
Describing Geospatial Assets in the Web of Data: A Metadata Management Scenario

 ,
,  ,
,  ,
,  ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Context
2.1. Semantic Web Essentials
<http://some/subject> <http://some/predicate> <http://some/object> .
<http://some/subject> <http://some/predicate> "some object"@en .
@prefix ex: <http://some/> .
ex:subject ex:predicate_1 ex:object_1 ;
ex:predicate_2 ex:object_2 .
ex:subject ex:predicate_3 ex:object_3 ,
ex:object_4 .
1 PREFIX dcat: <http://www.w3.org/ns/dcat#>
2 SELECT ?keyw ?label
3 WHERE {
4 <http://.../dataset_1> dcat:keyword ?keyw .
5
6 SERVICE <http://some/endpoint> {
7 ?keyw skos:prefLabel ?label .
8 FILTER( LANG(?label) = "en")
9 }
10 }
2.2. The RITMARE Flagship Project
- A set of peripheral nodes that expose standards-compliant metadata and services.
- A centralised catalogue service that provides access to the resources made available by the project as a whole.
2.3. Related Works
2.4. EDI, a Template-Driven Metadata Editor
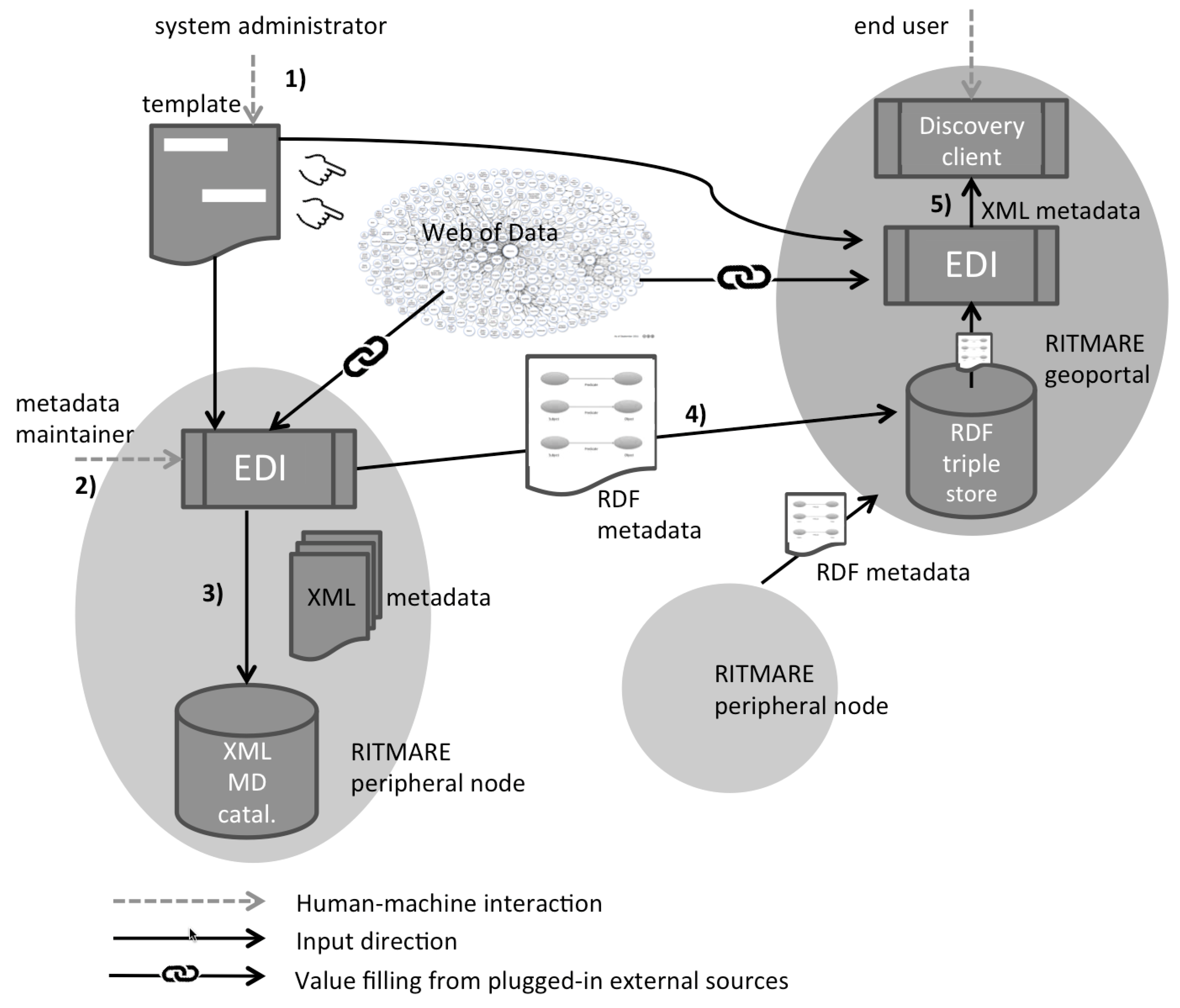
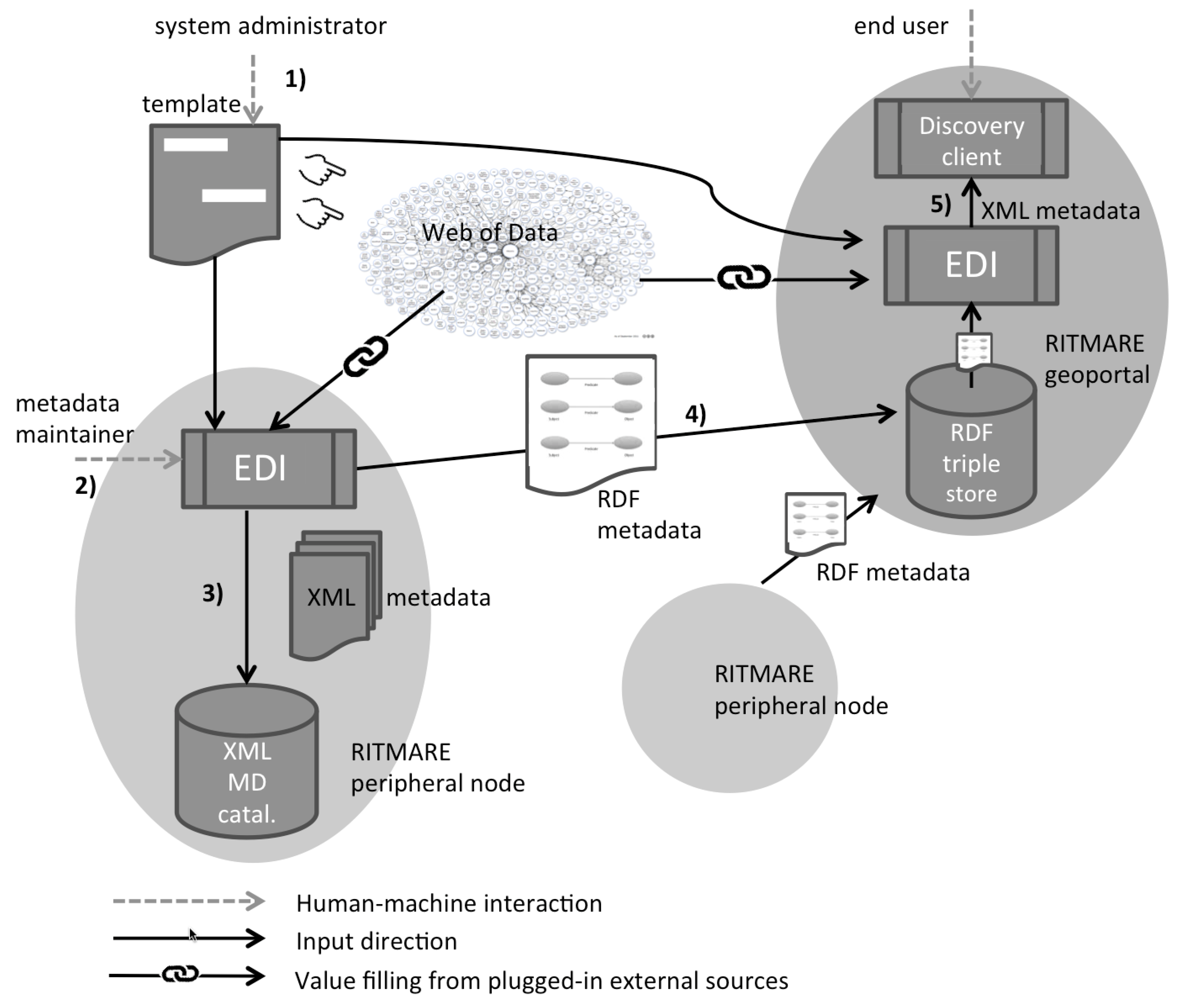
3. Metadata Management Scenario
- The system administrator executes the one-off creation or customisation of the template in order to set the metadata schema for the specific use case. In this phase, external data sources from the Web of Data can be plugged in: This allows metadata properties to refer to resources (persons, toponyms, code vales, etc.) that are managed by third parties. The template serves as input to EDI both in the peripheral and central nodes of RITMARE.
