A Framework for Evaluating Stay Detection Approaches

 , ,
, , 
Abstract
:
1. Introduction
2. Related Work
2.1. Stay Detection—An Approximation
2.2. Stay Detection Approaches
2.3. Data Acquisition
2.4. Data Pre-Processing
2.5. Parameterization
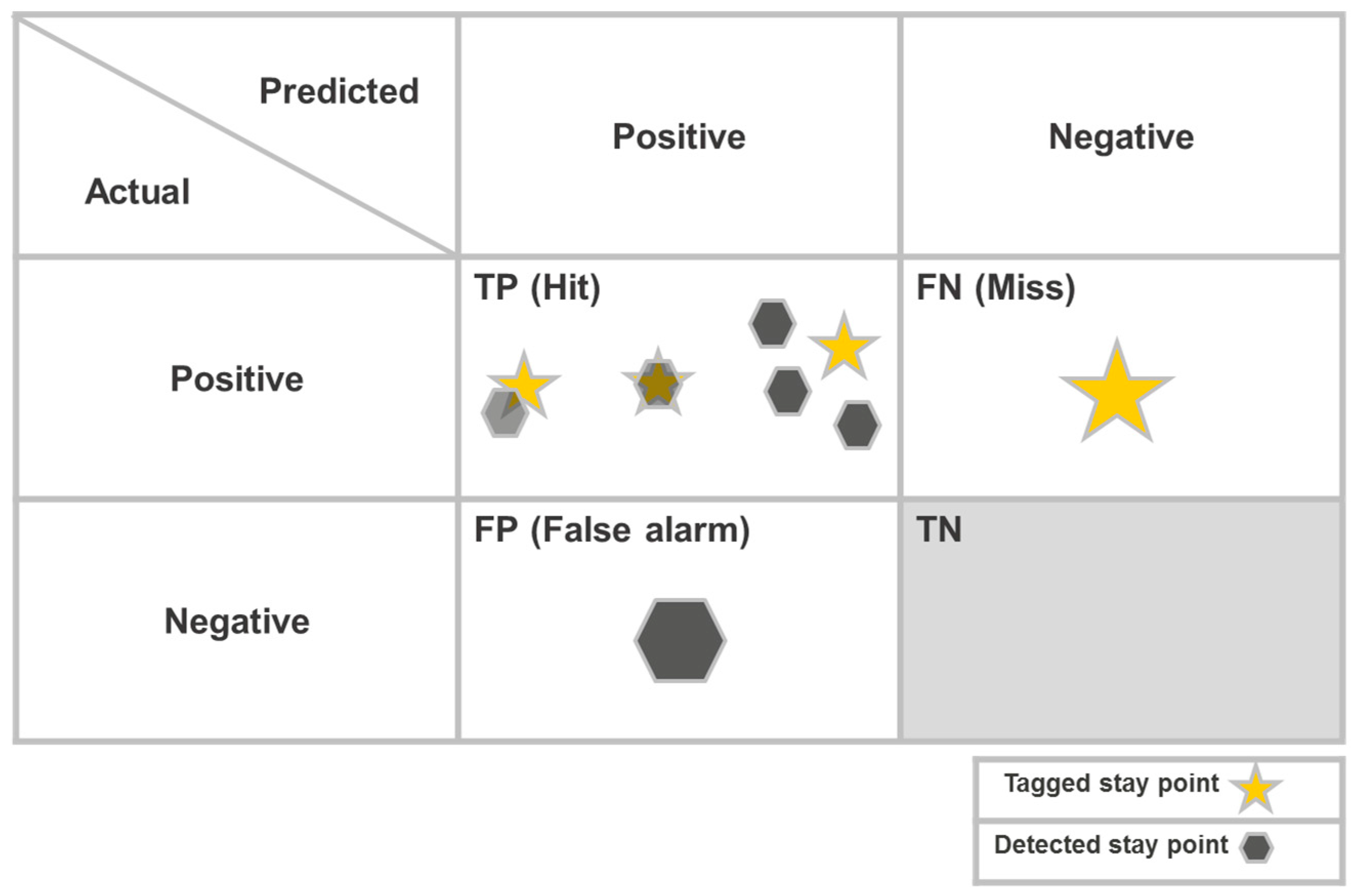
2.6. Established Evaluation Procedures and Measures
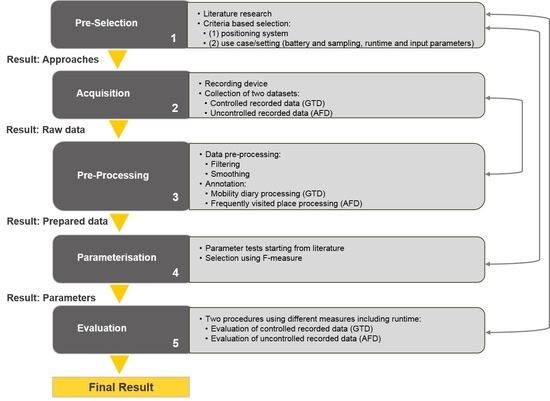
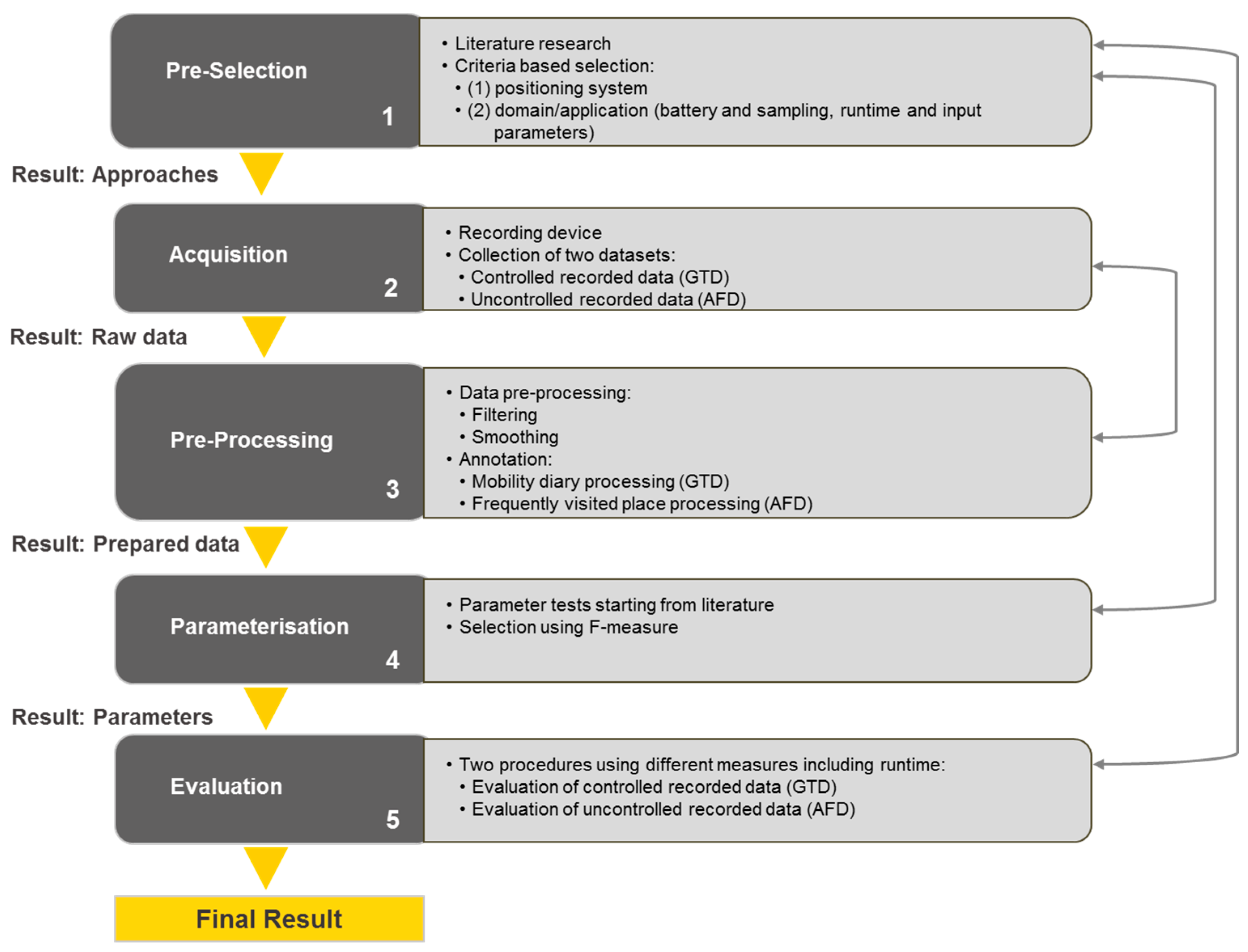
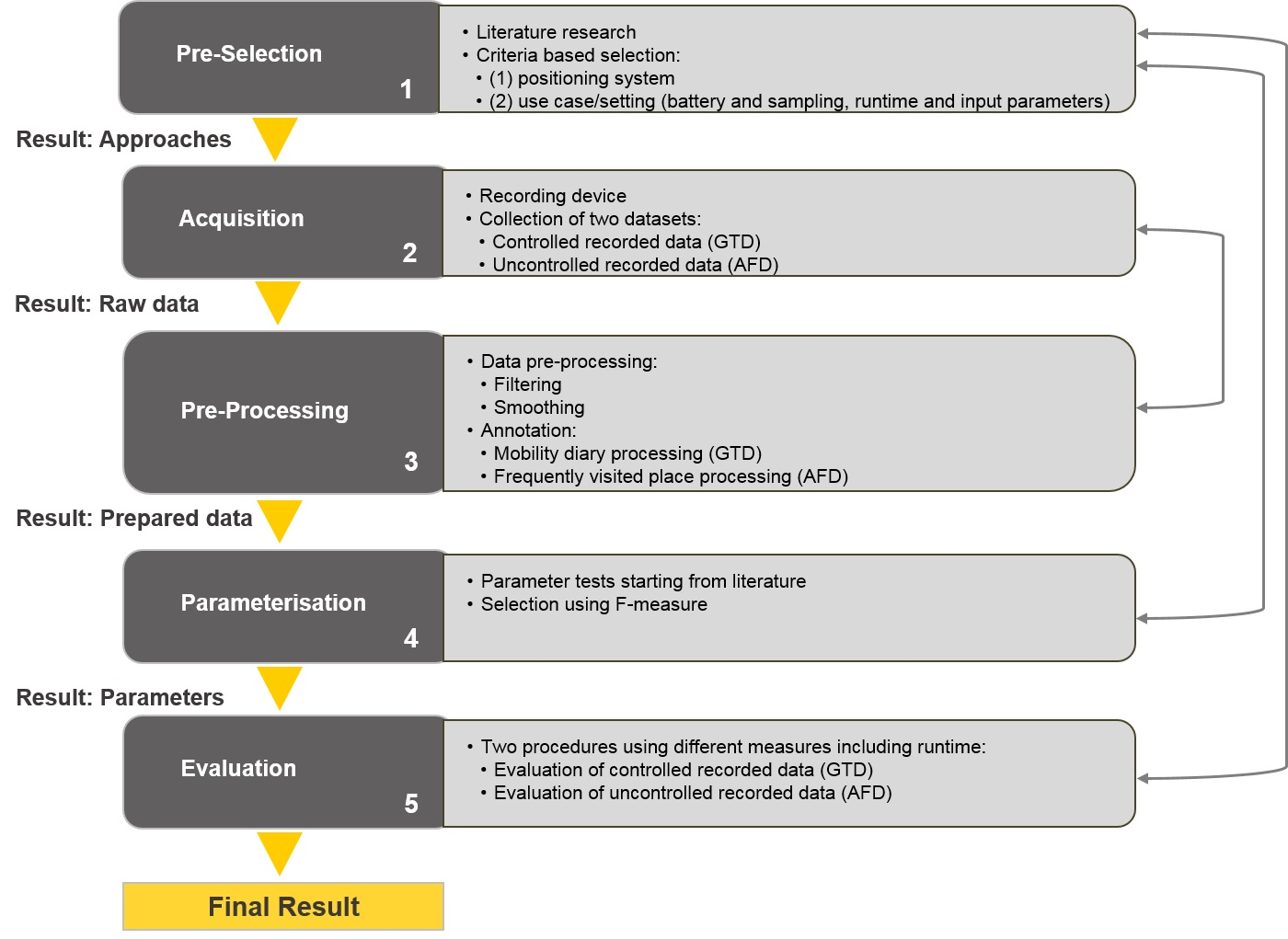
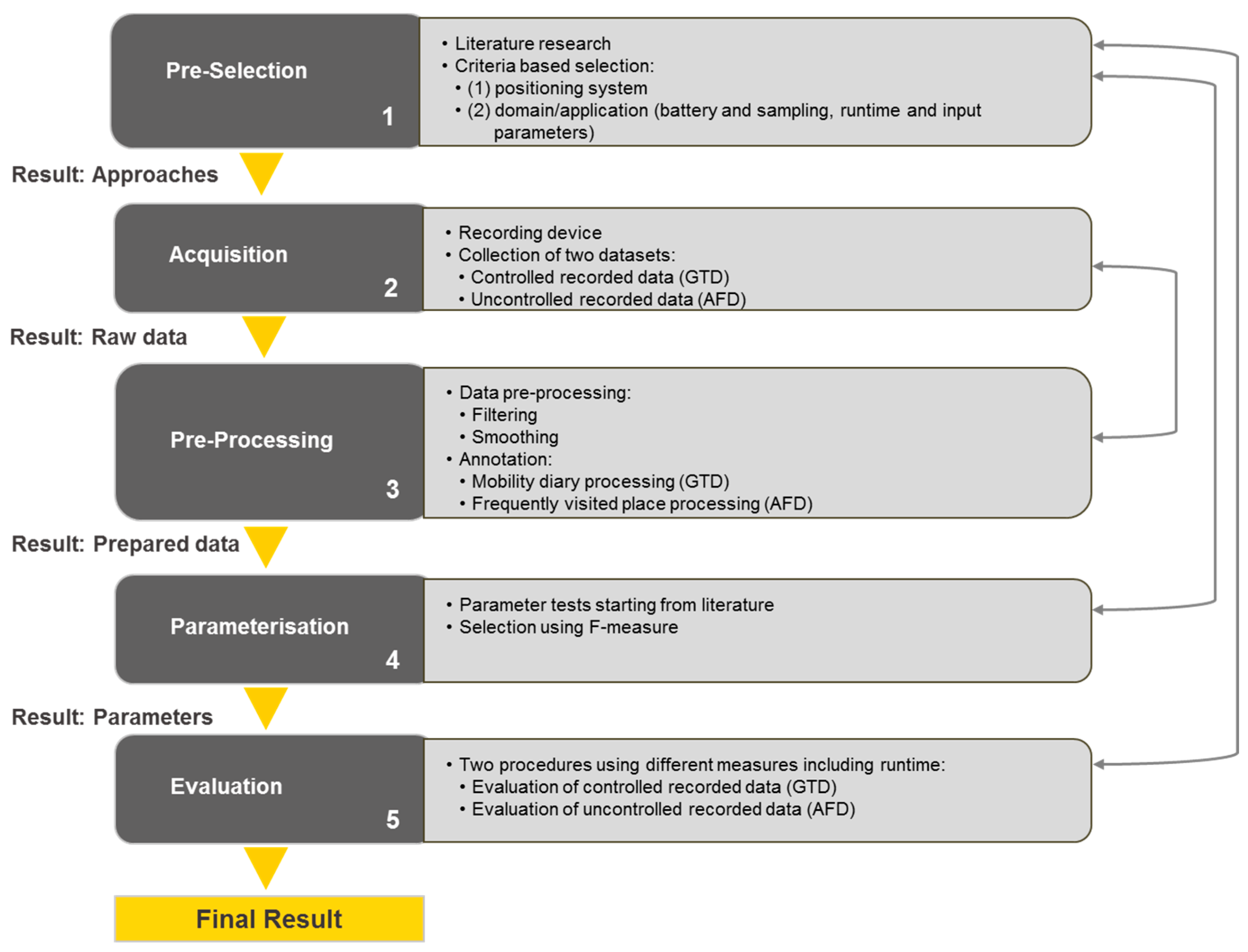
3. Definition of the Framework
3.1. Pre-Selection
3.2. Acquisition
3.2.1. Collection of Controlled Recorded GTD
3.2.2. Collection of Uncontrolled Recorded AFD
3.3. Pre-Processing
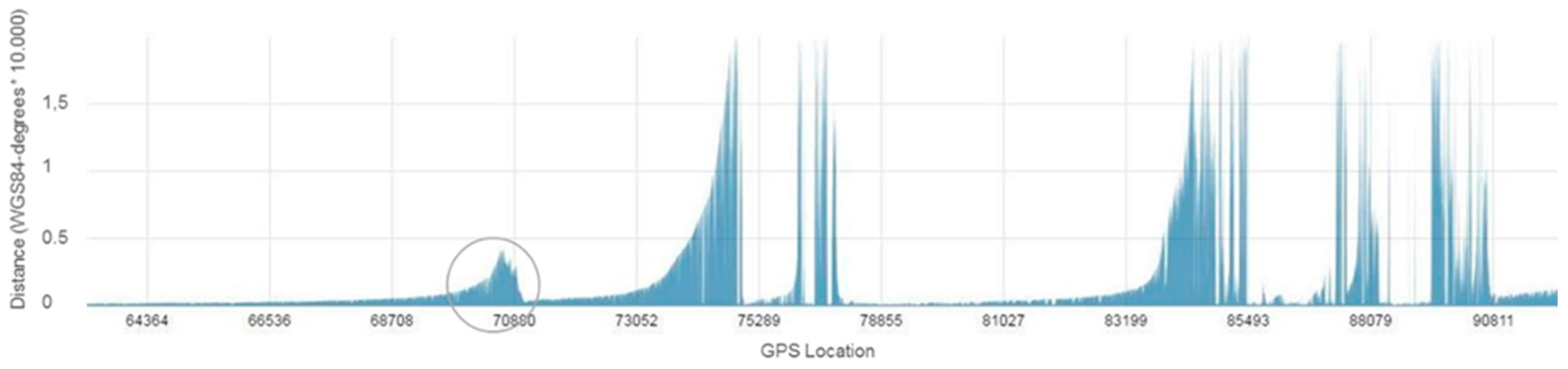
3.3.1. GPS Data Pre-Processing
3.3.2. Data Annotation
3.4. Parameterization
3.5. Evaluation
3.5.1. Evaluation of Controlled Recorded GTD
3.5.2. Evaluation of Controlled Recorded AFD
4. Application and Validation of the Framework
4.1. Pre-Selection
4.1.1. Time-Based/Incremental Clustering (TIC)
4.1.2. (Extended) Density-Based Clustering (xDBSCAN)
4.1.3. Mixed-Method Approach (MIXED)
4.2. Acquisition
4.2.1. Controlled Recorded GTD
4.2.2. Uncontrolled Recorded AFD
4.3. Pre-Processing
4.4. Parameterization
4.4.1. TIC
4.4.2. xDBSCAN
4.4.3. MIXED
4.5. Evaluation
