
Processing: A Python Framework for the Seamless Integration of Geoprocessing Tools in QGIS


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
2.1. Processing Goals and Motivation
- Heterogeneity: The implementation of existing tools was not homogeneous. Both in their implementation style (such as the availability of progress indicators, automatic loading of results) and GUI behavior (such as the order of entries in layer selectors, consistent closing of dialogues when processes are finished, location of help buttons), the analysis tools were not consistent.
- Duplication: Code was not being reused. Routines, such as implementing a layer selector, were implemented multiple times and not reused between tools.
- Isolation: Existing tools could not be combined into processes.
2.2. Development History
2.3. Existing Similar Technology
- Adding algorithms to Processing does not require external development tools, but can be done from within QGIS itself.
- Processing supports the customization of algorithm GUIs by providing access to UI libraries.
- All parts of Processing are open source. Like all QGIS plugins, the source code of Processing has to be released under a GPL license, since QGIS itself is released under GPL. Thus, it is possible to verify the inner workings of each Processing component.
- On the other hand, advanced features, such as conditional flows or loops, are currently not possible in the Processing Graphical Modeler.
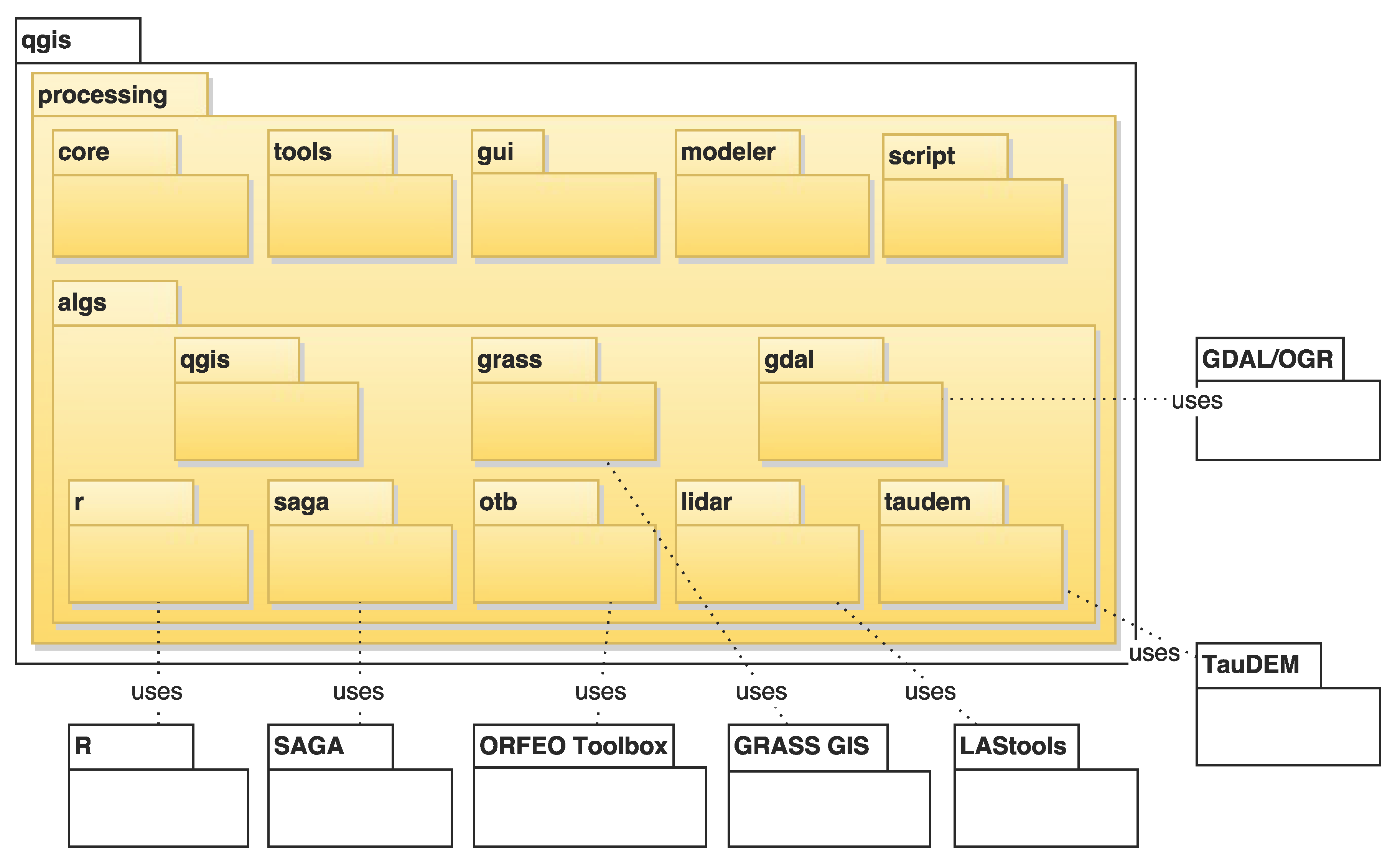
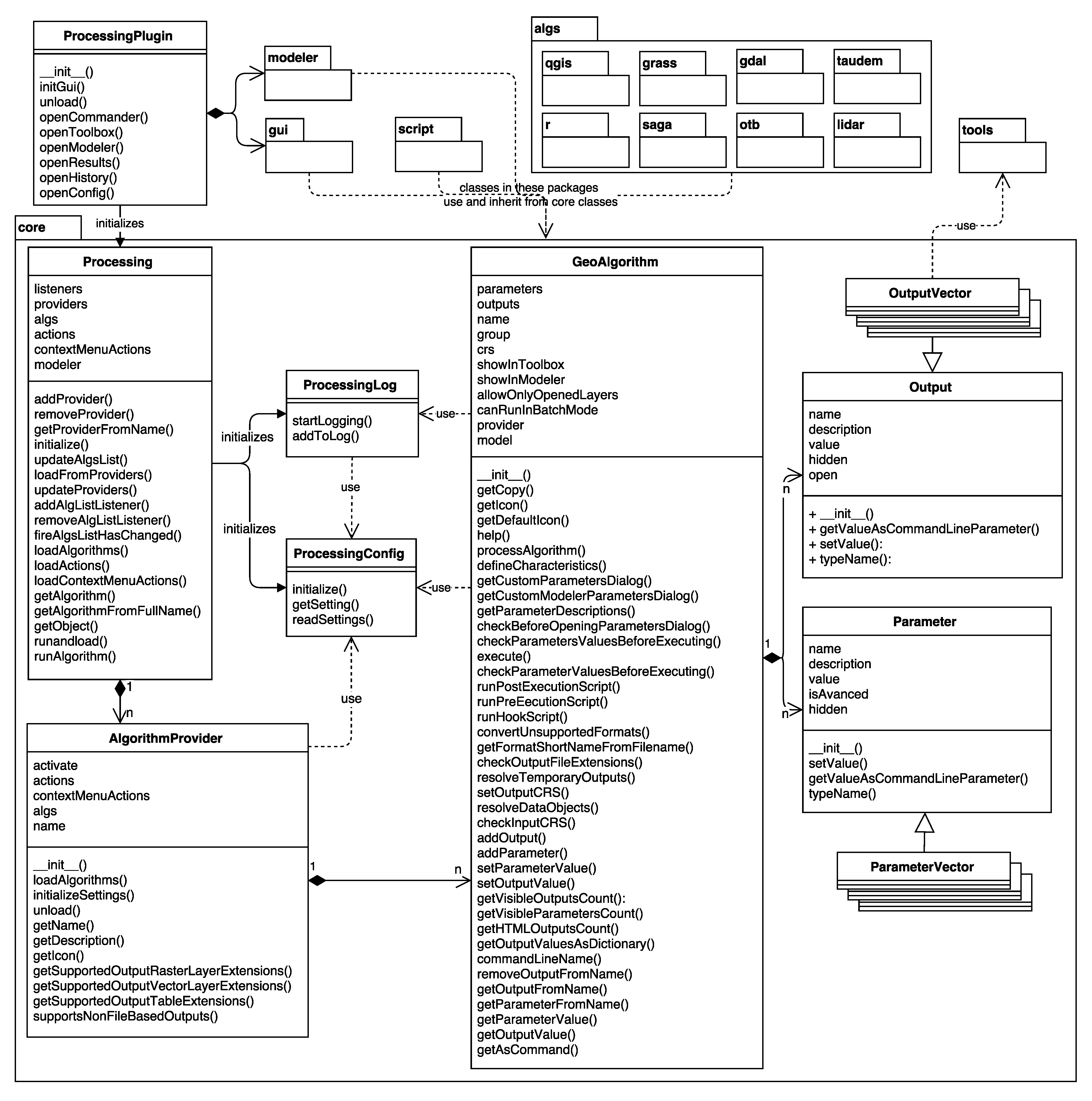
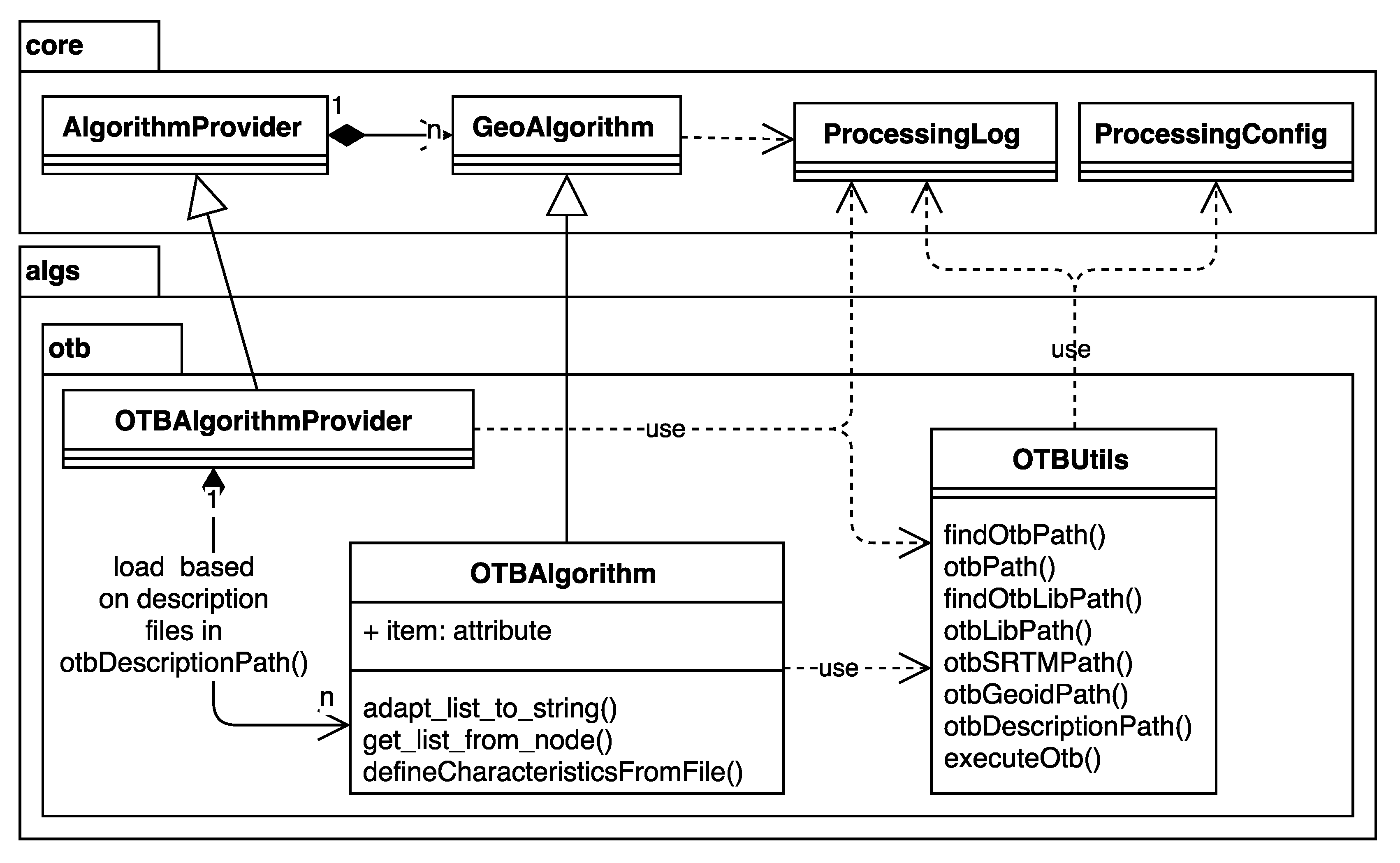
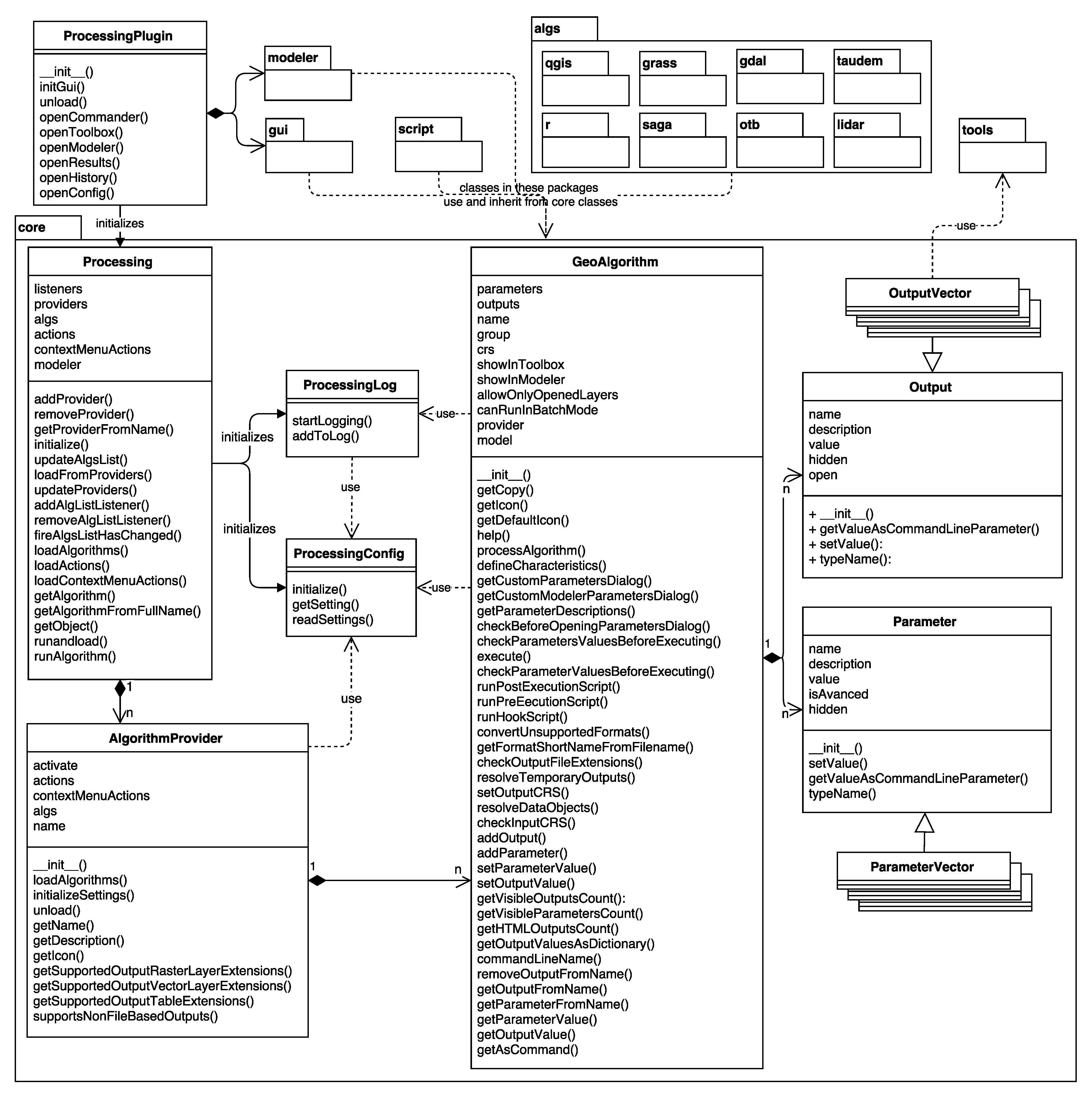
3. Framework Architecture
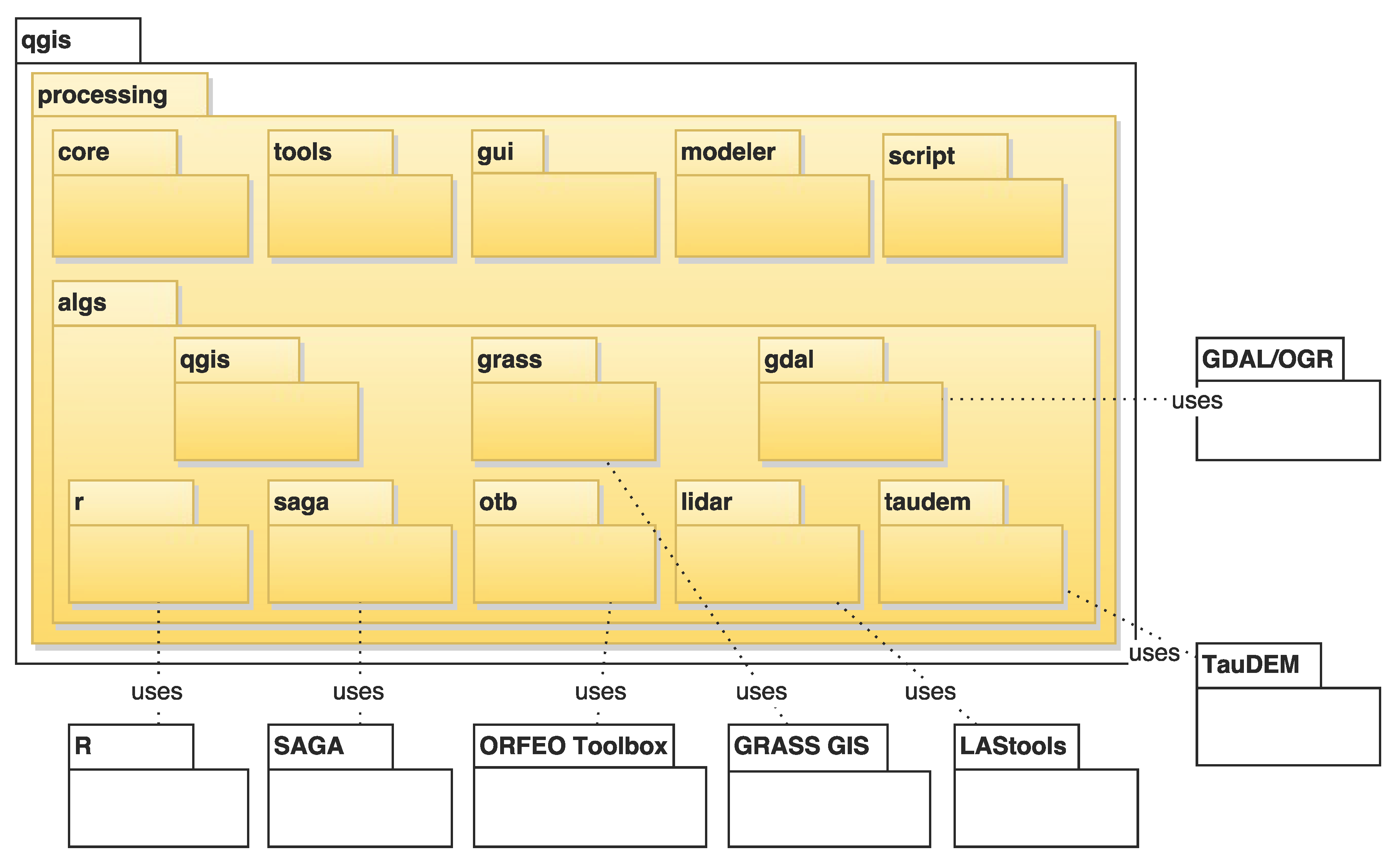
- Efficiency: This enables efficient integration of analytical capabilities by connecting to original binaries of other software, such as SAGA, GRASS GIS, R, or ORFEO Toolbox, instead of duplicating development effort.
- Modularity: To ease the implementation of algorithms and provide consistent behavior across different tools, the framework provides additional classes that implement commonly-needed routines for modular integration.
- Flexibility: The implemented algorithms can be reused in any of the graphical tools included in the framework, such as the graphical modeler or the batch processing interface. This does not require additional work by the algorithm developer, since this flexibility is a feature of all algorithms developed using the base Processing classes.
- Automatic GUI generation: Developers can focus on the algorithm itself instead of the GUI elements. Processing takes care of generating GUIs based on the algorithm description.
