Machine Learning Techniques for Modelling Short Term Land-Use Change



Abstract
1. Introduction
2. Methods
2.1. Formulating the Problem as a Classification Task
2.2. Forecasting Short-Term Land Use Change Based on ML Techniques
2.3. Machine Learning Techniques—Theoretical Background
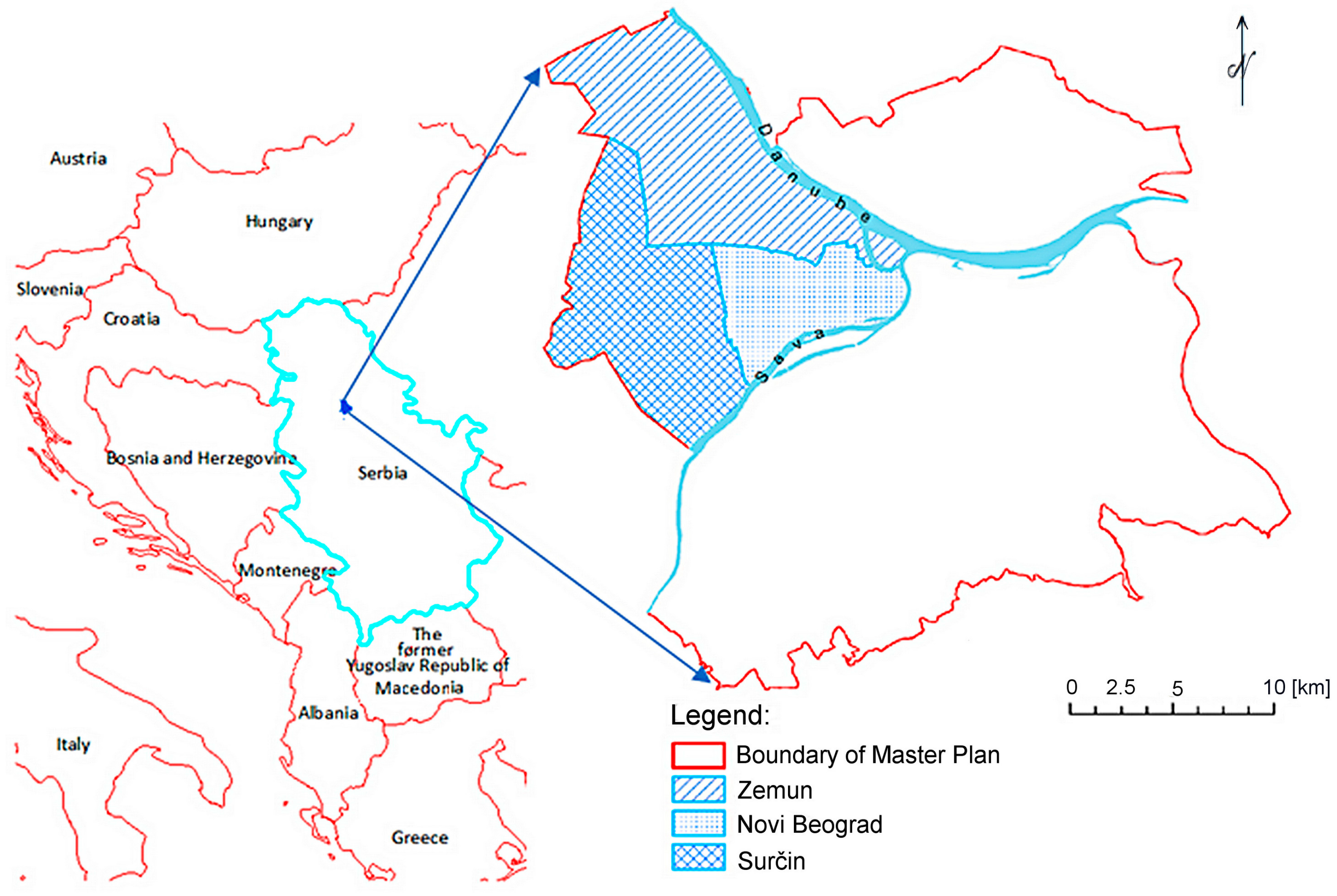
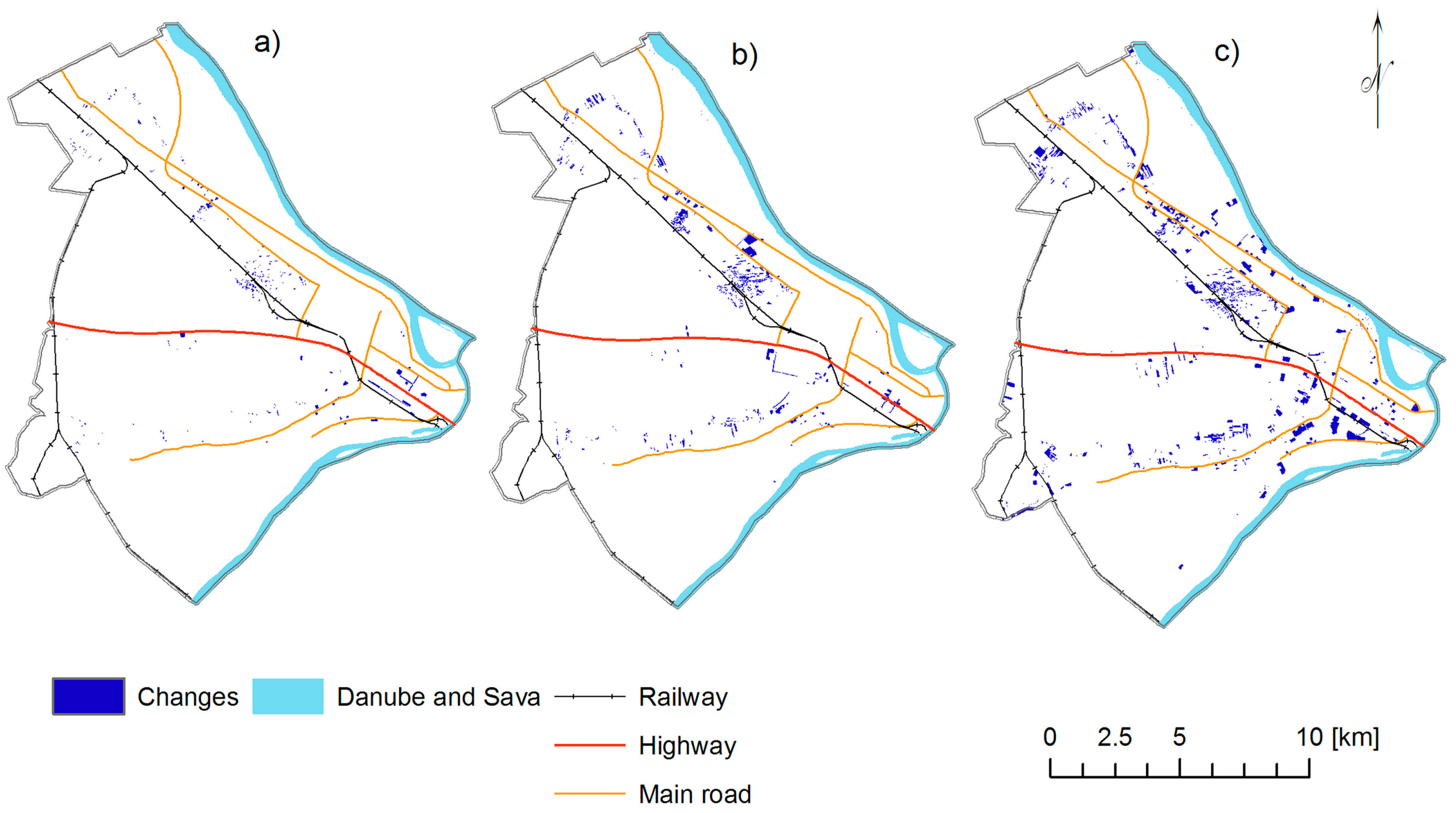
3. Study Area and Data Sets
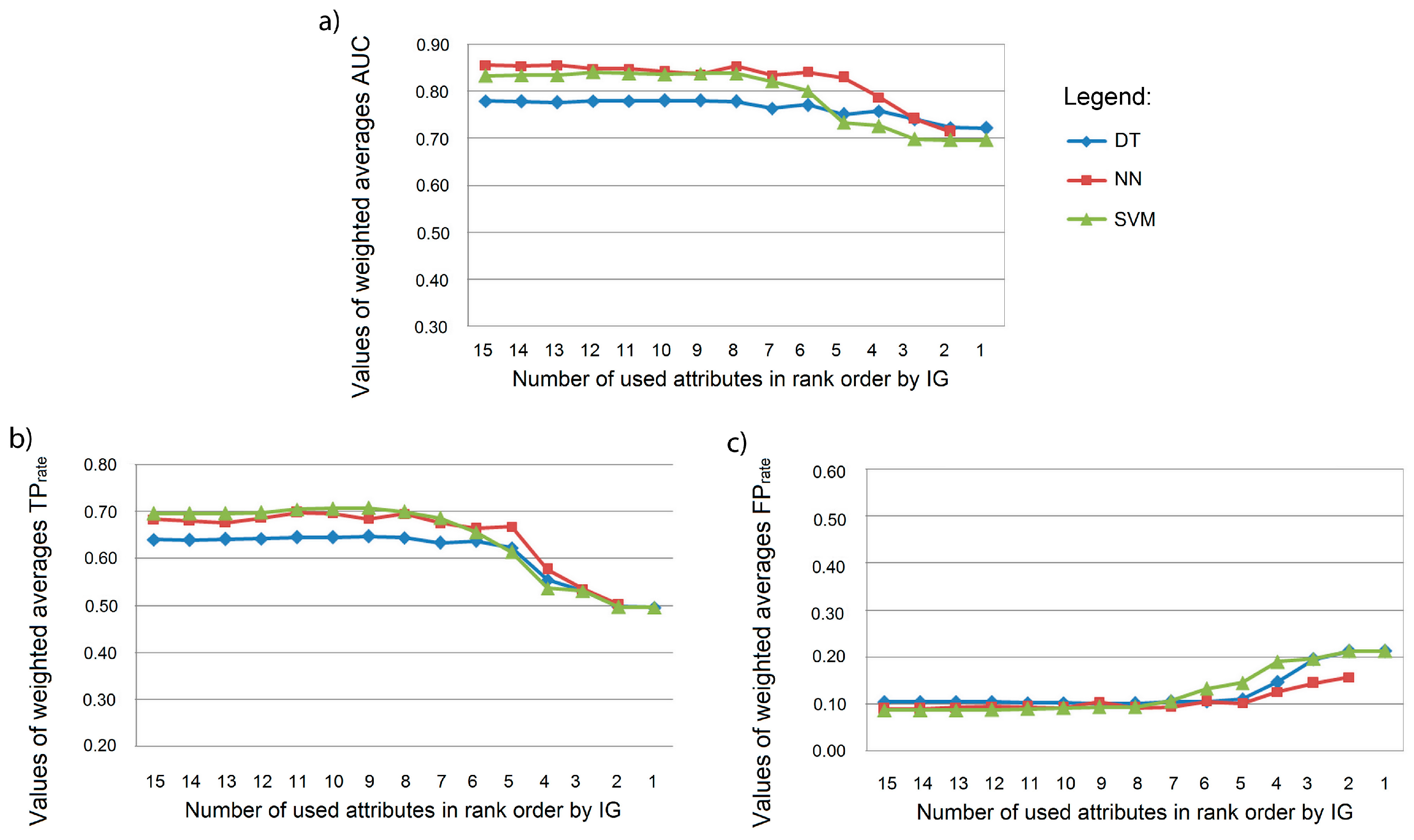
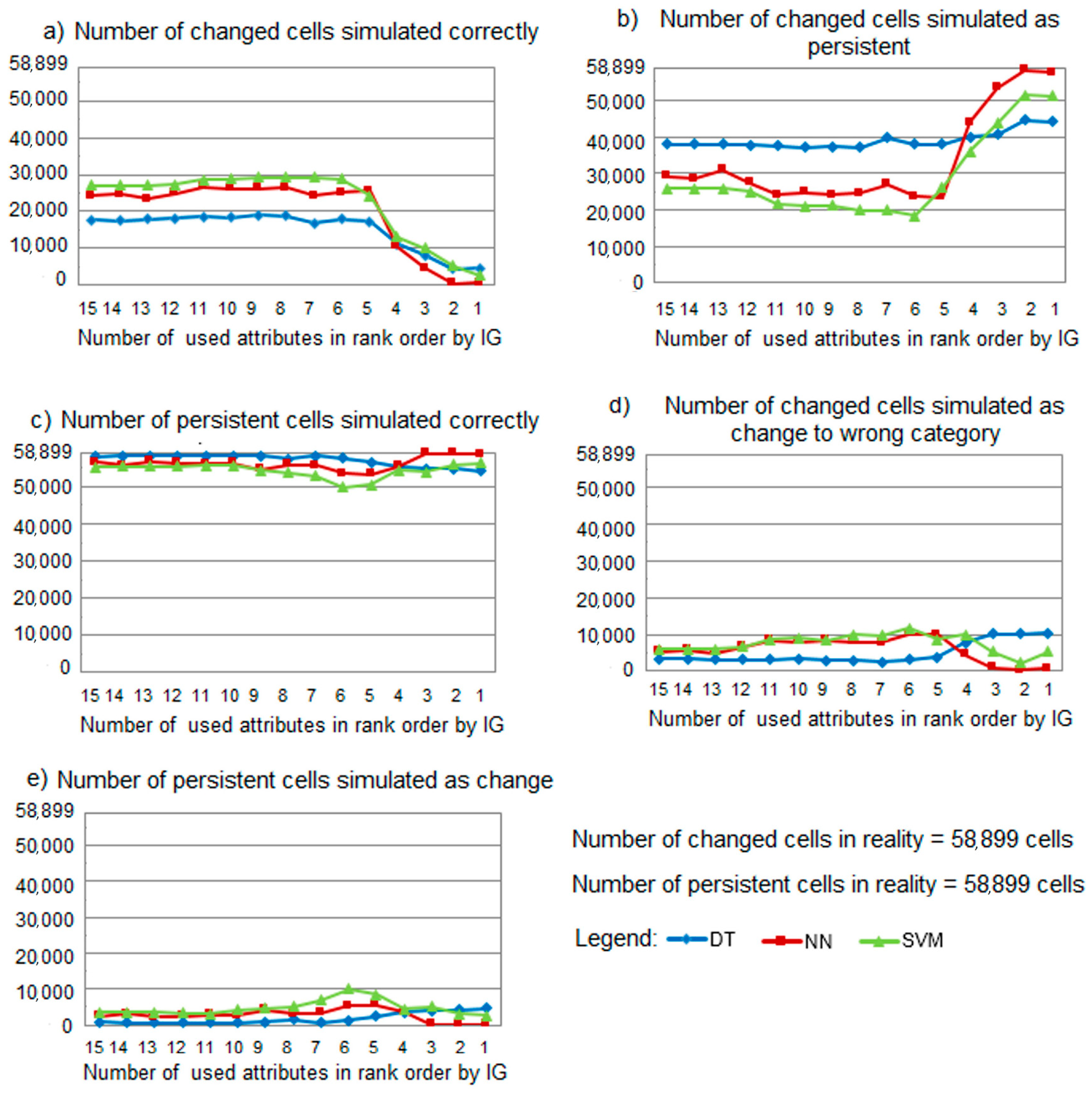
4. Results and Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Agarwal, C.; Green, G.M.; Grove, J.M.; Evans, T.P.; Schweik, C.M. A Review and Assessment of Land-Use Change Models: Dynamics of Space, Time, and Human Choice; General Technical Report NE 297; U.S. Department of Agriculture, Forest Service, Northeastern Research Station: Newton Square, PA, USA, 2002. [CrossRef]
- Verburg, P.; Schot, P.; Dijst, M.; Veldkamp, A. Land use change modelling: Current practice and research priorities. GeoJournal 2004, 61, 309–324. [Google Scholar] [CrossRef]
- Turner, B.L.; Lambin, E.F.; Reenberg, A. The emergence of land change science for global environmental change and sustainability. Proc. Natl. Acad. Sci. USA 2007, 104, 20666–20671. [Google Scholar] [CrossRef] [PubMed]
- Schneider, L.C.; Pontius, R.G. Modeling land-use change in the Ipswich watershed, Massachusetts, USA. Agric. Ecosyst. Environ. 2001, 85, 83–94. [Google Scholar] [CrossRef]
- Verburg, P.H.; De Koning, G.H.J.; Kok, K.; Veldkamp, A.; Bouma, J. A spatial explicit allocation procedure for modelling the pattern of land use change based upon actual land use. Ecol. Model. 1999, 116, 45–61. [Google Scholar] [CrossRef]
- Hu, Z.; Lo, C.P. Modeling urban growth in Atlanta using logistic regression. Comput. Environ. Urban Syst. 2007, 31, 667–688. [Google Scholar] [CrossRef]
- Muller, M.R.; Middleton, J. A Markov model of land-use change dynamics in the Niagara Region, Ontario, Canada. Landsc. Ecol. 1994, 9, 151–157. [Google Scholar] [CrossRef]