- The metadata maintainer of a RITMARE peripheral node uses the editing interface that is created by EDI on the basis of template definitions and creates/edits metadata (the output of EDI). The data sources that have been plugged in the previous phase enable autocompletion functionalities that reduce as much as possible the effort required for metadata provision.
- The metadata records in XML format are generated by EDI for insertion in catalogues and applications that understand the specific formalism, such as in the peripheral nodes of the RITMARE infrastructure. Typically, the entities referred to in the previous phase are rendered now as free-text property values.
- The semantics-aware counterpart of the metadata description is also produced by EDI and stored as RDF data in the project’s triple store (i.e., a database for RDF data). The record can also be published on the Web of Data and be accessed according to the same formats and protocols that allowed for plugging in external data sources in the first phase.
- The end user can search the RITMARE central geoportal through the discovery client. When metadata records are requested according to the XML metadata schema, they are produced again by EDI on the basis of template definitions. Specifically, property values drawn from the data sources that are referred to in the template are accessed again at user request-time. This allows for generating an XML description containing up-to-date property values, as detailed in the following of this Section.
3.1. Use Cases and Requirements
3.1.1. Specifying Points of Contact
3.1.2. Keywords from Controlled Vocabularies
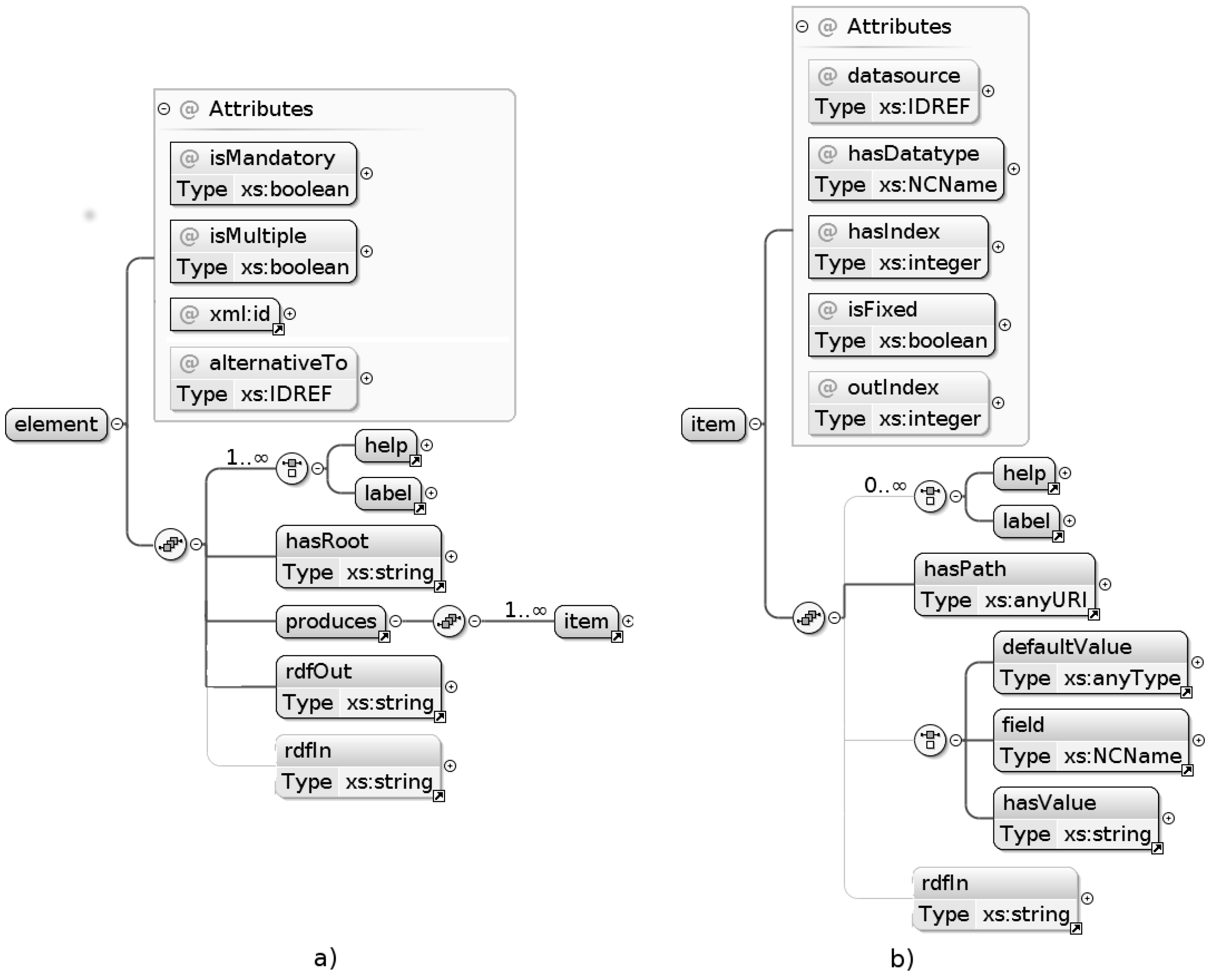