import processing
processing.alglist()
processing.alghelp(name_of_the_algorithm)
processing.runalg(name_of_the_algorithm, param1, param2, ..., paramN,
Output1, Output2, ..., OutputN)
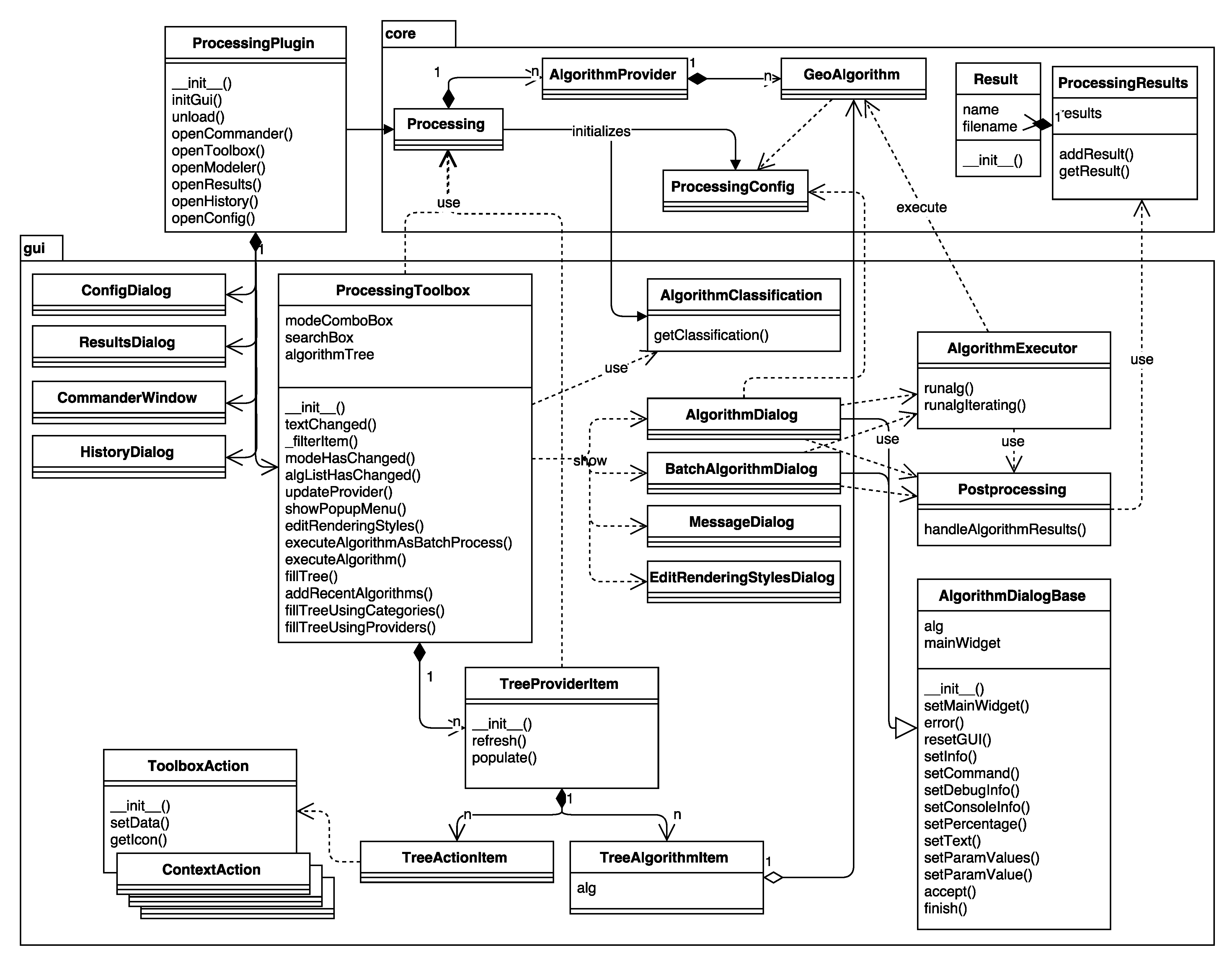
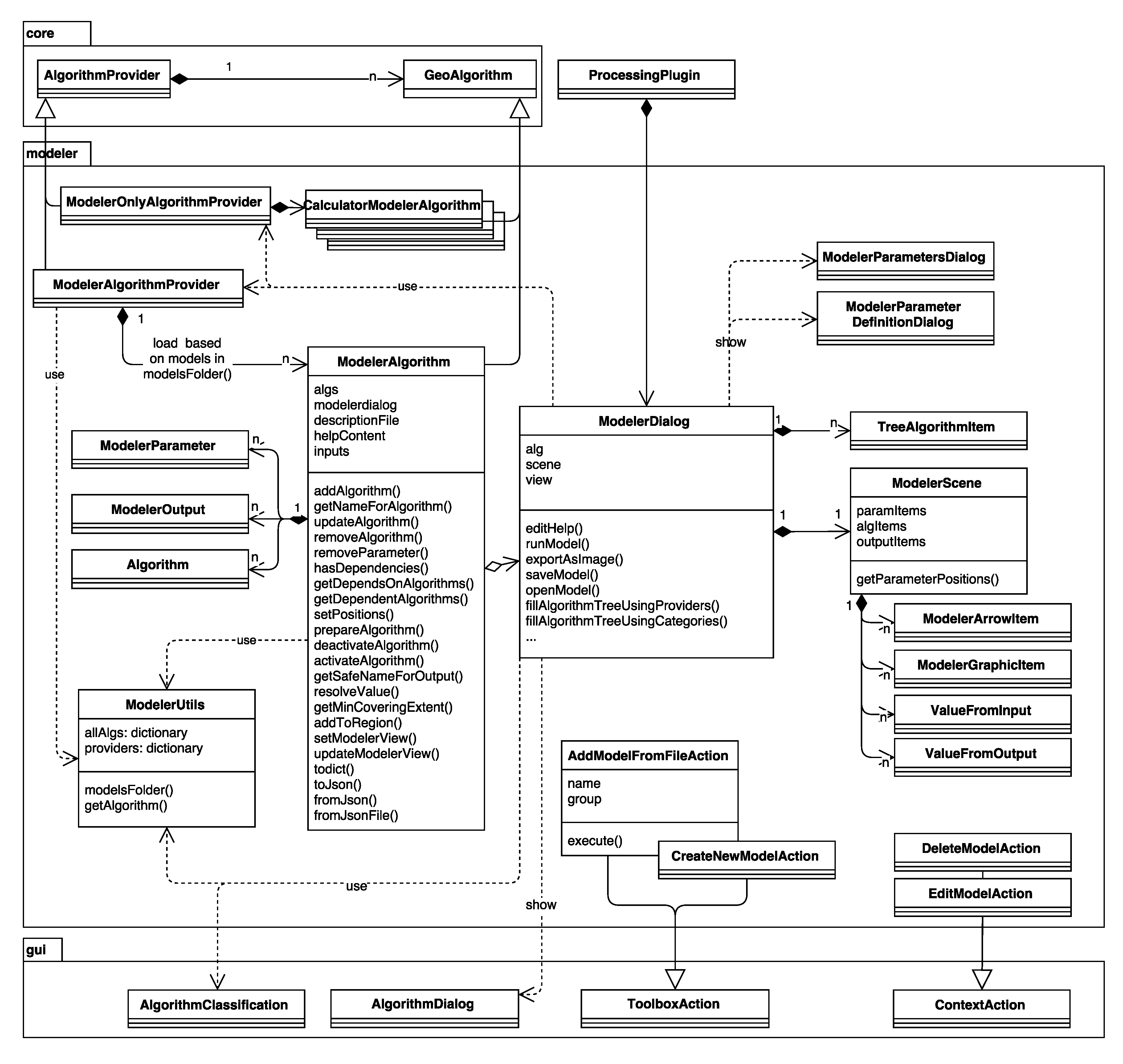
3.1. Graphical User Interface
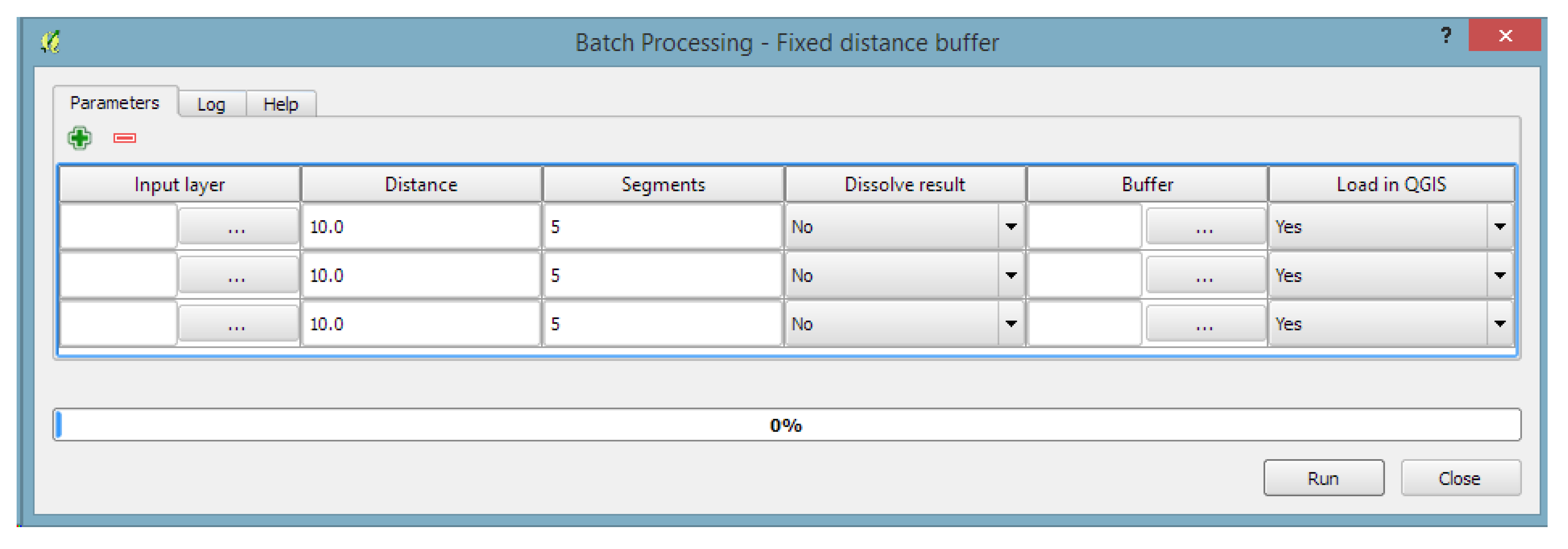
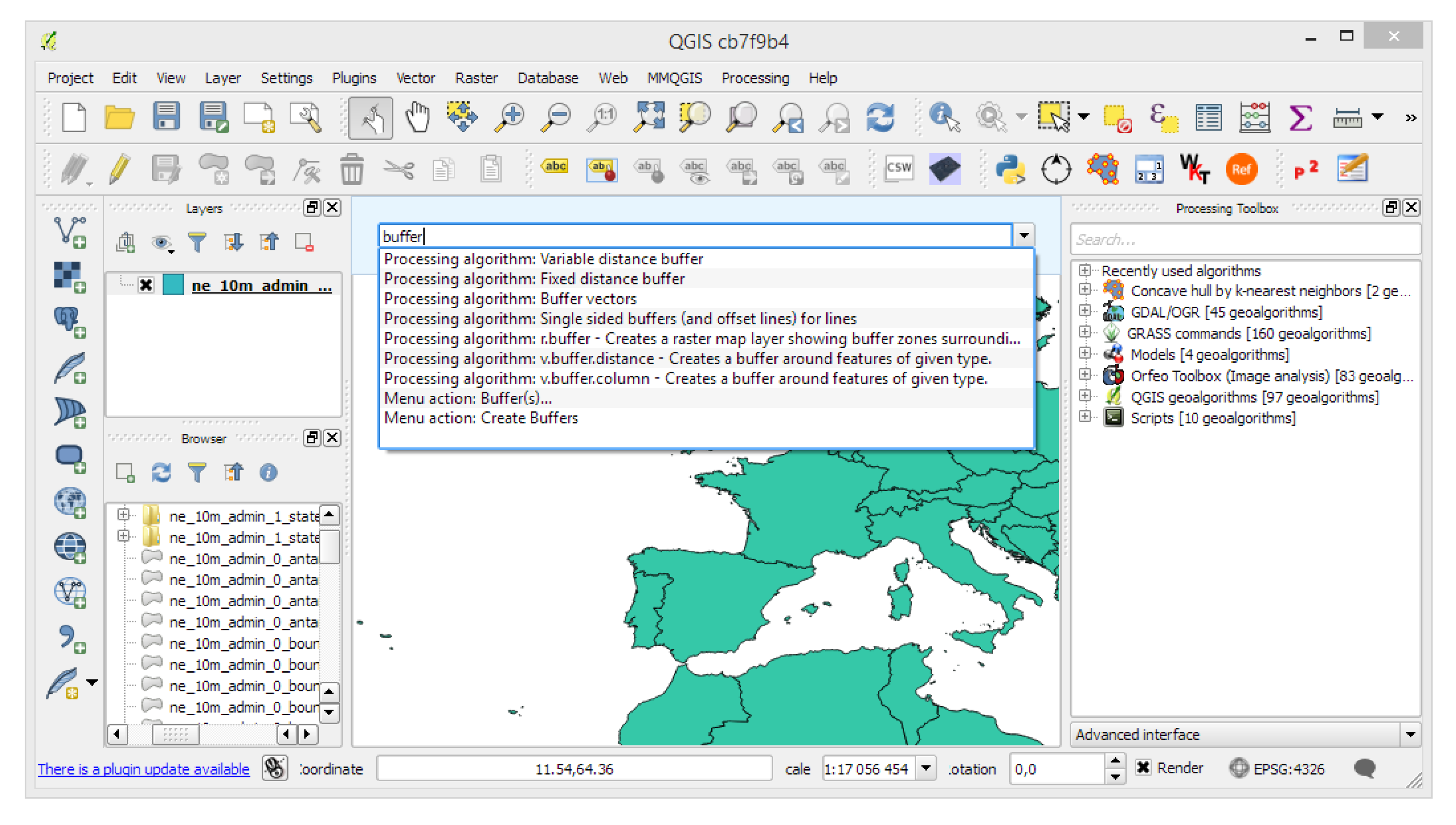
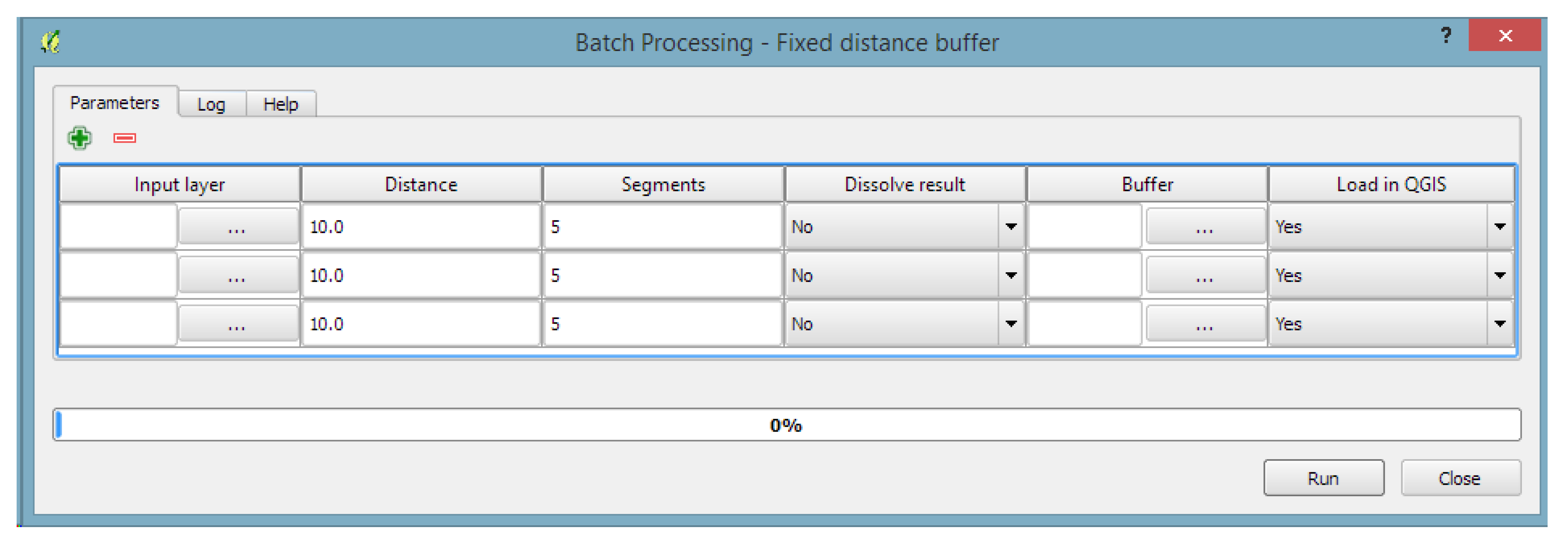
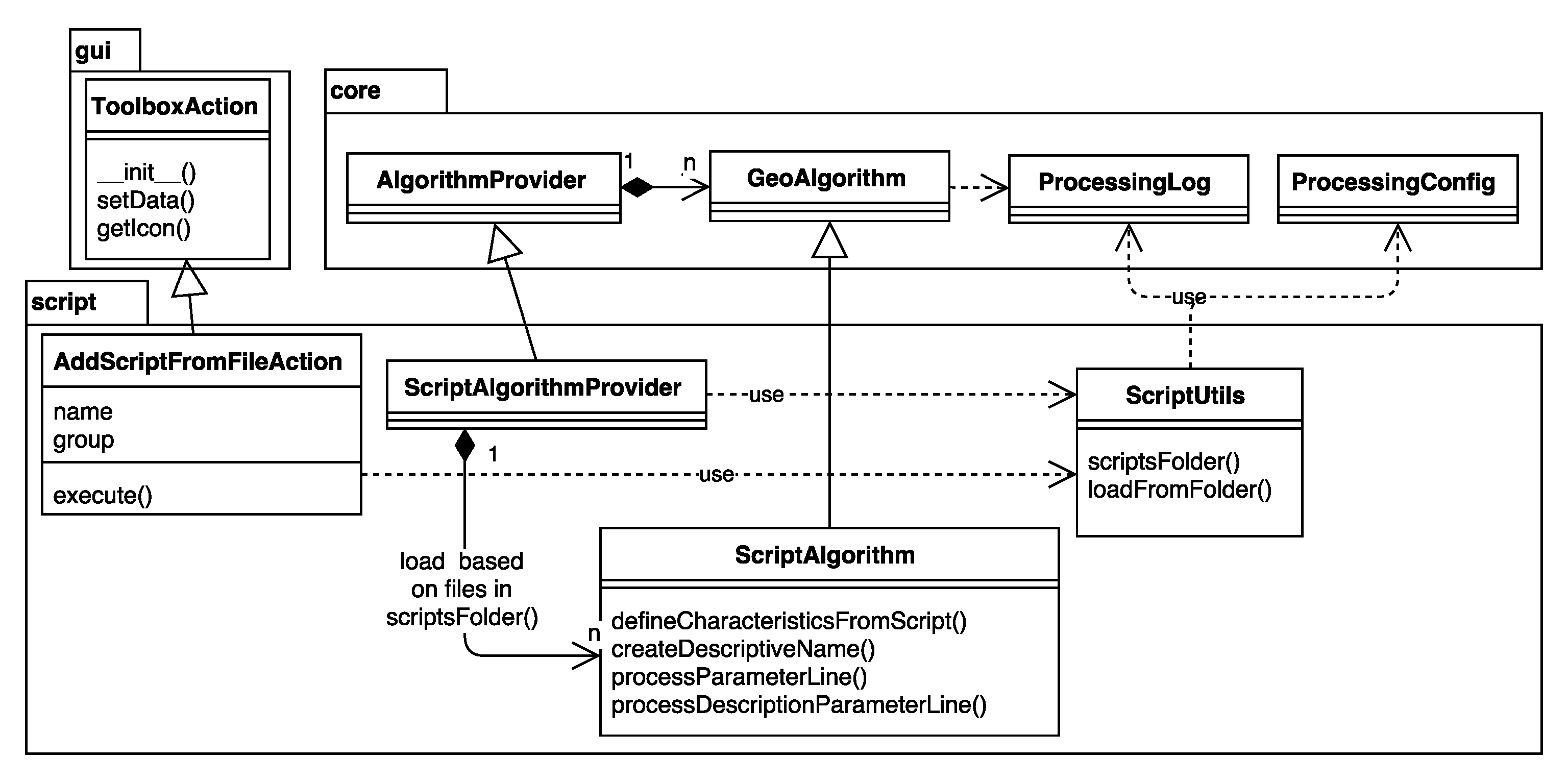
- The Toolbox (the gui.ProcessingToolbox class; for an example, see Figure 5) lists all available algorithms in its algorithmTree and allows one to execute algorithms and models using the AlgorithmDialog or BatchAlgorithmDialog. While the AlgorithmDialog is used to execute an algorithm or model once, the BatchAlgorithmDialog (for an example, see Figure 6) enables the repeated execution of an algorithm or model with varying parameter settings. The toolbox furthermore implements a mechanism that provides so-called Actions. This mechanism enables providers to extend the functionality of the toolbox and to provide tools that the provider needs. An example of this is the Create new script action that is added by the R provider, which opens a dialog for editing R scripts.
- The Commander (the gui.CommanderWindow class; for an example, see Figure 5) provides quick access to algorithms and models through a quick launcher interface. This enables the user to find and launch a geoprocessing tool by starting to type its name and picking the tool from the suggested search results.
