1. Introduction
Floating car data (FCD) are widely used to analyse traffic phenomena. Floating cars are vehicles equipped with positioning devices; most commonly these are GPS (Global Positioning System) devices, which record the movement of the cars and their location in space and time. FCD are an important data-source in traffic research. FCD allow to calculate time-dependent travel times along urban corridors [
1], reveal traffic congestions [
2] and unveil the complexity of human mobility [
3]. They help to identify flaws in urban traffic planning [
4] and to infer traffic states [
5]. FCD are used to derive real-time traffic information from the dynamics of single cars [
6]. Moreover, FCD are an important data source for eco-routing [
7] and help to detect emission hotspots in cities [
8].
FCD collected by a GPS are commonly stored as a trajectory. A trajectory is a sequence of tuples
, with
. A tuple
consists of position estimate
and a time stamp
and, therefore, is referred to as a spatio-temporal position. The intermediate movement between consecutive spatio-temporal positions is interpolated. For reasons of simplicity, linear interpolation is mostly used [
9].
A GPS trajectory is a discrete representation of the continuous movement of a floating car recorded with a measurement system; hence it is inevitably affected by two types of error: measurement error and interpolation error [
10].
Measurement error is a property of the measurement system used for recording the movement. For FCD, measurement error refers to the difference between the actual spatial position of the floating car at a specific time and the GPS position estimate at the same time.
Interpolation error is a property of the discretization of movement. For FCD, interpolation error arises from the difference between the continuous movement of the floating car and the discrete snapshots in the trajectory. Hence, interpolation error is closely connected to the temporal sampling rate at which the data are collected.
Measurement and interpolation error affect the calculation of movement parameters and consequently influence conclusions drawn from the FCD. A movement parameter is a physical quantity of movement [
11], such as speed or direction. Surprisingly, the influence of error on movement parameters has only been touched briefly in the aforementioned studies on FCD and in other published literature. The role of the sampling rate, for example, has been discussed for travel time estimation [
12] and traffic state estimation [
13] from FCD. Both studies rely on point speed measurements of fleets, which serve as indicators for the collective traffic situation in a road network. The authors evaluated at which temporal frequencies to collect these.
In this article we focus on the movement of individual cars rather than the collective behaviour of cars in traffic. We claim that an appropriate temporal sampling strategy for collecting individual FCD with a GPS is both crucial and missing in the published literature. We believe that a temporal sampling strategy must consider the following aspects:
Sampling must reflect the aim of the movement analysis. Which information is needed for the analysis and at which level of detail?
Sampling must address the characteristics of the measurement system. What is the influence of GPS measurement error when collecting the FCD?
Sampling must respond to the characteristics of the moving object under observation. What is the influence interpolation error when collecting the FCD?
In this article we mainly concentrate on the last two aspects. First, we evaluate how measurement and interpolation error affect real-world FCD on the basis of four movement parameters. These are the floating car’s spatial path, distance, speed and direction. Then we build on our experimental results and give temporal sampling recommendations for recording FCD with a GPS. Our recommendations aim at minimizing the influence of error while avoiding to record redundant information. We believe that our recommendations can help researchers to find an appropriate temporal interval for recording FCD with a GPS.
Section 2 introduces relevant work from previously published literature.
Section 3 describes the experimental data and defines the four movement parameters for which the effect of error is investigated.
Section 4 analyses the influence of measurement error,
Section 5 the influence of interpolation error on FCD.
Section 6 gives recommendations for recording FCD,
Section 7 discusses our results.
2. Related Work
In this section we first introduce the related work on measurement and interpolation error in movement data (1). Then we show existing filtering and smoothing approaches that aim to remove the effects of error and we discuss movement simulations (2). Finally, we explain how ideas put forward in movement simulations can be used to evaluate the influence of interpolation error in FCD (3).
(1) Both interpolation error and measurement error influence the information retrieved from GPS trajectory data. The temporal sampling rate has a fundamental impact on, for example, speed and heading calculations in pedestrian movements [
14] and on the distances travelled by fishing vessels [
15]: measurement errors result in overestimation of the distance travelled when the sampling rate is high, while interpolation errors result in underestimation of the distance travelled when the sampling rate is low [
15].
The accuracy of GPS position estimates and the influence of measurement error has been widely discussed in the published literature, for example in [
16]. The current performance of GPS and its accuracy are made publicly available in the quarterly
Global Positioning System (GPS) Standard Positioning Service (SPS) Performance Analysis Report [
17]. GPS accuracy has been shown to vary over time [
18], with the location [
19] and the device [
20]. However, GPS position estimates in a trajectory are commonly close in space and time, which influences the accuracy of the movement parameters. GPS measurement error has been found to follow spatial and temporal auto-correlation [
21,
22,
23] and to cause a systematic overestimation of distance [
24].
The problem of interpolation error in movement representations was already recognised in early
time geography. [
25]. Hägerstrand noted that the knowledge of a moving object’s position in space is irrevocably connected to time: the more time there is between an object’s two known positions the less certain are its whereabouts between these. Hägerstrand’s concept of error ellipses was later used to indicate the time-dependent probabilistic position of an object in unconstrained two-dimensional space [
26]. This approach was subsequently extended to moving objects within a constrained environment, such as cars in a road network [
27,
28].
(2) In navigation and geographic information science, filtering and smoothing have been used to reduce the influence of errors on movement trajectories. This includes least squares smoothing, kernel-based smoothing and Kalman filtering [
29]. Some smoothing methods preserve movement parameters better than others. For floating cars it was found, for example, that Kalman filtering resulted in the least difference between the travelled distance, speed and acceleration recorded with a GPS and those derived from the car’s
controller area network (CAN) bus [
30].
In the field of movement ecology, statistical models either take into account errors in recorded movement paths or simulate movement processes in a purely computational manner. We will briefly discuss three of the approaches used: state-space models (SSMs), Brownian bridge movement models (BBMMs) and random walk (RW) models.
State-space models allow for linking the true but unobserved movement of an object to the observation of this movement [
31]. The true movement is described by means of a process model, which is a model of the dynamics of movement, whereas the observations derive from measurements, such as positions from a GPS tracking device, and are generally affected by errors. The process models can be controlled by different parameters depending, for example, on the behaviour of an animal under observation, which allows different types of movement to be described [
32]. An example for an SSM is Kalman filtering.
Brownian bridge movement models (BBMMs) are used to reconstruct the movement between recorded positions. In contrast to simple linear interpolation, BBMMs assume either a random movement [
33] or a biased random movement [
34] between two recorded positions. Since BBMMs describe the probability of a moving object occupying a particular position during its movement they are often used to estimate animal space use [
34]. They can, however, also describe movement patterns, such as the encounter of two objects [
33].
Random walk (RW) models are widely used to simulate the movement of objects, mostly animals. In its simplest form, a RW model is a successive step-wise process, in which an object moves in a random direction at each step. Other more realistic versions of these models introduce a bias in the form of a tendency to prefer a particular direction, or a correlation in the form of a tendency to continue moving in the same direction [
35]. In addition, a purely spatial sinuosity index can control the “degree of winding” of the movement in the RW model [
36,
37]. A structured overview of the mathematical theory behind different types of RW models (biased and un-biased, correlated and uncorrelated), as well as possible application scenarios and limitations, can be found in [
35]. RW models provide an explicit theoretical foundation for movement-related observations and relate to findings in real-world data [
38]. In the following paragraph we show how we make use of this relationship.