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Castelli, G.; Mamei, M.; Rosi, A. The Whereabouts Diary. In Location- and Context-Awareness SE—11; Lecture Notes in Computer Science; Hightower, J., Schiele, B., Strang, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4718, pp. 175–192. ISBN 978-3-540-75159-5. [Google Scholar]
- Vazquez-Prokopec, G.M.; Stoddard, S.T.; Paz-Soldan, V.; Morrison, A.C.; Elder, J.P.; Kochel, T.J.; Scott, T.W.; Kitron, U. Usefulness of commercially available GPS data-loggers for tracking human movement and exposure to dengue virus. Int. J. Health Geogr. 2009, 8, 68. [Google Scholar] [CrossRef] [PubMed]
- Brunauer, R.; Rehrl, K. Deriving driver-centric travel information by mining delay patterns from single GPS trajectories. In Proceedings of the 7th ACM SIGSPATIAL International Workshop on Computational Transportation Science—IWCTS ’14, Dallas/Fort Worth, TX, USA, 4 November 2014; ACM Press: New York, NY, USA, 2014; pp. 25–30. [Google Scholar]
- Liu, Y.; Seah, H.S. Points of interest recommendation from GPS trajectories. Int. J. Geogr. Inf. Sci. 2015, 29, 953–979. [Google Scholar] [CrossRef]
- Shoval, N.; Wahl, H.-W.; Auslander, G.; Isaacson, M.; Oswald, F.; Edry, T.; Landau, R.; Heinik, J. Use of the global positioning system to measure the out-of-home mobility of older adults with differing cognitive functioning. Ageing Soc. 2011, 31, 849–869. [Google Scholar] [CrossRef]
