
The RADAR Project—A Service for Research Data Archival and Publication

 , , ,
, , ,
Abstract
:1. Introduction: Digitalization of Research Workflows
2. RADAR—Scope, Collaborations, Goals and Architecture
2.1. Collaboration
2.2. Goals
- guidelines for researchers to introduce and facilitate research data management in general and to store and/or publish their research data;
- a secure data preservation service including adequate storage periods (5, 10 and 15 years as well as permanent storage) by the use of distributed data storage mechanisms;
- (optional) data publication with Digital Object Identifier (DOI)-assignment to secure traceability, access and citeability; and
- technical implementation support for research institutions (e.g., by open API, the possibility of front end branding as well as the option for data peer-review)
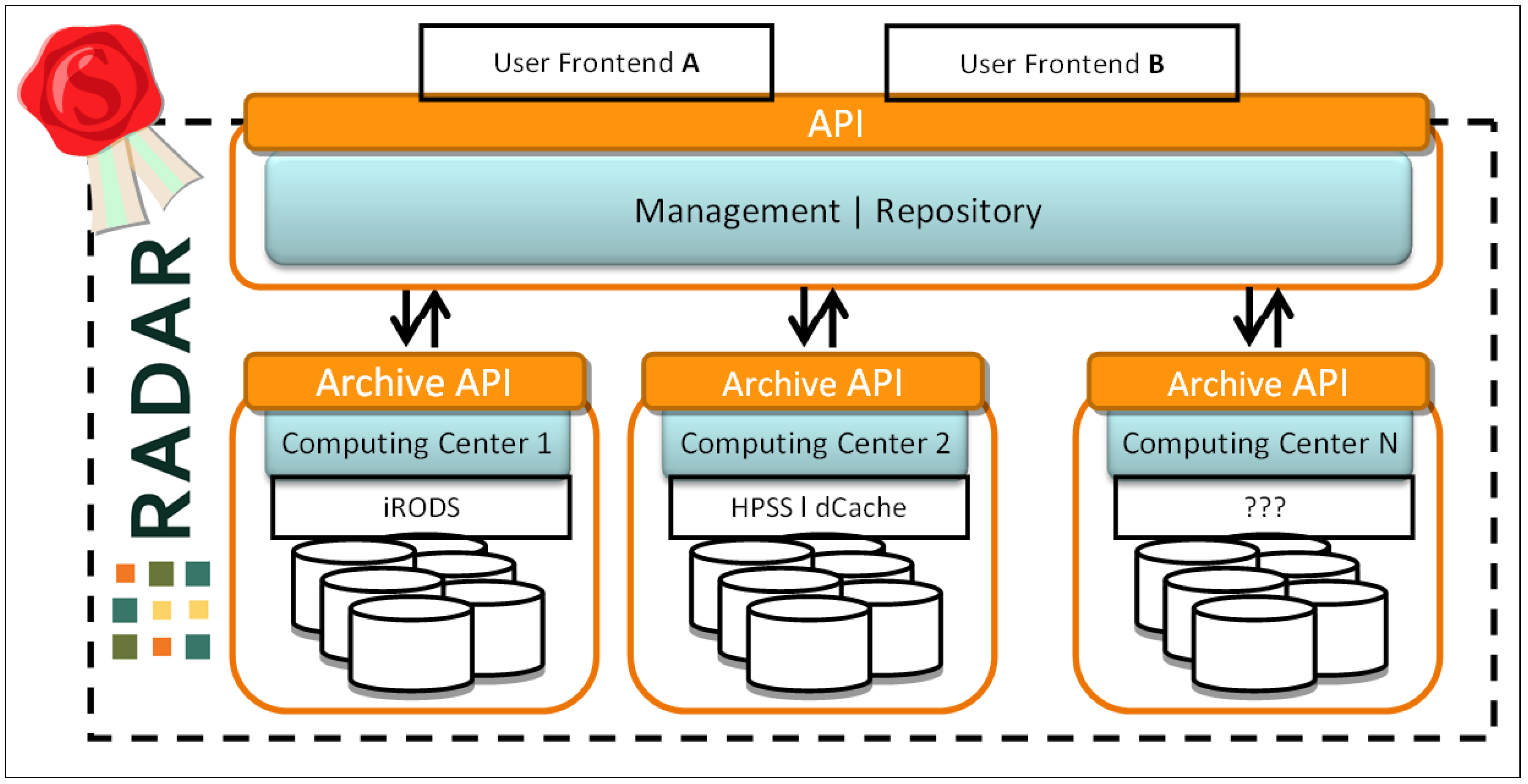
2.3. Architecture
2.4. Metadata Schema
3. Two-Stage Service Model
3.1. Basic service: Data Preservation
3.2. Extended Service: Data Publication
3.3. Data Management within RADAR: Access and Usage
4. The Business Model: Cost and Pricing
5. Conclusions and Outlook
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Whyte, J.; Stasis, A.; Lindkvist, C. Managing change in the delivery of complex projects: Configuration management, asset information and “big data”. Int. J. Proj. Manag. 2016, 34, 339–351. [Google Scholar] [CrossRef]
- Science Editorial. Challenges and opportunities. Science 2011, 331, 692–693. [Google Scholar]
- Harris, S.J. Long-distance corporations, big sciences and the geography of knowledge. In The Postcolonial Science and Technology Studies Reader; Harding, S., Ed.; Duke University Press: Durham, UK, 2011; pp. 61–83. [Google Scholar]
- Thessen, A.E.; Patterson, D.J. Data issues in the life sciences. Zookeys 2011, 150, 15–51. [Google Scholar] [CrossRef] [PubMed]
- National Science Foundation (NSF). Proposal Preparation Instructions. Available online: http://www.nsf.gov/pubs/policydocs/pappguide/nsf11001/gpg_2.jsp#dmp (accessed on 23 November 2015).