(3) In RW theory, temporal rediscretization is used to evaluate the effects of the sampling rate on statistics derived from the random walk. Rediscretization of a RW has a significant influence on the calculation of movement parameters [
39,
40]. When the sampling rate is decreased, the resulting increase in interpolation error causes the observed speed to decrease, the object appears to move more slowly.
In this work, we applied the concept of temporal rediscretization to real-world FCD. First, we made sure that the influence of measurement error was below a certain, tolerable threshold. Then we defined four movement parameters and calculated these for decreasing sampling frequencies. By comparing the difference between the movement parameters we evaluated the effects of interpolation error on FCD.
4. Assessing the Influence of Measurement Error
In this section we analyse the influence of measurement error on the experimental FCD from
Section 3.1. We follow the approach in [
24], which allows to calculate the autocorrelation of GPS measurement error in movement data without using positional ground truth. The authors show that GPS measurement error causes a systematic bias in movement data. Distances recorded with a GPS are—on average—bigger than the true distances travelled by a moving object, if interpolation error can be neglected. This systematic bias is functionally related to the autocorrelation of GPS measurement error. If measurement error is strongly autocorrelated the systematic bias must be low. This means that distances recorded with a GPS are only slightly longer than the true distances travelled by the floating car. This relationship is summarized in the following equation [
24]:
In Equation (
1)
C , is the non-normalized autocorrelation of GPS measurement error,
is the squared reference distance (or true distance) and
is the expected squared distance due to measurement error. Moreover,
is the combined variance of GPS measurement error at
both position estimates between which the distance was calculated. For reasons of simplicity, it is assumed that GPS measurement error follows the same distribution at both position estimates. This is realistic since these are close in space. Hence
is defined as
, where
and
are the GPS measurement error in
x and
y direction. We substitute
with
, the observed average of all distance measurements and normalize by
. This yields
, an estimate for the normalized autocorrelation of GPS measurement error.
We applied Equation (
1) to the experimental FCD described in
Section 3.1. Similar to [
30], the reference distance
was retrieved from the car’s
controller area network (CAN) bus, where a sensor recorded the rotation of the car’s drive axle. We set
. This value was chosen according to our experience with the GPS device in the recording environment. The results of Equation (2) imply the following: if the measurement error in the data has a variance of
and if it is not affected by autocorrelation, then
is exactly zero. If
is positive there must be autocorrelation in the data.
We found that
always exceeded the reference distance
derived from the CAN bus, such that the average of
equalled around
. Hence, the data confirm that the GPS overestimates distances and allow to calculate
.
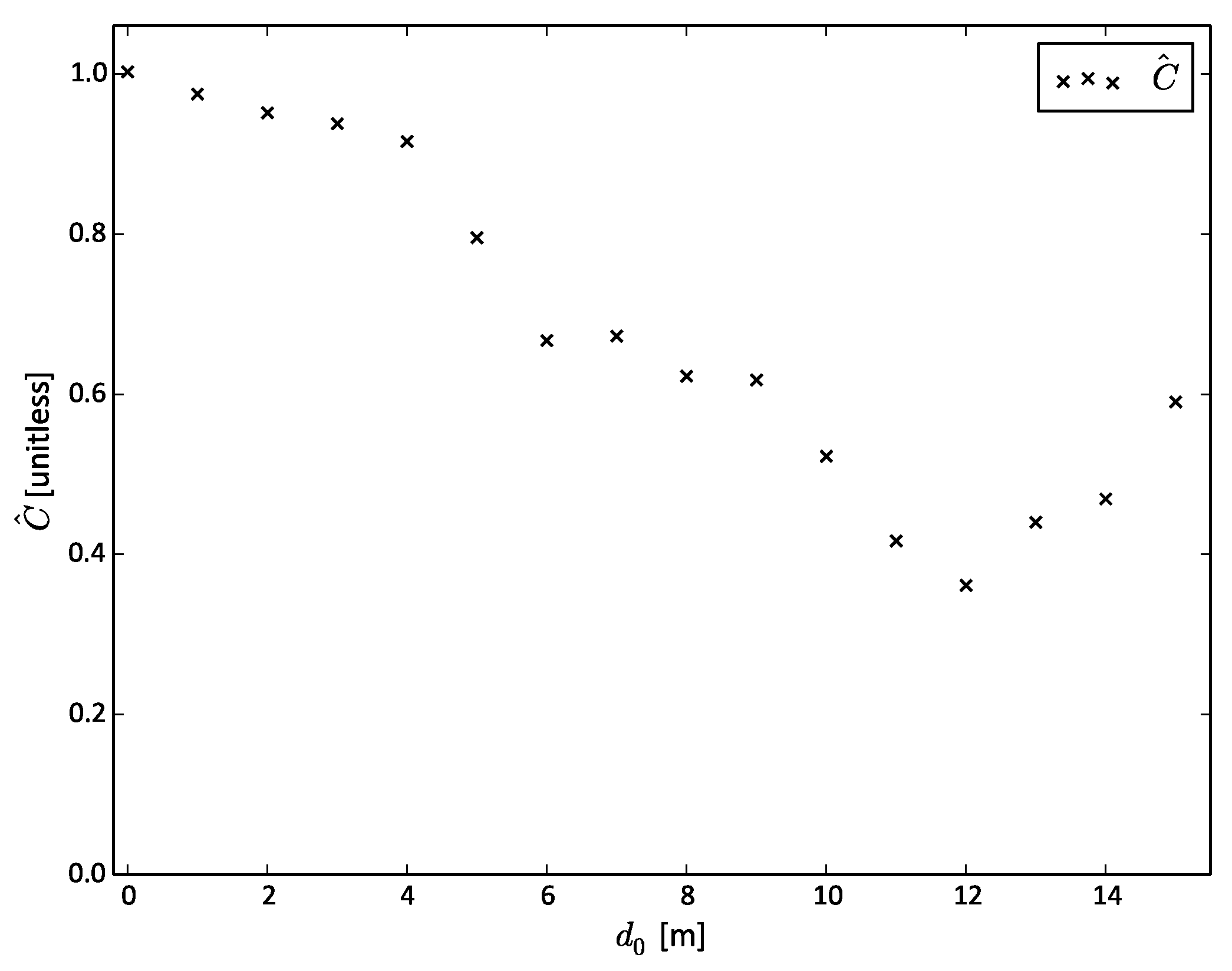
Figure 1 shows the value of
for different reference distances
in
bins.
is always positive. The measurement error in the experimental FCD is affected by positive autocorrelation. This means that consecutive position estimates have very similar error. The spread of this error is considerably less than suggested by
. The autocorrelation in
Figure 1 decreases with increasing reference distance
. This indicates that the measurement error in the data is also spatially autocorrelated. Note that Equation (
1) provides an estimate of the autocorrelation of GPS measurement error with respect to
. If we had chosen smaller values for
and
, for example
, the estimated autocorrelation in
Figure 1 would also be smaller. However,
would still be positive and it would still follow the same decreasing trend. This means that we could still conclude that there is temporal and spatial autocorrelation in the data.
Figure 1.
The autocorrelation of GPS measurement error in the experimental FCD. The autocorrelation () decreases as the reference distance () increases. is the distance between recording two consecutive position estimates according to the car’s CAN bus.
Figure 1.
