Web-Scale Normalization of Geospatial Metadata Based on Semantics-Aware Data Sources




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
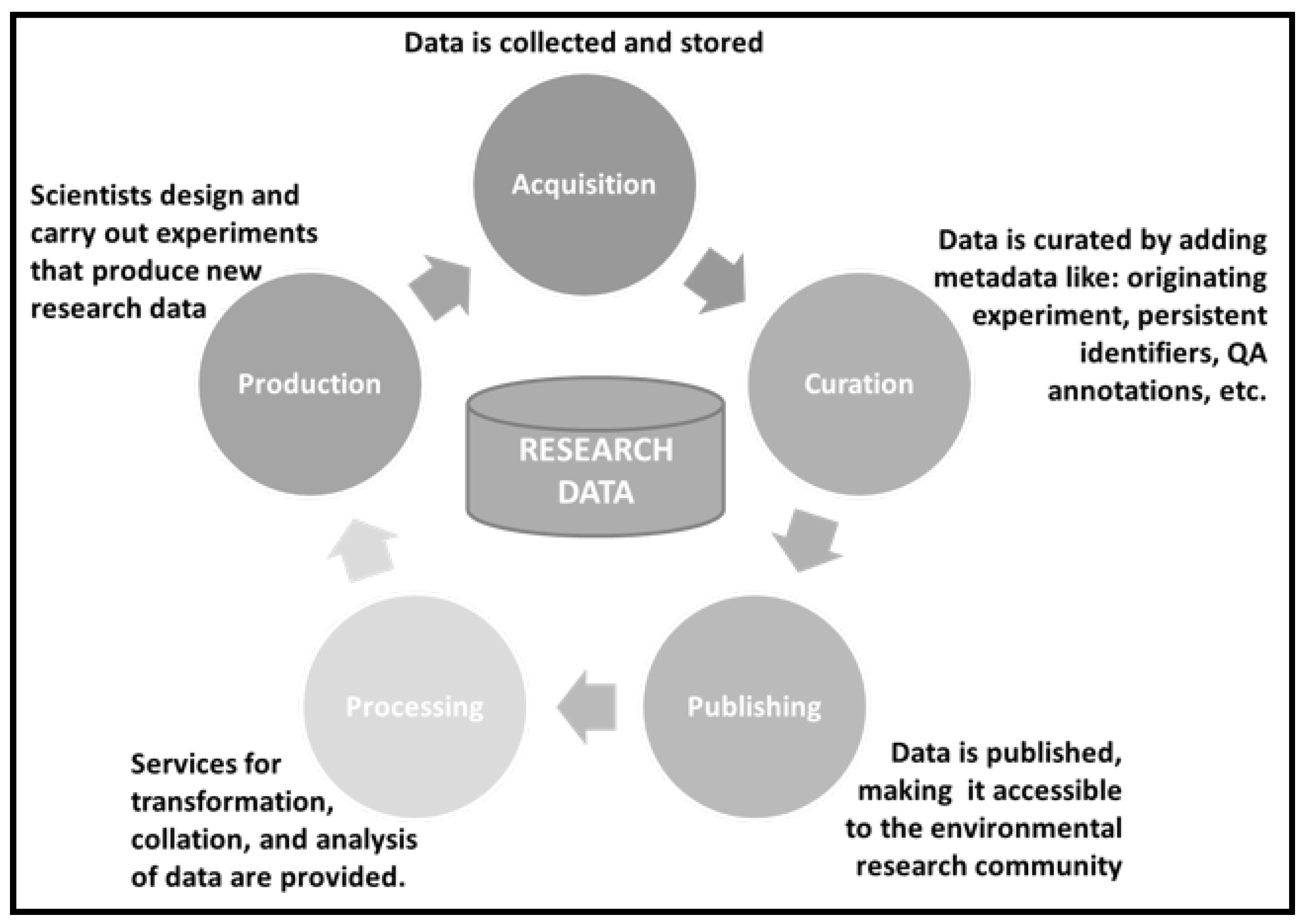
1. Introduction
2. Semantic Characterization of Geospatial Metadata
2.1. State of the Art
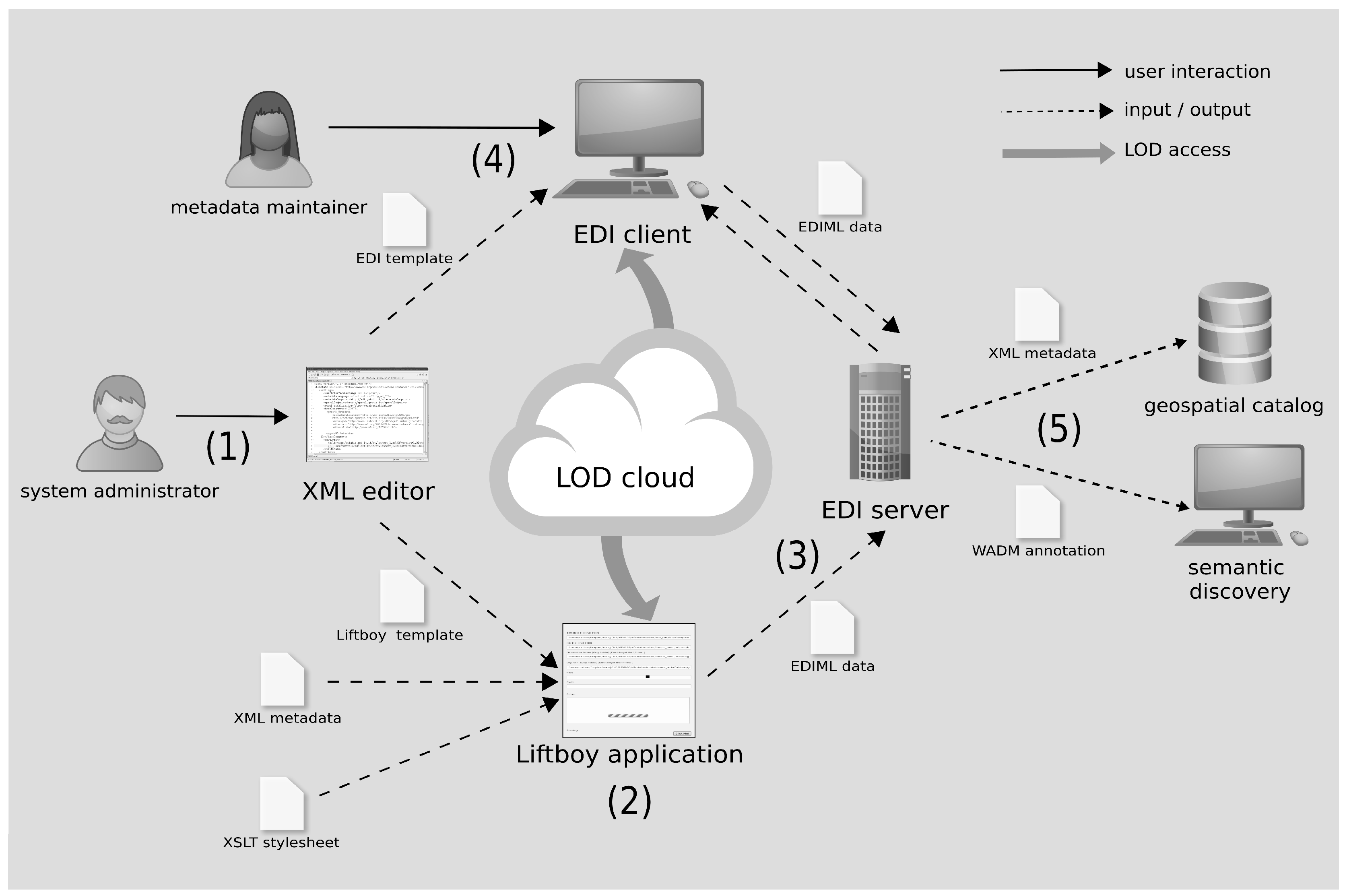
3. EDI and Liftboy for Semantic Lift
- 1
- <template>
- 2
- <sparql xml:id="person">
- 3
- <query><![CDATA[
- 4
- SELECT ?contact ?label
- 5
- WHERE {
- 6
- ?contact rdf:type foaf:Person .
- 7
- ?contact vcard:email ?label .
- 8
- FILTER( REGEX( STR(?label), "\$search_param", "i") ) }
- 9
- ORDER BY ASC(?label)
- 10
- ]]></query>
- 11
- <url>http://some.endpoint.org/sparql</url>
- 12
- </sparql>
- 13
- <element xml:id="resp">
- 14
- <label xml:lang="en">Responsible party</label>
- 15
- <hasRoot>/gmd:MD_Metadata/.../gmd:CI_Citation</hasRoot>
- 16
- ...
- 17
- <produces>
- 18
- <item
- 19
- hasDatatype="autoCompletion" datasource="person">
- 20
- <label xml:lang="en">Email</label>
- 21
- <hasPath>
- 22
- gmd:citedResponsibleParty/.../gmd:electronicMailAddress/...
- 23
- </hasPath>
- 24
- ...
- 25
- </item>
- 26
- ...
- 27
- </produces>
- 28
- </element>
- 29
- <template>
- The specification of the XML element to be produced for the specific metadata item, expressed as the XPath expression obtained by combining the paths in Lines 15 and 22. Note that the hasRoot tag is functional to indicate the root element where multiple instances of the same metadata element shall be nested.
- The specification of data source “person” (Line 2) as the one governing autocompletion of the item (Lines 18–25), on the basis of the output of the SPARQL query defined in Lines 4–9. Note that the client-side component of EDI substitutes placeholder “$search_param” in Line 8 with the characters entered by the user in the corresponding form field of the interface.