- Ni, Q.; Hernando, A.B.G.; de la Cruz, I.P. The Elderly’s Independent Living in Smart Homes: A Characterization of Activities and Sensing Infrastructure Survey to Facilitate Services Development. Sensors 2015, 15, 11312–11362. [Google Scholar] [CrossRef] [PubMed]
- Schneider, C.; Reich, S.; Feichtenschlager, M.; Willner, V.; Henneberger, S. Selbstbestimmtes Leben trotz Demenz. HMD Prax. Wirtschaftsinf. 2015, 52, 572–584. [Google Scholar] [CrossRef]
- Kang, J.H.; Welbourne, W.; Stewart, B.; Borriello, G. Extracting places from traces of locations. In Proceedings of the 2nd ACM International Workshop on Wireless Mobile Applications and Services on WLAN Hotspots—WMASH ’04, Philadelphia, PA, USA, 1 October 2004; ACM Press: New York, NY, USA, 2004; Volume 9, p. 110. [Google Scholar]
- Hightower, J.; Consolvo, S.; LaMarca, A.; Smith, I.; Hughes, J. Learning and Recognizing the Places We Go. In UbiComp 2005: Ubiquitous Computing SE—10; Lecture Notes in Computer Science; Beigl, M., Intille, S., Rekimoto, J., Tokuda, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3660, pp. 159–176. ISBN 978-3-540-28760-5. [Google Scholar]
- Changqing, Z.; Frankowski, D.; Ludford, P.; Shekhar, S.; Terveen, L. Discovering personally meaningful places : An interactive clustering approach. ACM Trans. Inf. Syst. 2007, 25, 12. [Google Scholar] [CrossRef]