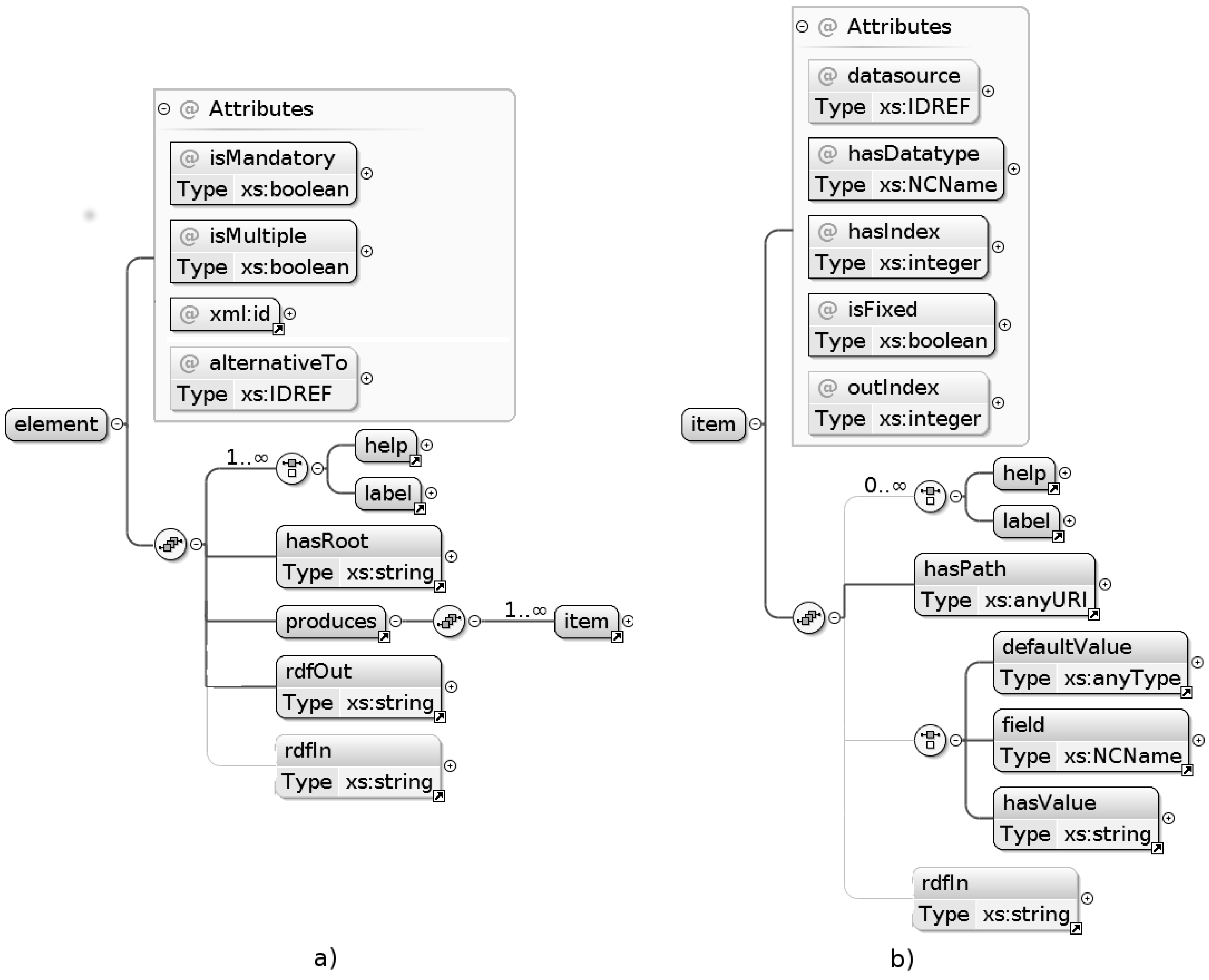
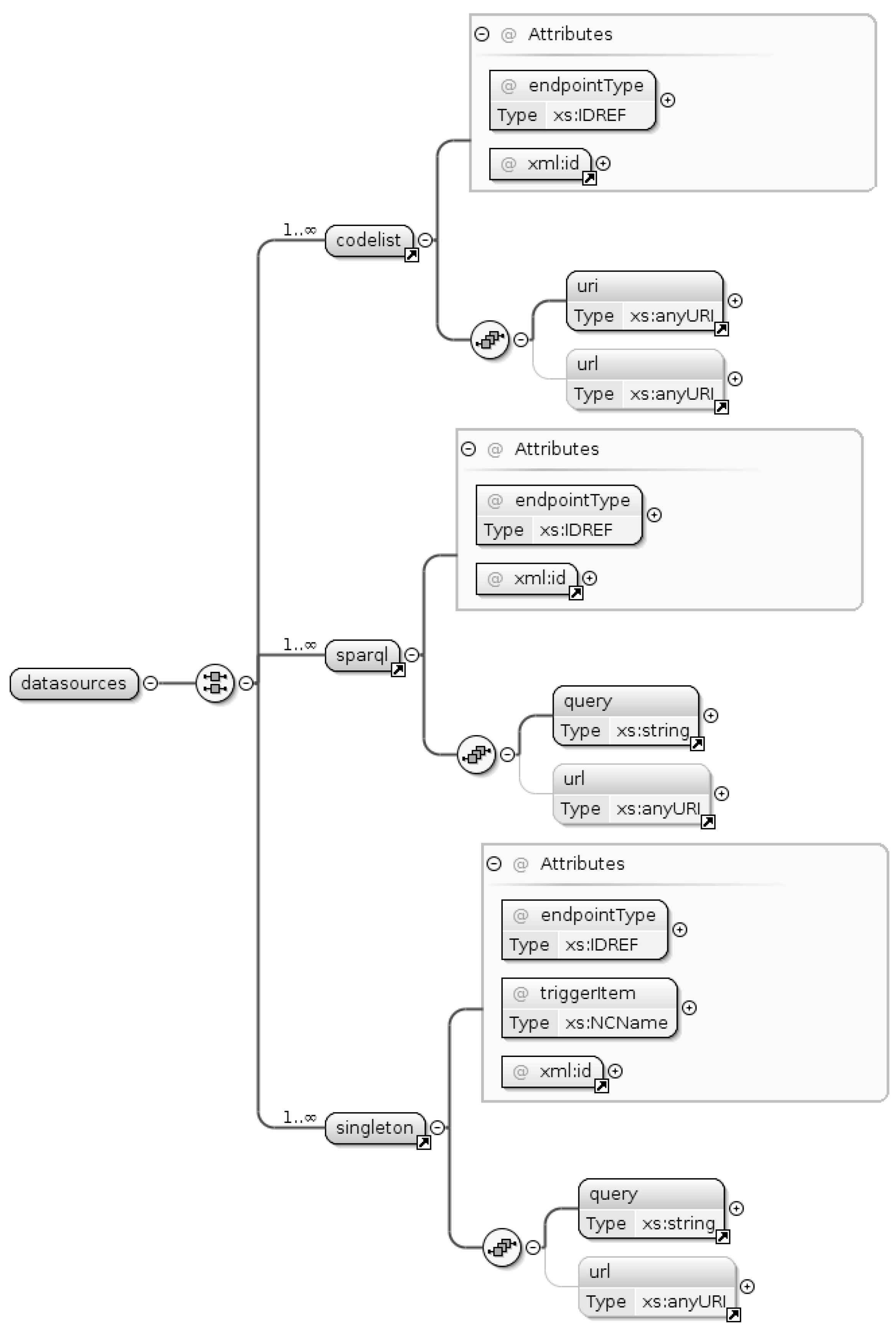
3.2. Template Structure
- Codelist: This category of datasources assumes that the nested uri tag refers to a SKOS thesaurus (a controlled vocabulary encoded according to this specific ontology) and executes a standard query for matching code values. This is the data source type allowing for creation of the drop-down list for selecting the role of a point of contact in Figure 2a.
- Sparql: This category allows for executing generic SPARQL queries. This comes handy in the example use cases because the SeaDataNet endpoint provides SKOS-compliant thesauri whose structure slightly differs from that expected by the previous datasource type. Both use cases involve a datasource of this type.
- Singleton: Executes queries that are required to return a single record (typically, as a consequence of a previous call to a datasource of the preceding type to provide autocompletion functionalities). Both use cases involve a datasource of this type.
1 PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
2 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
3 PREFIX foaf: <http://xmlns.com/foaf/0.1/>
4 SELECT ?contact ?label
5 FROM <http://ritmare.it/rdfdata/lotrx>
6 WHERE {
7 ?contact rdf:type foaf:Person .
8 ?contact vcard:email ?label .
9 FILTER( REGEX( STR(?label), "$search_param", "i") )
10 )
11 }
12 ORDER BY ASC(?label)
1 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
2 PREFIX foaf: <http://xmlns.com/foaf/0.1/>
3 SELECT ?inst
4 FROM <http://ritmare.it/rdfdata/lotrx>
5 WHERE {
6 <$search_param> vcard:org ?org.
7 ?org foaf:name ?inst .