- Lopez, E.; Bocco, G.; Mendoza, M.; Duhau, E. Predicting land-cover and land-use change in the urban fringe: A case in Morelia city, Mexico. Landsc. Urban Plan. 2001, 55, 271–285. [Google Scholar] [CrossRef]
- White, R.; Engelen, G.; Uljee, I. The use of constrained cellular automata for high-resolution modelling of urban land-use dynamics. Environ. Plan. B Plan. Des. 1997, 24, 323–343. [Google Scholar] [CrossRef]
- Van Vliet, J.; White, R.; Dragicevic, S. Modeling urban growth using a variable grid cellular automaton. Comput. Environ. Urban Syst. 2009, 33, 35–43. [Google Scholar] [CrossRef]
- Yao, Y.; Li, J.; Zhang, X.; Duan, P.; Li, S.; Xu, Q. Investigation on the Expansion of Urban Construction Land Use Based on the CART-CA Model. ISPRS Int. J. Geo-Inf. 2017, 6, 149. [Google Scholar] [CrossRef]
- Brown, D.G.; Page, S.; Riolo, R.; Zellner, M.; Rand, W. Path dependence and the validation of agent-based spatial models of land use. Int. J. Geogr. Inf. Sci. 2005, 19, 153–174. [Google Scholar] [CrossRef]
- Groeneveld, J.; Müller, B.; Buchmann, C.M.; Dressler, G.; Guo, C.; Hase, N.; Hoffmann, F.; John, F.; Klassert, C.; Lauf, T.; et al. Theoretical foundations of human decision-making in agent-based land use models—A review. Environ. Model. Softw. 2017, 87, 39–48. [Google Scholar] [CrossRef]
- Tayyebi, A.; Pijanowski, B.C. Modeling multiple land use changes using ANN, CART and MARS: Comparing tradeoffs in goodness of fit and explanatory power of data mining tools. Int. J. Appl. Earth. Obs. 2014, 28, 102–116. [Google Scholar] [CrossRef]
- Kamusoko, C.; Gamba, J. Simulating Urban Growth Using a Random Forest-Cellular Automata (RF-CA) Model. ISPRS Int. J. Geoinf. 2015, 4, 447–470. [Google Scholar] [CrossRef]
- Kjærulff, U.B.; Madsen, A.L. Bayesian Networks and Influence Diagrams: A Guide to Construction and Analysis; Springer: New York, NY, USA, 2008; ISBN 978-0-38-774100-0. [Google Scholar]