- Cao, X.; Cong, G.; Jensen, C.S. Mining significant semantic locations from GPS data. Proc. VLDB Endow. 2010, 3, 1009–1020. [Google Scholar] [CrossRef]
- Montoliu, R.; Blom, J.; Gatica-Perez, D. Discovering places of interest in everyday life from smartphone data. Multimed. Tools Appl. 2013, 62, 179–207. [Google Scholar] [CrossRef]
- Gröchenig, S.; Schneider, C. A Cookie-Cutter Approach for Determining Places and Stays from Movement Data. GI_Forum 2016, 1, 53–64. [Google Scholar] [CrossRef]
- Venek, V.; Brunauer, R.; Schneider, C. Evaluating the Brownian Bridge Movement Model to Determine Regularities of People’s Movements. GI_Forum 2016, 2, 20–35. [Google Scholar] [CrossRef]
- Ashbrook, D.; Starner, T. Using GPS to learn significant locations and predict movement across multiple users. Pers. Ubiquitous Comput. 2003, 7, 275–286. [Google Scholar] [CrossRef]
- Hariharan, R.; Toyama, K. Project Lachesis: Parsing and Modeling Location Histories. In Geographic Information Science SE—8; Lecture Notes in Computer Science; Egenhofer, M., Freksa, C., Miller, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3234, pp. 106–124. ISBN 978-3-540-23558-3. [Google Scholar]
- Ye, Y.; Zheng, Y.; Chen, Y.; Feng, J.; Xie, X. Mining Individual Life Pattern Based on Location History. In Proceedings of the 2009 Tenth International Conference on Mobile Data Management: Systems, Services and Middleware, Taipei, Taiwan, 18–20 May 2009; pp. 1–10. [Google Scholar]