8 FILTER( LANG(?inst) = "en")
9 }
1 PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
2 PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
3 SELECT ?concept ?label
4 WHERE {
5 ?concept rdf:type skos:Concept.
6 <http://vocab.nerc.ac.uk/collection/P07/current/>
7 skos:member ?concept.
8 ?concept skos:prefLabel ?label .
9 FILTER( LANG(?label) = "en" &&
10 REGEX( STR(?label), "$search_param", "i") )
11 }
1 PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
2 PREFIX dct: <http://purl.org/dc/terms/>
3 SELECT ?label ?date
4 WHERE {
5 ?voc skos:member <$search_param> .
6 ?voc skos:prefLabel ?label .
7 ?voc dct:date ?ts .
8 BIND( STRBEFORE(?ts, " ") AS ?date)
9 }
3.3. Generating and Storing Metadata
1 PREFIX dcat: <http://www.w3.org/ns/dcat#>
2 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
3 INSERT
4 {
5 <$id_1_uri> dcat:contactPoint [
6 rdf:type vcard:Individual ;
7 vcard:hasUID <$resp_1_uri> ;
8 vcard:hasRole <$resp_3_uri>
9 ] .
10 }
11 WHERE {}
1 PREFIX dcat: <http://www.w3.org/ns/dcat#>
2 INSERT
3 {
4 <$id_1_uri> dcat:keyword <$contr_voc_1_uri> .
5 }
6 WHERE {}
1 PREFIX dcat: <http://www.w3.org/ns/dcat#>
2 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
3 PREFIX foaf: <http://xmlns.com/foaf/0.1/>
4 PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
5 SELECT ?1 ?2 ?3
6 WHERE {
7 <$id_1_uri> dcat:contactPoint ?struct .
8 ?struct vcard:hasUID ?contact .
9 ?struct vcard:hasRole ?role .
10 SERVICE <http://sparql.get-it.it/> {
11 ?contact vcard:email ?1 .
12 ?contact vcard:org ?org .
13 ?org foaf:name ?2 .
14 }
15 SERVICE <http://sparql.get-it.it/> {
16 ?role skos:prefLabel ?3 .