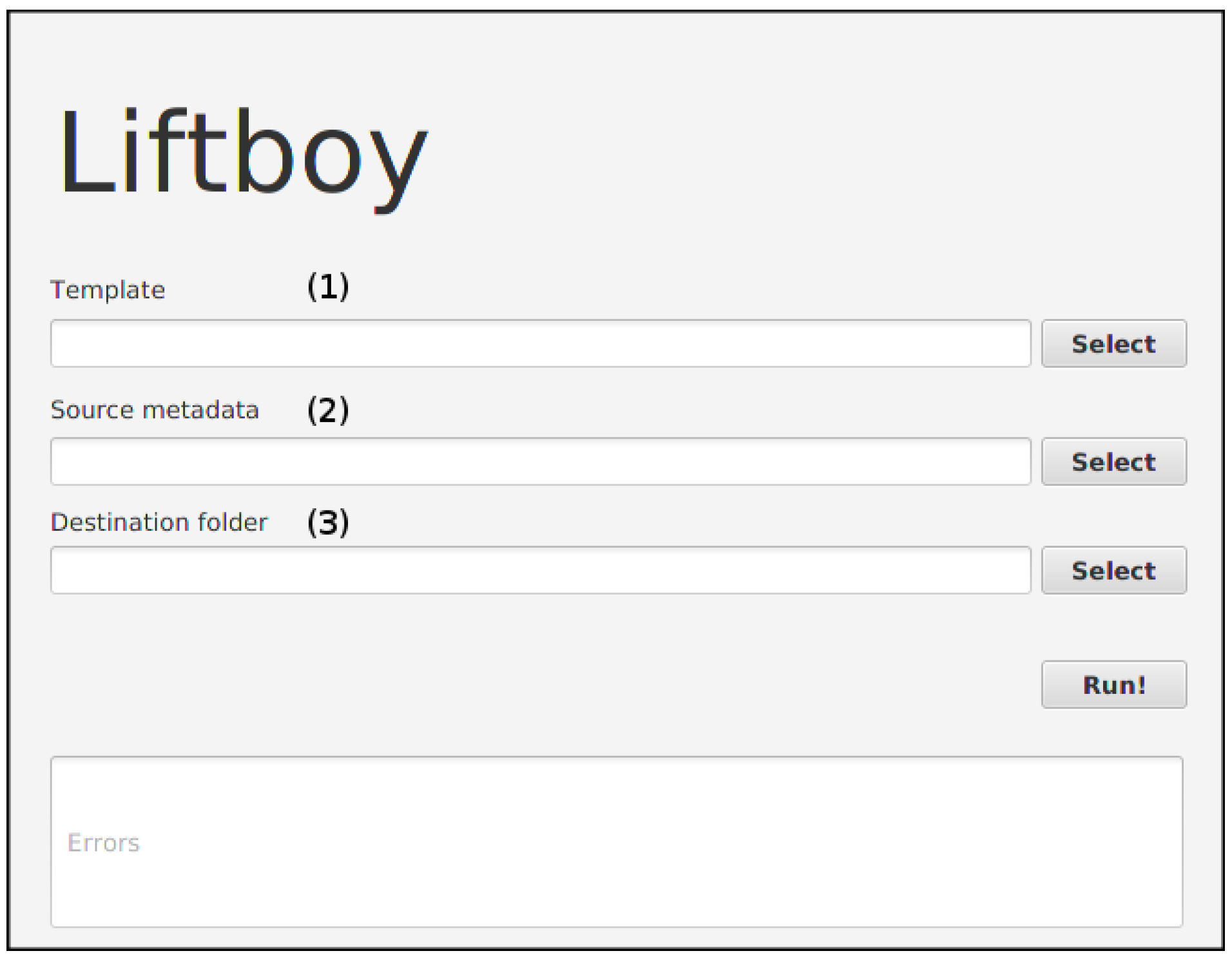
3.1. Writing Templates for Liftboy
3.1.1. Flexibility in Liftboy Templates
//gmd:electronicMailAddress[ancestor::gmd:CI_Contact//gmd:URL=’http://acme.org’]
3.1.2. Information Loss in Metadata Encoding
4. Decoupling Semantic Information from Metadata via WADM Annotations
- The specification of the source metadata file that is the subject of the annotations (Line 3).
- The specific path pinpointing the metadata element under consideration (Lines 12 and 14).
- The URI that is be related to the metadata item by semantic augmentation (Line 18).
- 1
- <elements>
- 2
- ...
- 3
- <fileUri>http://.../metadata/Dataset_ABC</fileUri>
- 4
- ...
- 5
- <element>
- 6
- <id>resp</id>
- 7
- ...
- 8
- <items>
- 9
- <item>
- 10
- <id>resp_1</id>
- 11
- <element_id>resp</element_id>
- 12
- <hasRoot>/gmd:MD_Metadata/.../gmd:CI_Citation</hasRoot>
- 13
- <path>
- 14
- gmd:citedResponsibleParty/.../gmd:electronicMailAddress/...
- 15
- </path>
- 16
- <value>john.doe@acme.org</value>
- 17
- <codeValue>
- 18
- http://acme.org/personnel/JohnDoe
- 19
- </codeValue>
- 20
- ...
- 21
- </item>
- 22
- ...
- 23
- <items>
- 24
- ...
- 25
- </element>
- 26
- <elements>
- 1
- {
- 2
- "@context": "http://www.w3.org/ns/anno.jsonld",
- 3
- "id": "http://example.org/anno1",
- 4
- "type": "Annotation",
- 5
- "motivation": "identifying",
- 6
- "creator": {
- 7
- "id": "http://example.org/liftboy/",
- 8
- "type": "Software",
- 9
- "name": "Liftboy v1.0beta",
- 10
- "nickname": "Liftboy",
- 11
- "homepage": "https://github.com/SP7-Ritmare/Liftboy/"
- 12
- },
- 13
- "created": "2015-01-28T12:00:00Z",
- 14
- "modified": "2015-01-29T09:00:00Z",
- 15
- "generator": "http://example.org/liftboy",
- 16
- "generated": "2015-02-04T12:00:00Z",
- 17
- "body": {
- 18
- "id":"http://acme.org/personnel/JohnDoe",
- 19
- "format":"rdf+xml"
- 20
- },
- 21
- "target": {
- 22
- "id":"http://.../metadata/Dataset_ABC",
- 23
- "format":"vnd.iso.19139+xml",
- 24
- "selector":{
- 25
- "type":"XPathSelector",
- 26
- "value":"/gmd:MD_Metadata/.../gmd:CI_Citation/
- 27
- gmd:citedResponsibleParty/.../gmd:electronicMailAddress/..."