- Marmasse, N.; Schmandt, C. Location-Aware Information Delivery withComMotion. In Handheld and Ubiquitous Computing SE—12; Lecture Notes in Computer Science; Thomas, P., Gellersen, H.-W., Eds.; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1927, pp. 157–171. ISBN 978-3-540-41093-5. [Google Scholar]
- Smouse, P.E.; Focardi, S.; Moorcroft, P.R.; Kie, J.G.; Forester, J.D.; Morales, J.M. Stochastic modelling of animal movement. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2010, 365, 2201–2211. [Google Scholar] [CrossRef] [PubMed]
- Merki, M.; Laube, P. Detecting reaction movement patterns in trajectory data. In Proceedings of the AGILE ’2012 International Conference on Geographic Information Science, Avignon, France, 24–27 April 2012; pp. 24–27. [Google Scholar]
- Krumm, J.; Rouhana, D. Placer: Semantic Place Labels from Diary Data. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing—UbiComp ’13, Zurich, Switzerland, 8–12 September 2013; ACM Press: New York, NY, USA, 2013; p. 163. [Google Scholar]
- Schmid, F.; Richter, K. Extracting Places from Location Data Streams. In Proceedings of the International Workshop on Ubiquitous Geographical Information Services, Münster, Germany, 20–23 September 2006; Available online: http://cindy.informatik.uni-bremen.de/cosy/staff/richter/pubs/schmidrichter_UbiGIS.pdf (accessed on 11 September 2017).