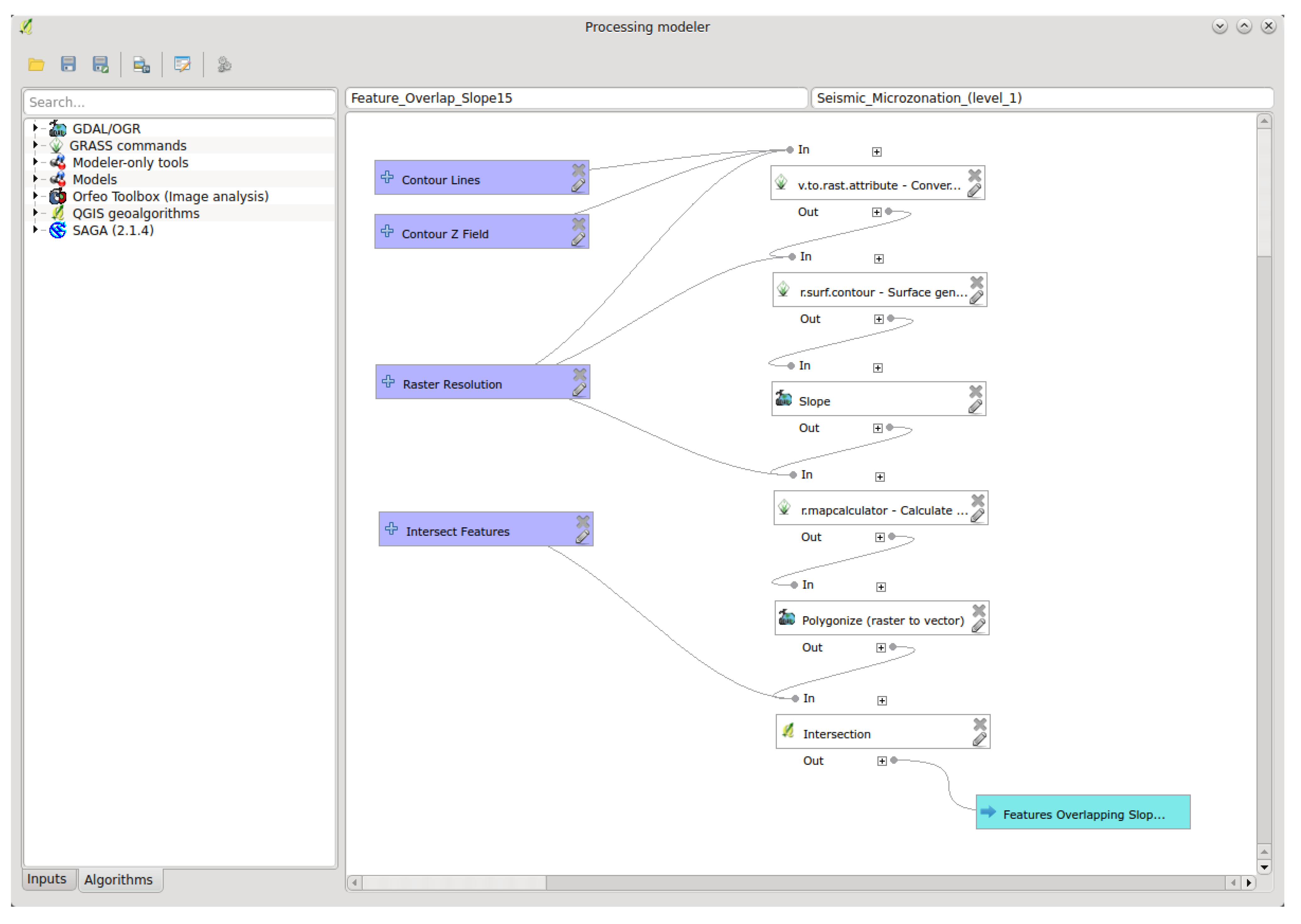
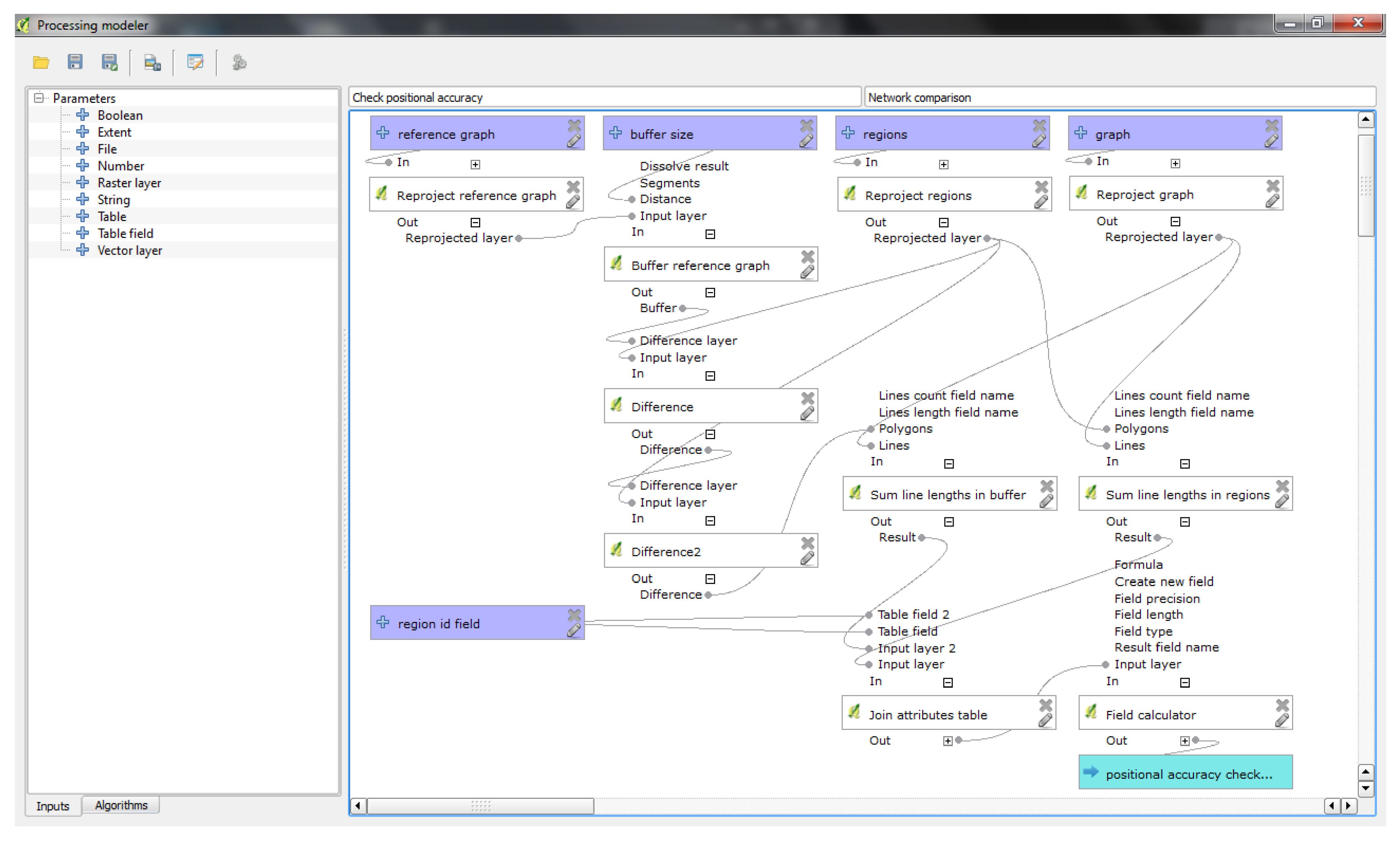
- The Graphical modeler (the modeler.ModelerDialog class; for examples, see Figure 7 and Figure 8) enables workflow automation by chaining individual tools into geoprocessing models. The visual representation of the model is drawn in the ModelerScene and consists of ModelerGraphicItems represented as boxes for input ModelParameters, Algorithms and ModelerOutputs, as well as ModelerArrowItems connecting them. The available input options and algorithms are listed in tree widgets similar to the one in the toolbox.

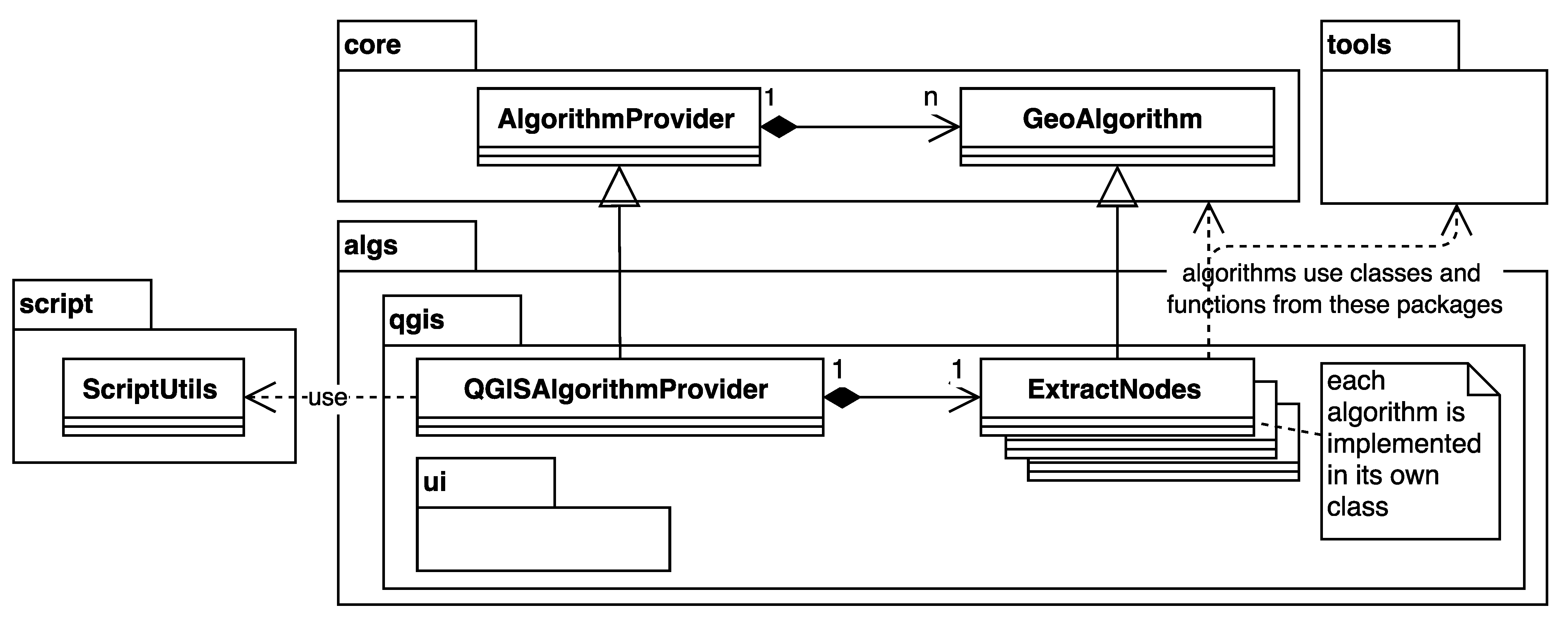
3.2. QGIS Ftools and MMQGIS Integration
from qgis.core import QGis, QgsFeature, QgsGeometry
from processing.core.GeoAlgorithm import GeoAlgorithm
from processing.core.parameters import ParameterVector
from processing.core.outputs import OutputVector
from processing.tools import dataobjects, vector
class ExtractNodes(GeoAlgorithm):
INPUT = ’INPUT’
OUTPUT = ’OUTPUT’
def defineCharacteristics(self):
self.name = ’Extract nodes’
self.group = ’Vector geometry tools’
self.addParameter(ParameterVector(self.INPUT,
self.tr(’Input layer’),
[ParameterVector.VECTOR_TYPE_POLYGON,
ParameterVector.VECTOR_TYPE_LINE]))
self.addOutput(OutputVector(self.OUTPUT,
self.tr(’Output layer’)))
def processAlgorithm(self, progress):
layer = dataobjects.getObjectFromUri(
self.getParameterValue(self.INPUT))
writer = self.getOutputFromName(self.OUTPUT)
.getVectorWriter(
layer.pendingFields().toList(),
QGis.WKBPoint, layer.crs())
outFeat = QgsFeature()
outGeom = QgsGeometry()
for f in vector.features(layer):
points = vector.extractPoints(f.geometry())
outFeat.setAttributes(f.attributes())
for i in points:
outFeat.setGeometry(outGeom.fromPoint(i))
writer.addFeature(outFeat)
del writer
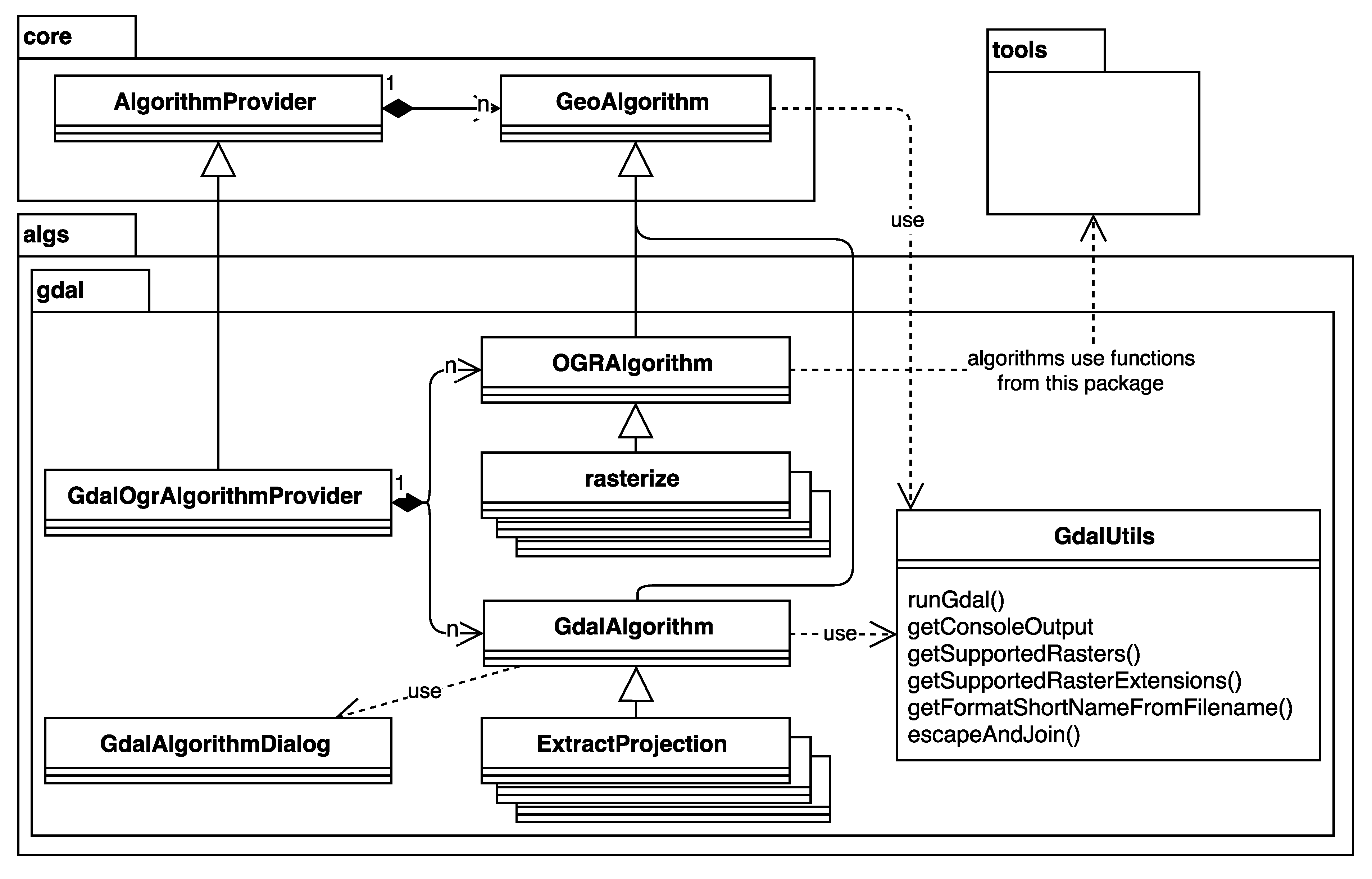
3.3. GDAL/OGR Integration

from osgeo import gdal, osr
from processing.algs.gdal.GdalAlgorithm import GdalAlgorithm
...