- Tafazzoli Moghaddam, E. Data-driven Process Monitoring and Diagnosis with Support Vector Data Description. Unpulished Master’s Thesis, Simon Fraser University, Burnaby, BC, Canada, 2011. [Google Scholar]
- Brown, D.G.; Band, L.E.; Green, K.O.; Irwin, E.G.; Jain, A.; Lambin, E.F.; Pontius, R.G., Jr.; Seto, K.C.; Turner, B.L.I.; Verburg, P.H. Advancing Land Change Modeling: Opportunities and Research Requirements; National Academies Press: Washington, DC, USA, 2014; ISBN 0309288363. [Google Scholar]
- Solomatine, D.P.; Ostfeld, A. Data-driven modelling: Some past experiences and new approaches. J. Hydroinform. 2008, 10, 3–22. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Pourghasemi, H.R.; Dixon, B. GIS-based groundwater potential mapping using boosted regression tree, classification and regression tree, and random forest machine learning models in Iran. Environ. Monit. Assess. 2016, 188, 1–27. [Google Scholar] [CrossRef] [PubMed]
- Marjanović, M.; Kovačević, M.; Bajat, B.; Voženilek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci.-UK 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Dickson, M.E.; Perry, G.L.W. Identifying the controls on coastal cliff landslides using machine-learning approaches. Environ. Model. Softw. 2016, 76, 117–127. [Google Scholar] [CrossRef]
- Corani, G. Air quality prediction in Milan: feed-forward neural networks, pruned neural networks and lazy learning. Ecol. Model. 2005, 185, 513–529. [Google Scholar] [CrossRef]
- Leuenberger, M.; Kanevski, M. Extreme Learning Machines for spatial environmental data. Comput. Geosci.-UK 2015, 85, 64–73. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Aretano, R.; Semeraro, T. Investigation of general indicators influencing on forest fire and its susceptibility modeling using different data mining techniques. Ecol. Indic. 2016, 64, 72–84. [Google Scholar] [CrossRef]