- Hu, D.H.; Wang, C. GPS-based Location Extraction and Presence Management for Mobile Instant Messenger. Embed. Ubiquitous Comput. 2007, 309–320. [Google Scholar] [CrossRef]
- Laasonen, K.; Raento, M.; Toivonen, H. Adaptive On-Device Location Recognition. In Pervasive Computing SE—21; Lecture Notes in Computer Science; Ferscha, A., Mattern, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3001, pp. 287–304. ISBN 978-3-540-21835-7. [Google Scholar]
- Agamennoni, G.; Nieto, J.; Nebot, E. Mining GPS data for extracting significant places. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation (ICRA ’09), Kobe, Japan, 12–17 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 855–862. [Google Scholar]
- Kim, M.; Kotz, D.; Kim, S. Extracting a Mobility Model from Real User Traces. In Proceedings of the 25th IEEE International Conference on Computer Communications, Barcelona, Spain, 23–26 April 2006. [Google Scholar]
- Scellato, S.; Musolesi, M.; Mascolo, C.; Latora, V.; Campbell, A.T. NextPlace: A spatio-temporal prediction framework for pervasive systems. In Proceedings of the 9th International Conference on Pervasive Computing Pervasive, San Francisco, CA, USA, 12–15 June 2011; pp. 152–169. [Google Scholar] [CrossRef]
- Ranacher, P.; Brunauer, R.; Trutschnig, W.; van der Spek, S.; Reich, S. Why GPS makes distances bigger than they are. Int. J. Geogr. Inf. Sci. 2016, 30, 316–333. [Google Scholar] [CrossRef] [PubMed]
- Schneider, C.; Zutz, S.; Rehrl, K.; Brunauer, R.; Gröchenig, S. Evaluating GPS sampling rates for pedestrian assistant systems. J. Local. Based Serv. 2016, 9725, 1–28. [Google Scholar] [CrossRef]
- Porras Bernárdez, F.D. Extraction of User’s Stays and Transitions from GPS Logs: A Comparison of Three Spatio-Temporal Clustering Approaches. Master’s Thesis, Technische Universität Wien, Wien, Austria, 2016. [Google Scholar]
- Schneider, C.; Henneberger, S. Electronic Spatial Assistance for People with Dementia: Choosing the Right Device. Technologies 2014, 2, 96–114. [Google Scholar] [CrossRef]
- Schneider, W.; Hennig, A. Lexikon Kennzahlen für Marketing und Vertrieb; Springer: Berlin/Heidelberg, Germany, 2008; ISBN 978-3-540-79861-3. [Google Scholar]
- Leroy, G. Designing User Studies in Informatics; Health Informatics; Springer: London, UK, 2011; ISBN 978-0-85729-621-4. [Google Scholar]
- Andreopoulos, B. Clustering Categorical Data. In Data Clustering; Chapman & Hall/CRC Data Mining and Knowledge Discovery Series; Aggarwal, C.C., Reddy, C.K., Eds.; Chapman and Hall/CRC: Palm Beach County, FL, USA, 2013; p. 652. ISBN 978-1-4665-5821-2. [Google Scholar]
- LaMarca, A.; Chawathe, Y.; Consolvo, S.; Hightower, J.; Smith, I.; Scott, J.; Sohn, T.; Howard, J.; Hughes, J.; Potter, F.; et al. Place Lab: Device Positioning Using Radio Beacons in the Wild. In Pervasive Computing SE—8; Lecture Notes in Computer Science; Gellersen, H.-W., Want, R., Schmidt, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3468, pp. 116–133. ISBN 978-3-540-26008-0. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), Portland, OR, USA, 2–4 August 1996; Simoudis, E., Han, J., Fayyad, U.M., Eds.; AAAI Press: Palo Alto, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.-P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. In Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data—SIGMOD ’99, Philadelphia, PA, USA, 31 May–3 June 1999; ACM Press: New York, NY, USA, 1999; pp. 49–60. [Google Scholar]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Apache Apache Commons Math 3.6.1 API. Available online: http://commons.apache.org/proper/commons-math/javadocs/api-3.6.1/index.html (accessed on 25 July 2017).