class ExtractProjection(GdalAlgorithm):
...
def processAlgorithm(self, progress):
rasterPath = self.getParameterValue(self.INPUT)
createPrj = self.getParameterValue(self.PRJ_FILE)
raster = gdal.Open(unicode(rasterPath))
crs = raster.GetProjection()
from processing.algs.gdal.GdalAlgorithm import GdalAlgorithm
from processing.algs.gdal.GdalUtils import GdalUtils
...
class ClipByExtent(GdalAlgorithm):
...
def processAlgorithm(self, progress):
out = self.getOutputValue(self.OUTPUT)
noData = str(self.getParameterValue(self.NO_DATA))
projwin = str(self.getParameterValue(self.PROJWIN))
extra = str(self.getParameterValue(self.EXTRA))
arguments = []
arguments.append(’-of’)
arguments.append(GdalUtils.getFormatShortNameFromFilename(out))
...
regionCoords = projwin.split(’,’)
arguments.append(’-projwin’)
arguments.append(regionCoords[0])
arguments.append(regionCoords[3])
arguments.append(regionCoords[1])
arguments.append(regionCoords[2])
...
GdalUtils.runGdal([’gdal_translate’,
GdalUtils.escapeAndJoin(arguments)], progress)
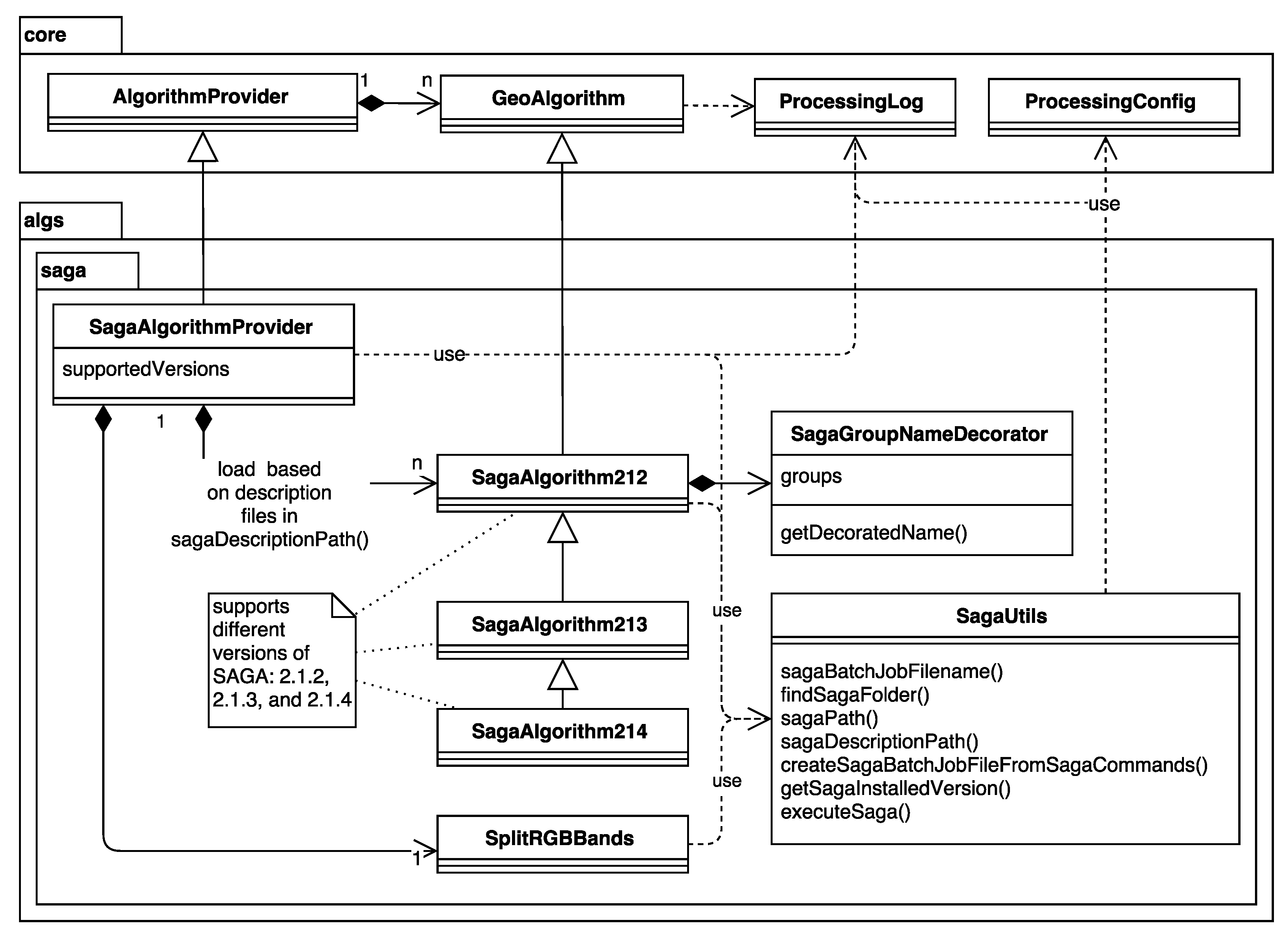
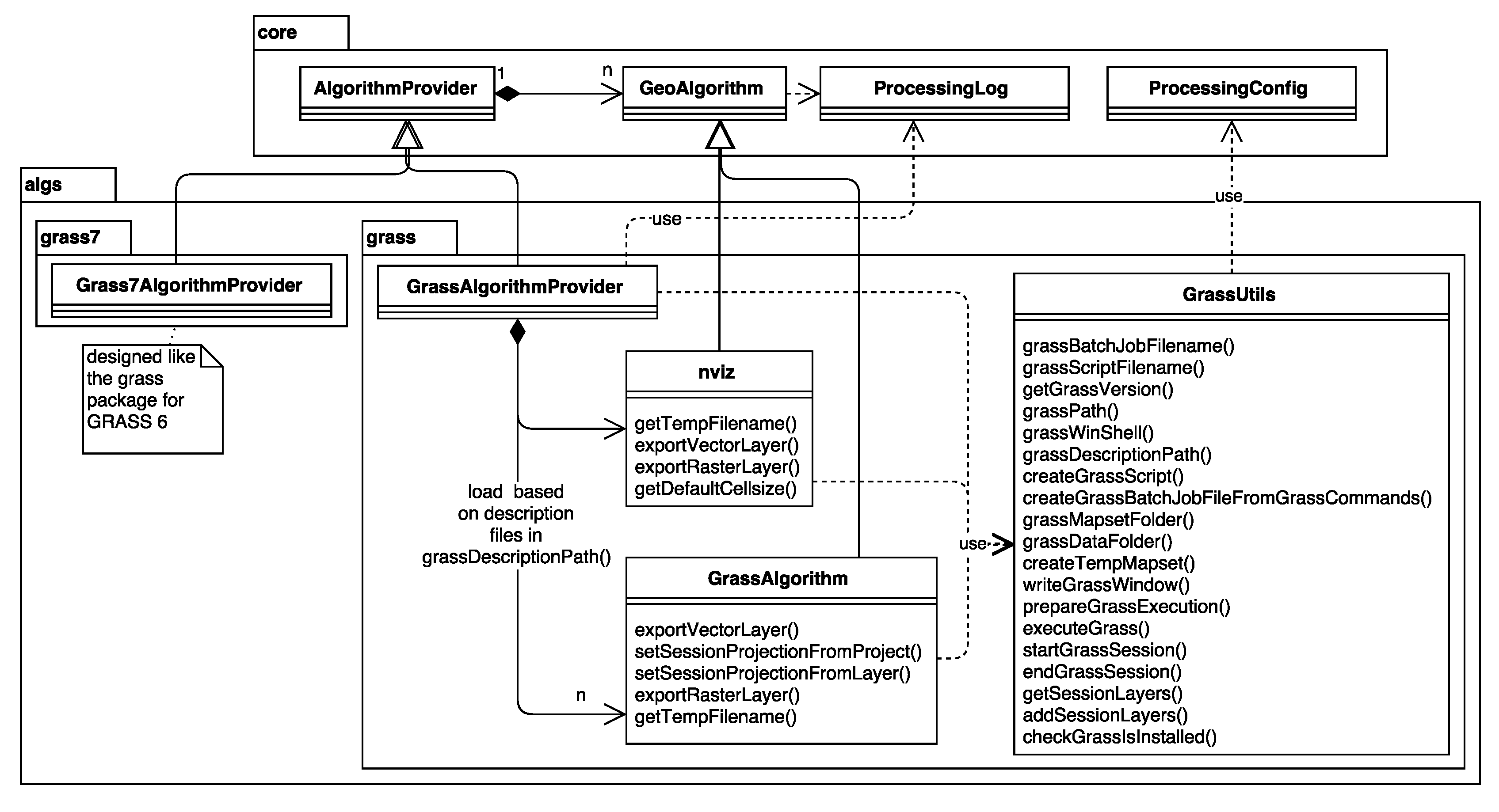
3.4. SAGA and GRASS GIS Integration

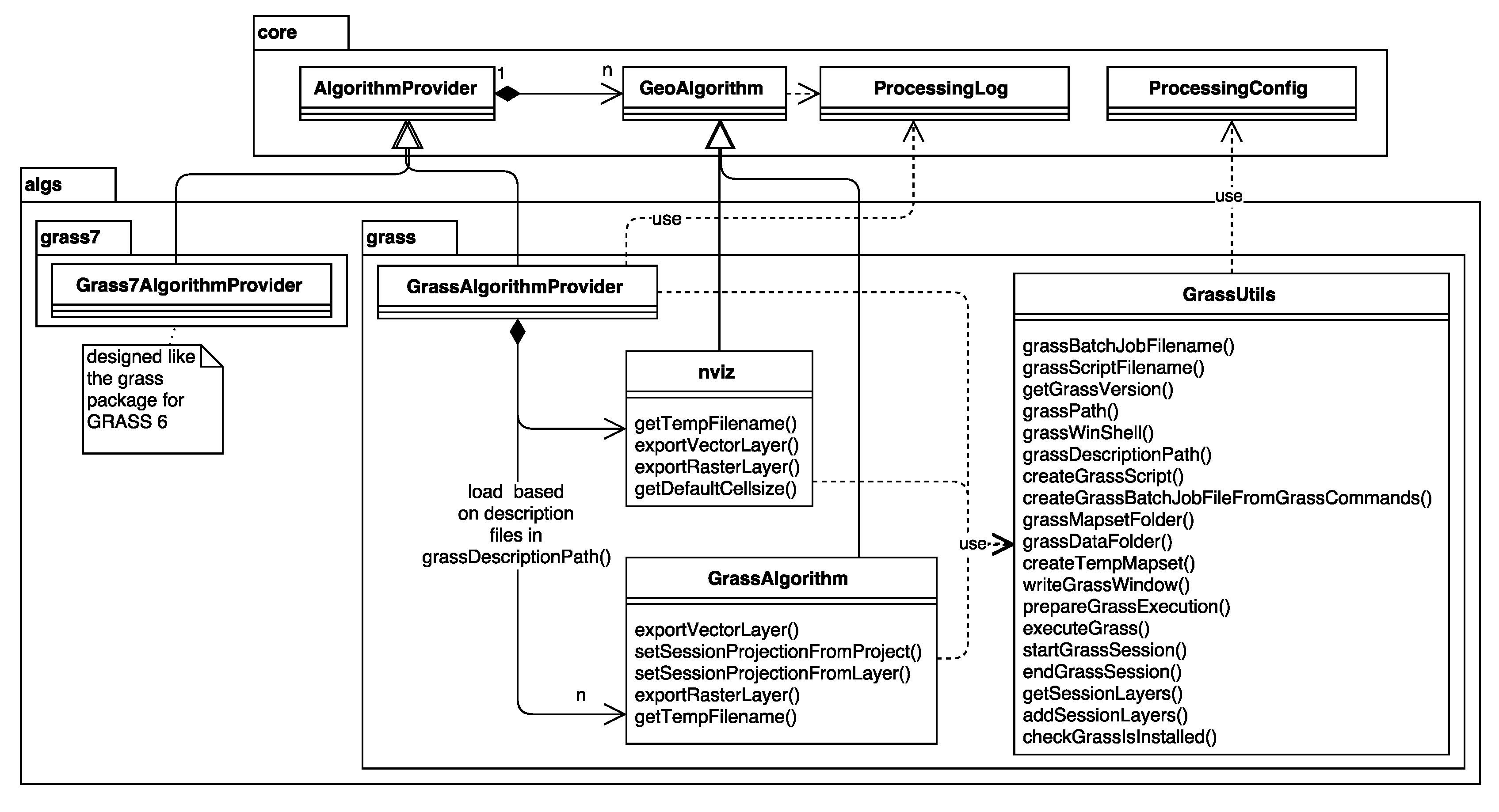
v.voronoi
v.voronoi - Creates a Voronoi diagram from an input vector layer
containing points.
Vector (v.*)
ParameterVector|input|Input points layer|0|False
ParameterBoolean|-l|Output tessellation as a graph (lines),not areas
|False
ParameterBoolean|-t|Do not create attribute table|False