- Bischof, H.; Schneider, W.; Pinz, A.J. Multispectral classification of Landsat-images using neural networks. IEEE Trans. Geosci. Remote Sens. 1992, 30, 482–490. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Schwert, B.; Rogan, J.; Giner, N.M.; Ogneva-Himmelberger, Y.; Blanchard, S.D.; Woodcock, C. A comparison of support vector machines and manual change detection for land-cover map updating in Massachusetts, USA. Remote Sens. Lett. 2013, 4, 882–890. [Google Scholar] [CrossRef]
- Goetz, J.N.; Brenning, A.; Petschko, H.; Leopold, P. Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput. Geosci.-UK 2015, 81, 1–11. [Google Scholar] [CrossRef]
- Qian, Y.G.; Zhou, W.Q.; Yan, J.L.; Li, W.F.; Han, L.J. Comparing Machine Learning Classifiers for Object-Based Land Cover Classification Using Very High Resolution Imagery. Remote Sens. 2015, 7, 153–168. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Heung, B.; Ho, H.C.; Zhang, J.; Knudby, A.; Bulmer, C.E.; Schmidt, M.G. An overview and comparison of machine-learning techniques for classification purposes in digital soil mapping. Geoderma 2016, 265, 62–77. [Google Scholar] [CrossRef]
- Hong, H.; Pourghasemi, H.R.; Pourtaghi, Z.S. Landslide susceptibility assessment in Lianhua County (China): A comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 2016, 259, 105–118. [Google Scholar] [CrossRef]
- Johnson, M.D.; Hsieh, W.W.; Cannon, A.J.; Davidson, A.; Bédard, F. Crop yield forecasting on the Canadian Prairies by remotely sensed vegetation indices and machine learning methods. Agric. For. Meteorol. 2016, 218, 74–84. [Google Scholar] [CrossRef]
- Meyer, H.; Kühnlein, M.; Appelhans, T.; Nauss, T. Comparison of four machine learning algorithms for their applicability in satellite-based optical rainfall retrievals. Atmos. Res. 2016, 169(Part B), 424–433. [Google Scholar] [CrossRef]
- Yeh, A.G.O.; Li, X. Simulation of development alternatives using neural networks, cellular automata, and GIS for urban planning. Photogramm. Eng. Remote Sens. 2003, 69, 1043–1052. [Google Scholar] [CrossRef]