- Zhou, A.; Zhou, S.; Cao, J.; Fan, Y.; Hu, Y. Approaches for scaling DBSCAN algorithm to large spatial databases. J. Comput. Sci. Technol. 2000, 15, 509–526. [Google Scholar] [CrossRef]
- Borah, B.; Bhattacharyya, D.K. An improved sampling-based DBSCAN for large spatial databases. Proceedings of International Conference on Intelligent Sensing and Information Processing, Chennai, India, 4–7 January 2004; pp. 92–96. [Google Scholar] [CrossRef]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN Revisited, Revisited. ACM Trans. Database Syst. 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Microsoft GeoLife: Building Social Networks Using Human Location History. Available online: https://www.microsoft.com/en-us/research/project/geolife-building-social-networks-using-human-location-history/ (accessed on 25 July 2017).
- Zheng, Y.; Chen, Y.; Li, Q.; Xie, X.; Ma, W.-Y. Understanding transportation modes based on GPS data for web applications. ACM Trans. Web 2010, 4, 1–36. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Framework Step | General | Domain/Application Specific | Approach Dependent |
|---|---|---|---|
| Pre-selection | X | ||
| Acquisition | X | ||
| Pre-processing | X | ||
| Parameterization | X | ||
| Evaluation | X |
| Property | Person A | Person B | Person C | Person D |
|---|---|---|---|---|
| Days of recording | 39 | 40 | 41 | 38 |
| Number of track points | 418,095 | 489,131 | 436,958 | 415,104 |
| Main mode of transportation | walking, car | train, walking | cycling | car |
| Unique visited places | 27 | 35 | 43 | 26 |
| Recorded trips between places | 131 | 109 | 157 | 104 |
| Approach | Person A (39 Days, 418,095 Points) | Person B (40 Days, 489,131 Points) | Person C (41 Days, 436,958 Points) | Person D (38 Days, 415,104 Points) |
|---|---|---|---|---|
| TIC (125 m, 83 m) | ||||
| Recall (0.65) | 0.71 | 0.65 | 0.45 | 0.73 |
| Precision (0.65) | 0.70 | 0.49 | 0.38 | 0.52 |
| F-measure (0.65) | 0.71 | 0.56 | 0.41 | 0.61 |
| Qsa (0.6) | 0.65 | 0.61 | 0.56 | 0.60 |
| Qstc (0.65) | 0.79 | 0.72 | 0.48 | 0.78 |
| Runtime (5 (s)) | 0.28 | 0.23 | 0.20 | 0.18 |
| xDBSCAN ( = 1, minPts = 200) | ||||
| Recall (0.65) | 0.37 | 0.29 | 0.43 | 0.59 |
| Precision (0.65) | 0.76 | 0.57 | 0.71 | 0.69 |
| F-measure (0.65) | 0.50 | 0.39 | 0.54 | 0.64 |
| Qsa (0.6) | 0.46 | 0.26 | 0.24 | 0.31 |
| Qstc (0.65) | 0.60 | 0.44 | 0.62 | 0.71 |
| Runtime (5 (s)) | 45,105.38 | 65,665.74 | 49,194.14 | 58,378.40 |
| MIXED (200 m) | ||||
| Recall (0.65) | 0.70 | 0.65 | 0.72 | 0.74 |
| Precision (0.65) | 0.70 | 0.50 | 0.62 | 0.54 |
| F-measure (0.65) | 0.70 | 0.57 | 0.67 | 0.62 |
| Qsa (0.6) | 0.56 | 0.60 | 0.56 | 0.54 |
| Qstc (0.65) | 0.77 | 0.69 | 0.80 | 0.83 |
| Runtime (5 (s)) | 0.28 | 0.24 | 0.24 | 0.21 |
| Record | TIC (125 m, 83 m) | xDBSCAN ( = 10, minPts = 400) | MIXED (200 m) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Rs (0.75 – 1.25) | Rst (0.65) | Runtime (5 (s)) | Rs (0.75 – 1.25) | Rst (0.65) | Runtime (5 (s)) | Rs (0.75 – 1.25) | Rst (0.65) | Runtime (5 (s)) | |
| Participant 1 (22 days, 3743 points) | 0.00 | 0.00 | 0.00 | 0.50 | 0.00 | 3.65 | 0.00 | 0.00 | 0.00 |
| Participant 2 (5 days, 10,731 points) | 1.00 | 1.00 | 0.01 | 1.00 | 0.33 | 27.16 | 1.00 | 1.00 | 0.01 |
| Participant 3 (17 days, 25,837 points) | 0.91 | 0.64 | 0.02 | 0.73 | 0.37 | 157.46 | 1.00 | 0.82 | 0.02 |
| Participant 4 (10 days, 8225) | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 17.33 | 1.50 | 0.50 | 0.01 |
| Participant 5 (34 days, 25,490 points) | 1.06 | 0.88 | 0.02 | 0.94 | 0.41 | 87.69 | 1.47 | 0.47 | 0.02 |
| Participant 6 (14 days, 10,013 points) | 1.11 | 0.67 | 0.01 | 0.67 | 0.11 | 19.54 | 1.00 | 0.44 | 0.00 |