OutputVector|output|Voronoi diagram
3.5. R Integration
3.6. ORFEO Toolbox Integration
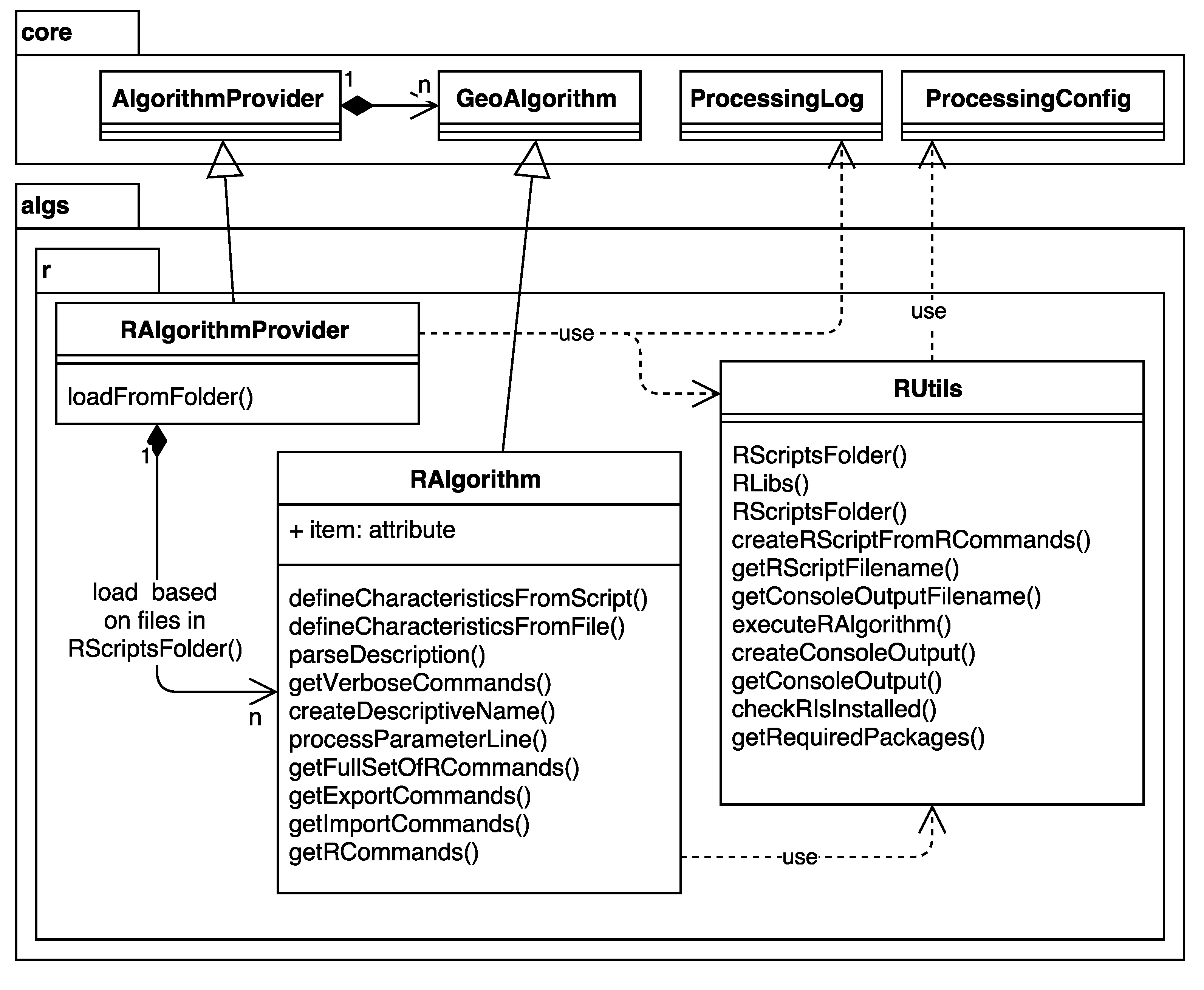
##Vector processing=group
##showplots
##Layer=vector
##Field=Field Layer
hist(Layer[[Field]], main=paste("Histogram of",Field),
xlab=paste(Field))
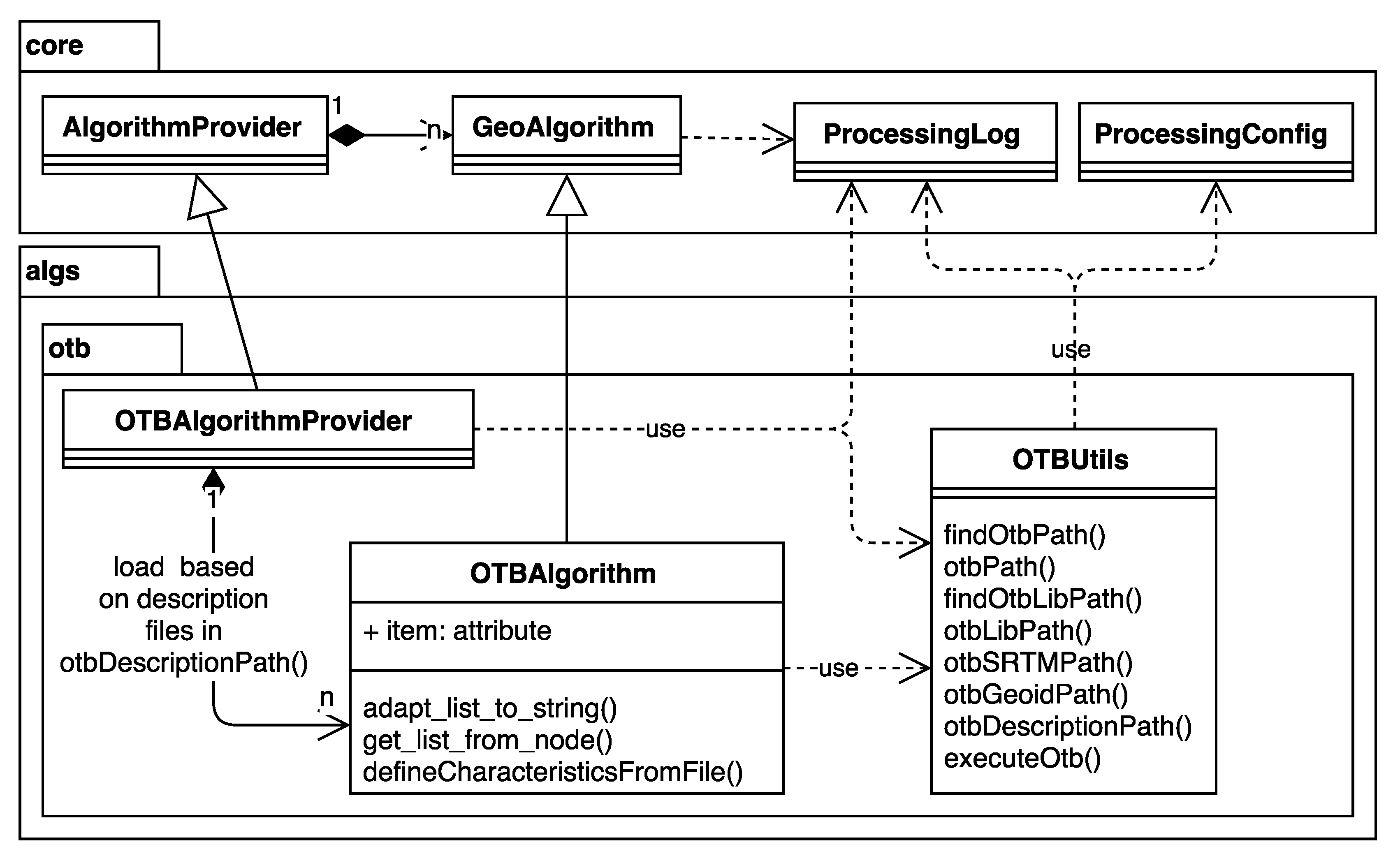
3.7. Integration with Other Backends
3.8. Development of New Algorithms
##input=vector
##field=field input
##results=output vector
from qgis.core import *
from processing.core.VectorWriter import VectorWriter
layer = processing.getObject(input)
writer = VectorWriter(results, None, layer.pendingFields(),
layer.dataProvider().geometryType(),
layer.crs())
for feat in layer.getFeatures():
feat.setAttribute(field, feat[field]+1)
writer.addFeature(feat)
del writer
3.9. Limitations
- Inputs and outputs are fixed, and optional parameters or outputs are not supported. This limitation was introduced deliberately in order to ensure correct working and efficient implementation of algorithm workflow support using Processing models. It is worth noting that the algorithm design, which handles the list of outputs and inputs, could easily accommodate optional parameters, but they would increase the complexity of Processing models. Therefore, restrictions were imposed when the GeoAlgorithm class was designed. There is currently no short- or medium-term plan to add support for optional parameters and outputs, since this might require a rewrite of the Modeler.