The autocorrelation of GPS measurement error in the experimental FCD. The autocorrelation () decreases as the reference distance () increases. is the distance between recording two consecutive position estimates according to the car’s CAN bus.
The results in
Figure 1 are in agreement with empirical findings from the published literature. GPS measurement error is affected by both spatial and temporal autocorrelation [
21,
22,
23]. This autocorrelation can be interpreted as a quality measure for movement data [
24]. Although there is measurement error in the FCD, this error is similar for consecutive position estimates. If movement parameters such as distance, direction or speed are calculated from these, the error tends to cancel out. Therefore, we claim that it is legitimate to treat the FCD sampled at
as an approximation of the true movement of the floating car. On a first glance, this conclusion contradicts with results obtained by other authors. In [
45], a Monte Carlo simulation is used to illustrate that measurement error in trajectories sampled at high frequencies does not allow to calculate realistic movement parameters. However, this simulation assumes that GPS measurement error scatters entirely randomly between each two consecutive position estimates.
Figure 1 shows that this is not the case for our experimental FCD.
5. Assessing the Influence of Interpolation Error
Interpolation error is closely related to the temporal sampling rate at which movement is recorded: the smaller the time interval between two position estimates, the smaller the interpolation error. In this section we show the influence of interpolation error on movement parameters derived from FCD at different sampling frequencies. We defined four metrics for interpolation error and evaluated these with the experimental FCD described in
Section 3.1.
5.1. Rediscretizing the Trajectories
As the true behaviour of a floating car cannot be described with discrete measurements, FCD recorded at different sampling frequencies have to be compared against one another. A similar approach is used in movement ecology to analyse the effects of the sampling rate on simulated random walks [
39,
40]. We define the experimental FCD recorded at
to be the reference movement. We showed in
Section 4 that the FCD were affected by autocorrelation. Hence, this approximation is legitimate. From the FCD at
we calculated the reference path (
), the reference distance (
), the reference speed (
) and the reference direction (
) according to
Table 1. Then we rediscretized the FCD and re-calculated the movement parameters for larger sampling intervals.
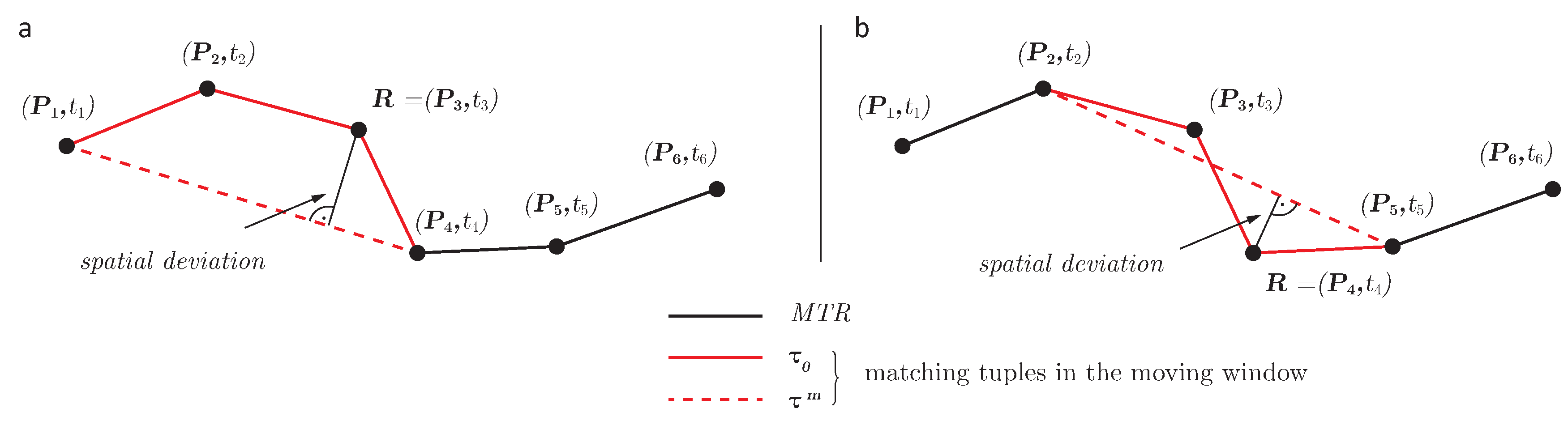
The rediscretization of factor
k describes how much the temporal sampling rate is reduced by. For example, a rediscretization of
means that the sampling rate is decreased from
to
(see
Figure 2). The use of a moving window during rediscretization ensures that only those elements of the reference and the rediscretized movement are compared that represent the same phases of movement. For a rediscretization of factor
k each moving window first partitions the movement into a trajectory segment
consisting of
spatio-temporal positions.
is then rediscretized to
consisting of two spatio-temporal positions, one at the start position of
and the other at the end position.
and
represent the same movement at different sampling intervals. They are therefore referred to as a pair of matching movement.
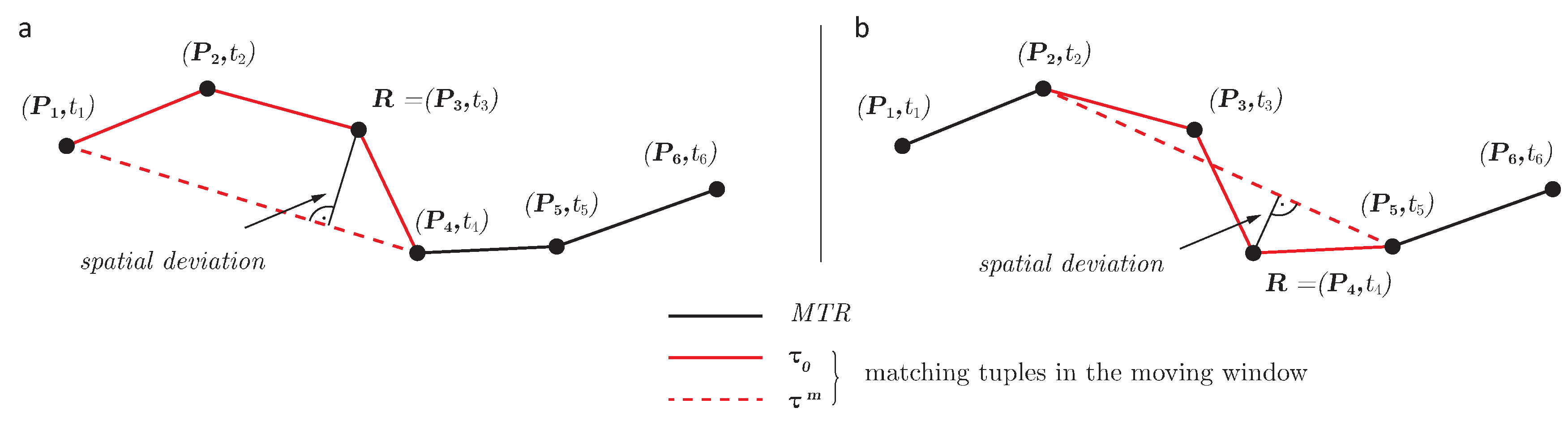
Figure 2.
Rediscretizing the FCD. The reference movement at is rediscretized to a resolution of , i.e., . In a the moving window is at its initial location and encompasses the movement between and . The solid red line represents the reference movement, the dashed red line its rediscretization. In b the moving window has shifted forward , so that the reference movement and its rediscretization are now compared between and .