- Almeida, C.M.; Gleriani, J.M.; Castejon, E.F.; Soares, B.S. Using neural networks and cellular automata for modelling intra-urban land-use dynamics. Int. J. Geogr. Inf. Sci. 2008, 22, 943–963. [Google Scholar] [CrossRef]
- Pijanowski, B.C.; Brown, D.G.; Shellito, B.A.; Manik, G.A. Using neural networks and GIS to forecast land use changes: A land transformation model. Comput. Environ. Urban Syst. 2002, 26, 553–575. [Google Scholar] [CrossRef]
- Liu, W.; Seto, K.; Sun, Z.; Tian, Y. Urban land use prediction model with spatiotemporal data mining and GIS. In Urban Remote Sensing; Weng, Q., Quattrochi, D.A., Eds.; CRC Press, Taylor and Francis Group: Boca Raton, FL, USA, 2007; pp. 165–178. ISBN 1420008803. [Google Scholar]
- Li, X.; Yeh, A.G.O. Data mining of cellular automata’s transition rules. Int. J. Geogr. Inf. Sci. 2004, 18, 723–744. [Google Scholar] [CrossRef]
- Yang, Q.; Li, X.; Shi, X. Cellular automata for simulating land use changes based on support vector machines. Comput. Geosci.-UK 2008, 34, 592–602. [Google Scholar] [CrossRef]
- Okwuashi, O.; McConchie, J.; Nwilo, P.; Isong, M.; Eyoh, A.; Nwanekezie, O. Predicting future land use change using support vector machine based GIS cellular automata: A case of Lagos, Nigeria. J. Sustain. Dev. 2012, 5, 132–139. [Google Scholar] [CrossRef]
- Huang, B.; Xie, C.; Tay, R. Support Vector Machines for urban growth modeling. Geoinformatica 2010, 14, 83–99. [Google Scholar] [CrossRef]
- Gong, Z.; Thill, J.C.; Liu, W. ART-P-MAP Neural Networks Modeling of Land-Use Change: Accounting for Spatial Heterogeneity and Uncertainty. Geogr. Anal. 2015, 47, 376–409. [Google Scholar] [CrossRef]
- Qiang, Y.; Lam, N.S. Modeling land use and land cover changes in a vulnerable coastal region using artificial neural networks and cellular automata. Environ. Monit. Assess. 2015, 187, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer: New York, NY, USA, 1998; ISBN 978-0-79-238198-3. [Google Scholar]