- Algorithms cannot have any type of interactivity and should work in a black box way, receiving inputs and providing output files without the user participating in the process. This limitation was introduced to ensure that models generated from Processing algorithms can run automatically without the need for user actions.
- Performance is reduced when the input dataset has to be converted. This is particularly noticeable with large datasets. Currently, Processing does not take advantage of the fact that it is not necessary to convert datasets when chaining several algorithms of the same provider. An optimization mechanism is currently under development.
- SAGA’s interactive algorithms, such as kriging with interactive variogram fitting, have not been added to Processing.
- Single algorithms implementing multiple methods with optional parameters were split into multiple Processing algorithms. This solution was used, for example, for the SAGA buffer algorithm, which was split into one Processing algorithm for each method with its respective parameters.
- SAGA support for vector data, when used on the command line, is limited to shapefiles. This leads to inconsistent results, especially when the original dataset contains field names longer than 10 characters, which are not supported by the DBF (dBASE database file) format used to store attribute data in shapefiles.
4. Use Cases and Application Examples
4.1. Workflow Automation and Documentation
import processing
out_path = "/home/user/output.shp"
processing.runalg("script:estimateenergy",
"input.shp","id","/home/user/input.tif",v, out_path)
stats = processing.runalg("qgis:basicstatisticsfornumericfields",
out_path,"kWh",None)
avg_kwh = stats[’MEAN’]
4.2. Integration of New Algorithms
4.3. Sharing and Reproducible Research
5. Conclusions and Outlook
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Star, J. Geographic Information Systems: An Introduction; Prentice Hall: Englewood Cliffs, NJ, USA, 1990. [Google Scholar]
- Goodchild, M.F.; Longley, P.A.; Maguire, D.J.; Rhind, D.W. Geographic Information Systems and Science, 2nd ed.; John Wiley and Sons: Chichester, UK, 2005. [Google Scholar]
- Sherman, G. Desktop GIS: Mapping the Planet with Open Source Tools; Pragmatic Bookshelf: Raleigh, US, 2008. [Google Scholar]
- Neteler, M.; Bowman, M.H.; Landa, M.; Metz, M. GRASS GIS: A multi-purpose open source GIS. Environ. Model. Softw. 2012, 31, 124–130. [Google Scholar] [CrossRef]
- What is Free Software? The Free Software Definition. Available online: https://www.gnu.org/philosophy/free-sw.html (accessed on 17 October 2015).
- Rocchini, D.; Neteler, M. Let the four freedoms paradigm apply to ecology. Trends Ecol. Evol. 2012, 27, 310–311. [Google Scholar] [CrossRef] [PubMed]
- QGIS Development Team. QGIS Geographic Information System. Available online: http://qgis.osgeo.org (accessed on 17 October 2015).
- Van Hoesen, J.; Menke, K.; Smith, R.; Davis, P. Introduction to Geospatial Technology Using QGIS. Available online: https://www.canvas.net/browse/delmarcollege/courses/introduction-to-geospatial-technology-1 (accessed on 17 October 2015).
- Berman, M.L. Open Source GIS with QGIS 2.0. Available online: http://maps.cga.harvard.edu/qgis/ (accessed on 17 October 2015).
- Graser, A. Learning QGIS, 2nd ed.; Packt Publishing: Birmingham, UK, 2014. [Google Scholar]
- Zambelli, P.; Gebbert, S.; Ciolli, M. Pygrass: An object oriented Python application programming interface (API) for geographic resources analysis support system (GRASS) geographic information system (GIS). ISPRS Int. J. Geo-Inf. 2013, 2, 201–219. [Google Scholar] [CrossRef]
- Neteler, M.; Mitasova, H. Open Source GIS: A GRASS GIS Approach, 3rd ed.; Springer: New York, NY, USA, 2008; Volume 773, p. 406. [Google Scholar]
- SAGA Development Team. System for Automated Geoscientific Analyses (SAGA). Available online: http://saga-gis.org (accessed on 17 October 2015).
- Olaya, V. SEXTANTE, a free platform for geospatial analysis. OSGeo J. 2009, 6, 32–39. [Google Scholar]
- Cosentino, G.; Coltella, M.; Cavuoto, G.; Ciotoli, G.; Cavinato, G.P.; Salaam, G. I.; Castorani, A.; Di Santo, A.R.; Trulli, I.; Caggiano, T. New map features in project on the first level seismic microzonation of 61 municipalities in the Foggia province (Apulia region, Italy). In Proceedings of 7th EUropean Congress on REgional GEOscientific Cartography and Information Systems, Bologna, Italy, 12–15 June 2012.
- Cosentino, G.; Pennica, F. QGIS Geoprocessing Model to Simplify First Level Seismic Microzonation Analysis—QGIS Case Studies. Available online: http://qgis.org/en/site/about/case_studies/italy_rome.html (accessed on 17 October 2015).
- Graser, A.; Straub, M.; Dragaschnig, M. Towards an open source analysis toolbox for street network comparison: Indicators, tools and results of a comparison of OSM and the official austrian reference graph. Trans. GIS 2014, 18, 510–526. [Google Scholar] [CrossRef]
- Minn, M. MMQGIS—QGIS Python Plugins Repository. Available online: http://plugins.qgis.org/plugins/mmqgis/ (accessed on 17 October 2015).
- GDAL Development Team. GDAL—Geospatial Data Abstraction Library. Available online: http://www.gdal.org (accessed on 17 October 2015).
- Olaya, V. A Gentle Introduction to SAGA GIS. Available online: http://prdownloads.sourceforge.net/saga-gis/SagaManual.pdf?download (accessed on 17 October 2015).
- GRASS Development Team. Geographic Resources Analysis Support System (GRASS GIS) Software. Available online: http://grass.osgeo.org (accessed on 17 October 2015).
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: http://www.R-project.org (accessed on 17 October 2015).
- Bivand, R.S.; Pebesma, E.J.; Gómez-Rubio, V. Applied Spatial Data Analysis with R; Springer: New York, NY, USA, 2008; p. 405. [Google Scholar]
- OTB Development Team. The ORFEO Tool Box Software Guide. Available online: http://www.orfeo-toolbox.org (accessed on 17 October 2015).
- Tarboton, D.G. Terrain Analysis Using Digital Elevation Models (TauDEM). Available online: http://hydrology.usu.edu/taudem/taudem5/ (accessed on 17 October 2015).
- Olaya, V. Github: qgis/QGIS-Processing. Available online: https://github.com/qgis/QGIS-Processing (accessed on 17 October 2015).
- Dias, F.S.; Bugalho, M.N.; Rodríguez-González, P.M.; Albuquerque, A.; Cerdeira, J.O. Effects of forest certification on the ecological condition of Mediterranean streams. J. Appl. Ecol. 2014, 52, 190–198. [Google Scholar] [CrossRef]
- Dias, F. Using QGIS to Map Hotspot Areas for Biodiversity and Ecosystem Services (HABEaS)—QGIS Case Studies. Available online: http://qgis.org/en/site/about/case_studies/portugal_lisbon.html (accessed on 17 October 2015).
- Venâncio, P. QGIS and Forest Fire Risk Mapping in Portugal—QGIS Case Studies. Available online: http://qgis.org/en/site/about/case_studies/portugal_pinhel.html (accessed on 17 October 2015).
- Graser, A.; Asamer, J.; Ponweiser, W. The elevation factor: Digital elevation model quality and sampling impacts on electric vehicle energy estimation errors. In Proceedings of IEEE International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Budapest, Hungary, 3–5 June 2015.
- Goodchild, M.F.; Hunter, G.J. A simple positional accuracy measure for linear features. Int. J. Geogr. Inf. Sci. 1997, 11, 299–306. [Google Scholar] [CrossRef]
- Google Summer of Code. QGIS—Multithread Support on QGIS Processing Toolbox. Available online: http://www.google-melange.com/gsoc/project/details/google/gsoc2015/mvcs/5741031244955648 (accessed on 17 October 2015).
- Graser, A. Github: anitagraser/QGIS-Processing-tools—PySAL Integration. Available online: https://github.com/anitagraser/QGIS-Processing-tools/wiki/PySAL-Integration (accessed on 17 October 2015).
- Rey, S.J.; Anselin, L.; Li, X.; Pahle, R.; Laura, J.; Li, W.; Koschinsky, J. Open geospatial analytics with PySAL. ISPRS Int. J. Geo-Inf. 2015, 4, 815–836. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Graser, A.; Olaya, V. Processing: A Python Framework for the Seamless Integration of Geoprocessing Tools in QGIS. ISPRS Int. J. Geo-Inf. 2015, 4, 2219-2245. https://doi.org/10.3390/ijgi4042219
Graser A, Olaya V. Processing: A Python Framework for the Seamless Integration of Geoprocessing Tools in QGIS. ISPRS International Journal of Geo-Information. 2015; 4(4):2219-2245. https://doi.org/10.3390/ijgi4042219
Chicago/Turabian StyleGraser, Anita, and Victor Olaya. 2015. "Processing: A Python Framework for the Seamless Integration of Geoprocessing Tools in QGIS" ISPRS International Journal of Geo-Information 4, no. 4: 2219-2245. https://doi.org/10.3390/ijgi4042219
APA StyleGraser, A., & Olaya, V. (2015). Processing: A Python Framework for the Seamless Integration of Geoprocessing Tools in QGIS. ISPRS International Journal of Geo-Information, 4(4), 2219-2245. https://doi.org/10.3390/ijgi4042219