Figure 2.
Rediscretizing the FCD. The reference movement at is rediscretized to a resolution of , i.e., . In a the moving window is at its initial location and encompasses the movement between and . The solid red line represents the reference movement, the dashed red line its rediscretization. In b the moving window has shifted forward , so that the reference movement and its rediscretization are now compared between and .
5.2. Metrics for Interpolation Error
Interpolation error causes the measured path
to differ from the reference path
. Henceforth, we refer to this as
path uncertainty. Path uncertainty affects not only the geometry of the path (see
Figure 3) but also the interpolated distance
. As
follows a straight line between two positions it is always less than or equal to the reference distance
.
Figure 3.
Path uncertainty and its effect on measured distance . The measured distance (dashed line) is smaller than the reference distance (solid line). Interpolation error causes a systematic underestimation of distance.
Figure 3.
Path uncertainty and its effect on measured distance . The measured distance (dashed line) is smaller than the reference distance (solid line). Interpolation error causes a systematic underestimation of distance.
Path uncertainty is a measure of the path difference after rediscretization. For each pair of matching movement we calculated two parameters that allow us to describe the path uncertainty, these being the distance difference and the maximum spatial deviation.
Distance difference, on the one hand, is a metric of how much the length of the rediscretized distance differs from the reference distance:
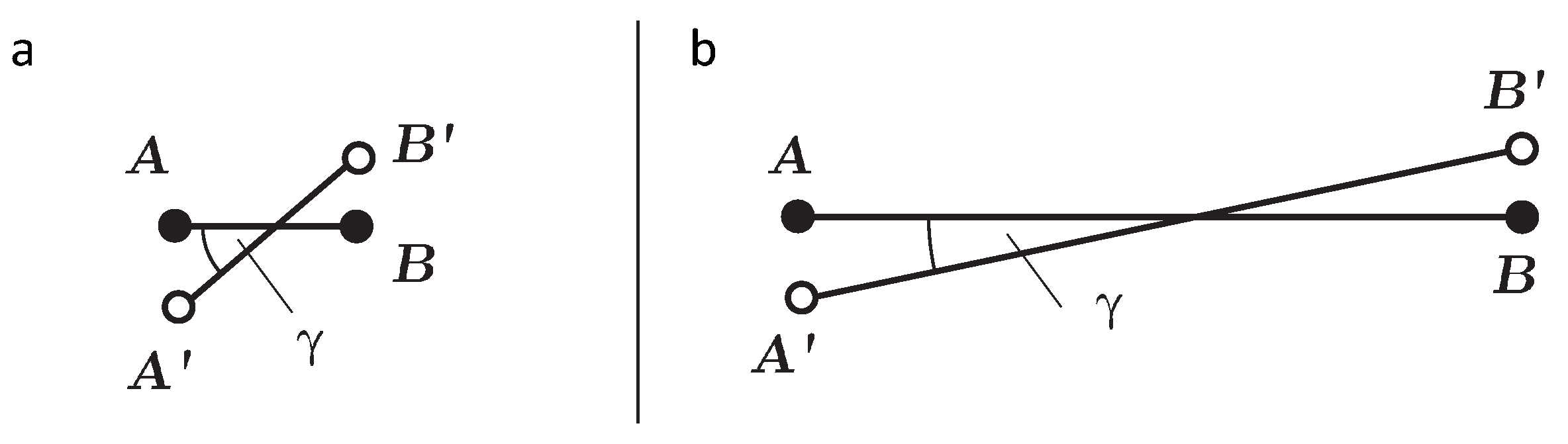
Spatial deviation, on the other hand, is a metric of how much the spatial location of the rediscretized path differs from that of the reference path. The calculation of the spatial deviation is based on
R, the point along
that is farthest from
. In
Figure 2a, for example,
R is at
. The perpendicular (spatial) distance from
R to
is the spatial deviation. Thus,
As each pair of matching movement has identical first and last positions and both are interpolated linearly, R is bound to be one of the positions along the reference path. Hence, it suffices to calculate the perpendicular distance from the measured positions between start and end point of to and to then select the maximum of these.
Interpolation error affects speed and direction in two ways: firstly, path uncertainty causes the measured speed and direction to differ from the reference speed and direction. Since , interpolation error tends to underestimate speed: the object can not have moved more slowly to reach the next known position than , but it could have moved more rapidly and taken a longer path.
Secondly, the object’s spatio-temporal progression along the path is uncertain. The measured speed is an average value over the time period between two position estimates. An object moving at a variable speed and another moving at a uniform speed can have the same average speed but only the latter of the two will be captured appropriately by a GPS trajectory.
Henceforth we refer to the uncertainty concerning the spatial path and spatio-temporal progression of an object as dynamic uncertainty. This uncertainty has two aspects. It causes to differ from , referred to as speed difference, and to differ from , referred to as angular deviation.
The speed difference provides a means of assessing information concerning the speed along the reference movement that has been averaged out by interpolation. For a rediscretization of factor
k, the measured speed
was first calculated between the two positions along
. Since
consists of
positions there are
k reference speed measurements between these. Consequently,
is the reference speed between the
and
consecutive positions along
, where
. Then, we retrieved the difference between each
and
. Hence, speed difference is defined as
The angular deviation, on the other hand, describes the absolute difference between the direction of
as compared to the direction of
. As we did with the speed difference, we first calculated the direction
between the two positions along
. Then, we calculated the direction
between the
and the
position along
, where
. Finally, we determined the absolute difference between each
and
. Hence, angular deviation is defined as
5.3. Evaluation of Interpolation Error in Real-World FCD
In this subsection we evaluate the effects of interpolation error on movement parameters derived from FCD at different sampling frequencies. We used the data set described in
Section 3.1.
Starting from the FCD at we performed 19 independent rediscretization steps of factor . For each rediscretization step we searched the trajectory data for all possible pairs of matching movement. We then calculated movement parameters and evaluated the four metrics for interpolation error. In the following paragraph we present our findings and interpret them with respect to well-known results from RW theory.
Figure 4 shows the distance difference after rediscretization. The distance difference is always positive; compared to
, trajectories sampled at lower sampling frequencies cause an underestimation of distance. The median, inter-quartile ranges and whiskers increase in an almost quadratic fashion. With less frequent sampling some of the
become very small, whereas others remain almost unchanged.
Figure 4.
Distance difference after a rediscretization of factor k. In (a), the box-plot has whiskers at the quantile; in (b) it has no whiskers.
Figure 4.
Distance difference after a rediscretization of factor k. In (a), the box-plot has whiskers at the quantile; in (b) it has no whiskers.
Similar results have also been previously explained and explored in velocity jump simulations of correlated random walks [
39,
40]. In a velocity jump process, an object moves with a fixed speed for a random time interval and then turns to a new direction, usually one drawn from a circular normal distribution; the iteration of these steps creates a correlated random walk. In [
39,
40] the authors rediscretized these random walks using decreasing sampling frequencies and recorded the change in speed after rediscretization. They found that the negative natural logarithm of mean observed speed increases in a linear manner with decreasing sampling rate. These findings can easily be related to distance: since the velocity jump process assumes true speed to be constant, any change in observed speed is caused by a change in the observed distance. These results therefore suggest a decay in the observed distance and an increase in its variability. Our results also indicate an increasing distance difference with decreasing sampling rate, as well as an increase in the variability of distance difference (see the interquartile range and the whiskers in
Figure 4).