- Kim, Y.; Street, W.N.; Menczer, F. Feature selection in data mining. In Data Mining: Opportunities and Challenges; Wang, J., Ed.; IRM Press (an imprint of Idea Group Inc.): London UK, 2003; Volume 3, pp. 80–105. ISBN 1591400511. [Google Scholar]
- Samardžić-Petrović, M.; Dragićević, S.; Bajat, B.; Kovačević, M. Exploring the Decision Tree Method for Modelling Urban Land Use Change. Geomatica 2015, 69, 313–325. [Google Scholar] [CrossRef]
- Arango, R.B.; Díaz, I.; Campos, A.; Canas, E.R.; Combarro, E.F. Automatic arable land detection with supervised machine learning. Earth Sci. Inform. 2016, 9, 535–545. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the roc curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Peethambaram, S.; Castella, J.C. Comparison of three maps at multiple resolutions: A case study of land change simulation in Cho Don District, Vietnam. Ann. Assoc. Am. Geogr. 2011, 101, 45–62. [Google Scholar] [CrossRef]
- Gahegan, M. On the application of inductive machine learning tools to geographical analysis. Geogr. Anal. 2000, 32, 113–139. [Google Scholar] [CrossRef]
- Samardžić-Petrović, M.; Dragićević, S.; Kovačević, M.; Bajat, B. Modeling Urban Land Use Changes Using Support Vector Machines. Trans. GIS 2016, 20, 718–734. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2011; ISBN 978-0-12-374856-0. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O. Data Mining with Decision Trees: Theory and Applications, 2nd ed.; World Scientific: Singapore, 2014; ISBN 9814590096. [Google Scholar]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Chapman and Hall/CRC, Taylor and Francis Groupe: Boca Raton, FL, USA, 1984; ISBN 0412048418. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1993; ISBN 978-0-08-050058-4. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Broomhead, D.S.; Lowe, D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks; Royal Signals and Radar Establishment Malvern: Malvern, UK, 1988; Available online: http://www.dtic.mil/docs/citations/ADA196234 (accessed on 27 November 2017).