- 28
- }
- 29
- }
- 30
- }
- 1
- {
- 2
- "@context": "http://www.w3.org/ns/anno.jsonld",
- 3
- "id": "http://example.org/collection1",
- 4
- "type": "AnnotationCollection",
- 5
- "label": "Semantic annotation collection",
- 6
- "creator": {
- 7
- "id": "http://example.org/user1",
- 8
- "type": "Software",
- 9
- "name": "Liftboy v1.0beta",
- 10
- "nickname": "Liftboy",
- 11
- "homepage": "https://github.com/SP7-Ritmare/Liftboy/"
- 12
- },
- 13
- "total": 2,
- 14
- "first": {
- 15
- "id": "http://example.org/page1",
- 16
- "type": "AnnotationPage",
- 17
- "startIndex": 0,
- 18
- "items": [
- 19
- "http://example.org/anno1",
- 20
- "http://example.org/anno2"
- 21
- ]
- 22
- }
- 23
- }
5. Exploiting Semantic Information
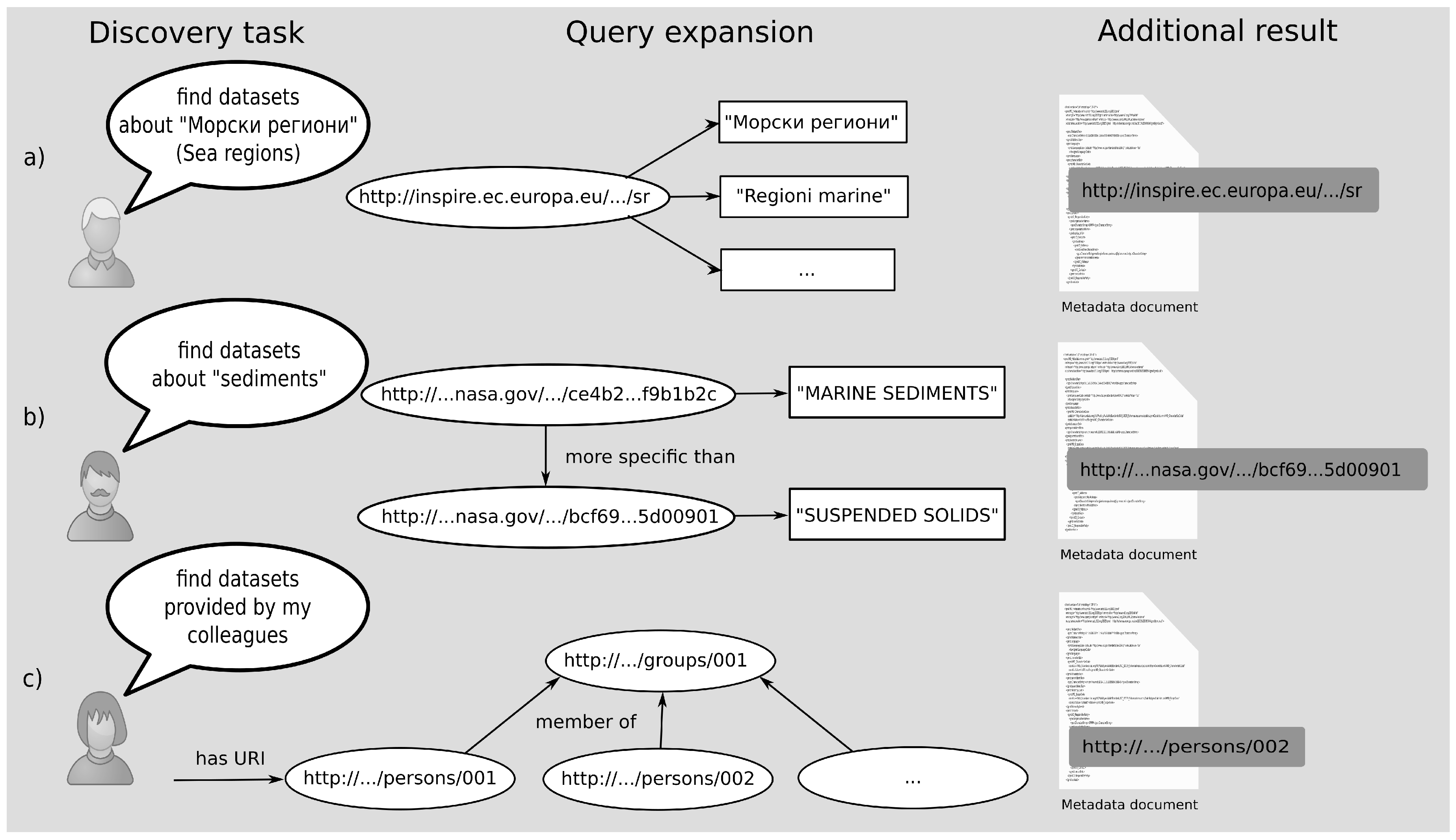
5.1. Cross-Language Discovery
- 1
- PREFIX def: <http://sp7.irea.cnr.it/rdfdata/schemas#>
- 2
- PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
- 3
- PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
- 4
- PREFIX foaf: <http://xmlns.com/foaf/0.1/>
- 5
- PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
- 6
- PREFIX sp7: <http://sp7.irea.cnr.it/rdfdata/project/>
- 7
- PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
- 8
- PREFIX dcat: <http://www.w3.org/ns/dcat#>
- 9
- PREFIX dct: <http://purl.org/dc/terms/>
- 10
- 11
- SELECT DISTINCT ?dataset ?title
- 12
- WHERE {
- 13
- ?dataset rdf:type dcat:Dataset .
- 14
- ?dataset dct:title ?title .
- 15
- ?dataset dcat:theme ?keyword .
- 16
- ?keyword skos:prefLabel ?label .
- 17
- FILTER( REGEX( STR(?label), "Морски региони", "i") )
- 18
- }
DESCRIBE <http://sp7.irea.cnr.it/data/6c43fd22-9659-11e4-a8cd-5254007ad55c>
5.2. Query Expansion
- 1
- PREFIX def: <http://sp7.irea.cnr.it/rdfdata/schemas#>
- 2
- PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
- 3
- PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
- 4
- PREFIX foaf: <http://xmlns.com/foaf/0.1/>
- 5
- PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
- 6
- PREFIX sp7: <http://sp7.irea.cnr.it/rdfdata/project/>
- 7
- PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
- 8
- PREFIX dcat: <http://www.w3.org/ns/dcat#>
- 9
- PREFIX dct: <http://purl.org/dc/terms/>
- 10
- 11
- SELECT DISTINCT ?dataset ?title
- 12
- WHERE {
- 13
- ?dataset rdf:type dcat:Dataset .