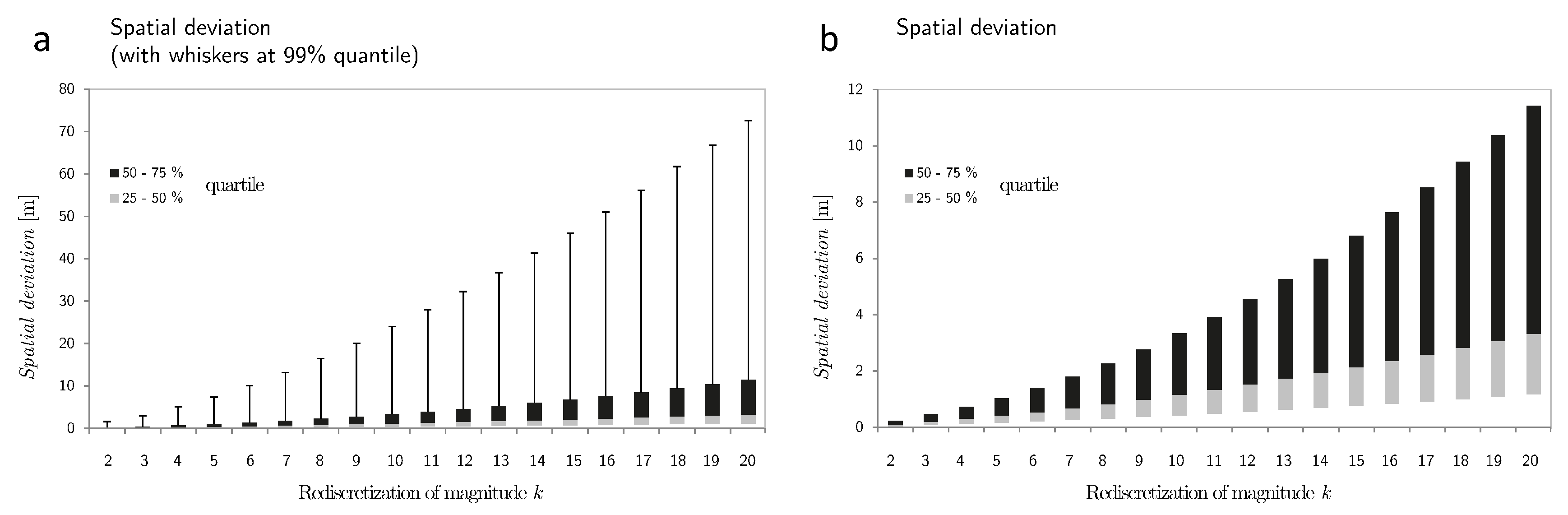
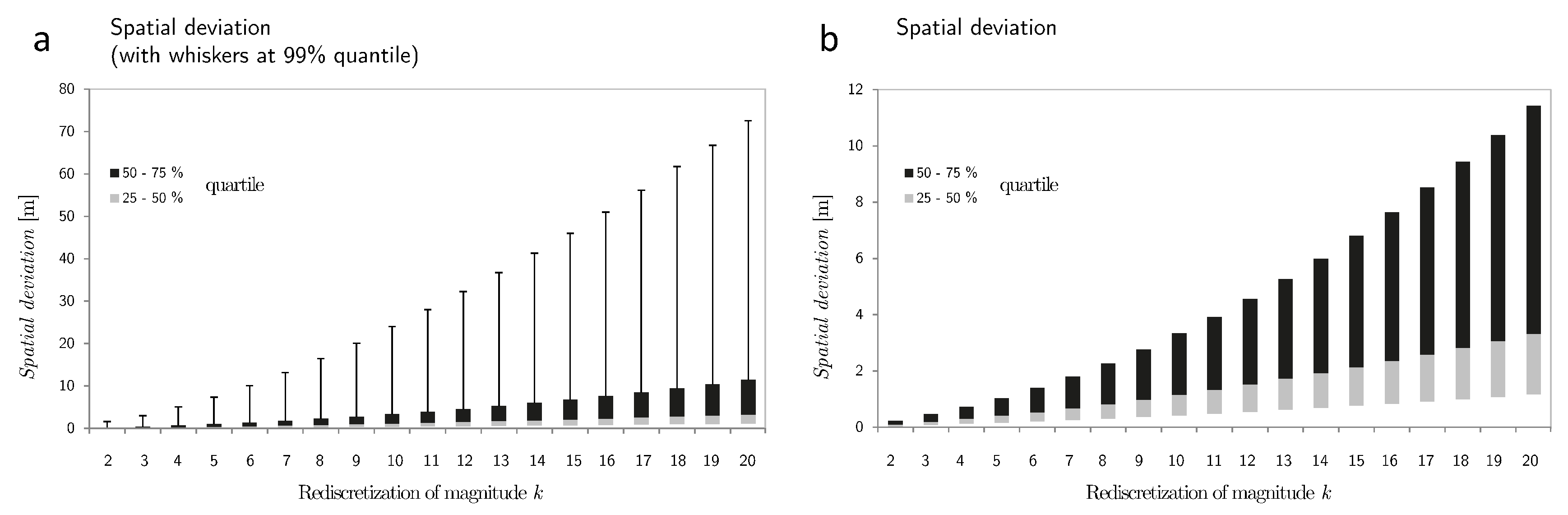
Figure 5 shows the spatial deviation after rediscretization. With decreasing sampling frequencies the spatial deviation increases quadratically. Again, this finding relates to random walk theory, where the
mean squared displacement (
) is used to describe the mean spatial extent of a random motion. In a random walk, the
increases as the sampling rate decreases [
36,
37].
Figure 5.
Spatial deviation after a rediscretization of factor k. In (a), the box-plot has whiskers at the quantile; in (b) it has no whiskers.
Figure 5.
Spatial deviation after a rediscretization of factor k. In (a), the box-plot has whiskers at the quantile; in (b) it has no whiskers.