| Participant 7 (17 days, 9426 points) | 1.00 | 1.00 | 0.00 | 1.25 | 0.75 | 22.66 | 1.25 | 0.75 | 0.01 |
| Participant 8 (36 days, 25,549) | 1.00 | 1.00 | 0.01 | 1.00 | 0.00 | 158.65 | 2.00 | 0.00 | 0.01 |
| Participant 9 (39 days, 42,083 points) | 1.00 | 1.00 | 0.02 | 1.00 | 0.60 | 397.10 | 1.00 | 1.00 | 0.02 |
| Participant 10 (7 days, 3518 points) | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 3.19 | 0.50 | 0.50 | 0.00 |
| Participant 11 (11 days, 13,274 points) | 1.00 | 1.00 | 0.01 | 0.75 | 0.50 | 30.74 | 1.00 | 0.50 | 0.01 |
| Participant 12 (10 days, 1801 points) | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.80 | 1.60 | 0.60 | 0.00 |
| Participant 13 (18 days, 43,402 points) | 0.75 | 0.63 | 0.02 | 0.75 | 0.13 | 464.51 | 0.75 | 0.25 | 0.02 |
| Participant 14 (7 days, 6076 points) | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 9.10 | 1.00 | 1.00 | 0.00 |
| Participant 15 (18 days, 55,591 points) | 0.80 | 0.40 | 0.02 | 0.40 | 0.00 | 793.90 | 0.20 | 0.00 | 0.03 |
| Participant 16 (35 days, 77,304 points) | 1.00 | 1.00 | 0.03 | 1.00 | 1.00 | 1510.00 | 1.00 | 1.00 | 0.04 |
| Participant 17 (21 days, 1529 points) | 0.43 | 0.14 | 0.00 | 0.00 | 0.00 | 0.55 | 0.14 | 0.00 | 0.00 |
| Participant 18 (5 days, 14,959 points) | 1.00 | 1.00 | 0.01 | 0.00 | 0.00 | 56.43 | 1.00 | 1.00 | 0.01 |
| Participant 19 (39 days, 98,866 points) | 1.00 | 1.00 | 0.04 | 1.00 | 1.00 | 2425.15 | 1.00 | 0.80 | 0.05 |
| Participant 20 (28 days, 16,454 points) | 1.00 | 1.00 | 0.01 | 1.00 | 1.00 | 63.81 | 1.00 | 1.00 | 0.01 |
| Participant 21 (3 days, 850 points) | 0.57 | 0.29 | 0.00 | 0.00 | 0.00 | 0.18 | 0.43 | 0.14 | 0.00 |
| Participant 22 (7 days, 1064 points) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.28 | 0.67 | 0.67 | 0.00 |
| Participant 23 (10 days, 18,916 points) | 1.00 | 1.00 | 0.01 | 1.29 | 0.57 | 90.02 | 1.00 | 1.00 | 0.01 |
| Participant 24 (3 days, 126 points) | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.01 | 2.00 | 0.00 | 0.00 |
| Participant 25 (40 days, 52,314) | 1.00 | 1.00 | 0.02 | 1.00 | 1.00 | 642.63 | 1.00 | 1.00 | 0.03 |
| Participant 26 (25 days, 140,612 points) | 0.82 | 0.64 | 0.06 | 0.55 | 0.27 | 4428.31 | 0.91 | 0.55 | 0.07 |
| Participant 27 (35 days, 11,577 points) | 1.00 | 1.00 | 0.01 | 1.00 | 0.00 | 32.44 | 1.00 | 1.00 | 0.01 |
| Participant 28 (11 days, 10,588 points) | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 28.23 | 1.00 | 1.00 | 0.00 |
| Participant 29 (13 days, 3536 points) | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 2.86 | 1.17 | 0.50 | 0.00 |
| Participant 30 (28 days, 33,379 points) | 1.00 | 0.67 | 0.01 | 0.67 | 0.50 | 256.46 | 0.17 | 0.00 | 0.02 |
| Participant 31 (8 days, 157 points) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schneider, C.; Gröchenig, S.; Venek, V.; Leitner, M.; Reich, S. A Framework for Evaluating Stay Detection Approaches. ISPRS Int. J. Geo-Inf. 2017, 6, 315. https://doi.org/10.3390/ijgi6100315
Schneider C, Gröchenig S, Venek V, Leitner M, Reich S. A Framework for Evaluating Stay Detection Approaches. ISPRS International Journal of Geo-Information. 2017; 6(10):315. https://doi.org/10.3390/ijgi6100315
Chicago/Turabian StyleSchneider, Cornelia, Simon Gröchenig, Verena Venek, Michael Leitner, and Siegfried Reich. 2017. "A Framework for Evaluating Stay Detection Approaches" ISPRS International Journal of Geo-Information 6, no. 10: 315. https://doi.org/10.3390/ijgi6100315
APA StyleSchneider, C., Gröchenig, S., Venek, V., Leitner, M., & Reich, S. (2017). A Framework for Evaluating Stay Detection Approaches. ISPRS International Journal of Geo-Information, 6(10), 315. https://doi.org/10.3390/ijgi6100315