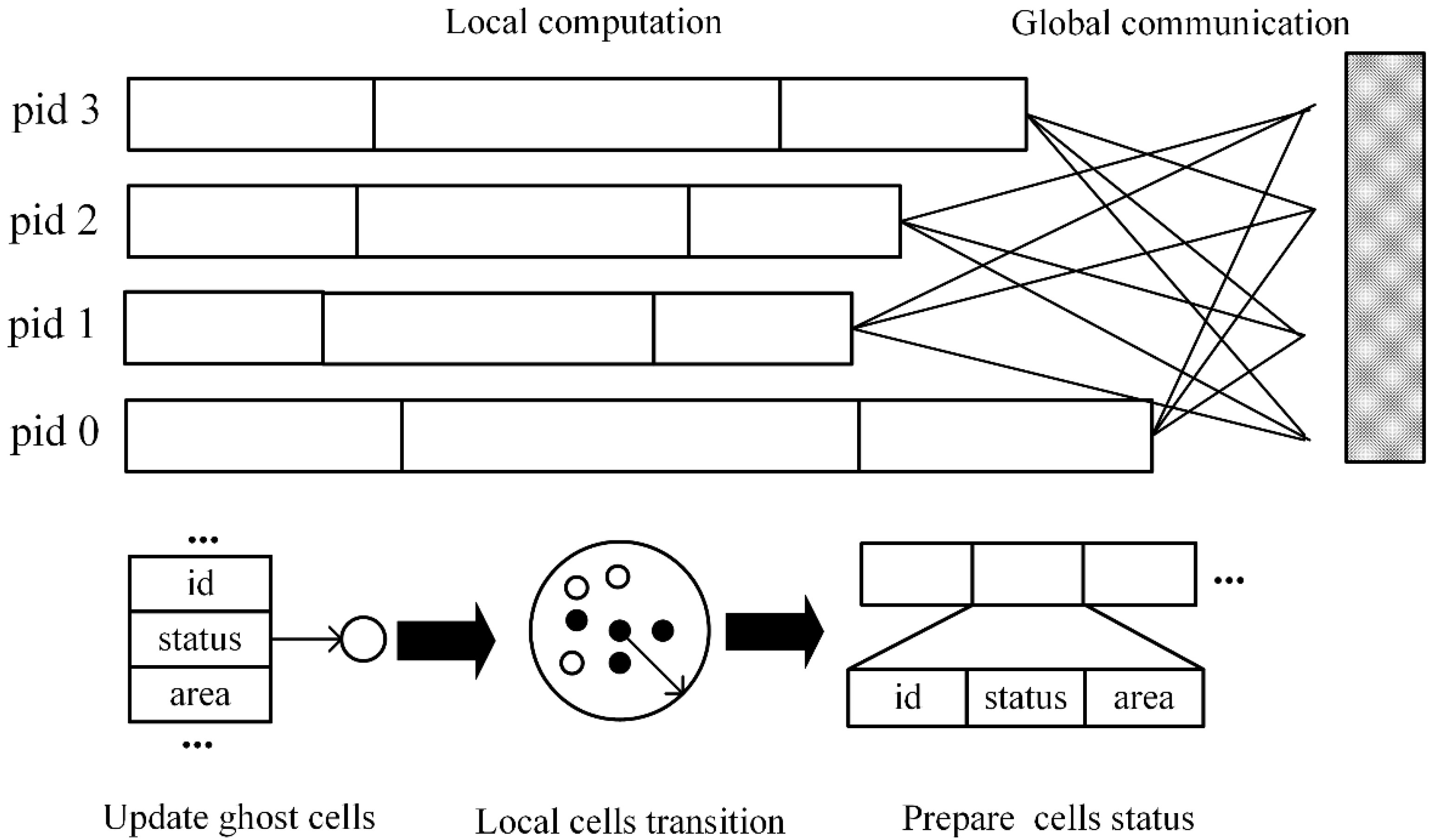
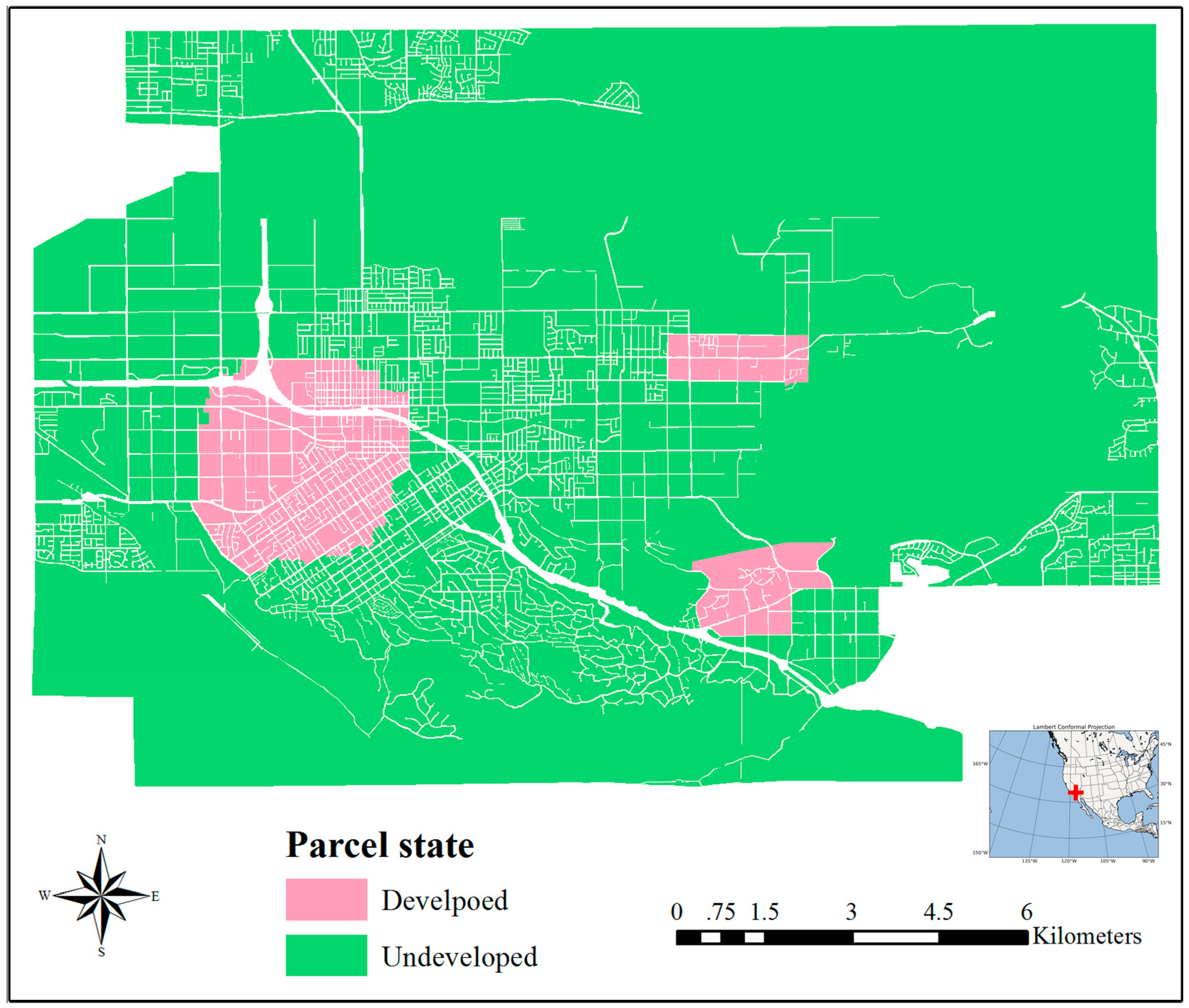
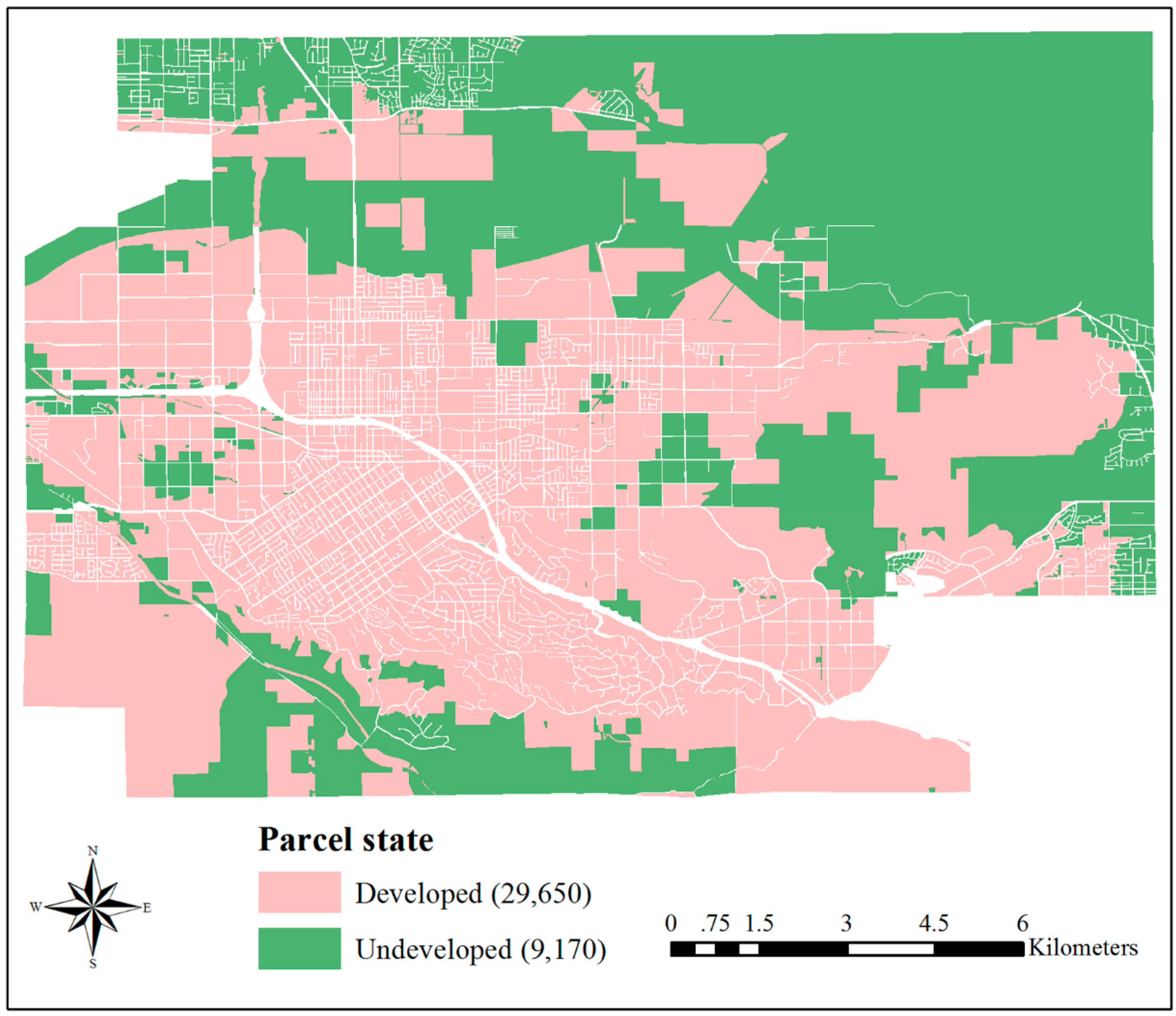
An additional VCA-based urban growth model was developed to evaluate the efficiency of the proposed KCP algorithm. Further, we parallelized the model based on a bulk synchronous parallel model and adopted the ghost agent strategy to reduce information exchange frequency. Two groups of experiments were designed, with four subdivision sizes, 4, 8, 16, and 32, to test their scalability and three buffer sizes, 120 m, 240 m, and 360 m, to test their effects on the communication overhead. In addition, we made a detailed study on the local workload and communication overhead separately using the NSD-PN, NSD-PA, and the number of total ghost agents. The experimental results show that KCP employs the least local computing time with acceptable communication overhead and achieves the best parallel performance, compared with two common decomposition methods, GRID and BSP. The proposed KCP method can be used to partition spatial tasks of large-scale detailed VCA models effectively, which can shorten the computing time and improve the efficiency of adopting a VCA model.