- 14
- ?dataset dct:title ?title .
- 15
- ?dataset dcat:theme ?keyword .
- 16
- ?keyword skos:broader ?broader_term .
- 17
- ?broader_term skos:prefLabel ?label .
- 18
- FILTER( REGEX( STR(?label), "sediments", "i") )
- 19
- }
5.3. Expansion Based on Social Network
- 1
- PREFIX def: <http://sp7.irea.cnr.it/rdfdata/schemas#>
- 2
- PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
- 3
- PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
- 4
- PREFIX foaf: <http://xmlns.com/foaf/0.1/>
- 5
- PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
- 6
- PREFIX sp7: <http://sp7.irea.cnr.it/rdfdata/project/>
- 7
- PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
- 8
- PREFIX dcat: <http://www.w3.org/ns/dcat#>
- 9
- PREFIX dct: <http://purl.org/dc/terms/>
- 10
- PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
- 11
- 12
- SELECT DISTINCT ?dataset ?title
- 13
- WHERE {
- 14
- sp7:CristianoFugazzaIREA vcard:org ?organization .
- 15
- ?dataset rdf:type dcat:Dataset .
- 16
- ?dataset dct:title ?title .
- 17
- ?dataset dcat:contactPoint/vcard:hasUID ?person .
- 18
- ?person vcard:org ?organization .
- 19
- }
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| ANZLIC | Australia New Zealand Land Information Council |
| CoP | Community of Practice |
| CNR-IREA | National Research Council, Institute for Electromagnetic Sensing of the Environment |
| EMF | Environmental Monitoring Facilities |
| ENVRI | ENVironmental Research Infrastructures |
| ERMES | Earth obseRvation Model based RicE information Service |
| EU | European Union |
| FOSS | Free and Open Source Software |
| GCMD | Global Change Master Directory |
| GEOSS | GEO System of Systems |
| GET-IT | Geoinformation Enabling ToolkIT |
| GIS | Geographic Information Systems |
| INSPIRE | INfrastructure for Spatial InfoRmation in Europe |
| IR | Information Retrieval |
| IT | Information Technology |
| JSON-LD | JavaScript Object Notation for Linking Data |
| LDP | Linked Data Platform |
| LSA | Latent Semantic Analysis |
| LTER | Long-Term Ecosystem Research |
| OGC | Open Geospatial Consortium |
| RDF | Resource Description Framework |
| RNDT | Repertorio Nazionale dei Dati Territoriali (National Repository of Territorial Data) |
| RITMARE | Ricerca ITaliana per il MARE (Italian Research for the Sea) |
| SDI | Spatial Data Infrastructures |
| SKOS | Simple Knowledge Organization System |
| SPARQL | SPARQL Protocol and RDF Query Language |
| URI | Uniform Resource Identifier |
| XPath | XML Path Language |
| XSLT | eXstensible Stylesheet Language Transformations |
| WADM | Web Annotation Data Model |
| WAP | Web Annotation Protocol |
Appendix A. EDI/Liftboy Template Fragment Defining a Keyword in INSPIRE Metadata
- 1
- <element xml:id="keyw_voc_contr" isMandatory="false" isMultiple="true">
- 2
- <label xml:lang="en">Keyword from controlled vocabularies</label>
- 3
- <hasRoot>/gmd:MD_Metadata/.../gmd:MD_DataIdentification</hasRoot>
- 4
- <produces>
- 5
- <item hasDatatype="autoCompletion" datasource="keywordFromContrVoc">
- 6
- <label xml:lang="en">Keyword</label>
- 7
- <hasPath>
- 8
- gmd:descriptiveKeywords/gmd:MD_Keywords/gmd:keyword/...
- 9
- </hasPath>
- 10
- </item>
- 11
- ...
- 12
- </produces>
- 13
- </element>
Appendix B. Fragment from ISO 19139 Metadata Defining a Keyword
- 1
- <gmd:descriptiveKeywords>
- 2
- <gmd:MD_Keywords>
- 3
- <gmd:keyword>
- 4
- <gco:CharacterString>Ocean Currents</gco:CharacterString>
- 5
- </gmd:keyword>
- 6
- </gmd:MD_Keywords>
- 7
- ...
- 8
- </gmd:descriptiveKeywords>
Appendix C. EDIML Produced by Liftboy Relative to the Keyword in Appendix B
- 1
- <element>
- 2
- <id>keyw_voc_contr</id>
- 3
- ...
- 4
- <items>
- 5
- <item>
- 6
- <id>keyw_voc_contr_1</id>
- 7
- <element_Id>keyw_voc_contr</element_Id>
- 8
- <path>
- 9
- /gmd:MD_Metadata/.../gmd:descriptiveKeywords/.../gmd:keyword/...
- 10
- </path>
- 11
- <value>Ocean Currents</value>
- 12
- <codeValue>http://gcmd.gsfc.nasa.gov/skos#ocean_currents</codeValue>
- 13
- ...
- 14
- </item>
- 15
- ...
- 16
- </items>
- 17
- </element>
Appendix D. WADM Annotation Relative to the Keyword Item in Appendix B
- 1
- {
- 2
- "@context": "http://www.w3.org/ns/anno.jsonld",
- 3
- "id": "http://example.org/anno2",
- 4
- "type": "Annotation",
- 5
- "motivation": "identifying",
- 6
- ...