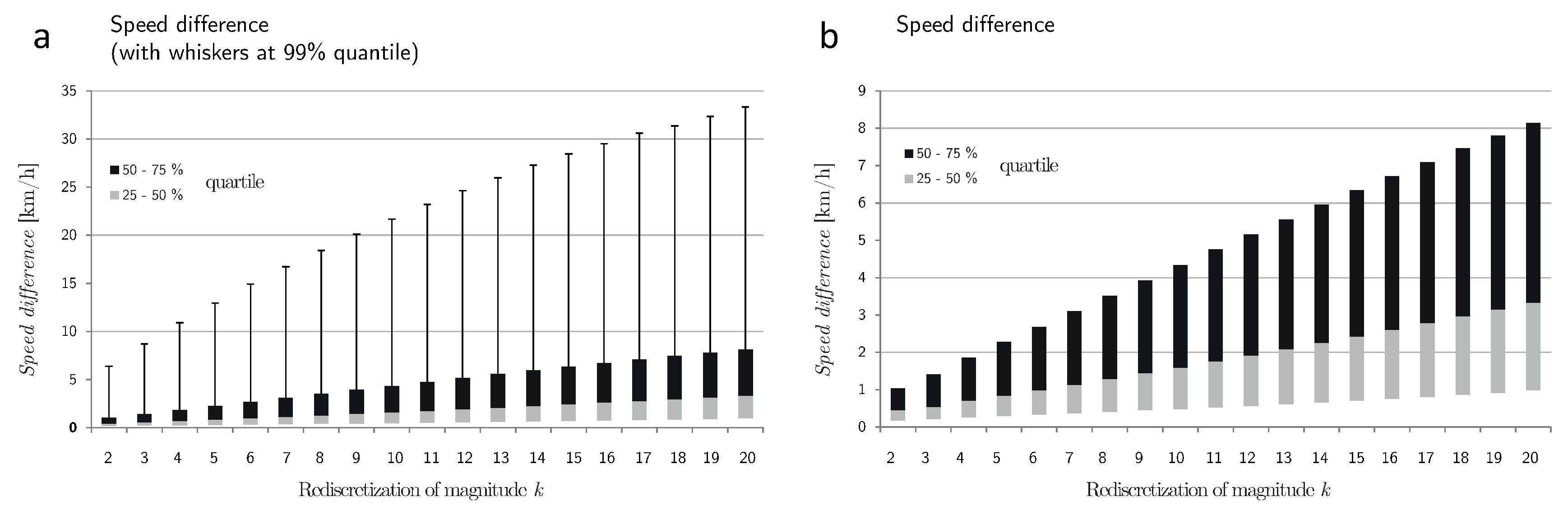
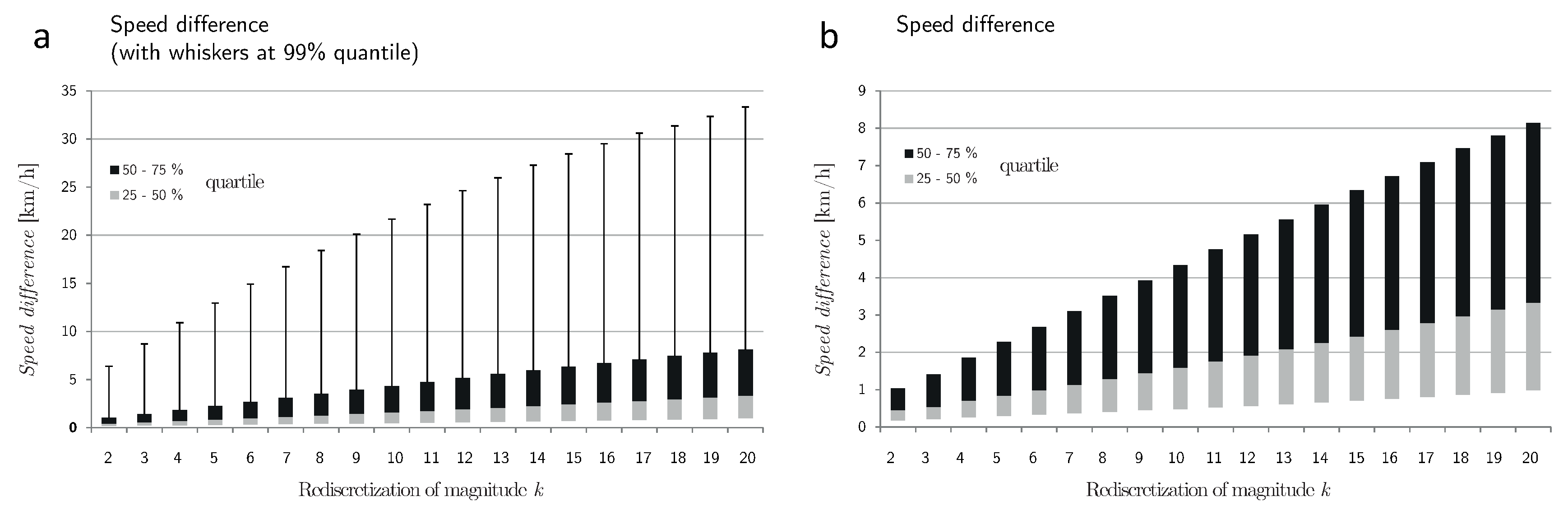
Figure 6 shows the speed difference after rediscretization. In contrast to path uncertainty, speed difference increases in an approximately logarithmic fashion. This means that the information loss caused by a decrease from high to medium sampling frequencies (e.g., from
to
) is considerably greater than the loss caused by a decrease from medium to low sampling frequencies (e.g., from
to
). This holds true for the median, the quartiles and the whiskers. Similarly,
Figure 7 illustrates the speed difference between matching sequences along a real-world GPS trajectory for a redicretization of
.
The findings in
Figure 6 are in agreement with the results obtained in [
39,
40], where the change of observed speed in a simulation was found to be exponential. Nonetheless, there is a fundamental difference: the change in speed reported by these authors was due to a change of observed distance in a rediscretized velocity jump process of constant speed. This corresponds to the distance difference in
Figure 5. In contrast, the speed difference in
Figure 7 is due to a change in the observed distance and to an incorrect perception of the dynamics of movement. The observed speed difference is therefore much greater than the distance difference in
Figure 4.
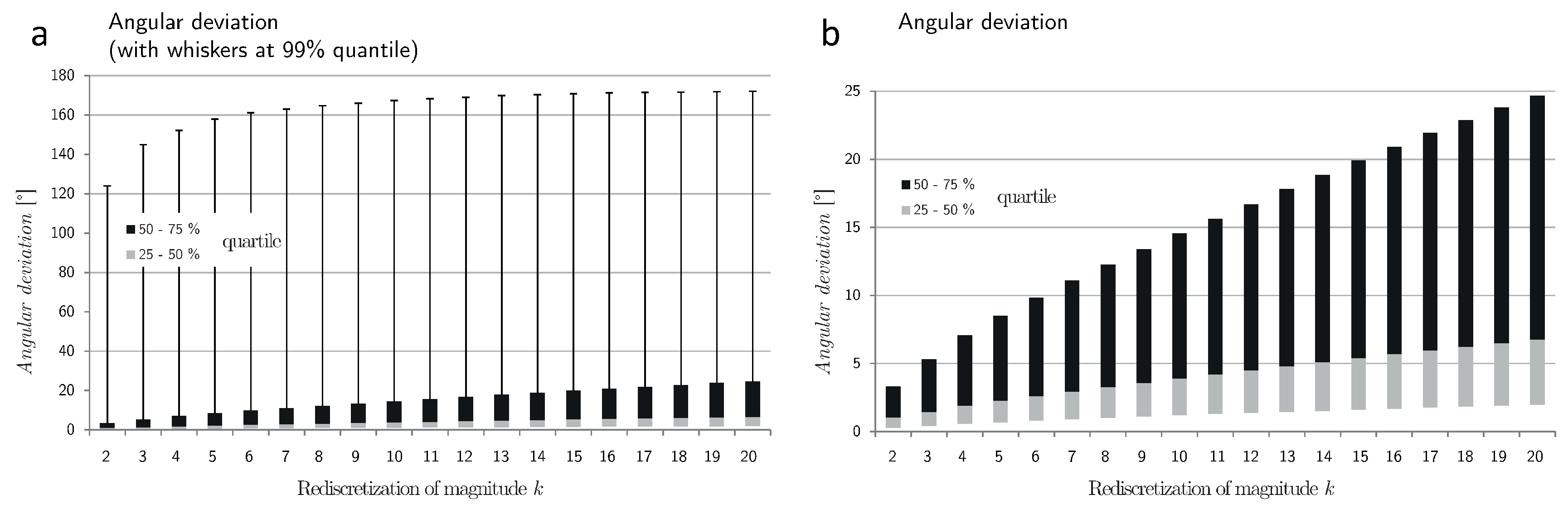
Figure 8 shows the angular deviation after rediscretization. As was the case with speed difference, angular deviation increases in an approximately logarithmic manner. Up to
the median of the angular deviation remains well below
. However, for even a very moderate increase of the sampling rate to
the upper quartile already shows considerable deviation of
. Again, the results in
Figure 8 are in good agreement with results from simulations where angular deviation was found to change logarithmically with decreasing sampling rate [
40].