17 }
18 FILTER( LANG(?2) = "en" && LANG(?3) = "en" )
19 }
1 PREFIX dcat: <http://www.w3.org/ns/dcat#>
2 PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
3 PREFIX dct: <http://purl.org/dc/terms/>
4 SELECT ?1 ?2 ?3
5 WHERE {
6 <$id_1_uri> dcat:keyword ?keyw .
7 SERVICE <http://vocab.nerc.ac.uk/sparql/> {
8 ?keyw skos:prefLabel ?1 .
9 ?thes skos:member ?keyw .
10 ?thes skos:prefLabel ?2 .
11 ?thes dct:date ?timestamp .
12 }
13 BIND( STRBEFORE(?timestamp, " ") AS ?3)
14 }
4. Discussion
4.1. Assuring Metadata Consistency
4.2. Recommending Assets
4.3. Expanding Queries
4.4. Exploiting Gazetteer Information
4.5. Further Suggestions for Semantic Enrichment
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| CoP | Community of Practice |
| FGDC | Federal Geographic Data Committee |
| FOAF | Friend Of A Friend |
| FOSS | Free and Open Source Software |
| INSPIRE | INfrastructure for SPatial InfoRmation in Europe |
| RDF | Resource Description Framework |
| RITMARE | Ricerca ITaliana per il MARE - Italian research for the sea |
| RNDT | Repertorio Nazionale dei Dati Territoriali—national repository of territorial data |
| SDI | Spatial Data Infrastructure |
| SPARQL | SPARQL Protocol and RDF Query Language |
| SWE | Sensor Web Enablement |
| Turtle | Terse RDF Triple Language |
| URI | Uniform Resource Identifiers |
| XML | eXtensible Markup Language |
Appendix A. Template Definitions for the Use Cases in Section 3
1 <element xml:id="resp" isMandatory="true" isMultiple="true">
2 <label xml:lang="en">Responsible party</label>
3 <help xml:lang="en">...</help>
4 <hasRoot>/gmd:MD_Metadata/.../gmd:MD_DataIdentification</hasRoot>
5 <produces>
6 <item hasIndex="1" outIndex="2" isFixed="false"
7 hasDatatype="autoCompletion" datasource="person">
8 <label xml:lang="en">Email</label>
9 <hasPath>/.../gmd:electronicMailAddress/...</hasPath>
10 <RDFin><![CDATA[
11 ?contact vcard:email ?1 .
12 ?contact vcard:org ?org .
13 ?org foaf:name ?2 .
14 ]]></RDFin>
15 </item>
16 <item hasIndex="2" outIndex="1" isFixed="false"
17 hasDatatype="select" datasource="personS">
18 <label xml:lang="en">Institute</label>
19 <hasPath>/.../gmd:organisationName/...</hasPath>
20 </item>
21 <item hasIndex="4" isFixed="false"
22 hasDatatype="codelist" datasource="roleCodes">
23 <label xml:lang="en">Role</label>
24 <hasPath>/.../gmd:CI_RoleCode/@codeListValue</hasPath>
25 <defaultValue>http://.../resourceProvider</defaultValue>
26 <RDFin><![CDATA[
27 ?role skos:prefLabel ?3 .
28 ]]></RDFin>
29 </item>
30 </produces>
31 <RDFout><![CDATA[
32 PREFIX dcat: <http://www.w3.org/ns/dcat#>
33 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
34 INSERT
35 {
36 <$id_1_uri> dcat:contactPoint [
37 rdf:type vcard:Individual ;
38 vcard:hasUID <$resp_1_uri> ;
39 vcard:hasRole <$resp_3_uri>
40 ] .
41 }
42 WHERE {}
43 ]]></RDFout>
44 <RDFin><![CDATA[
45 PREFIX dcat: <http://www.w3.org/ns/dcat#>
46 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
47 PREFIX foaf: <http://xmlns.com/foaf/0.1/>
48 PREFIX skos: <http://.../skos/core#>
49 SELECT ?1 ?2 ?3
50 WHERE {
51 <$id_1_uri> dcat:contactPoint ?struct .
52 ?struct vcard:hasUID ?contact .
53 ?struct vcard:hasRole ?role .
54 FILTER( LANG(?2) = "en" && LANG(?3) = "en" )
55 }
56 ]]></RDFin>
57 </element>
58
59 <element xml:id="contr_voc" isMandatory="false" isMultiple="true">
60 <label xml:lang="en">Keyword from controlled vocabularies</label>
61 <help xml:lang="en">...</help>
62 <hasRoot>/gmd:MD_Metadata/.../gmd:MD_DataIdentification</hasRoot>
63 <produces>
64 <item hasIndex="1" isFixed="false"
65 hasDatatype="autoCompletion" datasource="keyw_SDN">
66 <label xml:lang="en">Keyword</label>
67 <hasPath>/.../gmd:keyword/...</hasPath>
68 <RDFin><![CDATA[
69 ?keyw skos:prefLabel ?1 .
70 ?thes skos:member ?keyw .
71 ?thes skos:prefLabel ?2 .
72 ?thes dct:date ?timestamp .
73 BIND( STRBEFORE(?timestamp, " ") AS ?3)
74 ]]></RDFin>
75 </item>
76 <item hasIndex="2" isFixed="false"
77 hasDatatype="select" datasource="keyw_SDN_S">
78 <label xml:lang="en">Originating controlled vocabulary</label>
79 <hasPath>/.../gmd:title/...</hasPath>
80 <field>label</field>
81 </item>
82 <item hasIndex="3" isFixed="false"
83 hasDatatype="select" datasource="keyw_SDN_S">
84 <label xml:lang="en">Publication date (yyyy-mm-dd)</label>
85 <hasPath>/.../gco:Date</hasPath>
86 <field>date</field>
87 </item>
88 ...
89 </produces>
90 <RDFout><![CDATA[
91 PREFIX dcat: <http://www.w3.org/ns/dcat#>
92 INSERT
93 {
94 <$id_1_uri> dcat:keyword <$contr_voc_1_uri> .
95 }
96 WHERE {}
97 ]]></RDFout>
98 <RDFin><![CDATA[
99 PREFIX dcat: <http://www.w3.org/ns/dcat#>
100 PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
101 PREFIX dct: <http://purl.org/dc/terms/>
102 SELECT ?1 ?2 ?3
103 WHERE {
104 <$id_1_uri> dcat:keyword ?keyw .