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Jain, A.K.; Mao, J.C.; Mohiuddin, K.M. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, New York, NY, USA, 2000; ISBN 0521780195. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory, 2nd ed.; Springer: New York, NY, USA, 2000; ISBN 978-1-44-193160-3. [Google Scholar]
- Belousov, A.I.; Verzakov, S.A.; Von Frese, J. Applicational aspects of support vector machines. J. Chemom. 2002, 16, 482–489. [Google Scholar] [CrossRef]
- Abe, S. Support Vector Machines for Pattern Classification, 2nd ed.; Springer: London, UK; New York, NY, USA, 2010; ISBN 978-1-84-996097-7. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. SIGKDD Explor. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Weka (2016) Weka 3: Data Mining Software in Java. Machine Learning Group at the University of Waikato: New Zealand. Available online: https://www.cs.waikato.ac.nz/ml/weka/ (accessed on 27 November 2017).
- URBEL, Urban Planning Institute of Belgrade. The Master Plan of Belgrade 2021. Official Gazette of the City of Belgrade 27. 2003. Available online: http://www.urbel.com/home.aspx?ID=uzb_Home&LN=ENG (accessed on 7 March 2014).
- Bajat, B.; Krunić, N.; Samardžić-Petrović, M.; Kilibarda, M. Dasymetric modelling of population dynamics in urban areas. Geod. Vestn. 2013, 57, 777–792. [Google Scholar] [CrossRef]
- Conrad, O.; Bechtel, B.; Bock, M.; Dietrich, H.; Fischer, E.; Gerlitz, L.; Wehberg, J.; Wichmann, V.; Böhner, J. System for Automated Geoscientific Analyses (SAGA) v. 2.1.4. Geosci. Model Dev. 2015, 8, 1991–2007. [Google Scholar] [CrossRef]
- ESRI. Version ArcGIS Desktop: Release 10; Environmental Systems Research Institute: Redlands, CA, USA, 2011. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute Label | Attribute Description |
|---|---|
| x1 | Municipality code (mun_code) |
| x2 | Distance to city centre (dcitycentre) |
| x3 | Distance to municipality centre (dmuncentre) |
| x4 | Distance to rivers (driver) |
| x5 | Distance to green areas greater than 100 × 100 m (dgreen) |
| x6 | Distance to railway lines (drail) |
| x7 | Distance to highway (dhighway) |
| x8 | Distance to main road (droad) |
| x9 | Distance to the street of category I (dstreetI) |
| x10 | Distance to the street of category II (dstreetII) |
| x11 | Number of inhabitants (no_inhabitants) |
| x12 | Land use class (LU_class) |
| x13 | Most frequent land use class in Moore neighbourhood 7 × 7 (mf_LU_class) |
| x14 | Second most frequent land use class in Moore neighbourhood 7 × 7 (smf_LU_class) |
| x15 | Previous land use class (prev_LU_class) |
| Data Set | Attributes from | Class Label from | Number of Cells |
|---|---|---|---|
| S3–7 | 2001, 2003 | 2007 | 51,358 |
| S7–11 | 2003, 2007 | 2011 | 117,798 |
| Attribute Rank | Information Gain | Attribute |
|---|---|---|
| 1 | 0.8159 | prev_LU_class |
| 2 | 0.8073 | LU_class |
| 3 | 0.7361 | mf_LU_class |
| 4 | 0.5593 | dcitycentre |
| 5 | 0.4860 | dhighway |
| 6 | 0.4789 | dgreen |
| 7 | 0.4517 | dstreetI |
| 8 | 0.3699 | smf_LU_class |
| 9 | 0.3591 | droad |
| 10 | 0.3538 | dstreetII |
| 11 | 0.3406 | dmuncentre |
| 12 | 0.2545 | drail |
| 13 | 0.2014 | mun_code |