The rest of the paper is outlined as follows.
Section 2 provides a detailed introduction to VCA models and an overview of existing task decomposition methods with spatial-partitioning.
Section 3 explains the proposed KCP task decomposition method. In
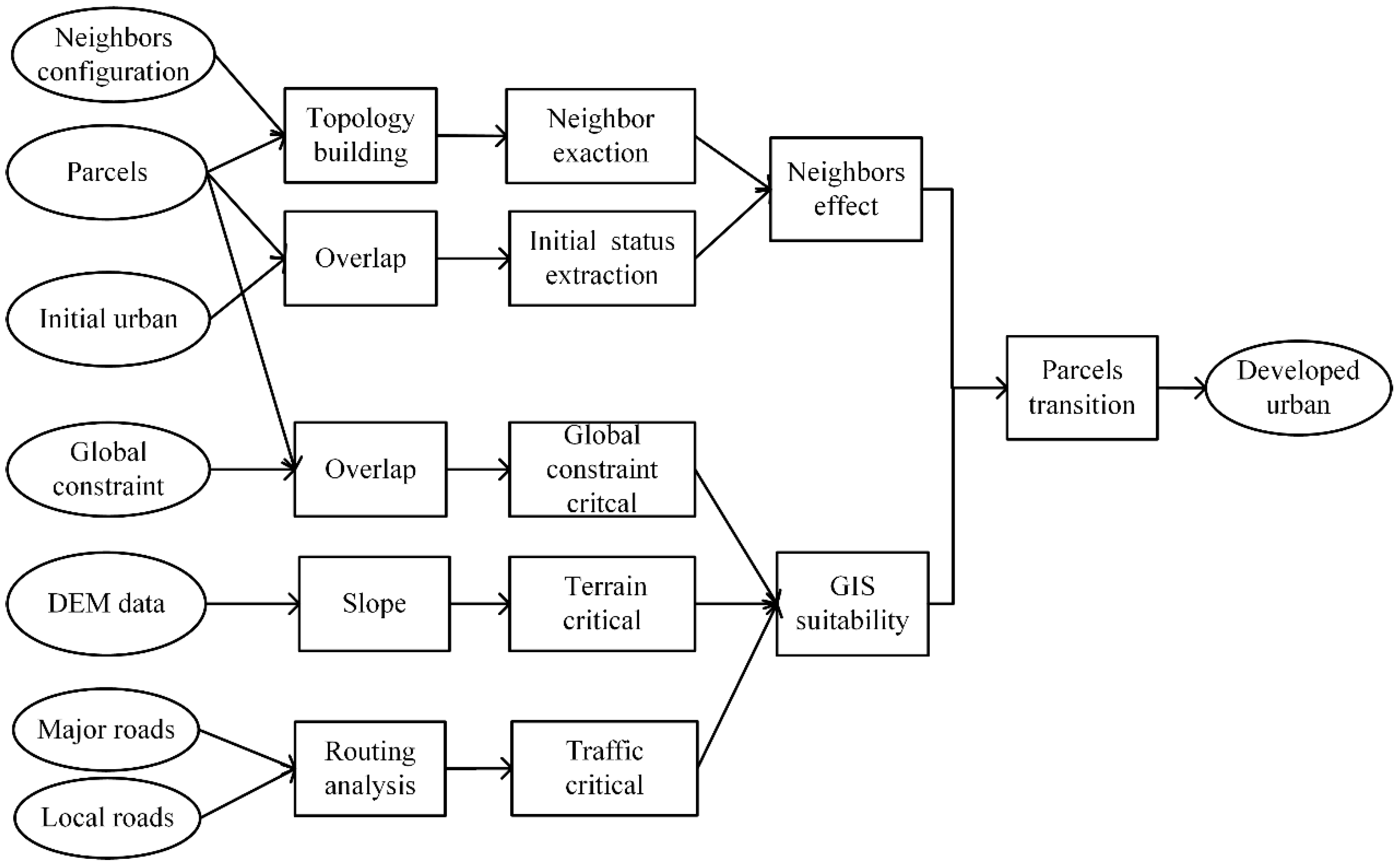
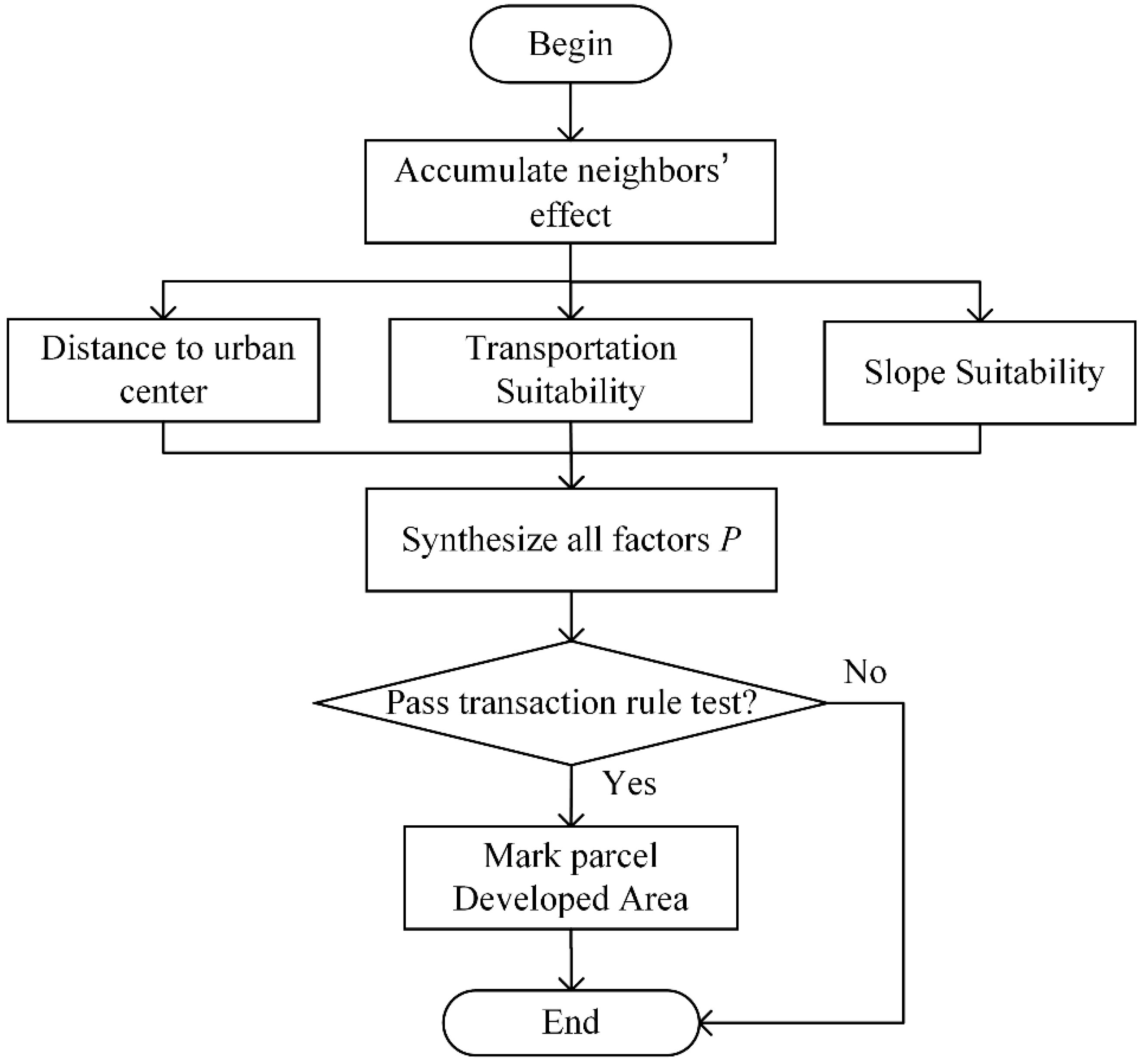