- Deutsche Forschungsgemeinschaft DFG. Safeguarding good scientific practice. In Recommendations of the Commission on Professional Self Regulation in Science; Wiley-VCH: Hoboken, NJ, USA, 2013; pp. 74–76. [Google Scholar]
- Treloar, A.; Harboe-Ree, C. Data management and the curation continuum: How the Monash experience is informing repository relationships. In Proceedings of the 14th Victorian Association for Library Automation Conference and Exhibition, Melbourne, VIC, Australia, 5–7 February 2008.
- Klump, J. Managing the Data Continuum. Available online: http://oa.helmholtz.de/fileadmin/user_upload/redakteur/Workshops/data_continuum_klump.pdf (accessed on 23 November 2015).
- Neuroth, H.; Strathmann, S.; Oßwald, A.; Scheffel, R.; Klump, J.; Ludwig, J. Langzeitarchivierung von Forschungsdaten—Eine Bestandsaufnahme. Available online: http://nestor.sub.uni-goettingen.de/bestandsaufnahme/nestor_lza_forschungsdaten_bestandsaufnahme.pdf (accessed on 23 November 2015).
- Razum, M. Repository Platforms. Available online: https://www.fiz-karlsruhe.de/en/leistungen/e-research/repository-platforms.html (accessed on 8 January 2016).
- Consultative Committee for Space Data Systems. Reference model for an Open Archival Information System (OAIS). Available online: public.ccsds.org/publications/archive/650x0m2.pdf (accessed on 8 January 2016).
- DataCite. DataCite Metadata Schema for the Publication and Citation of Research Data. Available online: http://schema.datacite.org/meta/kernel-3.1/doc/DataCite-MetadataKernel_v3.1.pdf (accessed on 23 November 2015).
- CreativeCommons.org. CC0 1.0 Universal (CC0 1.0) Public Domain Dedication. Available online: http://creativecommons.org/publicdomain/zero/1.0/deed.en (accessed on 23 November 2015).
- RDA/WDS Interest Group Publishing Data Cost Recovery for Data Centres: Income Streams for Data Repositories. Available online: https://rd-alliance.org/groups/rdawds-publishing-data-cost-recovery-data-centres.html (accessed on 14 January 2016).