105 }
106 ]]></RDFin>
107 </element>
Appendix B. Data Sources for Use Case “Specifying Points of Contact”
1 <sparql xml:id="person" endpointType="virtuoso">
2 <query><![CDATA[
3 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
4 SELECT ?contact ?label
5 FROM <http://ritmare.it/rdfdata/lotrx>
6 WHERE {
7 ?contact rdf:type foaf:Person .
8 ?contact vcard:email ?label .
9 FILTER( REGEX( STR(?label), "$search_param", "i") )
10 }
11 ORDER BY ASC(?label)
12 ]]></query>
13 </sparql>
14
15 <singleton xml:id="personS" endpointType="virtuoso"
16 triggerItem="resp_1_uri">
17 <query><![CDATA[
18 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
19 SELECT ?inst
20 FROM <http://ritmare.it/rdfdata/lotrx>
21 WHERE {
22 <$search_param> vcard:org ?org.
23 ?org foaf:name ?inst .
24 FILTER(LANG(?inst)=’en’)
25 }
26 ]]></query>
27 </singleton>
28
29 <codelist xml:id="roleCodes" endpointType="virtuoso">
30 <uri>http://.../ResponsiblePartyRole</uri>
31 </codelist>
Appendix C. Data Sources for Use Case “Keywords from Controlled Vocabularies”
1 <sparql xml:id="keyw_SDN" endpointType="fuseki">
2 <query><![CDATA[
3 PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
4 PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
5 SELECT ?concept ?label
6 WHERE {
7 ?concept rdf:type skos:Concept.
8 <http://vocab.nerc.ac.uk/collection/P07/current/>
9 skos:member ?concept .
10 ?concept skos:prefLabel ?label .
11 FILTER(
12 LANG(?label)="en" && REGEX(STR(?label),"$search_param","i")
13 )
14 }
15 ]]></query>
16 <url>http://vocab.nerc.ac.uk/sparql/sparql</url>
17 </sparql>
18
19 <singleton xml:id="keyw_SDN_S" endpointType="fuseki"
20 triggerItem="contr_voc_1_uri">
21 <query><![CDATA[
22 PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
23 PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
24 PREFIX dct: <http://purl.org/dc/terms/>
25 SELECT ?label ?date
26 WHERE {
27 ?voc skos:member <$search_param> .
28 ?voc skos:prefLabel ?label .
29 ?voc dct:date ?ts .
30 BIND( STRBEFORE(?ts, " ") AS ?date)
31 }
32 ]]></query>
33 <url>http://vocab.
34 .ac.uk/sparql/sparql</url>
35 </singleton>
Appendix D. ISO Metadata Fragments Produced by the Two Use Cases
1 <?xml version="1.0" encoding="UTF-8" encoding="UTF-8"?> 2 <gmd:MD_Metadata 3 xmlns:gmd="http://www.isotc211.org/2005/gmd" 4 xmlns:gco="http://www.isotc211.org/2005/gco" 5 xmlns:xlink="http://www.w3.org/1999/xlink" 6 xmlns:gml="http://www.opengis.net/gml/3.2" 7 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 8 xsi:schemaLocation="http://www.isotc211.org/2005/gmd 9 http://schemas.opengis.net/iso/19139/20060504/gmd/gmd.xsd"> 10 ... 11 <gmd:contact> 12 <gmd:CI_ResponsibleParty> 13 <gmd:organisationName> 14 <gco:CharacterString> 15 Fellowship of the Ring 16 </gco:CharacterString> 17 </gmd:organisationName> 18 <gmd:contactInfo> 19 <gmd:CI_Contact> 20 <gmd:address> 21 <gmd:CI_Address> 22 <gmd:electronicMailAddress> 23 <gco:CharacterString> 24 mailto:boromir.son-denethor@lotr.org 25 </gco:CharacterString> 26 </gmd:electronicMailAddress> 27 </gmd:CI_Address> 28 </gmd:address> 29 </gmd:CI_Contact> 30 </gmd:contactInfo> 31 <gmd:role> 32 <gmd:CI_RoleCode 33 codeList="http://.../gmxCodelists.xml#CI_RoleCode" 34 codeListValue="pointOfContact"> 35 pointOfContact 36 </gmd:CI_RoleCode> 37 </gmd:role> 38 </gmd:CI_ResponsibleParty> 39 </gmd:contact> 40 <gmd:descriptiveKeywords> 41 <gmd:MD_Keywords> 42 <gmd:keyword> 43 <gco:CharacterString> 44 19’-butanoyloxyfucoxanthin 45 </gco:CharacterString> 46 </gmd:keyword> 47 <gmd:thesaurusName> 48 <gmd:CI_Citation> 49 <gmd:title> 50 <gco:CharacterString> 51 Marisaurus Thesaurus 52 </gco:CharacterString> 53 </gmd:title> 54 <gmd:date> 55 <gmd:CI_Date> 56 <gmd:date> 57 <gco:Date>2010-09-22</gco:Date> 58 </gmd:date> 59 <gmd:dateType> 60 <gmd:CI_DateTypeCode 61 codeList="http://...#CI_DateTypeCode" 62 codeListValue="publication"> 63 publication 64 </gmd:CI_DateTypeCode> 65 </gmd:dateType> 66 </gmd:CI_Date> 67 </gmd:date> 68 </gmd:CI_Citation> 69 </gmd:thesaurusName> 70 </gmd:MD_Keywords> 71 </gmd:descriptiveKeywords> 72 ... 73 </gmd:MD_Metadata>
References
- De Smith, M.J.; Goodchild, M.F.; Longley, P. Geospatial Analysis: A Comprehensive Guide to Principles, Techniques and Software Tools; Troubador Publishing Ltd.: Leicester, UK, 2007. [Google Scholar]
- Khare, R.; Rifkin, A. XML: Modeling Data and Metadata. In Proceedings of the ACM CSCW98 Conference on Computer Supported Cooperative Work, Seattle, WA, USA, 14–18 November 1998; p. 430.
- RDM Working Group. Reference Data and Metadata Position Paper; 2002; p. 45. Available online: http://inspire.jrc.ec.europa.eu/reports/positionpapers/inspirerdmppv43en.pdf (accessed on 30 November 2016).
- European Commission. Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 Establishing an Infrastructure for Spatial Information in The European Community (INSPIRE). Technical Report. 2007. Available online: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32007L0002 (accessed on 30 November 2016).