| 14 | 0.0832 | driver |
| 15 | 0.0831 | no_inhabitants |
| Land Use Class | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Agricultural | Wetlands | Trans.net. | Infrastructure | Residential | Commercial | Industr. | Special Use | Green Area | ||
| N 1 in reality | 36,823 | 48 | 165 | 0 | 3698 | 59 | 4237 | 275 | 13,594 | |
| M 2 in reality | 33,530 | 2905 | 2409 | 264 | 9461 | 823 | 2688 | 2775 | 4468 | |
| Measure | ML | |||||||||
| AUC | DT | 0.88 | 0.99 | 0.82 | 1.00 | 0.78 | 0.55 | 0.71 | 0.79 | 0.74 |
| NN | 0.93 | 1.00 | 0.91 | 1.00 | 0.85 | 0.68 | 0.84 | 0.79 | 0.65 | |
| SVM | 0.91 | 0.99 | 0.88 | 1.00 | 0.80 | 0.69 | 0.84 | 0.90 | 0.79 | |
| TPrate | DT | 0.94 | 0.99 | 0.65 | 1.00 | 0.62 | 0.10 | 0.41 | 0.58 | 0.57 |
| NN | 0.92 | 0.97 | 0.64 | 0.99 | 0.72 | 0.34 | 0.52 | 0.58 | 0.45 | |
| SVM | 0.91 | 0.99 | 0.67 | 1.00 | 0.70 | 0.29 | 0.57 | 0.58 | 0.33 | |
| FPrate | DT | 0.20 | 0.00 | 0.01 | 0.00 | 0.09 | 0.01 | 0.05 | 0.00 | 0.10 |
| NN | 0.14 | 0.00 | 0.02 | 0.00 | 0.13 | 0.03 | 0.05 | 0.00 | 0.03 | |
| SVM | 0.14 | 0.00 | 0.01 | 0.00 | 0.15 | 0.03 | 0.06 | 0.00 | 0.03 | |
| N simulated correctly | DT | 16,990 | 10 | 32 | 0 | 569 | 3 | 157 | 43 | 1512 |
| NN | 21,965 | 12 | 45 | 0 | 1508 | 13 | 348 | 79 | 4521 | |
| SVM | 23,697 | 25 | 72 | 0 | 1873 | 19 | 578 | 102 | 5087 | |
| M simulated correctly | DT | 32,504 | 2481 | 2380 | 264 | 9400 | 802 | 2679 | 2769 | 4277 |
| NN | 30,797 | 2481 | 2262 | 264 | 9445 | 770 | 2660 | 2772 | 2489 | |
| SVM | 30,564 | 2478 | 2355 | 264 | 9429 | 758 | 2609 | 2746 | 3306 | |
| NS 3 change to wrong class | DT | 1508 | 0 | 25 | 0 | 34 | 10 | 65 | 16 | 1136 |
| NN | 2912 | 0 | 32 | 0 | 54 | 14 | 2 | 3 | 5491 | |
| SVM | 2680 | 0 | 39 | 0 | 24 | 13 | 258 | 34 | 5272 | |
| NS persistent | DT | 18,325 | 38 | 108 | 0 | 3095 | 46 | 4015 | 216 | 10,946 |
| NN | 11,946 | 36 | 88 | 0 | 2136 | 32 | 3887 | 193 | 3582 | |
| SVM | 10,446 | 23 | 54 | 0 | 1801 | 27 | 3401 | 139 | 3235 | |
| MS 4 change | DT | 1026 | 0 | 29 | 0 | 61 | 21 | 9 | 6 | 191 |
| NN | 2733 | 0 | 147 | 0 | 16 | 53 | 28 | 3 | 1979 | |
| SVM | 2966 | 3 | 54 | 0 | 32 | 65 | 79 | 29 | 1162 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samardžić-Petrović, M.; Kovačević, M.; Bajat, B.; Dragićević, S. Machine Learning Techniques for Modelling Short Term Land-Use Change. ISPRS Int. J. Geo-Inf. 2017, 6, 387. https://doi.org/10.3390/ijgi6120387
Samardžić-Petrović M, Kovačević M, Bajat B, Dragićević S. Machine Learning Techniques for Modelling Short Term Land-Use Change. ISPRS International Journal of Geo-Information. 2017; 6(12):387. https://doi.org/10.3390/ijgi6120387
Chicago/Turabian StyleSamardžić-Petrović, Mileva, Miloš Kovačević, Branislav Bajat, and Suzana Dragićević. 2017. "Machine Learning Techniques for Modelling Short Term Land-Use Change" ISPRS International Journal of Geo-Information 6, no. 12: 387. https://doi.org/10.3390/ijgi6120387
APA StyleSamardžić-Petrović, M., Kovačević, M., Bajat, B., & Dragićević, S. (2017). Machine Learning Techniques for Modelling Short Term Land-Use Change. ISPRS International Journal of Geo-Information, 6(12), 387. https://doi.org/10.3390/ijgi6120387