Figure 6.
Speed difference after a rediscretization of factor k. In (a), the box-plot has whiskers at the quantile; in (b) it has no whiskers.
Figure 6.
Speed difference after a rediscretization of factor k. In (a), the box-plot has whiskers at the quantile; in (b) it has no whiskers.
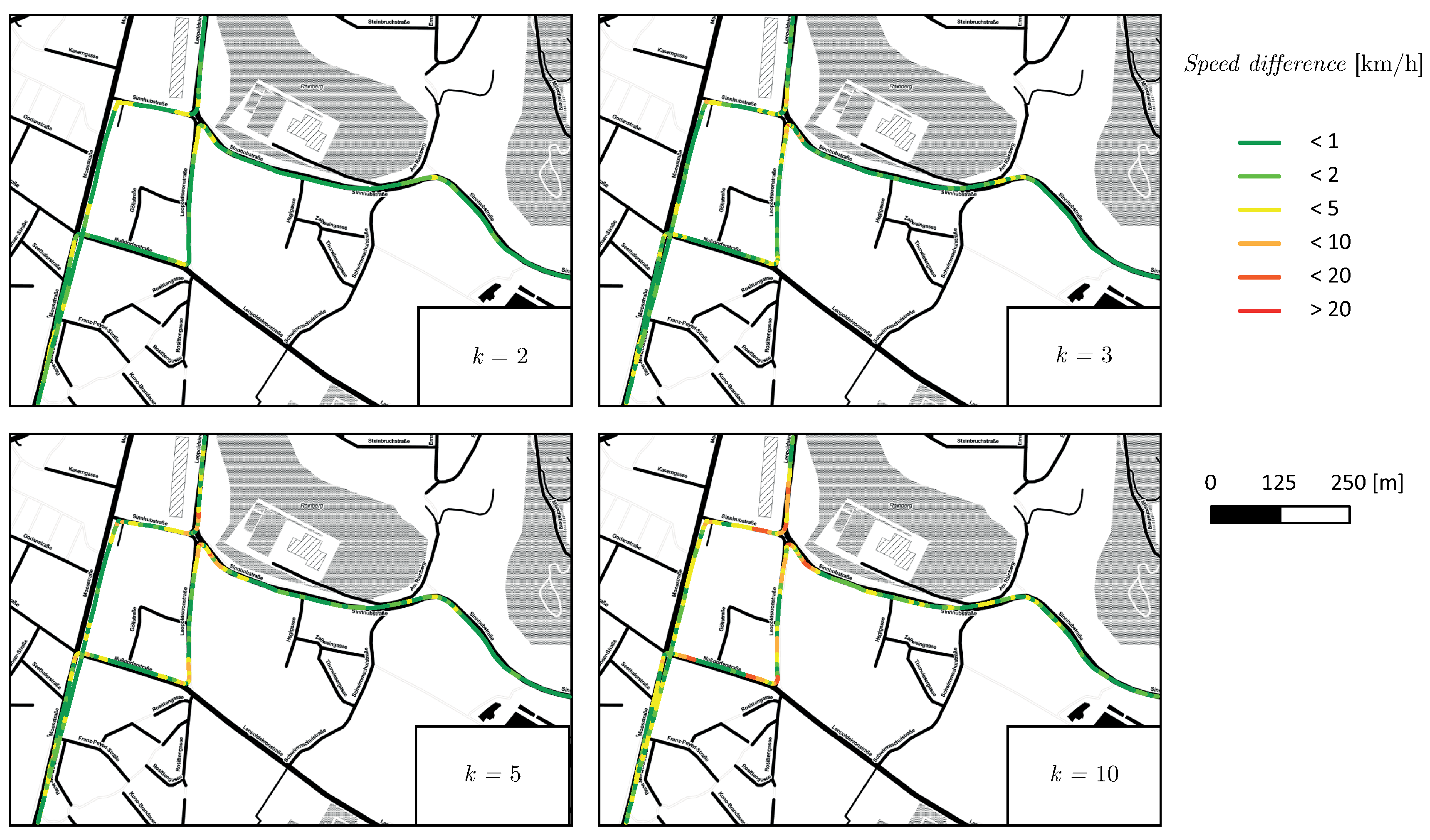
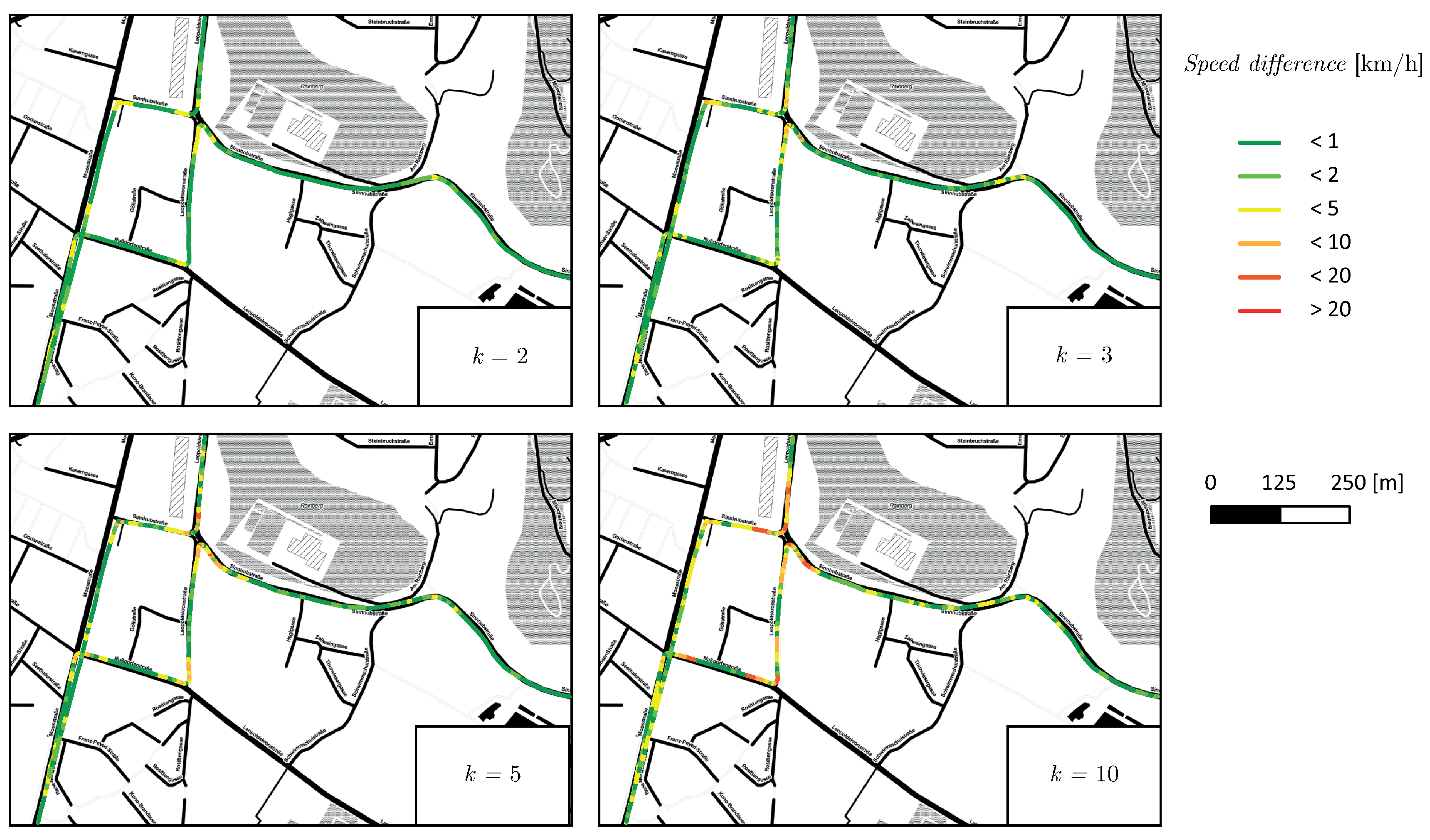
Figure 7.