- European Commission. Commission Regulation (EC) No 1205/2008 of 3 December 2008 Implementing Directive 2007/2/EC of the European Parliament and of the Council as Regards Metadata. Technical Report. 2008. Available online: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32008R1205 (accessed on 30 November 2016).
- European Commission. Corrigendum to Commission Regulation (EC) No 1205/2008 of 3 December 2008 Implementing Directive 2007/2/EC of the European Parliament and of the Council as Regards Metadata (OJ L 326, 4.12.2008). Technical Report. 2008. Available online: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32008R1205R%2802%29 (accessed on 30 November 2016).
- ISO. ISO 19115:2014 Geographic Information—Metadata. Standard, International Organization for Standardization (TC 211), 2014. Available online: http://www.iso.org/iso/isocatalogue/catalogueics/cataloguedetailics.htm?csnumber=53798 (accessed on 30 November 2016).
- ISO. ISO 19119:2005 Geographic Information—Services. Standard, International Organization for Standardization (TC 211), 2005. Available online: http://www.iso.org/iso/cataloguedetail.htm?csnumber=39890 (accessed on 30 November 2016).
- ISO. ISO 19136:2007 Geographic Information—Geography Markup Language (GML). Standard, International Organization for Standardization (TC 211), 2007. Available online: http://www.iso.org/iso/isocatalogue/cataloguetc/cataloguedetail.htm?csnumber=32554 (accessed on 30 November 2016).
- INSPIRE Thematic Working Group on Environmental Monitoring. D2.8.III.7 INSPIRE Data Specification on Environmental Monitoring Facilities—Draft Guidelines; European Commission Joint Research Centre: Petten, The Netherlands, 2011; p. 22. [Google Scholar]
- INSPIRE Thematic Working Group on Species Distribution. D2.8.III.19 INSPIRE Data Specification on Species Distribution – Technical Guidelines; European Commission Joint Research Centre: Petten, The Netherlands, 2013; p. 22. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The Semantic Web; Scientific American: New York, NY, USA, 2001; Volume 284, pp. 34–43. [Google Scholar]
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data-the story so far. In Semantic Services, Interoperability and Web Applications: Emerging Concepts; IGI Global: Hershey, PA, USA, 2009; pp. 205–227. [Google Scholar]
- Garcia, R.; Celma, O. Semantic integration and retrieval of multimedia metadata. In Proceedings of the 5th International Workshop on Knowledge Markup and Semantic Annotation, Bournemouth, UK, 9–11 October 2006; pp. 69–80.
- Kurki, T.; Jokela, S.; Sulonen, R.; Turpeinen, M. Agents in delivering personalized content based on semantic metadata. In Proceedings of the 1999 AAAI Spring Symposium Workshop on Intelligent Agents in Cyberspace, Stanford, CA, USA, 22–24 March 1999; pp. 84–93.
- Heß, A.; Kushmerick, N. Learning to attach semantic metadata to web services. In The Semantic Web-ISWC 2003; Springer: Berlin, Germany, 2003; pp. 258–273. [Google Scholar]
- AgID. Repertorio Nazionale dei Dati Territoriali—RNDT; Technical Report, Agenzia per l’Italia Digitale (AgID); 2012. Available online: http://archivio.digitpa.gov.it/repertorio-nazionale-dei-dati-territoriali-rndt (accessed on 30 November 2016).
- Open Geospatial Consortium. Open Geospatial Consortium. OpenGIS Sensor Model Language (SensorML) Implementation Specification. In Design; Open Geospatial Consortium: Wayland, MA, USA, 2007; p. 180. [Google Scholar]
- OGC. OGC® SensorML: Model and XML Encoding Standard; Encoding Standard OGC-12-000; Open Geospatial Consortium: Wayland, MA, USA, 2014. [Google Scholar]
- Bishr, Y.A. Overcoming the semantic and other barriers to GIS interoperability. Int. J. Geogr. Inf. Sci. 1998, 12, 229–314. [Google Scholar] [CrossRef]
- Lassila, O.; Hendler, J. Embracing Web 3.0; IEEE Internet Computing: Baltimore, MD, USA, 2007; Volume 11, pp. 90–93. [Google Scholar]
- Reed, C.; Botts, M.; Davidson, J. OGC® Sensor Web Enablement: Overview and High Level Architecture; 2007 IEEE Autotestcon: Baltimore, MD, USA, 2007; pp. 372–380. [Google Scholar] [CrossRef]
- Cyganiak, R.; Wood, D.; Lanthaler, M. RDF 1.1 Concepts and Abstract Syntax—W3C Recommendation 25 February 2014. Technical Report. 2014. Available online: http://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/ (accessed on 30 November 2016).
- Hitzler, P.; Krtzsch, M.; Rudolph, S. Foundations of Semantic Web Technologies, 1st ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2009. [Google Scholar]
- Berners-Lee, T.; Fielding, R.; Masinter, L. Uniform Resource Identifier (URI): Generic Syntax. Technical Report. 2005. Available online: https://tools.ietf.org/html/rfc3986 (accessed on 30 November 2016).
- World Wide Web Consortium. Namespaces in XML 1.0 (Third Edition). Technical Report. 2009. Available online: https://www.w3.org/TR/REC-xml-names/ (accessed on 30 November 2016).
- Beckett, D.; Berners-Lee, T.; Prud’hommeaux, E.; Carothers, G. RDF 1.1 Turtle—Terse RDF Triple Language. Technical Report. 2014. Available online: https://www.w3.org/TR/turtle/ (accessed on 30 November 2016).
- Harris, S.; Seaborne, A. SPARQL 1.1 Query Language—W3C Recommendation 21 March 2013. Technical Report. 2013. Available online: http://www.w3.org/TR/sparql11-query/ (accessed on 30 November 2016).
- Cambridge Semantics. SPARQL vs. SQL. Technical Report. Available online: http://www.cambridgesemantics.com/semantic-university/sparql-vs-sql-intro (accessed on 30 November 2016).