- 7
- "body": {
- 8
- "id":"http://gcmd.gsfc.nasa.gov/skos#ocean_currents",
- 9
- "format":"rdf+xml"
- 10
- },
- 11
- "target": {
- 12
- "id":"http://.../metadata/Dataset_ABC",
- 13
- "format":"vnd.iso.19139+xml",
- 14
- "selector":{
- 15
- "type":"XPathSelector",
- 16
- "value":"/gmd:MD_Metadata/.../gmd:descriptiveKeywords/.../gmd:keyword/
- 17
- gco:CharacterString[text()=’Ocean Currents’]"
- 18
- }
- 19
- }
- 20
- }
References
- Salvemini, M. From the GIS to the SDI: A design path. In Proceedings of the 7th AGILE Conference on Geographic Information Science, Crete, Greece, 29 April–1 May 2004; pp. 1–7. [Google Scholar]
- Craglia, M.; Nativi, S.; Santoro, M.; Vaccari, L.; Fugazza, C. Inter-disciplinary Interoperability for Global Sustainability Research. In Proceedings of the 4th International Conference on GeoSpatial Semantics (GeoS’11), Brest, France, 12–13 May 2011; Springer-Verlag: Berlin/Heidelberg, Germany, 2011; pp. 1–15. [Google Scholar]
- Perego, A.; Fugazza, C.; Vaccari, L.; Lutz, M.; Smits, P.; Kanellopoulos, I.; Schade, S. Harmonization and Interoperability of EU Environmental Information and Services. IEEE Intell. Syst. 2012, 27, 33–39. [Google Scholar] [CrossRef]
- European Commission. Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 Establishing an Infrastructure for Spatial Information in the European Community (INSPIRE). 2007. Available online: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32007L0002 (accessed on 5 November 2017).
- European Commission. Commission Regulation (EC) No 1205/2008 of 3 December 2008 Implementing Directive 2007/2/EC of the European Parliament and of the Council as Regards Metadata. 2008. Available online: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32008R1205 (accessed on 5 November 2017).
- European Commission. Corrigendum to Commission Regulation (EC) No 1205/2008 of 3 December 2008 Implementing Directive 2007/2/EC of the European Parliament and of The Council as Regards Metadata. 2008. Available online: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32008R1205R%2802%29 (accessed on 5 November 2017).
- Christian, E.J. GEOSS Architecture Principles and the GEOSS Clearinghouse. IEEE Syst. J. 2008, 2, 333–337. [Google Scholar] [CrossRef]
- Butterfield, M.L.; Pearlman, J.S.; Vickroy, S.C. A System-of-Systems Engineering GEOSS: Architectural Approach. IEEE Syst. J. 2008, 2, 321–332. [Google Scholar] [CrossRef]
- Gore, A. The digital earth. Aust. Surv. 1998, 43, 89–91. [Google Scholar] [CrossRef]
- Craglia, M.; de Bie, K.; Jackson, D.; Pesaresi, M.; Remetey-Fülöpp, G.; Wang, C.; Annoni, A.; Bian, L.; Campbell, F.; Ehlers, M.; et al. Digital Earth 2020: Towards the vision for the next decade. Int. J. Digit. Earth 2012, 5, 4–21. [Google Scholar] [CrossRef]
- Nieva de la Hidalga, A.; Hardisty, A. How the ENVRI Reference Model Helps to Design Research Infrastructures; Technical Report. ENVRIplus Newsletter, 2016. Available online: www.envriplus.eu/wp-content/uploads/2016/05/ENVRI-Reference-Model.pdf (accessed on 5 November 2017).
- Bishr, Y. Overcoming the semantic and other barriers to GIS interoperability. Int. J. Geogr. Inf. Sci. 1998, 12, 299–314. [Google Scholar] [CrossRef]
- Ouksel, A.M.; Sheth, A. Semantic Interoperability in Global Information Systems. SIGMOD Rec. 1999, 28, 5–12. [Google Scholar] [CrossRef]
- Ramakrishnan, C.; Sheth, A.; Thomas, C. Semantics for The Semantic Web: The Implicit, the Formal and the Powerful. Int. J. Semant. Web Inf. Syst. 2005, 1, 1–18. [Google Scholar]
- Nativi, S.; Bigagli, L. Discovery, Mediation, and Access Services for Earth Observation Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2009, 2, 233–240. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Fielding, R.; Masinter, L. Uniform Resource Identifiers (URI): Generic Syntax. 1998. Available online: https://tools.ietf.org/html/rfc3986 (accessed on 5 November 2017).
- Pavesi, F.; Basoni, A.; Fugazza, C.; Menegon, S.; Oggioni, A.; Pepe, M.; Tagliolato, P.; Carrara, P. EDI—A Template-Driven Metadata Editor for Research Data. J. Open Res. Softw. 2016, 4. [Google Scholar] [CrossRef]
- ISO. ISO 19115:2014 Geographic Information—Metadata. Standard, International Organization for Standardization (TC 211), 2014. Available online: http://www.iso.org/iso/iso_catalogue/catalogue_ics/catalogue_detail_ics.htm?csnumber=53798 (accessed on 5 November 2017).
- ISO. ISO 19119:2005 Geographic Information—Services. Standard, International Organization for Standardization (TC 211), 2005. Available online: http://www.iso.org/iso/catalogue_detail.htm?csnumber=39890 (accessed on 5 November 2017).
- ISO. ISO 191136:2007 Geographic Information—Geography Markup Language (GML). Standard, International Organization for Standardization (TC 211), 2007. Available online: http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=32554 (accessed on 5 November 2017).