- Kaur, K.; Herterich, P.; Dallmeier-Tiessen, S.; Schmitt, K.; Schrimpf, S.; Tjalsma, H.; Lambert, S.; McMeekin, S. D32.1 Report on Cost Parameters for Digital Repositories. Available online: http://www.alliancepermanentaccess.org/wp-content/uploads/sites/7/downloads/2014/06/APARSEN-REP-D32_1-01-1_0_incURN.pdf (accessed on 14 January 2016).
- 4C Project Collaboration to Clarify the Costs of Curation: D4.5 from Costs to Business Models. Available online: http://4cproject.eu/d4-5-from-costs-to-business-models (accessed on 14 January 2016).
- Palaiologk, A.S.; Economides, A.A.; Tjalsma, H.D.; Sesink, L.B. An activity-based costing model for long-term preservation and dissemination of digital research data: the case of DANS. Int. J. Digit. Libr. 2012, 12, 195–214. [Google Scholar] [CrossRef]
- DP4lib Project. Kostenmodell für Einen LZA-Dienst. Available online: http://dp4lib.langzeitarchivierung.de/downloads/DP4lib-Kostenmodell_eines_LZA-Dienstes_v1.0.pdf (accessed on 14 January 2016).


{kind=link}
{kind=link}
| General Service Concepts in RADAR | |
|---|---|
| (A) Contract | A customer (e.g., institution, publisher, research project) enters a contract and agrees to pay for services provided by RADAR |
| (B) Workspace | The workspace represents an organizational entity in RADAR where research data and metadata can be added, modified and structured |
| (C) Dataset | Represents a collection of digital data that—with regards to content—belong together and form a logical entity |
| Roles and responsibilities | |
| (A) RADAR Administrator | Supervision of contracts and provision of admin-accounts for customers (internal) |
| (B) Workspace Administrator | Creation of Workspaces and assigning Curator(s)—e.g., an institution, facility or project being a customer of RADAR |
| (C) Curator | Management within associated workspace(s) and optional set-up of additional (sub-)curators, e.g., being a scientist, data manager or editor within an institution |
| Dataset status and two-stage service model | |
| (1.) Pending | Initial mode of a dataset uploaded to RADAR; editing is possible (including modification, update, deletion) |
| (2.) Review | The dataset is “frozen” for the duration of the peer review process and receives a secure “review-URL” |
| (3.) Archived (= service: Data Preservation) | The dataset is archived and identified via Handle. As soon as this status is chosen by the curator, no further editing within a dataset is possible |
| (4.) Published (= service: Data Publication) | The dataset is published and identified via DOI. As soon as this status is chosen by the curator, no further editing within a dataset is possible. A landing page is created and the corresponding metadata can be found using discovery services |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kraft, A.; Razum, M.; Potthoff, J.; Porzel, A.; Engel, T.; Lange, F.; Van den Broek, K.; Furtado, F. The RADAR Project—A Service for Research Data Archival and Publication. ISPRS Int. J. Geo-Inf. 2016, 5, 28. https://doi.org/10.3390/ijgi5030028
Kraft A, Razum M, Potthoff J, Porzel A, Engel T, Lange F, Van den Broek K, Furtado F. The RADAR Project—A Service for Research Data Archival and Publication. ISPRS International Journal of Geo-Information. 2016; 5(3):28. https://doi.org/10.3390/ijgi5030028
Chicago/Turabian StyleKraft, Angelina, Matthias Razum, Jan Potthoff, Andrea Porzel, Thomas Engel, Frank Lange, Karina Van den Broek, and Filipe Furtado. 2016. "The RADAR Project—A Service for Research Data Archival and Publication" ISPRS International Journal of Geo-Information 5, no. 3: 28. https://doi.org/10.3390/ijgi5030028
APA StyleKraft, A., Razum, M., Potthoff, J., Porzel, A., Engel, T., Lange, F., Van den Broek, K., & Furtado, F. (2016). The RADAR Project—A Service for Research Data Archival and Publication. ISPRS International Journal of Geo-Information, 5(3), 28. https://doi.org/10.3390/ijgi5030028