- Hjelmager, J.; Moellering, H.; Cooper, A.K.; Delgado, T.; Rajabifard, A.; Rapant, P.; Danko, D.M.; Huet, M.; Laurent, D.; Aalders, H.; et al. An initial formal model for spatial data infrastructures. Int. J. Geogr. Inf. Sci. 2008, 22, 1295–1309. [Google Scholar] [CrossRef]
- Tagliolato, P.; Oggioni, A.; Fugazza, C.; Pepe, M.; Carrara, P. Sensor metadata blueprints and computer-aided editing for disciplined SensorML. IOP Conf. Ser. Earth Environ. Sci. 2016, 34, 012036. [Google Scholar] [CrossRef]
- Fugazza, C.; Pepe, M.; Oggioni, A.; Tagliolato, P.; Carrara, P. Streamlining geospatial metadata in the Semantic Web. IOP Conf. Ser. Earth Environ. Sci. 2016, 34, 012009. [Google Scholar] [CrossRef]
- Fugazza, C.; Menegon, S.; Pepe, M.; Oggioni, A.; Carrara, P. The RITMARE Starter Kit: Bottom-up capacity building for geospatial data providers. In Proceedings of the 9th International Conference on Software Paradigm Trends (ICSOFT-PT), Vienna, Austria, 29–31 August 2014; pp. 169–176.
- Oggioni, A.; Tagliolato, P.; Fugazza, C.; Pepe, M.; Menegon, S.; Pavesi, F.; Carrara, P. Oceanographic and Marine Cross-Domain Data Management for Sustainable Development; Diviacco, P., Leadbetter, A., Glaves, H., Eds.; IGI Global: Hershey, PA, USA, 2017; pp. 200–223. [Google Scholar]
- Pavesi, F.; Basoni, A.; Fugazza, C.; Menegon, S.; Oggioni, A.; Pepe, M.; Tagliolato, P.; Carrara, P. EDI—A template-driven metadata editor for research data. J. Open Res. Softw. 2016. [Google Scholar] [CrossRef]
- Open Geospatial Consortium. OGC Best Practice for Sensor Web Enablement Lightweight SOS Profile for Stationary In-Situ Sensors—OGC 11-169r1; Technical Report; Open Geospatial Consortium: Wayland, MA, USA, 2014. [Google Scholar]
- Leadbetter, A.; Lowry, R.; Clements, D. The NERC Vocabulary Server: Version 2.0; Geophysical Research Abstracts; EGU–European Geosciences Union GmbH: Munich, Germany, 2012; Volume 14. [Google Scholar]
- Leadbetter, A. Linked Ocean Data. In The Semantic Web in Earth and Space Science. Current Status and Future Directions; AKA GmbH: Berlin, Germany, 2015; pp. 11–31. [Google Scholar]
- RDF Working Group. RDF Schema 1.1. Technical Report. 2014. Available online: https://www.w3.org/TR/rdf-schema/ (accessed on 30 November 2016).
- OWL Working Group. Web Ontology Language (OWL). Technical Report. 2012. Available online: https://www.w3.org/2001/sw/wiki/OWL (accessed on 30 November 2016).
- Simon Cox. OWL Representation of the ISO/TC 211 Harmonized UML Model for Geographic Information. Technical Report, 2013. Available online: http://def.seegrid.csiro.au/static/isotc211/iso19115/2003/ (accessed on 30 November 2016).
- European Commission. GeoDCAT-AP v1.0. Technical Report. 2015. Available online: https://joinup.ec.europa.eu/asset/dcatapplicationprofile/assetrelease/geodcat-ap-v10 (accessed on 30 November 2016).
- Fugazza, C.; Pepe, M.; Oggioni, A.; Pavesi, F.; Carrara, P. A holistic, semantics-aware approach to Spatial Data Infrastructures. In Proceedings of the 3rd International Conference on Data Management Technologies and Applications (DATA), Vienna, Austria, 29–31 August 2014; pp. 349–356.
- Fugazza, C.; Luraschi, G. Semantics-Aware Indexing of Geospatial Resources Based on Multilingual Thesauri: Methodology and Preliminary Results. Int. J. Spat. Data Infrastruct. Res. 2012, 7, 16–37. [Google Scholar]
- Santoro, M.; Mazzetti, P.; Nativi, S.; Fugazza, C.; Granell, C.; Díaz, L. Methodologies for augmented discovery of geospatial resources. In Discovery of Geospatial Resources: Methodologies, Technologies, and Emergent Applications; Díaz, L., Granell, C., Huerta, J., Eds.; IGI Global: Hershey, PA, USA, 2012; pp. 172–203. [Google Scholar]
- Documento Per La Definizione Di Una Politica Nella Gestione E Utilizzo Dei Dati E Dei Prodotti Resi Disponibili Nell’ambito Del Progetto RITMARE. Available online: http://www.ritmare.it/area-download?download=187:data-policy-new (accessed on 30 November 2016).
- Reichman, O.; Jones, M.B.; Schildhauer, M.P. Challenges and opportunities of open data in ecology. Science 2011, 331, 703–705. [Google Scholar] [CrossRef] [PubMed]
- David, P.A. The economic logic of open science and the balance between private property rights and the public domain in scientific data and information: A primer. In The role of scientific and technical data and information in the public domain: Proceedings of a Symposium; The National Academies Press: Washington, DC, USA, 2003; pp. 19–34. [Google Scholar]
- Uhlir, P.F.; Schröder, P. Open data for global science. Data Sci. J. CODATA 2007, 6, 36–53. [Google Scholar] [CrossRef]

© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fugazza, C.; Pepe, M.; Oggioni, A.; Tagliolato, P.; Pavesi, F.; Carrara, P. Describing Geospatial Assets in the Web of Data: A Metadata Management Scenario. ISPRS Int. J. Geo-Inf. 2016, 5, 229. https://doi.org/10.3390/ijgi5120229
Fugazza C, Pepe M, Oggioni A, Tagliolato P, Pavesi F, Carrara P. Describing Geospatial Assets in the Web of Data: A Metadata Management Scenario. ISPRS International Journal of Geo-Information. 2016; 5(12):229. https://doi.org/10.3390/ijgi5120229
Chicago/Turabian StyleFugazza, Cristiano, Monica Pepe, Alessandro Oggioni, Paolo Tagliolato, Fabio Pavesi, and Paola Carrara. 2016. "Describing Geospatial Assets in the Web of Data: A Metadata Management Scenario" ISPRS International Journal of Geo-Information 5, no. 12: 229. https://doi.org/10.3390/ijgi5120229
APA StyleFugazza, C., Pepe, M., Oggioni, A., Tagliolato, P., Pavesi, F., & Carrara, P. (2016). Describing Geospatial Assets in the Web of Data: A Metadata Management Scenario. ISPRS International Journal of Geo-Information, 5(12), 229. https://doi.org/10.3390/ijgi5120229