- Fugazza, C.; Pepe, M.; Oggioni, A.; Tagliolato, P.; Carrara, P. Streamlining geospatial metadata in the Semantic Web. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2016; Volume 34. [Google Scholar]
- W3C—Web Annotation Working Group. Web Annotation Data Model. Available online: https://www.w3.org/TR/annotation-model/ (accessed on 5 November 2017).
- Agenzia per l’Italia Digitale (AgID). Repertorio Nazionale dei Dati Territoriali—RNDT; Technical Report; Agenzia per l’Italia Digitale (AgID): Rome, IT, 2012. Available online: http://archivio.digitpa.gov.it/repertorio-nazionale-dei-dati-territoriali-rndt (accessed on 5 November 2017).
- W3C. XSL Transformations (XSLT) Version 1.0. 1999. Available online: https://www.w3.org/TR/xslt (accessed on 5 November 2017).
- Patroumpas, K.; Georgomanolis, N.; Stratiotis, T.; Alexakis, M.; Athanasiou, S. Exposing INSPIRE on the Semantic Web. Web Semant. 2015, 35, 53–62. [Google Scholar] [CrossRef]
- Lutz, M.; Sprado, J.; Klien, E.; Schubert, C.; Christ, I. Overcoming semantic heterogeneity in spatial data infrastructures. Comput. Geosci. 2009, 35, 739–752. [Google Scholar] [CrossRef]
- Australia New Zealand Land Information Council. ANZLIC Metadata Profile. 2007. Available online: http://www.anzlic.gov.au/resources/metadata (accessed on 5 November 2017).
- Santoro, M.; Mazzetti, P.; Nativi, S.; Fugazza, C.; Granell, C.; Díaz, L. Methodologies for augmented discovery of geospatial resources. In Discovery of Geospatial Resources: Methodologies, Technologies, and Emergent Applications; Díaz, L., Granell, C., Huerta, J., Eds.; IGI Global: Hershey, PA, USA, 2012; Chapter 9; pp. 172–203. [Google Scholar]
- Fugazza, C.; Luraschi, G. Semantics-Aware Indexing of Geospatial Resources Based on Multilingual Thesauri: Methodology and Preliminary Results. Int. J. Spat. Data Infrastruct. Res. 2012, 7, 16–37. [Google Scholar]
- Kuhn, W. Geospatial Semantics: Why, of What, and How? In Journal on Data Semantics III; Spaccapietra, S., Zimányi, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–24. [Google Scholar]
- Kuhn, W. Modeling vs Encoding for the Semantic Web. Semant. Web 2010, 1, 11–15. [Google Scholar]
- World Wide Web Consortium. SKOS Simple Knowledge Organization System Reference. 2009. Available online: https://www.w3.org/TR/skos-reference/ (accessed on 5 November 2017).
- Bechhofer, S.; van Harmelen, F.; Hendler, J.; Horrocks, I.; McGuinness, D.L.; Patel-Schneider, P.F.; Stein, L.A. OWL Web Ontology Language Reference. 2004. Available online: https://www.w3.org/TR/owl-ref/ (accessed on 5 November 2017).
- Lassila, O.; Swick, R.R.; World Wide Web Consortium. Resource Description Framework (RDF) Model and Syntax Specification. 1998. Available online: https://www.w3.org/TR/1999/REC-rdf-syntax-19990222/ (accessed on 5 November 2017).
- Berners-Lee, T. Linked Data—Design Issues. 2006. Available online: http://www.w3.org/DesignIssues/LinkedData.html (accessed on 5 November 2017).
- Prud’hommeaux, E.; Seaborne, A. SPARQL Query Language for RDF. W3C, 2008. Available online: http://www.w3.org/TR/rdf-sparql-query/ (accessed on 5 November 2017).
- Chrisman, N. Exploring Geographic Information Systems; Wiley: Hoboken, NJ, USA, 1997. [Google Scholar]
- Riedemann, C.; Pundt, H.; Harvey, F.; Kuhn, W.; Bishr, Y. Semantic interoperability: A central issue for sharing geographic information. Ann. Reg. Sci. 1999, 33, 213–232. [Google Scholar]
- Martin, D.; Burstein, M.; Hobbs, J.; Lassila, O.; McDermott, D.; McIlraith, S.; Narayanan, S.; Paolucci, M.; Parsia, B.; Payne, T.; et al. OWL-S: Semantic Markup for Web Services. 2004. Available online: http://www.w3.org/Submission/2004/SUBM-OWL-S-20041122/ (accessed on 5 November 2017).