Speed difference for a rediscretization of factor k mapped to the FCD recorded at . The green color indicates a low speed difference (), the red color a high speed difference (). A slightly lower sampling rate () already results in a severe loss of information; green and red phases alternate frequently. Especially near to road intersections where the car is decelerating or accelerating speed differs by up to from the reference.
Figure 7.
Speed difference for a rediscretization of factor k mapped to the FCD recorded at . The green color indicates a low speed difference (), the red color a high speed difference (). A slightly lower sampling rate () already results in a severe loss of information; green and red phases alternate frequently. Especially near to road intersections where the car is decelerating or accelerating speed differs by up to from the reference.
Figure 8.
Angular deviation after a rediscretization of factor k. In (a), the box-plot has whiskers at the quantile; in (b) it has no whiskers.
Figure 8.
Angular deviation after a rediscretization of factor k. In (a), the box-plot has whiskers at the quantile; in (b) it has no whiskers.
7. Dicussion
Our approach differs from those adopted by previous authors: firstly, we have concentrated on the temporal sampling rate as the only regulatory instrument for controlling the quality of information in trajectory data. Filtering, for example, is not addressed in our research as it has already received considerable attention from other authors [
29,
30]. Secondly, our movement parameters have been derived from real-world movement data rather than generated in a simulation. Real-world data are affected by measurement and interpolation error and these have sometimes contradicting influence on the calculation of movement parameters [
15]. In this research we addressed both types of error, aiming to find a balanced strategy to reduce them. Naturally, the characteristics of the data influence our findings. The FCD were recorded in Salzburg, a city with many narrow and angled streets. The floating cars often change speed and turn frequently. Thus, interpolation error is expected to be higher than in a road network consisting of long straights where cars move uniformly.
It may sometimes not be possible to use the sampling frequencies recommended in this paper to record FCD. We therefore discuss ways of how to interpret useful results from sparsely sampled data. Firstly, some movement parameters are not affected by the sampling rate. The sinuosity index is a measure of how target-oriented movement is [
36] and it is not affected by the sampling rate. Secondly, the FCD can be enhanced with additional geographical information. Rather than moving freely in space, floating cars are confined to a road network. Geometric and attributive information of the network can be useful for reconstructing the movement of the car. The distance along a road network might, for example, allow an accurate estimate to be made of a vehicle’s travelled distance where the data is sparsely sampled. Thirdly, probabilistic models such as the Brownian bridge movement model [
34] can be used to describe the probable movement of an object rather than a crisp line as defined by linear interpolation. In a road network the probable movement is the set of all paths that allow a vehicle to reach the next measured position along the trajectory within the available time [
27]. However, even for FCD that were recorded at sparser sampling frequencies our findings can be instructive. They reveal the error that was most likely introduced when collecting the FCD.
Euclidean Space or Network Space?
In this article all movement parameters were calculated in two-dimensional Euclidean space. However, floating cars move in a road network. For many practical applications it is necessary to first map-match the FCD to network space. In network space the current position of the floating car can be expressed as a combination of the link ID and the relative position on the link [
46]. In this section we discuss the influence of the sampling rate on map-matching and movement parameters in network space. We focus on the following two aspects:
How can our findings support map-matching from two-dimensional space to network space?
Which movement parameters should rather be calculated from the trajectory in two-dimensional Euclidean space and which in network space?
(1) Since floating car data are affected by error, they cannot be simply projected to network space. Due to measurement error, position estimates are likely to lie off the roads. Moreover, due to interpolation error, it might not be possible to find a unique path between two correctly map-matched position estimates. Hence, a map-matching algorithm is needed to associate the GPS trajectory to the road network. There are four types of map-matching algorithms [
47]. Geometric algorithms use geometric properties of the trajectory and the road network. Topological algorithms also consider the connectivity and topology of the road network. Probabilistic algorithms create an error region around each GPS position estimates in order to single out candidate links in the road network, where the car might have travelled. From these candidates the algorithm picks the most probable. Advanced map-matching algorithms use advanced statistical concepts to link the trajectory to the road network.
Most map-matching algorithms require reliable movement parameters to associates a trajectory to a road network. These movement parameters inevitably have to be calculated in two-dimensional Euclidean space. Simple geometric algorithms only consider the path and its shape [
48,
49]. Other, more sophisticated algorithms compare the direction of the trajectory to the direction of the links in the road network [
50]. Yet other algorithms use information on the distance travelled [
51] or the speed of the floating car [
52]. Our findings can help to choose an appropriate map-matching algorithm for a given sampling rate. We showed that for trajectories sampled at
the direction tends to be unstable and distances tend to be overestimated; for trajectories sampled at
average speed fails to reflect the actual speed of the car; for trajectories sampled at
the recorded path already differs considerably from the actual path. These examples show that FCD require different map-matching approaches depending on the sampling rate at which they were recorded.
For FCD recorded at very low sampling rates (
) traditional map-matching algorithms are likely to provide poor results. Thus, special algorithms for low-frequency FCD have to be used [
46,
53]. These algorithms connect position estimates with candidate routes; the trajectory is matched to the most probable of these routes. However, also the accuracy of these algorithms decreases with the sampling rate [
54]. At lower sampling rates there are many possible paths between two consecutive position estimates and map-matching is more likely to choose an incorrect link [
28].
(2) Finally, we discuss, which data are more suitable for calculating movement parameters, the raw GPS trajectory data in two-dimensional space or the map-matched trajectory data in network space. In two-dimensional space, a trajectory will be longer than it really was if sampling is too frequent. It will be shorter, if sampling is too sparse. In order to avoid a systematic error in either direction, it is preferable to first map-match the FCD and to derive distances in network space. Similar arguments can be made for path and direction. The road network defines the path and the direction of a floating car. Therefore, it is more reasonable to deduce both from the map-matched trajectory. However, if average speed is derived from network space the projection from two-dimensional space might dislocate two positions, which makes speed occasionally faster or slower than it really was. As GPS trajectories are affected by strong spatio-temporal autocorrelation, speed calculations between two consecutive position estimates should be very accurate. Hence, it is preferable to calculate average speed in two-dimensional Euclidean space.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}