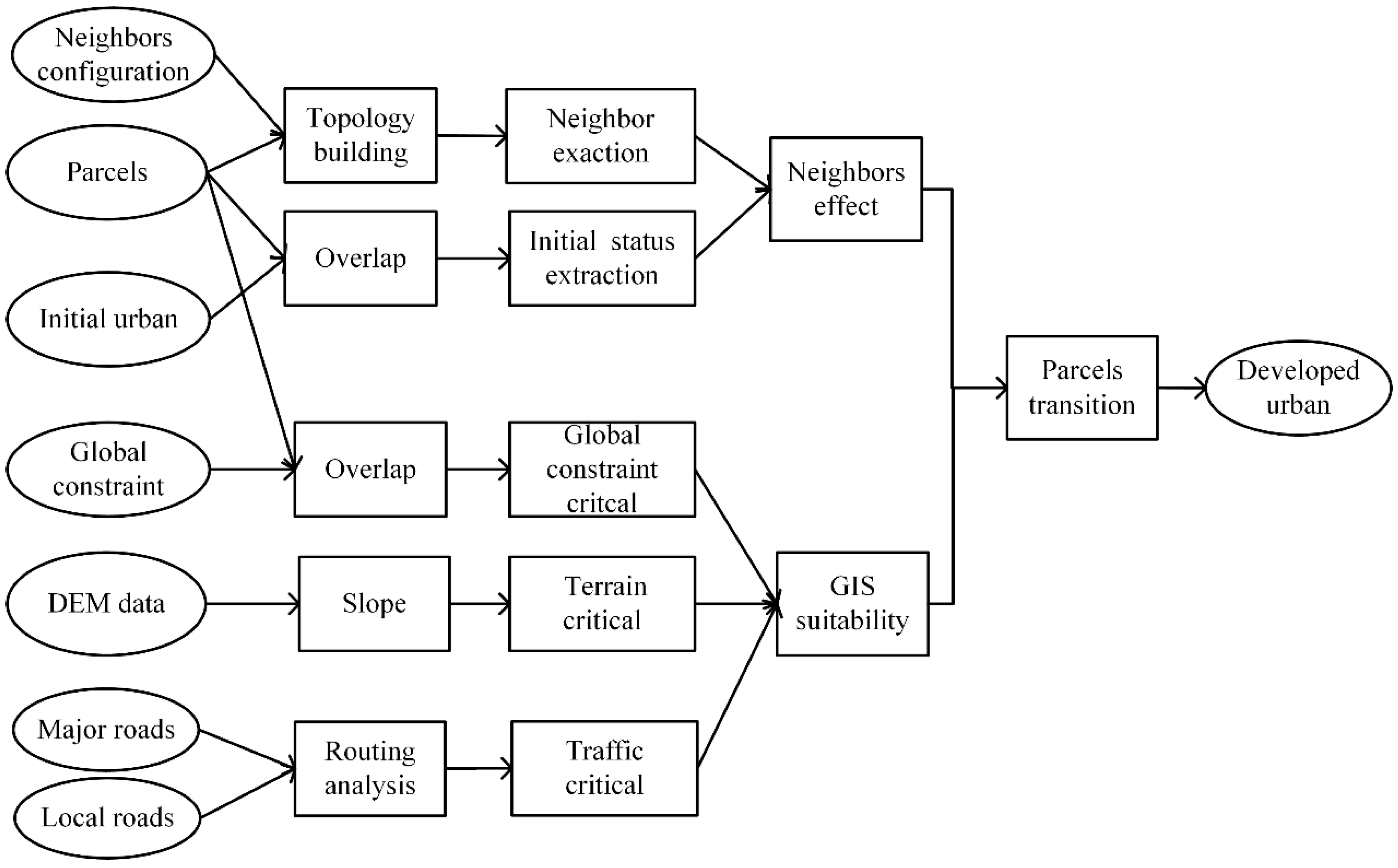
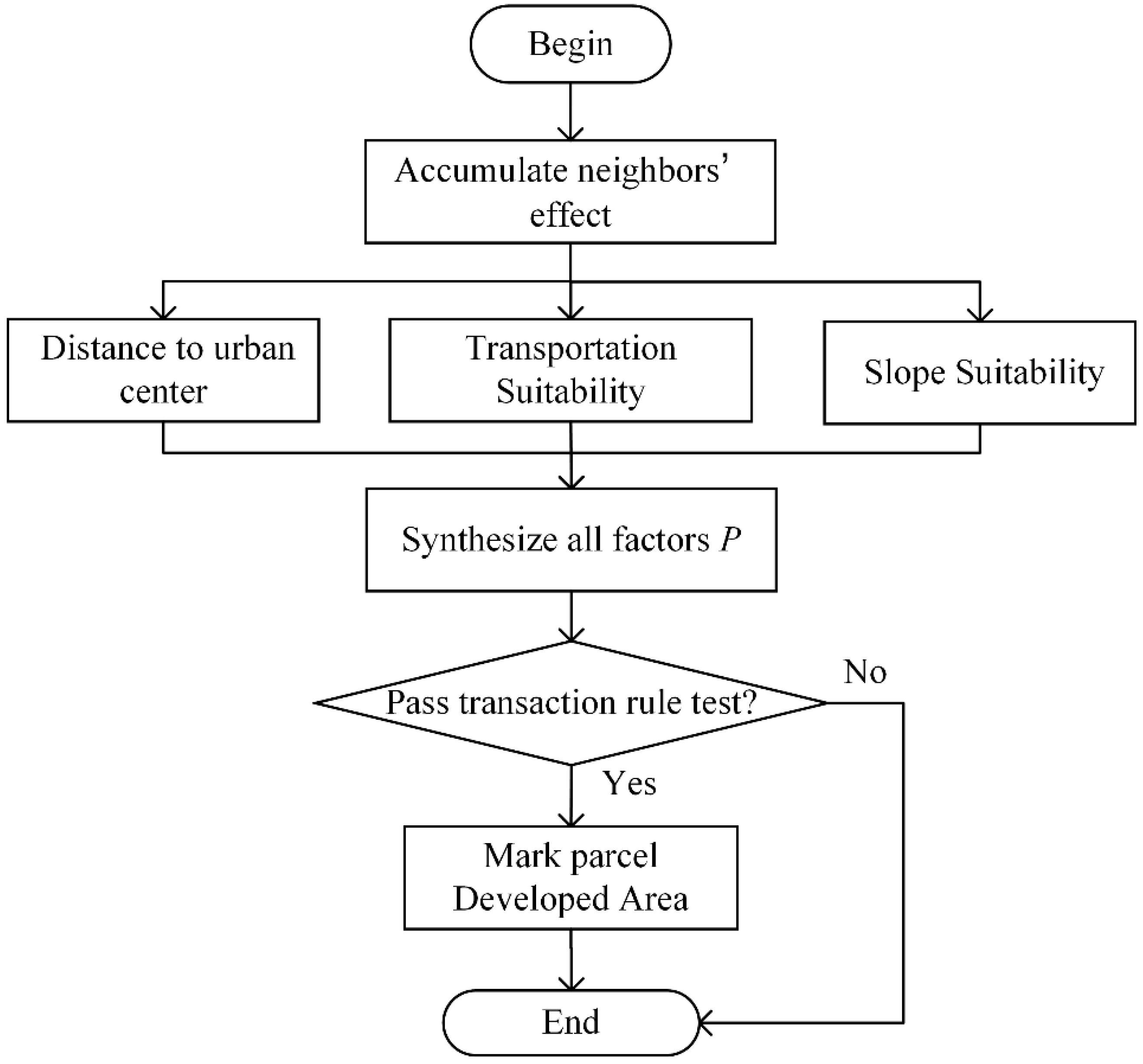
Section 4, a parallel VCA urban growth model is presented. In
Section 5, we evaluate and compare the KCP performance to the GRID and BSP performance. In
Section 6, we present a discussion and draw some conclusions.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}