- Szekely, P.; Knoblock, C.A.; Gupta, S.; Taheriyan, M.; Wu, B. Exploiting Semantics of Web Services for Geospatial Data Fusion. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Spatial Semantics and Ontologies (SSO ’11), Chicago, IL, USA, 1 November 2011; pp. 32–39. [Google Scholar]
- Dill, S.; Eiron, N.; Gibson, D.; Gruhl, D.; Guha, R. SemTag and Seeker: Bootstrapping the Semantic Web via Automated Semantic Annotation. In Proceedings of the 12th International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2003. [Google Scholar]
- Mahmoudi, K.; Faïz, S. From Text to Semantic Geodata Enrichment. Int. J. Agent Technol. Syst. 2014, 6, 28–44. [Google Scholar] [CrossRef][Green Version]
- Klien, E.; Lutz, M. The Role of Spatial Relations in Automating the Semantic Annotation of Geodata. In Proceedings of the International Conference on Spatial Information Theory (COSIT 2005), Ellicottville, NY, USA, 14–18 September 2005; pp. 133–148. [Google Scholar]
- Klien, E. A Rule-Based Strategy for the Semantic Annotation of Geodata. Trans. GIS 2007, 11, 437–452. [Google Scholar] [CrossRef]
- Gomes de Andrade, F.; de Souza Baptista, C.; Henriques, H.B. Semantic Annotation of Geodata Based on Linked-open Data. In Proceedings of the 7th International Conference on Management of Computational and Collective intElligence in Digital EcoSystems (MEDES ’15), Caraguatatuba, Brazil, 25–29 October 2015; ACM: New York, NY, USA, 2015; pp. 9–16. [Google Scholar]
- Vockner, B.; Mittlböck, M. Geo-Enrichment and Semantic Enhancement of Metadata Sets to Augment Discovery in Geoportals. ISPRS Int. J. Geo-Inf. 2014, 3, 345–367. [Google Scholar] [CrossRef]
- Nowak, J.; Nogueras-iso, J.; Peedell, S. Issues of multilinguality in creating a European SDI—The perspective for spatial data interoperability. In Proceedings of the 11th EC GI & GIS Workshop, ESDI Setting the Framework, Alghero, Italy, 29 June–1 July 2005. [Google Scholar]
- Li, W.; Goodchild, M.F.; Raskin, R. Towards geospatial semantic search: exploiting latent semantic relations in geospatial data. Int. J. Digit. Earth 2014, 7, 17–37. [Google Scholar] [CrossRef]
- Fox, P.; Mcguinness, D.; Cinquini, L.; West, P.; Garcia, J.; Benedict, J.; Middleton, D. Ontology-supported Scientific Data Frameworks: The Virtual Solar-Terrestrial Observatory Experience. Comput. Geosci. 2009, 35, 724–738. [Google Scholar] [CrossRef]
- Li, W.; Yang, C.; Raskin, R. A semantic enhanced search for spatial Web portals. In AAAI Spring Symposium —Technical Report; AAAI: Palo Alto, CA, USA, 2008; Volume SS-08-05, pp. 47–50. [Google Scholar]
- Akanbi, A.K.; Agunbiade, O.Y.; Kuti, S.; Dehinbo, O.J. A Semantic Enhanced Model for effective Spatial Information Retrieval. In Proceedings of the World Congress on Engineering and Computer Science (WCECS 2014), San Francisco, CA, USA, 22–24 October 2014. [Google Scholar]
- Tagliolato, P.; Oggioni, A.; Fugazza, C.; Cianferoni, F.; De Fellici, S. Georiferimento di campioni museali nell’infrastruttura LifeWatch Italia: Le nuove prospettive dal web semantico. In Proceedings of the XXVI Congresso ANMS, Trieste, Italy, 16–18 November 2016. [Google Scholar]
- Fugazza, C.; Pepe, M.; Oggioni, A.; Tagliolato, P.; Pavesi, F.; Carrara, P. Describing Geospatial Assets in the Web of Data: A Metadata Management Scenario. ISPRS Int. J. Geo-Inf. 2016, 5, 229. [Google Scholar] [CrossRef]
- XSL Working Group and the XML Linking Working Group. XML Path Language (XPath) Version 1.0. 1999. Available online: https://www.w3.org/TR/xpath/ (accessed on 5 November 2017).
- Open Geospatial Consortium Inc. (OGC). Semantic Annotations in OGC Standards; Discussion Paper OGC 08-167r1; Open Geospatial Consortium: Wayland, MA, USA, 2009. [Google Scholar]
- Web Annotation Working Group. Web Annotation Vocabulary. Available online: https://www.w3.org/TR/annotation-vocab/ (accessed on 5 November 2017).
- Bigagli, L.; Mazzetti, P.; Nativi, S.; Boldrini, E.; Papeschi, F. GI-Cat: A Mediation Solution for Building a Clearinghouse Catalog Service. In Proceedings of the 2009 International Conference on Advanced Geographic Information Systems & Web Services (GEOWS 2009), Cancun, Mexico, 1–7 February 2009; Volume 00, pp. 68–74. [Google Scholar]
- Bigagli, L.; Nativi, S.; Mazzetti, P.; Villoresi, G. GI-Cat: A Web Service for Dataset Cataloguing Based on ISO 19115. In Proceedings of the 15th International Workshop on Database and Expert Systems Applications (DEXA 2004), Zaragoza, Spain, 30 August–3 September 2004; pp. 846–850. [Google Scholar]
- Linked Data Platform Working Group. Linked Data Platform. 2015. Available online: https://www.w3.org/TR/ldp/ (accessed on 5 November 2017).
- Web Annotation Working Group. Web Annotation Protocol. Available online: https://www.w3.org/TR/annotation-protocol/ (accessed on 5 November 2017).




© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fugazza, C.; Tagliolato, P.; Frigerio, L.; Carrara, P. Web-Scale Normalization of Geospatial Metadata Based on Semantics-Aware Data Sources. ISPRS Int. J. Geo-Inf. 2017, 6, 354. https://doi.org/10.3390/ijgi6110354
Fugazza C, Tagliolato P, Frigerio L, Carrara P. Web-Scale Normalization of Geospatial Metadata Based on Semantics-Aware Data Sources. ISPRS International Journal of Geo-Information. 2017; 6(11):354. https://doi.org/10.3390/ijgi6110354
Chicago/Turabian StyleFugazza, Cristiano, Paolo Tagliolato, Luca Frigerio, and Paola Carrara. 2017. "Web-Scale Normalization of Geospatial Metadata Based on Semantics-Aware Data Sources" ISPRS International Journal of Geo-Information 6, no. 11: 354. https://doi.org/10.3390/ijgi6110354
APA StyleFugazza, C., Tagliolato, P., Frigerio, L., & Carrara, P. (2017). Web-Scale Normalization of Geospatial Metadata Based on Semantics-Aware Data Sources. ISPRS International Journal of Geo-Information, 6(11), 354. https://doi.org/10.3390/ijgi6110354